Today, I will explain how to use python to crawl the barrage and comments of mango TV, Tencent video, station B, iqiyi, Zhihu and microblog, which are commonly used in film and television and public opinion platforms. The results obtained by this kind of crawler are generally used for entertainment and public opinion analysis, such as crawling the barrage comments to analyze why a new hot film is so hot; Microblogging has a big melon again. Climb to the bottom comments to see what netizens say, and so on.

This paper crawls a total of six platforms and ten crawler cases. If you are only interested in individual cases, you can pull and watch them in the order of mango TV, Tencent video, station B, iqiyi, Zhihu and microblog. The complete actual combat source code has been in the article. We don't talk much nonsense. Let's start the operation!
Many people learn Python and don't know where to start. Many people learn to look for python,After mastering the basic grammar, I don't know where to start. Many people who may already know the case do not learn more advanced knowledge. These three categories of people, I provide you with a good learning platform, free access to video tutorials, e-books, and the source code of the course! QQ Group:101677771 Welcome to join us and discuss and study together
Mango TV
This article takes the climbing movie "on the cliff" as an example to explain how to climb the bullet screen and comment on Mango TV video!
Web address:
https://www.mgtv.com/b/335313/12281642.html?fpa=15800&fpos=8&lastp=ch_movie
bullet chat
Analyze web pages
The file where the barrage data is located is dynamically loaded. You need to enter the developer tool of the browser to capture the package to get the real url where the barrage data is located. When the video is played for one minute, it will update a json packet containing the barrage data we need.
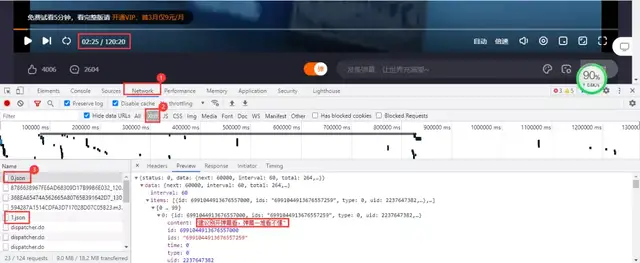
Real url obtained:
https://bullet-ali.hitv.com/bullet/2021/08/14/005323/12281642/0.json https://bullet-ali.hitv.com/bullet/2021/08/14/005323/12281642/1.json
It can be found that the difference between each url lies in the following numbers. The first url is 0, and the following url increases gradually. The video is 120:20 minutes in total, rounded up, that is, 121 packets.
Actual combat code
import requests
import pandas as pd
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
df = pd.DataFrame()
for e in range(0, 121):
print(f'Crawling to No{e}page')
resposen = requests.get(f'https://bullet-ali.hitv.com/bullet/2021/08/3/004902/12281642/{e}.json', headers=headers)
# Extracting data directly with json
for i in resposen.json()['data']['items']:
ids = i['ids'] # User id
content = i['content'] # Barrage content
time = i['time'] # Barrage occurrence time
# There are no likes in some files
try:
v2_up_count = i['v2_up_count']
except:
v2_up_count = ''
text = pd.DataFrame({'ids': [ids], 'bullet chat': [content], 'Time of occurrence': [time]})
df = pd.concat([df, text])
df.to_csv('Above the cliff.csv', encoding='utf-8', index=False)
Result display:
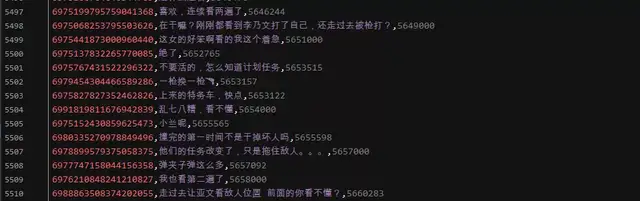
comment
Analyze web pages
Mango TV video comments need to be pulled to the bottom of the web page for viewing. The file where the comment data is located is still dynamically loaded. Enter the developer tool and capture the package according to the following steps: Network → js. Finally, click to view more comments.
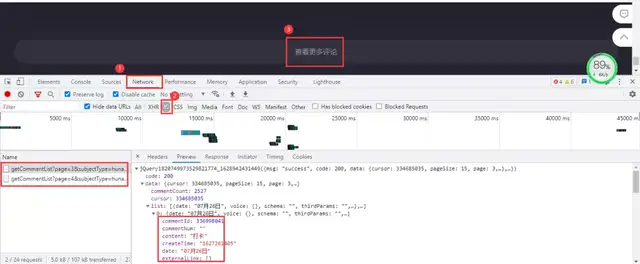
The loaded file is still a js file, which contains comment data. Real url obtained:
https://comment.mgtv.com/v4/comment/getCommentList?page=1&subjectType=hunantv2014&subjectId=12281642&callback=jQuery1820749973529821774_1628942431449&_support=10000000&_=1628943290494 https://comment.mgtv.com/v4/comment/getCommentList?page=2&subjectType=hunantv2014&subjectId=12281642&callback=jQuery1820749973529821774_1628942431449&_support=10000000&_=1628943296653
The different parameters are page and, Page is the number of pages_ Is a timestamp; The deletion of the timestamp in the url does not affect the data integrity, but the callback parameter in the url will interfere with the data parsing, so it is deleted. Finally get the url:
https://comment.mgtv.com/v4/comment/getCommentList?page=1&subjectType=hunantv2014&subjectId=12281642&_support=10000000
Each page of the data package contains 15 comments. The total number of comments is 2527, and the maximum page is 169.

Actual combat code
import requests
import pandas as pd
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
df = pd.DataFrame()
for o in range(1, 170):
url = f'https://comment.mgtv.com/v4/comment/getCommentList?page={o}&subjectType=hunantv2014&subjectId=12281642&_support=10000000'
res = requests.get(url, headers=headers).json()
for i in res['data']['list']:
nickName = i['user']['nickName'] # User nickname
praiseNum = i['praiseNum'] # Number of likes
date = i['date'] # Date sent
content = i['content'] # Comment content
text = pd.DataFrame({'nickName': [nickName], 'praiseNum': [praiseNum], 'date': [date], 'content': [content]})
df = pd.concat([df, text])
df.to_csv('Above the cliff.csv', encoding='utf-8', index=False)
Result display:
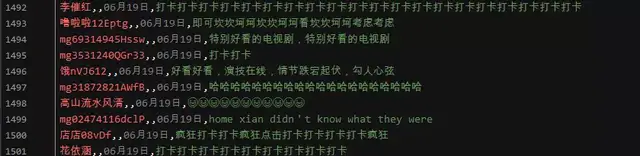
Tencent video
This article takes the film "the revolutionary" as an example to explain how to climb the bullet screen and comments of Tencent video!
Web address:
https://v.qq.com/x/cover/mzc00200m72fcup.html
bullet chat
Analyze web pages
Still enter the developer tool of the browser to capture packets. When the video is played for 30 seconds, it will update a json packet containing the barrage data we need.
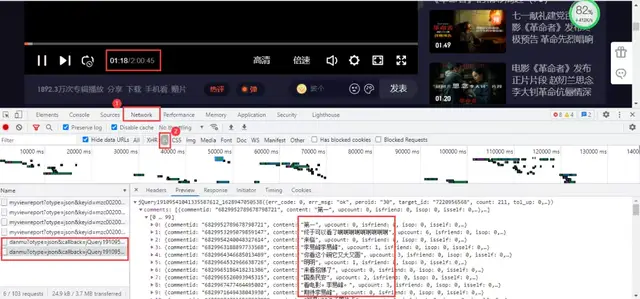
Get the real url:
https://mfm.video.qq.com/danmu?otype=json&callback=jQuery19109541041335587612_1628947050538&target_id=7220956568%26vid%3Dt0040z3o3la&session_key=0%2C32%2C1628947057×tamp=15&_=1628947050569 https://mfm.video.qq.com/danmu?otype=json&callback=jQuery19109541041335587612_1628947050538&target_id=7220956568%26vid%3Dt0040z3o3la&session_key=0%2C32%2C1628947057×tamp=45&_=1628947050572
The different parameters are timestamp and_ It's a timestamp. Timestamp is the number of pages. The first url is 15, followed by a tolerance of 30. The tolerance is based on the packet update time, and the maximum number of pages is 7245 seconds. Still delete unnecessary parameters and get the url:
https://mfm.video.qq.com/danmu?otype=json&target_id=7220956568%26vid%3Dt0040z3o3la&session_key=0%2C18%2C1628418094×tamp=15&_=1628418086509
Actual combat code
import pandas as pd
import time
import requests
headers = {
'User-Agent': 'Googlebot'
}
# The initial length is 157245 seconds, and the link is incremented by 30 seconds
df = pd.DataFrame()
for i in range(15, 7245, 30):
url = "https://mfm.video.qq.com/danmu?otype=json&target_id=7220956568%26vid%3Dt0040z3o3la&session_key=0%2C18%2C1628418094×tamp={}&_=1628418086509".format(i)
html = requests.get(url, headers=headers).json()
time.sleep(1)
for i in html['comments']:
content = i['content']
print(content)
text = pd.DataFrame({'bullet chat': [content]})
df = pd.concat([df, text])
df.to_csv('revolutionary_bullet chat.csv', encoding='utf-8', index=False)
Result display:

comment
Analyze web pages
Tencent video comment data is still dynamically loaded at the bottom of the web page. You need to enter the developer tool to capture packets according to the following steps:
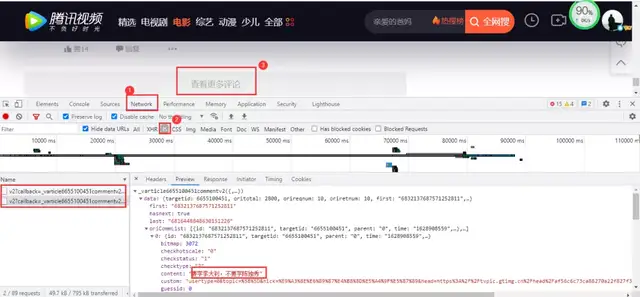
Click to view more comments. The data package contains the comment data we need. The real url is:
https://video.coral.qq.com/varticle/6655100451/comment/v2?callback=_varticle6655100451commentv2&orinum=10&oriorder=o&pageflag=1&cursor=0&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1628948867522 https://video.coral.qq.com/varticle/6655100451/comment/v2?callback=_varticle6655100451commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6786869637356389636&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1628948867523
The parameter callback in the url and_ Delete it. The important thing is the parameter cursor. The first url parameter cursor is equal to 0, and the second url appears, so you need to find out how the cursor parameter appears. After my observation, the cursor parameter is actually the last parameter of the previous url:
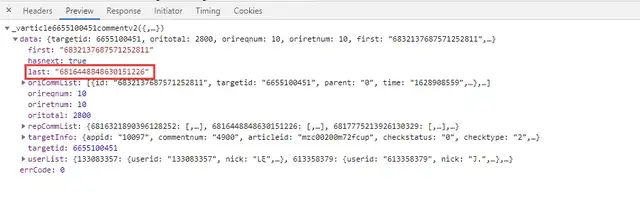
Actual combat code
import requests
import pandas as pd
import time
import random
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
df = pd.DataFrame()
a = 1
# The number of cycles must be set here, otherwise the crawling will be repeated indefinitely
# 281 refers to the oritotal in the data packet. There are 10 pieces of data in the data packet, and 2800 pieces of data are obtained after 280 cycles, but the comments replied below are not included
# The commentnum in the data packet is the total number of comment data including replies, and the data packet contains 10 comment data and the comment data of replies below, so you only need to divide 2800 by 10 to get an integer + 1!
while a < 281:
if a == 1:
url = 'https://video.coral.qq.com/varticle/6655100451/comment/v2?orinum=10&oriorder=o&pageflag=1&cursor=0&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132'
else:
url = f'https://video.coral.qq.com/varticle/6655100451/comment/v2?orinum=10&oriorder=o&pageflag=1&cursor={cursor}&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132'
res = requests.get(url, headers=headers).json()
cursor = res['data']['last']
for i in res['data']['oriCommList']:
ids = i['id']
times = i['time']
up = i['up']
content = i['content'].replace('\n', '')
text = pd.DataFrame({'ids': [ids], 'times': [times], 'up': [up], 'content': [content]})
df = pd.concat([df, text])
a += 1
time.sleep(random.uniform(2, 3))
df.to_csv('revolutionary_comment.csv', encoding='utf-8', index=False)
Effect display:

Station B
Taking the crawling video "this is the most dragged Olympic champion of the Chinese team I've ever seen" as an example, this paper explains how to climb the bullet screen and comments of station B video!
Web address:
https://www.bilibili.com/video/BV1wq4y1Q7dp
bullet chat
Analyze web pages
Unlike Tencent video, the barrage of station B video will trigger the barrage data packet when playing the video. He needs to click the expansion of the barrage list line on the right side of the web page, and then click view historical barrage to obtain the video barrage start date to end date link:
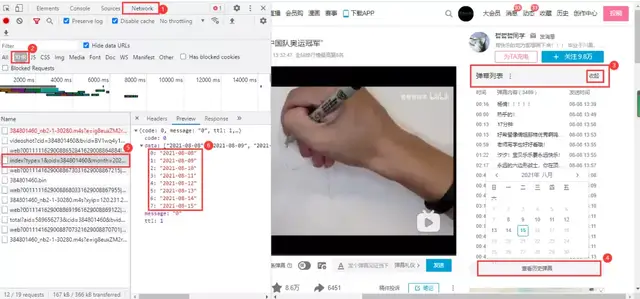
The end of the link and the url form the start date:
https://api.bilibili.com/x/v2/dm/history/index?type=1&oid=384801460&month=2021-08
On the basis of the above, click any effective date to obtain the barrage data package of this date. The content in it is not understandable at present. It is determined that it is a barrage data package because it is loaded only after clicking the date, and the link is related to the previous link:
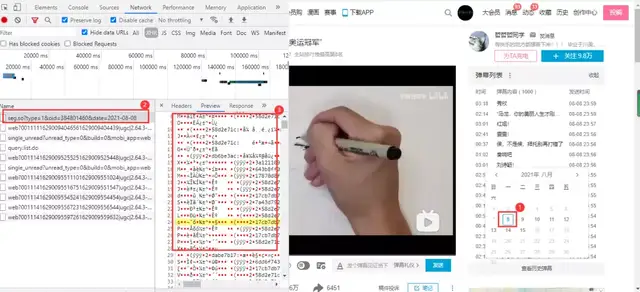
url obtained:
https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=384801460&date=2021-08-08
The oid in the url is the id value of the video barrage link; The data parameter is the date just, and to obtain all the bullet screen content of the video, you only need to change the data parameter. The data parameter can be obtained from the bullet screen date url above, or it can be constructed by itself; The web page data format is json format
Actual combat code
import requests
import pandas as pd
import re
def data_resposen(url):
headers = {
"cookie": "Yours cookie",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"
}
resposen = requests.get(url, headers=headers)
return resposen
def main(oid, month):
df = pd.DataFrame()
url = f'https://api.bilibili.com/x/v2/dm/history/index?type=1&oid={oid}&month={month}'
list_data = data_resposen(url).json()['data'] # Get all dates
print(list_data)
for data in list_data:
urls = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid={oid}&date={data}'
text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)
for e in text:
print(e)
data = pd.DataFrame({'bullet chat': [e]})
df = pd.concat([df, data])
df.to_csv('bullet chat.csv', encoding='utf-8', index=False, mode='a+')
if __name__ == '__main__':
oid = '384801460' # id value of video barrage link
month = '2021-08' # Start date
main(oid, month)
Result display:

comment
Analyze web pages
The comment content of station B video is at the bottom of the web page. After entering the developer tool of the browser, you only need to pull down to load the data package:
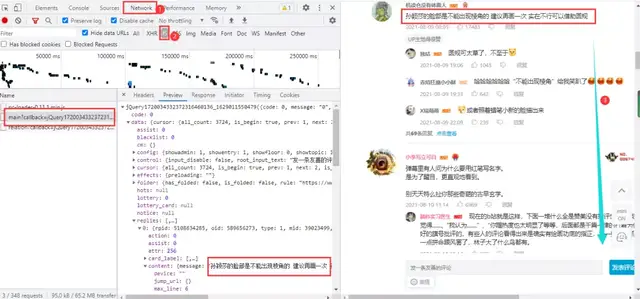
Get the real url:
https://api.bilibili.com/x/v2/reply/main?callback=jQuery1720034332372316460136_1629011550479&jsonp=jsonp&next=0&type=1&oid=589656273&mode=3&plat=1&_=1629012090500 https://api.bilibili.com/x/v2/reply/main?callback=jQuery1720034332372316460136_1629011550483&jsonp=jsonp&next=2&type=1&oid=589656273&mode=3&plat=1&_=1629012513080 https://api.bilibili.com/x/v2/reply/main?callback=jQuery1720034332372316460136_1629011550484&jsonp=jsonp&next=3&type=1&oid=589656273&mode=3&plat=1&_=1629012803039
Two urltext parameters, and_ And callback parameters_ And callback are time stamps and interference parameters, which can be deleted. The first next parameter is 0, the second is 2 and the third is 3, so the first next parameter is fixed to 0 and the second parameter starts to increase; The web page data format is json format.
Actual combat code
import requests
import pandas as pd
df = pd.DataFrame()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'}
try:
a = 1
while True:
if a == 1:
# The first url obtained by deleting unnecessary parameters
url = f'https://api.bilibili.com/x/v2/reply/main?&jsonp=jsonp&next=0&type=1&oid=589656273&mode=3&plat=1'
else:
url = f'https://api.bilibili.com/x/v2/reply/main?&jsonp=jsonp&next={a}&type=1&oid=589656273&mode=3&plat=1'
print(url)
html = requests.get(url, headers=headers).json()
for i in html['data']['replies']:
uname = i['member']['uname'] # User name
sex = i['member']['sex'] # User gender
mid = i['mid'] # User id
current_level = i['member']['level_info']['current_level'] # vip level
message = i['content']['message'].replace('\n', '') # User comments
like = i['like'] # Comment like times
ctime = i['ctime'] # Comment time
data = pd.DataFrame({'User name': [uname], 'User gender': [sex], 'user id': [mid],
'vip Grade': [current_level], 'User comments': [message], 'Comment like times': [like],
'Comment time': [ctime]})
df = pd.concat([df, data])
a += 1
except Exception as e:
print(e)
df.to_csv('Olympic Games.csv', encoding='utf-8')
print(df.shape)
The results show that the obtained content does not include secondary comments. If necessary, you can crawl it by yourself. The operation steps are similar:
Iqiyi
Taking the film Godzilla vs. King Kong as an example, this paper explains how to climb the bullet screen and comment on iqiyi video!
Web address:
https://www.iqiyi.com/v_19rr0m845o.html
bullet chat
Analyze web pages
The bullet screen of iqiyi video still needs to enter the developer tool to capture the package, get a br compressed file, and click to download it directly. The content in it is binary data. Every minute the video is played, a data package is loaded:
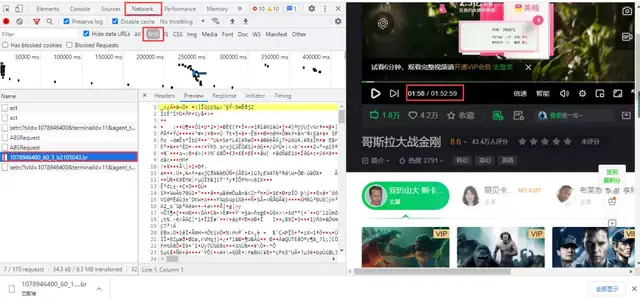
Get the url. The difference between the two URLs lies in the increasing number. 60 is the video. The data packet is updated every 60 seconds:
https://cmts.iqiyi.com/bullet/64/00/1078946400_60_1_b2105043.br https://cmts.iqiyi.com/bullet/64/00/1078946400_60_2_b2105043.br
br files can be decompressed with brotli library, but it is difficult to operate in practice, especially coding problems; When utf-8 is directly used for decoding, the following errors will be reported:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x91 in position 52: invalid start byte
If ignore is added to the decoding, the Chinese will not be garbled, but the html format will be garbled, and the data extraction is still difficult:
decode("utf-8", "ignore")
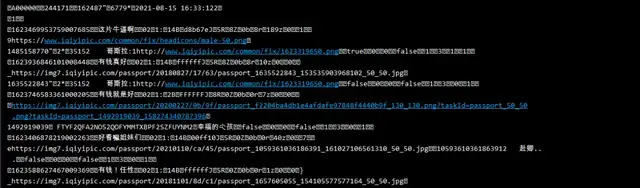
The knife is coded, which makes it a headache. If interested partners can continue to study the above content, this paper will not go further. Therefore, this paper uses another method to modify the obtained url to the following link z compressed files:
https://cmts.iqiyi.com/bullet/64/00/1078946400_300_1.z
The reason for this change is that this is the previous bullet screen interface link of iqiyi. It has not been deleted or modified and can still be used at present. In the interface link, 1078946400 is the video id; 300 is the previous barrage of iqiyi. A new barrage data packet will be loaded every 5 minutes. 5 minutes is 300 seconds. Godzilla vs. King Kong is 112.59 minutes, divided by 5, rounded up to 23; 1 is the number of pages; 64 is the 7th and 8th of the id value.
Actual combat code
import requests
import pandas as pd
from lxml import etree
from zlib import decompress # decompression
df = pd.DataFrame()
for i in range(1, 23):
url = f'https://cmts.iqiyi.com/bullet/64/00/1078946400_300_{i}.z'
bulletold = requests.get(url).content # Get binary data
decode = decompress(bulletold).decode('utf-8') # Decompression decoding
with open(f'{i}.html', 'a+', encoding='utf-8') as f: # Save as static html file
f.write(decode)
html = open(f'./{i}.html', 'rb').read() # Read html file
html = etree.HTML(html) # Parsing web pages with xpath syntax
ul = html.xpath('/html/body/danmu/data/entry/list/bulletinfo')
for i in ul:
contentid = ''.join(i.xpath('./contentid/text()'))
content = ''.join(i.xpath('./content/text()'))
likeCount = ''.join(i.xpath('./likecount/text()'))
print(contentid, content, likeCount)
text = pd.DataFrame({'contentid': [contentid], 'content': [content], 'likeCount': [likeCount]})
df = pd.concat([df, text])
df.to_csv('Godzilla vs. King Kong.csv', encoding='utf-8', index=False)
Result display:
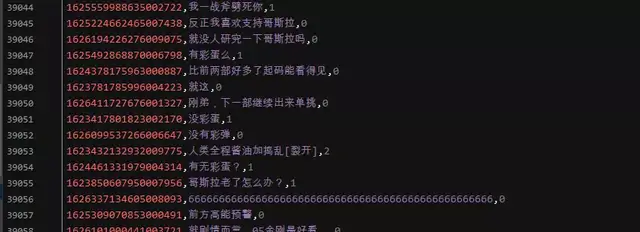
comment
Analyze web pages
Iqiyi video comments are still dynamically loaded at the bottom of the web page. You need to enter the developer tool of the browser to capture the package. When the web page is pulled down, a data package will be loaded, which contains comment data:
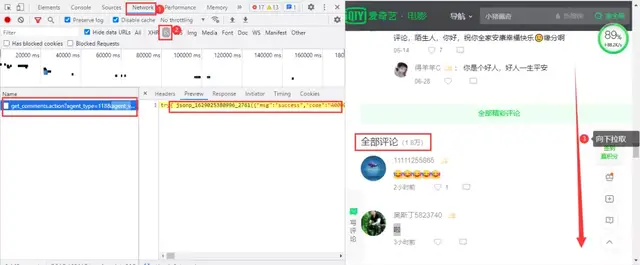
The actual url obtained:
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&channel_id=1&content_id=1078946400&hot_size=10&last_id=&page=&page_size=10&types=hot,time&callback=jsonp_1629025964363_15405 https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&channel_id=1&content_id=1078946400&hot_size=0&last_id=7963601726142521&page=&page_size=20&types=time&callback=jsonp_1629026041287_28685 https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&channel_id=1&content_id=1078946400&hot_size=0&last_id=4933019153543021&page=&page_size=20&types=time&callback=jsonp_1629026394325_81937
The first url loads the content of wonderful comments, and the second url starts to load the content of all comments. After deleting unnecessary parameters, the following url is obtained:
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&business_type=17&content_id=1078946400&last_id=&page_size=10 https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&business_type=17&content_id=1078946400&last_id=7963601726142521&page_size=20 https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&business_type=17&content_id=1078946400&last_id=4933019153543021&page_size=20
The difference is the parameter last_id and page_size. page_ The value of size in the first url is 10 and fixed to 20 from the second url. last_ The value of id in the first url is empty, and it will change from the second one. After my research, last_ The value of id is the user id of the last comment content in the previous url (it should be the user id); The web page data format is json format.
Actual combat code
import requests
import pandas as pd
import time
import random
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
df = pd.DataFrame()
try:
a = 0
while True:
if a == 0:
url = 'https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&business_type=17&content_id=1078946400&page_size=10'
else:
# Slave id_list to get the last id value in the content of the previous page
url = f'https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&business_type=17&content_id=1078946400&last_id={id_list[-1]}&page_size=20'
print(url)
res = requests.get(url, headers=headers).json()
id_list = [] # Create a list to hold the id value
for i in res['data']['comments']:
ids = i['id']
id_list.append(ids)
uname = i['userInfo']['uname']
addTime = i['addTime']
content = i.get('content', 'non-existent') # get extraction is used to prevent the occurrence of an error when the key value does not exist. The first parameter is the matching key value, and the second is output when it is missing
text = pd.DataFrame({'ids': [ids], 'uname': [uname], 'addTime': [addTime], 'content': [content]})
df = pd.concat([df, text])
a += 1
time.sleep(random.uniform(2, 3))
except Exception as e:
print(e)
df.to_csv('Godzilla vs. King Kong_comment.csv', mode='a+', encoding='utf-8', index=False)
Result display:
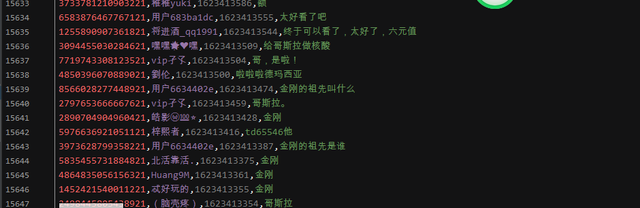
Know
This article is based on the hot topic "how to treat online Tencent interns, put forward suggestions to Tencent executives, and promulgate relevant regulations on refusing to accompany wine?" For example, the explanation is like crawling to know the answer!
Web address:
https://www.zhihu.com/question/478781972
Analyze web pages
After viewing the source code of the web page, it is determined that the answer content of the web page is dynamically loaded, and it is necessary to enter the developer tool of the browser to capture the package. Go to Noetwork → XHR and pull down the web page with the mouse to get the data package we need:
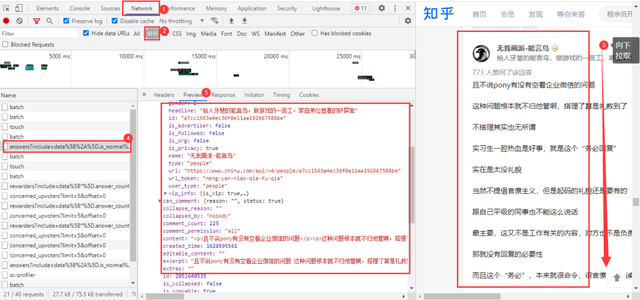
Real url obtained:
https://www.zhihu.com/api/v4/questions/478781972/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset=0&platform=desktop&sort_by=default https://www.zhihu.com/api/v4/questions/478781972/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset=5&platform=desktop&sort_by=default
url has many unnecessary parameters, which can be deleted in the browser. The difference between the two URLs lies in the following offset parameters. The offset parameter of the first url is 0, the second is 5, and the offset increases with a tolerance of 5; The web page data format is json format.
Actual combat code
import requests
import pandas as pd
import re
import time
import random
df = pd.DataFrame()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
for page in range(0, 1360, 5):
url = f'https://www.zhihu.com/api/v4/questions/478781972/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset={page}&platform=desktop&sort_by=default'
response = requests.get(url=url, headers=headers).json()
data = response['data']
for list_ in data:
name = list_['author']['name'] # Know the author
id_ = list_['author']['id'] # Author id
created_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(list_['created_time'] )) # Answer time
voteup_count = list_['voteup_count'] # Approval number
comment_count = list_['comment_count'] # Number of comments below
content = list_['content'] # Answer content
content = ''.join(re.findall("[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5]", content)) # Regular expression extraction
print(name, id_, created_time, comment_count, content, sep='|')
dataFrame = pd.DataFrame(
{'Know the author': [name], 'author id': [id_], 'Answer time': [created_time], 'Approval number': [voteup_count], 'Number of comments below': [comment_count],
'Answer content': [content]})
df = pd.concat([df, dataFrame])
time.sleep(random.uniform(2, 3))
df.to_csv('Know how to answer.csv', encoding='utf-8', index=False)
print(df.shape)
Result display:
micro-blog
Taking the hot search of "Huo Zun's handwritten apology letter" on crawling microblog as an example, this paper explains how to crawl microblog comments!
Web address:
https://m.weibo.cn/detail/4669040301182509
Analyze web pages
Microblog comments are dynamically loaded. After entering the developer tool of the browser, pull down on the web page to get the data package we need:
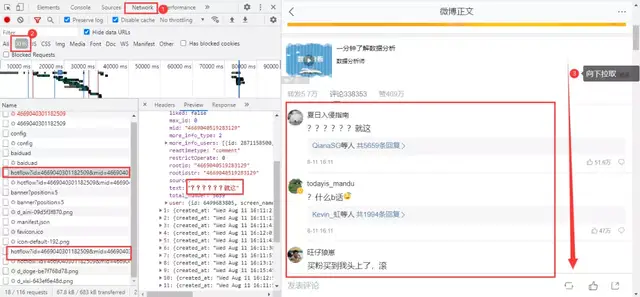
Get the real url:
https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id_type=0 https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id=3698934781006193&max_id_type=0
The difference between the two URLs is obvious. The first url has no parameter max_id, the second item starts max_id appears, and max_id is actually Max in the previous packet_ id:
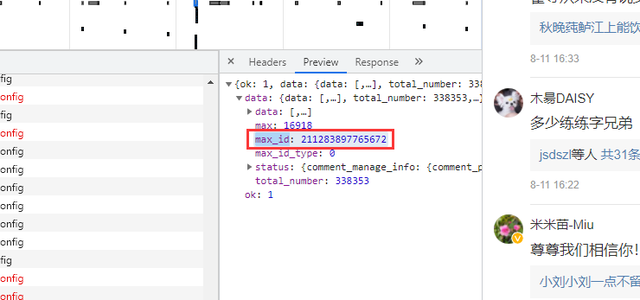
But one thing to note is the parameter max_id_type, which actually changes, so we need to get max from the packet_ id_ type:
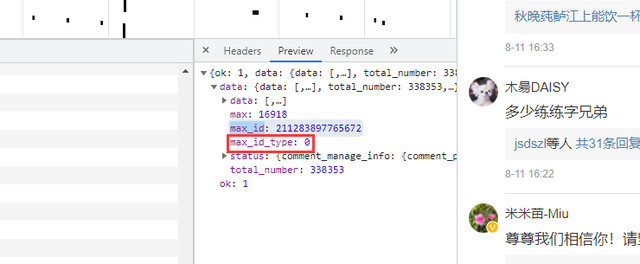
Actual combat code
import re
import requests
import pandas as pd
import time
import random
df = pd.DataFrame()
try:
a = 1
while True:
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
}
resposen = requests.get('https://m.weibo.cn/detail/4669040301182509', headers=header)
# Microblog crawling about dozens of pages will seal the account, and by constantly updating cookies, it will make the crawler more lasting
cookie = [cookie.value for cookie in resposen.cookies] # Generating cookie parts with list derivation
headers = {
# The cookie after login is used by SUB
'cookie': f'WEIBOCN_FROM={cookie[3]}; SUB=; _T_WM={cookie[4]}; MLOGIN={cookie[1]}; M_WEIBOCN_PARAMS={cookie[2]}; XSRF-TOKEN={cookie[0]}',
'referer': 'https://m.weibo.cn/detail/4669040301182509',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
}
if a == 1:
url = 'https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id_type=0'
else:
url = f'https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id={max_id}&max_id_type={max_id_type}'
html = requests.get(url=url, headers=headers).json()
data = html['data']
max_id = data['max_id'] # Get max_id and max_id_type returns to the next url
max_id_type = data['max_id_type']
for i in data['data']:
screen_name = i['user']['screen_name']
i_d = i['user']['id']
like_count = i['like_count'] # Number of likes
created_at = i['created_at'] # time
text = re.sub(r'<[^>]*>', '', i['text']) # comment
print(text)
data_json = pd.DataFrame({'screen_name': [screen_name], 'i_d': [i_d], 'like_count': [like_count], 'created_at': [created_at],'text': [text]})
df = pd.concat([df, data_json])
time.sleep(random.uniform(2, 7))
a += 1
except Exception as e:
print(e)
df.to_csv('micro-blog.csv', encoding='utf-8', mode='a+', index=False)
print(df.shape)
Result display:
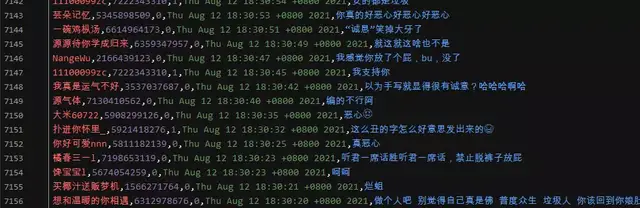
The above is all today's content. If you like today's content, I hope you can point praise and watch it below. Thank you!