Introduction: in history, the mobile Taobao client has received a variety of script engines, including js/python/wasm/lua. Among them, the js engine has received JavaScript core / duktape / V8 / quickjs, etc. Many engines will face problems related to package size and performance. Can we provide a scheme to support as many languages as possible with one engine on the premise of supporting business requirements, so as to give better consideration to small package size and excellent performance. In order to solve this problem, we began the exploration of hyengine.

Author Zhi Bing
Source: Ali technical official account
I. background introduction
In history, the mobile Taobao client has received a variety of script engines, including js/python/wasm/lua. Among them, the js engine has received JavaScript core / duktape / V8 / quickjs, etc. Many engines will face problems related to package size and performance. Can we provide a scheme to support as many languages as possible with one engine on the premise of supporting business requirements, so as to give better consideration to small package size and excellent performance. In order to solve this problem, we began the exploration of hyengine.
II. Introduction to design
"Hyengine is enough for the whole family" - hyengine is born for the execution engine of various scripting languages (wasm/js/python, etc.) required by unified mobile technology, with lightweight, high-performance and multilingual support as the design and R & D goal. At present, through jit compilation and runtime optimization of wasm3/quickjs, the execution speed of wasm/js has been improved by 2 ~ 3 times at the cost of very small package volume. In the future, support for Python and other languages will be increased by realizing its own bytecode and runtime.
Note: since most mobile phones currently support arm64, hyengine only supports the jit implementation of arm64.
Note: since ios does not support jit, hyengine currently has only android version.
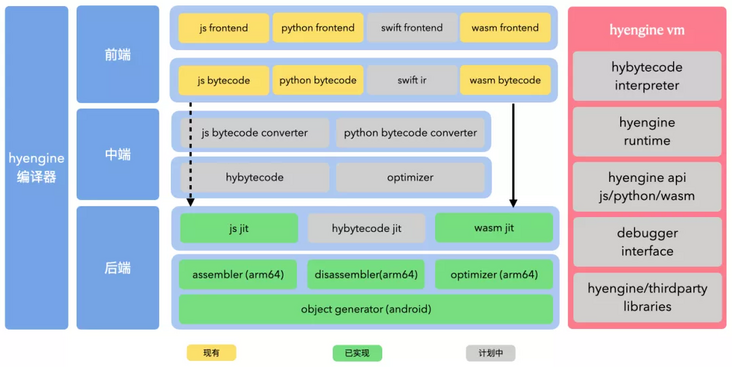
hyengine is divided into two parts as a whole, the compiler part and the engine part.
The compiler part is divided into front end, middle end and back end. The front end reuses the implementation of the existing script engine. For example, js uses quickjs and wasm uses emscripten. The middle end plans to implement its own set of bytecode, optimizer and bytecode converter. The back end implements the jit, assembler and optimizer of quickjs and wasm.
VM is divided into interpreter, runtime, api, debugging and basic library. Due to limited manpower, VM has no complete self implementation at present. It reuses quickjs/wasm3 code, improves performance by implementing its own internal allocator and gc and optimizing the existing runtime implementation.
The business code (take wasm as an example) is compiled into executable code through the process shown in the figure below:

c/c + + code is compiled into wasm file by emscripten. Wasm is loaded and compiled into arm64 instruction by hyengine(wasm3). Arm64 instruction is optimized by optimizer to produce optimized arm64 instruction. The business party executes the corresponding code by calling the entry api.
Note: hyengine itself expects to deposit a set of its own underlying (assembly level) basic capability library, which is not only used for jit related purposes, but also planned for scenarios such as package size, performance optimization and debugging assistance of mobile client.
Note: the ark compiler in this scheme may be similar to graalvm.
III. implementation introduction
1 compiler part
In order to make the implementation scheme simpler, hyengine is compiled by direct translation. The performance of the directly translated code is generally slow, which needs to be optimized by the optimizer to improve the performance. The following is the specific implementation of relevant modules:
Assembler
In order to generate the code that the cpu can execute, we need to implement an assembler to translate the opcode of the relevant script into machine code.
The core code of the assembler is generated according to the script based on the existing instruction data of golang's arch project, and assists in manual correction and corresponding tool code.
An example of a single assembly code is as follows:
// Name: ADC
// Arch: 32-bit variant
// Syntax: ADC <Wd>, <Wn>, <Wm>
// Alias:
// Bits: 0|0|0|1|1|0|1|0|0|0|0|Rm:5|0|0|0|0|0|0|Rn:5|Rd:5
static inline void ADC_W_W_W(uint32_t *buffer, int8_t rd, int8_t rn, int8_t rm) {
uint32_t code = 0b00011010000000000000000000000000;
code |= IMM5(rm) << 16;
code |= IMM5(rn) << 5;
code |= IMM5(rd);
*buffer = code;
}The function of the code is to assemble the ADC instruction. The first parameter is the buffer for storing the machine code, and the last three parameters are the operands Wd/Wn/Wm of the assembly instruction. The code in line 7 of the code is the fixed part of the machine code. Lines 8 to 10 put the register number corresponding to the operand into the position corresponding to the machine code (see the Bits section of the note type for details), and line 9 puts the machine code into the buffer. IMM5 represents the lower 5 Bits of the value, because the register is a 5 Bits long number. The advantage of this naming is that it can intuitively associate the method name of the assembler with the mnemonic form of the machine code it generates.
The implementation of IMM5 is as follows:
define IMM5(v) (v & 0b11111)
In order to ensure the correctness of the assembly method, we are based on GNU cases in golang's arch project Txt, using the method of machine generation + manual correction, the single test cases in the following format are output:
// 0a011f1a| adc w10, w8, wzr
ADC_W_W_W(&buffer, R10, R8, RZR);
assert(buffer == bswap32(0x0a011f1a));The first half of the comment in the first line is the big end representation of the machine code, and the second half is the assembly code corresponding to the machine code. The second line is the assembly method call of the assembler. The third line is to check the assembly result and confirm that the result is consistent with the machine code in the annotation. Since the machine code in the annotation is represented by the big end, byte swap needs to be done to match the assembly result.
Reverse assembler
The disassembler here does not include a complete disassembly function. The purpose is to identify the machine code in the optimizer and use the parameters in the machine code. Simple example:
#define IS_MOV_X_X(ins) \
(IMM11(ins >> 21) == IMM11(HY_INS_TEMPLATE_MOV_X_X >> 21) && \
IMM11(ins >> 5) == IMM11(HY_INS_TEMPLATE_MOV_X_X >> 5))This instruction can determine whether an instruction is mov, xd, XM in the optimizer, and then take out the specific value of d in xd through the following code:
#define RM(ins) IMM5(ins >> 16) #define RN(ins) IMM5(ins >> 5) #define RD(ins) IMM5(ins)
Similarly, we also made a corresponding single test for the disassembler:
// e7031eaa| mov x7, x30 assert(IS_MOV_X_X(bswap32(0xe7031eaa)));
wasm compilation
During compilation, we will traverse each method of wasm module, estimate the memory space required to store the product code, and then translate the bytecode in the method into machine code.
The overall implementation of the core translation is a large loop + switch. Each time an opcode is traversed, a corresponding machine code is generated. The code example is as follows:
M3Result h3_JITFunction(IH3JITState state, IH3JITModule hmodule,
IH3JITFunction hfunction) {
uint32_t *alloc = state->code + state->codeOffset;
......
// prologue
// stp x28, x27, [sp, #-0x60]!
// stp x26, x25, [sp, #0x10]!
// stp x24, x23, [sp, #0x20]
// stp x22, x21, [sp, #0x30]
// stp x20, x19, [sp, #0x40]
// stp x29, x30, [sp, #0x50]
// add x20, sp, #0x50
STP_X_X_X_I_PR(alloc + codeOffset++, R28, R27, RSP, -0x60);
STP_X_X_X_I(alloc + codeOffset++, R26, R25, RSP, 0x10);
STP_X_X_X_I(alloc + codeOffset++, R24, R23, RSP, 0x20);
STP_X_X_X_I(alloc + codeOffset++, R22, R21, RSP, 0x30);
STP_X_X_X_I(alloc + codeOffset++, R20, R19, RSP, 0x40);
STP_X_X_X_I(alloc + codeOffset++, R29, R30, RSP, 0x50);
ADD_X_X_I(alloc + codeOffset++, R29, RSP, 0x50);
......
for (bytes_t i = wasm; i < wasmEnd; i += opcodeSize) {
uint32_t index = (uint32_t)(i - wasm) / sizeof(u8);
uint8_t opcode = *i;
......
switch (opcode) {
case OP_UNREACHABLE: {
BRK_I(alloc + codeOffset++, 0);
break;
}
case OP_NOP: {
NOP(alloc + codeOffset++);
break;
}
......
case OP_REF_NULL:
case OP_REF_IS_NULL:
case OP_REF_FUNC:
default:
break;
}
if (spOffset > maxSpOffset) {
maxSpOffset = spOffset;
}
}
......
// return 0(m3Err_none)
MOV_X_I(alloc + codeOffset++, R0, 0);
// epilogue
// ldp x29, x30, [sp, #0x50]
// ldp x20, x19, [sp, #0x40]
// ldp x22, x21, [sp, #0x30]
// ldp x24, x23, [sp, #0x20]
// ldp x26, x25, [sp, #0x10]
// ldp x28, x27, [sp], #0x60
// ret
LDP_X_X_X_I(alloc + codeOffset++, R29, R30, RSP, 0x50);
LDP_X_X_X_I(alloc + codeOffset++, R20, R19, RSP, 0x40);
LDP_X_X_X_I(alloc + codeOffset++, R22, R21, RSP, 0x30);
LDP_X_X_X_I(alloc + codeOffset++, R24, R23, RSP, 0x20);
LDP_X_X_X_I(alloc + codeOffset++, R26, R25, RSP, 0x10);
LDP_X_X_X_I_PO(alloc + codeOffset++, R28, R27, RSP, 0x60);
RET(alloc + codeOffset++);
......
return m3Err_none;
}The above code will generate the prologue of the method, and then the for loop traverses the wasm bytecode to produce the corresponding arm64 machine code, and finally add the epilogue of the method.
Bytecode generates machine code to wasm opcode I32 Add as an example:
case OP_I32_ADD: {
LDR_X_X_I(alloc + codeOffset++, R8, R19, (spOffset - 2) * sizeof(void *));
LDR_X_X_I(alloc + codeOffset++, R9, R19, (spOffset - 1) * sizeof(void *));
ADD_W_W_W(alloc + codeOffset++, R9, R8, R9);
STR_X_X_I(alloc + codeOffset++, R9, R19, (spOffset - 2) * sizeof(void *));
spOffset--;
break;
}alloc in the code is the first address of the machine code of the method currently being compiled, codeOffset is the offset of the current machine code relative to the first address, R8/R9 represents the two temporary registers we agreed, R19 is the bottom address of the stack, and spOffset is the offset of the stack relative to the bottom of the stack when running to the current opcode.
This code will generate four machine codes, which are respectively used to load two pieces of data at spOffset - 2 and spOffset - 1 on the stack, add them, and then store the results at spOffset - 2 on the stack. Due to I32 The add instruction will consume two pieces of data on the stack and generate one piece of data on the stack. Finally, the offset of the stack will be - 1.
The machine code generated by the above code and its corresponding mnemonic form are as follows:
f9400a68: ldr x8, [x19, #0x10] f9400e69: ldr x9, [x19, #0x18] 0b090109: add w9, w8, w9 f9000a69: str x9, [x19, #0x10]
x represents the 64 bit register and w represents the lower 32 bits of the 64 bit register due to I32 The add instruction does 32-bit addition. Here, you only need to lower 32 bits.
The c code of fibonacci is as follows:
uint32_t fib_native(uint32_t n) {
if (n < 2) return n;
return fib_native(n - 1) + fib_native(n - 2);
}wasm code generated by compilation:
parse | load module: 61 bytes parse | found magic + version parse | ** Type [1] parse | type 0: (i32) -> i32 parse | ** Function [1] parse | ** Export [1] parse | index: 0; kind: 0; export: 'fib'; parse | ** Code [1] parse | code size: 29 compile | compiling: 'fib'; wasm-size: 29; numArgs: 1; return: i32 compile | estimated constant slots: 3 compile | start stack index: 1 compile | 0 | 0x20 .. local.get compile | 1 | 0x41 .. i32.const compile | | .......... (const i32 = 2) compile | 2 | 0x49 .. i32.lt_u compile | 3 | 0x04 .. if compile | 4 | 0x20 .... local.get compile | 5 | 0x0f .... return compile | 6 | 0x0b .. end compile | 7 | 0x20 .. local.get compile | 8 | 0x41 .. i32.const compile | | .......... (const i32 = 2) compile | 9 | 0x6b .. i32.sub compile | 10 | 0x10 .. call compile | | .......... (func= 'fib'; args= 1) compile | 11 | 0x20 .. local.get compile | 12 | 0x41 .. i32.const compile | | .......... (const i32 = 1) compile | 13 | 0x6b .. i32.sub compile | 14 | 0x10 .. call compile | | .......... (func= 'fib'; args= 1) compile | 15 | 0x6a .. i32.add compile | 16 | 0x0f .. return compile | 17 | 0x0b end compile | unique constant slots: 2; unused slots: 1 compile | max stack slots: 7
The output code compiled by hyengine jit is as follows:
0x107384000: stp x28, x27, [sp, #-0x60]! 0x107384004: stp x26, x25, [sp, #0x10] 0x107384008: stp x24, x23, [sp, #0x20] 0x10738400c: stp x22, x21, [sp, #0x30] 0x107384010: stp x20, x19, [sp, #0x40] 0x107384014: stp x29, x30, [sp, #0x50] 0x107384018: add x29, sp, #0x50 ; =0x50 0x10738401c: mov x19, x0 0x107384020: ldr x9, [x19] 0x107384024: str x9, [x19, #0x8] 0x107384028: mov w9, #0x2 0x10738402c: str x9, [x19, #0x10] 0x107384030: mov x9, #0x1 0x107384034: ldr x10, [x19, #0x8] 0x107384038: ldr x11, [x19, #0x10] 0x10738403c: cmp w10, w11 0x107384040: csel x9, x9, xzr, lo 0x107384044: str x9, [x19, #0x8] 0x107384048: ldr x9, [x19, #0x8] 0x10738404c: cmp x9, #0x0 ; =0x0 0x107384050: b.eq 0x107384068 0x107384054: ldr x9, [x19] 0x107384058: str x9, [x19, #0x8] 0x10738405c: ldr x9, [x19, #0x8] 0x107384060: str x9, [x19] 0x107384064: b 0x1073840dc 0x107384068: ldr x9, [x19] 0x10738406c: str x9, [x19, #0x10] 0x107384070: mov w9, #0x2 0x107384074: str x9, [x19, #0x18] 0x107384078: ldr x8, [x19, #0x10] 0x10738407c: ldr x9, [x19, #0x18] 0x107384080: sub w9, w8, w9 0x107384084: str x9, [x19, #0x10] 0x107384088: add x0, x19, #0x10 ; =0x10 0x10738408c: bl 0x10738408c 0x107384090: ldr x9, [x19] 0x107384094: str x9, [x19, #0x18] 0x107384098: mov w9, #0x1 0x10738409c: str x9, [x19, #0x20] 0x1073840a0: ldr x8, [x19, #0x18] 0x1073840a4: ldr x9, [x19, #0x20] 0x1073840a8: sub w9, w8, w9 0x1073840ac: str x9, [x19, #0x18] 0x1073840b0: add x0, x19, #0x18 ; =0x18 0x1073840b4: bl 0x1073840b4 0x1073840b8: ldr x8, [x19, #0x10] 0x1073840bc: ldr x9, [x19, #0x18] 0x1073840c0: add w9, w8, w9 0x1073840c4: str x9, [x19, #0x10] 0x1073840c8: ldr x9, [x19, #0x10] 0x1073840cc: str x9, [x19] 0x1073840d0: b 0x1073840dc 0x1073840d4: ldr x9, [x19, #0x10] 0x1073840d8: str x9, [x19] 0x1073840dc: mov x0, #0x0 0x1073840e0: ldp x29, x30, [sp, #0x50] 0x1073840e4: ldp x20, x19, [sp, #0x40] 0x1073840e8: ldp x22, x21, [sp, #0x30] 0x1073840ec: ldp x24, x23, [sp, #0x20] 0x1073840f0: ldp x26, x25, [sp, #0x10] 0x1073840f4: ldp x28, x27, [sp], #0x60 0x1073840f8: ret
This code runs fib_native(40) takes 1716ms, while wasm3 interprets and executes wasm. Running the same code takes 3637ms, which takes only about 47% of the interpretation execution, but is it fast enough?
optimizer
The above code seems to have no major problems, but when compared with the native code compiled by llvm, the gap comes out. fib_ The disassembly code of native c code compiled by llvm is as follows:

Hyengine produces 63 instructions, while llvm only produces 17 instructions. The number of instructions is about 3.7 times that of llvm! The actual performance gap is even greater. The code generated by hyengine runs fib_native(40) takes 1716ms, and the code produced by llvm takes 308ms, which is about 5.57 times longer than that of llvm.
In order to narrow the gap, it's time to do some optimization.
1) Main process of optimizer
The main process of the optimizer is as follows:

First, split the code of the whole method body according to the jump instruction (such as b/cbz) and its jump target address, and split the method body into multiple code blocks. Then run the optimized pass for each block to optimize the code in the block. Finally, the optimized instruction blocks are recombined into a method body, and the optimization is completed.
One of the reasons why the method body needs to be split into blocks is that the optimizer may delete or add code, so the jump target address of the jump instruction will change, and the jump target needs to be recalculated. After splitting into blocks, the jump target is easier to calculate.
In the implementation of block splitting and pass optimization, the disassembler and assembler mentioned earlier will be used, which is also the core dependency of the whole optimizer.
Let's take part of the code in the previous article as an example to introduce the optimization process. First, block splitting:
; --- code block 0 ---
0x107384048: ldr x9, [x19, #0x8]
0x10738404c: cmp x9, #0x0 ; =0x0
-- 0x107384050: b.eq 0x107384068 ; b.eq 6
|
| ; --- code block 1 ---
| 0x107384054: ldr x9, [x19]
| 0x107384058: str x9, [x19, #0x8]
| 0x10738405c: ldr x9, [x19, #0x8]
| 0x107384060: str x9, [x19]
| 0x107384064: b 0x1073840dc
|
| ; --- code block 2 ---
-> 0x107384068: ldr x9, [x19]
0x10738406c: str x9, [x19, #0x10]Here, the code will be split into three blocks according to the b.eq instruction in the fourth line of the code and its jump target address in line 14. Originally, the B instruction on line 11 also needs to be split, but the previous b.eq has been disassembled, so it will not be disassembled.
Next, a bunch of optimized pass es will be run for the code split into blocks. The results after running are as follows:
; --- code block 0 ---
0x104934020: cmp w9, #0x2 ; =0x2
-- 0x104934024: b.hs 0x104934038 ; b.hs 5
|
| ; --- code block 1 ---
| 0x104934028: mov x9, x20
| 0x10493402c: mov x21, x9
| 0x104934030: mov x20, x9
| 0x104934034: b 0x104934068
|
| ; --- code block 2 ---
-> 0x104934038: sub w22, w20, #0x2 ; =0x2After running a bunch of pass es, the code changes completely (see the next section for the implementation of Key Optimization), but it can be seen that the code of code block 1 has changed from 5 instructions to 4, and the previous b.eq has been optimized to reduce the offset of the target address of b.hs jump by 1, from 6 to 5.
Finally, the block is recombined into a new method body instruction:
0x104934020: cmp w9, #0x2 ; =0x2
0x104934024: b.hs 0x104934038 ; b.hs 5
0x104934028: mov x9, x20
0x10493402c: mov x21, x9
0x104934030: mov x20, x9
0x104934034: b 0x104934068
0x104934038: sub w22, w20, #0x2 ; =0x2
2) Register allocation for key optimization
One of the main reasons why the speed of 3.7 times the code volume is 5.57 times slower is that the data in our code is completely stored on the stack and on the memory. The access of various ldr/str instructions to the memory is 4 times slower than the access to the register even if the data is on the l1 cache of the cpu. Therefore, if we put the data in the register as much as possible and reduce the access to memory, we can further improve the performance.
There are some mature schemes for register allocation, including linear scan memory allocation based on live range, linear scan memory allocation based on live internal, and memory allocation based on graph coloring. In the common jit implementation, the linear scan memory allocation scheme based on live internal will be adopted to balance the product performance and the time complexity of register allocation code.
In order to achieve simplicity, hyengine uses a non mainstream minimalist scheme to allocate linear scan memory based on the number of code accesses. In other words, it allocates registers to the stack offset that occurs most frequently in the code.
The assumed code is as follows (excerpted from hyengine jit output code):
0x107384020: ldr x9, [x19] 0x107384024: str x9, [x19, #0x8] 0x107384028: mov w9, #0x2 0x10738402c: str x9, [x19, #0x10] 0x107384030: mov x9, #0x1 0x107384034: ldr x10, [x19, #0x8] 0x107384038: ldr x11, [x19, #0x10]
The code after allocating the register to the assumption code is as follows:
0x107384020: ldr x9, [x19] ; The offset 0 does not change 0x107384024: mov x20, x9 ; Offset 8 becomes x20 0x107384028: mov w9, #0x2 0x10738402c: mov x21, x9 ; Offset 16 becomes x21 0x107384030: mov x9, #0x1 0x107384034: mov x10, x20 ; Offset 8 becomes x20 0x107384038: mov x11, x21 ; Offset 16 becomes x21
After the previous jit product code is optimized, it is as follows (Note: a small amount of instruction fusion is done):
0x102db4000: stp x28, x27, [sp, #-0x60]! 0x102db4004: stp x26, x25, [sp, #0x10] 0x102db4008: stp x24, x23, [sp, #0x20] 0x102db400c: stp x22, x21, [sp, #0x30] 0x102db4010: stp x20, x19, [sp, #0x40] 0x102db4014: stp x29, x30, [sp, #0x50] 0x102db4018: add x29, sp, #0x50 ; =0x50 0x102db401c: mov x19, x0 0x102db4020: ldr x9, [x19] 0x102db4024: mov x20, x9 0x102db4028: mov x21, #0x2 0x102db402c: mov x9, #0x1 0x102db4030: cmp w20, w21 0x102db4034: csel x9, x9, xzr, lo 0x102db4038: mov x20, x9 0x102db403c: cmp x9, #0x0 ; =0x0 0x102db4040: b.eq 0x102db4054 0x102db4044: ldr x9, [x19] 0x102db4048: mov x20, x9 0x102db404c: str x20, [x19] 0x102db4050: b 0x102db40ac 0x102db4054: ldr x9, [x19] 0x102db4058: mov x21, x9 0x102db405c: mov x22, #0x2 0x102db4060: sub w9, w21, w22 0x102db4064: mov x21, x9 0x102db4068: add x0, x19, #0x10 ; =0x10 0x102db406c: str x21, [x19, #0x10] 0x102db4070: bl 0x102db4070 0x102db4074: ldr x21, [x19, #0x10] 0x102db4078: ldr x9, [x19] 0x102db407c: mov x22, x9 0x102db4080: mov x23, #0x1 0x102db4084: sub w9, w22, w23 0x102db4088: mov x22, x9 0x102db408c: add x0, x19, #0x18 ; =0x18 0x102db4090: str x22, [x19, #0x18] 0x102db4094: bl 0x102db4094 0x102db4098: ldr x22, [x19, #0x18] 0x102db409c: add w9, w21, w22 0x102db40a0: mov x21, x9 0x102db40a4: str x21, [x19] 0x102db40a8: nop 0x102db40ac: mov x0, #0x0 0x102db40b0: ldp x29, x30, [sp, #0x50] 0x102db40b4: ldp x20, x19, [sp, #0x40] 0x102db40b8: ldp x22, x21, [sp, #0x30] 0x102db40bc: ldp x24, x23, [sp, #0x20] 0x102db40c0: ldp x26, x25, [sp, #0x10] 0x102db40c4: ldp x28, x27, [sp], #0x60 0x102db40c8: ret
After optimization, the number of codes is reduced from 63 to 51, the number of memory accesses is significantly reduced, the time consumption is reduced to 1361ms, and the time consumption is reduced to about 4.42 times that of llvm.
3) Register parameter transfer for key optimization
In the last article of register allocation optimization, it is mentioned that the value of the register needs to be copied back to the stack during method call, which increases the overhead of memory access. The relevant assembly code is:
0x102db4068: add x0, x19, #0x10 ; =0x10
0x102db406c: str x21, [x19, #0x10]
0x102db4070: bl 0x102db4070
0x102db4074: ldr x21, [x19, #0x10]In the calling convention of arm64, parameters are passed through registers, so that each method call can reduce two memory accesses.
Here, the stack of wasm is put into x0, the first parameter x22 is directly put into x1, and the return value x0 after method call is directly put into x22. The optimized code is as follows:
0x1057e405c: add x0, x19, #0x10 ; =0x10
0x1057e4060: mov x1, x22
0x1057e4064: bl 0x1057e4064
0x1057e4068: mov x22, x0Note: here, because the stack offset 0 is also allocated with a register, the number of the register is 1 more than that of the code before optimization.
At the same time, take the code of parameter from the method header from:
0x102db4020: ldr x9, [x19] 0x102db4024: mov x20, x9
Optimized as:
0x1057e4020: mov x20, x1
Here, one memory access and one instruction are reduced.
The final complete code after optimization is as follows:
0x1057e4000: stp x28, x27, [sp, #-0x60]! 0x1057e4004: stp x26, x25, [sp, #0x10] 0x1057e4008: stp x24, x23, [sp, #0x20] 0x1057e400c: stp x22, x21, [sp, #0x30] 0x1057e4010: stp x20, x19, [sp, #0x40] 0x1057e4014: stp x29, x30, [sp, #0x50] 0x1057e4018: add x29, sp, #0x50 ; =0x50 0x1057e401c: mov x19, x0 0x1057e4020: mov x20, x1 0x1057e4024: mov x21, x20 0x1057e4028: mov x22, #0x2 0x1057e402c: mov x9, #0x1 0x1057e4030: cmp w21, w22 0x1057e4034: csel x9, x9, xzr, lo 0x1057e4038: mov x21, x9 0x1057e403c: cmp x9, #0x0 ; =0x0 0x1057e4040: b.eq 0x1057e404c 0x1057e4044: mov x21, x20 0x1057e4048: b 0x1057e409c 0x1057e404c: mov x22, x20 0x1057e4050: mov x23, #0x2 0x1057e4054: sub w9, w22, w23 0x1057e4058: mov x22, x9 0x1057e405c: add x0, x19, #0x10 ; =0x10 0x1057e4060: mov x1, x22 0x1057e4064: bl 0x1057e4064 0x1057e4068: mov x22, x0 0x1057e406c: mov x23, x20 0x1057e4070: mov x24, #0x1 0x1057e4074: sub w9, w23, w24 0x1057e4078: mov x23, x9 0x1057e407c: add x0, x19, #0x18 ; =0x18 0x1057e4080: mov x1, x23 0x1057e4084: bl 0x1057e4084 0x1057e4088: mov x23, x0 0x1057e408c: add w9, w22, w23 0x1057e4090: mov x22, x9 0x1057e4094: mov x20, x22 0x1057e4098: nop 0x1057e409c: mov x0, x20 0x1057e40a0: ldp x29, x30, [sp, #0x50] 0x1057e40a4: ldp x20, x19, [sp, #0x40] 0x1057e40a8: ldp x22, x21, [sp, #0x30] 0x1057e40ac: ldp x24, x23, [sp, #0x20] 0x1057e40b0: ldp x26, x25, [sp, #0x10] 0x1057e40b4: ldp x28, x27, [sp], #0x60 0x1057e40b8: ret
After optimization, the number of codes is reduced from 51 to 47, the time consumption is reduced to 687ms, and the time consumption is reduced to about 2.23 times that of llvm. Although the number of codes is reduced by only 4, the time consumption is significantly reduced by about 50%.
Note: this optimization only skips the methods with short method body and frequent calls, and the code effect with long method body is not obvious.
4) Feature matching for key optimization
Feature matching is to traverse the preset code features in the code and optimize the code that conforms to the features.
For example, in the above code:
0x1057e404c: mov x22, x20 0x1057e4050: mov x23, #0x2 0x1057e4054: sub w9, w22, w23 0x1057e4058: mov x22, x9
Can be optimized to:
0x104934038: sub w22, w20, #0x2 ; =0x2
Four instructions become one.
5) Optimization results
After the above optimization, the code becomes:
0x104934000: stp x24, x23, [sp, #-0x40]!
0x104934004: stp x22, x21, [sp, #0x10]
0x104934008: stp x20, x19, [sp, #0x20]
0x10493400c: stp x29, x30, [sp, #0x30]
0x104934010: add x29, sp, #0x30 ; =0x30
0x104934014: mov x19, x0
0x104934018: mov x20, x1
0x10493401c: mov x9, x20
0x104934020: cmp w9, #0x2 ; =0x2
0x104934024: b.hs 0x104934038
0x104934028: mov x9, x20
0x10493402c: mov x21, x9
0x104934030: mov x20, x9
0x104934034: b 0x104934068
0x104934038: sub w22, w20, #0x2 ; =0x2
0x10493403c: add x0, x19, #0x10 ; =0x10
0x104934040: mov x1, x22
0x104934044: bl 0x104934000
0x104934048: mov x22, x0
0x10493404c: sub w23, w20, #0x1 ; =0x1
0x104934050: add x0, x19, #0x18 ; =0x18
0x104934054: mov x1, x23
0x104934058: bl 0x104934000
0x10493405c: add w9, w22, w0
0x104934060: mov x22, x9
0x104934064: mov x20, x9
0x104934068: mov x0, x20
0x10493406c: ldp x29, x30, [sp, #0x30]
0x104934070: ldp x20, x19, [sp, #0x20]
0x104934074: ldp x22, x21, [sp, #0x10]
0x104934078: ldp x24, x23, [sp], #0x40
0x10493407c: retThe amount of optimized code is reduced from 63 to 32, the time-consuming is reduced from 1716ms to 493ms, and the time-consuming is reduced to about 1.6 times that of llvm.
quickjs compilation
Note: js mainly takes time at runtime, so jit only accounts for about 20% of the overall performance optimization of js. More details of jit optimization will be introduced later.
The compilation process of quickjs is similar to that of wasm, but the implementation of opcode will be a little more complex, with Op_ Take object as an example:
// *sp++ = JS_NewObject(ctx);
// if (unlikely(JS_IsException(sp[-1])))
// goto exception;
case OP_object: {
MOV_FUNCTION_ADDRESS_TO_REG(R8, JS_NewObject);
MOV_X_X(NEXT_INSTRUCTION, R0, CTX_REG);
BLR_X(NEXT_INSTRUCTION, R8);
STR_X_X_I(NEXT_INSTRUCTION, R0, R26, SP_OFFSET(0));
CHECK_EXCEPTION(R0, R9);
break;
}Here, first through mov_ FUNCTION_ ADDRESS_ TO_ The reg macro sets the JS to be called_ The address of the newobject method is placed in the R8 register:
#define MOV_FUNCTION_ADDRESS_TO_REG(reg, func) \
{ \
uintptr_t func##Address = (uintptr_t)func; \
MOVZ_X_I_S_I(NEXT_INSTRUCTION, reg, IMM16(func##Address), LSL, 0); \
if (IMM16(func##Address >> 16) != 0) { \
MOVK_X_I_S_I(NEXT_INSTRUCTION, reg, IMM16(func##Address >> 16), \
LSL, 16); \
} else { \
NOP(NEXT_INSTRUCTION); \
} \
if (IMM16(func##Address >> 32) != 0) { \
MOVK_X_I_S_I(NEXT_INSTRUCTION, reg, IMM16(func##Address >> 32), \
LSL, 32); \
} else { \
NOP(NEXT_INSTRUCTION); \
} \
if (IMM16(func##Address >> 48) != 0) { \
MOVK_X_I_S_I(NEXT_INSTRUCTION, reg, IMM16(func##Address >> 48), \
LSL, 48); \
} else { \
NOP(NEXT_INSTRUCTION); \
} \
}Then ctx_ Reg (ctx address stored inside) puts R0 as the first parameter and calls JS_NewObject, and then the result is stored in the SP of the js stack_ Offset (0) position. Then CHECK_EXCEPTION determines whether there is an exception in the result:
#define EXCEPTION(tmp) \
LDR_X_X_I(NEXT_INSTRUCTION, tmp, CTX_REG, HYJS_BUILTIN_OFFSET(0)); \
MOV_X_I(NEXT_INSTRUCTION, R0, SP_OFFSET(0)); \
BLR_X(NEXT_INSTRUCTION, tmp);
#define CHECK_EXCEPTION(reg, tmp) \
MOV_X_I(NEXT_INSTRUCTION, tmp, ((uint64_t)JS_TAG_EXCEPTION<<56)); \
CMP_X_X_S_I(NEXT_INSTRUCTION, reg, tmp, LSL, 0); \
B_C_L(NEXT_INSTRUCTION, NE, 4 * sizeof(uint32_t)); \
EXCEPTION(tmp)The arm64 machine code generated by this opcode is as many as 13! And that's not much.
It is also the implementation of fibonacci. There are only 32 jit product codes in wasm and 467 in quickjs!!! I remembered the fear of being dominated by compilation.
Note: such instructions are derived from the call, reference count and type judgment of builtin. Later, vm optimization reduces the number of codes to 420 after the reference count is eliminated.
2 engine (vm) part
Because wasm itself is a strongly typed bytecode, the runtime itself provides less capabilities, and the performance bottleneck is mainly in the interpretation and execution of the code, the vm part is basically not optimized. As a weak type of bytecode, the main function of quickjs needs to be realized by runtime. At the same time, because the language itself takes over the memory management, the gc overhead is also obvious.
After the performance analysis of a business js code, it is found that more than 50% of the performance overhead is on memory allocation and gc. Therefore, the engine part will mainly introduce the memory allocation and gc optimization of quickjs. At present, the optimization proportion of fast path and inline cache of some runtime builtin is not high, so only a few introduction will be made.
Memory allocator hymalloc
In order to realize hyengine's performance optimization of quickjs and give consideration to the memory management right required by gc optimization, a set of faster (lock free, non thread safe) memory allocator needs to be designed. At the same time, we need to consider customization for other engines to make hymalloc as common as possible.
1) Implementation introduction
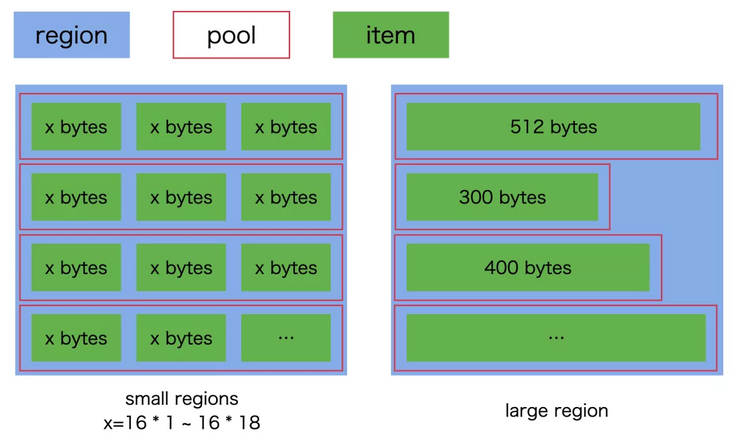
hymalloc divides the memory into 19 regions, 18 small regions / 1 large region. small region is mainly used to store rule memory. The size of each region ranges from 116 to 1916 bytes; Large region is used to store memory larger than 9*16 bytes.
Each area can contain multiple pools, and each pool can contain multiple items of target size. large region is special. There is only one entry in each pool. When applying for memory from the system, apply by pool, and then split the pool into corresponding items.
Each small region is initialized with a pool. The size of the pool is configurable. The default is 1024 item s; large region is empty by default.
The schematic diagram of area / block / pool is as follows:
Here are two key data structures:
// hymalloc item
struct HYMItem {
union {
HYMRegion* region; // set to region when allocated
HYMItem* next; // set to next free item when freed
};
size_t flags;
uint8_t ptr[0];
};
// hymalloc pool
struct HYMPool {
HYMRegion *region;
HYMPool *next;
size_t item_size;
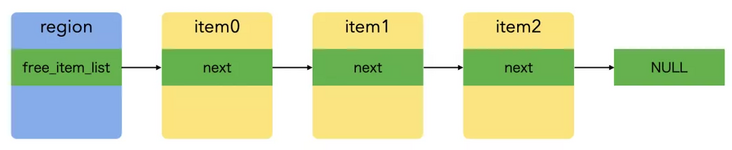
};HYMItem is the data structure of the item mentioned above. The size of the item here is not fixed, and the data structure itself is more like the description of the item header. flags currently exists as a special mark of gc, and ptr is used to get the address of the actual available memory of the item (obtained through & item - > ptr). region/next in the union is designed to save memory. Before the item is allocated, the value of next points to the next free item in the region; After the item is allocated, the region is set to the region address to which the item belongs.
The idle item chain of region indicates the following intentions:
During memory allocation, take the first item of the linked list as the allocation result. If the linked list is empty, apply to the system for a new pool and put the item of the pool into the linked list. The allocation diagram is as follows:
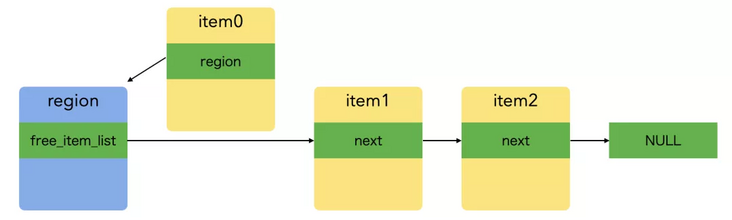
The allocation code is as follows:
static void* _HYMallocFixedSize(HYMRegion *region, size_t size) {
// allocate new pool, if no free item exists
if (region->free_item_list == NULL) {
// notice: large region's item size is 0, use 'size' instead
size_t item_size = region->item_size ? region->item_size : size;
int ret = _HYMAllocPool(region, region->pool_initial_item_count, item_size);
if (!ret) {
return NULL;
}
}
// get free list item head, and set region to item's region
HYMItem *item = region->free_item_list;
region->free_item_list = item->next;
item->region = region;
item->flags = 0;
return &item->ptr;
}When the memory is released, insert the item into the header of the free linked list of the region:
void HYMFree(void *ptr) {
HYMItem *item = (HYMItem *)((uint8_t *)ptr - HYM_ITEM_SIZE_OVERHEAD);
// set item as head of region's free item list
HYMRegion *region = item->region;
HYMItem *first_item_in_region = region->free_item_list;
region->free_item_list = item;
item->next = first_item_in_region;
}In the simple memory allocation / release test case, the above implementation is about 4 times faster than the malloc/free provided by the system on the macbook m1 device.
2) Memory compact + update
In order to reduce memory occupation, hymalloc implements partial memory compact, which can clean up all pools in small region and large region that are completely unused. However, the update function is not implemented at present, so it is impossible to really copy item s between different pools to save more memory.
However, from the use scenario of the client, the memory consumption of the running code itself is not high, and the implementation complexity of the complete combination of compact + update is high and the cost performance is insufficient. Subsequently, the necessity of implementing complete Compact + update will be evaluated according to the actual business usage.
3) Limitations of hymalloc
In order to improve the allocation and release performance, each item of hymalloc has a header, which requires additional memory space, which will lead to a certain waste of memory.
Moreover, although hymalloc provides the compact method to release the free memory, since the memory is applied in batches according to the pool, as long as an item in the pool is used, the pool will not be released, resulting in the memory can not be released completely and efficiently.
In addition, considering the probability of memory reuse, the memory of large region will be applied by 256bytes by default, which may also be wasted.
The above problems can reduce memory waste by setting a smaller number of default item s of the pool and a smaller alignment size at the expense of a small amount of performance.
Later, more reasonable data structures and more perfect compact + update mechanism can be introduced to reduce memory waste.
Garbage collector hygc
The original gc of quickjs is based on reference counting + mark sweep. The design and implementation itself is relatively simple and efficient, but it does not realize generation, multithreading, compact, idle gc and copy gc, which makes gc account for a high proportion of the overall execution time. At the same time, it also has the potential performance degradation caused by memory fragmentation. In addition, due to the existence of reference counting, there will be a large number of instructions of reference counting operation in the code generated by jit, which makes the code volume larger.
In order to optimize the performance of quick JS by hyengine, reduce the proportion of gc in the overall time-consuming species, and reduce the long-term operation stop caused by gc. Referring to the gc design ideas of v8 and other advanced engines, a set of lightweight, high-performance and simple gc suitable for mobile services is realized.
Note: this implementation is only for quickjs, and a general gc implementation may be derived later.
Note: in order to ensure that the business experience does not get stuck, it is necessary to control the pause time of gc within 30ms.
1) Implementation of common garbage collection
There are three main categories of commonly used garbage collection:
Reference count
Add one reference quantity to each object, one more reference quantity + 1 and one less reference quantity - 1. If the reference quantity is 0, it will be released.
Disadvantages: the circular reference problem cannot be solved.
mark sweep
Traverse the object and mark whether the object has a reference. If not, please clean it up.
Copy gc
Traverse the object, mark whether the object has a reference, copy a new copy of the referenced object, and discard all the old memory.
Based on these three categories, there will be some derivatives to realize multithreading and other support, such as:
Trichromatic marker gc
Traverse the object and mark whether the object has a reference. The state is one more intermediate state than the simple reference (black) and no reference (white). It is marked medium / uncertain (gray), and can support multithreading.
In order to reduce gc pause time and js execution time as much as possible, hygc adopts a multi-threaded three color gc scheme. In the business case test, it is found that the memory usage is not large, so generation support is not introduced.
2) Business strategy of hygc
hygc plans to expose the policies to users to meet the performance requirements of different usage scenarios. It provides three options: no gc, idle gc and multi-threaded gc to meet the different demands of different scenarios on memory and performance. The business selects the gc policy according to the actual needs. It is recommended to set the switch on the gc policy to avoid that the selected gc policy may lead to unexpected results.
- No gc
gc operations are not triggered during runtime.
When the code is completely run and the runtime is destroyed, do a full gc to release the memory as a whole.
- Idle time gc
The gc operation is not triggered during the running period. After the running, the gc is performed in the asynchronous thread.
When the code is completely run and the runtime is destroyed, do a full gc to release the memory as a whole.
- Default gc
The runtime triggers gc.
When the code is completely run and the runtime is destroyed, do a full gc to release the memory as a whole.
One of our business case s can set no gc or idle gc, because there is no memory to be recycled during code running, and gc is a waste of time.
3) Implementation scheme of hygc
Quickjs originally adopted the gc scheme of reference counting + mark sweep, which was removed during gc optimization and replaced by a new multi-threaded three color mark gc scheme. The implementation of hygc reuses part of the original quickjs code to achieve the required functions as simple as possible.
Three color marking process of hygc (single thread version):

First, the main operation of collecting the root object is to scan the js thread stack, and collect the js objects on the thread stack and the objects associated with the js call stack as the root object of the three color tag. Then, the child objects are marked recursively from the root object as the mark entry. Ergodic gc_obj_list (all objects requiring gc in quickjs are on this two-way linked list), and put the objects not marked into tmp_obj_list. Finally, release tmp_obj_list.
Single threaded gc will completely suspend the execution of js in the gc process, resulting in potential business jam risk (only potential, because the memory usage of the actual business is small, there is no jam caused by gc temporarily), and the execution time of js will be relatively long. To this end, hygc introduces multi-threaded three color tags. The process is as follows:

In the multi-threaded version, there are two threads: js and gc. js thread collects the root object and transfers the old object to the asynchronous gc linked list, and then js continues to execute. The gc thread will first set all the three color tags of the old object to 0, then start marking the living object, and then collect the garbage object. Here, the garbage object release is divided into two stages. One is the modification and emptying of garbage object related attributes that can be executed in the gc thread, and the other is the memory release that needs to be done in the js thread. The reason for this is that hymalloc is not thread safe. In this way, there are only three relatively time-consuming gc operations in js thread: root object collection, old object transfer and memory release.
Note: sadly, because mark and garbage collection are still only completed in a single thread, only two colors are used for marking here, and gray is not actually used. Subsequent optimizations enable the hygc implementation to coexist with the original gc of quickjs, thus reducing the migration risk of gc.
4) Limitations of hygc
When the asynchronous thread of hygc is doing garbage collection, it will only do gc for the old object. After the transfer of the old object, the new object will not participate in gc, which may increase the peak memory usage. The degree of improvement is related to the execution time of the gc thread.
This problem will also be solved by determining whether to optimize the scheme according to the actual situation.
Other optimization examples
1) inline cache of global objects
The operation of quickjs's global object is compiled separately as OP_get_var/OP_put_var and other OPS, and the implementation of these two OPS is particularly slow. Therefore, we add inline cache to global object access. The object attribute access of js can be simply understood as traversing the array to find the desired attribute. The purpose of inline cache is to cache the offset in the array where the attribute accessed by a piece of code is located, so that the offset can be directly used for the next retrieval, and there is no need to repeat the attribute array traversal.
The data structure of global inline cache is as follows:
typedef struct {
JSAtom prop; // property atom
int offset; // cached property offset
void *obj; // global_obj or global_var_obj
} HYJSGlobalIC;
Here's line 4 void *obj It's special because quickjs of global May exist context Object global_obj or global_var_obj Which of them need to be put together cache Yes.
The specific code is as follows:
case OP_get_var: { // 73
JSAtom atom = get_u32(buf + i + 1);
uint32_t cache_index = hyjs_GetGlobalICOffset(ctx, atom);
JSObject obj;
JSShape shape;
LDR_X_X_I(NEXT_INSTRUCTION, R8, CTX_REG, (int32_t)((uintptr_t)&ctx->global_ic - (uintptr_t)ctx));
ADD_X_X_I(NEXT_INSTRUCTION, R8, R8, cache_index * sizeof(HYJSGlobalIC));
LDP_X_X_X_I(NEXT_INSTRUCTION, R0, R9, R8, 0);
CBZ_X_L(NEXT_INSTRUCTION, R9, 12 * sizeof(uint32_t)); // check cache exsits
LSR_X_X_I(NEXT_INSTRUCTION, R1, R0, 32); // get offset
LDR_X_X_I(NEXT_INSTRUCTION, R2, R9, (int32_t)((uintptr_t)&obj.shape - (uintptr_t)&obj)); // get shape
ADD_X_X_I(NEXT_INSTRUCTION, R2, R2, (int32_t)((uintptr_t)&shape.prop - (uintptr_t)&shape)); // get prop
LDR_X_X_W_E_I(NEXT_INSTRUCTION, R3, R2, R1, UXTW, 3); // get prop
LSR_X_X_I(NEXT_INSTRUCTION, R3, R3, 32);
CMP_W_W_S_I(NEXT_INSTRUCTION, R0, R3, LSL, 0);
B_C_L(NEXT_INSTRUCTION, NE, 5 * sizeof(uint32_t));
LDR_X_X_I(NEXT_INSTRUCTION, R2, R9, (int32_t)((uintptr_t)&obj.prop - (uintptr_t)&obj)); // get prop
LSL_W_W_I(NEXT_INSTRUCTION, R1, R1, 4); // R1 * sizeof(JSProperty)
LDR_X_X_W_E_I(NEXT_INSTRUCTION, R0, R2, R1, UXTW, 0); // get value
B_L(NEXT_INSTRUCTION, 17 * sizeof(uint32_t));
MOV_FUNCTION_ADDRESS_TO_REG(R8, HYJS_GetGlobalVar);
MOV_X_X(NEXT_INSTRUCTION, R0, CTX_REG);
MOV_IMM32_TO_REG(R1, atom);
MOV_X_I(NEXT_INSTRUCTION, R2, opcode - OP_get_var_undef);
MOV_X_I(NEXT_INSTRUCTION, R3, cache_index);
BLR_X(NEXT_INSTRUCTION, R8);
CHECK_EXCEPTION(R0, R9);
STR_X_X_I(NEXT_INSTRUCTION, R0, R26, SP_OFFSET(0));
i += 4;
break;
}The first is hyjs on line 5_ Getglobalicoffset. This method will allocate an inline cache for the current opcode_ Index, this cache_ The index will be set to hyjs on line 31_ The fourth parameter of the getglobalvar method call. Lines 9 to 19 of the code will be based on the cache_index takes the cache, and according to the offset in the cache, takes the prop (that is, the attribute id and the data type is atom) stored in the corresponding offset of the global object, and compares it with the atom of the attribute of the object to be taken to confirm whether the cache is still valid. If the cache is valid, get the object attribute array directly through the code in lines 20-22. If it is invalid, go to the slow path in line 26, traverse the attribute array, and update the inline cache.
2) Fast path optimization of builtin
Fast path optimization is to put forward some parts of the code with higher execution probability separately to avoid the slow performance of redundant code.
In array Take the implementation of indexof as an example:
static JSValue hyjs_array_indexOf(JSContext *ctx, JSValueConst func_obj,
JSValueConst obj,
int argc, JSValueConst *argv, int flags)
{
......
res = -1;
if (len > 0) {
......
// fast path
if (JS_VALUE_GET_TAG(element) == JS_TAG_INT) {
for (; n < count; n++) {
if (JS_VALUE_GET_PTR(arrp[n]) == JS_VALUE_GET_PTR(element)) {
res = n;
goto done;
}
}
goto property_path;
}
// slow path
for (; n < count; n++) {
if (js_strict_eq2(ctx, JS_DupValue(ctx, argv[0]),
JS_DupValue(ctx, arrp[n]), JS_EQ_STRICT)) {
res = n;
goto done;e
}
}
......
}
done:
return JS_NewInt64(ctx, res);
exception:
return JS_EXCEPTION;
}The original implementation is a slow path starting from line 23, where JS needs to be called_ strict_ Eq2 method to determine whether the array indexes are equal. This comparison method will be relatively heavy. In fact, the index is of type int in most cases, so the fast path in line 12 is proposed. If the index itself is of type int, the direct comparison of int data will be better than calling js_strict_eq2 to compare faster.
IV. optimization results
The performance test equipment is macbook based on m1(arm64) chip, and the wasm service performance test is based on huawei mate 8 mobile phone; The test result selection method is to run 5 times for each case and take the third result; The test cases are Fibonacci series, benchmark and business case to evaluate the performance changes caused by optimization in different scenarios.
1 wasm performance
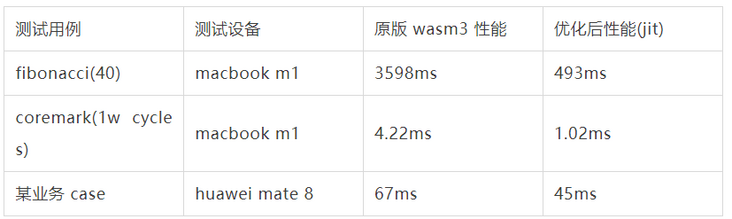
Note: the time obtained in the business case is the overall time-consuming of single frame rendering, including wasm execution and rendering time.
Note: coremark hyengine jit takes about three times as long as the compiled version of llvm. The reason is that the optimization of calculation instructions is insufficient. More calculation instructions can be optimized in the optimizer later.
Note: the above test compilation optimization option is O3.
2 js performance
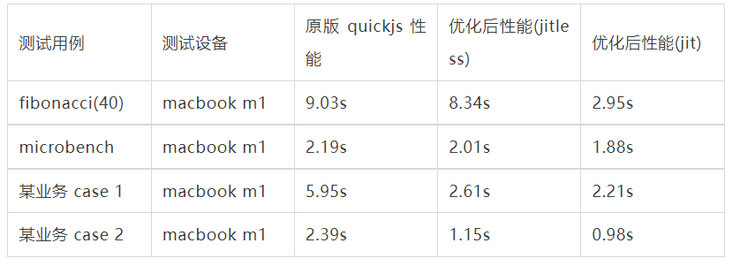
Note: some individual items of microbench have negative optimization in gc optimization, so that the improvement of overall optimization is not obvious, but the change of individual items has little impact on business.
Note: from the business case, it can be seen that the improvement brought by vm optimization is much greater than that brought by jit. The reason is that jit currently introduces few optimization methods, and there is still a lot of optimization space. In addition, in case 1, jit is only about 30% better than jitless in v8. In the implementation of jit, a single optimization may bring an improvement of less than 1%. Dozens or hundreds of different optimizations are needed to improve the performance, such as 30%. Later, there will be more performance requirements and development costs to make a balanced choice.
Note: the above test compilation optimization option is Os.
V. follow up plan
The follow-up plan is mainly divided into two directions: performance optimization and multilingual support, in which performance optimization will continue.
Performance optimization points include:
- Compiler optimization, introducing its own bytecode support.
- Optimizer optimization, introducing more optimized pass es.
- Its own runtime and assembly implementation of hot methods.
Vi. references
wasm3: https://github.com/wasm3/wasm3
quickjs: https://bellard.org/quickjs/
v8: https://chromium.googlesource...
javascriptcore: https://opensource.apple.com/...
golang/arch: https://github.com/golang/arch
libmalloc: https://opensource.apple.com/...
Trash talk: the Orinoco garbage collector: https://v8.dev/blog/trash-talk
JavaScript engine fundamentals: Shapes and Inline Caches: https://mathiasbynens.be/note...
cs143: https://web.stanford.edu/clas...
C in ASM(ARM64): https://www.zhihu.com/column/...
Original link
This article is the original content of Alibaba cloud and cannot be reproduced without permission.