Operator SDK: read relevant documents and explain some commands in combination with the official sample built based on GO
Read and translate some contents in the official document of operator SDK, and use go language to combine the contents in the official document Building Operators Sample of Quickstart for Go-based Operators : a set of simple instructions to set up and run a go based operator, partially explain and explain the built operator framework and the purpose of the commands, and solve some problems encountered in the actual deployment.
1 Operator Scope
Namespace wide operators monitor and manage resources in a single namespace, while cluster wide operators monitor and manage resources throughout the cluster.
If the operator can create resources in any namespace, it should be cluster wide. If you want to deploy the operator flexibly, you should limit it to namespace scope. Namespace scope allows decoupling of namespace isolation for upgrades, failures, and monitoring, as well as different API definitions.
By default, operator SDK init builds cluster wide operators. The following describes in detail the conversion from the default cluster wide operator project to namespace wide operators. In general, the operator may be more suitable for cluster scope.
In main When creating a Manager instance in go, Namespaces are set through Manager Options. The Manager should provide monitoring and caching of these Namespaces for clients. Only cluster wide Managers can provide the management of cluster wide CRDs for clients.
1.1 Manager Watching Options
1.1.1 listen for resources in the entire namespace (default)
In main The Manager initialized in go defaults to the option without Namespace, or Namespace: '', which means that it will listen to the whole Namespace.
...
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
MetricsBindAddress: metricsAddr,
Port: 9443,
LeaderElection: enableLeaderElection,
LeaderElectionID: "f1c5ece8.example.com",
})
...
1.1.2 listening for resources in a single namespace
In order to limit the scope of a specific Namespace cached by the Manager, you need to set the value of Namespace in Options:
...
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
MetricsBindAddress: metricsAddr,
Port: 9443,
LeaderElection: enableLeaderElection,
LeaderElectionID: "f1c5ece8.example.com",
Namespace: "operator-namespace", //Set Namespace to listen to a single Namespace
})
...
1.1.3 listening for resources in multiple namespaces
You can use the MultiNamespacedCacheBuilder option in Options to listen to and manage resources in a collection of namespaces:
...
namespaces := []string{"foo", "bar"} // List of Namespaces
...
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
MetricsBindAddress: metricsAddr,
Port: 9443,
LeaderElection: enableLeaderElection,
LeaderElectionID: "f1c5ece8.example.com",
NewCache: cache.MultiNamespacedCacheBuilder(namespaces),
})
...
In the above example, CR S created in namespaces passed outside the option set will not be coordinated by their controllers because the manager does not manage the namespace.
1.2 restrict role s and permissions
The operator scope defines the scope of its Manager's cache, but does not define the permissions to access resources. After the scope of the Manager is updated to namespace, the service account of role-based access control (RBAC) should be restricted.
These permissions can be found in the directory config/rbac /, clusterrole in role yaml and ClusterRoleBinding in role_ binding. Yaml is used to grant operator s access to and manage their resources.
To change the scope of the operator, you only need to update the role yaml and role_ binding. yaml. Other RBAC lists, such as < kind >__ editor_ role. yaml,<kind>_ viewer_ role. Yaml and auth_proxy_*.yaml has nothing to do with changing the resource permission of the operator.
1.2.1 change RBAC permissions to a specific namespace
To change the scope of RBAC permissions from cluster scope to specific namespace, you need to do two things:
-
Use Roles instead of ClusterRoles, such as config / RBAC / role Yaml updated to:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: creationTimestamp: null name: manager-role namespace: memcached-operator-system
Then run make manifest to update config / RBAC / role yaml.
-
Use RoleBindings instead of ClusterRoleBindings. config/rbac/role_binding.yaml needs to be updated manually:
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: manager-rolebinding roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: manager-role subjects: - kind: ServiceAccount name: controller-manager namespace: system
1.3 dynamic configuration monitoring namespace
Not in main It is a good practice to hard code any Namespaces in the go file, using environment variables to allow restrictive configuration. The recommended namespace here is WATCH_NAMESPACE, which is a comma separated list of Namespaces passed to the manager at deployment time.
1.3.1 configure the Namespace of the operator
In main Add a function to go:
// getWatchNamespace returns the Namespace the operator should be watching for changes
func getWatchNamespace() (string, error) {
// WatchNamespaceEnvVar is the constant for env variable WATCH_NAMESPACE
// which specifies the Namespace to watch.
// An empty value means the operator is running with cluster scope.
var watchNamespaceEnvVar = "WATCH_NAMESPACE"
ns, found := os.LookupEnv(watchNamespaceEnvVar)
if !found {
return "", fmt.Errorf("%s must be set", watchNamespaceEnvVar)
}
return ns, nil
}
The function getWatchNamespace returns the Namespace that the operator should monitor for changes. watchNamespaceEnvVar is a constant specifically used to represent the environment variable of the Namespace to be monitored. If the value is empty, it means that the operator is running within the cluster.
In main Use environment variables in go and add the following code:
...
//Call the function defined above
watchNamespace, err := getWatchNamespace()
//If a nil is returned, it means that all namespaces (cluster wide) will be monitored
if err != nil {
setupLog.Error(err, "unable to get WatchNamespace, " +
"the manager will watch and manage resources in all namespaces")
}
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
MetricsBindAddress: metricsAddr,
Port: 9443,
LeaderElection: enableLeaderElection,
LeaderElectionID: "f1c5ece8.example.com",
Namespace: watchNamespace, // Scope when value is not nil
})
...
In config / Manager / manager Define environment variables in yaml:
spec:
containers:
- command:
- /manager
args:
- --leader-elect
image: controller:latest
name: manager
resources:
limits:
cpu: 100m
memory: 30Mi
requests:
cpu: 100m
memory: 20Mi
env:
- name: WATCH_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
terminationGracePeriodSeconds: 10
WATCH_NAMESPACE will set the namespace of the operator deployment here. For example, defined as ns1 and ns2:
...
env:
- name: WATCH_NAMESPACE
value: "ns1,ns2"
terminationGracePeriodSeconds: 10
...
Use the environment variable value and check whether it is a multi namespace scheme. Use the above example:
...
watchNamespace, err := getWatchNamespace()
if err != nil {
setupLog.Error(err, "unable to get WatchNamespace, " +
"the manager will watch and manage resources in all Namespaces")
}
// Define options
options := ctrl.Options{
Scheme: scheme,
MetricsBindAddress: metricsAddr,
Port: 9443,
LeaderElection: enableLeaderElection,
LeaderElectionID: "f1c5ece8.example.com",
Namespace: watchNamespace, // Scope when value is not nil
}
// Add support for MultiNamespace set in WATCH_NAMESPACE (e.g ns1,ns2)
// If the watchNamespace contains "," it indicates that it is a multi namespace scheme
if strings.Contains(watchNamespace, ",") {
setupLog.Info("manager set up with multiple namespaces", "namespaces", watchNamespace)
// Configure cluster scope using MultiNamespacedCacheBuilder
options.Namespace = ""
options.NewCache = cache.MultiNamespacedCacheBuilder(strings.Split(watchNamespace, ","))
}
// The parameters in NewManager use the defined options
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), options)
...
2 CRD Scope
Custom Resource definitions Custom Resource Definitions (CRDs) contain a scope field to determine whether the generated Custom Resource (CR) is a cluster scope or a namespace scope. When writing the operator, you can use the CRD in the namespace range to restrict the access to Cr in some namespaces, or access different versions of Cr in different namespaces. When writing an operator, you may need a cluster wide CRD to view and access CRs for all namespaces.
Use the operator SDK create API command to generate the CRD list. The generated CRD will be in the config/crd/bases directory. The spec.scope field of CRD controls the scope of API. The valid values are Cluster and namespace. In an operator SDK project, this value will be determined by the operator SDK create API -- named, which will edit types Go file. In other operator types, this command will directly modify the spec.scpoe field in the YAML list of CRD.
2.1 setting - named flag
When creating a new API, the - named tag controls whether the generated CRD is a cluster range or a namespace range. By default, - named is set to true, which sets the range to namespace. A simple example of creating a cluster wide API:
operator-sdk create api --group cache --version v1alpha1 --kind Memcached --resource=true --controller=true --namespaced=false
2.2 in type Set the scope tag in go
You can manually type in GO Add and change in GO file kubebuilder scope marker To set the scope of our resource. This file is in API / < version > / < kind >_ types. Go or API / < group > / < version > / < kind >_ types. Go location.
The following is an example of setting a tag to a cluster wide API type:
//+kubebuilder:object:root=true
//+kubebuilder:subresource:status
//+kubebuilder:resource:scope=Cluster
// Memcached is the Schema for the memcacheds API
type Memcached struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec MemcachedSpec `json:"spec,omitempty"`
Status MemcachedStatus `json:"status,omitempty"`
}
If you want to set to namespace scope, replace the tag with / / + kubebuilder:resource:scope=Namespace.
2.3 setting scope in CRD YAML file
scope can be manually modified in YAML of Kind in CRD.
The file is generally located in config / CRD / bases / < group >< domain>_< kind>. YAML. A simple example of modifying CRD of namespace range using YAML file:
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
annotations:
controller-gen.kubebuilder.io/version: v0.2.5
creationTimestamp: null
name: memcacheds.cache.example.com
spec:
group: cache.example.com
names:
kind: Memcached
listKind: MemcachedList
plural: memcacheds
singular: memcached
scope: Namespaced
subresources:
status: {}
...
3 test with EnvTest
The Operator SDK project recommends using envtest in the controller runtime to write tests for the Operator project. Envtest has a more active contributor community, which is more mature than the testing framework of the Operator SDK, and it does not need an actual cluster to run tests, which may be a great benefit in CI scenarios.
You can see that the controller will automatically create a Controllers / suite when building the project_ test. Go file, which contains a template file for performing integration test using ring envtest and gomega.
This test can be performed using the native GO command:
go test controllers/ -v -ginkgo.v
The project generated using the SDK tool has a Makefile that contains a target test when running make test. When make docker build img = < some registry > / < project name >: < tag > is executed, the target test will also be executed.
4 advanced
4.1 managing CR status conditions
A common pattern is to include Conditions in the state of CR. a Condition represents the latest available observations of the object state.
The Conditions field added to the MemcachedStatus structure simplifies the management of CR Conditions. It has the following functions:
- Allows callers to add and delete conditions.
- Make sure there are no duplicates.
- The conditions are sorted decisively to avoid unnecessary adjustments.
- Automatically process LastTransitionTime for each condition
- Provide a helpful method to easily determine the status of conditions.
To use condition status in CR, add a Conditions field to_ type. In go structure:
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
type MyAppStatus struct {
// Conditions represent the latest available observations of an object's state
Conditions []metav1.Condition `json:"conditions"`
}
Then, you can use the Conditions method in the controller to make it easier to set and remove Conditions or view their current values.
4.2 adding third-party resources to the Operator
The manager of the Operator supports all the core resource types of Kubernetes in the client go package, and will register all custom resource types in the project.
import (
cachev1alpha1 "github.com/example/memcached-operator/api/v1alpha1
...
)
func init() {
// Setup Scheme for all resources
utilruntime.Must(cachev1alpha1.AddToScheme(scheme))
//+kubebuilder:scaffold:scheme
}
To add a third-party resource to the operator, you must add it to the Manager's solution. You can easily add a resource to a scheme by creating an AddToScheme() method or reusing a method. The above example shows how to define a function and then use the runtime package to create a SchemeBuilder.
4.2.1 register in Manager scheme
Call AddToScheme() function for the third-party resource, and in main Go through Mgr Getscheme() or scheme to pass it to the Manager scheme.
import (
routev1 "github.com/openshift/api/route/v1"
)
func init() {
...
// Adding the routev1
utilruntime.Must(clientgoscheme.AddToScheme(scheme))
utilruntime.Must(routev1.AddToScheme(scheme))
//+kubebuilder:scaffold:scheme
...
}
4.2.2 if the third-party resource does not have AddToScheme() function
Use the scheme builder package in the controller runtime to initialize a new scheme builder so that it can be used to register third-party resources with the Manager's scheme.
For example, register NSEndpoints third-party resources from external DNS:
import (
...
// You need to use packages such as controller runtime
"k8s.io/apimachinery/pkg/runtime/schema"
"sigs.k8s.io/controller-runtime/pkg/scheme"
...
// DNSEndoints
externaldns "github.com/kubernetes-incubator/external-dns/endpoint"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
func init() {
...
log.Info("Registering Components.")
// Use scheme Builder initializes a new schemeBuilder
schemeBuilder := &scheme.Builder{GroupVersion: schema.GroupVersion{Group: "externaldns.k8s.io", Version: "v1alpha1"}}
schemeBuilder.Register(&externaldns.DNSEndpoint{}, &externaldns.DNSEndpointList{})
if err := schemeBuilder.AddToScheme(mgr.GetScheme()); err != nil {
log.Error(err, "")
os.Exit(1)
}
...
}
After adding the new import path to the operator project, if the vendor / directory exists in the root directory of the project, you need to run go mod vendor to meet these dependencies.
Before adding a controller in Setup all Controllers, you need to add a third-party resource.
4.3 clean up when deleting
Operators may create objects as part of their operations. The accumulation of these objects will consume some unnecessary resources, slow down the API and clutter the user interface. Therefore, it is very important to maintain a good operating environment for operators and clean up unnecessary resources. The following are some common scenarios.
4.3.1 internal resources
A correct example of resource cleanup is the Jobs application. When a Job is created, one or more Pods are also created as sub resources. When a Job is deleted, the associated Pods are also deleted. This is a very common pattern by setting the reference from the parent object (Job) to the child object (Pod). The following are the code fields to perform this operation, where "r" represents the reconciler and "ctrl" represents the controller runtime runtime.
ctrl.SetControllerReference(job, pod, r.Scheme)
Note: the default behavior of cascading deletion is background propagation, which means that the deletion request of the child object occurs after the request of the parent object.
4.3.2 external resources
Sometimes, when deleting a parent resource, you need to clean up external resources or resources that do not belong to custom resources, such as cross namespace resources. In this case, you can use Finalizers . The delete request for the object with Finalizers will become an update, and the delete timestamp will be set during the update; When Finalizers exist, the object is not deleted. Then, the coordination loop of the custom resource controller needs to check whether the delete timestamp is set, perform external cleanup, and then delete Finalizers to allow garbage collection of objects. There may be multiple Finalizers on an object. Each finalizer has a key, which should indicate which external resources the controller needs to delete.
The following is a theoretical controller file in controllers/memcached_controller.go application finalizer processing:
import (
...
"sigs.k8s.io/controller-runtime/pkg/controller/controllerutil"
)
const memcachedFinalizer = "cache.example.com/finalizer"
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
reqLogger := r.log.WithValues("memcached", req.NamespacedName)
reqLogger.Info("Reconciling Memcached")
// Get Memcached instance
memcached := &cachev1alpha1.Memcached{}
err := r.Get(ctx, req.NamespacedName, memcached)
if err != nil {
if errors.IsNotFound(err) {
// The request object could not be found. It may have been deleted after coordinating the request
// Owned objects are automatically garbage collected. For other cleanup logic, you need to use finalizers.
// return and do not re request
reqLogger.Info("Memcached resource not found. Ignoring since object must be deleted.")
return ctrl.Result{}, nil
}
// Error reading object - re request
reqLogger.Error(err, "Failed to get Memcached.")
return ctrl.Result{}, err
}
...
// Check whether the Memcached instance is marked for deletion, which will be indicated by a deletion timestamp
// If the deletion timestamp is not empty, it indicates that it is marked
isMemcachedMarkedToBeDeleted := memcached.GetDeletionTimestamp() != nil
if isMemcachedMarkedToBeDeleted {
if controllerutil.ContainsFinalizer(memcached, memcachedFinalizer) {
// Run the finalization logic to execute memcached finalizer.
// If the finalization logic fails, do not remove the finalizer so that we can try again during the next coordination
if err := r.finalizeMemcached(reqLogger, memcached); err != nil {
return ctrl.Result{}, err
}
// Remove memcached finalizer. Once all finalizers are deleted, the object will be deleted
controllerutil.RemoveFinalizer(memcached, memcachedFinalizer)
// to update
err := r.Update(ctx, memcached)
if err != nil {
return ctrl.Result{}, err
}
}
return ctrl.Result{}, nil
}
// Add finalizer to CR
// If the instance does not contain memcachedFinalizer, you need to add one
if !controllerutil.ContainsFinalizer(memcached, memcachedFinalizer) {
controllerutil.AddFinalizer(memcached, memcachedFinalizer)
// to update
err = r.Update(ctx, memcached)
if err != nil {
return ctrl.Result{}, err
}
}
...
return ctrl.Result{}, nil
}
func (r *MemcachedReconciler) finalizeMemcached(reqLogger logr.Logger, m *cachev1alpha1.Memcached) error {
// TODO(user): add the cleanup steps that the operator needs to perform before deleting the CR
// For example, it includes performing backup and deleting resources that do not belong to this CR, such as PVC
reqLogger.Info("Successfully finalized memcached")
return nil
}
4.3.3 complex clear logic
Similar to the previous scenario, finalizers can be used to implement complex cleanup logic. Taking CronJobs as an example, the controller maintains a limited list of jobs created by the CronJob controller to check whether they need to be deleted. The size of these lists is determined by CronJob Spec.successfuljobsshistorylimit and The spec.failedjobsshistorylimit field controls how many completed and failed jobs should be retained.
4.3.4 sensitive resources
Sensitive resources need to be protected against accidental deletion. An intuitive example of resource conservation is the relationship between PV and PVC. First create a PV, and then users can access the storage of the PV by creating a PVC request bound to the PV. If the user attempts to delete a PV currently bound by PVC, the PV will not be deleted immediately. Instead, the deletion of the PV is delayed until the PV is not bound to any PVC.
Therefore, you can use finalizers again to implement similar behavior for your CR similar to PV: by setting finalizer on the object, our controller can ensure that no remaining objects are bound to it before deleting the finalizer and deleting the object. In addition, the user who creates the PVC can specify what happens to the underlying storage allocated in the PV when the PVC is deleted through the recycling policy. There are several options available, and each option defines the behavior to be realized again by using the finalizer. The key concept is that the operator can let users decide how to clean up their resources through the finalizer, which can be dangerous, but it can also be useful, depending on the workload.
4.3.5 Leader election
In the life cycle of the operator, there may be multiple instances running at any given time (for example, when the operator is upgraded). In this case, it is necessary to avoid contention among multiple operators through leader election, so that only one leader instance handles reconciliation. At this time, other instances are inactive, but are ready to take over when the leader steps down.
There are two different leader election implementations to choose from, and each implementation has its own load balancing.
- Leader with lead: this leader pod regularly renews the lease of the leader, and gives up leadership when the lease cannot be renewed. This implementation allows rapid transition to new leaders when existing leaders are isolated. However, in some cases, brain fissure may occur.
- Leader for life: the leader pod is deleted only when it gives up leadership (through garbage collection). This implementation eliminates the possibility that two instances run incorrectly as leaders (brain crack). However, this approach may delay the election of new leaders. For example, when the leader pod is located on a node that has no response or has been separated, the pod eviction timeout indicates the time required for the leader pod to be deleted from the node and exit (the default is 5min).
The SDK starts the implementation of leader with lease by default.
4.3.5.1 Leader for life
The following example calls leader Become () will block the operator until it can become a leader by creating a configmap named memcached operator lock:
import (
...
"github.com/operator-framework/operator-lib/leader"
)
func main() {
...
err = leader.Become(context.TODO(), "memcached-operator-lock")
if err != nil {
log.Error(err, "Failed to retry for leader lock")
os.Exit(1)
}
...
}
If the operator is not running in the cluster, the leader Become () will return directly without error to skip the leader election because it cannot detect the operator's namespace.
4.3.5.2 Leader with lease
leader with lead can be elected through Manager Options:
import (
...
"sigs.k8s.io/controller-runtime/pkg/manager"
)
func main() {
...
opts := manager.Options{
...
LeaderElection: true,
LeaderElectionID: "memcached-operator-lock"
}
mgr, err := manager.New(cfg, opts)
...
}
If the operator is running within a cluster, the Manager will return an error at startup because it does not recognize the operator's namespace to create a configmap for leader election. You can override this namespace by setting the LeaderElectionNamespace option.
5 related
5.1 Controller Runtime Client API
controller-runtime The runtime provides various abstractions. Resources in kubernetes cluster have been monitored and coordinated through CRUD (create, Update, Delete, Get, List, etc.). The operator uses at least one controller to perform a set of coherent tasks in the cluster, usually through the combination of CRUD operations. The operator SDK uses the controller runtime client interface to provide interfaces for these operations.
The controller runtime defines several interfaces for cluster interaction:
- client.Client: implement CRUD operation on Kubernetes cluster.
- manager.Manager: manages shared dependencies, such as Caches and Clients.
- reconcile.Reconciler: compare the provided status with the actual cluster status, and use the Client to update the cluster when the status difference is found.
5.1.1 use of client
5.1.1.1 default Client
SDK depends on manager Manager to create a Client The Client interface performs Create, Update, Delete, Get, and List operations. Reconcile function reconcile Reconciler. The SDK will generate code to create a manager, which contains a Cache and a Client for CRUD operation and communication with API server.
The following code is controllers/memcached_controller.go, showing how the client of the Manager is passed to the reconciler:
import (
appsv1 "k8s.io/api/apps/v1"
ctrl "sigs.k8s.io/controller-runtime"
cachev1alpha1 "github.com/example/memcached-operator/api/v1alpha1"
)
func (r *MemcachedReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr). // mgr's Client is passed to r.
For(&cachev1alpha1.Memcached{}).
Owns(&appsv1.Deployment{}).
Complete(r)
}
type MemcachedReconciler struct {
client.Client // Populated above from a manager.Manager.
Log logr.Logger
Scheme *runtime.Scheme
}
The separated client reads (Get, List) from the Cache and writes (Create, Update, Delete) to the API server. Reading from the Cache greatly reduces the request load on the API server. As long as the Cache is updated by the API server, the read and write operations are consistent.
The interface under controller Runtime / PKG / client is embedded:
// Client knows how to perform CRUD operations on Kubernetes objects.
type Client interface {
Reader
Writer
StatusClient
// Scheme returns the scheme this client is using.
Scheme() *runtime.Scheme
// RESTMapper returns the rest this client is using.
RESTMapper() meta.RESTMapper
}
5.1.1.2 non default Client
The operator developer may want to create his own Client to serve the read requests (Get, List) from the API server instead of the read requests from the Cache. The controller runtime provides a constructor for Clients:
// New returns a new Client using the provided config and Options. func New(config *rest.Config, options client.Options) (client.Client, error)
client.Options allows the caller to specify how the new Client should communicate with the API server:
// Options is the option to create a Client
type Options struct {
// Scheme, if provided, will be used to map the structure of go to groupversionkings
Scheme *runtime.Scheme
// Mapper, if provided, will be used to map groupversionkings to Resources
Mapper meta.RESTMapper
}
For example:
import (
"sigs.k8s.io/controller-runtime/pkg/client/config"
"sigs.k8s.io/controller-runtime/pkg/client"
)
cfg, err := config.GetConfig()
...
c, err := client.New(cfg, client.Options{})
...
When Options is empty, the default value is set by Client New settings. The default scheme will register the core Kubernetes resource types, and the caller must register custom operator types for a new Client. These types have been recognized.
Creating a new Client is usually unnecessary and not recommended because the default Client is sufficient for most use cases
5.1.2 Reconcile and client APIs
Reconciler implements reconcile.Reconciler Interface that exposes the method of reconcile. Reconciler is added to the corresponding Controller of a certain type; Reconcile is called to respond to the response by reconcile The cluster or external event of the request object parameter reads and writes the cluster status through the Controller and returns Ctrl Result. SDK Reconcilers can access the Client to call the Kubernetes API.
// Memcached reconciler tunes a memcached object
type MemcachedReconciler struct {
// client, from Mgr client() to initialize
// It is a split client that reads objects from cache and writes them to apiserver
client.Client
Log logr.Logger
// scheme defines methods for serializing and deserializing API objects,
// Used to convert group, version and kind information to Go mode,
// And the mapping between different versions of Go patterns. scheme is the basis of versioned API and versioned configuration.
Scheme *runtime.Scheme
}
// Reconcile monitors events and reconciles the cluster state with the desired state defined in the method body.
// If error is not empty or result If request is true, the Controller will re request
// Otherwise, it will be deleted from the queue
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error)
Reconcile is where the Controller business logic exists, that is, through memcached reconciler Client makes Client API calls. client. The client performs the following operations:
GET
// Get retrieves the API object of the given object key from the Kubernetes cluster and stores it in obj. func (c Client) Get(ctx context.Context, key client.ObjectKey, obj client.Object) error
Note: client Objectkey is just types.NamespacedName Alias for.
Example:
import (
"context"
ctrl "sigs.k8s.io/controller-runtime"
cachev1alpha1 "github.com/example/memcached-operator/api/v1alpha1"
)
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
...
memcached := &cachev1alpha1.Memcached{}
err := r.Get(ctx, request.NamespacedName, memcached)
...
}
List
// List retrieves a list of objects with a given namespace and list options and stores the list in the list. func (c Client) List(ctx context.Context, list client.Object, opts ...client.ListOption) error
client.ListOption is a setting client.ListOptions Interface for the field. client.ListOption is created using one of the provided implementations: MatchingLabels, MatchingFields, InNamespace.
Example:
import (
"context"
"fmt"
"k8s.io/api/core/v1"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
)
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
...
// Return all pod s in the request namespace with label "instance = < name >" and stage "Running".
podList := &v1.PodList{}
opts := []client.ListOption{
client.InNamespace(request.NamespacedName.Namespace),
client.MatchingLabels{"instance": request.NamespacedName.Name},
client.MatchingFields{"status.phase": "Running"},
}
err := r.List(ctx, podList, opts...)
...
}
Create
// Create saves the object obj in the Kubernetes cluster func (c Client) Create(ctx context.Context, obj client.Object, opts ...client.CreateOption) error
client.CreateOption is a setting client.CreateOptions Interface for the field. client.CreateOption is created by using one of the provided implementations: DryRunAll ,ForceOwnership . These options are not normally required.
Example:
import (
"context"
"k8s.io/api/apps/v1"
ctrl "sigs.k8s.io/controller-runtime"
)
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
...
dep := &v1.Deployment{ // Any cluster object you want to create
...
}
err := r.Create(ctx, dep)
...
}
Update
// Update updates the obj given in the Kubernetes cluster. // obj must be a pointer to a structure so that it can be updated using the content returned by API server // Update does not update child resources with resource status func (c Client) Update(ctx context.Context, obj client.Object, opts ...client.UpdateOption) error
client.UpdateOption is a setting client.UpdateOptions Interface for the field. client.UpdateOption is created using one of the provided implementations: DryRunAll ,ForceOwnership . These options are not normally required.
Example:
import (
"context"
"k8s.io/api/apps/v1"
ctrl "sigs.k8s.io/controller-runtime"
)
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
...
dep := &v1.Deployment{}
// Get the object you want to update
err := r.Get(ctx, request.NamespacedName, dep)
...
// Select the running object to update
dep.Spec.Selector.MatchLabels["is_running"] = "true"
err := r.Update(ctx, dep)
...
}
Patch
// Patch modifies the obj given in the cluster // obj must be a pointer to a structure so that it can be updated using the content returned by API server func (c Client) Patch(ctx context.Context, obj client.Object, patch client.Patch, opts ...client.PatchOption) error
client.PatchOption is a setting client.PatchOptions Interface for the field. client.PatchOption is created using one of the provided implementations: DryRunAll ,ForceOwnership . These options are not normally required.
Example:
import (
"context"
"k8s.io/api/apps/v1"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
)
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
...
dep := &v1.Deployment{}
// Get the object you want to update
err := r.Get(ctx, request.NamespacedName, dep)
...
// merge patch will retain other fields modified at run time
patch := client.MergeFrom(dep.DeepCopy())
dep.Spec.Selector.MatchLabels["is_running"] = "true"
err := r.Patch(ctx, dep, patch)
...
}
Update status sub resource
Update from Client status subresource Must be used when StatusWriter . Use Status() to retrieve status sub resources and update or patch with Update().
Update() accepts client Updateoption, Patch() accepts client PatchOption.
Status
// Status() returns a StatusWriter object that is used to update its status sub resources func (c Client) Status() (client.StatusWriter, error)
Example:
import (
"context"
ctrl "sigs.k8s.io/controller-runtime"
cachev1alpha1 "github.com/example/memcached-operator/api/v1alpha1"
)
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
...
mem := &cachev1alpha1.Memcached{}
err := r.Get(ctx, request.NamespacedName, mem)
...
// Update
mem.Status.Nodes = []string{"pod1", "pod2"}
err := r.Status().Update(ctx, mem)
...
// Patch
patch := client.MergeFrom(mem.DeepCopy())
mem.Status.Nodes = []string{"pod1", "pod2", "pod3"}
err := r.Status().Patch(ctx, mem, patch)
...
}
Delete
// Delete deletes the given obj from the cluster func (c Client) Delete(ctx context.Context, obj client.Object, opts ...client.DeleteOption) error
client.DeleteOption is a setting client.DeleteOptions Interface for the field. client.DeleteOption is created by using one of the provided implementations: GracePeriodSeconds, Preconditions, PropagationPolicy.
Example:
import (
"context"
"k8s.io/api/core/v1"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
)
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
...
pod := &v1.Pod{}
err := r.Get(ctx, request.NamespacedName, pod)
...
if pod.Status.Phase == v1.PodUnknown {
// Delete the pod after 5 seconds.
err := r.Delete(ctx, pod, client.GracePeriodSeconds(5))
...
}
...
}
DeleteAllOf
// DeleteAllOf deletes all objects of the given type that match the given option func (c Client) DeleteAllOf(ctx context.Context, obj client.Object, opts ...client.DeleteAllOfOption) error
client.DeleteAllOfOption is a setting client.DeleteAllOfOptions Interface for the field. client.DeleteAllOfOption package client.ListOption and client.DeleteOption.
Example:
import (
"context"
"fmt"
"k8s.io/api/core/v1"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
)
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
...
// After the Delete delay of five minutes, Delete all pods with the tag "instance = < name >" and the stage "Failed" in the request namespace
pod := &v1.Pod{}
opts := []client.DeleteAllOfOption{
client.InNamespace(request.NamespacedName.Namespace),
client.MatchingLabels{"instance", request.NamespacedName.Name},
client.MatchingFields{"status.phase": "Failed"},
client.GracePeriodSeconds(5),
}
err := r.DeleteAllOf(ctx, pod, opts...)
...
}
5.2 Logging
operators generated by the Operator SDK are used logr Interface for logging. This log interface has several back ends, such as zap , the SDK uses it in the generated code by default. logr.Logger expose structured logging Method helps create a machine-readable log and adds a lot of information to the log record.
5.2.1 default zap logger
The Operator SDK uses the zap based logr backend when building projects. To help configure and use this logger, the SDK includes several helper functions.
In the following simple example, we use BindFlags() to add the zap flag set to the command line flag of the operator, and then use zap Options {} set the logger of the controller runtime.
By default, zap Options {} will return a logger available for production. It uses a JSON encoder to log from the info level. To customize the default behavior, you can use the zap flag set and specify flags on the command line. The zap flag set includes the following flags that can be used to configure the logger:
- --Zap devel: default value of development mode (encoder=consoleEncoder,logLevel=Debug,stackTraceLevel=Warn)
Default value of production mode (encoder=jsonEncoder,logLevel=Info,stackTraceLevel=Error); - --Zap encoder: zap log code ('json 'or' console ');
- --Zap log level: configure the zap level of log details. It can be 'debug', 'info', 'error', or any integer value > 0, which corresponds to the user-defined debugging level with increased detail;
- --Zap stacktrace level: capture the zap level of stacktrace ('info 'or' error ')
A simple example
Operators are in main The logger is set for all operator s in go. To illustrate how it works, look at the following example:
package main
import (
"sigs.k8s.io/controller-runtime/pkg/log/zap"
logf "sigs.k8s.io/controller-runtime/pkg/log"
)
//A log record named global was added
var globalLog = logf.Log.WithName("global")
func main() {
// Add the zap logger flag set to the CLI. The flag set must
// be added before calling flag.Parse().
opts := zap.Options{}
opts.BindFlags(flag.CommandLine)
flag.Parse()
logger := zap.New(zap.UseFlagOptions(&opts))
logf.SetLogger(logger)
scopedLog := logf.Log.WithName("scoped")
globalLog.Info("Printing at INFO level")
globalLog.V(1).Info("Printing at DEBUG level")
scopedLog.Info("Printing at INFO level")
scopedLog.V(1).Info("Printing at DEBUG level")
}
Operation results:
2022-01-13T15:56:16.982+0800 INFO global Printing at INFO level 2022-01-13T15:56:16.982+0800 DEBUG global Printing at DEBUG level 2022-01-13T15:56:16.982+0800 INFO scoped Printing at INFO level 2022-01-13T15:56:16.982+0800 DEBUG scoped Printing at DEBUG level
5.3 event filtering of Operator SDK using predictions
Events Assigned by to the resource being monitored by the controller Sources Generate. These events are controlled by EventHandlers Convert to a request and pass it to Reconcile(). Predicates Allows the controller to filter events before they are provided to EventHandlers. Filtering is very useful because the controller may only want to handle specific types of events. Filtering helps to reduce the number of interactions with the API server, because Reconcile() is called only for events converted by EventHandlers.
5.3.1 Predicate type
Predict implements the following methods that accept specific types of events and return true if the event should be handled by Reconcile():
// Predicate filters events before enqueuing the keys.
type Predicate interface {
Create(event.CreateEvent) bool
Delete(event.DeleteEvent) bool
Update(event.UpdateEvent) bool
Generic(event.GenericEvent) bool
}
// Funcs implements Predicate.
type Funcs struct {
CreateFunc func(event.CreateEvent) bool
DeleteFunc func(event.DeleteEvent) bool
UpdateFunc func(event.UpdateEvent) bool
GenericFunc func(event.GenericEvent) bool
}
For example, all creation events for any monitoring resource will be passed to FuncS Create() and filter it out when the calculation result of the method is false. If the predict method is not registered for a specific type, events of that type will not be filtered.
All event types contain Kubernetes about the object that triggered the event and the object itself metadata . The predict logic uses this data to determine what should be filtered. Some event types include other fields related to the semantics of the event, for example, event Updateevent contains old and new metadata and objects:
type UpdateEvent struct {
// ObjectOld is the object from the event.
ObjectOld runtime.Object
// ObjectNew is the object from the event.
ObjectNew runtime.Object
}
Using predictions
You can set any number of predictions for the controller through the builder WithEventFilter() method. If any of the predictions evaluates to false, the method filters the events. The first example is an implementation of memcached operator controller. The controller receives all deletion events, but we may only care about the unfinished events, so the controller only filters the deletion events on the pod that has been confirmed to be deleted:
import (
...
corev1 "k8s.io/api/core/v1"
...
cachev1alpha1 "github.com/example/app-operator/api/v1alpha1"
)
...
func ignoreDeletionPredicate() predicate.Predicate {
return predicate.Funcs{
UpdateFunc: func(e event.UpdateEvent) bool {
// Ignore update metadata CR with no change in generation status
return e.ObjectOld.GetGeneration() != e.ObjectNew.GetGeneration()
},
DeleteFunc: func(e event.DeleteEvent) bool {
// If the deletion of the object is confirmed, the calculation result is false.
return !e.DeleteStateUnknown
},
}
}
func (r *MemcachedReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&cachev1alpha1.Memcached{}).
Owns(&corev1.Pod{}).
WithEventFilter(ignoreDeletionPredicate()).
Complete(r)
}
...
}
6 Go Operator Tutorial
Build and run a Go based operator drill.
Create a sample project to understand how it works. This example will:
- If Memcached Deployment does not exist, create it
- Ensure that the size of the Deployment is the same as that of the Memcached CR spec
- Use the status writer to update the Memcached CR status according to the CR name
Create a new project
Use the CLI to create a new memcached operator project
mkdir -p $HOME/projects/memcached-operator cd $HOME/projects/memcached-operator # we'll use a domain of example.com # so all API groups will be <group>.example.com operator-sdk init --domain example.com --repo github.com/example/memcached-operator
Command init
View the operator SDK init command:
operator-sdk init --help
Initialize a new project including the following files:
- a "go.mod" with project dependencies
- a "PROJECT" file that stores project configuration
- a "Makefile" with several useful make targets for the project
- several YAML files for project deployment under the "config" directory
- a "main.go" file that creates the manager that will run the project controllers
Usage:
operator-sdk init [flags]
Flags:
--component-config create a versioned ComponentConfig file, may be 'true' or 'false'
--domain string domain for groups (default "my.domain")
--fetch-deps ensure dependencies are downloaded (default true)
-h, --help help for init
--license string license to use to boilerplate, may be one of 'apache2', 'none' (default "apache2")
--owner string owner to add to the copyright
--project-name string name of this project
--project-version string project version (default "3")
--repo string name to use for go module (e.g., github.com/user/repo), defaults to the go package of the current working directory.
--skip-go-version-check if specified, skip checking the Go version
Global Flags:
--plugins strings plugin keys to be used for this subcommand execution
--verbose Enable verbose logging
Example:
Examples: # Initialize a new project with your domain and name in copyright operator-sdk init --plugins go/v3 --domain example.org --owner "Your name" # Initialize a new project defining an specific project version operator-sdk init --plugins go/v3 --project-version 3
official:
operator-sdk init --domain example.com --repo github.com/example/memcached-operator
If the init is not done under $GOPATH/src, you must specify a repo. In fact, the address of the repo does not exist. In actual development, you can specify the address of the github first, and then push the github for open source.
Command create
The create command is a scaffold for creating kubernetes api and webhook. The available parameters are api and webhook.
View the operator SDK create command:
operator-sdk create --help
Scaffold a Kubernetes API or webhook.
Usage:
operator-sdk create [command]
Available Commands:
api Scaffold a Kubernetes API
webhook Scaffold a webhook for an API resource
Flags:
-h, --help help for create
Global Flags:
--plugins strings plugin keys to be used for this subcommand execution
--verbose Enable verbose logging
Use "operator-sdk create [command] --help" for more information about a command.
Select api and view the detailed commands of operator SDK create api:
Build the Kubernetes API by writing resource definitions, resource and controller.
If the information about the resource and controller is not explicitly provided, it will prompt the user whether it should be provided.
After the scaffold is written, the dependency will be updated and make generate will be run.
operator-sdk create api --help
Scaffold a Kubernetes API by writing a Resource definition and/or a Controller.
If information about whether the resource and controller should be scaffolded
was not explicitly provided, it will prompt the user if they should be.
After the scaffold is written, the dependencies will be updated and
make generate will be run.
Usage:
operator-sdk create api [flags]
Flags:
--controller if set, generate the controller without prompting the user (default true)
--force attempt to create resource even if it already exists
--group string resource Group
-h, --help help for api
--kind string resource Kind
--make make generate if true, run make generate after generating files (default true)
--namespaced resource is namespaced (default true)
--plural string resource irregular plural form
--resource if set, generate the resource without prompting the user (default true)
--version string resource Version
Global Flags:
--plugins strings plugin keys to be used for this subcommand execution
--verbose Enable verbose logging
Example:
Examples: # Create a frigates API with Group: ship, Version: v1beta1 and Kind: Frigate operator-sdk create api --group ship --version v1beta1 --kind Frigate # Write api scheme nano api/v1beta1/frigate_types.go # Write Controller controller nano controllers/frigate/frigate_controller.go # Edit the Controller Test nano controllers/frigate/frigate_controller_test.go # Generate the manifests make manifests # Use the kubectl apply command to deploy CRDs to the Kubernetes cluster make install # Regenerate code and run against the Kubernetes cluster configured by ~/.kube/config make run
official:
#Create a domain with example com operator-sdk init --domain example.com --repo github.com/example/memcached-operator #Specify group as cache and version as v1alpha1 operator-sdk create api --group cache --version v1alpha1 --kind Memcached --resource --controller
– controller if set, the controller controller is generated without prompting the user (the default is true).
Controller: memcached will be generated under memcached operator / controllers_ controller. go
– resource if set, the resource is generated without prompting the user (the default is true).
resource: memcached will be generated under memcached operator / API / v1alpha1_ types. go
yaml will be generated in the simple folder under the config folder:
apiVersion: cache.example.com/v1alpha1 kind: Memcached metadata: name: memcached-sample spec: # Add fields here
Manager
The main program of the operator is main Go, initialize and run the Manager.
Manager can limit the resources that all controllers will monitor:
mgr, err := ctrl.NewManager(cfg, manager.Options{Namespace: namespace})
By default, this will be the namespace of the operator runtime. To monitor all namespaces, you need to leave the namespace options blank:
mgr, err := ctrl.NewManager(cfg, manager.Options{Namespace: ""})
This with 1.1 Manager Watching Option Consistent with the description of.
Create API and Controller
Create a CRD API, where the group is cache, the version is v1alpha1, and the type is Memcached. When prompted, enter y to create the resource and controller.
$ operator-sdk create api --group cache --version v1alpha1 --kind Memcached --resource --controller Writing scaffold for you to edit... api/v1alpha1/memcached_types.go controllers/memcached_controller.go ...
This will build an API for Memcached resources in the directory api/v1alpha1/memcached_types.go, the controller is in the directory controllers/memcached_controller.go.
In general, it is recommended that a controller be responsible for managing each API created for the project to properly follow controller-runtime Set your design goals.
Define API
First, we will represent the API by defining the memcached type, which has memcachedspec The size field is used to set the number of memcached instances (CRs) to be deployed and a memcachedstatus Nodes field to store the name of the Pod of the CR.
API / v1alpha1 / memcached_ types. The definition of Go type in Go is modified to the following spec and status to define the API of Memcached Custom Resource(CR):
// MemcachedSpec defines the desired state of Memcached
type MemcachedSpec struct {
//+kubebuilder:validation:Minimum=0
// Size is the size of the memcached deployment
Size int32 `json:"size"`
}
// MemcachedStatus defines the observed state of Memcached
type MemcachedStatus struct {
// Nodes are the names of the memcached pods
Nodes []string `json:"nodes"`
}
Size is the number of memcached type deployments, and its minimum value is set to 0.
By adding + kubebuilder:subresource:status marker take status subresource Add to the CRD manifest so that the controller can update the CR status without changing the rest of the CR object:
// Memcached is the Schema for the memcacheds API
//+kubebuilder:subresource:status
type Memcached struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec MemcachedSpec `json:"spec,omitempty"`
Status MemcachedStatus `json:"status,omitempty"`
}
Modification*_ types. After the go file, you must run the following command to update the generated code of the resource type:
make generate
The makefile target above will call controller-gen Utility to update the generated api/v1alpha1/zz_generated.deepcopy.go file to ensure that the go type definition of the API can implement the runtime applied to the Kind type Object interface.
Generate CRD manifest
After using the spec/status field and CRD to validate the markers definition API, you can generate and update CRD manifests using the following command:
make manifests
The makefile target will call controller-gen In config / CRD / bases / cache example. com_ memcacheds. Generate CRD manifests at yaml:
shark@root:~/go-project/memcached-operator$ make generate /home/shark/go-project/memcached-operator/bin/controller-gen object:headerFile="hack/boilerplate.go.txt" paths="./..." shark@root:~/go-project/memcached-operator$ make manifests /home/shark/go-project/memcached-operator/bin/controller-gen rbac:roleName=manager-role crd webhook paths="./..." output:crd:artifacts:config=config/crd/bases
You can see that the yaml file has changed, and the yaml of crd has added the following contents:
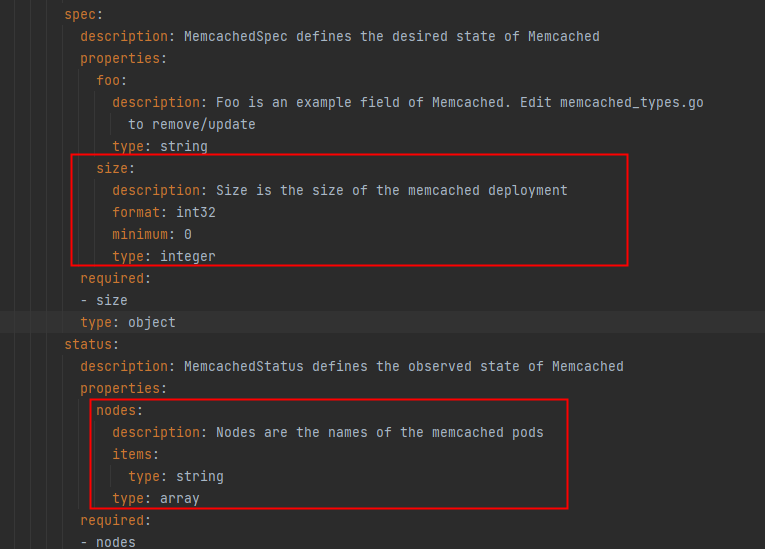
OpenAPI validation
When the manifest is generated, the OpenAPIv3 pattern is added to the CRD manifest in the spec.validation block. This validation block allows Kubernetes to validate the attributes of Memcached custom resources when they are created or updated.
Markers (note) can be used to configure validation for the API, and these tags will always have the prefix + kubebuilder:validation.
kubebuilder CRD generation and marker The use of tags in API code is discussed in the document. A complete list of OpenAPIv3 validation tags can be found here CRD Validation - The Kubebuilder Book .
Implement Controller
For this example, use memcached_controller.go
Replace the generated controller file controllers/memcached_controller.go
The next two sections will explain how the controller monitors resources and triggers the loop loop of reconcile.
The Controller monitors Resources
In Controllers / memcached_ controller. The SetupWithManager() function in go specifies how the controller builds the monitoring CR and other resources owned and managed by the controller.
import (
...
appsv1 "k8s.io/api/apps/v1"
...
)
func (r *MemcachedReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&cachev1alpha1.Memcached{}).
Owns(&appsv1.Deployment{}).
Complete(r)
}
The function NewControllerManagedBy() provides a controller generator that allows various controllers to be configured, such as the WithEventFilter filtering option mentioned in 5.3.
For (& cachev1alpha1. Memcached {}) specifies the memcached type as the primary resource to monitor. For each Add/Update/Delete event (event) of Memcache type, the coordination loop reconcile loop will send a reconcile request (namespace / name key) for the memcached object.
Owners (& appsv1. Deployment {}) specifies the deployment type as the secondary resource to monitor. For each deployment type Add/Update/Delete event, the event handler maps each event to the reconcile Request in the coordination request of the deployment Owner. In this case, it is a Memcached object created by deployment.
Controller configuration
When initializing the controller, you can make many other useful configurations. For details of these configurations, you can refer to builder and controller .
-
Set the maxconcurrent Reconciles option for the controller by using the predictions filter. The default value is 1. Set here to 2:
func (r *MemcachedReconciler) SetupWithManager(mgr ctrl.Manager) error { return ctrl.NewControllerManagedBy(mgr). For(&cachev1alpha1.Memcached{}). Owns(&appsv1.Deployment{}). WithOptions(controller.Options{MaxConcurrentReconciles: 2}). Complete(r) } -
use predicates Set filtering options
-
choice EventHandler To change how monitoring events are converted to reconcile requests of reconcile loop. For operator relationships that are more complex than primary and secondary resources, you can use EnqueueRequestsFromMapFunc The processor converts the monitoring event into any set of coordination requests.
Reconcile loop
The tuning function can be responsible for enforcing the required CR state on the actual state of the system. Each time the monitored CR or resource changes, it will run and return the corresponding value according to whether these states match.
Through this method, each controller has a Reconcile() method, which has the function of realizing tuning cycle. The Reconcile loop passes the request parameters Request , this parameter is applicable to finding the Namespace/Name key of the main resource object Memcached from the Cache:
import (
ctrl "sigs.k8s.io/controller-runtime"
cachev1alpha1 "github.com/example/memcached-operator/api/v1alpha1"
...
)
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
// Find the Memcached instance in this reconcile request
memcached := &cachev1alpha1.Memcached{}
err := r.Get(ctx, req.NamespacedName, memcached)
...
}
Here are some options that Reconciler may return:
-
error occurred:
return ctrl.Result{}, err -
No error occurred:
return ctrl.Result{Requeue: true}, nil -
Stop Reconcile:
return ctrl.Result{}, nil -
Reconcile after X time:
return ctrl.Result{RequeueAfter: nextRun.Sub(r.Now())}, nil
Specify permissions and generate RBAC list
Controller requires specific RBAC Permission to interact with the resources it manages RBAC markers Specified as follows:
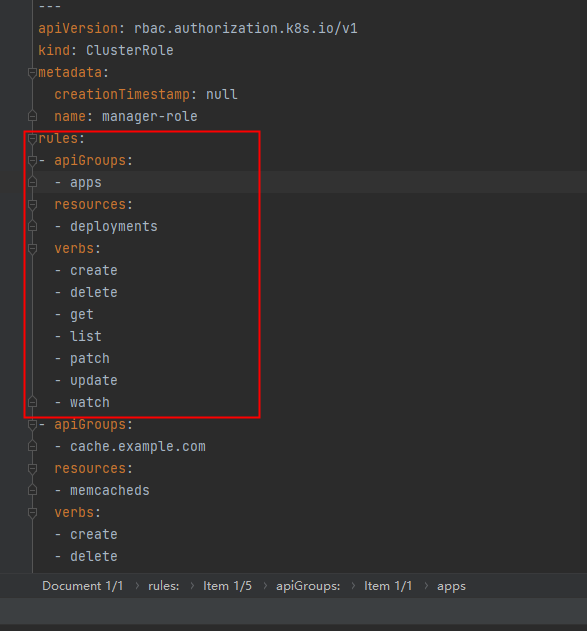
//+kubebuilder:rbac:groups=cache.example.com,resources=memcacheds,verbs=get;list;watch;create;update;patch;delete
//+kubebuilder:rbac:groups=cache.example.com,resources=memcacheds/status,verbs=get;update;patch
//+kubebuilder:rbac:groups=cache.example.com,resources=memcacheds/finalizers,verbs=update
//+kubebuilder:rbac:groups=apps,resources=deployments,verbs=get;list;watch;create;update;patch;delete
//+kubebuilder:rbac:groups=core,resources=pods,verbs=get;list;
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
...
}
The ClusterRole list is located in config / RBAC / role Yaml, which is generated from the above markers by the following command:
make manifests
//+kubebuilder:rbac:groups=apps,resources=deployments,verbs=get;list;watch;create;update;patch;delete //+kubebuilder:rbac:groups=core,resources=pods,verbs=get;list;
These two commands are not available in the originally generated controller. Add them to the Cong controller, run the command, and check the role again Yaml file, you can see more of these contents:
Configure the image registry of the operator
The rest is to build the operator image and push it to the required image registry.
Before building the operator image, ensure that the generated Dockerfile references the required basic image. We can change the default "runner" image GCR by replacing its tag with another tag IO / troubleshooting / static: nonroot, such as alpine:latest, and delete the USER 65532:65532 instruction.
The following is part of the Dockerfile:
# Build RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -a -o manager main.go # Use distroless as minimal base image to package the manager binary # Refer to https://github.com/GoogleContainerTools/distroless for more details FROM gcr.io/distroless/static:nonroot WORKDIR / COPY --from=builder /workspace/manager . USER 65532:65532 ENTRYPOINT ["/manager"]
Makefile combines mirrored tags based on the values written when the project is initialized or the values written in the CLI. In particular, IMAGE_TAG_BASE allows us to define a common image registry, namespace, and partial name for all image tags. If the current value is incorrect, please update it to another registry or namespace. After that, you can update the IMG variable definition, as shown below:
-IMG ?= controller:latest +IMG ?= $(IMAGE_TAG_BASE):$(VERSION)
After completion, it is not necessary to set IMG or any mirror variables in the CLI, and the following command will generate and push the flag as example com/memcached-operator:v0. Mirror the 0.1 operator to the Docker Hub:
make docker-build docker-push
docker's problem
Docker daemon permission problem
If you encounter the permission problem of docker:
Got permission denied while trying to connect to the Docker daemon socket at ...
Run command:
sudo chmod a+rw /var/run/docker.sock
If you encounter the problem of being unable to connect to docker:
docker: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?.
Enter the / var/run / directory and start docker:
cd /var/run/ sudo service docker start
timeout problem
If you encounter problems:
go: github.com/onsi/ginkgo@v1.16.4: Get "https://proxy.golang.org/github.com/onsi/ginkgo/@v/v1.16.4.mod": dial tcp 142.251.43.17:443: i/o timeout
Modify / etc / docker / daemon JSON configuration file:
sudo vim /etc/docker/daemon.json
add to:
{
"registry-mirrors":[
"https://hub-mirror.c.163.com",
"https://registry.aliyuncs.com",
"https://registry.docker-cn.com",
"https://docker.mirrors.ustc.edu.cn"
]
}
Restart docker:
sudo service docker restart
If there is still a problem, try to modify GOSUMDB. Original GOSUMDB:
GOSUMDB="sum.golang.org"
You can set GOSUMDB = "sum.golang.google.cn", which is a sum verification service specially provided for China.
go env -w GOSUMDB="sum.golang.google.cn"
If there is still a problem, it should be caused by the fact that docker does not share the proxy with the host. You need to configure the proxy environment variable inside the docker container:
Configure Docker to use proxy server | Docker document
User rights issues
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: ...
Add current user permissions:
sudo groupadd docker #Add docker user group sudo gpasswd -a $USER docker #Add the login user to the docker user group newgrp docker #Update user groups docker ps #Test whether the docker command can be used normally using sudo
Run the Operator
There are three ways to run the operator:
- As a Go program outside the cluster
- As a Deployment in the Kubernetes cluster
- from Operator Lifecycle Manager (OLM) with bundle (bundle) form management.
1. Run locally outside the cluster
The following steps explain how to deploy an operator on a cluster. However, to run locally and outside the cluster for development purposes, use the target make install run
2. Run as Deloyment in the cluster
By default, a namespace named < project name > - system, such as memcached operator system, will be created and used for deployment.
Run the following command to deploy the operator, which will also install the RBAC manifest from config/rbac:
make deploy
3. Deploy using OLM
Installation olm:
operator-sdk olm install
Bind the operator, and then build and push the binding image. The bundle target generates a bundle In the bundle directory, it contains the operator manifest and metadata. Bundle build and bundle push define and push bundle images Dockerfile.
Finally, run the bundle. If the bundle image is hosted in a private or custom CA registry, you must complete these installation steps configuration steps .
operator-sdk run bundle <some-registry>/memcached-operator-bundle:v0.0.1
Create Memcached CR
Update Memcached CR manifest config/samples/cache_v1alpha1_memcached.yaml and define spec:
apiVersion: cache.example.com/v1alpha1 kind: Memcached metadata: name: memcached-sample spec: size: 3
Create the CR:
kubectl apply -f config/samples/cache_v1alpha1_memcached.yaml
$ kubectl get pods NAME READY STATUS RESTARTS AGE memcached-sample-6fd7c98d8-7dqdr 1/1 Running 0 1m memcached-sample-6fd7c98d8-g5k7v 1/1 Running 0 1m memcached-sample-6fd7c98d8-m7vn7 1/1 Running 0 1m
eliminate
Run the following command to delete all deployed resources:
kubectl delete -f config/samples/cache_v1alpha1_memcached.yaml make undeploy
1-15-x.sdk. operatorframework. IO / docs / OLM integration / QuickStart bundle).
1. Run locally outside the cluster
The following steps explain how to deploy an operator on a cluster. However, to run locally and outside the cluster for development purposes, use the target make install run
2. Run as Deloyment in the cluster
By default, a namespace named < project name > - system, such as memcached operator system, will be created and used for deployment.
Run the following command to deploy the operator, which will also install the RBAC manifest from config/rbac:
make deploy
3. Deploy using OLM
Installation olm:
operator-sdk olm install
Bind the operator, and then build and push the binding image. The bundle target generates a bundle In the bundle directory, it contains the operator manifest and metadata. Bundle build and bundle push define and push bundle images Dockerfile.
Finally, run the bundle. If the bundle image is hosted in a private or custom CA registry, you must complete these installation steps configuration steps .
operator-sdk run bundle <some-registry>/memcached-operator-bundle:v0.0.1
Create Memcached CR
Update Memcached CR manifest config/samples/cache_v1alpha1_memcached.yaml and define spec:
apiVersion: cache.example.com/v1alpha1 kind: Memcached metadata: name: memcached-sample spec: size: 3
Create the CR:
kubectl apply -f config/samples/cache_v1alpha1_memcached.yaml
$ kubectl get pods NAME READY STATUS RESTARTS AGE memcached-sample-6fd7c98d8-7dqdr 1/1 Running 0 1m memcached-sample-6fd7c98d8-g5k7v 1/1 Running 0 1m memcached-sample-6fd7c98d8-m7vn7 1/1 Running 0 1m
eliminate
Run the following command to delete all deployed resources:
kubectl delete -f config/samples/cache_v1alpha1_memcached.yaml make undeploy