| Which course does this assignment belong to | Soft engineering practice in autumn 2021 |
|---|---|
| What are the requirements for this assignment | The first personal programming operation of software engineering practice in autumn 2021 - CSDN community |
| The goal of this assignment | Use of github; Write programs to extract keywords at different levels of C/C + + code |
| Student number | 031902218 |
GitHub usage
-
GitHub warehouse address
-
Screenshot of warehouse
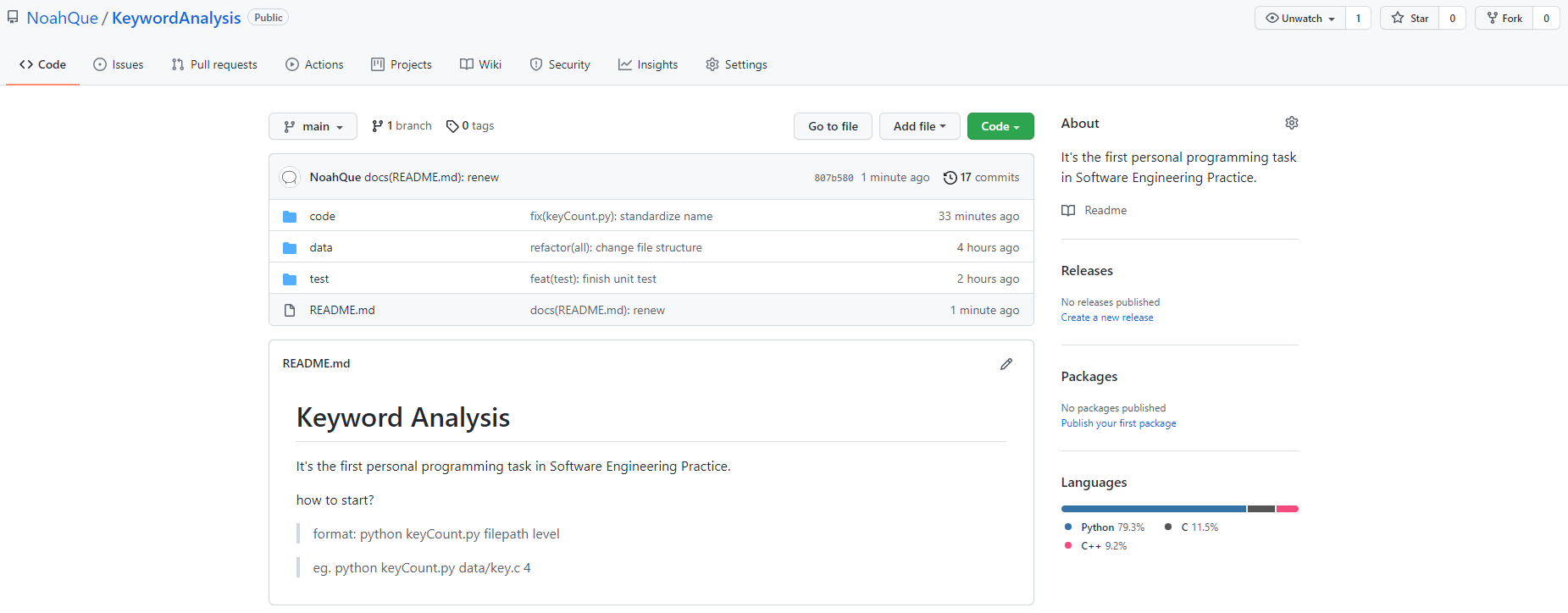
-
commit screenshot
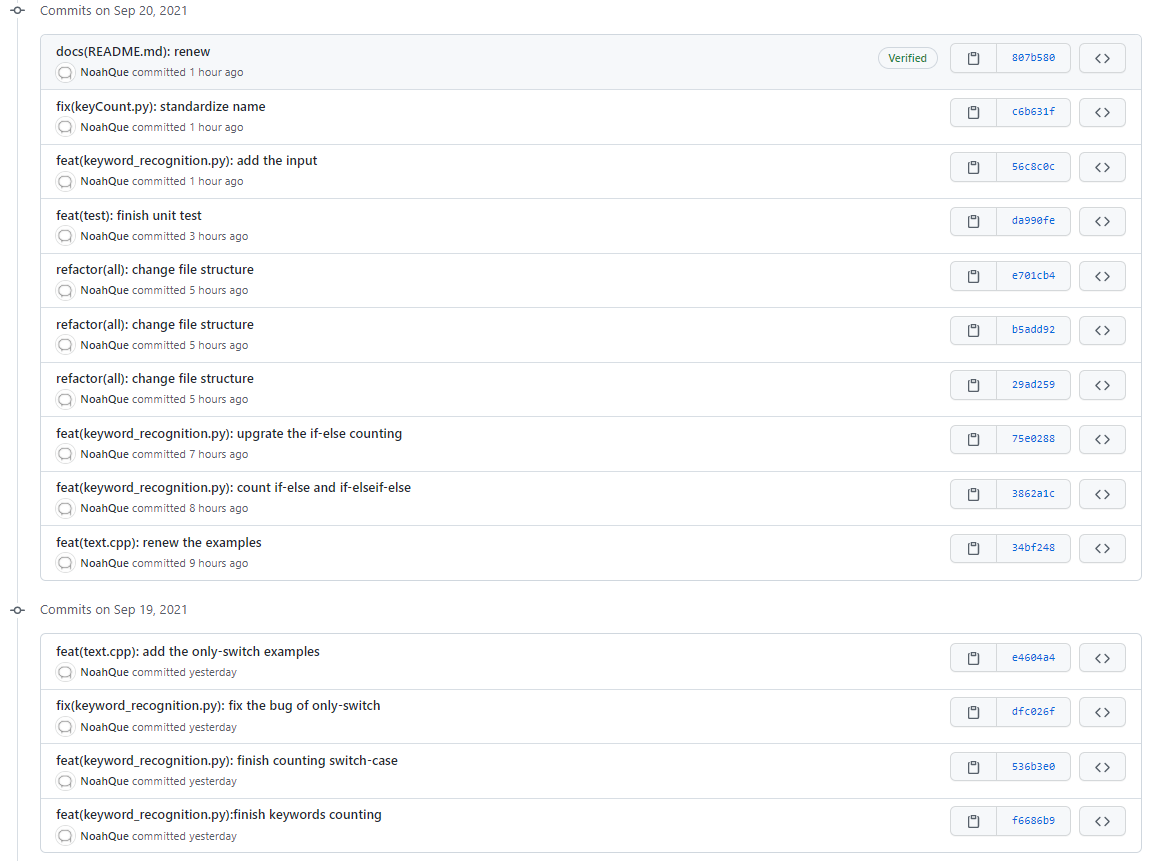
Code specification
PSP table
| PSP2.1 | Personal Software Process Stages | Estimated time (minutes) | Practice time (minutes) |
|---|---|---|---|
| Planning | plan | 60 | 60 |
| Estimate | Estimate how long this task will take | 30 | 20 |
| Development | development | 300 | 360 |
| Analysis | Needs analysis (including learning new technologies) | 60 | 60 |
| Design Spec | Generate design documents | 120 | 180 |
| Design Review | design review | 20 | 25 |
| Coding Standard | Code specification | 15 | 20 |
| Design | Specific design | 120 | 120 |
| Coding | Specific coding | 300 | 360 |
| Code Review | Code Review | 60 | 40 |
| Test | Test (self test, modify code, submit modification) | 100 | 120 |
| Reporting | report | 90 | 120 |
| Test Report | Test report | 60 | 60 |
| Size Measurement | Calculation workload | 15 | 15 |
| Postmortem & Process Improvement Plan | Summarize afterwards and put forward process improvement plan | 60 | 90 |
| total | 1410 | 1650 |
Description of problem solving ideas
-
Title first impression
At first, I felt very approachable when I saw this problem 😂, At least be able to fully understand the topic, and there are no words that people need to search to understand at the beginning; The topic mainly involves the string operation of text. You need to extract enough information from C/C + + files to judge the structure of the code, and finally achieve the purpose of keyword extraction; The main difficulty of the topic is to select an appropriate way to extract information from the document
-
Language selection
After reading this question, I first thought of using regular expression to solve the problem, because this question may involve a large number of string operations, and there may be a large amount of text information and more interference items. Using regular expression processing can greatly reduce the workload; Python has a relatively mature regular library re, and I have been in contact with some before, so I choose to use Python to solve this problem
-
Keyword statistics
Before making keyword statistics, I learned the usage of regular again and found some information related to regular, regex101 You can view the effect of regular expressions in real time, which is still very easy to use.
To search for keywords, you can use regular expressions to extract all strings containing only letters, and then use the count function to traverse the keyword list and count all qualified strings. However, if you want to realize the above ideas, you must first solve the data cleaning. According to the knowledge of C/C + +, the strings in the text and in the comments that meet the conditions do not belong to keywords and do not need to be counted; In addition, if a string with the same keyword appears in the variable name, it does not need to be counted, so we have to exclude the following situations before counting:
-
//Notes
-
/** / Notes
-
/*Comment (a single symbol will comment out all the following lines)
-
'' single quote string
-
”Double quoted string
-
Keyword in variable name (for example int1qq)
Regular expressions can be used to remove the first five above. In fact, the last one can also be used. However, in the keyword statistics phase, all strings containing only letters will be put in the list and then counted, so it will not have an impact
The following is the regular expression corresponding to the actual use
-
All comments: (/ /. *) | (/ \ * [\ s\S]*?\*/)|(/\*[\s\S] *)
-
Single quote string: (\ '[\ s \ S] *? \' | (\ '[\ s \ S] *)
-
Double quoted string: (\ "[\ s\S] *? \") | (\ "[\ s\S] *)
-
All strings that may be Keywords: [a-zA-Z]{2,}
PS. during the actual measurement in VSCode, it is found that a single single quotation mark "or a single double quotation mark" may also include all the following lines, so this part will also be taken into account during regularization
-
-
Switch case statistics
In this part, you can directly use the keyword list obtained from the C/C + + program code in the previous keyword statistics, and then calculate the number of cases from each switch to the next switch (the last switch is counted to the end). It is relatively simple on the basis of the previous keyword statistics. However, it should be noted that switches without internal case should be excluded (although this may not necessarily happen)
-
If else statistics
The idea of this part is also relatively clear. You can extract all if and else in the text through regular expressions and put them in the list. Then, since there are only two states of if else, you can use the stack in a way similar to the bracket matching problem. In this way, even if there are redundant and single if, you can handle it.
But this method also has preconditions: first, using this method, the text cannot contain if else if else structure; Secondly, it is also necessary to exclude interference items. For example, the variable names of qifsss and aelset will interfere with the statistics of if else. First screen out these interference items through [\ w](if|else)[\w], and then use (if|else) to screen out if else
-
if-(else if)-else statistics
This is the difficulty of this problem. First, if you use stack matching in the same way as if else statistics, there will be a problem: if - (else, if) - else has three states, and the stack has only two states: in stack and out of stack. You can't get the answer only through stack matching. This is very clear. If you want to use stack matching to solve problems, you need additional information, There are two kinds of information I can think of here:
1. Select the possible bracket information in the statement
2. Space length information in front of all if / else
If the bracket information is used, it should be considered that the statements in C/C + + do not need brackets if there is only a single line. Therefore, the use of bracket information needs classified discussion, and whether it can be solved cannot be determined in the analysis stage; Using regularization to obtain the space length in front of the keyword as auxiliary judgment information, as long as the code style of the sample can be maintained, that is, the keywords belonging to the same selection statement are aligned, this problem can be solved. Therefore, here I choose to be a gambling dog, so here I choose to use regularization to obtain the space length in front of the keyword, Then it can be used together with stack matching to solve this problem
Design and implementation process
Overall code framework
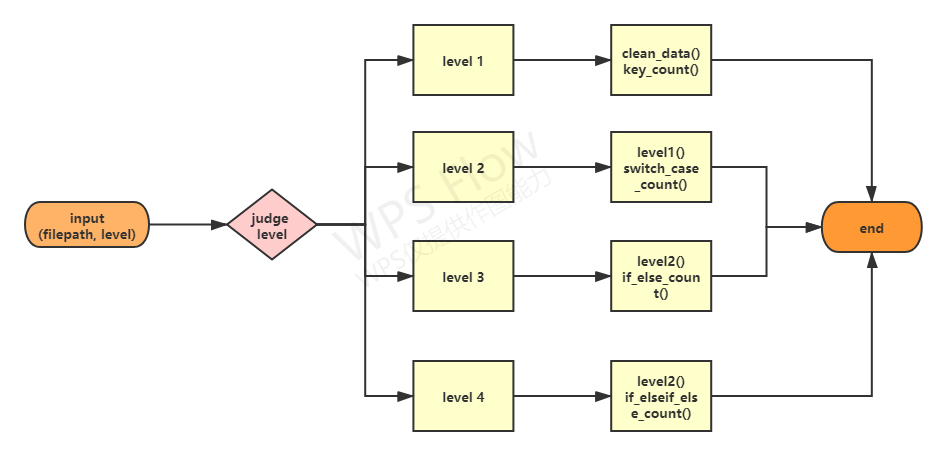
Key function flow chart
-
clean_data()
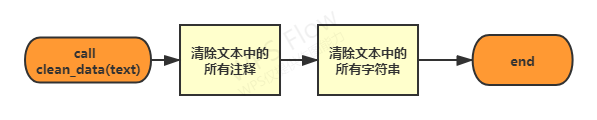
-
if_elseif_else_count()
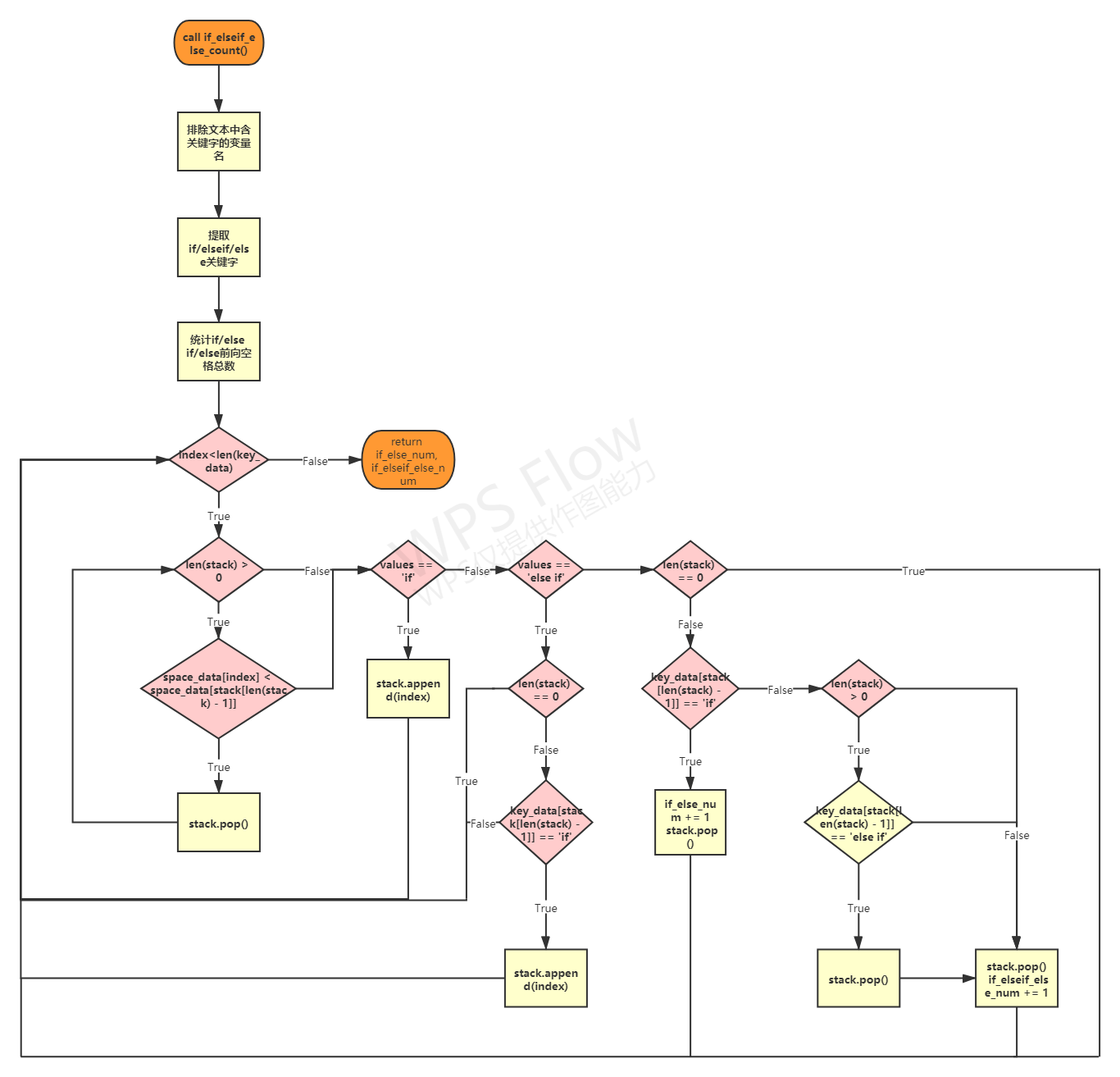
Stack operation description based on the number of forward spaces
- After extracting the keyword from the extracted keyword list, first judge the space position relationship between the keyword and the keyword at the top of the stack. If the number of forward spaces of the keyword at the top of the stack is greater than the keyword, the top of the stack will pop up; Repeat the above process until the judgment conditions are not met
- If the keyword extracted from the extracted keyword list is if, it is directly put on the stack
- If the keyword extracted from the extracted keyword list is else if, if the stack is not empty and the top of the stack is if, it will be put into the stack
- If the keyword extracted from the extracted keyword list is else, if the stack top is if, the stack top pops up, if_else structure number plus 1; If the top of the stack is else if, all else if will pop up from the top of the stack, and finally another if, if will pop up_ elseif_ Else structure number plus 1
- Cycle the above steps until the traversal of the extracted keyword list is completed
Code description
-
data processing
# Remove text interference components (notes, strings) def clean_data(text): # Match all comments pattern_notes = r'(//.*)|(/\*[\s\S]*?\*/)|(/\*[\s\S]*)' # Match single quote string pattern_str1 = r'(\'[\s\S]*?\')|(\'[\s\S]*)' # Match double quoted string pattern_str2 = r'(\"[\s\S]*?\")|(\"[\s\S]*)' text = re.sub(pattern_notes, lambda x: generate_str(x.group()), text, flags=re.MULTILINE) text = re.sub(pattern_str1, lambda x: generate_str(x.group()), text, flags=re.MULTILINE) text = re.sub(pattern_str2, lambda x: generate_str(x.group()), text, flags=re.MULTILINE) return text # Generate an equal length empty string when replacing with def generate_str(str): temp = "" for i in range(len(str)): temp += " " return tempUse regular to remove interference components (notes, character strings) in text
PS. since the spaces in front of if / else and if / else are used in step 4, you should pay great attention in the output preprocessing stage. Here, lambda expression is used to replace the interference item with spaces of equal length to prevent interference with if_ elseif_ else_ Statistics of count()
-
Keyword statistics
# Get the number of key words def key_count(text): pattern_num = r'[a-zA-Z]{2,}' key_data = re.findall(pattern_num, text) num = 0 for key in key_list: num += key_data.count(key) return key_data, num[a-zA-Z]{2} is used here because the length of the minimum keyword is 2, so only strings with a length greater than 2 and containing only letters are filtered
-
Switch case statistics
# Get switch_ Number of case structures def switch_case_count(key_data): case_num = [] switch_num = 0 temp_case = 0 for value in key_data: if value == "switch": if switch_num > 0: case_num.append(temp_case) temp_case = 0 switch_num += 1 if value == "case": temp_case += 1 case_num.append(temp_case) # Handle switch without case num = case_num.count(0) for i in range(num): case_num.remove(0) switch_num -= num return switch_num, case_numIt should be noted that the switch without case should be excluded
-
If else statistics
# Only if_else def if_else_count(text): pattern_out = r'[\w](if|else)[\w]' pattern_key = r'(if|else)' # Exclude variable name interference text = re.sub(pattern_out, ' ', text, flags=re.MULTILINE) key_data = re.findall(pattern_key, text) # print(key_data) stack = [] if_else_num = 0 for index, values in enumerate(key_data): if values == 'if': stack.append(index) else: if len(stack) == 0: continue stack.pop() if_else_num += 1 return if_else_numSince the if else if else structure is not considered in the design of this function, the stack matching operation is directly used to count the number of if else
-
if-(else if)-else statistics
# If else and if else def if_elseif_else_count(text): pattern_out = r'[\w](else if|if|else)[\w]' pattern_key = r'(else if|if|else)' # Exclude variable name interference text = re.sub(pattern_out, ' ', text, flags=re.MULTILINE) key_data = re.findall(pattern_key, text) # Count if / else forward spaces pattern_front_space = r'\n( *)(?=if|else if|else)' space_data = re.findall(pattern_front_space, text) space_data = [len(i) for i in space_data] # 1 for if/ 2 for else if/ 3 for else/ stack = [] if_else_num = 0 if_elseif_else_num = 0 for index, values in enumerate(key_data): while len(stack) > 0: if space_data[index] < space_data[stack[len(stack) - 1]]: stack.pop() else: break if values == 'if': stack.append(index) elif values == 'else if': if len(stack) == 0: continue if key_data[stack[len(stack) - 1]] == 'if': stack.append(index) else: if len(stack) == 0: continue if key_data[stack[len(stack) - 1]] == 'if': if_else_num += 1 stack.pop() else: while len(stack) > 0: if key_data[stack[len(stack) - 1]] == 'else if': stack.pop() else: break stack.pop() if_elseif_else_num += 1 return if_else_num, if_elseif_else_numThe stack operation based on the number of forward spaces is used here. It has been described in the flowchart stage and will not be repeated
unit testing
-
Test text
Three test texts have been constructed for the test, and the following is one of them
#include <stdio.h> void test(){ printf("asdfasdf xxd dsff"); printf('d'); } int main(){ int i=1; double j=0; long f;//sssasddd dcad //asdad switch(i){ case 0: break; case 1: break; case 2: break; default: break; }/*ddsfsfsfd*/ switch(i){ case 0: break; case 1: break; default: break; } if(i<0){ if(i<-1){} else{ if(i==2); } } else if(i>0){ if (i>2){ if(i!=1); else if(i>1); } else if (i==2) { if(i<-1){} else if(i==1){} else{} } else if (i>1) {} else { } } else{ if(j!=0){} else{} } switch(i){} return 0; } /*ds asdasdasd asdsadasd as? -
Test code
import unittest import sys sys.path.insert(0, "../code") from keyword_recognition import * class MyTestCase(unittest.TestCase): def test_clean_data(self): str1 = "/*sss*/ 'dd'" str_ans1 = " " str2 = "/*ddddd \n*/" str_ans2 = " " str3 = '"xxsubtxxxy"' str_ans3 = " " self.assertEqual(clean_data(str1), str_ans1) self.assertEqual(clean_data(str2), str_ans2) self.assertEqual(clean_data(str3), str_ans3) def test_key_count(self): text = read_file("../data/key.c") temp, num = key_count(text) self.assertEqual(num, 35) def test_switch_case_count(self): key_data = ['include', 'stdio', 'int', 'main', 'int', 'double', 'long', 'switch', 'case', 'break', 'case', 'break', 'case', 'break', 'default', 'break', 'switch', 'case', 'break', 'case', 'break', 'default', 'break', 'if', 'if', 'else', 'else', 'if', 'if', 'else', 'if', 'else', 'if', 'else', 'else', 'if', 'else', 'return'] switch_num, case_num = switch_case_count(key_data) self.assertEqual(switch_num, 2) self.assertEqual(case_num, [3, 2]) def test_if_else_count(self): text = read_file("../data/text.c") if_else_num = if_else_count(text) self.assertEqual(if_else_num, 4) def test_if_elseif_else_count(self): text = read_file("../data/key.c") temp, if_elseif_else_num = if_elseif_else_count(text) self.assertEqual(if_elseif_else_num, 2) if __name__ == '__main__': unittest.main()The unit test results show that the function functions normally
-
Screenshot of coverage test

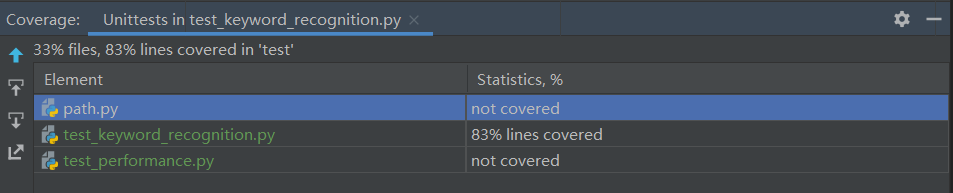
Since only a few key functions are tested here, the coverage is only 58%
-
performance testing
Because the single run time of the file is too short to present the test results well, the file will be run 10000 times
import sys sys.path.insert(0, "../code") from code.keyword_recognition import start if __name__ == '__main__': for i in range(10000): start(filepath='../data/key.c', level=4)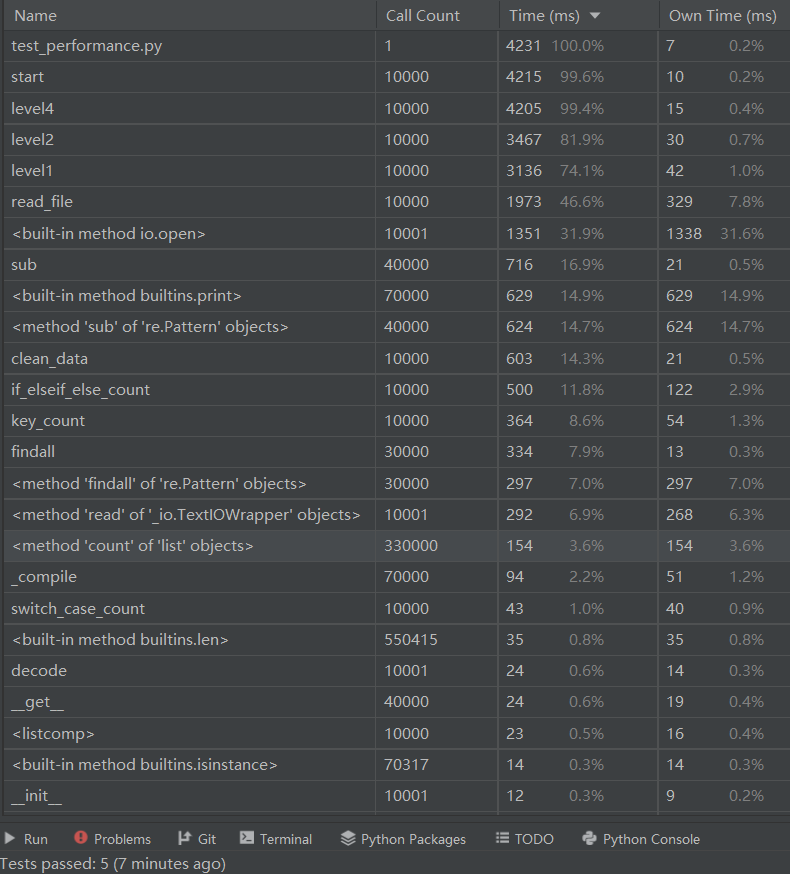
Through the performance test, we can see that since I adopt the nested method when selecting the mode level, the level type function here takes a very high time. In the future, we can consider redesigning and decoupling the level to improve efficiency
Difficulty description and solution
-
Problem Description: during data cleaning, the / * * / annotation can span multiple lines, but only re A newline character was not recognized when replacing \ nsub
Solution: after searching the data, it is found that re The parameter flags = RE can be set in sub Multiline for multiline recognition
-
Problem Description: during if-(else if)-else statistics, it is found that there are loopholes in the previous way of cleaning data. I originally used to directly change all interference items into "" single spaces, but this will invalidate the counted forward spaces
Solution: I've thought about changing the use of functions and no longer using re Sub uses a more complex method to find all interference items with the finder and then replace them one by one, but the implementation is very complex; After searching for information and thinking, I found re The match object of sub operation can use lambda expression, so lambda expression is directly used here to return an empty string with the same length as the matched string
summary
-
Through this assignment, I further learned the use of regular expressions and had a deeper understanding of string operation; At the same time, I was also exposed to unit testing, coverage and performance testing for the first time. I had a deeper understanding of how to better use coding to complete a problem. In addition, I also learned how to write python code more standardized.
-
Through this assignment, I also understand the following principles:
1. Selection and planning are more important than efforts: if the overall workflow is planned in advance and the approximate workload is estimated, it will be more directional. Blind efforts are likely to be a waste of time
2.Learning by doing can well mobilize the knowledge you have learned and are learning, increase your understanding of knowledge, and use the process of practice can increase your sense of excitement and let you improve yourself in happiness
3. Although deadline is the primary productive force, you should start early. More time can make you more relaxed (you can sleep more QAQ)
Generally speaking, this assignment is full of harvest!