Transferred from: https://www.eet-china.com/mp/a53927.html
Linux memory management is the only way to learn Linux well, and it is also the key knowledge point of Linux. Some people say that if you get through the knowledge of memory management, you will get through the Ren Du pulse of Linux, which is no exaggeration. Someone asked why I should read this article because there are many contents of Linux memory management on the Internet. This is the reason why I wrote this article. Most of the knowledge points related to online fragmentation are pieced together. Whether it is correct or not, even the basic logic is not clear. I can responsibly say that Linux memory management only needs to read this article to let you enter the door of Linux kernel, It saves you the time of looking around and allows you to form a closed loop of memory management knowledge.
The article is long. Get ready and take a deep breath. Let's open the door to the Linux kernel!
The process of CPU accessing memory in Linux memory management
I like to illustrate the problem in the form of diagram, which is simple and direct:
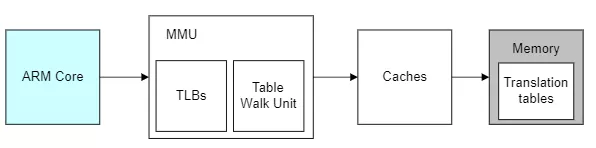
The blue part is cpu, the gray part is memory, and the white part is the process of cpu accessing memory and address conversion. Before explaining the essence of address translation, let's understand the following concepts:
- TLB: the working process of MMU is the process of querying page tables. If you put the page table in memory, the cost is too large. Therefore, in order to improve the search efficiency, you can use a small area to access the faster area to store the address translation entries. (when the contents of the page table change, you need to clear the TLB to prevent address mapping errors.)
- Caches: the cache mechanism between cpu and memory, which is used to improve the access rate. In the case of armv8 architecture, the caches in the figure above are actually L2 caches, which will not be further explained here.
The essence of converting virtual addresses to physical addresses
We know that the size of the addressing space in the kernel is determined by CONFIG_ARM64_VA_BITS control. Here, take 48 bits as an example. In ARMv8, the page table base address of Kernel Space is stored in ttbr1_ In the el1 register, the base address of the User Space page table is stored in ttbr0_ In the el0 register, the high order of the kernel address space is all 1, (0xffff0000_00000000 ~ 0xffffff_ffffffff), and the high order of the user address space is all 0, (0x00000000_00000000 ~ 0x0000FFFF_FFFFFFFF)
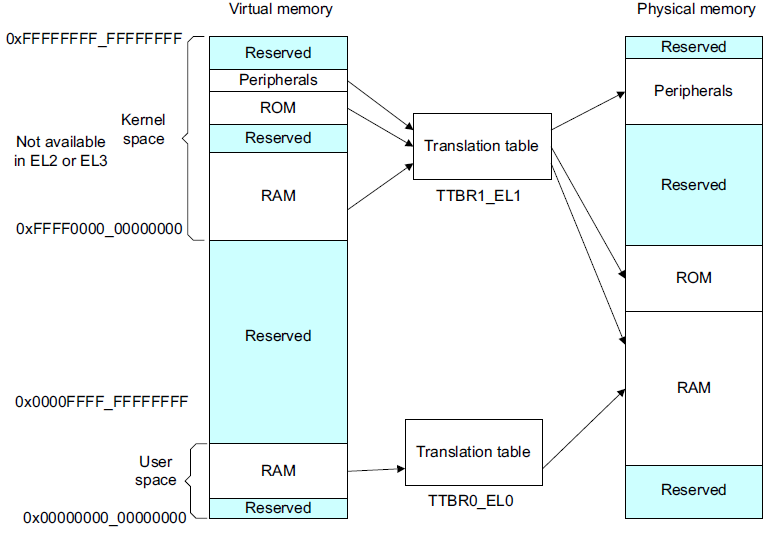
With the macro concept, let's take the internal core addressing process as an example to see how to convert the virtual address to the physical address.
We know that linux adopts paging mechanism, which usually adopts four level page table, page global directory (PGD), page parent directory (PUD), page intermediate directory (PMD) and page table (PTE). As follows:
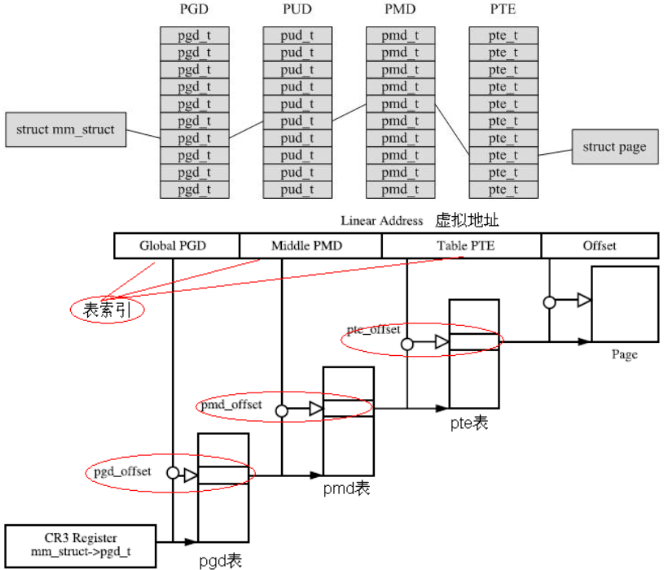
- Read the base address of the physical page where the page directory is located (the so-called page directory base address) from the CR3 register, obtain the index of the page directory item from the first part of the linear address, and add them to obtain the physical address of the page directory item.
- PGD is obtained by reading memory for the first time_ T structure, from which the physical page base address is taken, that is, the physical base address of the page's parent page directory.
- Take the index of the page parent directory item from the second part of the linear address and add it to the base address of the page parent directory to obtain the physical address of the page parent directory item.
- The second time the memory is read, the PUD is obtained_ T structure, from which the physical base address of the middle directory of the page is taken.
- Take the index of the page middle directory item from the third part of the linear address and add it to the page middle directory base address to obtain the physical address of the page middle directory item.
- Read the memory for the third time to get pmd_t structure, from which the physical base address of the page table is taken.
- Take the index of the page table item from the fourth part of the linear address and add it to the page table base address to obtain the physical address of the page table item.
- PTE is obtained by reading the memory for the fourth time_ T structure, from which the base address of the physical page is taken.
- Take the physical page offset from the fifth part of the linear address and add it to the physical page base address to obtain the final physical address.
- Read the memory for the fifth time to get the final data to be accessed.
The whole process is mechanical. Each conversion first obtains the physical page base address, then obtains the index from the linear address, synthesizes the physical address, and then accesses the memory. Both the page table and the data to be accessed are stored in the main memory in the unit of page. Therefore, each time you access the memory, you must first obtain the base address, and then access the data in the page through the index (or offset). Therefore, you can regard the linear address as a collection of several indexes.
Linux memory initialization
With the understanding of memory access in armv8 architecture, it is easier to understand the initialization of linux in memory.
Create startup page table:
Head. In the assembly code phase In the s file, the function responsible for creating the mapping relationship is create_page_tables. create_ page_ The tables function is responsible for identity mapping and kernel image mapping.
- identity map: refers to the idmap_ The physical address of the text area is mapped to the equivalent virtual address. After this mapping, the virtual address is equal to the physical address. idmap_ The text field contains codes related to opening MMU.
- kernel image map: map the addresses (kernel txt, rodata, data, bss, etc.) required for kernel operation.
arch/arm64/kernel/head.S:
ENTRY(stext)
bl preserve_boot_args
bl el2_setup // Drop to EL1, w0=cpu_boot_mode
adrp x23, __PHYS_OFFSET
and x23, x23, MIN_KIMG_ALIGN - 1 // KASLR offset, defaults to 0
bl set_cpu_boot_mode_flag
bl __create_page_tables
/*
* The following calls CPU setup code, see arch/arm64/mm/proc.S for
* details.
* On return, the CPU will be ready for the MMU to be turned on and
* the TCR will have been set.
*/
bl __cpu_setup // initialise processor
b __primary_switch
ENDPROC(stext)
__ create_page_tables mainly implements identity map and kernel image map:
__create_page_tables:
......
create_pgd_entry x0, x3, x5, x6
mov x5, x3 // __pa(__idmap_text_start)
adr_l x6, __idmap_text_end // __pa(__idmap_text_end)
create_block_map x0, x7, x3, x5, x6
/*
* Map the kernel image (starting with PHYS_OFFSET).
*/
adrp x0, swapper_pg_dir
mov_q x5, KIMAGE_VADDR + TEXT_OFFSET // compile time __va(_text)
add x5, x5, x23 // add KASLR displacement
create_pgd_entry x0, x5, x3, x6
adrp x6, _end // runtime __pa(_end)
adrp x3, _text // runtime __pa(_text)
sub x6, x6, x3 // _end - _text
add x6, x6, x5 // runtime __va(_end)
create_block_map x0, x7, x3, x5, x6
......
Which calls create_pgd_entry creates PGD and all intermediate level(PUD, PMD) page tables, and calls create_block_map to map the PTE page table. The relationship between the four level page table is shown in the figure below, which will not be further explained here.
The memory mapping relationship after assembly is shown in the following figure:
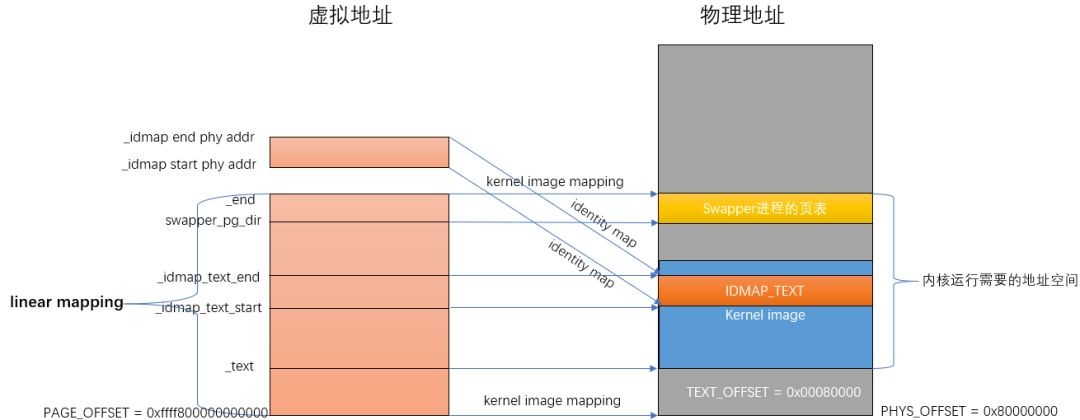
After memory initialization, you can enter the real memory management. Initialization is divided into four steps:
- Before physical memory enters the system
- memblock module is used to manage memory
- Page table mapping
- zone initialization
How does Linux organize physical memory?
- At present, node computer system has two architectures:
- Non uniform memory access (NUMA) means that memory is divided into nodes. The time spent accessing a node depends on the distance from the CPU to the node. Each CPU has a local node, and the time to access the local node is faster than that to access other nodes
- Uniform Memory Access (UMA) can also be called SMP (symmetric multi process) symmetric multiprocessor. It means that all processors spend the same time accessing memory. It can also be understood that there is only one node in the whole memory.
- zone
ZONE means that the whole physical memory is divided into several areas, and each area has a special meaning
- page
Represents a physical page. In the kernel, a physical page is represented by a struct page.
- page frame
To describe a physical page, the kernel uses the struct page structure to represent a physical page. Assuming that the size of a page is 4K, the kernel will divide the whole physical memory into 4K physical pages, and the area of 4K physical pages is called page frame
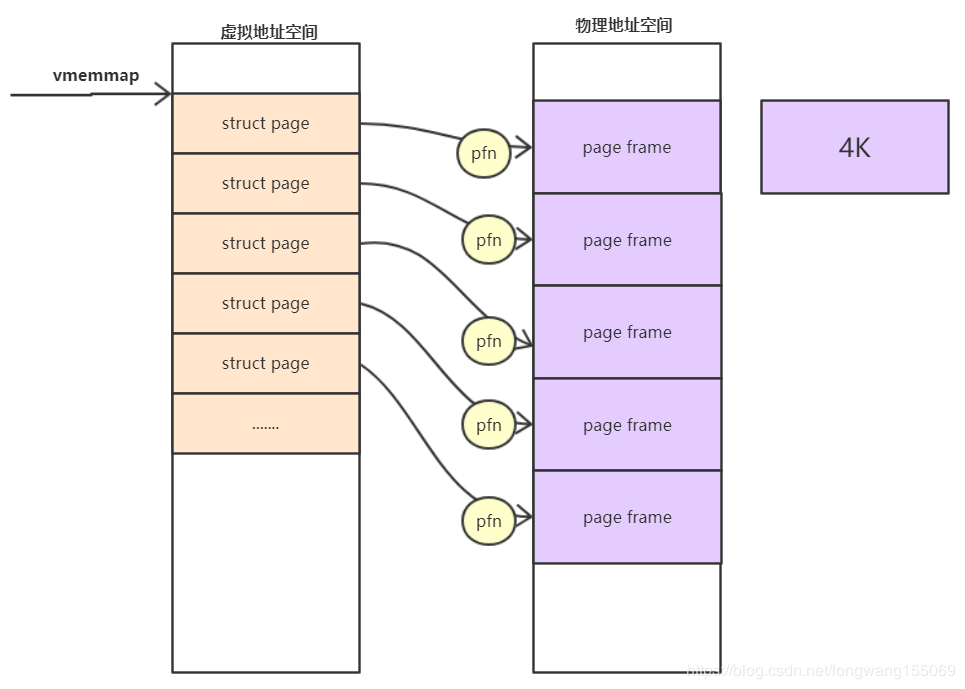
- page frame num(pfn)
pfn is the number of each page frame. Therefore, the relationship between physical address and pfn is:
Physical address > > page_ SHIFT = pfn
- Relationship between pfn and page
Several memory models are supported in the kernel: CONFIG_FLATMEM (flat memory model) CONFIG_DISCONTIGMEM (discontinuous memory model) CONFIG_SPARSEMEM_VMEMMAP (sparse memory model) is the sparse type mode currently used by ARM64.
When the system starts, the kernel will map the entire struct page to the area of the kernel virtual address space vmemmap, so we can simply think that the base address of struct page is vmemmap, then:
The address of vmemmap+pfn is the address corresponding to this struct page.
Linux partition page box allocator
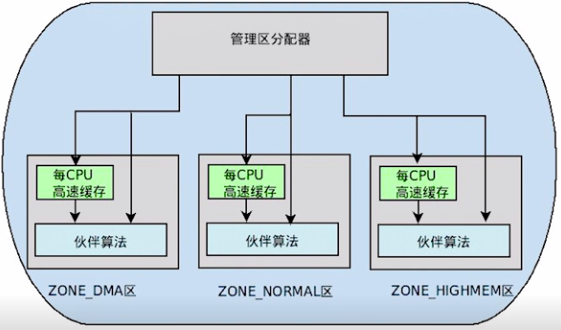
The mechanism of page frame allocation in the kernel is called zoned page frame allocator. In linux system, the zoned page frame allocator manages all physical memory. Whether you are a kernel or a process, you need to request the zoned page frame allocator, and then it will be allocated to the physical memory page frame you should obtain. When the page frames you own are no longer used, you must release these page frames and return them to the page frame allocator in the management area.
Sometimes the target management area does not necessarily have enough page frames to meet the allocation. At this time, the system will obtain the required page frames from the other two management areas, but this is implemented according to certain rules, as follows:
- If it is required to obtain from the DMA area, it can only be obtained from zone_ Get in DMA area.
- If it is not specified which area to obtain from, it will be obtained from zone in order_ NORMAL -> ZONE_ DMA acquisition.
- If it is specified to obtain from the highmem area, it shall be obtained from zone in sequence_ HIGHMEM -> ZONE_ NORMAL -> ZONE_ DMA acquisition.
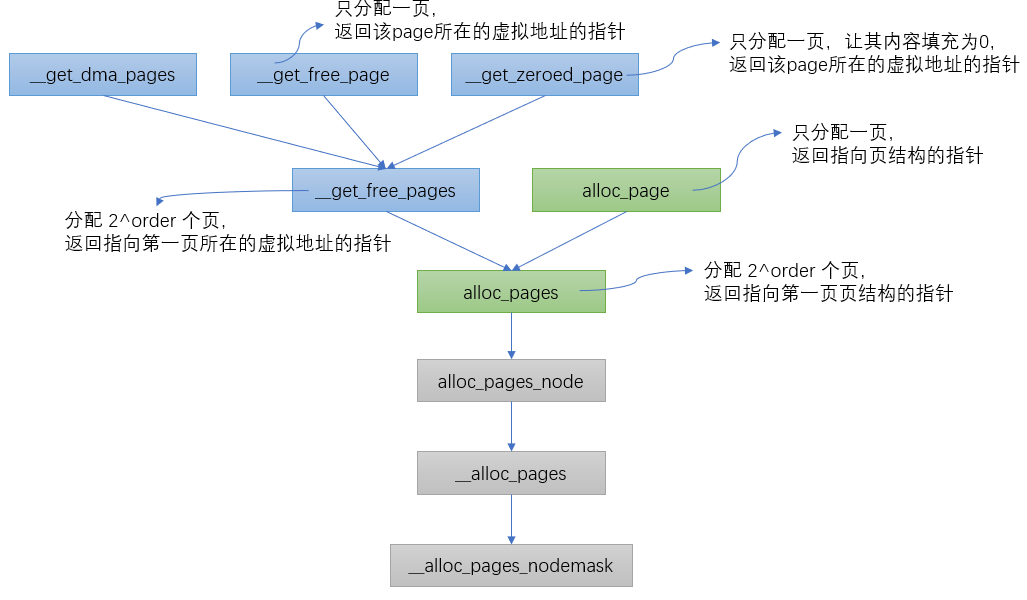
According to different allocation requirements, the kernel has six function interfaces to request page boxes, which will eventually be called__ alloc_pages_nodemask.
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);//fastpath allocation page: normally allocate memory space from pcp(per_cpu_pages) and partner systems
......
page = __alloc_pages_slowpath(alloc_mask, order, &ac);//slowpath allocation page: if there is no space allocated above, call the following function to allocate slowly, allowing waiting and recycling
......
}
During page allocation, there are two paths to choose from. If the allocation is successful in the fast path, the allocated page will be returned directly; If the fast path allocation fails, select the slow path for allocation. The summary is as follows:
- Normal allocation (or quick allocation):
- If a single page is allocated, consider allocating space from the per CPU cache. If there are no pages in the cache, extract pages from the partner system for supplement.
- When multiple pages are allocated, they are allocated from the specified type. If there are not enough pages in the specified type, they are allocated from the standby type linked list. Finally, we will try to keep the type linked list.
- Slow (allow waiting and page recycling) allocation:
- When the above two allocation schemes cannot meet the requirements, consider page recycling, killing process and other operations before trying.
Partner algorithm of Linux page frame allocator
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx, ac->nodemask)
{
if (!zone_watermark_fast(zone, order, mark, ac_classzone_idx(ac), alloc_flags))
{
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
switch (ret) {
case NODE_RECLAIM_NOSCAN:
continue;
case NODE_RECLAIM_FULL:
continue;
default:
if (zone_watermark_ok(zone, order, mark, ac_classzone_idx(ac), alloc_flags))
goto try_this_zone;
continue;
}
}
try_this_zone: //Normal water level of this zone
page = rmqueue(ac->preferred_zoneref->zone, zone, order, gfp_mask, alloc_flags, ac->migratetype);
}
return NULL;
}
First, traverse the current zone in the direction of highmem - > normal. The condition to judge whether the current zone can allocate memory is to first judge whether the free memory meets the low water mark water level value. If not, conduct a fast memory recovery operation, and then check whether the low water mark is met again. If not, The same steps traverse the next zone, and if satisfied, enter the normal allocation, that is, the rmqueue function, which is also the core of the partner system.
Buddy allocation algorithm
Before looking at the function, let's look at the algorithm first, because I always think that it is better to further understand "art" with the understanding of "Tao".

Suppose this is a continuous page box. The shaded part indicates the page box that has been used. Now you need to apply for five consecutive page boxes. At this time, if you can't find five consecutive free page frames in this memory, you will go to another memory to find five consecutive page frames. In this way, a waste of page frames will be formed over time. In order to avoid this situation, the buddy system algorithm is introduced into the Linux kernel. All free page frames are grouped into 11 block linked lists. Each block linked list contains page frame blocks with sizes of 1, 2, 4, 8, 16, 32, 64128256512 and 1024 consecutive page frames. A maximum of 1024 consecutive page boxes can be applied, corresponding to 4MB of continuous memory. The physical address of the first page frame of each page frame block is an integer multiple of the block size, as shown in the figure:

Suppose you want to apply for a block of 256 page frames, first find the free block from the linked list of 256 page frames. If not, go to the linked list of 512 page frames. If found, divide the page frame block into two blocks of 256 page frames, one is assigned to the application, and the other is moved to the linked list of 256 page frames. If there are still no free blocks in the linked list of 512 page frames, continue to search the linked list of 1024 page frames. If there are still no free blocks, an error is returned. When the page frame block is released, it will actively combine two consecutive page frame blocks into a larger page frame block.
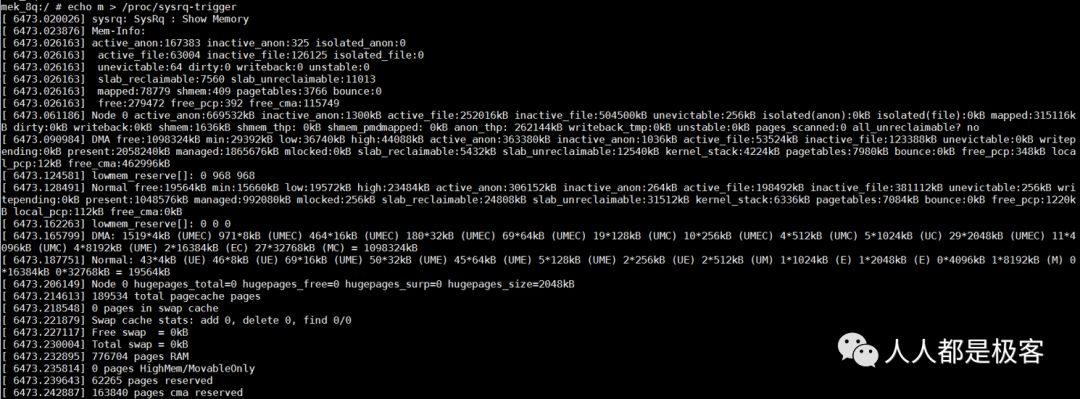
It can be seen from the above that the Buddy algorithm has been doing the action of opening and merging the page frame. The Buddy algorithm is used. Any positive integer in the world can be composed of the sum of 2^n. This is also the essence of the Buddy algorithm to manage the free page table. The information of free memory can be obtained through the following command:

You can also observe the buddy status through echo m > / proc / sysrq trigger, which is consistent with the information of / proc / buddy Info:
Buddy allocation function
static inline
struct page *rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
{
if (likely(order == 0)) { //If order=0, it is allocated from pcp
page = rmqueue_pcplist(preferred_zone, zone, order, gfp_flags, migratetype);
}
do {
page = NULL;
if (alloc_flags & ALLOC_HARDER) {//If alloc is set in the allocation flag_ Harder, from free_ Page allocation in the linked list of list [migrate_high]
page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);
}
if (!page) //If the first two conditions are not met, it is in normal free_ Assign in list [migrate *]
page = __rmqueue(zone, order, migratetype);
} while (page && check_new_pages(page, order));
......
}
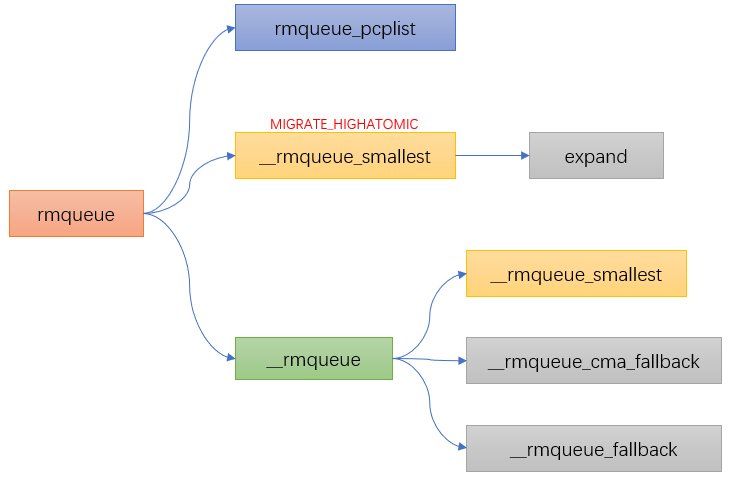
Water level of Linux partition page frame allocator
When we talked about the page box allocator, we talked about fast allocation and slow allocation. The partner algorithm is done in fast allocation. Let's look at the forgotten little partner again:
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx, ac->nodemask)
{
if (!zone_watermark_fast(zone, order, mark, ac_classzone_idx(ac), alloc_flags))
{
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
switch (ret) {
case NODE_RECLAIM_NOSCAN:
continue;
case NODE_RECLAIM_FULL:
continue;
default:
if (zone_watermark_ok(zone, order, mark, ac_classzone_idx(ac), alloc_flags))
goto try_this_zone;
continue;
}
}
try_this_zone: //Normal water level of this zone
page = rmqueue(ac->preferred_zoneref->zone, zone, order, gfp_mask, alloc_flags, ac->migratetype);
}
return NULL;
}
We can see that there is a judgment on the water level before the partner algorithm allocation. Today we will look at the concept of lower water level.
Simply put, when using the partition page allocator, the available free pages will be compared with the water level in the zone.
Water level initialization
-
nr_free_buffer_pages is to get ZONE_DMA and zone_ Total pages above high water level in normal area nr_free_buffer_pages = managed_pages - high_pages
-
min_free_kbytes is the total min size, min_free_kbytes = 4 * sqrt(lowmem_kbytes)
-
setup_per_zone_wmarks is based on the total min value and the proportion of each zone in the total memory, and then through do_div calculates their respective min values, and then calculates the water level of each zone. The relationship between min, low and high is as follows: low = min *125%;
-
high = min * 150%
-
min:low:high = 4:5:6
-
setup_per_zone_lowmem_reserve when Normal fails, it will attempt to apply for allocation from DMA through lowmem_reserve[DMA], which restricts allocation requests from Normal. Its value can be through / proc/sys/vm/lowmem_reserve_ratio to modify.
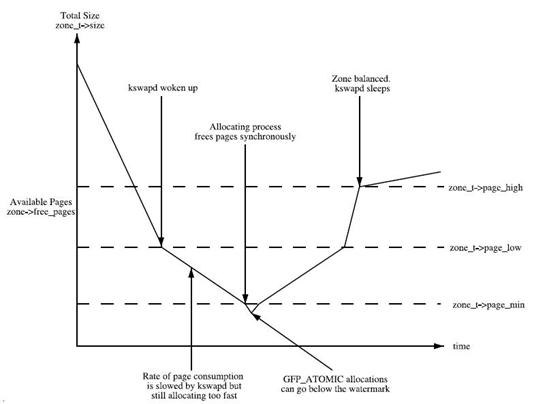
As can be seen from this figure:
- If the number of free pages is min, the zone is very short of pages and the page recycling pressure is great. The application's write memory operation will be blocked and recycled directly in the application's process context, that is, direct reclaim.
- If the number of free pages is less than the low value, the kswapd thread will wake up and start releasing recycled pages.
- If the value of the idle page is greater than the high value, the state of the zone is perfect and the kswapd thread will sleep again.
Memory defragmentation of Linux page frame allocator
What is memory fragmentation
Linux physical memory fragmentation includes two types: internal fragmentation and external fragmentation.
- Internal fragmentation:
It refers to the unused part of the memory space allocated to the user. For example, the process needs to use 3K bytes of physical memory, so it applies to the system for memory with a size equal to 3Kbytes. However, since the minimum particle of the Linux kernel partner system algorithm is 4K bytes, 4Kbytes of memory is allocated, and the unused memory of 1K bytes is the internal memory fragment.
- External fragmentation:
Refers to a small block of memory that cannot be utilized in the system. For example, the remaining memory of the system is 16K bytes, but the 16K bytes memory is composed of four 4K bytes pages, that is, the physical page frame number #1 of 16K memory is discontinuous. When 16K bytes of memory is left in the system, the system cannot successfully allocate continuous physical memory greater than 4K. This is caused by fragments outside the memory.
Defragmentation algorithm
The defragmentation algorithm of Linux memory mainly applies the page migration mechanism of the kernel, which is a method to free up continuous physical memory after migrating removable pages.
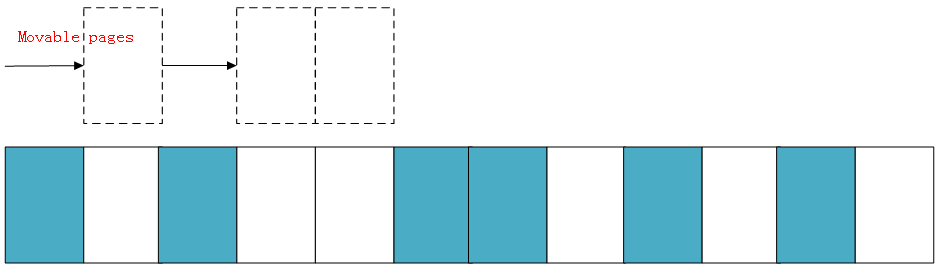
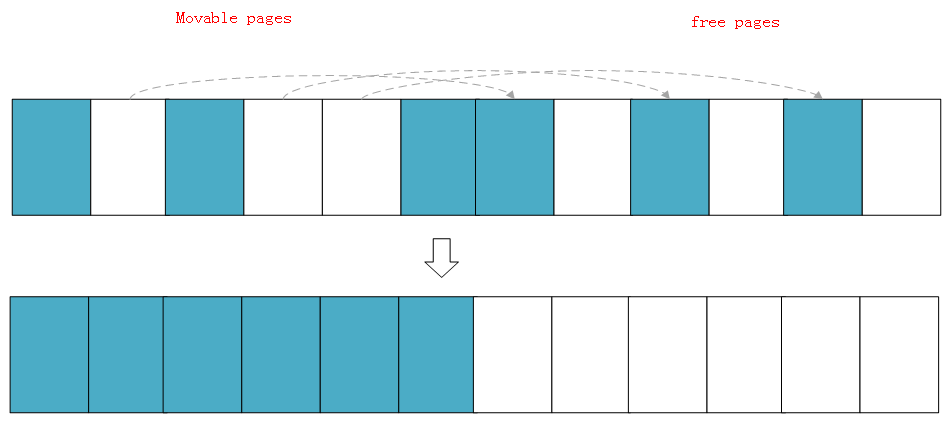
Suppose there is a very small memory domain, as follows:

Blue indicates idle pages and white indicates pages that have been allocated. You can see that the idle pages (blue) in the above memory domain are very scattered and cannot allocate more than two pages of continuous physical memory.
The following is a demonstration of the simplified working principle of memory regularization. The kernel will run two independent scanning actions: the first scanning starts from the bottom of the memory domain and records the allocated removable pages in a list while scanning:
In addition, the second scan starts from the top of the memory domain, scans the free page location that can be used as the page migration target, and then records it in a list:
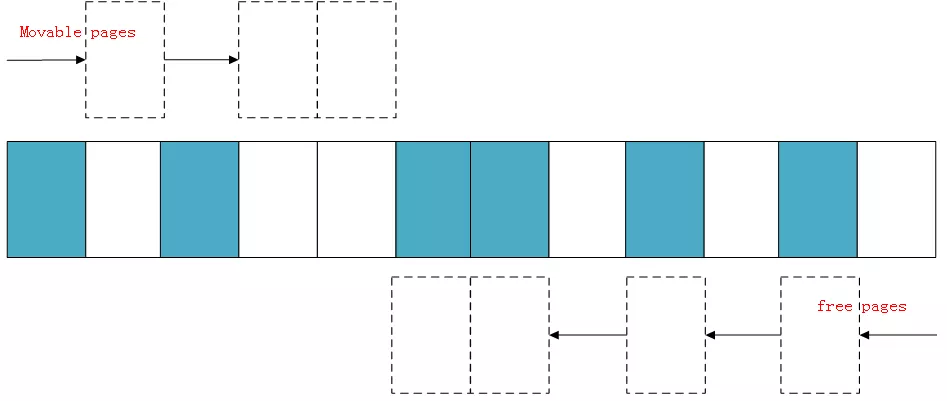
When the two scans meet in the middle of the domain, it means that the scan is over, and then the allocated pages scanned on the left are migrated to the free pages on the right. A continuous physical memory is formed on the left to complete page regularization.
Three ways of defragmentation
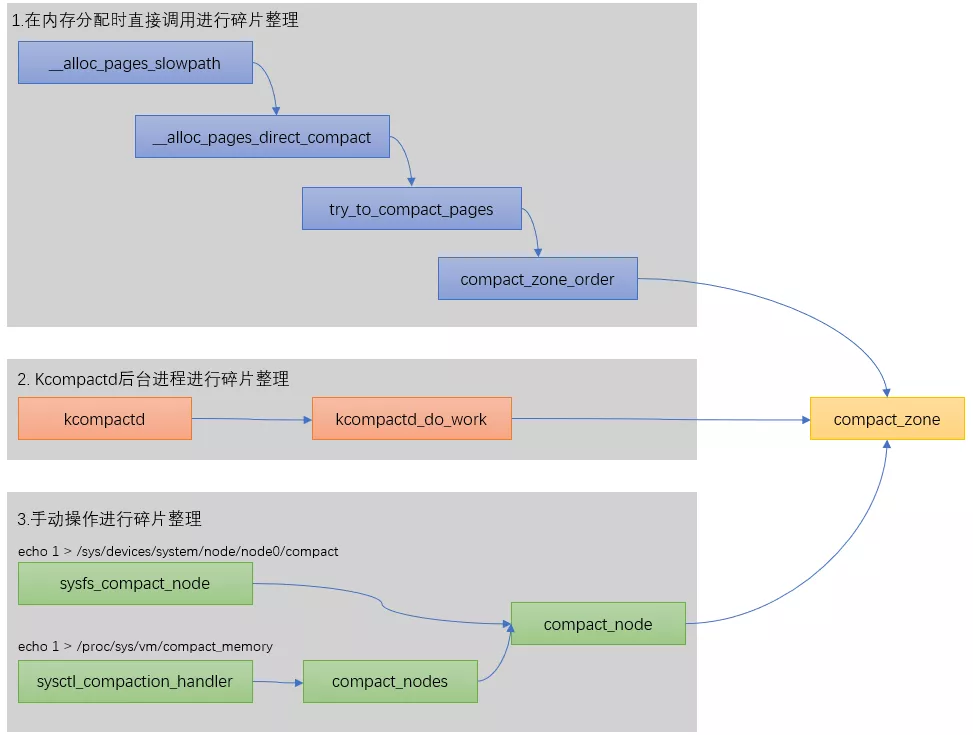
static struct page *
__alloc_pages_direct_compact(gfp_t gfp_mask, unsigned int order,
unsigned int alloc_flags, const struct alloc_context *ac,
enum compact_priority prio, enum compact_result *compact_result)
{
struct page *page;
unsigned int noreclaim_flag;
if (!order)
return NULL;
noreclaim_flag = memalloc_noreclaim_save();
*compact_result = try_to_compact_pages(gfp_mask, order, alloc_flags, ac,
prio);
memalloc_noreclaim_restore(noreclaim_flag);
if (*compact_result <= COMPACT_INACTIVE)
return NULL;
count_vm_event(COMPACTSTALL);
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page) {
struct zone *zone = page_zone(page);
zone->compact_blockskip_flush = false;
compaction_defer_reset(zone, order, true);
count_vm_event(COMPACTSUCCESS);
return page;
}
count_vm_event(COMPACTFAIL);
cond_resched();
return NULL;
}
There are three ways to defragment in the linux kernel, which are summarized as follows:
Linux slab allocator
In Linux, partner systems allocate memory on a page by page basis. But in reality, it is often in bytes, otherwise it would be too wasteful to apply for 10Bytes of memory and give 1 page. The slab allocator is designed for small memory allocation. The memory allocated by the slab allocator is in bytes. However, the slab allocator is not separated from the partner system, but is further subdivided into small memory allocation based on the large memory allocated by the partner system.
The relationship between them can be described by a diagram:
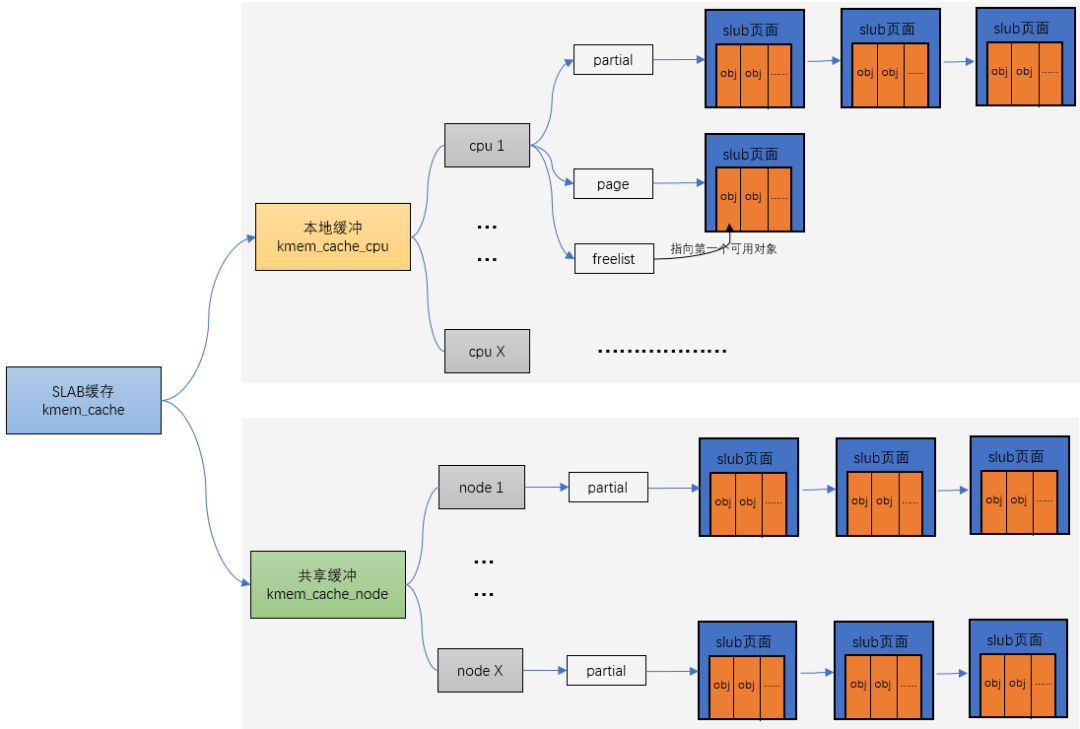
Process analysis
kmem_cache_alloc has four main steps:
- Start with kmem_ cache_ CPU - > freelist, if freelist is null
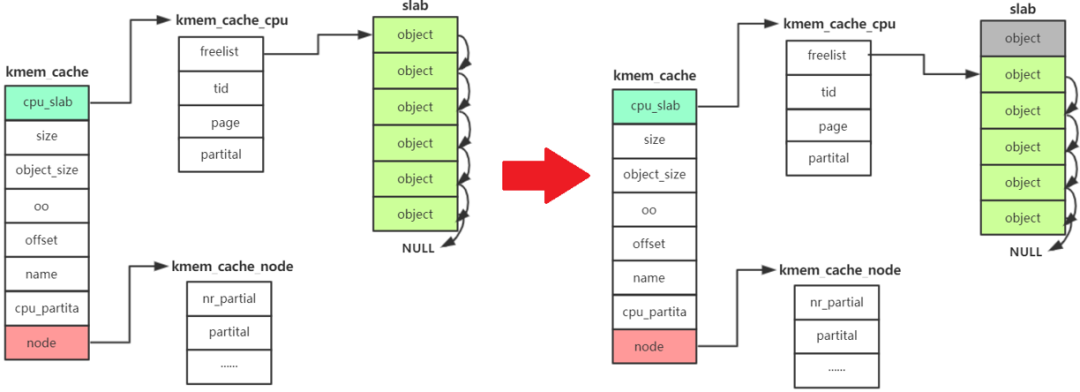
- Then go to kmem_ cache_ CPU - > partital is allocated in the linked list. If the linked list is null
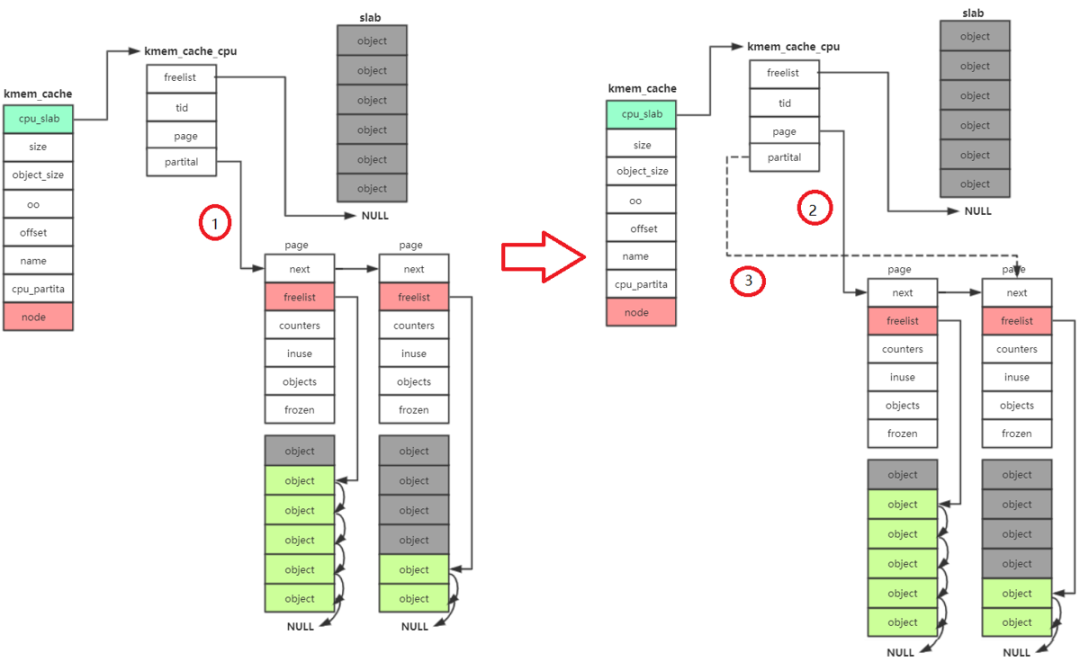
- Then go to kmem_ cache_ Node - > partital linked list allocation. If the linked list is null
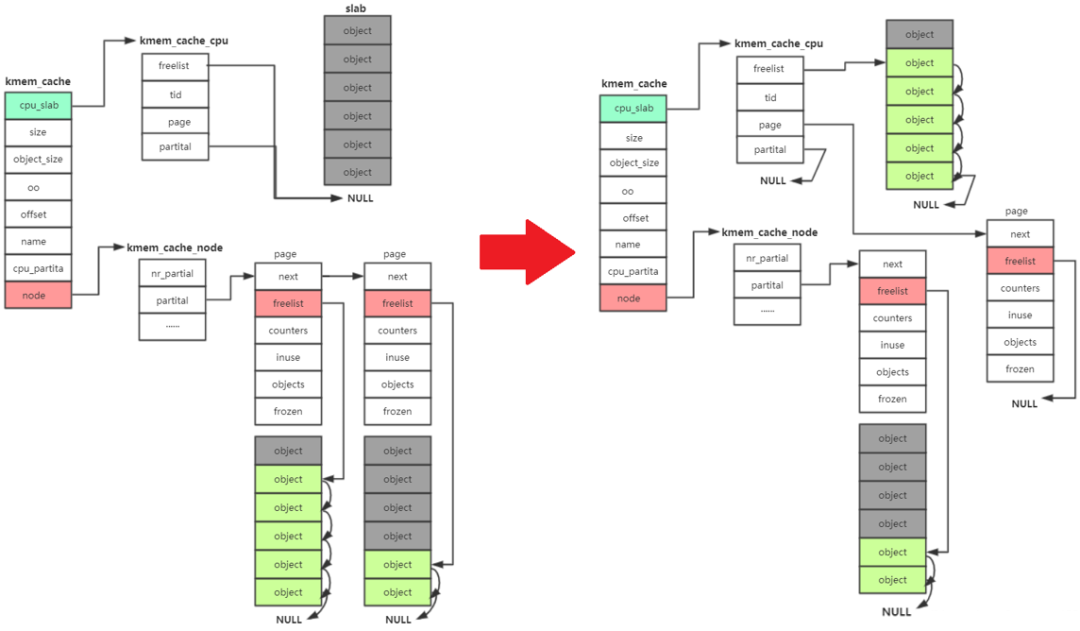
- Reassign a slab.
vmalloc for Linux memory management
According to the previous series of articles, we know that buddy system is based on page frame allocator and kmalloc is based on slab allocator, and these allocated addresses are continuous in physical memory. However, with the accumulation of fragmentation, the allocation of continuous physical memory will become difficult. For those non DMA accesses, if continuous physical memory is not necessary, the discontinuous physical memory page frame can be mapped to the continuous virtual address space like malloc (this is the source of vmap) (mapping discrete pages to the continuous virtual address space is provided), vmalloc allocation is implemented based on this mechanism.
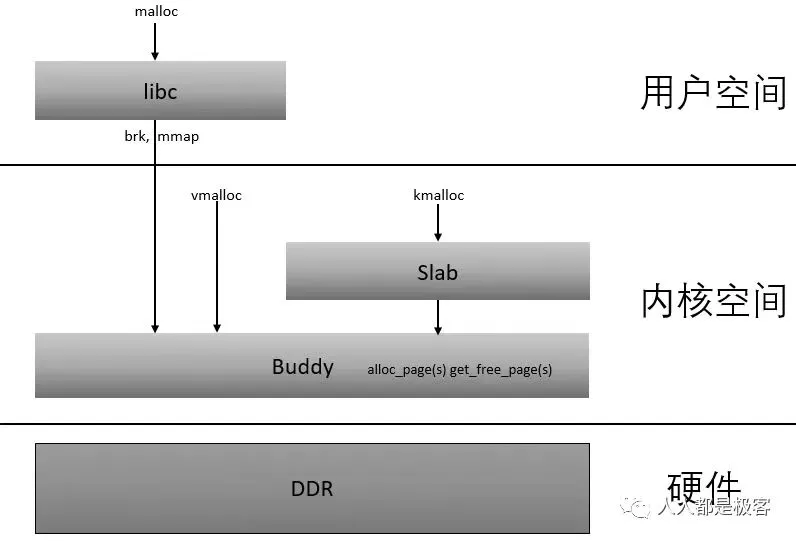
Vmalloc allocates at least one page, and the allocated pages are not guaranteed to be continuous, because vmalloc calls alloc internally_ Page assigns a single page multiple times.
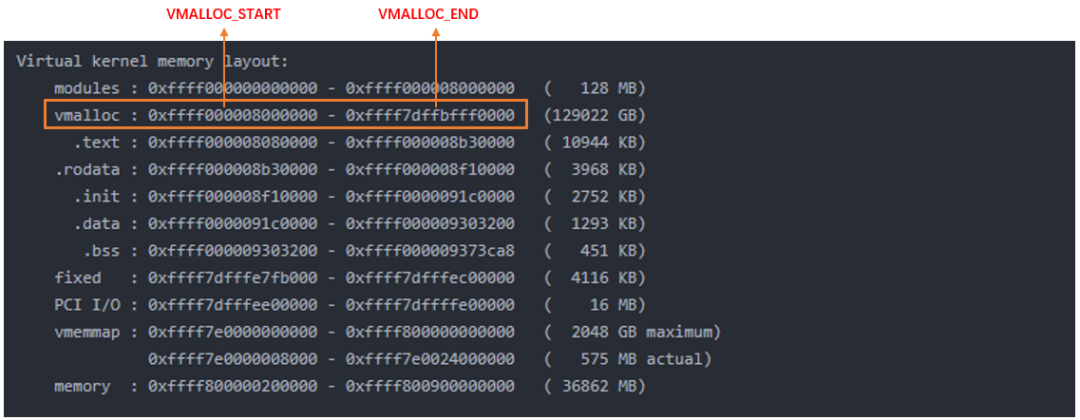
The area of vmalloc is vmalloc in the above figure_ START - VMALLOC_ Between end, you can view it through / proc/vmallocinfo.
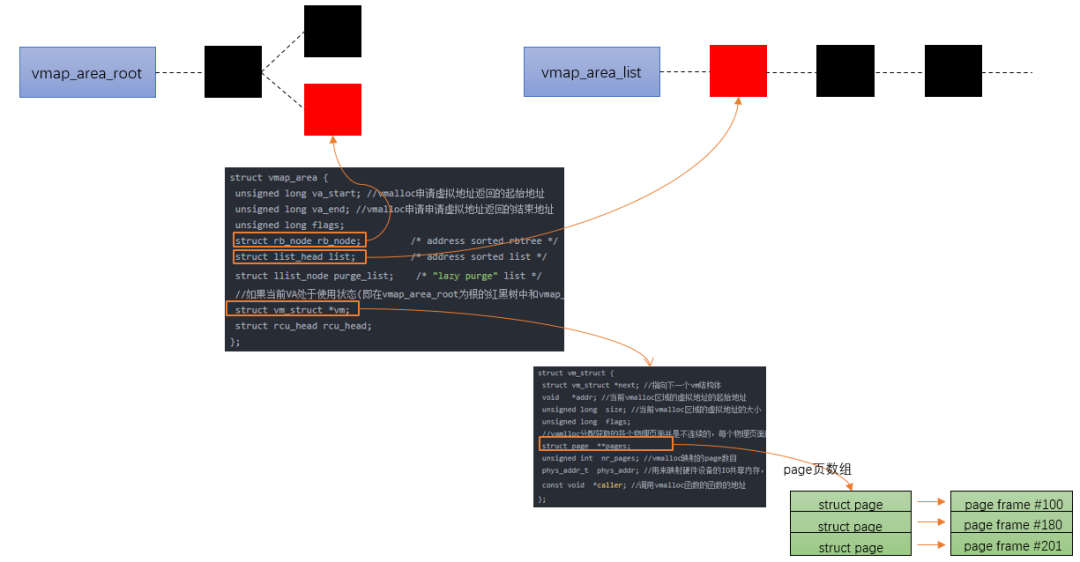
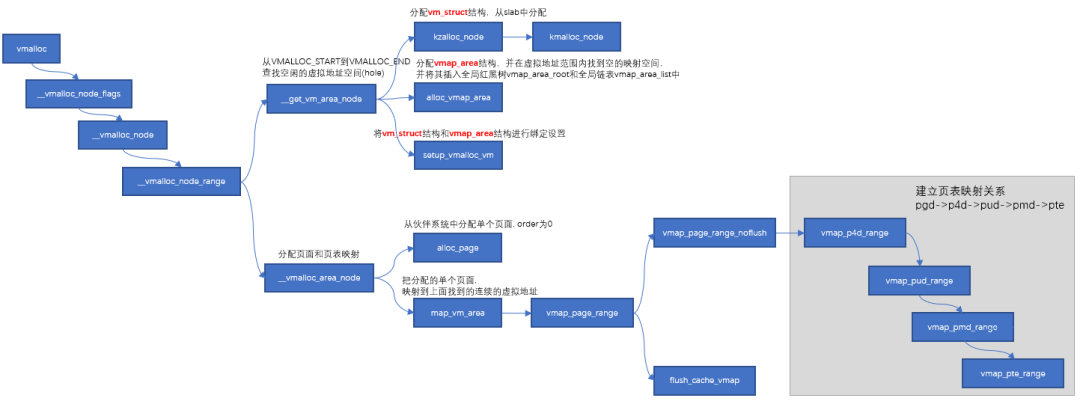
vmalloc process
It is mainly divided into the following three steps:
- From VMALLOC_START to VMALLOC_END find free virtual address space (hole)
- Call alloc according to the allocated size_ Page assigns a single page in turn
- Map the assigned single page to the continuous virtual addresses found in the first step. Map the assigned single page to the continuous virtual addresses found in the first step.
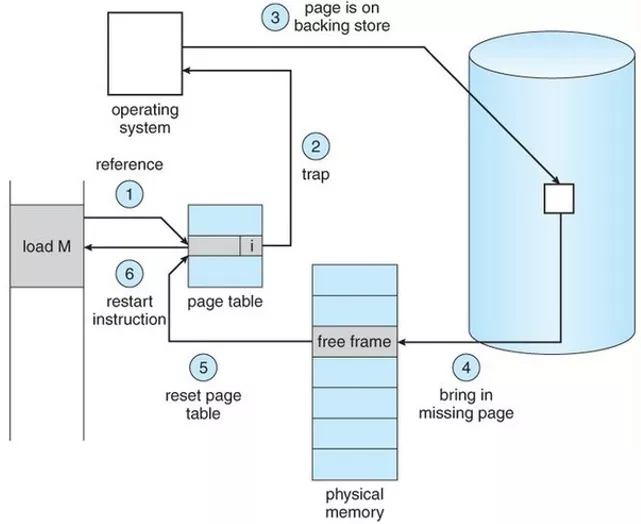
Missing page exception in memory management of Linux Process
When a process accesses these virtual addresses that have not yet established a mapping relationship, the processor will automatically trigger a page missing exception.
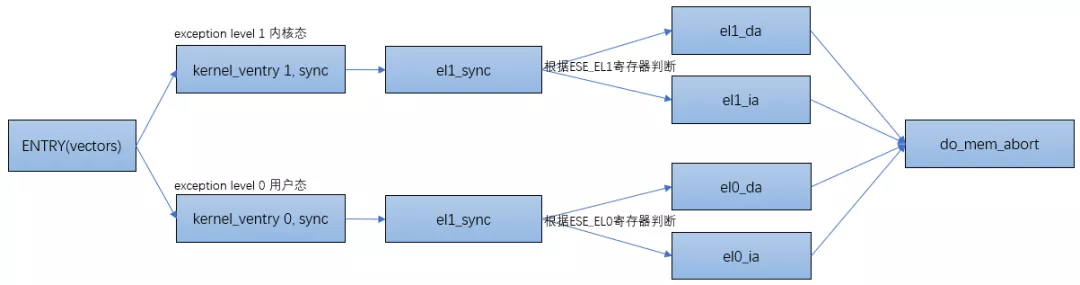
ARM64 divides exceptions into synchronous exceptions and asynchronous exceptions. Generally, asynchronous exceptions refer to interrupts (see God's perspective on interrupts), and synchronous exceptions refer to exceptions. For the article on ARM exception handling, please refer to introduction to ARMv8 exception handling.
When an exception occurs to the processor, the processor will jump to the exception vector table of ARM64 first:
ENTRY(vectors)
kernel_ventry 1, sync_invalid // Synchronous EL1t
kernel_ventry 1, irq_invalid // IRQ EL1t
kernel_ventry 1, fiq_invalid // FIQ EL1t
kernel_ventry 1, error_invalid // Error EL1t
kernel_ventry 1, sync // Synchronous EL1h
kernel_ventry 1, irq // IRQ EL1h
kernel_ventry 1, fiq_invalid // FIQ EL1h
kernel_ventry 1, error_invalid // Error EL1h
kernel_ventry 0, sync // Synchronous 64-bit EL0
kernel_ventry 0, irq // IRQ 64-bit EL0
kernel_ventry 0, fiq_invalid // FIQ 64-bit EL0
kernel_ventry 0, error_invalid // Error 64-bit EL0
#ifdef CONFIG_COMPAT
kernel_ventry 0, sync_compat, 32 // Synchronous 32-bit EL0
kernel_ventry 0, irq_compat, 32 // IRQ 32-bit EL0
kernel_ventry 0, fiq_invalid_compat, 32 // FIQ 32-bit EL0
kernel_ventry 0, error_invalid_compat, 32 // Error 32-bit EL0
#else
kernel_ventry 0, sync_invalid, 32 // Synchronous 32-bit EL0
kernel_ventry 0, irq_invalid, 32 // IRQ 32-bit EL0
kernel_ventry 0, fiq_invalid, 32 // FIQ 32-bit EL0
kernel_ventry 0, error_invalid, 32 // Error 32-bit EL0
#endif
END(vectors)
Take the exception under el1 as an example, when you jump to el1_ When the sync function is, the value of ESR is read to determine the exception type. Jump to different processing functions according to the type. If it is data abort, jump to el1_ In the DA function, if instruction abort, jump to el1_ In the IA function:
el1_sync:
kernel_entry 1
mrs x1, esr_el1 // read the syndrome register
lsr x24, x1, #ESR_ELx_EC_SHIFT // exception class
cmp x24, #ESR_ELx_EC_DABT_CUR // data abort in EL1
b.eq el1_da
cmp x24, #ESR_ELx_EC_IABT_CUR // instruction abort in EL1
b.eq el1_ia
cmp x24, #ESR_ELx_EC_SYS64 // configurable trap
b.eq el1_undef
cmp x24, #ESR_ELx_EC_SP_ALIGN // stack alignment exception
b.eq el1_sp_pc
cmp x24, #ESR_ELx_EC_PC_ALIGN // pc alignment exception
b.eq el1_sp_pc
cmp x24, #ESR_ELx_EC_UNKNOWN // unknown exception in EL1
b.eq el1_undef
cmp x24, #ESR_ELx_EC_BREAKPT_CUR // debug exception in EL1
b.ge el1_dbg
b el1_inv
The flow chart is as follows:
do_page_fault
static int __do_page_fault(struct mm_struct *mm, unsigned long addr,
unsigned int mm_flags, unsigned long vm_flags,
struct task_struct *tsk)
{
struct vm_area_struct *vma;
int fault;
vma = find_vma(mm, addr);
fault = VM_FAULT_BADMAP; //The vma region is not found, indicating that addr is not in the address space of the process
if (unlikely(!vma))
goto out;
if (unlikely(vma->vm_start > addr))
goto check_stack;
/*
* Ok, we have a good vm_area for this memory access, so we can handle
* it.
*/
good_area://A good vma
/*
* Check that the permissions on the VMA allow for the fault which
* occurred.
*/
if (!(vma->vm_flags & vm_flags)) {//Permission check
fault = VM_FAULT_BADACCESS;
goto out;
}
//Re establish the mapping relationship between physical pages and VMA
return handle_mm_fault(vma, addr & PAGE_MASK, mm_flags);
check_stack:
if (vma->vm_flags & VM_GROWSDOWN && !expand_stack(vma, addr))
goto good_area;
out:
return fault;
}
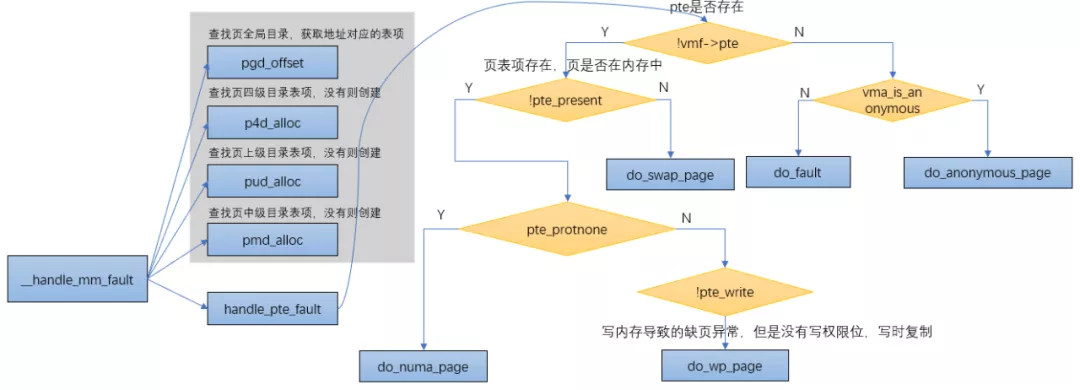
From__ do_ page_ The fault function can see that when the virtual address triggering the exception belongs to a vma and has the permission to trigger the page error exception, it will call the handle_mm_fault function to establish the mapping between vma and physical address, and handle_ mm_ The main logic of the fault function is through__ handle_mm_fault.
__handle_mm_fault
static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
......
//Find the global directory of the page and get the table entry corresponding to the address
pgd = pgd_offset(mm, address);
//Find page level 4 table of contents entries. If not, create
p4d = p4d_alloc(mm, pgd, address);
if (!p4d)
return VM_FAULT_OOM;
//Find the table entry of the page's parent directory. If not, create it
vmf.pud = pud_alloc(mm, p4d, address);
......
//Find page intermediate directory table entry, if not, create
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
......
//Process pte page table
return handle_pte_fault(&vmf);
}
do_anonymous_page
Anonymous page missing exception. For anonymous mapping, only a piece of virtual memory is obtained after mapping, and no physical memory is allocated. When accessing for the first time:
- In the case of read access, virtual pages are mapped to 0 pages to reduce unnecessary memory allocation
- For write access, use alloc_zeroed_user_highpage_movable allocates a new physical page, fills it with 0, and then maps it to the virtual page
- If the access is read before write, two page missing exceptions will occur: the first is the read processing of anonymous page missing exception (the mapping from virtual page to 0 page), and the second is the copy page missing exception processing during write.
From the above summary, we know that there are three cases when accessing anonymous pages for the first time, of which the first and third cases will involve page 0.
do_fault
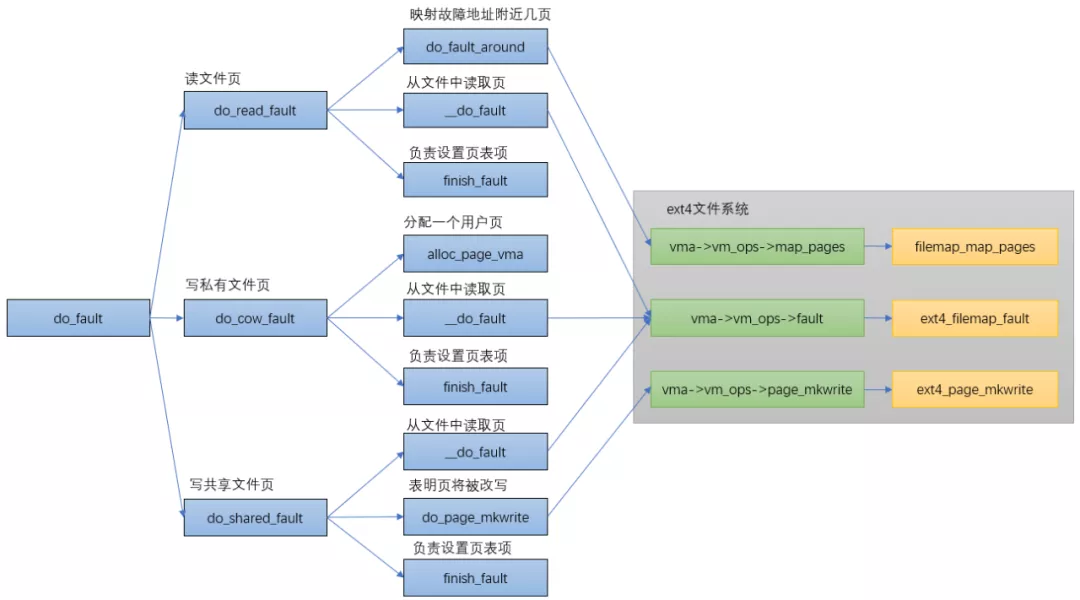
do_swap_page
As mentioned above, when the content corresponding to the pte is not 0 (the page table item exists), but the page corresponding to the pte is not in memory, it means that the page corresponding to the pte content is in the swap space at this time. If the page is missing, it will pass do_swap_page() function to allocate pages.
do_ swap_ When page occurs in swap in, i.e. find the slot on the disk and read the data back.
The process of switching in is as follows:
- Find out whether the searched page exists in the swap cache. If so, remap and update the page table according to the memory page referenced by the swap cache; If it does not exist, allocate a new memory page and add it to the reference of swap cache. After updating the contents of the memory page, update the page table.
- After the swap in operation, the page reference of the corresponding swap area is reduced by 1. When it is reduced to 0, it means that no process references the page and can be recycled.
int do_swap_page(struct vm_fault *vmf)
{
......
//Find swap} entry according to pte. swap} entry has a corresponding relationship with pte
entry = pte_to_swp_entry(vmf->orig_pte);
......
if (!page)
//Find the page from the swap cache according to the entry, and find the page corresponding to the entry in the swap cache
//Lookup a swap entry in the swap cache
page = lookup_swap_cache(entry, vma_readahead ? vma : NULL,
vmf->address);
//Page not found
if (!page) {
if (vma_readahead)
page = do_swap_page_readahead(entry,
GFP_HIGHUSER_MOVABLE, vmf, &swap_ra);
else
//If it cannot be found in the swap cache, find it in the swap area, allocate new memory pages and read them from the swap area
page = swapin_readahead(entry,
GFP_HIGHUSER_MOVABLE, vma, vmf->address);
......
//Get the entry of a pte and re-establish the mapping
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
&vmf->ptl);
......
//Add 1 to the anonpage number. Anonymous pages are exchanged from the swap space, so add 1
//The number of swap pages minus 1, and a new pte is created by the page and VMA attributes
inc_mm_counter_fast(vma->vm_mm, MM_ANONPAGES);
dec_mm_counter_fast(vma->vm_mm, MM_SWAPENTS);
pte = mk_pte(page, vma->vm_page_prot);
......
flush_icache_page(vma, page);
if (pte_swp_soft_dirty(vmf->orig_pte))
pte = pte_mksoft_dirty(pte);
//Add the newly generated PTE} entry to the hardware page table
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, pte);
vmf->orig_pte = pte;
//According to whether the page is swapcache
if (page == swapcache) {
//If so, use the swap cache page as an anon page and add it to the reverse map rmap
do_page_add_anon_rmap(page, vma, vmf->address, exclusive);
mem_cgroup_commit_charge(page, memcg, true, false);
//And add it to the active linked list
activate_page(page);
//If not
} else { /* ksm created a completely new copy */
//Use the new page and copy the swap cache page and add it to the reverse map rmap
page_add_new_anon_rmap(page, vma, vmf->address, false);
mem_cgroup_commit_charge(page, memcg, false, false);
//And added to lru linked list
lru_cache_add_active_or_unevictable(page, vma);
}
//Release swap entry
swap_free(entry);
......
if (vmf->flags & FAULT_FLAG_WRITE) {
//Copy on write if there is a write request
ret |= do_wp_page(vmf);
if (ret & VM_FAULT_ERROR)
ret &= VM_FAULT_ERROR;
goto out;
}
......
return ret;
}
do_wp_page
This shows that the page is in memory, but PTE only has read permission, and do will be triggered when it wants to write to memory_ wp_ page.
do_ wp_ The page function is used to handle copy on write. Its process is relatively simple. It is mainly to allocate a new physical page, copy the contents of the original page to the new page, and then modify the contents of the page table entry to point to the new page and change it to writable (vma has writable attribute).
static int do_wp_page(struct vm_fault *vmf)
__releases(vmf->ptl)
{
struct vm_area_struct *vma = vmf->vma;
//Get the page frame number from the page table item, and then get the page descriptor. The page structure of the address in case of exception
vmf->page = vm_normal_page(vma, vmf->address, vmf->orig_pte);
if (!vmf->page) {
//No page structure is a special mapping using page frame number
/*
* VM_MIXEDMAP !pfn_valid() case, or VM_SOFTDIRTY clear on a
* VM_PFNMAP VMA.
*
* We should not cow pages in a shared writeable mapping.
* Just mark the pages writable and/or call ops->pfn_mkwrite.
*/
if ((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))
//Handling shared writable mappings
return wp_pfn_shared(vmf);
pte_unmap_unlock(vmf->pte, vmf->ptl);
//Handle private writable mappings
return wp_page_copy(vmf);
}
/*
* Take out anonymous pages first, anonymous shared vmas are
* not dirty accountable.
*/
if (PageAnon(vmf->page) && !PageKsm(vmf->page)) {
int total_map_swapcount;
if (!trylock_page(vmf->page)) {
//Add the reference count of the original page, and the mode is released
get_page(vmf->page);
//Release page table lock
pte_unmap_unlock(vmf->pte, vmf->ptl);
lock_page(vmf->page);
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd,
vmf->address, &vmf->ptl);
if (!pte_same(*vmf->pte, vmf->orig_pte)) {
unlock_page(vmf->page);
pte_unmap_unlock(vmf->pte, vmf->ptl);
put_page(vmf->page);
return 0;
}
put_page(vmf->page);
}
//Processing of single anonymous pages
if (reuse_swap_page(vmf->page, &total_map_swapcount)) {
if (total_map_swapcount == 1) {
/*
* The page is all ours. Move it to
* our anon_vma so the rmap code will
* not search our parent or siblings.
* Protected against the rmap code by
* the page lock.
*/
page_move_anon_rmap(vmf->page, vma);
}
unlock_page(vmf->page);
wp_page_reuse(vmf);
return VM_FAULT_WRITE;
}
unlock_page(vmf->page);
} else if (unlikely((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))) {
//Sharing is writable, and there is no need to copy physical pages. You can set page table permissions
return wp_page_shared(vmf);
}
/*
* Ok, we need to copy. Oh, well..
*/
get_page(vmf->page);
pte_unmap_unlock(vmf->pte, vmf->ptl);
//Private writable, copy physical pages, and map virtual pages to physical pages
return wp_page_copy(vmf);
}
CMA of Linux memory management
CMA is a reserved block of memory, which is used to allocate continuous large blocks of memory. When the device driver is not used, the memory management system uses this area to allocate and manage removable type pages; When the device driver is used, the allocated pages need to be migrated and used for continuous memory allocation; Its usage is combined with DMA subsystem to act as the back end of DMA. For details, refer to DMA operation without IOMMU.
CMA area CMA_ Creating areas
There are two methods to create CMA area: one is through the reserved memory of dts, and the other is through the command line parameter and kernel configuration parameter.
- dts mode:
reserved-memory {
/* global autoconfigured region for contiguous allocations */
linux,cma {
compatible = "shared-dma-pool";
reusable;
size = <0 0x28000000>;
alloc-ranges = <0 0xa0000000 0 0x40000000>;
linux,cma-default;
};
};
The device tree can contain a reserved memory node, and rmem will be opened when the system starts_ cma_ setup
RESERVEDMEM_OF_DECLARE(cma, "shared-dma-pool", rmem_cma_setup);
- command line mode: cma=nn[MG]@[start[MG][-end[MG]]]
static int __init early_cma(char *p)
{
pr_debug("%s(%s)\n", __func__, p);
size_cmdline = memparse(p, &p);
if (*p != '@') {
/*
if base and limit are not assigned,
set limit to high memory bondary to use low memory.
*/
limit_cmdline = __pa(high_memory);
return 0;
}
base_cmdline = memparse(p + 1, &p);
if (*p != '-') {
limit_cmdline = base_cmdline + size_cmdline;
return 0;
}
limit_cmdline = memparse(p + 1, &p);
return 0;
}
early_param("cma", early_cma);
During startup, the system will transfer NN, start and end in cmdline to DMA function_ contiguous_ Reserve, the process is as follows:
setup_arch--->arm64_memblock_init--->dma_contiguous_reserve->dma_contiguous_reserve_area->cma_declare_contiguous
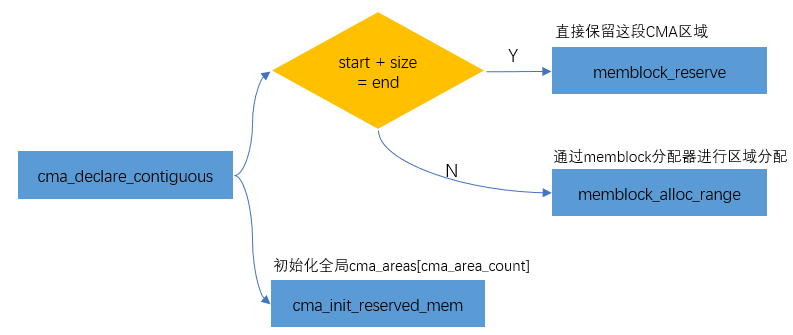
Add CMA area to Buddy System
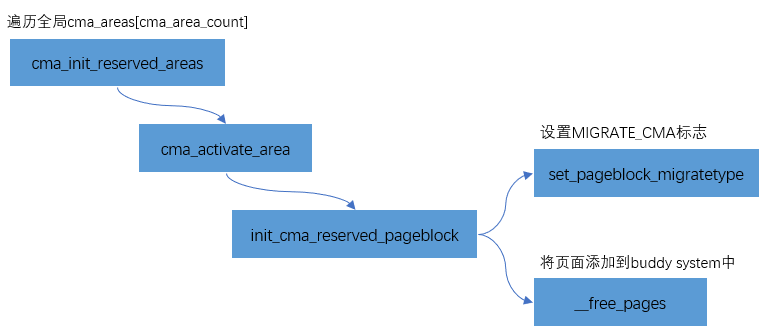
In order to avoid the waste of this reserved memory when not in use, the memory management module will add the CMA area to the Buddy System for the allocation and management of removable pages. CMA area is through cma_init_reserved_areas interface to add to the Buddy System.
static int __init cma_init_reserved_areas(void)
{
int i;
for (i = 0; i < cma_area_count; i++) {
int ret = cma_activate_area(&cma_areas[i]);
if (ret)
return ret;
}
return 0;
}
core_initcall(cma_init_reserved_areas);
The implementation is relatively simple, which is mainly divided into two steps:
- Set the page to MIGRATE_CMA logo
- Pass__ free_pages adds pages to the buddy system
CMA allocation
As mentioned in DMA operation without IOMMU, CMA is through cma_alloc allocated. cma_alloc->alloc_ contig_ range(..., MIGRATE_CMA,...), Migrate to the buffer system just released_ CMA type page, and "collect" it again.
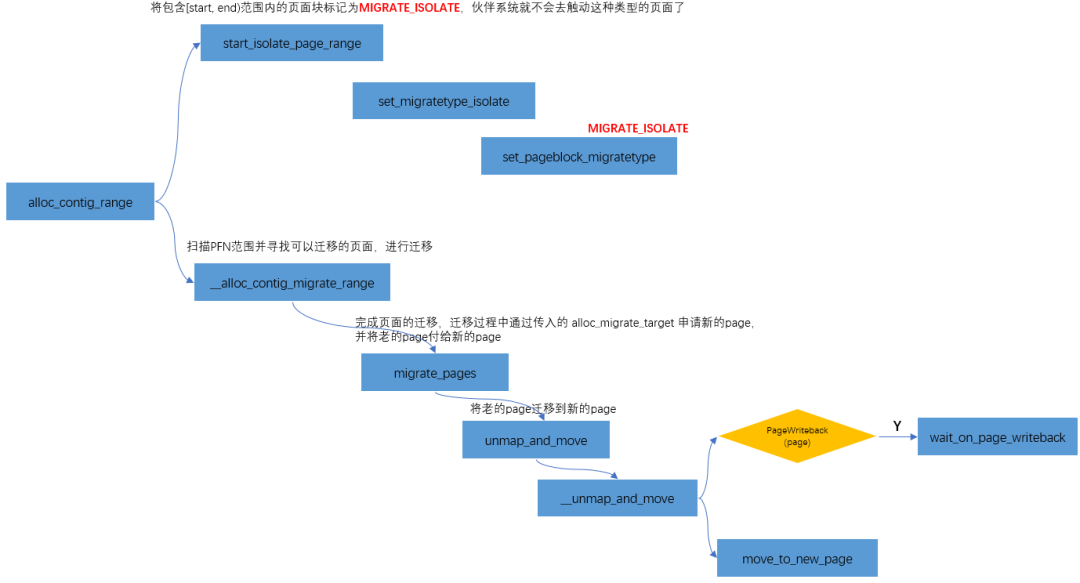
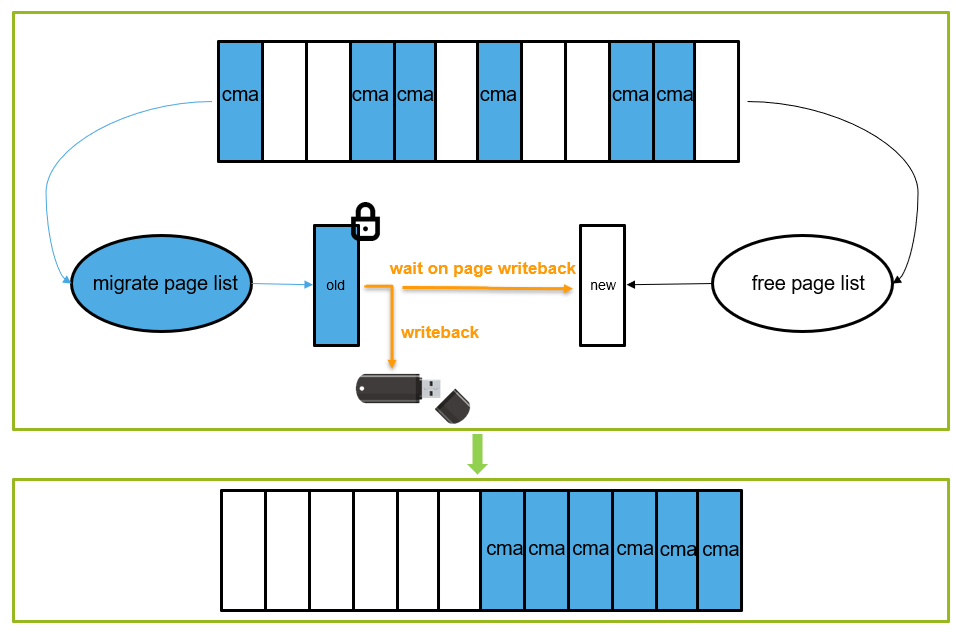
One thing to note when using CMA:
That is, the judgment of the yellow part in the figure above. CMA in memory allocation is a "heavy" operation, which may involve page migration, page recycling and other operations, so it is not suitable for atomic context. For example, there was a problem before. When the memory is insufficient, the operation interface will be stuck while writing data to the USB flash disk. This is because CMA needs to wait for the data in the current page to be written back to the USB flash disk during the migration process before further regulating the continuous memory for gpu/display, resulting in a stuck phenomenon.
summary
So far, from the CPU to access memory, to the division of physical pages, to the implementation of the kernel page frame allocator, and the implementation of the slab allocator, and finally to the use of continuous memory such as CMA, the knowledge of Linux memory management is connected, forming the whole closed loop. I believe that if you master the content of this article, you will certainly open the door to the Linux kernel. With this cornerstone, I wish everyone's kernel learning will be easier and easier in the future.

Big release of 5T technical resources! Including but not limited to: C/C + +, Arm, Linux, Android, artificial intelligence, MCU, raspberry pie, etc. Reply to "peter" in official account, and you can get it free!!
 Remember to click share, praise and watch, give it to me
Remember to click share, praise and watch, give it to me