preface
The homework record of digital compression course is attached with the complete code
1, Algorithm description
1.1 algorithm features
LZW compression algorithm is a lossless data compression algorithm. Among many compression technologies, LZW algorithm is a general compression algorithm with excellent performance and widely used. It is a completely reliable algorithm. Compared with other algorithms, it often has higher compression efficiency. LZW algorithm retains the adaptive function of LZ code, and the compression ratio is roughly the same. Its remarkable characteristics are simple logic (the typical LZW algorithm processes one character and no more than three clock cycles), cheap hardware implementation and fast operation speed. It can obtain satisfactory compression effect when the message length is in the order of 10000 characters.
1.2 basic principle of algorithm
LZW compression algorithm extracts different characters from the original text file data, creates a compilation table based on these characters, and then replaces the corresponding characters in the original text file data with the index of the characters in the compilation table to reduce the size of the original data [1]. It should be noted that the data from the original compiled table is not the same as the data from the original compiled table, but should be restored from the original compiled table
LZW compression has three important objects: CharStream, CodeStream and String Table. During encoding, the data stream is the input object (data sequence of text file), and the encoding stream is the output object (encoded data after compression operation); When decoding, the encoded stream is the input object and the data stream is the output object; The compilation table is an object that needs to be used in encoding and decoding.
Character: the most basic data element, which is a byte in the text file and the index value of the color of a pixel in the specified color list in the raster data;
String: composed of several consecutive characters;
Prefix: it is also a string, but it is usually used in front of another character, and its length can be 0;
Root: a string of length;
Code: a number, which is taken from the encoding stream according to a fixed length (encoding length), and the mapping value of the compilation table; Pattern: a string read out from the data stream by an indefinite length and mapped to the compilation table entry [2].
2, Algorithm flow
2.1 coding process [3]
Step 1: initialize the dictionary to contain all possible single characters, and initialize the current prefix P to null.
Step 2: current character C: = the next character in the character stream.
Step 3: judge whether P+C is in the dictionary. If "yes", expand P with C, that is, let P: = P+C and return to step 2. If "no", output the codeword W corresponding to the current prefix p; Add P+C to the dictionary, make P:=C, and return to step 2
Step 4: judge whether there are still characters in the character stream. If "yes", return to step 2. If not, output the codeword representing the current prefix P to the codeword stream.
Flow chart of LZW compression algorithm: 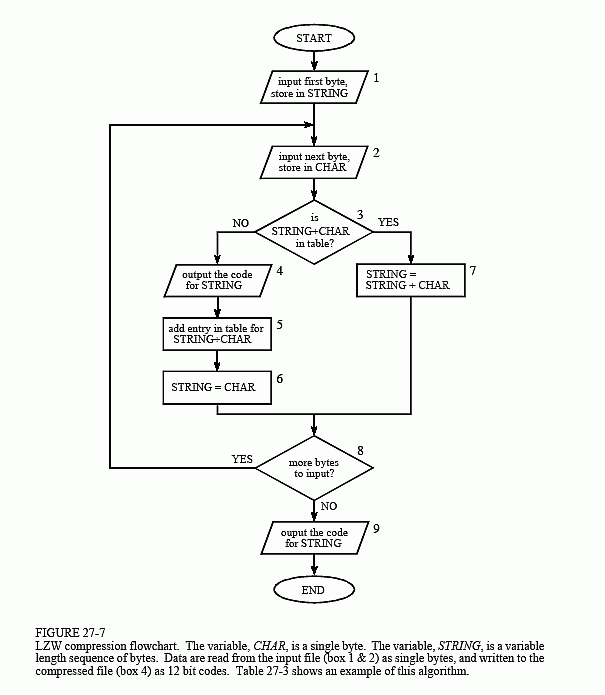
LZW algorithm example
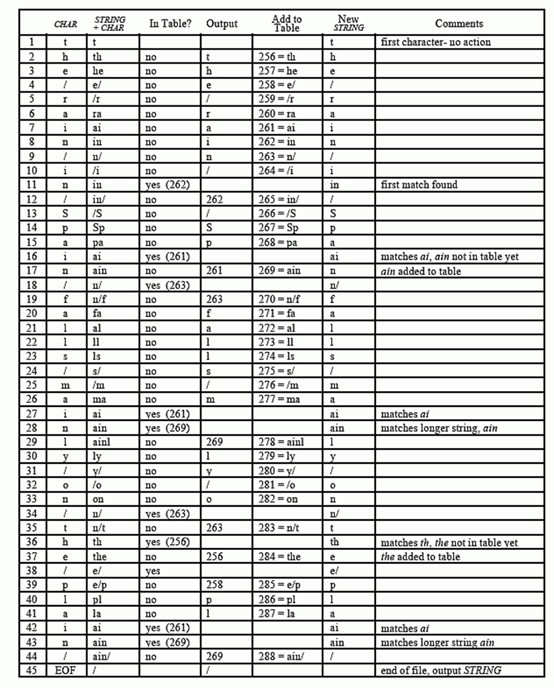
2.2 decoding process
Data decoding is actually the reverse process of data coding. Find the compilation table from the compiled data (encoding stream), and then restore the data against the compilation table.
: the dictionary contains all prefix roots (that is, each character forms a dictionary)
: remember the previous codeword (pW) before decoding
: read the previous codeword (cW) from the codeword stream
: output the word corresponding to the current codeword (cW), string (cW)
: string (pW) is combined with the first character of string (cW) and put into the dictionary.
LZW decoding process flow chart
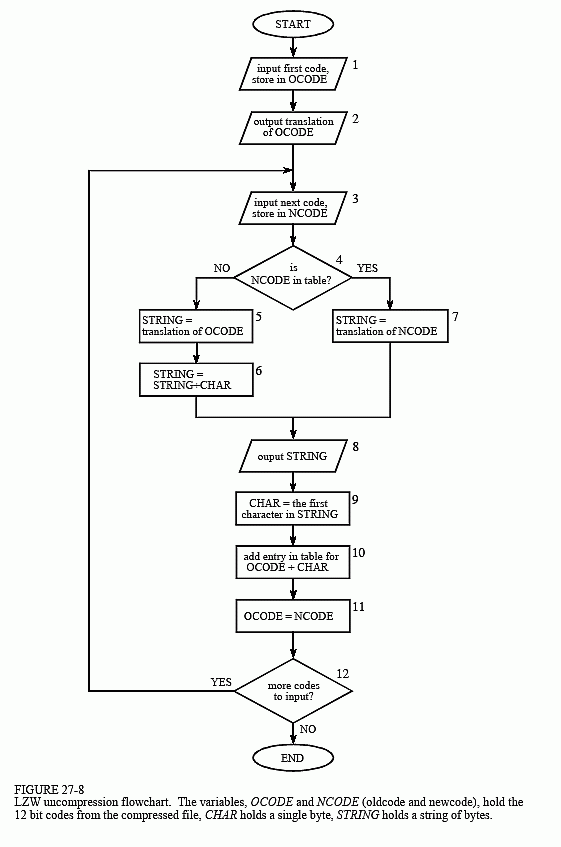
3, Experimental data and platform
Programming environment: VC++ 6.0
Computer configuration: Windows 10
Type of experimental data:
Experimental data 1: string type "ababcbabaaaa"
Experimental data 2: an English Literature “ Data compression has an undeserved reputation for being difficult to master, hard to implement, and tough to maintain. In fact, the techniques used in the previously mentioned programs are relatively simple, and can be implemented with standard utilities taking only a few lines of code. This article discusses a good all-purpose data compressio n technique: Lempel-Ziv-Welch, or LZW compression.”
Experimental data 3: floating point array
4, Experimental results
4.1 experimental data 1:
When we LZW compress a string of three letters in the example in the book:
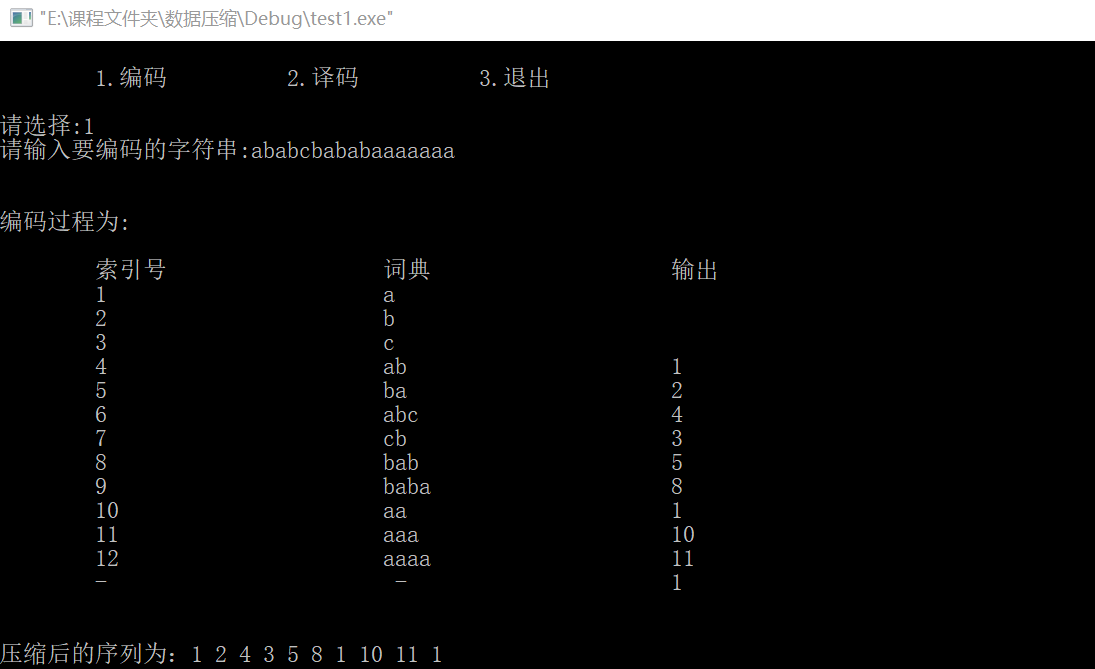
The findings are consistent with the results obtained in the book, and the correctness of the code is guaranteed.
Information entropy H(x) =1.166
4.2 experimental data 2:
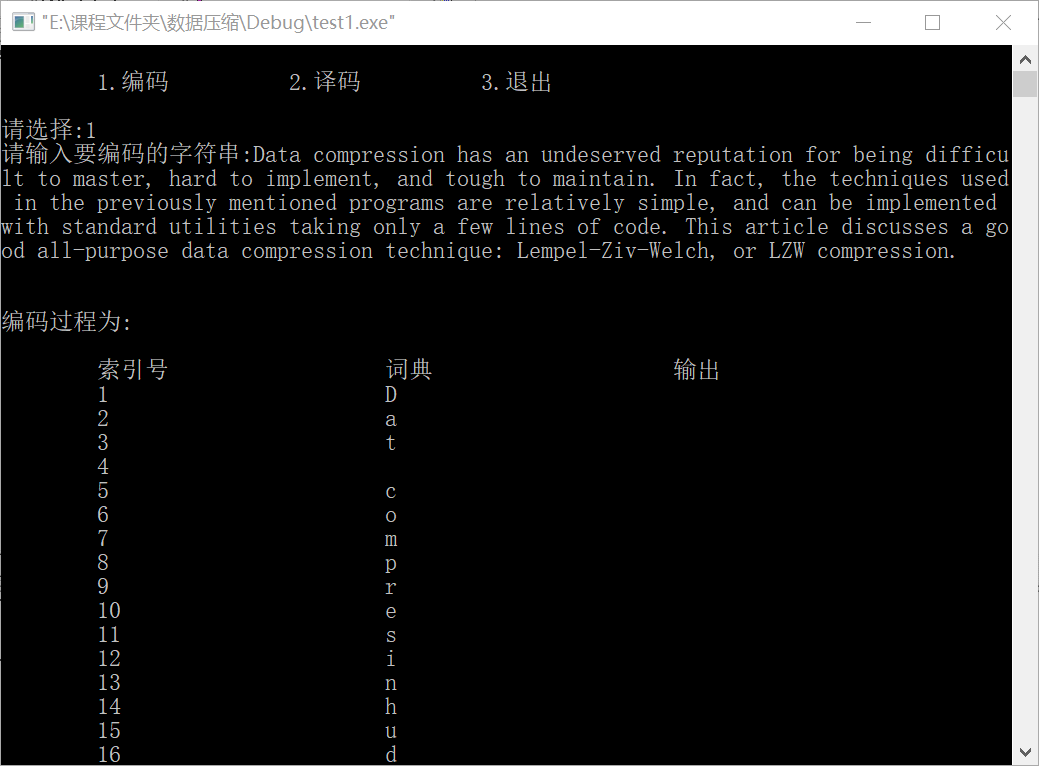
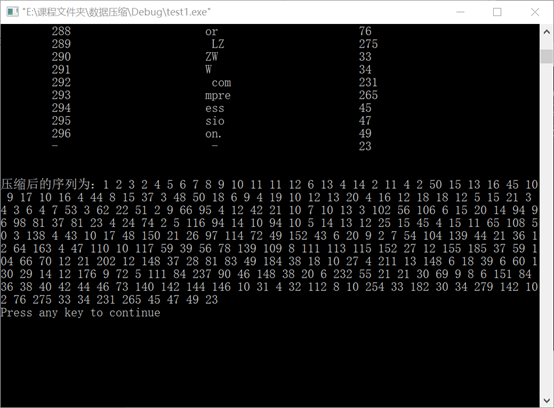
Experimental data 3:
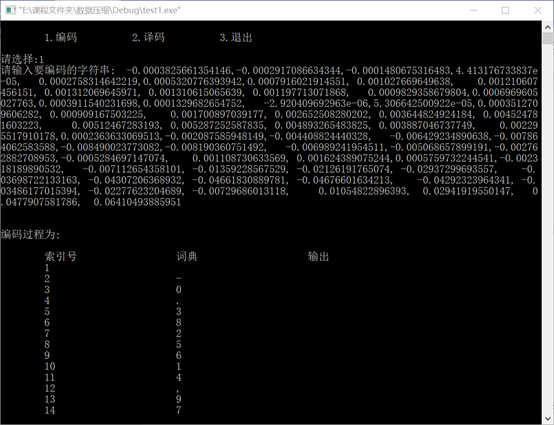
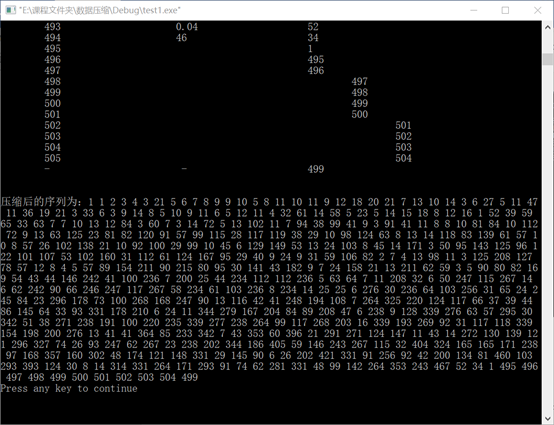
The code is as follows:
/*
* Description: LZW coding and decoding algorithm
*
*/
#include<iostream>
#include<cstring>
#define N 1000
using namespace std;
template <class T>
int getArrayLen(T& array){
//Use the template to define a function getArrayLen, which will return the length of the array
return (sizeof(array) / sizeof(array[0]));
}
class LZW{ //LZW algorithm class
public:
char encodeStr[N]; //String input to encode
int decodeList[N]; //Array to decode
int firstDictionaryNum; //Size of previous dictionary
int length; //The size of the current dictionary
char dictionary[N][N]; //Previous dictionary
LZW() //Constructor
{
encodeStr[0] = '\0';
for(int i=0;i<N;i++)
{
this->decodeList[i]=-INT_MAX; //initialization
}
for(int ii=0;ii<N;ii++){
this->dictionary[ii][0] = '\0';
}
firstDictionaryNum = 0;
length = 0;
}
bool initDictionary() //Initialize previous dictionary
{
if(encodeStr[0]=='\0')
{ //If there is no string to encode, the previous dictionary cannot be generated
return false;
}
dictionary[0][0] = encodeStr[0];//Adds the first character of the string to be encoded to the previous dictionary
dictionary[0][1] = '\0';
length = 1;
int i,j;
for(i=1;encodeStr[i]!='\0';i++){//Add all different characters in the string to be encoded to the previous dictionary
for(j=0;dictionary[j][0]!='\0';j++){
if(dictionary[j][0]==encodeStr[i]){
break;
}
}
if(dictionary[j][0]=='\0'){
dictionary[j][0] = encodeStr[i];
dictionary[j][1] = '\0';
length++;
}
}
firstDictionaryNum = length; //Size of previous dictionary
return true;
}
void Encode() //code
{
for(int g=0;g<firstDictionaryNum;g++)
{ //The initial code in the previous dictionary has no output code, so it is set to - 1
decodeList[g]=-1;
}
int num = firstDictionaryNum;
char *q,*p,*c;
q = encodeStr; //q is the flag pointer used to confirm the position
p = encodeStr; //p pointer as the first character of string matching
c = p; //Matching is achieved by constantly moving the c pointer
while(p-q != strlen(encodeStr))//If you haven't matched all the characters yet, loop
{
int i,j;
int index=0;
for(i=0;dictionary[i][0]!='\0'&&c-q!=strlen(encodeStr);i++)//Matching is achieved by constantly moving the c pointer backward
{
char temp[N];
strncpy(temp,p,c-p+1); //Each time a matching character is added, the matched string temp is incremented by one character
temp[c-p+1]='\0';
if(strcmp(temp,dictionary[i])==0)//Character matching succeeded
{
c++;
index = i;
}
}
decodeList[num++]=index; //If a mismatched character is encountered or there are no characters to match, the matched string will be output
if(c-q!=strlen(encodeStr))//If a mismatched character is found and there are still unmatched characters, it indicates that a new dictionary field appears and is added to the dictionary
{
strncpy(dictionary[length],p,c-p+1);
dictionary[length][c-p+1]='\0';
length++;
}
p = c; //p points to c when matching the next one
}
}
void Decode() //decoding
{
for(int i=1;decodeList[i]!=-INT_MAX;i++){ //Cycle according to the input code
if(decodeList[i]<=length){ //If the input code can be found in the previous dictionary, output all of the previous output + the first of the current output
strcpy(dictionary[length],dictionary[decodeList[i-1]-1]);
char temp[2];
strncpy(temp,dictionary[decodeList[i]-1],1);
temp[1]='\0';
strcat(dictionary[length],temp);
}
else{ //If the input code cannot be found in the previous dictionary, output all of the previous output + the first of the previous output
strcpy(dictionary[length],dictionary[decodeList[i-1]-1]);
char temp[2];
strncpy(temp,dictionary[decodeList[i-1]-1],1);
temp[1]='\0';
strcat(dictionary[length],temp);
}
length++;
}
}
};
int main(){
cout<<"\n\t1.code\t\t2.decoding\t\t3.sign out\n\n";
cout<<"Please select:";
char x;
cin>>x;
LZW lzw;
if(x=='1'){
cout<<"Please enter a string to encode:";
char a[] = {"ccccddcccccadccabbccbccacb"} ;
strcpy(lzw.encodeStr,a);
//cin>>lzw.encodeStr;
cout<<lzw.encodeStr<<endl<<endl;
if(lzw.initDictionary()==false)
{
cout<<"Please set the string to be encoded first encodeStr attribute"<<endl;
}
lzw.Encode(); //Start coding
cout<<endl<<"The encoding process is:"<<endl<<endl;
cout<<"\t Index number\t\t\t Dictionary\t\t\t output"<<endl;
for(int i=0;i<lzw.length;i++)
{
cout<<"\t"<<i+1<<"\t\t\t"<<lzw.dictionary[i]<<"\t\t\t";
if(i>=lzw.firstDictionaryNum)
{
cout<<lzw.decodeList[i]+1;
}
cout<<endl;
}
cout<<"\t- \t\t\t - \t\t\t"<<lzw.decodeList[lzw.length]+1<<endl<<endl<<endl;
//Calculate relevant parameters:
cout<<"The compressed sequence is:";
for(i = lzw.firstDictionaryNum;i<=lzw.length;i++)
{
cout<<lzw.decodeList[i]+1<<" ";
}
cout<<endl;
}
/*else if(x=='2'){
cout<<"Please input the initial previous dictionary in order: (example: 1 A) (input 0 to end) "< < endl;
int tempNum;
cin>>tempNum;
int index = 1;
while(tempNum!=0){
if(tempNum<0){
cout<<"Wrong serial number input, re-enter the line "< < endl < < endl;
getchar();//The two getchar() are to delete the characters already entered in this line
getchar();
cin>>tempNum;
continue;
}
if(tempNum!=index){
cout<<"Please enter the serial number in ascending order and re-enter the line "< < endl < < endl;
getchar();
getchar();
cin>>tempNum;
continue;
}
cin>>lzw.dictionary[tempNum-1];
cin>>tempNum;
index++;
}
lzw.firstDictionaryNum = index-1;
lzw.length = lzw.firstDictionaryNum;
cout<<endl<<"Please enter the code to be translated (end with 0): "< < endl < < endl;
int temp;
int j=0;
cin>>temp;
while(temp!=0){
if(temp<0){
cout<<"Enter the wrong code to be translated, and re-enter the code "< < endl < < endl;
cin>>temp;
continue;
}
lzw.decodeList[j] = temp;
j++;
cin>>temp;
}
lzw.Decode(); //Start decoding
cout<<endl<<"The decoding process is: "< < endl < < endl;
cout<<" Input code \ t\t index number \ t\t dictionary \ t\t Output "< < endl;
for(int i=0;i<lzw.firstDictionaryNum;i++){
cout<<" \t\t\t "<<i+1<<" \t\t "<<lzw.dictionary[i]<<endl;
}
cout<<"\t"<<lzw.decodeList[0]<<"\t\t -\t\t -\t\t "<<lzw.dictionary[lzw.decodeList[0]-1]<<endl;
for(int i1=1;lzw.decodeList[i1]!=-INT_MAX;i1++){
cout<<"\t"<<lzw.decodeList[i1]<<"\t\t "<<i1+3<<" \t\t "<<lzw.dictionary[i1+3-1]<<"\t\t "<<lzw.dictionary[lzw.decodeList[i1]-1]<<endl;
}
cout<<endl<<endl;
}
else if(x=='3'){
} */
else{
cout<<"Please enter the correct selection!"<<endl<<endl<<endl;
}
return 0;
}
5, Experimental conclusion
LZW algorithm is not only fast, but also has good compression effect on various computer files. For text files, the higher the degree of repetition, the higher the coding efficiency and the larger the compression ratio. In comparison, the compression ratio of LZW algorithm for floating-point data is lower than that for English paragraphs.
6, References
[1] Yang Guoliang, Zhang guangnian Lossless LZW compression algorithm and its implementation [J] Journal of Capital Normal University (NATURAL SCIENCE EDITION), 2004(S1):11-13+17
[2] https://wenku.baidu.com/view/dd4f06980912a216147929d4.html
[3] Guo Bin Research on entropy coding in video compression [D] Zhejiang University, 2007
The compression ratio of W algorithm for floating-point data is lower than that for English paragraphs.