Today I learned about the perceptron. The code is below and summarizes several problems.
1. Difference between MLP multi-layer perceptron and SVM support vector machine:
1.MLP needs to set W and b, but SVM is not sensitive to parameters, so it is relatively convenient;
2.SVM is more explanatory in mathematics;
3.SVM optimization is relatively easy.
2. Why is deep learning rather than breadth learning—— Intuitively, this thing has no theoretical basis
There is only one reason, breadth learning is not good at training. It's very easy to fit into a fat man at one breath.
Learning should start from the simple, start from the place similar to the input layer, and go deep slowly;
Instead of throwing everything complex and simple into your brain.
3. Essence of three functions:

4. Limitations of single-layer perceptron
At first, because the single-layer perceptron could not solve the XOR problem, it led to the first winter in the AI field.
5. Good video on maximum likelihood estimation:
https://www.bilibili.com/video/BV1Hb4y1m7rE/?spm_id_from=333.788.recommend_more_video.-1
The source code is as follows:
Perceptron implemented from 0
1 import torch 2 from torch import nn 3 from d2l import torch as d2l 4 5 # Perceptron implemented from 0 6 7 batch_size=256 8 train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size) #Using this data set again 9 10 num_inputs,num_outputs,num_hiddens=784,10,256 #The input and output are fixed, with a total pixel of 784,10 Class, the size of the hidden layer is determined by yourself 11 # Define parameters, W1 Is the weight matrix of the first layer. The rows and columns are input layer and hidden layer, W2 Nature is the hidden layer and output layer; b Is the offset matrix of the output 12 W1=nn.Parameter(torch.randn(num_inputs,num_hiddens,requires_grad=True)*0.01) 13 b1=nn.Parameter(torch.zeros(num_hiddens,requires_grad=True)) 14 W2=nn.Parameter(torch.randn(num_hiddens,num_outputs,requires_grad=True)*0.01) 15 b2=nn.Parameter(torch.zeros(num_outputs,requires_grad=True)) 16 17 params=[W1,b1,W2,b2] 18 19 # Activation function, ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha 20 def relu(X): 21 a=torch.zeros_like(X) 22 return torch.max(X,a) 23 24 # Define network 25 def net(X): 26 X=X.reshape((-1,num_inputs)) # Here this-1 It means I don't know how many lines it is (actually 1 line) 27 H=relu(X@W1+b1) 28 return H@W2+b2 29 30 num_epochs,lr=10,0.1 31 updater=torch.optim.SGD(params,lr=lr) 32 loss=nn.CrossEntropyLoss() 33 d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,updater) 34 d2l.plt.show()
Simple implementation of perceptron
1 # Simple implementation of perceptron 2 net = nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Linear(256,10)) #Flattening, first layer, activation function, second layer 3 4 # Weight initialization 5 def init_weights(m): 6 if type(m)==nn.Linear: 7 nn.init.normal_(m.weight,std=0.01) 8 net.apply(init_weights) 9 10 batch_size,lr,num_epochs=256,0.1,10 11 loss=nn.CrossEntropyLoss() 12 trainer=torch.optim.SGD(net.parameters(),lr) 13 14 train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size) 15 16 d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer) 17 d2l.plt.show()
Results from 0 implementation (left) and concise implementation (right):
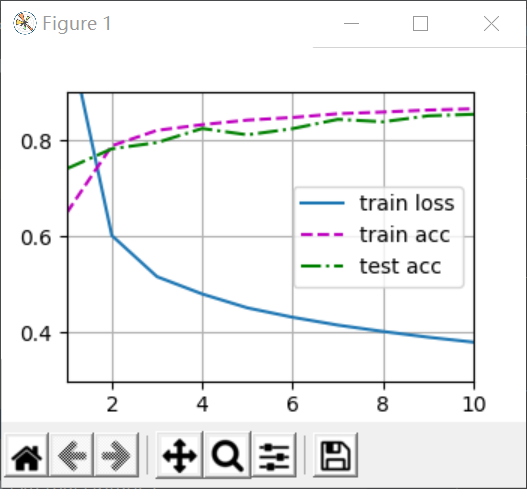
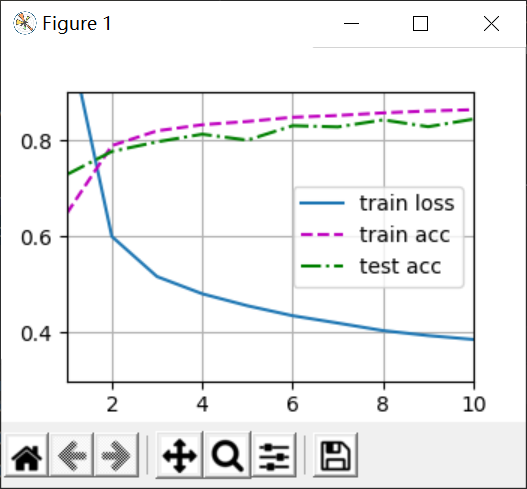
It can be found that there is almost no difference, but I found a problem when doing a concise implementation, that is, if W is not multiplied by 0.01, the loss of training will be reduced very slowly, so that in 10 iterations, the loss cannot be reduced to 0.5. When the training function in Torch outputs an assertion, assert loss < 0.5, the output image will produce an assertion error, as follows:

There are two ways to solve this problem. One is to throw assertion exceptions with try catch: https://www.cnblogs.com/fanjc/p/10072556.html
The other is to make the loss training smaller, because the assertion itself is written for the rationality of our results, so you can increase the number of iterations by increasing the epoch, for example, by changing it to 30 times, you can reduce the loss to about 0.5, as follows:
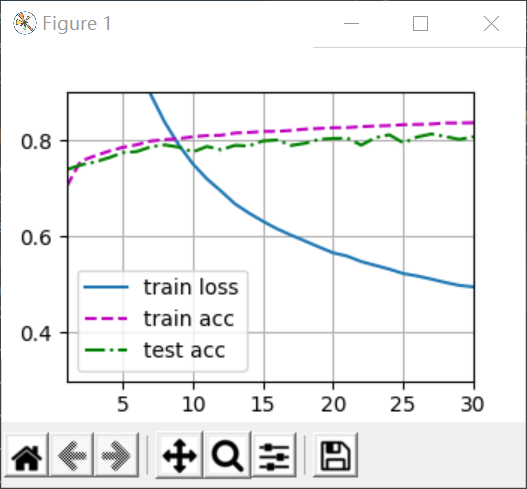
This is the positive solution.
But I personally don't understand why reducing the W by 100 times can speed up the training. Please see the big guys here in the comment area. Thank you~