Detailed explanation of BN core parameters of PyTorch
Original document: https://www.yuque.com/lart/ugkv9f/qoatss
affine
Modify during initialization
When fine is set to True, the BatchNorm layer will learn the parameters gamma and beta. Otherwise, these two variables are not included, and the variable names are weight and bias.
.train()
- If affine==True, affine transform the normalized batch, that is, multiply the weight inside the module (the initial value is [1,1,1,1.]) Then add the bias inside the module (the initial value is [0,0,0,0.]), These two variables are updated during back propagation.
- If fine = = false, BatchNorm does not contain weight and bias variables and does nothing.
.eval()
- If affine==True, the normalized batch is radially transformed, that is, multiplied by the weight inside the module, and then added with the bias inside the module. These two variables are learned during network training.
- If affine==False, BatchNorm does not contain weight and bias variables and does nothing.
Modify instance properties
No effect, still according to the setting at initialization.
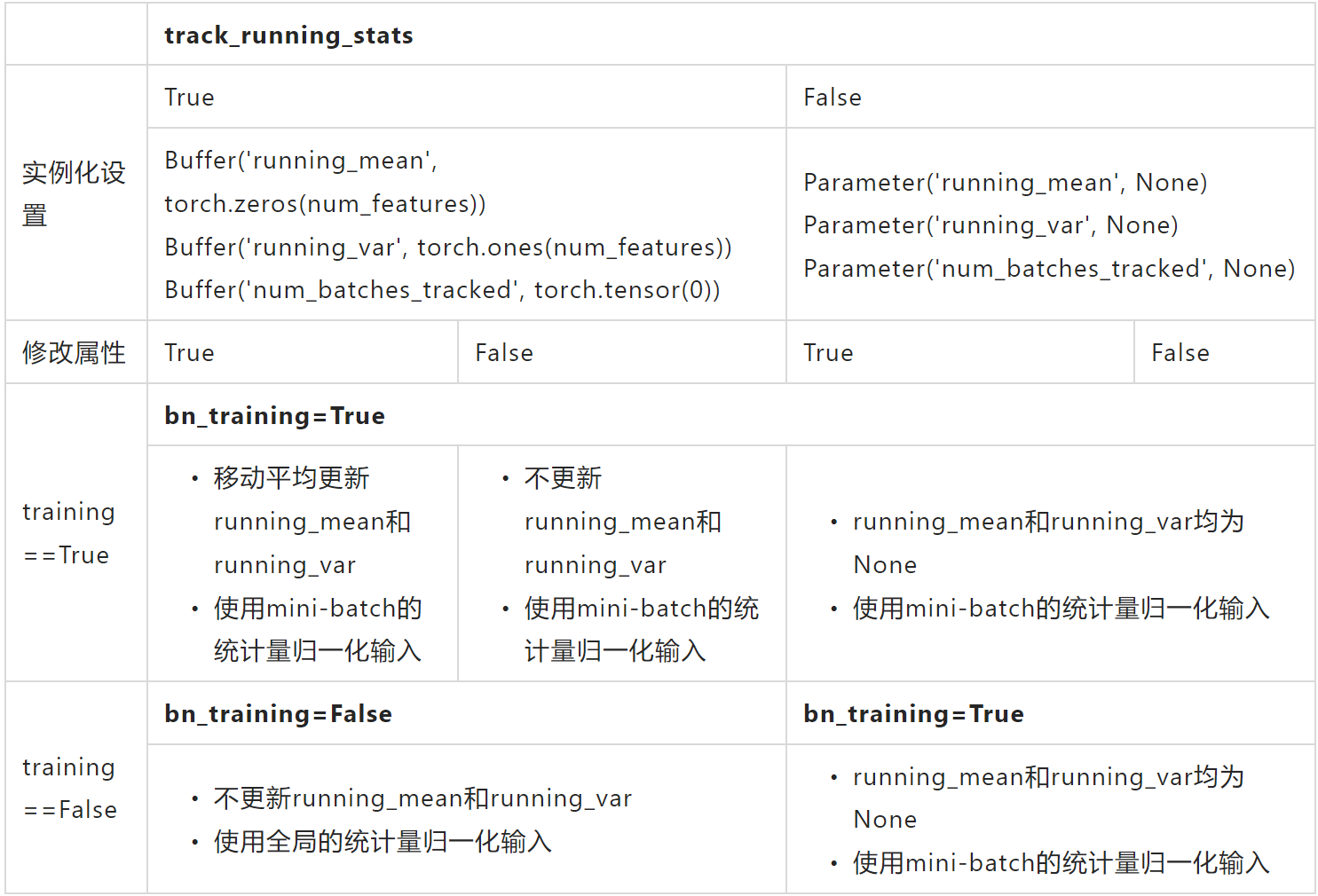
track_running_stats
Because the forward propagation of BN involves this attribute, the modification of instance attribute will affect the final calculation process.
class _NormBase(Module):
"""Common base of _InstanceNorm and _BatchNorm"""
_version = 2
__constants__ = ['track_running_stats', 'momentum', 'eps',
'num_features', 'affine']
num_features: int
eps: float
momentum: float
affine: bool
track_running_stats: bool
# WARNING: weight and bias purposely not defined here.
# See https://github.com/pytorch/pytorch/issues/39670
def __init__(
self,
num_features: int,
eps: float = 1e-5,
momentum: float = 0.1,
affine: bool = True,
track_running_stats: bool = True
) -> None:
super(_NormBase, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
self.affine = affine
self.track_running_stats = track_running_stats
if self.affine:
self.weight = Parameter(torch.Tensor(num_features))
self.bias = Parameter(torch.Tensor(num_features))
else:
self.register_parameter('weight', None)
self.register_parameter('bias', None)
if self.track_running_stats:
self.register_buffer('running_mean', torch.zeros(num_features))
self.register_buffer('running_var', torch.ones(num_features))
self.register_buffer('num_batches_tracked', torch.tensor(0, dtype=torch.long))
else:
self.register_parameter('running_mean', None)
self.register_parameter('running_var', None)
self.register_parameter('num_batches_tracked', None)
self.reset_parameters()
...
class _BatchNorm(_NormBase):
...
def forward(self, input: Tensor) -> Tensor:
self._check_input_dim(input)
if self.momentum is None:
exponential_average_factor = 0.0
else:
exponential_average_factor = self.momentum
if self.training and self.track_running_stats:
if self.num_batches_tracked is not None: # type: ignore
self.num_batches_tracked = self.num_batches_tracked + 1 # type: ignore
if self.momentum is None: # use cumulative moving average
exponential_average_factor = 1.0 / float(self.num_batches_tracked)
else: # use exponential moving average
exponential_average_factor = self.momentum
r"""
Decide whether the mini-batch stats should be used for normalization rather than the buffers.
Mini-batch stats are used in training mode, and in eval mode when buffers are None.
You can see here bn_training The control is that the data operation uses the current batch Calculated statistics(True)
"""
if self.training:
bn_training = True
else:
bn_training = (self.running_mean is None) and (self.running_var is None)
r"""
Buffers are only updated if they are to be tracked and we are in training mode. Thus they only need to be
passed when the update should occur (i.e. in training mode when they are tracked), or when buffer stats are
used for normalization (i.e. in eval mode when buffers are not None).
The emphasis here is on statistics buffer Service conditions of(self.running_mean, self.running_var)
- training==True and track_running_stats==False, These properties are passed in F.batch_norm When in, replace with None
- training==True and track_running_stats==True, The contents stored in these properties are used
- training==False and track_running_stats==True, The contents stored in these properties are used
- training==False and track_running_stats==False, The contents stored in these properties are used
"""
assert self.running_mean is None or isinstance(self.running_mean, torch.Tensor)
assert self.running_var is None or isinstance(self.running_var, torch.Tensor)
return F.batch_norm(
input,
# If buffers are not to be tracked, ensure that they won't be updated
self.running_mean if not self.training or self.track_running_stats else None,
self.running_var if not self.training or self.track_running_stats else None,
self.weight, self.bias, bn_training, exponential_average_factor, self.eps)
.train()
Note the note in the code: Buffers are only updated if they are to be tracked and we are in training mode That is, only if it is in training mode and track_ running_ These statistics buffers are updated when stats = = true.
In addition, self training==True. bn_training=True.
track_running_stats==True
The BatchNorm layer will count the global mean running_mean and variance running_var, while for batch normalization, only the statistics of the current batch are used.
self.register_buffer('running_mean', torch.zeros(num_features))
self.register_buffer('running_var', torch.ones(num_features))
self.register_buffer('num_batches_tracked', torch.tensor(0, dtype=torch.long))
Using momentum to update running inside the module_ mean.
- If momentum is None, the cumulative moving average is used (here, the attribute self.num_batches_tracked is used to count the number of batches that have passed). Otherwise, the exponential moving average is used (momentum is used as the coefficient). The basic framework of the two update formulas is the same: \ (x_{new}=(1 - factor) \times x_{cur} + factor \times x_{batch}\)
, but the specific \ (factor \) is different.- \(x_{new} \) represents the updated running_mean and running_var;
- \(x#{cur} \) indicates running before update_ Mean and running_var;
- $x_{batch} $represents the mean and unbiased sample variance of the current batch.
- Cumulative moving average updates \ (factor=1/num\_batches\_tracked \).
- The update formula of exponential moving average is \ (factor=momentum \).
Modify instance properties
If set track_running_stats==False, self num_ batches_ Tracked will not be updated, and exponential_ average_ The factor will not be readjusted.
And because:
self.running_mean if not self.training or self.track_running_stats else None,
self.running_var if not self.training or self.track_running_stats else None,
And now self Training = = true, and self track_ running_ Stats = = false, so it is sent to F.batch_norm's self running_ mean&self. running_ Both var parameters are None.
That is, set * * track in initialization at this time and directly_ running_ Stats = = false * * is the same effect.
But be careful of the ~ ~ exponential here_ average_ Change of factor ~ ~. However, usually when we initialize BN, only ~ ~ num will be sent_ Features ~ ~, so ~ ~ exponential will be used by default_ average_ factor = self. Momentum ~ ~ to construct exponential moving average update runtime statistics. (the exponential_average_factor will not work at this time)
track_running_stats==False
BatchNorm does not contain running_mean and running_var is two variables, that is, only the statistics of the current batch are used to normalize the batch.
self.register_parameter('running_mean', None)
self.register_parameter('running_var', None)
self.register_parameter('num_batches_tracked', None)
Modify instance properties
If set track_running_stats==True, self num_ batches_ Tracked is still not updated because its initial value is None.
On the whole, such changes have no practical impact.
.eval()
At this point, self training==False.
self.running_mean if not self.training or self.track_running_stats else None,
self.running_var if not self.training or self.track_running_stats else None,
At this time, send f.batch_ The two statistics buffer of norm are consistent with the initialization results.
track_running_stats==True
self.register_buffer('running_mean', torch.zeros(num_features))
self.register_buffer('running_var', torch.ones(num_features))
self.register_buffer('num_batches_tracked', torch.tensor(0, dtype=torch.long))
At this point bn_training = (self.running_mean is None) and (self.running_var is None) == False. So use global statistics.
Normalize batch with the formula \ (y=\frac{x-\hat{E}[x]}{\sqrt{\hat{Var}[x]+\epsilon} \). Note that the mean and variance here are running_mean and running_var, the global mean and unbiased sample variance during network training.
Modify instance properties
If set track_running_stats==False, bn_training remains unchanged and is not False, so the global statistics are still used. That is, self running_ mean, self. running_ Contents stored in var.
On the whole, modifying the attribute has no effect at this time.
track_running_stats==False
self.register_parameter('running_mean', None)
self.register_parameter('running_var', None)
self.register_parameter('num_batches_tracked', None)
At this point bn_training = (self.running_mean is None) and (self.running_var is None) == True. Therefore, the statistics of the current batch are used.
Normalize batch with the formula \ (y = \ frac {X - {e} [x]} {\ sqrt {var} [x] + \ epsilon} \). Note that the mean and variance here are batch's own mean and var. at this time, BatchNorm does not contain running_mean and running_var.
Note that the unbiased sample variance is used at this time (different from that during training), so if batch_ If size = 1, the denominator will be 0, and an error will be reported.
Modify instance properties
If set track_running_stats==True, bn_training remains unchanged and is still True, so the statistics of the current batch are still used. That is, ignore self running_ mean, self. running_ Contents stored in var.
The behavior at this time is the same as that without modification.
Summary
Screenshot from original document.