Beautiful soup Library
Although XPath is more convenient than regular expressions, it is not the most convenient, only more convenient. Our beautiful soup library can make it easier to crawl what you want.
Installing the BeautifulSoup Library
Before use, it is the old rule to install the BeautifulSoup library. The instructions are as follows:
pip install beautifulsoup4
Its Chinese development documents:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
Introduction to beautiful soup Library
The beautiful soup library is a powerful XML and HTML parsing library for the Python language. It provides some simple functions to handle navigation, search, modification of analysis tree and so on.
The beautiful soup library can also automatically convert the input document to Unicode encoding and the output document to UTF-8 encoding.
Therefore, in the process of using the beautiful soup library, there is no need to consider coding in development. Unless the document you parse does not specify the coding method, it needs to be coded in development.
Next, let's introduce the usage rules of the beautiful soup Library in detail.
Select interpreter
Next, let's introduce the key knowledge of the beautiful soup Library in detail.
First of all, an important concept in the beautiful soup library is to select an interpreter. Because its bottom layer depends on these interpreters, we need to know. The blogger specifically listed a table:
| interpreter | Mode of use | advantage | shortcoming |
|---|---|---|---|
| Python standard library | BeautifulSoup(code,'html.parser') | Python's built-in standard library has moderate execution speed and strong fault tolerance | Python2.7.3 and python 3 Versions before 2.2 have poor fault tolerance |
| lxml HTML parser | BeautifulSoup(code,'lxml') | Fast parsing speed and strong fault tolerance | The C language library needs to be installed |
| lxml XML parser | BeautifulSoup(code,'xml') | Fast parsing speed, the only parser that supports XML | C language library needs to be installed |
| html5lib | BeautifulSoup(code,'html5lib') | It has the best fault tolerance, parses documents in a browser way and generates documents in HTML5 format | Slow parsing speed |
From the above table, it can be seen that we generally use lxml HTML parser. It is not only fast, but also has strong compatibility. It only needs to install C language library (it should not be called disadvantage, but trouble).
Basic usage
To use the beautiful soup library, you need to import it like other libraries, but although you install beautiful soup 4, the imported name is not beautiful soup 4, but bs4. The usage is as follows:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<h1>Hello World</h1>', 'lxml')
print(soup.h1.string)
After running, the output text is as follows:

Node selector
The basic usage is very simple and will not be repeated here. From now on, let's learn all the important knowledge points of the beautiful soup Library in detail. The first is the node selector.
The so-called node selector is to select a node directly through the name of the node, and then use the string attribute to get the text in the node. This method is the fastest.
For example, in the basic usage, we use h1 to directly obtain the h1 node, and then use h1 String to get its text. However, this usage has an obvious disadvantage, that is, the hierarchy is complex and not suitable.
Therefore, we need to shrink the document before using the node selector. For example, there are many large documents, but the content we get is only in the div with id of blog, so it is very appropriate for us to get the div first and then use the node selector inside the Div.
HTML sample code:
<!DOCTYPE html> <html> <head lang="en"> <meta charset="utf-8"> <title>I am a test page</title> </head> <body> <ul class="ul"> <li class="li1"><a href="https://liyuanjinglyj. blog. csdn. Net / "> my home page</a></li> <li class="li2"><a href="https://www.csdn. Net / "> CSDN Homepage</a></li> <li class="li3"><a href="https://www.csdn. Net / NAV / Python "class =" AAA "> Python section</a></li> </ul> </body> </html>
In the following examples, we still use this HTML code to explain the node selector.
Get node name attribute content
Here, let's teach you how to obtain the name, attribute and content of a node. An example is as follows:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html, 'lxml')
# Gets the name of the node
print(soup.title.name)
# Gets the properties of the node
print(soup.meta.attrs)
print(soup.meta.attrs['charset'])
# Get the content of the node (if the document has multiple same attributes, the first one is obtained by default)
print(soup.a.string)
# You can also cover it layer by layer
print(soup.body.ul.li.a.string)
After running, the effect is as follows:
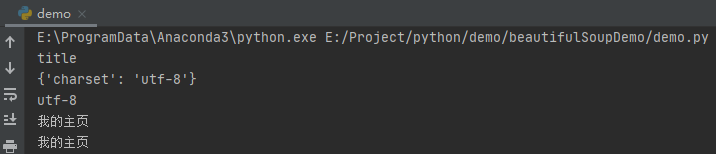
The comment codes here are very detailed, so I won't repeat them.
Get all child nodes
Generally speaking, there may be many child nodes of a node. Only the first one can be obtained through the above method. There are two ways to get all the child nodes of a label. Let's start with the code:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html, 'lxml')
# Get direct child node
print("Get direct child node")
contents = soup.head.contents
print(contents)
for content in contents:
print(content)
children = soup.head.children
print(children)
for child in children:
print(child)
After running, the effect is as follows:
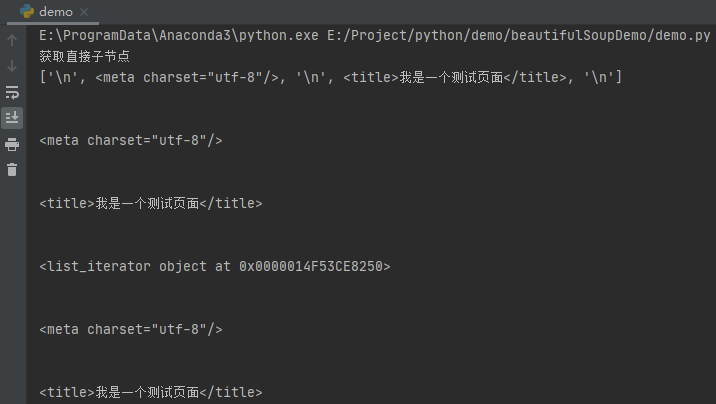
As shown in the above code, we have two ways to obtain all child nodes, one through the contents attribute and the other through the children attribute. The traversal results of both are the same.
However, it should be noted that all child nodes are obtained here, which takes the newline character into account, so you will see a lot of empty lines output from the console. Therefore, in the actual crawler, these empty lines must be deleted when traversing.
Get all descendant nodes
Since direct child nodes can be obtained, it is certainly possible to obtain all descendant nodes. The beautiful soup library provides us with the descendants attribute to obtain descendant nodes. An example is as follows:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html, 'lxml')
# Get all descendants of ul
print('obtain ul All descendant nodes of')
lis = soup.body.ul.descendants
print(lis)
for li in lis:
print(li)
After running, the effect is as follows:
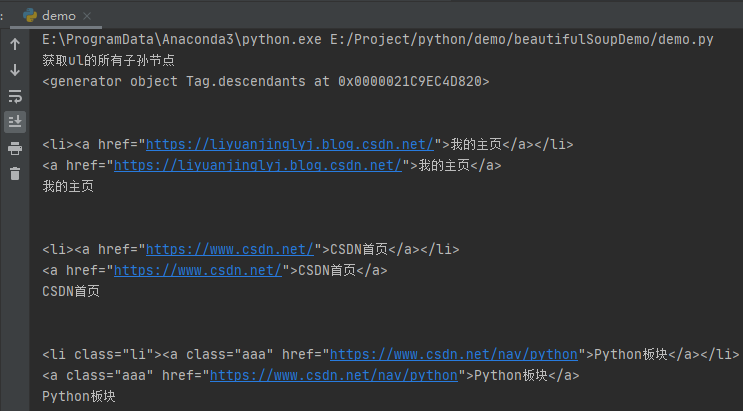
Similarly, the descendants node is also included in the newline character. In addition, it should be noted that the descendants attribute counts the text content itself as a descendant node.
Parent node and brother node
Similarly, in the actual crawler program, we sometimes need to find the parent node or brother node by reverse.
The beautiful soup library provides us with the parent attribute to obtain the parent node and the next_ The sibling property gets the next sibling node of the current node, previous_ The sibling property gets the previous sibling node.
The example code is as follows:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html, 'lxml')
# Gets the class attribute of the parent node of the first a tag
print(soup.a.parent['class'])
li1 = soup.li
li3 = li1.next_sibling.next_sibling.next_sibling.next_sibling
li2 = li3.previous_sibling.previous_sibling
print(li1)
print(li2)
print(li3)
for sibling in li3.previous_siblings:
print(sibling)
After running, the effect is as follows:
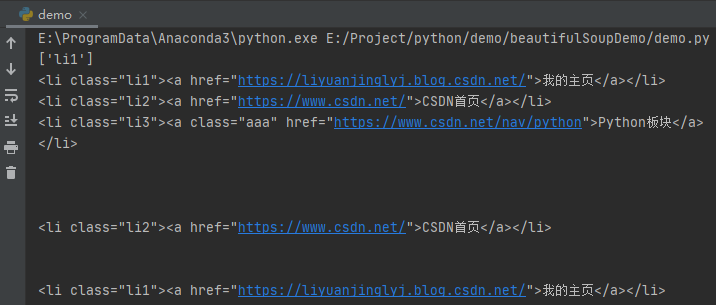
As mentioned earlier, the node selector counts the newline '\ n' as a node, so the first Li needs to pass two next_sibling can get the next li node. The same goes for the last one. In fact, there is a simpler way to avoid these line breaks being counted, that is, when obtaining the web page source code, just remove the line breaks and spaces directly.
Method selector
For node selectors, bloggers have introduced that they can do this with less text content. But the actual crawler's web address is a large amount of data, so it's not appropriate to start using node selector. Therefore, we should consider the first step through the method selector.
find_all() method
find_ The all () method is mainly used to select all qualified nodes according to the node name, attribute, text content, etc. Its complete definition is as follows:
def find_all(self, name=None, attrs={}, recursive=True, text=None,
limit=None, **kwargs):
| parameter | significance |
|---|---|
| name | Specify node name |
| attrs | Specify the attribute name and value. For example, find the node with value="text", attrs = {"value": "text"} |
| recursive | Boolean type. The value is True to find the descendant node. The value is False to directly the child node. The default is True |
| text | Specify the text to find |
| limit | Because find_all returns a list, so it can be long or short, and limit is similar to the database syntax, limiting the number of fetches. Return all without setting |
[actual combat] still test the HTML above. We get name=a, attr = {"class": "aaa"}, and the text is equal to the node of the text="Python section".
The example code is as follows:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
a_list = soup.find_all(name='a', attrs={"class": 'aaa'}, text='Python plate')
for a in a_list:
print(a)
After running, the effect is as follows:

find() method
find() and find_all() is only one all short, but the results are two different:
- find() finds only the first node that meets the criteria, and find_all() is to find all nodes that meet the criteria
- The find() method returns BS4 element. Tag object, and find_all() returns BS4 element. Resultset object
Next, let's find the a tag in the HTML above to see how the returned results are different. An example is as follows:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
a_list = soup.find_all(name='a')
print("find_all()method")
for a in a_list:
print(a)
print("find()method")
a = soup.find(name='a')
print(a)
After running, the effect is as follows:
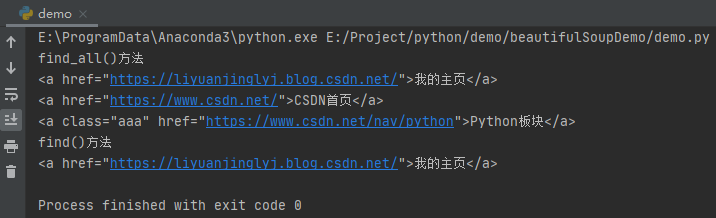
CSS selector
First, let's take a look at the rules of CSS selectors:
- . classname: select the node whose style name is classname, that is, the node whose class attribute value is classname
- #Idname: select the node whose id attribute is idname
- nodename: select a node named nodename
Generally speaking, we use the select function in the CSS library. Examples are as follows:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
li = soup.select('.li1')
print(li)
Here, we select the node whose class is equal to li1. After running, the effect is as follows:

Nested selection node
Because we need to implement the usage of nested CSS selectors, but the HTML above is not appropriate. Here, we modify it slightly and only change the code in the < UL > tag.
<ul class="ul"> <li class="li"><a href="https://liyuanjinglyj. blog. csdn. Net / "> my home page</a></li> <li class="li"><a href="https://www.csdn. Net / "> CSDN Homepage</a></li> <li class="li"><a href="https://www.csdn. Net / NAV / Python "class =" AAA "> Python section</a> </ul>
We just deleted the number after li. Now we can achieve the effect of nested selection nodes. The example code is as follows:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
ul = soup.select('.ul')
for tag in ul:
a_list = tag.select('a')
for a in a_list:
print(a)
After running, the effect is as follows:
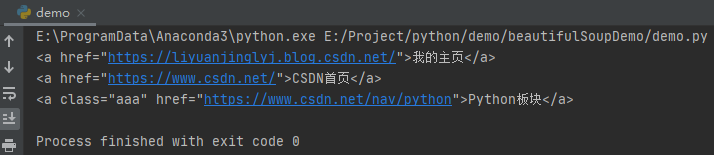
Get properties and text
Let's transform the above code again. Because of the tags obtained above, now let's get the text and the value of the href attribute. An example is as follows:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
ul = soup.select('.ul')
for tag in ul:
a_list = tag.select('a')
for a in a_list:
print(a['href'], a.get_text())
After running, the effect is as follows:
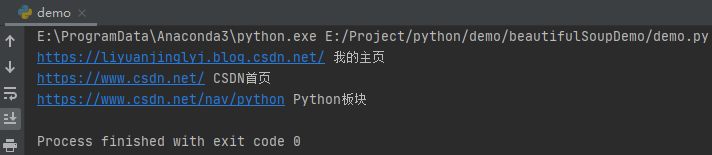
You can see that we get the attribute value through ['attribute name'], and through get_text() gets the text.
Copy CSS selector directly from browser
Similar to XPath, we can Copy CSS selector code of any node directly through F12 browser. The specific operation is shown in the figure below:
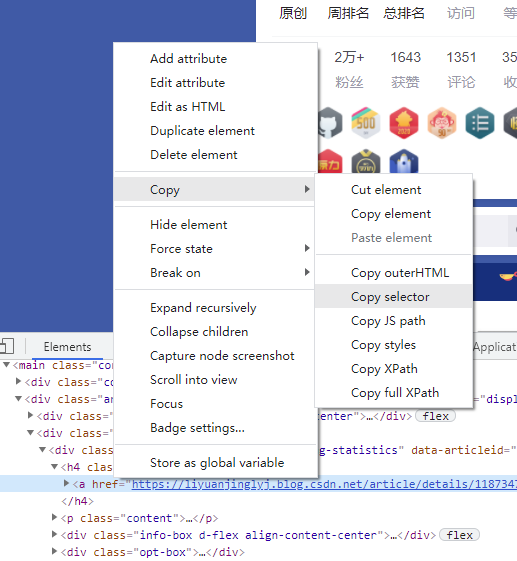

After copy, paste the copied content directly into the select() method.
Actual combat: capture the list of cool dog soaring list
The above is basically all the usage of the beautiful soup library. Since we have learned and mastered it, we always feel very bad if we don't hurry to climb something, so we choose the cool dog soaring list to climb.
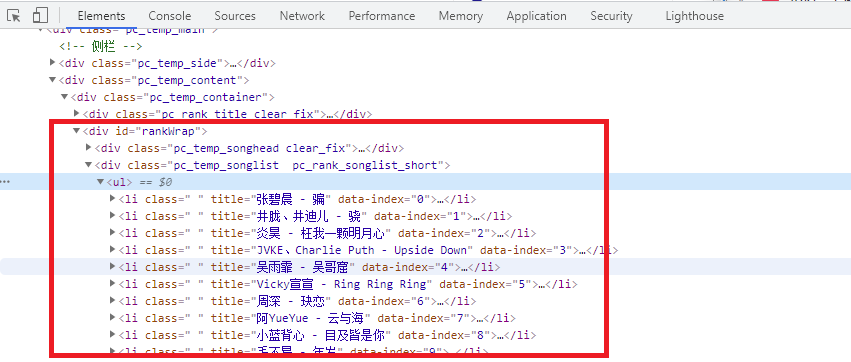
As shown in the figure above, our list information is all in the ul under the div tag of id="rankWrap". So, first of all, we must get ul. The example code is as follows:
from bs4 import BeautifulSoup
import requests
url = "https://www.kugou.com/yy/html/rank.html"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
result = requests.get(url=url, headers=headers)
print(result.text)
soup = BeautifulSoup(result.text.strip(), 'lxml')
ul = soup.select('#rankWrap > div.pc_temp_songlist.pc_rank_songlist_short > ul')
print(tbody)
After obtaining the ul, we can obtain all the li node information, and then decompose the li label to obtain the important song author, song name, etc. However, let's first analyze the internal code of the web page:
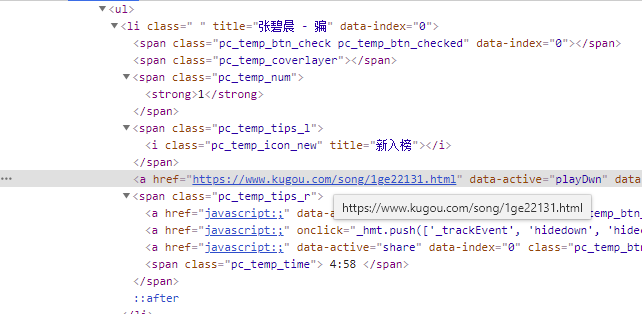
You can see that the song name and author we want are in the title attribute of li, and the web page link of the song is in the href attribute of node a under the label of the fourth span under li (or directly in the first a label). After knowing this, we can improve the code.
from bs4 import BeautifulSoup
import requests
url = "https://www.kugou.com/yy/html/rank.html"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
result = requests.get(url=url, headers=headers)
soup = BeautifulSoup(result.text.strip(), 'lxml')
ul = soup.select('#rankWrap > div.pc_temp_songlist.pc_rank_songlist_short > ul')
lis = ul[0].select('li')
for li in lis:
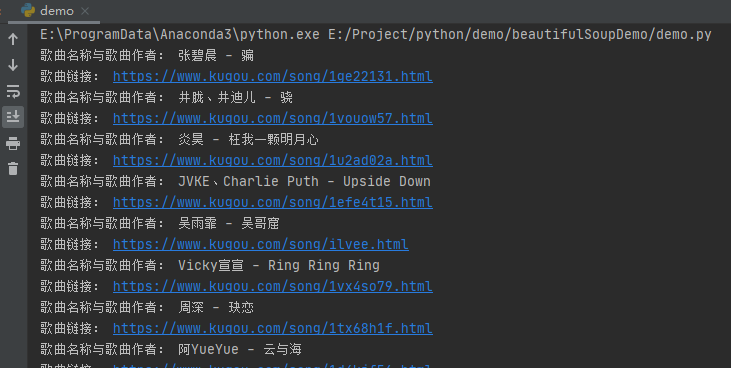
print("Song name and song Author:", li['title'])
print("Song link:", li.find('a')['href'])
As shown in the above code, we can climb the soaring list of cool dog music in less than 14 lines of code. Is the beautiful soup library very powerful?