preface
Multithreading concurrency is not only a very important part of Java language, but also a difficulty in the foundation of Java. It is important because multithreading is frequently used in daily development. It is difficult because multithreading concurrency involves many knowledge points. It is not easy to fully master the concurrency related knowledge of Java. Therefore, Java concurrency has become one of the most frequent knowledge points in Java interview. This series of articles will systematically understand the concurrency knowledge of Java from the aspects of JAVA memory model, volatile keyword, synchronized keyword, ReetrantLock, Atomic concurrency class and thread pool. Through the study of this series of articles, you will deeply understand the role of volatile keyword, understand the implementation principle of synchronized, AQS and CLH queue lock, and clearly understand a series of dazzling concurrency knowledge, such as spin lock, bias lock, optimistic lock, pessimistic lock, etc.
This article will deeply analyze the working principle of thread pool in Java. Personally, I think thread pool is a piece of knowledge that is difficult to understand in Java concurrency, because the internal implementation of thread pool uses a lot of concurrency related knowledge such as ReentrantLock, AQS, AtomicInteger, CAS and "producer consumer" model, which basically covers most of the knowledge points of the previous articles in the concurrency series.
1, Thread pool Basics
In the Java language, although it is very convenient to create and start a thread, because creating a thread requires certain operating system resources, in the case of high concurrency, frequent creation and destruction of threads will consume a lot of CPU and memory resources, which will have a great impact on the program performance. To avoid this problem, Java provides us with thread pools.
Thread pool is a tool to manage threads based on the idea of pooling technology. Multiple threads are maintained in the thread pool. Threads are uniformly managed and deployed by the thread pool to perform tasks. Through thread reuse, the overhead of frequently creating and destroying threads is reduced.
In this chapter, let's first understand some basic knowledge of thread pool, learn how to use thread pool and understand the life cycle of thread pool.
1. Use of thread pool
The use and creation of thread pool can be said to be very simple, thanks to the well encapsulated API provided by JDK. The implementation of thread pool is encapsulated in ThreadPoolExecutor. We can instantiate a thread pool through the construction method of ThreadPoolExecutor. The code is as follows:
// Instantiate a thread pool
ThreadPoolExecutor executor = new ThreadPoolExecutor(3, 10, 60,
TimeUnit.SECONDS, new ArrayBlockingQueue<>(20));
// Use the thread pool to perform a task
executor.execute(() -> {
// Do something
});
// Closing the thread pool will prevent the submission of new tasks, but it will not affect the submitted tasks
executor.shutdown();
// Close the thread pool, prevent new task submission, and interrupt the currently running thread
executor.showdownNow();
After creating the thread pool, directly call the execute method and pass in a Runnable parameter to hand over the task to the thread pool for execution. The thread pool can be closed through the shutdown / shutdown now method.
There are many parameters in the construction method of ThreadPoolExecutor. For beginners, it is difficult to configure an appropriate thread pool without understanding the role of each parameter. Therefore, Java also provides us with a thread pool tool class executors to quickly create a thread pool. Executors provide many simple methods to create thread pools. For example, the code is as follows:
// Instantiate a single threaded thread pool ExecutorService singleExecutor = Executors.newSingleThreadExecutor(); // Create a thread pool with a fixed number of threads ExecutorService fixedExecutor = Executors.newFixedThreadPool(10); // Create a reusable thread pool with a fixed number of threads ExecutorService executorService2 = Executors.newCachedThreadPool();
However, generally speaking, it is not recommended to directly use Executors to create a thread pool in actual development. Instead, you need to configure a thread pool suitable for your project according to the actual situation of the project. Later, we need to understand the parameters of the thread pool and the working principle of the thread pool.
2. Thread pool life cycle
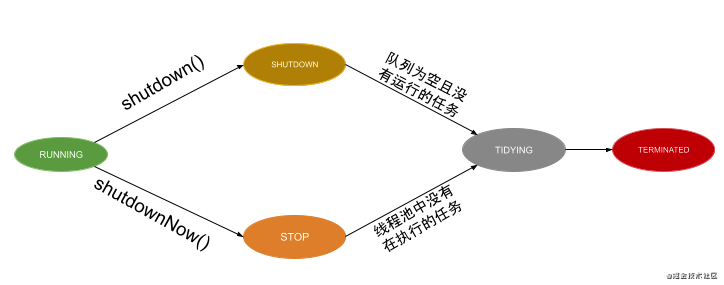
From birth to death, the thread pool will experience five Life Cycle States: RUNNING, SHUTDOWN, STOP, TIDYING and TERMINATED.
-
RUNNING means that the thread pool is RUNNING and can accept newly submitted tasks and process added tasks. The RUNNING state is the initialization state of the thread pool. Once the thread pool is created, it is in the RUNNING state.
-
The SHUTDOWN thread is closed and does not accept new tasks, but can process added tasks. The RUNNING thread pool will enter the SHUTDOWN state after calling SHUTDOWN.
-
The STOP thread pool is in a stopped state, does not receive tasks, does not process added tasks, and will interrupt the threads executing tasks. The RUNNING thread pool will enter the STOP state after calling shutdown now.
-
TIDYING when all tasks have been terminated and the number of tasks is 0, the thread pool will enter TIDYING. When the thread pool is in SHUTDOWN state, the tasks in the blocking queue are completed, and there are no executing tasks in the thread pool, the state will change from SHUTDOWN to TIDYING. When a thread is in the STOP state and there is no task being executed in the thread pool, it will change from STOP to TIDYING.
-
TERMINATED thread termination status. The thread in TIDYING state enters the TERMINATED state after executing terminated().
According to the above description of thread pool life cycle state, the following thread pool life cycle state flow diagram can be drawn.
2, Working mechanism of thread pool
1. Parameters in ThreadPoolExecutor
In the previous section, we used the construction method of ThreadPoolExecutor to create a thread pool. In fact, there are multiple construction methods in ThreadPoolExecutor, but they all call this construction method in the following code:
public class ThreadPoolExecutor extends AbstractExecutorService {
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
// ... Omit verification related codes
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
// ...
}
There are seven parameters in this construction method. Let's look at the meaning of each parameter one by one:
-
corePoolSize indicates the number of core threads in the thread pool. When a task is submitted to the thread pool, if the number of threads in the thread pool is less than corePoolSize, a new thread is directly created to execute the task.
-
workQueue task queue, which is a blocking queue used to store the queue of tasks that are too late to execute. When a task is submitted to the thread pool, if the number of threads in the thread pool is greater than or equal to corePoolSize, the task will be put into this queue first and wait for execution.
-
maximumPoolSize indicates the maximum number of threads supported by the thread pool. When a task is submitted to the thread pool, if the number of threads in the thread pool is greater than corePoolSize and the workQueue is full, a new thread will be created to execute the task, but the number of threads must be less than or equal to maximumPoolSize.
-
keepAliveTime the time that a non core thread remains alive when idle. Non core threads are those created when the workQueue is full and the task is submitted. Because these threads are not core threads, they will be recycled after their idle time exceeds keepAliveTime.
-
Unit the unit of time that a non core thread remains alive when idle
-
threadFactory is a factory for creating threads, where you can uniformly handle the properties of creating threads
-
handler reject policy: when the number of threads in the thread pool reaches maximumPoolSize and the workQueue is full, the task submitted to the thread pool will execute the corresponding reject policy
2. Thread pool workflow
The thread pool submission task starts with the execute method. We can analyze the workflow of the thread pool from the execute method.
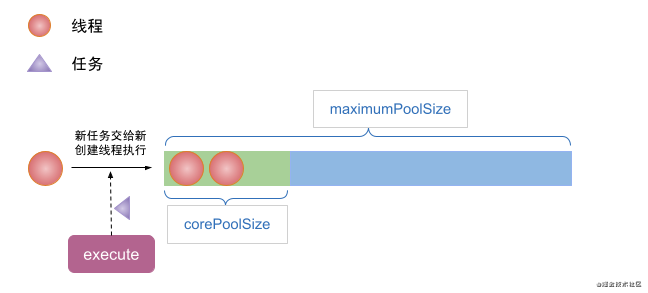
(1) When the execute method submits a task, if the number of threads in the thread pool is less than corePoolSize, a new thread will be created to execute the task regardless of whether there are idle threads in the thread pool.
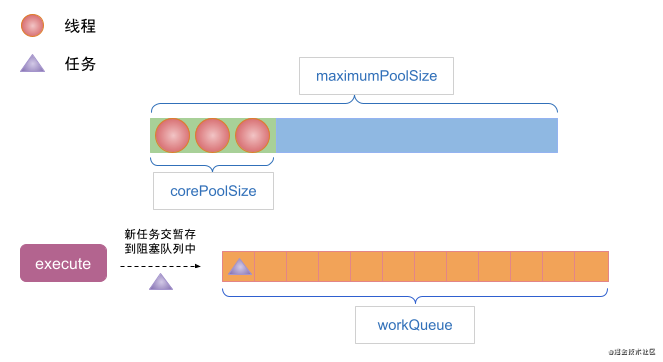
(2) When the execute method submits a task, the number of threads in the thread pool has reached corePoolSize, and there are no idle threads at this time, the task will be stored in the workQueue.
 (3) If the number of threads in the thread pool has reached corePoolSize and the workQueue is full when executing the task, a new thread will be created to execute the task, but the number of bus processes should be less than maximumPoolSize.
(3) If the number of threads in the thread pool has reached corePoolSize and the workQueue is full when executing the task, a new thread will be created to execute the task, but the number of bus processes should be less than maximumPoolSize. 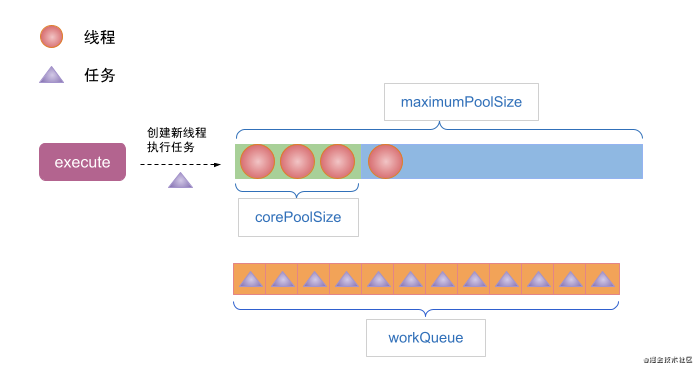
(4) If the thread in the thread pool finishes executing the current task, it will try to take the first task from the workQueue for execution. If workQueue is empty, the thread will be blocked.
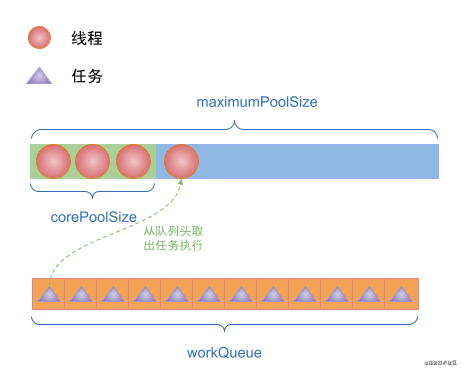
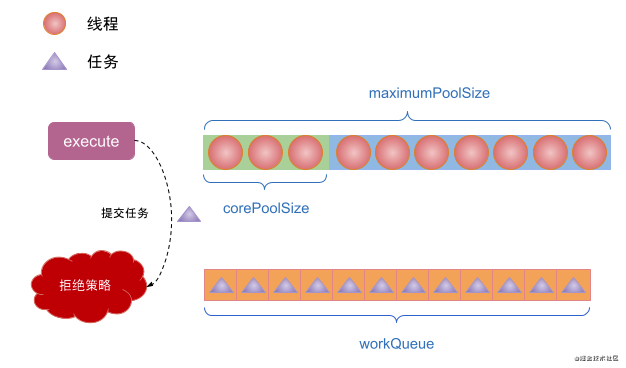
(5) If the number of threads in the thread pool reaches maximumPoolSize and the workQueue is full when the task is submitted by execute, a reject policy will be executed to reject the task.
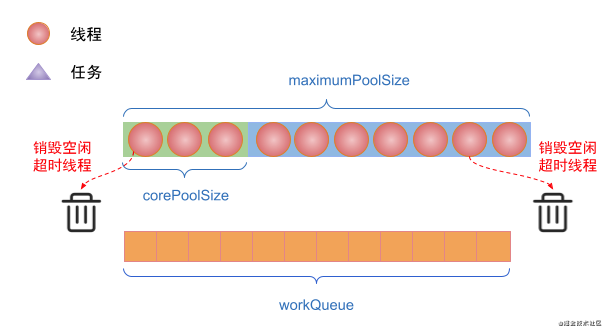
(6) If the number of threads in the thread pool exceeds corePoolSize, the threads with idle time exceeding keepAliveTime will be destroyed, but the number of threads in the thread pool will remain corePoolSize.
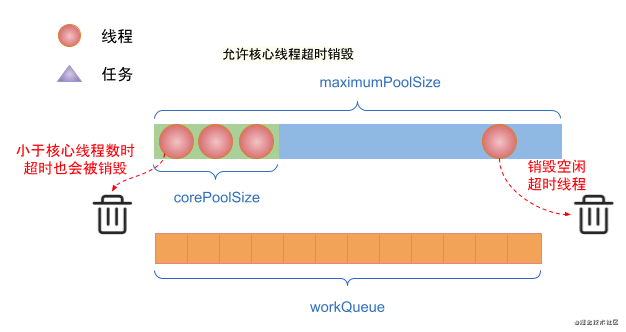
(7) If there are idle threads in the thread pool and allowCoreThreadTimeOut is set to true. Threads with idle time exceeding keepAliveTime will be destroyed.
3. Reject policy of thread pool
If the number of threads in the thread pool reaches maximumPoolSize and the workQueue queue is full, the thread pool will execute the corresponding rejection policy. The RejectedExecutionHandler interface is provided in the JDK to perform the reject operation. There are four classes that implement RejectedExecutionHandler, corresponding to four rejection policies. They are as follows:
-
DiscardPolicy when a task submitted to the thread pool is rejected, the thread pool will discard the rejected task
-
DiscardOldestPolicy when a task submitted to the thread pool is rejected, the thread pool will discard the oldest task in the waiting queue.
-
CallerRunsPolicy when a task submitted to the Thread pool is rejected, the rejected task will be processed in the Thread thread Thread currently running in the Thread pool. That is, which Thread submits the task and which Thread executes it.
-
AbortPolicy when a task submitted to the thread pool is rejected, a RejectedExecutionException exception is thrown directly.
3, Thread pool source code analysis
From the interpretation of the workflow of thread pool in the previous chapter, it seems that the principle of thread pool is not very difficult. However, at the beginning, I said that it is not allowed to read the source code of thread pool. The main reason is that a lot of concurrency related knowledge is used in thread pool, and it is also related to bit operations used in thread pool.
1. Bit operation in thread pool (understand the content)
When submitting a task to the thread pool, there are two parameters to be compared to determine the destination of the task. These two parameters are the status of the thread pool and the number of threads in the thread pool. The ThreadPoolExecutor uses an integer ctl of AtomicInteger type to represent these two parameters. The code is as follows:
public class ThreadPoolExecutor extends AbstractExecutorService {
// Integer.SIZE = 32. So COUNT_BITS= 29
private static final int COUNT_BITS = Integer.SIZE - 3;
// 000011111 11111111111111111111111111111 this value can represent the maximum thread capacity of the thread pool
private static final int COUNT_MASK = (1 << COUNT_BITS) - 1;
// Shift - 1 left by 29 bits to get the value of RUNNING status
private static final int RUNNING = -1 << COUNT_BITS;
// Thread pool running status and number of threads
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static int ctlOf(int rs, int wc) { return rs | wc; }
// ...
}
Because multi-threaded operations are involved, in order to ensure atomicity, the ctl parameter uses the AtomicInteger type, and the initial value of ctl is calculated through the ctlOf method. If you don't understand bit operations, it's probably difficult to understand the purpose of the above code.
As we know, int types occupy 4 bytes of memory in Java, and one byte occupies 8 bits, so int types in Java occupy 32 bits in total. For this 32bit, we can split the high and low bits. Students who develop Android should all know the MeasureSpec parameter in the View measurement process. This parameter divides the 32bit int into high 2 bits and low 30 bits, representing the measurement mode and measurement value of View respectively. The ctl here is similar to MeasureSpec. ctl splits the 32-bit int into high-3 bits and low-29 bits, indicating the running state of the thread pool and the number of threads in the thread pool respectively.
Let's verify how ctl works through bit operation. Of course, if you don't understand the process of bit operation, it has little impact on understanding the source code of thread pool, so students who are not interested in the following verification can skip it directly.
It can be seen that the value of RUNNING in the above code is - 1 and shifted 29 bits to the left. We know that in the computer, the * * negative number is represented by the complement of its absolute value, and the complement is obtained by adding 1 to the inverse code** Therefore, - 1 stores the inverse code of form 1 + 1 in the computer
1 Original code of: 00000000 00000000 00000000 00000001
+
1 Inverse code of: 11111111111111111111111111111111110
---------------------------------------
-1 Storage: 11111111111111111111111111111111111111
Next, shift - 1 by 29 bits to the left to obtain the value of RUNNING:
// The top three bits indicate the thread status, that is, the top three bits are 111, indicating RUNNING 11100000 00000000 00000000 00000000
The initial number of AtomicInteger threads is 0, so the "|" operation in ctlOf method is as follows:
RUNNING: 11100000 00000000 00000000 00000000
|
The number of threads is 0: 00000000 00000000 00000000 00000000
---------------------------------------
obtain ctl: 11100000 00000000 00000000 00000000
The initial value of ctl can be obtained by running|0 (number of threads). At the same time, ctl can be disassembled into running state and thread number by the following methods:
// 00001111 11111111 11111111 11111111
private static final int COUNT_MASK = (1 << COUNT_BITS) - 1;
// Get thread pool running status
private static int runStateOf(int c) { return c & ~COUNT_MASK; }
// Gets the number of threads in the thread pool
private static int workerCountOf(int c) { return c & COUNT_MASK; }
Assuming that the thread pool is RUNNING and the number of threads is 0, verify how runStateOf obtains the RUNNING state of the thread pool:
COUNT_MASK: 00001111 11111111 11111111 11111111
~COUNT_MASK: 11110000 00000000 00000000 00000000
&
ctl: 11100000 00000000 00000000 00000000
----------------------------------------
RUNNING: 11100000 00000000 00000000 00000000
If you don't understand the above verification process, it doesn't matter. Just know that the running state of the thread pool can be obtained through the runStateOf method and the number of threads in the thread pool can be obtained through workerCountOf.
Next, we enter the source code analysis of the source code of the thread pool.
2. execute of ThreadPoolExecutor
The method of submitting tasks to the thread pool is the execute method. The execute method is the core method of ThreadPoolExecutor. This method is used as an entry for analysis. The code of the execute method is as follows:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
// Get the value of ctl
int c = ctl.get();
// 1. The number of threads is less than corePoolSize
if (workerCountOf(c) < corePoolSize) {
// If the number of threads in the thread pool is less than the number of core threads, try to create a core thread to execute the task
if (addWorker(command, true))
return;
c = ctl.get();
}
// 2. This indicates that the number of threads in the thread pool is greater than the number of core threads or thread creation failed
if (isRunning(c) && workQueue.offer(command)) {
// If the thread is running and the task can be added to the blocking queue with offer, offer is a non blocking operation.
int recheck = ctl.get();
// Recheck the thread pool status because the thread pool status may change after the last detection. If it is not running, remove the task and execute the reject policy
if (! isRunning(recheck) && remove(command))
reject(command);
// If it is running and the number of threads is 0, a thread is created
else if (workerCountOf(recheck) == 0)
// If the number of threads is 0, a non core thread will be created without specifying the task to be executed for the first time. The second parameter here actually has no practical significance
addWorker(null, false);
}
// 3. The blocking queue is full. Create a non core thread to execute the task
else if (!addWorker(command, false))
// If it fails, the reject policy is executed
reject(command);
}
The logic in the execute method can be divided into three parts:
-
1. If the number of threads in the thread pool is less than the core thread, directly call the addWorker method to create a new thread to execute the task.
-
2. If the number of threads in the thread pool is greater than the number of core threads, add the task to the blocking queue, and then verify the running state of the thread pool again, because the thread pool state may have changed since the last detection. If the thread pool is closed, remove the task and execute the rejection policy. If the thread is still running, but there are no threads in the thread pool, call the addWorker method to create the thread. Note that the incoming task parameter is null, that is, the execution task is not specified, because the task has been added to the blocking queue. After creating the thread, take out the task execution from the blocking queue.
-
3. If step 2 fails to add a task to the blocking queue, it indicates that the blocking Queue task is full. Then step 3 will be executed, that is, create a non core thread to execute the task. If the creation of a non core thread fails, execute the reject policy.
As you can see, the execution logic of the code is the same as the workflow of the thread pool we analyzed in Chapter 2.
Next, take a look at the thread creation method addWoker in the execute method. The addWoker method is responsible for the creation of core threads and non core threads. It uses a boolean parameter core to distinguish whether to create core threads or non core threads. Let's first look at the code of the first half of the addWorker method:
// The return value indicates whether the thread was successfully created
private boolean addWorker(Runnable firstTask, boolean core) {
// Here is a retry flag, which is equivalent to goto
retry:
for (int c = ctl.get();;) {
// Check if queue empty only if necessary.
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP)
|| firstTask != null
|| workQueue.isEmpty()))
return false;
for (;;) {
// The maximum number of threads created is determined according to the core. If the maximum value is exceeded, thread creation fails. Note that the maximum values here may include s three corePoolSize, maximumPoolSize and the maximum capacity of thread pool threads
if (workerCountOf(c)
>= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK))
return false;
// Use CAS to increase the number of threads by 1. If successful, jump out of the loop and execute the following logic
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
// The state of the thread pool has changed, and it is returned to retry for re execution
if (runStateAtLeast(c, SHUTDOWN))
continue retry;
}
}
// ... Omit the second half
return workerStarted;
}
This part of the code will determine the value of the number of threads in the thread pool by whether to create a core thread. If you create a core thread, the maximum value cannot exceed corePoolSize. If you create a non core thread, the number of threads cannot exceed maximumPoolSize. In addition, whether you create a core thread or a non core thread, The maximum number of threads cannot exceed the maximum number of threads allowed in the thread pool count_ Mask (it is possible to set the maximumPoolSize to be greater than COUNT_MASK). If the number of threads is greater than the maximum value, false is returned and thread creation fails.
Next, increase the number of threads by 1 through CAS. If it succeeds, break retry ends the infinite loop. If CAS fails, continue retry starts the for loop again. Note that retry here is not a Java keyword, but a character that can be named arbitrarily.
Next, if you can continue to execute downward, you can start to create threads and execute tasks. See the second half of the code of addWorker method:
private boolean addWorker(Runnable firstTask, boolean core) {
// ... Omit the first half
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// Instantiate a Worker and encapsulate the thread internally
w = new Worker(firstTask);
// Remove the new thread
final Thread t = w.thread;
if (t != null) {
// ReentrantLock is used here to ensure thread safety
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int c = ctl.get();
// Get the lock lake and recheck the thread pool state. The thread will be created only when it is in RUNNING state or SHUTDOWN and firstTask==null
if (isRunning(c) ||
(runStateLessThan(c, STOP) && firstTask == null)) {
// If the thread is not in the NEW state, it indicates that the thread has been started and an exception is thrown
if (t.getState() != Thread.State.NEW)
throw new IllegalThreadStateException();
// Add the thread to the thread queue. The worker here is a HashSet
workers.add(w);
workerAdded = true;
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
// Start thread to execute task
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
In fact, this part of logic is easy to understand. It is the process of creating a worker and starting a thread to execute tasks. A worker is the encapsulation of a thread, and the created worker will be added to the HashSet in ThreadPoolExecutor. That is, the threads in the thread pool are maintained in the HashSet named workers and managed by the ThreadPoolExecutor. The threads in the HashSet may be working or idle. Once the specified idle time is reached, the threads will be recycled according to the conditions.
We know that after calling start, the thread will start to execute the logical code of the thread, and the life cycle of the thread will end after execution. How can the thread pool ensure that the Worker does not end after executing the task? When the thread is idle and timeout or the thread pool is closed, how to recycle the thread? The implementation logic is actually in the Worker. Take a look at the code of the Worker:
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable {
// Thread executing task
final Thread thread;
// The task passed in when initializing the Worker may be null. If it is not empty, create and immediately execute this task, corresponding to the creation of the core thread
Runnable firstTask;
Worker(Runnable firstTask) {
// Set setate to - 1 during initialization
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
// Creating threads through thread Engineering
this.thread = getThreadFactory().newThread(this);
}
// The real execution logic of a thread
public void run() {
runWorker(this);
}
// Judge whether the thread is in exclusive state. If not, it means that the thread is in idle state
protected boolean isHeldExclusively() {
return getState() != 0;
}
// Acquire lock
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
// Release lock
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
// ...
}
Worker is an internal class in ThreadPoolExecutor. It inherits AQS and uses AQS to implement the exclusive lock function, but does not support reentry. Here, the non reentrant feature is used to represent the execution state of the thread, that is, it can be judged through the isHeldExclusively method. If it is exclusive, it means that the thread is executing a task. If it is non exclusive, it means that the thread is idle. We have analyzed AQS in detail in the previous article. Those who do not understand AQS can refer to the previous ReentrantLock article.
In addition, the Worker also implements the Runnable interface, so its execution logic is in the run method, which calls the runWorker(this) method in the thread pool. The execution logic of the task is in the runWorker method, and its code is as follows:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
// Take out the task in the Worker, which may be empty
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// If the task is not null or there are tasks in the blocking queue, the task is continuously taken out from the blocking queue for execution through a cycle
while (task != null || (task = getTask()) != null) {
w.lock();
// ...
try {
// hook point before task execution
beforeExecute(wt, task);
try {
// Perform tasks
task.run();
// hook point after task execution
afterExecute(task, null);
} catch (Throwable ex) {
afterExecute(task, ex);
throw ex;
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// If the task is not retrieved after the timeout, the idle timeout thread will be recycled
processWorkerExit(w, completedAbruptly);
}
}
It can be seen that the core logic of runWorker is to continuously obtain and execute tasks from the blocking queue through the getTask method In this way, the reuse of threads is realized and the creation of threads is avoided. It should be noted that this is a "producer consumer" mode. getTask takes tasks from the blocking queue, so if there are no tasks in the blocking queue, it will be in the blocking state. In getTask, the wait timeout is set by judging whether to recycle the thread. If there is no task in the blocking queue, an exception will be thrown after waiting for keepAliveTime. Finally, it will go to the finally method of the above code, which means that if the idle time of a thread exceeds the keepAliveTime, call the processWorkerExit method to remove the Worker. There is no complicated logic in the processWorkerExit method, so the code will not be pasted here. Let's focus on how getTask is handled. The code is as follows:
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
// ...
// Flag1. If allowCoreThreadTimeOut==true is configured, or the number of threads in the thread pool is greater than the number of core threads, timed is true, indicating that the specified thread will be recycled after timeout
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// ...
try {
// Flag2. Take out the tasks in the blocking queue. Note that if timed is true, the poll method of the blocking queue will be called and the timeout time will be set to keepAliveTime. If the task is not taken in the timeout, an exception will be thrown.
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
Focus on how getTask handles the logic of idle timeout. We know that the condition for recycling threads is that the number of threads is greater than the number of core threads or allowCoreThreadTimeOut is configured to be true. When the thread is idle and timeout, the thread will be recycled. The above code first judges at Flag1 that if the number of threads in the thread pool is greater than the number of core threads, or allowCoreThreadTimeOut is enabled, thread idle timeout recovery needs to be enabled. At Flag2, when timed is true, the poll method of the blocking queue is called and the timeout time is passed in as keepAliveTime. If the blocking queue has been null for so long within the keepAliveTime time, an exception will be thrown to end the loop of runWorker. Then perform the operation of reclaiming threads in the runWorker method.
Here we need to understand the use of the blocking queue poll method. The poll method accepts a time parameter, which is a blocking operation. If no data is obtained within a given time, an exception will be thrown. In fact, to put it bluntly, blocking queue is a "producer consumer" mode implemented by ReentrantLock.
Attachment: Xiao Wang, who studied hard for the last three months, won offers from Ali, Tencent, meituan, byte and many other big manufacturers
Note: This article is limited to space, so it only shows part of the document screenshots. The complete Java learning document, brother bald, has helped you sort it out. Friends in need have a way to get it at the end of the article!
java high concurrency core programming
Multithreading principle and practice;
The core principle of Java built-in lock;
CAS principle and JUC atomic class;
The principle of visibility and order;
The principle and practice of JUC explicit lock;
AQS abstracts the core principle of synchronizer;
JUC container class;
High concurrency design pattern;
Asynchronous callback mode of high concurrency core mode;
Completabilefuture asynchronous callback;
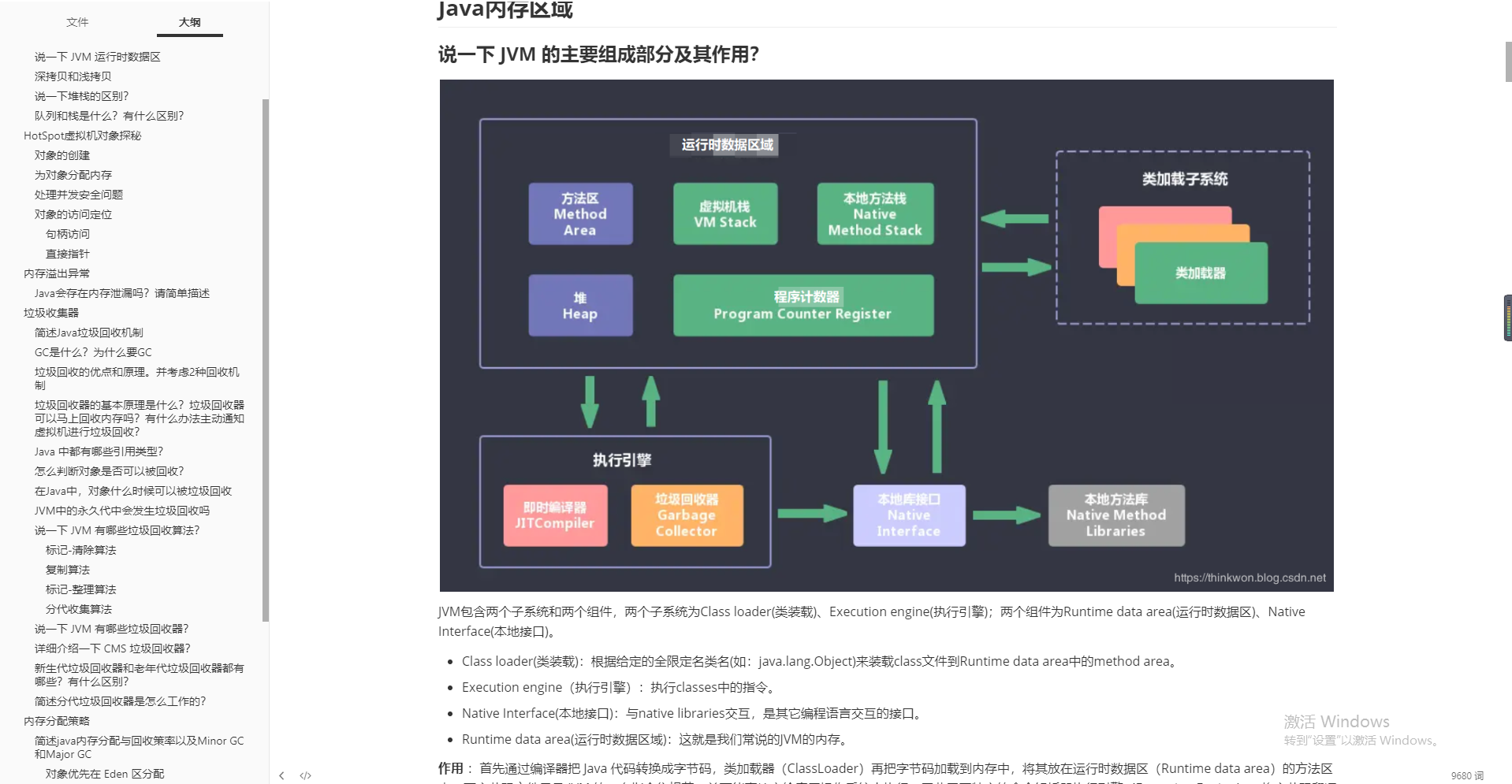
JVM
- JVM memory area
- Memory overflow exception
- garbage collector
- Memory allocation strategy
- Class loading mechanism
- JVM tuning
Spring
- spring overview
- Spring inversion of control (IOC)
- SpringBean
- Spring annotation
- Spring data access
- SpringAOP

SpringCloud
- What is service fusing and what is service degradation
- Advantages and disadvantages of microservices
- Pit encountered in use
- Enumerate microservice technology stack
- eureka and zookeeper can provide service registration and discovery. What are their differences
- Principle of eureka service registration and discovery
- Principles of dubbo service registration and discovery
- ...

Redis
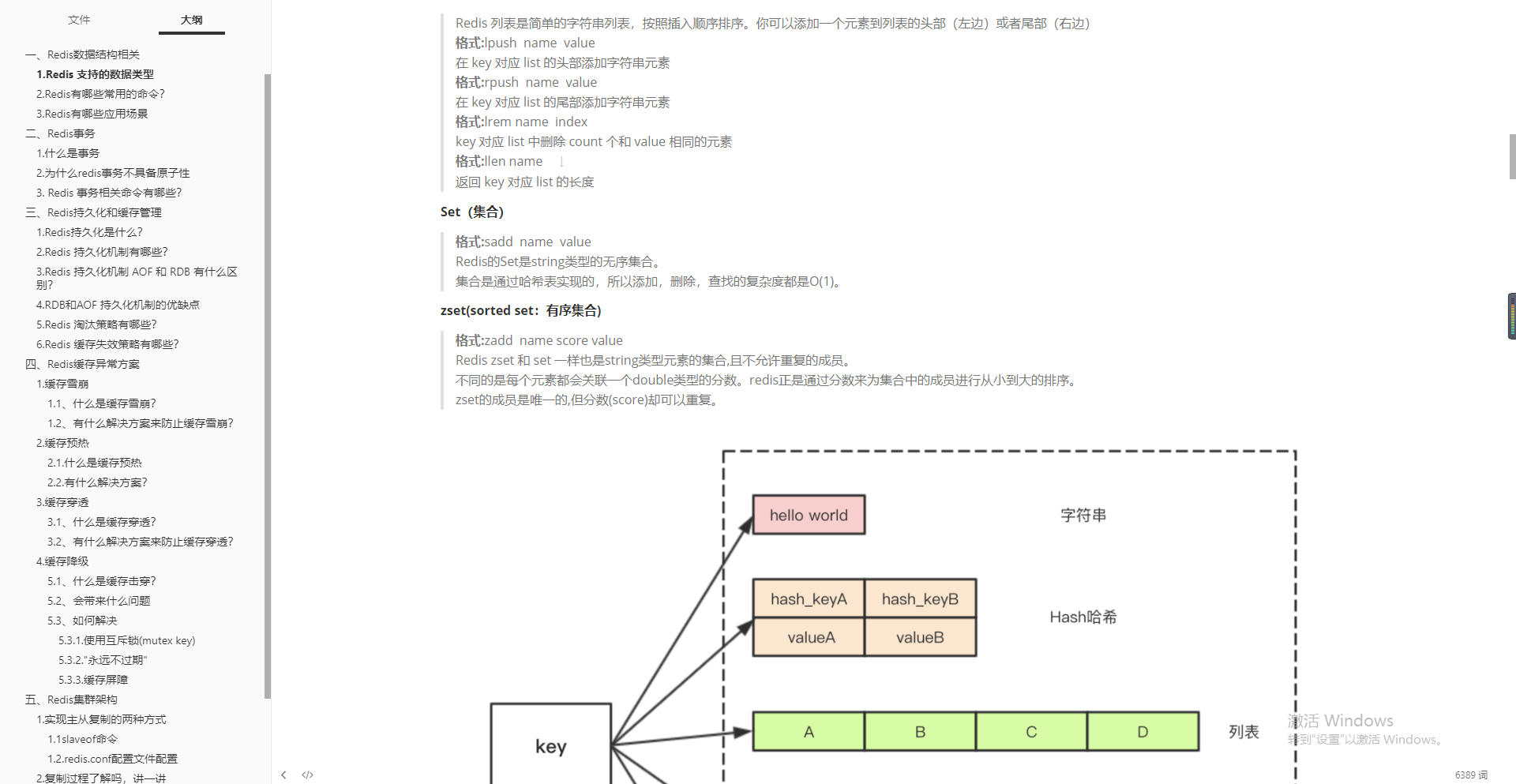
- Redis data type
- Redis transaction
- Redis persistence and caching
- Redis cache exception scheme
- Redis cluster architecture
MySQL
RabbitMQ
- How do I ensure that messages are sent to RabbitMQ correctly?
- How to ensure that the message receiver consumes the message?
- How to avoid repeated delivery or consumption of messages?
- What transmission is the message based on?
- How are messages distributed?
- How do messages route?
- How to ensure that messages are not lost?
- What are the benefits of using RabbitMQ?
- What are the disadvantages of message queuing?
- How to select MQ?
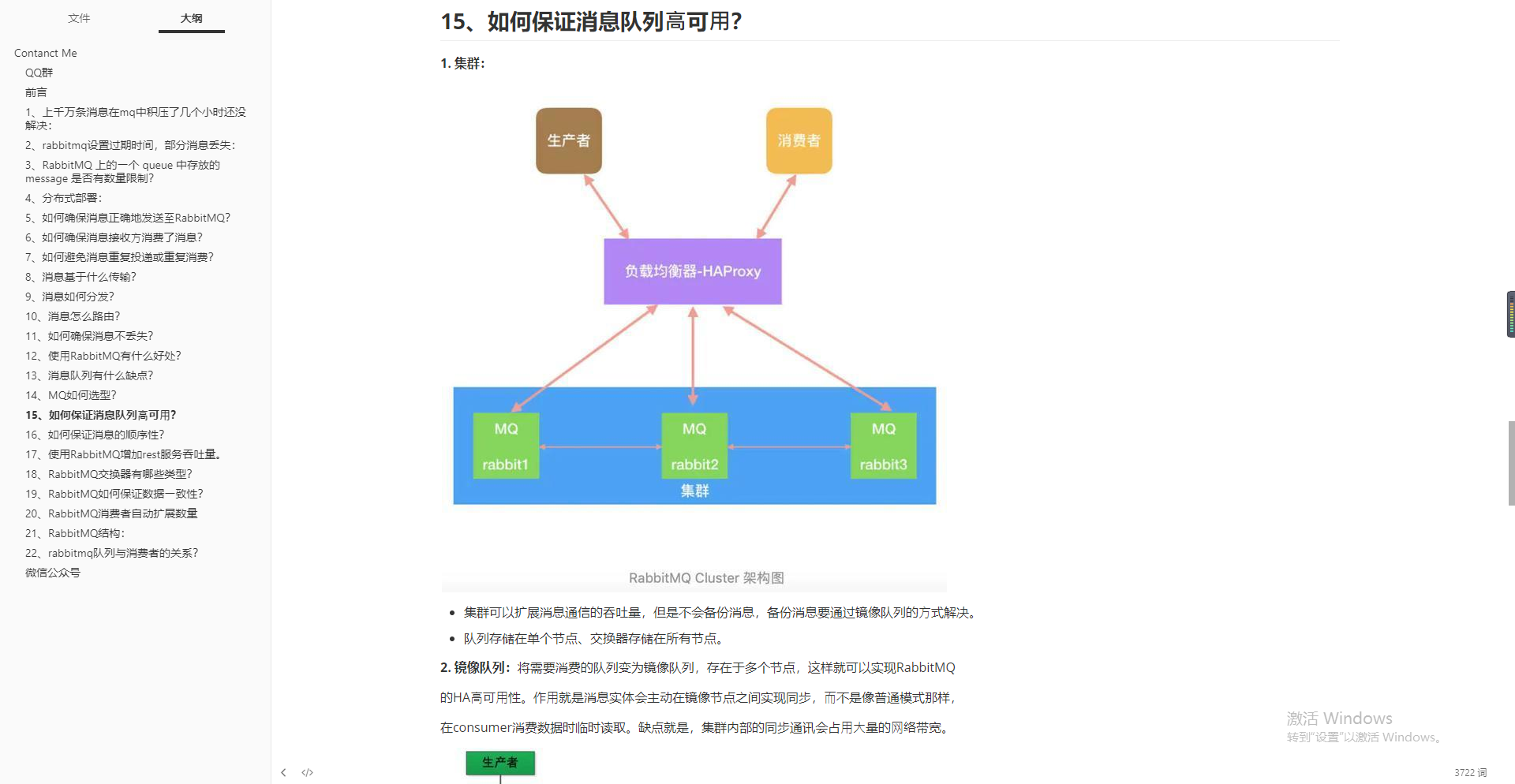
- How to ensure high availability of message queuing?
- How to ensure the order of messages?
architecture design
Due to space reasons, there will be no exhibitions on SpringBoot, MyBatis, spring MVC, Dubbo, Linux, Tomcat, ZooKeeper, Netty and other topics! This note has been prepared online and offline!!
If you need all the above notes, you can click three times and get the free way below!
