3, Zookeeper cluster operation
3.1 cluster operation
3.1.1 installation of zookeeper on Cluster
We learned earlier Installation of Zookeeper locally , the basic steps are similar, but after we install it on a host in the cluster, we still need to install the installation files Distribute across hosts , and the number of the configuration host, cfg configuration file
Step 1 Single host installation in cluster
Step 2 Configure server number
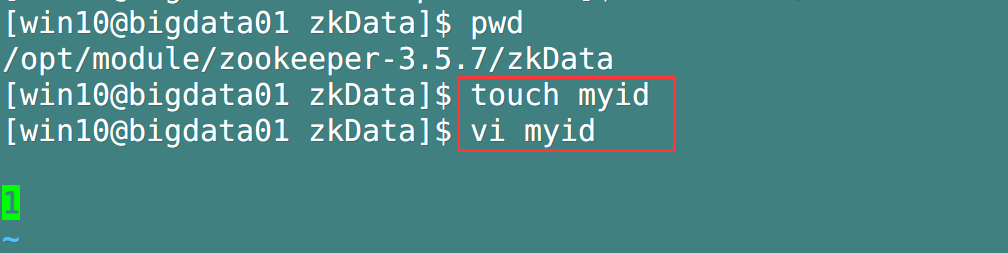
- In the zkData directory we created in the previous step, create a new myid file and add the number corresponding to the server in the file (there is no blank line at the top and bottom, and there is no space at the left and right.)
- Take Bigdata01 host as an example:
- Distribute the entire Zookeeper installation directory to other hosts in the cluster, and modify the myid number on different hosts (for example, bigdata02 is 2 and bigdata03 is 3)
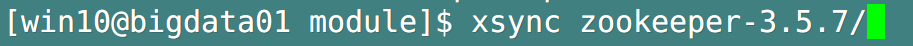


Step 3 Configure zoo cfg
- In step 1, we put zoo_samle.cfg is named zoo CFG, and modify the dataDir (path to save zookeeper data). Now we open this file and add the following contents:

#######################cluster########################## server.1=bigdata01:2888:3888 server.2=bigdata02:2888:3888 server.3=bigdata03:2888:3888
Interpretation of configuration parameters:
server.A=B:C:D
- A is a number indicating the server number (the number has been defined in the * *... / zkData/myid * * file on the pinch surface. When Zookeeper starts, it will read this file and compare the data with the configuration information in zoo.cfg to determine which server it is)
- B is the address (IP address or domain name) of the server
- C is the port where the Follower of this server exchanges information with the Leader server in the cluster
- D is that in case the Leader server in the cluster hangs up, a port is needed to re elect and select a new Leader, and this port is the port used to communicate with each other during the election
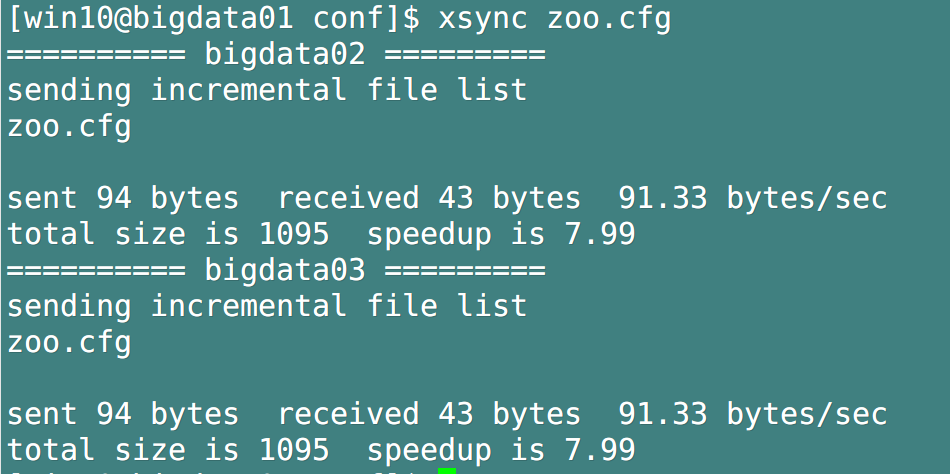
- Synchronous distribution of zoo cfg
Step 4 Cluster operation
- Start zookeeper separately for all hosts in the cluster

- View the status of each host in the cluster
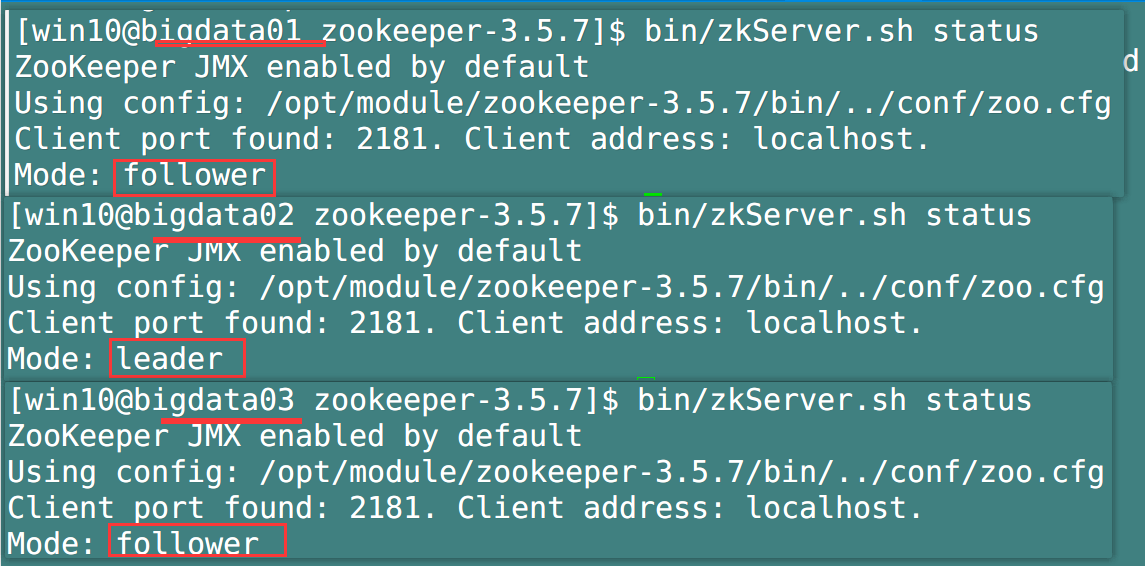
At this point, the deployment of zookeeper in the cluster is completed, which is very simple
Zookeeper start / stop / status script
In order to improve productivity (laziness), we write a one click execution script for Zookeeper's start / stop / status check just as we wrote the cluster start / stop script when deploying Hadoop cluster
- Create zk in / opt/module/zookeeper-3.5.7/bin directory and enter the following
#!/bin/bash
case $1 in
"start"){
for i in bigdata01 bigdata02 bigdata03
do
echo ---------- zookeeper $i start-up ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh
start"
done
};;
"stop"){
for i in bigdata01 bigdata02 bigdata03
do
echo ---------- zookeeper $i stop it ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh
stop"
done
};;
"status"){
for i in bigdata01 bigdata02 bigdata03
do
echo ---------- zookeeper $i state ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh
status"
done
};;
esac
-
Add execution permission to the script
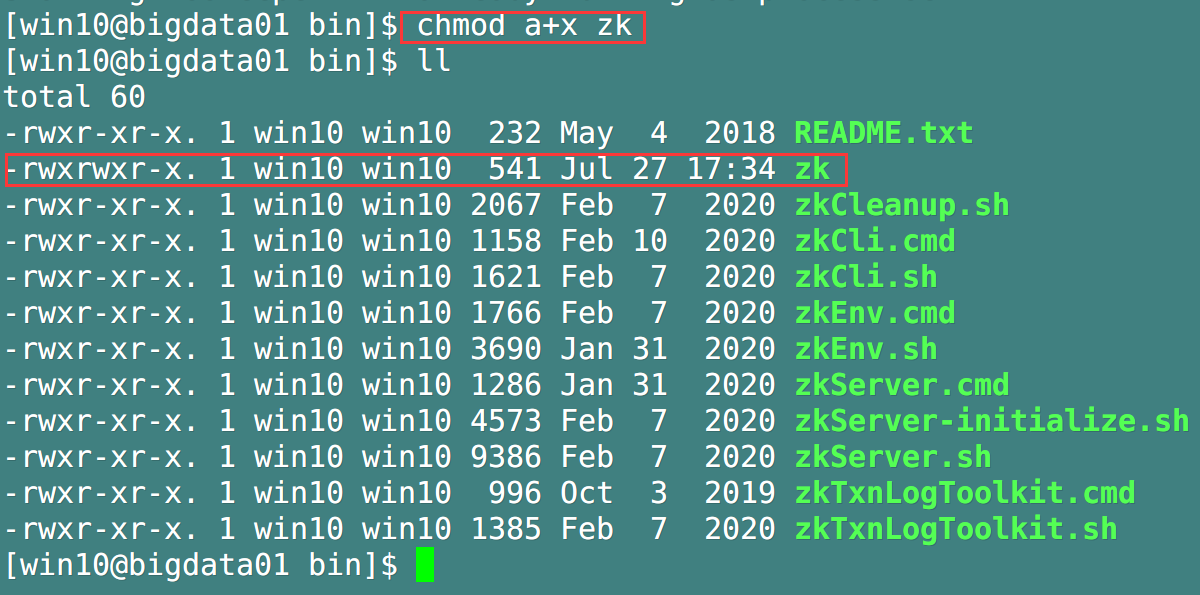
-
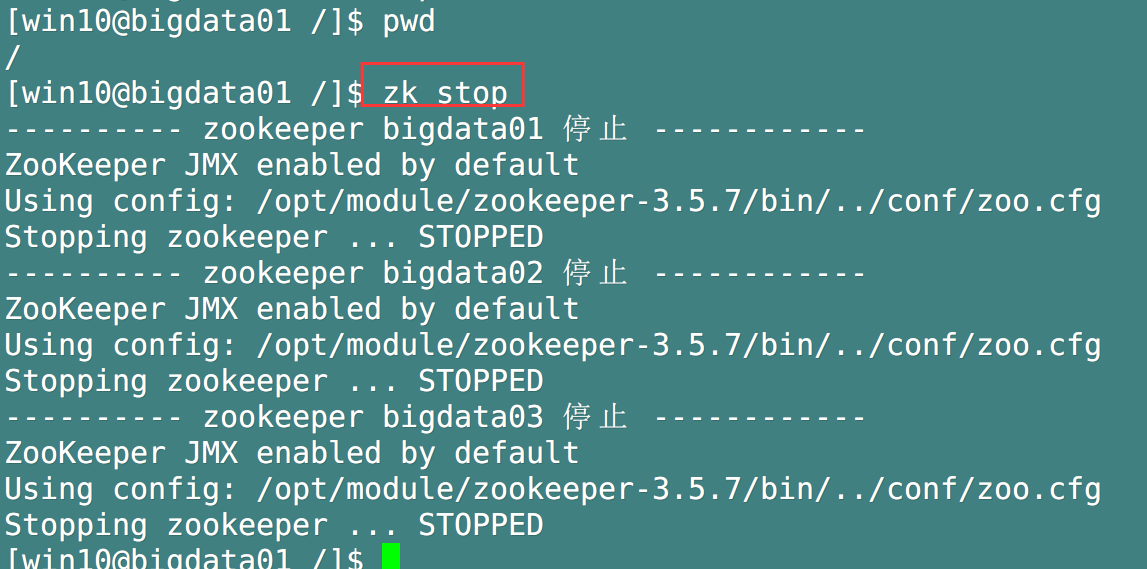
Test the start / stop / status detection of zookeeper
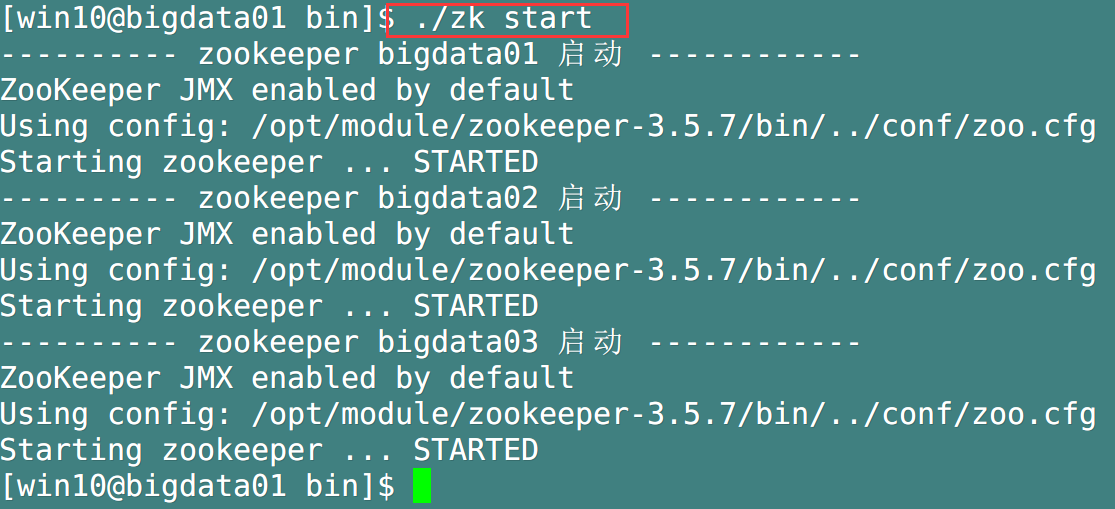
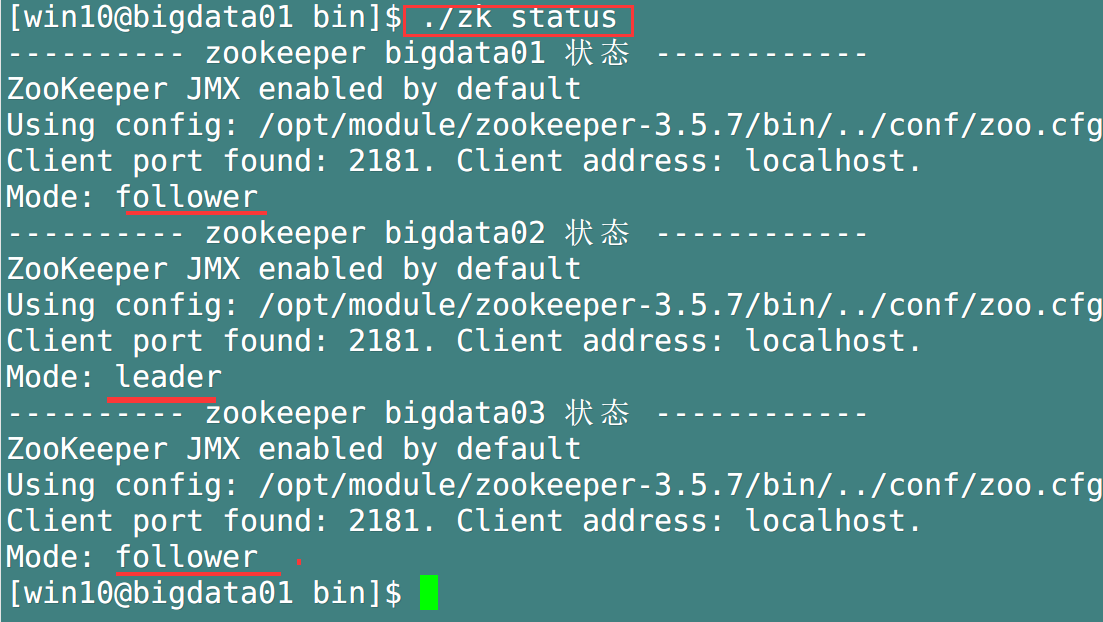
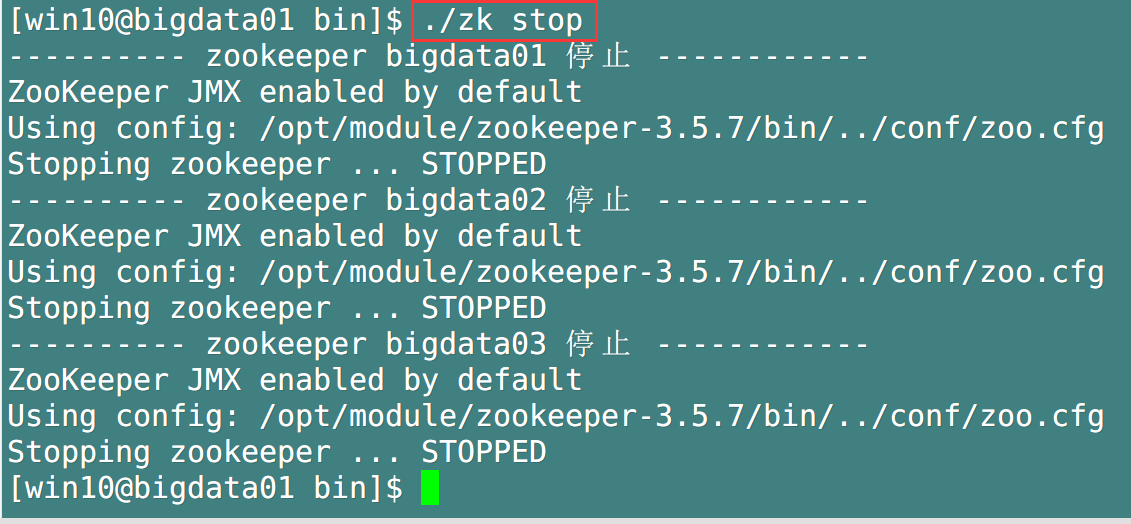
-
Similarly, in order to further improve productivity (even laziness), we add this script path to the system environment variable to operate Zookeeper anytime, anywhere;

- Add the following content and source /etc/profile. Don't forget to source!!

- Just find a directory to test (such as root directory, cd /)
3.1.2 ZooKeeper election mechanism
Core election principles:
- Only more than half of the servers in the Zookeeper cluster are started can the cluster work normally;
- Before the cluster works normally, the server with small myId votes for the server with large myId until the cluster works normally and selects the Leader;
- After selecting the Leader, the status of the previous server is Looking – > following, and the servers after the Leader are followers;
Election mechanism I, at the initial launch
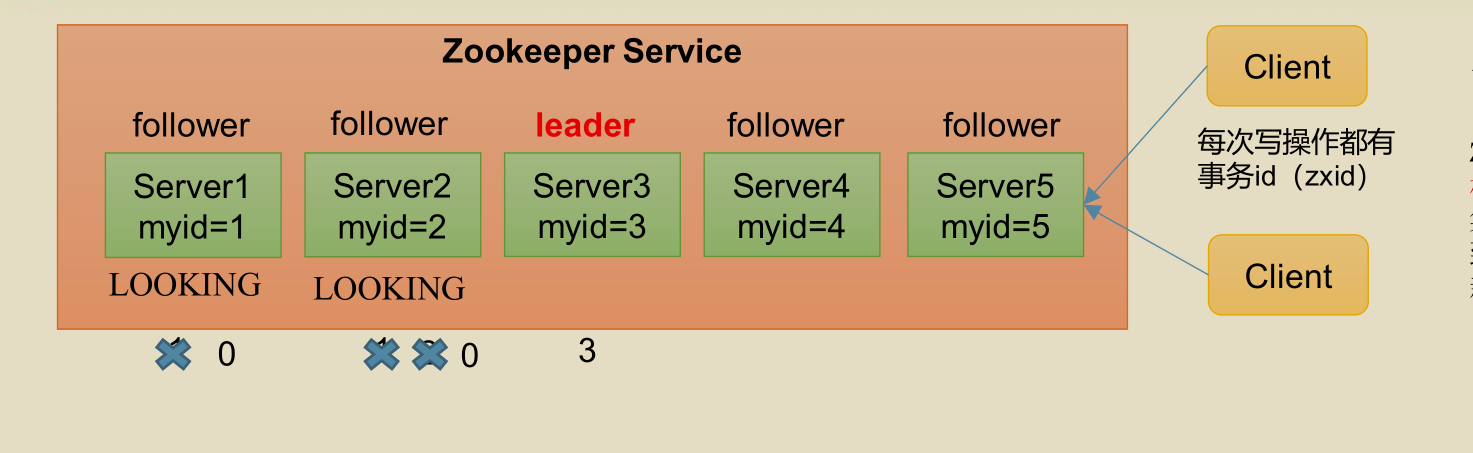
- Server 1 starts, initiates an election and votes for itself; At this time, the number of votes of server 1 is 1, less than half (3 votes), and the election cannot be completed; The status of server 1 is Looking;
- Server 2 starts and initiates an election. At this time, servers 1 and 2 vote for themselves and exchange vote information. At this time, server 1 finds that the myId of server 2 is larger than its own, and will change the vote to server 2; At this time, the number of votes of server 1 is 0 and the number of votes of server 2 is 2, which is less than half, and the election cannot be completed; The status of servers 1 and 2 is Looking;
- Server 3 starts and initiates an election. Since the myId of server 3 is currently the largest, servers 1 and 2 will change the ballot to server 3; At this time, the votes of server 1 and 2 are 0, the votes of server 3 are 3, more than half of the votes have been obtained, and server 3 is elected Leader; The status of servers 1 and 2 is changed to Following, and the status of server 3 is changed to LEADING;
- Server 4 starts and initiates an election. At this time, servers 1, 2 and 3 are no longer in the LOOKING state and will not change the ballot information; At this time, server 3 is 3 tickets and server 4 is 1 ticket; Server 4 obeys the majority, changes the vote information to server 3, and changes the status to FOLLOWING;
- Server 5 starts, just like 4.
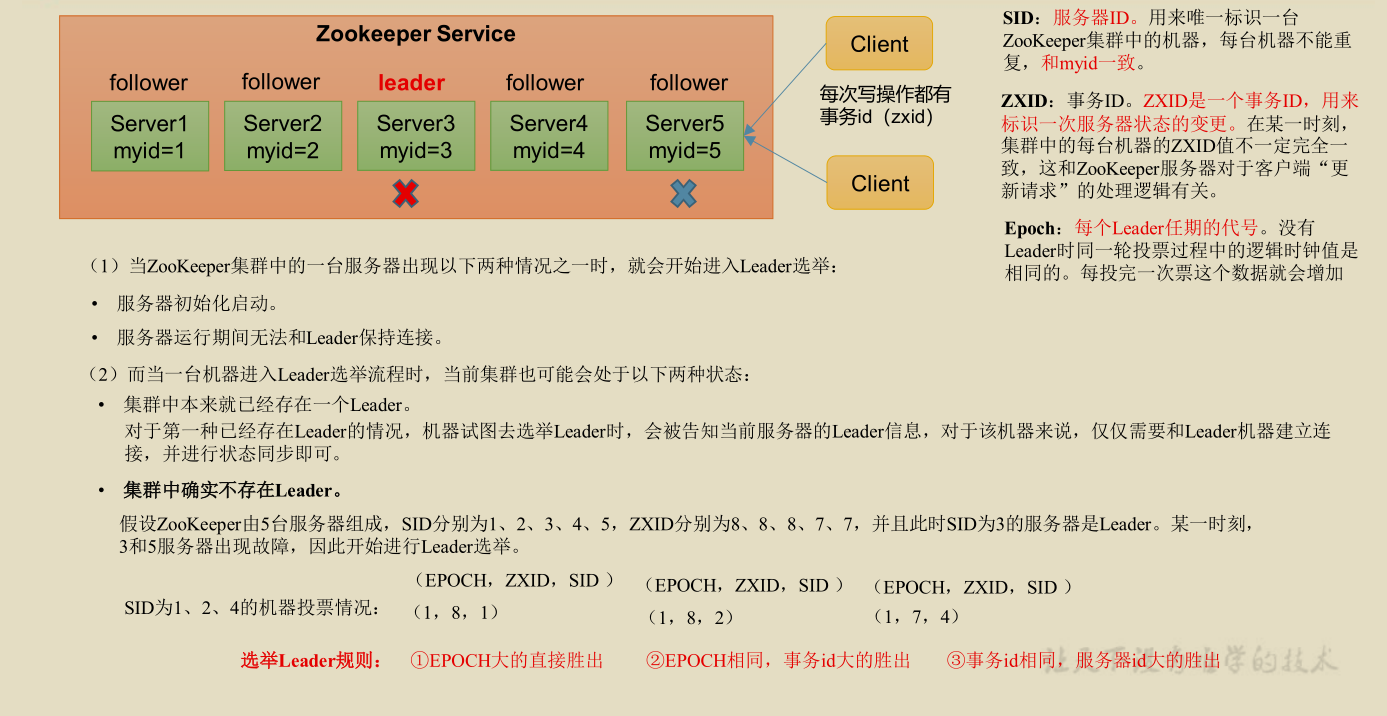
Election mechanism II, not at the initial launch (to be understood)
3.2 client command line operation
- Pre work, start Zookeeper service, and then open its client;
- bin/zkServer. SH start (or use the previous start / stop script, zk start)
- Then bin / zkcli SH, note that this method is to connect clients with local IP: port number
- We can use bin / zkcli SH - server bigdata01:2181 connect to the remote host: the client with the port number
Q: 2181, that is, where is the port number of the client set?
A: zoo.cfg, 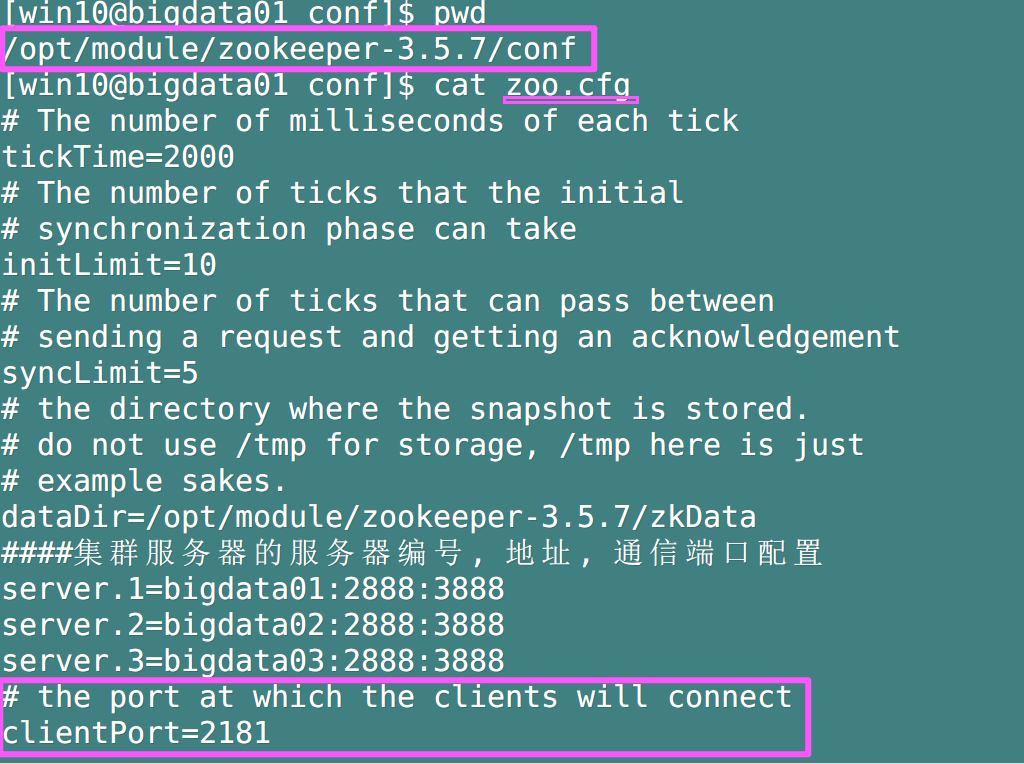
3.2.1 command line syntax
| Command line syntax | Function description |
|---|---|
| help | Display all operation commands |
| ls path | Use the ls command to view the child nodes of the current znode [listening], - w to listen for changes in child nodes, - s to attach secondary information |
| create | Normal creation, - s contains sequence, - e is temporary (restart or timeout disappears) |
| get path | Get the value of the node [listening] - w listen for changes in the content of the node, and -s attach secondary information |
| set | Set the specific value of the node |
| stat | View node status |
| delete | Delete node |
| deleteall | Recursively delete nodes |
3.2.2 znode node data information
1. View the contents of the current znode node
Note: the format of ls command is ls [-s] [-w] [-R] path
[zk: bigdata01:2181(CONNECTED) 4] ls / [zookeeper]
2. View the detailed data of the current znode node
[zk: bigdata01:2181(CONNECTED) 5] ls -s / [zookeeper]cZxid = 0x0 ctime = Thu Jan 01 08:00:00 CST 1970 mZxid = 0x0 mtime = Thu Jan 01 08:00:00 CST 1970 pZxid = 0x0 cversion = -1 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 0 numChildren = 1
The above contents are explained one by one as follows:
- cZxid: created transaction zxid
Every time the zookeeper state is modified, a zookeeper transaction ID will be generated. The transaction ID is the total order of all modifications in the zookeeper Each modification has a unique zxid. If zxid1 is less than zxid2, zxid1 occurs before zxid2 - CTime: the number of milliseconds znode was created (since 1970)
- Mzxid: transaction zxid last updated by znode
- Mtime: the number of milliseconds znode was last modified (since 1970)
- Pzxid: the last updated child node zxid of znode
- Cversion: change number of znode child node, modification times of znode child node
- Data version: znode data change number
- aclVersion: change number of znode access control list
- Ephemeral owner: if it is a temporary node, this is the session id of the znode owner. 0 if it is not a temporary node.
- dataLength: the data length of znode
- numChildren: number of child nodes of znode
3.2.3 znode node type (persistent / transient / with serial number / without serial number)
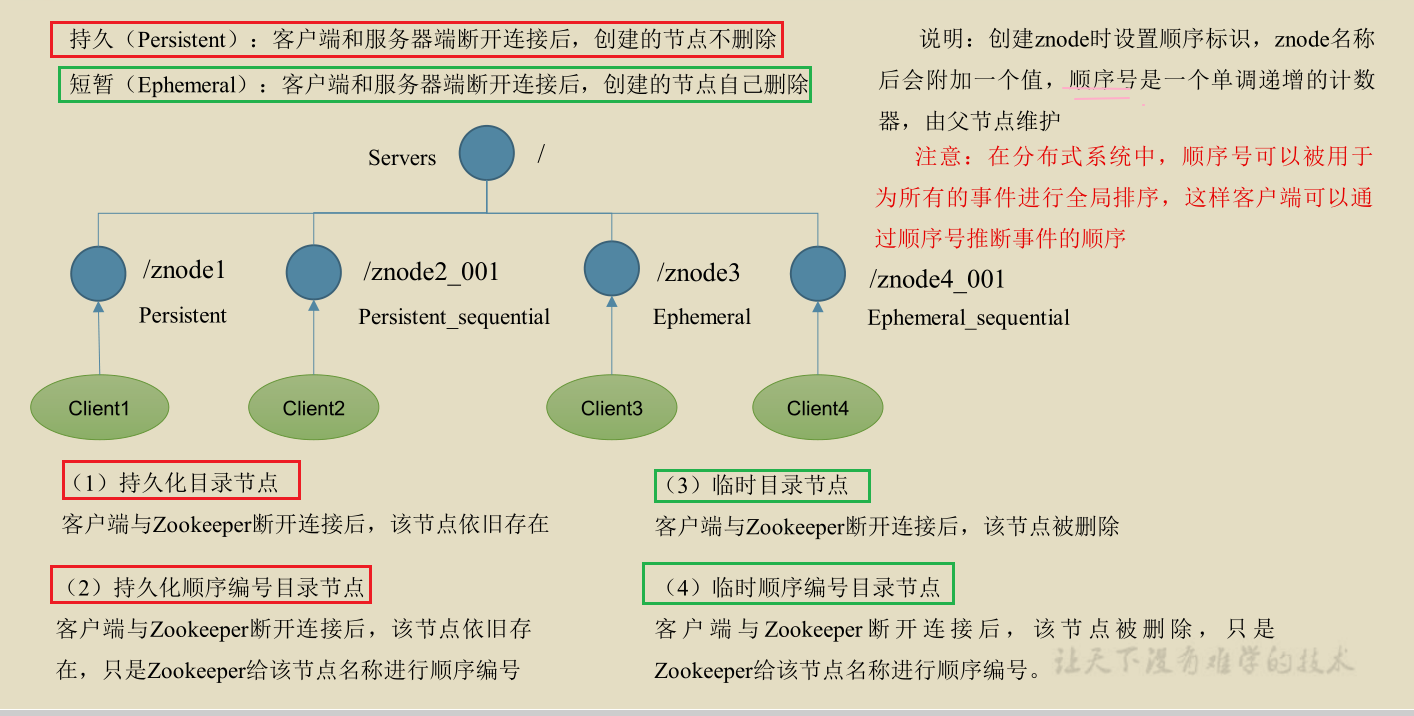
[case practice]
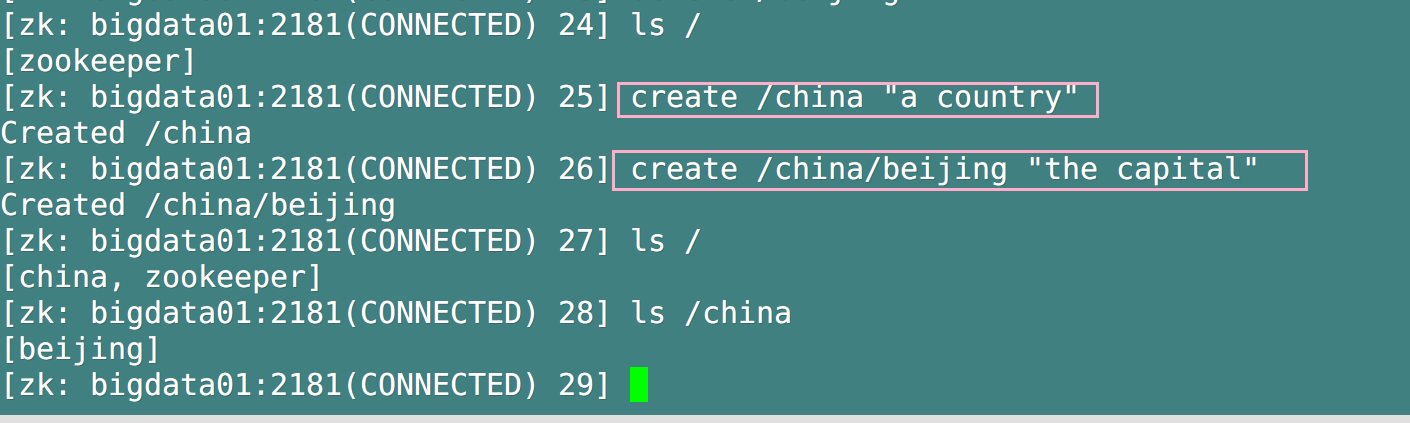
1. Create 2 ordinary nodes respectively (the default is permanent node without serial number)
- Format: create / path "value"
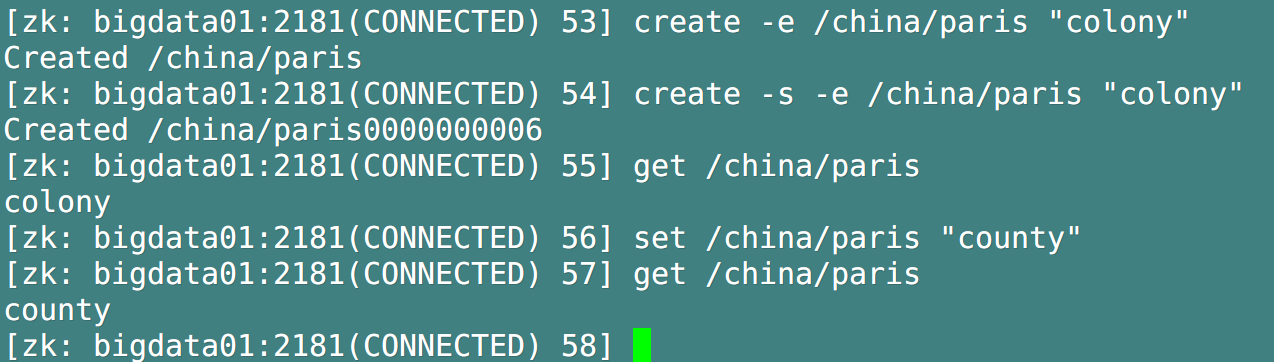
2. Create a transient node
- Format: create -e / path "value". Create plus - e is to create a temporary node

3. Create node with serial number
- Format: create -s / path. create-s is to add sequence number to the node


4. Obtain the value of the node
- Format: get [-s] / path. Get plus - s is the detailed information of the display node
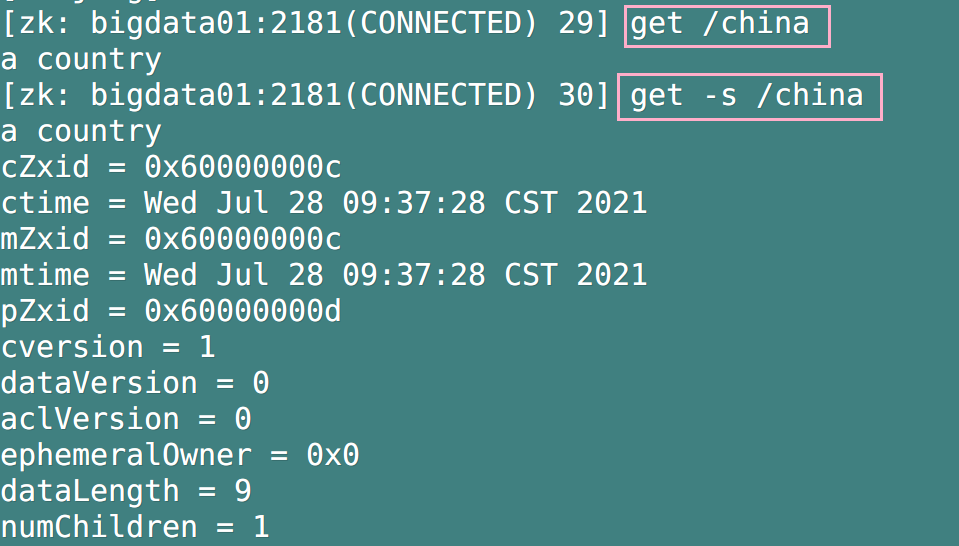
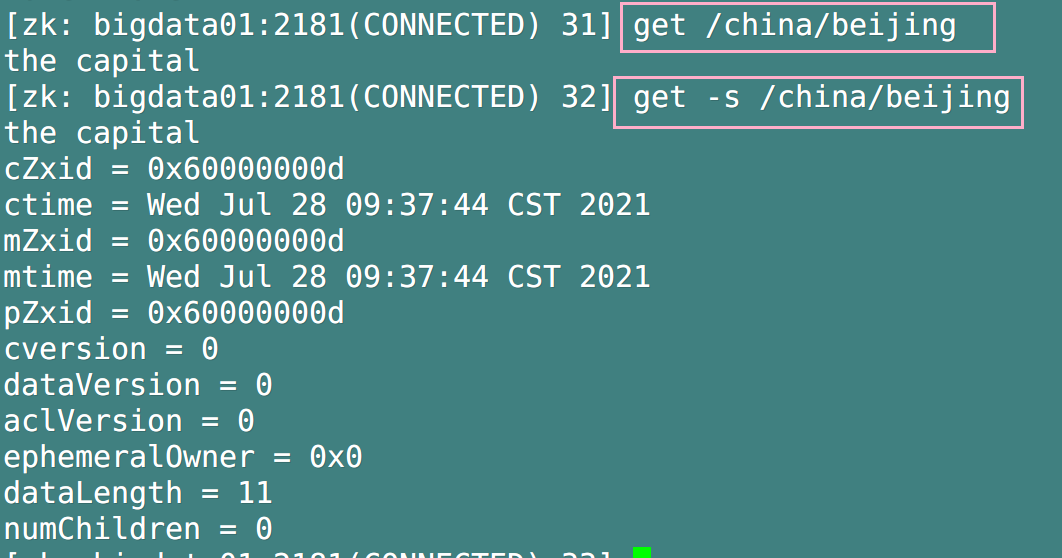
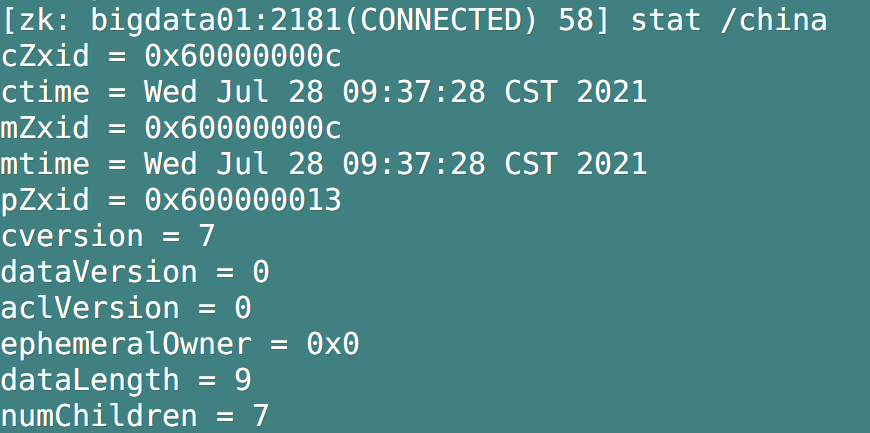
If we only need the details of the node and do not need to display the value of the node, we can use stat / path
5. Modify node data
- Format: set / path "value"
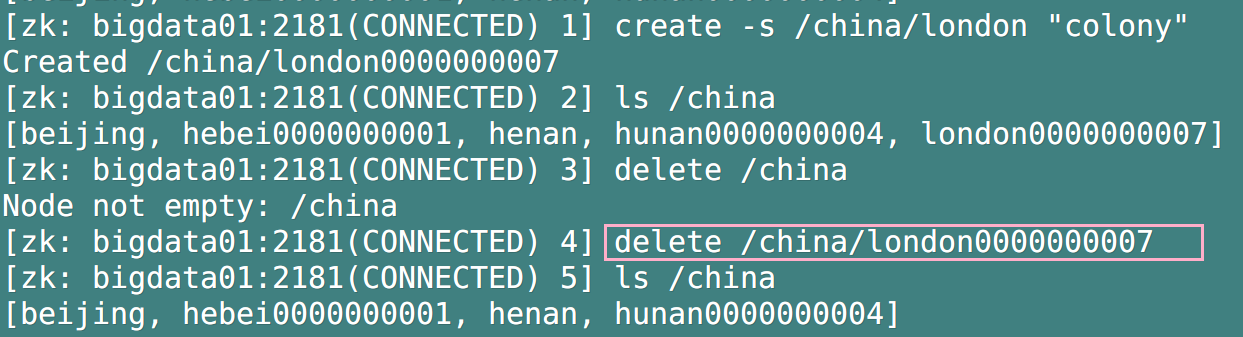
6. Node deletion
- Format: delete / path / root node
- deleteall / path

3.2.4 listener principle
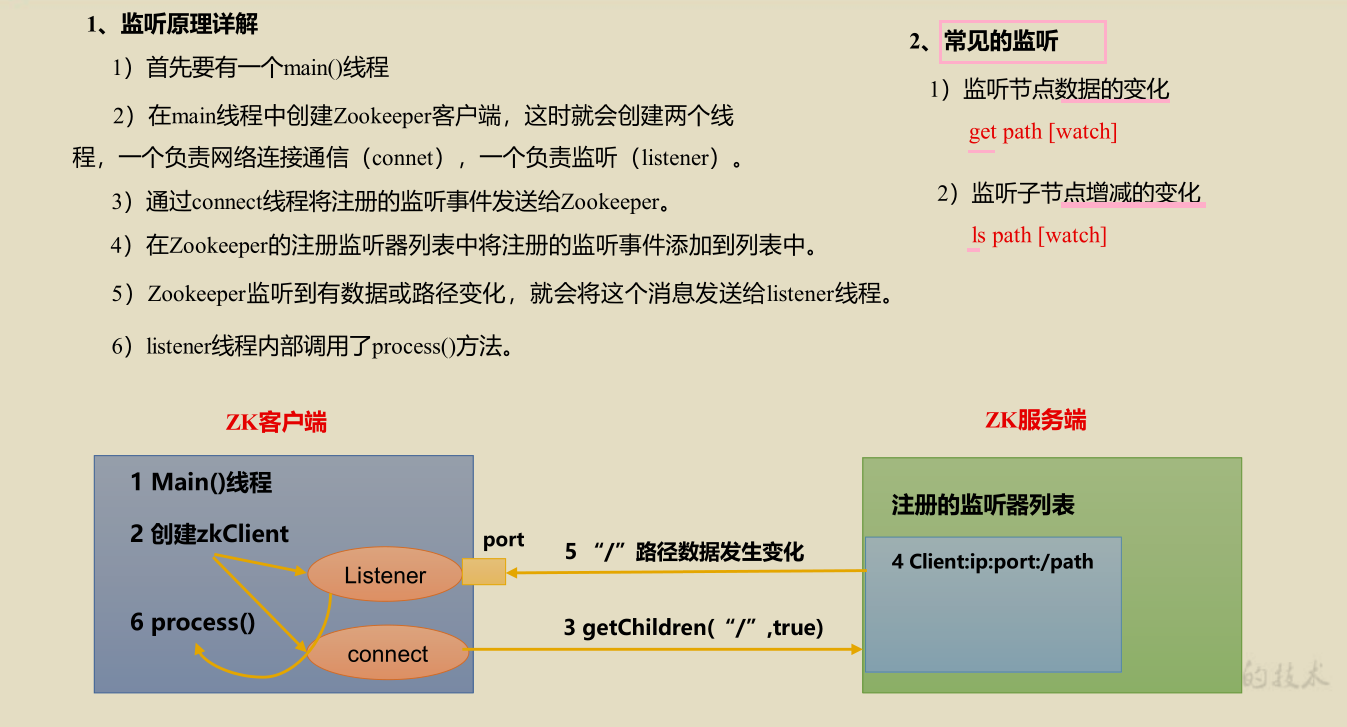
1. Listen for changes in node values (get -w)
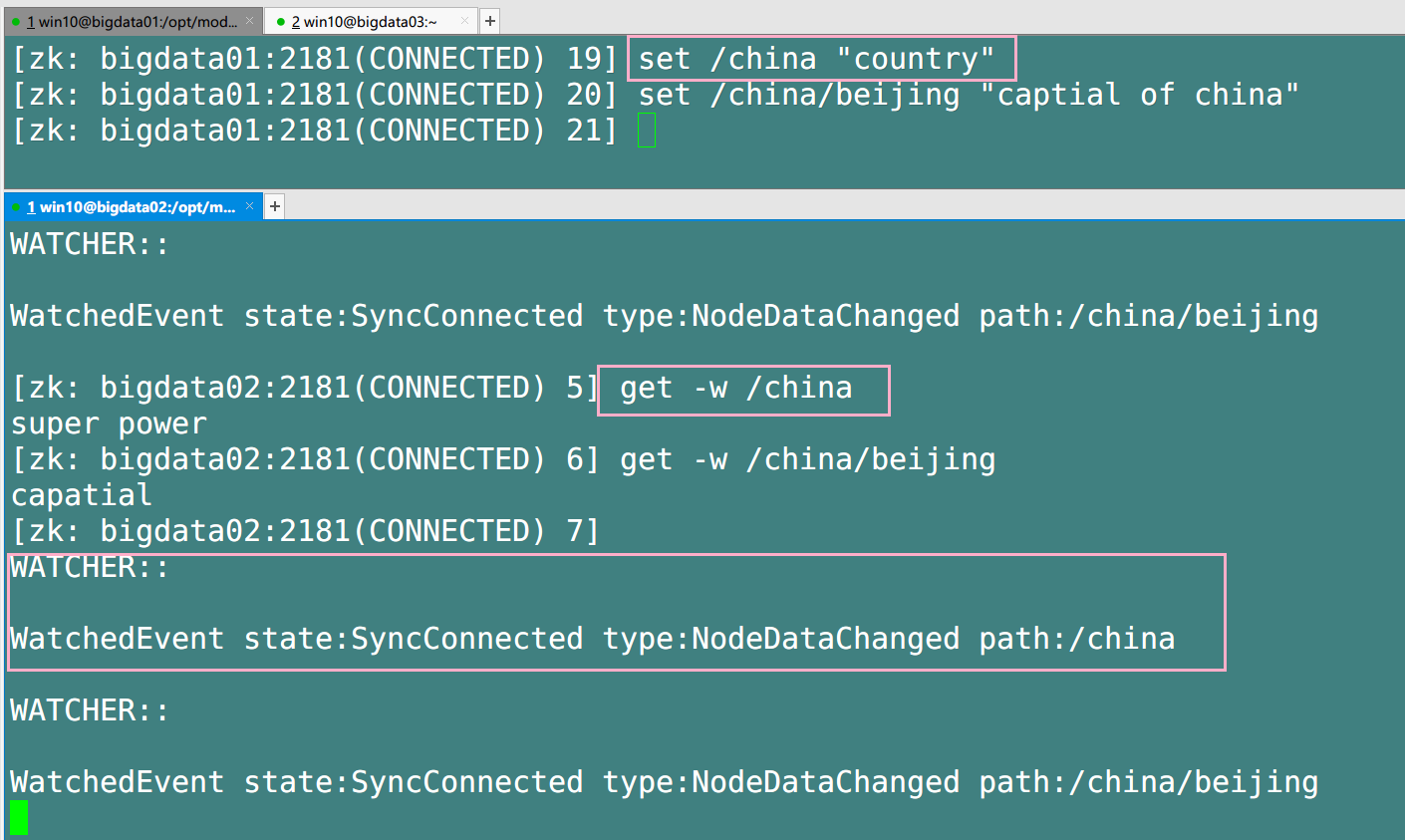
Note: if you modify the value of / china/beijing in bigdata01, you will no longer receive listening on bigdata02. Because the listener is registered once, it can only listen once. If you want to listen again, you need to register again.
2. Listen for changes of child nodes (i.e. path changes) (ls -w)


3.3 client API operation
1. Build an IDEA environment
-
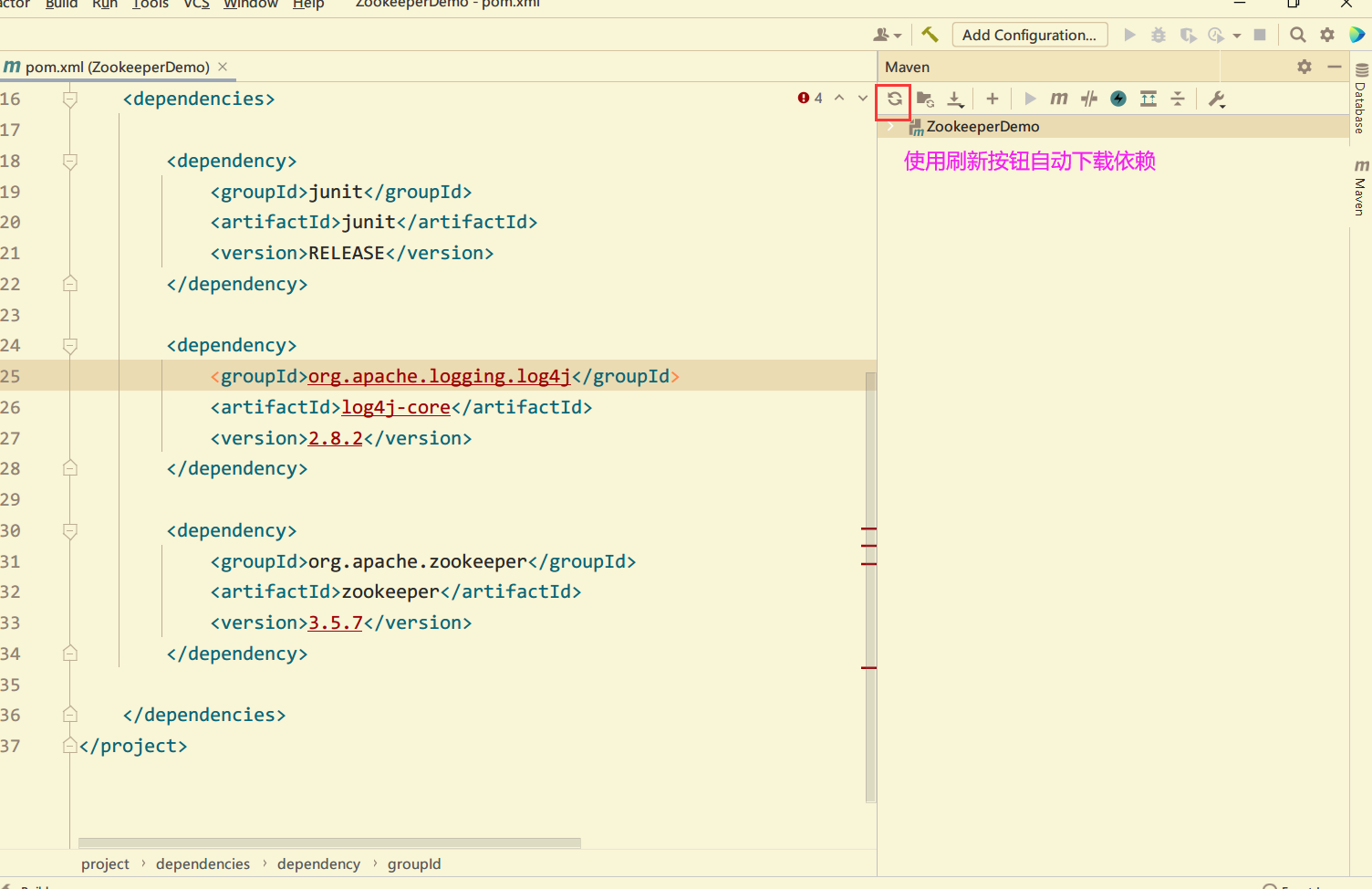
Create a Maven project, zookeepedemo
-
Add the following dependencies to the pom file:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.7</version>
</dependency>
</dependencies>
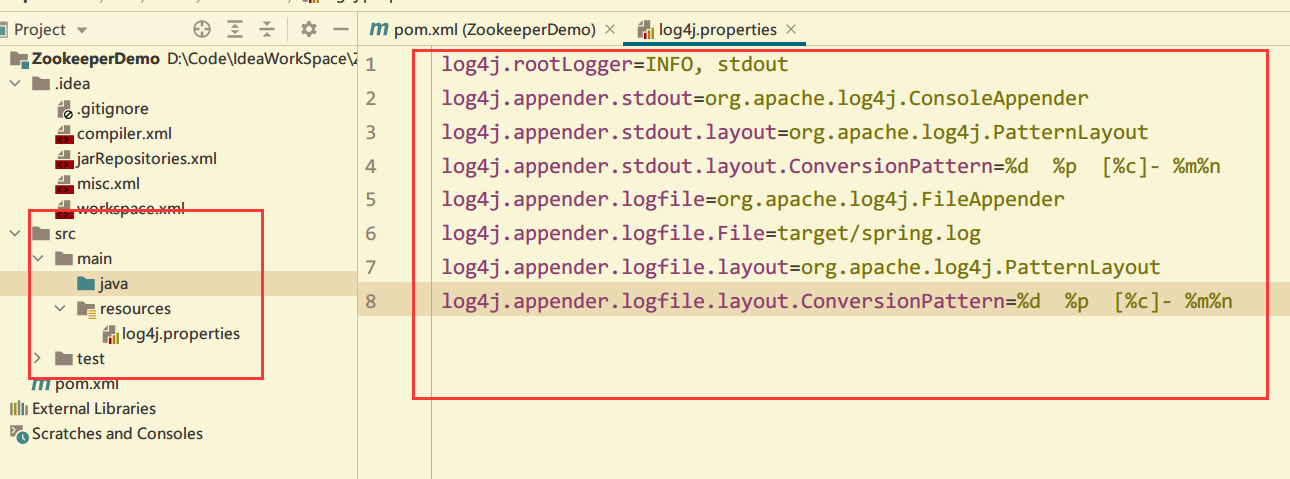
- Create a new log4j. In the root directory Properties and add the following
- You need to create a new file named "log4j.properties" in the src/main/resources directory of the project, and fill in the file.
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
- New package name and java file
2. Create Zookeeper client

Note that since creating zk client is the basis for creating child nodes and listeners, the comment in junit test should be @ Before, otherwise null pointer exceptions will occur when run ning other test methods, such as creating child nodes
//Initialization operation (connect cluster)
yes @Before instead of @Test
@Before
public void init() throws IOException {
zkClient= new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
}
});
}
3. Create child nodes
@Test
public void create() throws InterruptedException, KeeperException {
// Parameter 1: the path of the node to be created; Parameter 2: node data; Parameter 3: node permission; Parameter 4: type of node
zkClient.create("/china","super power".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
The above code is written as follows:
The first parameter is to enter the path and name of the node to be created
The second parameter is node data getBytes(), which converts the node data into a byte array for transmission


The third parameter describes the permissions of the node, IDS XX (IDE auto completion)
The fourth parameter describes the mode of the current node (persistent / transient / with sequence number / without sequence number), createmode XX (IDE auto completion)
4. Obtain child nodes and listen for changes of child nodes
- Basic writing method (listen once and the program ends)
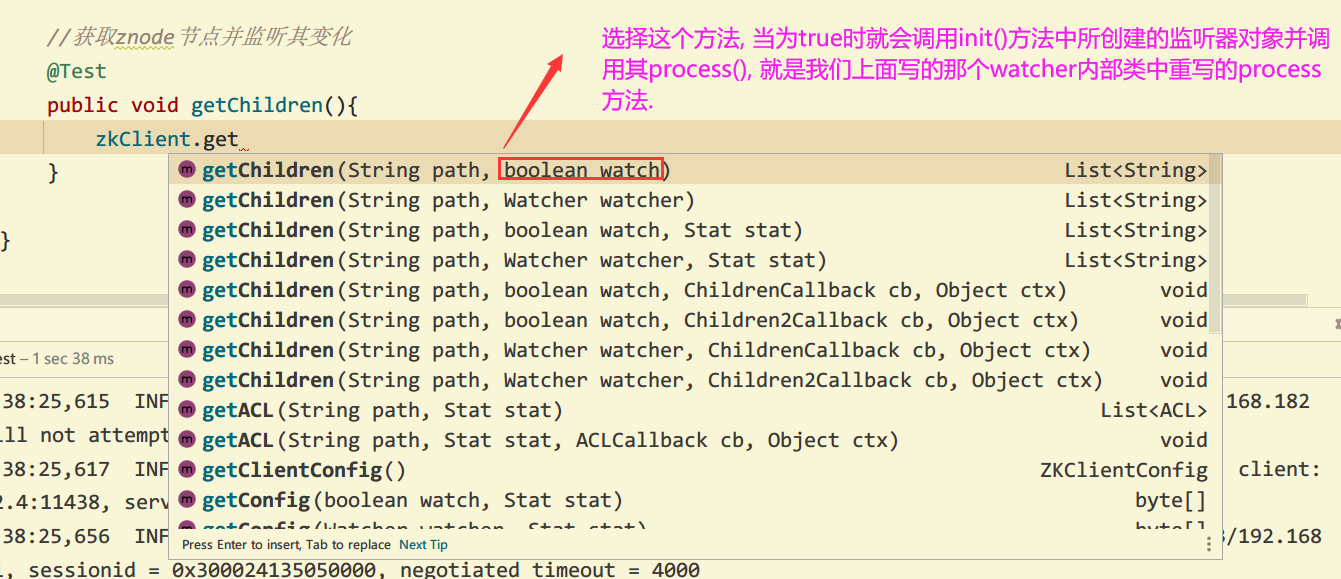
//Get the znode node and listen for its changes
@Test
public void getChildren() throws InterruptedException, KeeperException {
// Node path is "/", whether to use the watcher in the initialization method: true
List<String> children = zkClient.getChildren("/", true);
for (String child : children) {
System.out.println(child);
}
}
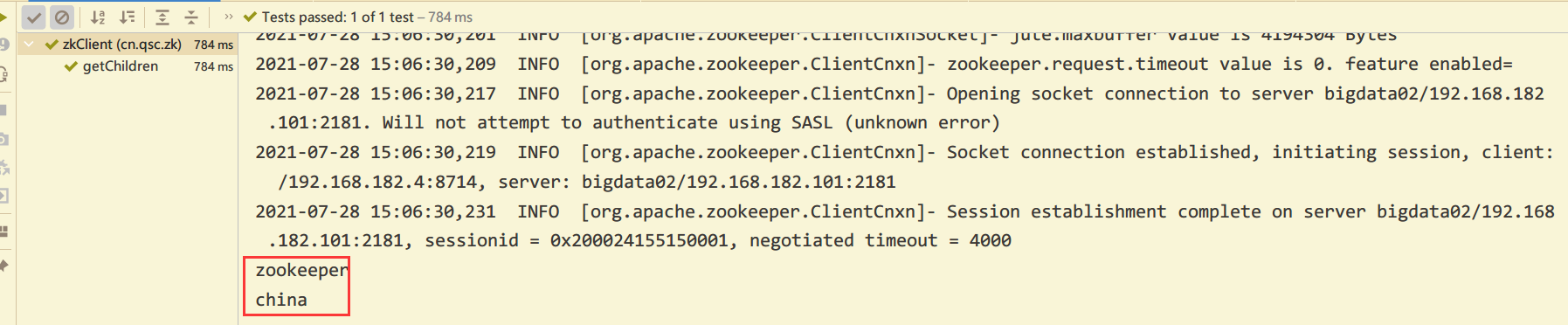
- Improved writing method (constantly creating listeners)
- As mentioned earlier, a listener can only be registered once and can only listen once. If you want to listen again, you can only register a listener again. Moreover, when operating this API, the program will terminate at the end of execution
- resolvent:
-
- Prevent the end of the entire program: thread sleep(Long.MAX_VALUE);
-
- Put the operation of obtaining child nodes into the listener's processing method
//Initialization operation (connect cluster)
@Before
public void init() throws IOException {
zkClient= new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
List<String> children = null;
try {
System.out.println("=================================");
children = zkClient.getChildren("/", true);
for (String child : children) {
System.out.println(child);
}
System.out.println("==================================");
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
//Get the znode node and listen for its changes
@Test
public void getChildren() throws InterruptedException, KeeperException {
// Node path is "/", whether to use the watcher in the initialization method: true
Thread.sleep(Long.MAX_VALUE);
}
5. Judge whether znode exists
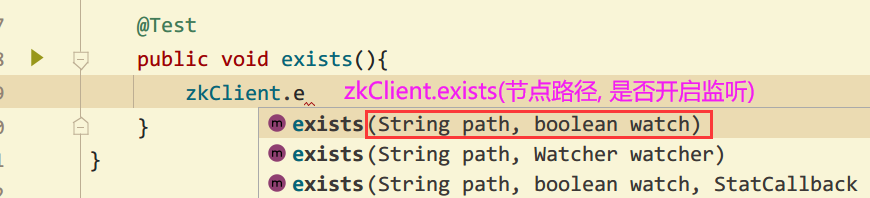
@Test
public void exists() throws InterruptedException, KeeperException {
Stat stat = zkClient.exists("/china", false);
System.out.println(stat == null ? "not exist" : "exist");
}
3.4 data writing process from client to server
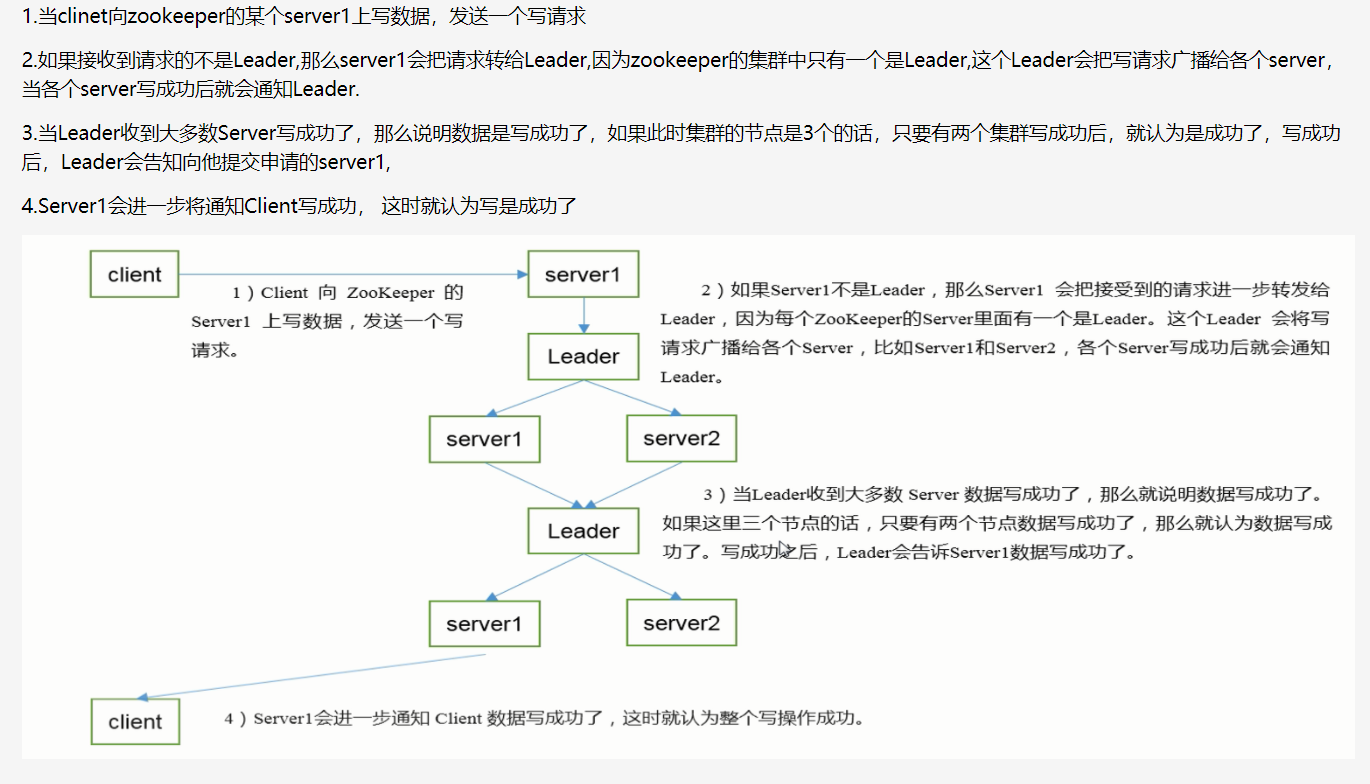
Compared with the process of writing data, the process of reading data is much simpler; Because the data consistency in each server is the same, you can access any server to read data;
There are no such steps as request forwarding, data synchronization and success notification in the write data process.