1. Summary
For basic data types and user-defined types, we need to use precompiled instructions to ensure stack memory alignment, and rewrite operator new to ensure heap memory alignment. For nested custom types, the alignment of their internal data types will be automatically guaranteed when applying for stack memory, and operator new still needs to be overridden when applying for heap memory.
There is a special case not mentioned in this article. If you use std::vector, you need to pass in a custom memory applicant, that is, std::vector < vector4d, AlignedAllocator >, where AlignedAllocator is our custom memory applicant. This is because the std::vector uses the dynamically requested space to save data, so the default operator new cannot align its memory. When the operator new of the std::vector class cannot be overridden, the standard library provides a mechanism to customize the memory requester so that users can apply for memory in their own way. This paper will not start the specific practice. After understanding the previous content, this problem should be easy to solve.
2. EIGEN_MAKE_ALIGNED_OPERATOR_NEW
SSE supports 128bit multi instruction parallelism, but one requirement is that the processing object must start at an integer multiple of 16byte in the memory address. However, these details will be handled by Eigen when parallelizing.
However, if you put some Eigen structures into the std container, such as vector and map. These containers will continuously discharge one Eigen structure after another in memory.
It can be imagined that if these Eigen structures are not 16byte in size, after a continuous discharge, naturally many objects do not start at an integer multiple of 16byte.
Eigen provides two solutions:
Use special memory allocation objects
std::map<int, Eigen::Vector4f, std::less<int>, Eigen::aligned_allocator<std::pair<const int, Eigen::Vector4f> > > std::vector<Eigen::Vector4f,Eigen::aligned_allocator<Eigen::Vector4f> >
For vector, you need to add an additional header file #include < eigen / stdvector >
Use special macros when defining objects
EIGEN_DEFINE_STL_VECTOR_SPECIALIZATION(Matrix2d)
Note that you must use this macro before all Eigen objects appear
Eigen structures with this problem include:
Eigen::Vector2d Eigen::Vector4d Eigen::Vector4f Eigen::Matrix2d Eigen::Matrix2f Eigen::Matrix4d Eigen::Matrix4f Eigen::Affine3d Eigen::Affine3f Eigen::Quaterniond Eigen::Quaternionf
In addition, if these structures mentioned above are members of an object, for example:
class Foo
{
...
Eigen::Vector2d v;
...
};
...
Foo *foo = new Foo;
At this time, you need to use another macro in the class definition:
class Foo
{
...
Eigen::Vector2d v;
...
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
};
...
Foo *foo = new Foo;
Cause analysis: the internal memory allocation of the object is relative to the address of the object. If the address of the object is not 16 byte aligned, the members inside will not know this information, so there is no way to allocate the address of 16 byte to it. The solution is to force a 16 byte aligned address when allocating objects.
EIGEN_MAKE_ALIGNED_OPERATOR_NEW overloads the new function.
3. problem solver record
Check the memory problem with valgrind and find that all kinds of clues point to g2o. G2o is a SLAM back-end optimization library, which encapsulates a large number of SLAM related optimization algorithms, and Eigen is used internally for matrix operation.
Turn off the - march=native compilation option to run normally. In fact, this compilation option tells the compiler which SIMD instruction sets the current processor supports. In Eigen, SSE, AVX and other instruction sets are just used for vectorization acceleration. At this time, tactfully, I found a chapter in the Eigen document called Alignment issues, which mentioned that in some cases, Eigen objects may not have memory alignment, resulting in program crash.
Now that the evidence is complete, I can basically determine the real problem I have encountered: when compiling and installing g2o, it does not use - march=native by default, so the Eigen code in it does not use vectorization acceleration, so they do not have memory alignment. In my program, vectorization acceleration is enabled, and all Eigen objects are memory aligned. After the two programs are linked, once the misaligned Eigen object in g2o is passed to my code, the instruction of vectorization operation will trigger an exception. The solution is very simple. Either use - march=native or not.
4. Let's talk about vectorization and memory alignment.
What is vectorization?
Vectorization operation is to use SIMD (Single Instruction Multiple Data) instruction sets such as SSE and AVX to realize the operation of one instruction on multiple operands, so as to improve the code throughput and realize the acceleration effect. SSE is a series, from the original SSE to the latest SSE4 2. It supports simultaneous operation of 16 bytes of data, that is, 4 floats or 2 doubles. AVX is also a series. It is an upgraded version of SSE and supports simultaneous operation of 32 bytes of data, that is, 8 floats or 4 doubles.
But there is a premise for vectorization, that is, memory alignment. The operands of SSE must be aligned with 16 bytes, while the operands of AVX must be aligned with 32 bytes. In other words, if we have four float numbers, we must put them in a continuous memory space with a multiple of the first address of 16 before calling the SSE Instruction for operation.
A Simple Example
In order to give some intuitive feelings to students who have not been in contact with vectorization programming, I wrote a simple example program:
#include <immintrin.h>
#include <iostream>
int main() {
double input1[4] = {1, 1, 1, 1};
double input2[4] = {1, 2, 3, 4};
double result[4];
std::cout << "address of input1: " << input1 << std::endl;
std::cout << "address of input2: " << input2 << std::endl;
__m256d a = _mm256_load_pd(input1);
__m256d b = _mm256_load_pd(input2);
__m256d c = _mm256_add_pd(a, b);
_mm256_store_pd(result, c);
std::cout << result[0] << " " << result[1] << " " << result[2] << " " << result[3] << std::endl;
return 0;
}
This code uses the vectorization addition instruction in AVX to calculate the sum of 4 pairs of double at the same time. These four logarithms are stored in input1 and input2_ mm256_ load_ The PD instruction is used to load operands_ mm256_ add_ The PD instruction performs vectorization. Finally_ mm256_ store_ The PD instruction reads the operation result into the result. Unfortunately, the program runs to the first_ mm256_ load_ It collapsed at PD. The reason for the crash is that the input variables are not memory aligned. I specially printed out the addresses of two input variables, and the results are as follows
address of input1: 0x7ffeef431ef0 address of input2: 0x7ffeef431f10
As mentioned in the previous section, AVX requires 32 byte alignment. We can divide the addresses of these two input variables by 32 to see whether they can be divided. It is found that 0x7ffeef431ef0 and 0x7ffeef431f10 cannot be divisible. Of course, we can directly see whether the penultimate digit is an even number. If it is an even number, it can be divided by 32, and if it is an odd number, it can not be divided by 32.
How to align input variables with memory? We know that for local variables, their memory address is determined at compile time, that is, determined by the compiler. Therefore, we only need to tell the compiler to align the first address with 32 bytes when applying for space for input1 and input2, which needs to be implemented through precompiled instructions. The precompiled instructions of different compilers are different. For example, the syntax of gcc is__ attribute__((aligned(32))), the syntax of MSVC is__ declspec(align(32)) . Taking gcc syntax as an example, you can get the correct code with a few modifications
#include <immintrin.h>
#include <iostream>
int main() {
__attribute__ ((aligned (32))) double input1[4] = {1, 1, 1, 1};
__attribute__ ((aligned (32))) double input2[4] = {1, 2, 3, 4};
__attribute__ ((aligned (32))) double result[4];
std::cout << "address of input1: " << input1 << std::endl;
std::cout << "address of input2: " << input2 << std::endl;
__m256d a = _mm256_load_pd(input1);
__m256d b = _mm256_load_pd(input2);
__m256d c = _mm256_add_pd(a, b);
_mm256_store_pd(result, c);
std::cout << result[0] << " " << result[1] << " " << result[2] << " " << result[3] << std::endl;
return 0;
}
The output result is
address of input1: 0x7ffc5ca2e640 address of input2: 0x7ffc5ca2e660 2 3 4 5
It can be seen that both addresses are multiples of 32 this time, and the final operation result is completely correct.
Although the above code correctly implements the vectorization operation, the implementation method is too rough. Each variable declaration is preceded by a long string of precompiled instructions, which seems uncomfortable. Let's try refactoring this code.
5. Reconstruction
First, the easiest thing to think of is to declare a memory aligned double array as a custom data type, as shown below
using aligned_double4 = __attribute__ ((aligned (32))) double[4];
aligned_double4 input1 = {1, 1, 1, 1};
aligned_double4 input2 = {1, 2, 3, 4};
aligned_double4 result;
It looks much cooler. Further, if the four double is a frequently used data type, we can encapsulate it as a Vector4d class, so that the user can not see the specific implementation of memory alignment, as shown below.
#include <immintrin.h>
#include <iostream>
class Vector4d {
using aligned_double4 = __attribute__ ((aligned (32))) double[4];
public:
Vector4d() {
}
Vector4d(double d1, double d2, double d3, double d4) {
data[0] = d1;
data[1] = d2;
data[2] = d3;
data[3] = d4;
}
aligned_double4 data;
};
Vector4d operator+ (const Vector4d& v1, const Vector4d& v2) {
__m256d data1 = _mm256_load_pd(v1.data);
__m256d data2 = _mm256_load_pd(v2.data);
__m256d data3 = _mm256_add_pd(data1, data2);
Vector4d result;
_mm256_store_pd(result.data, data3);
return result;
}
std::ostream& operator<< (std::ostream& o, const Vector4d& v) {
o << "(" << v.data[0] << ", " << v.data[1] << ", " << v.data[2] << ", " << v.data[3] << ")";
return o;
}
int main() {
Vector4d input1 = {1, 1, 1, 1};
Vector4d input2 = {1, 2, 3, 4};
Vector4d result = input1 + input2;
std::cout << result << std::endl;
return 0;
}
This code implements the Vector4d class and puts the vectorization operation in operator +, and the main function becomes very simple.
But don't be happy too soon. This Vector4d actually has serious vulnerabilities. If we create objects dynamically, the program will still crash, such as this code
int main() {
Vector4d* input1 = new Vector4d{1, 1, 1, 1};
Vector4d* input2 = new Vector4d{1, 2, 3, 4};
std::cout << "address of input1: " << input1->data << std::endl;
std::cout << "address of input2: " << input2->data << std::endl;
Vector4d result = *input1 + *input2;
std::cout << result << std::endl;
delete input1;
delete input2;
return 0;
}
The output before crash is
address of input1: 0x1ceae70 address of input2: 0x1ceaea0
It's weird. It seems that the memory alignment we set just now has failed. The memory first address of these two input variables is not a multiple of 32.
6.Heap vs Stack
The root of the problem lies in different ways of object creation. The directly declared object is stored on the stack, and its memory address is determined by the compiler at compile time, so the precompiled instruction will take effect. However, objects created dynamically with new are stored in the heap, and their addresses are determined at run time. The runtime library of C + + does not care about the alignment of precompiled instruction declarations. We need more powerful means to ensure memory alignment.
The new keyword provided by C + + is a good thing. It avoids the ugly malloc operation in C language, but it also hides the implementation details. If we look at the official C + + documentation, we can find that new Vector4d actually does two things. The first step is to apply for a sizeof(Vector4d) size space, and the second step is to call the constructor of Vector4d. To achieve memory alignment, we must modify the way we apply for space in the first step. Fortunately, the first step actually calls the function operator new. We only need to rewrite this function to implement the custom memory application. The following is the Vector4d class after adding this function.
class Vector4d {
using aligned_double4 = __attribute__ ((aligned (32))) double[4];
public:
Vector4d() {
}
Vector4d(double d1, double d2, double d3, double d4) {
data[0] = d1;
data[1] = d2;
data[2] = d3;
data[3] = d4;
}
void* operator new (std::size_t count) {
void* original = ::operator new(count + 32);
void* aligned = reinterpret_cast<void*>((reinterpret_cast<size_t>(original) & ~size_t(32 - 1)) + 32);
*(reinterpret_cast<void**>(aligned) - 1) = original;
return aligned;
}
void operator delete (void* ptr) {
::operator delete(*(reinterpret_cast<void**>(ptr) - 1));
}
aligned_double4 data;
};
There are still some skills in the implementation of operator new. Let's explain it in detail. First, according to the C + + standard, the parameter count of operator new is the size of the space to be opened up. In order to ensure that the memory space with count size and 32 byte alignment can be obtained, we expand the actually applied memory space to count + 32. It is conceivable that in this count + 32 byte space, there must be a continuous count byte space with the first address as a multiple of 32. Therefore, in the second line of code, we first find the address smaller than the original and a multiple of 32 by performing some bit operations on the original address applied, and then add 32 to get the aligned address we want, which is recorded as aligned. Next, the third line of code is very critical. It saves the value of the original address in the previous position of the aligned address. The reason for doing so is that we also need to customize the memory free function operator delete. After all, the aligned address is not the actual requested address, so calling the default delete on this address will make an error. As you can see, we also define an operator delete in the code, and the passed in parameter is the aligned address returned by the previous operator new. At this time, the original address saved in the previous location of aligned is very useful. We just need to take it out and use the standard delete to free the memory.
In order to facilitate you to understand this code, there are several details that need to be specially emphasized The:: in operator new represents the global namespace, so you can call the standard operator new. The third line needs to convert aligned to void type first, because we want to save a void * type address in the previous location of aligned. Since the saved element is an address, the address corresponding to the location is the address, that is, void.
This is a small trick. Many memory management processes in C + + often have such operations. But I don't know if you have found a problem here: reinterpret_ Cast < void * * > (aligned) - 1 is this address necessarily in the space we apply for? In other words, does it have to be greater than original? The reason why this question exists is that - 1 here is actually minus one to the pointer. You know, in a 64 bit computer, the length of the pointer is 8 bytes, so the address obtained here is actually reinterpret_ cast<size_ t>(aligned) - 8. See the difference here. Subtracting 1 from the pointer is equivalent to subtracting 8 from the value of the address. So think about it carefully. If the distance from original to aligned is less than 8 bytes, this code will assign a value to the memory outside the requested space. It's terrible.
In fact, there's nothing terrible. Why do I dare to say so, because Eigen realized it in this way. This relies on the consensus of modern compilers that all memory allocations are 16 byte aligned by default. This fact can explain many problems. First, never worry about whether the distance from original to aligned will be less than 8. It will be stable at 16, which is enough to save a pointer. Second, why do we use AVX instruction set as an example instead of SSE? Because SSE requires 16 byte alignment, and modern compilers have defaulted to 16 byte alignment, this article cannot be expanded. Finally, why did my code run normally on NVIDIA TX2 and hang up on the server? Because TX2 is an ARM processor, the vectorization instruction set NEON only requires 16 byte alignment.
Nightmare again!
If you think it's over here, it's a big mistake. Another sinkhole is not shown to you. In the following code, my custom class Point contains a member of Vector4d. At this time
class Point {
public:
Point(Vector4d position) : position(position) {
}
Vector4d position;
};
int main() {
Vector4d* input1 = new Vector4d{1, 1, 1, 1};
Vector4d* input2 = new Vector4d{1, 2, 3, 4};
Point* point1 = new Point{*input1};
Point* point2 = new Point{*input2};
std::cout << "address of point1: " << point1->position.data << std::endl;
std::cout << "address of point2: " << point2->position.data << std::endl;
Vector4d result = point1->position + point2->position;
std::cout << result << std::endl;
delete input1;
delete input2;
delete point1;
delete point2;
return 0;
}
The output address is no longer a multiple of 32, and the program stops suddenly. Let's analyze why. In the main function, new Point dynamically creates a Point object. As mentioned earlier, this process is divided into two steps. The first step is to apply for the space required by the Point object, that is, the space of sizeof(Point), and the second step is to call the constructor of Point. We hope that the space applied in the first step just aligns the internal position object, which is unrealistic. Because the operator new of Vector4d is not called in the whole process, only the operator new of Point is called, and we have not rewritten this function.
Unfortunately, there is no elegant solution here. The only solution is to add a custom operator new in the Point class, which requires the assistance of users. The author of the class library is powerless. However, what the author of the class library can do is to make it easier for users to add operator new, such as encapsulating it as a macro definition. Users only need to add a macro in the Point class. Finally, the complete code is as follows.
#include <immintrin.h>
#include <iostream>
#define ALIGNED_OPERATOR_NEW
void* operator new (std::size_t count) {
void* original = ::operator new(count + 32);
void* aligned = reinterpret_cast<void*>((reinterpret_cast<size_t>(original) & ~size_t(32 - 1)) + 32);
*(reinterpret_cast<void**>(aligned) - 1) = original;
return aligned;
}
void operator delete (void* ptr) {
::operator delete(*(reinterpret_cast<void**>(ptr) - 1));
}
class Vector4d {
using aligned_double4 = __attribute__ ((aligned (32))) double[4];
public:
Vector4d() {
}
Vector4d(double d1, double d2, double d3, double d4) {
data[0] = d1;
data[1] = d2;
data[2] = d3;
data[3] = d4;
}
ALIGNED_OPERATOR_NEW
aligned_double4 data;
};
Vector4d operator+ (const Vector4d& v1, const Vector4d& v2) {
__m256d data1 = _mm256_load_pd(v1.data);
__m256d data2 = _mm256_load_pd(v2.data);
__m256d data3 = _mm256_add_pd(data1, data2);
Vector4d result;
_mm256_store_pd(result.data, data3);
return result;
}
std::ostream& operator<< (std::ostream& o, const Vector4d& v) {
o << "(" << v.data[0] << ", " << v.data[1] << ", " << v.data[2] << ", " << v.data[3] << ")";
return o;
}
class Point {
public:
Point(Vector4d position) : position(position) {
}
ALIGNED_OPERATOR_NEW
Vector4d position;
};
int main() {
Vector4d* input1 = new Vector4d{1, 1, 1, 1};
Vector4d* input2 = new Vector4d{1, 2, 3, 4};
Point* point1 = new Point{*input1};
Point* point2 = new Point{*input2};
std::cout << "address of point1: " << point1->position.data << std::endl;
std::cout << "address of point2: " << point2->position.data << std::endl;
Vector4d result = point1->position + point2->position;
std::cout << result << std::endl;
delete input1;
delete input2;
delete point1;
delete point2;
return 0;
}
In this code, the macro defines ALIGNED_OPERATOR_NEW includes operator new and operator delete, which are applicable to all classes requiring memory alignment. Therefore, you need to add this macro whether it is a class that needs memory alignment or a class that contains these classes.
7. Talk about Eigen again
There is such a page in Eigen's official documents
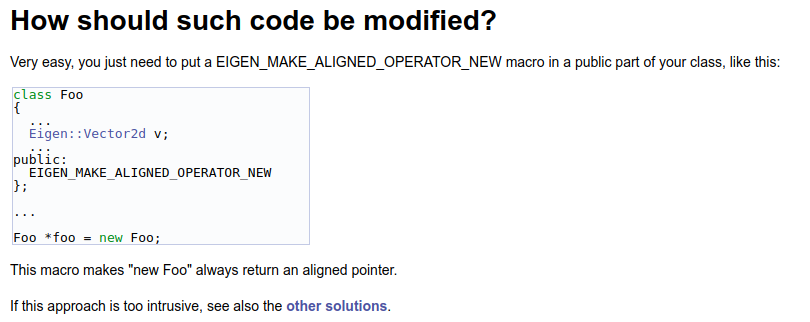
Do you feel deja vu? Eigen's solution to this problem coincides with ours. This is certainly not a coincidence. In fact, the inspiration of this article comes from eigen. But eigen only told us what to do without explaining its principle in detail. This paper analyzes the problems and specific solutions one by one, hoping to give you some deeper understanding.
8. References
https://blog.csdn.net/ziliwangmoe/article/details/87563498
Eigen Memory Issues ethz-asl/eigen_catkin wiki
How cmake compiles eigen c++_ On memory alignment from Eigen Vectorization