Optimization of RabbitMQ
channel
Producers, consumers and RabbitMQ all establish connections. In order to avoid establishing too many TCP connections and reduce resource consumption.
AMQP protocol introduces channels. Multiple channels use the same TCP connection to multiplex TCP connections.
However, there is an upper limit on the number of connections in the channel. Too many connections will lead to multiplexed TCP congestion.
const ( maxChannelMax = (2 << 15) - 1 defaultChannelMax = (2 << 10) - 1 )
adopt http://github.com/streadway/amqp This client connects to RabbitMQ, which defines the maximum value of 65535 and the default maximum value of 2047.
prefetch Count
What is prefetch Count? Take chestnuts first:
Assuming that there are N consumption queues in the RabbitMQ queue, the messages in the RabbitMQ queue will be sent to consumers in the form of polling.
If the number of messages is m, the data obtained by each consumer is M%N. If consumers in a certain machine consume slowly because of their own reasons or because the message itself takes a long time to process, but the messages allocated by other consumers are consumed quickly and then idle, this will cause a waste of resources and reduce the throughput of the message queue.
At this time, prefetch Count is introduced to avoid the situation that message queues with limited consumption capacity allocate too many messages, while consumers with better message processing capacity do not have message processing.
RabbitM will save a list of consumers. Each message sent will count the corresponding consumers. If the set upper limit is reached, RabbitMQ will not send any messages to this consumer. After the consumer confirms a message, RabbitMQ reduces the corresponding count by 1, and then the consumer can continue to receive messages until the upper count limit is reached again. This mechanism can be similar to the "sliding window" in TCP/IP.
Therefore, the message will not be occupied by consumers with slow processing speed, and can be well distributed to other consumers with better processing speed. Generally speaking, it is the maximum number of non consumed messages that consumers can get from RabbitMQ.
How much is the prefetch Count appropriate? It's about 30. For details, see Finding bottlenecks with RabbitMQ 3.3
When it comes to prefetch Count, we also need to look at the global parameter. RabbitMQ redefines the global parameter on the AMQPO-9-1 protocol in order to improve related performance
| global parameter | AMQPO-9-1 | RabbitMQ |
|---|---|---|
| false | All consumers on the channel need to comply with the prefetchC unt limit | New consumers on the channel need to comply with the limit value of prefetchCount |
| true | All consumers on the current communication link (Connection) must comply with the limit value of prefetchCount, which is shared by consumers on the same Connection | All consumers on the channel need to comply with the upper limit of prefetchcut, which is shared by consumers on the same channel |
prefetchSize: the upper limit (inclusive) of the content size of a single pre read message, which can be simply understood as the maximum length limit of the message payload byte array. 0 means no upper limit, and the unit is B.
If prefetch Count is 0, there is no upper limit on the number of prefetched messages.
Take a misused Chestnut:
The consumption speed of consumers in the previous queue was too slow, and the prefetch Count was 0. Then a new consumer was written, the prefetch Count was set to 30, and 10 pod s were used to process messages. Old consumers are still processing messages before they go offline.
However, it is found that the consumption speed is still very slow, and a large number of messages are unacknowledged. If you understand the meaning of prefetch Count, you can already guess the cause of the problem.
The old consumer prefetch Count is 0, so many unacknowledged messages are held by it. Although several new consumers are added, they are idle. Finally, the consumer with prefetch Count of 0 is stopped, and the consumption speed is normal soon.
Dead letter queue
What is a dead letter queue
A general message will become a dead letter if it meets the following conditions:
-
If the message is negative, use channel Basicnack or channel Basicreject, and the request attribute is set to false at this time;
-
When the message expires, the lifetime of the message in the queue exceeds the set TT L time;
-
The queue has reached the maximum length, and the number of messages in the message queue has exceeded the maximum queue length.
When a message meets the above conditions and becomes a dead message, it will be pushed back to the dead letter exchange (DLX, fully known as dead letter exchange). The queue bound to DLX is the dead letter queue.
Therefore, the dead letter queue is not a special queue, but is bound to the dead letter switch. The dead letter switch is not special. We just use this to deal with the dead letter queue, which is not essentially different from other switches.
For the business that needs to process the dead letter queue, just like our normal business processing, we also define a unique routing key, configure a dead letter queue to listen, and then bind the key to the dead letter switch.
Usage scenario
When there is a problem with message consumption, the problem message will not be lost. The message will be temporarily stored to facilitate subsequent troubleshooting.
code implementation
For the use of dead letter queue, see the following to cooperate with delay queue to realize the message retry mechanism.
Delay queue
What is a delay queue
Delay queue is used to store messages for delay consumption.
What is a deferred message?
It is a message that consumers do not want to consume immediately and wait for a specified time to consume.
Usage scenario
1. Close idle connections. In the server, there are many client connections, which need to be closed after being idle for a period of time;
2. Clean up expired data business. For example, objects in the cache need to be removed from the cache when they exceed their idle time;
3. Task timeout processing. When the sliding window of the network protocol requests responsive interaction, handle the request that is not responded after timeout;
4. If there is no payment within 30 minutes after placing the order, the order will be automatically cancelled;
5. Ordering notice: Send a short message notice to the user 60s after the order is successfully placed;
6. How to close the order in time and return the inventory when the order has been unpaid;
7. Regularly check whether the order in refund status has been refunded successfully;
8. How can the system know the information and send activation SMS if the newly created store does not upload goods within N days;
9. Scheduled task scheduling: use DelayQueue to save the tasks and execution time that will be executed on the current day. Once the task is obtained from DelayQueue, it will be executed.
To sum up, there are some business scenarios with delayed processing
How to implement delay queue
RabbitMQ itself does not directly provide the function of delay queue, which can be through dead letter queue and TTL. To realize the function of delay team.
Let's first understand the expiration time TTL. Once the message exceeds the set TTL value, it will become a dead letter. Note that the unit of TTL is milliseconds. There are two ways to set the expiration time
-
1. Through queue attribute setting, messages in the queue have the same expiration time;
-
2. By setting the message itself separately, each message has its own expiration time.
If the two are set together, the TTL of the message shall be subject to the smaller value between them.
For the above two TTL expiration times, the processing of message queue is different. First, once the message expires, it will be deleted from the message queue. Second, when the message expires, it will not be deleted immediately. The deletion operation is judged before it is delivered to the consumer.
In the first method, the messages with the same expiration time are in the same queue, so the expired messages are always in the header. Just scan the header. In the second way, the expiration time is different, but the messages are in the same message queue. If you want to clean up all the expired time, you need to traverse all the messages. Of course, this is unreasonable, so you will judge the expiration when the messages are consumed. This processing idea is a little similar to the cleaning up of redis expired key s.
Queue TTL
Via channel The x-expires parameter in the queuedeclare method controls how long the queue is unused before it is automatically deleted. Unused means that there are no consumers on the queue, the queue has not been redeclared, and basic has not been called within the expiration period Get command.
if _, err := channel.QueueDeclare("delay.3s.test",
true, false, false, false, amqp.Table{
"x-dead-letter-exchange": b.exchange,
"x-dead-letter-routing-key": ps.key,
"x-expires": 3000,
},
); err != nil {
return err
}
Message TTL
There are two ways to set Message TTL
- Per-Queue Message TTL
Through in the queue Set the x-message-ttl parameter in declare to control the expiration time of messages in the current queue. However, the same message is put into multiple queues. Set the queue of x-message-ttl. The expiration of messages in the queue will not affect the same messages in other queues. Expiration of messages processed by different queues is isolated.
if _, err := channel.QueueDeclare("delay.3s.test",
true, false, false, false, amqp.Table{
"x-dead-letter-exchange": b.exchange,
"x-dead-letter-routing-key": ps.key,
"x-message-ttl": 3000,
},
); err != nil {
return err
}
- Per-Message TTL
You can set the expiration time of each message through expiration. It should be noted that expiration is a string type.
delayQ := "delay.3s.test"
if _, err := channel.QueueDeclare(delayQ,
true, false, false, false, amqp.Table{
"x-dead-letter-exchange": b.exchange,
"x-dead-letter-routing-key": ps.key,
},
); err != nil {
return err
}
if err := channel.Publish("", delayQ, false, false, amqp.Publishing{
Headers: amqp.Table{"x-retry-count": retryCount + 1},
Body: d.Body,
DeliveryMode: amqp.Persistent,
Expiration: "3000",
}); err != nil {
return err
}
The scenario of delayed consumption can be handled through the delay queue with the help of the dead letter queue
Common use of delay queue: consumers subscribe to dead letter queue deadQueue, and then all messages that need to be delayed are sent to delayNormal. Then, when the TTL expiration time of the message in delayNormal expires, the message will be stored in the dead letter queue deadQueue. We only need to consume the data in the dead letter queue deadQueue normally, so as to realize the logic of delaying the consumption of data.
Set expiration time using Queue TTL
For example, chestnuts for online message retransmission:
Consumers process messages in the queue. Errors will occur in the process of processing a message. For errors with certain characteristics, we hope that these messages can be returned to the queue and consumed over a period of time. Of course, if the Ack is not performed, or the Ack is pushed back to the queue, the consumer can retry the consumption again. However, there will be a problem. The message consumption in the consumption queue is very fast. The newly pushed message will immediately reach the head of the queue. The consumer may get the message immediately, and then it has been in an endless cycle of retry, affecting the consumption of other messages. At this time, the delay queue will appear. We can use the delay queue to set a specific delay time so that the retry of these messages can occur to a later point in time. After a certain number of retries, you can choose to discard the message.
Let's look at the flow chart below:

Specific processing steps:
1. The producer pushes the message to the work exchange and then sends it to the work queue;
2. Consumers subscribe to the work queue, which is normal business consumption;
3. Send the message requiring delay retry to the delay queue;
4. The delay queue will be bound with a dead letter series. The exchange and routing key of the dead letter queue are the exchange and routing key of the above normal business work queue message team. In this way, expired messages can be pushed back to the service queue. The number of message re push will be recorded each time they are pushed to the delay queue. If the upper limit set by us is reached, You can discard data, drop database or other operations;
5. Therefore, consumers only need to listen and process the work queue queue;
6. Useless delay queues will be automatically deleted at the deletion time node.
On the code, The address of Demo in the text 👏🏻
func (b *Broker) readyConsumes(ps *params) (bool, error) {
key := ps.key
channel, err := b.getChannel(key)
if err != nil {
return true, err
}
queue, err := b.declare(channel, key, ps)
if err != nil {
return true, err
}
if err := channel.Qos(ps.prefetch, 0, false); err != nil {
return true, fmt.Errorf("channel qos error: %s", err)
}
deliveries, err := channel.Consume(queue.Name, "", false, false, false, false, nil)
if err != nil {
return true, fmt.Errorf("queue consume error: %s", err)
}
channelClose := channel.NotifyClose(make(chan *amqp.Error))
pool := make(chan struct{}, ps.concurrency)
go func() {
for i := 0; i < ps.concurrency; i++ {
pool <- struct{}{}
}
}()
for {
select {
case err := <-channelClose:
b.channels.Delete(key)
return true, fmt.Errorf("channel close: %s", err)
case d := <-deliveries:
if ps.concurrency > 0 {
<-pool
}
go func() {
var flag HandleFLag
switch flag = ps.Handle(d.Body); flag {
case HandleSuccess:
d.Ack(false)
case HandleDrop:
d.Nack(false, false)
// Processing messages that require delayed retries
case HandleRequeue:
if err := b.retry(ps, d); err != nil {
d.Nack(false, true)
} else {
d.Ack(false)
}
default:
d.Nack(false, false)
}
if ps.concurrency > 0 {
pool <- struct{}{}
}
}()
}
}
}
func (b *Broker) retry(ps *params, d amqp.Delivery) error {
channel, err := b.conn.Channel()
if err != nil {
return err
}
defer channel.Close()
retryCount, _ := d.Headers["x-retry-count"].(int32)
// Determine the upper limit of the number of attempts
if int(retryCount) >= len(ps.retryQueue) {
return nil
}
delay := ps.retryQueue[retryCount]
delayDuration := time.Duration(delay) * time.Millisecond
delayQ := fmt.Sprintf("delay.%s.%s.%s", delayDuration.String(), b.exchange, ps.key)
if _, err := channel.QueueDeclare(delayQ,
true, false, false, false, amqp.Table{
// Configure exchange and routing key for sending dead letter
"x-dead-letter-exchange": b.exchange,
"x-dead-letter-routing-key": ps.key,
// Expiration time of the message
"x-message-ttl": delay,
// Time setting for automatic deletion of delay queue
"x-expires": delay * 2,
},
); err != nil {
return err
}
// Exchange is empty. Use Default Exchange
return channel.Publish("", delayQ, false, false, amqp.Publishing{
// Set the number of attempts
Headers: amqp.Table{"x-retry-count": retryCount + 1},
Body: d.Body,
DeliveryMode: amqp.Persistent,
})
}
Test it
Start a RabbitMQ using docker first
$ sudo mkdir -p /usr/local/docker-rabbitmq/data $ docker run -d --name rabbitmq3.7.7 -p 5672:5672 -p 15672:15672 -v /usr/local/docker-rabbitmq/data:/var/lib/rabbitmq --hostname rabbitmq -e RABBITMQ_DEFAULT_VHOST=/ -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin rabbitmq:3.7.7-management
The account number and password are admin
const (
DeadTestExchangeQueue = "dead-test-delayed-queue_queue"
)
func main() {
ch := make(chan os.Signal, 1)
signal.Notify(ch, syscall.SIGHUP, syscall.SIGQUIT, syscall.SIGTERM, syscall.SIGINT)
broker := rabbitmq.NewBroker("amqp://admin:admin@127.0.0.1:5672", &rabbitmq.ExchangeConfig{
Name: "worker-exchange",
Type: "direct",
})
broker.LaunchJobs(
rabbitmq.NewDefaultJobber(
"dead-test-key",
HandleMessage,
rabbitmq.WithPrefetch(30),
rabbitmq.WithQueue(DeadTestExchangeQueue),
rabbitmq.WithRetry(help.FIBONACCI, help.Retry{
Delay: "5s",
Max: 6,
Queue: []string{
DeadTestExchangeQueue,
},
}),
),
)
for {
s := <-ch
switch s {
case syscall.SIGQUIT, syscall.SIGTERM, syscall.SIGINT:
fmt.Println("job-test-exchange service exit")
time.Sleep(time.Second)
return
case syscall.SIGHUP:
default:
return
}
}
}
func HandleMessage(data []byte) error {
fmt.Println("receive message", "message", string(data))
return rabbitmq.HandleRequeue
}
Retry the received message directly. Let's look at the execution of the delay queue
After startup, let's take a look at the message queue panel

push a piece of data through the control panel

You can see the execution process of messages in the delay queue, and the unused delay queue will be automatically deleted at the set expiration time point


Finally, you can see that this message has been retried many times
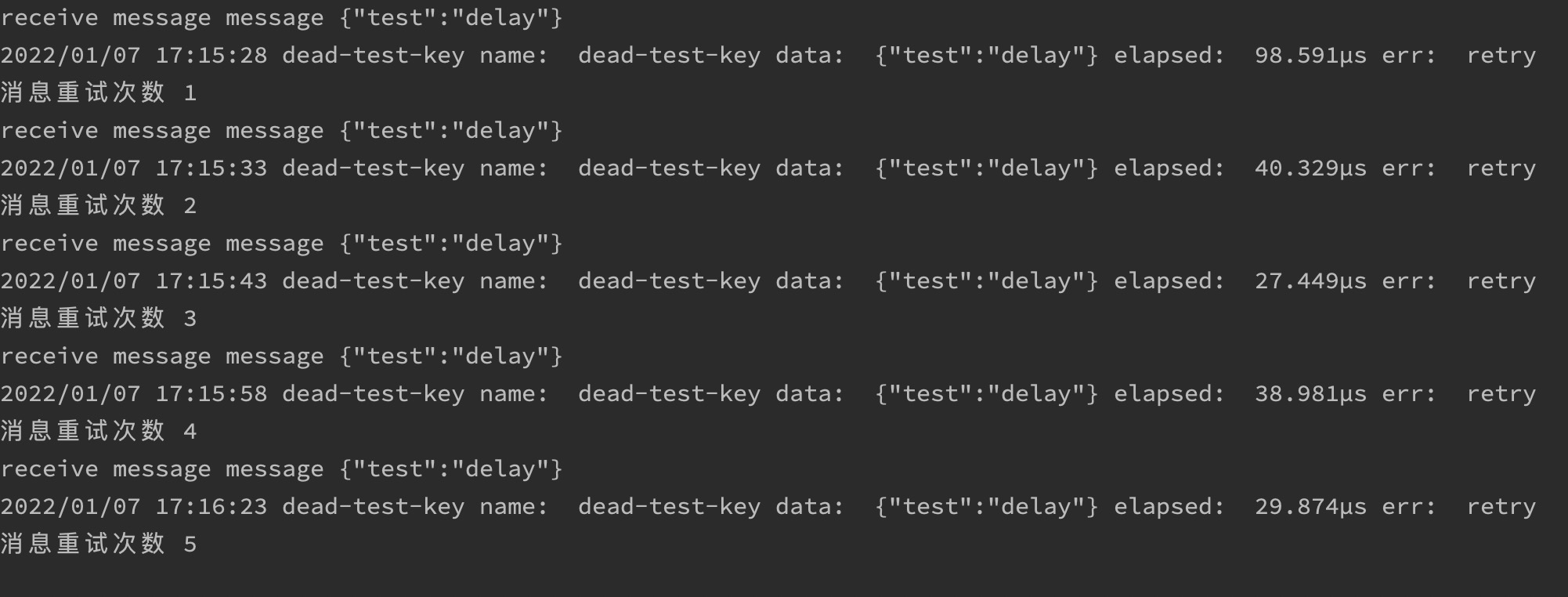
Finally, after reaching the retry limit we set, the message will be lost
Set expiration time using Message TTL
Using Message TTL, there will be timing problems in our queue. Here's an analysis:
Using Message TTL, all messages set to expire will be put into a queue. Because messages are sent out one by one, only the first message is consumed can the second message be processed. If the first message expires for 10s, the second message expires for 1s. Article 2 must expire before article 1. In theory, Article 2 should be dealt with first. However, with the limitations discussed above, if the first message is not consumed, the second message cannot be processed. This causes timing problems. Of course, this will not happen if Queue TTL is used. Messages with the same expiration time should be in the same queue, so the message at the head of the queue always expires first. So how to avoid this situation?
This can be handled using the rabbitmq delayed message exchange plug-in. Rabbitmq delayed message exchange plug-in address
Implementation principle:
After installing the plug-in, a new Exchange type x-delayed-message will be generated. The principle of processing is delayed delivery. After receiving the delayed message, it is not directly delivered to the target queue, but will be stored in the mnesia database. What is mnesia for reference Mnesia database . When the delay time is up, it is pushed to the target queue through x-delayed-message. Then go to the consumption target queue to avoid the timing problem of expiration.
Let's see how to use it
Here, a virtual machine is used to demonstrate. First, install RabbitMQ. Please refer to the installation process RabbitMQ 3.8.5
Then download the rabbitmq delayed message exchange plug-in
https://github.com/rabbitmq/rabbitmq-delayed-message-exchange/releases/download/3.9.0/rabbitmq_delayed_message_exchange-3.9.0.ez $ cp rabbitmq_delayed_message_exchange-3.9.0.ez /usr/lib/rabbitmq/lib/rabbitmq_server-3.8.5/plugins # View installed plug-ins $ rabbitmq-plugins list Listing plugins with pattern ".*" ... Configured: E = explicitly enabled; e = implicitly enabled | Status: * = running on rabbit@centos7-1 |/ [ ] rabbitmq_amqp1_0 3.8.5 [ ] rabbitmq_auth_backend_cache 3.8.5 [ ] rabbitmq_auth_backend_http 3.8.5 [ ] rabbitmq_auth_backend_ldap 3.8.5 [ ] rabbitmq_auth_backend_oauth2 3.8.5 [ ] rabbitmq_auth_mechanism_ssl 3.8.5 [ ] rabbitmq_consistent_hash_exchange 3.8.5 [E*] rabbitmq_delayed_message_exchange 3.9.0 [ ] rabbitmq_event_exchange 3.8.5 [ ] rabbitmq_federation 3.8.5 $ rabbitmq-plugins enable rabbitmq_delayed_message_exchange $ systemctl restart rabbitmq-server
Modify the chestnuts above and use x-delayed-message
On the code, demo address 👏🏻
func (b *Broker) declareDelay(key string, job Jobber) error {
keyNew := fmt.Sprintf("delay.%s", key)
channel, err := b.getChannel(fmt.Sprintf("delay.%s", key))
if err != nil {
return err
}
defer channel.Close()
exchangeNew := fmt.Sprintf("delay.%s", b.exchange)
if err := channel.ExchangeDeclare(exchangeNew, "x-delayed-message", true, false, false, false, nil); err != nil {
return fmt.Errorf("exchange declare error: %s", err)
}
queue, err := channel.QueueDeclare(fmt.Sprintf("delay.%s", job.Queue()), true, false, false, false, amqp.Table{
"x-dead-letter-exchange": b.exchange,
"x-dead-letter-routing-key": key,
})
if err != nil {
return fmt.Errorf("queue declare error: %s", err)
}
if err = channel.QueueBind(queue.Name, keyNew, exchangeNew, false, nil); err != nil {
return fmt.Errorf("queue bind error: %s", err)
}
return nil
}
func (b *Broker) retry(ps *params, d amqp.Delivery) error {
channel, err := b.conn.Channel()
if err != nil {
return err
}
defer channel.Close()
retryCount, _ := d.Headers["x-retry-count"].(int32)
if int(retryCount) >= len(ps.retryQueue) {
return nil
}
fmt.Println("Message retries", retryCount+1)
delay := ps.retryQueue[retryCount]
if err := channel.ExchangeDeclare(fmt.Sprintf("delay.%s", b.exchange), "x-delayed-message", true, false, false, false, amqp.Table{
"x-delayed-type": "direct",
}); err != nil {
return err
}
return channel.Publish(fmt.Sprintf("delay.%s", b.exchange), fmt.Sprintf("delay.%s", ps.key), false, false, amqp.Publishing{
Headers: amqp.Table{"x-retry-count": retryCount + 1},
Body: d.Body,
DeliveryMode: amqp.Persistent,
Expiration: fmt.Sprintf("%d", delay),
})
}
Set the message type in the retry queue to x-delayed-message, so that you can use the plug-in that just came down.
After pushing a message through the panel, look at the running results

Where dead test delayed message_ Queue is the queue for our normal business consumption, delay dead-test-delayed-message_ The queue stores messages that need to be delayed. When they expire, they will be pushed back to dead test delayed message through the dead letter mechanism_ In queue
Look at the output of the console

Do you use a plug-in or Queue TTL to handle delay queues?
Rabbitmq delayed message exchange related restrictions:
-
1. The plug-in does not support the replication of delayed messages. In the RabbitMQ image cluster mode, if one of the nodes goes down, there will be messages unavailable, which can be recovered only after the node is restarted;
-
2. At present, the plug-in only supports disk nodes, and does not support ram nodes at present;
-
3. It is not suitable for situations with a large number of delayed messages (for example, thousands or millions of delayed messages).
This plugin is considered to be experimental yet fairly stable and potential suitable for production use as long as the user is aware of its limitations.
This plugin is not commercially supported by Pivotal at the moment but it doesn't mean that it will be abandoned or team RabbitMQ is not interested in improving it in the future. It is not, however, a high priority for our small team.
So, give it a try with your workload and decide for yourself.
This is the official explanation, which roughly means that this is still in the experimental stage, but it is still relatively stable. The team's priority for updating this plug-in is not very high, so if we encounter problems, we may need to modify it ourselves.
If you have the ability to change this plug-in, after all, this is written by erlang, you can choose this.
The advantages are also obvious. It can be used out of the box and the processing logic is relatively simple.
Queue TTL related restrictions
If we need to process many types of delayed data, we need to create many queues. Of course, the advantages of this scheme are transparency, stability and easy troubleshooting in case of problems.
reference resources
[Finding bottlenecks with RabbitMQ 3.3]https://blog.rabbitmq.com/posts/2014/04/finding-bottlenecks-with-rabbitmq-3-3
[do you really know about delay queues] https://juejin.cn/post/6844903648397525006
[RabbitMQ practical guide] https://book.douban.com/subject/27591386/
[artificial intelligence rabbitmq based on rabbitmq] https://www.dazhuanlan.com/ajin121212/topics/1209139
[rabbitmq-delayed-message-exchange]https://blog.51cto.com/kangfs/4115341
[Scheduling Messages with RabbitMQ]https://blog.rabbitmq.com/posts/2015/04/scheduling-messages-with-rabbitmq
[Centos7 installs the latest version 3.8.5 of RabbitMQ, the simplest and practical installation step in history] https://blog.csdn.net/weixin_40584261/article/details/106826044
[use of prefetch_count, dead letter queue and delay queue in RabbitMQ] https://boilingfrog.github.io/2022/01/07/rabbitmq Use of advanced features/