An unknown double non undergraduate in Northeast China successfully landed on Alibaba on all sides. Here, I share my face Sutra. You are welcome to read it.
Just a meal - > Alibaba Java development manual is a development standard generally followed in the industry
| Serial number | Article name | Hyperlinks |
|---|---|---|
| 1 | Operating system overview - Dual non landing Alibaba series | 2021 latest version via - > portal 1 |
| 2 | A comprehensive collection of computer networks -- double non landing Alibaba series | 2021 latest version via - > Portal 2 |
| 3 | Complete classics of Java Concurrent Programming -- double non landing Alibaba series | 2021 latest version via - > portal 3 |
| 4 | Java virtual machine (JVM) - Double non landing Alibaba series | 2021 latest version via - > portal 4 |
| 5 | A comprehensive collection of MySQL databases -- Alibaba series of dual non landing | 2021 latest version via - > portal 5 |
| 6 | A comprehensive collection of Java collections -- Alibaba series of double non landing | 2021 latest version via - > portal 6 |
| 5 | Interview Ali, you must know the background knowledge - Double non landing Alibaba series | 2021 latest version via - > portal 7 |
The content of this blog continues to be maintained. If there is any improvement, I hope you can point out. Thank you very much!
Dubbo section
Chapter I related concepts of distributed system
1.1 architecture objectives of large Internet projects

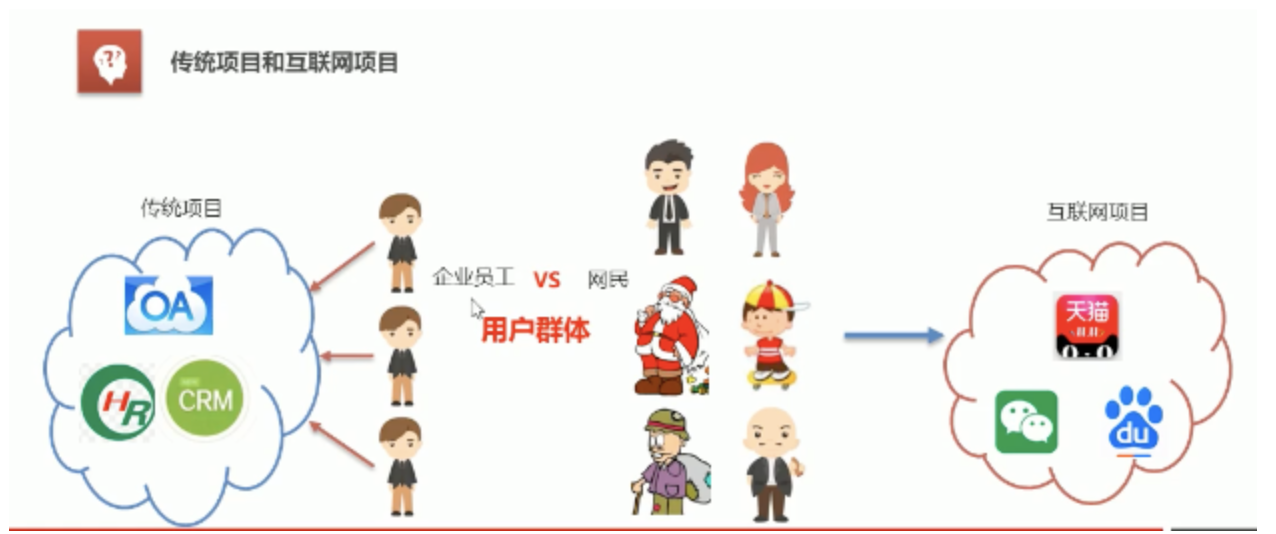
Internet project features: many users, large traffic, high concurrency, massive data, vulnerable to attack, cumbersome functions and fast change
Performance indicators of large-scale Internet project architecture: response time, concurrency and throughput
Architecture objectives of large-scale Internet projects: high performance, high availability (websites can always be accessed normally), scalability (processing capacity can be improved / reduced through hardware increase / decrease), high scalability (low coupling, easy to add / reduce functional modules through addition / removal), security and agility
1.2 cluster and distributed
Cluster: a business module deployed on multiple servers.
Distributed: a large business system is divided into small business modules and deployed on different machines.

1.3 architecture evolution





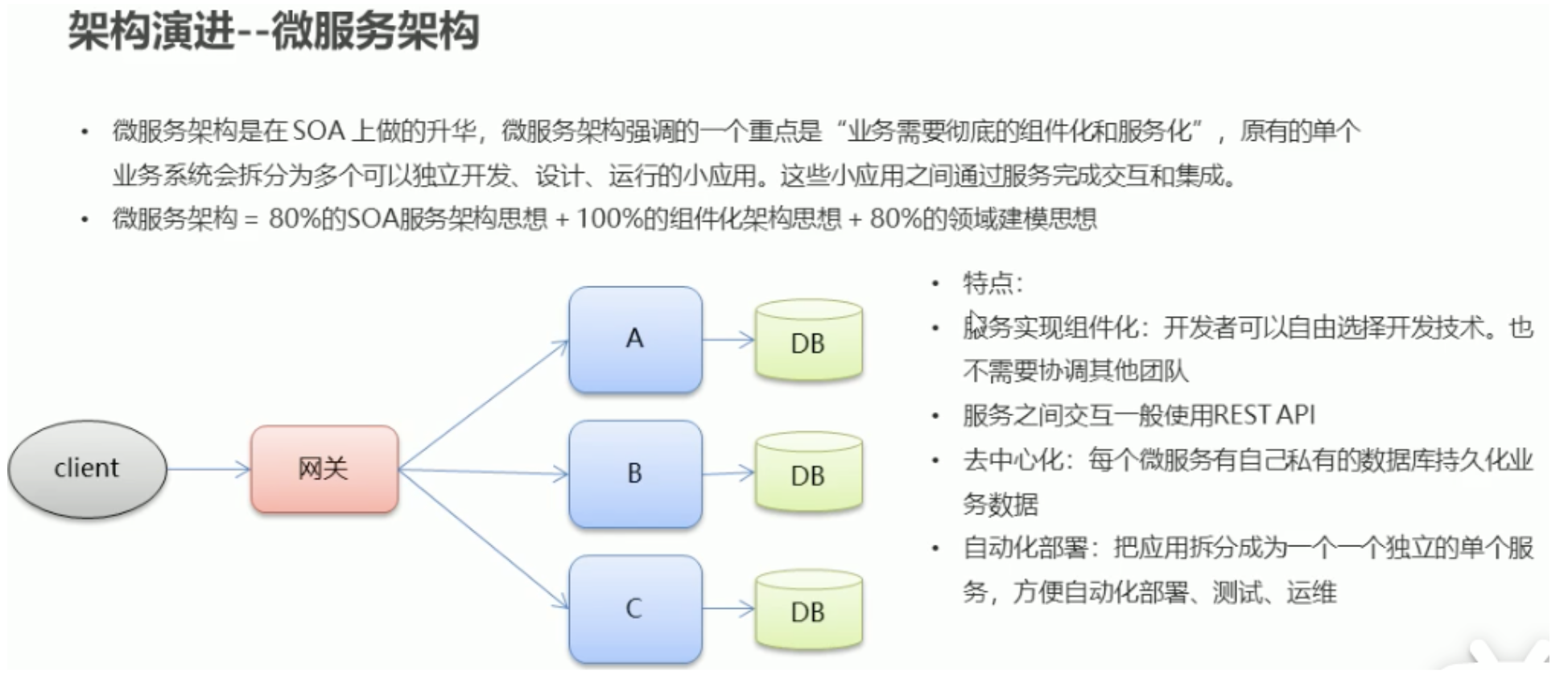
Personal understanding: microservice architecture is the further splitting and refinement of SOA architecture
Dubbo is the product of the SOA era, and spring cloud is the product of the microservice era
Chapter II overview of Dubbo
2.1 Dubbo concept
- Dubbo is a high-performance and lightweight Java RPC framework open source by Alibaba
- It is committed to providing high-performance and transparent RPC remote service invocation scheme and SOA Service governance scheme.
- Official website: http://dubbo.apache.org
2.2 Dubbo architecture
2.2.1 Dubbo architecture and calling sequence
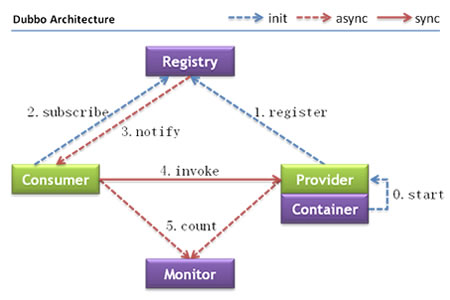
Node role description
| node | Role description |
|---|---|
| Provider | Service provider of exposed services |
| Consumer | The service consumer that invokes the remote service |
| Registry | Registry for service registration and discovery |
| Monitor | The monitoring center that counts the number and time of service calls |
| Container | Service run container |
Call relation description Reference documents
- The service container is responsible for starting, loading and running the service provider.
- When a service provider starts, it registers its services with the registry.
- When the service consumer starts, it subscribes to the service it needs from the registry.
- The registry returns the service provider address list to the consumer. If there is any change, the registry will push the change data to the consumer based on the long connection.
- From the provider address list, the service consumer selects one provider to call based on the soft load balancing algorithm. If the call fails, it selects another provider to call.
- Service consumers and providers accumulate call times and call times in memory, and regularly send statistical data to the monitoring center every minute.
Dubbo architecture has the following characteristics: connectivity, robustness, scalability, and upgrading to the future architecture
Personal understanding: Registry is equivalent to ESB, through which consumers and providers are connected
2.2.2 Dubbo features
Connectivity
- The registry is responsible for the registration and search of service addresses, which is equivalent to a directory service. Service providers and consumers only interact with the registry at startup. The registry does not forward requests, so the pressure is small
- The monitoring center is responsible for counting the number and time of service calls. The statistics are summarized in memory and sent to the monitoring center server every minute and displayed in a report
- The service provider registers its services with the registry and reports the call time to the monitoring center. This time does not include network overhead
- The service consumer obtains the address list of the service provider from the registration center, directly calls the provider according to the load algorithm, and reports the call time to the monitoring center, which includes network overhead
- Registration Center, service provider and service consumer are all long connections, except for monitoring center
- The registry perceives the existence of service providers through long connections. If the service providers are down, the registry will immediately push events to inform consumers
- The registration center and monitoring center are all down, which does not affect the running providers and consumers. Consumers cache the provider list locally
- Both registration center and monitoring center are optional, and service consumers can directly connect to service providers
Robustness
- The downtime of the monitoring center will not affect the use, but only lose some sampling data
- After the database goes down, the registry can still query the service list through the cache, but can not register new services
- The peer-to-peer cluster of the registry will automatically switch to another one after any one goes down
- After the registry is completely down, service providers and service consumers can still communicate through the local cache
- The service provider is stateless. After any one goes down, it will not affect the use
- After all the service providers are down, the service consumer application will not be available and will be reconnected indefinitely waiting for the service provider to recover
Flexibility
- The registry is a peer-to-peer cluster, which can dynamically add machine deployment instances, and all clients will automatically discover a new registry
- The service provider is stateless and can dynamically add machine deployment instances. The registry will push new service provider information to consumers
Escalation
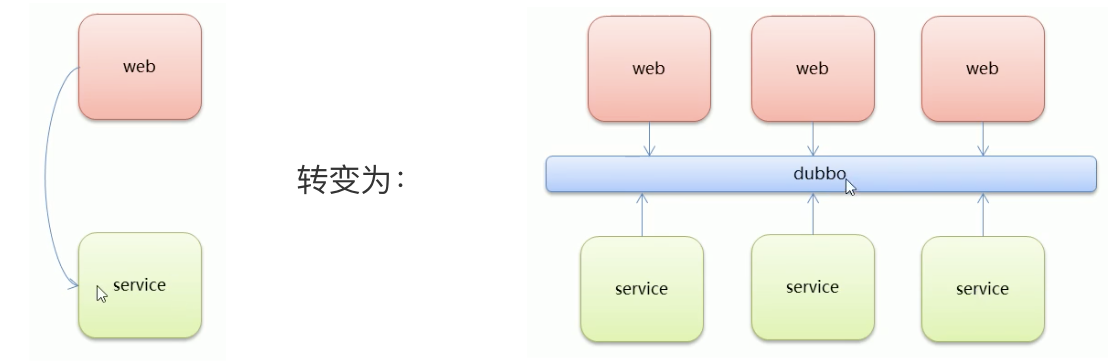
When the scale of service cluster is further expanded and IT governance structure is further upgraded, dynamic deployment and mobile computing need to be realized, and the existing distributed service architecture will not bring resistance. The following figure shows a possible architecture in the future:
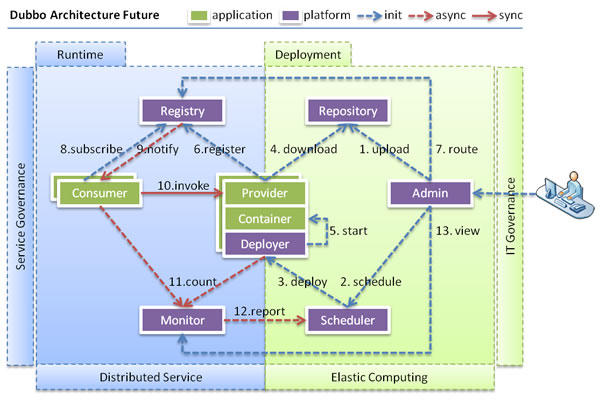
Node role description
| node | Role description |
|---|---|
| Deployer | Local agent for automatic deployment service |
| Repository | The warehouse is used to store service application release packages |
| Scheduler | The dispatching center automatically increases or decreases service providers based on access pressure |
| Admin | Unified management console |
| Registry | Registry for service registration and discovery |
| Monitor | The monitoring center that counts the number and time of service calls |
Chapter 3 Dubbo quick start
3.1 Zookeeper
3.1.1 Zookeeper overview
Registration Center: https://dubbo.apache.org/zh/docs/v2.7/user/references/registry/
Zookeeper is a sub project of Apache Hadoop. It is a tree directory service. It is suitable for being the registry of Dubbo services. It has high industrial strength and can be used in production environment. It is recommended.

For a more detailed overview, see my HSF notes
3.1.2 Zookeeper installation and configuration
Download and install
1. Environment preparation: Java 1 7+
2. Upload: put the downloaded ZooKeeper in the / opt/ZooKeeper directory
#Upload zookeeper alt+p put f:/setup/apache-zookeeper-3.5.6-bin.tar.gz #Open the opt directory cd /opt #Create a zooKeeper directory mkdir zooKeeper #Move the zookeeper installation package to / opt/zooKeeper mv apache-zookeeper-3.5.6-bin.tar.gz /opt/zookeeper/
3. Unzip: unzip the tar package to the / opt/zookeeper directory
tar -zxvf apache-ZooKeeper-3.5.6-bin.tar.gz
Configuration startup
1. Configure zoo cfg
Enter the conf directory and copy a zoo_sample.cfg and complete the configuration (zoo_sample is not a configuration in essence, but a template. You need to create zoo.cfg and modify the configuration content.)
#Enter the conf directory cd /opt/zooKeeper/apache-zooKeeper-3.5.6-bin/conf/ #Copy (copy zoo_sample.cfg with the name of zoo.cfg) cp zoo_sample.cfg zoo.cfg
Modify zoo cfg
#Open Directory cd /opt/zooKeeper/ #Create a zooKeeper storage directory mkdir zkdata #Modify zoo cfg vim /opt/zooKeeper/apache-zooKeeper-3.5.6-bin/conf/zoo.cfg
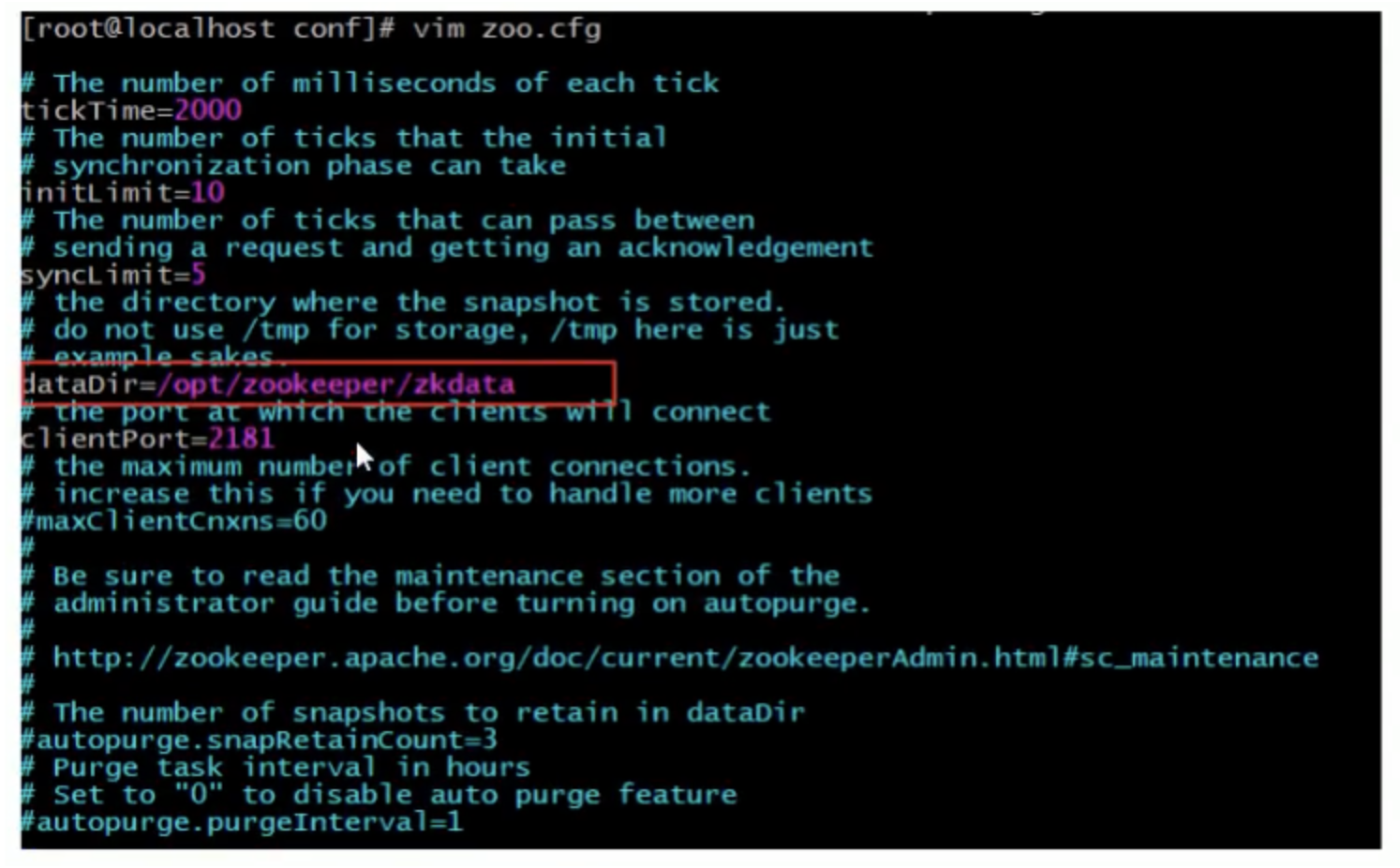
Modify storage directory: dataDir = /opt/zookeeper/zkdata
2. Start zookeeper
cd /opt/zooKeeper/apache-zooKeeper-3.5.6-bin/bin/ #Startup (. sh file is generally a script execution file, and zkServer means Registry) ./zkServer.sh start

The above figure shows that zookeeper has been started successfully.
3. View zookeeper status
./zkServer.sh status
zookeeper started successfully. standalone means zk has not set up a cluster and is now a single node

zookeeper did not start successfully

3.2 Dubbo quick start
3.2.1 integration of spring and spring MVC
Code: 1 Spring and spring MVC integrated code
Implementation steps:
1. Create service Provider module
2. Create a service Consumer module
3. Write UserServiceImpl in the service provider module to provide services
4. UserController remote call in Service consumer (provider is Service, consumer is Controller)
5. Services provided by UserServiceImpl
6. Start two services respectively and test.
As an RPC framework, Dubbo's core function is to realize cross network remote call. This section is to create two applications, one as a service provider and the other as a service consumer. Dubbo enables the service consumer to remotely call the method of the service provider.
0. Create project and prepare environment
Create an empty project first
Next, configure the Maven address
Next, create Maven's Module
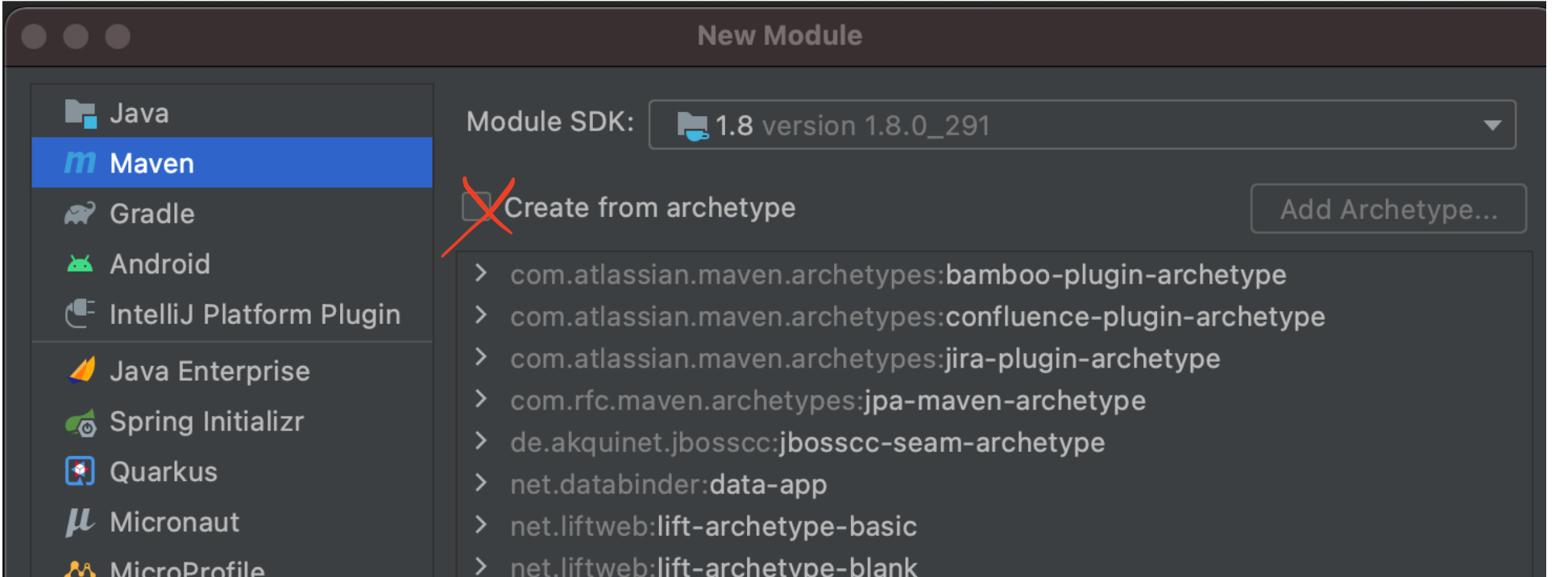
New service provider:
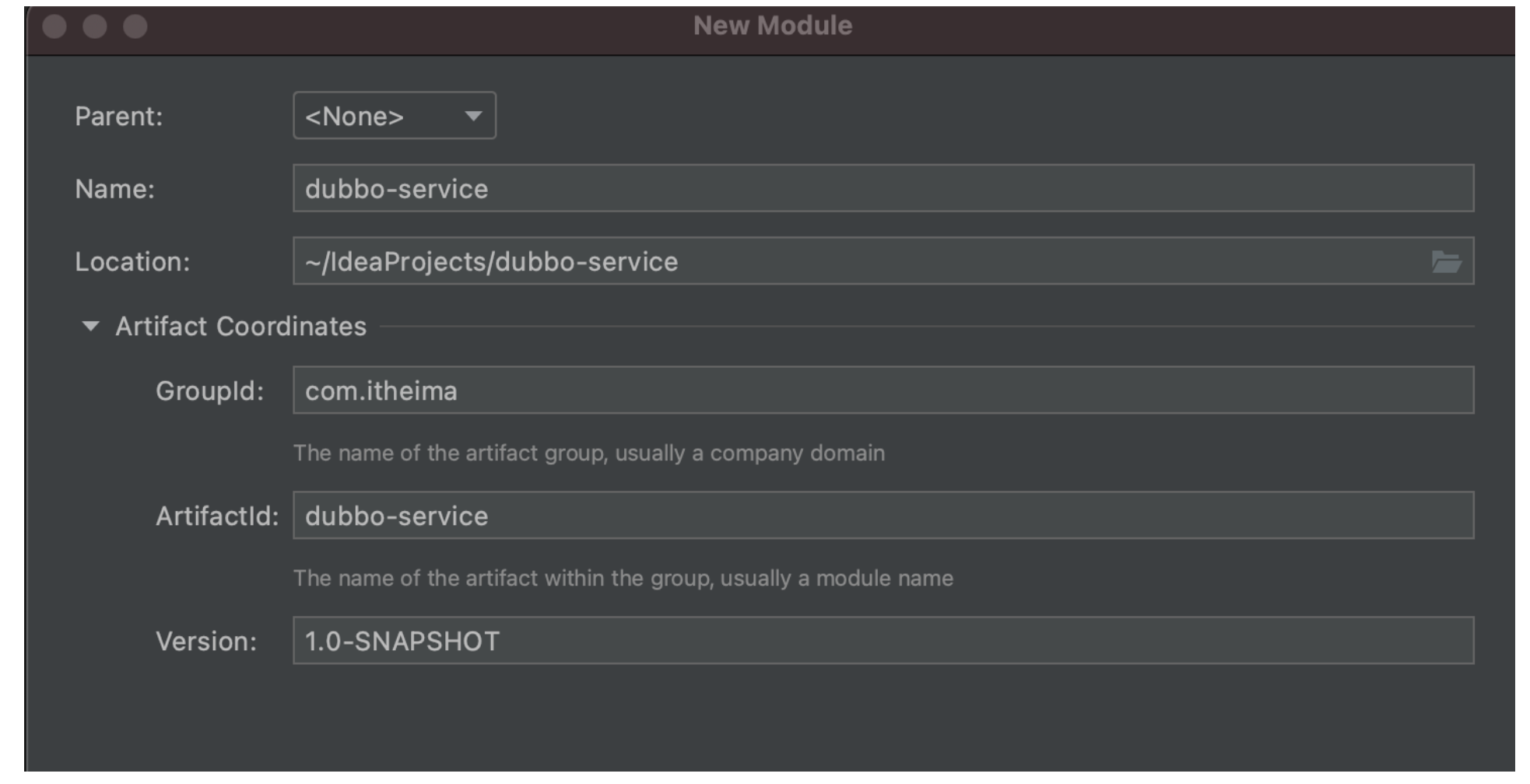
New consumer:
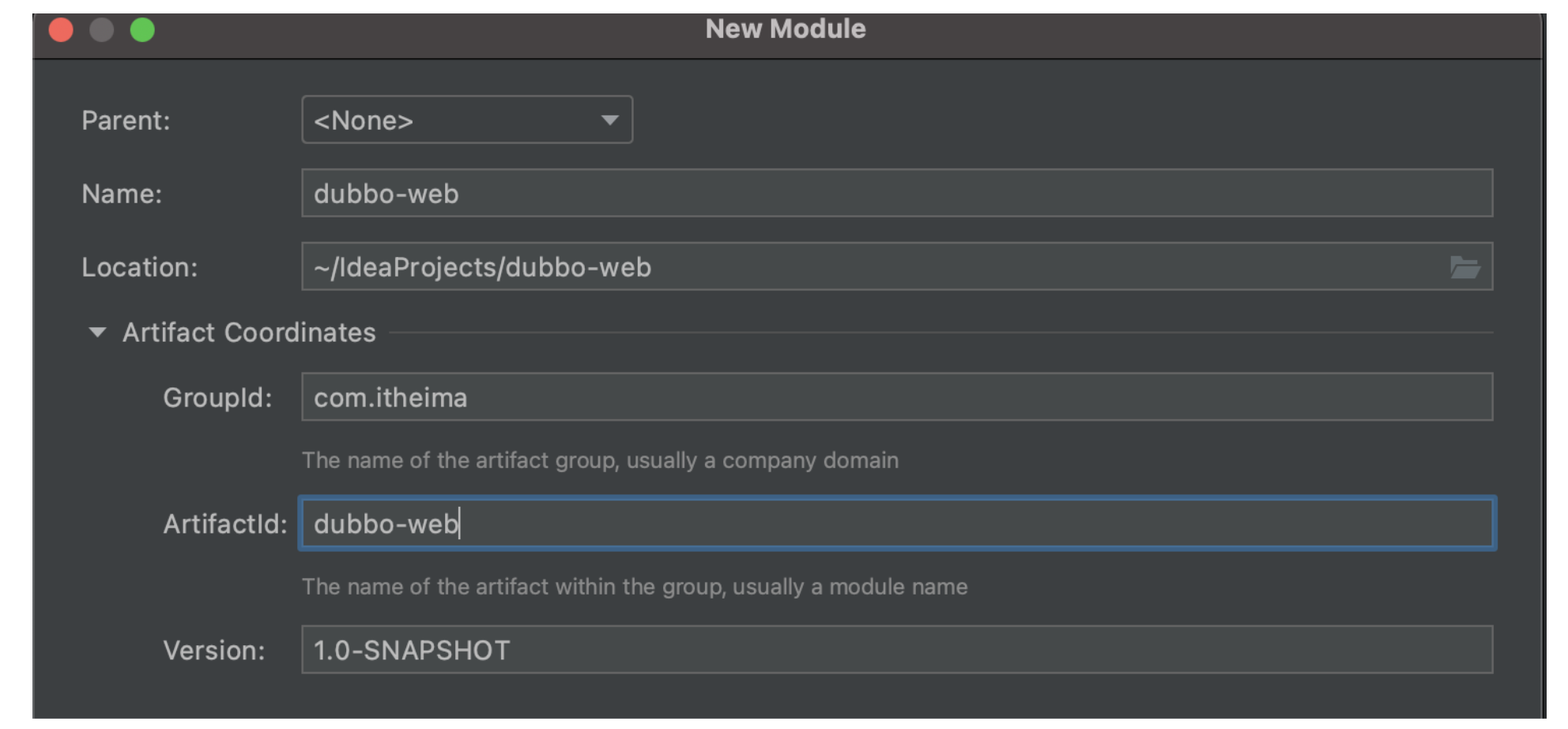
The next step is to write logical code.
Core principle: pom in consumer The pom dependency of servicer is added to XML, and dubbo is not used in essence
3.2.2 service providers
See: 2 Dubbo quick start
dubbo's role:
Service provider authoring process:
1. Register Servicer's services in Zookeeper (Registry)
2. Write the configuration of dubbo in the xml of mvc, including the name of the configuration item (unique identification), the address of the configuration registry (zookeeper), and the path to configure dubbo package scanning
3. Configure web xml
3.2.3 service consumers
Service consumer authoring process:
1. Remotely inject userService into the Controller, that is, obtain its url (discard the Autowired annotation and use the Reference annotation)
2. Write the configuration of dubbo in the xml of mvc, including the name of the configuration item (unique identification), the address of the configuration registry (local ip + port), and the scanning path of dubbo package
3. Configure web xml
Both the server and the consumer follow the above configuration. The difference is that the consumer configures the Controller and does not need to be placed in the registry
**Note: when the Consumer calls the Service method of the provider, the Consumer should also define the interface of the corresponding Service class. Therefore, in order to remove redundancy design, a new interface module is defined for code extraction** As for how to call, it is directly in the POM of Servicer and Consumer XML.
Above, the simplest function implementation of Dubbo has been completed.
Chapter IV advanced features Dubbo
4.1 Dubbo admin management platform
Introduction:
- Dubbo admin management platform is a graphical service management page
- Obtain all providers / consumers from the registry for configuration management
- Routing rules, dynamic configuration, service degradation, access control, weight adjustment, load balancing and other management functions
- Dubbo admin is a front-end and back-end separate project. The front end uses vue and the back end uses springboot
- Installing Dubbo admin is actually deploying the project
4.1.1 Dubbo admin installation
1. Environmental preparation
Dubbo admin is a front-end and back-end separate project. The front end uses vue and the back end uses springboot. Installing Dubbo admin is actually deploying the project. We installed Dubbo admin on the development environment. Ensure that the development environment has jdk, maven and nodejs
Install node * * (ignore if the current machine is already installed)**
Because the front-end project is developed with vue, you need to install node js,node.js comes with npm. We will start it later through npm
Put node JS can be understood as more awesome tomcat
Download address
https://nodejs.org/en/
2. Download Dubbo admin
Enter github and search Dubbo admin
https://github.com/apache/dubbo-admin
Download:
3. Unzip the downloaded zip package to the specified folder (unzip it to that folder at will)

4. Modify profile
After decompression, we go to... \ Dubbo admin development \ Dubbo admin server \ SRC \ main \ resources directory and find application Modify the configuration using the properties configuration file

Modify zookeeper address

# centers in dubbo2.7 admin.registry.address=zookeeper://192.168.149.135:2181 admin.config-center=zookeeper://192.168.149.135:2181 admin.metadata-report.address=zookeeper://192.168.149.135:2181
admin.registry.address Registry (mediation of service information (non persistent))
admin. Config center configuration center (stores various governance rules (persistence) of Dubbo services)
admin.metadata-report.address metadata Center (metadata refers to the method list, parameter structure and other information corresponding to Dubbo service)
5. Package project
Execute the package command in the Dubbo admin development directory
mvn clean package

6. Start backend
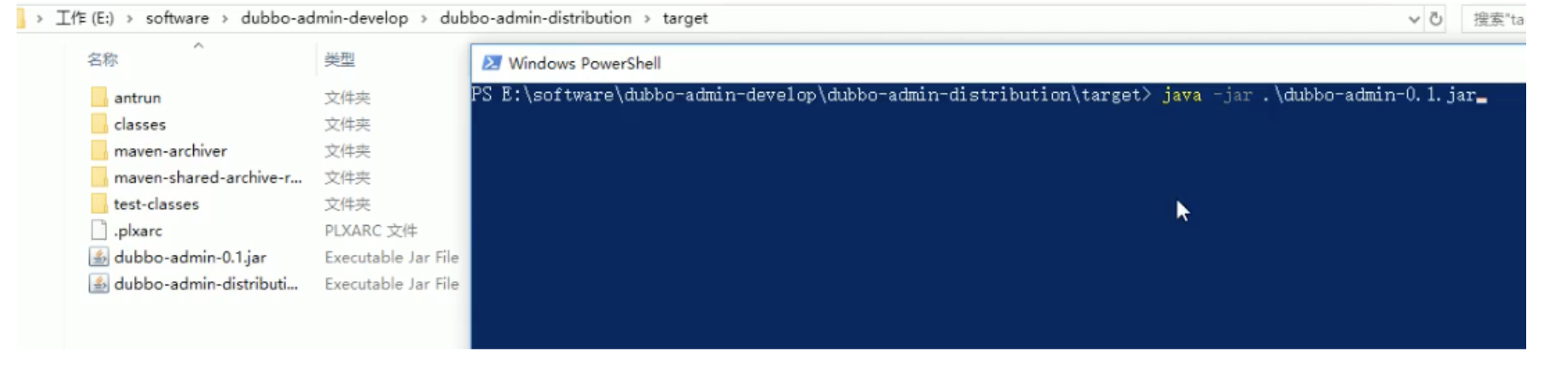
Switch to directory
dubbo-Admin-develop\dubbo-admin-distribution\target>
Execute the following command to start Dubbo admin. The background of Dubbo admin is built by spring boot.
java -jar .\dubbo-admin-0.1.jar
7. Front end
Execute the command in the Dubbo admin UI directory
npm run dev

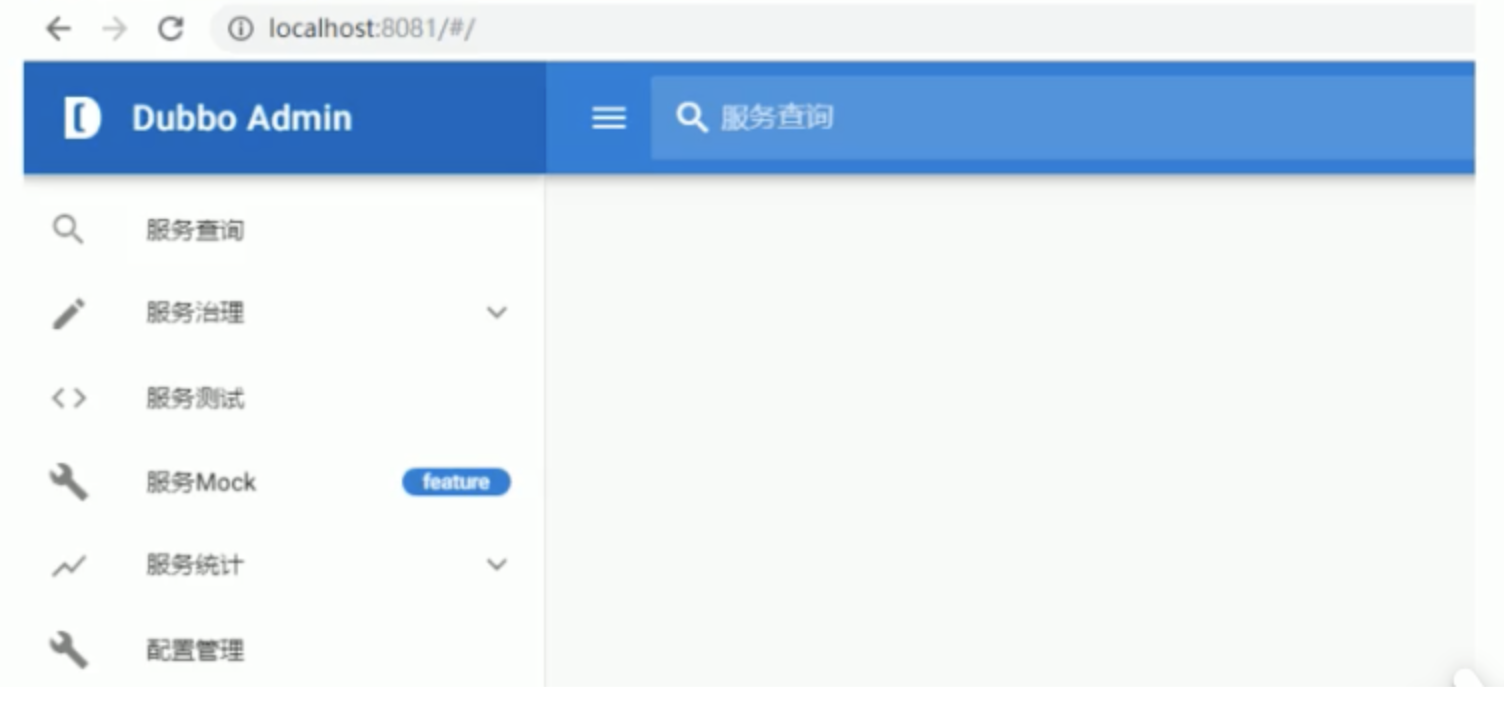
8. Visit
Browser input. The user name and password are root
http://localhost:8081/
4.1.2 simple use of Dubbo admin
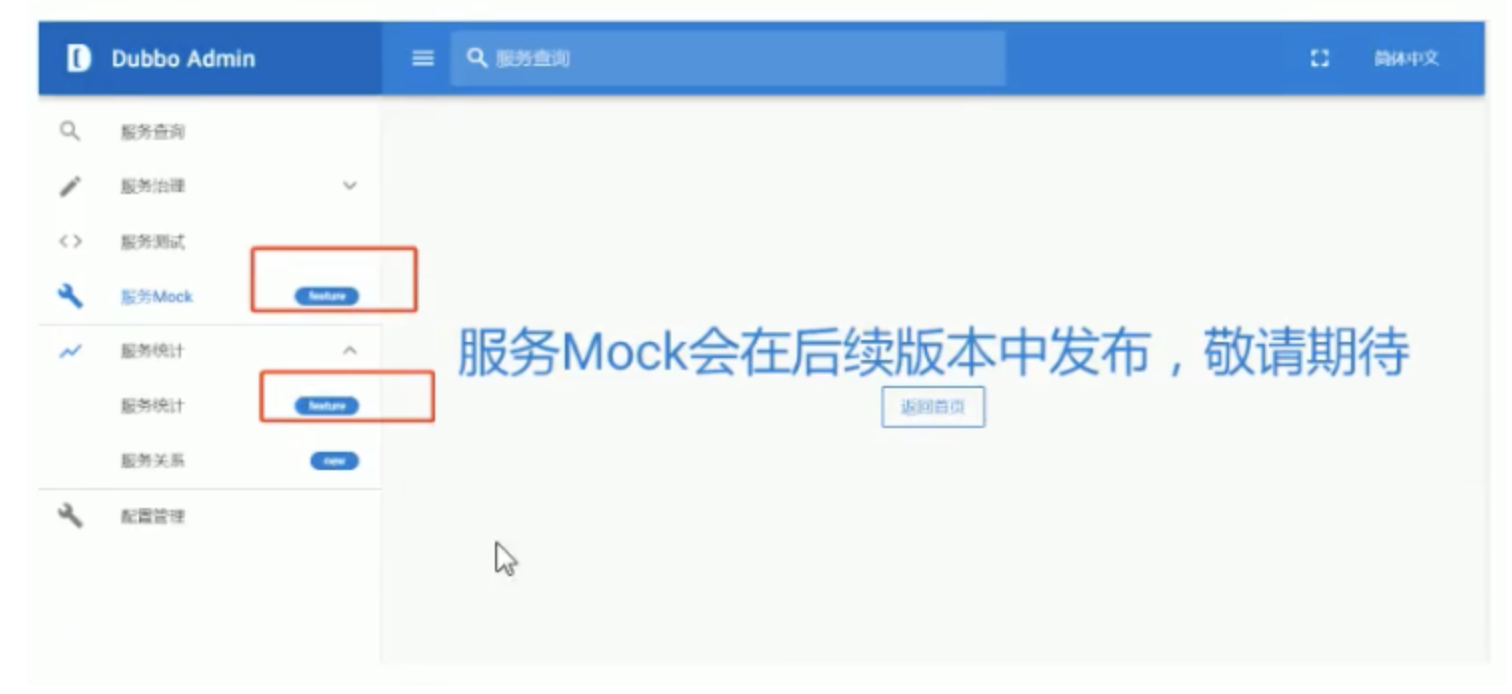
Note: Dubbo Admin [service Mock] and [service statistics] will be released in subsequent versions
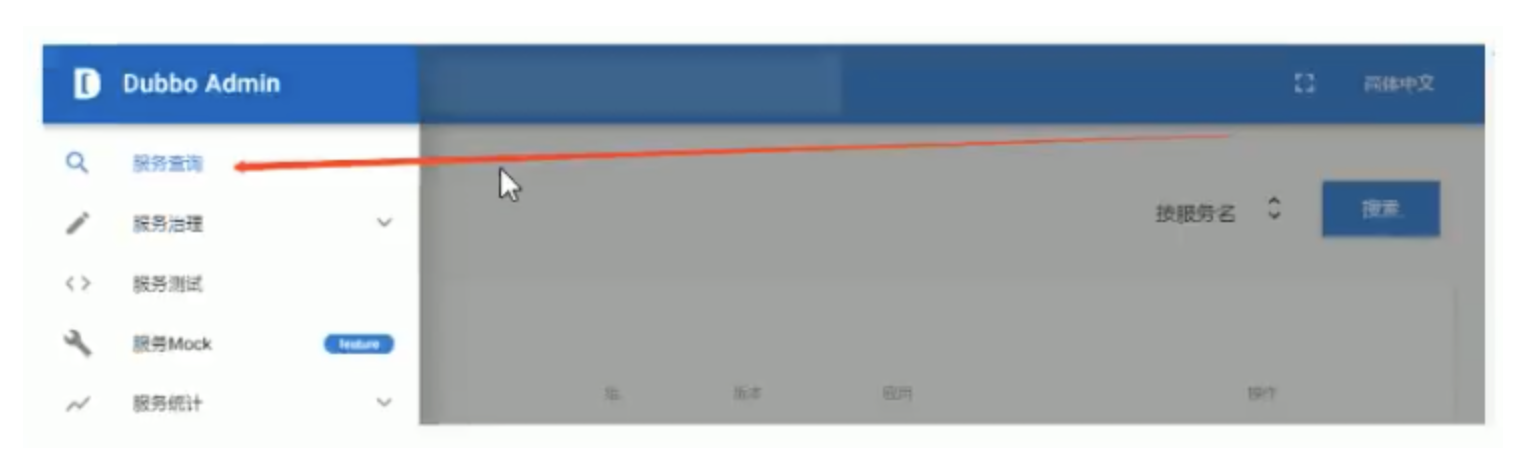
In the above steps, we have entered the main interface of Dubbo admin. In the [quick start] chapter, we have defined service producers, and service consumers. Next, we find these two services from the Dubbo admin management interface
1. Click service query
2. Query results
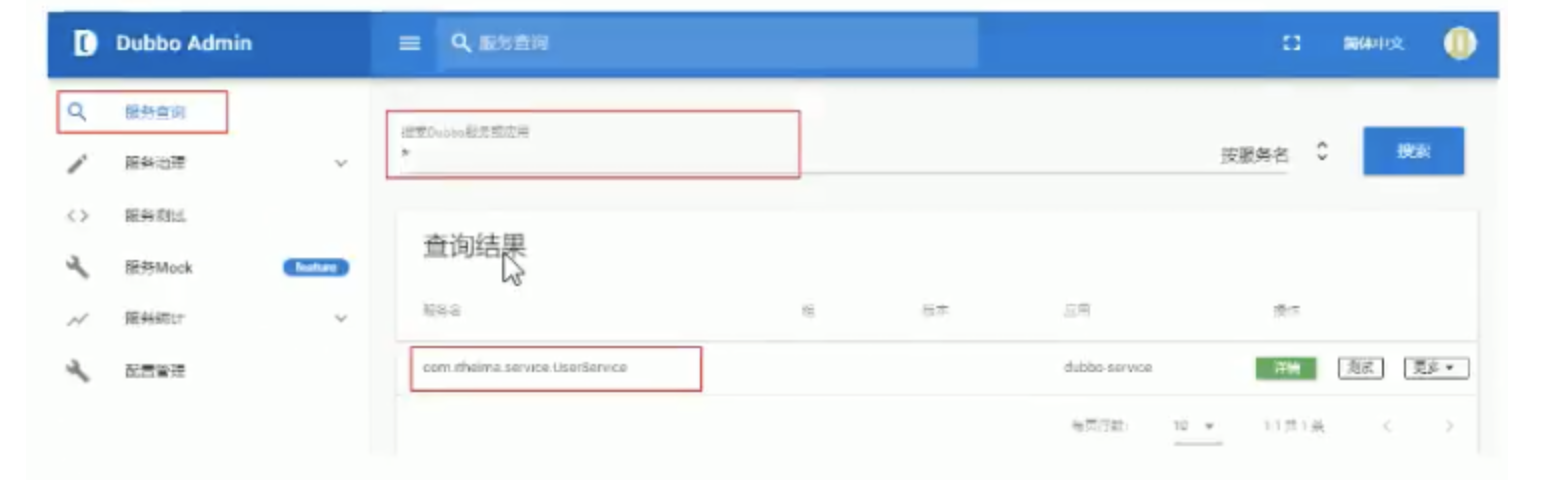
A: Enter the query criteria com itheima. service. UserService
B: Search types are mainly divided into three types: by service name, by IP address and by application
C: Search results
3.1.4 Dubo admin view details
Let's check out com itheima. service. Specific details of userservice (service provider), including metadata information
1) Click Details
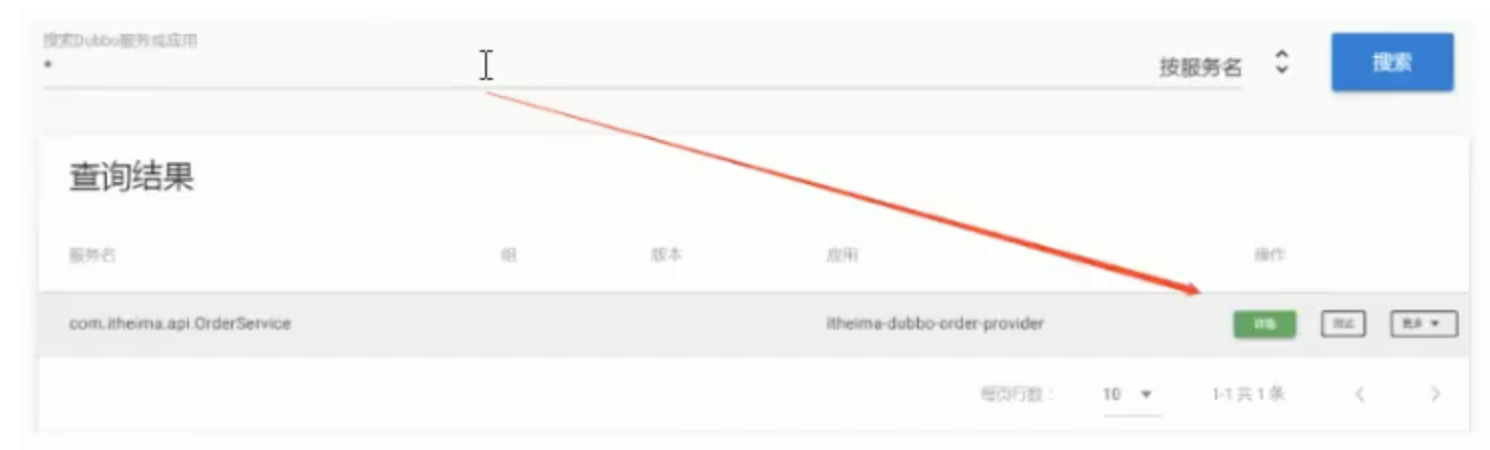
Viewed from the [details] interface, it is mainly divided into three areas
Area A: mainly contains the basic information of the server, such as service name, application name, etc
Area B: it mainly contains some basic information of producers and consumers
Area C: metadata information. Pay attention to the figure above. Metadata information is empty
We need to open our producer profile and add the following configuration
<!-- Metadata Configuration -->
<dubbo:metadata-report address="zookeeper://192.168.149.135:2181" />
Restart the producer and open Dubbo admin again
In this way, our metadata information comes out
4.2 Dubbo common advanced configuration
4.2.1 serialization
be careful!!! In the future, all pojo classes need to implement the Serializable interface!
For code implementation, see: 3 Dubbo advanced features - serialization
Data is transferred between two machines, and Java objects are transferred through serialization and deserialization
- dubbo has internally encapsulated the process of serialization and deserialization
- We only need to implement the Serializable interface when defining the pojo class
- Generally, a common pojo module is defined, so that both producers and consumers can rely on it.
The User object does not implement the Serializable interface
Error message:

terms of settlement:
User implements Serializable
The following figure shows the infrastructure of the project:
- Write the dependency of pojo in pom of interface. Write interface dependency in pom of service and web.
- User inherits the serialization interface
4.2.2 address cache
The registry has hung up. Can the service be accessed normally?
- Yes, because the dubbo service consumer will cache the service provider address locally during the first - call, and will not access the registry in the future.
- When the service provider address changes, the registry notifies the service consumer.

After running, it is found that you can continue to access.

4.2.3 timeout
Reference code: 4 Timeout and retry
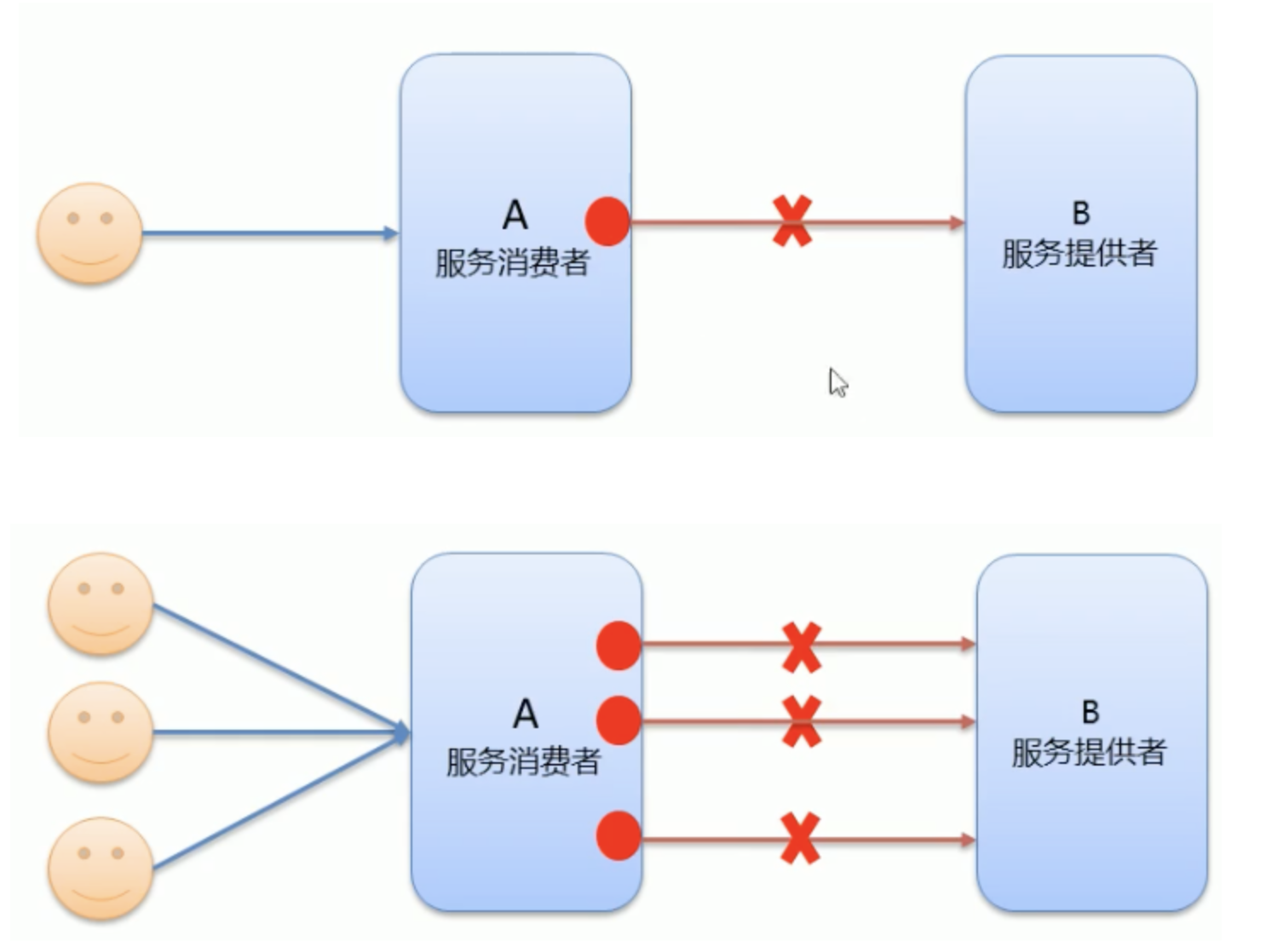
- When the service consumer calls the service provider, it blocks and waits. At this time, the service consumer will wait.
- At a peak time, a large number of requests are requesting service consumers at the same time, which will cause a large number of threads to accumulate, which is bound to cause an avalanche.
- dubbo uses the timeout mechanism to solve this problem. It sets a timeout period. During this period, if the service access cannot be completed, the connection will be automatically disconnected.
- Use the timeout property to configure the timeout. The default value is 1000 and the unit is milliseconds
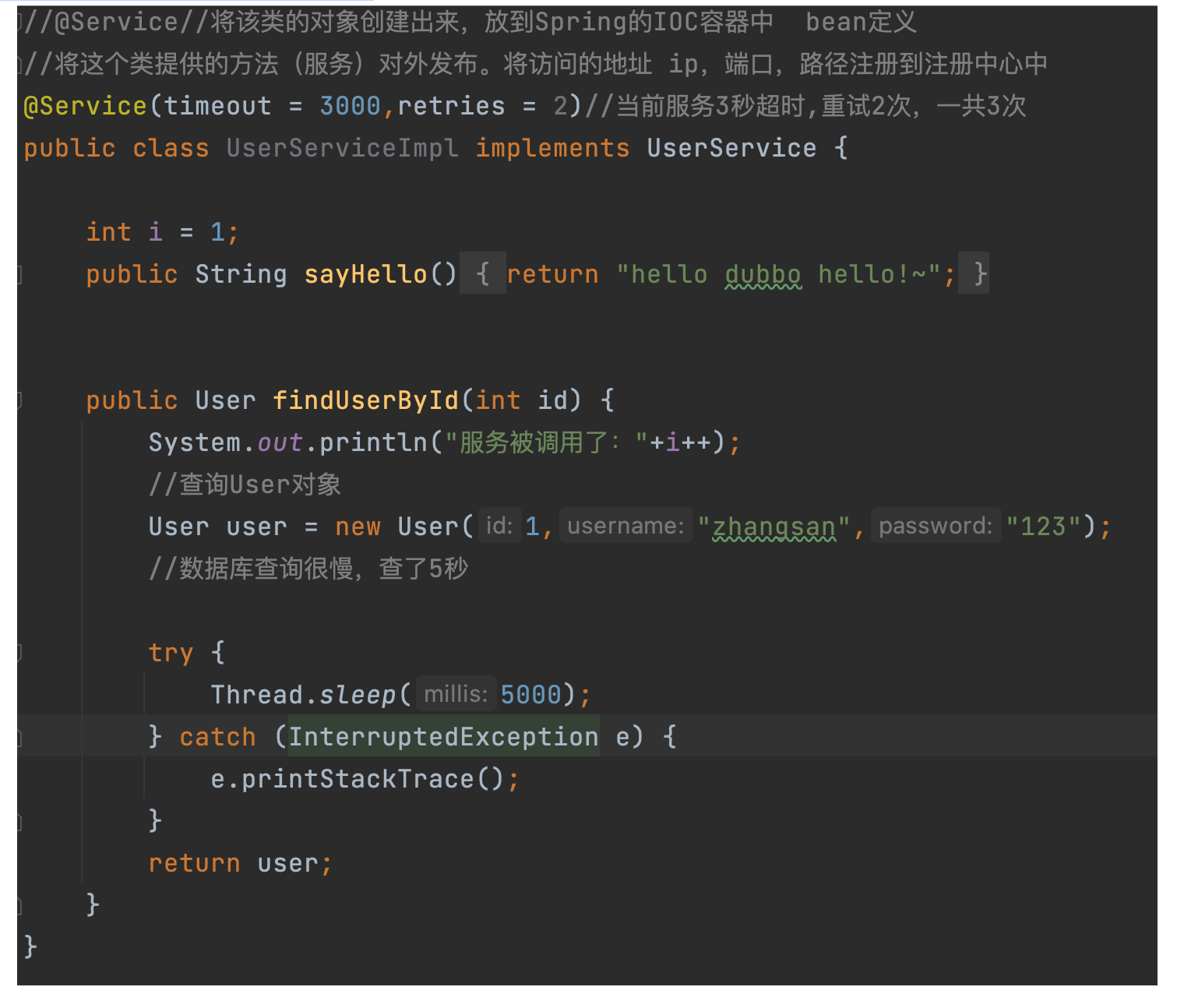
//Timeout timeout in milliseconds retries retries @Service(timeout = 3000,retries=0)
Code implementation: using sleep to simulate server query is very slow:
4.2.4 retry
- Timeout is set. If service access cannot be completed within this time period, the connection will be automatically disconnected.
- If network jitter occurs, this - request will fail.
- Dubbo provides a retry mechanism to avoid similar problems.
- Set the number of retries through the retries property. The default is 2 times
//Timeout timeout in milliseconds retries retries @Service(timeout = 3000,retries=2)
4.2.5 multi version
Reference code: 5 Multi version
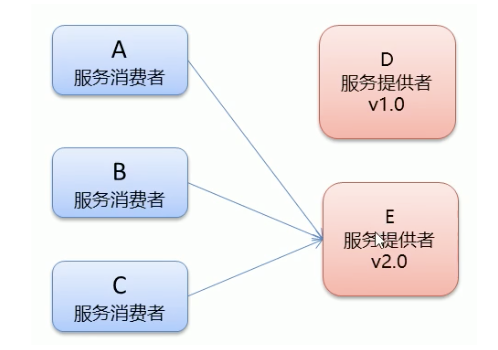
**Grayscale Publishing: * * when a new function appears, some users will use the new function first. When the user feedback is no problem, all users will be migrated to the new function.
dubbo uses the version attribute to set and call different versions of the same interface
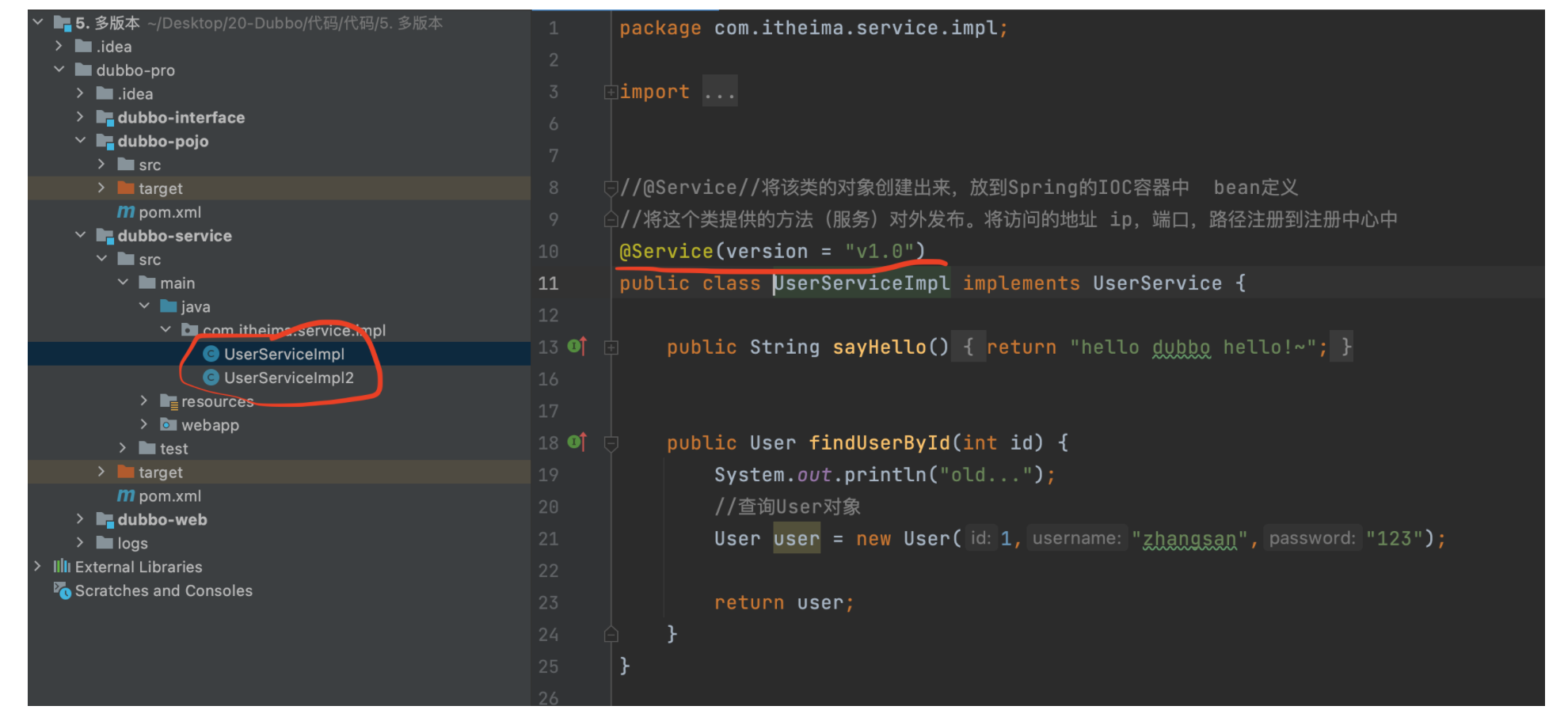
Producer configuration (annotated by @ Service)
@Service(version="v2.0")
public class UserServiceImp12 implements UserService {...}
Consumer configuration (annotated by @ Reference)
@Reference(version = "v2.0")//Remote injection private UserService userService;
Code example:
4.2.6 load balancing
Explanation: when there are multiple service providers, how should consumers consume in order to balance the load of multiple service providers.
Load balancing strategies (4 kinds):
-
**Random: * * random by weight, default value. Set random probability by weight.
-
RoundRobin: poll by weight.
-
Leadactive: minimum number of active calls, random calls with the same number of active calls.
-
*** * ConsistentHash: the consistency of requests is always the same.
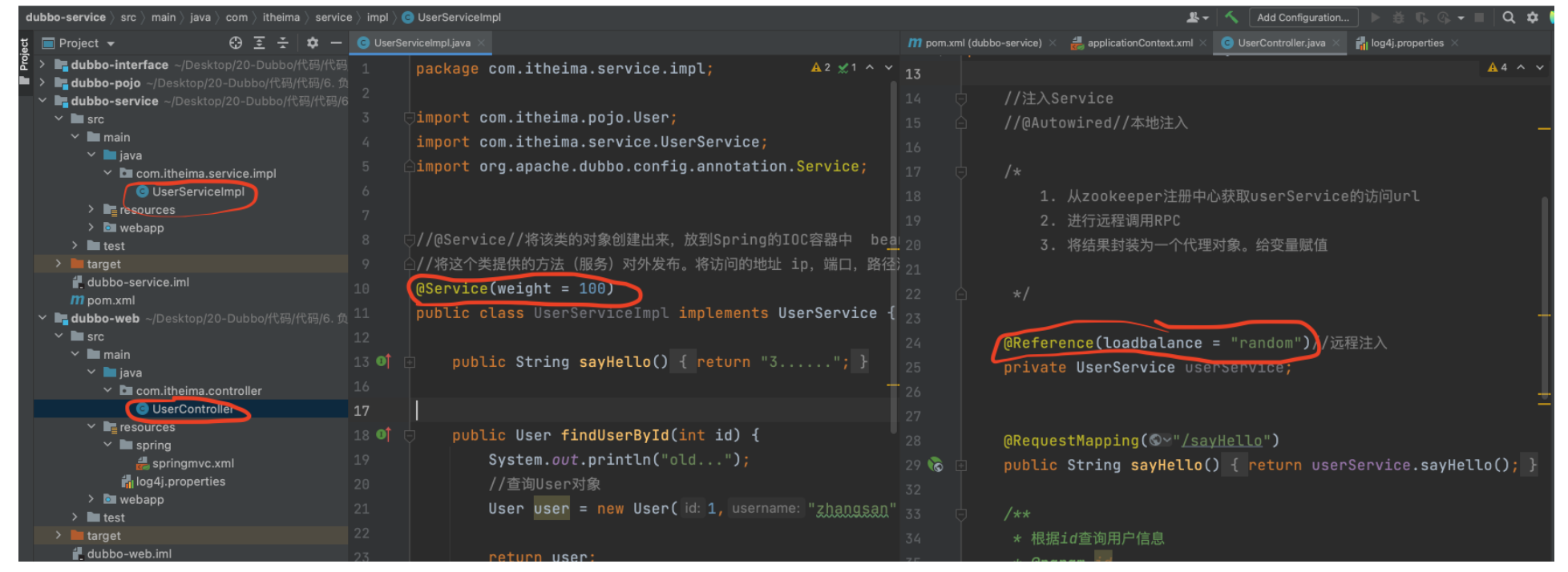
Service provider configuration
@Service(weight = 100)
public class UserServiceImp12 implements UserService {...}
application.xml configuration parameter key
Consumer configuration
//@Reference(loadbalance = "roundrobin") //@Reference(loadbalance = "leastactive") //@Reference(loadbalance = "consistenthash") @Reference(loadbalance = "random")//Default random by weight private UserService userService;
Code reference:
4.2.7 cluster fault tolerance
Explanation: if a server fails, choose what policy to implement. Whether to change another server to retry, or directly return failure, etc.
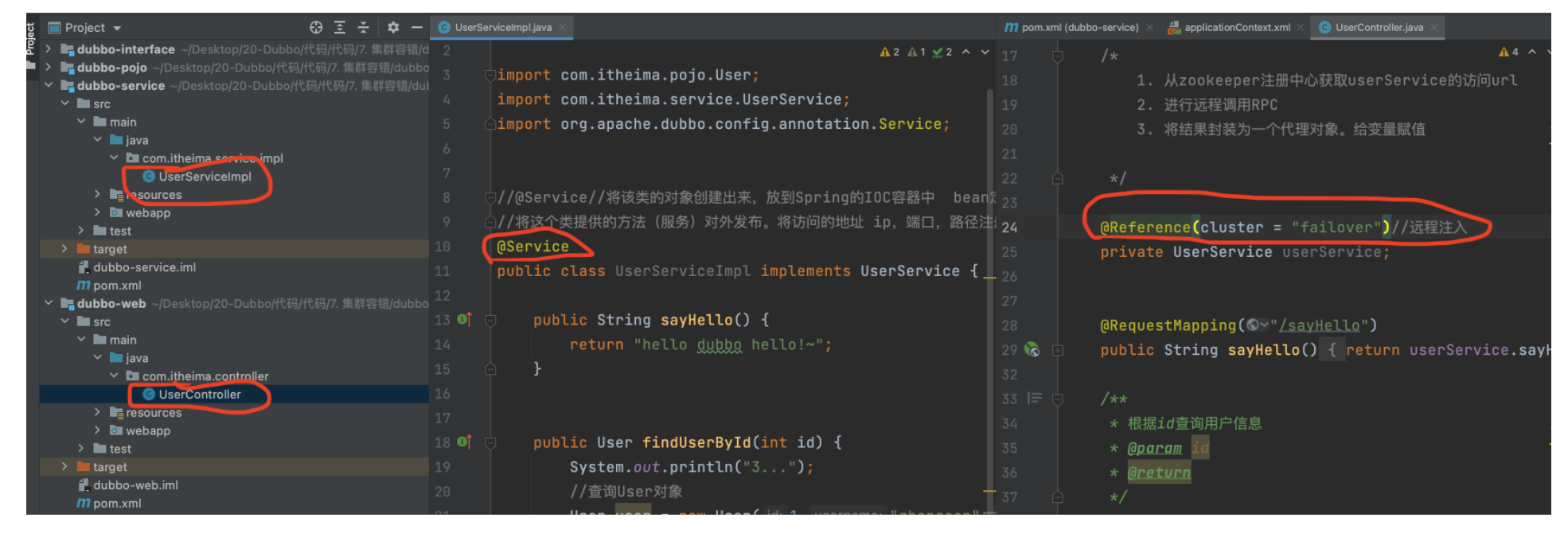
Cluster fault tolerance mode:
**Failover Cluster: * * failed to retry. Default value. In case of failure, retry other servers. By default, retry twice, using the retries configuration. Generally used for read operations
**Failfast Cluster 😗* Fast failure, initiate - calls, and report an error immediately after failure. Usually used for write operations.
**Failsafe Cluster: * * fail safe. When an exception occurs, it is ignored directly. Returns an empty result.
**Failback Cluster: * * automatic recovery after failure, background record failure requests, and resend regularly.
**Forking Cluster 😗* Call multiple servers in parallel, and return as long as one succeeds.
Broadcast Cluster: broadcast calls all providers one by one. If any one reports an error, it will report an error.
Consumer configuration
@Reference(cluster = "failover")//Remote injection private UserService userService;
Code example:
4.2.8 service degradation
Service degradation: when the server pressure increases sharply, some services and pages are not processed strategically or handled in a simple way according to the actual business situation and traffic, so as to release the server resources to ensure the normal or efficient operation of core transactions
Service degradation method:
mock= force:return null: it means that the method calls of the consumer to the service directly return null values and do not initiate remote calls. It is used to shield the impact on the caller when unimportant services are unavailable.
mock=fail:return null: indicates that the method call of the consumer to the service returns null value after failure, and no exception is thrown. It is used to tolerate the impact on callers when unimportant services are unstable
Consumer configuration
//Remote injection @Reference(mock ="force :return null")//No longer call the service of userService private UserService userService;
Zookeeper section
Chapter 1 getting to know Zookeeper
1.1 Zookeeper concept
-
Zookeeper is a sub project under the Apache Hadoop project. It is a tree directory service.
-
Zookeeper is translated as the zookeeper, who is used to manage Hadoop (elephant), hive (bee) and pig (pig). zk for short
-
Zookeeper is a distributed, open source coordination service for distributed applications.
-
The functions provided by Zookeeper mainly include
- Configuration management (addition, deletion, modification and query)
- Distributed lock (the conventional lock is invalid because it is provided by different machines (the conventional lock is provided by JDK) and different clusters, so the distributed lock should be adopted)
- Cluster management
Chapter II Zookeeper installation and configuration
See 3.1
Chapter 3 Zookeeper command operation
3.1 Zookeeper command operation data type
-
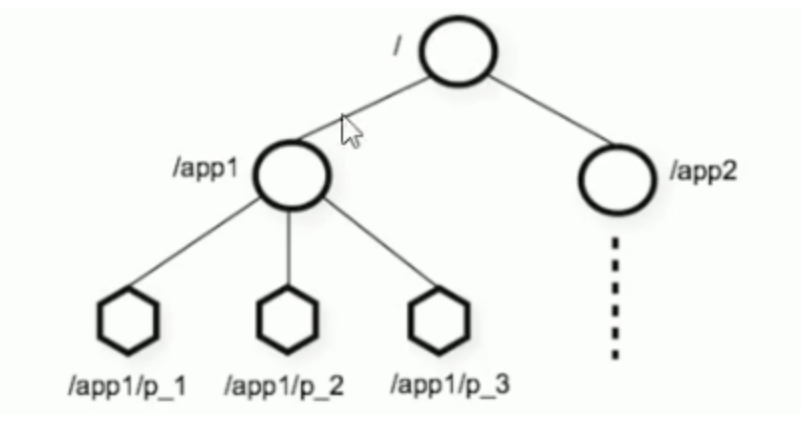
ZooKeeper is a tree directory service. Its data model is very similar to the Unix file system directory tree and has a hierarchical structure.
-
Each node is called ZNode, and each node will save its own data and node information.
-
A node can have child nodes and allow a small amount (1MB) of data to be stored under the node.
-
Nodes can be divided into four categories:
- PERSISTENT persistent node
- EPHEMERAL temporary node: - e (disappears after the server is closed)
- PERSISTENT_SEQUENTIAL persistent order node: - s (i.e. node followed by sequence number)
- EPHEMERAL_SEQUENTIAL temporary sequence node: - es
3.2 Zookeeper command operation server command
Enter Zookeeper/bin and perform the following operations
-
Start ZooKeeper service:/ zkServer.sh start
-
View ZooKeeper service status:/ zkServer.sh status
-
Stop ZooKeeper service:/ zkServer.sh stop
-
Restart ZooKeeper service:/ zkServer.sh restart
3.3 common commands of zookeeper client
Overview: after connecting to the Server, operate the node.
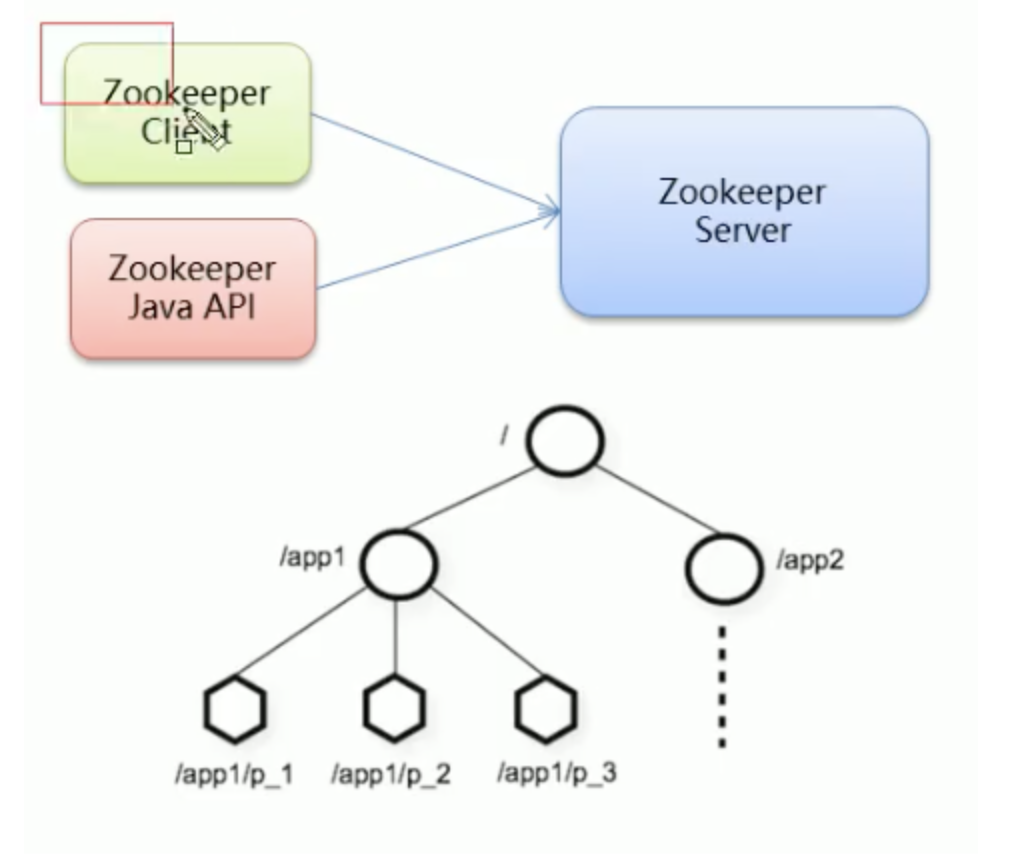
- Connect ZooKeeper server
./zkCli.sh –server ip:port
- Disconnect
quit
- View command help
help
- Displays the nodes under the specified directory (if the directory is /, it is the root node)
ls catalogue
- Create a node (value is stored in the node)
create /node path value example: create /app1
- Get node value
get /node path
- Set node value
set /node path value
- Delete a single node
delete /node path
- Delete nodes with child nodes
deleteall /node path
3.4 client command - create temporary ordered node
- Create temporary node
create -e /node path value
- Create order node
create -s /node path value
- Query node details
ls –s /node path
-
czxid: transaction ID of the node to be created
-
ctime: creation time
-
mzxid: last updated transaction ID
-
mtime: modification time
-
pzxid: transaction ID of the last updated child node list
-
cversion: version number of the child node
-
Data version: data version number
-
aclversion: permission version number
-
ephemeralOwner: used for temporary nodes, representing the transaction ID of the temporary node. If it is a persistent node, it is 0
-
dataLength: the length of the data stored by the node
-
numChildren: the number of child nodes of the current node
The above commands also reflect the role of Zookeeper, that is, persistent or non persistent data storage, configuration management, distributed lock and cluster management (nodes store information, tree structure and easy to find)
Chapter 4 zookeeper Java API operation
4.1 introduction to cursor
Its core is the operation of nodes. The operation of nodes runs through three modules: configuration management, distributed lock and cluster construction
-
Cursor is the Java client library for Apache ZooKeeper.
-
Common zookeeper Java APIs:
- Native Java API
- ZkClient
- Curator
-
The goal of the cursor project is to simplify the use of ZooKeeper clients.
-
Cursor was originally developed by Netfix and later donated to the Apache foundation. At present, it is a top-level project of Apache.
-
Official website: http://curator.apache.org/
4.2 basic operation (configuration management)
Action - establish connection
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-kf4w6jb7-1626871686069) (/ users / Zhanglong / library / Application Support / typera user images / image-20210720110747301. PNG)]
See data for specific code
1. Construction project
Create project curator ZK
Introducing pom and log files
POM. In the data folder XML and log4j properties
2. Create a test class and connect zookeeper with curator
@Before
public void testConnect() {
//Retry policy
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
//2. The second method
//CuratorFrameworkFactory.builder();
client = CuratorFrameworkFactory.builder()
.connectString("192.168.200.130:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(retryPolicy)
.namespace("itheima")
.build();
//Open connection
client.start();
}
Action - create node
/**
* Create node: create persistent temporary sequence data
* 1. Basic creation: create() forPath("")
* 2. Create node with data: create() forPath("",data)
* 3. Set the type of node: create() withMode(). forPath("",data)
* 4. Create multi-level node / app1/p1: create() creatingParentsIfNeeded(). forPath("",data)
*/
@Test
public void testCreate() throws Exception {
//2. Create node with data
//If no data is specified when creating a node, the ip address of the current client is used as the data store by default
String path = client.create().forPath("/app2", "hehe".getBytes());
System.out.println(path);
}
@Test
public void testCreate2() throws Exception {
//1. Basic creation
//If no data is specified when creating a node, the ip address of the current client is used as the data store by default
String path = client.create().forPath("/app1");
System.out.println(path);
}
@Test
public void testCreate3() throws Exception {
//3. Set node type
//Default type: persistent
String path = client.create().withMode(CreateMode.EPHEMERAL).forPath("/app3");
System.out.println(path);
}
@Test
public void testCreate4() throws Exception {
//4. Create multi-level node / app1/p1
//creatingParentsIfNeeded(): if the parent node does not exist, the parent node is created
String path = client.create().creatingParentsIfNeeded().forPath("/app4/p1");
System.out.println(path);
}
Operation - query node
/**
* Query node:
* 1. Query data: get: getdata() forPath()
* 2. Query child node: LS: getchildren() forPath()
* 3. Query node status information: LS - s: getdata() Storingstatin (status object) forPath()
*/
@Test
public void testGet1() throws Exception {
//Data query: 1
byte[] data = client.getData().forPath("/app1");
System.out.println(new String(data));
}
@Test
public void testGet2() throws Exception {
// 2. Query child nodes: ls
List<String> path = client.getChildren().forPath("/");
System.out.println(path);
}
@Test
public void testGet3() throws Exception {
Stat status = new Stat();
System.out.println(status);
//3. Query node status information: ls -s
client.getData().storingStatIn(status).forPath("/app1");
System.out.println(status);
}
Action - modify node
/**
* Modify data
* 1. Basic modification data: setdata() forPath()
* 2. Modify according to version: setdata() withVersion(). forPath()
* * version It is found through query. The purpose is to let other clients or threads not interfere with me.
*
* @throws Exception
*/
@Test
public void testSet() throws Exception {
client.setData().forPath("/app1", "itcast".getBytes());
}
@Test
public void testSetForVersion() throws Exception {
Stat status = new Stat();
//3. Query node status information: ls -s
client.getData().storingStatIn(status).forPath("/app1");
int version = status.getVersion();//Found 3
System.out.println(version);
client.setData().withVersion(version).forPath("/app1", "hehe".getBytes());
}
Action - delete node
/**
* Delete node: delete deleteall
* 1. Delete a single node: delete() forPath("/app1");
* 2. Delete nodes with child nodes: delete() deletingChildrenIfNeeded(). forPath("/app1");
* 3. Must be successfully deleted: in order to prevent network jitter. The essence is to try again. client.delete().guaranteed().forPath("/app2");
* 4. Callback: inBackground
* @throws Exception
*/
@Test
public void testDelete() throws Exception {
// 1. Delete a single node
client.delete().forPath("/app1");
}
@Test
public void testDelete2() throws Exception {
//2. Delete nodes with child nodes
client.delete().deletingChildrenIfNeeded().forPath("/app4");
}
@Test
public void testDelete3() throws Exception {
//3. It must be deleted successfully
client.delete().guaranteed().forPath("/app2");
}
@Test
public void testDelete4() throws Exception {
//4. Callback
client.delete().guaranteed().inBackground(new BackgroundCallback(){
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception {
System.out.println("I was deleted~");
System.out.println(event);
}
}).forPath("/app1");
}
Operation - overview of Watch monitoring
-
ZooKeeper allows users to register some watchers on the specified node, and when some specific events are triggered, the ZooKeeper server will notify the interested clients of the events. This mechanism is an important feature of ZooKeeper's implementation of distributed coordination services.
-
The Watcher mechanism is introduced into ZooKeeper to realize the publish / subscribe function, which enables multiple subscribers to listen to an object at the same time. When the state of an object changes, it will notify all subscribers.
-
ZooKeeper natively supports event monitoring by registering Watcher, but its use is not particularly convenient
Developers need to register Watcher repeatedly, which is cumbersome.
-
Cursor introduces Cache to monitor ZooKeeper server events.
-
ZooKeeper offers three watchers:
- NodeCache: only listens to a specific node
- PathChildrenCache: monitors the child nodes of a ZNode
- TreeCache: it can monitor all nodes in the whole tree, similar to the combination of PathChildrenCache and NodeCache
Listen - NodeCache
/**
* Demonstrate NodeCache: register listeners for a specified node
*/
@Test
public void testNodeCache() throws Exception {
//1. Create NodeCache object
final NodeCache nodeCache = new NodeCache(client,"/app1");
//2. Register for listening
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
System.out.println("The node has changed~");
//Get the data after modifying the node
byte[] data = nodeCache.getCurrentData().getData();
System.out.println(new String(data));
}
});
//3. Enable monitoring If set to true, enable listening and load buffered data
nodeCache.start(true);
while (true){
}
}
Listen - PathChildrenCache
@Test
public void testPathChildrenCache() throws Exception {
//1. Create a listening object
PathChildrenCache pathChildrenCache = new PathChildrenCache(client,"/app2",true);
//2. Bind listener
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() { @Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
System.out.println("The child nodes have changed~");
System.out.println(event);
//Monitor the data changes of child nodes and get the changed data
//1. Get type
PathChildrenCacheEvent.Type type = event.getType();
//2. Judge whether the type is update
if(type.equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)){
System.out.println("Data changed!!!");
byte[] data = event.getData().getData();
System.out.println(new String(data));
}
}
});
//3. Open
pathChildrenCache.start();
while (true){
}
}
Listening TreeCache
/**
* Demonstrate TreeCache: listen to a node itself and all child nodes
*/
@Test
public void testTreeCache() throws Exception {
//1. Create listener
TreeCache treeCache = new TreeCache(client,"/app2");
//2. Register for listening
treeCache.getListenable().addListener(new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {
System.out.println("The node has changed");
System.out.println(event);
}
});
//3. Open
treeCache.start();
while (true){
}
}
4.3 Zookeeper distributed lock
Core implementation principle: temporary sequential node.
Distributed lock concept
-
When we develop stand-alone applications and involve concurrent synchronization, we often use synchronized or Lock to solve the problem of code synchronization between multiple threads. At this time, multiple threads run under the same JVM without any problem.
-
However, when our application works in a distributed cluster, it belongs to the working environment of multiple JVMs, and the synchronization problem can not be solved through multi-threaded locks between different JVMs.
-
Then a more advanced locking mechanism is needed to deal with the problem of data synchronization between processes across machines - this is distributed locking.
Distributed lock implementation at different architecture levels
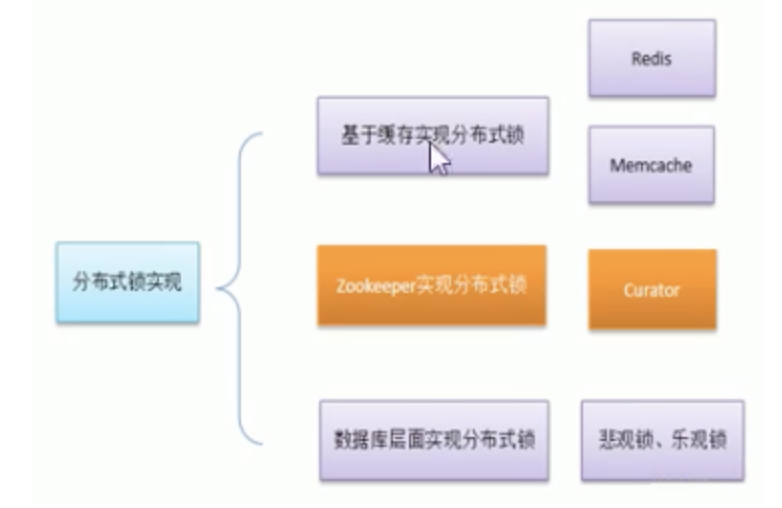
Distributed lock principle
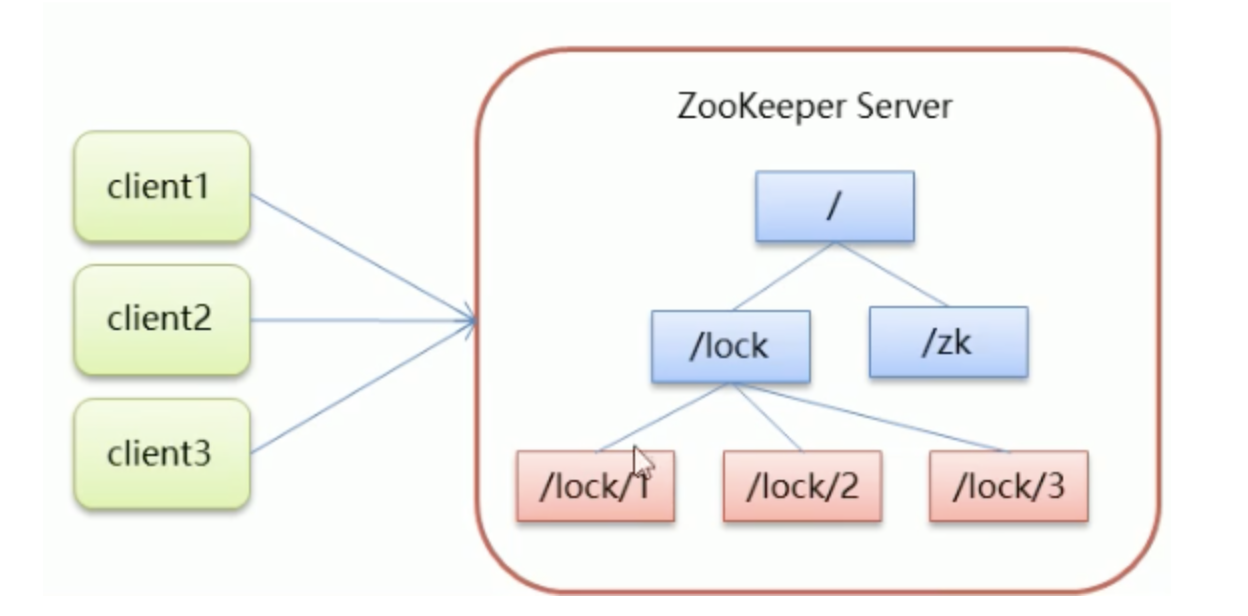
- Core idea: when the client wants to obtain a lock, it creates a node. After using the lock, it deletes the node.
- When a client acquires a lock, a temporary sequence node is created under the lock node.
- Then obtain all the child nodes under the lock. After the client obtains all the child nodes, if it finds that the serial number of the child node it created is the smallest, it is considered that the client has obtained the lock. After using the lock, delete the node.
- If you find that the node you created is not the smallest of all the child nodes of lock, it means that you have not obtained the lock. At this time, the client needs to find the node smaller than itself, register an event listener for it, and listen for deletion events.
- If it is found that the node smaller than itself is deleted, the Watcher of the client will receive the corresponding notification. At this time, judge again whether the node you created is the one with the lowest sequence number among the lock child nodes. If so, you will obtain the lock. If not, repeat the above steps to continue to obtain a node smaller than yourself and register to listen.
Principle: determine the acquisition order by judging whether the last node is obtained, or whether it can be obtained, so as to ensure that the data is only used by one process at the same time
Distributed lock - Simulation of 12306 ticketing case
To sum up: it is the same as the normal lock, but different methods are called. Because it's all encapsulated for us.
Cursor implements distributed lock API
-
There are five locking schemes in cursor:
-
InterProcessSemaphoreMutex: distributed exclusive lock (non reentrant lock)
-
InterProcessMutex: distributed reentrant exclusive lock
-
InterProcessReadWriteLock: distributed read / write lock
-
Interprocess multilock: multiple locks are managed as a container for a single entity (a container is set separately, and multiple locks are managed in this container)
-
InterProcessSemaphoreV2: shared semaphore (if the semaphore is set to, how many people are allowed to access at the same time)
-
1. Create a thread to set the lock
public class Ticket12306 implements Runnable{
private int tickets = 10;//Number of votes in the database
private InterProcessMutex lock ;
@Override
public void run() {
while(true){
//Acquire lock
try {
lock.acquire(3, TimeUnit.SECONDS);
if(tickets > 0){
System.out.println(Thread.currentThread()+":"+tickets);
Thread.sleep(100);
tickets--;
}
} catch (Exception e) {
e.printStackTrace();
}finally {
//Release lock
try {
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
2. Create a connection and initialize the lock
public Ticket12306(){
//Retry policy
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
//2. The second method
//CuratorFrameworkFactory.builder();
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("192.168.149.135:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(retryPolicy)
.build();
//Open connection
client.start();
lock = new InterProcessMutex(client,"/lock");
}
3. Run multiple threads for testing
public class LockTest {
public static void main(String[] args) {
Ticket12306 ticket12306 = new Ticket12306();
//Create client
Thread t1 = new Thread(ticket12306,"Ctrip");
Thread t2 = new Thread(ticket12306,"Fliggy");
t1.start();
t2.start();
}
}
4.4 ZooKeeper cluster construction
Cluster introduction
Leader election:
-
Serverid: server ID
For example, there are three servers with numbers of 1, 2 and 3.
The larger the number, the greater the weight in the selection algorithm.
-
Zxid: data ID
The maximum data ID stored in the server. The larger the value, the newer the data, and the greater the weight in the election algorithm.
-
In the process of Leader election, if a ZooKeeper obtains more than half of the votes, the ZooKeeper can become a Leader.
Construction requirements
Real clusters need to be deployed on different servers, but when we test, we can't afford to start many virtual machines at the same time. Therefore, we usually build pseudo clusters, that is, build all services on one virtual machine and distinguish them by ports.
We need to build a Zookeeper cluster (pseudo cluster) with three nodes.
preparation
Redeploy a virtual machine as the test server for our cluster.
(1) Install JDK [this step is omitted].
(2) Upload the Zookeeper compressed package to the server (put command)
(3) Unzip the Zookeeper, create the / usr / local / Zookeeper cluster directory, and copy the unzipped Zookeeper to the following three directories
/usr/local/zookeeper-cluster/zookeeper-1
/usr/local/zookeeper-cluster/zookeeper-2
/usr/local/zookeeper-cluster/zookeeper-3
[root@localhost ~]# mkdir /usr/local/zookeeper-cluster [root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-1 [root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-2 [root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-3
(4) Create the data directory and add the conf to the zoo_ sample. The cfg file is renamed zoo cfg
mkdir /usr/local/zookeeper-cluster/zookeeper-1/data mkdir /usr/local/zookeeper-cluster/zookeeper-2/data mkdir /usr/local/zookeeper-cluster/zookeeper-3/data mv /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg mv /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg mv /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
(5) The dataDir and clientPort configured for each Zookeeper are 2181, 2182 and 2183 respectively
Modify / usr / local / zookeeper cluster / zookeeper-1 / conf / zoo cfg
vim /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg clientPort=2181 dataDir=/usr/local/zookeeper-cluster/zookeeper-1/data
Modify / usr / local / zookeeper cluster / zookeeper-2 / conf / zoo cfg
vim /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg clientPort=2182 dataDir=/usr/local/zookeeper-cluster/zookeeper-2/data
Modify / usr / local / zookeeper cluster / zookeeper-3 / conf / zoo cfg
vim /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg clientPort=2183 dataDir=/usr/local/zookeeper-cluster/zookeeper-3/data
Configure cluster
(1) Create a myid file in the data directory of each zookeeper, with the contents of 1, 2 and 3 respectively. This file records the ID of each server
echo 1 >/usr/local/zookeeper-cluster/zookeeper-1/data/myid echo 2 >/usr/local/zookeeper-cluster/zookeeper-2/data/myid echo 3 >/usr/local/zookeeper-cluster/zookeeper-3/data/myid
(2) In every zookeeper's zoo CFG configure the client access port and cluster server IP list.
The cluster server IP list is as follows:
vim /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg vim /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg vim /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg server.1=192.168.149.135:2881:3881 server.2=192.168.149.135:2882:3882 server.3=192.168.149.135:2883:3883
Explanation: server Server ID = server IP address: communication port between servers: voting port between servers (judge whether it is the same cluster according to IP address)
Start cluster
Starting a cluster is to start each instance separately.
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh start /usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh start /usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh start
After startup, let's query the running status of each instance
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status /usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status /usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh status
First query the first service
Mode is follower, which means follower (slave)
Then query the second service. Mod is leader, indicating leader (Master)
Query that the third is a follower (from)

Fault test
(1) First, let's test what happens if we hang up from the server
Stop server 3 and observe No. 1 and No. 2. It is found that the status has not changed
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh stop /usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status /usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
It is concluded that the cluster with three nodes hangs up from the server and the cluster is normal
(2) We also shut down server 1 (slave server), check the status of server 2 (master server), and find that it has stopped running.
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh stop /usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
It is concluded that in a cluster of three nodes, two slave servers are hung up, and the master server cannot run. Because there are no more than half of the total number of running machines in the cluster.
(3) We started server 1 again and found that server 2 began to work normally again. And still a leader.
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh start /usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
(4) We also started server 3, stopped server 2, and observed the status of No. 1 and No. 3 after stopping.
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh start /usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh stop /usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status /usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh status
A new leader was found~
From this, we conclude that when the primary server in the cluster hangs, other servers in the cluster will automatically conduct election status, and then generate a new leader
(5) Let's test again. What happens when we restart server 2? Will server 2 become the new leader again? Let's see the results
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh start /usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status /usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh status
We will find that after server 2 is started, it is still a follower (slave server) and server 3 is still a leader (master server), which does not shake the leadership of server 3.
Therefore, we come to the conclusion that after the leader is born, new servers join the cluster again, which will not affect the current leader.
Zookeeper core theory
Zookeepe cluster role
There are three roles in ZooKeeper cluster service:
-
Leader leader:
- Processing transaction requests
- Scheduler of servers in the cluster
-
Follower followers:
- Handle the non transaction request of the client and forward the transaction request to the Leader server
- Participate in Leader election voting
-
Observer:
- Handle the non transaction request of the client and forward the transaction request to the Leader server
The schematic diagram is as follows:
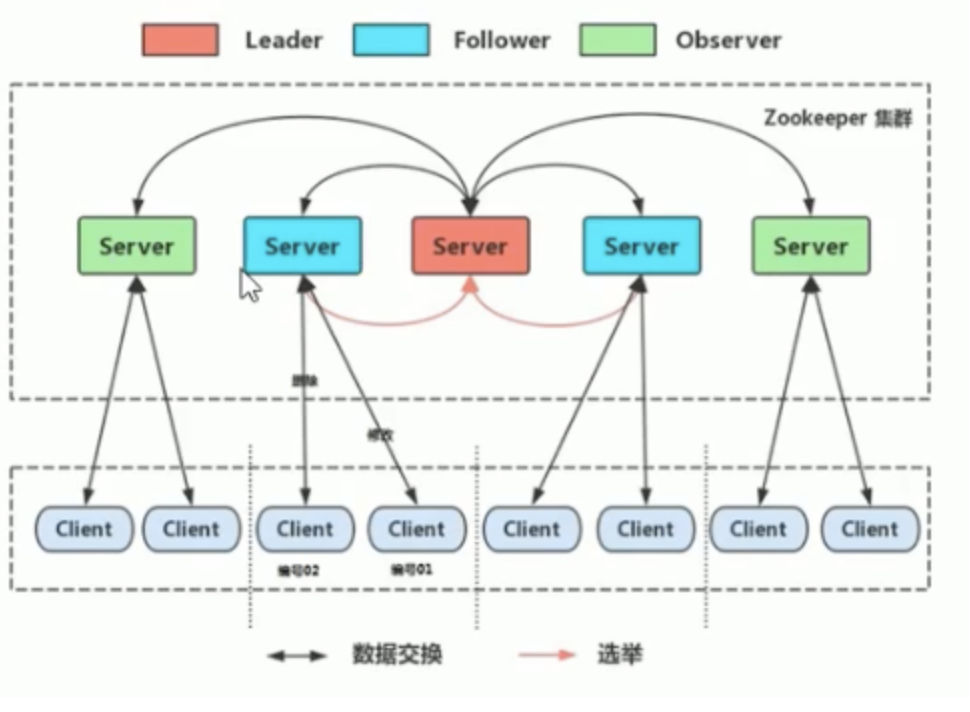
Related notes
@Service
Import path: import org apache. dubbo. config. annotation. Service;
Function: publish the methods provided by this class, and register the accessed address, ip, port and path in the registry.
@Reference
Translation: reference, involved.
Replace @ Autowired.
@Autowired is local injection and @ Reference is remote injection.
Reserve knowledge
QoS service
QoS (Quality of Service) refers to that a network can use various basic technologies to provide better service capability for specified network communication. It is a security mechanism of the network and a technology used to solve the problems of network delay and congestion. dubbo provides users with similar network services for online and offline service s to solve problems such as network delay and congestion.
QoS configuration:
The QoS of dubbo is enabled by default. The port is 22222. You can modify the port through configuration
<dubbo:application name="demo-provider"> <dubbo:parameter key="qos.port" value="33333"/> </dubbo:application>
Or shut down the service
<dubbo:application name="demo-provider"> <dubbo:parameter key="qos.enable" value="false"/> </dubbo:application>
For security reasons, dubbo's qos only supports local connections by default. If you want to enable any ip connection, you need to do the following configuration
<dubbo:application name="demo-provider"> <dubbo:parameter key="qos.port" value="33333"/> <dubbo:parameter key="qos.accept.foreign.ip" value="false"/> </dubbo:application>
Node. What's JS for
If you noticed the technical news last year, I bet you saw at least node JS no more than once or twice. So the question is "what is node.js?". Some people may tell you that "this is a thing that develops web services through JavaScript language". If this obscure explanation doesn't confuse you, you may then ask, "why do we use node. JS?", Others will usually tell you: node JS has the characteristics of non blocking and event driven I/O, which makes high concurrency possible in applications built by Polling and comet.
When you read these explanations and feel like reading heavenly books, you probably don't bother to ask. But it's okay. My article is to help you understand node while avoiding high-end terms JS.
The process of sending requests to websites by browsers has not changed much. When the browser sends a request to the website. The server receives the request and starts searching for the requested resource. If necessary, the server will query the database and finally send the response result back to the browser. However, in a traditional web server (such as Apache), every request causes the server to create a new process to process the request.
Then there was Ajax. With Ajax, we don't need to request a complete new page every time. Instead, we only need some page information every time. This is clearly a step forward. But for example, if you want to build a social networking site such as FriendFeed (a website that swipes friends' news like Renren), your friends will push new status at any time, and then your news will be refreshed automatically in real time. To meet this requirement, we need to keep users in an effective connection with the server all the time. At present, the simplest implementation method is to maintain long polling between users and servers.
HTTP request is not a continuous connection. You request once, the server responds once, and then it's over. Long rotation is a technique to simulate a continuous connection using HTTP. Specifically, as long as the page is loaded, whether you need the server to respond to you or not, you will send an Ajax request to the server. This request is different from the general Ajax request. The server will not directly return information to you, but it will wait until the server thinks it is time to send you a message. For example, if your friend sends a news, the server will send it to your browser as a response, and then your browser will refresh the page. After the browser receives the response, it sends a new request to the server, and the request will not be responded immediately. So I began to repeat the above steps. Using this method, you can keep the browser waiting for a response all the time. Although only non persistent HTTP is involved in the above process, we simulated a seemingly persistent connection state
Let's look at traditional servers (such as Apache). Every time a new user connects to your website, your server has to open a connection. Each connection needs to occupy a process, and these processes are idle most of the time (for example, waiting for your friends to send new news, waiting for your friends to send response information to users, or waiting for the database to return query results). Although these processes are idle, they still occupy memory. This means that if the number of user connections increases to a certain scale, your server may run out of memory and collapse directly.
How to solve this situation? The solution is just mentioned above: non blocking and event driven. These concepts are actually not so difficult to understand in the scenario we are talking about. You think of a non blocking server as a loop that runs all the time. When a new request comes, the loop receives the request, passes the request to other processes (for example, to a process engaged in database query), and then responds to a callback. When it's done, the loop will continue to run and accept other requests. Come down like this. The server will not wait for the database to return the results as before.
If the database returns the results, loop will send the results back to the user's browser, and then continue to run. In this way, the process of your server will not wait idle. Thus, in theory, there is no limit to the number of database queries and user requests at the same time. The server responds only when an event occurs on the user's side, which is event driven.
FriendFeed uses the Python based non blocking framework Tornado (I know it also uses this framework) to realize the above new thing function. However, node JS is better than the former. Node.js application is developed through javascript, and then runs directly on Google's abnormal V8 engine. Node JS, you don't have to worry that the client's request will run a piece of blocking code in the server. Because javascript itself is an event driven scripting language. Recall that when you write javascript to the front end, you are mostly engaged in event handling and callback functions. javascript itself is a language tailored for event handling.
Node.js is still in its infancy. If you want to develop a node based JS application, you should need to write some very low-level code. However, the next generation of browsers will soon adopt WebSocket technology, so long polling will disappear. In Web development, node This type of JS technology will only become more and more important.
Summary:
Apache: processes are independent. Each process occupies certain resources and cannot be released.
ajax: long polling
node.js: non blocking, event driven.
Role of project packaging
If you use Linux statements to run the project, you must package it first, because we don't have a tool to integrate the project like Idea, so we can only make it into a Jar package and run it again.
serialization and deserialization
Serialization refers to the process of converting Java objects into byte sequences, while deserialization refers to the process of converting byte sequences into Java objects.
Java object serialization is to convert the object that implements the Serializable interface into a byte sequence, which can be transmitted through network transmission, file storage, etc. in the transmission process, there is no need to worry about data changes in different machines and environments, nor about byte order or any other details, And can completely restore the byte sequence to the original object in the future (the recovery process is called deserialization).
Object serialization is very interesting because it can realize lightweight persistence. "Persistence" means that the life cycle of an object does not only depend on whether the program is running, but also can survive between program calls. The persistence of the object is achieved by writing a serialized object to disk and then restoring the object when the program is called again.
In essence, serialization is to write the entity object state to the ordered byte stream according to a certain format. Deserialization is to reconstruct the object from the ordered byte stream and restore the object state.