
Article catalog
First of all, what is a web crawler and what it can be used for?
Here is a brief discussion about the legitimacy of web crawlers
Statistical analysis of CSDN blog reading data
Parsing web pages using Beautiful Soup
Statistics of blog reading in blog Park
Recommended supplementary reading: "Python development practical rookie tutorial" tool: hand-in-hand teaching, using VSCode to develop Python
0x01: Primer
This is a quick start practical tutorial for web crawlers. I hope readers can follow this blog to practice, so as to master the principle and basic operation of web crawlers. Some contents refer to: http://c.biancheng.net/view/2011.html
Source code address: https://github.com/xiaosongshine/simple_spider_py3
This blog includes the following:
- Understand web crawlers;
- Understand web pages;
- Use the requests library to grab website data;
- Use Beautiful Soup to parse web pages;
- Hand in hand combat operation statistical analysis of CSDN and blog reading data of blog Park
First of all, what is a web crawler and what it can be used for?
Baidu Encyclopedia Internet worm The introduction is as follows:
Web crawler is a method of automatically capturing World Wide Web information according to certain rules program perhaps script . Other infrequently used names include ants, automatic indexing, emulators, or worms.
It can be seen that a crawler is a program or script, and its essence is a code. The content of the code is a specific rule designed by programmers. The result of code execution is that information can be automatically retrieved from the world wide web (Internet).
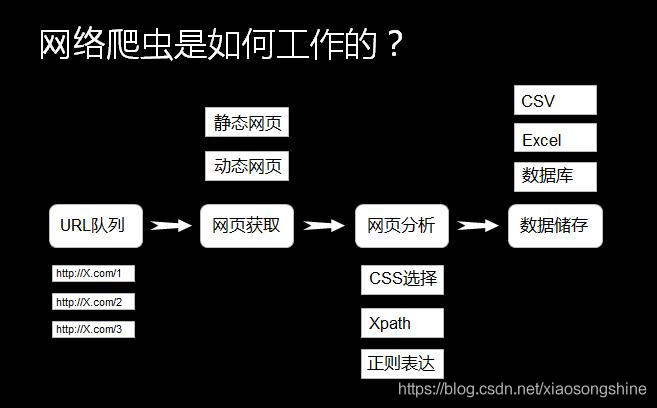
The principle of web crawler is shown in the figure above. Readers may not understand some terms. Don't be afraid. There will be a detailed description later. Take a practical example to illustrate the usage of web crawler:
For example, if you want to collect the photos of my goddess Liu Yifei, the general operation is to search for the photos of Liu Yifei from Baidu, and then download them from the web page one by one:
Manual downloading is time-consuming and laborious. In fact, you can write a web crawler (code) in Python to automatically (regularly) download pictures from this web page (obtain data from the Internet).
Xiao Song said: the above is a simple usage of the next web crawler. In fact, the function of the web crawler is very powerful. You can crawl photos, videos, music and text, but these are only basic usage. More applications can be realized based on the above functions. With the development of big data and artificial intelligence, data is becoming more and more important. The rapid development of computer vision and language model is inseparable from large-scale data, and many data are on the Internet, which needs to be screened and captured by web crawlers.
Here is a brief discussion about the legitimacy of web crawlers
Almost every website has one called robots Txt document, of course, some websites do not set robots txt. For robots that are not set Txt website can obtain data encrypted without password through web crawler, that is, all page data of the website can be crawled. If the website has robots Txt document, it is necessary to judge whether there is data that visitors are not allowed to obtain. Take Taobao as an example, visit in the browser https://www.taobao.com/robots.txt , as shown in the figure below.
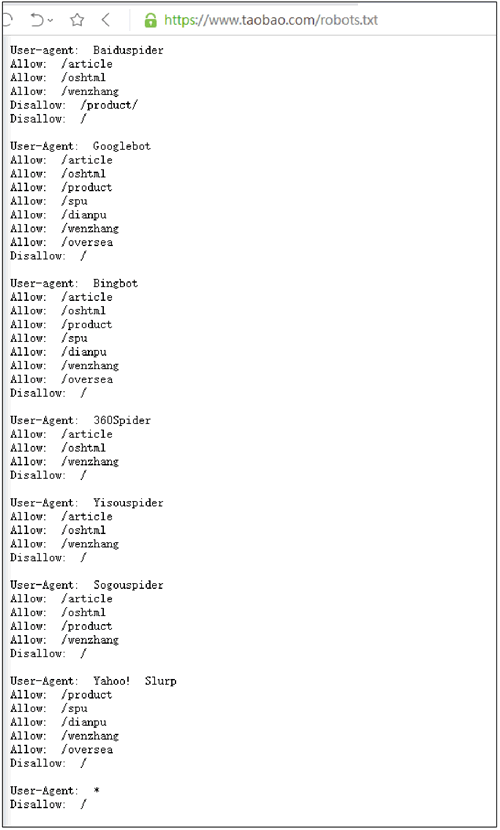
Taobao allows some crawlers to access some of its paths, while users who are not allowed are prohibited from crawling. The code is as follows:
User-Agent:* Disallow:/
This code means that other crawlers are not allowed to crawl any data except the crawlers specified above.
Before officially entering the actual battle of crawler, we need to understand the web page structure
Web pages are generally composed of three parts: HTML (Hypertext Markup Language), CSS (cascading style sheet) and JScript (Active Scripting Language).
HTML
Html is the structure of the whole web page, which is equivalent to the framework of the whole website. Tags with "<" and ">" symbols are HTML tags, and tags appear in pairs. Common labels are as follows:
<html>..</ HTML > indicates that the element in the middle of the tag is a web page <body>..</ Body > indicates the content visible to the user <div>..</ Div > represents the framework <p>..</ p> Represents a paragraph <li>..</ Li > indicates a list <img>..</ IMG > indicates a picture <h1>..</ H1 > indicates the title <a href="">..</ a> Represents a hyperlink
CSS
CSS represents style. Line 13 in Figure 1 < style type = "text/css" > indicates that a CSS is referenced below and the appearance is defined in CSS.
JScript
JScript represents the function. Interactive content and various special effects are in JScript, which describes various functions in the website. If the human body is used as an analogy, HTML is the human skeleton and defines where people's mouth, eyes and ears should grow. CSS is the appearance details of people, such as what the mouth looks like, whether the eyes are double eyelids or single eyelids, whether the eyes are big or small, whether the skin is black or white, etc. JScript represents human skills, such as dancing, singing or playing musical instruments.
Write a simple HTML
By writing and modifying HTML, you can better understand HTML. First open a notepad, and then enter the following:
<html>
<head>
<title> Python 3 Introduction and practice of crawler and data cleaning</title>
</head>
<body>
<div>
<p>Python 3 Introduction and practice of crawler and data cleaning</p>
</div>
<div>
<ul>
<li><a href="http://c.biancheng. Net "> crawler</a></li>
<li>Data cleaning</li>
</ul>
</div>
</body>After entering the code, save Notepad, and then modify the file name and suffix to "HTML.html"; The effect after running the file is shown in the following figure.
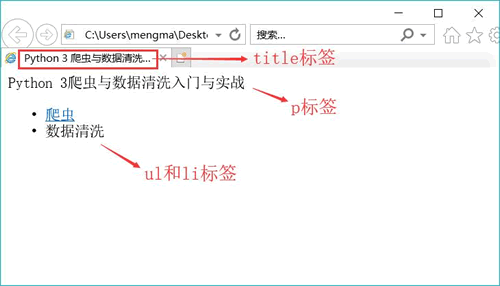
This code only uses HTML. Readers can modify the Chinese in the code and observe its changes.
Through the above content, we understand the basic principle and purpose of web crawler, and also understand the web page structure. Now let's enter the actual operation part to quickly master the web crawler through statistical analysis of the reading data of blog Park and CSDN blog.
0x02: practical operation
Installation dependency
The actual operation part is based on Python language, python 3 version, and the requests and Beautiful Soup libraries are used to request network connection and parse web page data respectively.
Because the Beautiful Soup has been ported to the bs4 library, that is, the bs4 library needs to be installed before importing the Beautiful Soup. After installing the bs4 library, you need to install the lxml library. If we don't install the lxml library, we will use Python's default parser. Although Beautiful Soup supports both HTML parsers in the python standard library and some third-party parsers, the lxml library has the characteristics of more powerful functions and faster speed. Therefore, the author recommends installing the lxml library.
Therefore, the first step is to install these libraries and execute them on the command line:
pip install requests pip install bs4 pip install lxml
Basic principles of reptiles
The process of web page request is divided into two links:
- Request: every web page displayed in front of the user must go through this step, that is, send an access request to the server.
- Response: after receiving the user's request, the server will verify the validity of the request, and then send the content of the response to the user (client). The client receives the content of the server response and displays the content, which is the familiar Web page request, as shown in the figure below.

There are also two ways to request web pages:
- GET: the most common method, which is generally used to obtain or query resource information. It is also used by most websites, with fast response speed.
- POST: compared with GET mode, it has more functions of uploading parameters in form. Therefore, in addition to querying information, you can also modify information.
Therefore, before writing a crawler, you should first determine who to send the request to and how to send it.
Since this blog is a simple introductory tutorial, only GET is used to realize the statistical analysis of CSDN and blog reading data. The complex POST method will not be introduced first, but will be introduced in detail in the next article.
Statistical analysis of CSDN blog reading data
First, we learn the basic operation of web crawler by how to count CSDN data.
Grab data using GET
First, demonstrate how to use GET for network access, and write the following Python code:
import requests #Import requests package url = 'https://xiaosongshine.blog.csdn.net/' strhtml = requests.get(url) #Get web page data print(strhtml.text)
The operation results are as follows:
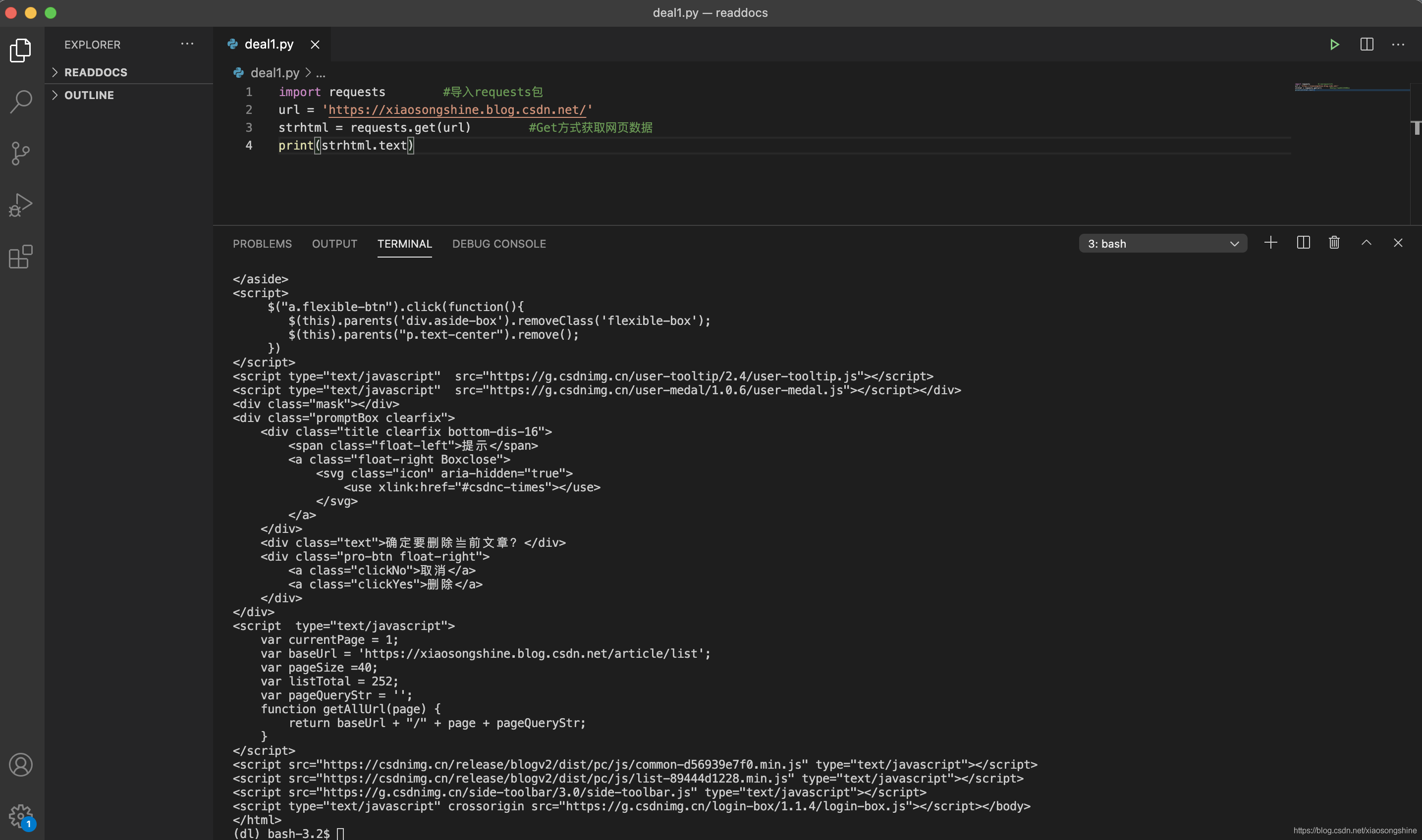
The author's home page data can be obtained correctly: https://xiaosongshine.blog.csdn.net/
The statement used to load the library is the name of the import + library. In the above process, the statement to load the requests library is: import requests. To obtain data by get, you need to call the get method in the requests library. The use method is to enter the English point number after requests, as shown below:
requests.get
Save the obtained data into strhtml variable. The code is as follows:
strhtml = request.get(url)
At this time, strhtml is a URL object, which represents the whole web page, but only the source code in the web page is needed. The following statement represents the web page source code:
strhtml.text
Parsing web pages using Beautiful Soup
Through the requests library, you can already catch the web page source code. Next, you need to find and extract data from the source code.
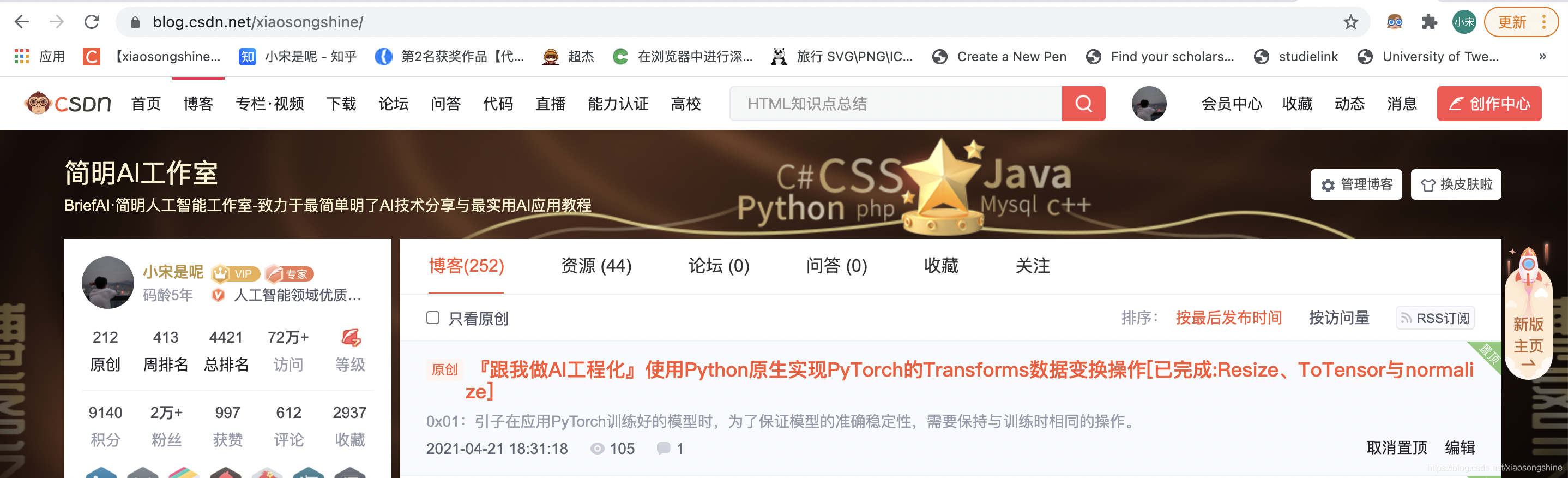
Enter the following code to start the Beautiful Soup tour and capture the reading of the first blog:
import requests #Import requests package
from bs4 import BeautifulSoup
url = 'https://xiaosongshine.blog.csdn.net/'
strhtml=requests.get(url)
soup=BeautifulSoup(strhtml.text,'lxml')
data = soup.select('#articleMeList-blog > div.article-list > div:nth-child(1) > div.info-box.d-flex.align-content-center > p > span:nth-child(2)')
print(data)The code running results are as follows:
[<span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>105</span>]
It can be seen that the corresponding reading amount of the first article 105 has been obtained (this number will increase with the reading amount, subject to the actual situation).
Beautiful Soup library can easily resolve web page information, it is integrated in the bs4 library, and can be invoked from the bs4 library when needed. The expression is as follows:
from bs4 import BeautifulSoup
First, the HTML document will be converted to Unicode encoding format, and then the Beautiful Soup selects the most appropriate parser to parse this document. Here, the lxml parser is specified for parsing. After parsing, the complex HTML document is transformed into a tree structure, and each node is a Python object. Here, the parsed document is stored in the new variable soup. The code is as follows:
soup=BeautifulSoup(strhtml.text,'lxml')
Next, use select to locate the data. When locating the data, you need to use the developer mode of the browser, pause the mouse cursor at the corresponding data position and right-click, and then select the "check" command in the shortcut menu, as shown in the following figure:
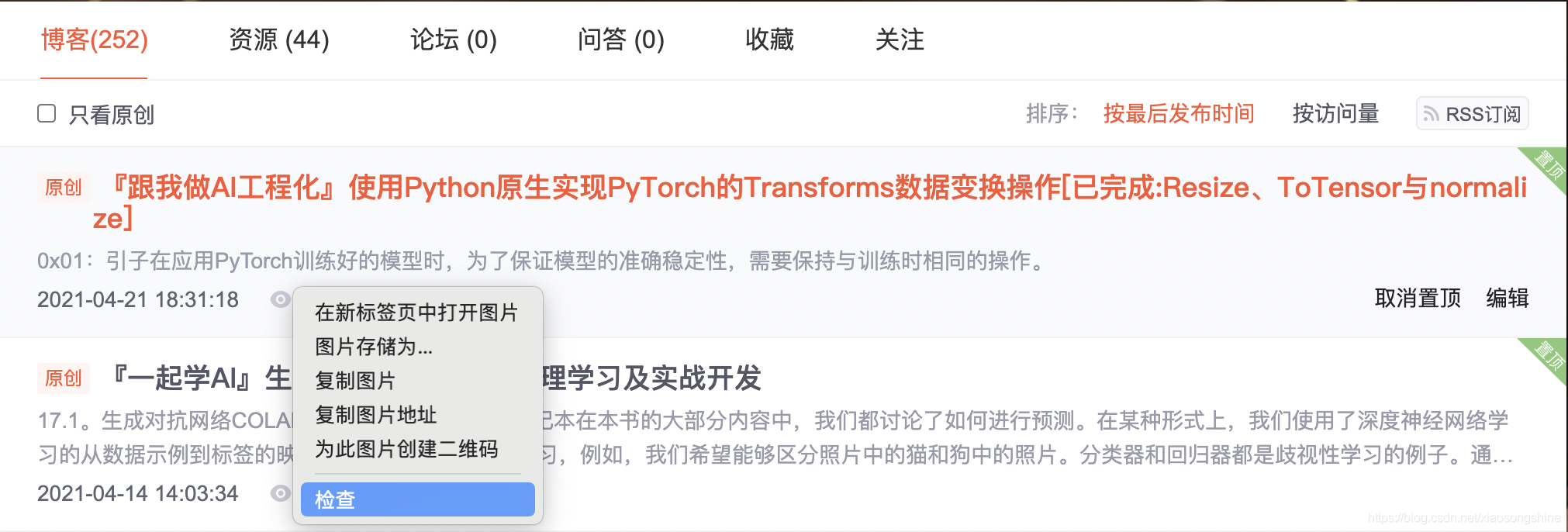
Then the developer interface will pop up on the right side of the browser, and the highlighted code on the right corresponds to the highlighted data text on the left. Right click the highlighted data on the right, and select "Copy" and "Copy Selector" in the pop-up shortcut menu to Copy the path automatically.
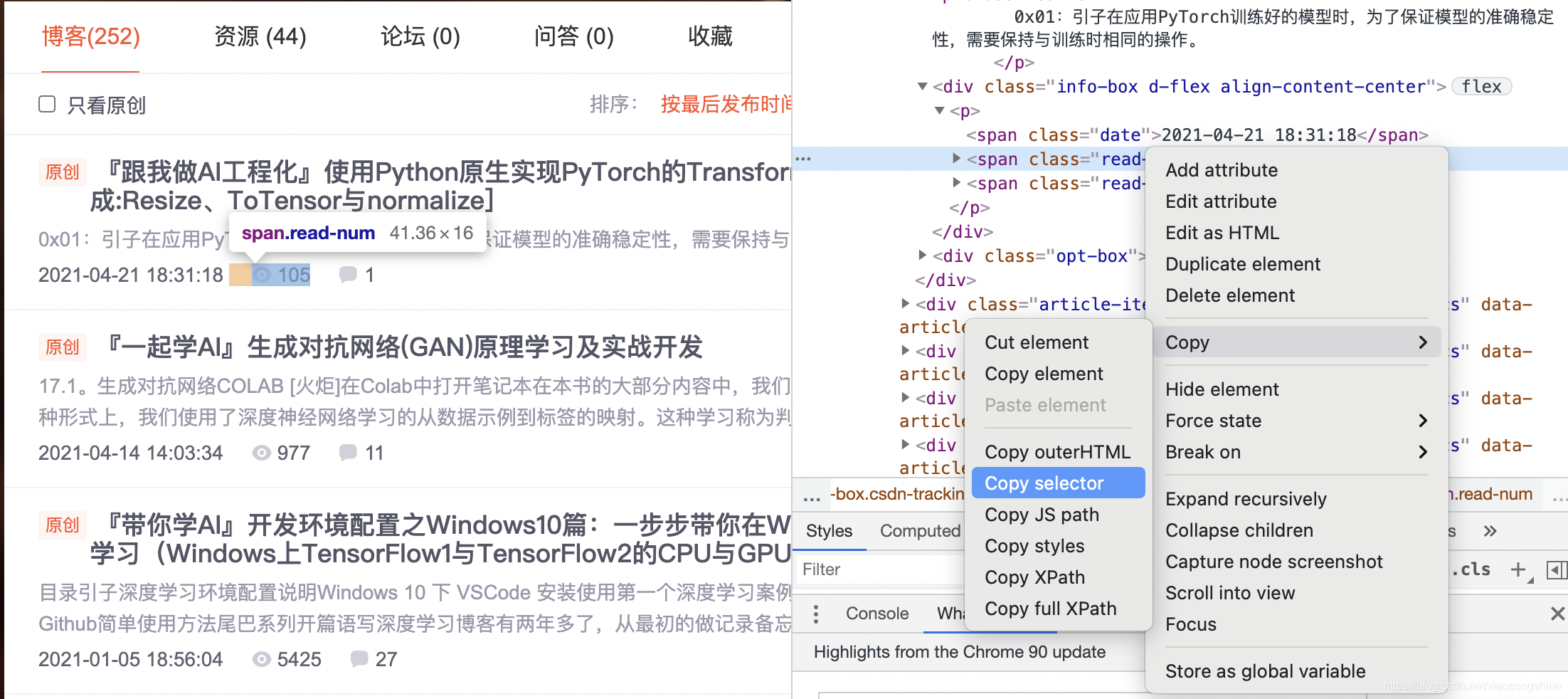
Paste the path into the document with the following code:
#articleMeList-blog > div.article-list > div:nth-child(1) > div.info-box.d-flex.align-content-center > p > span:nth-child(2)
Div: nth child (1) here actually corresponds to the first article. If you want to get the reading of all articles on the current page, you can delete the part after the colon (including colon) in div: nth child (1). The code is as follows:
#articleMeList-blog > div.article-list > div > div.info-box.d-flex.align-content-center > p > span:nth-child(2)
Using soup Select refers to this path. The code is as follows:
data = soup.select('#articleMeList-blog > div.article-list > div > div.info-box.d-flex.align-content-center > p > span:nth-child(2)')
To facilitate viewing, we can traverse the output data. The overall code is as follows: Text can get the text in the element, but note that it is of string type.
import requests #Import requests package
from bs4 import BeautifulSoup
url = 'https://xiaosongshine.blog.csdn.net/'
strhtml=requests.get(url)
soup=BeautifulSoup(strhtml.text,'lxml')
data = soup.select('#articleMeList-blog > div.article-list > div > div.info-box.d-flex.align-content-center > p > span:nth-child(2)')
for d in data:
print(d,d.text,type(d.text))Output is:
<span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>105</span> 105 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>977</span> 977 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>5425</span> 5425 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>4093</span> 4093 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>539</span> 539 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>170</span> 170 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>510</span> 510 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>695</span> 695 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>1202</span> 1202 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>969</span> 969 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>3126</span> 3126 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>2779</span> 2779 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>7191</span> 7191 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>27578</span> 27578 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>2167</span> 2167 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>7046</span> 7046 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>40308</span> 40308 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>13571</span> 13571 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>10535</span> 10535 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>6367</span> 6367 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>1820</span> 1820 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>1947</span> 1947 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>5054</span> 5054 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>3046</span> 3046 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>6491</span> 6491 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>3103</span> 3103 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>13892</span> 13892 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>14816</span> 14816 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>342</span> 342 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>5276</span> 5276 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>13097</span> 13097 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>64</span> 64 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>65</span> 65 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>246</span> 246 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>446</span> 446 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>128</span> 128 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>30</span> 30 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>207</span> 207 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>355</span> 355 <class 'str'> <span class="read-num"><img alt="" src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png"/>19</span> 19 <class 'str'>
In fact, through the above code, we can already get the reading volume of the first page. Below, we only need to make a statistics on all pages.
In order to obtain the url of paging information, you can get it by clicking the page navigation bar at the bottom:
As you can see, the url of page 1 is: https://xiaosongshine.blog.csdn.net/article/list/1
The following number 1 represents the first page. The author tries to use the selector to obtain the number of pages, as follows:
data = soup.select('#Paging_04204215338304449 > ul > li.ui-pager')The output is empty. I don't know if it is restricted. Welcome to the comment area.
Statistics CSDN blog data
It can be seen that the total number of pages of bloggers' articles is 7. Here, the author directly sets the total number of pages to 7 and makes a cycle to obtain the reading volume of all blogs. The overall code is as follows:
import requests #Import requests package
from bs4 import BeautifulSoup
read_all = 0
for i in range(7):
url = 'https://blog.csdn.net/xiaosongshine/article/list/%d'%(i+1)
strhtml=requests.get(url)
soup=BeautifulSoup(strhtml.text,'lxml')
data = soup.select('#articleMeList-blog > div.article-list > div > div.info-box.d-flex.align-content-center > p > span:nth-child(2)')
##Paging_04204215338304449 > ul > li.ui-pager
for d in data:
#print(d,d.text,type(d.text))
read_all += eval(d.text)
print(read_all)Output: 710036 (this number will increase with the number of readings, subject to the actual situation)
If you want to count your own reading, just change the url and set the number of pages.
Statistics of blog reading in blog Park
The method is similar to counting CSDN, obtaining the reading volume of the current page, and then summing all pages.
Statistics of current page reading code:
import requests #Import requests package
from bs4 import BeautifulSoup
url = 'https://www.cnblogs.com/xiaosongshine'
strhtml=requests.get(url)
soup=BeautifulSoup(strhtml.text,'lxml')
data = soup.select('#mainContent > div > div > div.postDesc > span.post-view-count')
for d in data:
print(d,d.text[3:-1],type(d.text))Output:
<span class="post-view-count" data-post-id="11615639">read(16603)</span> 16603 <class 'str'> <span class="post-view-count" data-post-id="11394918">read(880)</span> 880 <class 'str'> <span class="post-view-count" data-post-id="11362228">read(3217)</span> 3217 <class 'str'> <span class="post-view-count" data-post-id="11346550">read(2812)</span> 2812 <class 'str'> <span class="post-view-count" data-post-id="11303187">read(1599)</span> 1599 <class 'str'> <span class="post-view-count" data-post-id="10929934">read(3386)</span> 3386 <class 'str'> <span class="post-view-count" data-post-id="10926391">read(803)</span> 803 <class 'str'> <span class="post-view-count" data-post-id="10880094">read(3527)</span> 3527 <class 'str'> <span class="post-view-count" data-post-id="10874644">read(12612)</span> 12612 <class 'str'> <span class="post-view-count" data-post-id="10858829">read(245)</span> 245 <class 'str'> <span class="post-view-count" data-post-id="10858690">read(824)</span> 824 <class 'str'> <span class="post-view-count" data-post-id="10841818">read(3043)</span> 3043 <class 'str'> <span class="post-view-count" data-post-id="10831931">read(20058)</span> 20058 <class 'str'> <span class="post-view-count" data-post-id="10765958">read(3905)</span> 3905 <class 'str'> <span class="post-view-count" data-post-id="10750908">read(4254)</span> 4254 <class 'str'> <span class="post-view-count" data-post-id="10740050">read(2854)</span> 2854 <class 'str'> <span class="post-view-count" data-post-id="10739257">read(1759)</span> 1759 <class 'str'> <span class="post-view-count" data-post-id="10644401">read(1729)</span> 1729 <class 'str'> <span class="post-view-count" data-post-id="10618638">read(2585)</span> 2585 <class 'str'> <span class="post-view-count" data-post-id="10615575">read(1861)</span> 1861 <class 'str'> <span class="post-view-count" data-post-id="11652871">read(1704)</span> 1704 <class 'str'> <span class="post-view-count" data-post-id="11651856">read(2301)</span> 2301 <class 'str'> <span class="post-view-count" data-post-id="11635312">read(3648)</span> 3648 <class 'str'> <span class="post-view-count" data-post-id="11620816">read(671)</span> 671 <class 'str'> <span class="post-view-count" data-post-id="11615639">read(16603)</span> 16603 <class 'str'> <span class="post-view-count" data-post-id="11394918">read(880)</span> 880 <class 'str'> <span class="post-view-count" data-post-id="11362228">read(3217)</span> 3217 <class 'str'> <span class="post-view-count" data-post-id="11359003">read(2209)</span> 2209 <class 'str'> <span class="post-view-count" data-post-id="11356047">read(696)</span> 696 <class 'str'> <span class="post-view-count" data-post-id="11346550">read(2812)</span> 2812 <class 'str'>
Get pages:
import requests #Import requests package
from bs4 import BeautifulSoup
url = "https://www.cnblogs.com/xiaosongshine/default.html?page=2"
#When the page is the first page, the total number of pages cannot be displayed, so choose to visit the second page
htxt = requests.get(url)
soup=BeautifulSoup(htxt.text,'lxml')
data = soup.select("#homepage_top_pager > div > a")
for d in data:
print(d)
MN = len(data)-2
#Subtract previous and subsequent tabsComplete code for statistics of blog reading:
import requests #Import requests package
from bs4 import BeautifulSoup
url = "https://www.cnblogs.com/xiaosongshine/default.html?page=2"
#When the page is the first page, the total number of pages cannot be displayed, so choose to visit the second page
htxt = requests.get(url)
soup=BeautifulSoup(htxt.text,'lxml')
data = soup.select("#homepage_top_pager > div > a")
for d in data:
print(d)
MN = len(data)-2
#Subtract previous and subsequent tabs
read_all = 0
for i in range(MN):
url = "https://www.cnblogs.com/xiaosongshine/default.html?page=%d"%(i+1)
strhtml=requests.get(url)
soup=BeautifulSoup(strhtml.text,'lxml')
data = soup.select('#mainContent > div > div > div.postDesc > span.post-view-count')
for d in data:
#print(d,d.text[3:-1],type(d.text))
read_all += eval(d.text[3:-1])
print(read_all)Output:
<a href="https://www.cnblogs. com/xiaosongshine/default. html? Page = 1 "> previous page</a> <a href="https://www.cnblogs.com/xiaosongshine/default.html?page=1">1</a> <a href="https://www.cnblogs.com/xiaosongshine/default.html?page=3">3</a> <a href="https://www.cnblogs.com/xiaosongshine/default.html?page=4">4</a> <a href="https://www.cnblogs.com/xiaosongshine/default.html?page=5">5</a> <a href="https://www.cnblogs. com/xiaosongshine/default. html? Page = 3 "> next page</a> 217599
With simple emotion, CSDN reads 72w +, blog Park 21W +, Zhihu 63W +, Tencent cloud community 15W +, and the total reading is 180W +, which is getting closer and closer to 200W. Continue to work hard..
0x03: Postscript
This is the first content of the introduction to web crawler literacy. It is relatively simple. The later content will continue to deepen and become difficult. The content will involve how to use POST to realize simulated Login and how to capture and save complex data text. I hope the lovely and studious readers can stick to it with me. Source code address: https://github.com/xiaosongshine/simple_spider_py3 Finally, an after-school assignment is arranged. This blog demonstrates how to count the total reading volume. I hope readers can also count the number and content of praise and comments. If you have any questions, please communicate and interact with me in time.