stypora-copy-images-to: img
typora-root-url: ./
Spark Day08: Spark SQL

01 - [understand] - yesterday's course content review
The last course mainly explained three aspects: overview of SparkSQL module, DataFrame dataset and comprehensive case analysis.
1,SparkSQL Module overview - Development history [past life and present life] Shark -> SparkSQL(1.0) -> DataFrame(1.3) -> Dataset(1.6) -> Dataset/DataFrame(2.0) Spark2.0 in SparkSQL modular It can process not only offline data (batch processing), but also streaming data (stream computing) spark.read Batch processing spark.readStream Flow calculation take SparkSQL The streaming data processing function is proposed separately, which is called: StructuredStreaming Structured flow Spark2.2 edition StructuredStreaming release Release edition - Official definition: Spark Framework module for structured data processing module - Module,Structure Structured data - DataFrame,Data structure, underlying or RDD,add Schema constraint - SQL Analysis engine, which can be similar to Hive Framework, analysis SQL,Convert to RDD operation - 4 Characteristics Ease of use, multiple data sources JDBC/ODBC Mode, and Hive integrate 2,DataFrame What is it? - be based on RDD Distributed data sets, and Schema Information, Schema It is the internal result of data, including field name and field type RDD[Person] And DataFrame compare DataFrame Knowing the internal structure of data, you can make targeted optimization and improve performance before calculating data - DataFrame = RDD[Row] + Schema + optimization source Python in Pandas Data structure or R Language data type - RDD transformation DataFrame mode First: RDD[CaseClass]Direct conversion DataFrame Second: RDD[Row] + Schema toDF Function, specifying the column name, precondition: RDD The data type in is tuple type, or Seq The data type in the sequence is tuple 3,Statistical analysis of film scoring [use] DataFrame [package] - SparkSQL There are two methods of data analysis in the: Mode 1: SQL programming similar Hive in SQL sentence Mode 2: DSL programming call DataFrame Functions in, including similar RDD Conversion functions and similar SQL Keyword function - case analysis - step1,Load text data as RDD - step2,adopt toDF Function conversion to DataFrame - step3,to write SQL analysis Register first DataFrame Rewrite for temporary view SQL implement - step4,to write DSL analysis groupBy,agg,filter,sortBy,limit Import function library: import org.apache.spark.sql.functions._ - step5,Save result data Save to MySQL In the table Save to CSV file Whether it's writing DSL still SQL,The performance is the same. Pay attention to adjusting parameters: Shuffle Is the number of partitions spark.sql.shuffle.partitions=200 Spark 3.0 No adjustment required
02 - [understand] - outline of today's course content
It mainly explains four aspects: what is Dataset, external data source, UDF definition and distributed SQL Engine
1,Dataset data structure Dataset = RDD[T] + Schema,You can know the external data type or the internal data structure Store data in special code, compared with RDD Data structure storage saves more space RDD,DataFrame and Dataset Difference and connection 2,External data source How to load and save data, programming module Save mode when saving data Internal support external data sources Customize external data sources to achieve HBase,Direct use, simple version integrate Hive,from Hive Table reads data for analysis, or you can save data to Hive Table, most used in Enterprises use Hive Framework for data management, using SparkSQL Analyze and process data 3,custom UDF function 2 Two ways, respectively SQL Used in and DSL Used in 4,Distributed SQL engine This part is related to Hive Frame function has been spark-sql Command line, dedicated to writing SQL sentence similar Hive Frame species hive SparkSQL ThriftServer Run as a service and use JDBC/ODBC Connection mode, send SQL Statement execution similar HiveServer2 service - jdbc code - beeline Command line, writing SQL
03 - [Master] - what is a Dataset
Dataset is in Spark1 The new interface added in 6 is an extension of DataFrame API and the latest data abstraction of Spark, which combines the advantages of RDD and DataFrame.

Dataset is a strongly typed domain specific object that can be converted in parallel by functional or relational operations.

Starting from Spark 2.0, DataFrame and Dataset are merged. Each Dataset also has a typed view called a DataFrame. This DataFrame is a Dataset of Row type, that is, Dataset[Row].
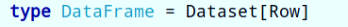
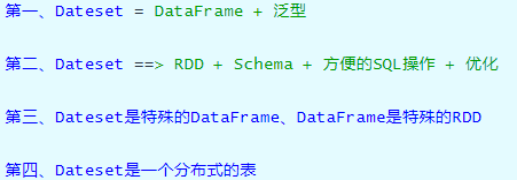
For the Dataset data structure, you can simply remember and understand it from the following four points:
Spark framework starts from the original data structure RDD to the data structure DataFrame encapsulated for structured data in SparkSQL,
Finally, the Dataset is used for encapsulation, and the development process is as follows.
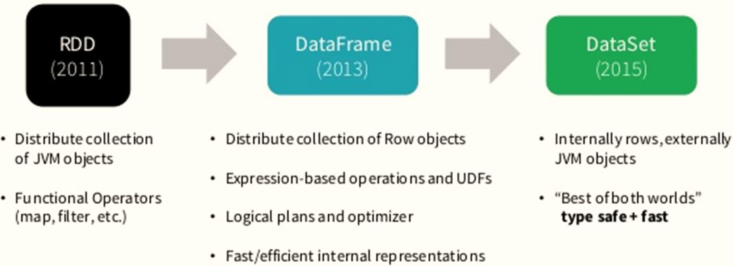
Therefore, in the actual project, it is recommended to use Dataset for data encapsulation, so that the data analysis performance and data storage are better.
Compared with RDD, DataFrame and Dataset programming, Dataset API can find syntax errors and analysis errors at compile time. However, some RDD and DataFrame can be found at run time.
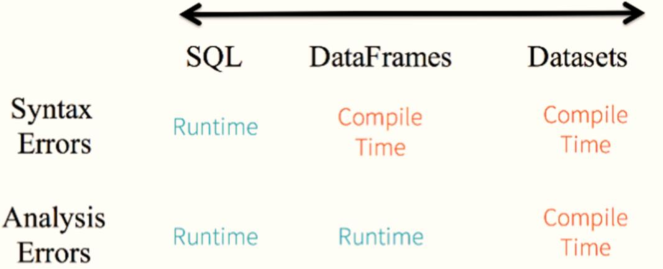
In addition, compared with Dataset, RDD saves more memory when storing data because Dataset data uses special coding.
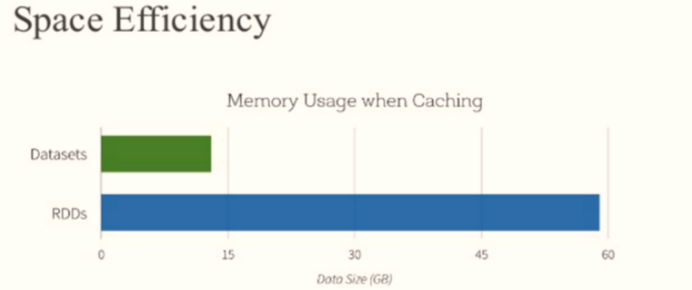
Because the Dataset data structure is a strongly typed distributed collection, and the data is encoded in a special way, compared with DataFrame, syntax errors and analysis errors are found during compilation, and the space is saved when caching data than RDD.
package cn.itcast.spark.ds
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* RDD is converted to Dataset by reflection
*/
object _01SparkDatasetTest {
def main(args: Array[String]): Unit = {
// Build the SparkSession instance object and set the application name and master
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
// 1. Load movie scoring data and encapsulate the data structure RDD
val rawRatingRDD: RDD[String] = spark.sparkContext.textFile("datas/ml-100k/u.data")
// 2. Convert RDD data type to movierrating
/*
Encapsulate each row of data (movie scoring data) in the original RDD into the CaseClass sample class
*/
val ratingRDD: RDD[MovieRating] = rawRatingRDD.mapPartitions { iter =>
iter.map { line =>
// Split by tab
val arr: Array[String] = line.trim.split("\\t")
// Encapsulate sample objects
MovieRating(
arr(0), arr(1), arr(2).toDouble, arr(3).toLong
)
}
}
// TODO: 3. RDD can be converted to Dataset by implicit conversion. It is required that the RDD data type must be CaseClass
val ratingDS: Dataset[MovieRating] = ratingRDD.toDS()
ratingDS.printSchema()
ratingDS.show(10, truncate = false)
/*
Dataset From spark1 6 proposed
Dataset = RDD + Schema
DataFrame = RDD[Row] + Schema
Dataset[Row] = DataFrame
*/
// Get RDD from Dataset
val rdd: RDD[MovieRating] = ratingDS.rdd
val schema: StructType = ratingDS.schema
// Get DataFrame from Dataset
val ratingDF: DataFrame = ratingDS.toDF()
// Adding a strong type (CaseClass) to the DataFrame is the Dataset
/*
DataFrame The field name in is consistent with that in CaseClass
*/
val dataset: Dataset[MovieRating] = ratingDF.as[MovieRating]
// After application, close the resource
spark.stop()
}
}
04 - [Master] - conversion between RDD, DS and DF
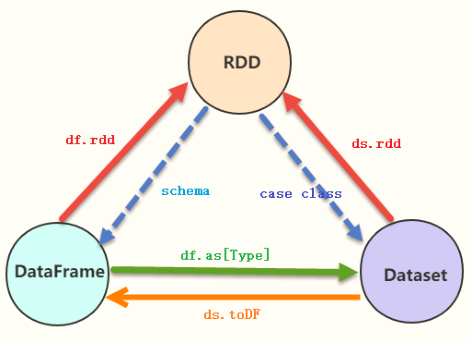
In actual project development, it is often necessary to convert RDD, DataFrame and Dataset. The key point is Schema constraint structure information.
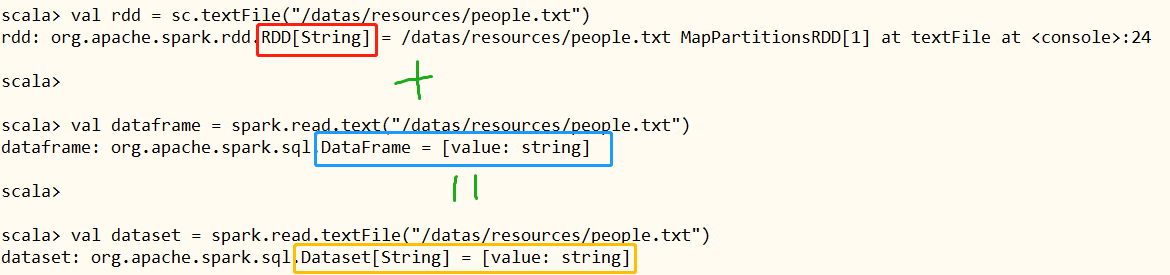
Example demonstration: respectively read people Txt file data is encapsulated into RDD, DataFrame and Dataset to see the differences and mutual conversion.
[root@node1 ~]# /export/server/spark/bin/spark-shell --master local[2]
21/04/27 09:12:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://node1.itcast.cn:4040
Spark context available as 'sc' (master = local[2], app id = local-1619485981944).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.5
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_241)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val rdd = sc.textFile("/datas/resources/people.txt")
rdd: org.apache.spark.rdd.RDD[String] = /datas/resources/people.txt MapPartitionsRDD[1] at textFile at <console>:24
scala>
scala> val dataframe = spark.read.text("/datas/resources/people.txt")
dataframe: org.apache.spark.sql.DataFrame = [value: string]
scala>
scala> val dataset = spark.read.textFile("/datas/resources/people.txt")
dataset: org.apache.spark.sql.Dataset[String] = [value: string]
scala>
scala> dataframe.rdd
res0: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[6] at rdd at <console>:26
scala> dataset.rdd
res1: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[11] at rdd at <console>:26
scala>
scala> dataset.toDF()
res2: org.apache.spark.sql.DataFrame = [value: string]
scala> dataframe.as[String]
res3: org.apache.spark.sql.Dataset[String] = [value: string]
Read Json data, package it into DataFrame, specify CaseClass, and convert it into Dataset
scala> val empDF = spark.read.json("/datas/resources/employees.json")
empDF: org.apache.spark.sql.DataFrame = [name: string, salary: bigint]
scala>
scala> empDF.show()
+-------+------+
| name|salary|
+-------+------+
|Michael| 3000|
| Andy| 4500|
| Justin| 3500|
| Berta| 4000|
+-------+------+
scala>
scala> case class Emp(name: String, salary: Long)
defined class Emp
scala>
scala> val empDS = empDF.as[Emp]
empDS: org.apache.spark.sql.Dataset[Emp] = [name: string, salary: bigint]
scala> empDS.printSchema()
root
|-- name: string (nullable = true)
|-- salary: long (nullable = true)
scala> empDS.show()
+-------+------+
| name|salary|
+-------+------+
|Michael| 3000|
| Andy| 4500|
| Justin| 3500|
| Berta| 4000|
+-------+------+
05 - [Master] - load and save data from external data sources
In the SparkSQL module, a set of completion API interfaces are provided to facilitate reading and writing data from external data sources (provided from spark version 1.4). External data sources are built in the framework itself:
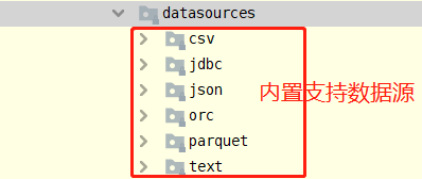
SparkSQL provides a set of general external data source interfaces to facilitate users to load and save data from the data source. For example, from the MySQL table, you can load and read data: load/read, and save and write data: save/write.

- Load load data
Reading data in SparkSQL uses SparkSession and is encapsulated in the data structure Dataset/DataFrame.
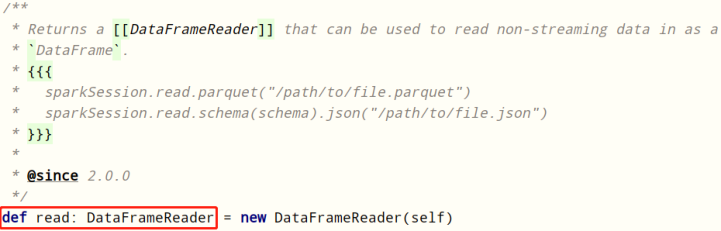
DataFrameReader is specially used to load and read data from external data sources. The basic format is as follows:

The SparkSQL module itself supports reading data from external data sources:

- Save save data
In the SparkSQL module, you can read data from an external data source, save data to an external data source, provide corresponding interfaces, and save data through the DataFrameWrite class

Similar to DataFrameReader, it provides a set of rules to save data datasets. The basic format is as follows:

The SparkSQL module supports saving data sources as follows:

When saving the result data DataFrame/Dataset to Hive table, you can set partition and bucket, as follows:

06 - [understand] - case demonstration and application scenario of external data source
scala> val peopleDF = spark.read.json("/datas/resources/people.json")
peopleDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> peopleDF.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
scala>
scala> val resultDF = peopleDF.select("name", "age")
resultDF: org.apache.spark.sql.DataFrame = [name: string, age: bigint]
scala>
scala> resultDF.show()
+-------+----+
| name| age|
+-------+----+
|Michael|null|
| Andy| 30|
| Justin| 19|
+-------+----+
scala>
scala> resultDF.write.parquet("/datas/people-parquet")
scala> spark.read.parquet("/datas/people-parquet/part-00000-a967d124-52d8-4ffe-91c6-59aebfed22b0-c000.snappy.parquet")
res11: org.apache.spark.sql.DataFrame = [name: string, age: bigint]
scala> res11.show(
| )
+-------+----+
| name| age|
+-------+----+
|Michael|null|
| Andy| 30|
| Justin| 19|
+-------+----+
View the HDFS file system directory, the data has been saved to the value parquet file, and compressed with snappy.

07 - [Master] - save mode of external data source SaveMode
When saving DataFrame or Dataset data, by default, an exception will be thrown if it exists.

A mode method in the DataFrameWriter specifies the mode:

When the SaveMode is found through the source code, the enumeration class is written in Java language. There are four save modes:
⚫ First: Append Append mode: continue to append when data exists; ⚫ Second: Overwrite Overwrite mode: when data exists, overwrite the previous data and store the current latest data; ⚫ Third: ErrorIfExists Existence and error reporting; ⚫ Fourth: Ignore Ignore, and do not do any operation when the data exists;
When saving the DataFrame, the saving mode needs to be set reasonably, so there are some problems when saving the data to the database.
- Append mode:
- Duplicate data. The most obvious error is that the primary key already exists
- Overwrite overwrite mode:
- Deleting the original data is also necessary for the actual project and cannot be deleted
08 - [Master] - case demonstration of external data sources (parquet, text and json)
The default read data file format in the SparkSQL module is parquet columnar data storage. It is set through the parameter [spark.sql.sources.default], and the default value is [parquet].
Example demonstration code: load parquet data directly and load data in specified parquet format.
// Building a SparkSession instance object
val spark: SparkSession = SparkSession.builder()
.master("local[4]")
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.config("spark.sql.shuffle.partitions", "4")
.getOrCreate()
import spark.implicits._
// TODO 1. parquet columnar storage data
// Loading in format mode
//val df1 = spark.read.format("parquet").load("datas/resources/users.parquet")
val df1: DataFrame = spark.read
.format("parquet")
.option("path", "datas/resources/users.parquet")
.load()
df1.printSchema()
df1.show(10, truncate = false)
// Loading in parquet mode
val df2: DataFrame = spark.read.parquet("datas/resources/users.parquet")
df2.show(10, truncate = false)
// load mode. In SparkSQL, when loading and reading file data, if no format is specified, the default is parquet format data
val df3: DataFrame = spark.read.load("datas/resources/users.parquet")
df3.show(10, truncate = false)
SparkSession loads text file data and provides two methods. The return values are DataFrame and Dataset respectively

When text data is read by text method or textFile method, the data is loaded line by line. Each line of data uses UTF-8 encoded string, and the column name is called [value].
// TODO: 2. Text data loading, text - > dataframe textfile - > dataset
// When loading text data, whether text or textFile, field name: value, type: String
val peopleDF: DataFrame = spark.read.text("datas/resources/people.txt")
peopleDF.show(10, truncate = false)
val peopleDS: Dataset[String] = spark.read.textFile("datas/resources/people.txt")
peopleDS.show(10, truncate = false)
There are two ways to read text data in JSON format:
- Method 1: directly specify the data source as json, load data, and automatically generate Schema information
spark.read.json("")
- Method 2: load it as a text file, and then use the function (get_json_object) to extract the field value in JSON
val dataset = spark.read.textFile("")
dataset.select(
get_json_object($"value", "$.name")
)
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-Z6rA4Zfq-1627175964710)(/img/image-20210427101740141.png)]
/* =========================================================================== */
// TODO: 3. Read JSON format data, automatically parse and generate Schema information
val empDF: DataFrame = spark.read.json("datas/resources/employees.json")
empDF.printSchema()
empDF.show(10, truncate = false)
/* =========================================================================== */
// TODO: in actual development, text/textFile is directly used to read text data in JSON format, and then the field information is parsed and extracted
/*
{"name":"Andy", "salary":30} - value: String
| Parse JSON format and extract fields
name: String, -> Andy
salary : Int, -> 30
*/
val dataframe: Dataset[String] = spark.read.textFile("datas/resources/employees.json")
// For JSON format strings, SparkSQL provides the function: get_json_object, def get_json_object(e: Column, path: String): Column
import org.apache.spark.sql.functions.get_json_object
val df = dataframe
.select(
get_json_object($"value", "$.name").as("name"),
get_json_object($"value", "$.salary").cast(IntegerType).as("salary")
)
df.printSchema()
df.show(10, truncate = false)
09 - [Master] - case demonstration of external data source (csv and jdbc)
Description of CSV/TSV format data:

To read CSV format data in SparkSQL, you can set some options, including key options:

// TODO: 1. CSV format data text file data - > the method of reading data is different according to whether the first row of CSV file is column name
/*
CSV Format data:
The fields of each row of data are separated by commas
It can also mean that each field of each row of data is separated by a single delimiter
*/
// Method 1: the first row is the column name, and the data file is u.dat
val dataframe: DataFrame = spark.read
.format("csv")
.option("sep", "\\t")
.option("header", "true")
.option("inferSchema", "true")
.load("datas/ml-100k/u.dat")
dataframe.printSchema()
dataframe.show(10, truncate = false)
// Method 2: the first row is not a column name. You need to customize the Schema information and the data file u.data
// Custom schema information
val schema: StructType = new StructType()
.add("user_id", IntegerType, nullable = true)
.add("iter_id", IntegerType, nullable = true)
.add("rating", DoubleType, nullable = true)
.add("timestamp", LongType, nullable = true)
val df: DataFrame = spark.read
.format("csv")
.schema(schema)
.option("sep", "\\t")
.load("datas/ml-100k/u.data")
df.printSchema()
df.show(10, truncate = false)
Corresponding interfaces are provided in the SparkSQL module to read data in three ways:
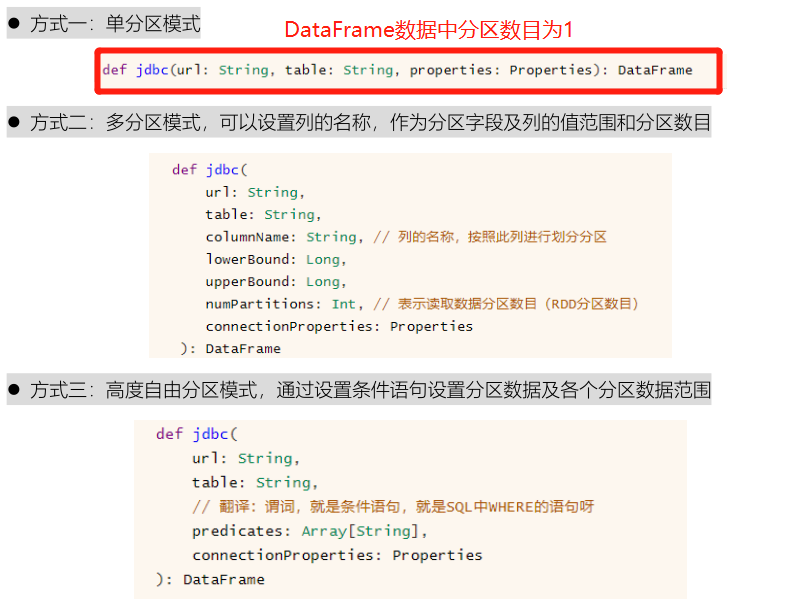
// TODO: 2. Read data in MySQL table
// First, concise format
/*
def jdbc(url: String, table: String, properties: Properties): DataFrame
*/
val props = new Properties()
props.put("user", "root")
props.put("password", "123456")
props.put("driver", "com.mysql.cj.jdbc.Driver")
val empDF: DataFrame = spark.read.jdbc(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true", //
"db_test.emp", //
props //
)
println(s"Partition Number = ${empDF.rdd.getNumPartitions}")
empDF.printSchema()
empDF.show(10, truncate = false)
// Second, write in standard format
/*
WITH tmp AS (
select * from emp e join dept d on e.deptno = d.deptno
)
*/
val table: String = "(select ename,deptname,sal from db_test.emp e join db_test.dept d on e.deptno = d.deptno) AS tmp"
val joinDF: DataFrame = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.option("dbtable", table)
.load()
joinDF.printSchema()
joinDF.show(10, truncate = false)
To read data from the RDBMS table, you need to set the information related to connecting to the database. The basic attribute options are as follows:

10 - [Master] - integration of external data sources Hive (spark shell)
In terms of development, Spark SQL module comes from Apache Hive framework. Its development process is Hive (MapReduce) - > shark (Hive on spark) - > Spark SQL (schemardd - > dataframe - > dataset). Therefore, SparkSQL naturally integrates Hive seamlessly and can load Hive table data for analysis.
- Step 1: when compiling the Spark source code, you need to specify the integrated Hive. The commands are as follows

- Step 2: the essence of SparkSQL integration Hive is to read Hive framework metadata MetaStore and start Hive MetaStore here
Service is OK.
# Directly run the following command to start the HiveMetaStore service [root@node1 ~]# hive-daemon.sh metastore
- Step 3: connect the HiveMetaStore service configuration file hive site XML in the [$SPARK_HOME/conf] directory
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1.itcast.cn:9083</value>
</property>
</configuration>
- Step 4: case demonstration, read dB in Hive_ Hive. EMP table data, analysis data
[root@node1 spark]# bin/spark-shell --master local[2]
21/04/27 10:55:37 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://node1.itcast.cn:4040
Spark context available as 'sc' (master = local[2], app id = local-1619492151923).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.5
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_241)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
scala> val empDF = spark.read.table("db_hive.emp")
empDF: org.apache.spark.sql.DataFrame = [empno: int, ename: string ... 6 more fields]
scala> empDF.show()
+-----+------+---------+----+----------+------+------+------+
|empno| ename| job| mgr| hiredate| sal| comm|deptno|
+-----+------+---------+----+----------+------+------+------+
| 7369| SMITH| CLERK|7902|1980-12-17| 800.0| null| 20|
| 7499| ALLEN| SALESMAN|7698| 1981-2-20|1600.0| 300.0| 30|
| 7521| WARD| SALESMAN|7698| 1981-2-22|1250.0| 500.0| 30|
| 7566| JONES| MANAGER|7839| 1981-4-2|2975.0| null| 20|
| 7654|MARTIN| SALESMAN|7698| 1981-9-28|1250.0|1400.0| 30|
| 7698| BLAKE| MANAGER|7839| 1981-5-1|2850.0| null| 30|
| 7782| CLARK| MANAGER|7839| 1981-6-9|2450.0| null| 10|
| 7788| SCOTT| ANALYST|7566| 1987-4-19|3000.0| null| 20|
| 7839| KING|PRESIDENT|null|1981-11-17|5000.0| null| 10|
| 7844|TURNER| SALESMAN|7698| 1981-9-8|1500.0| 0.0| 30|
| 7876| ADAMS| CLERK|7788| 1987-5-23|1100.0| null| 20|
| 7900| JAMES| CLERK|7698| 1981-12-3| 950.0| null| 30|
| 7902| FORD| ANALYST|7566| 1981-12-3|3000.0| null| 20|
| 7934|MILLER| CLERK|7782| 1982-1-23|1300.0| null| 10|
+-----+------+---------+----+----------+------+------+------+
scala> empDF.printSchema()
root
|-- empno: integer (nullable = true)
|-- ename: string (nullable = true)
|-- job: string (nullable = true)
|-- mgr: integer (nullable = true)
|-- hiredate: string (nullable = true)
|-- sal: double (nullable = true)
|-- comm: double (nullable = true)
|-- deptno: integer (nullable = true)
scala>
scala> spark.sql("select * from db_hive.emp").show()
+-----+------+---------+----+----------+------+------+------+
|empno| ename| job| mgr| hiredate| sal| comm|deptno|
+-----+------+---------+----+----------+------+------+------+
| 7369| SMITH| CLERK|7902|1980-12-17| 800.0| null| 20|
| 7499| ALLEN| SALESMAN|7698| 1981-2-20|1600.0| 300.0| 30|
| 7521| WARD| SALESMAN|7698| 1981-2-22|1250.0| 500.0| 30|
| 7566| JONES| MANAGER|7839| 1981-4-2|2975.0| null| 20|
| 7654|MARTIN| SALESMAN|7698| 1981-9-28|1250.0|1400.0| 30|
| 7698| BLAKE| MANAGER|7839| 1981-5-1|2850.0| null| 30|
| 7782| CLARK| MANAGER|7839| 1981-6-9|2450.0| null| 10|
| 7788| SCOTT| ANALYST|7566| 1987-4-19|3000.0| null| 20|
| 7839| KING|PRESIDENT|null|1981-11-17|5000.0| null| 10|
| 7844|TURNER| SALESMAN|7698| 1981-9-8|1500.0| 0.0| 30|
| 7876| ADAMS| CLERK|7788| 1987-5-23|1100.0| null| 20|
| 7900| JAMES| CLERK|7698| 1981-12-3| 950.0| null| 30|
| 7902| FORD| ANALYST|7566| 1981-12-3|3000.0| null| 20|
| 7934|MILLER| CLERK|7782| 1982-1-23|1300.0| null| 10|
+-----+------+---------+----+----------+------+------+------+
scala> spark.sql("select e.ename, e.sal, d.dname from db_hive.emp e join db_hive.dept d on e.deptno = d.deptno").show()
+------+------+----------+
| ename| sal| dname|
+------+------+----------+
| SMITH| 800.0| RESEARCH|
| ALLEN|1600.0| SALES|
| WARD|1250.0| SALES|
| JONES|2975.0| RESEARCH|
|MARTIN|1250.0| SALES|
| BLAKE|2850.0| SALES|
| CLARK|2450.0|ACCOUNTING|
| SCOTT|3000.0| RESEARCH|
| KING|5000.0|ACCOUNTING|
|TURNER|1500.0| SALES|
| ADAMS|1100.0| RESEARCH|
| JAMES| 950.0| SALES|
| FORD|3000.0| RESEARCH|
|MILLER|1300.0|ACCOUNTING|
+------+------+----------+
11 - [Master] - integration of external data sources Hive (IDEA development)
Develop applications in IDEA, integrate Hive, read the data from the table for analysis, set the HiveMetaStore server address and integrate Hive options when building a SparkSession, and first add MAVEN dependency package:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
The example demonstration code is as follows:
package cn.itcast.spark.hive
import org.apache.spark.sql.SparkSession
/**
* SparkSQL Integrate Hive and read the data in Hive table for analysis
*/
object _04SparkSQLHiveTest {
def main(args: Array[String]): Unit = {
// TODO: integrate Hive. Set the HiveMetaStore service address when creating a SparkSession instance object
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// Displays the specified integrated Hive
.enableHiveSupport()
// Set Hive MetaStore service address
.config("hive.metastore.uris", "thrift://node1.itcast.cn:9083")
.getOrCreate()
import spark.implicits._
// Method 1: DSL analysis data
val empDF = spark.read
.table("db_hive.emp")
empDF.printSchema()
empDF.show(10, truncate = false)
println("==================================================")
// Mode 2: SQL writing
spark.sql("select * from db_hive.emp").show()
// After application, close the resource
spark.stop()
}
}
12 - [understand] - custom implementation interface of external data source HBase
SparkSQL does not implement the data reading interface from HBase internally. You can implement the external data source interface yourself, which is provided here.
Need to register the implementation data source
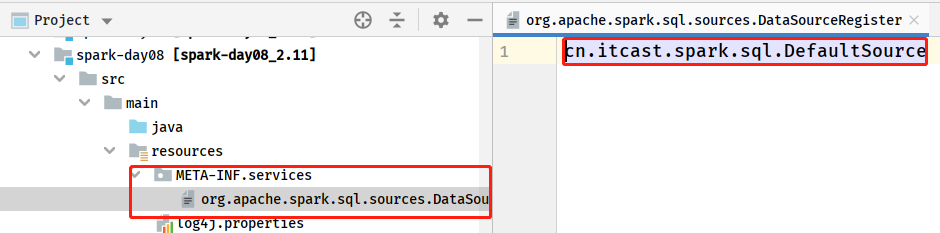
The test implements an external data source and reads data from the HBase table:
package cn.itcast.spark.hbase
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* Customize the external data source HBase to realize the data reading and writing function
*/
object _05SparkHBaseTest {
def main(args: Array[String]): Unit = {
// When creating a SparkSession instance object
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.config("spark.sql.shuffle.partitions", "2")
.getOrCreate()
import spark.implicits._
// Load data from HBase table
val hbaseDF: DataFrame = spark.read
.format("hbase")
.option("zkHosts", "node1.itcast.cn")
.option("zkPort", "2181")
.option("hbaseTable", "stus")
.option("family", "info")
.option("selectFields", "name,age")
.load()
// Implement the data source by yourself. All data types of data read from the Hbase table are String types
hbaseDF.printSchema()
hbaseDF.show(10, truncate = false)
// After application, close the resource
spark.stop()
}
}
Start HBase database related services
[root@node1 ~]# zookeeper-daemon.sh start JMX enabled by default Using config: /export/server/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@node1 ~]# [root@node1 ~]# hbase-daemon.sh start master starting master, logging to /export/server/hbase/logs/hbase-root-master-node1.itcast.cn.out Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0 Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0 [root@node1 ~]# [root@node1 ~]# hbase-daemon.sh start regionserver starting regionserver, logging to /export/server/hbase/logs/hbase-root-regionserver-node1.itcast.cn.out Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0 Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0 [root@node1 ~]# hbase shell 2021-04-27 11:21:05,566 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/export/server/hbase-1.2.0-cdh5.16.2/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/export/server/hadoop-2.6.0-cdh5.16.2/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 1.2.0-cdh5.16.2, rUnknown, Mon Jun 3 03:50:06 PDT 2019 hbase(main):001:0> hbase(main):001:0> list TABLE stus 1 row(s) in 0.2420 seconds => ["stus"] hbase(main):002:0> hbase(main):003:0* scan "stus" ROW COLUMN+CELL 10001 column=info:age, timestamp=1585823829856, value=24 10001 column=info:name, timestamp=1585823791372, value=zhangsan 10002 column=info:age, timestamp=1585823838969, value=26 10002 column=info:name, timestamp=1585823807947, value=lisi 10003 column=info:age, timestamp=1585823845516, value=28 10003 column=info:name, timestamp=1585823819460, value=wangwu 3 row(s) in 0.1450 seconds
13 - [Master] - using custom UDF functions in SQL and DSL
Like Hive, SparkSQL supports defining functions: UDF and UDAF. In particular, UDF functions are most widely used in practical projects.

At present, various versions of Spark framework and various languages support user-defined functions:
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-DApgGzLd-1627175964714)(/img/image-20210427112425417.png)]
There are two methods for SparkSQL data analysis: DSL programming and SQL programming, so there are also two methods for defining UDF functions. Different methods can be used in different analysis.
- Method 1: use in SQL
use SparkSession in udf Method to define and register functions in SQL Used in, defined as follows:

- Mode 2: used in DSL
use org.apache.sql.functions.udf Function definition and registration functions, in DSL Used in, as follows

The case demonstration is as follows:
package cn.itcast.spark.udf
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* SparkSQL Definition and use of UDF functions in: in SQL and DSL respectively
*/
object _06SparkUdfTest {
def main(args: Array[String]): Unit = {
// Build the SparkSession instance object and set the application name and master
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
val empDF: DataFrame = spark.read.json("datas/resources/employees.json")
/*
root
|-- name: string (nullable = true)
|-- salary: long (nullable = true)
*/
//empDF.printSchema()
/*
+-------+------+
|name |salary|
+-------+------+
|Michael|3000 |
|Andy |4500 |
|Justin |3500 |
|Berta |4000 |
+-------+------+
*/
//empDF.show(10, truncate = false)
/*
Custom UDF function function: convert a column data to uppercase
*/
// TODO: use in SQL
spark.udf.register(
"to_upper_udf", // Function name
(name: String) => {
name.trim.toUpperCase
}
)
// Register DataFrame as a temporary view
empDF.createOrReplaceTempView("view_temp_emp")
// Write and execute SQL
spark.sql("select name, to_upper_udf(name) AS new_name from view_temp_emp").show()
println("=====================================================")
// TODO: use in DSL
import org.apache.spark.sql.functions.udf
val udf_to_upper: UserDefinedFunction = udf(
(name: String) => {
name.trim.toUpperCase
}
)
empDF
.select(
$"name",
udf_to_upper($"name").as("new_name")
)
.show()
// After application, close the resource
spark.stop()
}
}
14 - [understand] - spark SQL interactive command line of distributed SQL Engine
Review how Hive is used for data analysis and what interactive analysis methods are provided???


SparkSQL module is derived from Hive framework, so all functions (interactive data analysis) provided by Hive are supported. Document: http://spark.apache.org/docs/2.4.5/sql-distributed-sql-engine.html .
SparkSQL provide spark-sql Command, similar Hive in bin/hive Command, specially written SQL After analysis, the startup command is as follows:
[root@node1 ~]# SPARK_HOME=/export/server/spark
[root@node1 ~]# ${SPARK_HOME}/bin/spark-sql --master local[2] --conf spark.sql.shuffle.partitions=4

This method is rarely used by enterprises at present. It mainly uses the ThriftServer service described below to execute SQL through Beeline connection.
15 - [Master] - ThriftServer service and beeline of distributed SQL Engine
Spark Thrift Server runs Spark Applicaiton as a service, providing Beeline client and JDBC access, which is the same as HiveServer2 service in Hive.
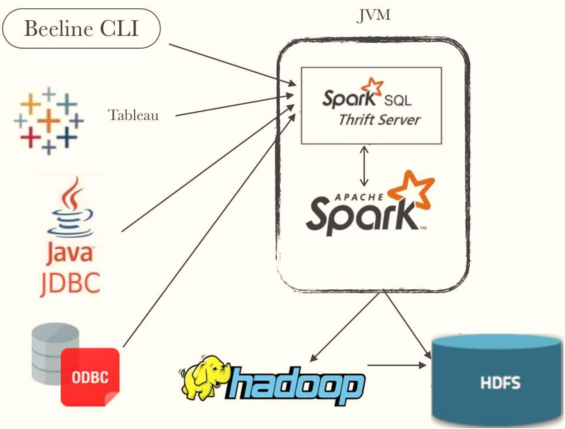
Spark Thrift JDBC/ODBC Server depends on HiveServer2 service (JAR package). To use this function, Hive Thrift is supported when compiling spark source code.
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-jE9BfbCw-1627175964716)(/img/image-20210427113944882.png)]
At $spark_ The sbin directory under the home directory has related service startup commands:
SPARK_HOME=/export/server/spark $SPARK_HOME/sbin/start-thriftserver.sh \ --hiveconf hive.server2.thrift.port=10000 \ --hiveconf hive.server2.thrift.bind.host=node1.itcast.cn \ --master local[2] \ --conf spark.sql.shuffle.partitions=2
Monitoring WEB UI interface:

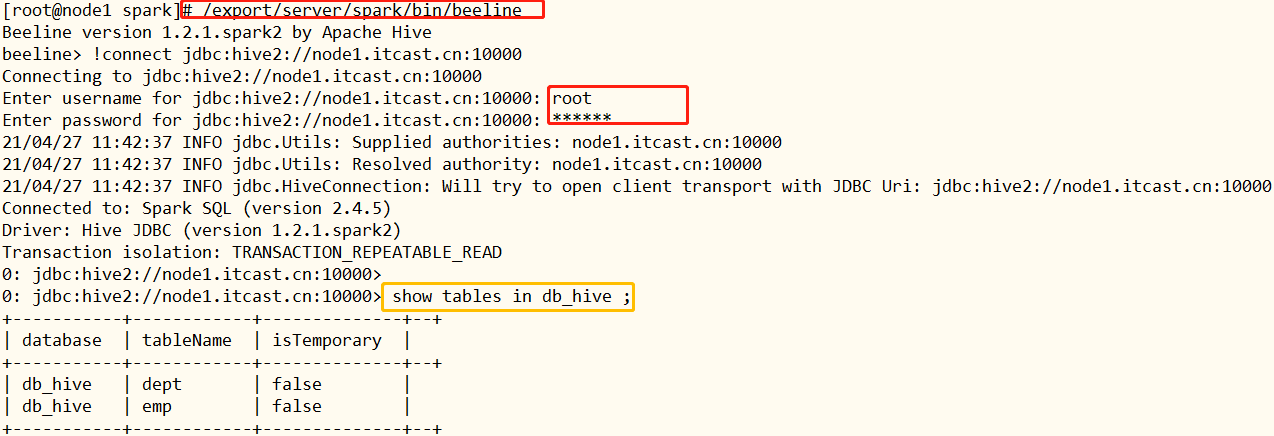
- beeline client, Similar to beeline client in Hive
/export/server/spark/bin/beeline Beeline version 1.2.1.spark2 by Apache Hive beeline> !connect jdbc:hive2://node1.itcast.cn:10000 Connecting to jdbc:hive2://node1.itcast.cn:10000 Enter username for jdbc:hive2://node1.itcast.cn:10000: root Enter password for jdbc:hive2://node1.itcast.cn:10000: ****
- JDBC/ODBC client, Write code similar to MySQL JDBC
SparkSQL provides a JDBC/ODBC like way to connect to Spark ThriftServer service and execute SQL statements. First, add Maven dependency Library:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive-thriftserver_2.11</artifactId>
<version>2.4.5</version>
</dependency>
Example demonstration: using JDBC to read dB in Hive_ Hive. Data from the EMP table.
package cn.itcast.spark.thrift
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet}
/**
* SparkSQL Start ThriftServer service and access data analysis query through JDBC
* i). Access Thrift JDBC/ODBC server through Java JDBC, call Spark SQL, and directly query the data in Hive
* ii). Through Java JDBC, the thrift RPC message must be sent through the HTTP transport protocol, and the Thrift JDBC/ODBC server must start the HTTP mode through the above command
*/
object _07SparkThriftJDBCTest {
def main(args: Array[String]): Unit = {
// Related instance objects are defined and not initialized
var conn: Connection = null
var pstmt: PreparedStatement = null
var rs: ResultSet = null
try {
// TODO: a. load driver class
Class.forName("org.apache.hive.jdbc.HiveDriver")
// TODO: b. get Connection
conn = DriverManager.getConnection(
"jdbc:hive2://node1.itcast.cn:10000/db_hive",
"root",
"123456"
)
// TODO: c. build query statement
val sqlStr: String =
"""
|select * from user
""".stripMargin
pstmt = conn.prepareStatement(sqlStr)
// TODO: d. execute the query to obtain the results
rs = pstmt.executeQuery()
// Print query results
while (rs.next()) {
println(s"empno = ${rs.getInt(1)}, ename = ${rs.getString(2)}, sal = ${rs.getDouble(3)}, dname = ${rs.getString(4)}")
}
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (null != rs) rs.close()
if (null != pstmt) pstmt.close()
if (null != conn) conn.close()
}
}
}
16 - [understand] - Catalyst optimizer for distributed SQL Engine
In Chapter 4 [case: movie scoring data analysis], run the application code and monitor through the WEB UI interface. It can be seen that whether DSL or SQL is used, the DAG diagram of Job construction is the same and the performance is the same. The reason is that the engine in SparkSQL:
Catalyst: convert SQL and DSL to the same logical plan.
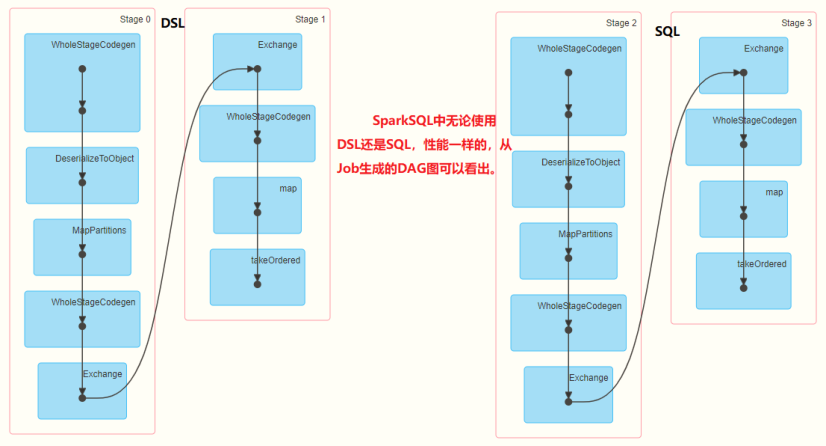
The core of Spark SQL is the Catalyst optimizer, which uses high-level programming language functions (such as Scala's pattern matching and quasiquotes) to build an extensible query optimizer in a novel way.
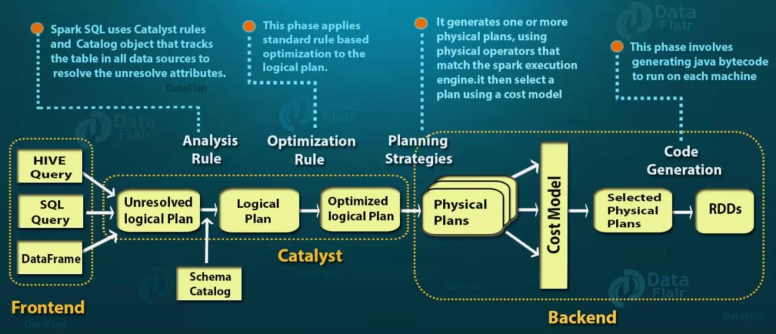
Three points can be seen in the figure above: 1,Frontend: Anterior segment to write SQL and DSL Statement place 2,Catalyst: optimizer take SQL and DSL Convert to logical plan LogicalPlan It consists of three parts Unresolved Logical Plan Unresolved logical plan | Logical Plan Logical plan | Optimized Logical Plan Optimize logical plan 3,Backend: back-end Converting a logical plan to a physical plan is RDD Conversion operation
Appendix I. creating Maven module
1) . Maven engineering structure
2) . POM file content
Contents in the POM document of Maven project (Yilai package):
<!-- Specify the warehouse location, in order: aliyun,cloudera and jboss Warehouse -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
<hbase.version>1.2.0-cdh5.16.2</hbase.version>
<mysql.version>8.0.19</mysql.version>
</properties>
<dependencies>
<!-- rely on Scala language -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL And Hive Integration dependency -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive-thriftserver_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client rely on -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- HBase Client rely on -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-hadoop2-compat</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- MySQL Client rely on -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven Compiled plug-ins -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
<version>${mysql.version}</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven Compiled plug-ins -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>