How to obtain information in time and facilitate reading when you can't operate your mobile phone or always stare at your mobile phone? Listening with your ears is a good way. Huawei machine learning service The speech synthesis service adopts deep neural network technology to provide highly anthropomorphic, smooth and natural speech synthesis services. Developers can integrate this capability in novel reading, intelligent hardware and map navigation applications to provide users with real-time, replaceable and multi tone voice playback experience.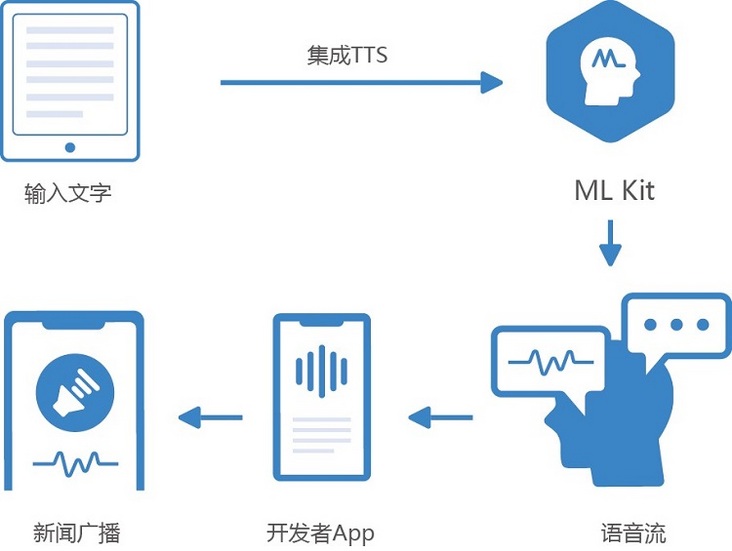
Speech synthesis for timely content delivery
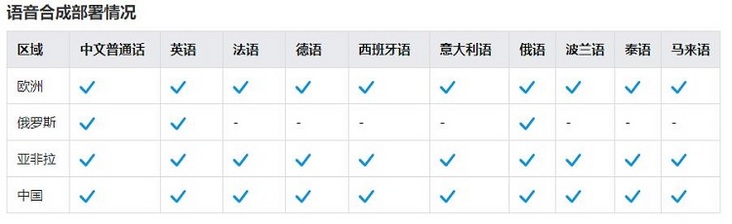
The voice synthesis service supports the online conversion of text messages into voice output, and has been deployed worldwide. The advantages of this service are——
- Multi language and multi timbre: support mixed reading and synthesis of Chinese, English and Chinese and English. There are two standard male pronunciation and six standard female pronunciation to choose from. The following is the tone audition:
- Adjustable speech speed and volume: it supports multiple parameter configurations and can adjust the speaker's speech speed and volume according to the needs of the scene.
Flexible and rich integration methods: provide rapid integration of offline SDK and online SDK to fully meet the needs of speech synthesis in different scenarios.
Speech synthesis service can be applied to reading broadcast, news broadcast, virtual broadcast, map broadcast, information notification and other timely scenes. For example, it is inconvenient for users to keep looking at their mobile phones on the road when they are cycling or driving to use map navigation. Speech synthesis broadcasting can ensure clear expression and accurate arrival at the destination; In the scenarios of taxi software, catering call number and queuing software at the driver's end, order broadcasting is carried out through voice synthesis, so that users can easily obtain notification information; Popular electronic reading applications on the market provide voice broadcasting and listening functions. Users can easily "listen to books". Even when the screen is locked, you can continue to listen through voice broadcast to eliminate the restrictions of subway, bus, running and other reading environments. Some old people and children who are inconvenient to read can also solve the problems of unclear reading and emotional companionship through "listening to books".

In the field of intelligent hardware, speech synthesis services can be integrated into children's story machines, intelligent robots, tablet devices and other intelligent devices to make human-computer interaction more natural and friendly. For the content creators of the short video App, some voice effects can be synthesized by specifying words in the video application, which speeds up the short video production process.
Customize the timbre to meet the personalized needs of users
Recently, Huawei's voice synthesis service will be launched to customize the voice function. Users can record and synthesize their own voice into the application, making daily life and learning scenes such as listening to novels and navigation more interesting and friendly. Parents with children at home can also tell stories to their children in their own voice to release the fatigue of parenting and deepen parent-child interaction and companionship.
Development practice
Development preparation
For the configuration steps of Maven warehouse and SDK, please refer to the application development introduction in the developer website:
https://developer.huawei.com/...
Configure integrated SDK packages
In application build.gradle In the document, dependencies Add inside TTS of SDK Dependency: // Import basic SDK implementation 'com.huawei.hms:ml-computer-voice-tts:3.3.0.274' // Introduce offline speech synthesis bee speech package implementation 'com.huawei.hms:ml-computer-voice-tts-model-bee:3.3.0.274' // Introduce offline speech synthesis eagle speech package implementation 'com.huawei.hms:ml-computer-voice-tts-model-eagle:3.3.0.274'
Configure androidmanifest xml
open main In folder AndroidManifest.xml File, you can configure the network and read-write permissions according to the scenario and use needs<application>Add before <uses-permission android:name="android.permission.INTERNET" /> <uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" /> <uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" />
- Code development (online TTS)
3.1 create an activity interface customized by the application to select online or offline TTS through api_key or Access Token to set application authentication information
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
MLApplication.getInstance().setAccessToken("your access token");
}
}3.2 create TTS configuration and TTS engine, and configure different parameters as required
MLTtsEngine mlTtsEngine;
MLTtsConfig mlConfigs;
mlConfigs = new MLTtsConfig()
// Setting the language for synthesis.
.setLanguage(MLTtsConstants.TTS_ZH_HANS)
// Set the timbre.
.setPerson(MLTtsConstants.TTS_SPEAKER_FEMALE_ZH)
// Set the speech speed. Range: 0.2–4.0 1.0 indicates 1x speed.
.setSpeed(1.0f)
// Set the volume. Range: 0.2–4.0 1.0 indicates 1x volume.
.setVolume(1.0f)
// set the synthesis mode.
.setSynthesizeMode(MLTtsConstants.TTS_ONLINE_MODE);
mlTtsEngine = new MLTtsEngine(mlConfigs);
//Sets the volume of the built-in player.
mlTtsEngine.setPlayerVolume(20);
Set callback (see 3).3)
// Pass the TTS callback to the TTS engine.
mlTtsEngine.setTtsCallback(callback);3.3 configure TTS callback to receive and process speech synthesis results
MLTtsCallback callback = new MLTtsCallback() {
String task = "";
String fileName = "audio_" + task;
@Override
public void onError(String taskId, MLTtsError err) {
String str = taskId + " " + err;
sendMsg(str);
}
@Override
public void onWarn(String taskId, MLTtsWarn warn) {
String str = taskId + " Tips:" + warn;
sendMsg(str);
}
@Override
public void onRangeStart(String taskId, int start, int end) {
String str = taskId + " onRangeStart [" + start + "," + end + "]";// + temp.get(taskId).substring(start);
sendMsg(taskId + " onRangeStart[" + start + "," + end + "]");
sendMsg1(taskId, start, end);
}
@Override
public void onAudioAvailable(String taskId, MLTtsAudioFragment audioFragment, int offset,
Pair<Integer, Integer> range, Bundle bundle) {
if (!task.equals(taskId)) {
task = taskId;
fileName = "/sdcard/audio_" + task + ".pcm";
}
writeTxtToFile(audioFragment.getAudioData(), fileName, true);
}
@Override
public void onEvent(String taskId, int eventId, Bundle bundle) {
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(taskId + " ");
switch (eventId) {
case MLTtsConstants.EVENT_PLAY_START:
stringBuffer.append("onPlayStart ");
break;
case MLTtsConstants.EVENT_PLAY_STOP:
stringBuffer.append("onPlayStop ");
stringBuffer.append(bundle.getBoolean(MLTtsConstants.EVENT_PLAY_STOP_INTERRUPTED));
break;
case MLTtsConstants.EVENT_PLAY_RESUME:
stringBuffer.append("onPlayResume ");
break;
case MLTtsConstants.EVENT_PLAY_PAUSE:
stringBuffer.append("onPlayPause ");
break;
case MLTtsConstants.EVENT_SYNTHESIS_COMPLETE:
stringBuffer.append("onSynthesisComplete ");
PCMCovWavUtil.convertWaveFile(fileName);
break;
case MLTtsConstants.EVENT_SYNTHESIS_START:
stringBuffer.append("onSynthesisStart ");
break;
case MLTtsConstants.EVENT_SYNTHESIS_END:
stringBuffer.append("onSynthesisEnd ");
break;
}
Log.d(TAG, "onEvent: " + stringBuffer.toString());
}
};3.4 call speak synthesis request and playback control
String id = mlTtsEngine.speak(text, MLTtsEngine.QUEUE_APPEND));
mlTtsEngine.pause();
mlTtsEngine.resume();
mlTtsEngine.stop();
After the call, release the engine
if (mlTtsEngine != null) {
mlTtsEngine.stop();
mlTtsEngine.shutdown();
}- Offline TTS
4.1 the offline function requires a new step of downloading the speaker model package
private MLLocalModelManager mLocalModelManager;
mLocalModelManager = MLLocalModelManager.getInstance();
MLTtsLocalModel mLocalModel = new MLTtsLocalModel.Factory('informant'
).create();
mLocalModelManager.isModelExist(mLocalModel).addOnSuccessListener(new OnSuccessListener<Boolean>() {
@Override
public void onSuccess(Boolean aBoolean) {
if (aBoolean) {
mlTtsEngine.speak(text, MLTtsEngine.QUEUE_APPEND)
} else {
downloadModel(true);
}
}
}).addOnFailureListener(new OnFailureListener() {
@Override
public void onFailure(Exception e) {
Log.e(TAG, e.getMessage());
}
});The method of downloading the model is:
private void downloadModel(final boolean needSpeak) {
MLModelDownloadStrategy request = new MLModelDownloadStrategy.Factory().needWifi().create();
MLModelDownloadListener modelDownloadListener = new MLModelDownloadListener() {
@Override
public void onProcess(long alreadyDownLength, long totalLength) {
showProcess(alreadyDownLength, "Model download is complete", totalLength);
}
};
mLocalModelManager.downloadModel(mLocalModel, request, modelDownloadListener)
.addOnSuccessListener(new OnSuccessListener<Void>() {
@Override
public void onSuccess(Void aVoid) {
Log.i(TAG, "downloadModel: " + mLocalModel.getModelName() + " success");
showToast("downloadModel Success");
updateconfig();
if (needSpeak) {
speak();
}
}
})
.addOnFailureListener(new OnFailureListener() {
@Override
public void onFailure(Exception e) {
Log.e(TAG, "downloadModel failed: " + e.getMessage());
showToast(e.getMessage());
}
});
}Other uses are consistent with online TTS
Learn more > >
visit Official website of Huawei developer Alliance
obtain Development guidance document
Huawei mobile service open source warehouse address: GitHub,Gitee
Follow us and learn the latest technical information of HMS Core for the first time~