👻👻 I believe many friends have learned the requests library from entering the pit to meeting through the repeated bombing of my two ten thousand word blog posts, and can independently develop their own small crawler projects—— The reptile road is endless~ 👻👻
chapter I reptile entering the pit: A ten thousand word blog post takes you to the no return road of the pit reptile (what are you hesitating about & hurry up to get on the bus)[ ❤️ Stay up late to tidy up & suggestions collection ❤️]
Part II detailed explanation of crawler library requests: Twenty thousand word blog post teaches you the python crawler requests library. I won't give you all my girlfriends after reading it[ ❤️ Stay up late to tidy up & suggestions collection ❤️]
😬😬 Then, the second step is to parse the data we want from the page! I believe that my friends have deeply learned the structure of web pages (HTML) through the repeated bombing of my last two ten thousand word blog posts, and can skillfully parse pages through XPath. But another friend said - some web pages hide data deeply! I can't figure it out by XPath. What should I do? 😬😬
summary of HTML essential knowledge of web page structure: Front end HTML 20000 word graphic summary, come and see how much you can! [ ❤️ Stay up late to tidy up & suggestions collection ❤️]
detailed explanation of the first parsing library XPath Library: The ten thousand character blog teaches you the necessary XPath library for python crawlers. I won't give you all my girlfriends after reading it[ ❤️ Recommended collection ❤️]
😜😜 There are two reasons why you can't analyze the data: first, you don't have enough skills (you should practice more!); Second, XPath is not omnipotent. It can't work after all (although it's enough!). Therefore, in response to the needs of fans - the blogger will teach another unique skill: Beautiful Soup!!! 😜😜

here comes the key! Here comes the point!! 💗💗💗
for a web page, it has a certain special structure and hierarchical relationship, and many nodes have id or class to distinguish, so it's not very fragrant to extract with their structure and attributes? Well said! Beautiful Soup, a powerful parsing tool, was born because of this. It parses web pages with the help of the structure and properties of web pages! Now let's enter the world of Beautiful Soup!
| Learn the parsing library well and let me take the web data!!! |

1.BeautifulSoup
(1) Introduction:
| Beautiful soup is a Python library that can extract data from HTML or XML files. Its use is more simple and convenient than regular, and can often save us a lot of time. It uses the structure and properties of web pages to analyze web pages! |
🙉 The official explanation is as follows 🙉:
- Beautiful Soup provides some simple Python functions to handle navigation, search, modification of analysis tree and other functions. It is a toolbox that provides users with the data they need to grab by parsing documents. Because it is simple, it doesn't need much code to write a complete application.
- Beautiful Soup automatically converts the input document to Unicode encoding and the output document to UTF-8 encoding. You don't need to consider the coding method unless the document does not specify a coding method. At this time, you just need to explain the original coding method.
- Beautiful Soup has become a Python interpreter as excellent as lxml, providing users with different parsing strategies or strong speed flexibly.
(tip: Beautiful Soup is also referred to as bs4 for short! Don't know it if you hear the name!)
The official Chinese document is here!

(2) Installation:
😻 CMD command installation 😻 (an order is in place in one step [mom doesn't have to worry about me anymore!]:
pip install beautifulsoup4
(3) Parser:
it should be noted that the parser needs to be specified when using Beautiful Soup (because Beautiful Soup actually depends on the parser when parsing. In addition to supporting HTML parsers in Python standard library, it also supports some third-party parsers [such as lxml])
when parsing web pages, you must specify an available parser! The following are the main parsers:
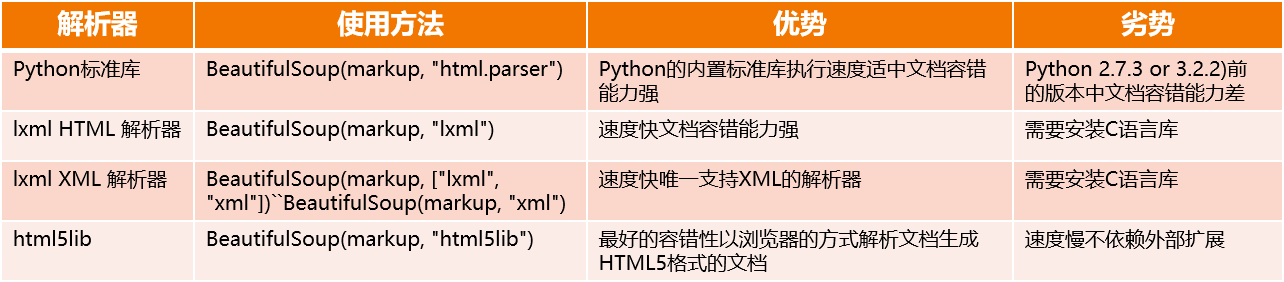
because this parsing process will affect the speed of the whole crawler system in large-scale crawling, and from the above comparison, it can be seen that lxml parser has the function of parsing HTML and XML, and it is fast and has strong fault tolerance, so it is recommended to use it, and it is always used by our bloggers! Note - lxml needs to be installed separately (also a CMD command!):
pip install lxml
| Warm tip: if the format of an HTML or XML document is incorrect, the results returned in different parsers may be different, so be sure to specify a definite parser! |
(4) Instance introduction:
(we define an html_doc string to simulate the crawled page data to be parsed)
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title" name="dromouse"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ from bs4 import BeautifulSoup # The first parameter: the above HTML string; The second parameter: the type of parser (using lxml) -- complete the initialization of the beautifulsup object! soup = BeautifulSoup(html_doc, "lxml") # Convert html into actionable objects print(type(soup))
the output is as follows (it will be found that it is already a BeautifulSoup object. Next, we can call various methods and properties of soup to resolve it at will!):
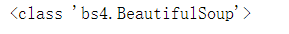
let's start with an operation -- call the prettify() method. Function: output the string to be parsed in standard indentation format.
print(soup.prettify())
output is:
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title" name="dromouse">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>
we observed the output and the original HTML string and found that for non-standard HTML strings, beautiful soup can automatically correct its format (let's see if the previous etree module can also!). However, it should be noted that this operation of automatically correcting its format is completed when initializing BeautifulSoup, rather than calling the prettify() method!

(5) Detailed explanation of various common operations / selectors:
Initial stage - required operations:
1. Gas training period - basic operation 6:
Qi training period (absorb the aura of heaven and earth, turn it into yuan force into the body, and the longevity can reach a hundred years old; the elixir field is Qi, and preliminarily master the application of aura technique. It already has divine consciousness and does not need to be used It can penetrate the valley, and the vitality in the body can't support the imperial sword flying for too long)
print(soup.title) # Get title tag print(soup.title.name) # Get the tag name of the title tag, get the node name, and call the name attribute! print(soup.title.string) # Gets the text content of the title tag print(soup.title.parent) # Gets the parent tag of the title tag print(soup.find(id="link2")) # Find the tag with id=link2

2. Foundation period - Tag object:
Foundation building period (the elixir field is liquid, which can open valleys, double divine consciousness, and can live for more than 200 years. It can't escape light and fly for a long time)
|
print("I am Tag Object:", type(soup.a))
# 1. Get tag only gets the first qualified tag, and other subsequent nodes will be ignored!
print(soup.a) # Output as: < a class = "sister" href=“ http://example.com/elsie " id="link1">Elsie</a>
# 2. Get attribute only gets the attribute value of the first qualified tag
print(soup.a["href"]) # Output is: http://example.com/elsie

Expand - get attributes:
1. Each node may have multiple attributes, such as id and class. After selecting this node element, you can call attrs to obtain all attributes:
print(soup.p.attrs) print(soup.p.attrs['name'])
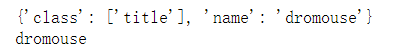
2. You can see that the return result of attrs is in dictionary form. If you want to get the name attribute, it is equivalent to getting a key value from the dictionary. Instead of writing attrs, you can directly add brackets after the node element as described above, and pass in the attribute name:
print(soup.p['name']) print(soup.p['class'])
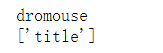
3. Note: some return strings, and some return results are lists composed of strings. For example, the value of the name attribute is unique, and the returned result is a single string; For class, a node element may have multiple classes, so the returned is a list!
3. Jindan period - obtain text content:
Golden elixir period (there are regular round solid elixirs in the elixir field. The valley has been opened. The longevity of the elixir can reach 500 years, and it can fly by running light)
# The first method: print(soup.a.text) print(soup.a.get_text()) # The second method: print(soup.body.get_text()) # Note: this method will get all text contents under the selected tag


Intermediate stage - Association selection:
| In actual use, we often can't publicize the desired node element in one step. In this case, we need to select a node element first, and then select its child node, parent node, brother node, etc. based on it. This is the association selection to be explained next: |
Pre war preparation:
first get the whole body tag, and then nest and select in the body:
body = soup.body # Get the entire body tag print(body)

1. Primipara - selection of offspring labels:
Yuanying period (breaking the pill into a baby, with a life of up to 1000 years, flying away from the light, and breaking the body, Yuanying can move rapidly)
| contents and children: |
|
①contents
print(body.contents)

②children
tags = body.children # Print body Children know that this is an iterator. All direct child nodes are also obtained. print(tage)
You can use the for loop to output the contents of the iterator, or you can convert the type to a list and directly output all its contents:


Extension - briefly talk about NavigableString objects:
NavigableString means a string that can be traversed. Generally, the text wrapped by the label is in NavigableString format. Based on this type, we choose this type again, and the result is the same every time! In this way, nested selection can be achieved (the Tag object mentioned earlier can also be used to realize nested selection)!
print(type(soup.body.get_text())) # The output is: < class' STR '> print(type(soup.p.string)) # Output: < class' BS4 element. NavigableString'>

2. Deification period - selection of offspring labels:
Spirit transforming period (Yuan Ying doubles in the body, Yuan Ying transits to Yuan Shen, can live for more than 2000 years, master the field of yuan power, and can break Yuan Ying's blink)
| descendants: |
|
tags_des = body.descendants # Print body The descendants know that this is a generator. What you get is the descendant (descendant) tag print(list(tags_des))

3. Deficiency refining period - brother label selection:
Deficiency refining period (the longevity of yuan can reach nearly 5000 years old, and the yuan infant in the body becomes the yuan God, returns to the virtual body, and becomes a separate body or many separate bodies)
| Sibling node - refers to a node with the same parent node. |
|
① First get the first p tag in the body tag:
p = body.p # You can get the specified label layer by layer, but you can only get the first qualified label print(p)
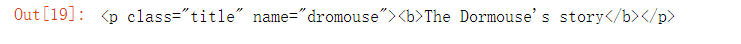
② Get the second tag that meets the criteria and use next_sibling method (Note: the next sibling node of the first p tag in the body tag selected in the previous step is \ n!):
print(p.next_sibling.next_sibling)

③ Get the previous label of the matching sibling label, and use previous_sibling method (Note: the first upward sibling node of the body tag is \ n!):
print(body.previous_sibling.previous_sibling)
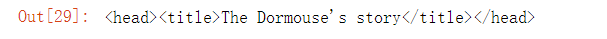
4. Integration phase - selection of parent node label:
Integration period (the separation and noumenon are combined into one, so as to return to simplicity and return to truth. At the beginning, you can break and refine thousands of virtual incarnations, and your longevity can reach tens of thousands of years)
| parent node and parents: |
|
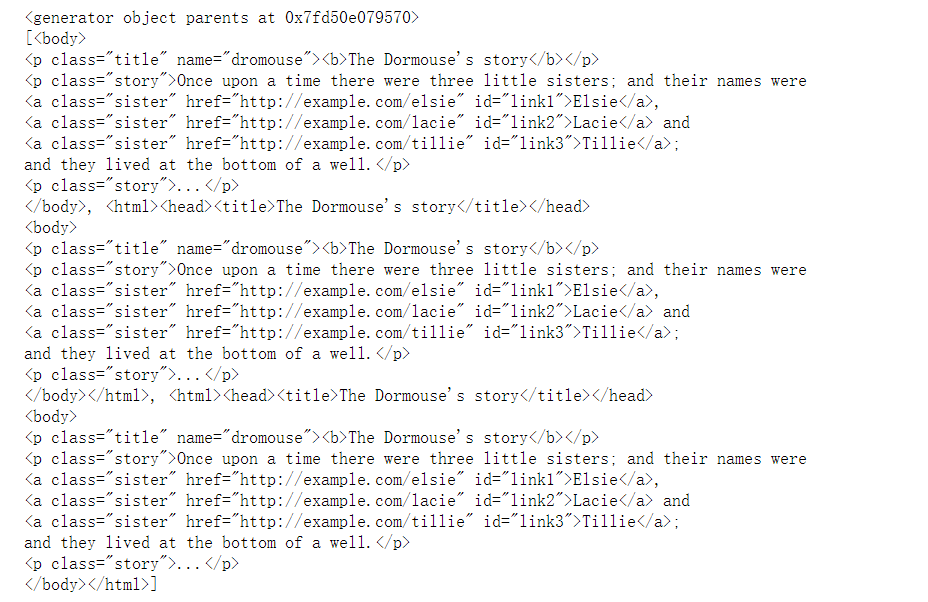
① Parent -- only the parent node of the selected tag can be obtained:
p = body.p print(p.parent)

② parents - all parent elements of the selected tag can be obtained:
p_parents = p.parents print(p_parents) #Printing shows that this is a generator print(list(p_parents))
5. Mahayana - information extraction:
Mahayana period (longevity can reach more than 20000 years, skillfully use or create their own magic powers, and the physical body of mana has the conditions to ascend to the upper world. Chen is a monk with great power)
| strings and strings: |
|
① String -- extract a single string in the current node:
p = body.p print(p.string)
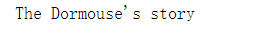
② Strings -- extract multiple strings in the current node:
gg = body.strings # A generator is returned print(type(gg)) print(list(gg))

Operation - use striped_ Strings remove all blank lines:
print(list(body.stripped_strings)) # You will find the difference between the returned string and the string directly used above: there is no blank that 's ok
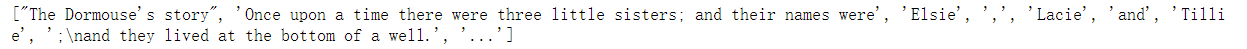

Research stage - method selector (transition period):
During the period of robbery (the transition from mortal to immortal), after the friar soared to the upper world, he first learned the law of heaven and earth, and the yuan force in his body gradually changed to immortal yuan force or immortal spirit force, and failure will lead to failure For the sake of robbing friars, they die with the years; If you succeed in conversion, you will understand the laws of heaven and earth, and you can live the same life as heaven and earth. You are an immortal.)
| The above methods are selected through attributes. The speed is fast! However, if the node location to be selected is very complex, it will be very troublesome (it can only be applied to some simple scenes in many cases)!!! Therefore, beautiful soup also provides a method to search the entire document tree, find_all(). |
Source code:
def find_all(self, name=None, attrs={}, recursive=True, text=None)
Function: get all qualified elements
Return value: an iteratable object (list)
note: find_ The content obtained by all is in the list!!!
1. Search by name and query by node name:
find_all('p ') can directly find all P tags in the whole document tree and return the list:
print(soup.find_all("p"))

operation - obtain all p tags and a Tags:
print(soup.find_all(["p", "a"]))

2. Through attribute search, we can query by passing a dictionary parameter to attrs.
get the p tag with class story in the p tag:

3. Search through text content:
Text returned result list of all parameters of text node:
print(soup.find_all(text="Elsie"))
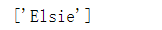
get the a tag with Elsie text in the a tag / soup find_ all(text=“Elsie”)[0].parent can also:
print(soup.find_all("a", text="Elsie"))
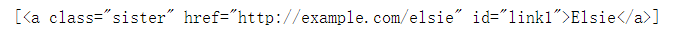
Expand - get attribute value:
get the href of the a tag that meets the conditions:
print(soup.find_all("a", text="Elsie")[0]["href"])

4. Restrict the search range to child nodes:
|
print(soup.html.find_all("body", recursive=False))

5. Extension - Search with regular expressions:
|
find labels starting with B (b label and body label):
import re
tags = soup.find_all(re.compile("^b"))
print(tags)


Sublimation stage (multiple transitions):
Part I - method selector:
the method selector provided by Beautiful Soup is far more than one find_ Oh! And find_all() is the opposite of the find() method. The only difference between the two is: find_ The all () method returns a list of all matching elements; The find() method returns the first matching element!
Part II - CSS selector:
in addition, if you have some research on WEB development, Beautiful Soup has also customized a selector for you - CSS selector.
1. Usage:
| Just call the select() method and pass in the corresponding CSS selector! |
2. Practical explanation:
① Get all p Tags:
print(soup.select("p"))
print(type(soup.select("p")[0]))
 Note: We observed that the result type selected through CSS selector is still Tag type! This means that we can still do whatever we want with the nodes selected using the CSS selector! (for example, nested selection, getting attributes, getting text...)
Note: We observed that the result type selected through CSS selector is still Tag type! This means that we can still do whatever we want with the nodes selected using the CSS selector! (for example, nested selection, getting attributes, getting text...)
② Get the a tag under the p tag, and the returned results are in the list:
print(soup.select("p>a"))
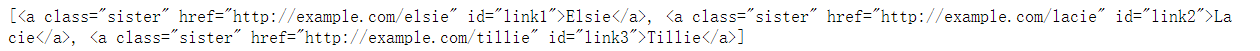
2.In The End!

| From now on, stick to it and make progress a little bit a day. In the near future, you will thank you for your efforts! |
the blogger will continue to update the crawler basic column and crawler actual combat column. After reading this article carefully, you can praise the collection and comment on your feelings after reading it. And you can pay attention to this blogger and read more crawler articles in the future!
If there are mistakes or inappropriate words, you can point them out in the comment area. Thank you!
If you reprint this article, please contact me for my consent, and mark the source and the blogger's name, thank you! >!