I Interview questions and analysis
1. Today's interview question
What is the underlying principle of ConcurrentHashMap?
Do you know how concurrent HashMap is expanded?
.......
2. Topic analysis
In the previous four articles, Yige introduced the general functions and features of ConcurrentHashMap, the underlying data structure of ConcurrentHashMap in JDK 7 and 8, as well as the core attributes in ConcurrentHashMap. The links are as follows:
High paid programmer & interview question series 45 are you familiar with concurrent HashMap?
Starting from this article, brother Yi will focus on analyzing the source code of the ConcurrentHashMap#transfer() method in JDK 8, focusing on the capacity expansion mechanism. This is the high-frequency test site during our interview.
II Implementation logic of transfer() expansion method [key points]
1. Capacity expansion mechanism of concurrenthashmap
During our interview, another common test point in ConcurrentHashMap is about the capacity expansion mechanism of arrays, so next I will focus on how to expand ConcurrentHashMap.
When the capacity of ConcurrentHashMap is insufficient, the table array needs to be expanded. In fact, the basic logic of capacity expansion is very similar to that of HashMap, and the capacity expansion of ConcurrentHashMap is also doubled. After capacity expansion, the array capacity is twice that of the original. However, because it supports concurrent capacity expansion, it is more complex because it supports multi-threaded capacity expansion without locking.
The purpose of this is not only to meet the requirements of concurrency, but also to reduce the time impact of capacity expansion. Because during capacity expansion, it always involves copying from one "array" to another. If this operation can be carried out concurrently, it is very efficient.
2. Implementation steps of capacity expansion mechanism
The implementation steps of concurrent HashMap expansion can be divided into two parts, which are as follows:
Part 1 starts by building a nextTable array. Its capacity is twice that of the original. This operation is completed in a single thread. This operation will use RESIZE_STAMP_SHIFT constant is realized through one operation.
The second part is to copy the data from the original table array to the nextTable array, where multi-threaded operation is allowed.
2.1 constructing nextTable array in single thread
The general implementation process of the array is actually a process of traversal and replication.
In this process, the number of times i to be traversed will be obtained according to the operation, and then the element at position i will be obtained by using the tabAt() method, and the following judgment will be made:
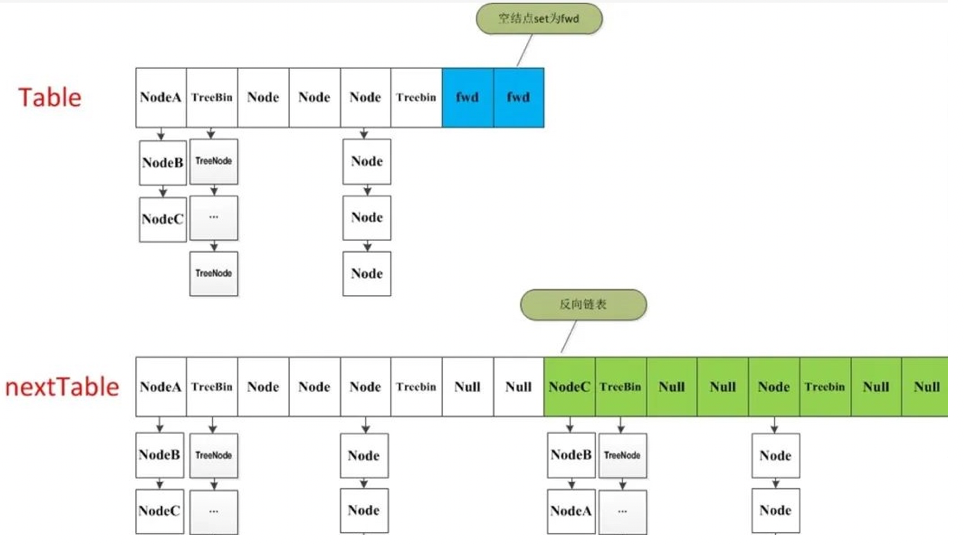
- If this location is empty, the forwardNode node is placed at the i location in the original table, which is also the key point to trigger concurrent capacity expansion;
- If this position is a Node node (FH > = 0) and is the head Node of a linked list, construct an inverted linked list and place them at the i and i+n positions of the nextTable respectively;
- If this position is a TreeBin node (FH < 0), do a reverse order processing, judge whether untreefi is required, and put the processing results at the i and i+n positions of the nextTable respectively.
After traversing all nodes, the data replication is completed. At this time, let nextTable be the new table, and update sizeCtl to 0.75 times the new capacity to complete the capacity expansion.
2.2 node traversal in multithreading
There is a judgment in the source code of the transfer() method. If the traversed node is a forward node, it will continue to traverse backward. Coupled with the locking operation to the node, the multithreading control is completed. When multithreading traverses a node, it processes a node and sets the value of the corresponding node to forward; When another thread sees forward, it will traverse backward. In this way, the cross operation completes the replication work, and also solves the problem of thread safety.
3. Transfer expansion method
The transfer() capacity expansion method is a very efficient and complex method. Before reading the specific transfer source code, let's first understand when the capacity expansion operation of ConcurrentHashMap will be triggered. There are two situations in which the capacity expansion operation may be triggered:
- After calling the put() method to add an element, the addCount() method will be called to update the size and check whether expansion is needed. When the number of array elements reaches the expansion threshold, the transfer() method will be triggered;
- Trigger the tryprevize() operation, which will trigger capacity expansion. There are two cases that trigger the tryprevize operation. The first case: when the number of linked list elements on a node reaches the threshold of 8, it is necessary to turn the linked list into a red black tree. Before structure conversion, it will first judge whether the array length n is less than the threshold min_ TREEIFY_ Capability, the default value is 64. If it is less than, it will call the tryprevize method to expand the array length to twice the original length, trigger the transfer() method, and then readjust the position of the node. The second case: the tryprevize operation will be triggered first during the putAll operation.
4. transfer() source code
Next, let's take a look at the source code of the transfer() method and see how the concurrent HashMap achieves capacity expansion.
/**
* A transitional table can only be used during capacity expansion
*/
private transient volatile Node<K,V>[] nextTable;
/**
* Moves and/or copies the nodes in each bin to new table. See
* above for explanation.
*/
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];//Construct a nextTable object with twice the original capacity
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);//Construct a connected node pointer for flag bit
boolean advance = true;//If the key attribute of concurrent capacity expansion is equal to true, it indicates that this node has been processed
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
//The function of the while loop body is to control i -- through i -- to traverse the nodes in the original hash table in turn
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
//If all nodes have finished copying, assign nextTable to table and empty the temporary object nextTable
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);//The capacity expansion threshold is set to 1.5 times the original capacity, which is still 0.75 times the current capacity
return;
}
//The CAS method is used to update the capacity expansion threshold, where the sizectl value is reduced by one, indicating that a new thread is added to participate in the capacity expansion operation
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
//If the traversed node is null, it is put into the ForwardingNode pointer
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
//If you traverse the ForwardingNode node, it indicates that this point has been processed. Skip it directly. This is the core of controlling concurrent expansion
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
//Node locking
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
//If FH > = 0, it proves that this is a Node node
if (fh >= 0) {
int runBit = fh & n;
//The following work is to construct two linked lists. One is the original linked list, and the other is the reverse order of the original linked list
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
//Insert a linked list at the i position of the nextTable
setTabAt(nextTab, i, ln);
//Insert another linked list at the i+n position of nextTable
setTabAt(nextTab, i + n, hn);
//Inserting a forwardNode node at the i position of the table indicates that the node has been processed
setTabAt(tab, i, fwd);
//Set advance to true and return to the while loop above to perform i-- operations
advance = true;
}
//Processing the TreeBin object is similar to the above procedure
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
//Construct positive order and reverse order linked lists
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
//If the tree structure is no longer needed after capacity expansion, it is inversely converted to a linked list structure
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
//Insert a linked list at the i position of the nextTable
setTabAt(nextTab, i, ln);
//Insert another linked list at the i+n position of nextTable
setTabAt(nextTab, i + n, hn);
//Inserting a forwardNode node at the i position of the table indicates that the node has been processed
setTabAt(tab, i, fwd);
//Set advance to true and return to the while loop above to perform i-- operations
advance = true;
}
}
}
}
}
}The transfer() method is really complex. I believe many people don't have the patience to read it line by line. Even after reading it for a while, they don't understand what it means, so brother Yi will split and interpret the above source code for you.
5. Interpretation of the source code of transfer [ key ]
5.1 set step stripe
In the transfer() method, a step size stripe will be set first, and the minimum value of this stripe is equal to MIN_TRANSFER_STRIDE=16
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range5.2 initialize the nextTab array
Then judge whether the nextTab is empty. If the incoming nextTab is empty, it will be initialized. The periphery will ensure that when the first thread initiating migration calls this method, nextTab=null, and when subsequent threads call again, nextTab will no longer be null. Then assign nextTab to the global variable nextTable.
if (nextTab == null) {// initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}5.3 create ForwardingNode node
Next, a new ForwardingNode is created. The hash value of this node = MOVED=-1.
int nextn = nextTab.length; ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab); boolean advance = true; boolean finishing = false; // to ensure sweep before committing nextTab
5.4 execute a dead cycle
Then, the state will be changed in an endless loop. There may be three situations here.
In the first case, - I > = bound or finishing is True:
After subtracting 1 from i, judge whether i is greater than the minimum bound of the boundary. If it is less than bound, it indicates that the last interval task received has been completed and the next interval task needs to be received. Normally, when entering the loop for the first time, i this judgment will fail, and the following nextIndex assignment operation will be performed.
In the second case, if it is less than or equal to 0, it means that there is no interval, then change i to - 1, and the advance status becomes false, so it will no longer advance, indicating that the expansion has ended and the current thread can exit. This - 1 will be judged in the following if block to enter the completion state.
The third case is to get the task interval of the thread. The lower limit is bound, the upper limit is i, bound = nextindex stripe, i=nextIndex.
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}5.5 judge whether to end the capacity expansion task of the current thread
If i is less than 0 or not within the subscript range of the tab array, get the last interval task according to the above judgment and end the capacity expansion task of the current thread.
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
//Assign the new nextTab to the table attribute to complete the migration
nextTable = null;
table = nextTab; // Update table
//Recalculate sizeCtl: n is the length of the original array, so the value obtained by sizeCtl will be 0.75 times the length of the new array
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}5.6 create a fwd node for occupation
Next, judge that if the value at position i in the old tab is null, CAS will be used to write a fwd node for occupation.
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);5.7 lock to add data
Next, this part is the key code for capacity expansion.
else {// Here, it means that this position has an actual value and is not a placeholder. Lock this node. Why is it locked to prevent inserting data into the linked list when putVal
synchronized (f) {
// Judge whether the bucket node at i subscript is the same as f
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;// Low, high bucket
// If the hash value of f is greater than 0. The hash of TreeBin is - 2
if (fh >= 0) {
// Sum the old length (the nth of the first operand is in the nth bit of the second operand. If both are 1, the nth of the result is also 1, otherwise it is 0)
// Since the length of the Map is to the power of 2 (numbers such as 00000, 1000), there are only two results taken from the length, one is 0 and the other is 1
// If the result is 0, Doug Lea puts it in the low position and vice versa. The purpose is to re hash the linked list and put it in the corresponding position so that the new take in algorithm can hit him.
int runBit = fh & n;
Node<K,V> lastRun = f; // The hash value of the tail node is not equal to that of the head node
// Traverse this bucket
for (Node<K,V> p = f.next; p != null; p = p.next) {
// Take the hash value of each node in the bucket
int b = p.hash & n;
// If the hash value of the node is different from that of the first node
if (b != runBit) {
runBit = b; // Update runBit to determine whether lastRun should be assigned to ln or hn.
lastRun = p; // This lastRun ensures that the values of the following nodes are the same as their own values, so as to avoid unnecessary loops later
}
}
if (runBit == 0) {// If the last updated runBit is 0, set the lower node
ln = lastRun;
hn = null;
}
else {
hn = lastRun; // If the last updated runBit is 1, set the high node
ln = null;
}// Loop again and generate two linked lists with lastRun as the stop condition, so as to avoid unnecessary loops (the same results are taken after lastRun)
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
// If the result of the sum operation is 0, it is still in the low order
if ((ph & n) == 0) // If it is 0, create a low node
ln = new Node<K,V>(ph, pk, pv, ln);
else // 1 creates a high order
hn = new Node<K,V>(ph, pk, pv, hn);
}
// In fact, this is similar to hashMap
// Set the lower linked list to the i of the new linked list
setTabAt(nextTab, i, ln);
// Set the high linked list and add n to the original length
setTabAt(nextTab, i + n, hn);
// Set the old linked list as a placeholder
setTabAt(tab, i, fwd);
// Keep pushing back
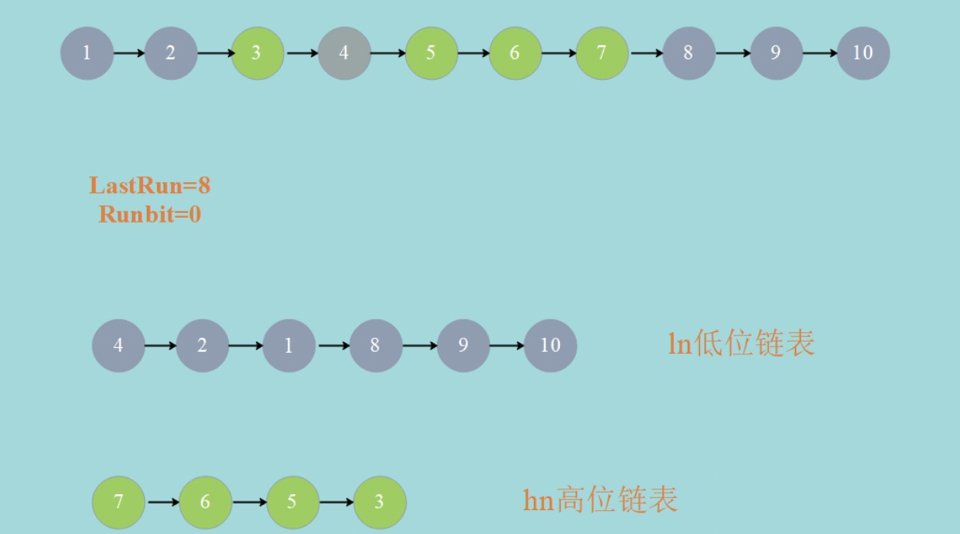
advance = true;The above code is difficult to understand. We can cooperate with the following figure to help understand it. In the figure, the gray circle represents FH & n = 0, and the green circle represents FH & n= 0 After a cycle, if LastRun=8 and Runbit=0, ln=LastRun(8 nodes) and hn=null. After another cycle, you can get both ln low-level linked list and hn high-level linked list.
5.8 turn linked list into red black tree
The last piece of code is to judge whether the red black tree transfer is required.
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
// ergodic
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
// The same judgment as the linked list, and the operation = = 0 are placed in the low order
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
} // Not 0, put it high
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// If the number of nodes in the tree is less than or equal to 6, it will be converted to a linked list. On the contrary, a new tree will be created
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
// Low tree
setTabAt(nextTab, i, ln);
// High order number
setTabAt(nextTab, i + n, hn);
// Set old as placeholder
setTabAt(tab, i, fwd);
// Keep pushing back
advance = true;
}
}
}6. Transfer summary [ key points ]
This transfer() method is really too complex for us to remember, so brother Yi will give you a brief summary. We just need to remember that transfer() roughly performs the following functions:
- Step 1: calculate the number of bit buckets that each thread can process each time. According to the length of the Map, calculate the number of bit buckets (table array) to be processed by each thread (CPU). By default, each thread processes 16 bit buckets at a time. If it is less than 16, it is forced to become 16 bit buckets.
- Step 2: initialize nextTab. If the new nextTab passed in is empty, the nextTab is initialized, which is twice the original table by default.
- Step 3: introduce ForwardingNode, advance and finishing variables to assist in capacity expansion. ForwardingNode indicates that the node has been processed and does not need to be processed again; Advance indicates whether the thread can move down to the next bit bucket (true: indicates it can move down); Finishing indicates whether to end capacity expansion (true: end capacity expansion, false: not end capacity expansion).
- Step 4: lock before data migration. In the process of data transfer, a synchronized lock will be added to lock the head node and synchronize the operation to prevent inserting data into the linked list during putVal.
- Step 5: perform data migration. If the node on the bit bucket is a linked list or red black tree, the node data will be divided into low and high. The calculation rule is to sum the hash value of the node with the length of the table container before capacity expansion. If the result is 0, the data will be placed in the low order of the new table (the i-th position in the current table, or the i-th position in the new table); If the result is not 0, it will be placed in the high position of the new table (the i-th position in the current table, and the position in the new table is I + the length of the current table container).
- Step 6: judge whether tree is needed. If the red black tree is mounted on the bit bucket, it is not only necessary to separate the low and high nodes, but also to judge whether the low and high nodes are stored in the form of linked list or red black tree in the new table.
III epilogue
This article {focuses on the source code of the concurrent hashmap#transfer() expansion method of JDK 8 and the process of the expansion mechanism. Next, I} will explain the source code of the ConcurrentHashMap#get() method in JDK 8 through another article. Please get ready.