preface
Over the past few years, I have been struggling in the it industry. Along the way, many have summarized some high-frequency interviews in the python industry. I see most of the new blood in the industry, and I still have all kinds of difficult questions for the answers to all kinds of interview questions or collection
Therefore, I developed an interview dictionary myself, hoping to help everyone, and also hope that more Python newcomers can really join the industry, so that Python fire does not just stay in advertising.
Wechat applet search: Python interview dictionary
Or follow the original personal blog: https://lienze.tech
You can also focus on WeChat official account and send all kinds of interesting technical articles at random: Python programming learning.
colony
The cluster should first understand the working principle of two types of nodes in rq
Memory node: better performance. Save all metadata information of queues, switches, binding relationships, users, permissions, and vhost in memory
Disk node: save this information on disk
Each node in the cluster is either a memory node ram or a disk node disk
-
If it is a memory node, all metadata information will be stored only in memory
-
The disk node will not only store all metadata in memory, but also persist it to disk
On a RabbitMQ cluster, at least one disk node is required
Other nodes are set as memory nodes, which will make operations such as queue and switch declaration faster and metadata synchronization more efficient
Ordinary cluster
General cluster of rabbitmq
In the cluster mode, only the metadata is synchronized, and the contents of each queue are still on its own server node. In this cluster mode, the data will be temporarily pulled according to the stored metadata when the consumer obtains the data
Build environment
- ubuntu
- docker
- stand-alone
Build process
The cluster is built mainly based on the support of erlang language for cookies. Nodes exchange and authenticate directly through erlang cookie s
- Start three nodes
docker run -d --name rabbitmq -e RABBITMQ_DEFAULT_USER=guest -e RABBITMQ_DEFAULT_PASS=guest -p 15672:15672 -p 5672:5672 rabbitmq:3-management
docker run -d \ --hostname rabbit_node1 \ --name rabbitmq1 \ -p 15672:15672 -p 5672:5672 \ -e RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie' \ -e RABBITMQ_DEFAULT_USER=guest -e RABBITMQ_DEFAULT_PASS=guest \ rabbitmq:3-management
sudo docker run -d \ --hostname rabbit_node2 \ --name rabbitmq2 \ -p 15673:15672 -p 5673:5672 \ -e RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie' \ -e RABBITMQ_DEFAULT_USER=guest -e RABBITMQ_DEFAULT_PASS=guest \ --link rabbitmq1:rabbit_node1 \ rabbitmq:3-management
sudo docker run -d \ --hostname rabbit_node3 \ --name rabbitmq3 \ -p 15674:15672 -p 5674:5672 \ --link rabbitmq1:rabbit_node1 --link rabbitmq2:rabbit_node2 \ -e RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie' \ -e RABBITMQ_DEFAULT_USER=guest -e RABBITMQ_DEFAULT_PASS=guest \ rabbitmq:3-management
- Enter the docker container to join the nodes
One disk node
docker exec -it rabbitmq1 bash rabbitmqctl stop_app rabbitmqctl reset rabbitmqctl start_app
Two memory nodes join the cluster
docker exec -it rabbitmq2/3 bash rabbitmqctl stop_app rabbitmqctl reset rabbitmqctl join_cluster --ram rabbit@rabbit_node1 rabbitmqctl start_app
This configuration starts 3 nodes, 1 disk node and 2 memory nodes
– ram indicates that it is set as a memory node. Ignoring the secondary parameter, it defaults to a disk node

In the cluster, for a node operation, it will be synchronized to other nodes
When a queue is established at node 2, no matter whether consumers or producers connect to node 2 in the cluster in the future, it will cause a certain pressure on the cpu access of node 2
This is also well understood because the synchronization of data will come from node 2
Mirror cluster queue
The last node to stop in the image queue will be the master. The start order must be that the master starts first
If the slave starts first, it will have a waiting time of 30 seconds, wait for the master to start, and then join the cluster
If the master does not start within 30 seconds, the slave will stop automatically
When all nodes are offline at the same time for some reason, each node thinks it is not the last node to stop. To restore the mirror queue, you can try to start all nodes within 30 seconds
The image queue realizes more reliable high availability than ordinary clusters
In an ordinary cluster, the data in the memory node queue does not really exist. By building a mirror queue, each node can actually backup and copy a copy of the data of the primary node
You can configure the image queue cluster on the console or control the policy on the command line
rabbitmqctl set_policy my-policy "^order" '{"ha-mode": "all"}'
my-policy: Policy name ^order: Matching exchange/queue Regular rules
Parameters in synchronization policy
- Ha mode: synchronization policy
- All: the mirror will take effect to all nodes of the cluster
- exctl: used in combination with HA params to specify how many copies of machine replication are replicated in the cluster
- Nodes: array type, which specifies which host nodes to copy
- Ha params: parameters matched with HA mode
- Ha mode: all: not effective
- Ha mode: exactly: a numeric type. It refers to the number of mirror nodes in the queue in the cluster. This number also includes hosts
- If the specified number of cluster nodes are hung and the remaining number of nodes is greater than or equal to 2, rq will continue to automatically select two slave nodes from the remaining nodes
- Ha mode: nodes: specifies which specific nodes are currently mirror nodes
Reference configuration
{
"ha-mode":"nodes",
"ha-params":["rabbit@node1","rabbit@node2"]
}
- Ha sync mode: queue synchronization parameters
- manual: in the default mode, the new queue image will not receive existing messages, it will only receive new messages
- automatic: when a new image is added, the queue will be synchronized automatically
Cluster effect

Actual mirror effect of a node
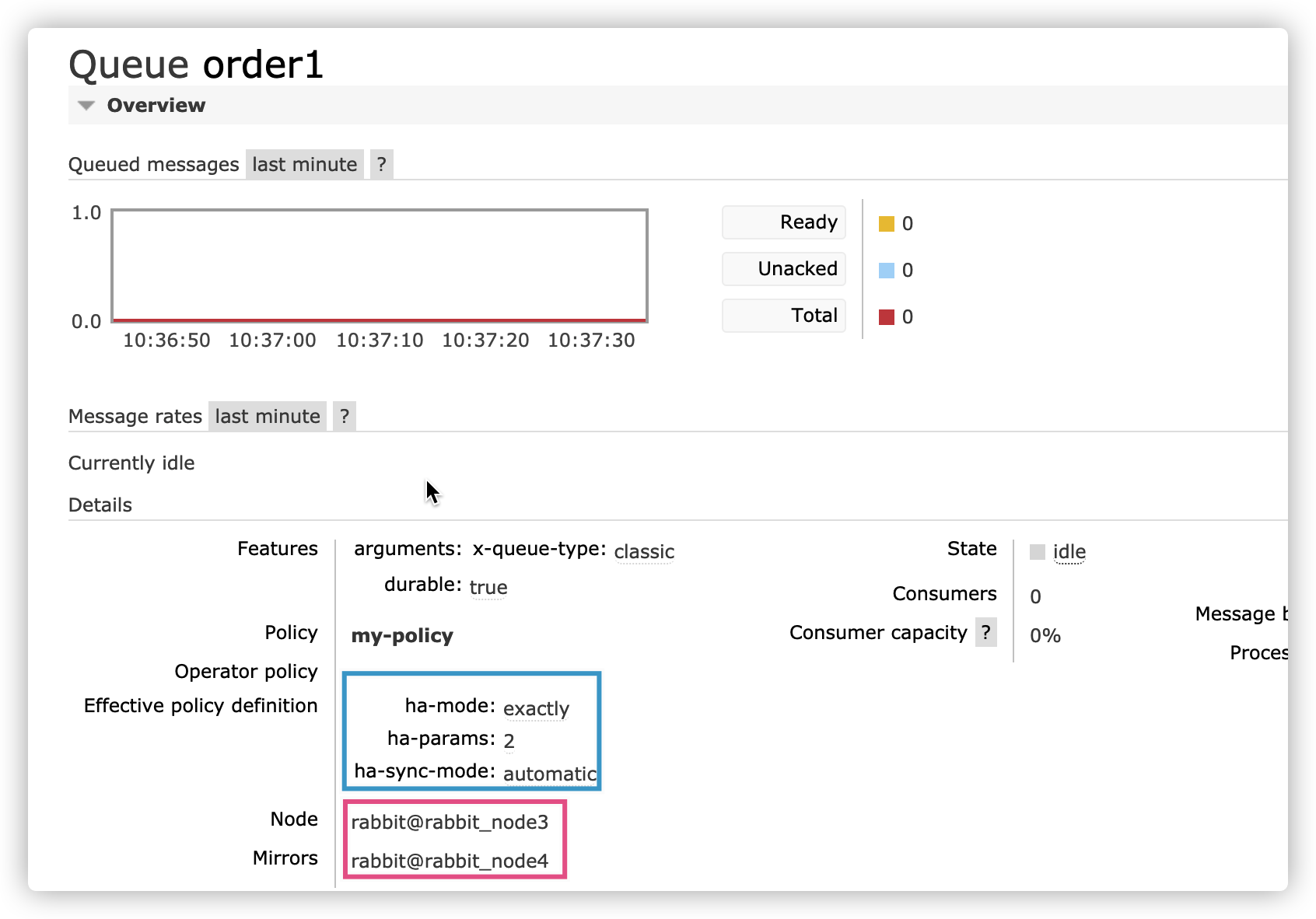
synchronization
Queue synchronization is a blocking operation. It is recommended to use it when the queue is small or the network io between nodes is small
- Manual synchronization
rabbitmqctl sync_queue {name}
- Manually cancel synchronization
rabbitmqctl cancel_sync_queue {name}
View node synchronization status
rabbitmqctl list_queues name slave_pids synchronised_slave_pids
- Name: queue name
- slave_pids: indicates the synchronized nodes
- synchronised_slave_pids: unsynchronized nodes
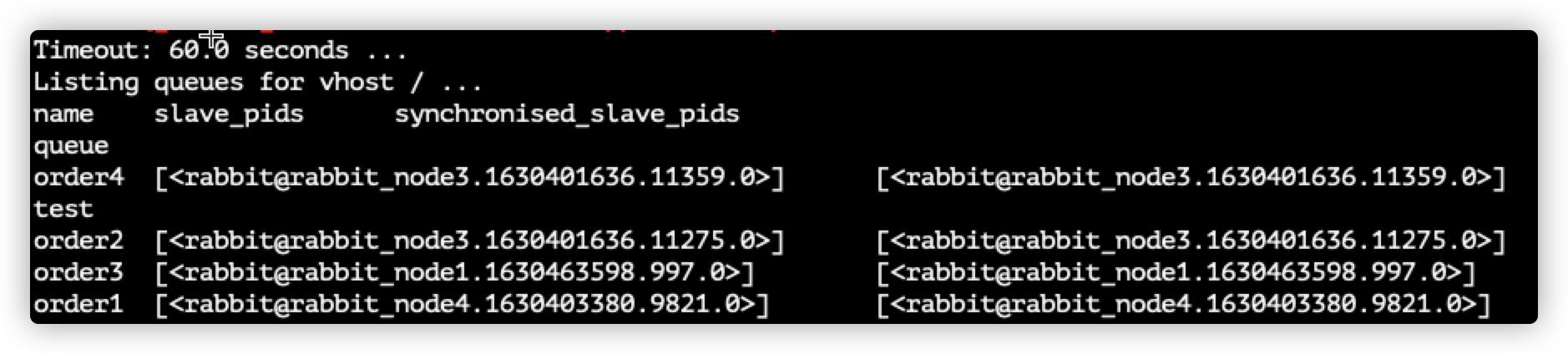
If slave_pids and synchronized_ slave_ The nodes in PIDs are consistent, which means that they are all synchronized
example
Mirror 2 nodes in the cluster, and match the queue / switch that starts with order
rabbitmqctl set_policy my-policy "^order" '{"ha-mode": "exactly","ha-sync-mode":"automatic","ha-params":2}'
load balancing
Installing haprocxy
sudo apt install haproxy
/usr/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -S /run/haproxy-master.sock
Default configuration modification
defaults
log global
mode tcp
option tcplog
option dontlognull
contimeout 5s
clitimeout 30s
srvtimeout 15s
Load balancing configuration
listen rabbitmq_cluster
bind 0.0.0.0:5671
mode tcp
balance roundrobin
server server1 127.0.0.1:5672 check inter 5000 rise 2 fall 2
server server2 127.0.0.1:5673 check inter 5000 rise 2 fall 2
server server3 127.0.0.1:5674 check inter 5000 rise 2 fall 2
rabbitmq cluster node configuration
- inter checks the health of the mq cluster every five seconds
- 2 times to correctly prove that the server is available
- Two failures prove that the server is unavailable
- And configure the active and standby mechanisms
Monitoring configuration
listen stats
bind 0.0.0.0:15671
mode http
option httplog
stats enable
stats uri /rabbitmq-stats
stats refresh 5s
haproxy provides a web monitoring console for load balancing. The viewing address is http://ip/rabbitmq-stats
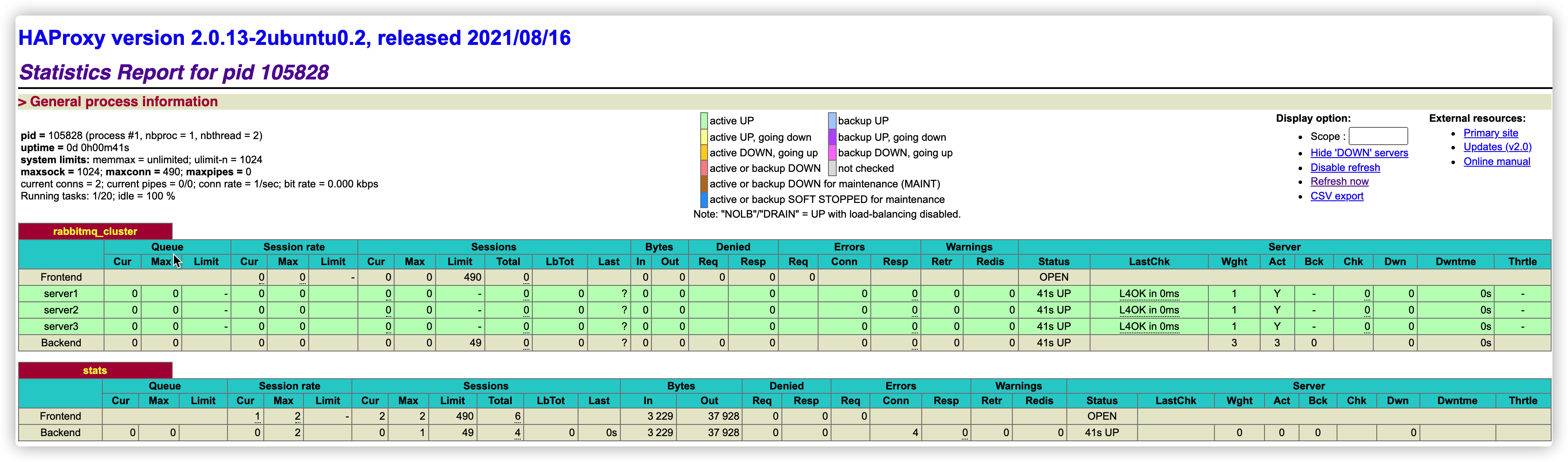
Pressure measurement
Test on a normal stand-alone node. One producer and one consumer have a message throughput of 100000, and the cpu occupancy is as follows

In the case of load balancing, one host, two clusters, three cluster nodes, one producer and two consumers, the cpu occupation is as follows

Since the queues of rabbitmq1 and rabbitmq2 are mirrored at this time, the additional burden of the producer will bring a share to the mirrored queue
other
- Mirror queue Publishing
For the mirror queue, the client basic The publish operation will be synchronized to all nodes,
- Number of image queues
Mirroring to all nodes is the most conservative choice. It puts additional pressure on all cluster nodes, including network I/O, disk I/O, and disk space usage
In most cases, it is not necessary to have a copy on each node
Election strategy
After the primary node hangs up, the following events will occur in the cluster
- All clients connected to the master are disconnected
- Elect the oldest slave as the new master
- The new master re queues all unack messages. At this time, the client may have duplicate messages
rabbitmq provides the following two parameters for users to decide whether to ensure the availability or consistency of the queue
- Ha promote on shutdown: the master node selects the parameter configuration. When the controllable master node is closed, how can other nodes replace the master node and select the behavior of the master node
- When synchronized (default): if the master node is actively stopped, if the save node is not synchronized, the master node will not be taken over at this time
- Give priority to ensuring that messages are reliable and not lost, and give up availability
- always: an asynchronous slave has the opportunity to take over the master regardless of the reason why the master is stopped
- Priority guarantee availability
- When synchronized (default): if the master node is actively stopped, if the save node is not synchronized, the master node will not be taken over at this time
- Ha promote on failure: the master node selects the parameter configuration. When the uncontrollable master node is closed, how can other nodes replace the master node and select the behavior of the master node
- When synchronized: ensure that unsynchronized mirrors are not promoted
- always: promotes an unsynchronized mirror
If the HA promote on failure policy key is set to when synchronized, the unsynchronized image will not be promoted even if the HA promote on shutdown key is set to always
Ha promote on shutdown is set to when synchronized by default, while ha promote on failure is set to always by default
Election test
At this time, start three nodes, consider node1 as the master node, and set the mirroring policy. The number of mirroring queues is 2
rabbitmqctl set_policy my-policy "^order" '{"ha-mode": "exactly","ha-params":2}'
Create a new node queue
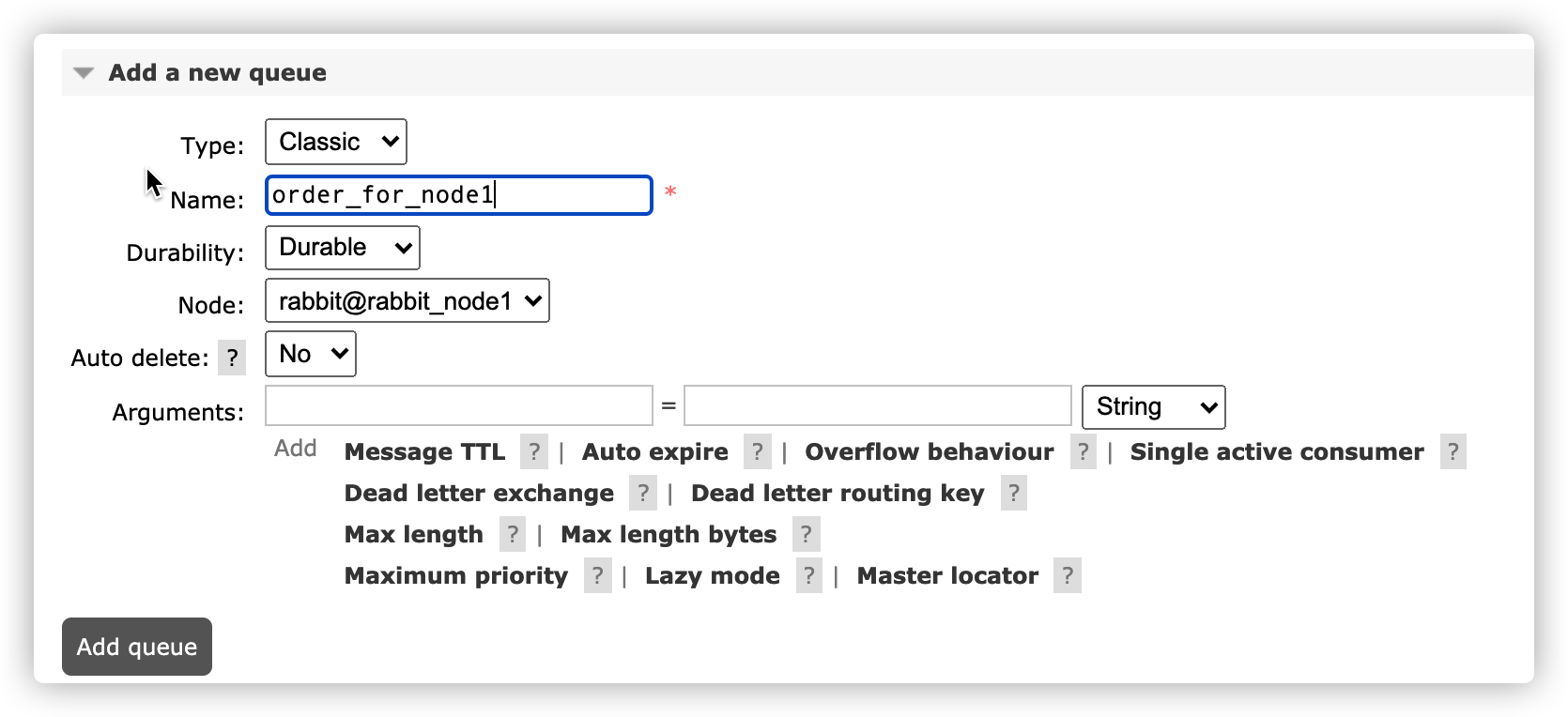
Basic mirroring has been completed

Stop node 2, 3
sudo docker stop rabbitmq2 sudo docker stop rabbitmq3
At this time, the node has no synchronizable objects

Add 50000 messages to the primary node queue as many as possible

At this time, restart the slave node. Since the policy ha sync mode is the default, the history messages of the master node will not be synchronized
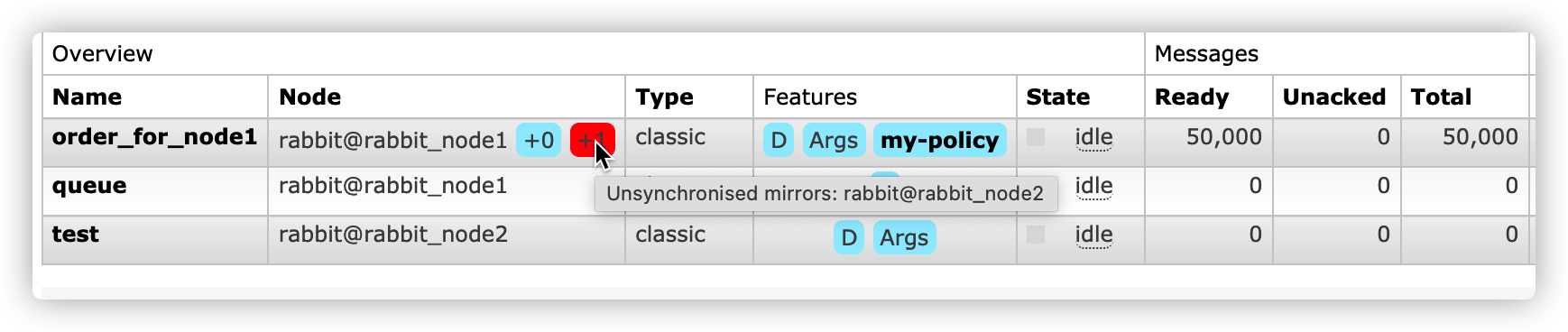
Close the primary node node1 and view the node election status
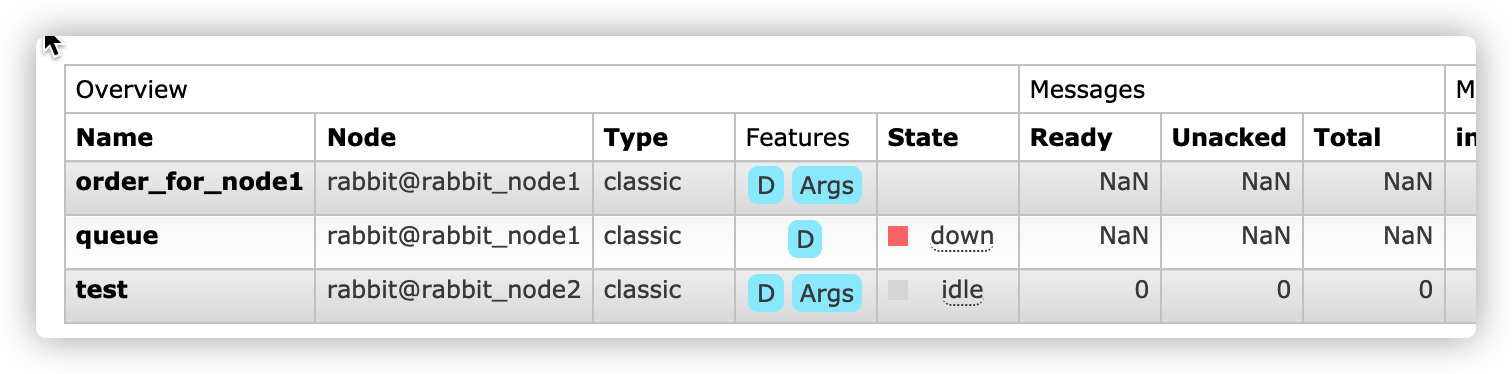
At this time, due to the election policy, nodes 2 and 3 are not synchronized and cannot become the primary master, so the current queue data is empty
Details are as follows
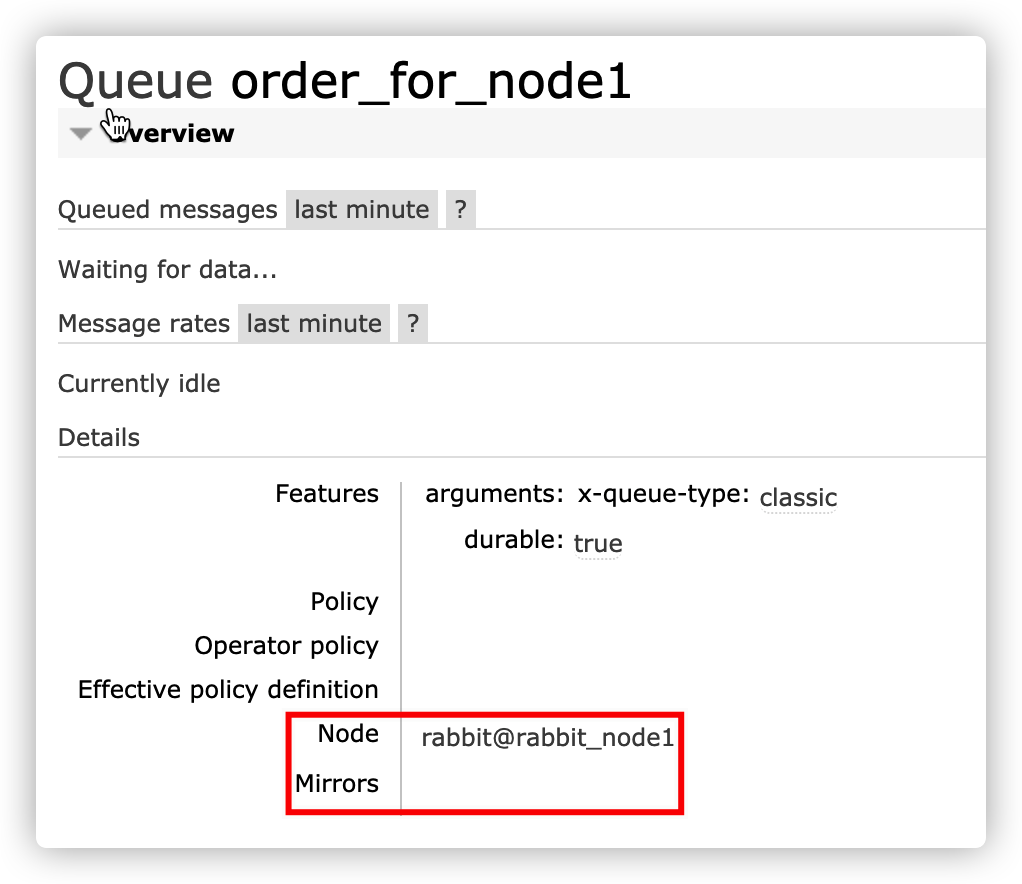
Fault recovery
The primary node is down, and the new node cannot be elected normally
The master node needs to be restarted
docker start rabbitmq1
After that, normal consumption is carried out. When the consumption of old tasks is completed, the master node and the slave node are fully synchronized
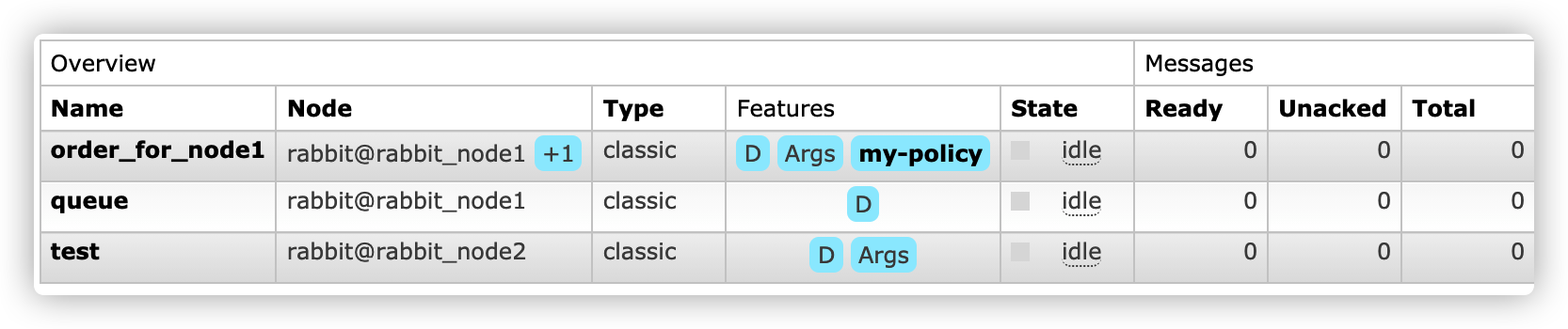
If both the master node and the slave node are disconnected, the slave node cannot start normally due to the master stop
Can pass
rabbitmqctl forget_cluster_node master --offline
--Offline: rabbitmqctl is allowed to execute on offline nodes
forget_ cluster_ The node command removes the node from the cluster, which forces RabbitMQ to select one of the non started slave nodes as the master
When shutting down the entire RabbitMQ cluster, the first node to restart should be the last node to shut down, because it can see things that other nodes cannot see
If the node cannot be started, you can copy and restore it through the disk file. Remember to modify the hostname
