The ZooKeeper source code provides the implementation of distributed queues, distributed locks and elections under the ZooKeeper receipts directory (GitHub address: https://github.com/apache/zookeeper/tree/master/zookeeper-recipes ). This paper mainly analyzes the implementation principle and source code of these implementations:
1. Distributed queue
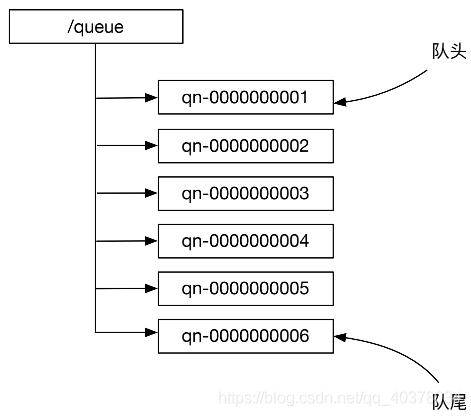
The nodes under the znode with the path / queue are used to represent the elements in the queue/ All nodes under the queue are sequentially persistent znodes. The suffix number of these znode names indicates the position of the corresponding queue element in the queue. The smaller the suffix number of znode name, the higher the position of the corresponding queue element in the queue
1) . offer method
The offer method creates a sequential znode under / queue. Because the suffix number of znode is the maximum suffix number of existing znode under / queue plus 1, the queue element corresponding to the znode is at the end of the queue
public class DistributedQueue {
public boolean offer(byte[] data) throws KeeperException, InterruptedException {
for (; ; ) {
try {
zookeeper.create(dir + "/" + prefix, data, acl, CreateMode.PERSISTENT_SEQUENTIAL);
return true;
} catch (KeeperException.NoNodeException e) {
zookeeper.create(dir, new byte[0], acl, CreateMode.PERSISTENT);
}
}
}
2) . element method
public class DistributedQueue {
public byte[] element() throws NoSuchElementException, KeeperException, InterruptedException {
Map<Long, String> orderedChildren;
while (true) {
try {
//Get all ordered child nodes
orderedChildren = orderedChildren(null);
} catch (KeeperException.NoNodeException e) {
throw new NoSuchElementException();
}
if (orderedChildren.size() == 0) {
throw new NoSuchElementException();
}
//Returns the data of the queue head node
for (String headNode : orderedChildren.values()) {
if (headNode != null) {
try {
return zookeeper.getData(dir + "/" + headNode, false, null);
} catch (KeeperException.NoNodeException e) {
//Another client has removed the queue head node and tried to get the next node
}
}
}
}
}
private Map<Long, String> orderedChildren(Watcher watcher) throws KeeperException, InterruptedException {
Map<Long, String> orderedChildren = new TreeMap<>();
List<String> childNames;
childNames = zookeeper.getChildren(dir, watcher);
for (String childName : childNames) {
try {
if (!childName.regionMatches(0, prefix, 0, prefix.length())) {
LOG.warn("Found child node with improper name: {}", childName);
continue;
}
String suffix = childName.substring(prefix.length());
Long childId = Long.parseLong(suffix);
orderedChildren.put(childId, childName);
} catch (NumberFormatException e) {
LOG.warn("Found child node with improper format : {}", childName, e);
}
}
return orderedChildren;
}
3) . remove method
public class DistributedQueue {
public byte[] remove() throws NoSuchElementException, KeeperException, InterruptedException {
Map<Long, String> orderedChildren;
while (true) {
try {
//Get all ordered child nodes
orderedChildren = orderedChildren(null);
} catch (KeeperException.NoNodeException e) {
throw new NoSuchElementException();
}
if (orderedChildren.size() == 0) {
throw new NoSuchElementException();
}
//Remove queue head node
for (String headNode : orderedChildren.values()) {
String path = dir + "/" + headNode;
try {
byte[] data = zookeeper.getData(path, false, null);
zookeeper.delete(path, -1);
return data;
} catch (KeeperException.NoNodeException e) {
//Another client has removed the queue head node, trying to remove the next node
}
}
}
}
2. Distributed lock
1) . exclusive lock
The core of the exclusive lock is how to ensure that there is only one transaction to obtain the lock, and after the lock is released, all transactions waiting to obtain the lock can be notified
Definitional lock
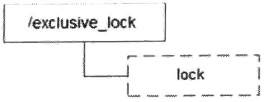
A lock is represented by creating a child node on the ZooKeeper, such as / exclusive_ The lock / lock node can be defined as a lock
Acquire lock
When it is necessary to obtain an exclusive lock, all clients will try to create an exclusive lock in / exclusive by calling the create() interface_ Create temporary child node under lock node / exclusive_lock/lock. ZooKeeper will ensure that only one client can be created successfully in the end, so it can be considered that the client has obtained the lock.
At the same time, all clients that have not obtained the lock need to go to / exclusive_ Register a watcher to monitor the change of a child node on the lock node in order to monitor the change of the lock node in real time
Release lock
/exclusive_lock/lock is a temporary node, so it is possible to release the lock in both cases
-
If the client machine currently acquiring the lock goes down, the temporary node on ZooKeeper will be removed
-
After the normal execution of business logic, the client will actively delete the temporary node created by itself
In any case, ZooKeeper will notify all / exclusive nodes when the lock node is removed_ A child node is registered on the lock node to change the client monitored by the watcher. After receiving the notification, these clients re initiate the distributed lock acquisition, that is, repeat the lock acquisition process
2) Herd effect
The implementation of the above exclusive lock may cause herding: when a specific znode changes, ZooKeeper triggers all watcher events. Because there are many notification clients, the notification operation will cause a sudden decline in ZooKeeper performance, which will affect the use of ZooKeeper
Improved distributed lock implementation
Acquire lock
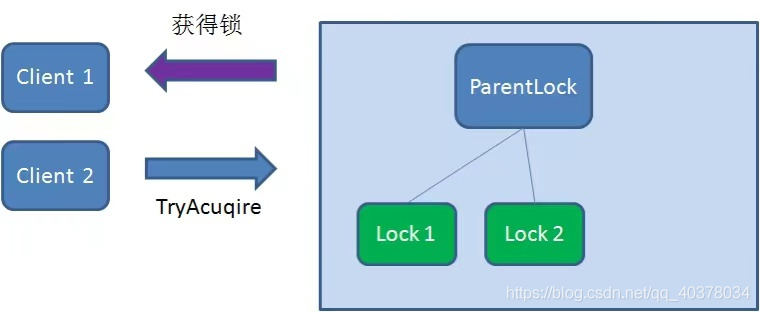
First, create a persistent node ParentLock in Zookeeper. When the first client wants to obtain a lock, it needs to create a temporary sequence node Lock1 under the ParentLock node
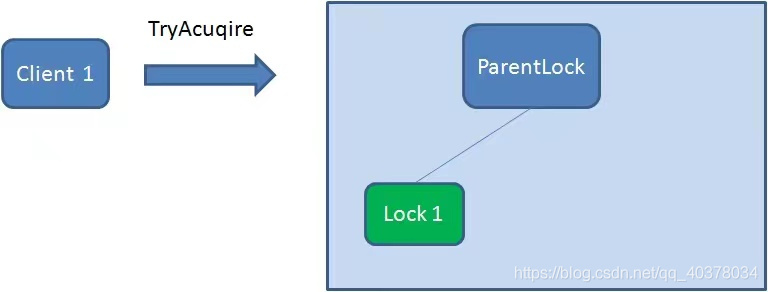
After that, Client1 finds all temporary order nodes under ParentLock and sorts them to determine whether the node Lock1 created by itself is the one with the highest order. If it is the first node, the lock is successfully obtained
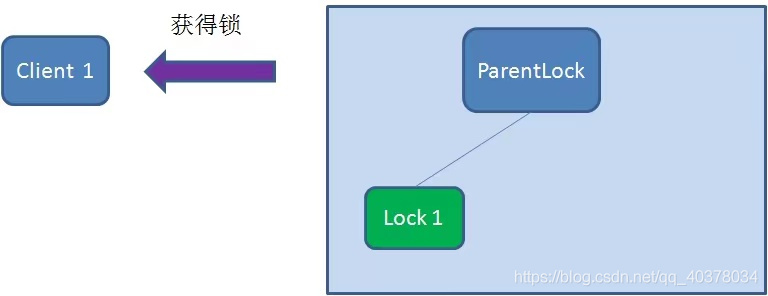
At this time, if another client Client2 comes to obtain the lock, create another temporary sequence node Lock2 under ParentLock
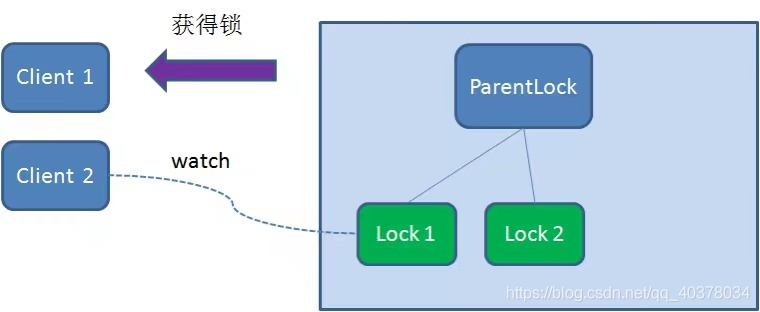
Client2 finds all temporary order nodes under ParentLock and sorts them. It judges whether the node Lock2 created by itself is the one with the highest order. It is found that node Lock2 is not the smallest
Therefore, Client2 registers a watcher with the node Lock1 that is only ahead of it to listen for the existence of the Lock1 node. This means that Client2 failed to grab the lock and entered the waiting state
At this time, if another client Client3 comes to obtain the lock, create a temporary sequence node Lock3 under ParentLock
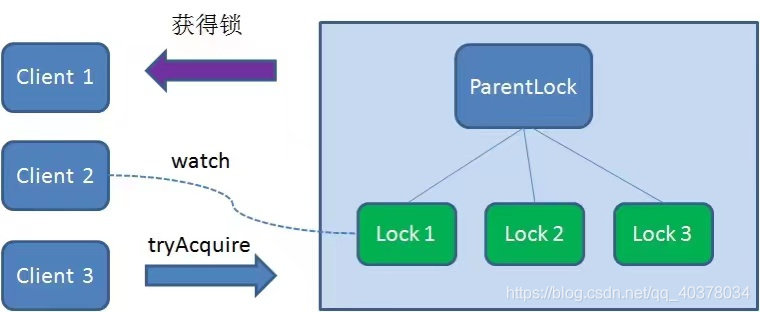
Client3 finds and sorts all temporary order nodes under ParentLock, and judges whether the node Lock3 created by itself is the one with the highest order. It is also found that node Lock3 is not the smallest
Therefore, Client3 registers a watcher with the node Lock2 whose ranking is only higher than it to listen for the existence of the Lock2 node. This means that Client3 also failed to grab the lock and entered the waiting state
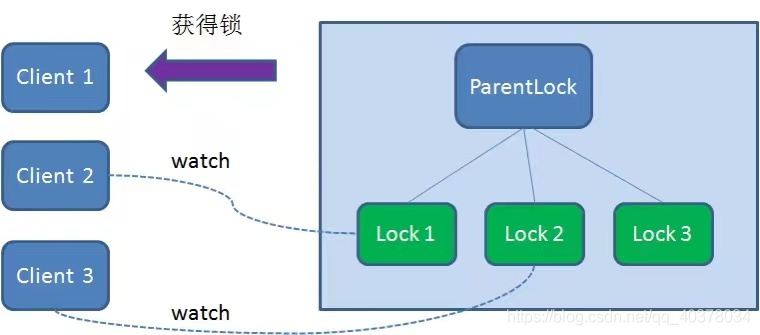
In this way, Client1 gets the lock, Client2 listens to Lock1, and Client3 listens to Lock2. This just forms a waiting queue, much like the AQS that ReentrantLock relies on in Java
Release lock
There are two situations to release the lock:
1. When the task is completed, the client displays release
When the task is completed, Client1 will display the instruction calling to delete node Lock1

2. The client crashes during task execution
Client1 that obtains the lock will disconnect from the Zookeeper server if the client crashes during task execution. Depending on the properties of the temporary node, the associated node Lock1 is automatically deleted
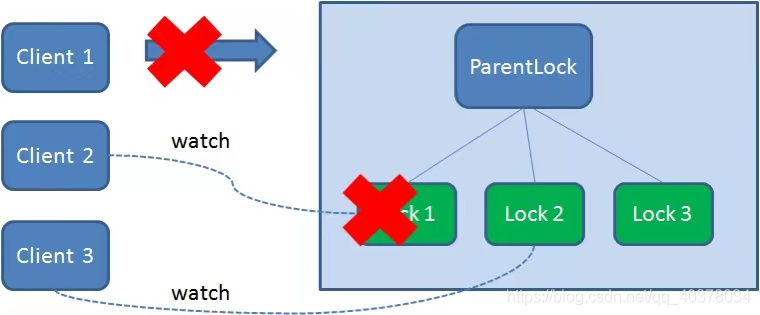
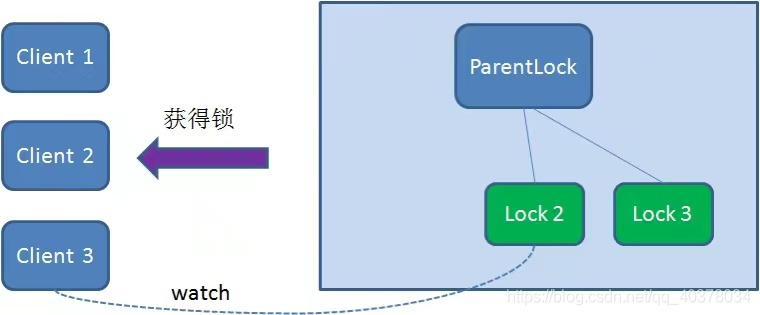
Because Client2 has been monitoring the existence status of Lock1, when the Lock1 node is deleted, Client2 will immediately receive a notification. At this time, Client2 will query all nodes under ParentLock again to confirm whether the created node Lock2 is the smallest node at present. If it is the smallest, Client2 obtains the lock
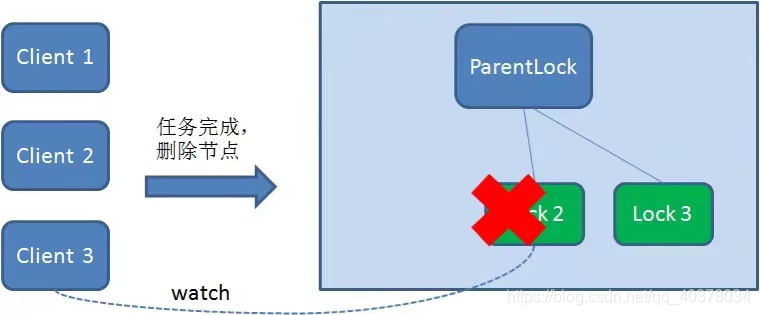
Similarly, if Client2 deletes node Lock2 because the task is completed or the node crashes, Client3 will be notified
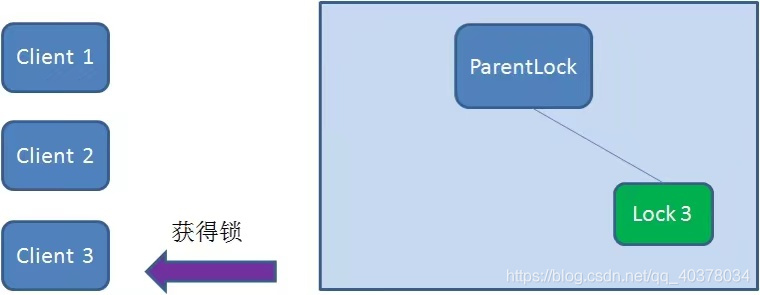
Finally, Client3 successfully got the lock
3) . shared lock
Shared locks, also known as read locks, can be accessed by multiple threads at the same time. A typical example is the read lock in ReentrantReadWriteLock. Its read lock can be shared, but its write lock can only be exclusive each time
Definitional lock
Like the exclusive lock, a lock is represented by the data node on the ZooKeeper, which is similar to / shared_lock/[Hostname] - request type - temporary sequence node of sequence number, for example, / shared_lock/192.168.0.1-R-0000000001, then this node represents a shared lock, as shown in the following figure:
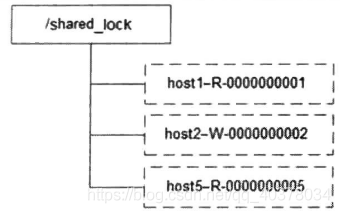
Acquire lock
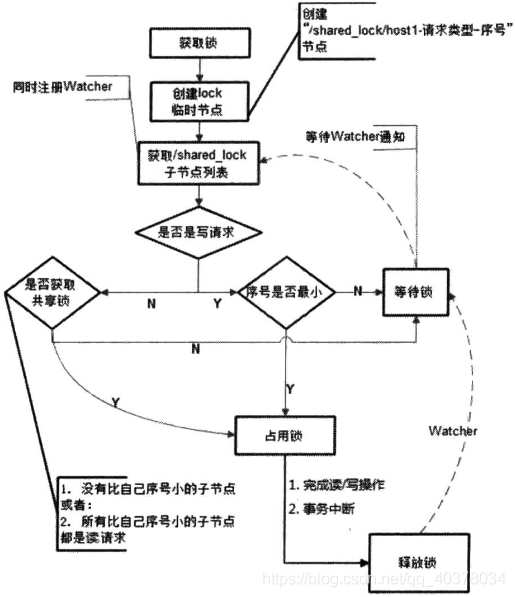
Get when needed Shared lock All clients will be to / shared_ A temporary sequential node is created under the lock node. If it is a read request, for example, / shared is created_ Lock / 192.168.0.1-r- 000000000 1; If it is a write request, for example, / shared is created_ Node of lock / 192.168.0.1-w- 000000000 1
Judge the reading and writing order
Each lock competitor only needs to pay attention to / shared_ Whether the node with a smaller serial number under the lock node exists is sufficient. The specific implementation is as follows:
1) The client calls the create() method to create a file similar to / shared_lock/[Hostname] - request type - temporary sequence node of sequence number
2) The client calls the getChildren() interface to get a list of all the child nodes that have been created
3) Determine whether the shared lock can be obtained:
-
Read request: no node smaller than its own serial number or all nodes smaller than its own serial number are read requests
-
Write request: is the serial number the smallest
4) If you can't get the shared lock, you can call exist() to register the watcher compared with the smaller node
-
Read request: register a watcher to listen to the last write request node smaller than its serial number
-
Write request: register a watcher to listen to the last node smaller than its serial number
5) Wait for the watcher notification and continue to step 2
Release lock
The logic of releasing locks is consistent with that of exclusive locks
The acquisition and release process of the whole shared lock is as follows:
4) Analysis of exclusive lock source code
1) Locking process
public class WriteLock extends ProtocolSupport {
public synchronized boolean lock() throws KeeperException, InterruptedException {
if (isClosed()) {
return false;
}
//Confirm whether the persistent parent node exists
ensurePathExists(dir);
//The logic that actually obtains the lock calls the retryOperation() method of ProtocolSupport
return (Boolean) retryOperation(zop);
}
class ProtocolSupport {
protected Object retryOperation(ZooKeeperOperation operation)
throws KeeperException, InterruptedException {
KeeperException exception = null;
for (int i = 0; i < RETRY_COUNT; i++) {
try {
//Call the execute() method of LockZooKeeperOperation
return operation.execute();
} catch (KeeperException.SessionExpiredException e) {
LOG.warn("Session expired {}. Reconnecting...", zookeeper, e);
throw e;
} catch (KeeperException.ConnectionLossException e) {
if (exception == null) {
exception = e;
}
LOG.debug("Attempt {} failed with connection loss. Reconnecting...", i);
retryDelay(i);
}
}
throw exception;
}
public class WriteLock extends ProtocolSupport {
private class LockZooKeeperOperation implements ZooKeeperOperation {
private void findPrefixInChildren(String prefix, ZooKeeper zookeeper, String dir)
throws KeeperException, InterruptedException {
List<String> names = zookeeper.getChildren(dir, false);
for (String name : names) {
if (name.startsWith(prefix)) {
id = name;
LOG.debug("Found id created last time: {}", id);
break;
}
}
if (id == null) {
id = zookeeper.create(dir + "/" + prefix, data, getAcl(), EPHEMERAL_SEQUENTIAL);
LOG.debug("Created id: {}", id);
}
}
@SuppressFBWarnings(
value = "NP_NULL_PARAM_DEREF_NONVIRTUAL",
justification = "findPrefixInChildren will assign a value to this.id")
public boolean execute() throws KeeperException, InterruptedException {
do {
if (id == null) {
long sessionId = zookeeper.getSessionId();
String prefix = "x-" + sessionId + "-";
//Create temporary sequence node
findPrefixInChildren(prefix, zookeeper, dir);
idName = new ZNodeName(id);
}
//Get all child nodes
List<String> names = zookeeper.getChildren(dir, false);
if (names.isEmpty()) {
LOG.warn("No children in: {} when we've just created one! Lets recreate it...", dir);
id = null;
} else {
//Sort all child nodes
SortedSet<ZNodeName> sortedNames = new TreeSet<>();
for (String name : names) {
sortedNames.add(new ZNodeName(dir + "/" + name));
}
ownerId = sortedNames.first().getName();
SortedSet<ZNodeName> lessThanMe = sortedNames.headSet(idName);
//Is there a node with a smaller sequence number than itself
if (!lessThanMe.isEmpty()) {
ZNodeName lastChildName = lessThanMe.last();
lastChildId = lastChildName.getName();
LOG.debug("Watching less than me node: {}", lastChildId);
//If there is a node with a smaller sequence number than itself, call exist() to register a watcher with the previous node
Stat stat = zookeeper.exists(lastChildId, new LockWatcher());
if (stat != null) {
return Boolean.FALSE;
} else {
LOG.warn("Could not find the stats for less than me: {}", lastChildName.getName());
}
}
//If there is no node with a smaller sequence number than itself, the lock is obtained
else {
if (isOwner()) {
LockListener lockListener = getLockListener();
if (lockListener != null) {
lockListener.lockAcquired();
}
return Boolean.TRUE;
}
}
}
}
while (id == null);
return Boolean.FALSE;
}
2) Unlocking process
public class WriteLock extends ProtocolSupport {
public synchronized void unlock() throws RuntimeException {
if (!isClosed() && id != null) {
try {
//Deleting the current node will trigger the watcher of the next node
ZooKeeperOperation zopdel = () -> {
zookeeper.delete(id, -1);
return Boolean.TRUE;
};
zopdel.execute();
} catch (InterruptedException e) {
LOG.warn("Unexpected exception", e);
Thread.currentThread().interrupt();
} catch (KeeperException.NoNodeException e) {
} catch (KeeperException e) {
LOG.warn("Unexpected exception", e);
throw new RuntimeException(e.getMessage(), e);
} finally {
LockListener lockListener = getLockListener();
if (lockListener != null) {
lockListener.lockReleased();
}
id = null;
}
}
}
3. Election
The temporary order znode is used to represent the election request, and the election request with the minimum suffix number znode is created successfully. In collaborative design, it is the same as distributed lock, but the difference lies in the specific implementation. Different from the distributed lock, the specific implementation of the election carefully monitors each stage of the election
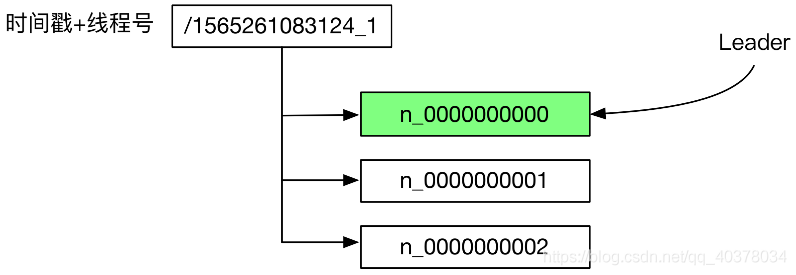
public class LeaderElectionSupport implements Watcher {
public synchronized void start() {
state = State.START;
dispatchEvent(EventType.START);
LOG.info("Starting leader election support");
if (zooKeeper == null) {
throw new IllegalStateException(
"No instance of zookeeper provided. Hint: use setZooKeeper()");
}
if (hostName == null) {
throw new IllegalStateException(
"No hostname provided. Hint: use setHostName()");
}
try {
//Initiate an election request} to create a temporary sequence node
makeOffer();
//Is the election request satisfied
determineElectionStatus();
} catch (KeeperException | InterruptedException e) {
becomeFailed(e);
}
}
private void makeOffer() throws KeeperException, InterruptedException {
state = State.OFFER;
dispatchEvent(EventType.OFFER_START);
LeaderOffer newLeaderOffer = new LeaderOffer();
byte[] hostnameBytes;
synchronized (this) {
newLeaderOffer.setHostName(hostName);
hostnameBytes = hostName.getBytes();
newLeaderOffer.setNodePath(zooKeeper.create(rootNodeName + "/" + "n_",
hostnameBytes, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL));
leaderOffer = newLeaderOffer;
}
LOG.debug("Created leader offer {}", leaderOffer);
dispatchEvent(EventType.OFFER_COMPLETE);
}
private void determineElectionStatus() throws KeeperException, InterruptedException {
state = State.DETERMINE;
dispatchEvent(EventType.DETERMINE_START);
LeaderOffer currentLeaderOffer = getLeaderOffer();
String[] components = currentLeaderOffer.getNodePath().split("/");
currentLeaderOffer.setId(Integer.valueOf(components[components.length - 1].substring("n_".length())));
//Get all child nodes and sort
List<LeaderOffer> leaderOffers = toLeaderOffers(zooKeeper.getChildren(rootNodeName, false));
for (int i = 0; i < leaderOffers.size(); i++) {
LeaderOffer leaderOffer = leaderOffers.get(i);
if (leaderOffer.getId().equals(currentLeaderOffer.getId())) {
LOG.debug("There are {} leader offers. I am {} in line.", leaderOffers.size(), i);
dispatchEvent(EventType.DETERMINE_COMPLETE);
//If the current node is the first, it becomes a Leader
if (i == 0) {
becomeLeader();
}
//If there is an election request in front of the current node, wait and call exist() to register a watcher with the previous node
else {
becomeReady(leaderOffers.get(i - 1));
}
break;
}
}
}