This is the 541st technical share of "attacking Coder"
Author: Cui Qingcai
Source: Cui Qingcai Jingmi
Hello, I'm Cui Qingcai.
An article was published some time ago to introduce a new automatic crawling tool similar to Selenium and pyppeeer, called Playwright. See the article: Powerful and easy to use! Introduction to Playwright, a new generation of reptile weapon
After the article came out, everyone began to try this new artifact.
Some friends shouted after trying: "this Playwright is really easy to use. It is more convenient and powerful than Selenium and pyppeter."
Some friends said, "I've known Playwright before. Now it has been running stably in the production environment for a long time."
Of course, some friends said, "it would be nice if such a easy-to-use Playwright could be used in scripy. Unfortunately, I didn't find a easy-to-use package to connect scripy to Playwright."
Scripy docking Playwright? It seems that this is indeed a demand. I happen to have experience in developing screeny, Selenium and pyppeter before. I happen to be on vacation these days. Let's directly develop a screeny docking Playwright package.
It was developed at 2 p.m. yesterday, and the first test version was released around 6 p.m.
introduce
Let's introduce the basic usage of this package.
This package, called gerapyplaywright, has been released to GitHub( https://github.com/Gerapy/GerapyPlaywright )And PyPi( https://pypi.org/project/gerapy-playwright/ ).
GitHub
PyPi
In a word, this package can easily realize the docking between scripy and Playwright, so as to crawl JavaScript rendered web pages in scripy, and support asynchronous and concurrent crawling of multiple browsers.
It is also very easy to use. First, install:
pip3 install gerapy-playwright
Then, in the settings of the Scrapy project Py by adding the corresponding Downloader Middleware:
DOWNLOADER_MIDDLEWARES = {
'gerapy_playwright.downloadermiddlewares.PlaywrightMiddleware': 543,
}
Well, that's it!
Next, if we want to crawl a URL with Playwright, we just need to replace the original Request with PlaywrightRequest, as shown below:
yield PlaywrightRequest(url, callback=self.parse_detail)
Yes, it's that simple.
In this way, the url will be crawled with Playwright, and the Response will be the HTML rendered by the browser.
to configure
At the same time, of course, this package is not only so simple, but also supports many configurations.
For example, if you want Playwright to support Headless mode (without pop-up browser window), you can click settings Py configuration:
GERAPY_PLAYWRIGHT_HEADLESS = True
If you want to specify the default timeout configuration, you can set it in settings Py configuration:
GERAPY_PLAYWRIGHT_DOWNLOAD_TIMEOUT = 30
If such a web page cannot be loaded in 30 seconds, the web page will timeout.
In addition, WebDriver detection has been added to some websites. We can hide the WebDriver feature by adding a real browser camouflage configuration in Playwright, which can be found in settings Py configuration:
GERAPY_PLAYWRIGHT_PRETEND = True
If you want to support proxy settings during crawling, you can configure the global proxy in settings Py configuration:
GERAPY_PLAYWRIGHT_PROXY = 'http://tps254.kdlapi.com:15818'
GERAPY_PLAYWRIGHT_PROXY_CREDENTIAL = {
'username': 'xxx',
'password': 'xxxx'
}
If you want to support page screenshots, you can enable the global screenshot configuration in settings Py configuration:
GERAPY_PLAYWRIGHT_SCREENSHOT = {
'type': 'png',
'full_page': True
}
There are many other configurations that you can refer to https://github.com/Gerapy/GerapyPlaywright/blob/main/README.md The instructions in.
PlaywrightRequest
Of course, the configuration described above is the global configuration of the project. Of course, we can also use PlaywrightRequest to configure a request. The configuration with the same meaning will override the project settings Py specified configuration.
For example, if you use PlaywrightRequest to specify that the timeout is 30 seconds, and in item settings Py specifies that the timeout is 10 seconds, which will give priority to the configuration of 30 seconds.
So what parameters does PlaywrightRequest support?
For detailed configuration, refer to readme md: https://github.com/Gerapy/GerapyPlaywright#playwrightrequest .
The following is an introduction:
- URL: that's enough. It's the URL to climb.
- Callback: callback method. The Response after crawling will be passed to callback as a parameter.
- wait_until: wait for a loading event, such as domcontentloaded, which means that the whole HTML document is loaded before continuing to execute downward.
- wait_for: you can pass a Selector, such as in the waiting page The item will continue to execute downward only after it is loaded.
- Script: after loading, execute the corresponding JavaScript script.
- actions: you can customize a Python method to handle the page object of Playwright.
- Proxy: the proxy setting can override the global proxy setting_ PLAYWRIGHT_ PROXY.
- proxy_credential: proxy user name and password, which can override the global proxy user name and password settings_ PLAYWRIGHT_ proxy_credential.
- sleep: the waiting time after loading is completed. It can be used to set the forced waiting time.
- Timeout: load timeout, which can override the global timeout setting_ PLAYWRIGHT_ DOWNLOAD_ TIMEOUT.
- pretend: whether to hide the WebDriver feature, which can override the global setting geography_ PLAYWRIGHT_ pretend.
Example
For example, I have a website here https://antispider1.scrape.center , the content of this website can only be displayed after JavaScript rendering. At the same time, this website detects the WebDriver feature. Under normal circumstances, it will be deleted by Ban when crawling with Selenium, pyppeeer and Playwright, as shown in the figure:
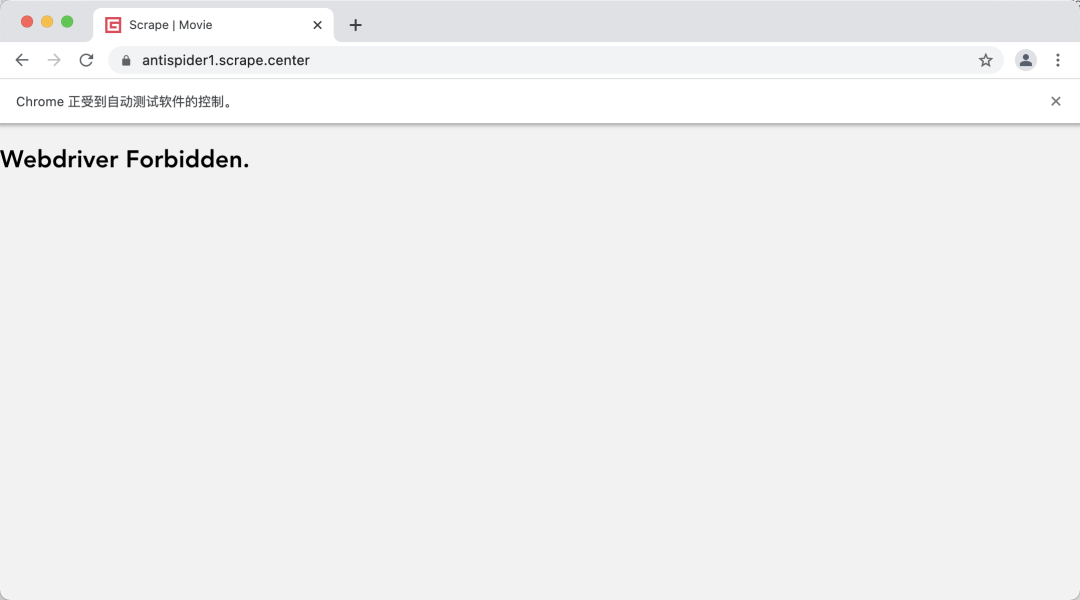
Therefore, if we want to use Scrapy to crawl the website, we can use GerapyPlaywright.
Create a new scratch project. The key configurations are as follows:
class MovieSpider(scrapy.Spider):
name = 'movie'
allowed_domains = ['antispider1.scrape.center']
base_url = 'https://antispider1.scrape.center'
max_page = 10
custom_settings = {
'GERAPY_PLAYWRIGHT_PRETEND': True
}
def start_requests(self):
for page in range(1, self.max_page + 1):
url = f'{self.base_url}/page/{page}'
logger.debug('start url %s', url)
yield PlaywrightRequest(url, callback=self.parse_index, priority=10, wait_for='.item')
def parse_index(self, response):
items = response.css('.item')
for item in items:
href = item.css('a::attr(href)').extract_first()
detail_url = response.urljoin(href)
logger.info('detail url %s', detail_url)
yield PlaywrightRequest(detail_url, callback=self.parse_detail, wait_for='.item')
As you can see, here we specify geography_ Playwright_ The preset global configuration is True, so that the Playwright will not be lost by the website Ban when it is started. At the same time, we use the PlaywrightRequest to specify that each URL is loaded with Playwright and wait_for specifies that a selector is Item, this Item represents the key extracted information. Playwrite will wait for the node to load before returning. Callback method parse_ The Response object of the index method contains the corresponding HTML text, right The content in item can be extracted.
You can also specify the number of concurrent:
CONCURRENT_REQUESTS = 5
In this way, five browsers corresponding to Playwright can crawl concurrently, which is very efficient.
The operation results are similar as follows:
2021-12-27 16:54:14 [scrapy.utils.log] INFO: Scrapy 2.2.0 started (bot: example)
2021-12-27 16:54:14 [scrapy.utils.log] INFO: Versions: lxml 4.7.1.0, libxml2 2.9.12, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 21.7.0, Python 3.7.9 (default, Aug 31 2020, 07:22:35) - [Clang 10.0.0 ], pyOpenSSL 21.0.0 (OpenSSL 1.1.1l 24 Aug 2021), cryptography 35.0.0, Platform Darwin-21.1.0-x86_64-i386-64bit
2021-12-27 16:54:14 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.asyncioreactor.AsyncioSelectorReactor
2021-12-27 16:54:14 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'example',
'CONCURRENT_REQUESTS': 1,
'NEWSPIDER_MODULE': 'example.spiders',
'RETRY_HTTP_CODES': [403, 500, 502, 503, 504],
'SPIDER_MODULES': ['example.spiders']}
2021-12-27 16:54:14 [scrapy.extensions.telnet] INFO: Telnet Password: e931b241390ad06a
2021-12-27 16:54:14 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.logstats.LogStats']
2021-12-27 16:54:14 [gerapy.playwright] INFO: playwright libraries already installed
2021-12-27 16:54:14 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'gerapy_playwright.downloadermiddlewares.PlaywrightMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2021-12-27 16:54:14 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2021-12-27 16:54:14 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2021-12-27 16:54:14 [scrapy.core.engine] INFO: Spider opened
2021-12-27 16:54:14 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2021-12-27 16:54:14 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2021-12-27 16:54:14 [example.spiders.movie] DEBUG: start url https://antispider1.scrape.center/page/1
2021-12-27 16:54:14 [gerapy.playwright] DEBUG: processing request <GET https://antispider1.scrape.center/page/1>
2021-12-27 16:54:14 [gerapy.playwright] DEBUG: playwright_meta {'wait_until': 'domcontentloaded', 'wait_for': '.item', 'script': None, 'actions': None, 'sleep': None, 'proxy': None, 'proxy_credential': None, 'pretend': None, 'timeout': None, 'screenshot': None}
2021-12-27 16:54:14 [gerapy.playwright] DEBUG: set options {'headless': False}
cookies []
2021-12-27 16:54:16 [gerapy.playwright] DEBUG: PRETEND_SCRIPTS is run
2021-12-27 16:54:16 [gerapy.playwright] DEBUG: timeout 10
2021-12-27 16:54:16 [gerapy.playwright] DEBUG: crawling https://antispider1.scrape.center/page/1
2021-12-27 16:54:16 [gerapy.playwright] DEBUG: request https://antispider1.scrape.center/page/1 with options {'url': 'https://antispider1.scrape.center/page/1', 'wait_until': 'domcontentloaded'}
2021-12-27 16:54:18 [gerapy.playwright] DEBUG: waiting for .item
2021-12-27 16:54:18 [gerapy.playwright] DEBUG: sleep for 1s
2021-12-27 16:54:19 [gerapy.playwright] DEBUG: taking screenshot using args {'type': 'png', 'full_page': True}
2021-12-27 16:54:19 [gerapy.playwright] DEBUG: close playwright
2021-12-27 16:54:20 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://antispider1.scrape.center/page/1> (referer: None)
2021-12-27 16:54:20 [example.spiders.movie] DEBUG: start url https://antispider1.scrape.center/page/2
2021-12-27 16:54:20 [gerapy.playwright] DEBUG: processing request <GET https://antispider1.scrape.center/page/2>
2021-12-27 16:54:20 [gerapy.playwright] DEBUG: playwright_meta {'wait_until': 'domcontentloaded', 'wait_for': '.item', 'script': None, 'actions': None, 'sleep': None, 'proxy': None, 'proxy_credential': None, 'pretend': None, 'timeout': None, 'screenshot': None}
2021-12-27 16:54:20 [gerapy.playwright] DEBUG: set options {'headless': False}
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/1
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/2
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/3
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/4
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/5
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/6
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/7
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/8
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/9
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/10
cookies []
2021-12-27 16:54:21 [gerapy.playwright] DEBUG: PRETEND_SCRIPTS is run
2021-12-27 16:54:21 [gerapy.playwright] DEBUG: timeout 10
2021-12-27 16:54:21 [gerapy.playwright] DEBUG: crawling https://antispider1.scrape.center/page/2
2021-12-27 16:54:21 [gerapy.playwright] DEBUG: request https://antispider1.scrape.center/page/2 with options {'url': 'https://antispider1.scrape.center/page/2', 'wait_until': 'domcontentloaded'}
2021-12-27 16:54:23 [gerapy.playwright] DEBUG: waiting for .item
2021-12-27 16:54:24 [gerapy.playwright] DEBUG: sleep for 1s
2021-12-27 16:54:25 [gerapy.playwright] DEBUG: taking screenshot using args {'type': 'png', 'full_page': True}
2021-12-27 16:54:25 [gerapy.playwright] DEBUG: close playwright
2021-12-27 16:54:25 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://antispider1.scrape.center/page/2> (referer: None)
2021-12-27 16:54:25 [gerapy.playwright] DEBUG: processing request <GET https://antispider1.scrape.center/detail/10>
2021-12-27 16:54:25 [gerapy.playwright] DEBUG: playwright_meta {'wait_until': 'domcontentloaded', 'wait_for': '.item', 'script': None, 'actions': None, 'sleep': None, 'proxy': None, 'proxy_credential': None, 'pretend': None, 'timeout': None, 'screenshot': None}
2021-12-27 16:54:25 [gerapy.playwright] DEBUG: set options {'headless': False}
...
Test code you can refer to: https://github.com/Gerapy/GerapyPlaywright/tree/main/example .
Well, the above is the introduction of the package written yesterday. You can try it. Welcome to put forward your valuable opinions and suggestions. Thank you! (thank you for giving a star!
End