- Container: structures that store data in memory, such as arrays and collections, are memory structures that use various data structures to store data
- Collection: different from array, array stores the same type of data with length limit. Most sets have no length limit, such as LinkedList. In theory, linked list data structures have no length limit, except for artificial limit or full memory.
- Collection features: only reference data types can be stored, not basic data types. If we store basic data types, the corresponding packaging classes will be automatically boxed.
- Significance: different business scenarios have different requirements for data storage. In order to cope with various scenarios, many kinds of containers are provided
| Look at the most basic set |
|---|
- Complete class diagram: file location simple_collection/uml/collection.puml
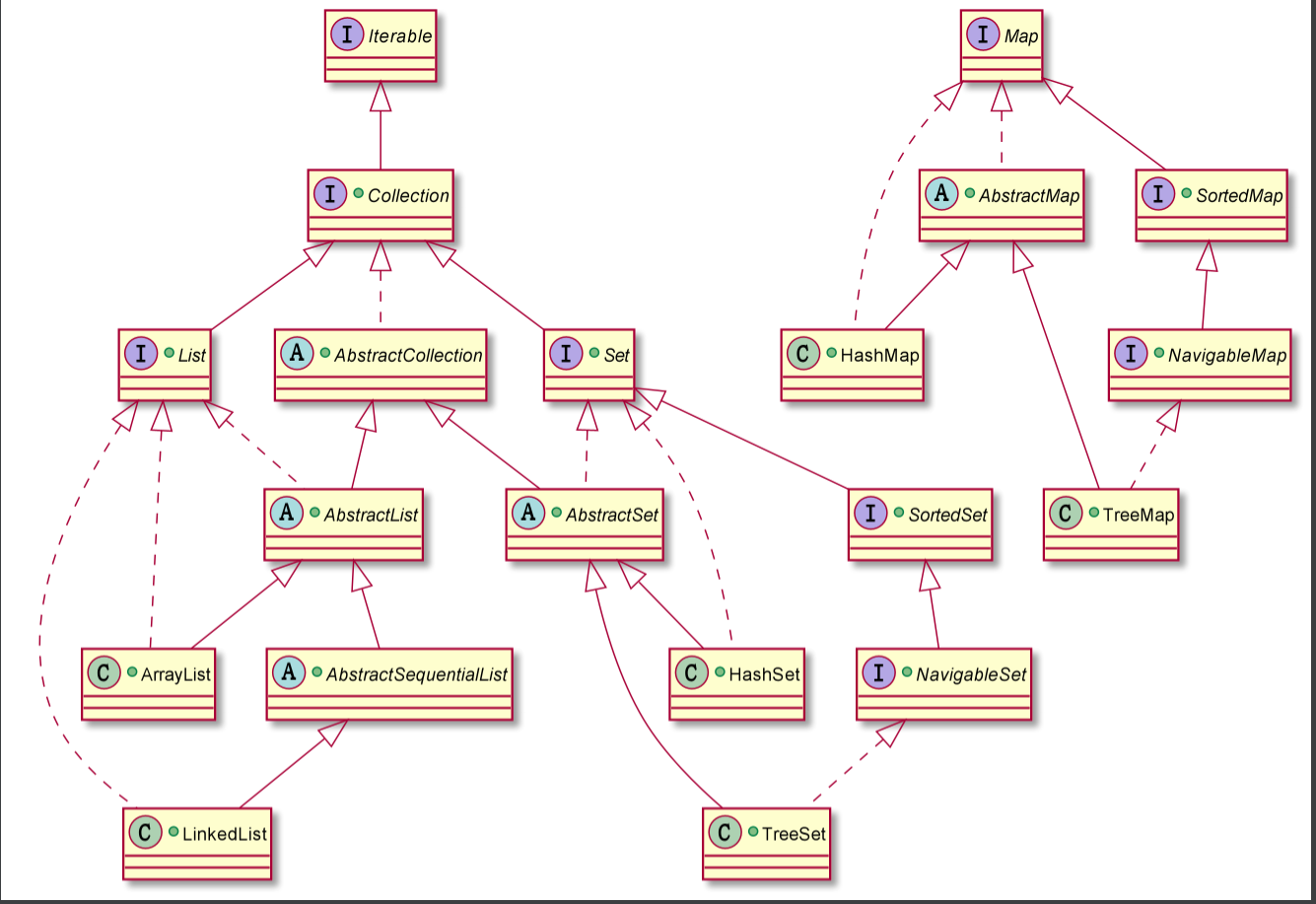
- You can find duplicate inheritance, such as ArrayList extensions, AbstractList implementations List, AbstractList implementations List. ArrayList extensions AbstractList does not need to implement List because AbstractList has been implemented
- The people who wrote the JDK source code Collection also admitted this mistake, but in the later version, it was not changed because they felt it was unnecessary and really unnecessary
- Simple: file location simple_collection/uml/collection-simple.puml
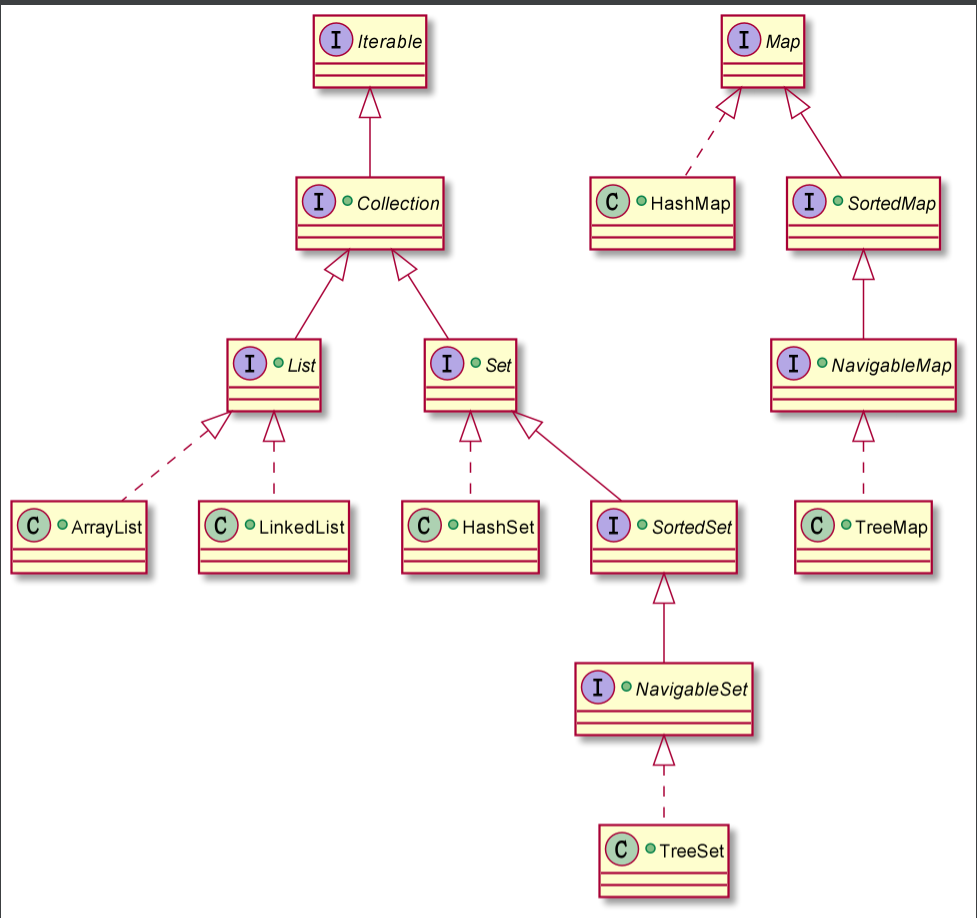
| Statement: when looking at the source code, you often see this variable modCount, which marks the number of times the container has been operated. Let's talk about it here. Otherwise, you'll say it once and want to kill yourself |
|---|
1, Collection interface
| Collectiono is a top-level interface. Let's introduce its common APIs |
|---|
- The interface cannot be a new object, so we need to use its subclasses, ArrayList, LinkedList, HashSet, TreeSet,
- Choose a simple one. Let's use ArrayList
1. Common Api analysis
| describe | API |
|---|
| Add a single element | add(E e) |
| Add a collection | addAll(Collection<? extends E> c) |
| Clear collection | clear() |
| Removes the specified element | remove(Object o) |
| iterator | iterator() |
| Number of collection elements | size() |
| Determines whether the specified element is in the collection | contains(Object o) |
| Compares whether the elements of two sets are equal | equals(Object o) |
| Is the collection empty | isEmpty() |
| Test API: simple_collection/CollectionAPITest.java |
|---|
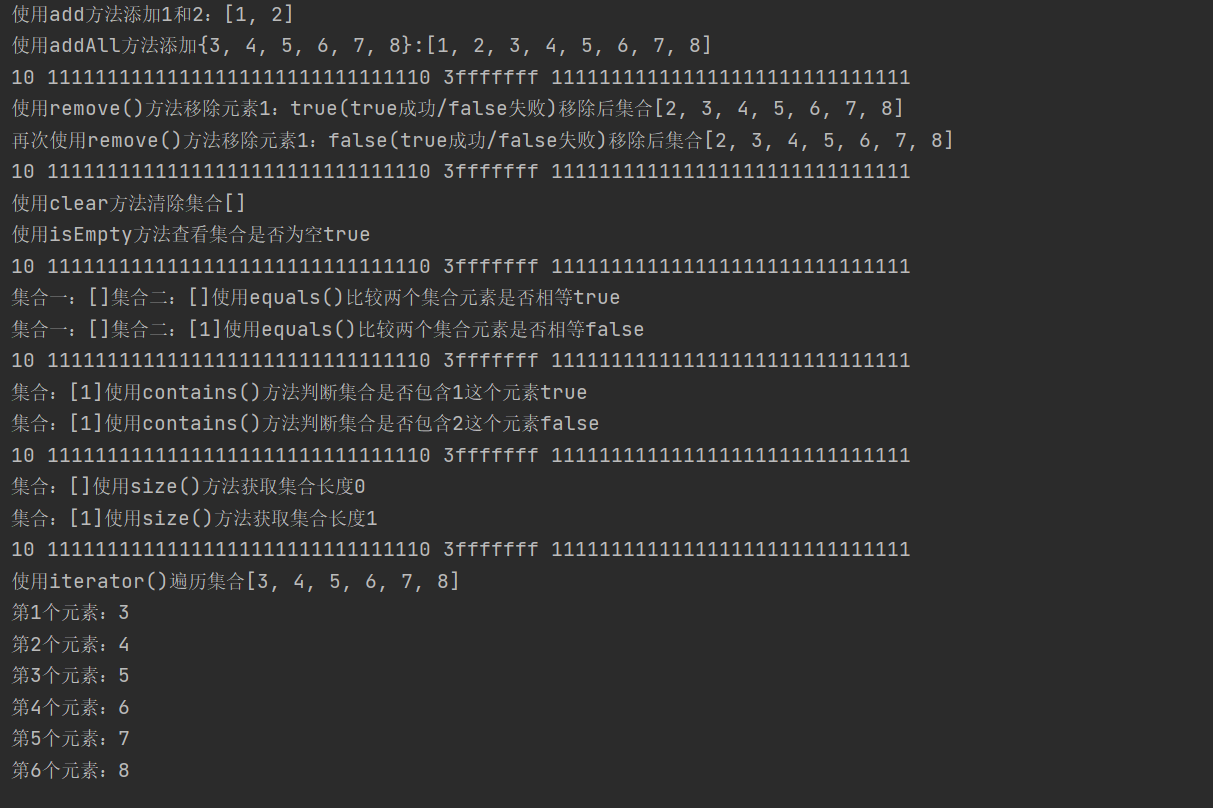
import java.util.*;
public class CollectionAPITest {
public static void main(String[] args) {
//Collection is an interface and needs to implement classes
Collection col = new ArrayList();
//add() adds an element and basic data type, which will be automatically boxed, int --- > integer
col.add(1);
col.add(2);
System.out.println("use add Methods add 1 and 2:"+col);
//addALl() adds all the elements of a collection
List<Integer> integers = Arrays.asList(new Integer[]{3, 4, 5, 6, 7, 8});
col.addAll(integers);
System.out.println("use addAll Method addition{3, 4, 5, 6, 7, 8}:"+col);
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//The remove() method removes the specified element
System.out.println("use remove()Method to remove element 1:"+col.remove(1)+"(true success/false fail)Collection after removal"+col);
System.out.println("Reuse remove()Method to remove element 1:"+col.remove(1)+"(true success/false fail)Collection after removal"+col);
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//The clear() method clears the collection
col.clear();
System.out.println("use clear Method to clear the collection"+col);
//The isEmpty() method checks to see if the collection is empty
System.out.println("use isEmpty Method to see if the collection is empty"+col.isEmpty());
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//The equals() method compares whether two sets are equal
ArrayList<Object> objects = new ArrayList<>();
System.out.println("Set 1:"+col+"Set 2:"+objects+"use equals()Compares whether two collection elements are equal"+col.equals(objects));
objects.add(1);
System.out.println("Set 1:"+col+"Set 2:"+objects+"use equals()Compares whether two collection elements are equal"+col.equals(objects));
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//The contains() method determines whether the collection contains the specified element
System.out.println("Set:"+objects+"use contains()Method to determine whether the collection contains the element 1"+objects.contains(1));
System.out.println("Set:"+objects+"use contains()Method to determine whether the collection contains 2 this element"+objects.contains(2));
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//The size() method gets the collection length
System.out.println("Set:"+col+"use size()Method to get the collection length"+col.size());
System.out.println("Set:"+objects+"use size()Method to get the collection length"+objects.size());
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//Iterate over the collection using the iterator() iterator
col.addAll( Arrays.asList(new Integer[]{3, 4, 5, 6, 7, 8}));
System.out.println("use iterator()Traversal set"+col);
Iterator iterator = col.iterator();//Get Iterator object
int i = 1;
while(iterator.hasNext()){//Iterator. The hasnext () method determines whether there is a next iteratable object
Object next = iterator.next();//Return the current element and move the pointer back. The pointer points to the next element. If not, the hasNext method will handle it next time
System.out.println("The first"+i+"Elements:"+next);
i++;
}
}
}
2. Iterator interface
| First, the collection extends iteratable, and the Iterator iterator(); is defined in the iteratable interface;, Return the Iterator interface object. The methods we operate iteratively are all in the Iterator interface |
|---|
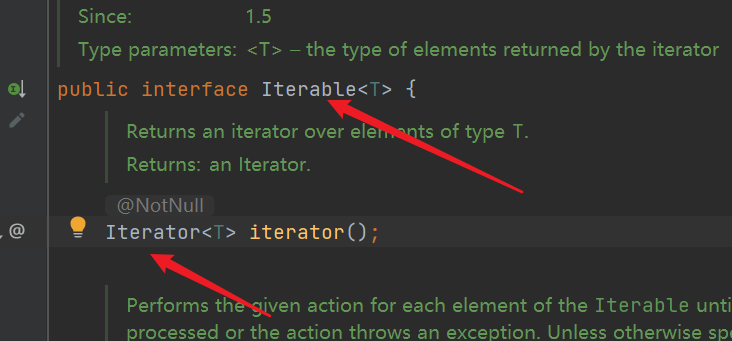
| The interface is not available. If you want to use an implementation class, we can see from the ArrayList source code that the implementation class is Itr class and Itr class is an internal class |
|---|
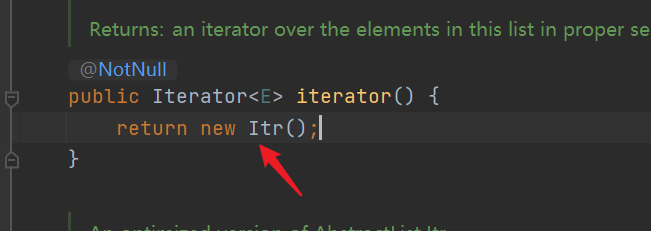
3. Source code of iterator() method of ArrayList (JDK1.8)
| Iterator iterator resolution of ArrayList |
|---|
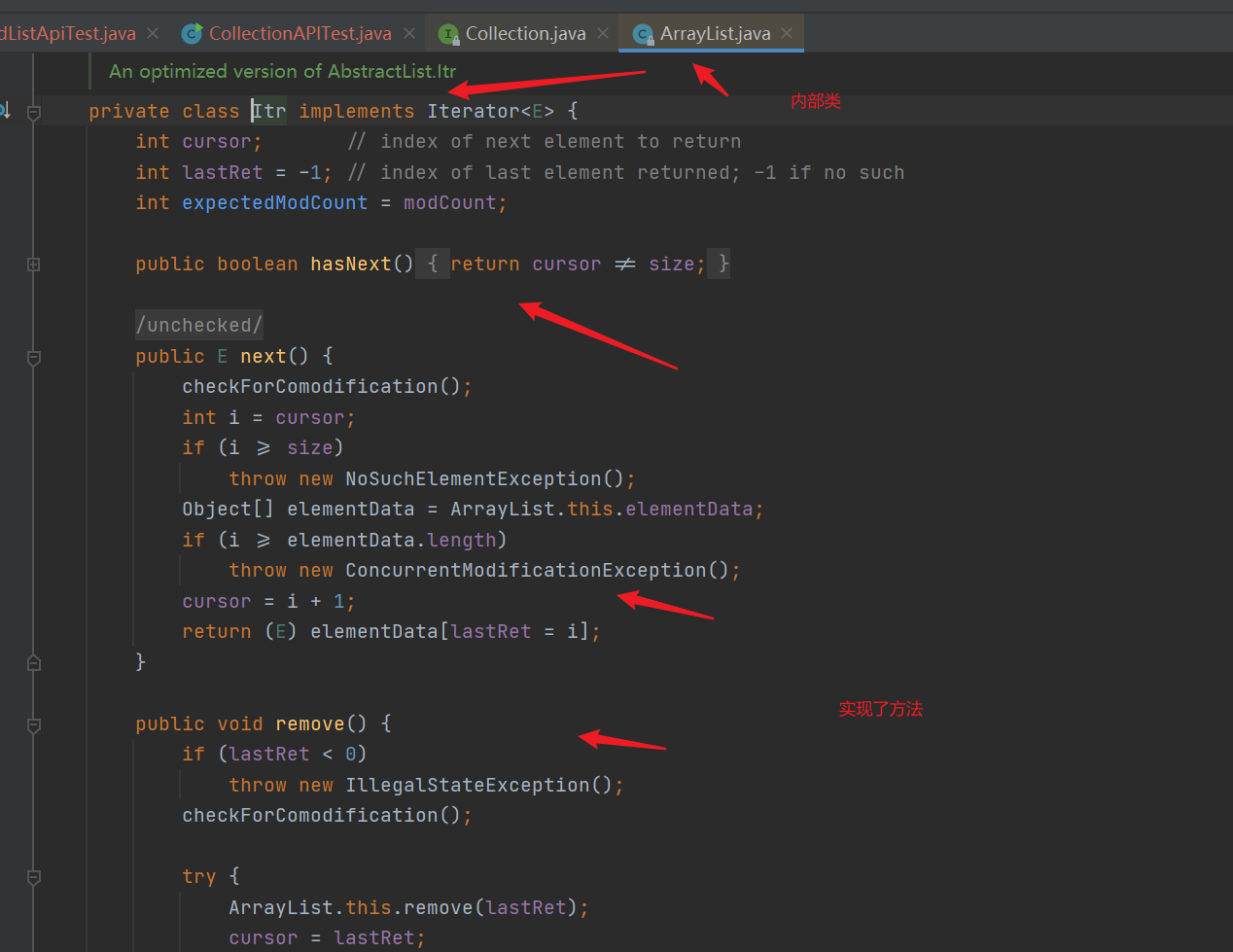
- iterator(): we found that the iterator() method just creates its own internal class Itr, which contains the current element pointer cursor and the previous element pointer lastRet of the current element
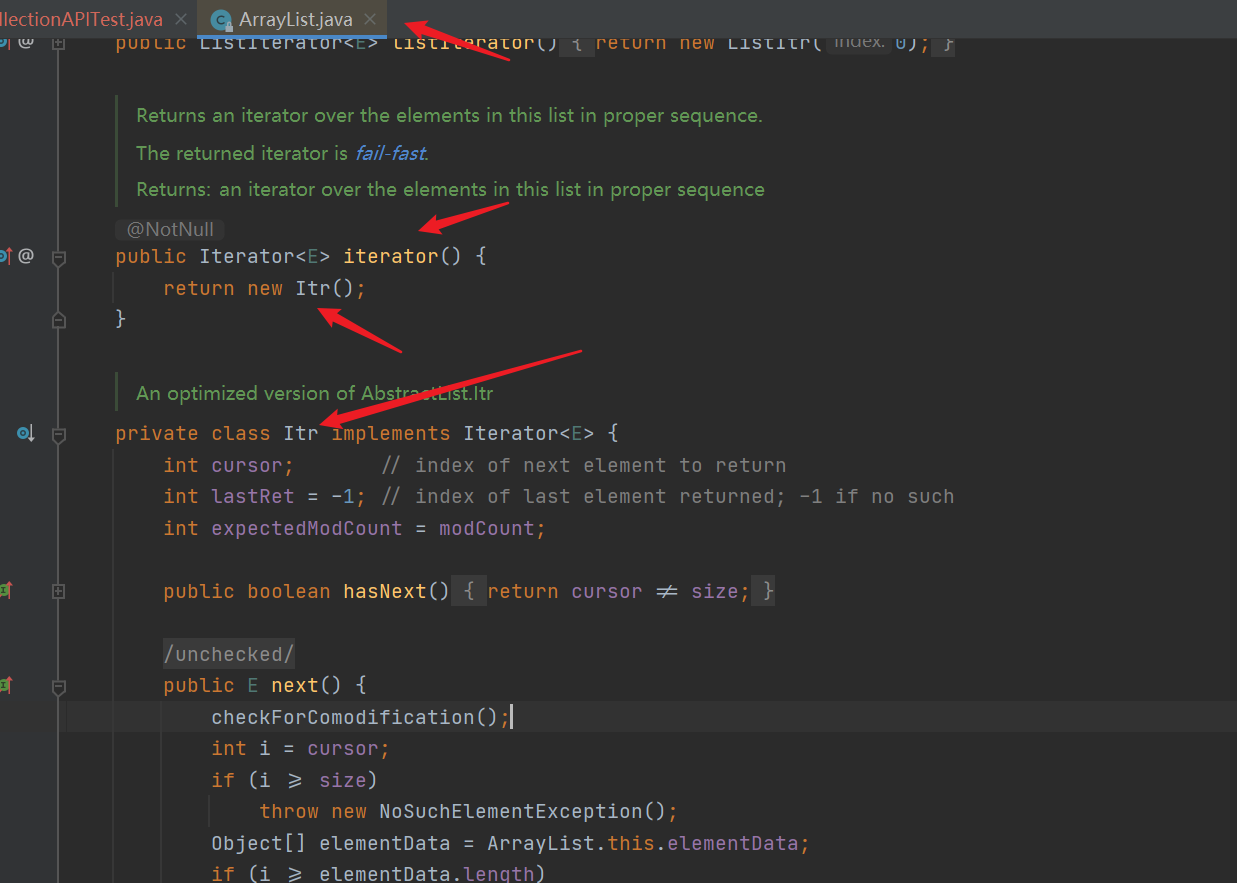
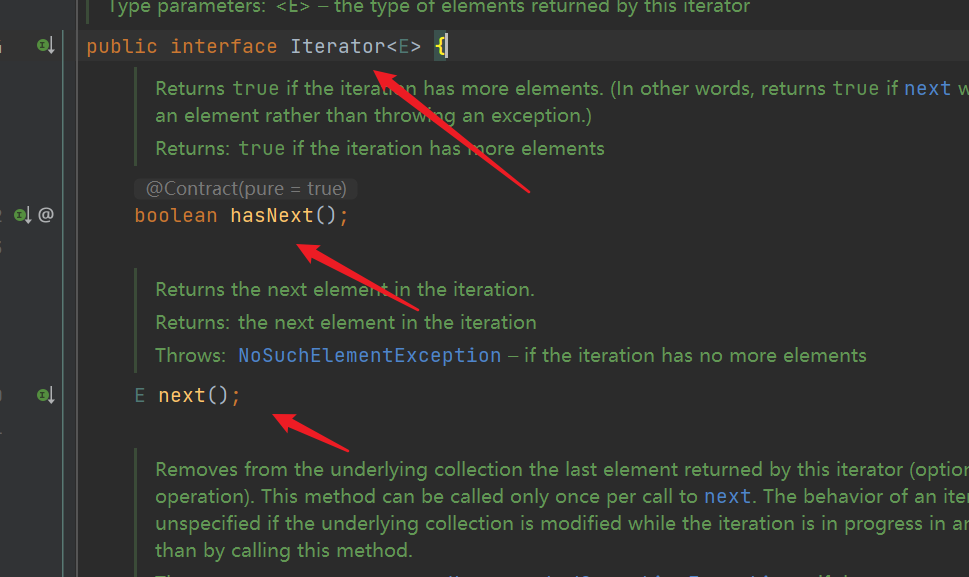
- hasNext() method: it only determines whether the current pointer is valid or not= size. If it is not equal to, it indicates that there are still elements that can be traversed and returns true
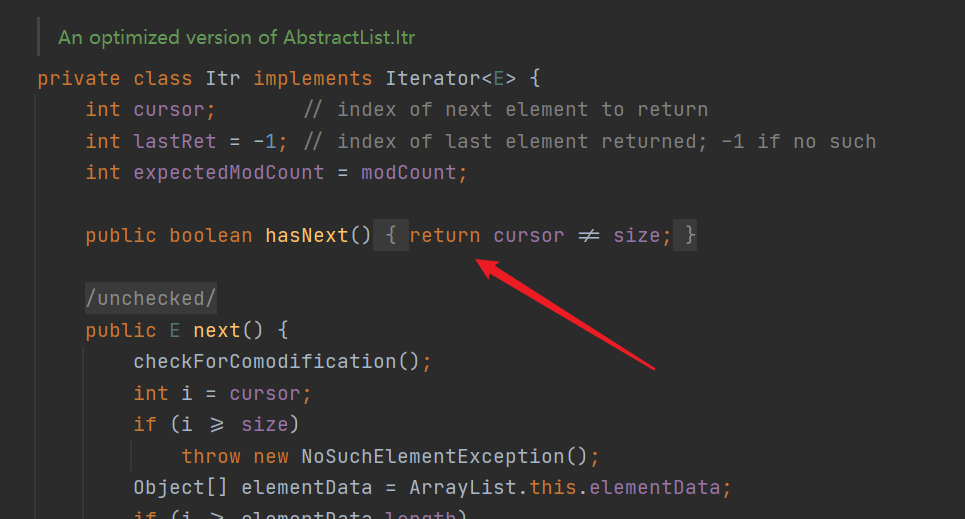
- next() method: return the current element, move the pointer back, and the pointer points to the next element. In the source code, the variable i records the current element pointer. If i > = size, it indicates that the subscript is out of range (throwing exception). Otherwise, judge whether i is within the subscript range of the data set again. If not, report an exception. No problem. Move cursor backward, lastRet = i (record the current element, which is the previous element of the next iteration), and then return the element pointed to by lastRet (i)
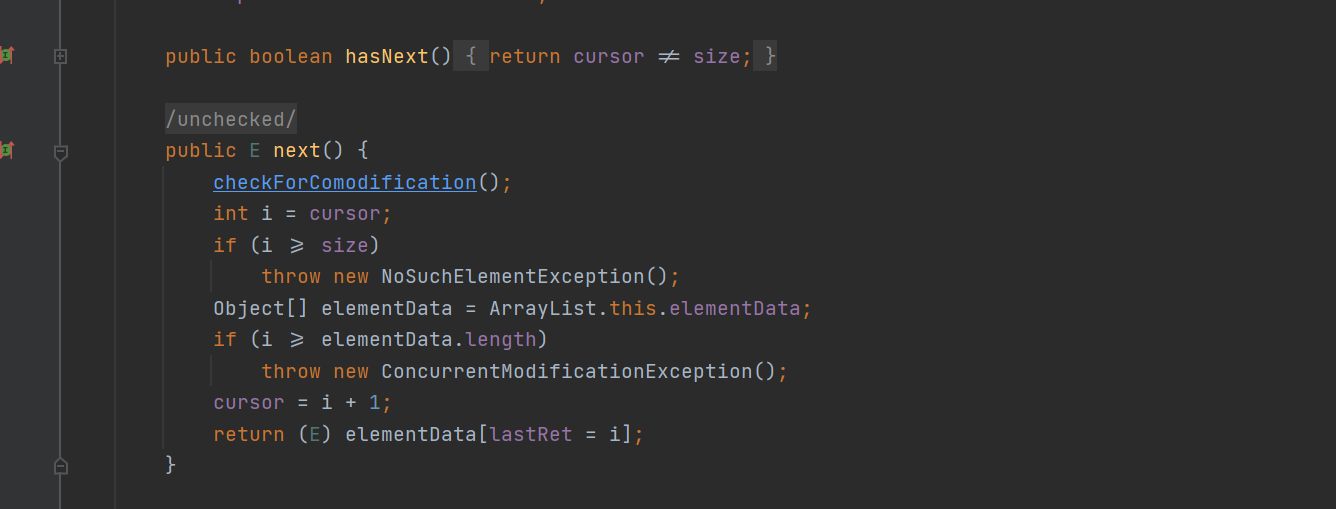
4. How to compare sets
1. Comparable and Comparator
- Comparabel interface (internal comparator), Java Lang package, there is a compareTo(Obj) method to sort. Compare Obj with this (internal self)
- Comparator interface (external comparator), Java Under the util package, there is a compare(Obj1,Obj2) method to sort and compare Obj1 and Obj2
- Generally, for custom sorting of collections, we need to override the compareTo or compare methods. When we need to implement two sorting methods for collections, such as one sorting method for song names and singer names in a song object, we can override the compareTo method and use the self-made Comparator method, or two comparators to implement song name sorting and singer name sorting, The second means that we can only use two parameter versions of collections sort()
- Assume num1 = 10;num2=20; How do you compare them? Who is older? Num1-num2 > 0 means num1 > num2. If = 0, it means they are the same size. If < 0, it means num2 is larger than num1
- Of course, the above two numbers are easy to compare, but what about the object? How to compare two objects, which is bigger and which is smaller? This requires you to use these two interfaces to customize comparison rules for objects (similarly, the return value > 0 means num1 > num2...)
- The following describes the usage of Comparable and Comparator respectively, and how to correctly sort collections
- Comparable requires the object to implement the comparable interface. When sorting collections sort(list); compareTo() for object overrides is automatically called
- Comparator can be directly implemented with anonymous internal classes, and two objects to be sorted are given to it, collection sorting and collections Sort (list, new comparator())
- Comparabel interface (internal Comparator) is simpler to implement and Comparator interface (external Comparator) is more flexible
import java.util.*;
public class Test implements Comparable<Test>{
private Integer age;
public Test(Integer age) {
this.age = age;
}
/**
* Returns an int value. A positive number means this is greater than o, 0 means this=o2, and a negative number means this is less than o2
*/
@Override
public int compareTo(Test o) {
//Who is older depends on age
return this.age-o.age;
}
@Override
public String toString() {
return "Test{" +
"age=" + age +
'}';
}
public static void main(String[] args) {
Test test = new Test(1);
Test test1 = new Test(2);
ArrayList<Test> tests = new ArrayList<>();
tests.add(test1);
tests.add(test);
System.out.println("list Before collection sorting"+Arrays.toString(tests.toArray())+"\n\n");
System.out.println("==========Comparable sort===========");
int i = test.compareTo(test1);
System.out.println("Comparable: test and test1 Who is big (positive number) test Large, 0 means equal, negative number means equal test1 (large)"+i);
Collections.sort(tests);
System.out.println("list After collection sorting"+Arrays.toString(tests.toArray())+"\n\n");
System.out.println("==========Comparator sort===========");
Comparator<Test> comparator = new Comparator<Test>() {
/**
* Returns an int value. A positive number means o2 > o1, 0 means o1=o2, and a negative number means o2 is less than o1
*/
@Override
public int compare(Test o1, Test o2) {
//Who is older depends on age
return o2.age-o1.age;
}
};
int compare = comparator.compare(test, test1);
System.out.println("Comparator: test and test1 Who is big (positive number) test1 Large, 0 means equal, negative number means equal test (large)"+compare);
Collections.sort(tests, new Comparator<Test>() {
/**
* Returns an int value. A positive number means o2 > o1, 0 means o1=o2, and a negative number means o2 is less than o1
*/
@Override
public int compare(Test o1, Test o2) {
return o2.age-o1.age;
}
});
System.out.println("list After collection sorting"+Arrays.toString(tests.toArray()));
}
}
2, List interface
| List is also an interface that inherits from Collection. It has all kinds of Collection, so let's introduce its unique common APIs |
|---|
- The interface cannot be a new object, so we need to use its subclasses, ArrayList and LinkedList
- Choose a simple one. Let's use ArrayList
1. Common Api analysis
| Methods such as listIterator() and listinterlator (int index) will be introduced in a unified way later. They are abrupt here |
|---|
| describe | API |
|---|
| Adds a single element to the specified subscript | add(int index,E e) |
| Sets (replaces) a single element to the specified subscript | set(int index,E e) |
| Gets the specified subscript element | get(int index) |
| Removes the specified subscript element | remove(int index) |
| Test API: simple_collection/ListApiTest.java |
|---|
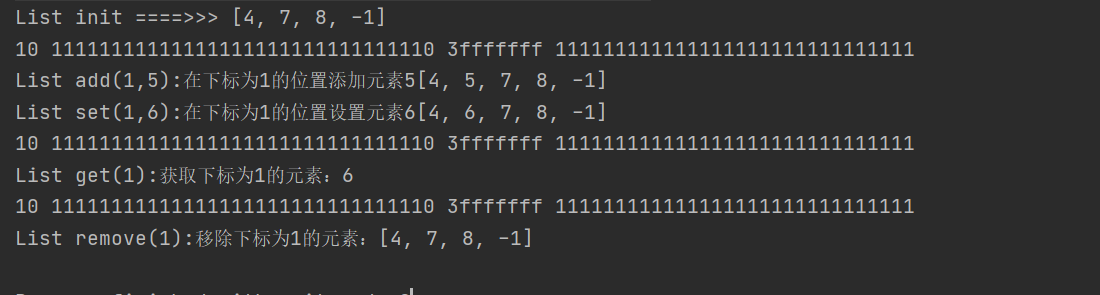
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class ListApiTest {
public static void main(String[] args) {
//List is an interface, and subclasses are required
List list = new ArrayList();
list.addAll(Arrays.asList(new Integer[]{4,7,8,-1}));
System.out.println("List init ====>>> "+list);
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//Add (int index, e) adds a single element to the specified subscript
list.add(1,5);
System.out.println("List add(1,5):Add element 5 where the subscript is 1"+list);
//Set (int index, e) sets a single element to the specified subscript
list.set(1, 6);
System.out.println("List set(1,6):Set element 6 where the subscript is 1"+list);
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//get(int index) gets the specified subscript element
System.out.println("List get(1):Get element with subscript 1:"+list.get(1));
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//remove(int index) removes the specified subscript element
list.remove(1);
System.out.println("List remove(1):Remove elements with subscript 1:"+list);
}
}
2. ArrayList source code (JDK1.8)
| Advantages and disadvantages of ArrayList |
|---|
- The bottom layer is based on array, query and modification are efficient. Delete, increase, low efficiency
- The data can be repeated because the underlying array is of Object type and can store any type of data
| Briefly, jdk1 For details of version 7, see jdk1.0 for the specific source code 8 |
|---|
- ArrayList maintains an Object type array, elementData, and size variables
- Initial size 10 (default)
- In the add method, there is no system arraycopy(elementData, index, elementData, index + 1,size - index); This line of code
| JDK1.8 ArrayList source code |
|---|
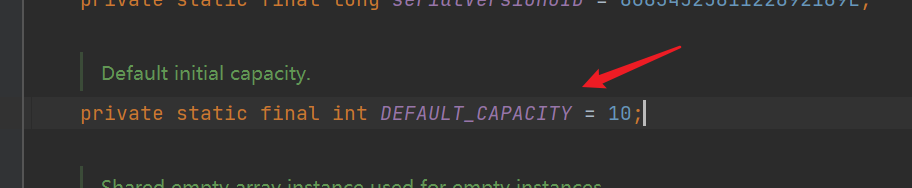
- As in 1.7, maintain the Object type array, elementData, and size variables
- The default size is still 10, but instead of the initial direct assignment, it first points to an empty array {}, and elementData points to defaultcapability by default_ EMPTY_ elementData
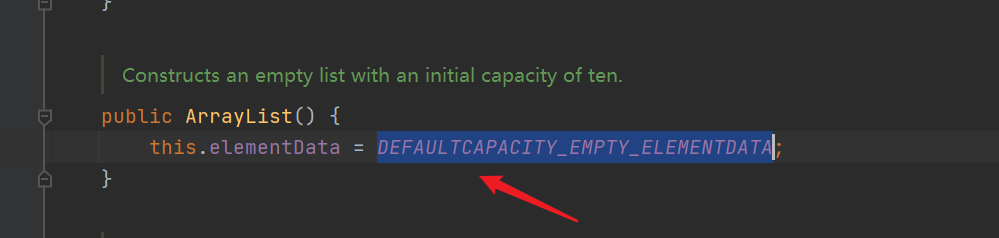
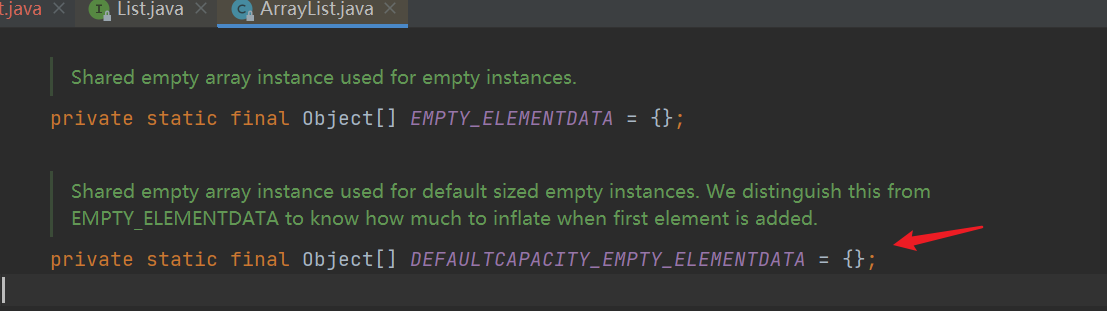
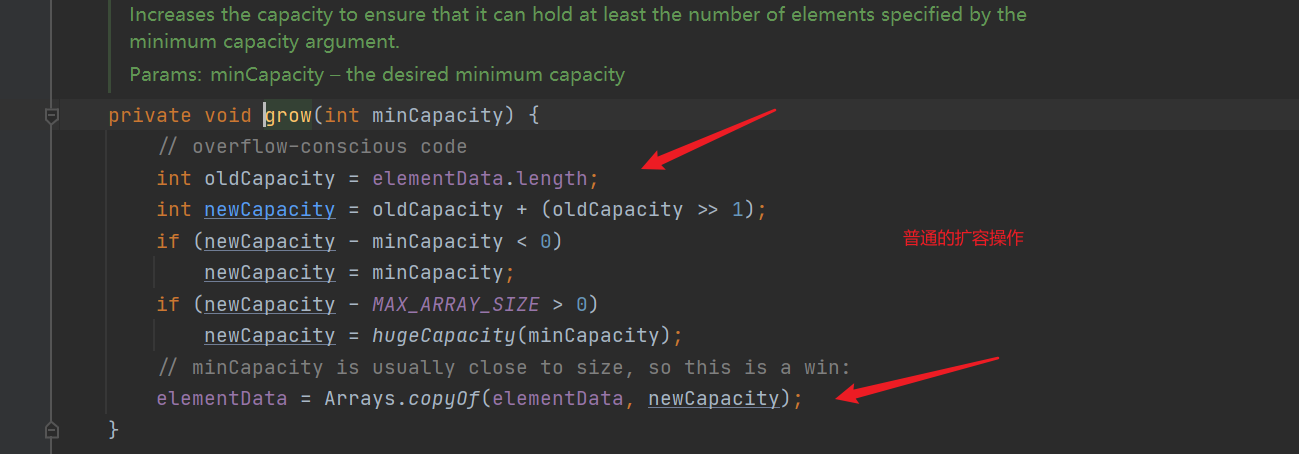
- The add() method will expand the array (because the initialization array length is 0 (size = 0), the expansion operation must be carried out)
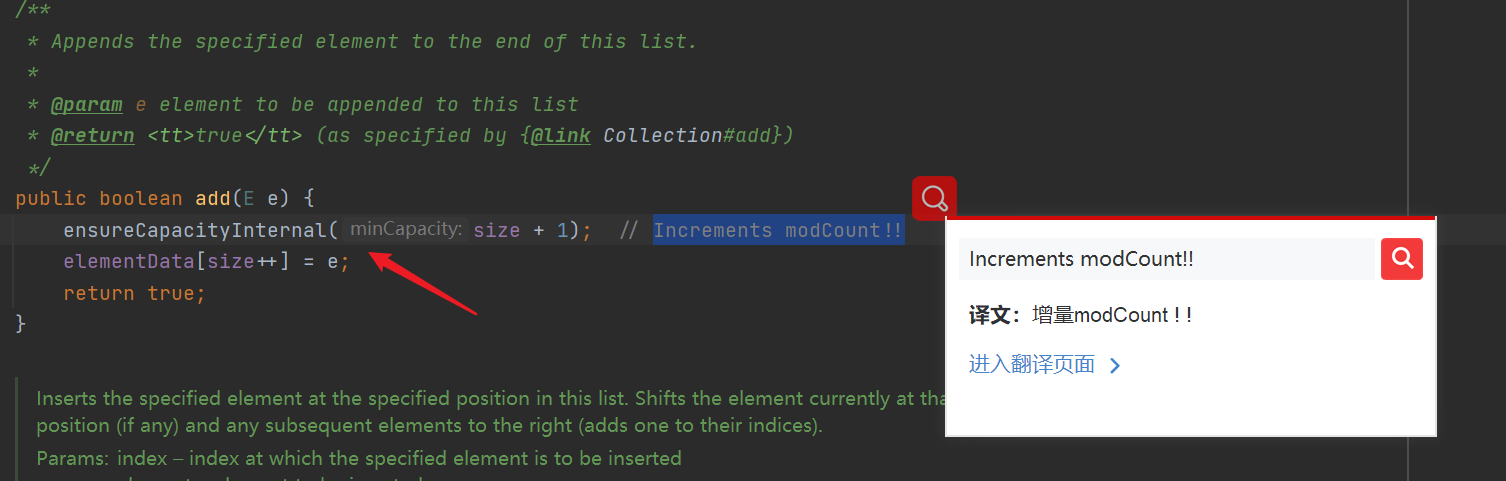
- Judge whether capacity expansion is required. If the ArrayList is created by default, ensure that the capacity expansion value is greater than or equal to DEFAULT_CAPACITY (10) does not directly determine whether capacity expansion is required. If the array is not full, capacity expansion is not required
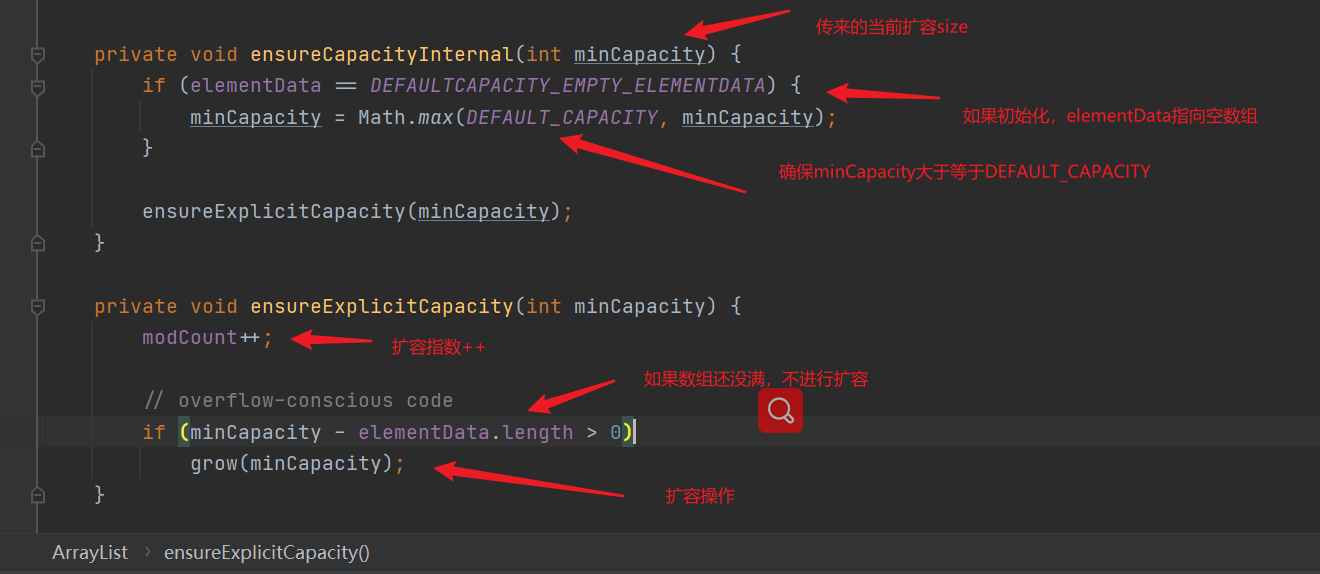
- Capacity expansion operation (1.5 times of the original array each time)
- The default size is 10
3. Vector source code (JDK1.8)
| An obsolete container, but interviews often ask |
|---|
- The bottom expansion length of ArrayList is 1.5 times that of the original array, which is unsafe and efficient
- The bottom expansion length of Vector is twice that of the original array, which is low in thread safety and efficiency
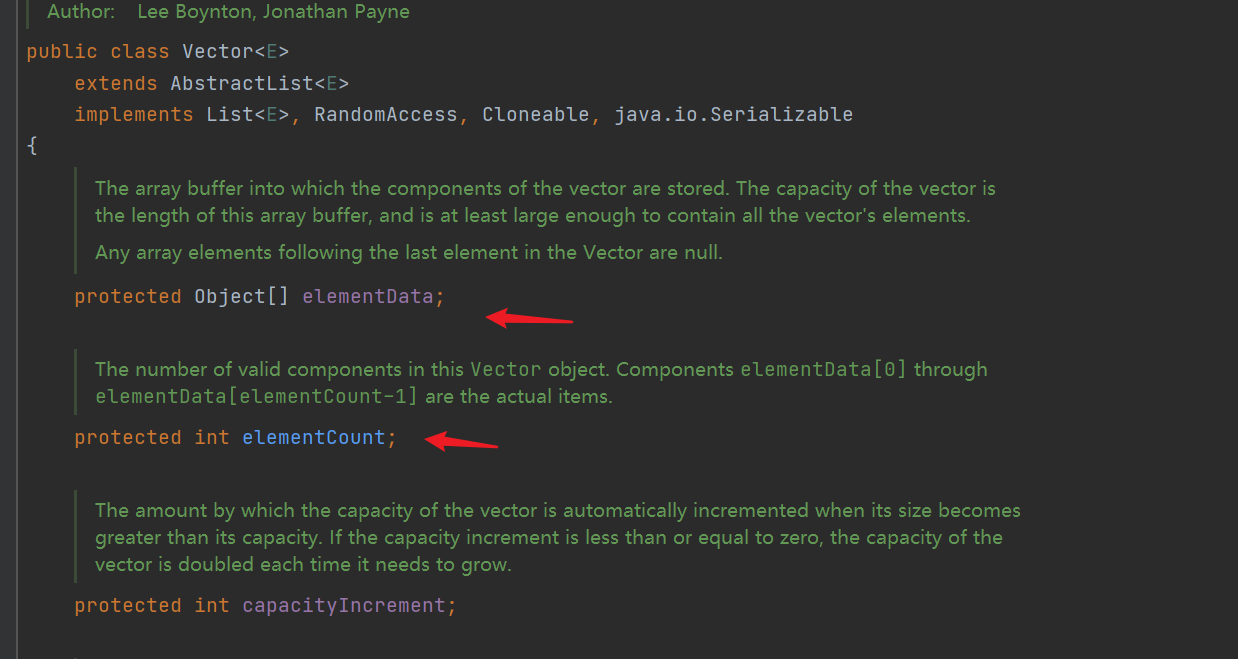
- The underlying maintenance Object type array elementData and int variable elementCount represent the number of elements
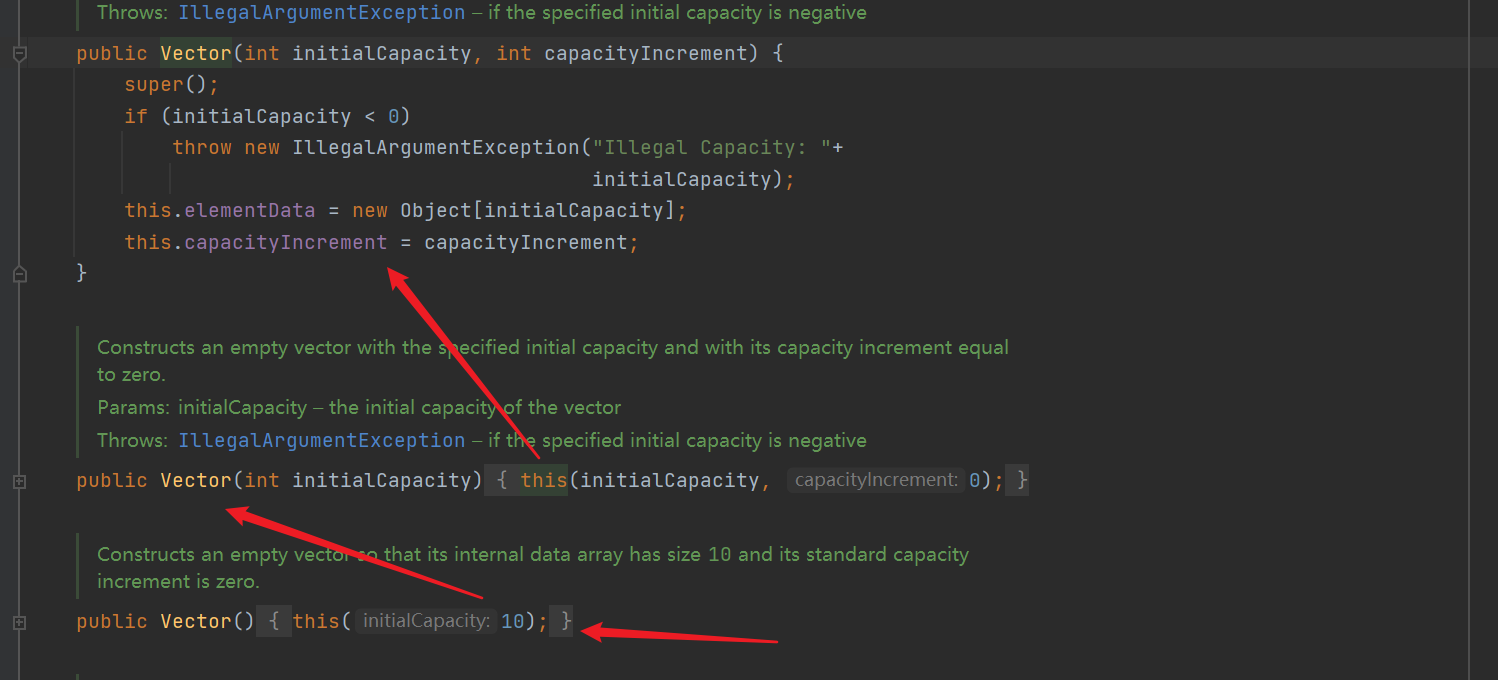
- The default length is 10
- add() method, locking, capacity expansion in the method
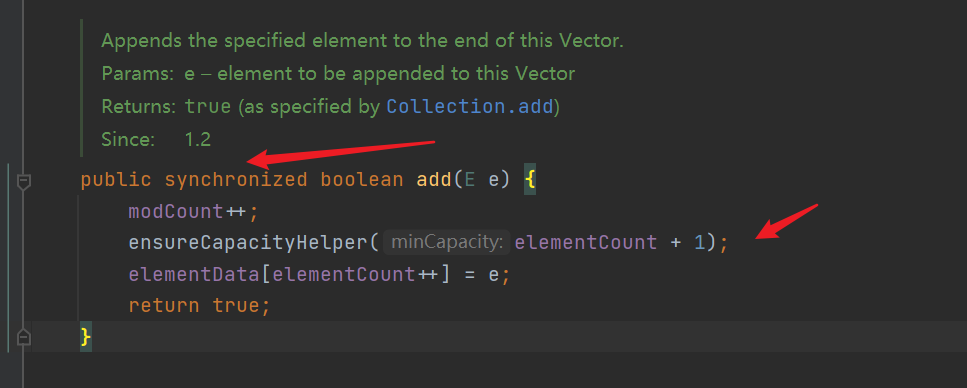
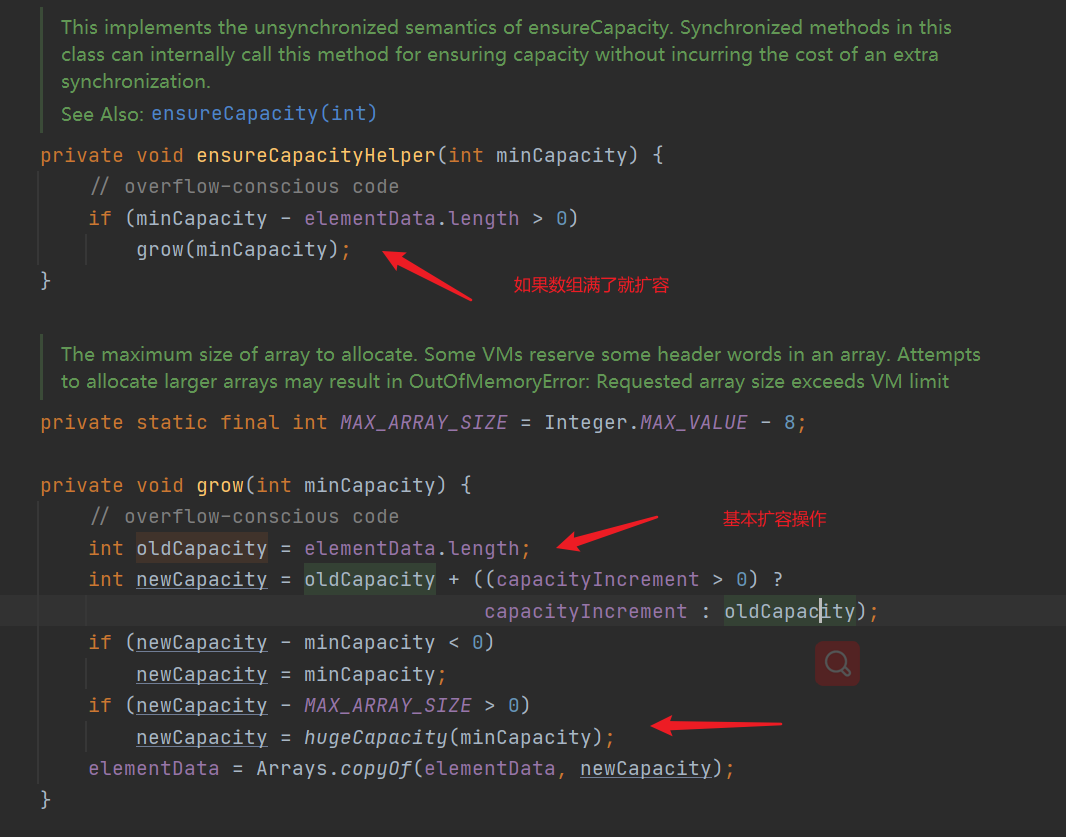
- Expansion method (each expansion is twice the original array)
4. Itr iterator concurrent modification exception of iterator () method
| ArrayList is thread unsafe. When using iterators, you can't perform other operations on the collection at the same time, such as adding data with iterators. If one pointer iterates and another pointer operates on the collection, an error will be reported |
|---|
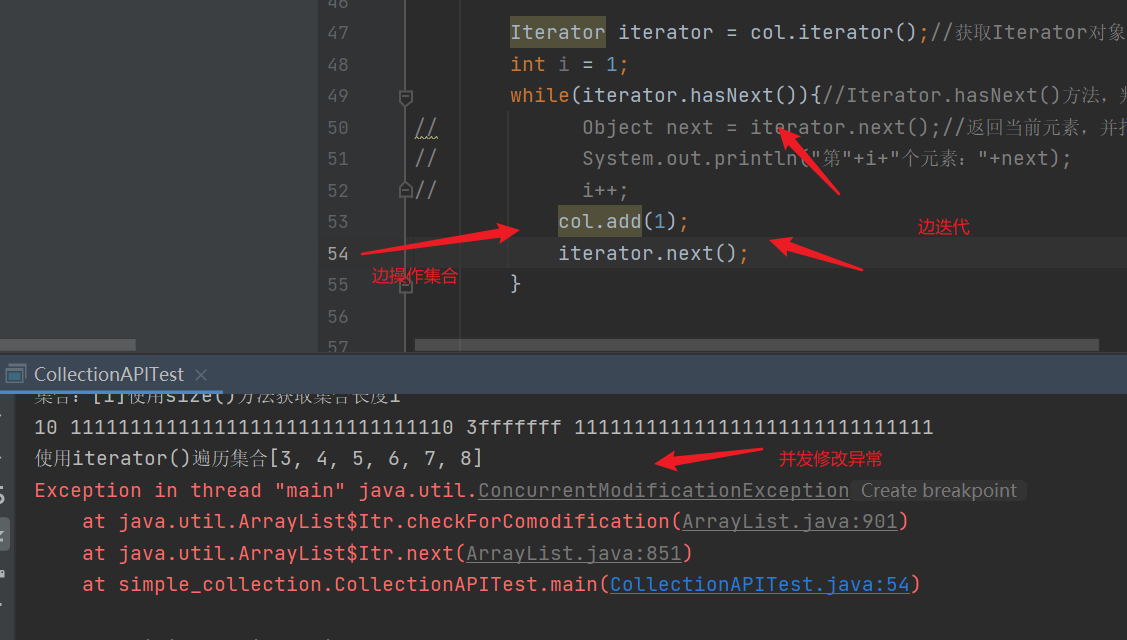
| Then we can let a person do this, solve the concurrent modification exception, and use the ListIterator interface |
|---|
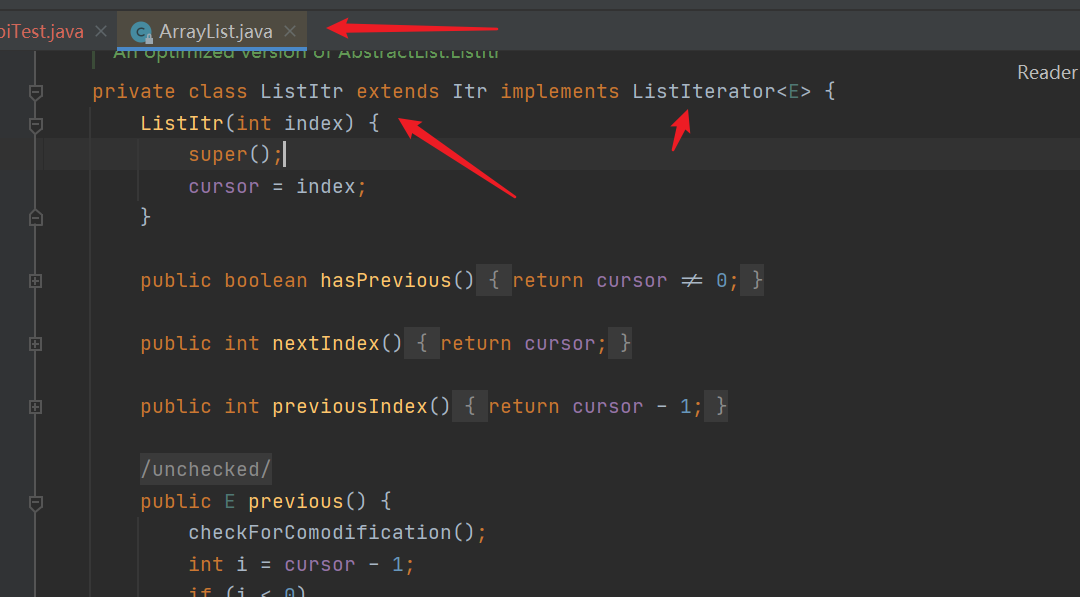
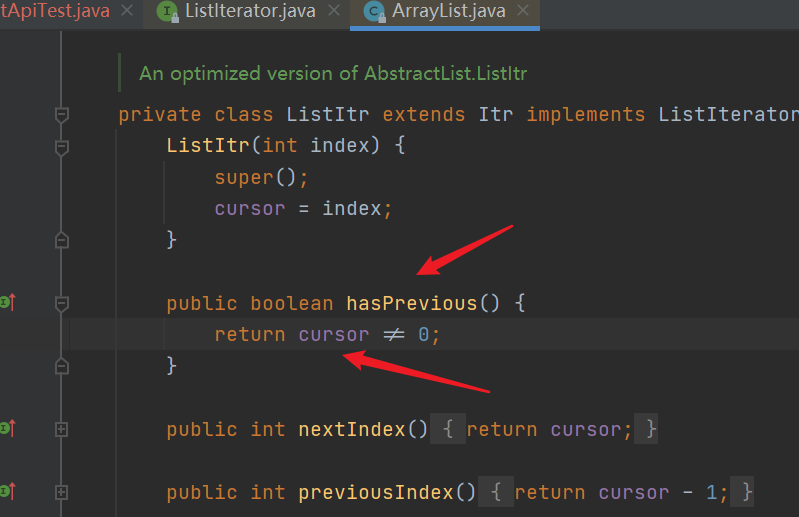
5. ListIterator interface, ListItr implementation class of ArrayList
| The ListIterator interface inherits from the Iterator interface. At the same time, ArrayList also implements this interface using the internal class ListItr, which also inherits the internal class of Itr |
|---|
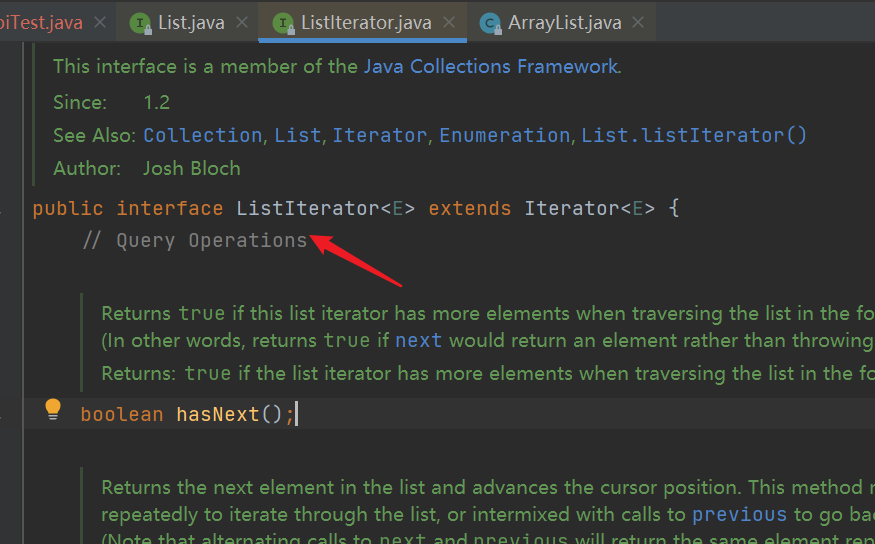
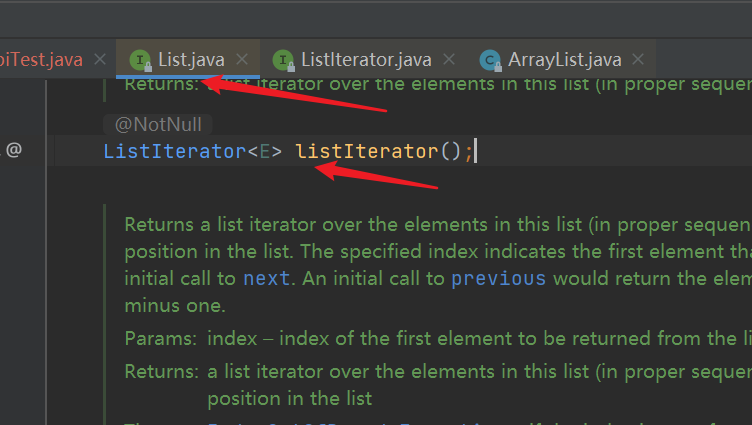
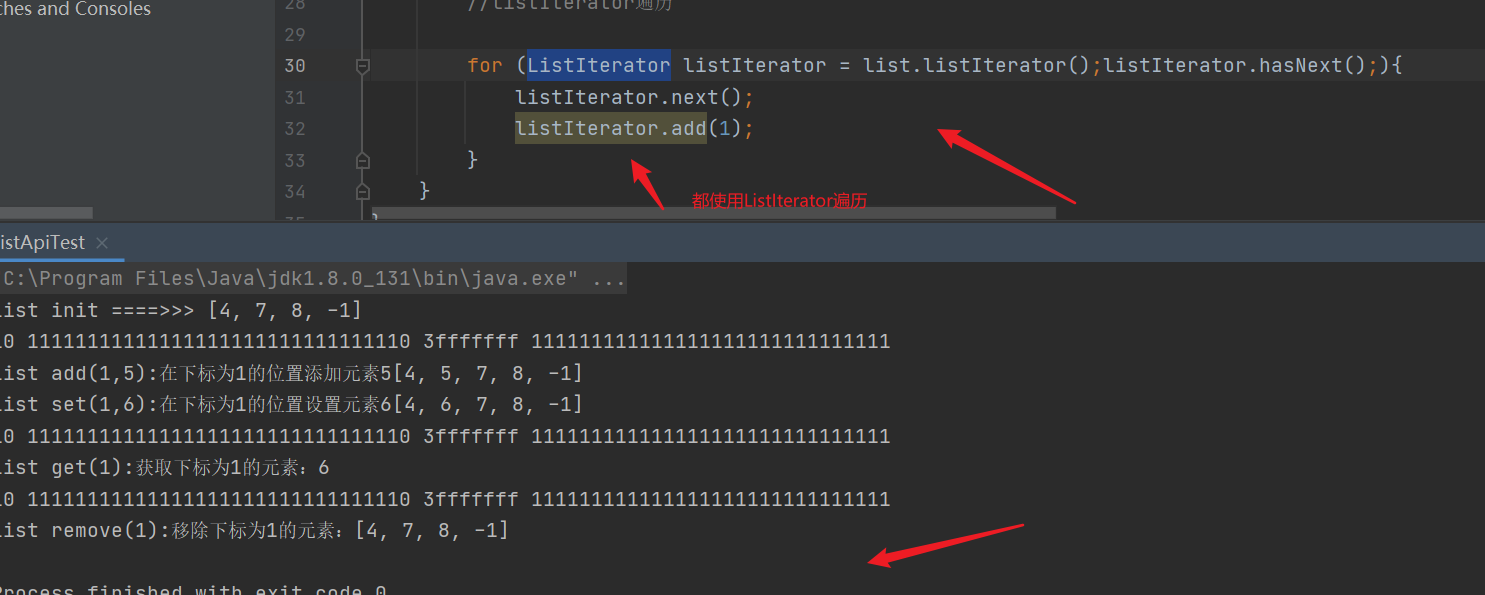
| Both traversal and addition use ListIterator objects without reporting concurrent modification exceptions |
|---|
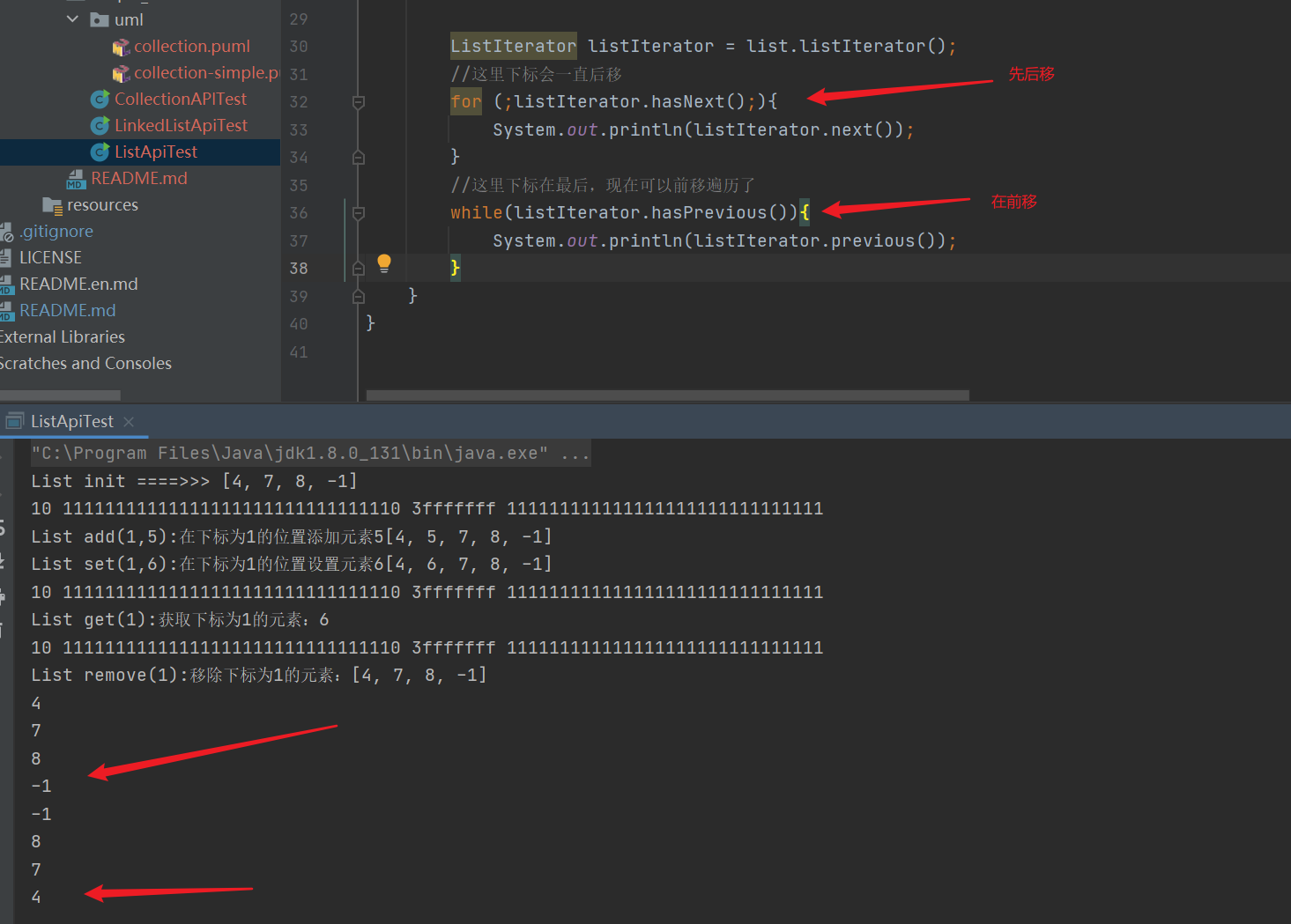
| During traversal, you can also judge the previous element to complete the reverse traversal, provided that the current ListIterator pointer is already in the back position (not equal to 0) |
|---|
The source code is as follows
3, LinkedList implementation class
1. Common Api analysis
| describe | API |
|---|
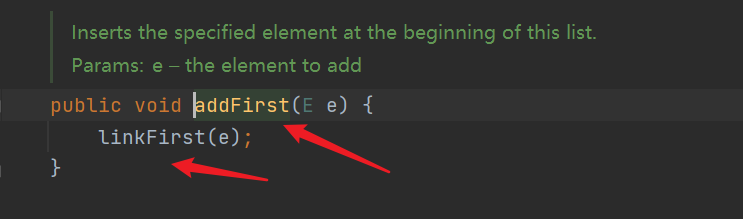
| Inserts the specified element at the beginning of the list | addFirst(E e) |
| Inserts the specified element to the end of the list | addLast(E e) |
| Gets but does not remove the header of this list | E element() |
| Gets but does not remove the header of this list | E peek() |
| Gets but does not remove the first element of the list. The list is empty and returns null | E peekFirst() |
| Gets but does not remove the last element of the list. The list is empty and returns null | E peekLast() |
| Returns the first element of this list | getFirst() |
| Returns the last element of this list | getLast() |
| Returns the index of the specified element that appears for the first time in this list. If there is no element, returns - 1 | indexOf(Object o) |
| Returns the index of the specified element that appears last in this list. If there is no element, returns - 1 | lastIndexOf(Object o) |
| Gets and removes the header of this list | poll() |
| Gets and removes the first element of the list. The list is empty and returns null | pollFirst() |
| Gets and removes the last element of the list. The list is empty and returns null | pollLast() |
| Pop an element from the stack represented by this list | pop() |
| Pushes an element onto the stack represented by this list | push(E e) |
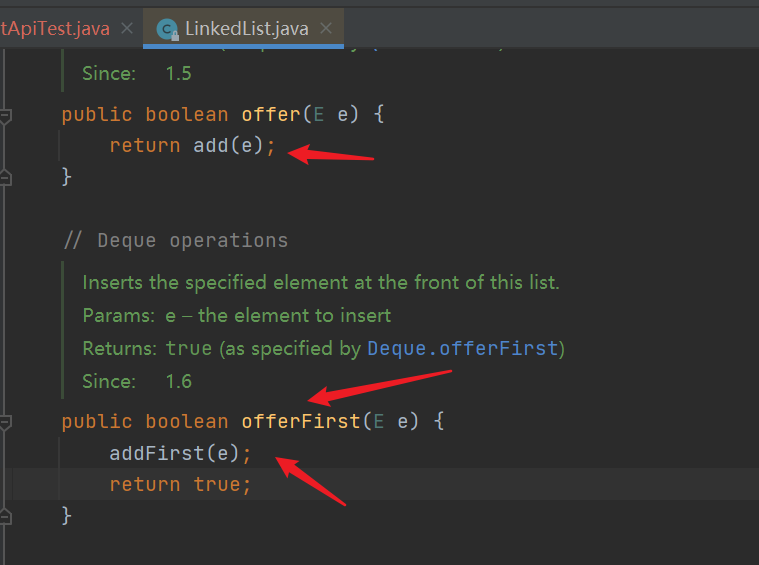
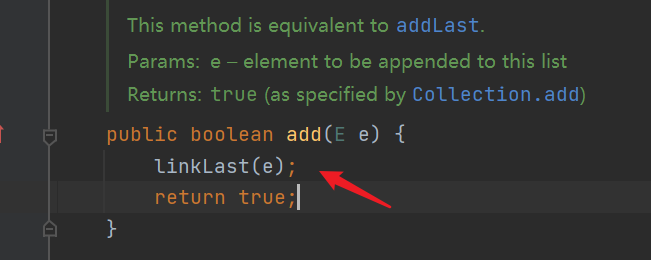
| Adds the specified element to the end of this list | offer(E e) |
| Inserts the specified element at the beginning of this list | offerFirst(E e) |
| Inserts the specified element at the end of this list | offerLast(E e) |
| Remove and return the first element of this list. The list is empty and an error is reported | E removeFirst() |
| Remove and return the last element of this list | E removeLast() |
- Many of the above API s seem to have the same functions and repeat, but the details are different in order to adapt to various scenarios
- For example, pollFirst() and removeFirst(), when a list is empty, continue to remove elements, an empty list will be returned, and an error will be reported directly. removeFirst from jdk1 0. Throw exceptions directly. The system is not robust. pollFirst is in jdk1 6. Join to improve the robustness of the system and do not throw exceptions casually
| Test API: simple_collection/LinkedListApiTest.java |
|---|
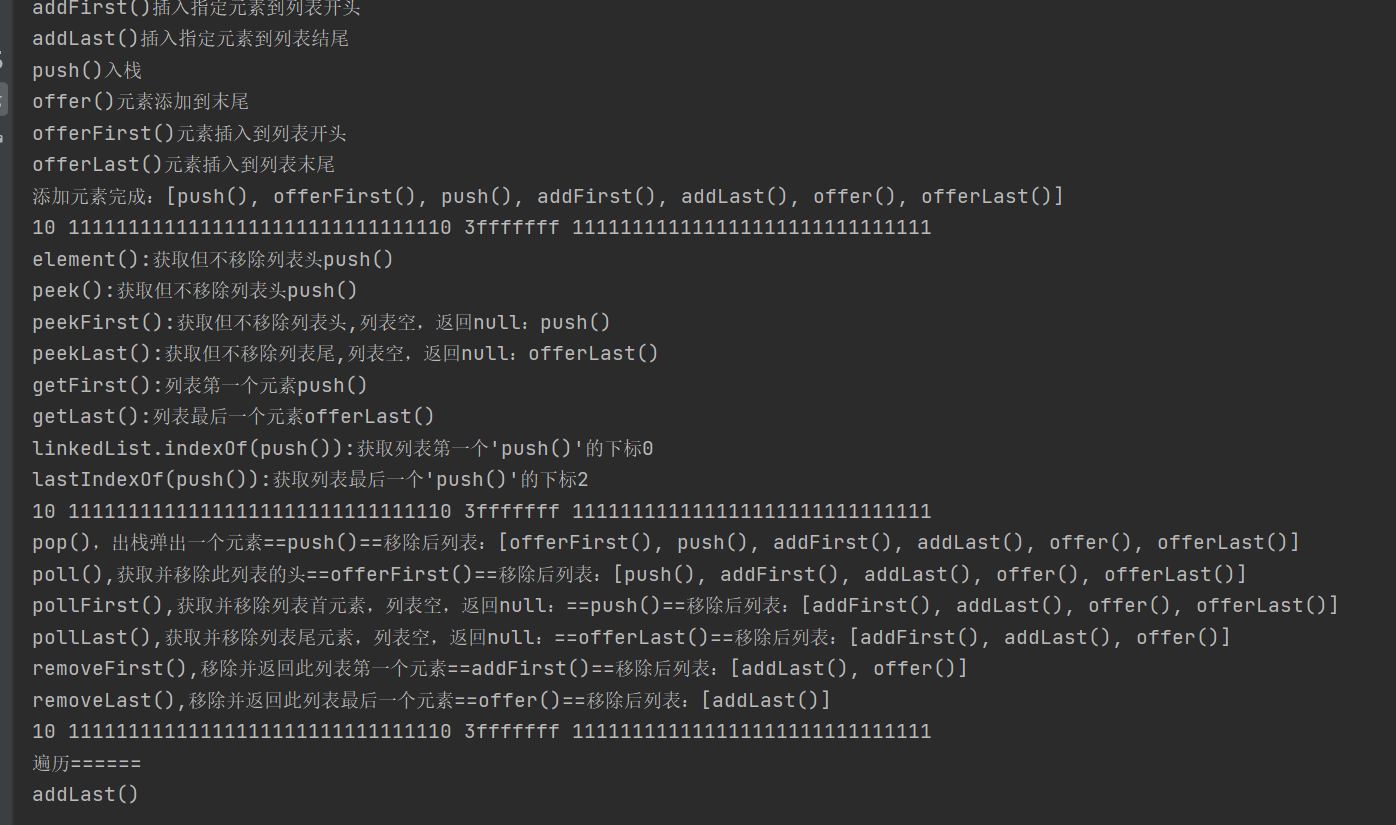
import java.util.LinkedList;
public class LinkedListApiTest {
public static void main(String[] args) {
//Create LinkedList
LinkedList linkedList = new LinkedList();
//Unique addition method
System.out.println("addFirst()Inserts the specified element at the beginning of the list");linkedList.addFirst("addFirst()");
System.out.println("addLast()Inserts the specified element to the end of the list");linkedList.addLast("addLast()");
System.out.println("push()Push ");linkedList.push("push()");
System.out.println("offer()Add element to end");linkedList.offer("offer()");
System.out.println("offerFirst()Insert element at the beginning of the list");linkedList.offerFirst("offerFirst()");
System.out.println("offerLast()Insert element at the end of the list");linkedList.offerLast("offerLast()");
linkedList.push("push()");//Add one more to test lastIndexOf()
System.out.println("Add element complete:"+linkedList);
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//Unique method of getting elements
System.out.println("element():Gets but does not remove the column header"+linkedList.element());
System.out.println("peek():Gets but does not remove the column header"+linkedList.peek());
System.out.println("peekFirst():Gets but does not remove the column header,List empty, return null: "+linkedList.peekFirst());
System.out.println("peekLast():Gets but does not remove the end of the list,List empty, return null: "+linkedList.peekLast());
System.out.println("getFirst():First element of the list"+linkedList.getFirst());
System.out.println("getLast():Last element of the list"+linkedList.getLast());
System.out.println("linkedList.indexOf(push()):Get the first in the list'push()'Subscript of"+linkedList.indexOf("push()"));
System.out.println("lastIndexOf(push()):Get the last in the list'push()'Subscript of"+linkedList.lastIndexOf("push()"));
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//Unique element removal method
System.out.println("pop(),Pop up an element out of the stack=="+linkedList.pop()+"==List after removal:"+linkedList);
System.out.println("poll(),Gets and removes the header of this list=="+linkedList.poll()+"==List after removal:"+linkedList);
System.out.println("pollFirst(),Get and remove the first element of the list. If the list is empty, return null: =="+linkedList.pollFirst()+"==List after removal:"+linkedList);
System.out.println("pollLast(),Get and remove the tail element of the list. If the list is empty, return null: =="+linkedList.pollLast()+"==List after removal:"+linkedList);
System.out.println("removeFirst(),Remove and return the first element of this list=="+linkedList.removeFirst()+"==List after removal:"+linkedList);
System.out.println("removeLast(),Remove and return the last element of this list=="+linkedList.removeLast()+"==List after removal:"+linkedList);
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//ergodic
System.out.println("ergodic======");
for(Iterator iterator =linkedList.iterator();iterator.hasNext();){
System.out.println(iterator.next());
}
}
}
2. Comparison of two iterators
//Not recommended. The iterator is used up and will not be recycled immediately
Iterator iterator = col.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
//Better, the iterator is a local variable, the for loop ends, and the iterator is directly recycled
for(Iterator iterator =linkedList.iterator();iterator.hasNext();){
System.out.println(iterator.next());
}
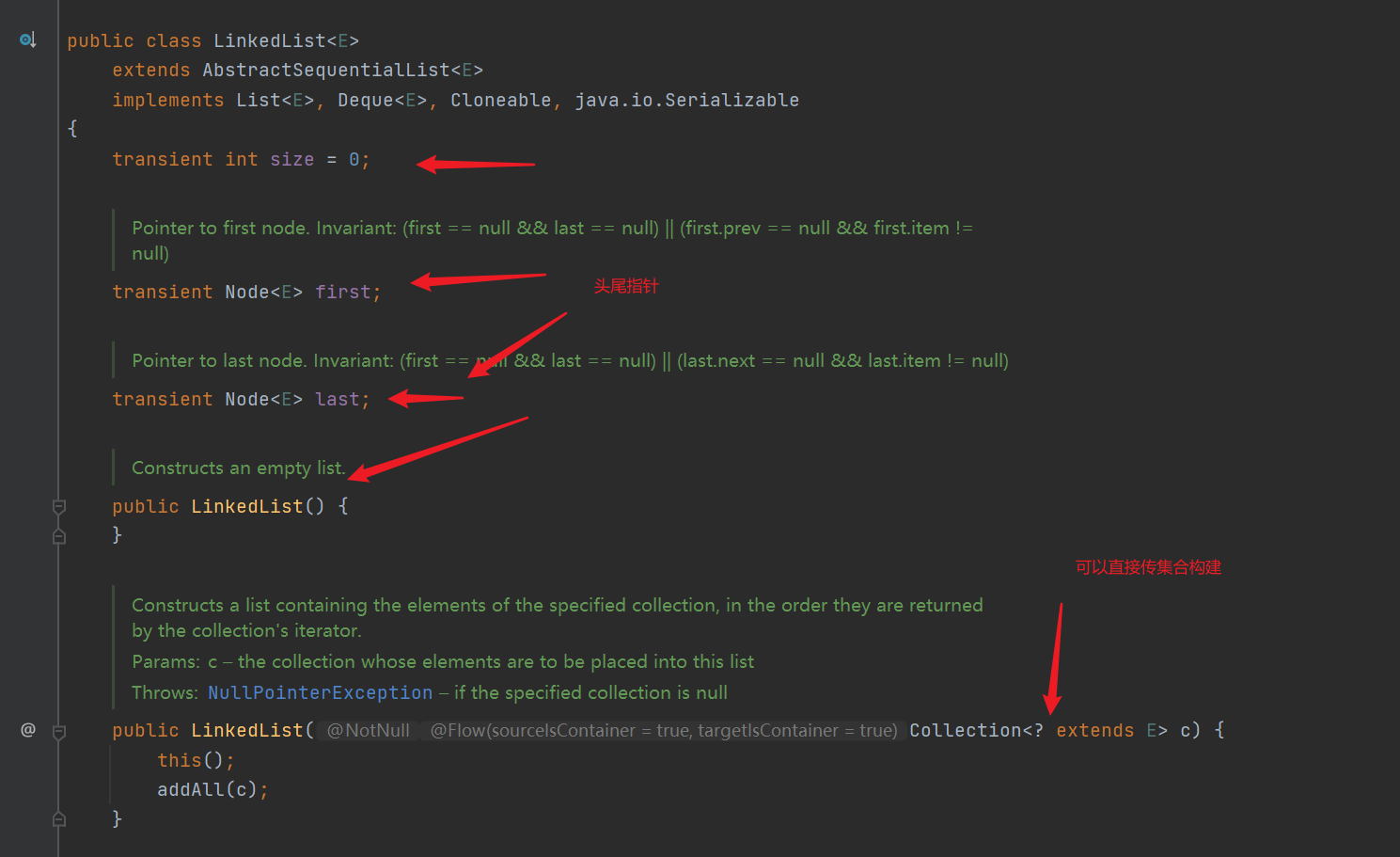
3. LinkedList source code (JDK1.8)
- The LinkedList bottom layer is implemented by a two-way linked list, maintaining the internal class node < E >, which represents a single node in the linked list, and first and last represent the head and tail nodes respectively
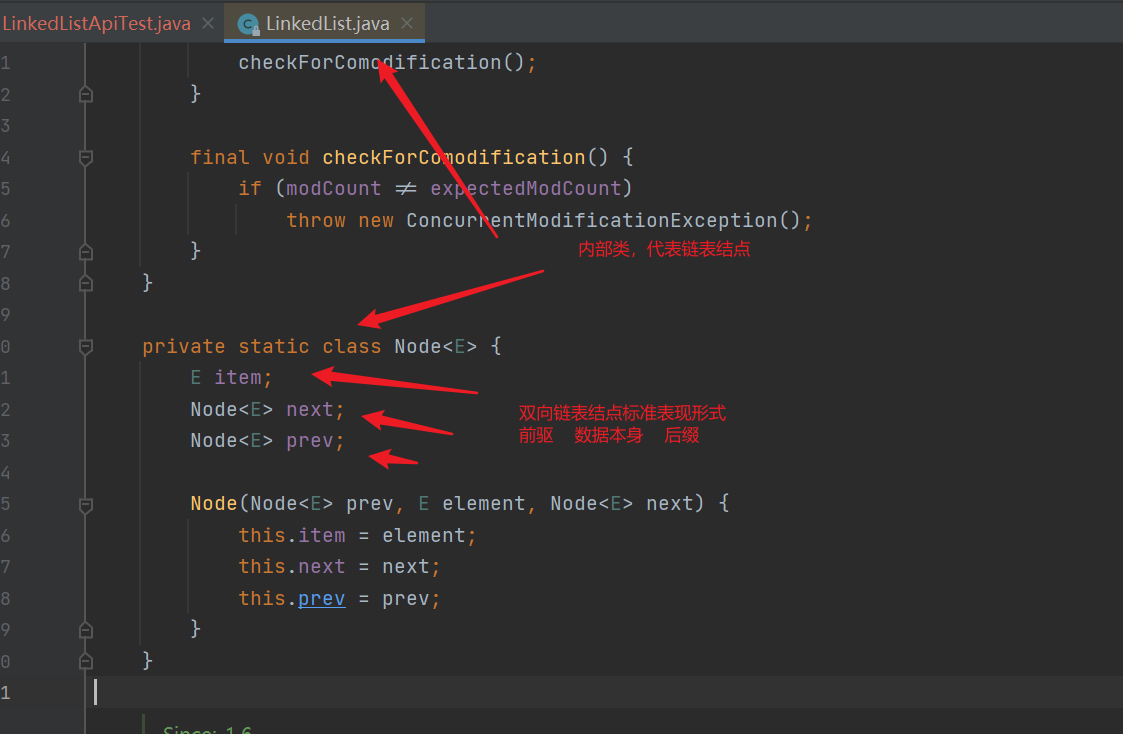
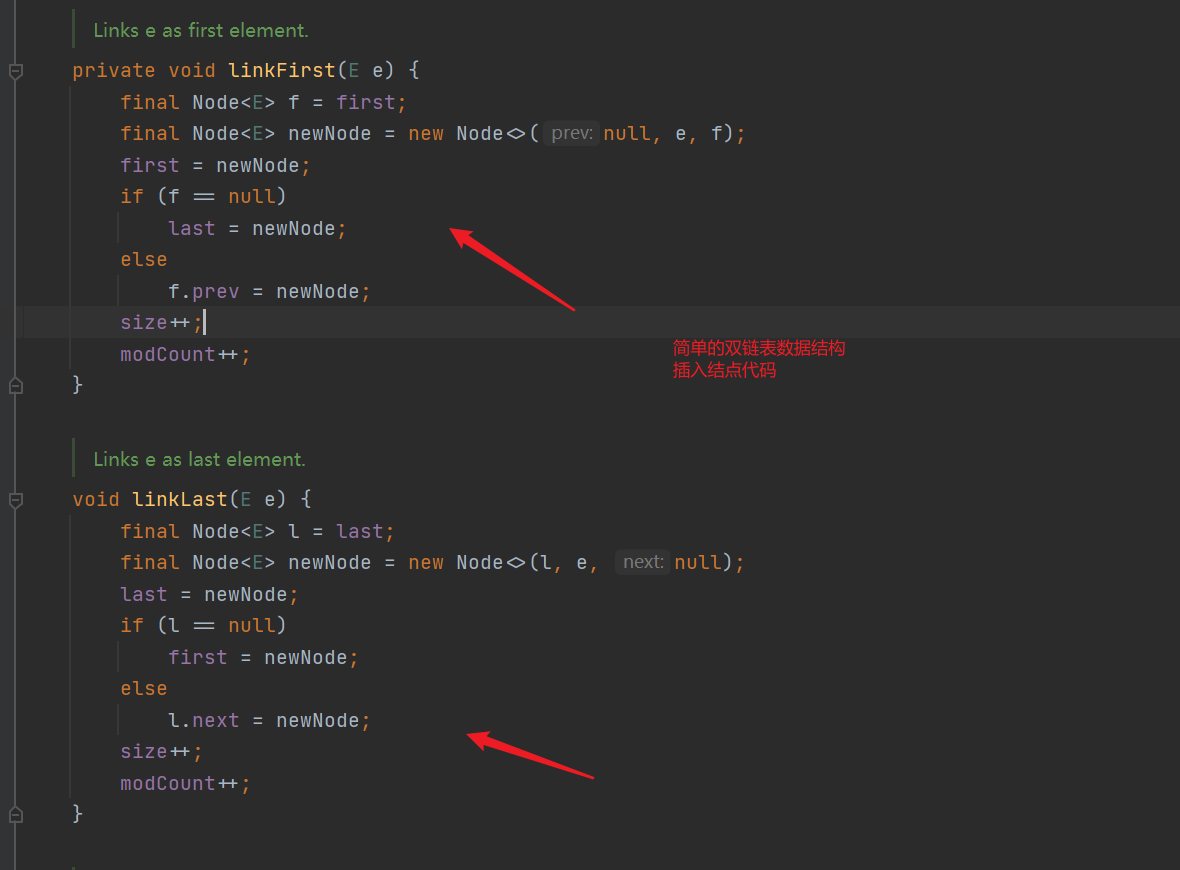
- Add the head and tail nodes, and all the bottom layers call linkFirst and linkLast methods
- linkFirst and linkLast are the node codes inserted into the usual double linked list data structure. First or last is saved first, and then points to the node to be inserted. The newly saved first or last becomes the successor or precursor of the newly inserted node, and then determines whether it is the first time to insert the node. If it is the first time, first and last point to the same node. If not, Let the newly saved first or last become the successor or precursor of the new node (specifically, whether to become the precursor or successor depends on whether to insert to the end or the head)
- The get(index) method first considers the program robustness, checks the index, and then calls the node(index) method to return the specified node.
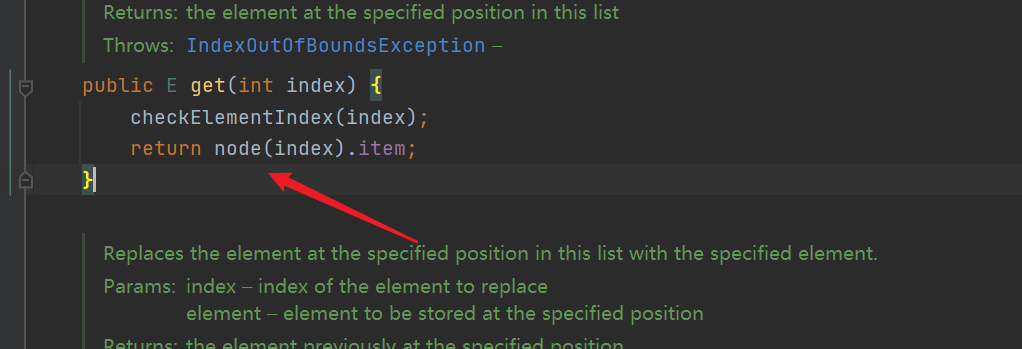
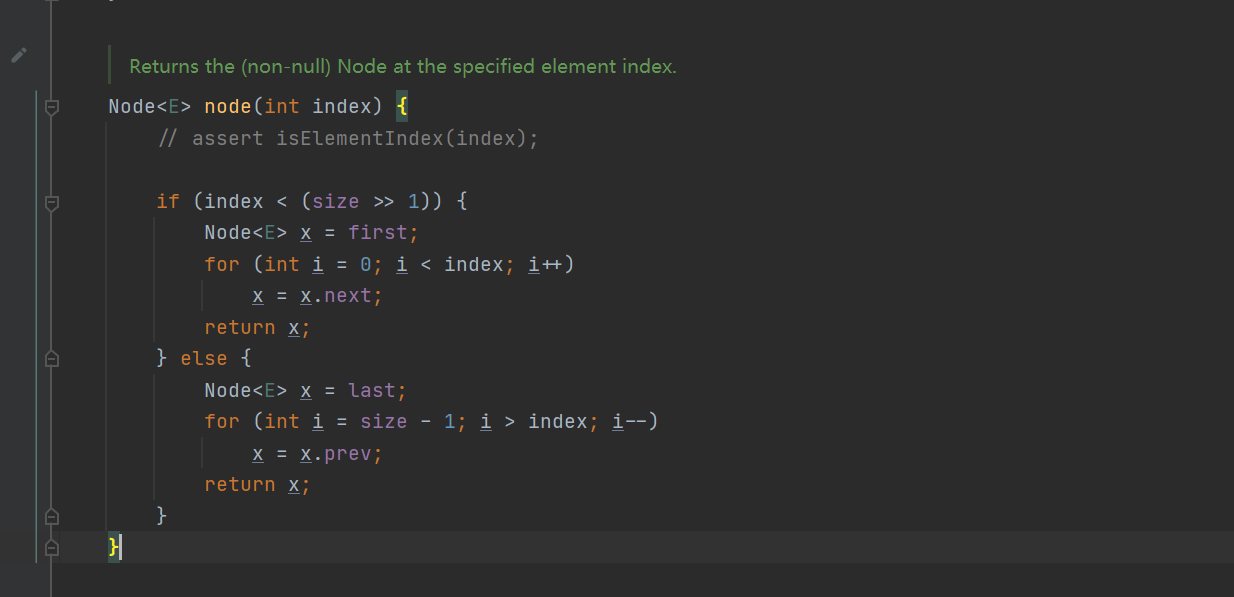
- node(int index) method: size > > 1 means that the size is reduced to twice the original size, and 10 becomes 5. First, judge whether the index you want to retrieve is in the first half or the second half of the list. If it is the first half, traverse the search from first, and the second half from last
4, Set interface
| The Set interface inherits from the Collection interface. He has all the features of the Collection as follows |
|---|
- Except for the special Set (which will be introduced later), other sets are all: unique elements (not repeated), disordered (select the element placement location according to a certain hash algorithm, and the memory address is not next to each other), and the storage element location is fixed but not fixed. When we obtain elements, the order of elements and insertion elements will be inconsistent (determine the element storage location and storage elements according to a certain hash algorithm)
- The bottom layer uses Map implementation (Hash table), the bottom layer of HashSet maintains HashMap, and the bottom layer of TreeSet maintains TreeMap
- TreeHashSet can basically achieve the effect of automatically sorting for you, but this is not important. It mainly calls Comparable and Comparator
| The API of the Set interface is roughly the same as that of the List interface, but the API related to the index is missing. There is no index in the Set, so we will not introduce the unique API |
|---|
| The underlying layer of Set is implemented by Map, so when we study the source code, we only look at how to use the Map. For the specific principle, please see the source code of Map later |
|---|
1. HashSet implementation class and source code (JDK1.8)
| Basic feature test: simple_collection/HashSetApiTest.java |
|---|

import java.util.HashSet;
import java.util.Set;
public class SetApiTest {
public static void main(String[] args) {
Set set = new HashSet();
//De duplication. According to the Set feature, the data is unique
set.add(1);set.add(1);set.add(1);set.add(1);set.add(1);set.add(1);
System.out.println("towards set Six elements 1 are added to the set. According to the unique characteristics of the data, there is only one 1 in the set:"+set);
//radom test
set.add("a");set.add("b");set.add(2);set.add(3);set.add(4);
set.add(5);set.add(6);set.add(7);set.add("asdfsdf");set.add("asdasdffsdf");set.add("asdfasdfasdfsdf");
System.out.println("Set Test the collection out of order to see if it is consistent with the insertion order from 1 to:" +set);
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//The add method returns true if the element is added successfully, false if the element fails to be added, indicating that there is a duplicate element in the collection
System.out.println("Add values that are not in the test set, add element 10:"+set.add(10));
System.out.println("There are already values in the test set. Add element 1:"+set.add(1));
}
}
| Source code analysis: if you don't understand, look down or look at the Map first |
|---|
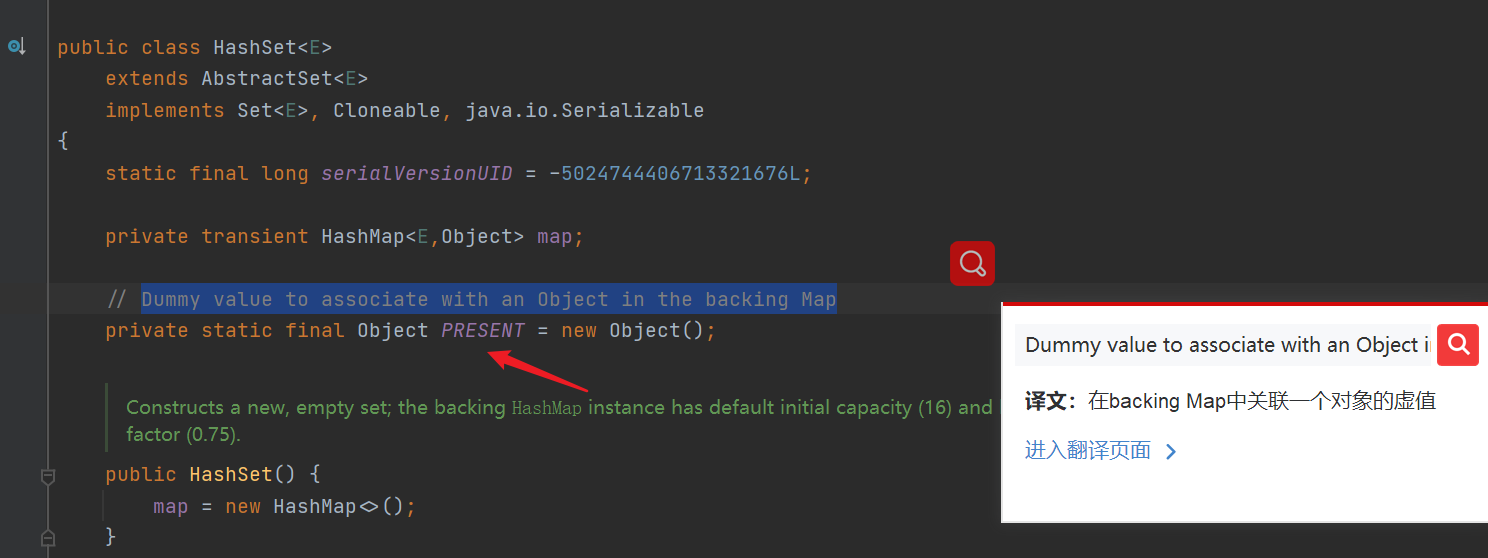
- HashSet, the underlying maintenance HashMap
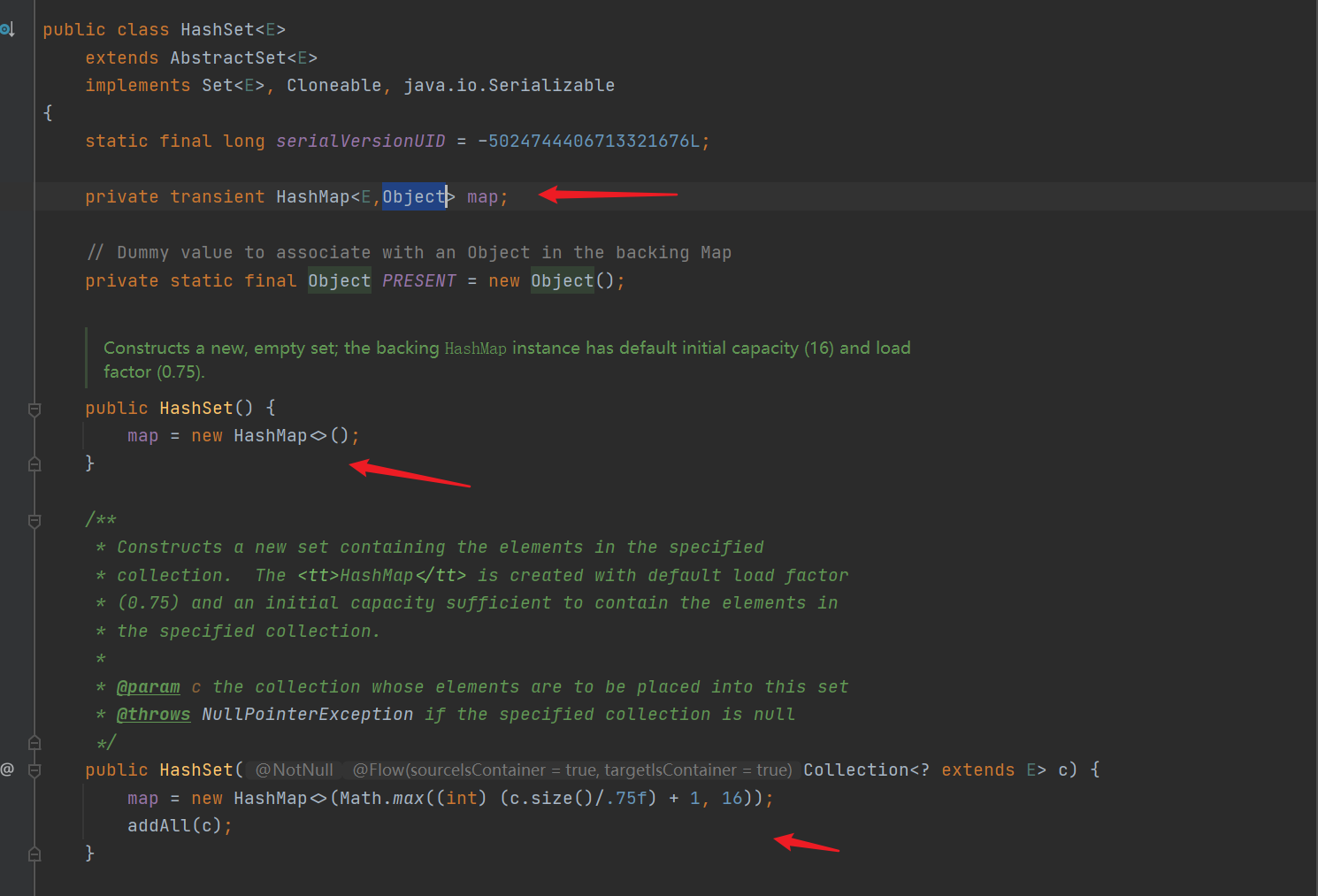
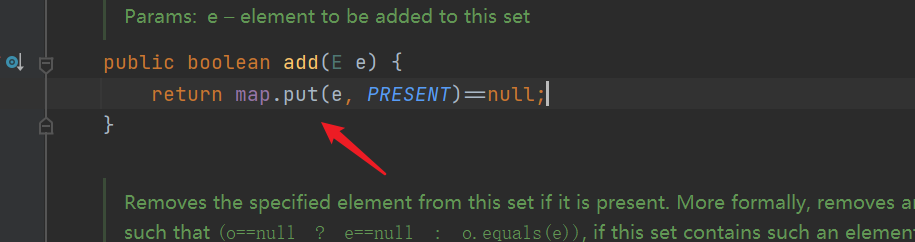
- Add the method add(), and put the element to be added into the map as a key. The value is PRESENT and points to an empty Object object (the value in the map can be repeated, so the same Object can be added all the time)
2. LinkedHashSet implementation class and source code (JDK1.8)
| The difference between LinkedHashSet and HashSet |
|---|
- The underlying implementation adds a linked list, and the data is stored in order and output according to the input order
- Although the underlying Map still determines the location of elements through the hash algorithm, there is an additional linked list in the LinkedHashSet, which records the location of these elements in the hash table in order
- The underlying layer still uses the Map, using the LinkedHashMap
| Test and find out the order: simple_collection/LinkedHashSetTest.java |
|---|

import java.util.LinkedHashSet;
public class LinkedHashSetTest {
public static void main(String[] args) {
LinkedHashSet set = new LinkedHashSet();
//De duplication. According to the Set feature, the data is unique
set.add(1);set.add(1);set.add(1);set.add(1);set.add(1);set.add(1);
System.out.println("towards set Six elements 1 are added to the set. According to the unique characteristics of the data, there is only one 1 in the set:"+set);
//radom test
set.add("a");set.add("b");set.add(2);set.add(3);set.add(4);
set.add(5);set.add(6);set.add(7);set.add("asdfsdf");set.add("asdasdffsdf");set.add("asdfasdfasdfsdf");
System.out.println("Set Test the collection out of order to see if it is consistent with the insertion order from 1 to:" +set);
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//The add method returns true if the element is added successfully, false if the element fails to be added, indicating that there is a duplicate element in the collection
System.out.println("Add values that are not in the test set, add element 10:"+set.add(10));
System.out.println("There are already values in the test set. Add element 1:"+set.add(1));
}
}
| Source code analysis: if you don't understand, read the map first |
|---|
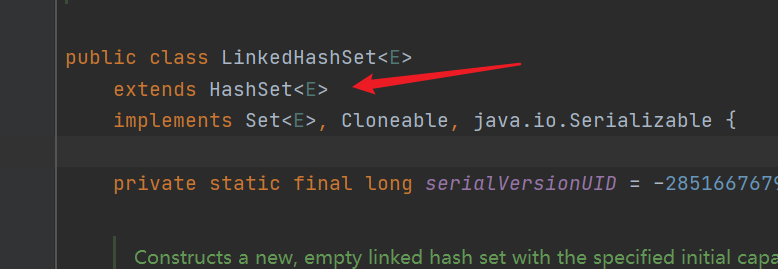
- LinkedHashSet inherits from HashSet, and the construction method of HashSet is called when creating an object
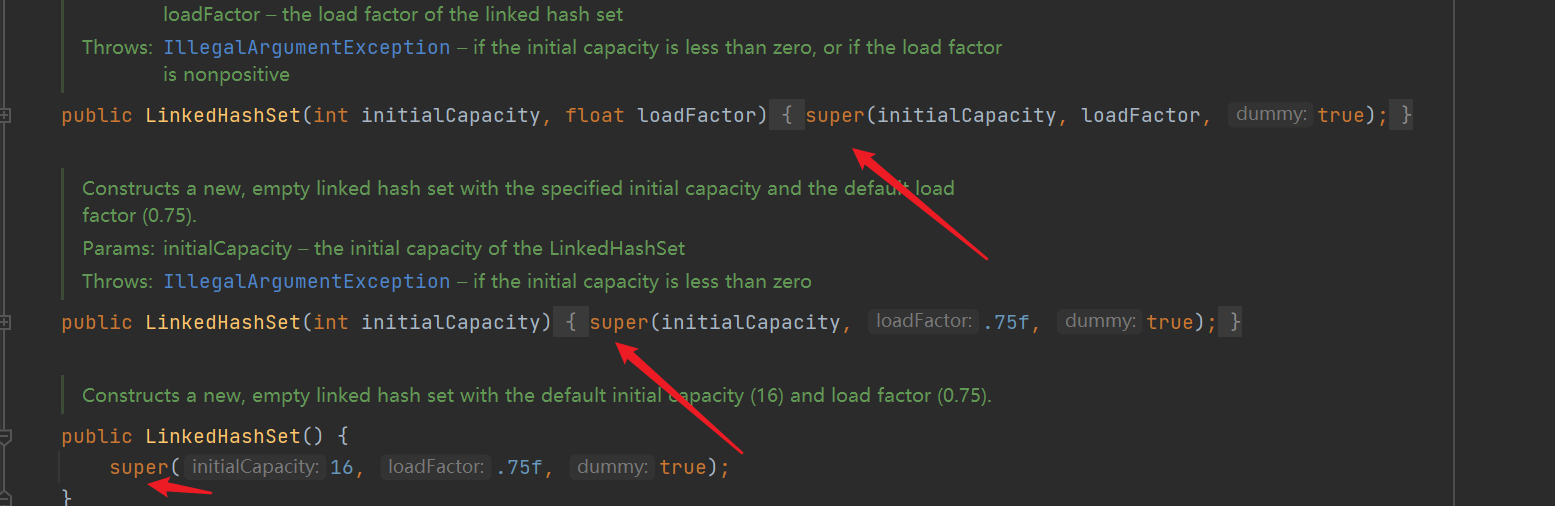
- For the construction method of linked list in HashSet, it is found that LinkedHashMap is created
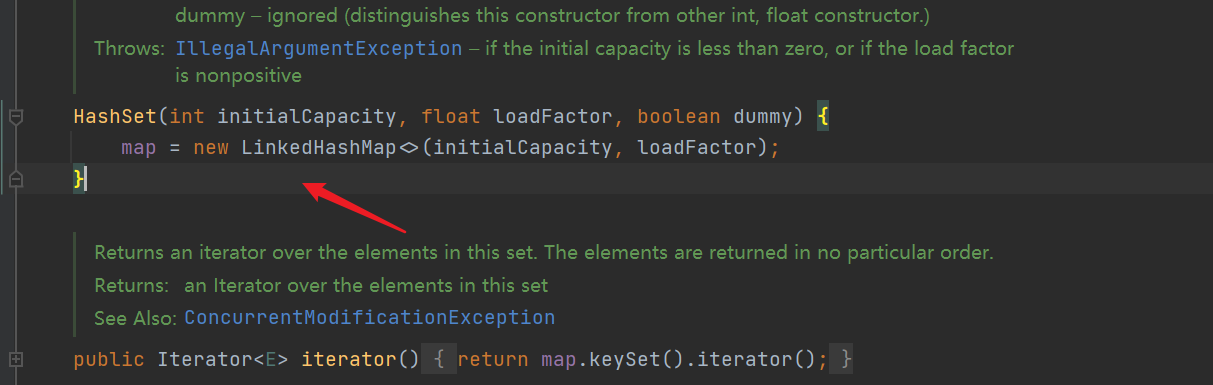
- That is, the methods called are all called in LinkedHashMap, as we will say later
3. TreeSet implementation class and source code (JDK1.8)
| It is basically the same as HashSet, except that the bottom layer is implemented by binary tree (the traversal method is medium order traversal). The same is not sorted according to the insertion order, and the same is not allowed to be repeated, but will be sorted: simple_collection/TreeSetTest.java |
|---|
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet();//Use default comparator
//De duplication. According to the Set feature, the data is unique
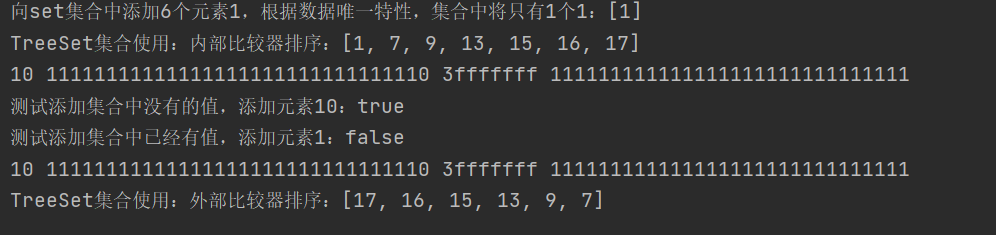
set.add(1);set.add(1);set.add(1);set.add(1);set.add(1);set.add(1);
System.out.println("towards set Six elements 1 are added to the set. According to the unique characteristics of the data, there is only one 1 in the set:"+set);
//radom test
set.add(9);set.add(13);set.add(7);set.add(16);set.add(17);set.add(15);
System.out.println("TreeSet Collection sorting using internal comparator:" +set);
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
//The add method returns true if the element is added successfully, false if the element fails to be added, indicating that there is a duplicate element in the collection
System.out.println("Add values that are not in the test set, add element 10:"+set.add(10));
System.out.println("There are already values in the test set. Add element 1:"+set.add(1));
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
TreeSet<Integer> integers = new TreeSet<>(new Comparator<Integer>() {//Using an external comparator
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
integers.add(9);integers.add(13);integers.add(7);integers.add(16);integers.add(17);integers.add(15);
System.out.println("TreeSet Collection sorting using external comparator:" +integers);
}
}
| Source code: mainly understand why you can sort |
|---|
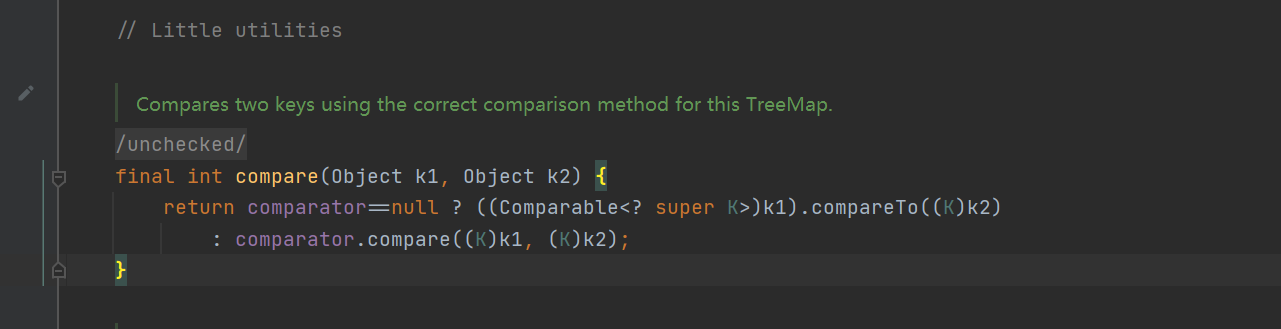
- TreeMap is maintained at the bottom of TreeSet, and the comparator can be customized
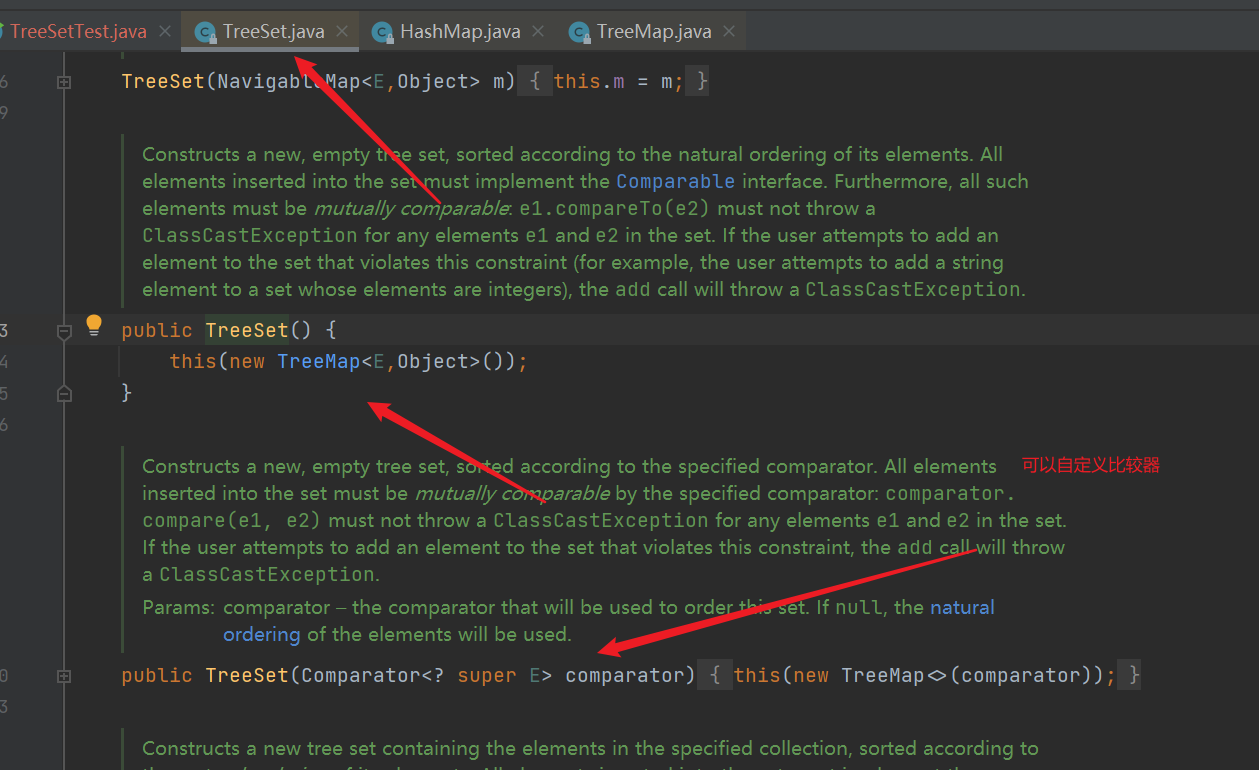
- add() method to see why it can be sorted automatically: call the put method of TreeMap
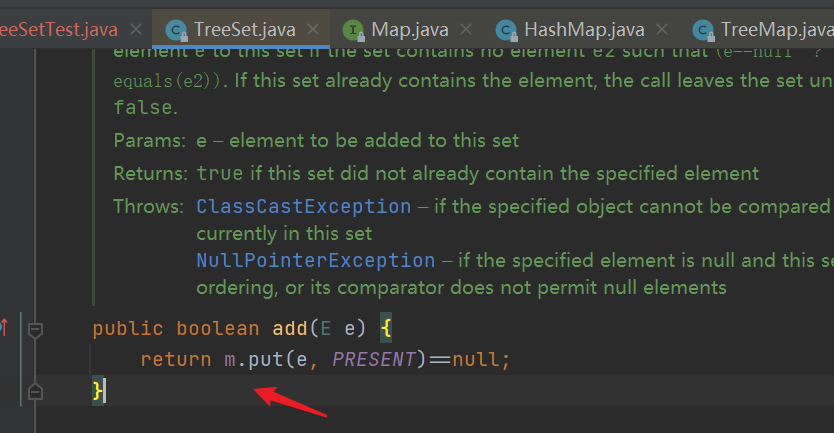
- put() method of TreeMap: it can be seen that the compare() method is called for comparison
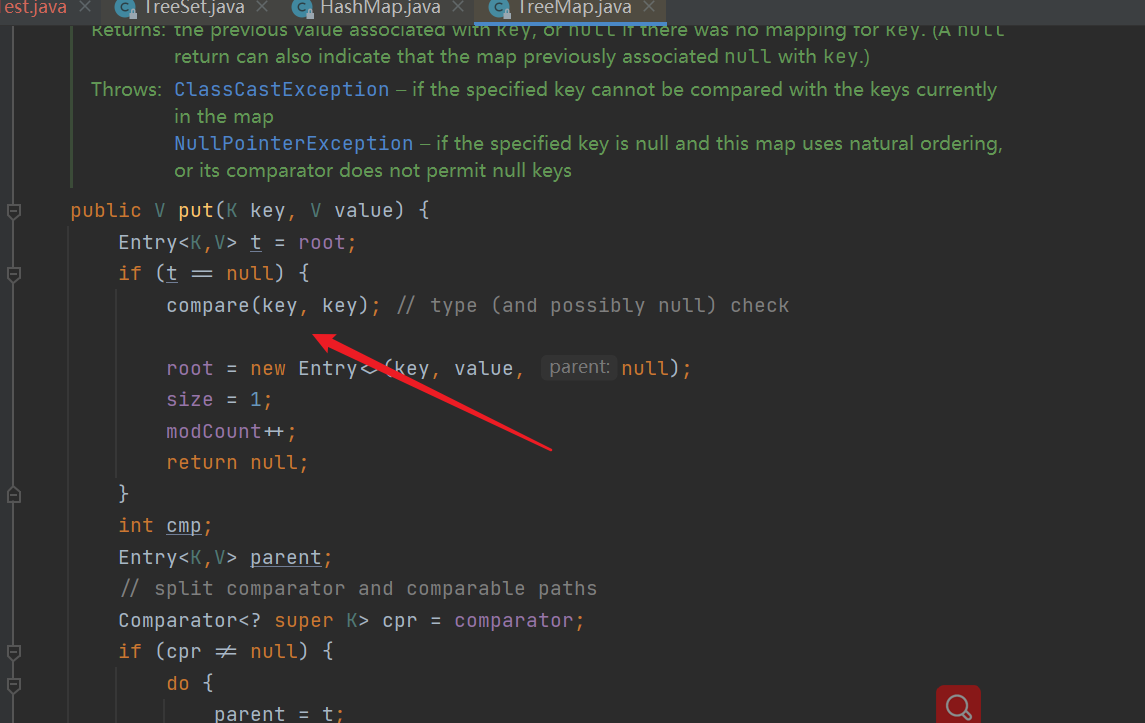
- compare method: if the comparator is passed in, use the one we passed in. If not, use the default internal comparator
5, Map interface
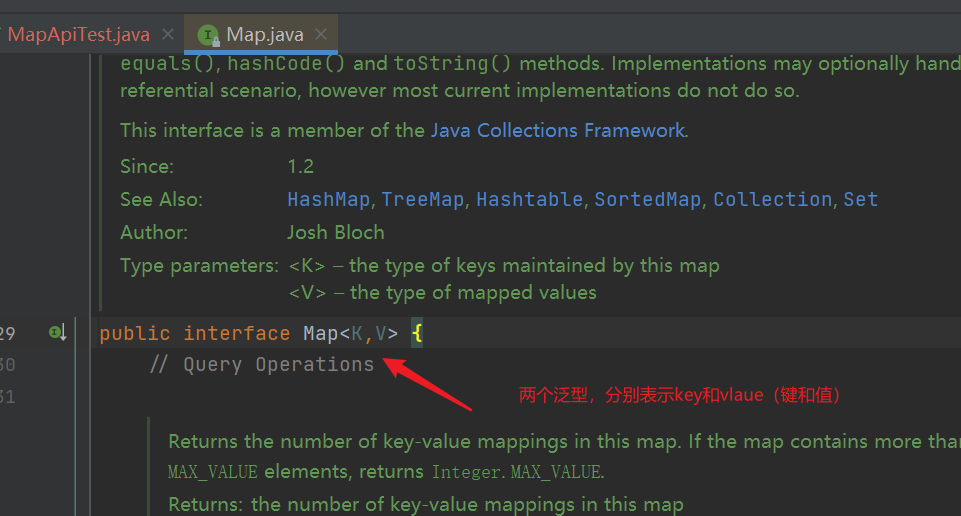
| Map is a top-level interface, which mainly specifies that data is stored in the form of key value pairs. It is mostly implemented in two data structures: Hash table and binary tree. The interface cannot use new objects. We use HashMap to introduce the Api of map |
|---|
- K:key: the unique identifier of data mapping is not repeatable, equivalent to the ID number of a person.
- Value (V:Value): specific data, which can be repeated, is equivalent to a person's name. There are many people with the same name in the world, such as "Zhang Wei"
1. Common Api analysis
| describe | API |
|---|
| Remove all implicit relationships from this mapping | clear() |
| Returns true if the mapping contains a mapping relationship for the specified key | boolean containsKey(Object key) |
| Returns true if this mapping maps one or more keys to the specified value | boolean containsValue(Object value) |
| Returns the Set view of the mapping relationships contained in this mapping | Set<Map.Entry<K,V>> entrySet() |
| Compares whether the specified object is equal to this mapping | boolean equals(Object o) |
| Returns the value mapped by the specified key; Returns null if the mapping does not contain a mapping relationship for the key | V get(Object key) |
| Returns the hash code value for this map | int hashCode() |
| Returns true if the mapping does not contain a key value mapping relationship | boolean isEmpty() |
| Returns the Set view of the keys contained in this map | Set< K > keySet() |
| Optionally, associate the specified value with the specified key in this mapping | V put(K key,V value) |
| Copy all mapping relationships from the specified mapping to this mapping (optional) | void putAll(Map<? extends K,? extends V> m) |
| If there is a mapping relationship for a key, remove it from this mapping (optional) | V remove(Object key) |
| Returns the number of key value mapping relationships in this mapping | int size() |
| Returns a Collection view of the values contained in this map | Collection< V > values() |
| Test API: simple_collection/MapApiTest.java |
|---|
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapApiTest {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
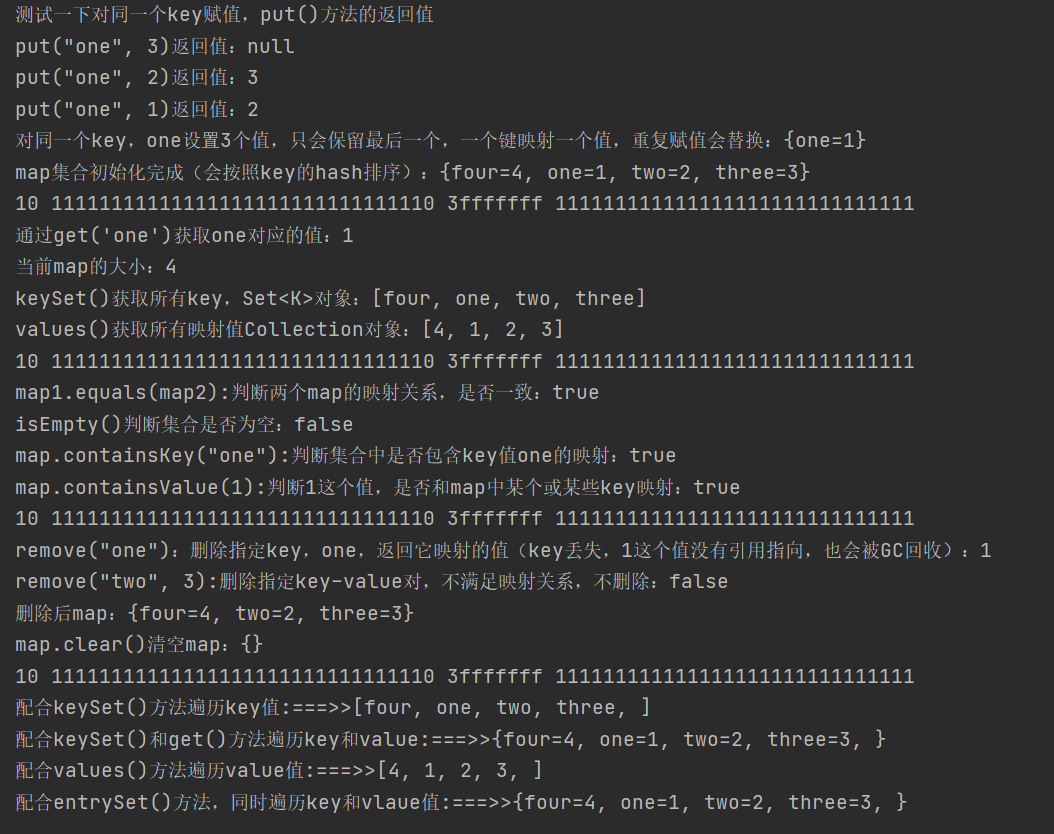
System.out.println("Test the same key Assignment, put()Method");
System.out.println("put(\"one\", 3)Return value:"+map.put("one", 3));
System.out.println("put(\"one\", 2)Return value:"+map.put("one", 2));
System.out.println("put(\"one\", 1)Return value:"+map.put("one", 1));
System.out.println("For the same key,one If you set three values, only the last one will be retained. One key maps to one value. Repeated assignment will replace:"+map);
map.put("two",2);
map.put("three",3);
map.put("four",4);
System.out.println("map Collection initialization is complete (as shown in key of hash Sort:"+map);
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
System.out.println("adopt get('one')obtain one Corresponding value:"+map.get("one"));
System.out.println("current map Size of:"+map.size());
System.out.println("keySet()Get all key,Set<K>Object:"+map.keySet());
System.out.println("values()Get all mapped values Collection Object:"+map.values());
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
System.out.println("map1.equals(map2):Judge two map Is the mapping relationship consistent"+map.equals(map));
System.out.println("isEmpty()Judge whether the collection is empty:"+map.isEmpty());
System.out.println("map.containsKey(\"one\"):Determine whether the set contains key value one Mapping of:"+map.containsKey("one"));
System.out.println("map.containsValue(1):Judge whether the value of 1 and map One or more of key Mapping:"+map.containsValue(1));
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
System.out.println("remove(\"one\"): Delete assignment key,one,Returns the value it maps( key Missing. The value of 1 is not referenced and will also be deleted GC Recycling):"+map.remove("one"));
System.out.println("remove(\"two\", 3):Delete assignment key-value Yes, if the mapping relationship is not satisfied, do not delete:"+map.remove("two", 3));
System.out.println("After deletion map: "+map);
map.clear();
System.out.println("map.clear()empty map: "+map);
System.out.println(Integer.toBinaryString(2)+" "+Integer.toBinaryString(-2)+" "+Integer.toHexString(-2>>>2)+" "+Integer.toBinaryString(-2>>>2));
map.put("one", 1);map.put("two",2);map.put("three",3);map.put("four",4);
System.out.print("coordination keySet()Method traversal key value:===>>[");
Set<String> keySet = map.keySet();
for(String s:keySet){
System.out.print(s+", ");
}
System.out.println("]");
System.out.print("coordination keySet()and get()Method traversal key and value:===>>{");
for(String s:keySet){
System.out.print(s+"="+map.get(s)+", ");
}
System.out.println("}");
System.out.print("coordination values()Method traversal value value:===>>[");
Collection<Integer> values = map.values();
for(Integer i : values){
System.out.print(i+", ");
}
System.out.println("]");
System.out.print("coordination entrySet()Method while traversing key and vlaue value:===>>{");
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.print(entry.getKey()+"="+entry.getValue()+", ");
}
System.out.println("}");
}
}
2. HashMap source code (JDK1.8)
| The bottom layer of HashMap is realized by hash table data structure (array + linked list + red black tree JDK1.8) |
|---|
- According to the data structure of direct access to key value pairs, value is mapped through key, so that we can quickly get the corresponding value through key. This mapping function is called a hash function, and the array of records is called a hash table
- Array is a hash table representing key, and each array element is a linked list representing value, so a key can only have one, but a key can map multiple values (because value exists in the linked list)
- The size of the hash table must be a power of 2. In order to make the hash result more uniform, if it is not to the power of 2, it is likely to get some extreme values, such as 0 or 1, which makes there are many elements at the position of 0 or 1, and the linked list is very long (the red black tree is very large). The power of 2 can make the root distribution of the element hash even

| How to calculate hash must be understood, otherwise the source code behind cannot be understood |
|---|
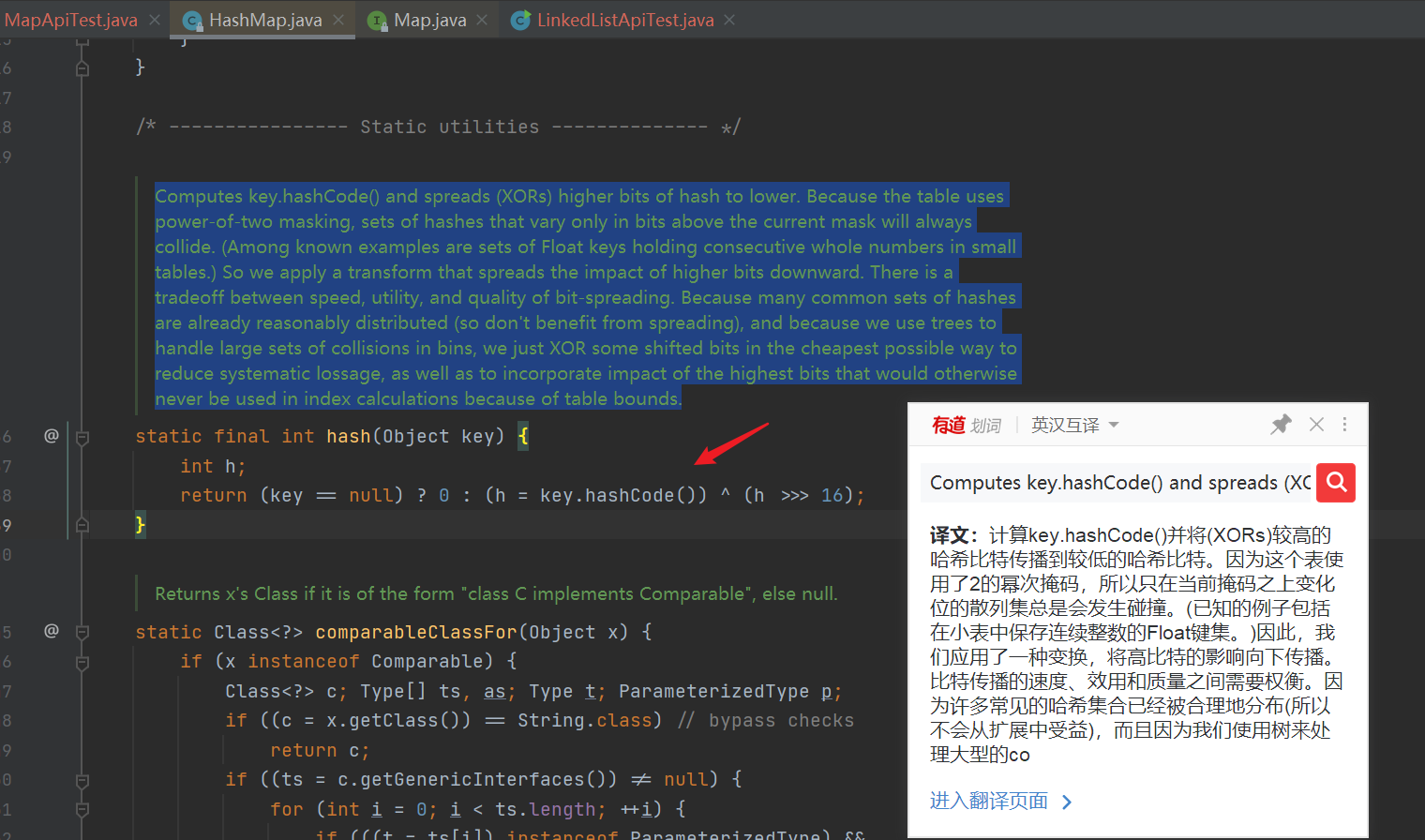
- The hashCode() method provided by java provides the hash value. The hash values in java are of type int, represented by 4 bytes and 32 bits in total
- However, in order to reduce collisions and reduce the probability of hash conflicts. Moving the 16 bit XOR right can preserve the feature that the high 16 bits are located in the low 16 bits at the same time The features of the high 16 bits and the low 16 bits are mixed, and the information of the high and low bits in the new value is retained
- XOR operation can better preserve the characteristics of each part Some features represented by the upper 16 bits of the & operation may be lost. If the value calculated by the & operation is close to 1, and the value calculated by the | operation is close to 0
- The high-order and low-order values of hashcode can be mixed for XOR operation, and after mixing, the high-order information is added to the low-order information, so that the high-order information is retained in disguise
- It means that the high 16 bits of hash are also involved in the calculation of subscript. If there are more doped elements, the randomness of the generated hash value will increase and the hash collision will be reduced.

| Hash is different, but how to do if the subscripts are the same (hash collision), you must understand it, otherwise you can't understand the later source code |
|---|
- If the key is the same, replace the value directly
- If the key is different, it is added to the linked list (7 up and 8 down, JDK1.7 is added before the linked list, and JDK1.8 is added after the linked list)
Code test
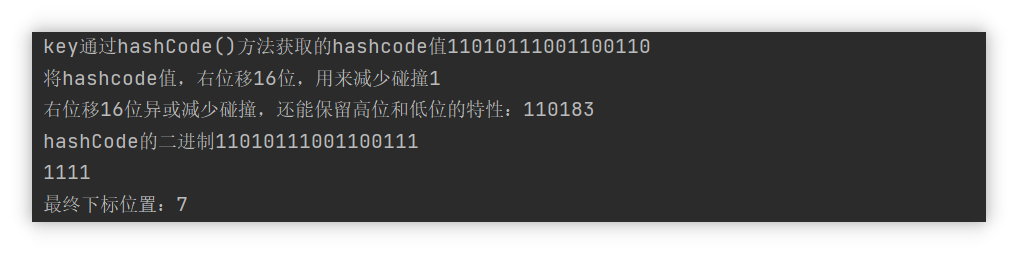
//Get the hashCode value h of the key, then save the binary i with unsigned right shift of 16 bits of H, and get the hashCode we need by h ^ i
//1101011100110 ^ XOR indicates that the value is the same, take 0, and the value difference is 1
//00000000000000001
//11010111001100111
int h;
String key = "one";
h = key.hashCode();//Get hashCode value
System.out.println("key adopt hashCode()Method hashcode value"+Integer.toBinaryString(h));
int i = h >>> 16;//Right displacement 16 bits,
System.out.println("take hashcode Value, right displacement 16 bits, used to reduce collision"+Integer.toBinaryString(i));
int hashCode = (h) ^ (i);//XOR
System.out.println("The right displacement 16 bit XOR can reduce the collision and retain the characteristics of high and low positions:"+hashCode);
System.out.println("hashCode Binary"+Integer.toBinaryString(hashCode));
//Calculate the subscript, N - 1, n is the length of the hash table, and let the high bit participate in the operation,
int n = 16;
int i1 = 16 - 1;
System.out.println(Integer.toBinaryString(i1));
System.out.println("Final subscript position:"+(i1&hashCode));
| Analysis source code 1: calculate hash |
|---|
- How to calculate hash,hash(),hashCode code, shift 16 bits of XOR to the right, and the high bits participate in the operation to reduce collision
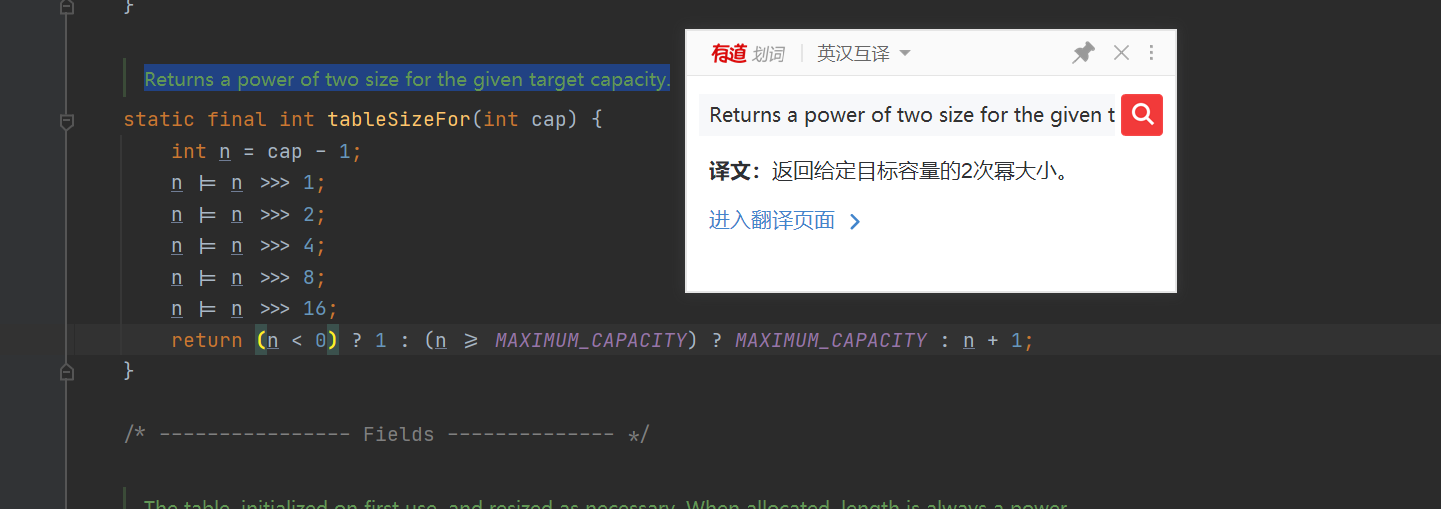
| Source code analysis 2: how to ensure the power of size 2 when the user specifies the size (the user may specify an even number or a negative number, so it doesn't need to be so troublesome if it can't be specified. It's OK to < < 1 every time). tableSizeFor means to generate a minimum integer greater than or equal to cap and to the nth power of 2 |
|---|
In the following source code, return the value of the given target capacity, which is greater than it and closest to its second power. If this value is greater than the set maximum capacity_ Capacity (1 < < 30), the maximum capacity is returned
- Let's test the value of the above code (assuming that the cap is 8, let's look at the final result of cap-1 and not minus 1). We find that although we want the space to be 8, we can get 16 without subtracting one, which is a lot of space waste (the cardinality has no great impact, so we don't explain it, mainly if there is a problem with the even number)
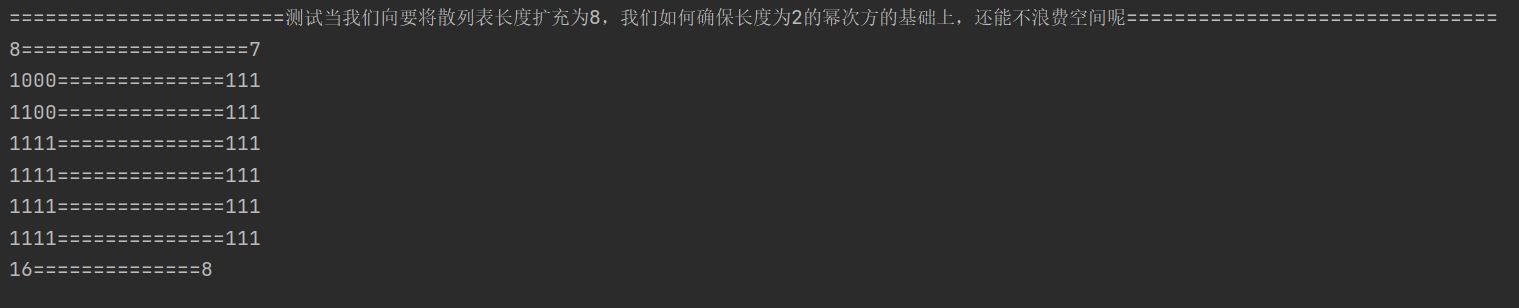
System.out.println("=======================When we want to expand the length of the hash table to 8, how can we ensure that we don't waste space based on the power of length 2===============================");
int n = 8;//
int n2 = n-1;//-1. It can solve the waste of space
System.out.println(n+"==================="+n2);
System.out.println(Integer.toBinaryString(n)+"=============="+Integer.toBinaryString(n2));
// n = n - 1;//7
System.out.println(Integer.toBinaryString(n |= n >>> 1)+"=============="+Integer.toBinaryString(n2|= n2 >>> 1));
System.out.println(Integer.toBinaryString(n |= n >>> 2)+"=============="+Integer.toBinaryString(n2|= n2 >>> 2));
System.out.println(Integer.toBinaryString(n |= n >>> 4)+"=============="+Integer.toBinaryString(n2|= n2 >>> 4));
System.out.println(Integer.toBinaryString(n |= n >>> 8)+"=============="+Integer.toBinaryString(n2|= n2 >>> 8));
System.out.println(Integer.toBinaryString(n |= n >>> 16)+"=============="+Integer.toBinaryString(n2|= n2 >>> 16));
System.out.println((n + 1)+"=============="+(n2+1));
- Why? First, we subtract 1 from n, then move the unsigned right, and then move the result bit or "|" n to the right. The function is to fill the top 1 with 1 (as can be seen from the above figure)
- Why is it only shifted to 16 and even every time? Firstly, n is int type, with a maximum of 4 bytes and 32 bits, and 1 + 2 + 4 + 8 + 16 = 31, which just meets the requirements. We use the maximum value specified in HashMap to test

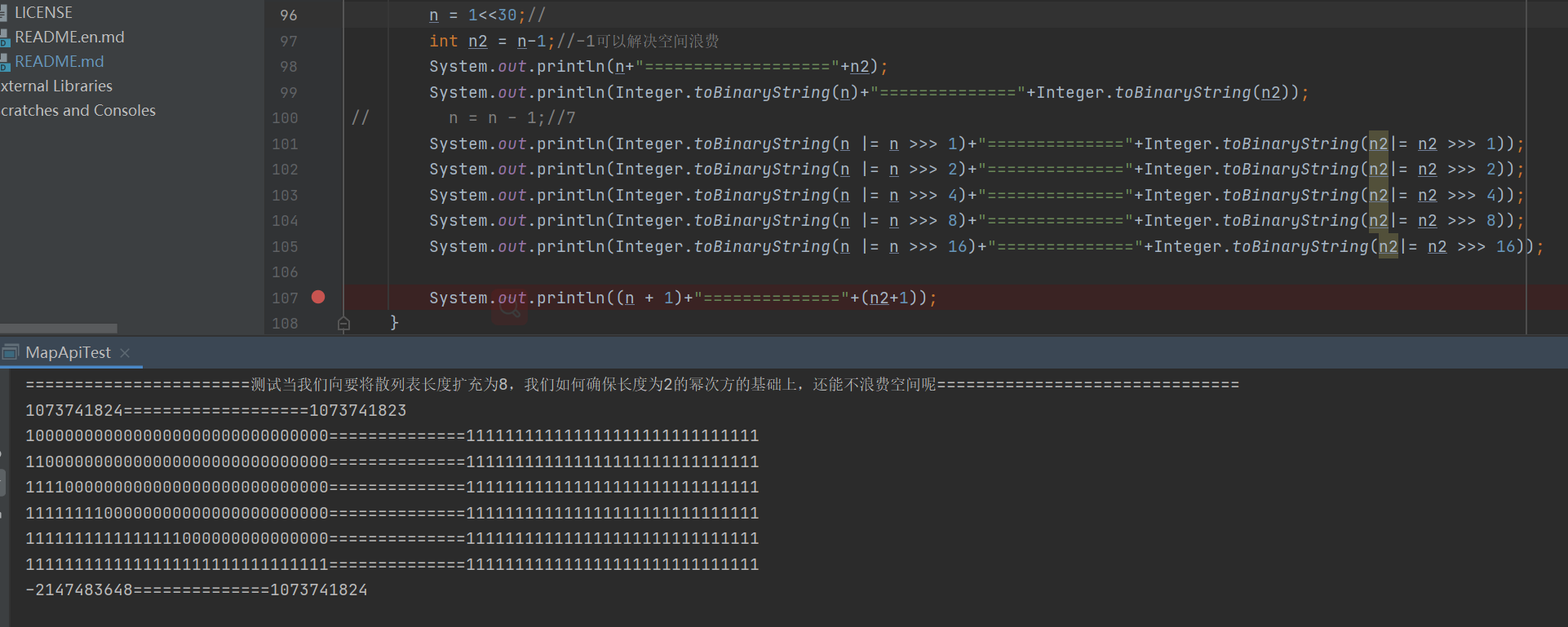
- We found that if we didn't subtract 1, we would get a negative number. 1000-1, exactly 111, plus 1, it becomes 1000 again
- Why fill 1? Suppose the number 8 is 1000, and after - 1 is 111 Always shift, fill in 1 after its highest position (because it is all 1, so it has no effect), and finally + 11000, which is exactly carried to the power of the smallest 2
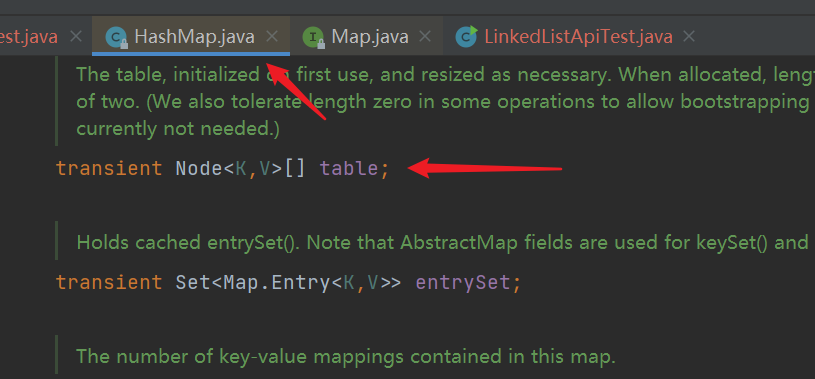
| Analysis source code 3: important attributes |
|---|
-
Constant, array default size 16, maximum 1 < < 30 (2 ^ 30), default loading factor 0.75f,

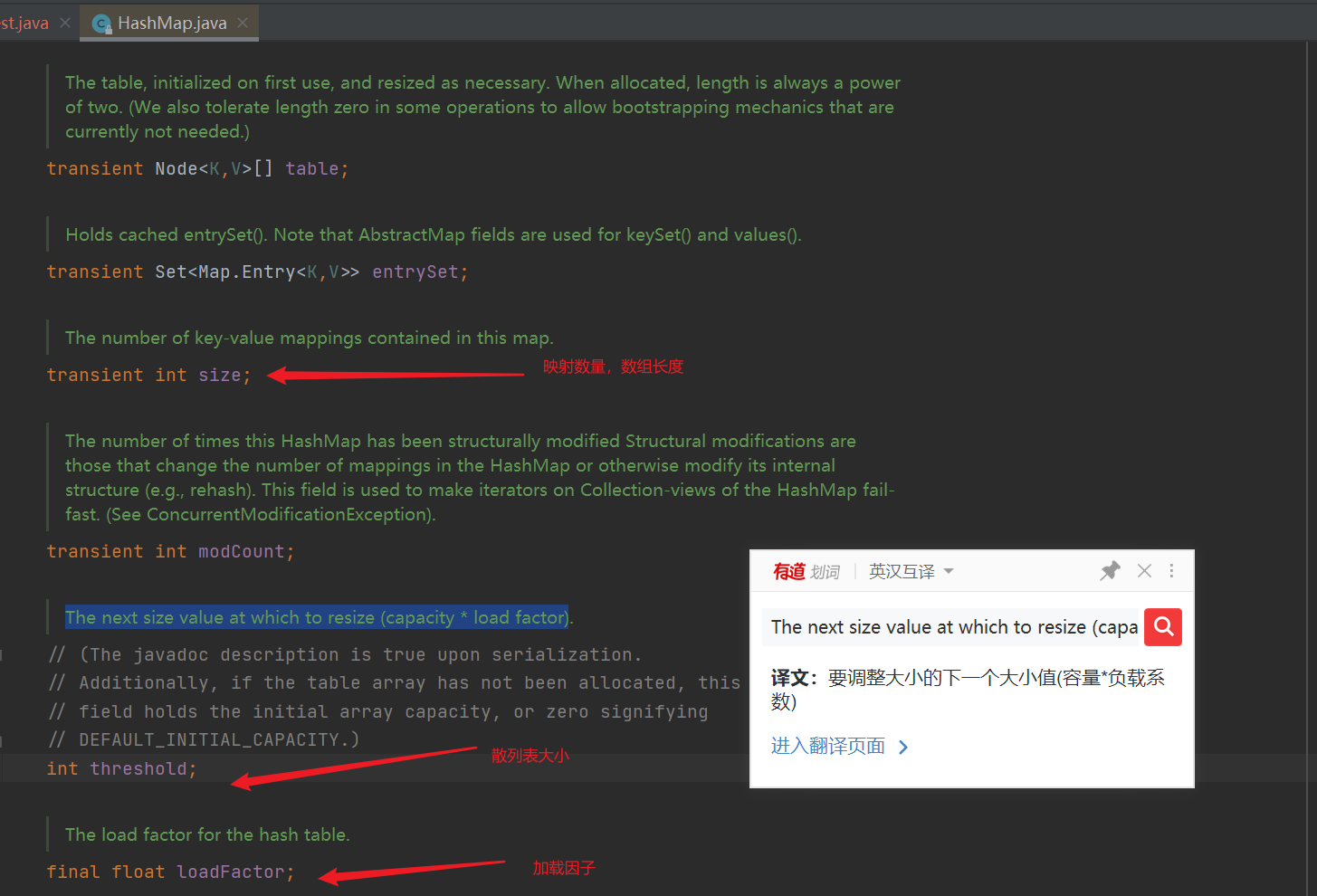
-
Array and size, as well as the variable threshold specially used to process the load factor, and threshold, which represents the next size value to be resized (capacity * load factor)
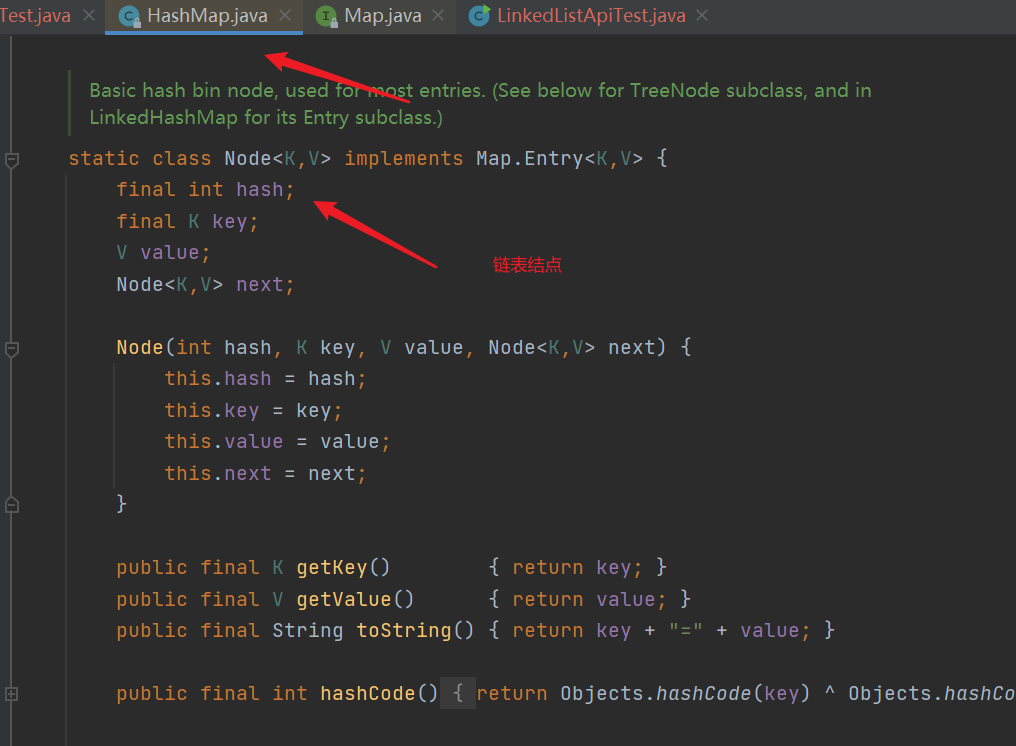
-
Linked list node
-
Red black tree node
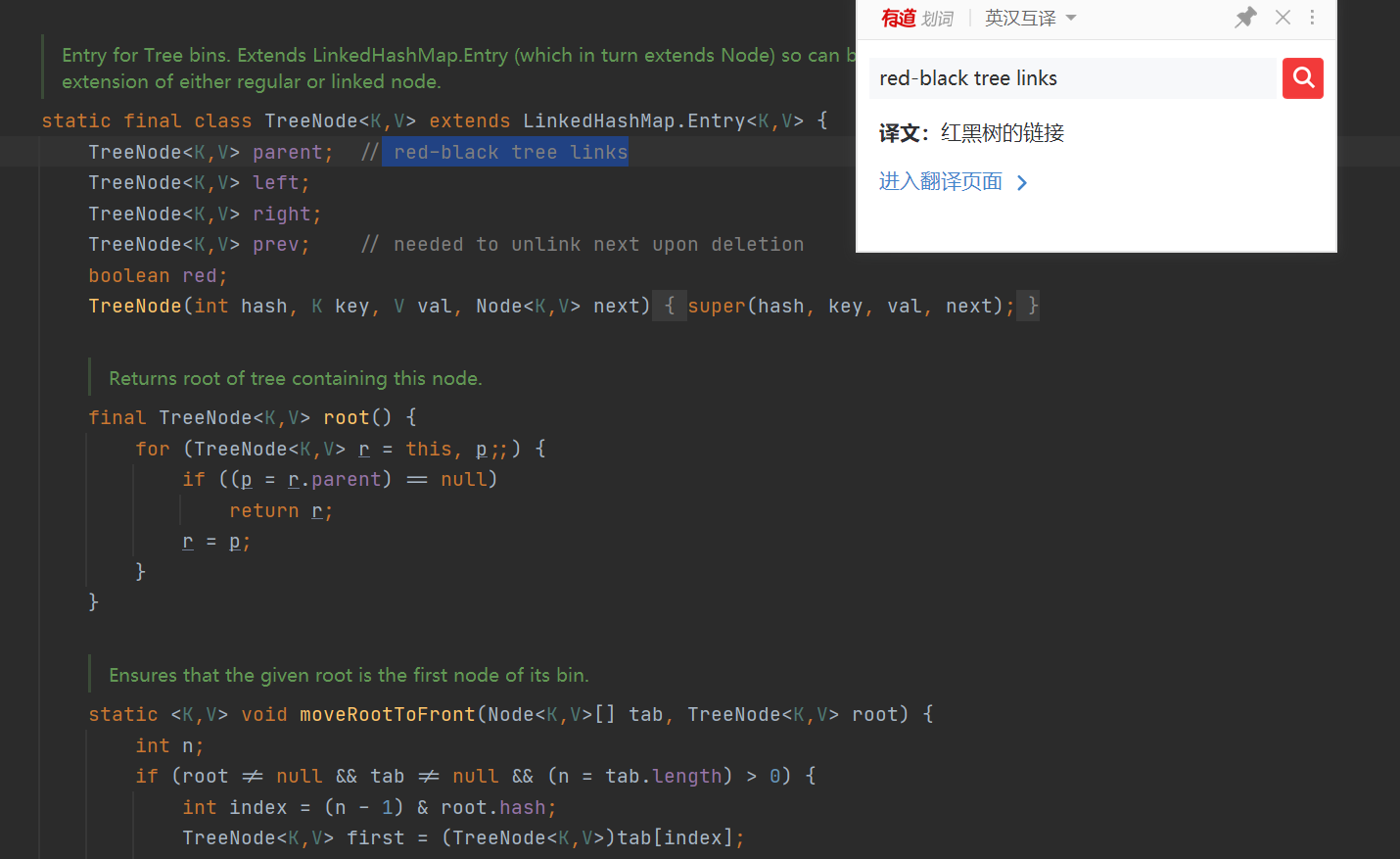
-
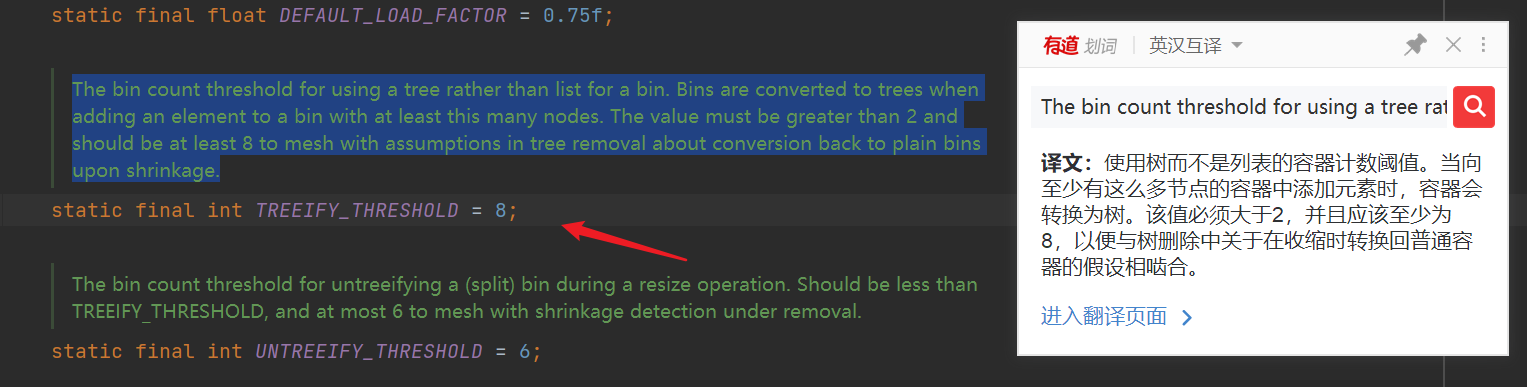
Important attribute jdk1 8. If the length of the linked list exceeds this value, you need to convert the linked list into a red black tree
| Source code analysis 4: create hash table |
|---|
- The default constructor directly sets the loading factor to 0.75, and the initial capacity must be 16, but the logic is not here

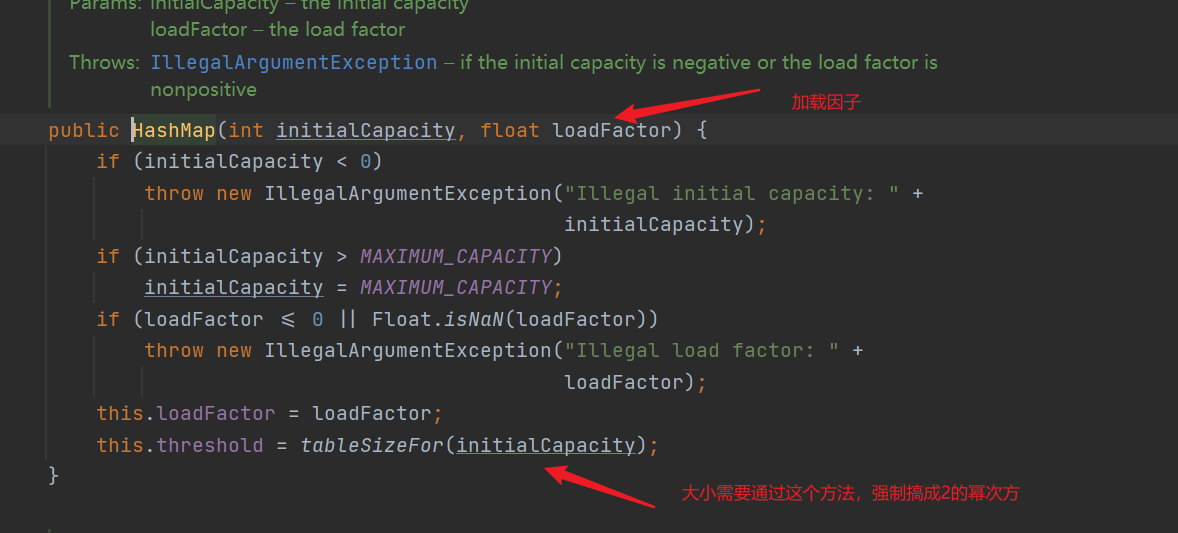
- The constructor specifying the initial size needs to ensure that the size is to the power of 2, and the loading factor is still the default 0.75f
| Source code analysis 5: add |
|---|
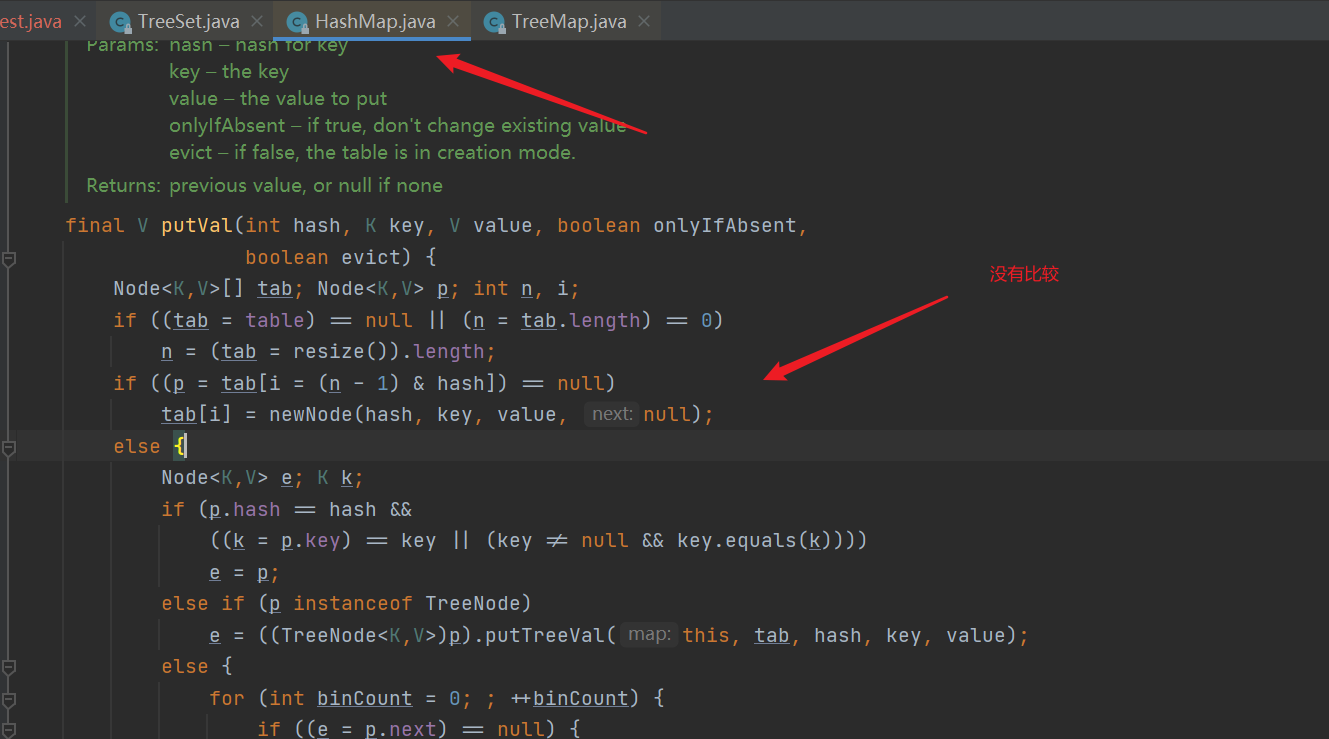
- put() adds an element, calls the putVal method, and calls the hash(key) method to calculate the hash value
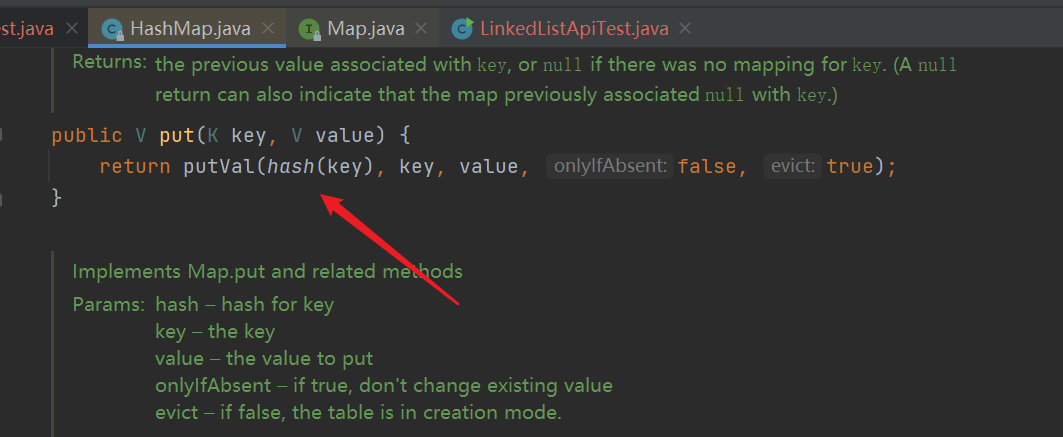
- putVal() method, if the hash table is empty, initialize the hash table, and then directly insert the node into the location subscript calculated by the hash algorithm. If the hash table is not empty, judge whether the hash determines whether the location is correct. If it is correct, judge whether the keys are consistent, and the consistency is the replacement value. Otherwise, judging whether the node is a red black tree node means that it is still a linked list node, but it is not the head node of the linked list of the current subscript array, so it needs to be inserted behind the linked list. If the length of the linked list is greater than 8, it needs to be transformed into a red black tree. No more than 8. You also need to judge whether the key of each node in the linked list is the same. The same is to replace, rather than insert a new node.
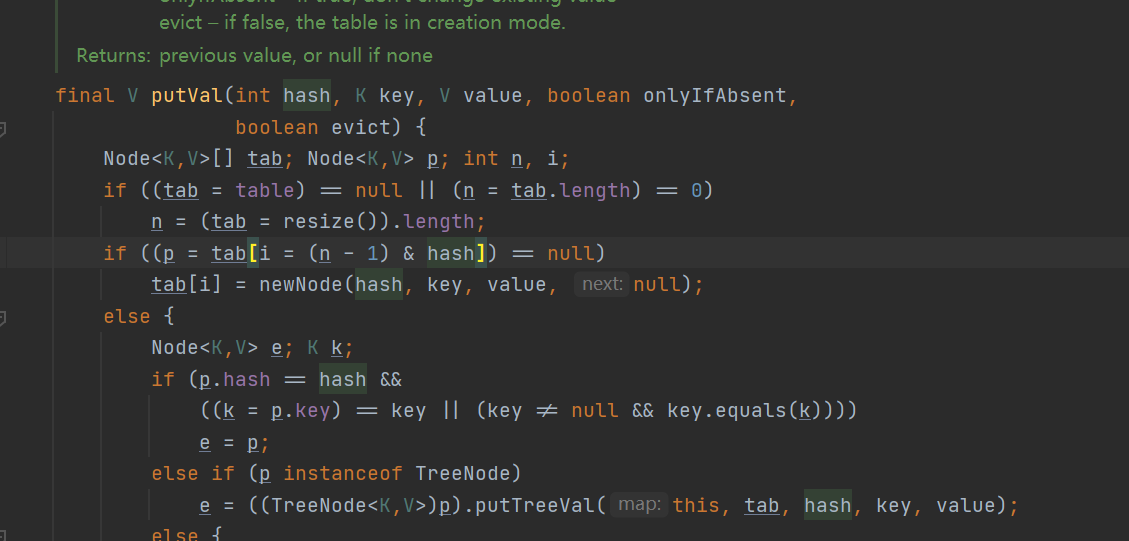
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//Declare a local variable tab, the data p of local variable Node type, int type n,i
Node<K,V>[] tab; Node<K,V> p; int n, i;
//First, assign the table (hash table) in the current hashmap to the current local variable tab, and then judge whether the tab is empty or the length is 0. In fact, judge whether the hash table in the current hashmap is empty or the length is equal to 0
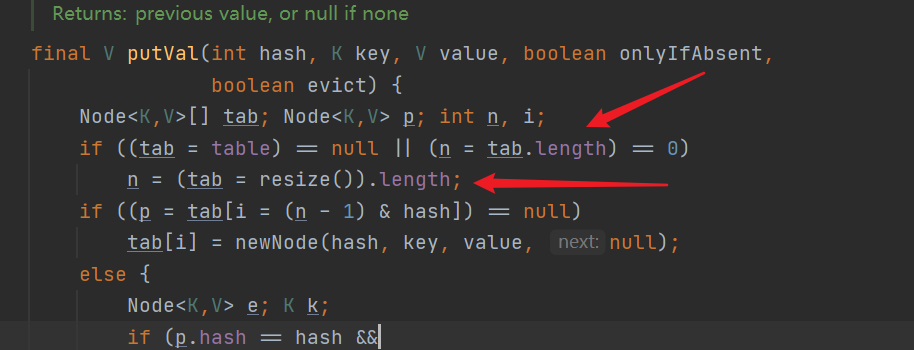
if ((tab = table) == null || (n = tab.length) == 0)
//If it is empty or the length is equal to 0, it means that there is no hash table, so a new hash table needs to be created. By default, a hash table with a length of 16 is created
n = (tab = resize()).length;
//Take out the data corresponding to the position of the data to be inserted in the current hash table, (n - 1) & hash]) is to find the position of the data to be inserted in the hash table. If it is not found, it means that the current position in the hash table is empty. Otherwise, it means that the data is found and assigned to the variable p
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);//Create a new data, which has no next item, and put the data in the current position
else {//Indicates that the location of the data to be inserted has content
//A node e and a key k are declared
Node<K,V> e; K k;
if (p.hash == hash && //If the hash of the data in the current position is the same as the hash we want to insert, it means that there is no wrong position
//If the key of the current data is the same as the key we want to put, the actual operation should be to replace the value
((k = p.key) == key || (key != null && key.equals(k))))
//Assign the current node to the local variable e
e = p;
else if (p instanceof TreeNode)//If the key of the current node is different from the key to be inserted, then judge whether the current node is a red black node
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//If so, create a new tree node and put the data in it
else {
//If it is not a tree node and represents a linked list, it will traverse the linked list
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {//If the next node of the current node is empty, it means that there is no subsequent data
p.next = newNode(hash, key, value, null);//Create a new node data and put it after the currently traversed node
if (binCount >= TREEIFY_THRESHOLD - 1) // Recalculate whether the length of the current linked list exceeds the limit
treeifyBin(tab, hash);//After exceeding, convert the current linked list into a tree. Note that when converting the tree, if the length of the current array is less than MIN_TREEIFY_CAPACITY(64 by default) will trigger capacity expansion. Personally, I think it may be because I think the data under a node exceeds 8, indicating that the hash addressing is severely repeated (for example, the array length is 16, and the hash value is just a multiple of 0 or 16, resulting in all going to the same location). It is necessary to re expand the capacity and re hash
break;
}
//If the key of the currently traversed data is the same as that of the data to be inserted, assign it to the variable e as before, and replace it below
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { //If the current node is not equal to null,
V oldValue = e.value;//Assign the value of the current node to oldvalue
if (!onlyIfAbsent || oldValue == null)
e.value = value; //Replace the value to be inserted with the value in the current node
afterNodeAccess(e);
return oldValue;
}
}
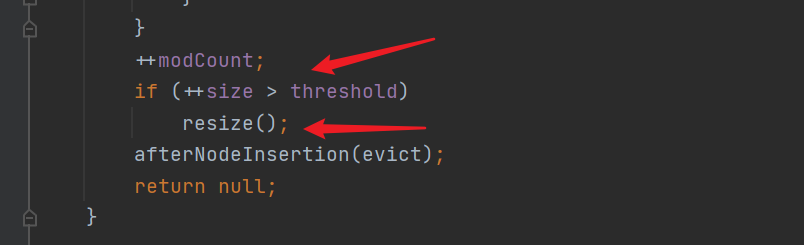
++modCount;//Increase length
if (++size > threshold)
resize();//If the length of the current hash table has exceeded the length of the current hash that needs to be expanded, re expand the capacity if the data stored in the hash map exceeds the critical value (tested), rather than the subscript used in the array
afterNodeInsertion(evict);
return null;
}
| Source code analysis 6: expansion of underlying array |
|---|
- How to judge whether to expand capacity when adding? When the hash table is empty, the value of the current number of array elements + 1 is greater than the array length (the current size of the hash table)
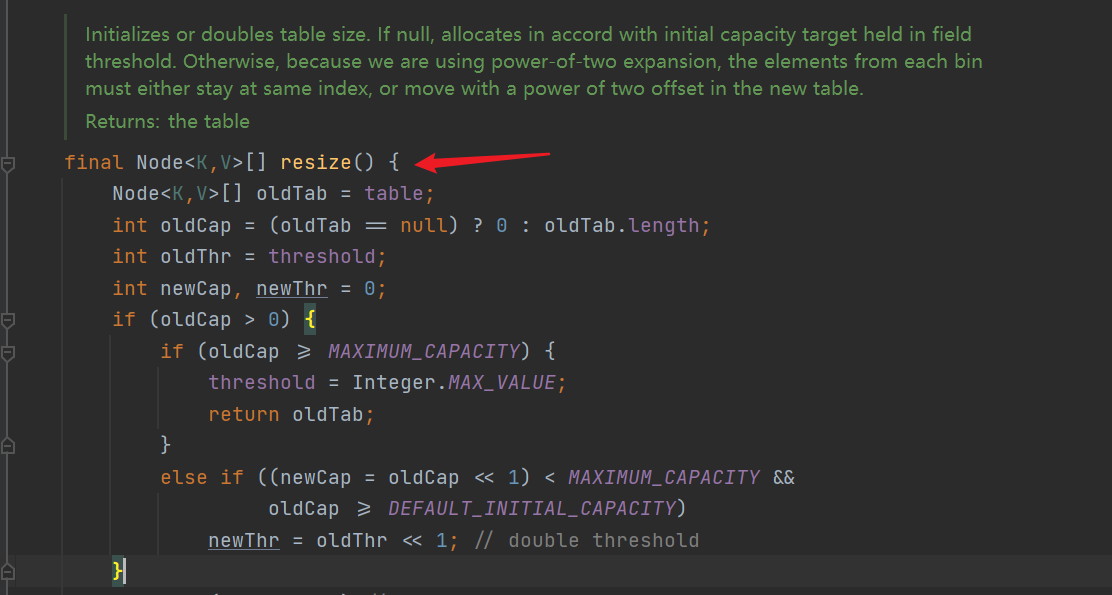
- Inclusiveness calls the resize() method. If table == null, it is the initialization of HashMap, and an empty table is generated and returned. If the table is not empty, the length of the table needs to be recalculated, newLength = oldLength < < 1 (the original oldLength has reached the upper limit, then newLength = oldLength). The first node of the traversal oldTable is empty. This cycle ends, there are no subsequent nodes, and the hash bit needs to be recalculated, At the end of this cycle, the red black tree is currently in the red black tree, and the relocation of the popular black tree is currently a linked list. The hash bit needs to be recalculated in JAVA7, but JAVA8 is optimized to judge whether the shift is required by (e.hash & oldCap) = = 0; If it is true, it will remain in the original position. Otherwise, it needs to be moved to the current hash slot + oldCap position
- Why is the loading factor 0.75f (why is the capacity expanded when the length reaches 0.75 times of the array)
- If the filling factor (loading factor) is 1, the space utilization is greatly satisfied, it is easy to collide and generate linked lists - the query efficiency is low
- If it is 0.5, the collision probability is low, and the capacity is often expanded before collision. The probability of generating linked list is low, the query efficiency is high, and the space utilization is low,
- So take the middle value of 0.75
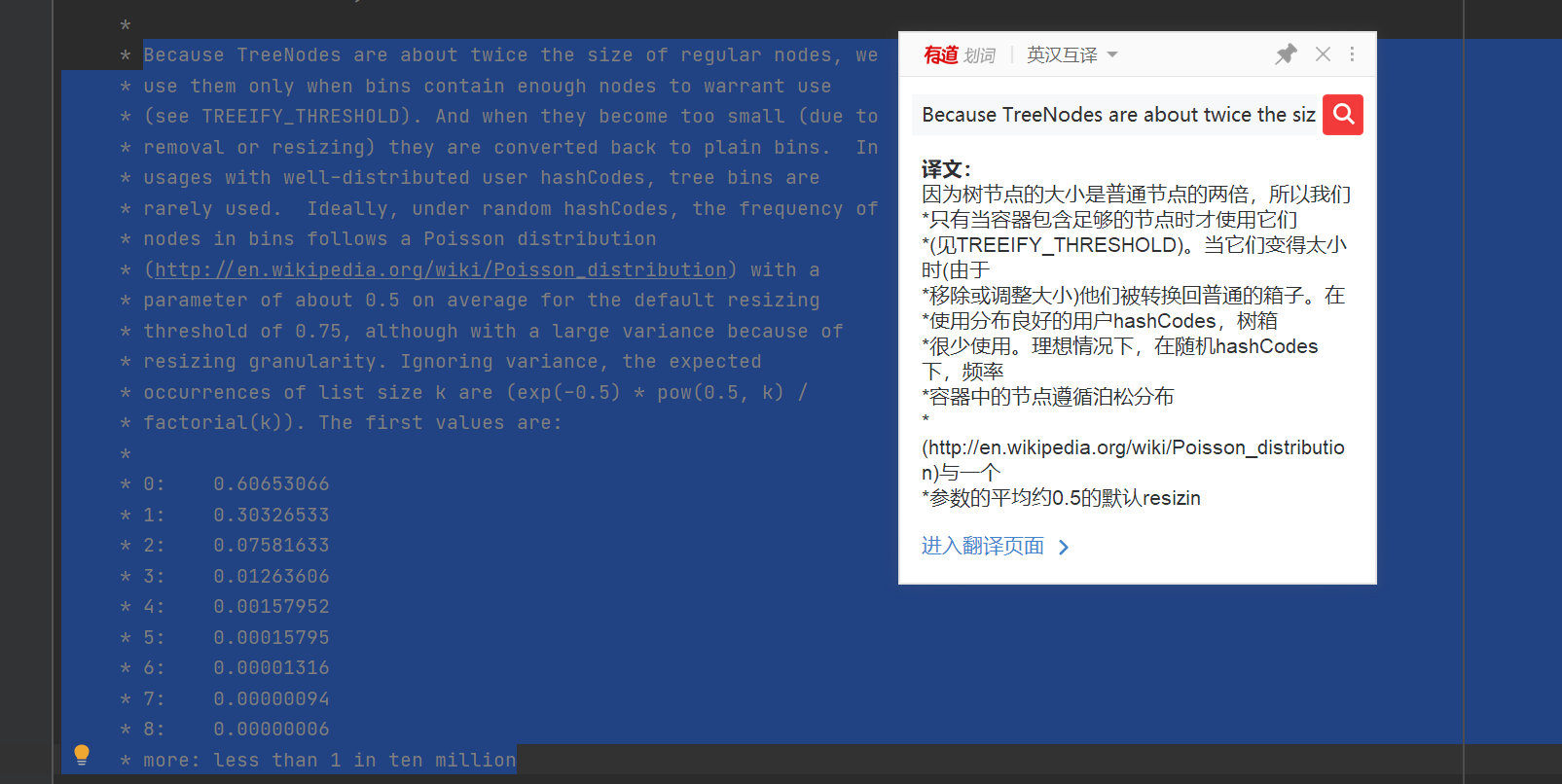
- Officially annotated, On the interpretation of Statistics (according to the statistical results, hash conflict conforms to Poisson distribution, and the smallest conflict probability is between 7-8, which is less than one in a million; therefore, any value between 7-8 can be selected for HashMap.loadFactor, 7.1, 7.2, 7.3... But 7.5 is used, because HashMap's capacity expansion mechanism is explained in a special article, which is not mentioned here)
3. TreeMap source code (JDK1.8)
| The bottom layer of TreeMap is a binary sort tree. Just learn the binary sort tree. There's nothing to talk about. Just go through the source code process |
|---|
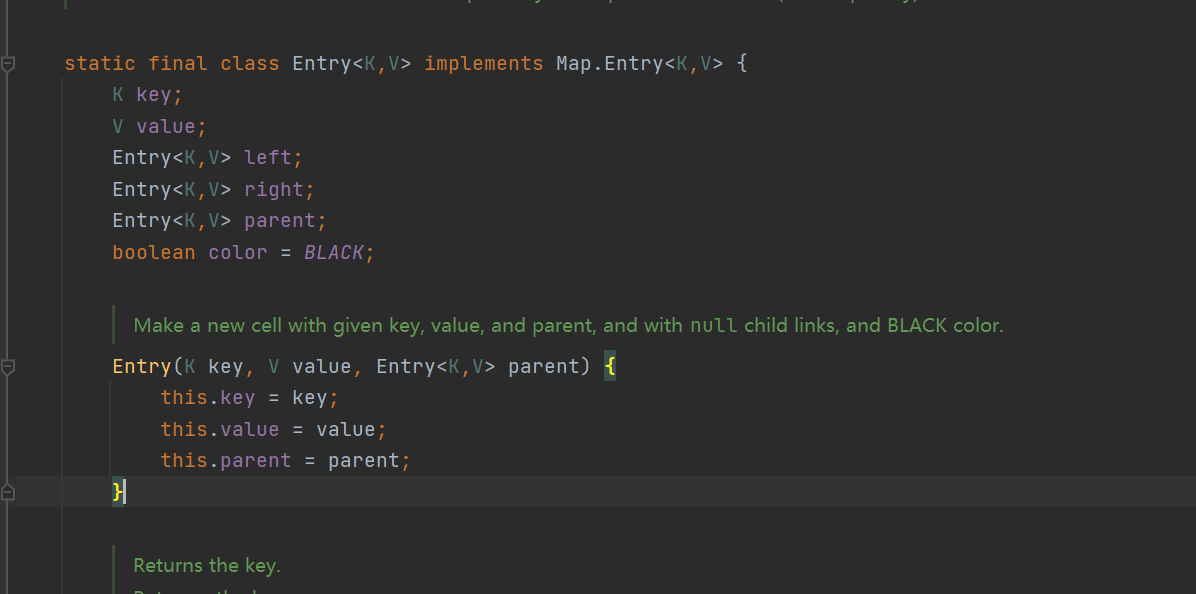
- The bottom layer maintains a binary sort tree. The nodes are of internal class entry < K, V > type, save key value, left child node, right child node and parent node
- put() method, simple binary sort tree insertion logic, first take the root node for traversal, call the comparator to compare (compare key), and insert (or replace) the elements to the appropriate position
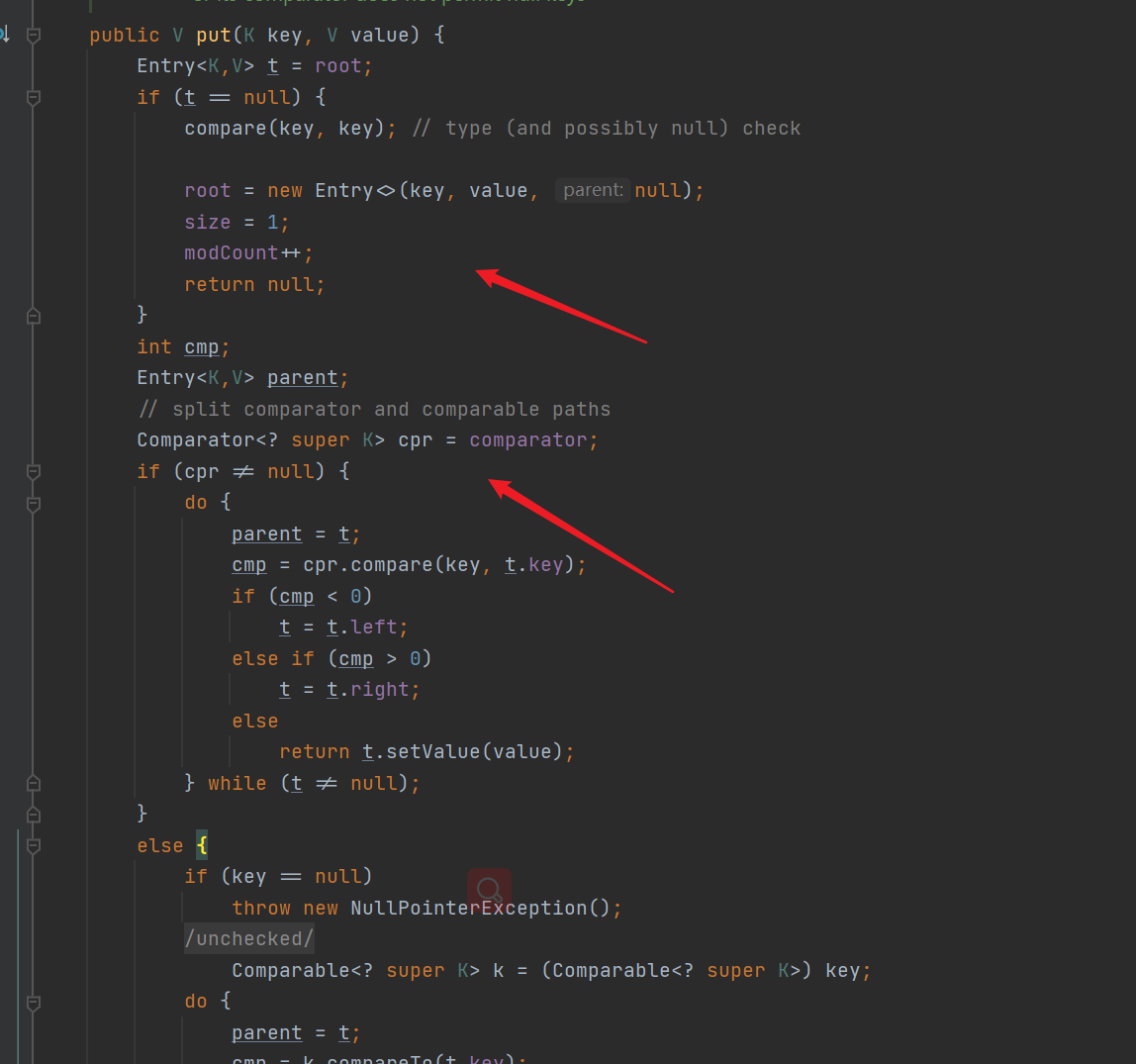
6, Synchronization class container
1. Collections tool class conversion
| First of all, the collection has a tool class, Collections, which provides some APIs to facilitate us to operate the collection, but it is not commonly used. However, we can use it to convert thread unsafe containers into thread safe containers. |
|---|
ArrayList<Integer> arrayList = new ArrayList<>();
List<Integer> synchronizedList = Collections.synchronizedList(arrayList);//Become thread safe
- Thread unsafe ArrayList
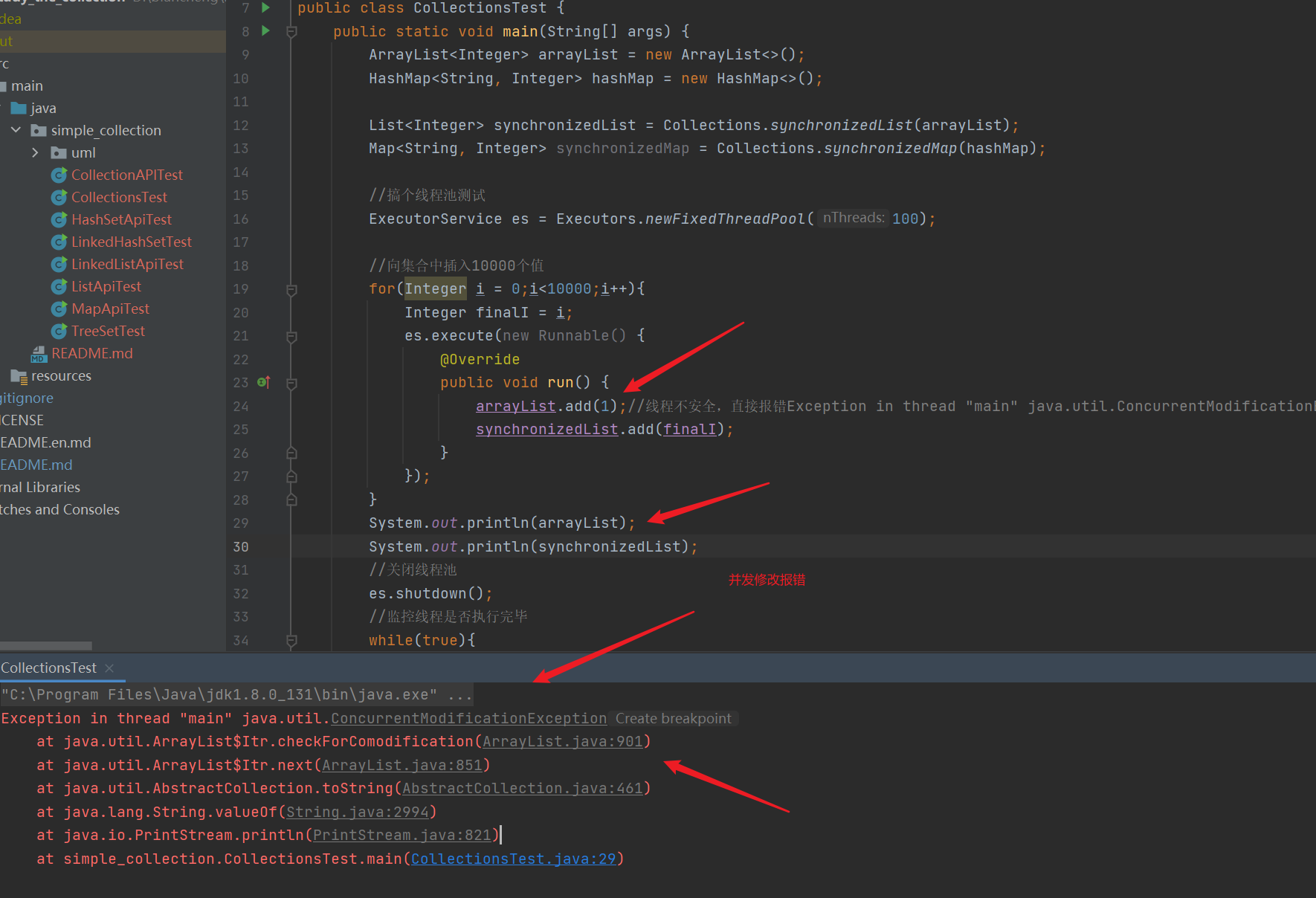
- Make ArrayList thread safe
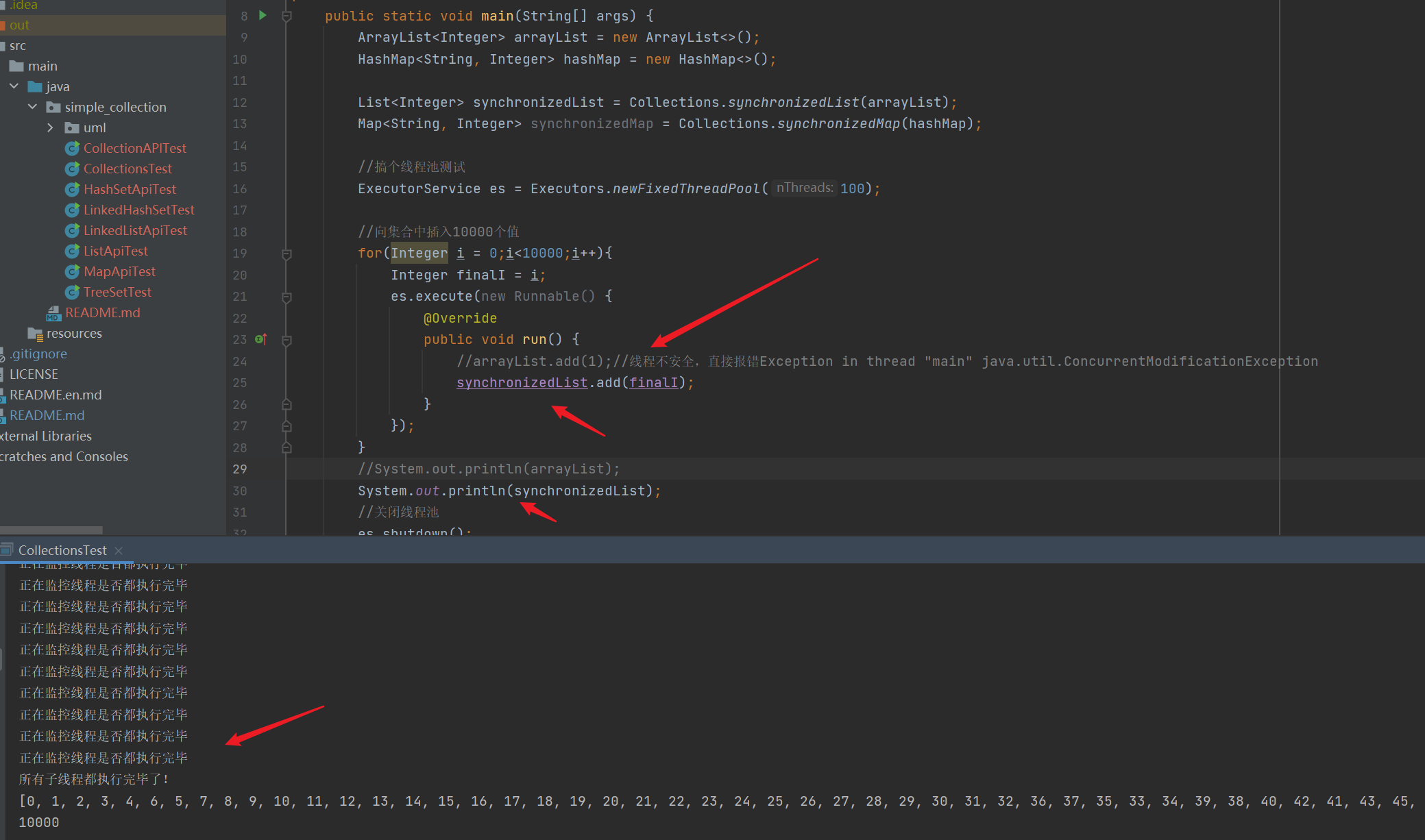
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class CollectionsTest {
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList<>();
HashMap<String, Integer> hashMap = new HashMap<>();
List<Integer> synchronizedList = Collections.synchronizedList(arrayList);
Map<String, Integer> synchronizedMap = Collections.synchronizedMap(hashMap);
//Do a thread pool test
ExecutorService es = Executors.newFixedThreadPool(100);
//Insert 10000 values into the collection
for(Integer i = 0;i<10000;i++){
Integer finalI = i;
es.execute(new Runnable() {
@Override
public void run() {
//arrayList.add(1);// The thread is unsafe, and an error exception in thread "main" Java. Net is reported directly util. ConcurrentModificationException
synchronizedList.add(finalI);
}
});
}
//System.out.println(arrayList);
System.out.println(synchronizedList);
//Close thread pool
es.shutdown();
//Monitor whether the thread has completed execution
while(true){
System.out.println("Monitoring whether all threads have completed execution");
//Returns true after all threads are executed
if(es.isTerminated()){
System.out.println("All sub threads have been executed!");
//Output set
System.out.println(synchronizedList);
//After execution, look at the number of elements in the collection
System.out.println(synchronizedList.size());
if(synchronizedList.size() == 10000){
System.out.println("Thread safe!");
}else{
System.out.println("Thread unsafe!!!");
}
break;
}
}
}
}
2. Source code of collections (JDK1.8)
- synchronizedList() method: judge whether the list is a RandomAccess object (the list interface inherits RandomAccess). If it is, the SynchronizedRandomAccessList object is returned; otherwise, the SynchronizedList object is returned
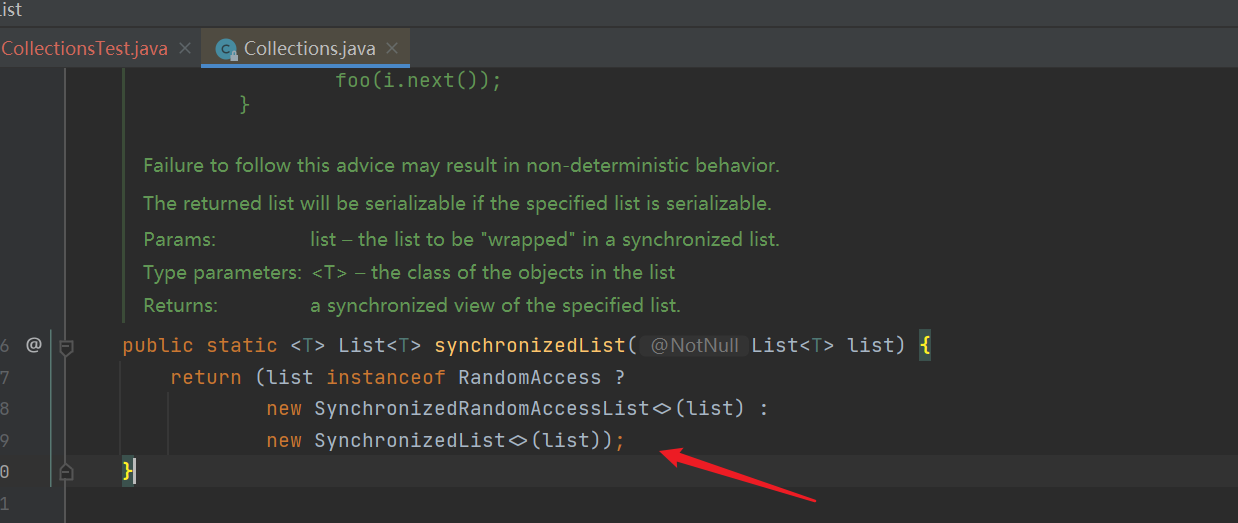
- SynchronizedRandomAccessList: it is the internal class of Collections. The constructor calls the construction of the parent class SynchronizedList
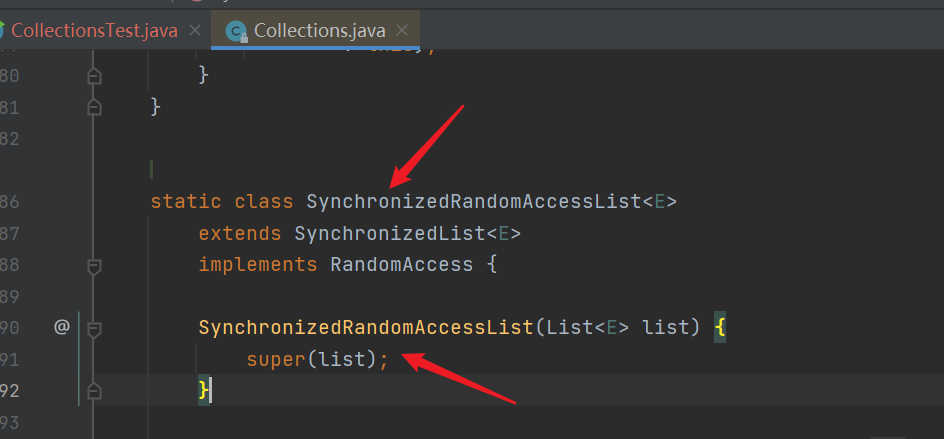
- Construction of SynchronizedList: SynchronizedList is also an internal class of Collections. After calling the parent class SynchronizedCollection for construction, make the list in the class equal to the constructed list
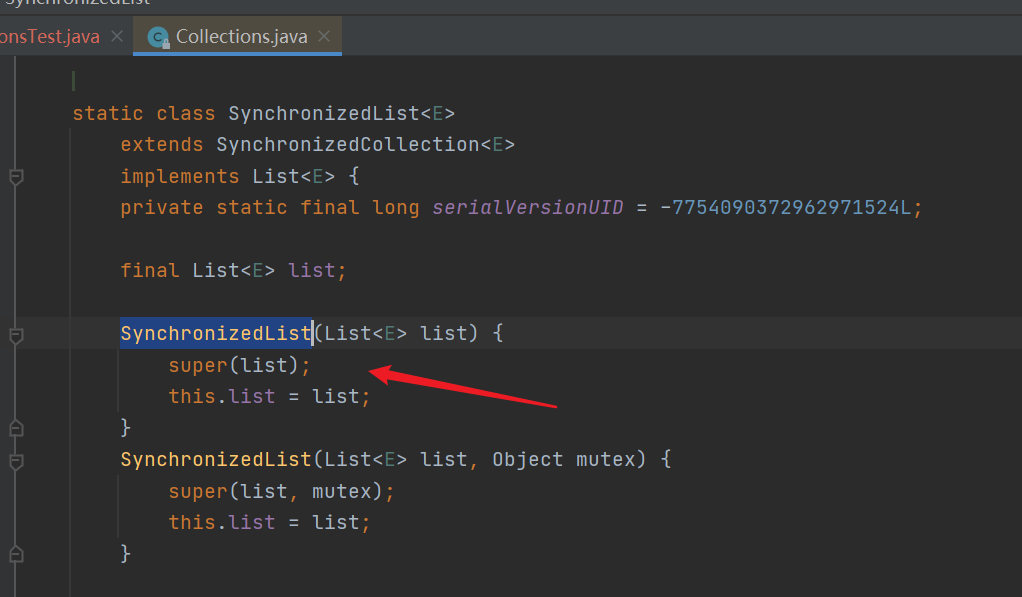
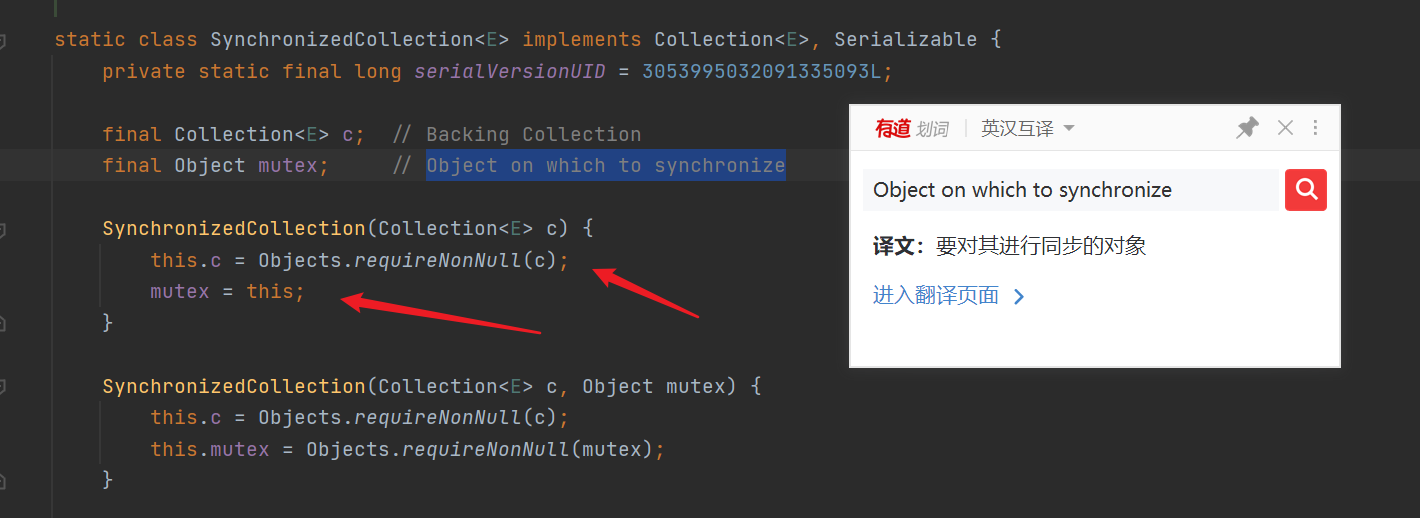
- SynchronizedCollection structure. If the Collection passed is empty, an error will be reported directly. Otherwise, the synchronized object will point to it
- add() method: all mutex (container to be synchronized) are locked
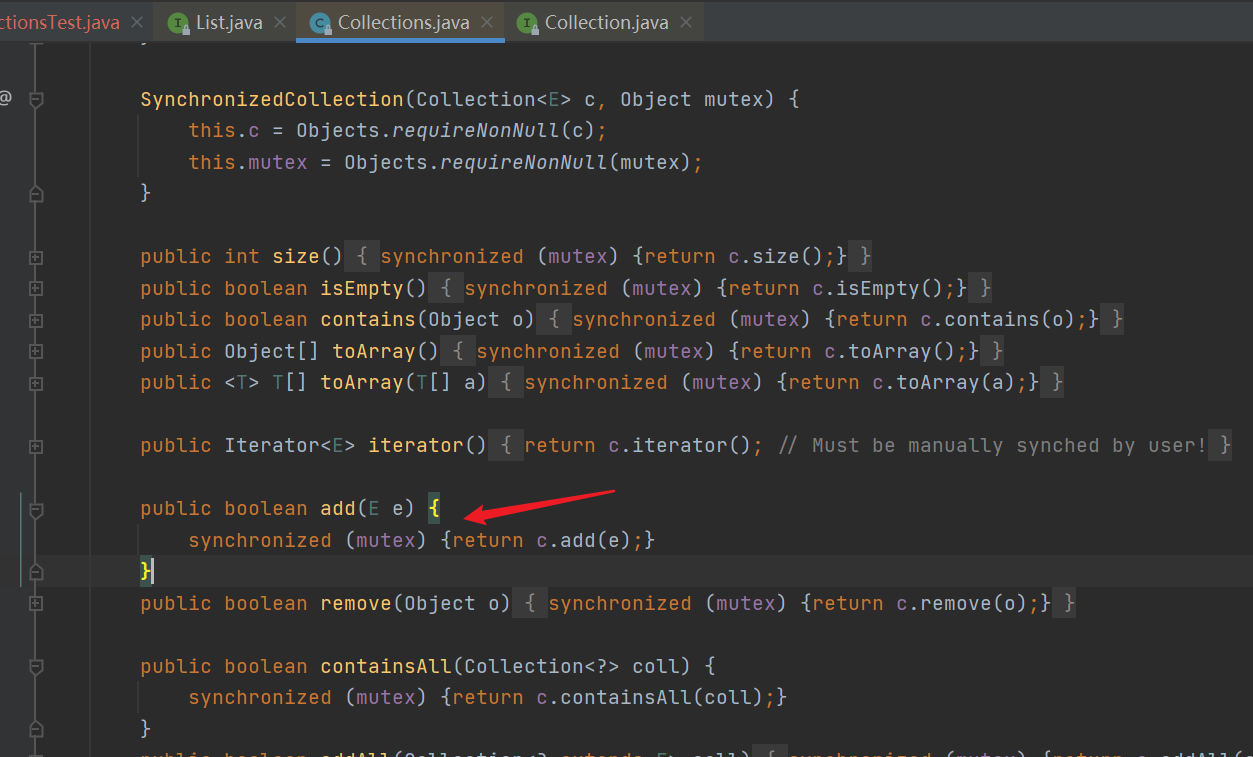
| It can be found that it locks the entire collection, which greatly affects the performance |
|---|
7, Concurrent class container
| JDK1. After 5, a variety of concurrent class containers are provided to replace synchronous class containers and improve performance and throughput |
|---|
- ConcurrentMap: interface with two implementation classes
- The ConcurrentHashMap implementation class replaces the locked version of HashMap and HashTable (thread safe in itself)
- The ConcurrentSkipListMap implementation class replaces TreeMap
1. ConcurrentMap
| Why was HashTable eliminated? Why is it inefficient |
|---|
- This thing locks the whole container directly
- When one thread stores data, other threads cannot access it
- If the save and fetch are not in the same location, they should not conflict
- Just like you go to the Internet cafe to surf the Internet. There are 100 machines in the Internet cafe. One person has to open one machine. Others actually have to wait until he gets on the machine. The next person can go in and open another one, although the two machines are not the same
| Why is ConcurrentMap efficient |
|---|
- It divides the set into multiple areas (16) and locks them respectively to reduce the granularity of locks
- When a thread goes to the first area, the first area is locked, and other areas are not affected
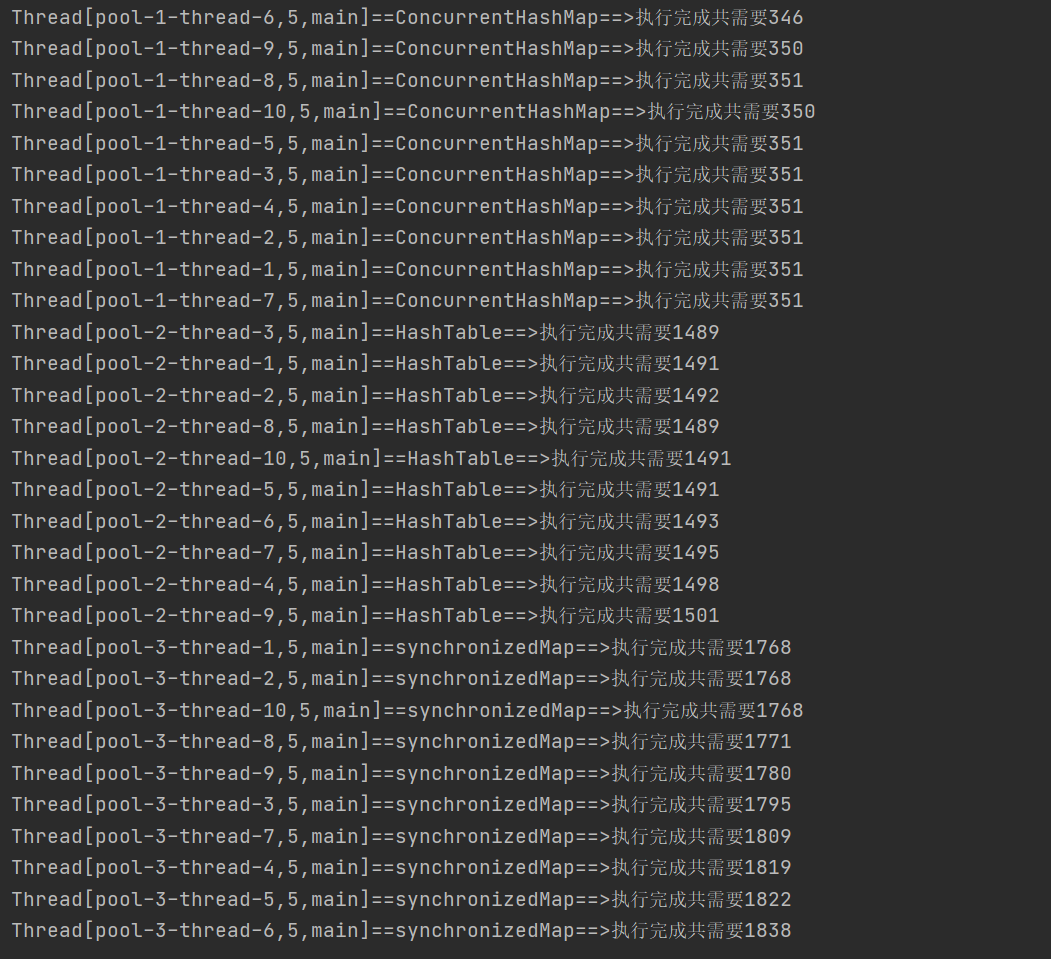
| To test, ConcurrentMap is the fastest, HashTable is four times slower, and synchronized map is the slowest: simple_collection/ConcurrentMapApiTest.java |
|---|
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ConcurrentMapApiTest {
public static void main(String[] args) {
ConcurrentHashMap<String, Integer> cHMap = new ConcurrentHashMap<>();
//Thread pool
ExecutorService es = Executors.newFixedThreadPool(10);
for (int i = 0;i<10;i++){
es.execute(new Runnable() {
@Override
public void run() {
long startTime = System.currentTimeMillis();
for (int j = 0;j<1000000;j++){
cHMap.put("test"+j,j);
}
long endTime = System.currentTimeMillis();
System.out.println(Thread.currentThread()+"==ConcurrentHashMap==>"+"Total requirements for execution completion"+(endTime - startTime));
}
});
}
es.shutdown();
System.out.println("========================HashTable=============================");
//Thread pool
ExecutorService es2 = Executors.newFixedThreadPool(10);
Hashtable<String, Integer> hashtable = new Hashtable<>();
for (int i = 0;i<10;i++){
es2.execute(new Runnable() {
@Override
public void run() {
long startTime = System.currentTimeMillis();
for (int j = 0;j<1000000;j++){
hashtable.put("test"+j,j);
}
long endTime = System.currentTimeMillis();
System.out.println(Thread.currentThread()+"==HashTable==>"+"Total requirements for execution completion"+(endTime - startTime));
}
});
}
es2.shutdown();
System.out.println("========================synchronizedMap=============================");
//Thread pool
ExecutorService es3 = Executors.newFixedThreadPool(10);
Map<String, Integer> synchronizedMap = Collections.synchronizedMap(new HashMap<>());
for (int i = 0;i<10;i++){
es3.execute(new Runnable() {
@Override
public void run() {
long startTime = System.currentTimeMillis();
for (int j = 0;j<1000000;j++){//It's too slow. I cut him a 0
synchronizedMap.put("test"+j,j);
}
long endTime = System.currentTimeMillis();
System.out.println(Thread.currentThread()+"==synchronizedMap==>"+"Total requirements for execution completion"+(endTime - startTime));
}
});
}
es3.shutdown();
}
}
2. COW(Copy On Write) concurrent container, copy container when writing
- When adding elements to a container, first copy the container to a new container, add the elements to the new container, and then point the original container reference to the adjective.
- There is no need to lock the container when reading concurrently, because the original container will not change. The idea of separation of reading and writing
- However, it can only ensure the final consistency, not the real-time consistency of data
- Do not use the CopyOnWrite container if you want to read the data immediately after writing
- It is applicable to the scenario of more reads and less writes (in the case of high concurrent reads). Each write operation will copy the container. Once there are too many write processes, the JVM must have high memory consumption or even memory overflow.
| Two kinds of COW containers |
|---|
- CopyWriteArrayList: replaces ArrayList
- CopyOnWriteArraySet: override Set
1. CopyOnWriteArrayList implementation class
| Simple use: simple_collection/COWApiTest.java |
|---|

import java.util.concurrent.CopyOnWriteArrayList;
public class COWApiTest {
public static void main(String[] args) {
CopyOnWriteArrayList<Integer> cOWList = new CopyOnWriteArrayList<>();
//Add elements to add duplicate elements
cOWList.add(1);
cOWList.add(1);
cOWList.add(1);
System.out.println("use add Add, the element can be repeated:"+cOWList);
cOWList.addIfAbsent(1);
System.out.println("use addIfAbsent Add. If there are already the same in the collection, you cannot add:"+cOWList);
}
}
2. CopyOnWriteArrayList source code (JDK1.8)
| Reentrant lock |
|---|
| A thread executes a locked code. At this time, the thread executes another locked code. If the two locks are found to be the same thread, the thread can enter. This is a reentrant lock |
- In the source code, the reentrant lock is declared. All operations are locked with this lock. In this way, the thread that gets the lock can complete its own operations on one line
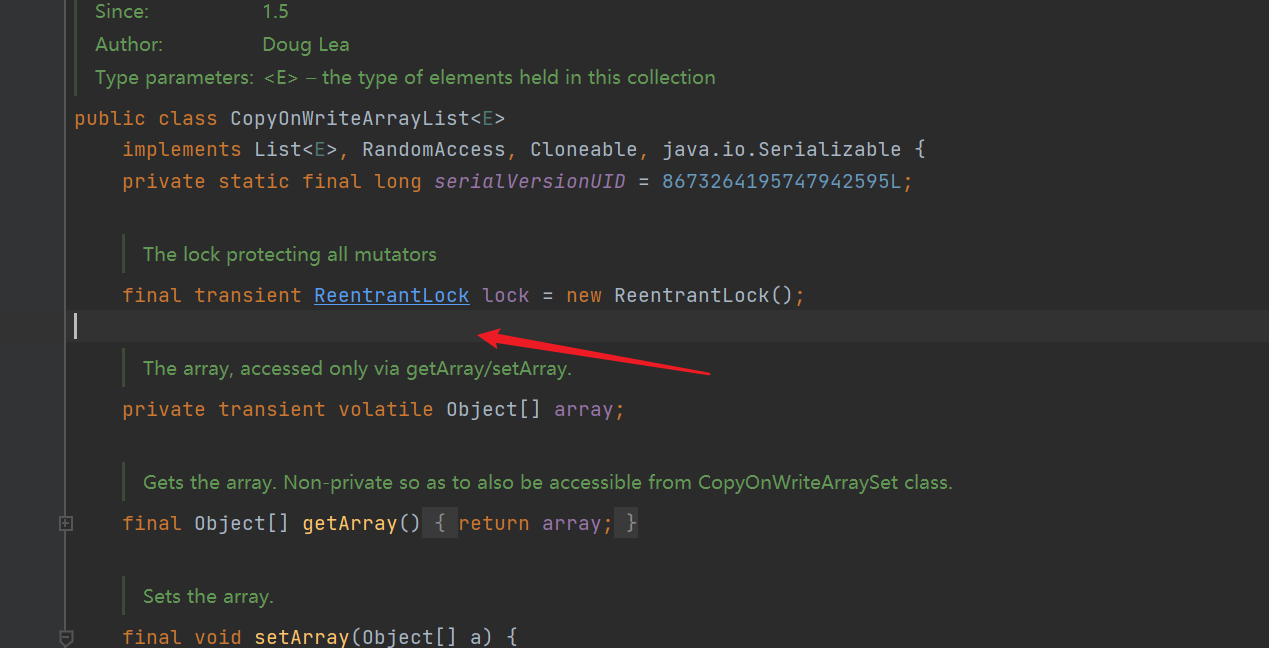
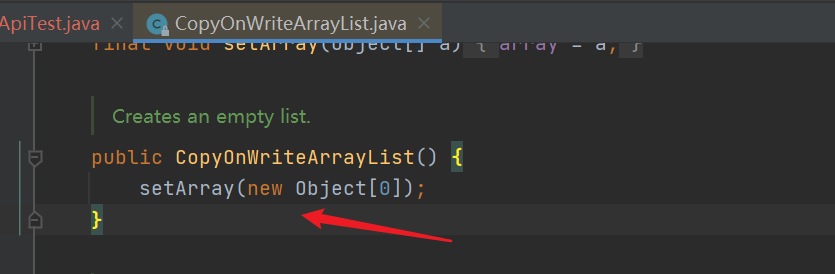
- Construction method: create an empty list, and maintain a volatile modified Object type array at the bottom
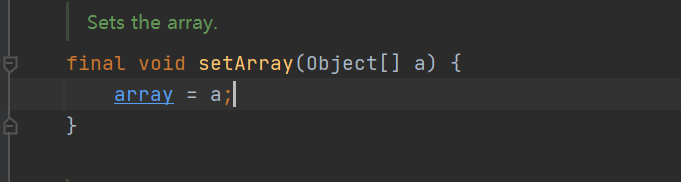
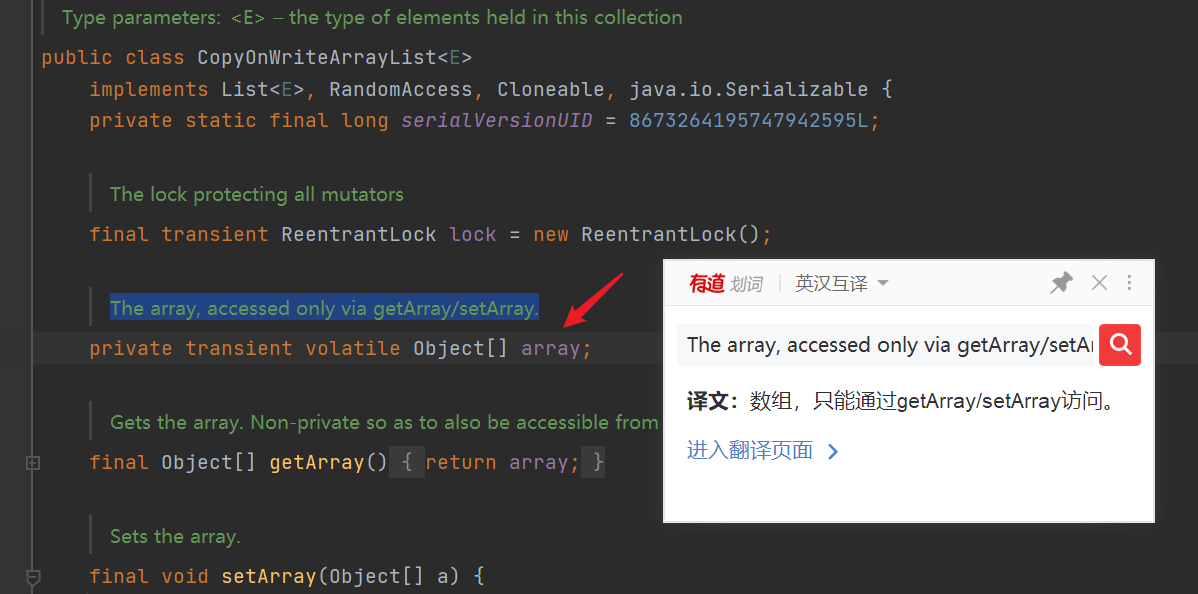
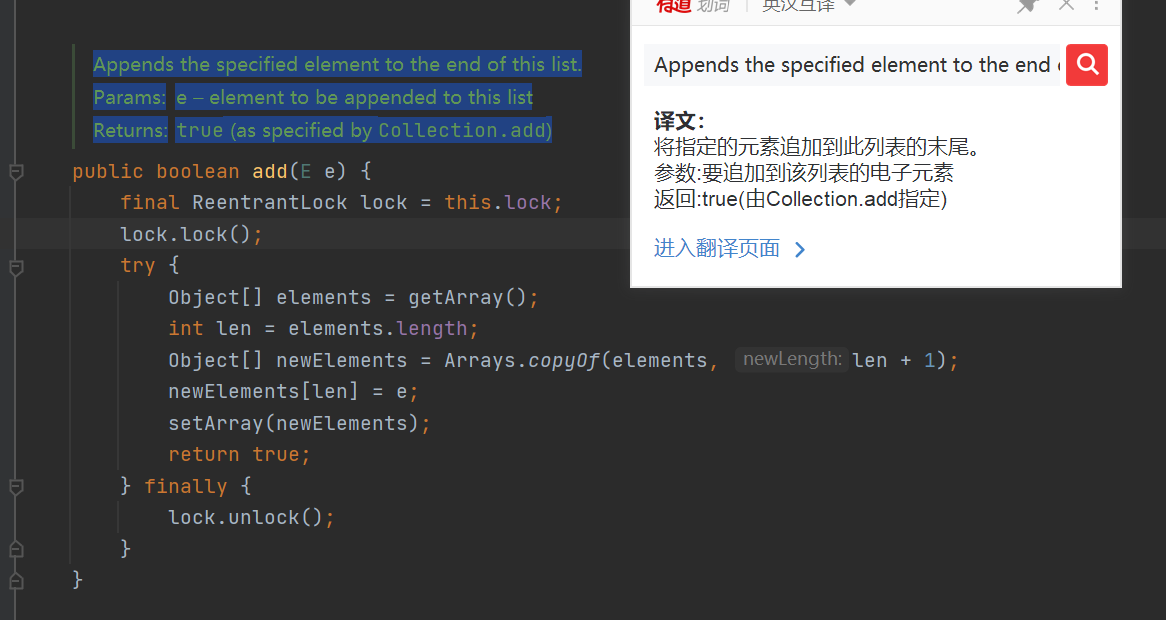
- add() method: first, get the reentrant lock, lock the try code block, copy a copy of the current array, length + 1, add the element to be inserted to the end of the array, and then update the array
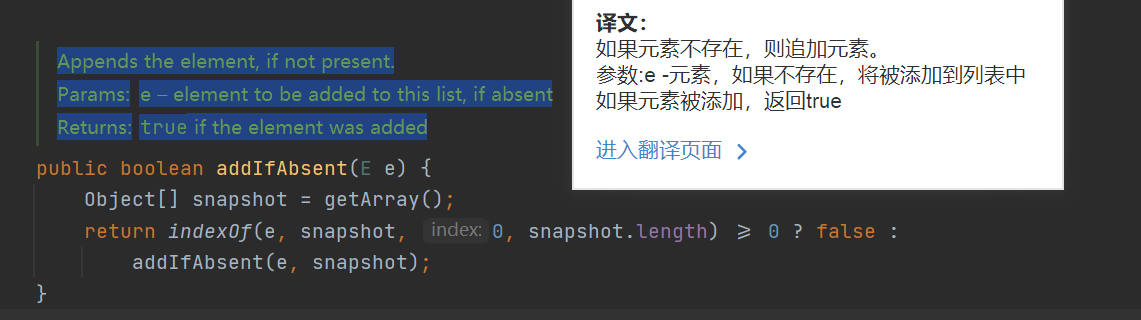
- addIfAbsent() method: first get the array object, save the reference to a variable, and then judge whether the element exists. If it exists, return false, otherwise add it;
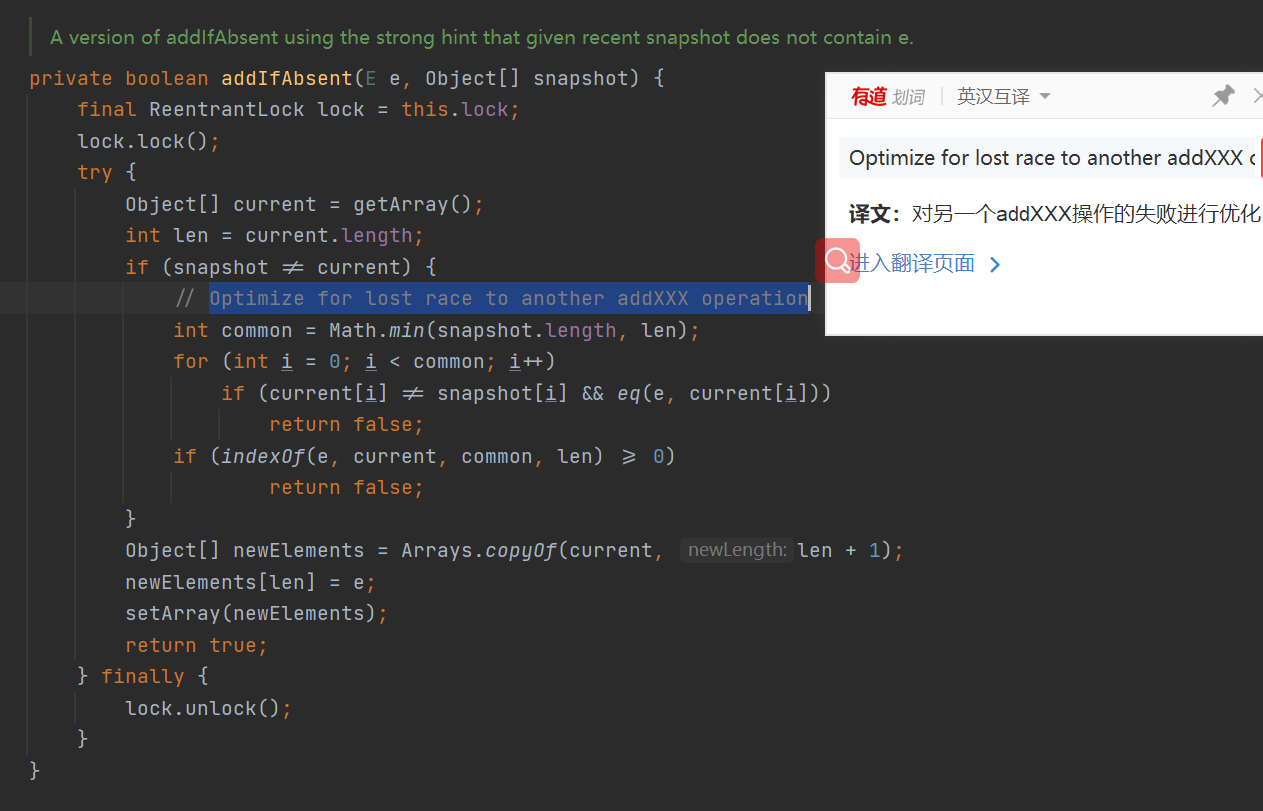
- addIfAbsent() method details: first take the reentrant lock, lock the try, and obtain the array current again (high concurrency, we just judged whether the element exists, and other threads can operate the array). If the current saved array is different from the array current obtained again, optimize it. Otherwise, it is not optimized, and the logic is the same as that of the add() method
- Optimization: first obtain the current array length and the array length we have obtained, and then traverse according to this value. Compare each element of the array we have obtained with the actual array. If an element of the array is inconsistent, or the current element to be inserted is the same as an element in the array (eq() method, processed null value), return false directly
- The above does not exit. Judge whether the element to be inserted currently exists. If it exists, false will be returned
| The addIfAbsent() method is much less efficient than add() because it needs to be compared every time |
|---|
3. CopyOnWriteArraySet source code (JDK1.8)
| The use of set is no different from that of ordinary set. Instead of introducing the api, you can directly analyze the source code. In fact, it is only implemented with CopyOnWriteArrayList. I feel that it is completely unnecessary to see it |
|---|
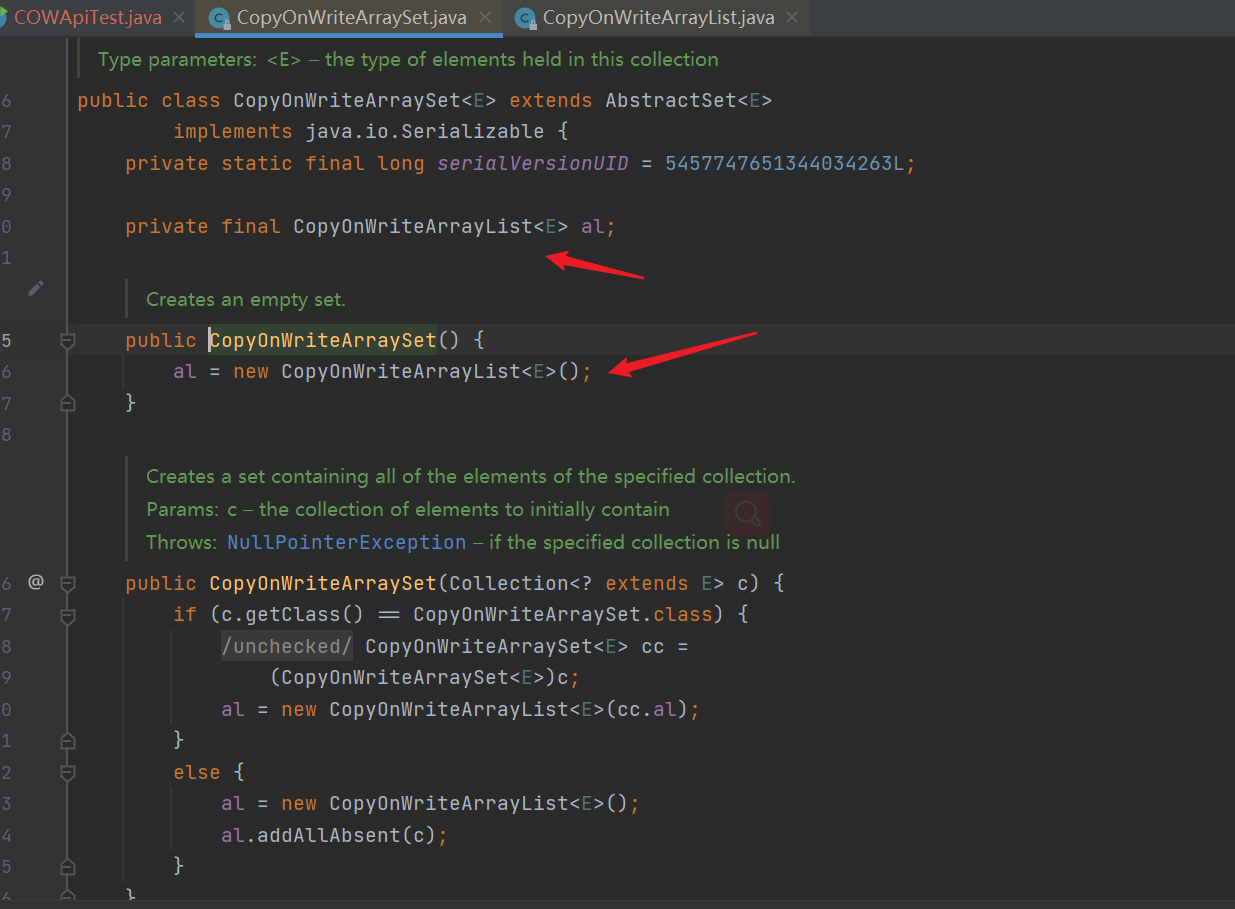
- Construction method: the bottom layer maintains CopyOnWriteArrayList
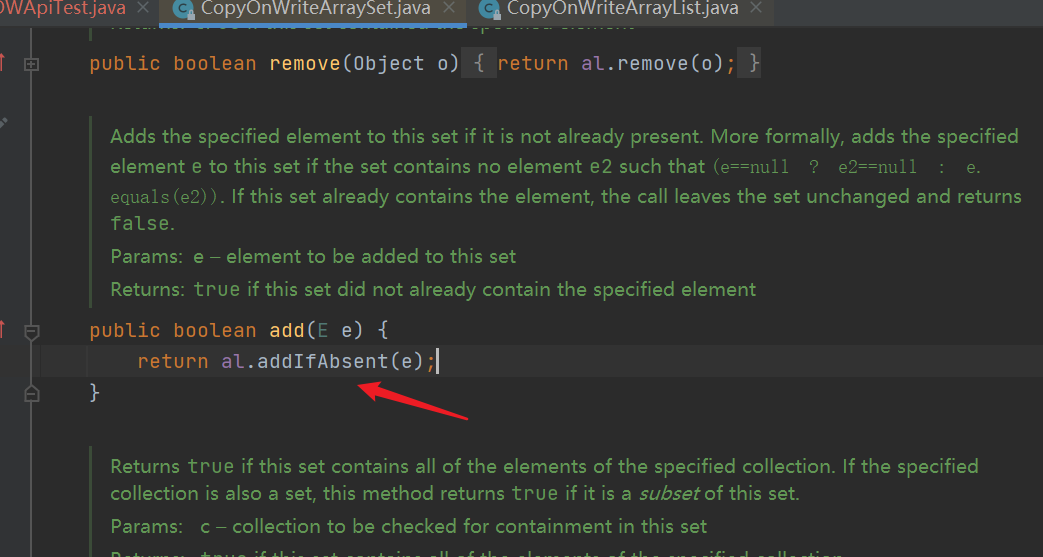
- add() method: call the addIfAbsent() method of CopyOnWriteArrayList
8, Queue
| Simple class diagram (it's annoying. How can you write more and more things?): simple_collection/uml/Queue.puml |
|---|
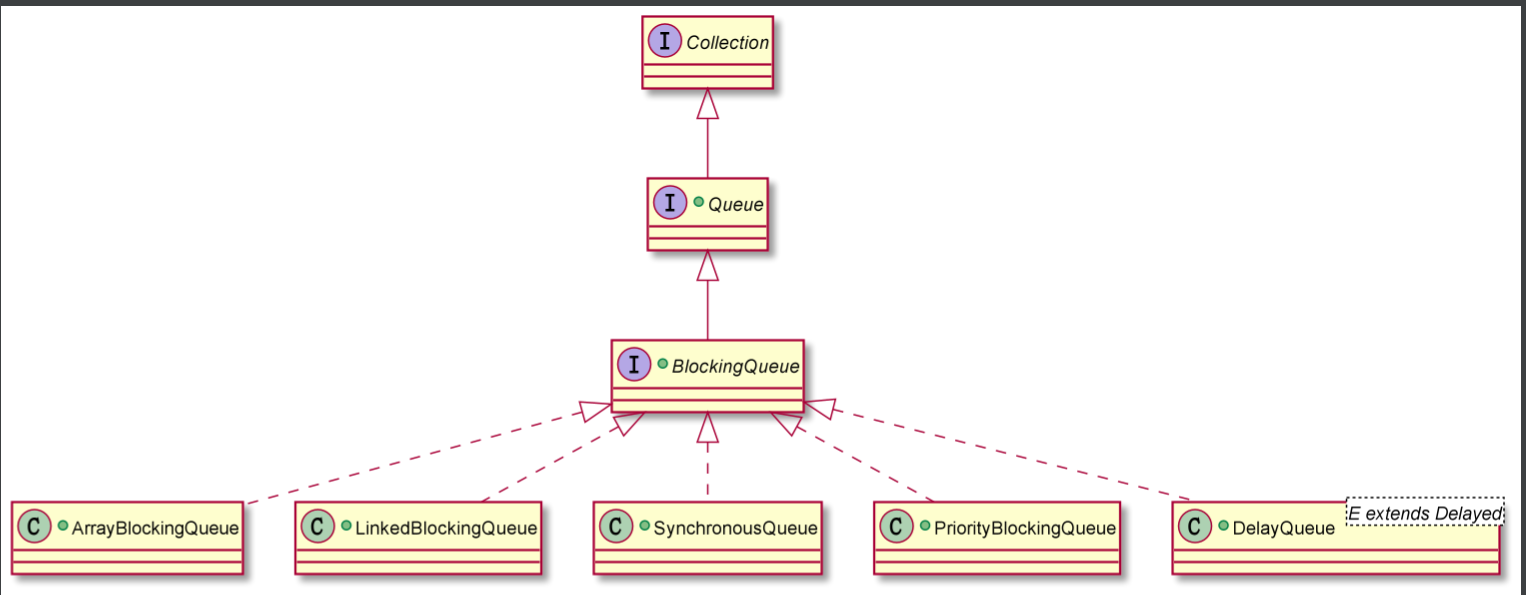
- Queue is also a kind of Collection container, which additionally specifies the characteristics of queue
- BlockingQueue, blocking queue, is blocked because the data structure of queue itself is used in multi-threaded scenarios
- There are many blocking queues. We will only introduce the above
| Why not use non blocking queues |
|---|
- Assuming that the queue capacity is 10, the queue is now full
- When the 11th man wants to enter the queue, he will be lost directly
- Blocking the queue will make the man wait first. When someone is finished, you can go in
- When fetching data from the queue, the queue is empty
- Non blocking queue, get a null value
- The queue is blocked. If the queue is empty, this guy will wait first. When there is something in the queue, you can pick it up
1. Common API analysis of BlockingQueue interface
| BlockingQueue is an interface. It needs to implement a specific class. Give the APi and don't test it |
|---|
| Description( 🍅: No blocking/ 🏆: Blocking) | API |
|---|
| 🍅 Insert the specified element into this queue (if it is feasible immediately and will not violate the capacity limit), return true on success, and throw an IllegalStateException if there is no free space | boolean add(E e) |
| 🍅 Insert the specified element into this queue (if it is feasible immediately and will not violate the capacity limit), and return true on success. If there is no free space, return false | boolean offer(E e) |
| 🏆 Insert the specified element into this queue and wait for available space, if necessary | void put(E e) |
| 🏆 Gets and removes the queue header, waiting (if necessary) until the element becomes available | E take() |
| 🏆 Gets and removes the header of this queue, waiting for available elements before the specified wait time, if necessary | E poll(Long timeout,TimeUnit unit) |
| 🍅 Removes a single instance, if any, of the specified element from this queue | boolean remove(Object o) |
| 🍅 The number of additional elements that can be accepted by this queue under the ideal condition of no blocking (no memory or resource constraints); If there is no internal restriction, integer is returned MAX_ VALUE | int remainingCapacity() |
2. ArrayBlockingQueue implementation class and source code (JDK1.8)
- The bottom layer is based on arrays and does not support simultaneous read and write operations. Queues with boundaries / boundaries are first in first out
- The elements at the head of the queue have the longest survival time and the elements at the tail of the queue have the shortest survival time (queue characteristics)
- Put the element from the bottom, take the element from the head (queue feature)
- The added element cannot be null: otherwise, a null pointer exception is reported
| Basic usage: in fact, it is the two blocking methods put and take |
|---|
import java.util.concurrent.ArrayBlockingQueue;
public class QueueTest {
public static void main(String[] args) throws InterruptedException {
//ArrayBlockingQueue, initialize 3 spaces
ArrayBlockingQueue<Integer> arrayBlockingQueue = new ArrayBlockingQueue<Integer>(3);
//Add data
arrayBlockingQueue.offer(1);
arrayBlockingQueue.offer(2);
arrayBlockingQueue.offer(3);
// arrayBlockingQueue.put(4);// If no brother takes it out, it will be blocked all the time
System.out.println("==================="+arrayBlockingQueue+"===================================");
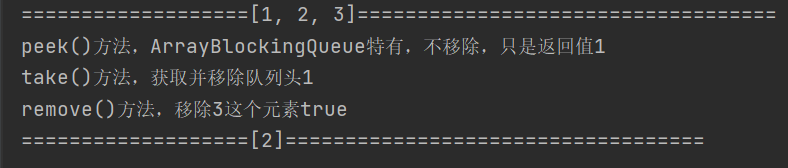
System.out.println("peek()method, ArrayBlockingQueue Unique, not removed, but returned value"+arrayBlockingQueue.peek());
System.out.println("take()Method to get and remove the queue header"+arrayBlockingQueue.take());
System.out.println("remove()Method to remove 3 this element"+arrayBlockingQueue.remove(3));
System.out.println("==================="+arrayBlockingQueue+"===================================");
}
}
- Underlying implementation parameters: final Object [] type array, take element index: takeIndex, put element index putIndex, number of valid elements in the array: int count, reentrant lock, empty queue, take element thread waiting pool: notEmpty, queue full, put element waiting pool: notFull
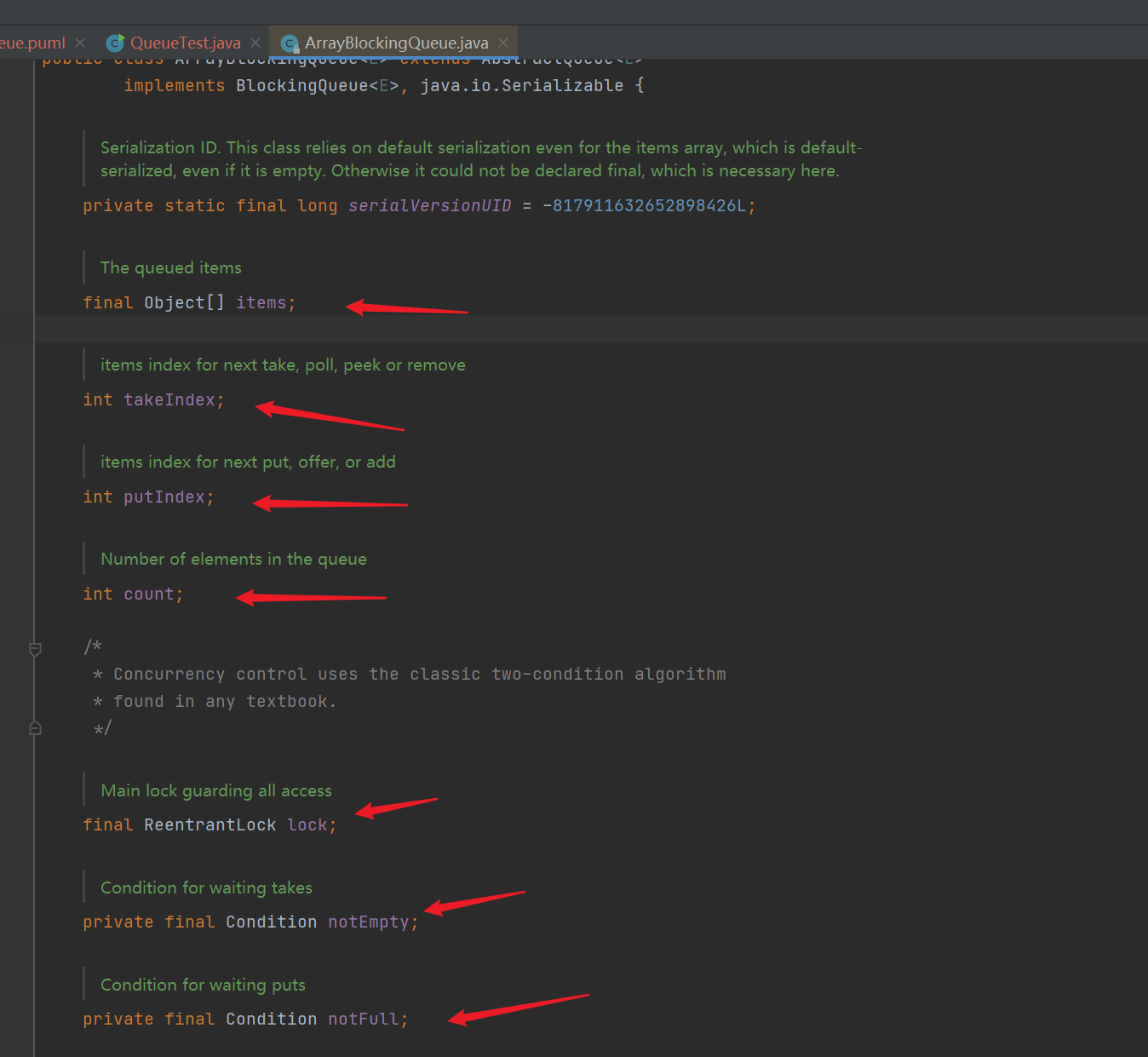
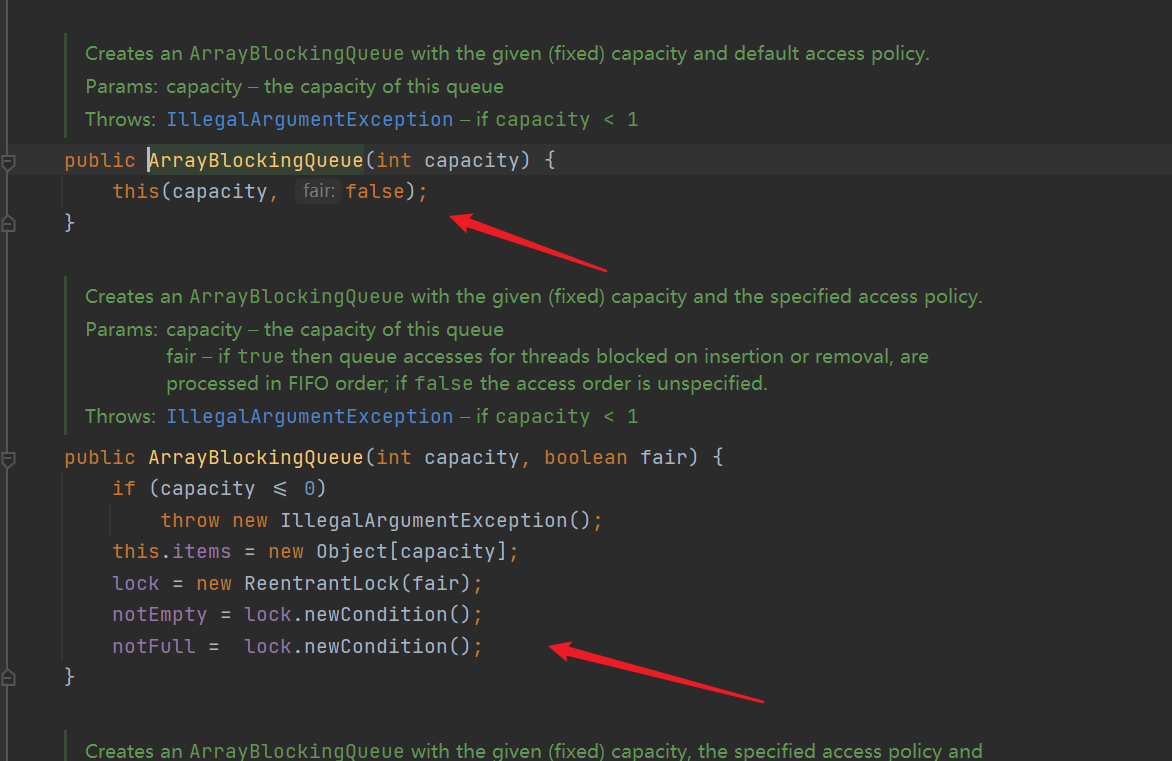
- Constructor: by default, after specifying the queue length, if the queue length is not 0, the array, lock and two waiting pools (waiting pools that can re-enter the lock) will be initialized
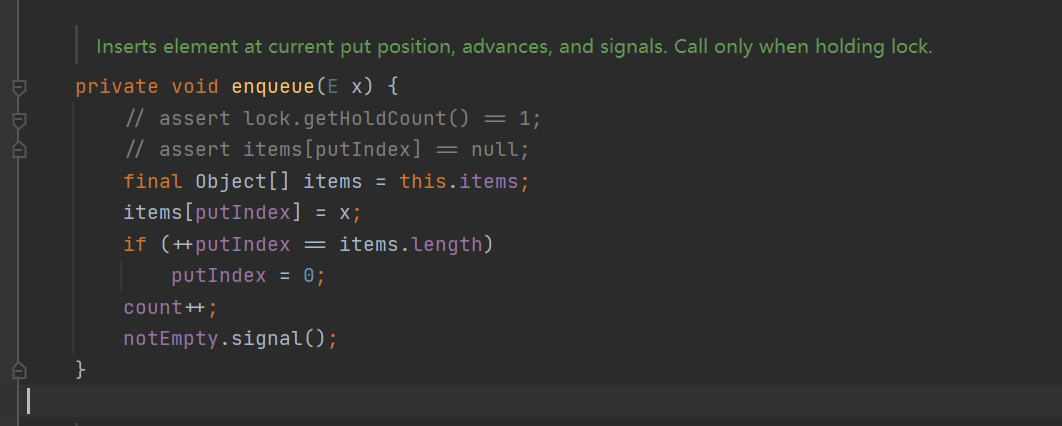
- Queue in / queue out methods (the queue data structure is enqueue/dequeue, and other queue in / queue out methods call them)
- enqueue(): get the array, insert the element according to the insertion position pointer, and then insert the pointer + +. If it has reached the end of the array, reset it to 0 The number of queue elements count + +, which tells the queue that the queue is empty and the element fetching thread waiting pool can fetch elements (the blocked element fetching thread can continue to fetch elements)
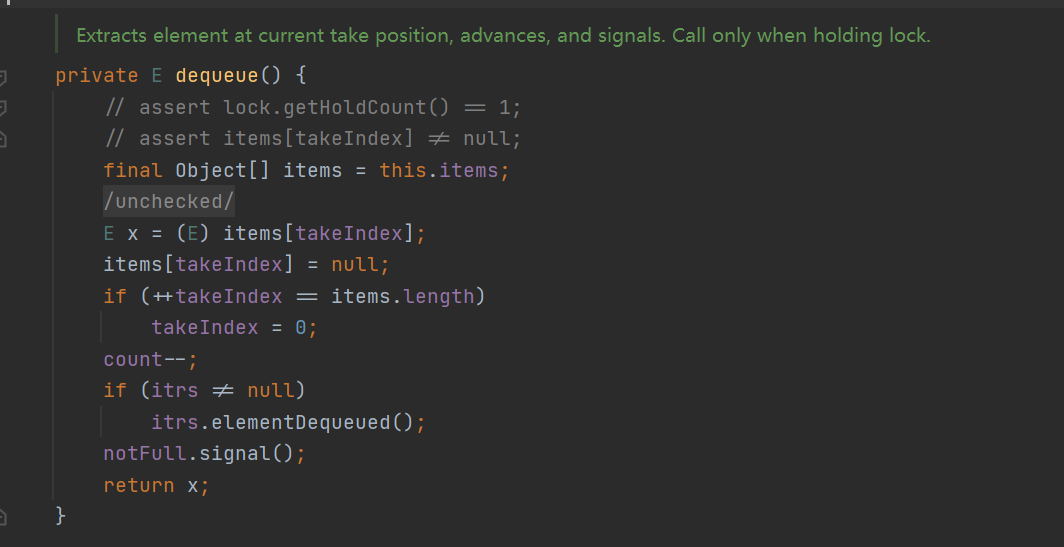
- dequeue(): get the array, get the data according to the element subscript, and then set the subscript position to null. If the subscript + + exceeds the queue size, reset it to 0; Number of queue elements –; If the iterator is not empty, notify the iterator to execute logic (called when the queue is empty. Notify all active iterators that the queue is empty, clear all weak references, and unlink the itrs data structure. Call when takeIndex goes around 0. Notify all iterators and delete any obsolete iterators). Notify the queue that the element waiting pool is full and you can continue to put elements.
- block
- put() method: obtain the reentrant lock and lock the try. If the number of current queue elements is equal to the queue length, it means that the queue is full. Let the thread go to the notFUll waiting pool to wait (blocking). Otherwise, enqueue is inserted directly.
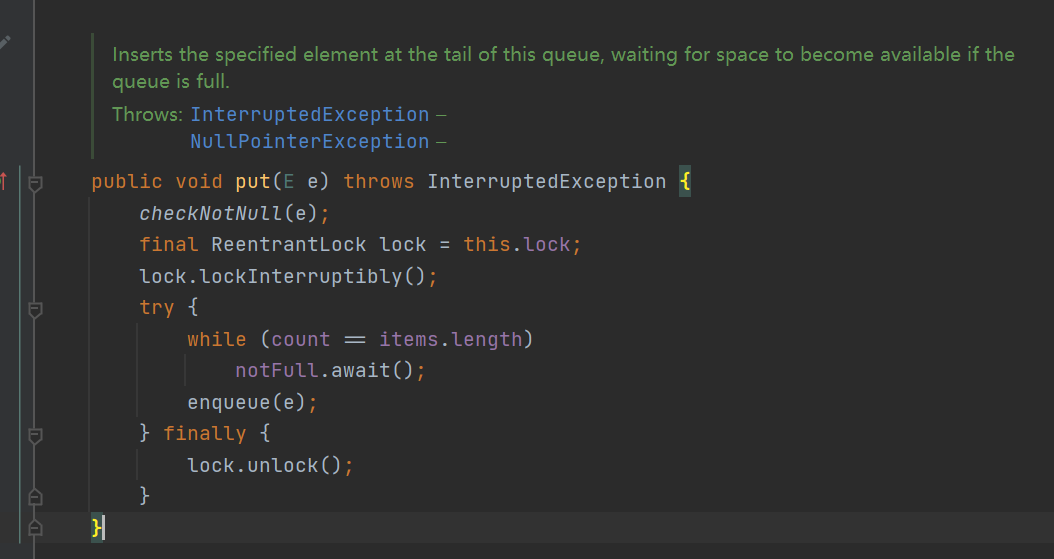
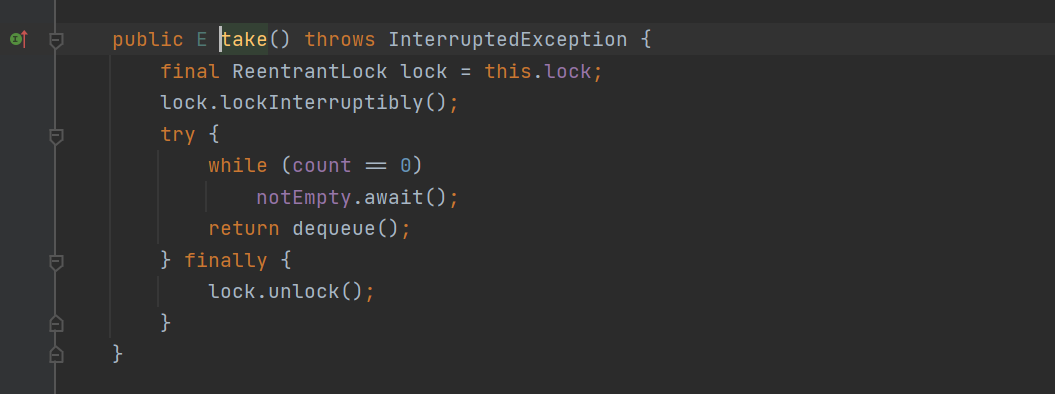
- take() method: obtain the reentrant lock and lock the try; If the number of queue elements is 0, let the thread wait in the notEmpty waiting pool (blocking), otherwise directly return dequeue(); Is the value, and then return the value
| For the put and take() methods above, while is required (not if), because if the thread in the pool is activated and other threads put in / take out data, making the queue full / empty again, there will be an error in executing after await |
|---|
- In addition, people who may not understand blocking will have such a question: does the while loop always cycle without consuming resources?
- In fact, while does not run all the time, because after the first judgment, the thread is blocked and does not continue to execute. When the thread is activated, the loop condition of while will be judged again. If the condition is still met, the logic can be executed
3. Linkedblockingqueue implementation class and source code (JDK1.8)
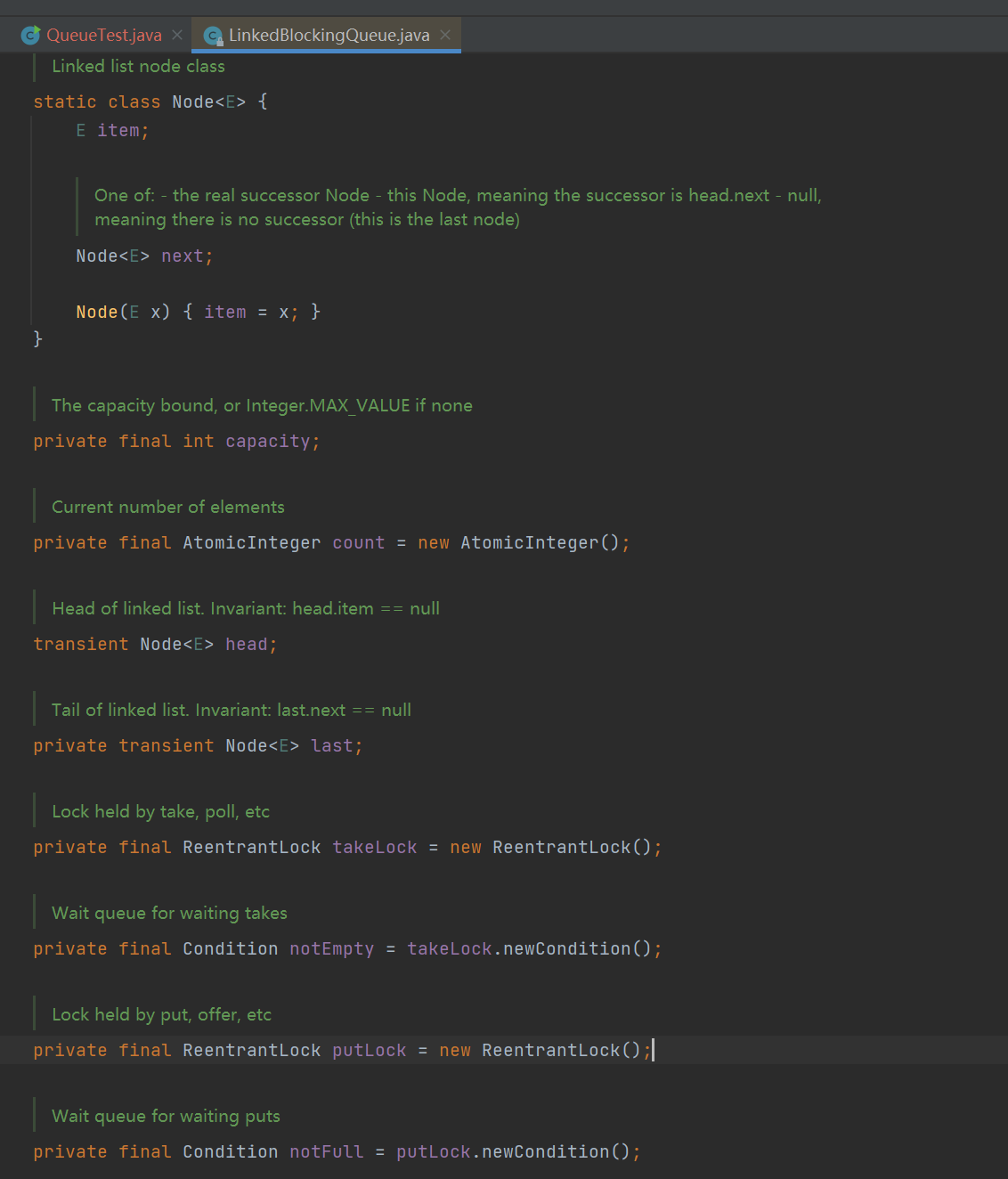
- The bottom layer is based on linked list (single linked list, each node has only successor), which supports simultaneous read and write operations. In case of concurrency, it is efficient. Selectable bounded queue
- The queue length can be specified or not. No upper limit is MAX_VALUE
- The operation effect is as like as two peas ArrayBlockingQueue, and not much is introduced.
- Bottom implementation parameters: linked list node < E >; Capacity limit, no is MAX_VALUE: capacity; Current number of elements count (AtomicInteger thread safe); Head and last of head and tail nodes; Reentrant lock (direct declaration) takeLock for placing data; putLock of data fetched by reentrant lock (direct declaration); Get element waiting pool notempty = takeLock newCondition(); Put element waiting pool notfull = putLock newCondition();
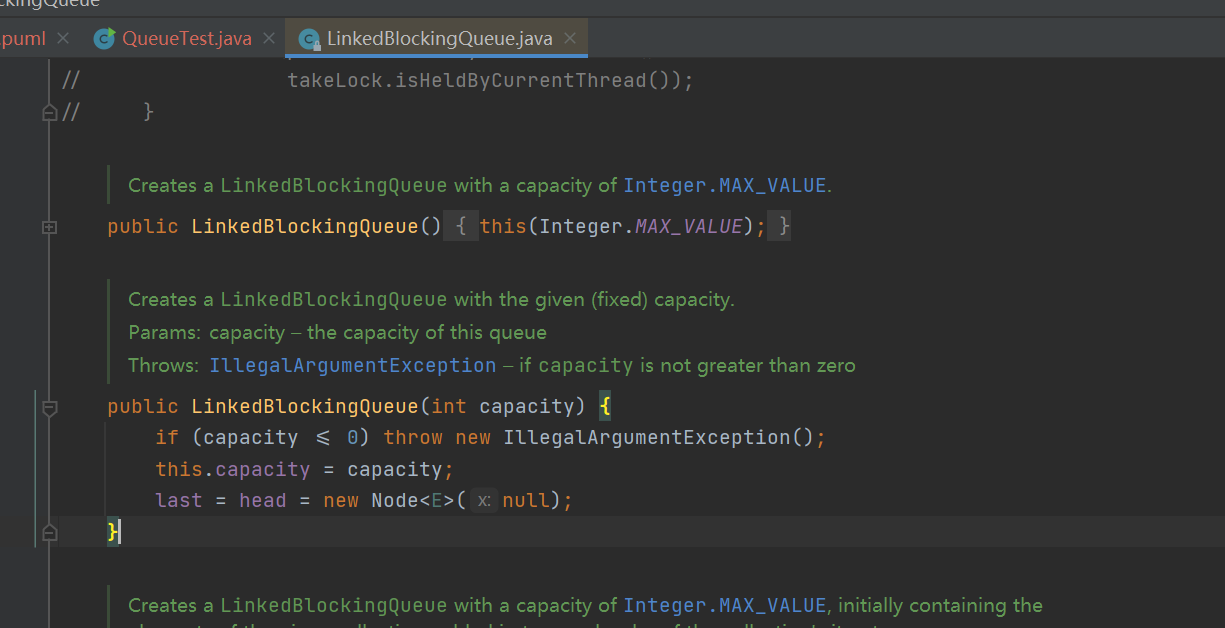
- Construction method: nonparametric construction, direct maximum value at the boundary, and parametric construction will specify the queue size; Finally, the queue is initialized. The head and tail pointers point to an empty node, indicating the previous node of the head node (useless node)
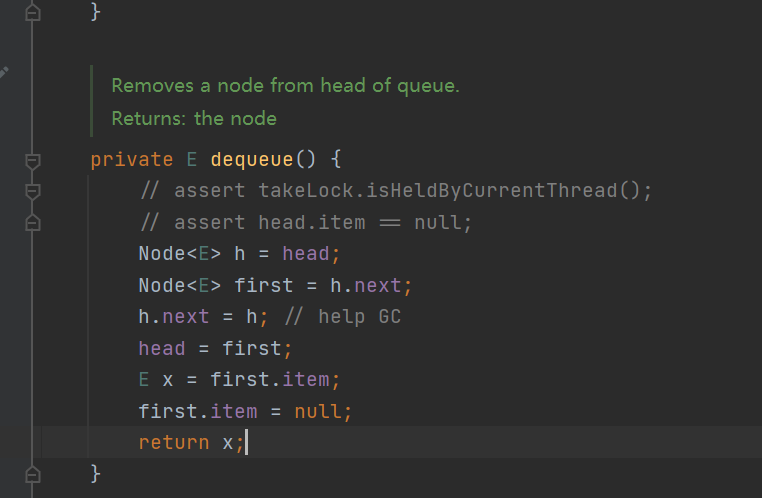
- enqueue() and dequeue(), queue in and queue out methods are the common queue methods implemented by linked lists. Let's briefly introduce dequeue out: save the previous waste node of the header node to h, obtain the header node and save it to first, and then let h recycle it. head points to first (first becomes a waste node), the value of first returns, and set the value of first to null (save space)
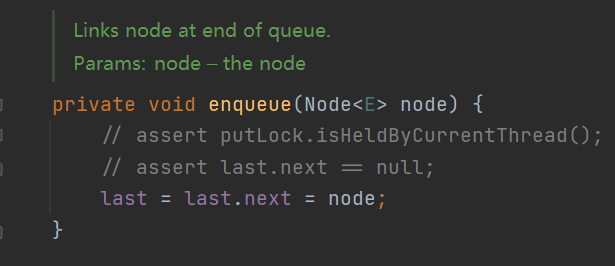
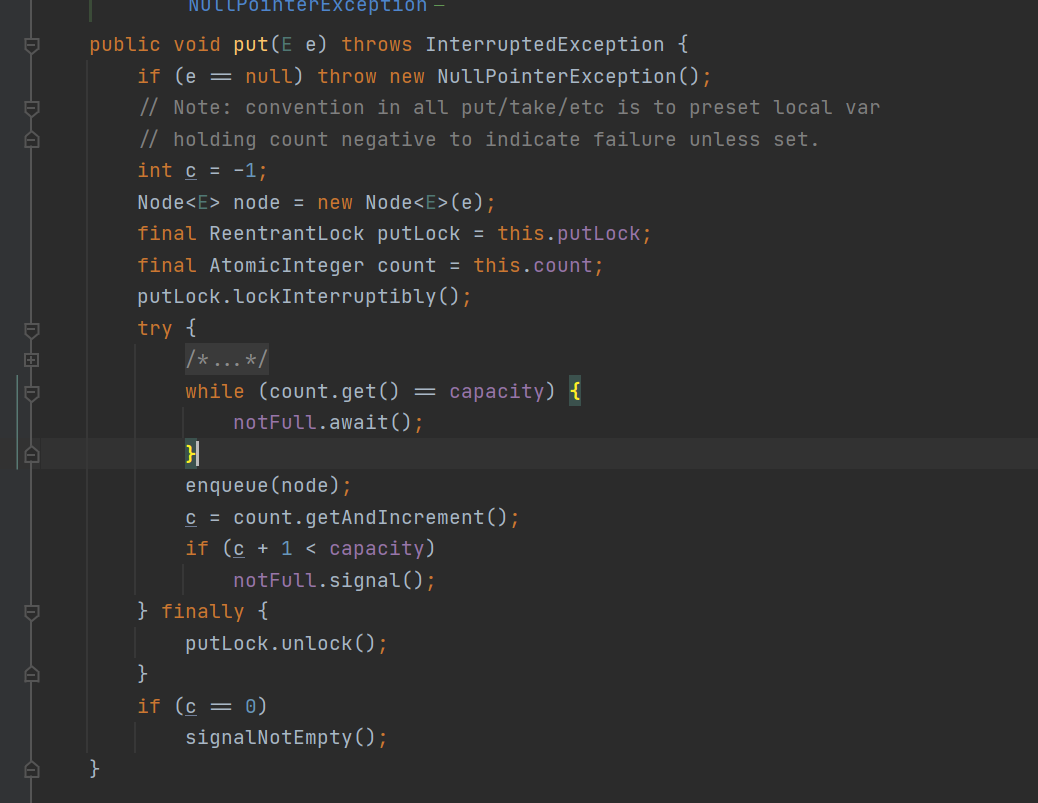
- put() method: obtain the lock and thread safe count; Lock try; If the queue is full, the thread is blocked in the notFull pool; otherwise, enqueue() is executed; Finally, let count + + (getAndIncrement: first + 1 and then get the value); At this time, if count+1 still does not cause the queue to be full, notify notFull to wait for the pool and activate the thread
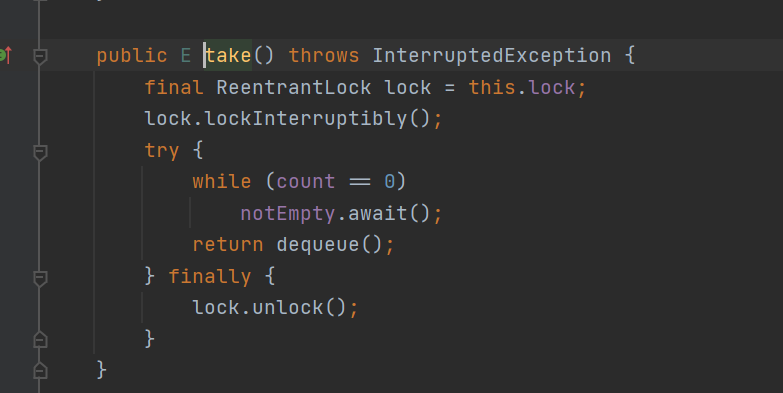
- take() method: take the lock and lock try; If the queue has no elements, it will be blocked. Otherwise, dequeue() will be executed
4. SynchronousQueue queue
| Synchronous queue: a special queue that facilitates efficient data transmission between threads |
|---|
| The capacity of this queue is 0. When inserting elements, there must be two threads fetching out at the same time |
|---|
| That is, when you insert an element into the queue, it will stand (block) with the element until a thread takes the element, and it will give the element to it |
| It is used to synchronize data, that is, a special queue for data interaction between threads |
package com.mashibing.juc.c_025;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.SynchronousQueue;
public class T08_SynchronusQueue { //Capacity is 0
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> strs = new SynchronousQueue<>();
new Thread(()->{//This thread is the consumer to get the value
try {
System.out.println(strs.take());//And synchronization queue values
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
strs.put("aaa"); //Blocking waiting for consumers to consume, they stand with aaa and wait for the thread to get it
//strs.put("bbb");
//strs.add("aaa");// Because the capacity is 0, an error will be reported directly if it is added
System.out.println(strs.size());
}
}
5. PriorityQueque queue
| Priority queue (binary tree algorithm, that is, sorting); The queue is accessed in sequence, and the data has different weights |
|---|
- Unbounded queue, no length limit, no length specified. The default initial length is 11, which can be specified manually
- The bottom layer maintains the Object array, which will be automatically expanded. If data is added all the time, it will be expanded until memory is exhausted and OutOfMemoryError (memory overflow) is reported before the program ends
- null elements and non comparable objects are not allowed (ClassCastException will be thrown)
- Object must implement an internal comparator or an external comparator
- Order means that when fetching out, it will be fetched according to the priority. When not saving, it will be saved according to the priority

import java.util.PriorityQueue;
public class T07_01_PriorityQueque {
public static void main(String[] args) {
PriorityQueue<String> q = new PriorityQueue<>();
q.add("c");
q.add("e");
q.add("a");
q.add("d");
q.add("z");
for (int i = 0; i < 5; i++) {
System.out.println(q.poll());
}
}
}
6. DelayQueue queue
| Unbounded blocking queue: it can only store the queue of Delayed objects. Therefore, when we want to use this queue, our class must implement the Delayed interface and override the getDelay and compareTo methods |
|---|
- An unbounded BlockingQueue is used to place objects that implement the Delayed interface. Objects in the queue can only be removed from the queue when they expire
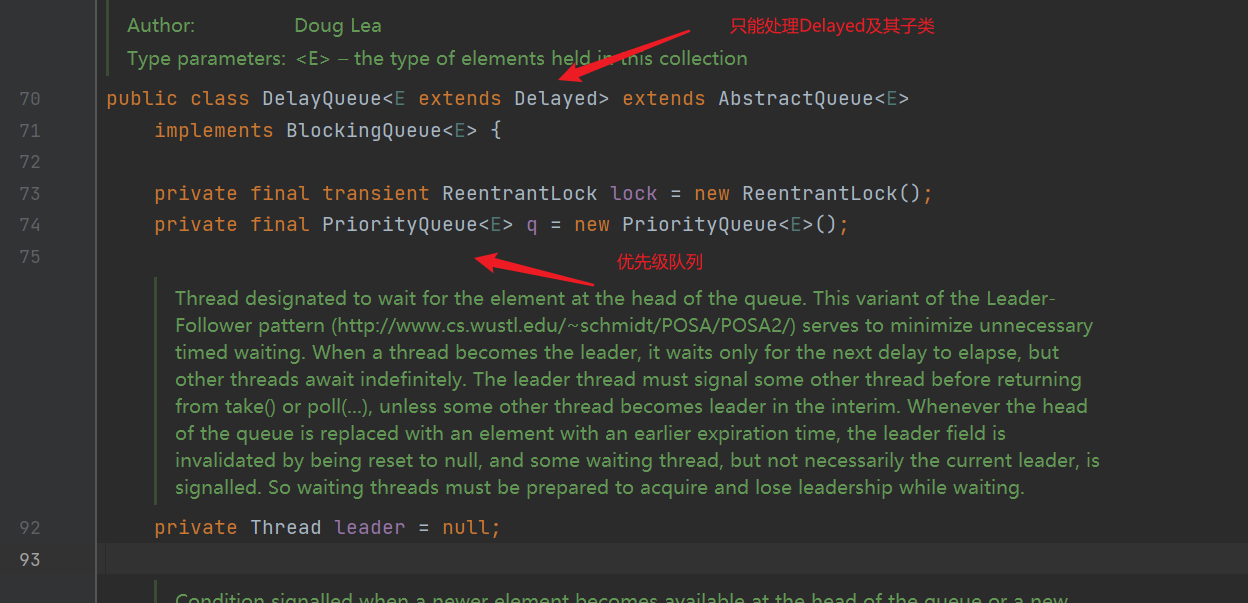
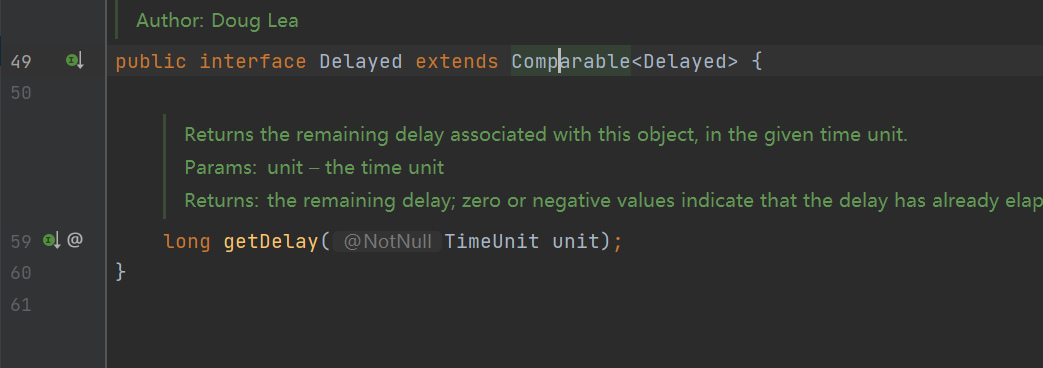
- When the producer thread calls methods such as put to add elements, it will trigger the compareTo method in the Delayed interface to sort (the elements in the queue are sorted according to the expiration time, not the queue entry order). The elements in the queue head arrive at the earliest, and the later the expiration time, the later the position
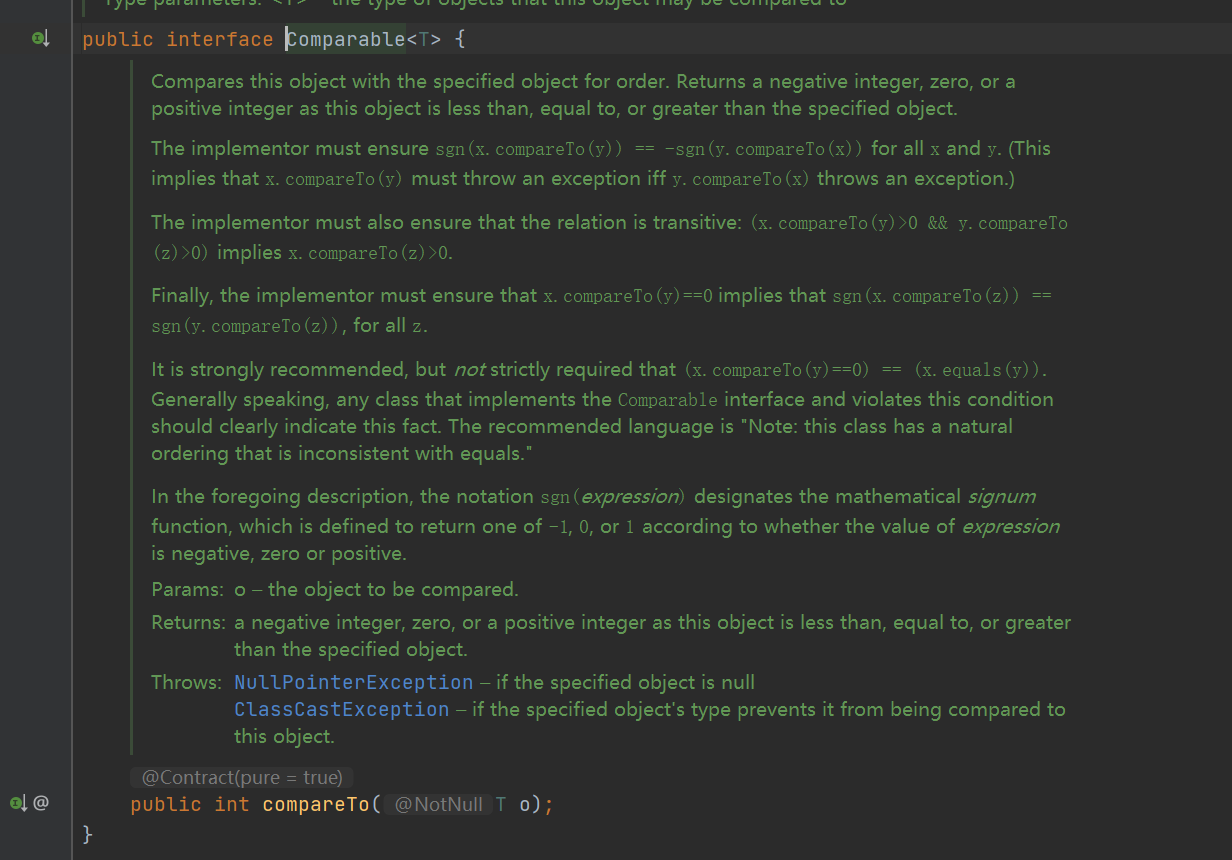
- The consumer thread looks at the elements of the queue header and then calls the getDelay method of the element. If the method returns less than 0 or equal to 0, the consumer thread will take the element from the queue. If it is greater than 0, then the return value is obtained. The consumer thread returns the corresponding time according to the return value, wait (blocking), then wakes up and extracts the element from the queue header.
- This queue also cannot put null values
- For Taobao orders, if there is no payment within 30 minutes after placing the order, the order will be automatically cancelled
- Hungry? Order a meal. Send a text message to the user 60s after the order is successfully placed
- Close idle connections. Many client connections in the server need to be closed after idle for a period of time
- Cache, objects in the cache, exceeding idle time, need to be removed from the cache
- Task timeout processing: when the network protocol sliding window requests responsive interaction, handle the requests that are not responded after timeout, etc
- Suppose I have a User class that implements the Delayed interface, and then I need to define an expiration time endTime. Then override the getDelay() method to return the remaining expiration time. Rewrite the compareTo() method to determine who has a shorter expiration time and who has a higher priority.
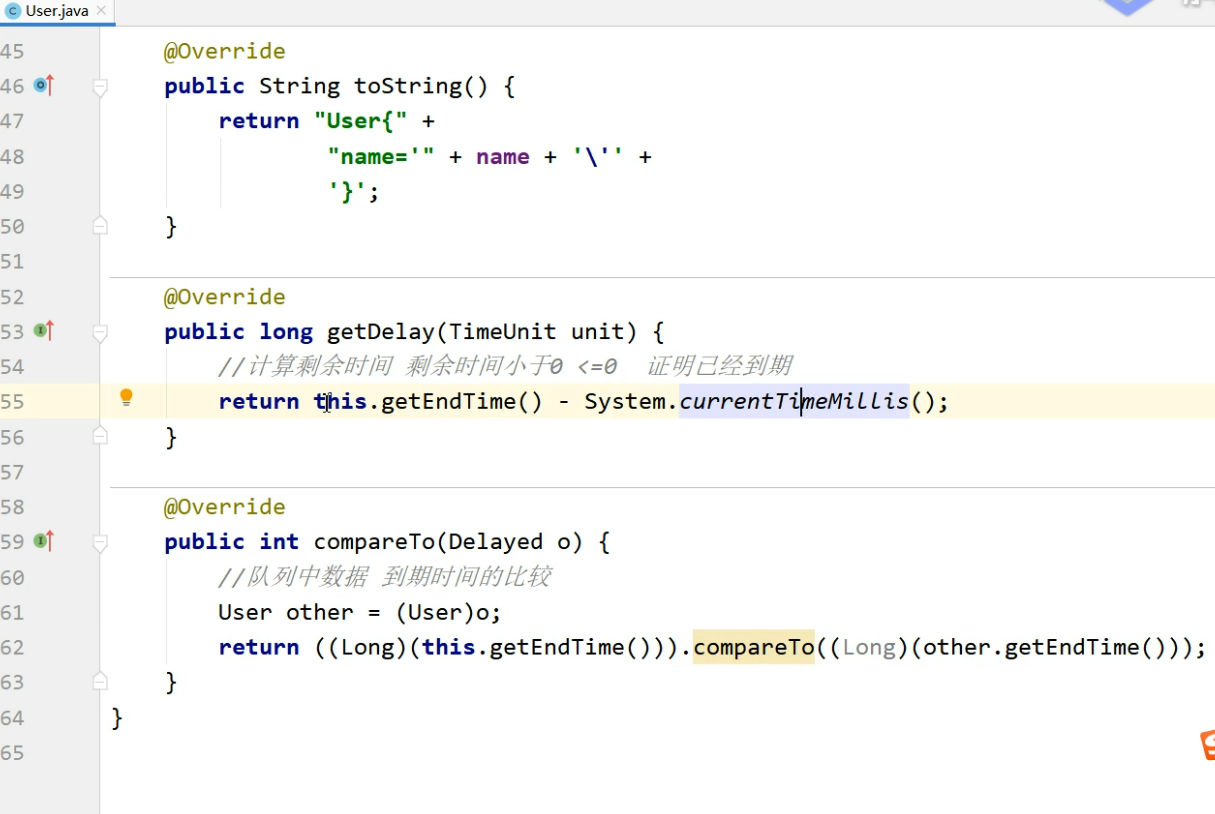
- It mainly provides the logout() method to take out the queue data. Other methods can be implemented if they are willing to
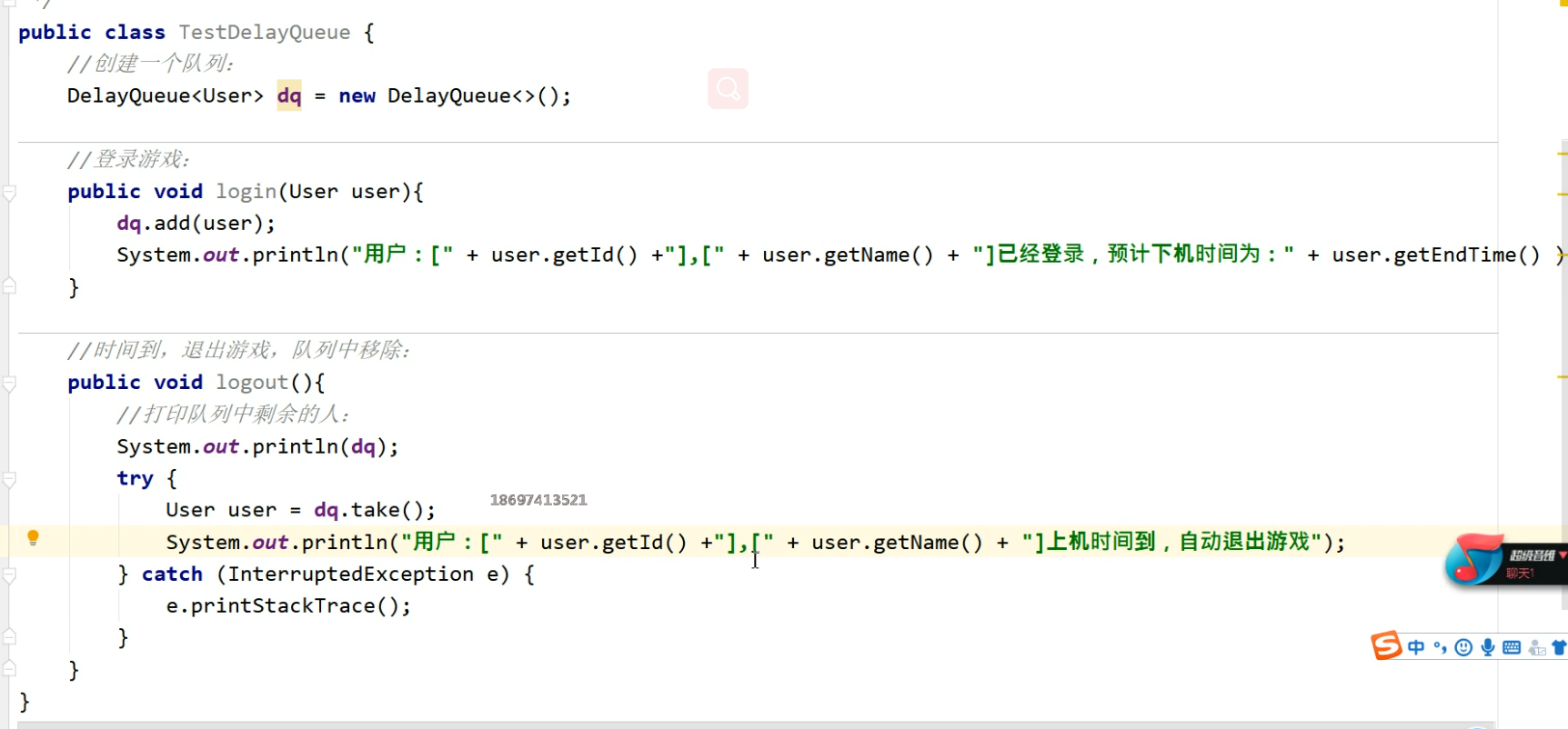
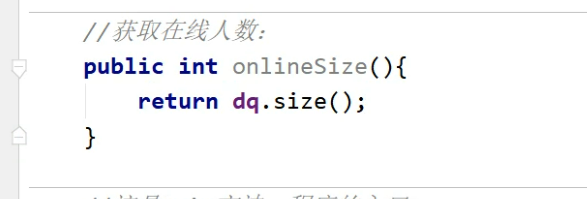
- Add 3 users and exit after 5 seconds, 2 seconds and 10 seconds respectively
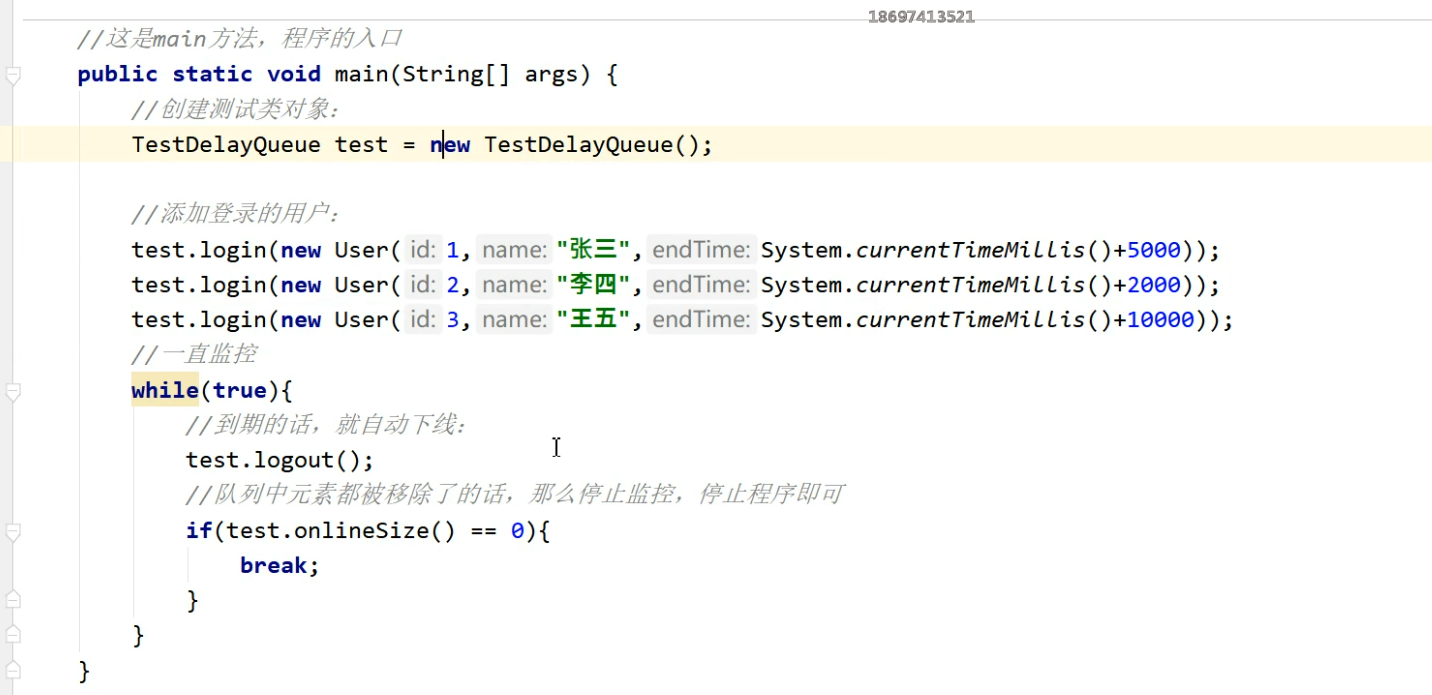

7. Deque double ended queue
| The front is placed at one end and taken at the other end; This can be placed or taken at both ends |
|---|
- It inherits from the Queue interface, that is, single ended operations. It also extends double ended operations on the basis of Queue (it can be seen that there are both addFirst front-end insertion and addLast back-end insertion)
- The operation is the same. There's nothing to say