After studying the previous chapters, we began to be reptiles in the real sense.
Climb target
The website we want to climb this time is: Baidu Post Bar. The specific post bar is the big bang of life.
Post bar address:
https://tieba.baidu.com/f?kw=%E7%94%9F%E6%B4%BB%E5%A4%A7%E7%88%86%E7%82%B8&ie=utf-8
Python version: 3.6.2 (Python 3 is recommended)
Browser version: Chrome
Target analysis
- Climb down a page with a specific page number from the Internet
- Simple filtering and analysis of the content of the page climbing down
- Find the title, sender, date, floor, and jump link of each post
- Save results to text.
preparation in advance
Do you feel confused when you see the url address of the post bar? Is there a large string of unrecognizable characters? In fact, these are Chinese characters,
%E7%94%9F%E6%B4%BB%E5%A4%A7%E7%88%86%E7%82%B8
After coding: the big bang of life.
At the end of the link: & ie = utf-8 indicates that the connection adopts utf-8 encoding.
Since the default global encoding of Python 3 is utf-8, there is no need to convert the encoding here.
Then we turn to the second page of the post bar:
https://tieba.baidu.com/f?kw=%E7%94%9F%E6%B4%BB%E5%A4%A7%E7%88%86%E7%82%B8&ie=utf-8&pn=50
Notice that there is one more parameter at the end of the connection
&pn=50
Here we can easily guess the relationship between this parameter and page number:
- &PN = 0: home page
- &PN = 50: page 2
- &PN = 100: page 3
- &PN = 50 * n page n
50 means there are 50 posts on each page.
Now we can turn the page through simple url modification.
chrome development tools
To write a crawler, we must be able to use the development tool. Generally speaking, this tool is for front-end developers, but we can quickly locate the information we want to crawl through it and find the corresponding rules.
Right click, check and open the chrome tool.
Use the simulated click tool to quickly locate a single post. (mouse arrow icon in the upper left corner)
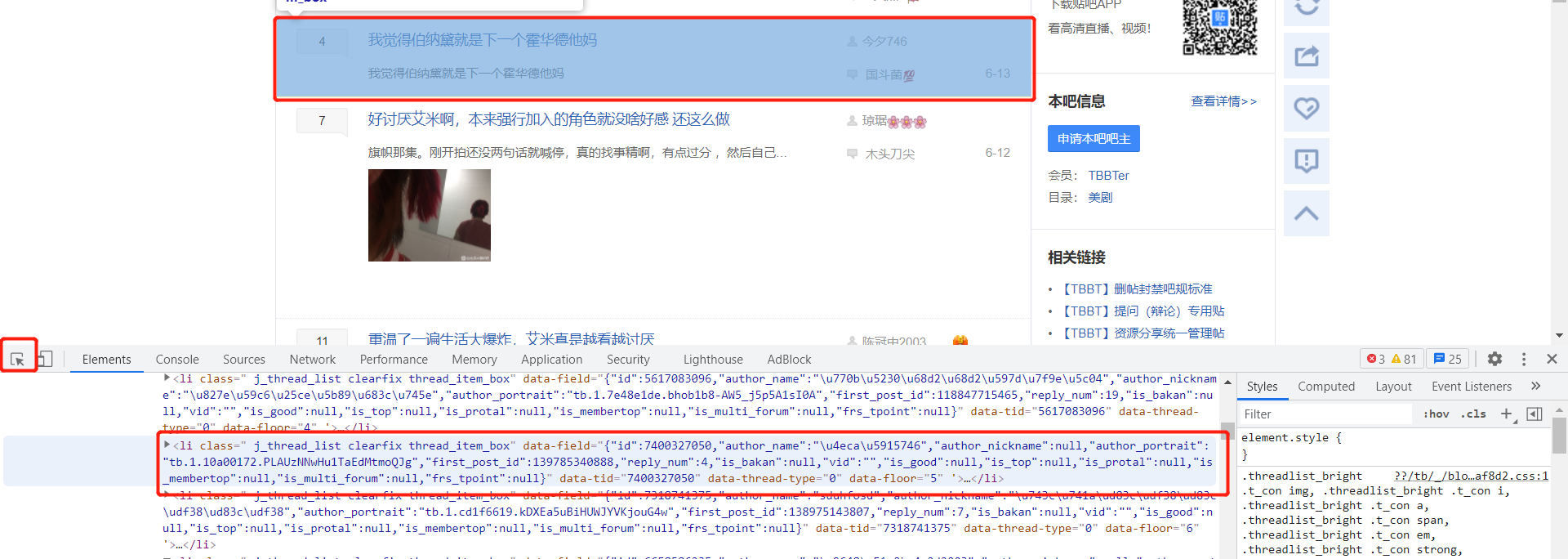
After careful observation, we find that the content of each post is wrapped in a li tag:
<li class=" j_thread_list clearfix">
In this way, we just need to quickly find all the tags that meet the rules, further analyze the contents, and finally filter out the data.
Start writing code
Let's first write the function to grab people on the page:
This is the crawling framework introduced earlier, which we will often use in the future.
import requests
from bs4 import BeautifulSoup
# First, we write the function to grab the web page
def get_html(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
#Here we know that the code of Baidu Post Bar is utf-8, so it is set manually. When crawling to other pages, it is recommended to use:
# r.endcodding = r.apparent_endconding
r.encoding='utf-8'
return r.text
except:
return " ERROR "
Then we extract the details:
Let's divide the internal structure of each li tag:
- A large li tag is wrapped with many div tags
The information we want is in the div Tags:
# Title & post link:
<a href="/p/4830198616" title="Let's go over the score of this side face in season 9 again" target="_blank" class="j_th_tit ">How many points do you give to the ninth season</a>
#Posted by:
<span class="tb_icon_author " title="Subject author: Li Xinyuan" data-field='{"user_id":836897637}'><i class="icon_author"></i><span class="frs-author-name-wrap"><a data-field='{"un":"Li\u6b23\u8fdc"}' class="frs-author-name j_user_card " href="/home/main/?un=Li%E6%AC%A3%E8%BF%9C&ie=utf-8&fr=frs" target="_blank">Li Xinyuan</a></span>
#Number of replies:
<div class="col2_left j_threadlist_li_left">
<span class="threadlist_rep_num center_text" title="reply">24</span>
</div>
#Posting date:
<span class="pull-right is_show_create_time" title="Creation time">2016-10</span>
After the analysis, we can easily pass the soup The find () method gets the result we want
Implementation of specific code:
'''
Grab Baidu Post Bar---The basic content of the big bang bar
Crawler route: requests - bs4
Python Version: 3.6
OS: mac os 12.12.4
'''
import requests
import time
from bs4 import BeautifulSoup
# First, we write the function to grab the web page
def get_html(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
# Here we know that the code of Baidu Post Bar is utf-8, so it is set manually. When crawling to other pages, it is recommended to use:
# r.endcodding = r.apparent_endconding
r.encoding = 'utf-8'
return r.text
except:
return " ERROR "
def get_content(url):
'''
Analyze the web page file of the post bar, sort out the information and save it in the list variable
'''
# Initialize a list to save all post information:
comments = []
# First, we download the web pages that need to crawl information to the local
html = get_html(url)
# Let's make a pot of soup
soup = BeautifulSoup(html, 'lxml')
# According to the previous analysis, we find all with 'J'_ thread_ The li tag of the 'list Clearfix' attribute. Returns a list type.
liTags = soup.find_all('li', attrs={'class': ' j_thread_list clearfix'})
# Find the information we need in each post through circulation:
for li in liTags:
# Initialize a dictionary to store article information
comment = {}
# Here, a try except ion is used to prevent the crawler from stopping running because it cannot find the information
try:
# Start filtering information and save it to the dictionary
comment['title'] = li.find(
'a', attrs={'class': 'j_th_tit '}).text.strip()
comment['link'] = "http://tieba.baidu.com/" + \
li.find('a', attrs={'class': 'j_th_tit '})['href']
comment['name'] = li.find(
'span', attrs={'class': 'tb_icon_author '}).text.strip()
comment['time'] = li.find(
'span', attrs={'class': 'pull-right is_show_create_time'}).text.strip()
comment['replyNum'] = li.find(
'span', attrs={'class': 'threadlist_rep_num center_text'}).text.strip()
comments.append(comment)
except:
print('There's a little problem')
return comments
def Out2File(dict):
'''
Write the crawled file to the local
Saved to the current directory TTBT.txt File.
'''
with open('TTBT.txt', 'a+') as f:
for comment in dict:
f.write('title: {} \t Link:{} \t Posted by:{} \t Posting time:{} \t Number of replies: {} \n'.format(
comment['title'], comment['link'], comment['name'], comment['time'], comment['replyNum']))
print('Current page crawling completed')
def main(base_url, deep):
url_list = []
# Save all URLs that need to be crawled into the list
for i in range(0, deep):
url_list.append(base_url + '&pn=' + str(50 * i))
print('All web pages have been downloaded locally! Start filtering information....')
#Write all data circularly
for url in url_list:
content = get_content(url)
Out2File(content)
print('All the information has been saved!')
base_url = 'http://tieba.baidu.com/f?kw=%E7%94%9F%E6%B4%BB%E5%A4%A7%E7%88%86%E7%82%B8&ie=utf-8'
# Set the number of pages to crawl
deep = 3
if __name__ == '__main__':
main(base_url, deep)
There are detailed comments and ideas in the code. Read it several times if you don't understand it
Well, that's the end of today's article.