I am a 21-year-old junior college student and have just worked in Java back-end for 2 weeks. It's not well written. Please give me more advice! The following is a more confident explanation of application + config. You can have a detailed look.
introduction
I have roughly sorted out and mastered some preliminary conceptual knowledge of Redis. This article basically ends most of the knowledge introduction of Redis. I didn't read a piece of advice Redis beginner . One is mainly theory. This one is a little deeper. More practical.
Next, it is expected that some Redis articles in simple terms, such as SDS dynamic string.
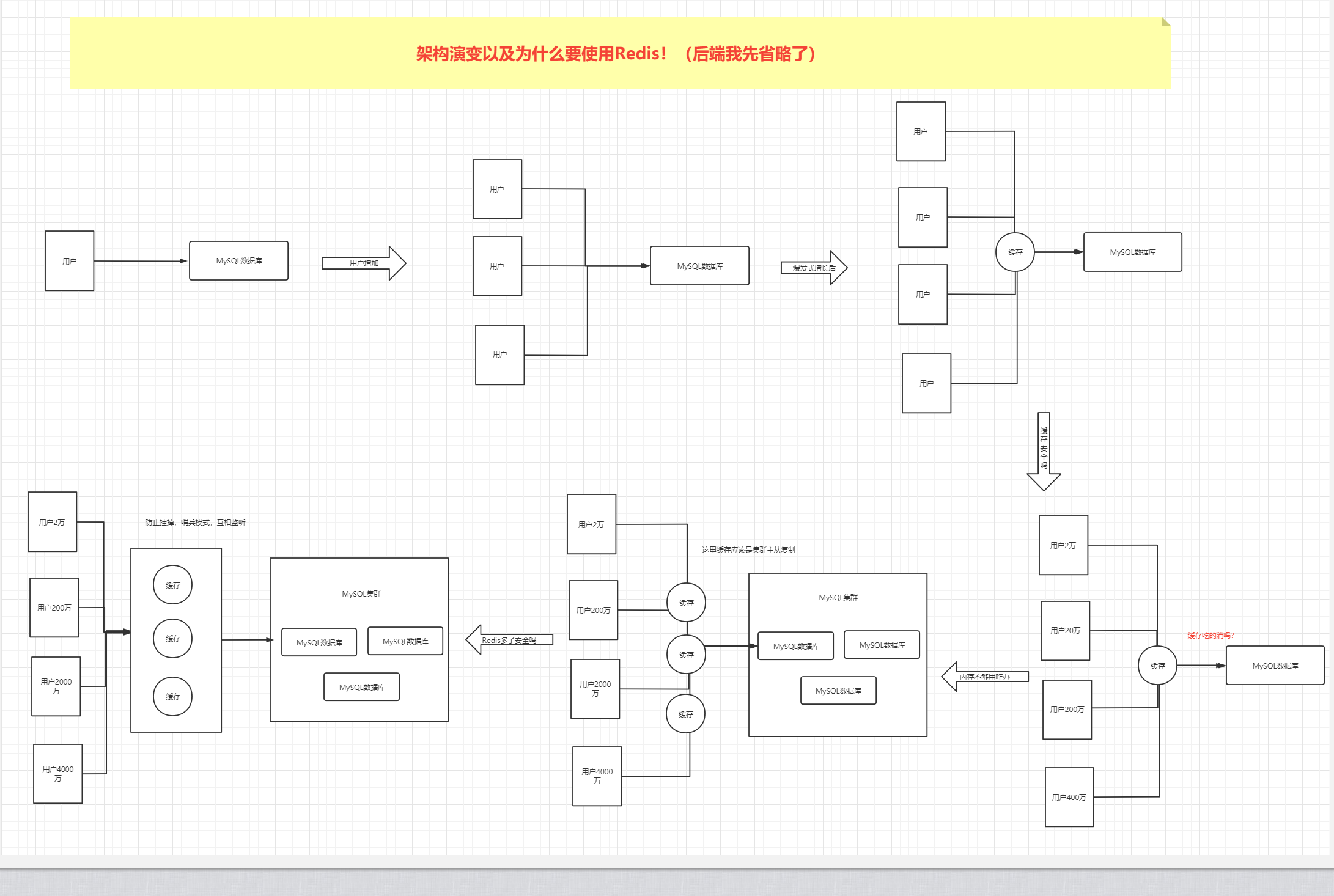
background
The background of Redis iteration is from
① Stand alone Era
② Cached + MySQL + vertical split
③ Sub database and sub table + horizontal split + MySQL Cluster
④ Multi user access era (still resistant)
⑤ The number of users increases sharply, and the cache layer is increased to protect the database
⑥ The number of users has increased explosively, and a single machine can not meet the requirements of users
⑦ Redis cluster (sentinel mode)
NoSQL
Before learning about Redis, it is necessary to learn about NoSQL. Databases are divided into relational databases and non relational databases. NoSQL is special. It contains both relational and non relational types. It is very necessary to understand all of them.
Advantages: the data is irrelevant and easy to expand. High performance advantage in case of large amount of data. The amount of data is diverse, which does not need to be designed in advance and can be used as needed
Practical application: it is certainly impossible to use only one database in practical application. It is generally used in combination with MySQL+NoSQL.
Classification: kv key value pairs, document database, column storage, graph relational database
Five common data types
Verify service connection
[root@iZ2zebzs5dnocz7mu3p6wnZ bin]# redis-cli -p 6379 127.0.0.1:6379> ping PONG
String
Application: temporary storage of data such as number of followers, number of views, number of hits, etc
set get command operation data access
127.0.0.1:6379> get demo (nil) 127.0.0.1:6379> set demo huanshao OK 127.0.0.1:6379> get demo "huanshao" 127.0.0.1:6379> set demo1 nb OK 127.0.0.1:6379> keys* (error) ERR unknown command `keys*`, with args beginning with: 127.0.0.1:6379> keys * 1) "\xac\xed\x00\x05t\x00\x04Demo" 2) "demo" 3) "demo1"
Determine whether the key exists
127.0.0.1:6379> exists demo (integer) 1 127.0.0.1:6379> exists demo2 (integer) 0 127.0.0.1:6379> type demo string
Set get key expiration time
127.0.0.1:6379> setex demo2 30 wc OK 127.0.0.1:6379> ttl demo2 (integer) 25 127.0.0.1:6379> ttl demo2 (integer) 21 127.0.0.1:6379> keys * 1) "\xac\xed\x00\x05t\x00\x04Demo" 2) "demo" 3) "demo1" 127.0.0.1:6379> get demo1 "nb"
The key value append is similar to append in Java
127.0.0.1:6379> append demo1 lth (integer) 5 127.0.0.1:6379> get demo1 "nblth"
value replacement
127.0.0.1:6379> get demo1 "nblth" 123.56.240.222:6379> setrange demo1 2 S (integer) 5 123.56.240.222:6379> get demo1 "nbSth"
Judge whether it exists. If it does not exist, create it
123.56.240.222:6379> keys * 1) "\xac\xed\x00\x05t\x00\x04Demo" 2) "demo" 3) "demo1" 123.56.240.222:6379> setnx demo2 LTH (integer) 1 123.56.240.222:6379> keys * 1) "\xac\xed\x00\x05t\x00\x04Demo" 2) "demo" 3) "demo1" 4) "demo2" 123.56.240.222:6379> get demo2 "LTH"
Batch operation data insertion and batch retrieval
123.56.240.222:6379> mset hs1 5 hs2 6 OK 123.56.240.222:6379> keys * 1) "hs2" 2) "\xac\xed\x00\x05t\x00\x04Demo" 3) "demo" 4) "demo2" 5) "hs1" 6) "demo1" 123.56.240.222:6379> mget hs1 hs2 1) "5" 2) "6"
numerical calculation
123.56.240.222:6379> incr hs1 (integer) 6 123.56.240.222:6379> get hs1 "6" 123.56.240.222:6379> decr hs2 (integer) 5 123.56.240.222:6379> get hs2 "5" 123.56.240.222:6379> get hs1 "6" 123.56.240.222:6379> get hs2 "5" 123.56.240.222:6379> incrby hs1 4 (integer) 10 123.56.240.222:6379> get hs1 "10" (0.81s) 123.56.240.222:6379> decrby hs2 3 (integer) 2 123.56.240.222:6379> get hs2 "2" 123.56.240.222:6379> keys * 1) "hs2" 2) "\xac\xed\x00\x05t\x00\x04Demo" 3) "demo" 4) "demo2" 5) "hs1" 6) "demo1"
wipe data
123.56.240.222:6379> flushdb OK 123.56.240.222:6379> keys * (empty array)
Ensuring atomicity will either succeed or fail
123.56.240.222:6379> msetnx k1 v1 k2 v2 (integer) 1 123.56.240.222:6379> keys * 1) "k1" 2) "k2" 123.56.240.222:6379> flushdb OK 123.56.240.222:6379> keys * (empty array)
If no value exists, nill is returned and a
123.56.240.222:6379> getset k3 v3 (nil) 123.56.240.222:6379> get k3 "v3"
Switch database to get database size
123.56.240.222:6379> dbsize (integer) 1 123.56.240.222:6379> select 2 OK 123.56.240.222:6379[2]> keys * (empty array) 123.56.240.222:6379[2]> select 1 OK 123.56.240.222:6379[1]> select 1 OK 123.56.240.222:6379[1]> keys * (empty array) 123.56.240.222:6379[1]> select 0 OK 123.56.240.222:6379> keys * 1) "k3"
List
Application: attention list, hot data list, analysis data list, etc
Put the data into the list set and get the data in the list set
123.56.240.222:6379> keys * 1) "k3" 123.56.240.222:6379> flushdb OK 123.56.240.222:6379> keys * (empty array) 123.56.240.222:6379> lpush mylist lth (integer) 1 123.56.240.222:6379> lpush mylist jia (integer) 2 123.56.240.222:6379> lpush mylist you (integer) 3 123.56.240.222:6379> lrange mylist 0-1 (error) ERR wrong number of arguments for 'lrange' command 123.56.240.222:6379> lrange mylist 0 -1 1) "you" 2) "jia" 3) "lth" 123.56.240.222:6379> lrange mylist 0 1 1) "you" 2) "jia" 123.56.240.222:6379> rpush mylist xiaofang (integer) 4 123.56.240.222:6379> lrange mylist 0 1 1) "you" 2) "jia" 123.56.240.222:6379> lrange mylist 0 -1 1) "you" 2) "jia" 3) "lth" 4) "xiaofang"
Get data length according to subscript
123.56.240.222:6379> lindex mylist 1 "lth" 123.56.240.222:6379> llen mylist (integer) 2 123.56.240.222:6379> lrange mylist 0 -1 1) "jia" 2) "lth"
Remove list data
123.56.240.222:6379> lpush mylist xiaofang (integer) 3 123.56.240.222:6379> lpush mylist mao rpop lth (integer) 6 123.56.240.222:6379> lrange mylist 0 -1 1) "lth" 2) "rpop" 3) "mao" 4) "xiaofang" 5) "jia" 6) "lth" 123.56.240.222:6379> lpush mylist sql (integer) 7 123.56.240.222:6379> lrange mylist 0 -1 1) "sql" 2) "lth" 3) "rpop" 4) "mao" 5) "xiaofang" 6) "jia" 7) "lth" 123.56.240.222:6379> rpop mylist 1 1) "lth" 123.56.240.222:6379> flushdb OK 123.56.240.222:6379> lrange mylist 0 -1 (empty array)
Simulation stack and queue
lpush rpop queue lpush lpop Stack
Set
Application: out of order. Duplicate storage is not supported. It mainly realizes some functions similar to microblog, such as common friends, common fans, random events, lucky draw, name selection and so on
Price difference set data
123.56.240.222:6379> sadd myset lth (integer) 1 123.56.240.222:6379> sadd myset lth (integer) 0 123.56.240.222:6379> sadd myset hs (integer) 1
Get the set data and judge whether the key exists in the set
123.56.240.222:6379> smembers myset 1) "hs" 2) "lth" 123.56.240.222:6379> sismember myset hs (integer) 1 123.56.240.222:6379> sismember myset hss (integer) 0
Get set size
123.56.240.222:6379> smembers myset 1) "hs" 2) "xiaofang" 3) "lth" 123.56.240.222:6379> scard myset (integer) 3
set remove element
123.56.240.222:6379> srem myset lth (integer) 1 123.56.240.222:6379> smembers myset 1) "hs" 2) "xiaofang"
Randomly take out a set element
123.56.240.222:6379> smembers myset 1) "hs" 2) "xiaofang" 123.56.240.222:6379> srandmember myset "xiaofang" 123.56.240.222:6379> srandmember myset "xiaofang" 123.56.240.222:6379> srandmember myset "xiaofang" 123.56.240.222:6379> srandmember myset "hs"
Randomly delete an element
123.56.240.222:6379> spop myset 1 1) "hs" 123.56.240.222:6379> smembers myset "xiaofang"
Creates the intersection of a new collection and a collection
123.56.240.222:6379> keys * 1) "youset" 2) "myset" (0.82s) 123.56.240.222:6379> smembers youset 1) "xiaohuan" 123.56.240.222:6379> smembers myset 1) "xiaofang" 123.56.240.222:6379> sadd youset xiaofang (integer) 1 123.56.240.222:6379> smembers youset 1) "xiaofang" 2) "xiaohuan" 123.56.240.222:6379> smembers myset 1) "xiaofang" 123.56.240.222:6379> sdiff youset myset 1) "xiaohuan"
Take set difference set
123.56.240.222:6379> smembers youset 1) "xiaofang" 2) "xiaohuan" 123.56.240.222:6379> smembers myset 1) "xiaofang" 123.56.240.222:6379> sinter myset youset 1) "xiaofang"
Fetch and merge sets
123.56.240.222:6379> sunion youset myset 1) "xiaohuan" 2) "xiaofang"
Hash
Application: because of its mapping relationship, it is especially suitable for storing some storage objects. Such as user details, product details, order details, etc.
set get hash data
123.56.240.222:6379> hset myhash name lth (integer) 1 123.56.240.222:6379> hset myhash age 18 (integer) 1 123.56.240.222:6379> hget myhash name "lth" 123.56.240.222:6379> hget myhash age "18"
Get all values
123.56.240.222:6379> hgetall myhash 1) "name" 2) "lth" 3) "age" 4) "18"
Get multiple filed s in batch
123.56.240.222:6379> hmget myhash name age 1) "lth" 2) "18"
Delete the name field of the current myhash
123.56.240.222:6379> hdel myhash name (integer) 1 123.56.240.222:6379> hgetall myhash 1) "age" 2) "18"
Get hash length
123.56.240.222:6379> hlen myhash (integer) 1 123.56.240.222:6379> hset myhash name lll (integer) 1 123.56.240.222:6379> hlen myhash (integer) 2
Judge whether the current myhash key and the name field in myhash exist
123.56.240.222:6379> hexists myhash name (integer) 1 123.56.240.222:6379> hexists myhash names (integer) 0
Get all key s and get all value values
123.56.240.222:6379> hkeys myhash 1) "age" 2) "name" 123.56.240.222:6379> hvals myhash 1) "18" 2) "lll"
Add 3 to the age field of the myhash key
123.56.240.222:6379> hincrby myhash age 3 (integer) 21
Judge whether the wight field exists. If it does not exist, create it
123.56.240.222:6379> hsetnx myhash wight 160 (integer) 1 123.56.240.222:6379> hkeys myhash 1) "age" 2) "name" 3) "wight"
ZSet
Application: mainly used for real-time ranking information in some live broadcasting systems. Including online user list, gift ranking list, bullet screen message list and other functions.
Add data, traverse data
127.0.0.1:6379> zadd myzset 1 lth (integer) 1 127.0.0.1:6379> zadd myzset 2 xf (integer) 1 127.0.0.1:6379> zrange myzset (error) ERR wrong number of arguments for 'zrange' command 127.0.0.1:6379> zrange myzset 0 -1 1) "lth" 2) "xf"
Batch add data
127.0.0.1:6379> zadd myzset 3 zsq 4 zyn (integer) 2 127.0.0.1:6379> zrange myzset 1 -1 1) "xf" 2) "zsq" 3) "zyn" 127.0.0.1:6379> zrange myzset 0 -1 1) "lth" 2) "xf" 3) "zsq" 4) "zyn"
Query interval range values in zset set
127.0.0.1:6379> zrange myzset 0 -1 1) "lth" 2) "xf" 3) "zsq" 4) "zyn" 127.0.0.1:6379> zrangebyscore myzset -inf +inf 1) "lth" 2) "xf" 3) "zsq" 4) "zyn" 127.0.0.1:6379> zrangebyscore myzset -inf +inf withscores 1) "lth" 2) "1" 3) "xf" 4) "2" 5) "zsq" 6) "3" 7) "zyn" 8) "4"
Gets the number of members in the range in zset
127.0.0.1:6379> zcount myzset 1 2 (integer) 2 127.0.0.1:6379> zcount myzset 1 3 (integer) 3
Sort from large to small
127.0.0.1:6379> zrevrange myzset 0 -1 1) "zyn" 2) "zsq" 3) "xf" 4) "lth"
Gets the number of in the zset element
127.0.0.1:6379> zcard myzset (integer) 4
Three special types
Geospatial
Application: geographical location query distance, nearby people, takeout delivery distance
Test website: Longitude and latitude distance test
Add geographic location
127.0.0.1:6379> geoadd china:city 116.4 39.9 beijing (integer) 1 127.0.0.1:6379> geoadd china:city 119.9 34.7 changzhou (integer) 1 127.0.0.1:6379> geoadd china:city 120.2 31.5 wuxi (integer) 1 127.0.0.1:6379> geoadd china:city 120.1 30.3 hangzhou (integer) 1
Get the added Beijing location
127.0.0.1:6379> geopos china:city beijing 1) 1) "116.39999896287918091" 2) "39.90000009167092543"
Get the distance between two cities
127.0.0.1:6379> geodist china:city changzhou wuxi km "357.0194"
Find data of 1000 km in a radius of 110 30
127.0.0.1:6379> geodist chain:city changzhou wuxi km (nil) 127.0.0.1:6379> geodist china:city changzhou wuxi km "357.0194" 127.0.0.1:6379> georadius china:city 110 30 400 km (empty array) 127.0.0.1:6379> georadius china:city 110 30 500 km (empty array) 127.0.0.1:6379> georadius china:city 110 30 100 km (empty array) 127.0.0.1:6379> georadius china:city 110 30 1000 km 1) "hangzhou" 2) "wuxi"
Find other elements around any specified element. The meaning of the instruction here is to find a city with a radius of 400 kilometers based on Changzhou
127.0.0.1:6379> georadiusbymember china:city changzhou 400 km 1) "changzhou" 2) "wuxi"
BitMaps
Application: clock in and check in. This can be used for those in only two states.
Set status
127.0.0.1:6379> setbit signs 0 0 (integer) 0 127.0.0.1:6379> setbit signs 1 0 (integer) 0 127.0.0.1:6379> setbit signs 2 1 (integer) 0 127.0.0.1:6379> setbit signs 2 1 (integer) 1 127.0.0.1:6379> setbit signs 3 1 (integer) 0 127.0.0.1:6379> setbit signs 4 1 (integer) 0 127.0.0.1:6379> setbit signs 5 1 (integer) 0 127.0.0.1:6379> setbit signs 6 1 (integer) 0
Get the number of States
127.0.0.1:6379> bitcount signs (integer) 5
Hayperloglog
Application: the memory occupied by this type is very small. So think about this. If fault tolerance is allowed, it is highly recommended
Add element
127.0.0.1:6379> pfadd haplog hs (integer) 1 127.0.0.1:6379> pfadd haplog lth (integer) 1 127.0.0.1:6379> pfadd haplog xf (integer) 1 127.0.0.1:6379> pfcount haplog (integer) 3
Merge two groups of data without duplication
127.0.0.1:6379> pfadd haplogs xxxlll (integer) 1 127.0.0.1:6379> pfmerge haplog haplogs OK 127.0.0.1:6379> keys * 1) "haplog" 2) "haplogs" 127.0.0.1:6379> pfcount haplog (integer) 4 127.0.0.1:6379> pfcount haplogs (integer) 1
Config file introduction
Redis is case insensitive and insensitive
units are case insensitive so 1GB 1Gb 1gB are all the same.
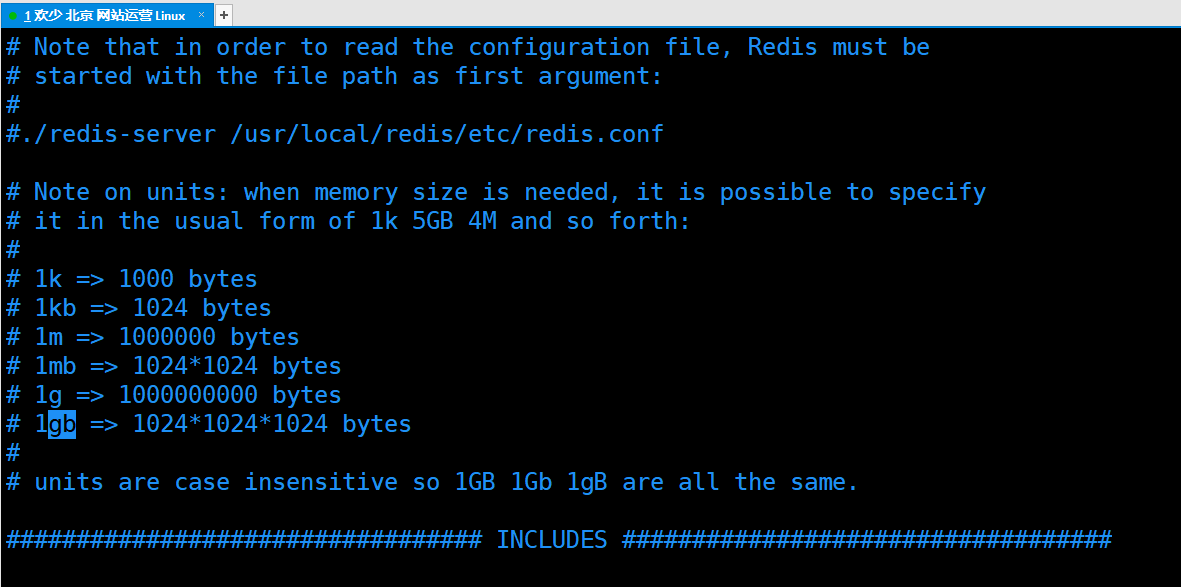
It can contain multiple configuration files, which are used when building a cluster
# include /path/to/local.conf # include /path/to/other.conf
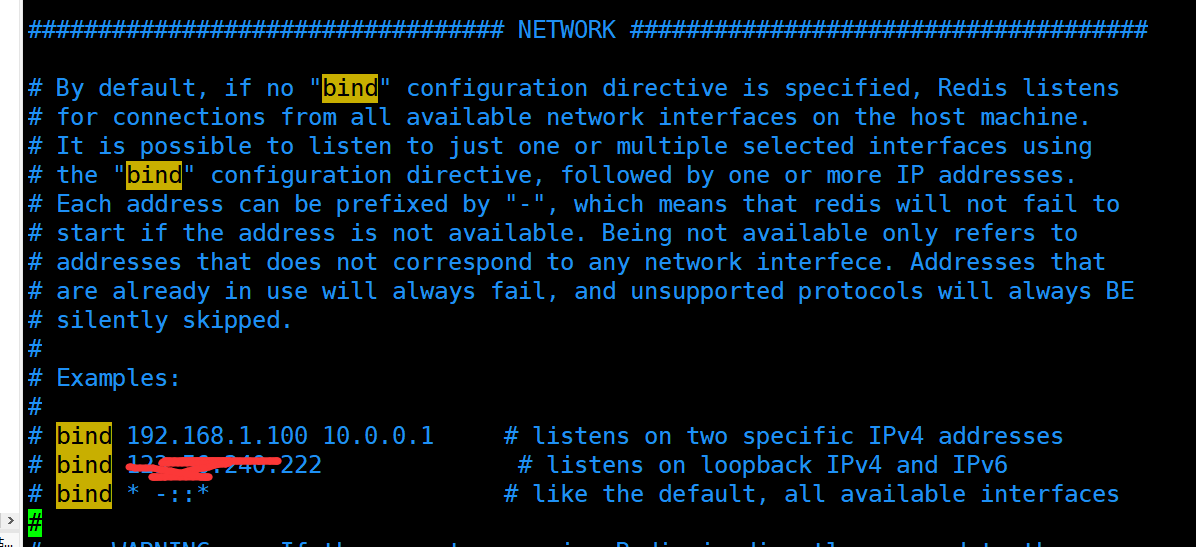
Gateway configuration, configuration of IP address, protection mode and port number
# bind 192.168.1.100 10.0.0.1 # listens on two specific IPv4 addresses # bind 123.56.240.222 # listens on loopback IPv4 and IPv6 # protected-mode yes # port 6379
The general configuration is carried out in the way of daemon thread, that is, the difference between background operation and foreground operation. The second is to manage the daemon process
daemonize yes supervised no
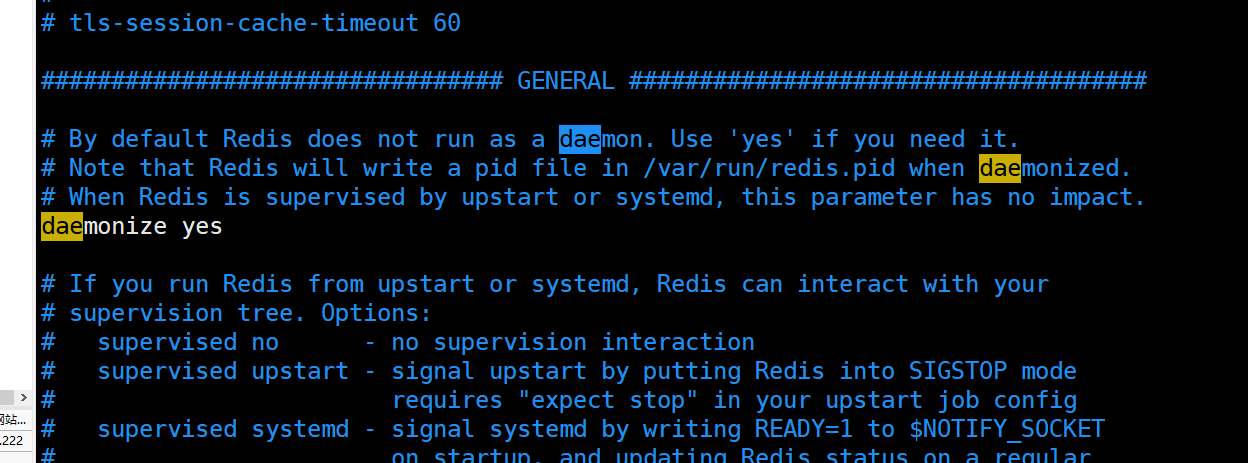
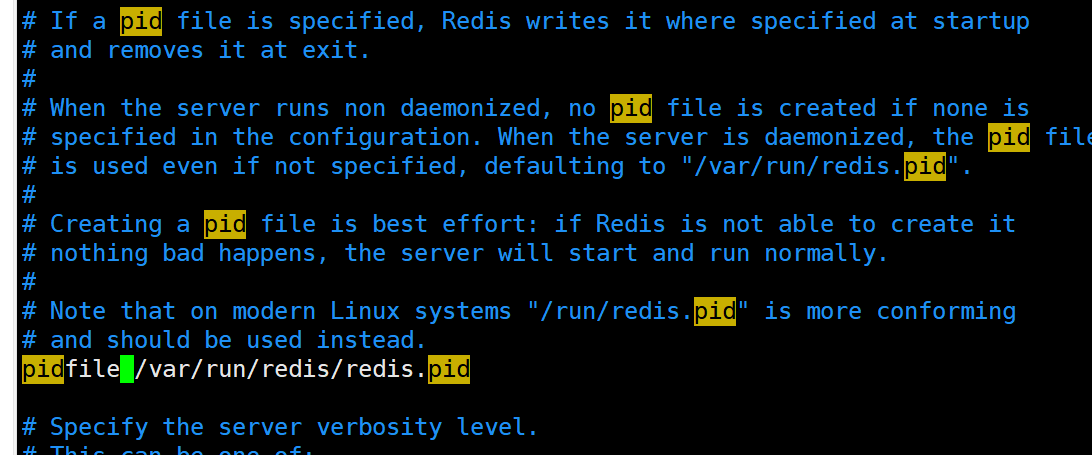
If the background runs, you must specify a pid file.
The purpose of the pid file is to prevent multiple process copies from starting. The principle is that the process will be given after running A file lock is added to the pid file. Only the process that obtains the lock has write permission (F_WRLCK) and writes its own pid to the file. Other processes that attempt to acquire the lock automatically exit.
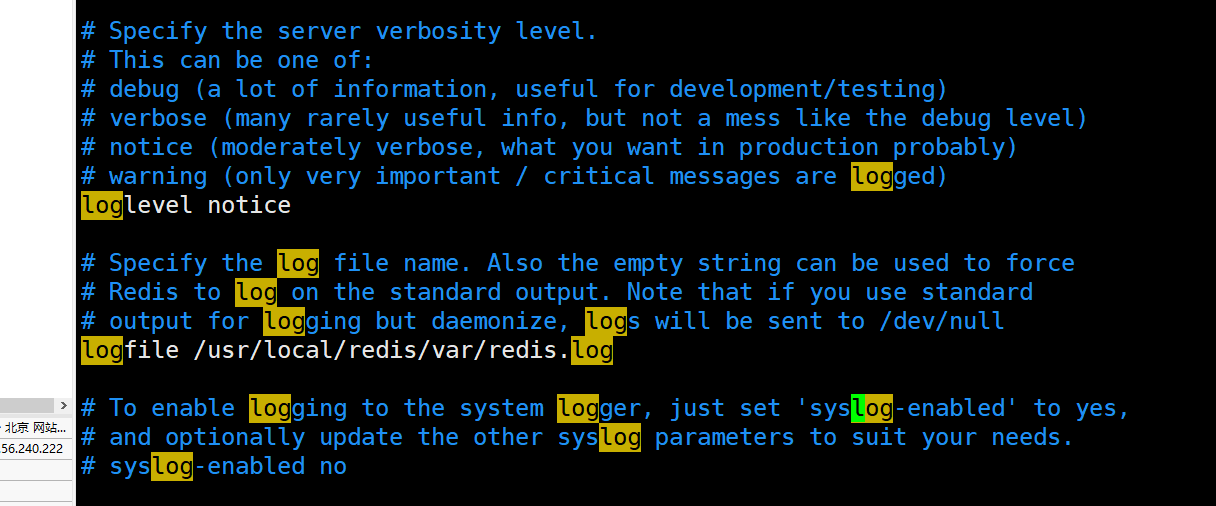
Log level
Log levels are mainly divided into notic, debug, verbose and warning
The default setting of Redis is verbose. debug can be used in the development and testing stage, and notice is generally used in the production mode
- debug: it will print out a lot of information, which is suitable for the development and testing stages
- Verbose (verbose): it contains a lot of less useful information, but it is cleaner than debug
- notice: applicable to production mode
- Warning: warning message
log file path
logfile /usr/local/redis/var/redis.log
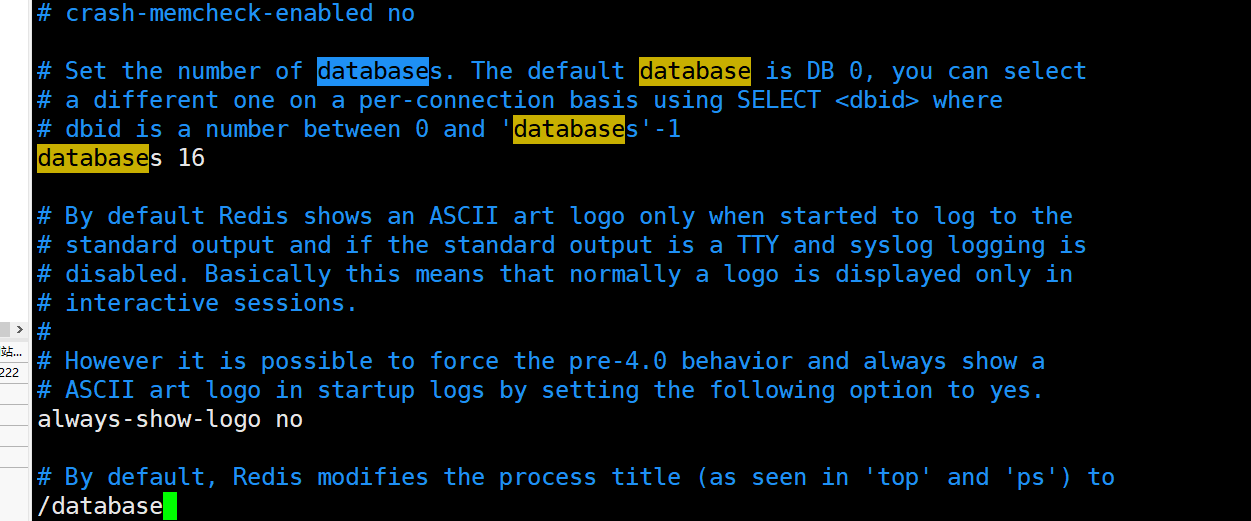
By default, there are 16 databases. The second means that the output logo is not displayed when running
databases 16 always-show-logo no
Snapshot configuration. If a key is modified within 3600 seconds, it will be persisted
# save 3600 1 # save 300 100 # save 60 10000
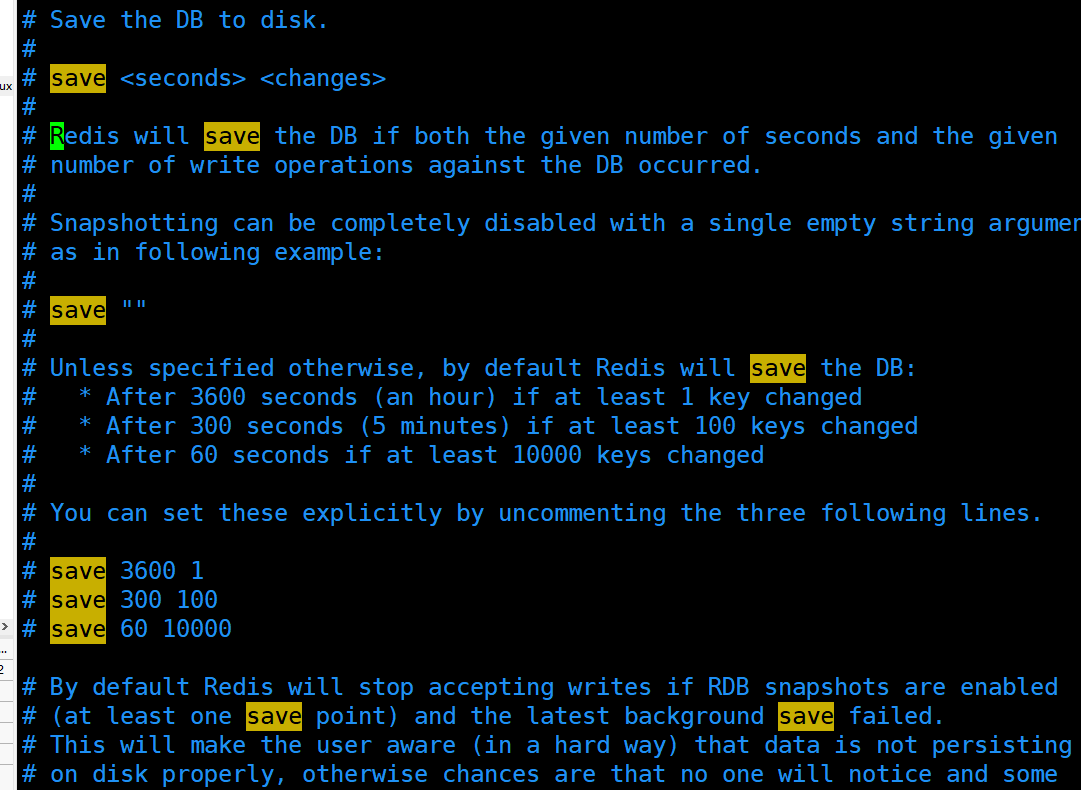
RDB file, whether to continue after persistence error, whether to compress RDB file,
stop-writes-on-bgsave-error yes rdbcompression yes
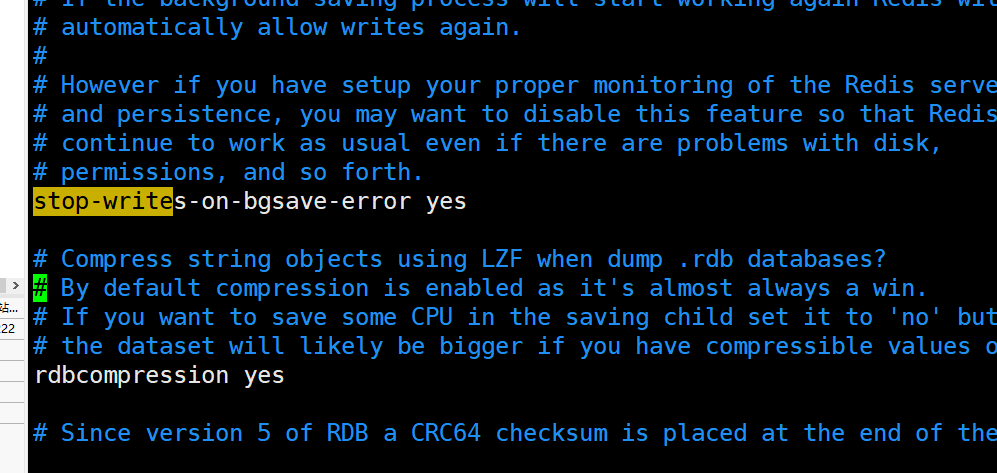
Check and verify errors when saving rdb files
rdbchecksum yes
rdb backup file save directory
dir /usr/local/redis/var
Cluster configuration
# replicaof <masterip> <masterport>
Transaction (internal lock)
Transaction syntax
watch key1 key2 ... : Monitor one or more key,If it is monitored before the transaction is executed key If it is changed by other commands, the transaction is interrupted (similar to optimistic lock) multi : Mark the beginning of a transaction block( queued ) exec : Execute commands for all transaction blocks (once executed) exec After, the previously added monitoring lock will be cancelled) discard : Cancels the transaction and discards all commands in the transaction block unwatch : cancel watch For all key Monitoring of
Transaction execution code (all OK)
127.0.0.1:6379> multi OK 127.0.0.1:6379(TX)> set k1 v1 QUEUED 127.0.0.1:6379(TX)> set k2 v2 QUEUED 127.0.0.1:6379(TX)> exec 1) OK 2) OK 127.0.0.1:6379> get k1 "v1" 127.0.0.1:6379> get k2 "v2"
Transaction execution code (one instruction is incorrect)
127.0.0.1:6379> multi OK 127.0.0.1:6379(TX)> set q1 11 QUEUED 127.0.0.1:6379(TX)> set q2 33 QUEUED 127.0.0.1:6379(TX)> set q3 44 op QUEUED 127.0.0.1:6379(TX)> exec 1) OK 2) OK 3) (error) ERR syntax error 127.0.0.1:6379> mget q1 q2 1) "11" 2) "33"
Redis transactions are a little special, and they are a little special from databases and programs. The transactions in MySQL are either all successful or all failed, and the transactions in the program are the same, either all successful or all failed. Redis's transactions here are all executed correctly. If there is an error, an error should be reported, which will not affect the general execution.
Redis does not guarantee atomicity, and there is no concept of isolation level for transactions
Summary: redis transaction is a one-time, sequential and exclusive execution of a series of commands in a queue
Transaction locks are divided into optimistic locks and pessimistic locks. As the name suggests, pessimistic lock means that I lock any operation. I don't trust anyone. Optimistic lock is just the opposite. It mainly trusts anyone. It will not have the operation of locking. It just needs to give him a watch operation when it is opened, that is, to monitor this value. When executing a transaction, it will judge whether this value is consistent with the value of the open transaction. If it is inconsistent, it will not be executed. If it is consistent, it is considered to be executed correctly!
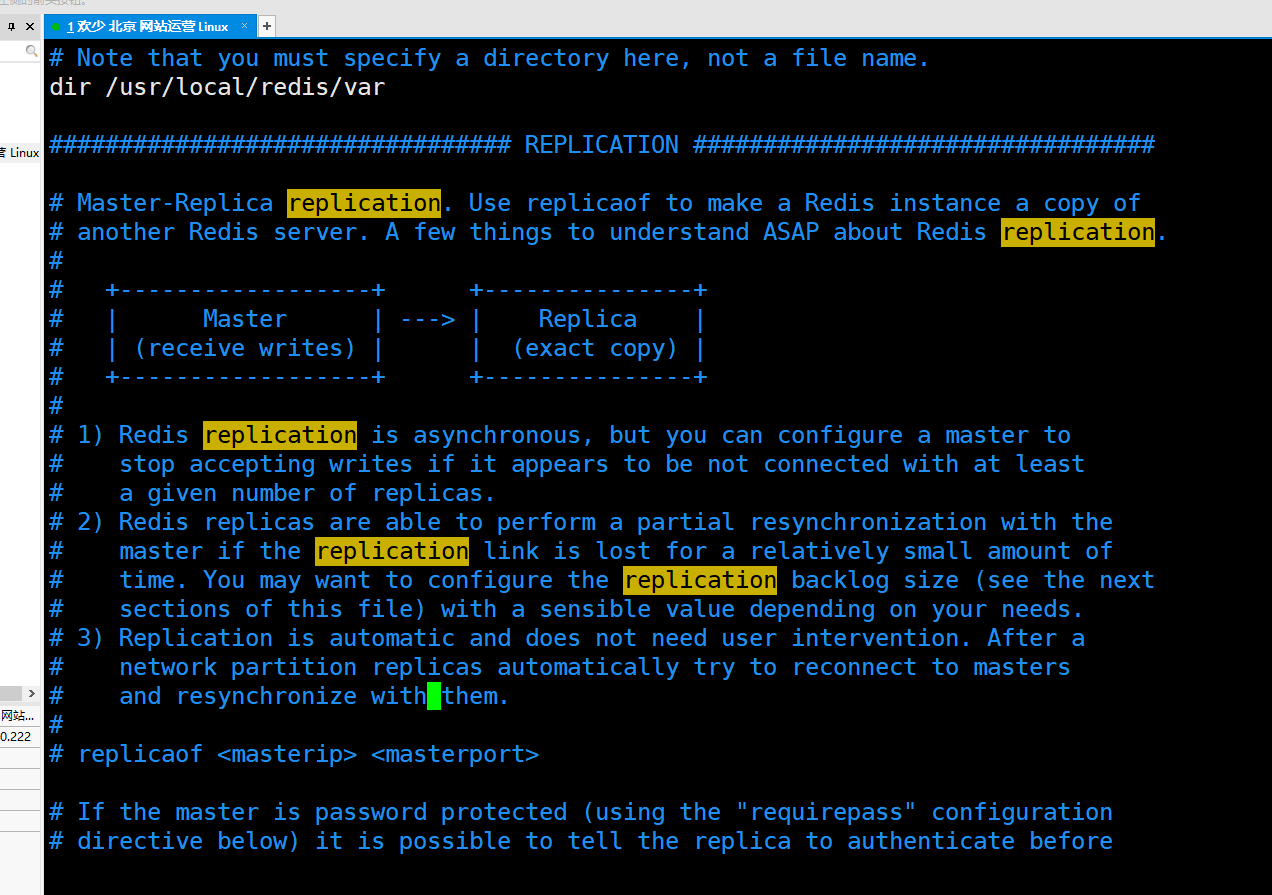
The execution example is not distributed for the time being. It directly opens two windows for simulation, that is, two threads

① : first set a value of 66 in the first window, then watch monitors the change of this value, and start the transaction. Add this value 44 to the transaction, that is, the final value of 66 + 44 should be 100
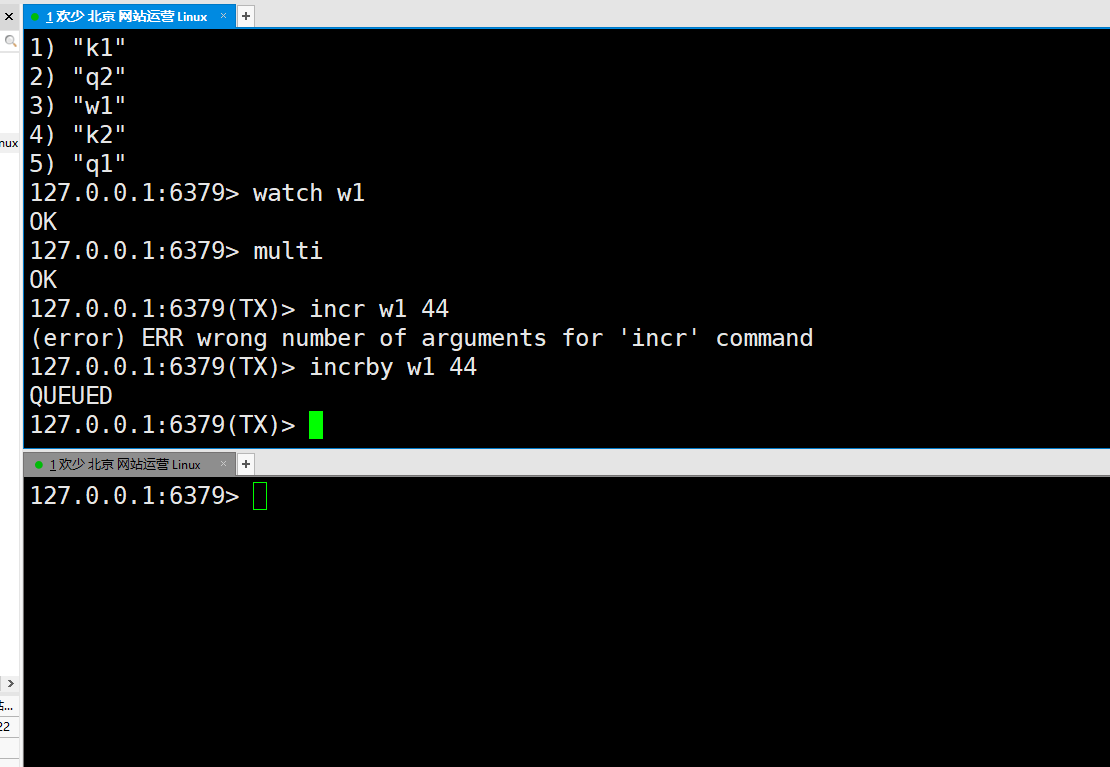
② : do not execute the transaction at this time, operate the second operation and change the value
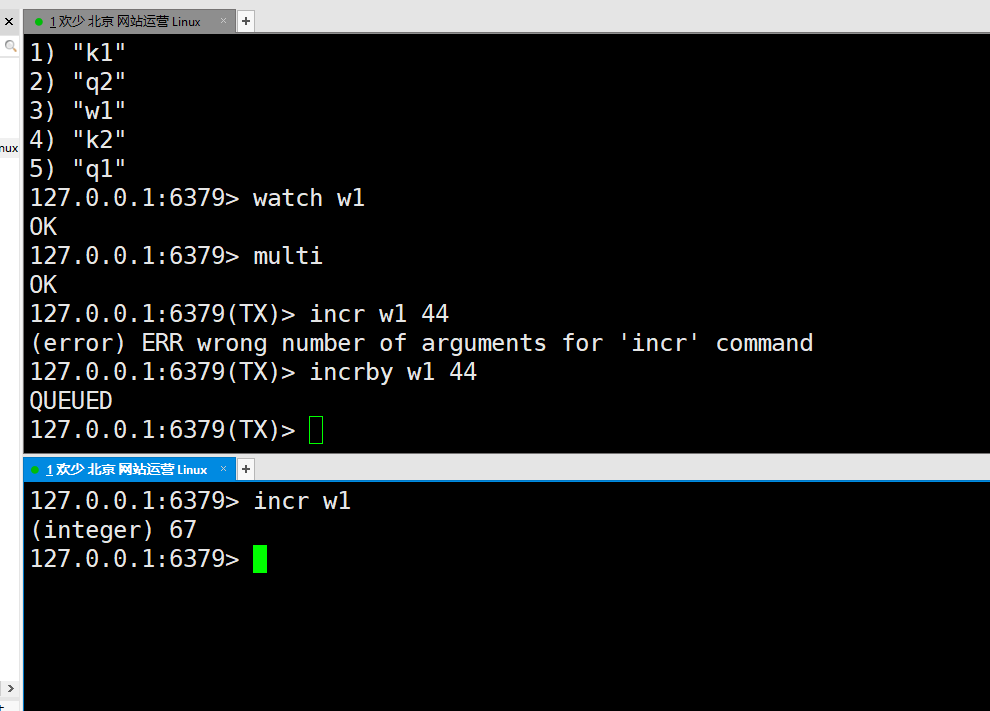
③ : w1 at this time is 67, not 66, so the transaction of the first window should not be executed successfully. The reason is that this value has been changed
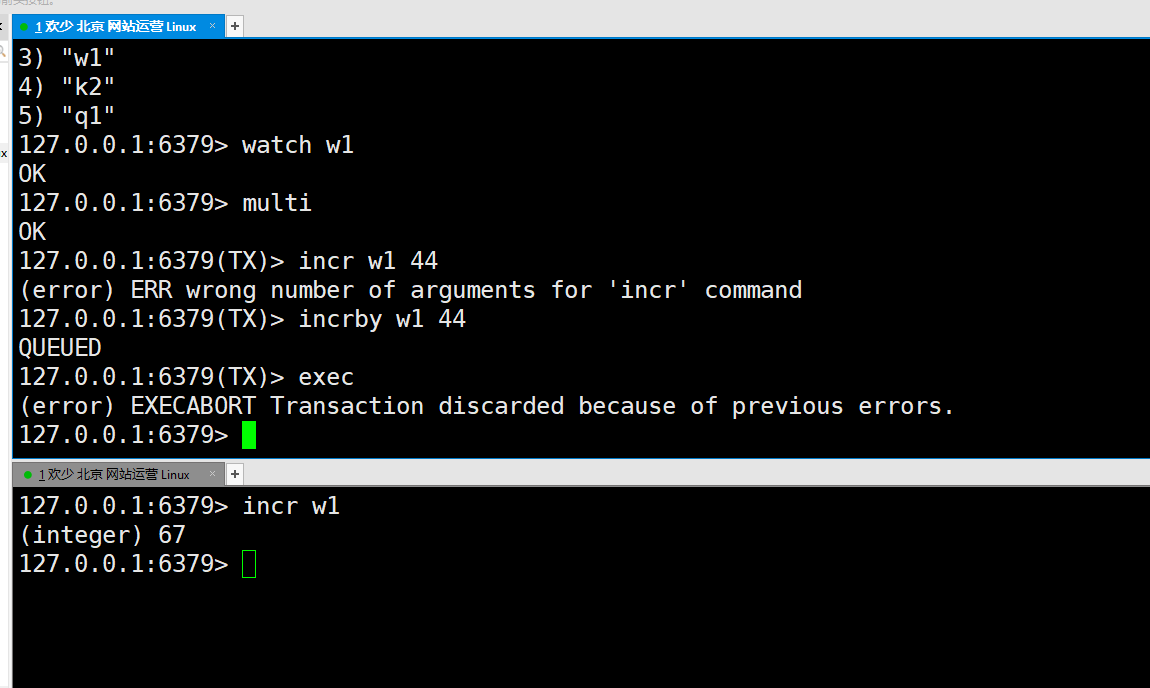
This is the optimistic lock. Specifically, the implementation principle of the optimistic lock. Later, I will discuss my own ideas. Here is Redis, so I won't talk about the optimistic lock.
AOF, RDB persistence
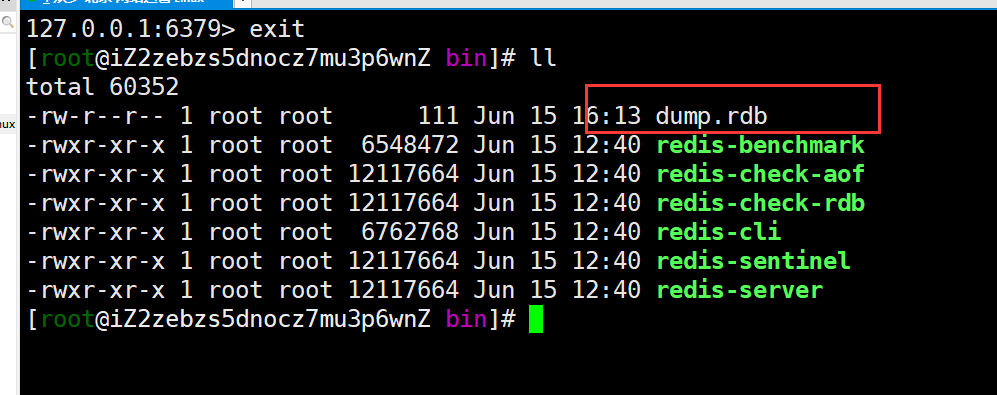
This is the rdb backup file. The configuration of this file is determined by dbfilename in config
This is the raof backup file. The configuration of this file is determined by the appendfilename in config
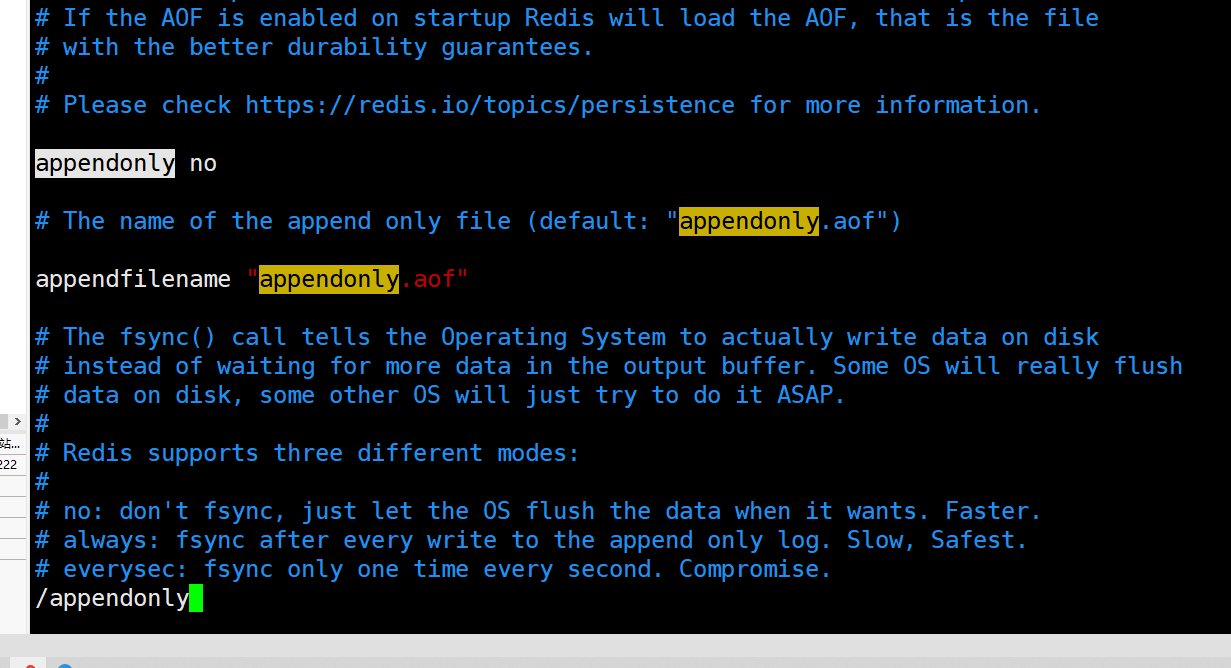
The difference between RDB and AOF is that RDB is in the form of snapshot, which is directly copied and backed up, and AOF is in the form of addition.
Redis will judge dump first every time it starts Whether the RDB file and appendonly file have data to be restored. If a file is deleted, a file is automatically created.
A tool is also involved in restoring data. This tool is used to repair the instructions in the backup file. I will introduce the common tools below one by one
colony
Cluster construction
When it comes to clusters, I think everyone is familiar with high availability, which is often referred to. When it comes to high availability, it has nothing to do with 3v3 high availability. Massive, diverse, real-time. High concurrency, high performance and high availability.
First of all, because it is a Redis cluster, at least three computers must be used. In order to simplify, I will start three Redis with one server and three Redis configurations. It's the same as multiple computers.
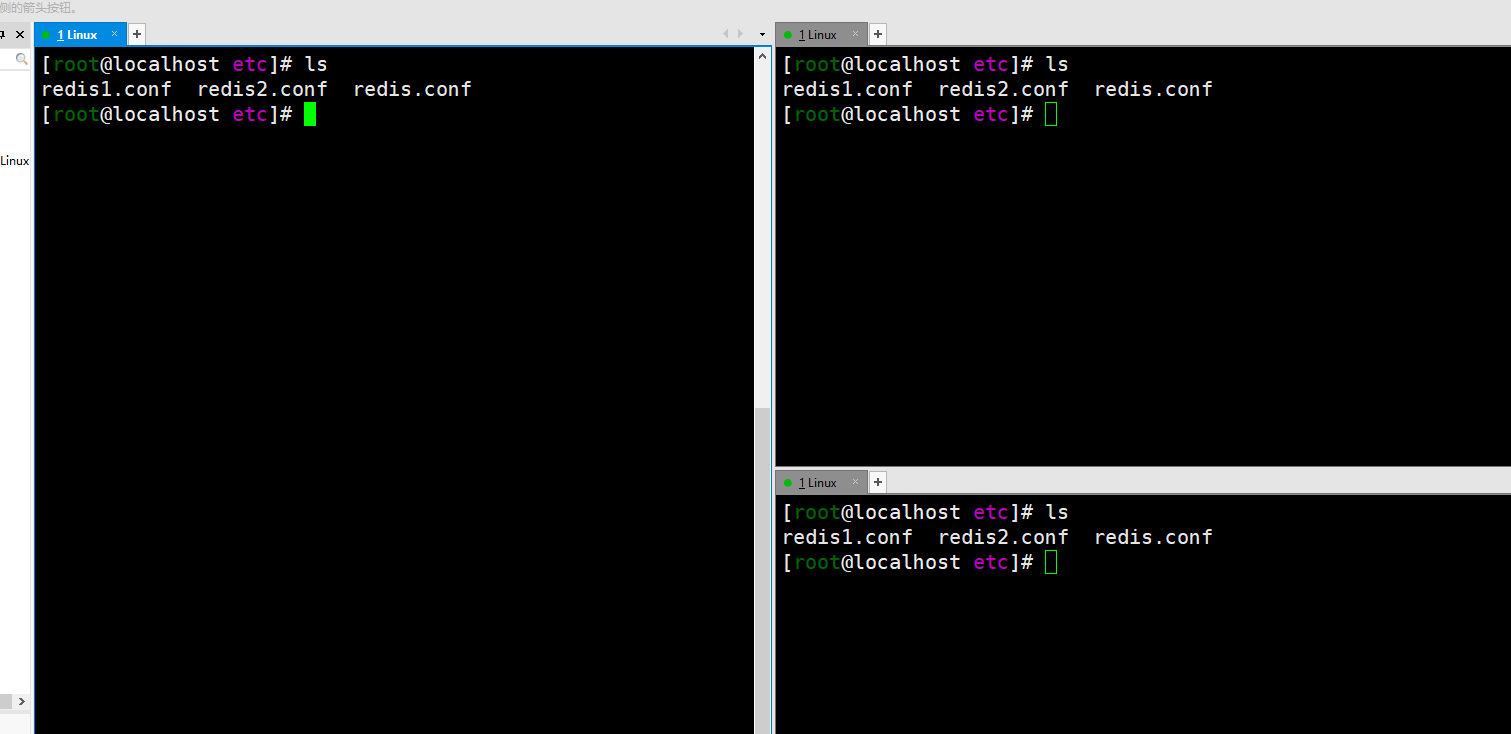
The three windows correspond to three Redis
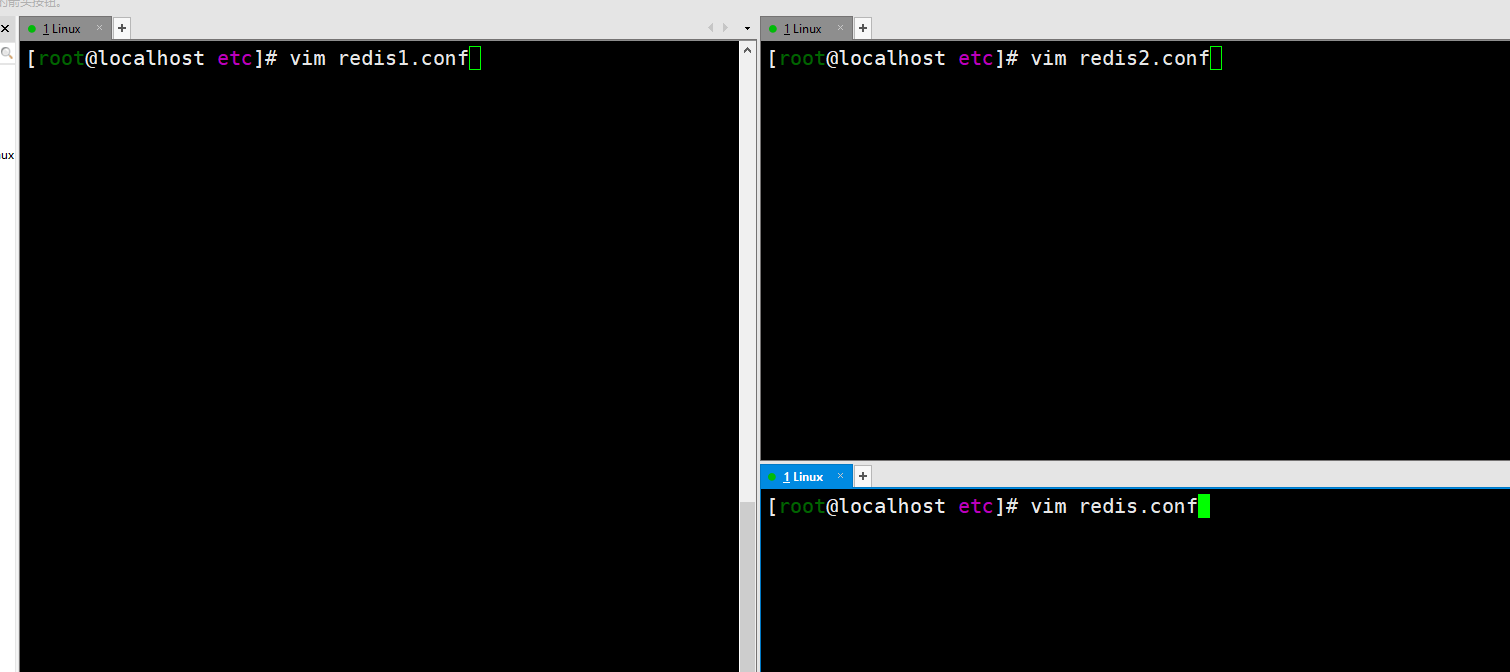
The operation here is to modify the configuration of the three configuration files in the three windows. The ports are 637963806381 respectively. Then start three Redis instances respectively.
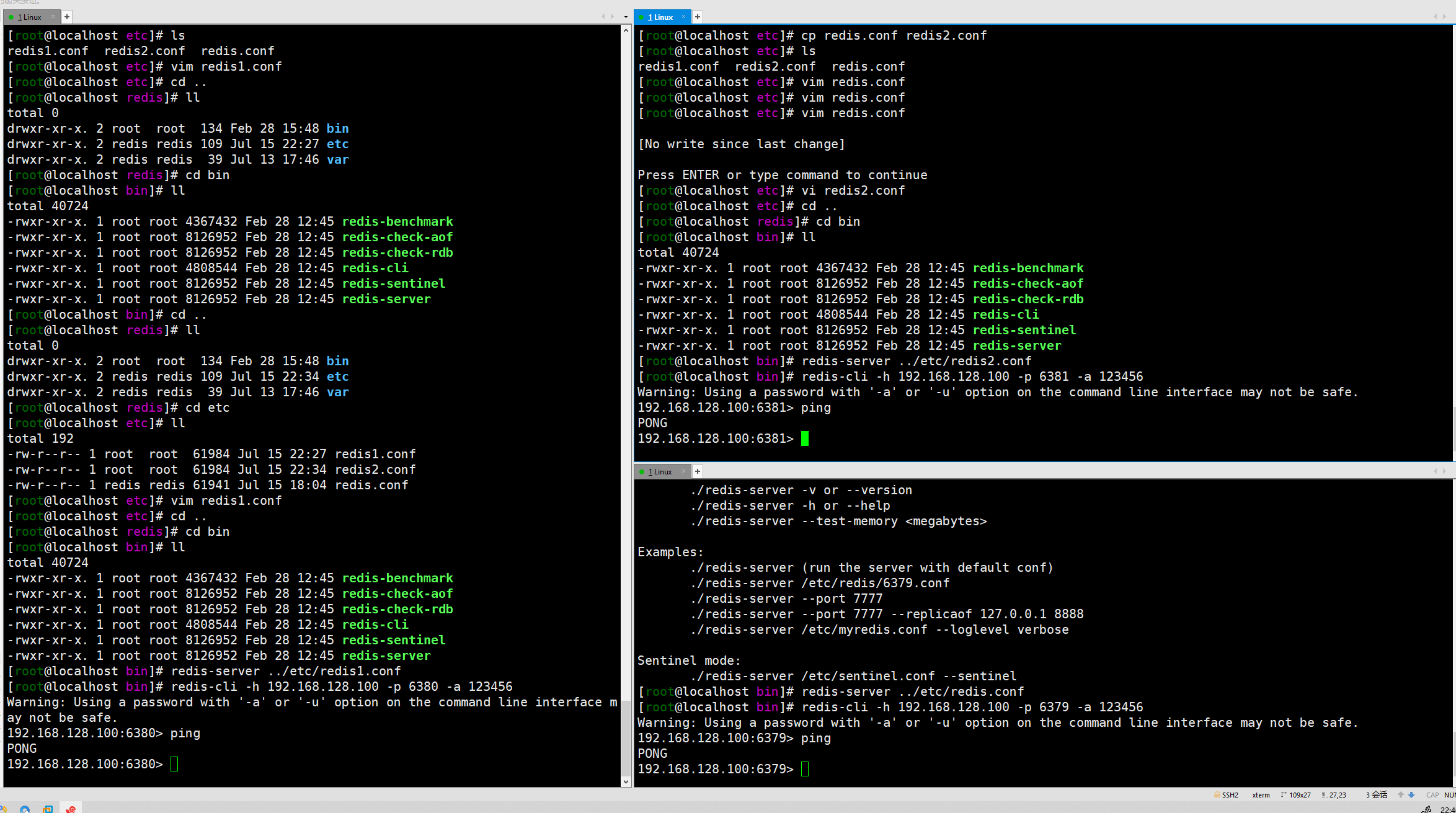
Check the operation status of the three instances and confirm that 637963806381 is correct.
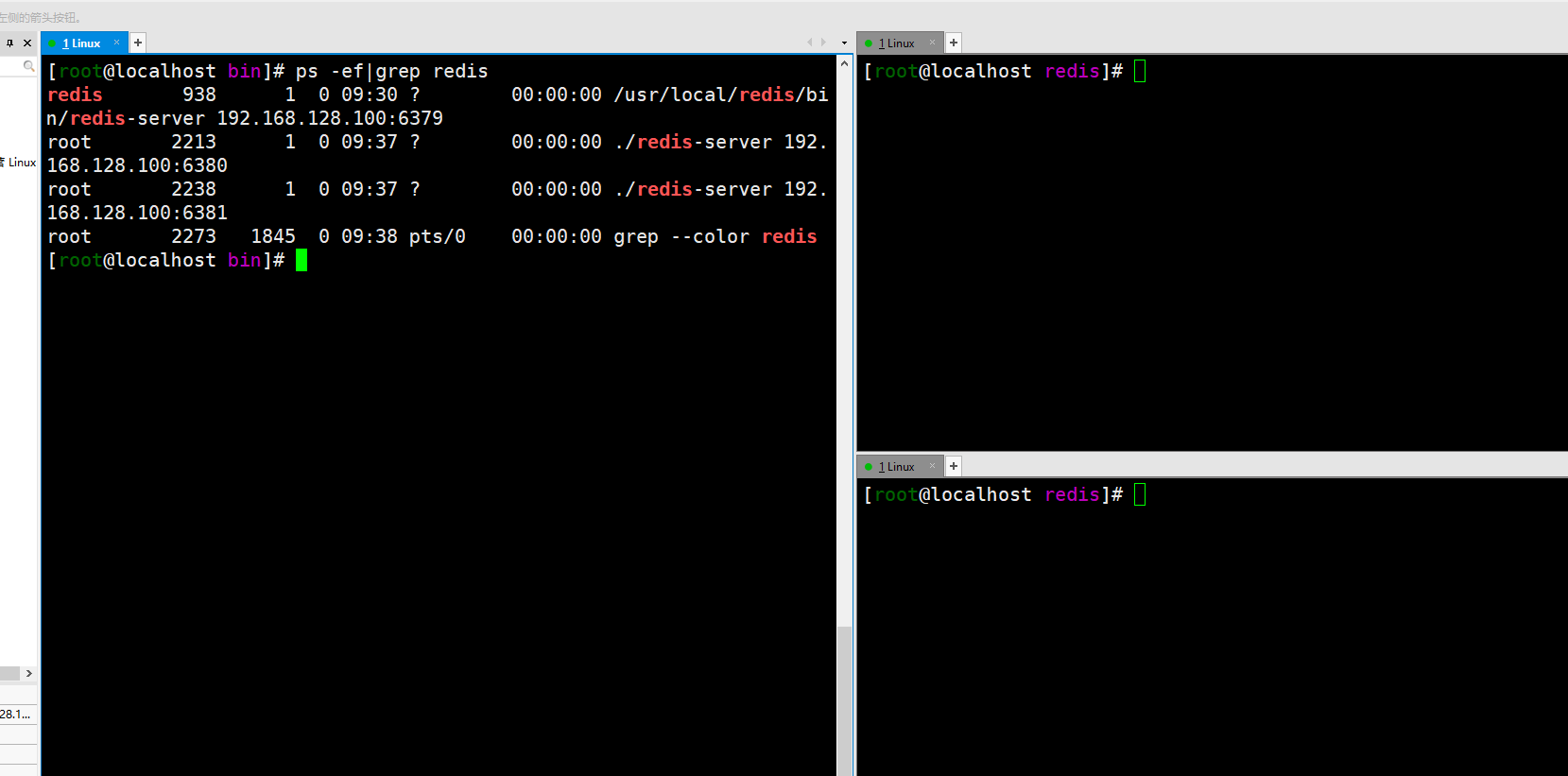
View the status of the current library through the info replication command. Role is the current role and connected_ Slave is a sub library
To build a cluster, you only need to configure the slave database, not the master database
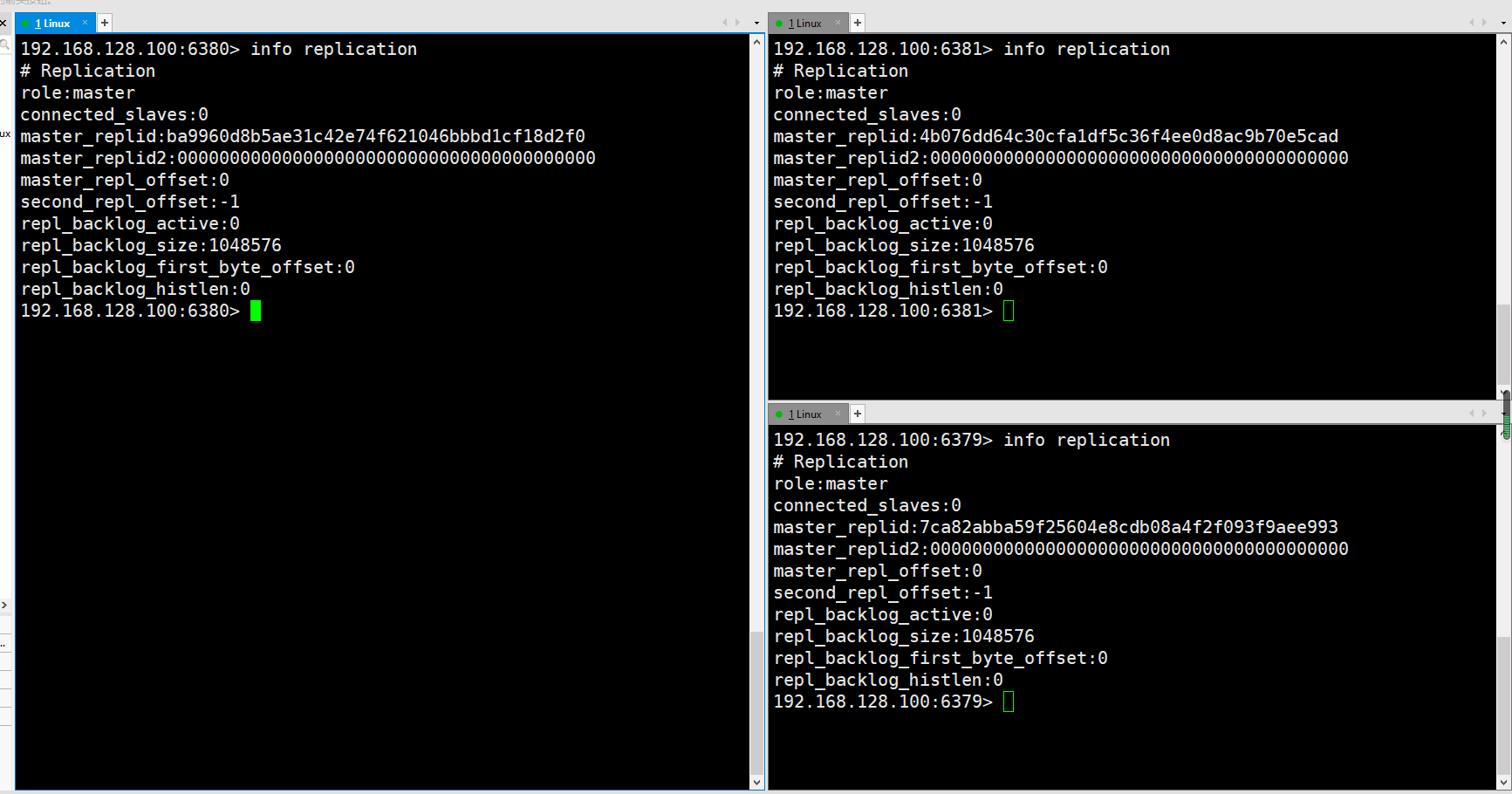
Configure master-slave libraries through instructions
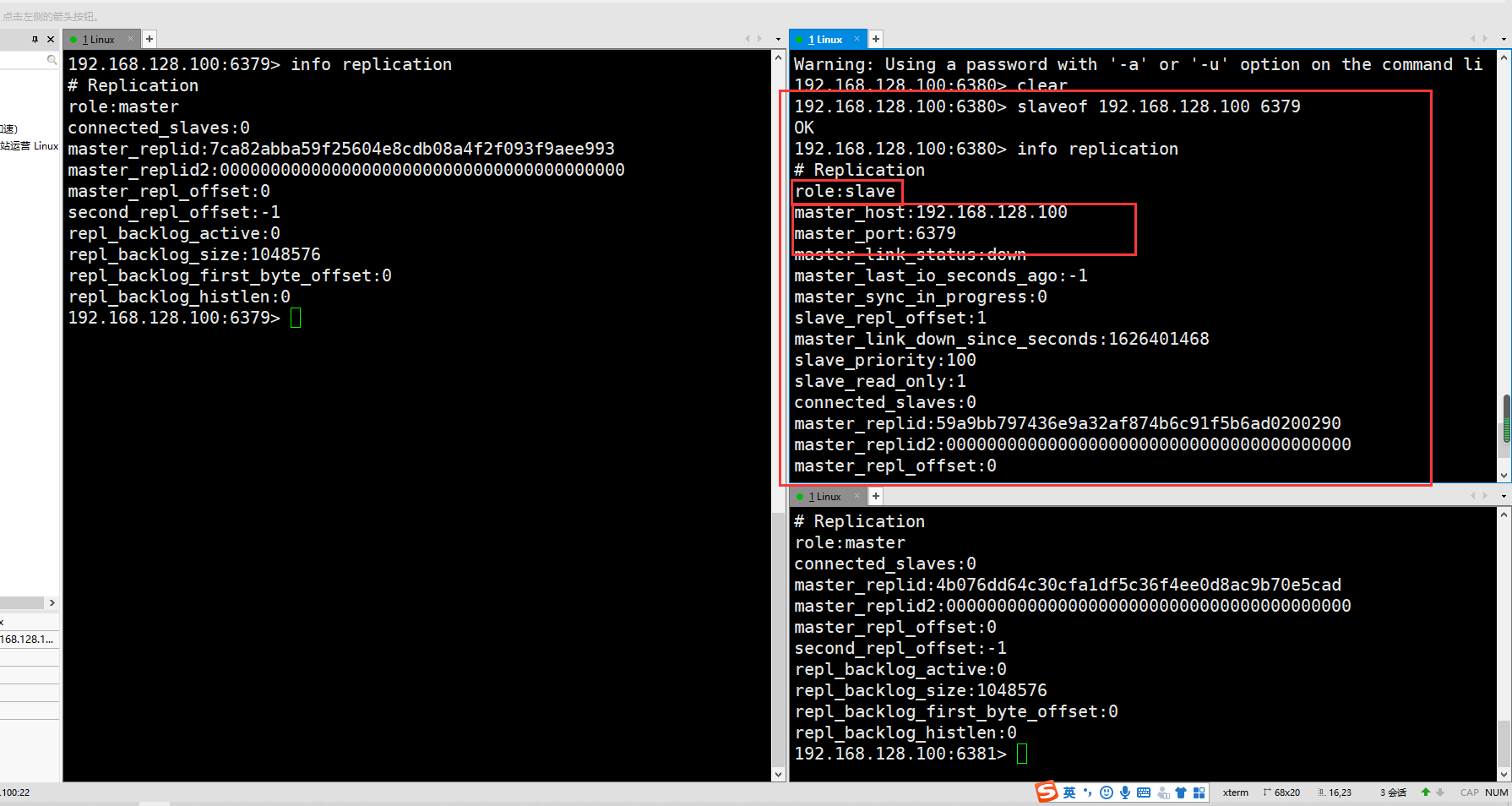
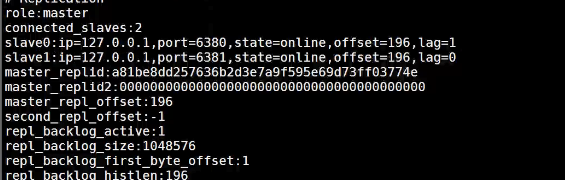
The above is the instruction to build a cluster. In real practice, it is built with configuration. So the steps are the same, but the way has changed. Enter redis Conf can modify the configuration of replication. The modification method has been solved above, that is, through ip+port. If you have a password, you can change the requirepass in about 5 lines below.
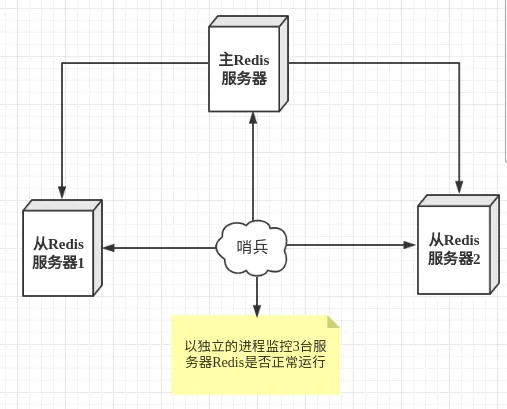
Sentinel mode
The technical method of master-slave switching is: when the master server is down, a slave server needs to be manually switched to the master server, which requires manual intervention, which is laborious and laborious, and the service will not be available for a period of time. This is not a recommended way. More often, we give priority to sentinel mode.
Sentinel mode is a special mode. Firstly, Redis provides sentinel commands. Sentinel is an independent process. As a process, it will run independently. The principle is that the sentinel sends a command and waits for the response of the Redis server, so as to monitor multiple running Redis instances.
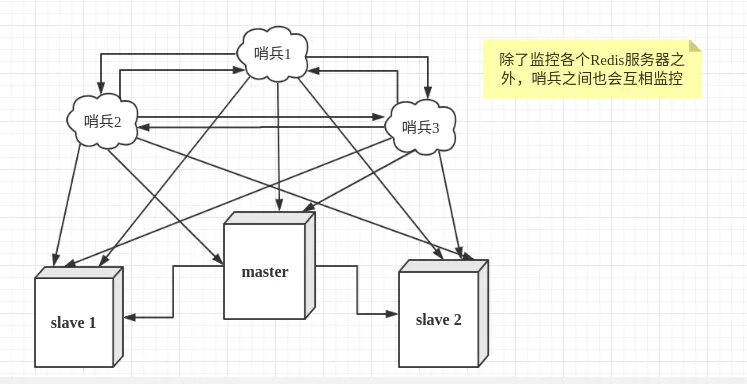
The last picture is the entrance of sentinel mode, which is an independent process. Once the main database goes down, the sentinel process will automatically vote for a new host.
Introduction to common tools
Introduce some common Redis tools
Stress test tool: redis benchmark
Aof file checking tool: redis check AOF
RDB file checking tool: redis check RDB
Sentinel mode monitoring tool: redis sentinel (introduced in cluster)
You can look at the data measured by the stress test tool. Just refer to it.
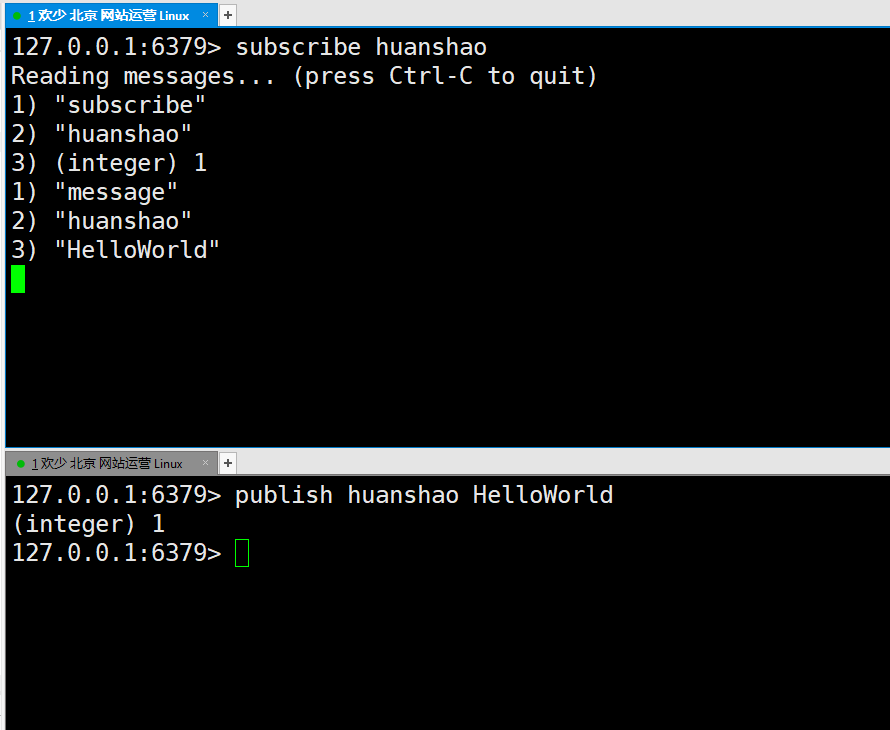
Publish and subscribe
The publish subscription must have two windows or multiple Redis before it can be tested. The following case is
① : the first window is responsible for subscribing to a channel called huanshao. After subscribing, it is in the state of waiting for reception.
② : the second window is used to send messages. Send a HelloWord to the huanshao channel, and then the first window automatically receives it
This is the Redis's publish subscribe. This application scenario is similar to WeChat's public address. Bloggers upload a new article. People who subscribe to the official account will receive all the official account data.
Cache penetration, cache avalanche, cache warm-up, cache degradation
For more details, please go to the beginning of Redis An access portal for Redis
Cache penetration: cache penetration: the general process of accessing the cache. If the queried commodity data exists in the cache, it will be returned directly. If there is no commodity data in the cache, access the database. Due to improper business function implementation or external malicious attacks, some nonexistent data memory is constantly requested. Because the data is not saved in the cache, all requests will fall on the database, which may bring some pressure or even crash to the database.
Cache avalanche: when the cache is restarted or a large number of caches fail in a certain period of time, a large number of traffic will directly access the database, causing pressure on the DB, resulting in DB failure and system crash. For example, we are preparing a rush purchase promotion operation activity, which will bring a lot of inquiries about commodity information, inventory and other related information. In order to avoid the pressure of the commodity database, the commodity data is stored in the cache. Unfortunately, during the rush buying activity, a large number of popular commodity caches expired at the same time, resulting in a large amount of query traffic falling on the database. It causes great pressure on the database.
Cache preheating: cache preheating is to load relevant cache data directly into the cache system after the system is online. This can avoid the problem of querying the database first and then caching the data when the user requests. The user directly queries the pre warmed cache data. If preheating is not carried out, Redis's initial status data is empty. At the initial stage of system online, high concurrent traffic will be accessed to the database, causing traffic pressure on the database
Cache degradation: in the case of degradation, we do not access the database when the cache fails or the cache service hangs up. We directly access part of the data cache in memory or directly return the default data. For example, the home page of an application is usually a place with a large number of visits. The home page often contains the display information of some recommended products. These recommended products will be stored in the cache. At the same time, in order to avoid cache exceptions, we also store the hot product data in memory. At the same time, some default product information is retained in memory.
Cache penetration solution: for cache penetration, the simple solution is to store the nonexistent data access results in the cache to avoid cache access penetration. Finally, the access results of non-existent commodity data are also cached. Effectively avoid the risk of cache penetration
Cache avalanche solution
- Classify the goods according to the category heat, buy more categories, the cache cycle of goods is longer, and buy relatively unpopular categories
For commodities, the cache cycle is shorter; - When setting the specific cache effective time of goods, add a random interval factor, such as 5 ~ 10 minutes
Choose the failure time at will; - Predict the DB capacity in advance. If the cache hangs, the database can still resist the pressure of traffic to a certain extent
Cache preheating solution:
- When the amount of data is small, load and cache when the project starts;
- When the amount of data is large, set a scheduled task script to refresh the cache;
- When the amount of data is too large, give priority to ensuring that the hot data is loaded into the cache in advance
After writing articles in recent days, my understanding of Redis is a step closer. I will share the project details as scheduled in the later application!
Thank you for your support for WeChat official account.