This article involves many related articles. Please take it yourself if necessary (follow the blogger, let's go to big factory happy)
VMware installation of CentOS (nanny tutorial, recommended Collection)
VMware+CentOS 7 static IP setting method - Nanny level tutorial, recommended collection
CentOS installation click Redis
Redis primary and secondary Sentinel monitoring configuration (nanny level tutorial)
1, Introduction
Distributed knowledge is a good measure to test the breadth and depth of a programmer's knowledge, and distributed lock is a very important knowledge point. It can be said that as long as you talk about distributed in the interview, you don't ask about distributed locks.
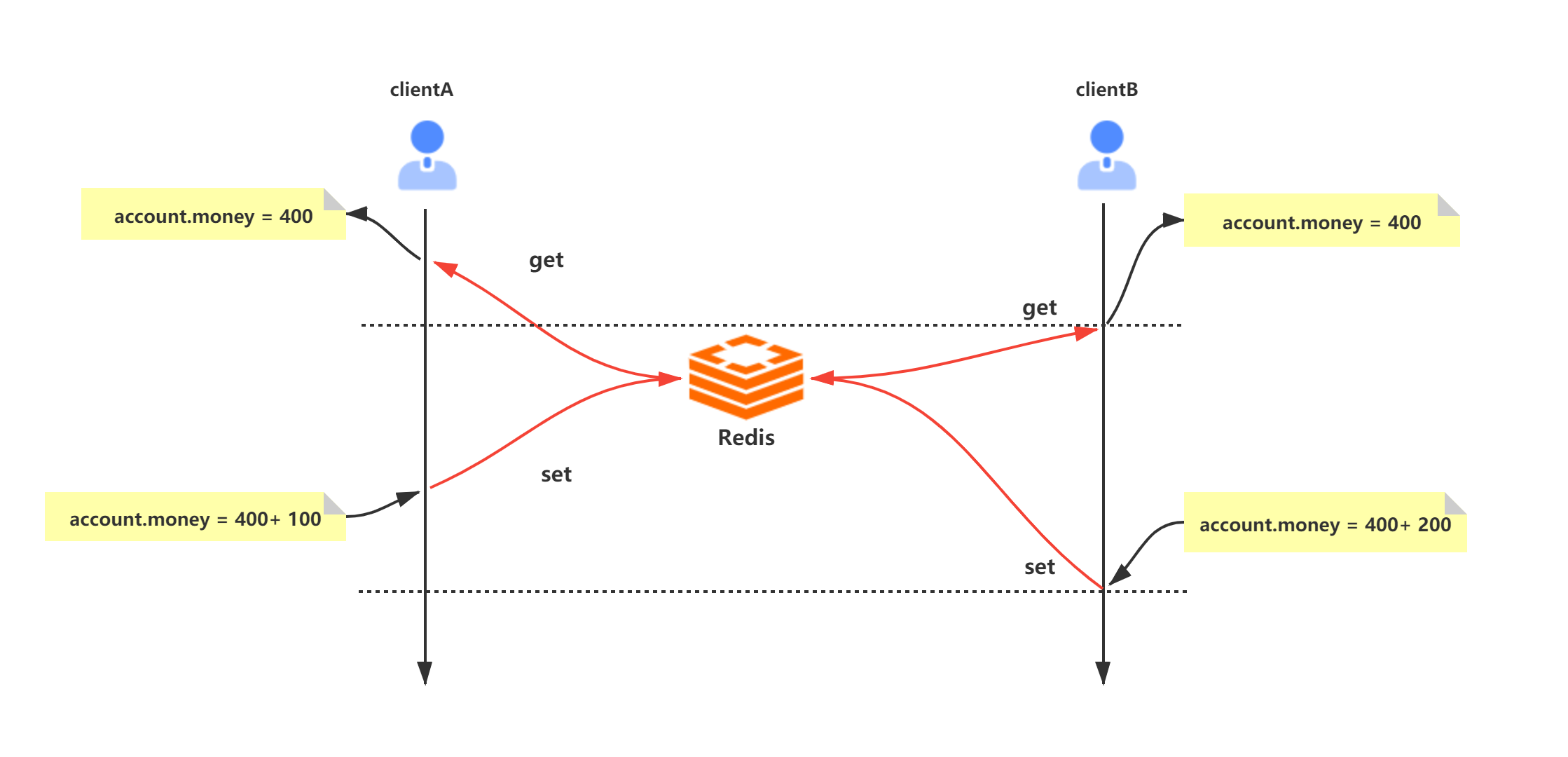
We know that the logic processing of distributed applications often involves concurrency. For example, modifying the account amount data of a user for a transfer may involve multiple users transferring the user at the same time. They all need to read the data into each memory for modification, and then save and refresh it back. At this time, concurrency problems will occur:
The initial account is assumed here money = 400
- Client A transfers 100 to the account and does not submit it to Redis
- Client B reads the amount of 400 and transfers 200 to the account
- Client A submit
- Client B submission
Finally, account money = 600
The execution process is as follows:
The main reason for the above problems is that the "read" and "write" operations are not atomic operations (atomic operations refer to operations that will not be interrupted by the thread scheduling mechanism; once this operation starts, it runs until the end, and there will be no context switch in the middle).
Distributed locks can be used to solve the above problems. We use distributed locks to limit the concurrent execution of programs, just like synchronized in Java. Common distributed lock solutions are as follows:
- Distributed lock based on database lock mechanism
- Distributed lock based on Zookeeper
- Redis based distributed lock
This paper discusses Redis based distributed locks with you.
2, Evolution of distributed locks
2.1 love story between sperm cell and egg cell
Well... Babies who have studied biology know that in the story of the encounter between sperm cells and eggs, only one lucky sperm cell and egg cell will have a sweet love story in the end. This is because when a sperm enters the egg, the egg will have cortical reaction and zona pellucida reaction, which will reduce the binding ability of zona pellucida to sperm and prevent polysperm fertilization. Distributed locks are like eggs, and thousands of clients are like sperm cells. No matter how intense the concurrency of client access, we should also ensure that distributed locks are obtained by only one thread.

2.2 distributed locks in redis
2.2.1 setnx
We understand Redis's implementation of distributed locks as going to the toilet, squatting and queuing. There is only one pit, but many people have to go to the pit, so they can only come one by one.

Many people first thought that Redis generally uses the setnx(set if no exists) instruction to implement it. Setnx is the abbreviation of SET if it does not exist. This instruction is described as follows:
- Set the value of the key to value only when the key does not exist.
- If the key already exists, the SETNX command does not do any action.
127.0.0.1:6379> exists lock # lock key does not exist (integer) 0 127.0.0.1:6379> setnx lock true # Setting succeeded (integer) 1 127.0.0.1:6379> setnx lock false # Overwrite failed (integer) 0 127.0.0.1:6379> del lock # Delete lock release (integer) 1
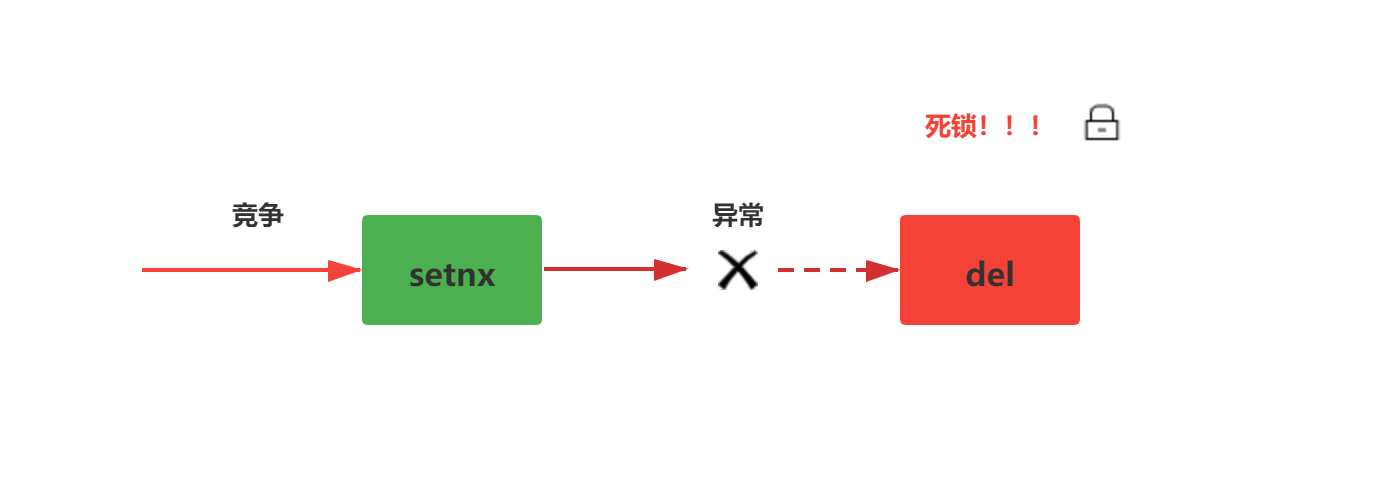
The problems of the above scheme are very obvious. If an exception occurs in the middle of the logic execution process, the del key instruction may not be executed, resulting in deadlock. As shown in the figure below:
2.2.2 setnx + expire
On the basis of the first solution, some people may notice that since there may be exceptions when actively deleting keys, set the expiration time of the key to automatically delete when it expires.
127.0.0.1:6379> setnx lock true (integer) 1 127.0.0.1:6379> expire lock 10 # Set value expiration time 10s (integer) 1 127.0.0.1:6379> setnx lock true # Failed to set value again within 10s (integer) 0 127.0.0.1:6379> setnx lock true # 10skey expired, setting succeeded (integer) 1
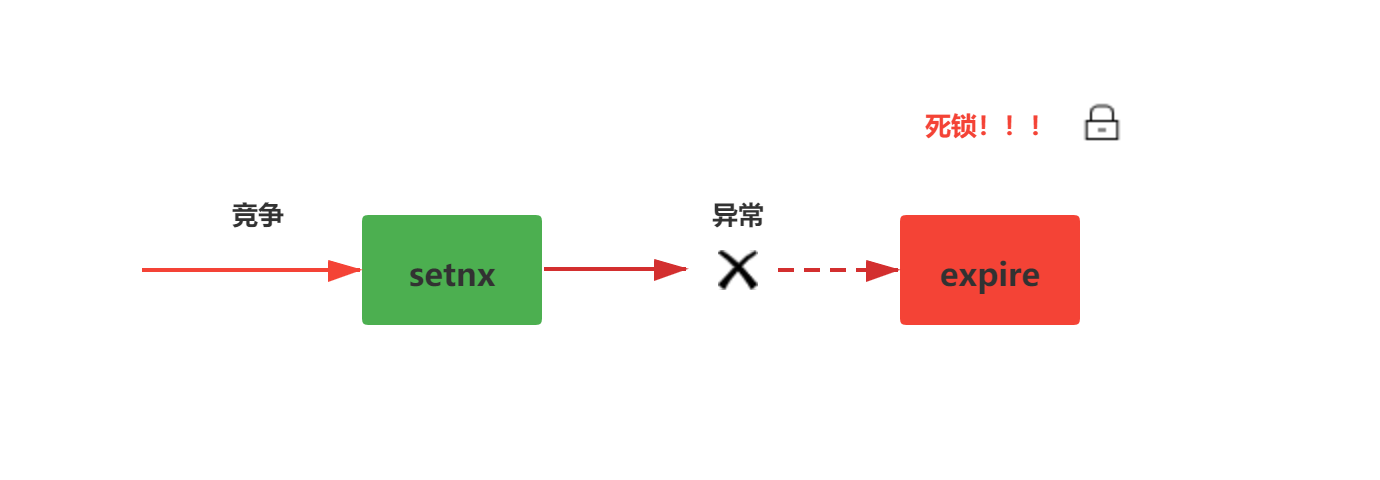
In fact, this scheme is not fundamentally different from the previous scheme. It may still have server exceptions, resulting in the failure to execute the expire. Change the soup without changing the dressing, as shown in the following figure:
2.2.3 atomic operation
Based on the above two schemes, we can find that the essence of the problem is that the two operations are not atomic operations. In scheme 1, setnx instruction plus a del instruction, and in scheme 2, setnx instruction plus an expire instruction. These two instructions are not atomic instructions. Based on this problem, Redis officials combined these two instructions to solve the problem of Redis distributed lock atomic operation.
First, take a closer look at the optional parameters EX and NX of the set instruction
set key value [EX seconds] [PX milliseconds] [NX|XX]
EX seconds: set the expiration time of the key to seconds. Executing SET key value EX seconds has the same effect as executing SETEX key seconds value.
PX milliseconds: set the expiration time of the key to milliseconds. Executing SET key value PX milliseconds has the same effect as executing PSETEX key milliseconds value.
Nx: set the key only when the key does not exist. Executing SET key value NX has the same effect as executing SETNX key value.
20: Set the key only when it already exists.
127.0.0.1:6379> set lock true EX 10 NX #The setting takes effect in 10 seconds OK 127.0.0.1:6379> set lock true EX 10 NX #Failed to set value again within 10s (nil) 127.0.0.1:6379> set lock true EX 10 NX #Set successfully after 10s OK
The above operation successfully solves the atomic operation problem of Redis distributed lock.
2.2.4 unlocking
Redis distributed lock locking is described above, and the unlocking process of redis distributed lock is actually to delete the key. The deletion of the key includes the client calling the del instruction to delete, and also setting the expiration time of the key to delete automatically. However, this deletion cannot be arbitrarily deleted. It cannot be said that the lock requested by client A is deleted by client B.. Then this lock is A rotten lock.
In order to prevent the lock requested by client A from being deleted by client B, we judge by matching whether the value of the lock passed in by the client is equal to the value of the current lock (this value is random and guaranteed not to be repeated). If it is equal, it will be deleted and unlocked successfully.
However, Redis does not provide such a function. We can only handle it through Lua script, because Lua script can ensure the atomic execution of multiple instructions.
Example:
First, set a key whose value is 123456789. Check whether the key is allowed to be deleted by checking whether the value values passed in by the client are equal
127.0.0.1:6379> get lock (nil) 127.0.0.1:6379> set lock 123456789 # Set a key value to 123456789 OK 127.0.0.1:6379> get lock "123456789"
Write lua script on the client, lock lua file, the contents of the file are as follows


if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
endThe test executes the lua script through the wrong value. At this time, deleting the key fails and returns 0

If it is executed with the correct value, 1 will be returned, indicating that the key has been deleted.
2.2.5 code implementation
Let's demonstrate a spring boot project to implement Redis distributed lock. In order to facilitate everyone's use, the code I posted is relatively comprehensive and a little more space.
pom dependency
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.4.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.0.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.3.4</version>
</dependency>
</dependencies>Redis profile
package com.lizba.config;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* <p>
* Redis Simple profile
* </p>
*
* @Author: Liziba
* @Date: 2021/7/11 11:17
*/
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
protected static final Logger logger = LoggerFactory.getLogger(RedisConfig.class);
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private int port;
@Value("${spring.redis.jedis.pool.max-active}")
private int maxTotal;
@Value("${spring.redis.jedis.pool.max-idle}")
private int maxIdle;
@Value("${spring.redis.jedis.pool.min-idle}")
private int minIdle;
@Value("${spring.redis.password}")
private String password;
@Value("${spring.redis.timeout}")
private int timeout;
@Bean
public JedisPool redisPoolFactory() {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(maxTotal);
jedisPoolConfig.setMaxIdle(maxIdle);
jedisPoolConfig.setMinIdle(minIdle);
JedisPool jedisPool = new JedisPool(jedisPoolConfig, host, port, timeout, null);
logger.info("JedisPool Injection succeeded!!");
logger.info("redis Address:" + host + ":" + port);
return jedisPool;
}
}application.yml profile
server:
port: 18080
spring:
redis:
database: 0
host: 127.0.0.1
port: 6379
timeout: 10000
password:
jedis:
pool:
max-active: 20
max-idle: 20
min-idle: 0Acquire lock and release lock code
package com.lizba.utill;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.params.SetParams;
import java.util.Arrays;
import java.util.concurrent.TimeUnit;
/**
* <p>
* Redis Distributed lock simple tool class
* </p>
*
* @Author: Liziba
* @Date: 2021/7/11 11:42
*/
@Service
public class RedisLockUtil {
private static Logger logger = LoggerFactory.getLogger(RedisLockUtil.class);
/**
* Lock - > key
*/
private final String LOCK_KEY = "lock_key";
/**
* Lock expiration time - > TTL
*/
private Long millisecondsToExpire = 10000L;
/**
* Get lock timeout - > get lock timeout for return
*/
private Long timeout = 300L;
/**
* LUA Script - > distributed lock unlocking atomic operation script
*/
private static final String LUA_SCRIPT =
"if redis.call('get',KEYS[1]) == ARGV[1] then" +
" return redis.call('del',KEYS[1]) " +
"else" +
" return 0 " +
"end";
/**
* set Command parameters
*/
private SetParams params = SetParams.setParams().nx().px(millisecondsToExpire);
@Autowired
private JedisPool jedisPool;
/**
* Lock - > timeout lock
*
* @param lockId A random non duplicate ID - > distinguish different clients
* @return
*/
public boolean timeLock(String lockId) {
Jedis client = jedisPool.getResource();
long start = System.currentTimeMillis();
try {
for(;;) {
String lock = client.set(LOCK_KEY, lockId, params);
if ("OK".equalsIgnoreCase(lock)) {
return Boolean.TRUE;
}
// Sleep - > failed to get, temporarily giving up CPU resources
TimeUnit.MILLISECONDS.sleep(100);
long time = System.currentTimeMillis() - start;
if (time >= timeout) {
return Boolean.FALSE;
}
}
} catch (Exception e) {
e.printStackTrace();
logger.error(e.getMessage());
} finally {
client.close();
}
return Boolean.FALSE;
}
/**
* Unlock
*
* @param lockId A random non duplicate ID - > distinguish different clients
* @return
*/
public boolean unlock(String lockId) {
Jedis client = jedisPool.getResource();
try {
Object result = client.eval(LUA_SCRIPT, Arrays.asList(LOCK_KEY), Arrays.asList(lockId));
if (result != null && "1".equalsIgnoreCase(result.toString())) {
return Boolean.TRUE;
}
return Boolean.FALSE;
} catch (Exception e) {
e.printStackTrace();
logger.error(e.getMessage());
}
return Boolean.FALSE;
}
}Test class
package com.lizba.controller;
import cn.hutool.core.util.IdUtil;
import com.lizba.utill.RedisLockUtil;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashSet;
import java.util.Set;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;
/**
* <p>
* test
* </p>
*
* @Author: Liziba
* @Date: 2021/7/11 12:27
*/
@RestController
@RequestMapping("/redis")
public class TestController {
@Autowired
private RedisLockUtil redisLockUtil;
private AtomicInteger count ;
@GetMapping("/index/{num}")
public String index(@PathVariable int num) throws InterruptedException {
count = new AtomicInteger(0);
CountDownLatch countDownLatch = new CountDownLatch(num);
ExecutorService executorService = Executors.newFixedThreadPool(num);
Set<String> failSet = new HashSet<>();
long start = System.currentTimeMillis();
for (int i = 0; i < num; i++) {
executorService.execute(() -> {
long lockId = IdUtil.getSnowflake(1, 1).nextId();
try {
boolean isSuccess = redisLockUtil.timeLock(String.valueOf(lockId));
if (isSuccess) {
count.addAndGet(1);
System.out.println(Thread.currentThread().getName() + " lock success" );
} else {
failSet.add(Thread.currentThread().getName());
}
} finally {
boolean unlock = redisLockUtil.unlock(String.valueOf(lockId));
if (unlock) {
System.out.println(Thread.currentThread().getName() + " unlock success" );
}
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdownNow();
failSet.forEach(t -> System.out.println(t + " lock fail" ));
long time = System.currentTimeMillis() - start;
return String.format("Thread sum: %d, Time sum: %d, Success sum: %d", num, time, count.get());
}
}test result

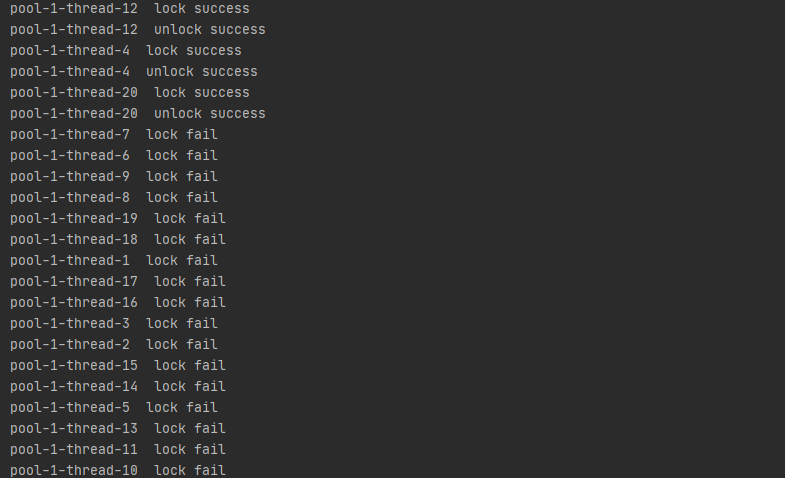
2.3 Redis timeout
One problem with Redis distributed locks is the lock timeout problem. That is, if client A executes the task after acquiring the lock, and the task is not finished, the lock will be automatically released when the timeout time of the lock expires. At this time, client B can take advantage of the opportunity to enter, and the lock will have A problem!
In fact, there is no complete solution to this problem, but it can be optimized by the following means:
- Try not to perform long tasks in Redis distributed locks, and execute code in the lock interval as small as possible. Just like the synchronized optimization in a single JVM lock, we can consider optimizing the lock interval
- Do more stress tests and online real scene simulation tests to estimate an appropriate lock timeout
- Make preparations for data recovery after the Redis distributed lock timeout task is not completed
3, Distributed locks in clusters
3.1 problems of cluster distributed lock
The above distributed locks are feasible for Redis of single node instances; However, we don't use single node Redis instances at all in the company. The simplest configuration is Redis one master two slave + sentinel monitoring; In sentinel cluster, although the slave node will replace the master node when it hangs up, and the client does not perceive it, the above distributed locks may have the problem of abnormal data synchronization between nodes, resulting in the failure of distributed locks.
Under normal circumstances, the client applies for distributed locks from the Redis cluster monitored by sentinel:
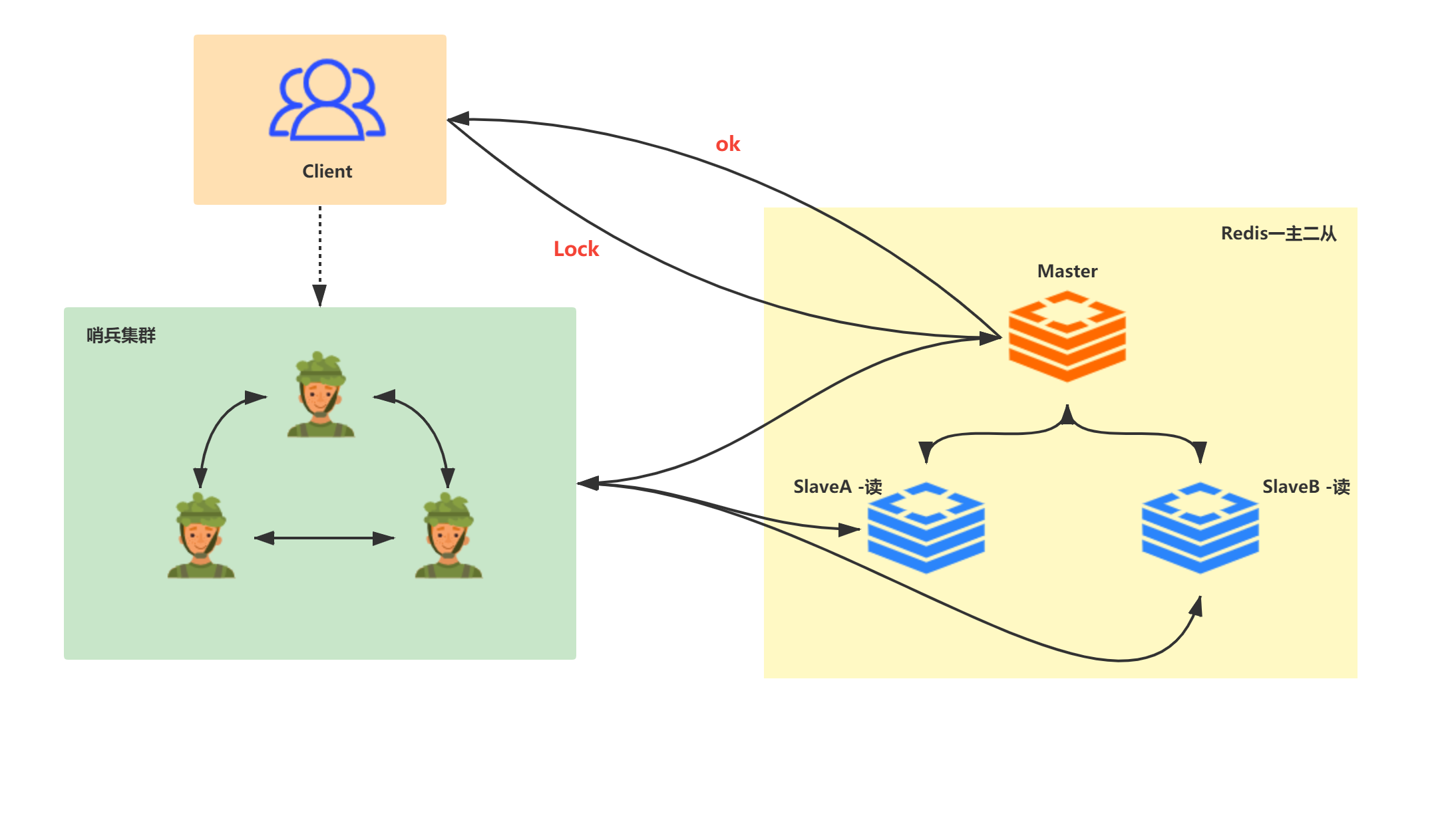
For example, client A applies for A lock on the master node (machine 1). At this time, the master node (machine 1) hangs up and the lock has not been synchronized to the slave nodes (machine 2 and machine 3). At this time, the slave node (machine 2) becomes A new master node, but the lock does not exist on the new master node (machine 2), so client B applies for the lock successfully, The definition of lock is problematic in this scenario!
When the master node goes down and lock synchronization fails, other clients successfully apply for locks: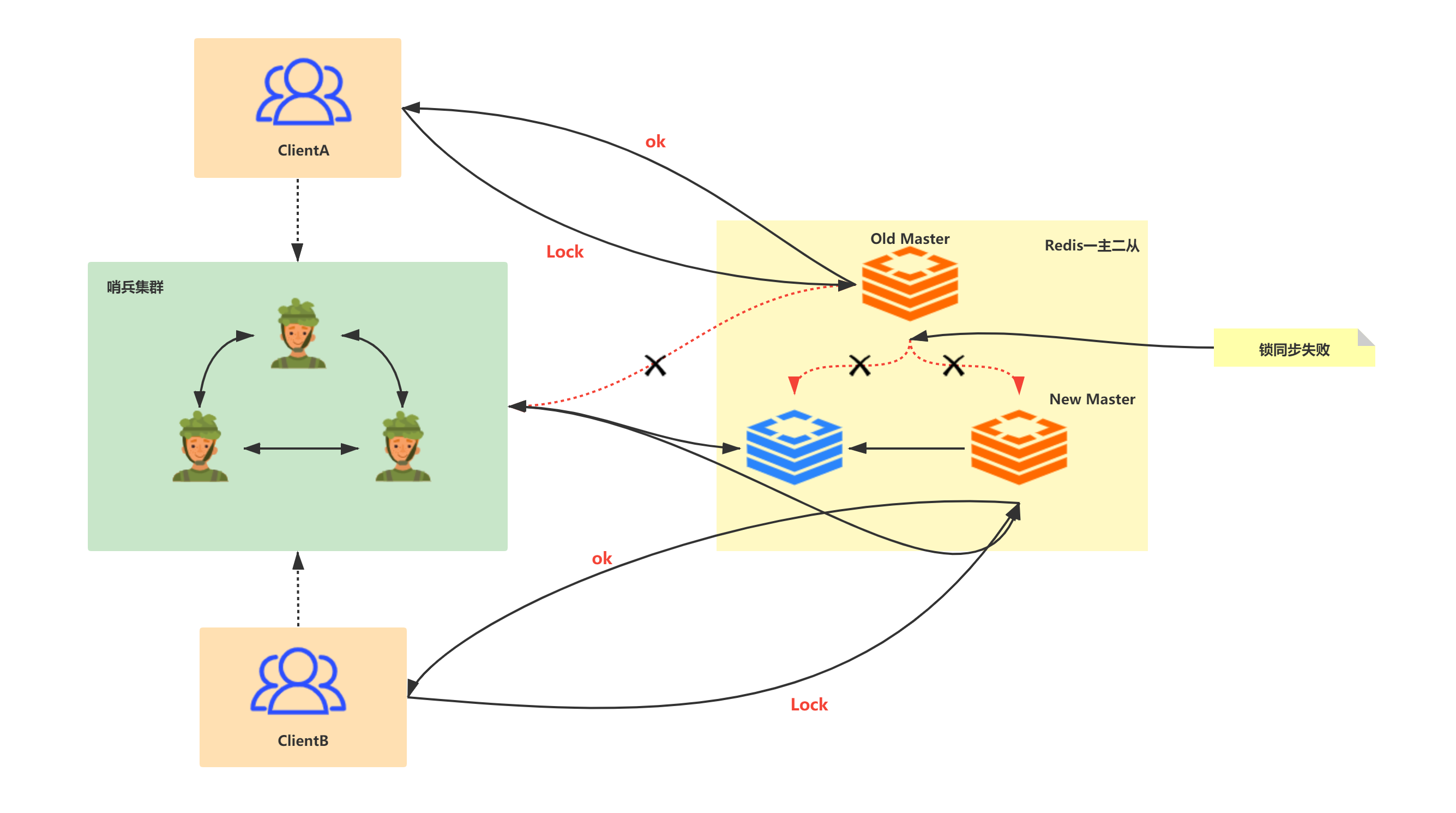
Although the above situation occurs after the master-slave failover, it is obviously unsafe. Ordinary business systems may be acceptable, but large amount business scenarios are not allowed.
3.2 RedLock
3.2.1 introduction
The way to solve this problem is to use RedLock algorithm, also known as red lock. RedLock uses multiple Redis instances. Each instance has no master-slave relationship and is independent of each other; When locking, the client sends locking instructions to all nodes. If more than half of the nodes set successfully, the locking is successful. When releasing a lock, you need to send a del instruction to all nodes to release the lock. The implementation idea of RedLock is relatively simple, but the actual algorithm is relatively complex, and many details need to be considered, such as error retry, clock drift, etc. In addition, RedLock needs to add more instances to apply for distributed locks, which will not only consume server resources, but also degrade its performance.
The frame composition is as follows: the client sends locking instructions to multiple independent Redis services (in order to pursue high throughput and low delay, the client needs to use multiplexing to communicate with N Redis Server servers). If more than half of the feedback is successful, the locking is successful, and the number of Redis servers is odd at last.
Introduction to Redis Chinese website
http://redis.cn/topics/distlock.html
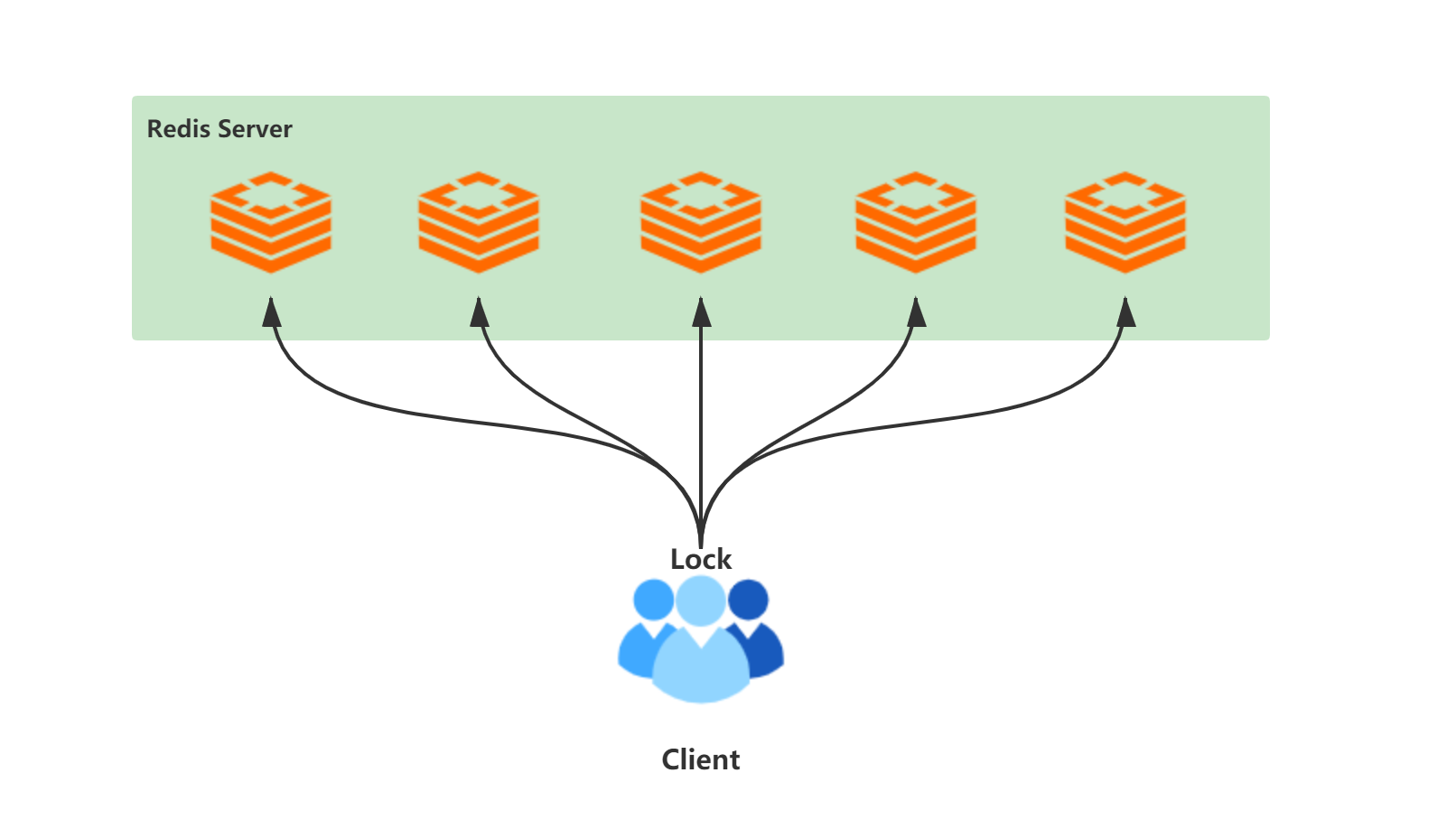
In the above architecture diagram, there are five Redis servers used to obtain locks. What should a client do to obtain locks?
- Get current system time (ms)
- The same key and random value are used to request locks on five nodes. The process of requesting locks includes the definition of multiple time values, including the timeout time of requesting a single lock, the total time-consuming time of requesting locks, and the automatic release time of locks. The timeout of a single lock request should not be too long to prevent the Redis service from blocking for too long.
- The client calculates the total time to acquire locks and the number of successful locks. It is successful only when the number is greater than or equal to 3 and the time to acquire locks is less than the automatic release time of locks
- If the lock is acquired successfully, the automatic lock release time is equal to the time consumed by TTL minus acquisition (the calculation of the time consumed by this lock is complex)
- Lock acquisition failed. Send a delete instruction to all Redis servers. All Redis servers must send it
- Retry after failure. Retry after lock acquisition failure. The retry time should be a random value to avoid increasing the possibility of failure by requesting locks at the same time with other clients, and this time should be greater than the time consumed to obtain locks
3.2.2 minimum effective length of lock
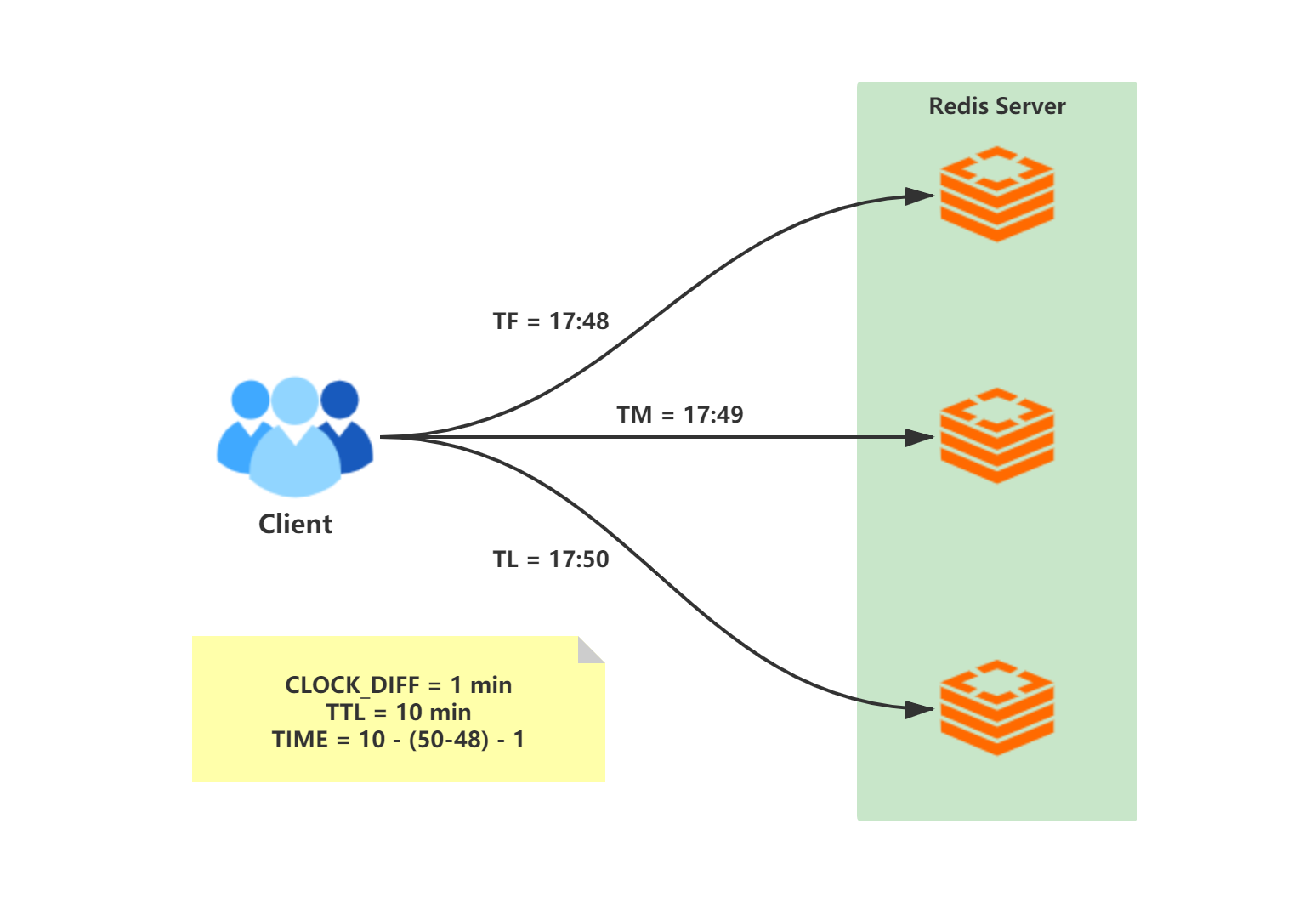
As mentioned above, there is a problem of clock drift, and the time when the client requests a lock from different Redis servers will be slightly different, it is necessary to carefully study the calculation of the minimum effective time of the lock obtained by the client:
Assuming that the client successfully applies for a lock, the first key is set to TF, the last key is set to TL, the lock timeout is TTL, and the clock difference between different processes is CLOCK_DIFF, the minimum effective length of the lock is:
TIME = TTL - (TF- TL) - CLOCK_DIFF
3.2.3 fault recovery
Redis is used to implement distributed locks, which is inseparable from server downtime and other unavailability problems. The same is true for RedLock red locks. Even if multiple servers apply for locks, we should also consider the processing after server downtime. AOF persistence is officially recommended.
However, AOF persistence can only restart and recover the normal SHUTDOWN instruction. However, in case of power failure, the lock data from the last persistence to the power failure may be lost. After the server is restarted, distributed lock semantic errors may occur. Therefore, in order to avoid this situation, it is officially recommended that after the Redis service is restarted, the Redis service is unavailable within a maximum client TTL time (the service for applying for lock is not provided), which can indeed solve the problem, but it is obvious that this will certainly affect the performance of the Redis server, and when this situation occurs in most nodes, the system will be in a global unavailable state.
3.3 Redisson implements distributed locks
3.3.1 introduction to redistribution
Redisson is set up in Redis A Java in memory data grid based on. [ Redis official recommendation]
Redisson in NIO based Netty Based on the framework, it makes full use of a series of advantages provided by Redis key database, and provides users with a series of common tool classes with distributed characteristics on the basis of common interfaces in Java utility toolkit. As a tool kit for coordinating single machine multithreaded concurrent programs, it has the ability to coordinate distributed multi machine multithreaded concurrent systems, which greatly reduces the difficulty of designing and developing large-scale distributed systems. At the same time, combined with various characteristic distributed services, it further simplifies the cooperation between programs in the distributed environment.
Redismission GitHub address:
https://github.com/redisson/redisson
Redistribution distributed lock and synchronizer Wiki:
All in all - Redisson is very powerful
3.3.2 RedLock usage of reddison
pom dependency
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.3.2</version> </dependency>
Test class
package com.liziba.util;
import org.redisson.Redisson;
import org.redisson.RedissonRedLock;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import java.util.concurrent.TimeUnit;
/**
* <p>
* Test RedLock of Redisson
* </p>
*
* @Author: Liziba
* @Date: 2021/7/11 20:55
*/
public class LockTest {
private static final String resourceName = "REDLOCK_KEY";
private static RedissonClient cli_79;
private static RedissonClient cli_89;
private static RedissonClient cli_99;
static {
Config config_79 = new Config();
config_79.useSingleServer()
.setAddress("127.0.0.1:6379") // Note that my Redis test instance here does not have a password
.setDatabase(0);
cli_79 = Redisson.create(config_79);
Config config_89 = new Config();
config_89.useSingleServer()
.setAddress("127.0.0.1:6389")
.setDatabase(0);
cli_89 = Redisson.create(config_89);
Config config_99 = new Config();
config_99.useSingleServer()
.setAddress("127.0.0.1:6399")
.setDatabase(0);
cli_99 = Redisson.create(config_99);
}
/**
* Locking operation
*/
private static void lock () {
// Try locking three Redis instances
RLock lock_79 = cli_79.getLock(resourceName);
RLock lock_89 = cli_89.getLock(resourceName);
RLock lock_99 = cli_99.getLock(resourceName);
RedissonRedLock redLock = new RedissonRedLock(lock_79, lock_89, lock_99);
try {
boolean isLock = redLock.tryLock(100, 10000, TimeUnit.MILLISECONDS);
if (isLock) {
// do something ...
System.out.println(Thread.currentThread().getName() + "Get Lock Success!");
TimeUnit.MILLISECONDS.sleep(10000);
} else {
System.out.println(Thread.currentThread().getName() + "Get Lock fail!");
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// In any case, release the lock - > this will release the lock like all Redis services
redLock.unlock();
}
}
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new Thread(() -> lock()).start();
}
}
}3.3.3 source code analysis of reddisonredlock
Please pay attention to