OpenVINO computer vision model acceleration tutorial
1, Foundation
1. OpenVINO introduction
OpenVINO is the first version released in May 2018. Why choose this time? Before that, deep learning was very popular. There were many computer vision frameworks. Before deep learning, such as opencv and matlab, there were these computer vision development frameworks, but after the development of deep learning, these visual frameworks faced embarrassing problems? That is, they are all aimed at traditional computer vision. Although they also support these computer vision for deep learning to varying degrees, in essence, they are not a new framework that fully supports the deployment of computer deep learning, Therefore, at this time, intel found the market demand energy and the needs of developers, so it opened the computer vision framework OpenVINO.
What are the advantages of this framework over other traditional visual frameworks such as opencv and matlab? It supports accelerated computing on a variety of edge hardware platforms (take a simple example: compare OpenCV to running a training model of computer face recognition such as CDNN on a computer or other computer vision hardware platform. There are 5 frames per second on the CPU, but if it is used for OpenVINO acceleration, 20 frames per second and 30 frames are possible. Therefore, OpenVINO can complete an average speed increase of 5-10 times).
Why can we increase such a high speed? openVINO is intel, which adopts a variety of hardware platform instructions and multithreading methods to accelerate the fusion of the training model from the bottom instruction set.
The latest version is 2021.2, and intel also uses a large number of pre training models in the openVINO framework, Therefore, it supports the rapid demonstration of visual tasks in a variety of common scenes (for example, for our face recognition, it has four lightweight models with only a few M, and then the speed can reach more than 100 frames per second, which is particularly stable. Pedestrian detection, license plate detection and recognition, scene text detection and recognition. For these common visual tasks, its demo can be run quickly based on openVINO, that is, it can achieve the effect of rapid demonstration, which is also the goal of openVINO A big advantage, so you can omit a lot of training, find data training model, and these times can complete rapid delivery)
https://docs.openvinotoolkit.org/2021.1/index.html official website
OpenVINO is also divided into two parts. The two most important components are the model optimizer for model transformation and the reasoning engine for model acceleration. With these two things, our OpenVINO can receive the model trained by Epoch, then I can convert it to orx and transfer it to OpenVINO for accelerated call. For example, we are the model trained by tensorflow. After you generate the pp file, we can also convert it to OpenVINO, convert it to intermediate format through its MO model optimizer, and then speed up the call. Therefore, it can be realized that the models generated by the training received from almost all our in-depth learning can be deployed by OpenVINO, and then the computing of various multi edge hardware such as graphics card, fpga and computing stick supported by CPU and intel can be deployed, and some public computers can be deployed.
Its advantage is that it can remove the N card. When the control model is not very large, I can support it through the CPU when the production conditions are met, and then we don't need to change a high-level n card (n card means NVIDIA Series graphics card), so as to significantly improve the cost advantage. Therefore, it is a good deployment framework for deep learning model.
At the same time, intel has integrated some basic traditional computer vision related things of the original opencv in openvino. Therefore, once you have openvino, you will have all the functions of OpenCV, plus the functions of in-depth learning and deployment framework acceleration. Therefore, openvino is such a computer vision related framework.
2. Course involves
OpenVINO C++/Python development environment configuration, OpenVINO C++/Python SDK development skills, support for ONNX format model, Tensorflow model and openvino, and code demonstration of the combination of the latest yoov5 to ONNX and openvino.
3. Installation and construction of OpenVINO development environment
The introduction of OpenVINO is to quickly build a visual application prototype system and solution, deploy and run the model in real time on the end-side equipment, and its role is to run it in real time on our pc and some boards. The version used is 2021.2, the latest version.

Picture 1
3.1. System uninstall vs. installation tool VS2019, OpenVINO_2021.2.185 ,Python3.6.5 ,cmake
Install uninstall vs tool https://www.cnblogs.com/kuangqiu/p/7760281.html ,
Tools vs delete links; https://github.com/Microsoft/VisualStudioUninstaller/releases
regedit can view the registry vs delete; https://blog.csdn.net/inch2006/article/details/102372940
VS2019 download; https://visualstudio.microsoft.com/zh-hans/ Then execute exe and download the c + + library for installation
OpenVINO_2021.2.185 you need to register, download and double-click to install https://docs.openvinotoolkit.org/2021.2/openvino_docs_install_guides_installing_openvino_windows.html There are corresponding installation steps and corresponding environment installation web page steps. Pay attention to executing scripts
Python3.6.5 installation link https://www.jb51.net/article/147615.htm Official website link https://www.python.org/downloads/windows/
Pycham ide tutorial https://www.runoob.com/python/python-ide.html Official website link https://www.jetbrains.com/pycharm/download/#section=windows
cmake: CMake 3.10 or higher 64-bit NOTE: If you want to use Microsoft Visual Studio 2019, you are required to install CMake 3.14.
Cmake: link: https://cmake.org/download/ Pay attention to configuring environment variables
3.2. Familiar with OpenVINO installation directory
deployment_tools inference_engine Inference engine model_optimizer Model optimizer ngraph The latest also belongs to the reasoning engine open_model_zoo Open model library models intel interl The model library we have trained is for us to use. There are only descriptions of the model, Real use or need tools->downloader ->downloader Tools to download public Various model libraries provided by others tools Help us download some models we need downloader Download and convert tools, such as pytorch_to_onnx Conversion
3.3 installation environment test
Execute openvino_2021.2.185\deployment_tools\demo\demo_security_barrier_camera.bat this script to test the C + + environment. This is a case of vehicle license plate number recognition model. If the environment is correct, the final effect picture is.
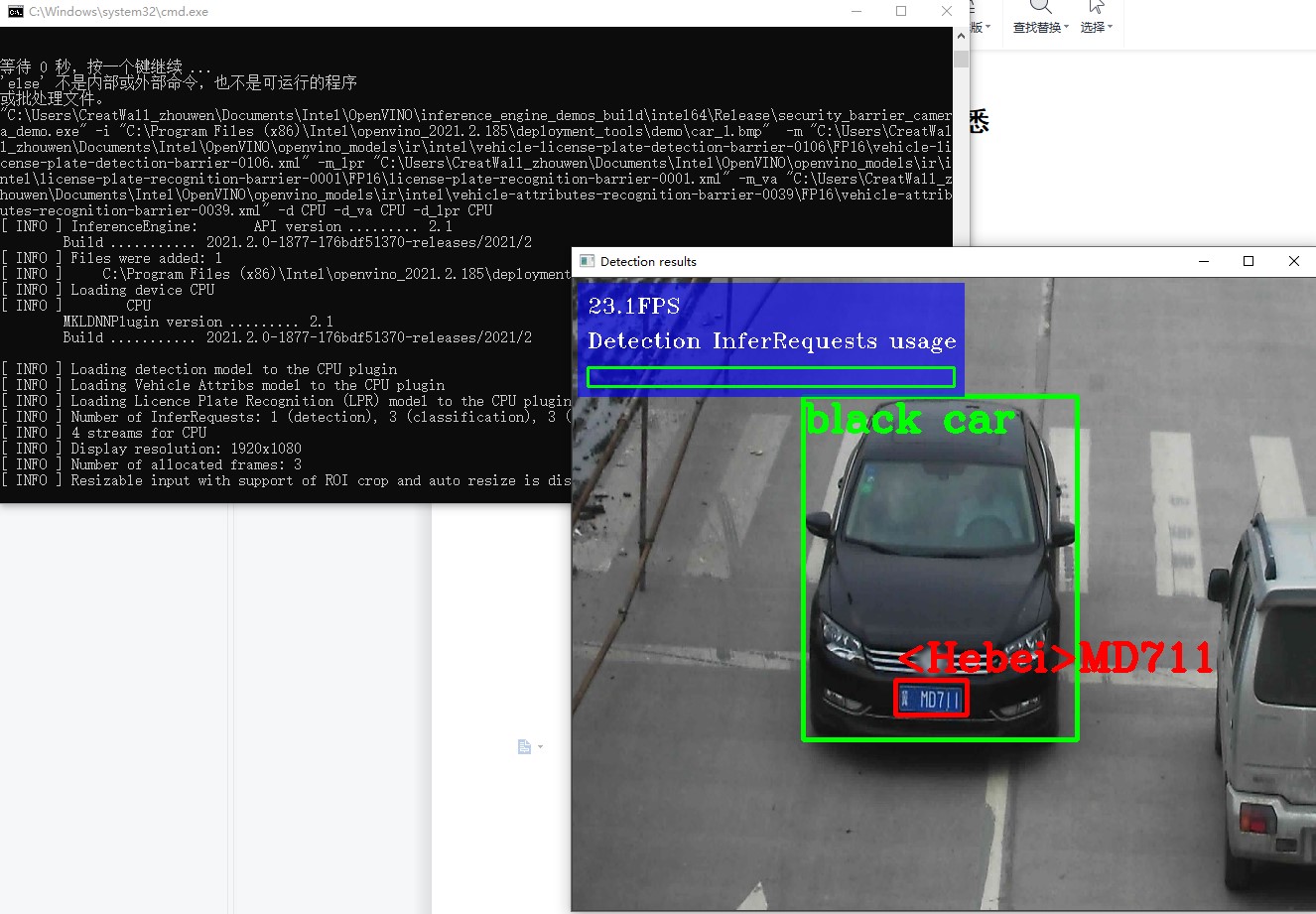
Figure 2
3.4 basic overview of OpenVINO
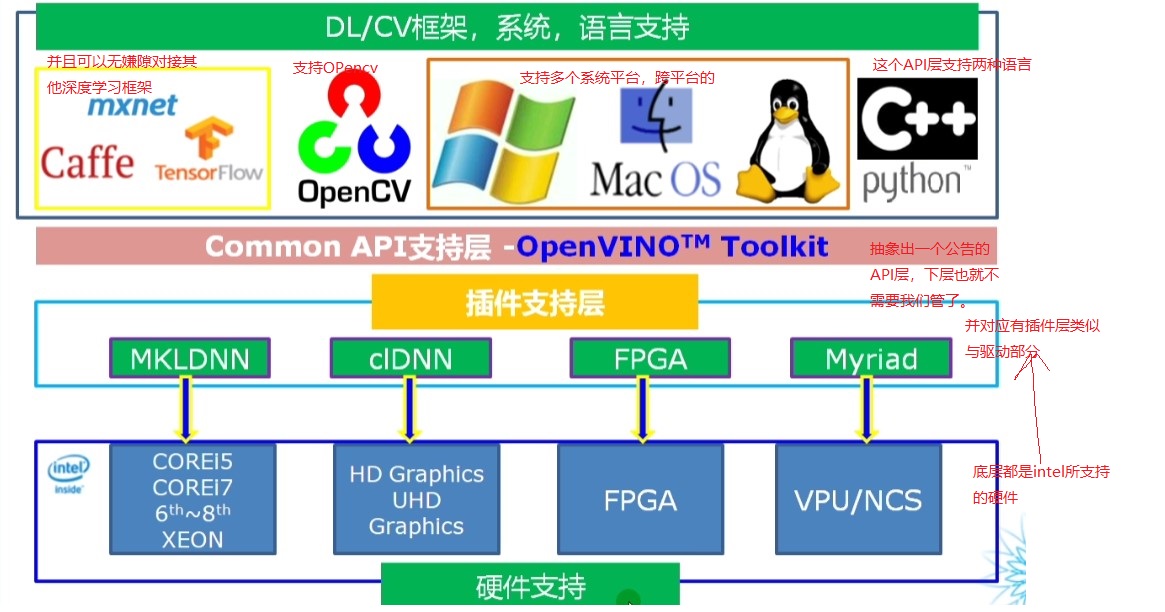
Figure 3
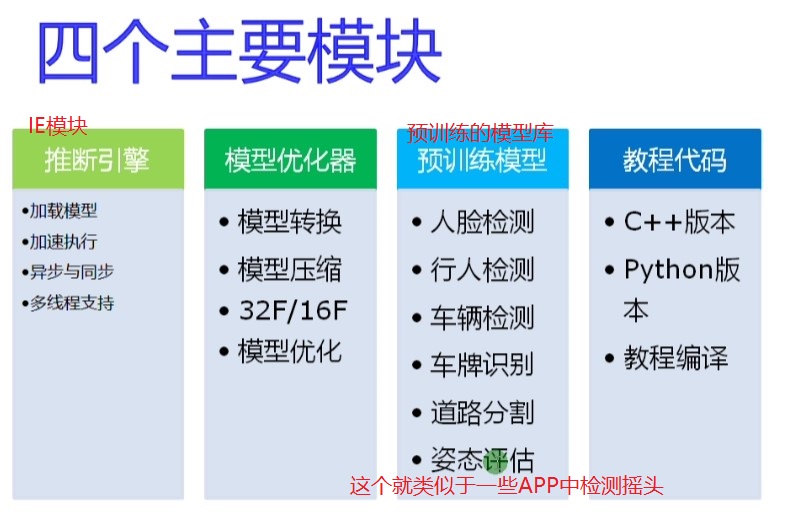
Figure 4
3.5 C++ vs development environment configuration test
Configure include directory
C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\inference_engine\include
C:\Program Files (x86)\Intel\openvino_2021.2.185\opencv\include\opencv2
Configuration Library Directory
C:\Program Files (x86)\Intel\openvino_2021.2.185\opencv\lib
C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\inference_engine\lib\intel64\Release
Configure link dependent Libraries
Using python script output
C:\Program Files (x86)\Intel\openvino_2021.2.185\opencv\lib 451 without d Lib Library
C:\Program Files (x86)\Intel\openvino_ 2021.2.185\deployment_ tools\inference_ Lib Library of engine \ lib \ Intel 64 \ release
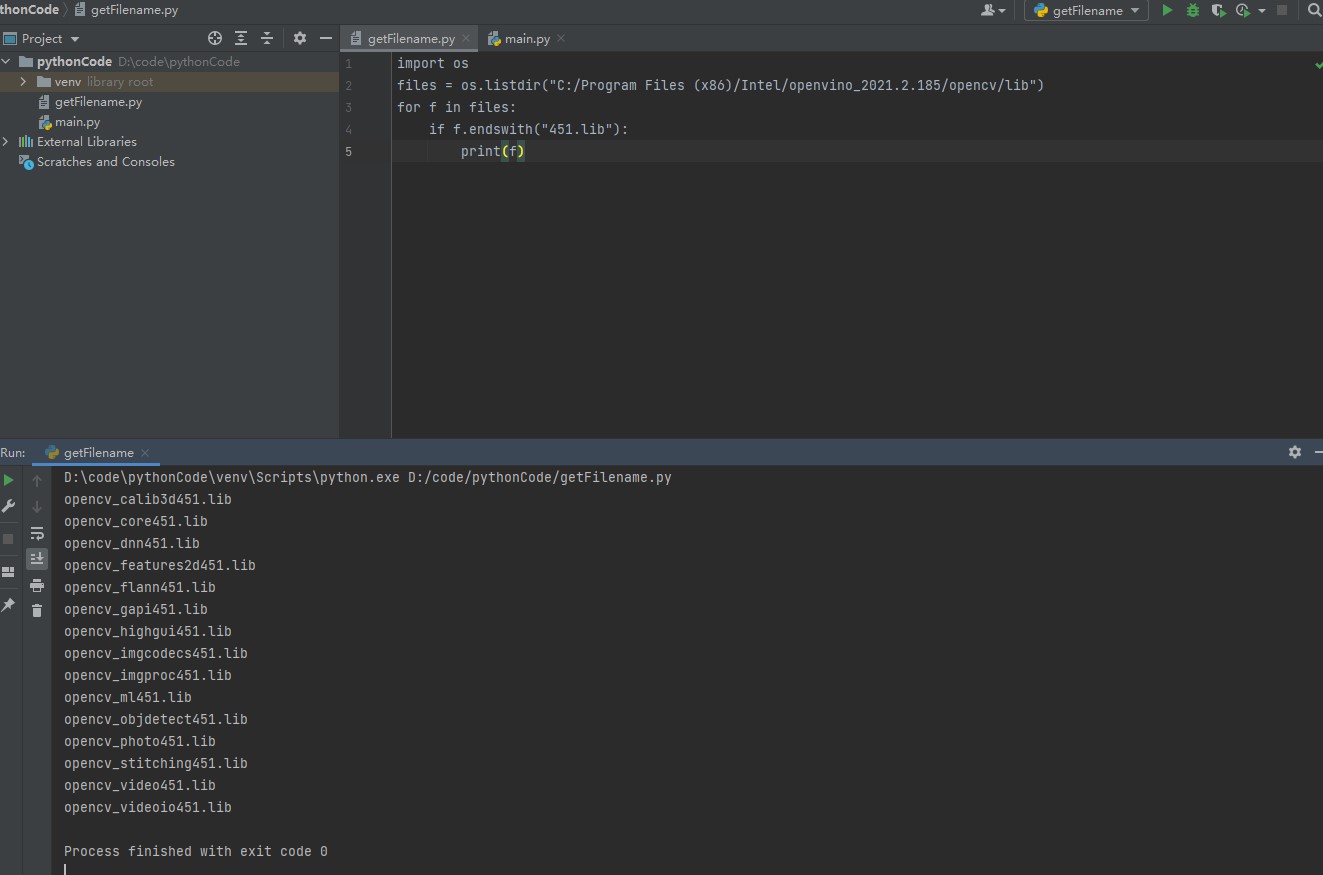
Figure 5
Configure environment variables
C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\inference_engine\external\tbb\bin
C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\inference_engine\bin\intel64\Release
C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\ngraph\lib
C:\Program Files (x86)\Intel\openvino_2021.2.185\opencv\bin
Test code
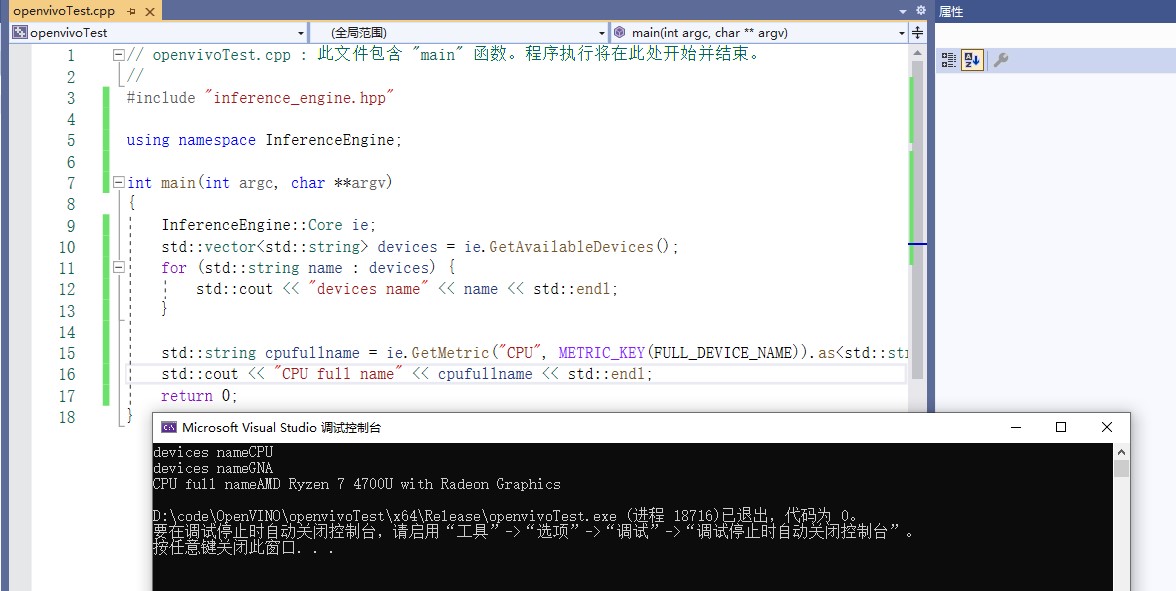
Figure 6
For example, a group of friends learning together encountered a problem: unable to locate the program input point report dynamic link library information_ engine. DLL error, as shown in the figure
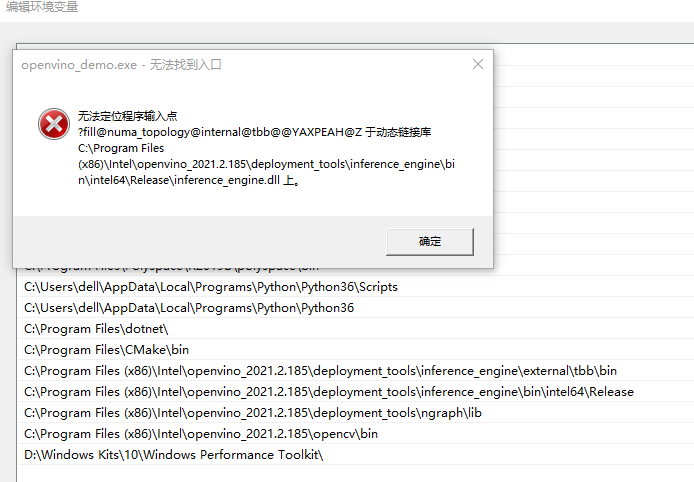
Figure 9
Problem solving method: when setting environment variables, the four environment variables related to openVINO should be set to the front to solve this problem.
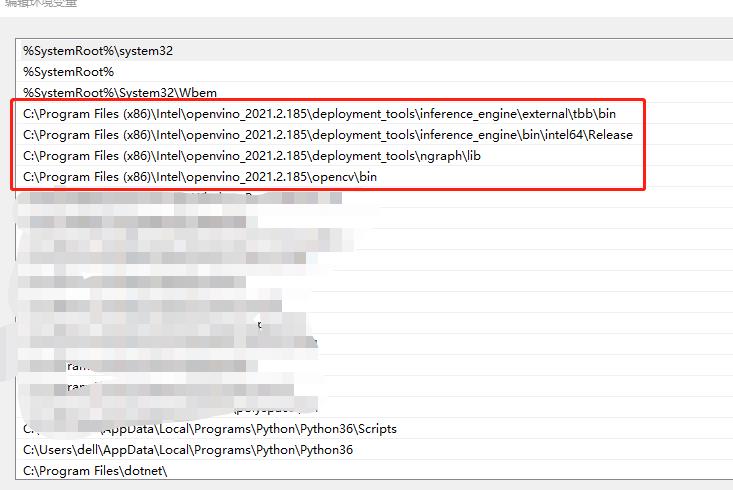
Figure 10
3.6. OpenVINO SDK learning
The starting IE module is the reasoning module, which is the most commonly used. It's easy to look at the conversion module after getting familiar with it.
The first is the OpenVINO development process, which gives you a model. How do you run a model to complete reasoning, and then display and other links.
The second is to query whether your current device hardware support does not support. There are some functions to query the hardware support, where the device module can support model acceleration, etc.
The third is the application and function introduction of the SDK integrated with your application,
OpenVINO IE development process:
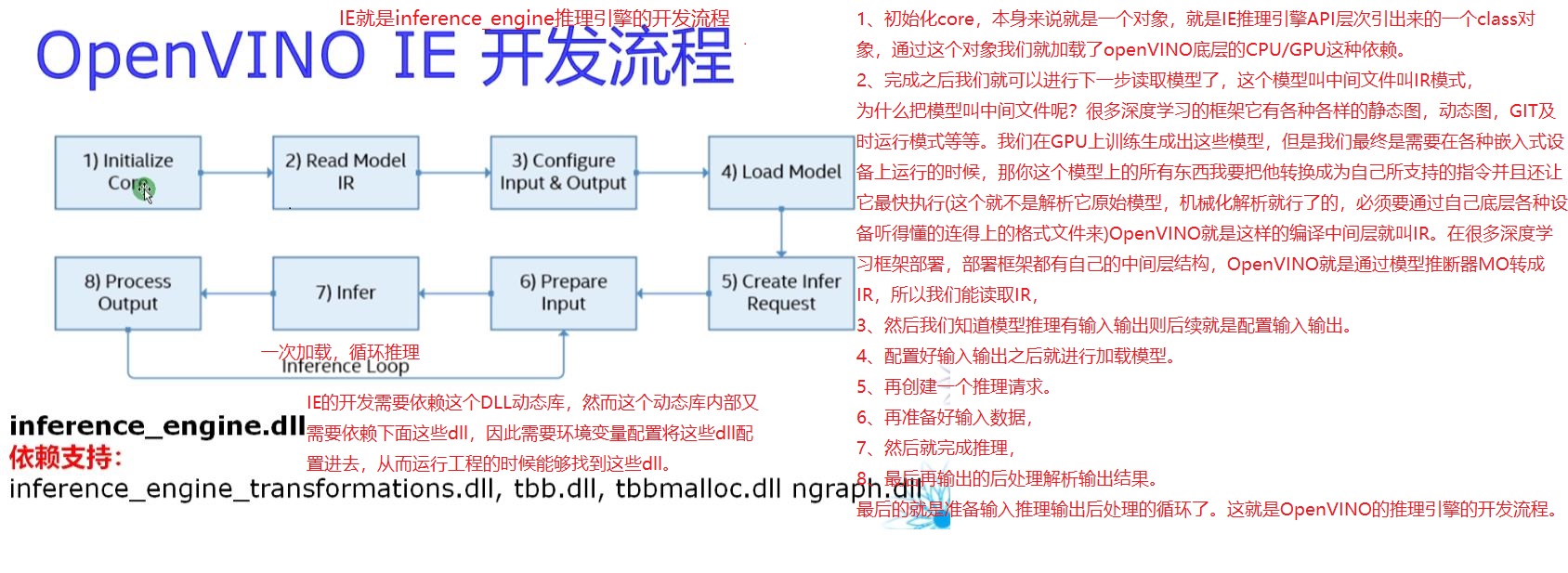
Figure 7
1. Initializing the core itself is an object, which is a class object introduced from the API level of IE inference engine. Through this object, we load the CPU/GPU dependency at the bottom of openVINO.
2. After that, we can read the model in the next step. This model is called intermediate file and IR mode,
Why call the model an intermediate file? There are many deep learning frameworks. It has a variety of static diagrams, dynamic diagrams, GIT timely operation mode and so on. We train and generate these models on GPU, but we finally need to run on various embedded devices, I want to convert all the things on your model into instructions that I support and let it execute as quickly as possible (this is not to parse its original model, but to mechanically parse it, which must be through the connected format files understood by various devices at the bottom). OpenVINO is such a compilation intermediate layer, which is called IR. In the deployment of many deep learning frameworks, the deployment framework has its own middle tier structure. OpenVINO is converted to IR through the model inference MO, so we can read IR.
3. Then we know that there are inputs and outputs in model reasoning, and the subsequent is to configure inputs and outputs.
4. After configuring the input and output, load the model.
5. Create another inference request.
6. Then prepare the input data.
7. Then complete the reasoning.
8. Finally, the output result of post-processing analysis is output.
9. The last is to prepare the loop for input reasoning and output post-processing. This is the development process of OpenVINO's reasoning engine.
Hardware support query:
Import header file:#include "inference_engine.hpp"
Namespace introduction: using namespace InferenceEngine;
Device query function:
To create a core class object: InferenceEngine::Core ie;
Query available devices: std::vector<std::string> devices = ie.GetAvailableDevices();
Full name of output device: ie.GetMetric("CPU", METRIC_KEY(FULL_DEVICE_NAME)).as<std::string>();
IE related API functions support:
Core class: InferenceEngine::Core ie; For data conversion: InferenceEngine::Blob,InferenceEngine::TBlob, InferenceEngine:: NV12Blob Formatting: InferenceEngine::BlobMap Input / output format read settings:InferenceEngine::InputsDataMap,InferenceEngine::InputInfo,InferenceEngine::OutputDataMap Some packaging classes: adopt Core conduct read Later get CNN Network: InferenceEngine::CNNNetwork take CNN The network becomes an executable network: InferenceEngine::ExecutableNetwork Request, you can get the reasoning object, and finally parse the output: InferenceEngine::InferRequest
2, Project practice
1. ResNet18 implementation of image classification
1.1 introduction to pre training model: OpenVINO's own model ResNet18 image classification model. How does this image classification model turn it into IR? ResNet18 itself is a pytorch model. How is it converted into ONNX format, and then into IR format? Finally, the demonstration is completed. There is a set of process for how to turn this. We'll talk about it later.
Now, if there is a ready-made model, how can we use it through the SDK of OpenVINO IE to realize the reasoning deployment of image classification.
1.2 image preprocessing: the image has a preprocessing process, that is, to use all images of this model, we must first convert it to 0-1. The normal image is between 0-255, RGB three channels, and the output here is between 0-1.
1.3. mean=[0.485, 0.456, 0.406] variance std=[0.229, 0.224, 0.225] the operation is to subtract its mean value and divide it by its variance. This part is processed through opencv API.
1.4. Input format output format. The input and output of each deep learning framework has its own defined format. The input format NCHW (number of images, number of channels of channel images, H height, W width) = 13244 * 244 indicates that it is a color image. The width and height of one image is 244 each time.
Output format after reasoning: 1x1000 (this model is trained based on the number set of imagenet_classes, because it has 1000 classifications, so its output is 1 times 1000). In this case, we find the string corresponding to its largest index, which is the exact classification of our image.
1.5 what to do at the code level:
1,initialization Core ie 2,ie.ReadNetwork read CNN The network needs two files in the model resnet18.bin resnet18.xml 3,Gets the input and output formats and sets the precision 4,Get executable network and link hardware 5,After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting 6,Get input Blob Format conversion class object 7,Input image data preprocessing(include BGR->RGB,Size floating point number calculation conversion image sequence conversion HWC->NCHW) 8,Executive reasoning 9,Get our output 10,Finally, we need to obtain the output dimension information, analyze the data and output the largest one is us resnet18 Results of image recognition
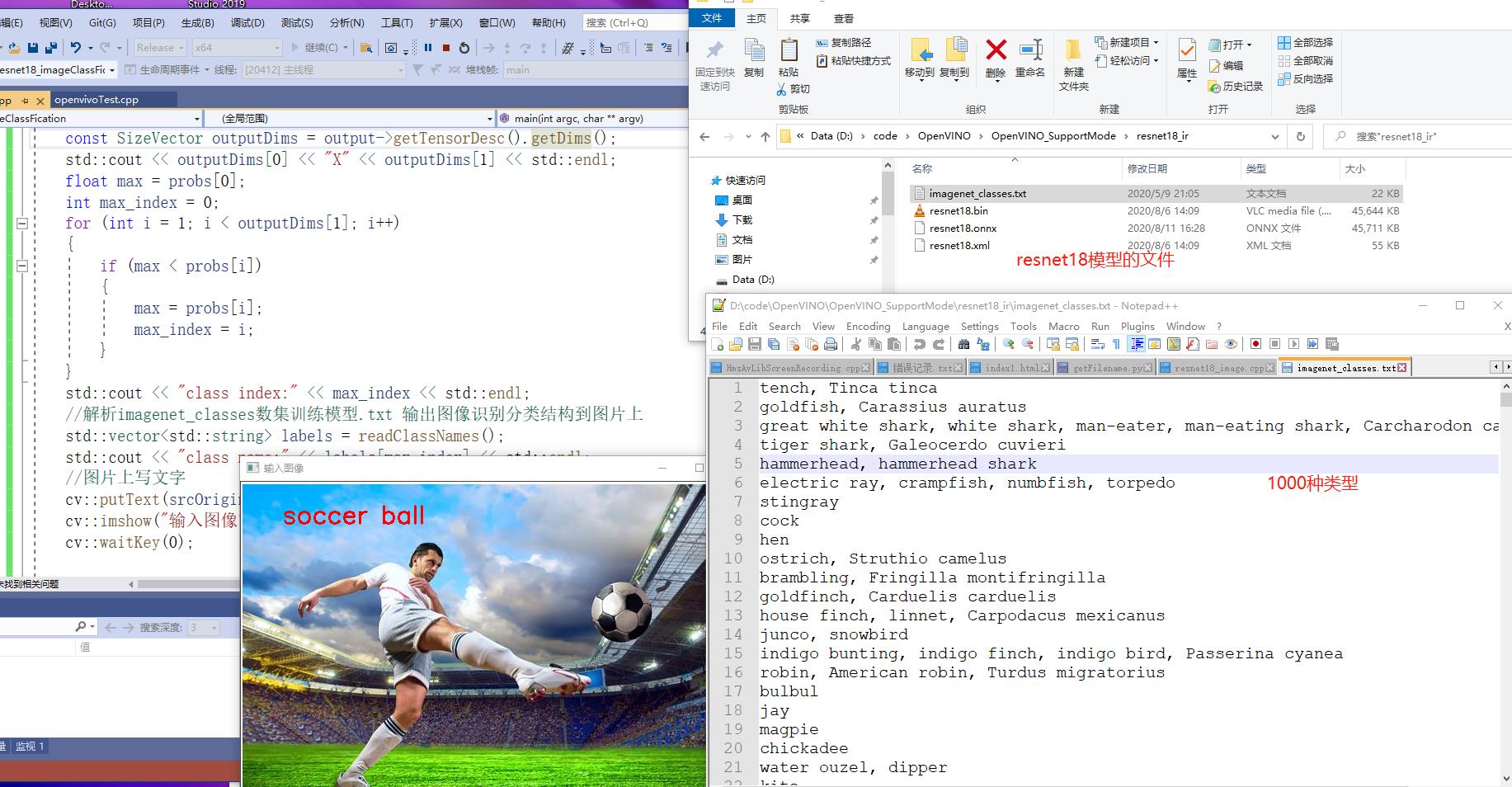
Figure 8
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
std::string labels_txt_file = "D:/code/OpenVINO/OpenVINO_SupportMode/resnet18_ir/imagenet_classes.txt"; //File name of the model
std::vector<std::string> readClassNames();//Functions to read files
int main(int argc, char** argv)
{
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
std::string xmlFilename = "D:/code/OpenVINO/OpenVINO_SupportMode/resnet18_ir/resnet18.xml";
std::string binFilename = "D:/code/OpenVINO/OpenVINO_SupportMode/resnet18_ir/resnet18.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
//Because this model is from the pytorch digital set, its accuracy is the full accuracy of FP32, so we need to set FP32 at this time
input_data->setPrecision(Precision::FP32);
//This is also the input data mode set according to the model
input_data->setLayout(Layout::NCHW);
//ColorFormat is also input according to the model settings
input_data->getPreProcess().setColorFormat(ColorFormat::RGB);
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
//Because this model is from the pytorch digital set, its accuracy is the full accuracy of FP32, so we need to set FP32 at this time
output_data->setPrecision(Precision::FP32);
std::cout << "output name = " << output_name << std::endl;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
auto infer_request = executable_network.CreateInferRequest();
//6. Gets the input Blob format conversion class object
auto input = infer_request.GetBlob(input_name);//Get the blob of input (class object for input formatting)
size_t num_channels = input->getTensorDesc().getDims()[1];
size_t h = input->getTensorDesc().getDims()[2];
size_t w = input->getTensorDesc().getDims()[3];
size_t image_size = h * w;
//7. Preprocessing of input image data (including BGR - > RGB, size floating point calculation conversion, image sequence conversion HWC - > nchw)
cv::Mat srcOriginal = cv::imread("D:/succoBlar.png");//Original drawing to be parsed
cv::Mat src;
cv::cvtColor(srcOriginal, src, cv::COLOR_BGR2RGB);// Because the receiving order of resnet18 model is RGB and the order of opencv is BGR, it is necessary to convert and then preprocess the image of resnet18 model
cv::Mat blob_image;//Convert to network, you can parse the picture format
cv::resize(src, blob_image, cv::Size(w, h));//Conversion size
blob_image.convertTo(blob_image, CV_32F);//Convert to floating point number
blob_image = blob_image / 255.0;//Convert to 0-1
cv::subtract(blob_image, cv::Scalar(0.485, 0.456, 0.406), blob_image);//The value of each channel is subtracted from the mean
cv::divide(blob_image, cv::Scalar(0.229, 0.224, 0.225), blob_image);// The value of each channel is divided by the variance
//8. Set the set data into the input Blob - > in fact, the memory space for storing the input image data has been opened up when GetBlob()
float* data = static_cast<float*>(input->buffer());//This is to directly fill the data into the specified space of input after data conversion
//be careful; The order of mat images returned by opencv is HWC. To convert it to NCHW is to convert a matrix of HWC type to NCHW type, which is the problem of matrix filling
// HWC = NCHW conversion
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
for (size_t ch = 0; ch < num_channels; ch++) {
//blob_image is the HWC format from opencv - "conversion to NCHW" means that each channel becomes a graph according to the channel order. The of the first few channels is the storage of the first few pictures
data[image_size * ch + row * w + col] = blob_image.at<cv::Vec3f>(row, col)[ch];
}
}
}
//8. Executive reasoning
infer_request.Infer();
//9. Get our output
auto output = infer_request.GetBlob(output_name);
const float* probs = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//Convert output data to Precision
//10. Finally, we need to obtain the output dimension information, analyze the data and output the largest one, which is the result of resnet18 image recognition
const SizeVector outputDims = output->getTensorDesc().getDims();
std::cout << outputDims[0] << "X" << outputDims[1] << std::endl;
float max = probs[0];
int max_index = 0;
for (int i = 1; i < outputDims[1]; i++)
{
if (max < probs[i])
{
max = probs[i];
max_index = i;
}
}
std::cout << "class index:" << max_index << std::endl;
//Parsing imagenet_classes data set training model txt output image recognition classification structure to the picture
std::vector<std::string> labels = readClassNames();
std::cout << "class name:" << labels[max_index] << std::endl;
//Write text on the picture
cv::putText(srcOriginal, labels[max_index], cv::Point(50,50), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
cv::imshow("input image ", srcOriginal);
cv::waitKey(0);
return 0;
}
//Parsing imagenet_classes.txt file to get 1000 categories
std::vector<std::string> readClassNames()
{
std::vector<std::string> classNames;
std::ifstream fp(labels_txt_file);
if (!fp.is_open())
{
printf("could not open file...\n");
exit(-1);
}
std::string name;
while (!fp.eof())
{
std::getline(fp, name);
if (name.length())
classNames.push_back(name);
}
fp.close();
return classNames;
}
2. SSD vehicle and license plate detection
In the above project, we use the resnet18 model to realize the function of image classification. Resnet18, a residual series network, is also a basic backbone network. Realizing image classification is one of its basic functions. In computer vision, in addition to classification, another most common is target detection. So next, we will realize how to deploy and accelerate an object detection network through openvino. Here, we use a model that comes with openvino model library. This model can quickly help us realize the object detection of a specific application scenario. This application scenario is the detection of vehicles and license plates, which is very common at highway checkpoints. This case is how to realize a fast vehicle and license plate detection through openvino framework.
2.1 practical cases of vehicle license plate detection
2.1.1 introduction to the model

Figure 11
We should also explain it here; You may have some very common models, and then you can detect the whole scene. This is open scene detection, but in practical applications, your application scenario may be applied in a vertical field. You just need to do your best in this, so you may build your model very small at this time, However, the model will also be used in specific scenes to achieve high recognition rate. For example, our current model of vehicle license plate detection is very small, but it is very good in the application scenario of highway bayonet.
"C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\open_model_zoo\models\intel\vehicle-license-plate-detection-barrier-0106\description\vehicle-license-plate-detection-barrier-0106.html" you can view this file, which is the official description of the model ehicle-license-plate-detection-barrier-0106.
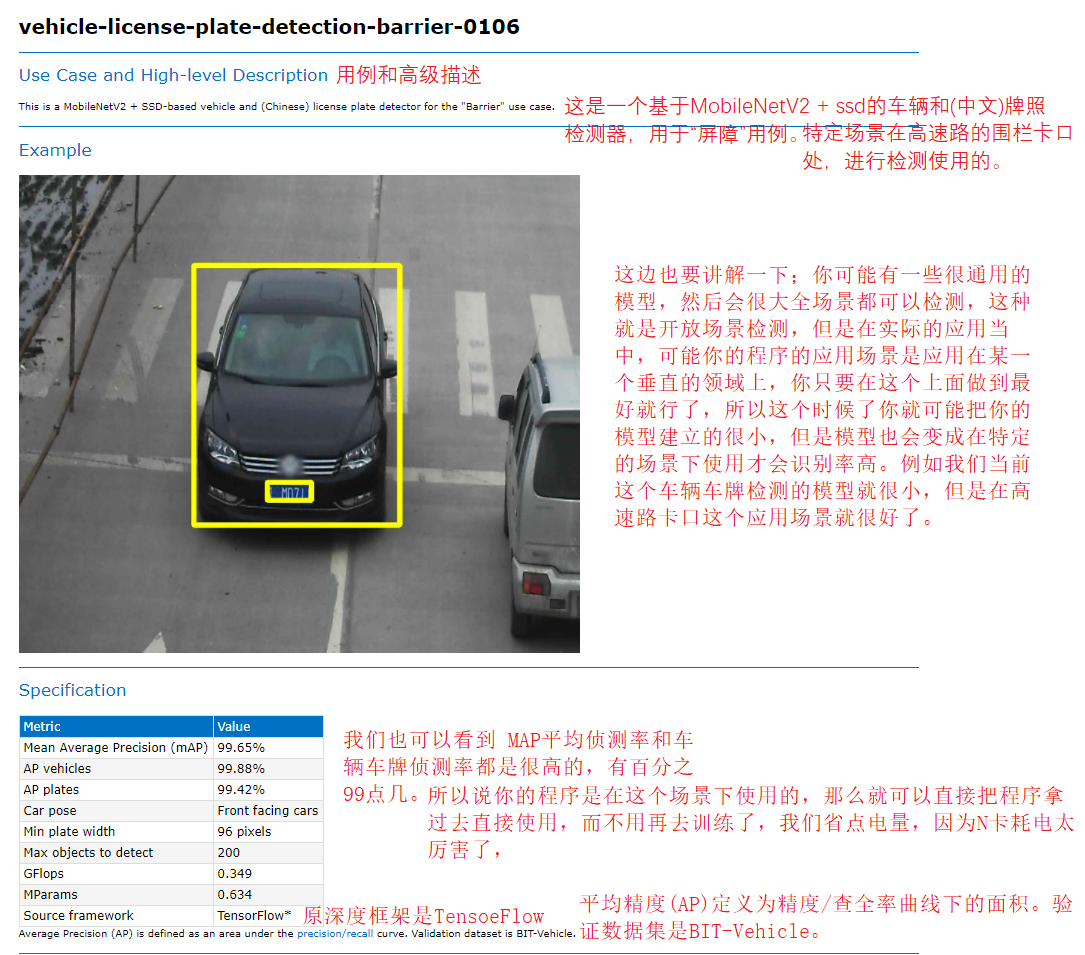
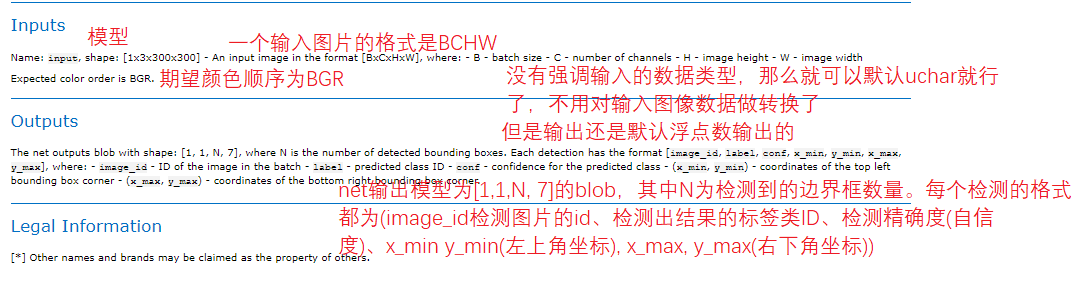
Figure 12 13
2.1.2 process calling sequence of code
It is similar to the previous resnet18 image classification,
Loading model
Set input and output
Build input
Execute inference
Parse output
Display results
Can directly take the last code for transformation.
2.1.3. Download the model in OpenVINO model library
I knew OpenVINO before_ 2021.2.185\deployment_ tools\open_ model_ Zoo \ models \ intel in this directory is all the model libraries of intel supported by OpenVINO, but only the introduction here shows that the practice model download still needs to be downloaded through the tool.
Download tools of Intel official model;
Use the script in this directory; “C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\open_model_zoo\tools\downloader\downloader.py”,
Execute orders;
Previously encountered the problem that permissions cannot be downloaded: the solution is to find CMD Exe can be opened by administrator.
After the download is successful, the vehicle-license-plate-detection-barrier-0106 folder will be generated
vehicle-license-plate-detection-barrier-0106 will download three models with different quantization ratios
FP16 semi precision
FP16-INT8 8-bit quantized
FP32 full precision
We use FP32 full precision on PC.
2.1.4 code demonstration

Figure 14
Example code
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
int main(int argc, char** argv)
{
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
std::string xmlFilename = "D:/code/OpenVINO/OpenVINO_SupportMode/vehicle-license-plate-detection-barrier-0106/FP32/vehicle-license-plate-detection-barrier-0106.xml";
std::string binFilename = "D:/code/OpenVINO/OpenVINO_SupportMode/vehicle-license-plate-detection-barrier-0106/FP32/vehicle-license-plate-detection-barrier-0106.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
input_data->setPrecision(Precision::U8);//The input image data format is unsigned char, which is the precision of 8 bits
//This is also the input data mode set according to the model
input_data->setLayout(Layout::NCHW);
//ColorFormat is also input according to the model settings
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//The model specifies that the input picture is BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << output_name << std::endl;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
auto infer_request = executable_network.CreateInferRequest();
//6. Gets the input Blob format conversion class object
auto input = infer_request.GetBlob(input_name);//Get the blob of input (class object for input formatting)
size_t num_channels = input->getTensorDesc().getDims()[1];
size_t h = input->getTensorDesc().getDims()[2];
size_t w = input->getTensorDesc().getDims()[3];
size_t image_size = h * w;
//7. Preprocessing of input image data (including BGR - > RGB, size floating point calculation conversion, image sequence conversion HWC - > nchw)
cv::Mat src = cv::imread("D:/Vihecle.jpg");//Original drawing to be parsed
//cv::namedWindow("input",cv::WINDOW_FREERATIO);// Set the free scale of the window to ensure that the picture can be displayed normally even if it is too large
int im_h = src.rows;
int im_w = src.cols;
cv::Mat blob_image;//Convert to network, you can parse the picture format
cv::resize(src, blob_image, cv::Size(w, h));//Conversion size
//8. Set the set data into the input Blob - > in fact, the memory space for storing the input image data has been opened up when GetBlob()
unsigned char* data = static_cast<unsigned char*>(input->buffer());//This is to directly fill the data into the specified space of input after data conversion
//be careful; The order of mat images returned by opencv is HWC. To convert it to NCHW is to convert a matrix of HWC type to NCHW type, which is the problem of matrix filling
// HWC = NCHW conversion
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
for (size_t ch = 0; ch < num_channels; ch++) {
//blob_image is the HWC format from opencv - "conversion to NCHW" means that each channel becomes a graph according to the channel order. The of the first few channels is the storage of the first few pictures
data[image_size * ch + row * w + col] = blob_image.at<cv::Vec3b>(row, col)[ch];
}
}
}
//8. Executive reasoning
infer_request.Infer();
//9. Get our output
auto output = infer_request.GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//Output result of detection
//10. Finally, you need to obtain the output dimension information and parse the data
const SizeVector outputDims = output->getTensorDesc().getDims();
std::cout << outputDims[2] << "X" << outputDims[3] << std::endl;
const int max_num = outputDims[2];//Is the output N
const int object_size = outputDims[3];//It's the output 7
for (int n = 0; n < max_num; n++)
{
float lable = detection_out[n*object_size + 1];// +1 indicates that the output is the second lableID of the seven
float confidence = detection_out[n * object_size + 2];
float xmin = detection_out[n * object_size + 3] * im_w; //The floating point coordinates obtained from the output are 0-1, and the actual coordinates are multiplied by the original width and height
float ymin = detection_out[n * object_size + 4] * im_h;
float xmax = detection_out[n * object_size + 5] * im_w;
float ymax = detection_out[n * object_size + 6] * im_h;
if (confidence > 0.5)
{
printf("lable id = %d\n", static_cast<int>(lable));
cv::Rect box;
box.x = static_cast<int>(xmin);
box.y = static_cast<int>(ymin);
box.width = static_cast<int>(xmax - xmin);
box.height = static_cast<int>(ymax - ymin);
if (lable == 2)//License plate
{
cv::rectangle(src, box, cv::Scalar(0, 255, 0), 2, 8, 0);
}
else
{
cv::rectangle(src, box, cv::Scalar(0, 0, 255), 2, 8, 0);
}
cv::putText(src, cv::format("%.2f", confidence), box.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
}
}
cv::imshow("input", src);
cv::waitKey(0);
return 0;
}
2.2 Chinese license plate recognition
Why Chinese license plate recognition? Because the model trained by OpenVINO is very friendly, it can directly detect Chinese license plates and output results. Of course, this is also a specific scenario applied to license plate detection and recognition at highway checkpoints. It can be used in fixed application scenarios, but you can train it in other scenarios. There is a training framework and script on github, which is based on tersorflow1 Developed by version X.
2.2.1 model introduction

Figure 15
View license-plate-recognition-barrier-0001 Introduction to the official template provided by HTML

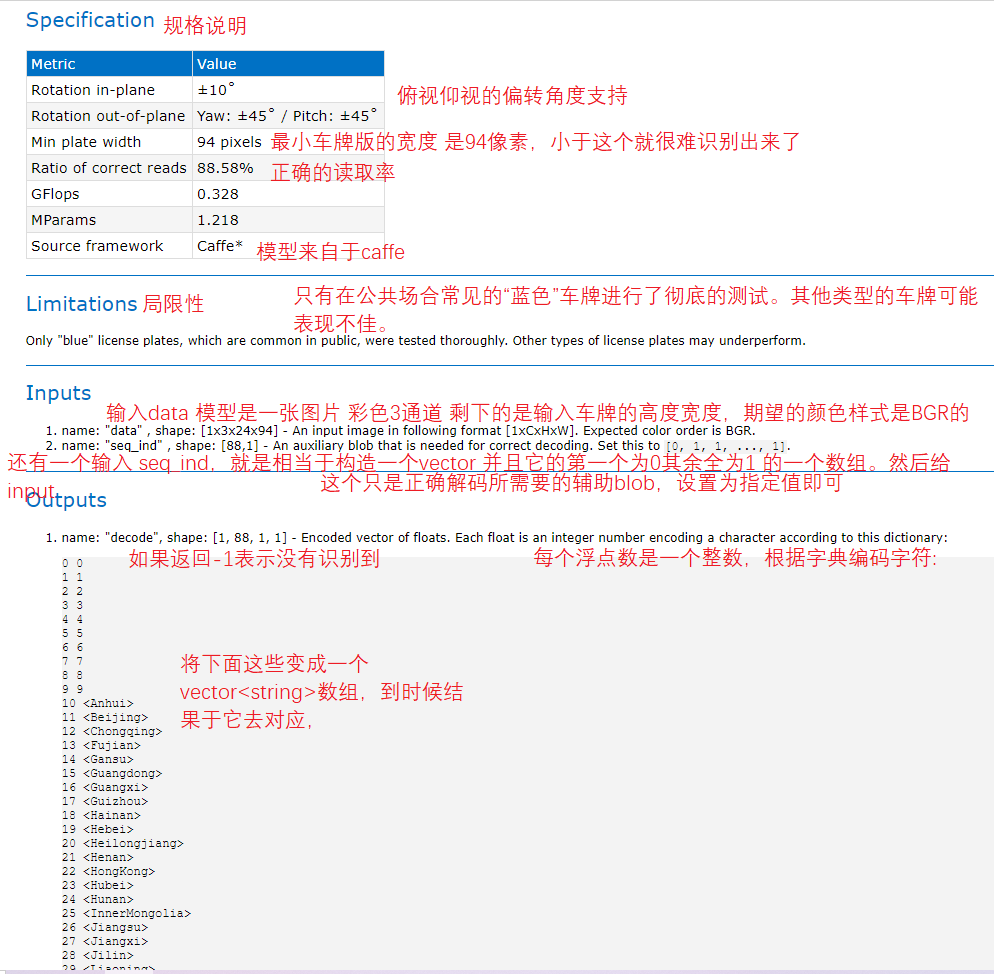
Figure 16, 17
2.2.2 call execution process
Load model (two models (detection and recognition), both loaded only once)
Detect the vehicle and license plate. If it is a license plate, identify the license plate. If it is a vehicle, do not deal with it
2.2.3 code demonstration
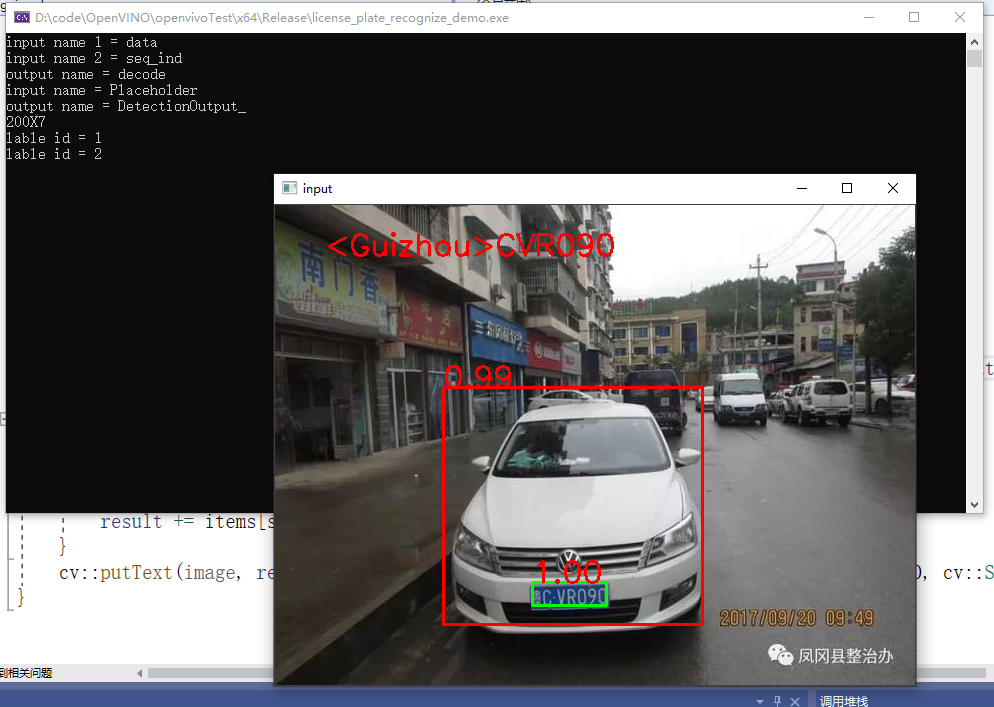
Figure 18
Practice code
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
static const char* const items[] = {
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9",
"<Anhui>", "<Beijing>", "<Chongqing>", "<Fujian>",
"<Gansu>", "<Guangdong>", "<Guangxi>", "<Guizhou>",
"<Hainan>", "<Hebei>", "<Heilongjiang>", "<Henan>",
"<HongKong>", "<Hubei>", "<Hunan>", "<InnerMongolia>",
"<Jiangsu>", "<Jiangxi>", "<Jilin>", "<Liaoning>",
"<Macau>", "<Ningxia>", "<Qinghai>", "<Shaanxi>",
"<Shandong>", "<Shanghai>", "<Shanxi>", "<Sichuan>",
"<Tianjin>", "<Tibet>", "<Xinjiang>", "<Yunnan>",
"<Zhejiang>", "<police>",
"A", "B", "C", "D", "E", "F", "G", "H", "I", "J",
"K", "L", "M", "N", "O", "P", "Q", "R", "S", "T",
"U", "V", "W", "X", "Y", "Z"
};
void load_plate_recog_model(InferenceEngine::InferRequest &plate_request, std::string &plate_input_name1, std::string &plate_input_name2, std::string &plate_output_name);
void fetch_plate_text(InferenceEngine::InferRequest& plate_request, std::string& plate_input_name1, std::string& plate_input_name2, std::string& plate_output_name, cv::Mat &image, cv::Mat plateROI);
int main(int argc, char** argv)
{
InferenceEngine::InferRequest plate_request;
std::string plate_input_name1;//Although the official document says what the name is, there are sometimes bug s, so the code gets the name at last
std::string plate_input_name2;
std::string plate_output_name;
load_plate_recog_model(plate_request, plate_input_name1, plate_input_name2, plate_output_name);//Load license plate recognition model
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
std::string xmlFilename = "D:/code/OpenVINO/OpenVINO_SupportMode/vehicle-license-plate-detection-barrier-0106/FP32/vehicle-license-plate-detection-barrier-0106.xml";
std::string binFilename = "D:/code/OpenVINO/OpenVINO_SupportMode/vehicle-license-plate-detection-barrier-0106/FP32/vehicle-license-plate-detection-barrier-0106.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
input_data->setPrecision(Precision::U8);//The input image data format is unsigned char, which is the precision of 8 bits
//This is also the input data mode set according to the model
input_data->setLayout(Layout::NCHW);
//ColorFormat is also input according to the model settings
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//The model specifies that the input picture is BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << output_name << std::endl;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
auto infer_request = executable_network.CreateInferRequest();
//6. Gets the input Blob format conversion class object
auto input = infer_request.GetBlob(input_name);//Get the blob of input (class object for input formatting)
size_t num_channels = input->getTensorDesc().getDims()[1];
size_t h = input->getTensorDesc().getDims()[2];
size_t w = input->getTensorDesc().getDims()[3];
size_t image_size = h * w;
//7. Preprocessing of input image data (including BGR - > RGB, size floating point calculation conversion, image sequence conversion HWC - > nchw)
cv::Mat src = cv::imread("D:/Vihecle.jpg");//Original drawing to be parsed
//cv::namedWindow("input",cv::WINDOW_FREERATIO);// Set the free scale of the window to ensure that the picture can be displayed normally even if it is too large
int im_h = src.rows;
int im_w = src.cols;
cv::Mat blob_image;//Convert to network, you can parse the picture format
cv::resize(src, blob_image, cv::Size(w, h));//Conversion size
//8. Set the set data into the input Blob - > in fact, the memory space for storing the input image data has been opened up when GetBlob()
unsigned char* data = static_cast<unsigned char*>(input->buffer());//This is to directly fill the data into the specified space of input after data conversion
//be careful; The order of mat images returned by opencv is HWC. To convert it to NCHW is to convert a matrix of HWC type to NCHW type, which is the problem of matrix filling
// HWC = NCHW conversion
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
for (size_t ch = 0; ch < num_channels; ch++) {
//blob_image is the HWC format from opencv - "conversion to NCHW" means that each channel becomes a graph according to the channel order. The of the first few channels is the storage of the first few pictures
data[image_size * ch + row * w + col] = blob_image.at<cv::Vec3b>(row, col)[ch];
}
}
}
//8. Executive reasoning
infer_request.Infer();
//9. Get our output
auto output = infer_request.GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//Output result of detection
//10. Finally, you need to obtain the output dimension information and parse the data
const SizeVector outputDims = output->getTensorDesc().getDims();
std::cout << outputDims[2] << "X" << outputDims[3] << std::endl;
const int max_num = outputDims[2];//Is the output N
const int object_size = outputDims[3];//It's the output 7
for (int n = 0; n < max_num; n++)
{
float lable = detection_out[n * object_size + 1];// +1 indicates that the output is the second lableID of the seven
float confidence = detection_out[n * object_size + 2];
float xmin = detection_out[n * object_size + 3] * im_w; //The floating point coordinates obtained from the output are 0-1, and the actual coordinates are multiplied by the original width and height
float ymin = detection_out[n * object_size + 4] * im_h;
float xmax = detection_out[n * object_size + 5] * im_w;
float ymax = detection_out[n * object_size + 6] * im_h;
if (confidence > 0.5)
{
printf("lable id = %d\n", static_cast<int>(lable));
cv::Rect box;
box.x = static_cast<int>(xmin);
box.y = static_cast<int>(ymin);
box.width = static_cast<int>(xmax - xmin);
box.height = static_cast<int>(ymax - ymin);
if (lable == 2)//License plate
{
// recognize plate
cv::Rect plate_roi;//Each side is a little more than the detected rectangle for easy identification
plate_roi.x = box.x - 5;
plate_roi.y = box.y - 5;
plate_roi.width = box.width + 10;
plate_roi.height = box.height + 10;
fetch_plate_text(plate_request, plate_input_name1, plate_input_name2, plate_output_name, src, src(plate_roi));
cv::rectangle(src, box, cv::Scalar(0, 255, 0), 2, 8, 0);
}
else
{
cv::rectangle(src, box, cv::Scalar(0, 0, 255), 2, 8, 0);
}
cv::putText(src, cv::format("%.2f", confidence), box.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
}
}
cv::imshow("input", src);
cv::waitKey(0);
return 0;
}
void load_plate_recog_model(InferenceEngine::InferRequest& plate_request, std::string& plate_input_name1, std::string& plate_input_name2, std::string& plate_output_name)
{
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
std::string xmlFilename = "D:/code/OpenVINO/license-plate-recognition-barrier-0001/FP32/license-plate-recognition-barrier-0001.xml";
std::string binFilename = "D:/code/OpenVINO/license-plate-recognition-barrier-0001/FP32/license-plate-recognition-barrier-0001.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
int cnt = 0;
for (auto item : inputs)//Because this model has two inputs, it will cycle twice
{
if (cnt == 0)
{
plate_input_name1 = item.first;
auto input_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
input_data->setPrecision(Precision::U8);//The input image data format is unsigned char, which is the precision of 8 bits
//This is also the input data mode set according to the model
input_data->setLayout(Layout::NCHW);
//ColorFormat is also input according to the model settings
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//The model specifies that the input picture is BGR
}
if (cnt == 1)
{
plate_input_name2 = item.first;
auto input_data = item.second;
input_data->setPrecision(Precision::FP32);
}
//input_name = item.first;
std::cout << "input name " << cnt+1 << " = " << item.first << std::endl;
cnt++;
}
for (auto item : outputs)
{
plate_output_name = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << plate_output_name << std::endl;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
plate_request = executable_network.CreateInferRequest();
}
void fetch_plate_text(InferenceEngine::InferRequest& plate_request, std::string& plate_input_name1, std::string& plate_input_name2, std::string& plate_output_name, cv::Mat& image, cv::Mat plateROI)
{
//Set input
auto input1 = plate_request.GetBlob(plate_input_name1);
size_t num_channels = input1->getTensorDesc().getDims()[1];
size_t h = input1->getTensorDesc().getDims()[2];
size_t w = input1->getTensorDesc().getDims()[3];
size_t image_size = h * w;
cv::Mat blob_image;//Convert to network, you can parse the picture format
cv::resize(plateROI, blob_image, cv::Size(w, h));//Conversion size
unsigned char* data = static_cast<unsigned char*>(input1->buffer());//This is to directly fill the data into the specified space of input after data conversion
//be careful; The order of mat images returned by opencv is HWC. To convert it to NCHW is to convert a matrix of HWC type to NCHW type, which is the problem of matrix filling
// HWC = NCHW conversion
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
for (size_t ch = 0; ch < num_channels; ch++) {
//blob_image is the HWC format from opencv - "conversion to NCHW" means that each channel becomes a graph according to the channel order. The of the first few channels is the storage of the first few pictures
data[image_size * ch + row * w + col] = blob_image.at<cv::Vec3b>(row, col)[ch];
}
}
}
auto input2 = plate_request.GetBlob(plate_input_name2);
int max_sequence = input2->getTensorDesc().getDims()[0];//The first dimension of the second input is the length of the sequence
float* blob2 = input2->buffer().as<float*>();
blob2[0] = 0.0f;
std::fill(blob2 + 1, blob2 + max_sequence, 1.0f);
//Executive reasoning
plate_request.Infer();
//Output results
auto output = plate_request.GetBlob(plate_output_name);
const float* plate_data = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//Output result of detection
std::string result;
for (int i = 0; i < max_sequence; i++)
{
if (plate_data[i] == -1)
break;
result += items[std::size_t(plate_data[i])];
}
cv::putText(image, result.c_str(), cv::Point(50, 50), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
}
3. Pedestrian detection
3.1 model introduction

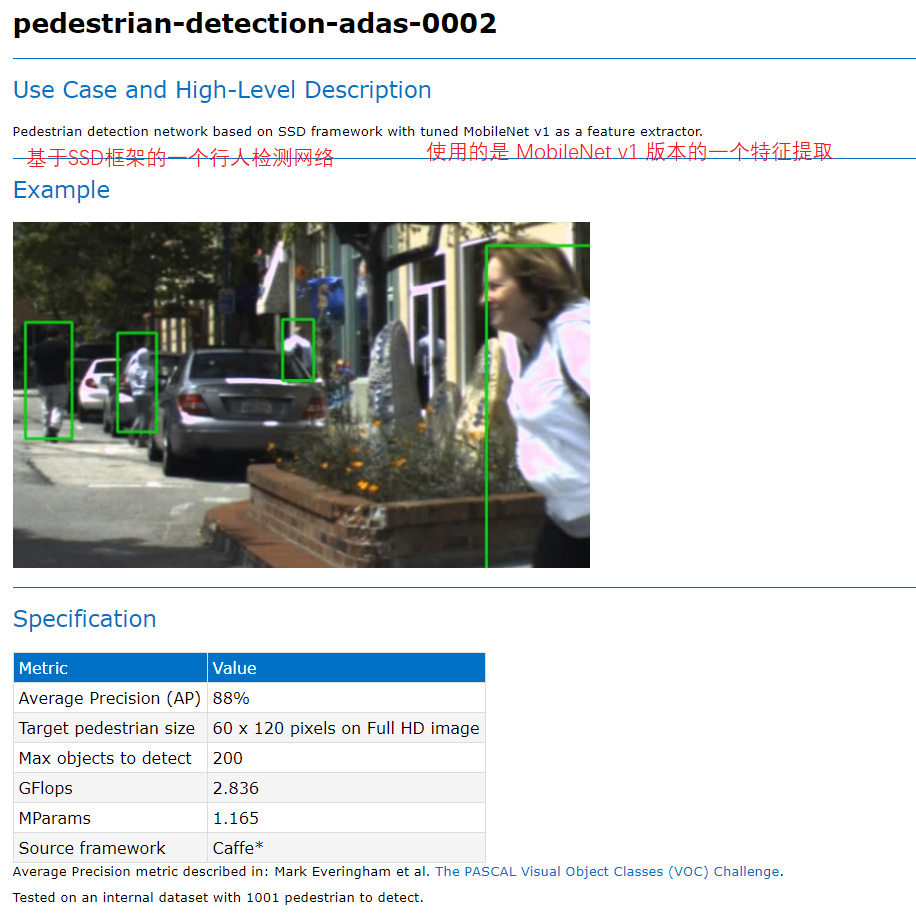
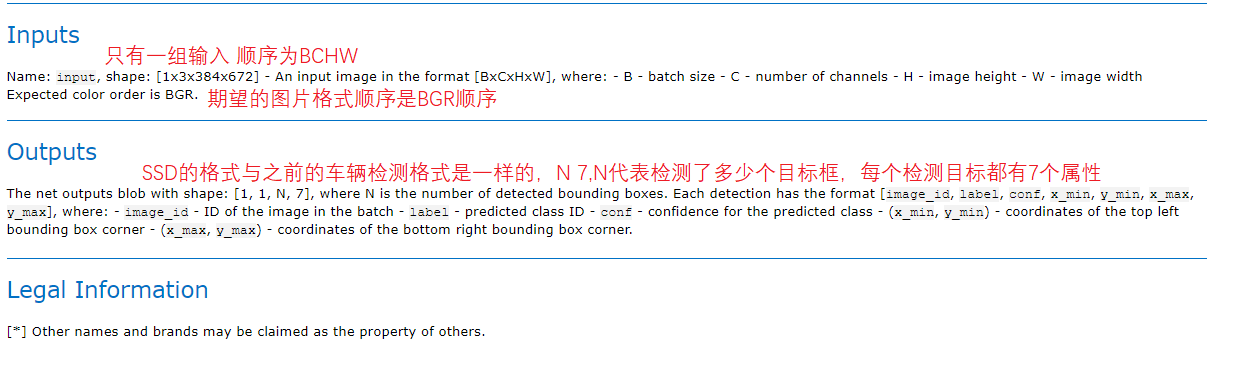
Figure 19 20 21
3.2 procedure execution process
Because they are SSD models and consistent with the input and output format of the vehicle detection model, they are BCHW inputs and 1 N 7 format outputs. Therefore, the overall code of vehicle detection can be directly taken for use. You only need to change the model path.
3.3 program demonstration
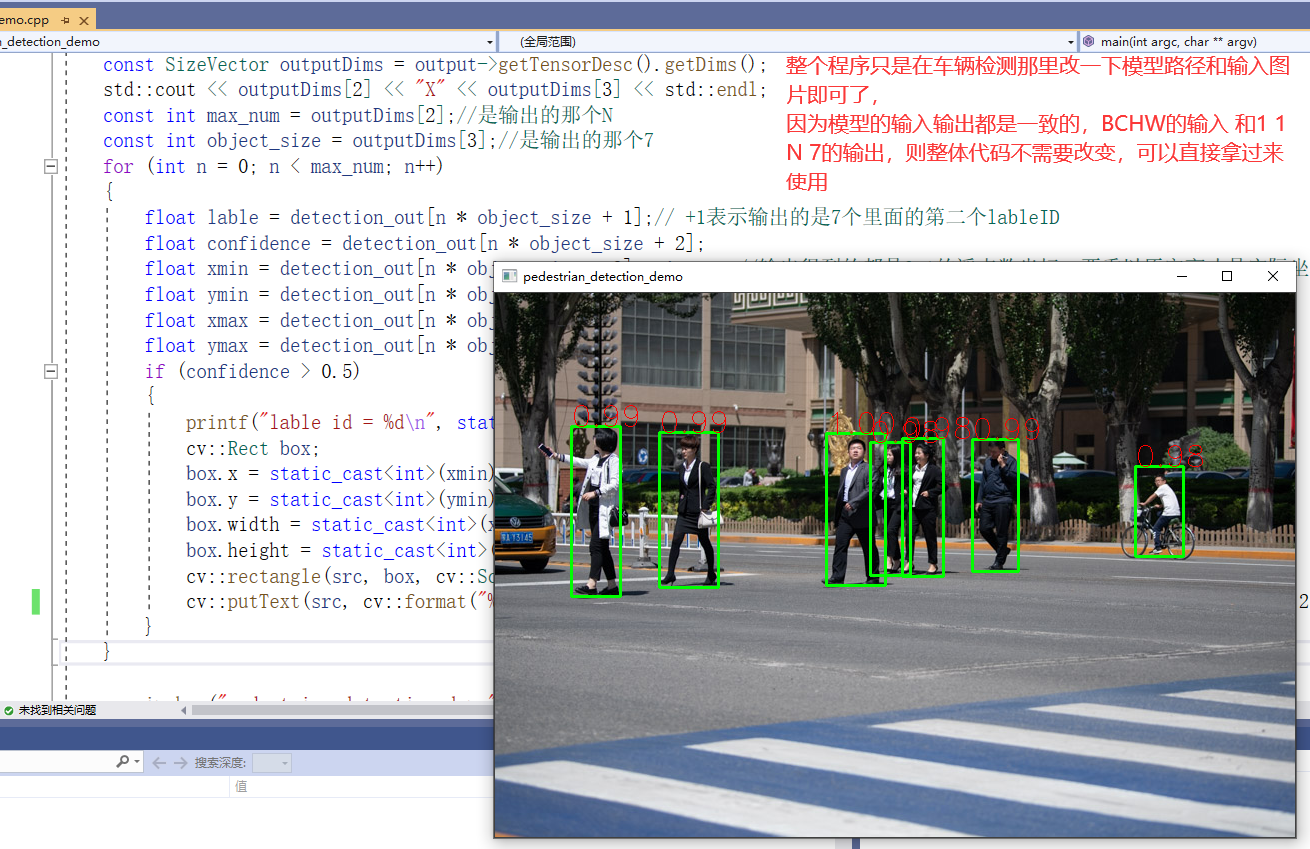
Figure 22
3.4 pedestrian detection in video
The code flow is similar, but the reasoning part is extracted into a function, which is passed in by passing parameters. The input is changed to read the video, and each frame is displayed after image reasoning.
It can be seen that openVINO model detection is used for video. It has no effect on the speed, and for this video with small width and height. openVINO model has the effect of hundreds of frames per second for video processing. You can also specify that openVINO has a significant acceleration effect on the model after using the model.
Practical effect
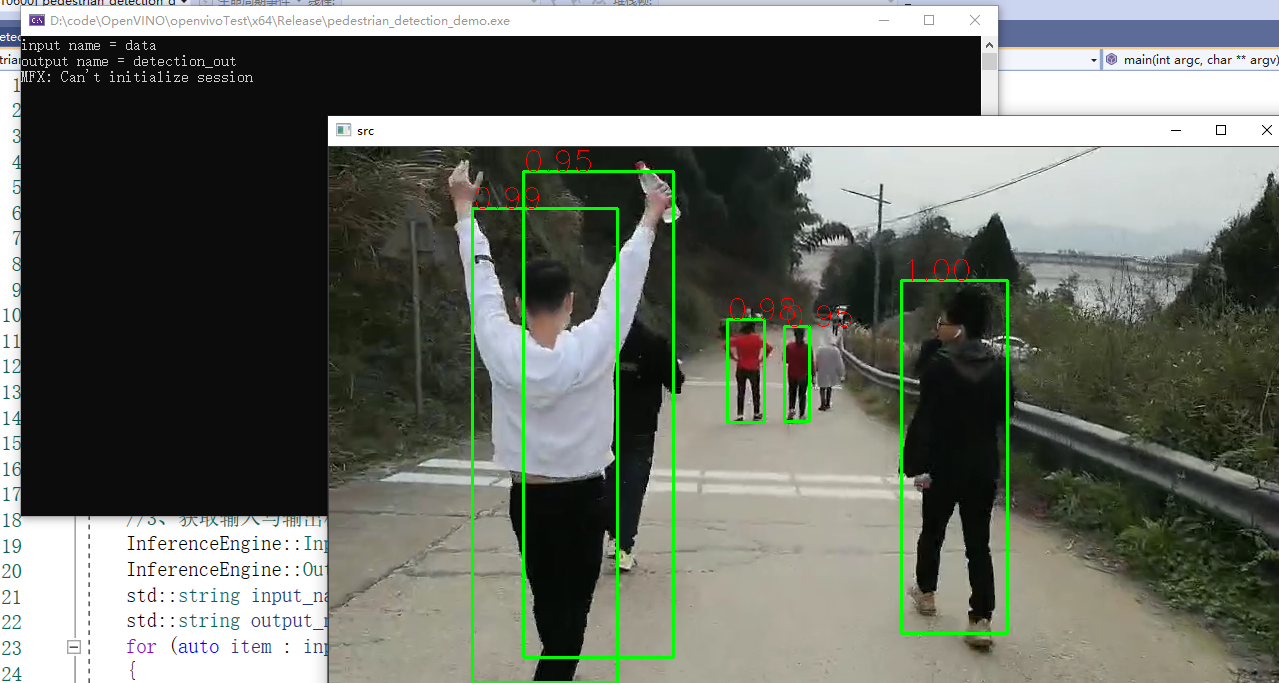
Figure 23
Code practice
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
void infer_process(cv::Mat &src, InferenceEngine::InferRequest & infer_request, std::string& input_name, std::string& output_name);
//Image pedestrian detection
int main(int argc, char** argv)
{
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
std::string xmlFilename = "D:/code/OpenVINO/pedestrian-detection-adas-0002/FP32/pedestrian-detection-adas-0002.xml";
std::string binFilename = "D:/code/OpenVINO/pedestrian-detection-adas-0002/FP32/pedestrian-detection-adas-0002.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
input_data->setPrecision(Precision::U8);//The input image data format is unsigned char, which is the precision of 8 bits
//This is also the input data mode set according to the model
input_data->setLayout(Layout::NCHW);
//ColorFormat is also input according to the model settings
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//The model specifies that the input picture is BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << output_name << std::endl;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
auto infer_request = executable_network.CreateInferRequest();
//6. Create video stream / load video file
cv::VideoCapture capture("D:/padestrian_detection.mp4");
cv::Mat src;
while (true)
{
bool ret = capture.read(src);
if (ret == false)
break;
//7. Loop execution reasoning
infer_process(src, infer_request, input_name, output_name);
cv::imshow("src", src);
char c = cv::waitKey(1);
if (c == 27)//Press esc
break;
}
//cv::imshow("pedestrian_detection_demo", src);
cv::waitKey(0);
return 0;
}
void infer_process(cv::Mat& src, InferenceEngine::InferRequest& infer_request, std::string& input_name, std::string& output_name)
{
//1. Through the incoming reasoning engine; Gets the input Blob format conversion class object
auto input = infer_request.GetBlob(input_name);//Get the blob of input (class object for input formatting)
size_t num_channels = input->getTensorDesc().getDims()[1];
size_t h = input->getTensorDesc().getDims()[2];
size_t w = input->getTensorDesc().getDims()[3];
size_t image_size = h * w;
//2. Convert input image
int im_h = src.rows;
int im_w = src.cols;
cv::Mat blob_image;//Convert to network, you can parse the picture format
cv::resize(src, blob_image, cv::Size(w, h));//Conversion size
//3. Set the set data into the input Blob - > in fact, the memory space for storing the input image data has been opened up when GetBlob()
unsigned char* data = static_cast<unsigned char*>(input->buffer());//This is to directly fill the data into the specified space of input after data conversion
//be careful; The order of mat images returned by opencv is HWC. To convert it to NCHW is to convert a matrix of HWC type to NCHW type, which is the problem of matrix filling
// HWC = NCHW conversion
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
for (size_t ch = 0; ch < num_channels; ch++) {
//blob_image is the HWC format from opencv - "conversion to NCHW" means that each channel becomes a graph according to the channel order. The of the first few channels is the storage of the first few pictures
data[image_size * ch + row * w + col] = blob_image.at<cv::Vec3b>(row, col)[ch];
}
}
}
//4. Executive reasoning
infer_request.Infer();
//5. Get our output
auto output = infer_request.GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//Output result of detection
//6. Finally, you need to obtain the output dimension information and parse the data
const SizeVector outputDims = output->getTensorDesc().getDims();
//std::cout << outputDims[2] << "X" << outputDims[3] << std::endl;
const int max_num = outputDims[2];//Is the output N
const int object_size = outputDims[3];//It's the output 7
for (int n = 0; n < max_num; n++)
{
float lable = detection_out[n * object_size + 1];// +1 indicates that the output is the second lableID of the seven
float confidence = detection_out[n * object_size + 2];
float xmin = detection_out[n * object_size + 3] * im_w; //The floating point coordinates obtained from the output are 0-1, and the actual coordinates are multiplied by the original width and height
float ymin = detection_out[n * object_size + 4] * im_h;
float xmax = detection_out[n * object_size + 5] * im_w;
float ymax = detection_out[n * object_size + 6] * im_h;
if (confidence > 0.5)
{
//printf("lable id = %d\n", static_cast<int>(lable));
cv::Rect box;
box.x = static_cast<int>(xmin);
box.y = static_cast<int>(ymin);
box.width = static_cast<int>(xmax - xmin);
box.height = static_cast<int>(ymax - ymin);
cv::rectangle(src, box, cv::Scalar(0, 255, 0), 2, 8, 0);
cv::putText(src, cv::format("%.2f", confidence), box.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 1, 8);
}
}
}
4. Asynchronous reasoning for real-time face detection
4.1 model introduction
OpenVINO comes with a series of lightweight face detection models, most of which can reach 100 or higher fps, so it can be more suitable for deployment on edge end devices.

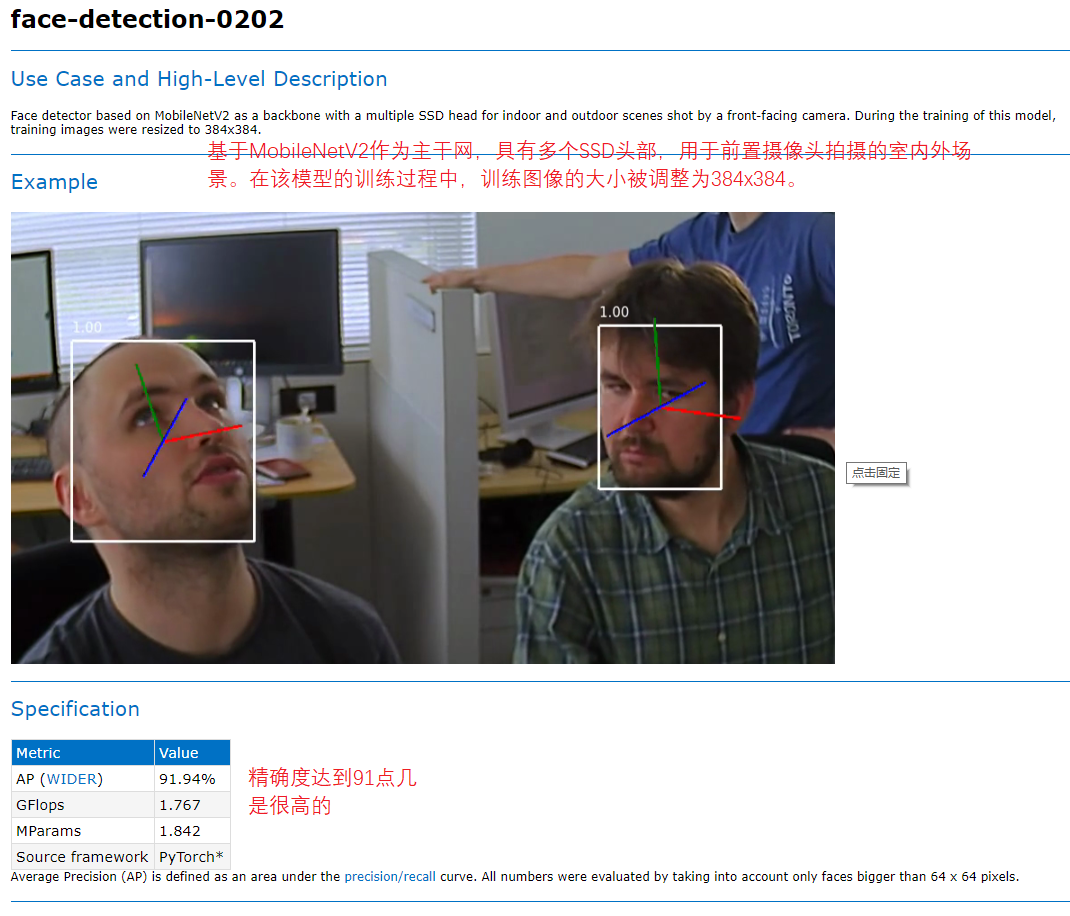

Figure 24, 25, 26
It can be compared with OpenCV. Opencv is a traditional module, and OpenVINO is also an algorithm. The difference is that each algorithm here is a module based on deep learning, and each model provided. You can get different algorithm performance by developing around this model
4.2. Synchronous / asynchronous execution
Previous model practices used infer_request.Infer() is a synchronous model, but asynchronous is different,
4.3 code demonstration
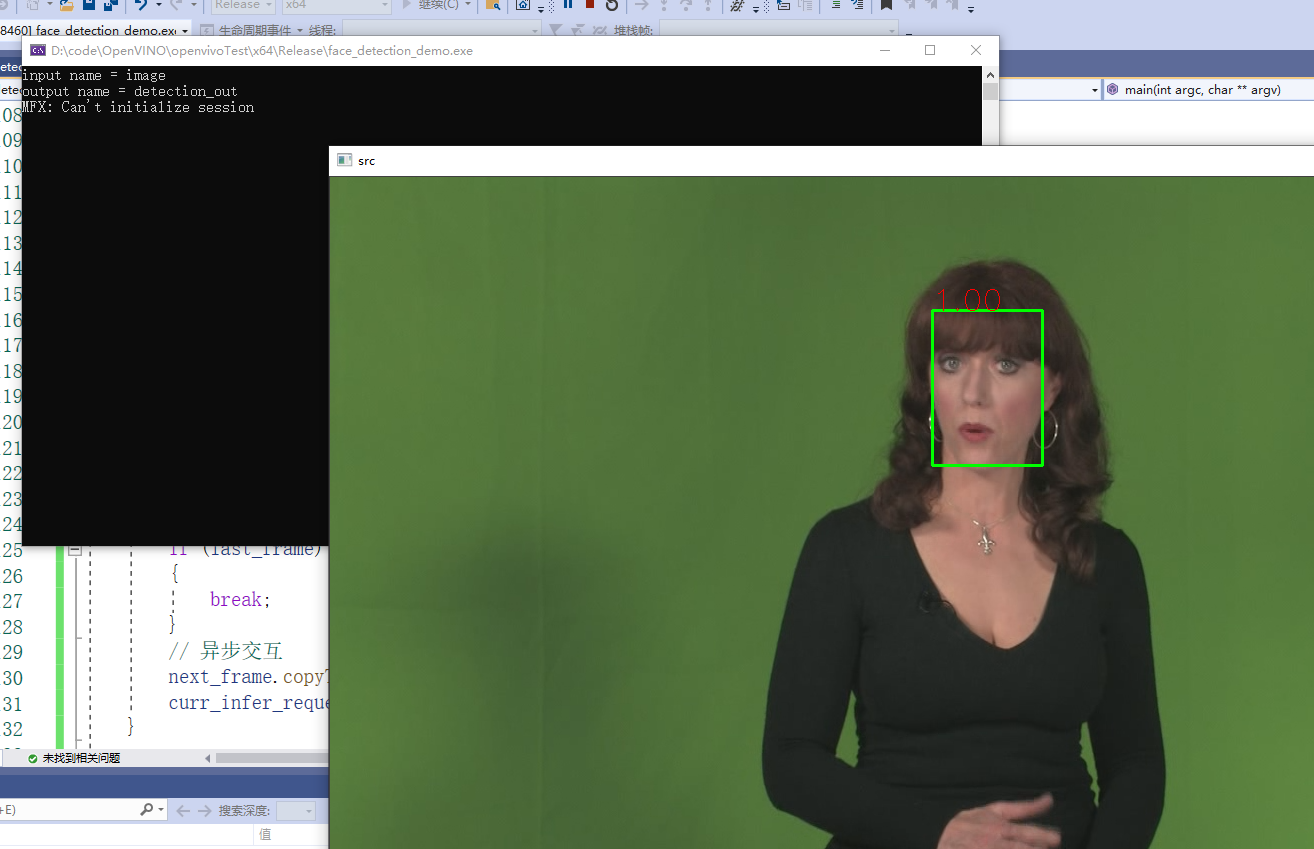
Figure 30
Synchronous implementation
Asynchronous implementation
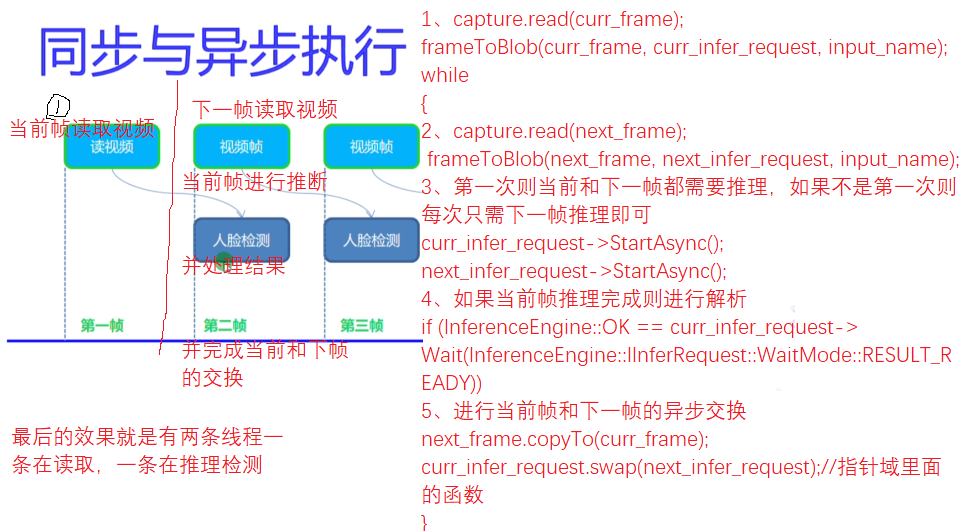
Figure 27
Code practice
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
//Convert the U8 type data from mat to Blob. Because Blob is of any type, it is also declared as a template
template <typename T> void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name);
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name);
int main(int argc, char** argv)
{
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
std::string xmlFilename = "D:/code/OpenVINO/face-detection-0202/FP32/face-detection-0202.xml";
std::string binFilename = "D:/code/OpenVINO/face-detection-0202/FP32/face-detection-0202.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
input_data->setPrecision(Precision::U8);//The input image data format is unsigned char, which is the precision of 8 bits
//This is also the input data mode set according to the model
input_data->setLayout(Layout::NCHW);
//ColorFormat is also input according to the model settings
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//The model specifies that the input picture is BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << output_name << std::endl;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
auto curr_infer_request = executable_network.CreateInferRequestPtr();
auto next_infer_request = executable_network.CreateInferRequestPtr();
//6. Preprocessing of input image data (including BGR - > RGB, size floating point calculation conversion, image sequence conversion HWC - > nchw)
cv::VideoCapture capture(0);
cv::Mat curr_frame;
cv::Mat next_frame;
capture.read(curr_frame);
frameToBlob(curr_frame, curr_infer_request, input_name);
bool first_frame = true;
bool last_frame = false;
while (true)
{
bool ret = capture.read(next_frame);
if (ret == false)//It's the last frame
{
last_frame = true;//No more settings entered
}
if (!last_frame)//The next frame is not set at the last frame
{
frameToBlob(next_frame, next_infer_request, input_name);
}
if (first_frame)
{
curr_infer_request->StartAsync();//Start reasoning
next_infer_request->StartAsync();
first_frame = false;
}
else
{
if (!last_frame)//Each start is the next frame ready for asynchronous exchange
{
next_infer_request->StartAsync();
}
}
//7. Loop execution reasoning, each reasoning is the current frame, and it will be parsed after the reasoning is successful
if (InferenceEngine::OK == curr_infer_request->Wait(InferenceEngine::IInferRequest::WaitMode::RESULT_READY))
{
infer_process(curr_frame, curr_infer_request, output_name);
}
cv::imshow("src", curr_frame);
char c = cv::waitKey(1);
if (c == 27)//Press esc
break;
if (last_frame)
{
break;
}
// Asynchronous interaction
next_frame.copyTo(curr_frame);
curr_infer_request.swap(next_infer_request);//Function in pointer field
}
return 0;
}
// SSD MobileNetV2 model input reasoning setting function encapsulation because the infer needs to be modified_ All requests still need to pass pointers, smart pointers
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name)
{
//1. Through the incoming reasoning engine; Gets the input Blob format conversion class object
auto input = infer_request->GetBlob(input_name);//Get the blob of input (class object for input formatting)
matU8ToBlob<uchar>(src, input);
return;
}
// SSD MobileNetV2 model output reasoning function encapsulation
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name)
{
//1. Executive reasoning
//infer_ request->Infer(); Asynchronous reasoning does not need this step
//2. Get our output
auto output = infer_request->GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//Output result of detection
//3. Finally, you need to obtain the output dimension information and parse the data
const SizeVector outputDims = output->getTensorDesc().getDims();
//std::cout << outputDims[2] << "X" << outputDims[3] << std::endl;
const int max_num = outputDims[2];//Is the output N
const int object_size = outputDims[3];//It's the output 7
int im_h = src.rows;
int im_w = src.cols;
for (int n = 0; n < max_num; n++)
{
float lable = detection_out[n * object_size + 1];// +1 indicates that the output is the second lableID of the seven
float confidence = detection_out[n * object_size + 2];
float xmin = detection_out[n * object_size + 3] * im_w; //The floating point coordinates obtained from the output are 0-1, and the actual coordinates are multiplied by the original width and height
float ymin = detection_out[n * object_size + 4] * im_h;
float xmax = detection_out[n * object_size + 5] * im_w;
float ymax = detection_out[n * object_size + 6] * im_h;
if (confidence > 0.5)
{
//printf("lable id = %d\n", static_cast<int>(lable));
cv::Rect box;
box.x = static_cast<int>(xmin);
box.y = static_cast<int>(ymin);
box.width = static_cast<int>(xmax - xmin);
box.height = static_cast<int>(ymax - ymin);
cv::rectangle(src, box, cv::Scalar(0, 255, 0), 2, 8, 0);
cv::putText(src, cv::format("%.2f", confidence), box.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 1, 8);
}
}
}
5. Real time facial expression recognition
It mainly loads the model of facial expression recognition based on face detection to recognize five common facial expressions.
5.1 model introduction
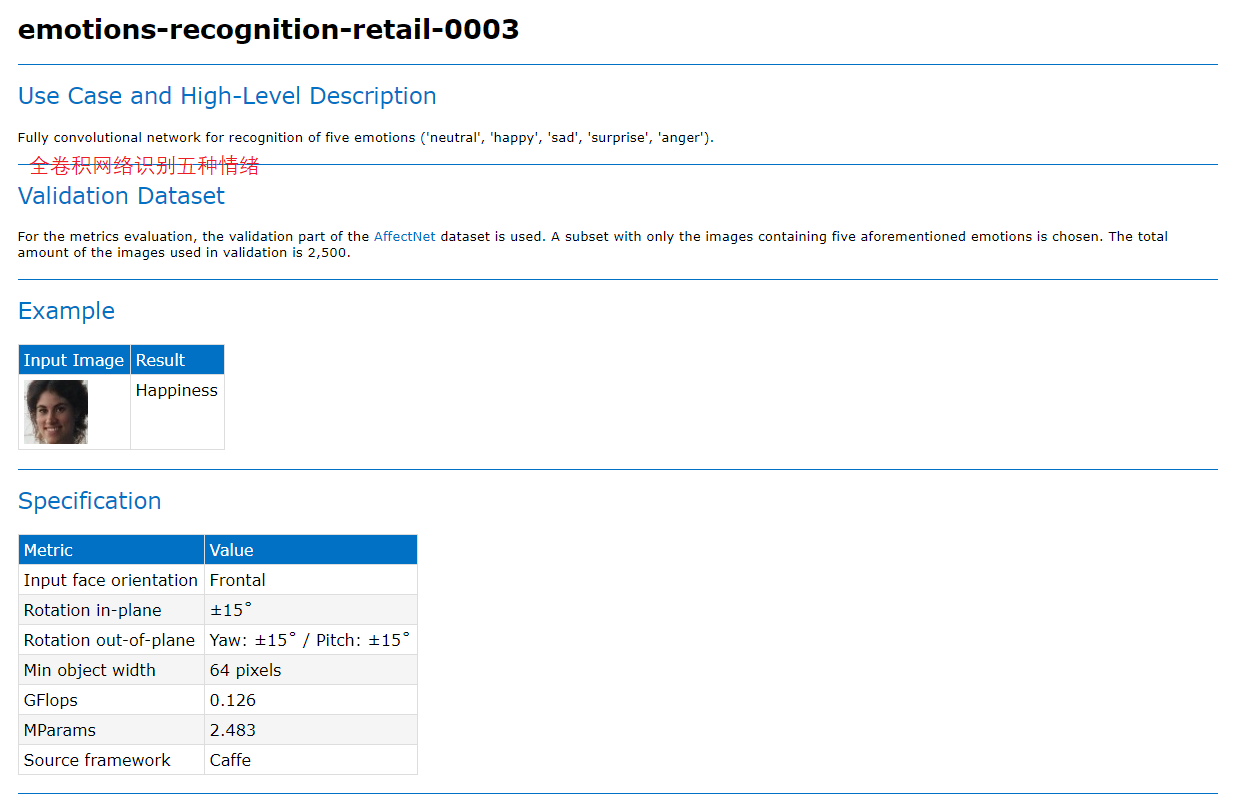

Figure 28, 29
5.2 procedure execution process
After face detection, the ROI area of face detection is sent to the expression recognition model, and then the detection results are output.
be careful; Do some protection to ensure that the rectangle obtained by face detection is in the image, and make size judgment rather than coordinate judgment, otherwise the setting input will collapse during face expression detection.
5.3 code demonstration
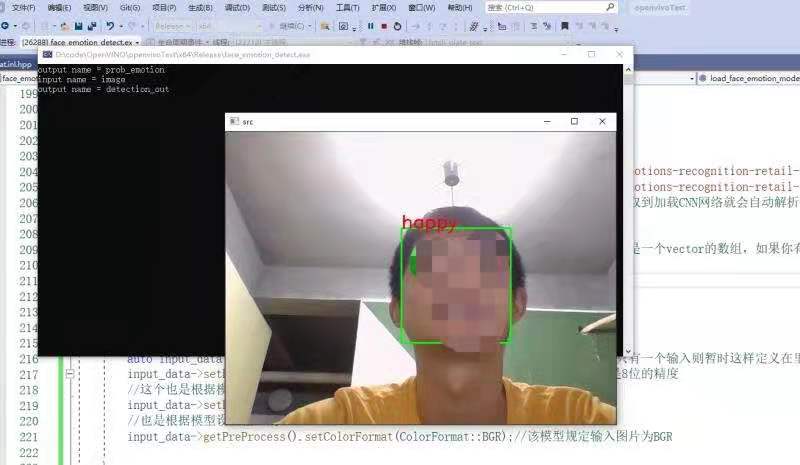
Figure 31
Code practice
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
//Convert the U8 type data from mat to Blob. Because Blob is of any type, it is also declared as a template
template <typename T> void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
//Several values of expression
static const char* const items[] = {
"neutral", "happy", "sad", "surprise", "anger"
};
//Load the model of facial expression recognition, outgoing reasoning and input / output name
void load_face_emotion_model(std::shared_ptr<InferenceEngine::InferRequest>& face_emotion_request, std::string& face_emotion_input_name, std::string& face_emotion_output_name);
//Facial expression detection setting input reasoning analysis output
std::string text_recognization_text(std::shared_ptr<InferenceEngine::InferRequest>& face_emotion_request, std::string& face_emotion_input_name, std::string& face_emotion_output_name, cv::Mat& image, cv::Rect& face_roi);
//After asynchronous reasoning of face detection, the results are processed
cv::Rect infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name);
//The input reasoning setting function of SSD MobileNetV2 model is to convert the input src into the corresponding format and set it to infer_ Blob of request
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name);
int main(int argc, char** argv)
{
//Loading the model of facial expression recognition
std::shared_ptr<InferenceEngine::InferRequest> face_emotion_request;
std::string face_emotion_input_name;
std::string face_emotion_output_name;
load_face_emotion_model(face_emotion_request, face_emotion_input_name, face_emotion_output_name);
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
std::string xmlFilename = "D:/code/OpenVINO/face-detection-0202/FP32/face-detection-0202.xml";
std::string binFilename = "D:/code/OpenVINO/face-detection-0202/FP32/face-detection-0202.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
input_data->setPrecision(Precision::U8);//The input image data format is unsigned char, which is the precision of 8 bits
//This is also the input data mode set according to the model
input_data->setLayout(Layout::NCHW);
//ColorFormat is also input according to the model settings
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//The model specifies that the input picture is BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << output_name << std::endl;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
auto curr_infer_request = executable_network.CreateInferRequestPtr();
auto next_infer_request = executable_network.CreateInferRequestPtr();
//6. Preprocessing of input image data (including BGR - > RGB, size floating point calculation conversion, image sequence conversion HWC - > nchw)
cv::VideoCapture capture(0);
cv::Mat curr_frame;
cv::Mat next_frame;
capture.read(curr_frame);
frameToBlob(curr_frame, curr_infer_request, input_name);
bool first_frame = true;
bool last_frame = false;
while (true)
{
bool ret = capture.read(next_frame);
if (ret == false)//It's the last frame
{
last_frame = true;//No more settings entered
}
if (!last_frame)//The next frame is not set at the last frame
{
frameToBlob(next_frame, next_infer_request, input_name);
}
if (first_frame)
{
curr_infer_request->StartAsync();//Start reasoning
next_infer_request->StartAsync();
first_frame = false;
}
else
{
if (!last_frame)//Each start is the next frame ready for asynchronous exchange
{
next_infer_request->StartAsync();
}
}
//7. Loop execution reasoning, each reasoning is the current frame, and it will be parsed after the reasoning is successful
if (InferenceEngine::OK == curr_infer_request->Wait(InferenceEngine::IInferRequest::WaitMode::RESULT_READY))
{
//The reasoning of face detection returns the face rectangle
cv::Rect face_box = infer_process(curr_frame, curr_infer_request, output_name);
//Set the expression recognition input for the returned face position rectangle, and output the reasoning analysis
if(face_box.width > 64 && face_box.height > 64 && face_box.x > 0 && face_box.y > 0)//Protect, or it's easy to run away
text_recognization_text(face_emotion_request, face_emotion_input_name, face_emotion_output_name, curr_frame, face_box);
}
cv::imshow("src", curr_frame);
char c = cv::waitKey(1);
if (c == 27)//Press esc
break;
if (last_frame)
{
break;
}
// Asynchronous interaction
next_frame.copyTo(curr_frame);
curr_infer_request.swap(next_infer_request);//Function in pointer field
}
return 0;
}
// SSD MobileNetV2 model input reasoning setting function encapsulation because the infer needs to be modified_ All requests still need to pass pointers, smart pointers
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name)
{
//1. Through the incoming reasoning engine; Gets the input Blob format conversion class object
auto input = infer_request->GetBlob(input_name);//Get the blob of input (class object for input formatting)
matU8ToBlob<uchar>(src, input);
return;
}
// SSD MobileNetV2 model output reasoning function encapsulation
cv::Rect infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name)
{
//1. Executive reasoning
//infer_ request->Infer(); Asynchronous reasoning does not need this step
cv::Rect box;
//2. Get our output
auto output = infer_request->GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//Output result of detection
//3. Finally, you need to obtain the output dimension information and parse the data
const SizeVector outputDims = output->getTensorDesc().getDims();
//std::cout << outputDims[2] << "X" << outputDims[3] << std::endl;
const int max_num = outputDims[2];//Is the output N
const int object_size = outputDims[3];//It's the output 7
int im_h = src.rows;
int im_w = src.cols;
for (int n = 0; n < max_num; n++)
{
float lable = detection_out[n * object_size + 1];// +1 indicates that the output is the second lableID of the seven
float confidence = detection_out[n * object_size + 2];
float xmin = detection_out[n * object_size + 3] * im_w; //The floating point coordinates obtained from the output are 0-1, and the actual coordinates are multiplied by the original width and height
float ymin = detection_out[n * object_size + 4] * im_h;
float xmax = detection_out[n * object_size + 5] * im_w;
float ymax = detection_out[n * object_size + 6] * im_h;
if (confidence > 0.9)
{
//printf("lable id = %d\n", static_cast<int>(lable));,
//Do some protection to ensure that the size of the rectangle is judged in the image class rather than the coordinates
xmin = std::min(std::max(0.0f, xmin), static_cast<float>(im_w));
ymin = std::min(std::max(0.0f, ymin), static_cast<float>(im_h));
xmax = std::min(std::max(0.0f, xmax), static_cast<float>(im_w));
ymax = std::min(std::max(0.0f, ymax), static_cast<float>(im_h));
box.x = static_cast<int>(xmin);
box.y = static_cast<int>(ymin);
box.width = static_cast<int>(xmax - xmin);
box.height = static_cast<int>(ymax - ymin);
//std::cout << box.x << " " << box.y << " " << box.width << " " << box.height;
cv::rectangle(src, box, cv::Scalar(0, 255, 0), 2, 8, 0);
return box;
//cv::putText(src, cv::format("%.2f", confidence), box.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 1, 8);
}
}
return box;
}
void load_face_emotion_model(std::shared_ptr<InferenceEngine::InferRequest>& face_emotion_request, std::string& face_emotion_input_name, std::string& face_emotion_output_name)
{
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
std::string xmlFilename = "D:/code/OpenVINO/emotions-recognition-retail-0003/FP32/emotions-recognition-retail-0003.xml";
std::string binFilename = "D:/code/OpenVINO/emotions-recognition-retail-0003/FP32/emotions-recognition-retail-0003.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)//Because this model has two inputs, it will cycle twice
{
face_emotion_input_name = item.first;
auto input_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
input_data->setPrecision(Precision::U8);//The input image data format is unsigned char, which is the precision of 8 bits
//This is also the input data mode set according to the model
input_data->setLayout(Layout::NCHW);
//ColorFormat is also input according to the model settings
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//The model specifies that the input picture is BGR
}
for (auto item : outputs)
{
face_emotion_output_name = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << face_emotion_output_name << std::endl;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
face_emotion_request = executable_network.CreateInferRequestPtr();
}
std::string text_recognization_text(std::shared_ptr<InferenceEngine::InferRequest>& face_emotion_request, std::string& face_emotion_input_name, std::string& face_emotion_output_name, cv::Mat& image, cv::Rect& face_roi)
{
//Set input
cv::Mat faceROI = image(face_roi);
frameToBlob(faceROI, face_emotion_request, face_emotion_input_name);
//Executive reasoning
face_emotion_request->Infer();
//Output string result return
auto output = face_emotion_request->GetBlob(face_emotion_output_name);
const float* probs = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//Convert output data to Precision
//10. Finally, we need to obtain the output dimension information, analyze the data and output the largest one, which is the result of resnet18 image recognition
const SizeVector outputDims = output->getTensorDesc().getDims();
float max = probs[0];
int max_index = 0;
for (int i = 1; i < outputDims[1]; i++)
{
if (max < probs[i])
{
max = probs[i];
max_index = i;
}
}
cv::putText(image, items[max_index], face_roi.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
return items[max_index];
}
6. Face key point landmark detection
6.1 model introduction
Figure 32, 33
6.2 procedure execution process
Complete face detection, obtain ROI area, and directly perform landMark detection. Consistent with facial expression process
6.3 code demonstration

Figure 34
It is essential to check how many input structures are, what output structures are, how to parse them, how to call multiple networks together at the same time, and the use of synchronization and asynchrony.
Code practice
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
//Convert the U8 type data from mat to Blob. Because Blob is of any type, it is also declared as a template
template <typename T> void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
//Several values of expression
static const char* const items[] = {
"neutral", "happy", "sad", "surprise", "anger"
};
//Load the model of facial expression recognition, outgoing reasoning and input / output name
void load_textRecognization_model(std::string xmlFilename, std::string binFilename, std::shared_ptr<InferenceEngine::InferRequest>& face_request, std::string& face_input_name, std::string& face_output_name);
//Facial expression detection setting input reasoning analysis output
void text_recognization_text(std::shared_ptr<InferenceEngine::InferRequest>& face_emotion_request, std::string& face_emotion_input_name, std::string& face_emotion_output_name, cv::Mat& image, cv::Rect& face_roi);
//After asynchronous reasoning of face detection, the results are processed
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name, std::vector<cv::Rect>& vc_RoiRect);
//The input reasoning setting function of SSD MobileNetV2 model is to convert the input src into the corresponding format and set it to infer_ Blob of request
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name);
int main(int argc, char** argv)
{
//Loading the model of facial expression recognition
std::shared_ptr<InferenceEngine::InferRequest> face_landmarks_request;
std::string face_landmarks_input_name;
std::string face_landmarks_output_name;
std::string facial_landmarks_xmlFilename = "D:/code/OpenVINO/facial-landmarks-35-adas-0002/FP32/facial-landmarks-35-adas-0002.xml";
std::string facial_landmarks_binFilename = "D:/code/OpenVINO/facial-landmarks-35-adas-0002/FP32/facial-landmarks-35-adas-0002.bin";
load_textRecognization_model(facial_landmarks_xmlFilename, facial_landmarks_binFilename, face_landmarks_request, face_landmarks_input_name, face_landmarks_output_name);
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
std::string xmlFilename = "D:/code/OpenVINO/face-detection-0202/FP32/face-detection-0202.xml";
std::string binFilename = "D:/code/OpenVINO/face-detection-0202/FP32/face-detection-0202.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
input_data->setPrecision(Precision::U8);//The input image data format is unsigned char, which is the precision of 8 bits
//This is also the input data mode set according to the model
input_data->setLayout(Layout::NCHW);
//ColorFormat is also input according to the model settings
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//The model specifies that the input picture is BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << output_name << std::endl;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
auto curr_infer_request = executable_network.CreateInferRequestPtr();
auto next_infer_request = executable_network.CreateInferRequestPtr();
//6. Preprocessing of input image data (including BGR - > RGB, size floating point calculation conversion, image sequence conversion HWC - > nchw)
//Picture reading
#if 1
cv::Mat curr_frame = cv::imread("D:/face_emotion.jpg");
std::vector<cv::Rect> vc_RoiRect;
frameToBlob(curr_frame, curr_infer_request, input_name);
curr_infer_request->Infer();
infer_process(curr_frame, curr_infer_request, output_name, vc_RoiRect);
//Set the expression recognition input for the returned face position rectangle, and output the reasoning analysis
for (int i = 0; i < vc_RoiRect.size(); i++)
{
if (vc_RoiRect[i].width > 64 && vc_RoiRect[i].height > 64 && vc_RoiRect[i].x > 0 && vc_RoiRect[i].y > 0)//Protect, or it's easy to run away
text_recognization_text(face_landmarks_request, face_landmarks_input_name, face_landmarks_output_name, curr_frame, vc_RoiRect[i]);
}
cv::imshow("src", curr_frame);
char c = cv::waitKey(0);
#endif
#if 0
//Video reading
cv::VideoCapture capture(0);
cv::Mat curr_frame;
cv::Mat next_frame;
capture.read(curr_frame);
frameToBlob(curr_frame, curr_infer_request, input_name);
bool first_frame = true;
bool last_frame = false;
std::vector<cv::Rect> vc_RoiRect;
while (true)
{
vc_RoiRect.clear();
bool ret = capture.read(next_frame);
if (ret == false)//It's the last frame
{
last_frame = true;//No more settings entered
}
if (!last_frame)//The next frame is not set at the last frame
{
frameToBlob(next_frame, next_infer_request, input_name);
}
if (first_frame)
{
curr_infer_request->StartAsync();//Start reasoning
next_infer_request->StartAsync();
first_frame = false;
}
else
{
if (!last_frame)//Each start is the next frame ready for asynchronous exchange
{
next_infer_request->StartAsync();
}
}
//7. Loop execution reasoning, each reasoning is the current frame, and it will be parsed after the reasoning is successful
if (InferenceEngine::OK == curr_infer_request->Wait(InferenceEngine::IInferRequest::WaitMode::RESULT_READY))
{
//The reasoning of face detection returns the face rectangle
infer_process(curr_frame, curr_infer_request, output_name, vc_RoiRect);
//Set the expression recognition input for the returned face position rectangle, and output the reasoning analysis
for (int i = 0; i < vc_RoiRect.size(); i++)
{
if (vc_RoiRect[i].width > 64 && vc_RoiRect[i].height > 64 && vc_RoiRect[i].x > 0 && vc_RoiRect[i].y > 0)//Protect, or it's easy to run away
face_lanmarks_text(face_landmarks_request, face_landmarks_input_name, face_landmarks_output_name, curr_frame, vc_RoiRect[i]);
}
}
cv::imshow("src", curr_frame);
char c = cv::waitKey(1);
if (c == 27)//Press esc
break;
if (last_frame)
{
break;
}
// Asynchronous interaction
next_frame.copyTo(curr_frame);
curr_infer_request.swap(next_infer_request);//Function in pointer field
}
#endif
return 0;
}
// SSD MobileNetV2 model input reasoning setting function encapsulation because the infer needs to be modified_ All requests still need to pass pointers, smart pointers
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name)
{
//1. Through the incoming reasoning engine; Gets the input Blob format conversion class object
auto input = infer_request->GetBlob(input_name);//Get the blob of input (class object for input formatting)
matU8ToBlob<uchar>(src, input);
return;
}
// SSD MobileNetV2 model output reasoning function encapsulation
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name, std::vector<cv::Rect> &vc_RoiRect)
{
//1. Executive reasoning
//infer_ request->Infer(); Asynchronous reasoning does not need this step
cv::Rect box;
//2. Get our output
auto output = infer_request->GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//Output result of detection
//3. Finally, you need to obtain the output dimension information and parse the data
const SizeVector outputDims = output->getTensorDesc().getDims();
//std::cout << outputDims[2] << "X" << outputDims[3] << std::endl;
const int max_num = outputDims[2];//Is the output N
const int object_size = outputDims[3];//It's the output 7
int im_h = src.rows;
int im_w = src.cols;
for (int n = 0; n < max_num; n++)
{
float lable = detection_out[n * object_size + 1];// +1 indicates that the output is the second lableID of the seven
float confidence = detection_out[n * object_size + 2];
float xmin = detection_out[n * object_size + 3] * im_w; //The floating point coordinates obtained from the output are 0-1, and the actual coordinates are multiplied by the original width and height
float ymin = detection_out[n * object_size + 4] * im_h;
float xmax = detection_out[n * object_size + 5] * im_w;
float ymax = detection_out[n * object_size + 6] * im_h;
if (confidence > 0.95)
{
//printf("lable id = %d\n", static_cast<int>(lable));,
//Do some protection to ensure that the size of the rectangle is judged in the image class rather than the coordinates
xmin = std::min(std::max(0.0f, xmin), static_cast<float>(im_w));
ymin = std::min(std::max(0.0f, ymin), static_cast<float>(im_h));
xmax = std::min(std::max(0.0f, xmax), static_cast<float>(im_w));
ymax = std::min(std::max(0.0f, ymax), static_cast<float>(im_h));
box.x = static_cast<int>(xmin);
box.y = static_cast<int>(ymin);
box.width = static_cast<int>(xmax - xmin);
box.height = static_cast<int>(ymax - ymin);
//std::cout << box.x << " " << box.y << " " << box.width << " " << box.height;
cv::rectangle(src, box, cv::Scalar(0, 255, 0), 2, 8, 0);
vc_RoiRect.push_back(box);
//cv::putText(src, cv::format("%.2f", confidence), box.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 1, 8);
}
}
return ;
}
void load_textRecognization_model(std::string xmlFilename, std::string binFilename, std::shared_ptr<InferenceEngine::InferRequest>& face_emotion_request, std::string& face_emotion_input_name, std::string& face_emotion_output_name)
{
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
/*std::string xmlFilename = "D:/code/OpenVINO/facial-landmarks-35-adas-0002/FP32/facial-landmarks-35-adas-0002.xml";
std::string binFilename = "D:/code/OpenVINO/facial-landmarks-35-adas-0002/FP32/facial-landmarks-35-adas-0002.bin";*/
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)//Because this model has two inputs, it will cycle twice
{
face_emotion_input_name = item.first;
auto input_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
input_data->setPrecision(Precision::U8);//The input image data format is unsigned char, which is the precision of 8 bits
//This is also the input data mode set according to the model
input_data->setLayout(Layout::NCHW);
//ColorFormat is also input according to the model settings
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//The model specifies that the input picture is BGR
}
for (auto item : outputs)
{
face_emotion_output_name = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << face_emotion_output_name << std::endl;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
face_emotion_request = executable_network.CreateInferRequestPtr();
}
void text_recognization_text(std::shared_ptr<InferenceEngine::InferRequest>& face_lanmarks_request, std::string& face_lanmarks_input_name, std::string& face_lanmarks_output_name, cv::Mat& image, cv::Rect& face_roi)
{
//Set input
cv::Mat faceROI = image(face_roi);
frameToBlob(faceROI, face_lanmarks_request, face_lanmarks_input_name);
//Executive reasoning
face_lanmarks_request->Infer();
//Output string result return
auto output = face_lanmarks_request->GetBlob(face_lanmarks_output_name);
const float* probs = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//Convert output data to Precision
//10. Finally, it is necessary to obtain the output dimension information and analyze the data. The coordinates obtained here are equivalent to the coordinates of the face, and the last drawing point is the coordinates of the picture
const SizeVector outputDims = output->getTensorDesc().getDims();//
int i_width = face_roi.width;
int i_height = face_roi.height;
for (int i = 0; i < outputDims[1]; i+=2)
{
float x = probs[i] * i_width + face_roi.x;
float y = probs[i + 1] * i_height + face_roi.y;
cv::circle(image, cv::Point(x, y), 3, cv::Scalar(255, 0, 0), 2, 8, 0);//Draw circle
}
//cv::putText(image, items[max_index], face_roi.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
return ;
}
7. Real time semantic road segmentation model
OpenVINO also supports the semantic road segmentation model, that is, the semantic road segmentation model, which divides the road into four parts: background, road, roadside and marking line (lane line, etc.).
7.1 model introduction
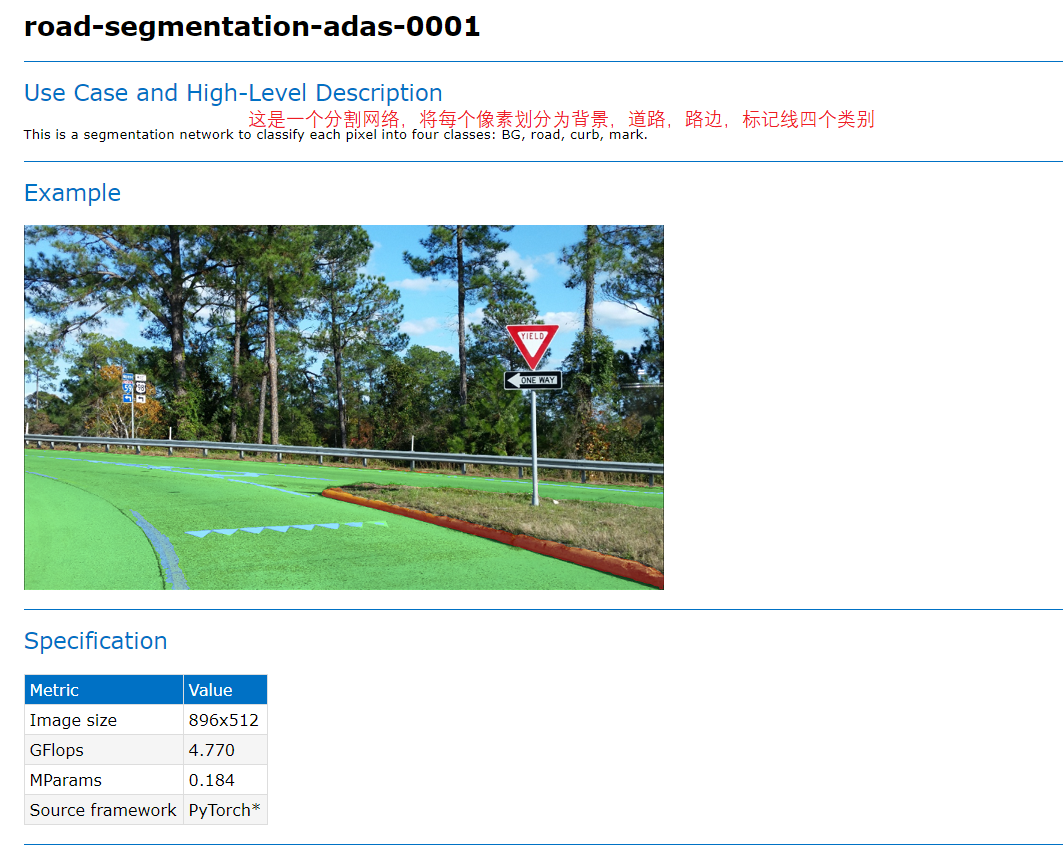
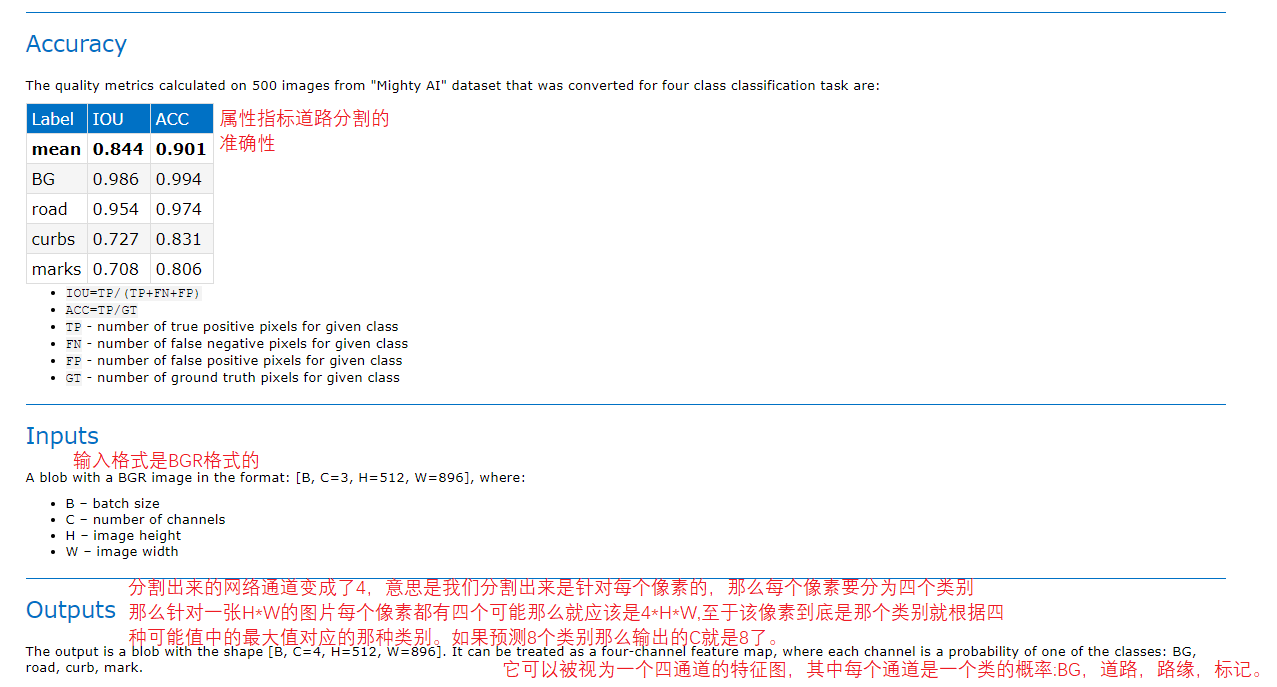
Figure 35, 36
7.2 procedure flow
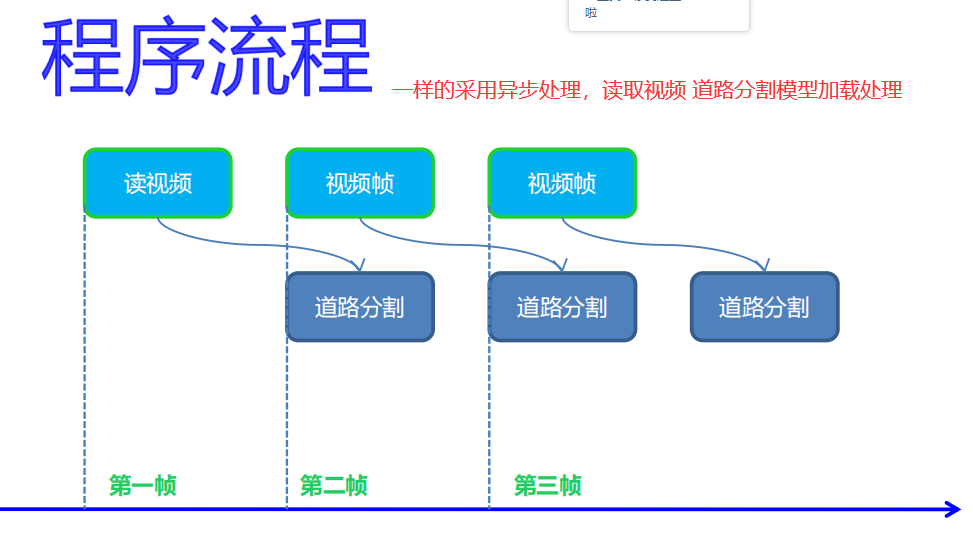
Figure 37
7.3 code demonstration
The key is how to analyze the multi-channel output in the segmented network
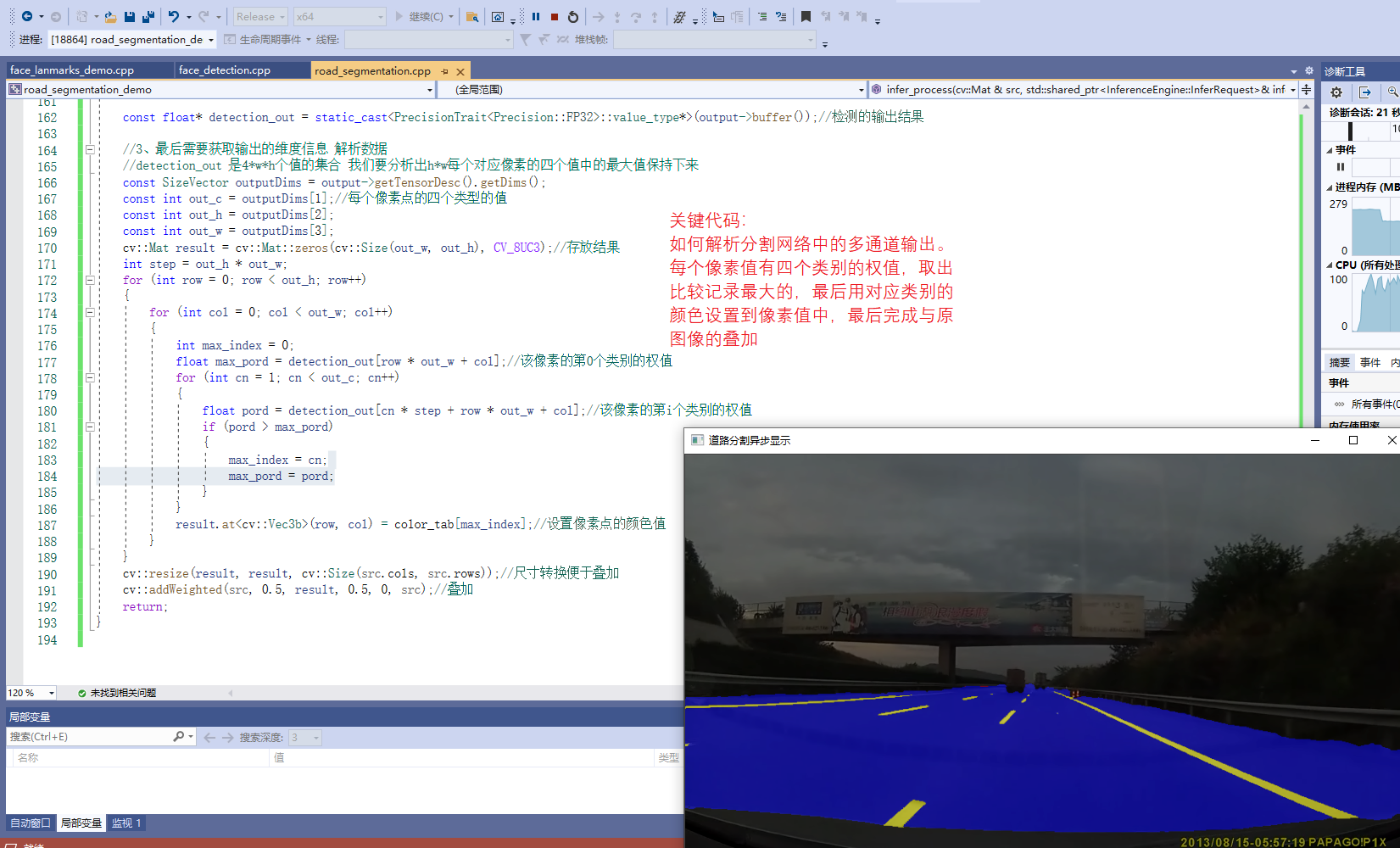
Figure 38
Code practice
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
//Convert the U8 type data from mat to Blob. Because Blob is of any type, it is also declared as a template
template <typename T> void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
// SSD MobileNetV2 model input reasoning setting function encapsulation because the infer needs to be modified_ All requests still need to pass pointers, smart pointers
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name);
// SSD MobileNetV2 model output reasoning function encapsulation
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name);
std::vector<cv::Vec3b> color_tab;
int main(int argc, char** argv)
{
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
std::string xmlFilename = "D:/code/OpenVINO/road-segmentation-adas-0001/FP32/road-segmentation-adas-0001.xml";
std::string binFilename = "D:/code/OpenVINO/road-segmentation-adas-0001/FP32/road-segmentation-adas-0001.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
input_data->setPrecision(Precision::U8);//The input image data format is unsigned char, which is the precision of 8 bits
//This is also the input data mode set according to the model
input_data->setLayout(Layout::NCHW);
//ColorFormat is also input according to the model settings
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//The model specifies that the input picture is BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << output_name << std::endl;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
auto curr_infer_request = executable_network.CreateInferRequestPtr();
auto next_infer_request = executable_network.CreateInferRequestPtr();
//6. Preprocessing of input image data (including BGR - > RGB, size floating point calculation conversion, image sequence conversion HWC - > nchw)
cv::VideoCapture capture("D:/lane.avi");
cv::Mat curr_frame;
cv::Mat next_frame;
capture.read(curr_frame);
//Set inference input
frameToBlob(curr_frame, curr_infer_request, input_name);
bool first_frame = true;
bool last_frame = false;
color_tab.push_back(cv::Vec3b(0, 0, 0));//Corresponding BG
color_tab.push_back(cv::Vec3b(255, 0, 0));//Corresponding road
color_tab.push_back(cv::Vec3b(0, 0, 255));//Corresponding curb
color_tab.push_back(cv::Vec3b(0, 255, 255));//Corresponding mark
while (true)
{
bool ret = capture.read(next_frame);
if (ret == false)//It's the last frame
{
last_frame = true;//No more settings entered
}
if (!last_frame)//The next frame is not set at the last frame
{
frameToBlob(next_frame, next_infer_request, input_name);
}
if (first_frame)
{
curr_infer_request->StartAsync();//Start reasoning
next_infer_request->StartAsync();
first_frame = false;
}
else
{
if (!last_frame)//Each start is the next frame ready for asynchronous exchange
{
next_infer_request->StartAsync();
}
}
//7. Loop execution reasoning, each reasoning is the current frame, and it will be parsed after the reasoning is successful
if (InferenceEngine::OK == curr_infer_request->Wait(InferenceEngine::IInferRequest::WaitMode::RESULT_READY))
{
infer_process(curr_frame, curr_infer_request, output_name);
}
cv::imshow("Asynchronous display of road segmentation", curr_frame);
char c = cv::waitKey(1);
if (c == 27)//Press esc
break;
if (last_frame)
{
break;
}
// Asynchronous interaction
next_frame.copyTo(curr_frame);
curr_infer_request.swap(next_infer_request);//Function in pointer field
}
return 0;
}
// SSD MobileNetV2 model input reasoning setting function encapsulation because the infer needs to be modified_ All requests still need to pass pointers, smart pointers
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name)
{
//1. Through the incoming reasoning engine; Gets the input Blob format conversion class object
auto input = infer_request->GetBlob(input_name);//Get the blob of input (class object for input formatting)
matU8ToBlob<uchar>(src, input);
return;
}
// SSD MobileNetV2 model output reasoning function encapsulation
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name)
{
//1. Executive reasoning
//infer_ request->Infer(); Asynchronous reasoning does not need this step
//2. Get our output
auto output = infer_request->GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//Output result of detection
//3. Finally, you need to obtain the output dimension information and parse the data
//detection_out is a set of 4*w*h values. We need to analyze the maximum of the four values of each corresponding pixel of h*w and keep it
const SizeVector outputDims = output->getTensorDesc().getDims();
const int out_c = outputDims[1];//Four types of values per pixel
const int out_h = outputDims[2];
const int out_w = outputDims[3];
cv::Mat result = cv::Mat::zeros(cv::Size(out_w, out_h), CV_8UC3);//Storage results
int step = out_h * out_w;
for (int row = 0; row < out_h; row++)
{
for (int col = 0; col < out_w; col++)
{
int max_index = 0;
float max_pord = detection_out[row * out_w + col];//The weight of the 0th category of the pixel
for (int cn = 1; cn < out_c; cn++)
{
float pord = detection_out[cn * step + row * out_w + col];//The weight of the ith category of the pixel
if (pord > max_pord)
{
max_index = cn;
max_pord = pord;
}
}
result.at<cv::Vec3b>(row, col) = color_tab[max_index];//Sets the color value of pixels
}
}
cv::resize(result, result, cv::Size(src.cols, src.rows));//Size conversion for easy stacking
cv::addWeighted(src, 0.5, result, 0.5, 0, src);//superposition
return;
}
8. Instance segmentation
Our most common example segmentation model is the Mask R-CNN model, and openVINO also supports a variety of Mask R-CNN at different levels and resolutions.
8.1 instance segmentation model


Figure 39 40
8.2 procedure execution process
The key to the process is to process the output, especially to parse raw_ The mask matrix attribute of masks needs to be conducive to the conversion and superposition of the relevant knowledge of opencv.
8.3 code demonstration
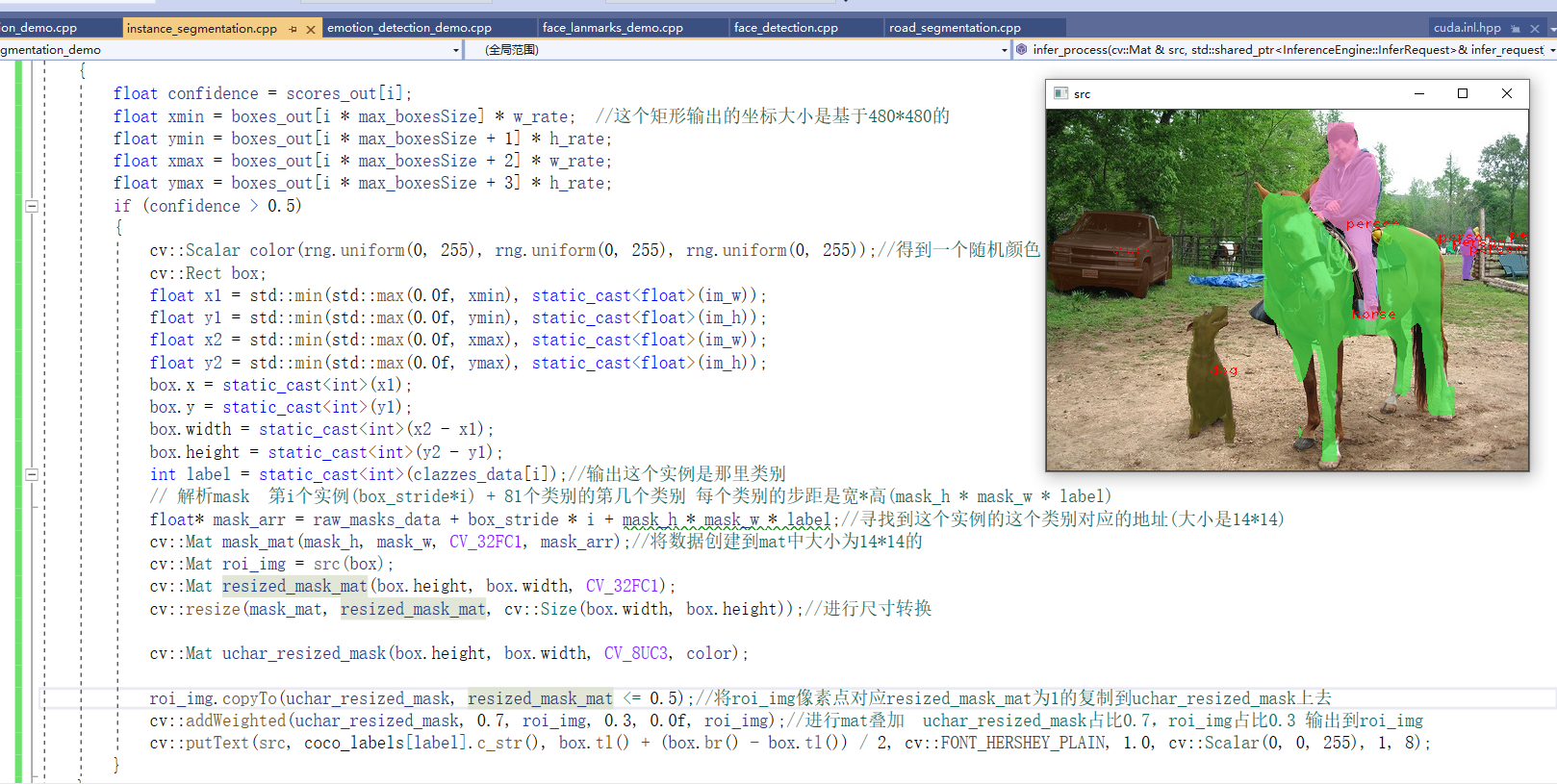
Figure 41
Code practice
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
//Convert the U8 type data from mat to Blob. Because Blob is of any type, it is also declared as a template
template <typename T> void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
void read_coco_labels(std::vector<std::string>& labels) {
std::string label_file = "coco_labels.txt";
std::ifstream fp(label_file);
if (!fp.is_open())
{
printf("could not open file...\n");
exit(-1);
}
std::string name;
while (!fp.eof())
{
std::getline(fp, name);
if (name.length())
labels.push_back(name);
}
fp.close();
}
// SSD MobileNetV2 model input reasoning setting function encapsulation because the infer needs to be modified_ All requests still need to pass pointers, smart pointers
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request);
// SSD MobileNetV2 model output reasoning function encapsulation
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name);
std::vector<std::string> coco_labels;
int main(int argc, char** argv)
{
read_coco_labels(coco_labels);
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
std::string xmlFilename = "D:/code/OpenVINO/instance-segmentation-security-0050/FP32/instance-segmentation-security-0050.xml";
std::string binFilename = "D:/code/OpenVINO/instance-segmentation-security-0050/FP32/instance-segmentation-security-0050.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string info_name = "";
int in_index = 0;
for (auto item : inputs)
{
if (in_index == 0)
{
input_name = item.first;
auto input_data = item.second;
input_data->setPrecision(Precision::U8);
input_data->setLayout(Layout::NCHW);
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);
std::cout << "input name = " << input_name << std::endl;
}
else
{
info_name = item.first;
auto input_data = item.second;
input_data->setPrecision(Precision::FP32);
std::cout << "info_name name = " << info_name << std::endl;
}
in_index++;
}
for (auto item : outputs)//Because the name of the model is accurate, you can directly specify the name according to the official document when accessing
{
std::string output_name = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << output_name << std::endl;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
auto curr_infer_request = executable_network.CreateInferRequestPtr();
//6. Preprocessing of input image data (including BGR - > RGB, size floating point calculation conversion, image sequence conversion HWC - > nchw)
cv::Mat curr_frame = cv::imread("D:/objects.jpg");
std::vector<cv::Rect> vc_RoiRect;
frameToBlob(curr_frame, curr_infer_request, input_name);//Set first input
//Set second input
auto input2 = curr_infer_request->GetBlob(info_name);
auto imInfoDim = inputs.find(info_name)->second->getTensorDesc().getDims()[1];
InferenceEngine::MemoryBlob::Ptr minput2 = InferenceEngine::as<InferenceEngine::MemoryBlob>(input2);
auto minput2Holder = minput2->wmap();
float* p = minput2Holder.as<InferenceEngine::PrecisionTrait<InferenceEngine::Precision::FP32>::value_type*>();
p[0] = static_cast<float>(inputs[input_name]->getTensorDesc().getDims()[2]);
p[1] = static_cast<float>(inputs[input_name]->getTensorDesc().getDims()[3]);
p[2] = 1.0f;
std::cout << p[0] << " " << p[1] << std::endl;
infer_process(curr_frame, curr_infer_request);
cv::imshow("src", curr_frame);
char c = cv::waitKey(0);
return 0;
}
// SSD MobileNetV2 model input reasoning setting function encapsulation because the infer needs to be modified_ All requests still need to pass pointers, smart pointers
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name)
{
//1. Through the incoming reasoning engine; Gets the input Blob format conversion class object
auto input = infer_request->GetBlob(input_name);//Get the blob of input (class object for input formatting)
matU8ToBlob<uchar>(src, input);
return;
}
// SSD MobileNetV2 model output reasoning function encapsulation
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request)
{
//1. Executive reasoning
infer_request->Infer(); //Asynchronous reasoning does not need this step
//2. Get our output
auto scores = infer_request->GetBlob("scores");
auto boxes = infer_request->GetBlob("boxes");
auto clazzes = infer_request->GetBlob("classes");
auto raw_masks = infer_request->GetBlob("raw_masks");
const float* scores_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(scores->buffer());//Output result of detection
const float* boxes_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(boxes->buffer());// The output coordinate size of this rectangle is based on 480 * 480
const float* clazzes_data = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(clazzes->buffer());
const auto raw_masks_data = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(raw_masks->buffer());//The output is raw_masks structure
//3. Finally, you need to obtain the output dimension information and parse the data
const SizeVector scores_outputDims = scores->getTensorDesc().getDims();
const SizeVector boxes_outputDims = boxes->getTensorDesc().getDims();
const SizeVector mask_outputDims = raw_masks->getTensorDesc().getDims();
const int max_scoresSize = scores_outputDims[0];//100
const int max_boxesSize = boxes_outputDims[1];//4
int mask_h = mask_outputDims[2];//raw_ The width and height of masks are inconsistent with the official documents. Now it is 14 * 14
int mask_w = mask_outputDims[3];
size_t box_stride = mask_h * mask_w * mask_outputDims[1];//Represents the step distance between each instance 81 * 14 * 14. Each instance between these 100 instances is separated by so many bytes
int im_w = src.cols;
int im_h = src.rows;
float w_rate = static_cast<float>(im_w) / 480.0;
float h_rate = static_cast<float>(im_h) / 480.0;
cv::RNG rng(12345);
for (int i = 0; i < max_scoresSize; i++)
{
float confidence = scores_out[i];
float xmin = boxes_out[i * max_boxesSize] * w_rate; //The output coordinate size of this rectangle is based on 480 * 480
float ymin = boxes_out[i * max_boxesSize + 1] * h_rate;
float xmax = boxes_out[i * max_boxesSize + 2] * w_rate;
float ymax = boxes_out[i * max_boxesSize + 3] * h_rate;
if (confidence > 0.5)
{
cv::Scalar color(rng.uniform(0, 255), rng.uniform(0, 255), rng.uniform(0, 255));//Get a random color
cv::Rect box;
float x1 = std::min(std::max(0.0f, xmin), static_cast<float>(im_w));
float y1 = std::min(std::max(0.0f, ymin), static_cast<float>(im_h));
float x2 = std::min(std::max(0.0f, xmax), static_cast<float>(im_w));
float y2 = std::min(std::max(0.0f, ymax), static_cast<float>(im_h));
box.x = static_cast<int>(x1);
box.y = static_cast<int>(y1);
box.width = static_cast<int>(x2 - x1);
box.height = static_cast<int>(y2 - y1);
int label = static_cast<int>(clazzes_data[i]);//Where is the category to output this instance
// Parse the ith instance of the mask (box_stripe * i) + the first category of 81 categories. The step of each category is width * height (mask_h * mask_w * label)
float* mask_arr = raw_masks_data + box_stride * i + mask_h * mask_w * label;//Find the address corresponding to this category of this instance (size is 14 * 14)
cv::Mat mask_mat(mask_h, mask_w, CV_32FC1, mask_arr);//Create data in mat with size of 14 * 14
cv::Mat roi_img = src(box);
cv::Mat resized_mask_mat(box.height, box.width, CV_32FC1);
cv::resize(mask_mat, resized_mask_mat, cv::Size(box.width, box.height));//Size conversion
cv::Mat uchar_resized_mask(box.height, box.width, CV_8UC3, color);
roi_img.copyTo(uchar_resized_mask, resized_mask_mat <= 0.5);//Set roi_img pixel corresponding to resized_ mask_ Copy mat 1 to uchar_resized_mask up
cv::addWeighted(uchar_resized_mask, 0.7, roi_img, 0.3, 0.0f, roi_img);//Perform mat stack uchar_resized_mask accounts for 0.7, roi_img ratio 0.3 output to roi_img
cv::putText(src, coco_labels[label].c_str(), box.tl() + (box.br() - box.tl()) / 2, cv::FONT_HERSHEY_PLAIN, 1.0, cv::Scalar(0, 0, 255), 1, 8);
}
}
return;
}
9. Scene text detection
9.1 model introduction
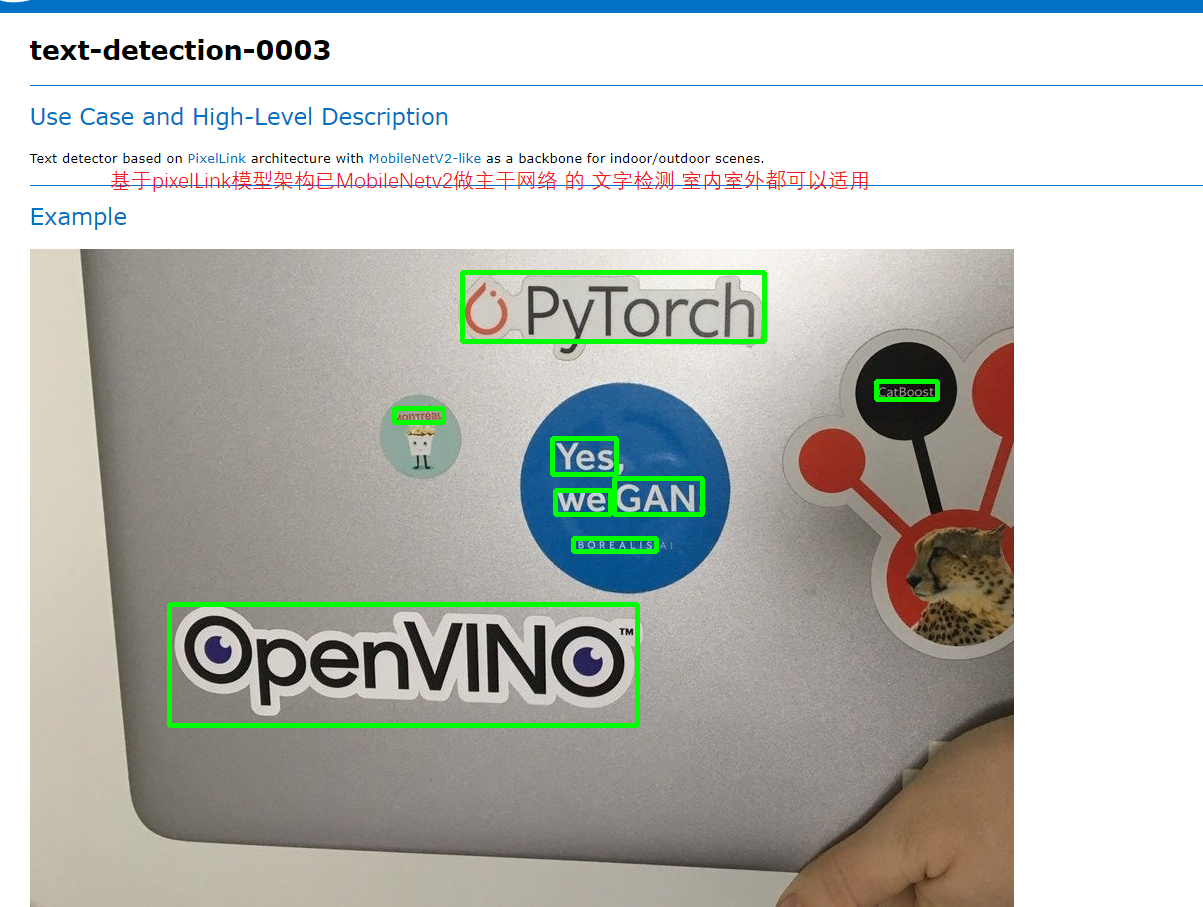
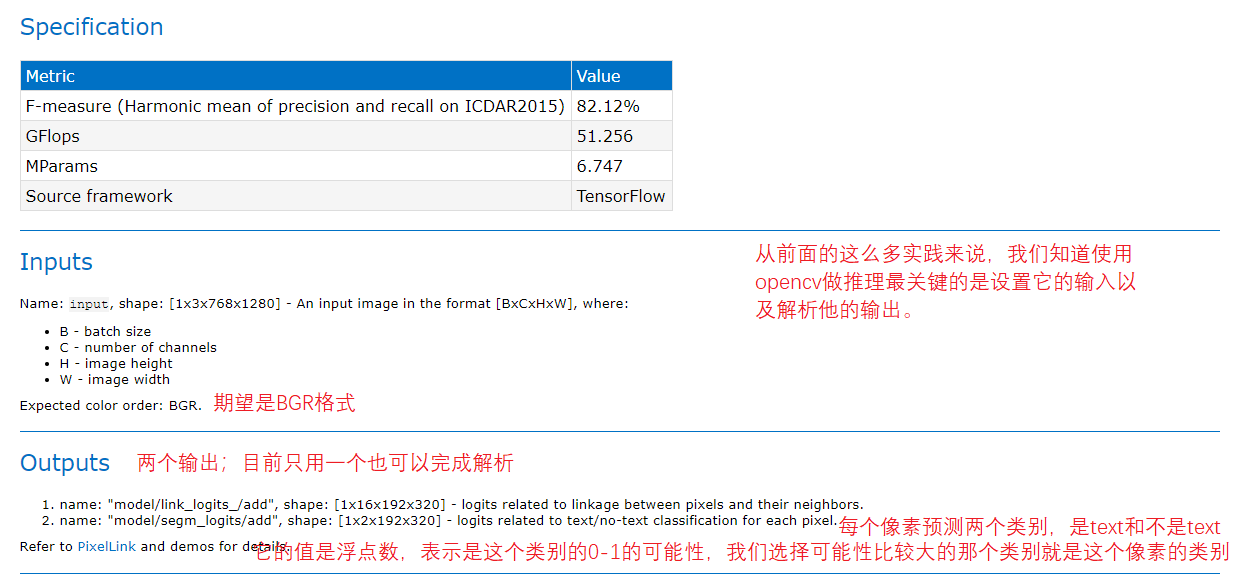
Figure 42 43
9.2 procedure execution steps
Loading mode
Set input
Parse output
9.3 code demonstration
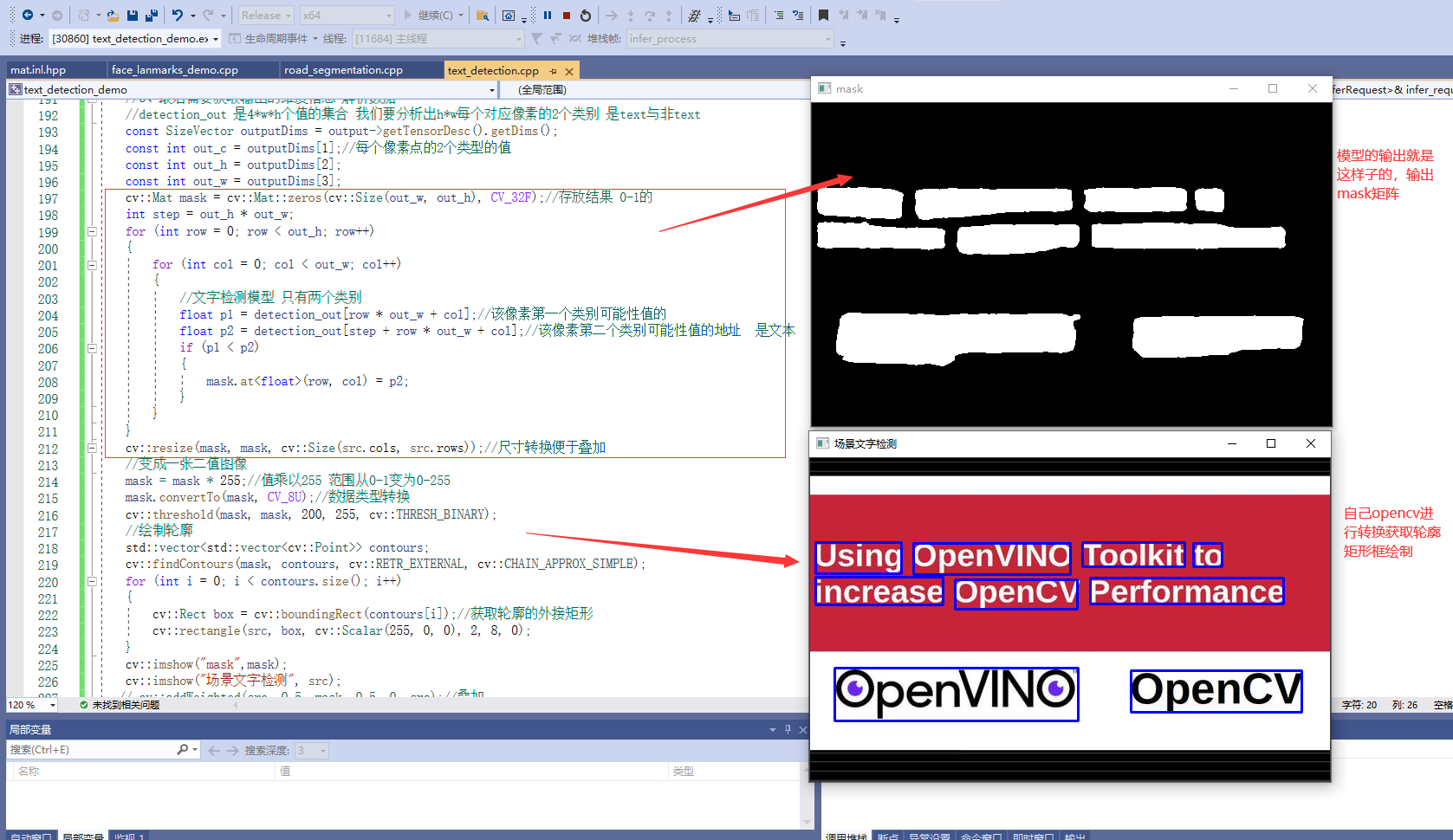
Figure 44
Code practice
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
//Convert the U8 type data from mat to Blob. Because Blob is of any type, it is also declared as a template
template <typename T> void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
// SSD MobileNetV2 model input reasoning setting function encapsulation because the infer needs to be modified_ All requests still need to pass pointers, smart pointers
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name);
// SSD MobileNetV2 model output reasoning function encapsulation
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name);
std::vector<cv::Vec3b> color_tab;
int main(int argc, char** argv)
{
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
std::string xmlFilename = "D:/code/OpenVINO/text-detection-0003/FP32/text-detection-0003.xml";
std::string binFilename = "D:/code/OpenVINO/text-detection-0003/FP32/text-detection-0003.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name1 = "";
std::string output_name2 = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
input_data->setPrecision(Precision::U8);//The input image data format is unsigned char, which is the precision of 8 bits
//This is also the input data mode set according to the model
input_data->setLayout(Layout::NCHW);
//ColorFormat is also input according to the model settings
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//The model specifies that the input picture is BGR
std::cout << "input name = " << input_name << std::endl;
}
int out_index = 0;
for (auto item : outputs)
{
if (out_index == 1)
{
output_name2 = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << output_name1 << std::endl;
}
else
{
output_name1 = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << output_name1 << std::endl;
}
out_index++;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
auto curr_infer_request = executable_network.CreateInferRequestPtr();
auto next_infer_request = executable_network.CreateInferRequestPtr();
//6. Preprocessing of input image data (including BGR - > RGB, size floating point calculation conversion, image sequence conversion HWC - > nchw)
#if 1
cv::Mat curr_frame = cv::imread("D:/openvino_ocr.jpg");
std::vector<cv::Rect> vc_RoiRect;
frameToBlob(curr_frame, curr_infer_request, input_name);
curr_infer_request->Infer();
infer_process(curr_frame, curr_infer_request, output_name2);//For the time being, only the second output is needed to accurately locate it
//cv::imshow("src", curr_frame);
char c = cv::waitKey(0);
#endif
#if 0
cv::VideoCapture capture("D:/lane.avi");
cv::Mat curr_frame;
cv::Mat next_frame;
capture.read(curr_frame);
//Set inference input
frameToBlob(curr_frame, curr_infer_request, input_name);
bool first_frame = true;
bool last_frame = false;
color_tab.push_back(cv::Vec3b(0, 0, 0));//Corresponding BG
color_tab.push_back(cv::Vec3b(255, 0, 0));//Corresponding road
color_tab.push_back(cv::Vec3b(0, 0, 255));//Corresponding curb
color_tab.push_back(cv::Vec3b(0, 255, 255));//Corresponding mark
while (true)
{
bool ret = capture.read(next_frame);
if (ret == false)//It's the last frame
{
last_frame = true;//No more settings entered
}
if (!last_frame)//The next frame is not set at the last frame
{
frameToBlob(next_frame, next_infer_request, input_name);
}
if (first_frame)
{
curr_infer_request->StartAsync();//Start reasoning
next_infer_request->StartAsync();
first_frame = false;
}
else
{
if (!last_frame)//Each start is the next frame ready for asynchronous exchange
{
next_infer_request->StartAsync();
}
}
//7. Loop execution reasoning, each reasoning is the current frame, and it will be parsed after the reasoning is successful
if (InferenceEngine::OK == curr_infer_request->Wait(InferenceEngine::IInferRequest::WaitMode::RESULT_READY))
{
infer_process(curr_frame, curr_infer_request, output_name);
}
cv::imshow("Asynchronous display of road segmentation", curr_frame);
char c = cv::waitKey(1);
if (c == 27)//Press esc
break;
if (last_frame)
{
break;
}
// Asynchronous interaction
next_frame.copyTo(curr_frame);
curr_infer_request.swap(next_infer_request);//Function in pointer field
}
#endif
return 0;
}
// SSD MobileNetV2 model input reasoning setting function encapsulation because the infer needs to be modified_ All requests still need to pass pointers, smart pointers
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name)
{
//1. Through the incoming reasoning engine; Gets the input Blob format conversion class object
auto input = infer_request->GetBlob(input_name);//Get the blob of input (class object for input formatting)
matU8ToBlob<uchar>(src, input);
return;
}
// SSD MobileNetV2 model output reasoning function encapsulation
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name)
{
//1. Executive reasoning
//infer_ request->Infer(); Asynchronous reasoning does not need this step
//2. Get our output
auto output = infer_request->GetBlob(output_name);
//The output value is a floating-point number between 0 and 1, indicating the confidence of this category. We can select the category with high confidence
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//Output result of detection
//3. Finally, you need to obtain the output dimension information and parse the data
//detection_out is a set of 2*w*h values. We want to analyze that the 2 categories of each corresponding pixel of h*w are text and non text
const SizeVector outputDims = output->getTensorDesc().getDims();
const int out_c = outputDims[1];//2 types of values per pixel
const int out_h = outputDims[2];
const int out_w = outputDims[3];
cv::Mat mask = cv::Mat::zeros(cv::Size(out_w, out_h), CV_32F);//Storing results 0-1
int step = out_h * out_w;
for (int row = 0; row < out_h; row++)
{
for (int col = 0; col < out_w; col++)
{
//The text detection model has only two categories
float p1 = detection_out[row * out_w + col];//The probability value of the first category of the pixel
float p2 = detection_out[step + row * out_w + col];//The address of the second category possibility value of the pixel is text
if (p1 < p2)
{
mask.at<float>(row, col) = p2;
}
}
}
cv::resize(mask, mask, cv::Size(src.cols, src.rows));//Size conversion for easy stacking
//Become a binary image
mask = mask * 255;//The value multiplied by 255 changes from 0-1 to 0-255
mask.convertTo(mask, CV_8U);//Data type conversion
cv::threshold(mask, mask, 200, 255, cv::THRESH_BINARY);
//Draw outline
std::vector<std::vector<cv::Point>> contours;
cv::findContours(mask, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);
for (int i = 0; i < contours.size(); i++)
{
cv::Rect box = cv::boundingRect(contours[i]);//Gets the bounding rectangle of the profile
cv::rectangle(src, box, cv::Scalar(255, 0, 0), 2, 8, 0);
}
cv::imshow("mask",mask);
cv::imshow("Scene text detection", src);
// cv::addWeighted(src, 0.5, mask, 0.5, 0, src);// superposition
return;
}
10. Character recognition
10.1 model introduction
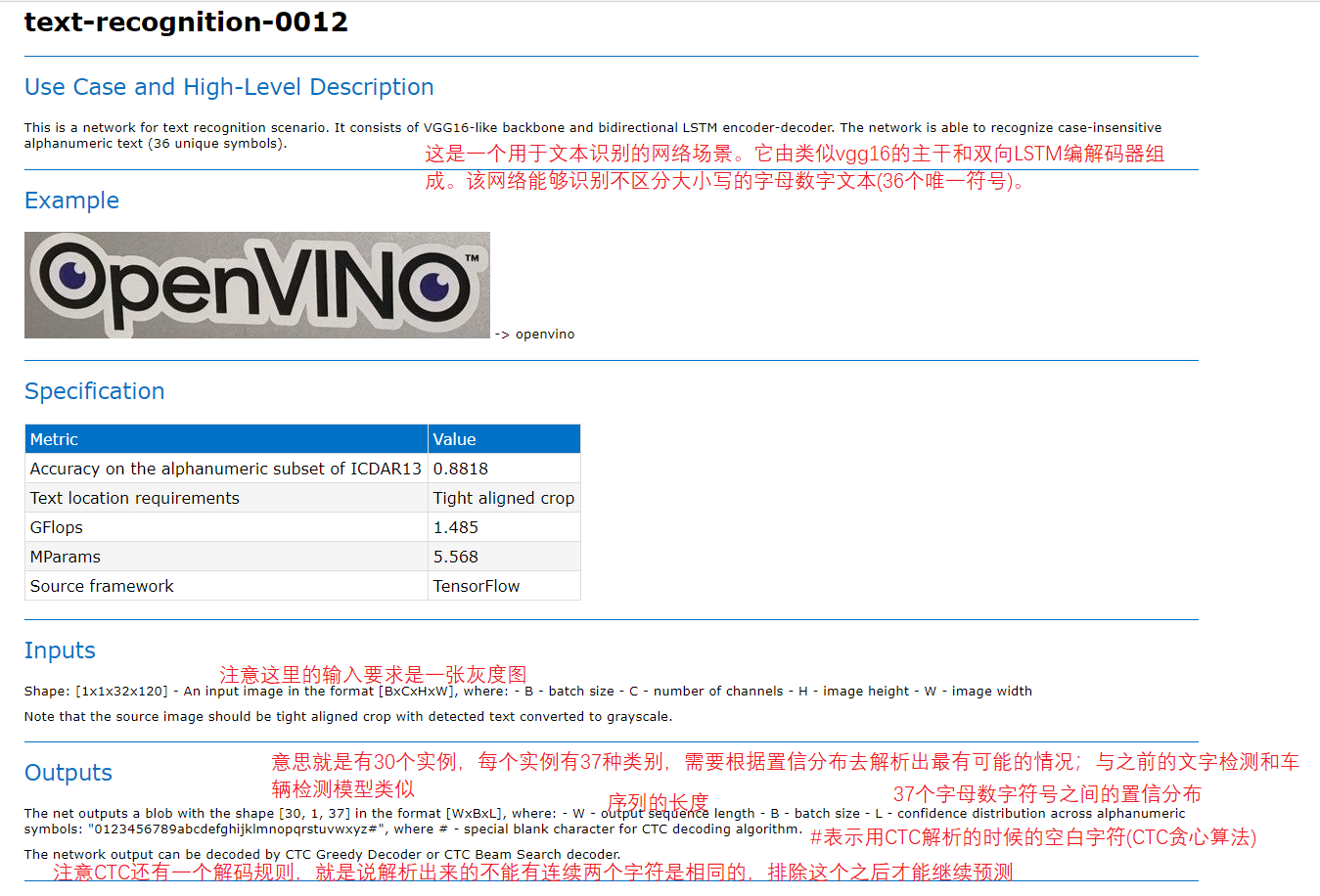
Figure 45
10.2 procedure execution steps
After text detection, return the text area to the text recognition model as input for recognition
10.3 code demonstration
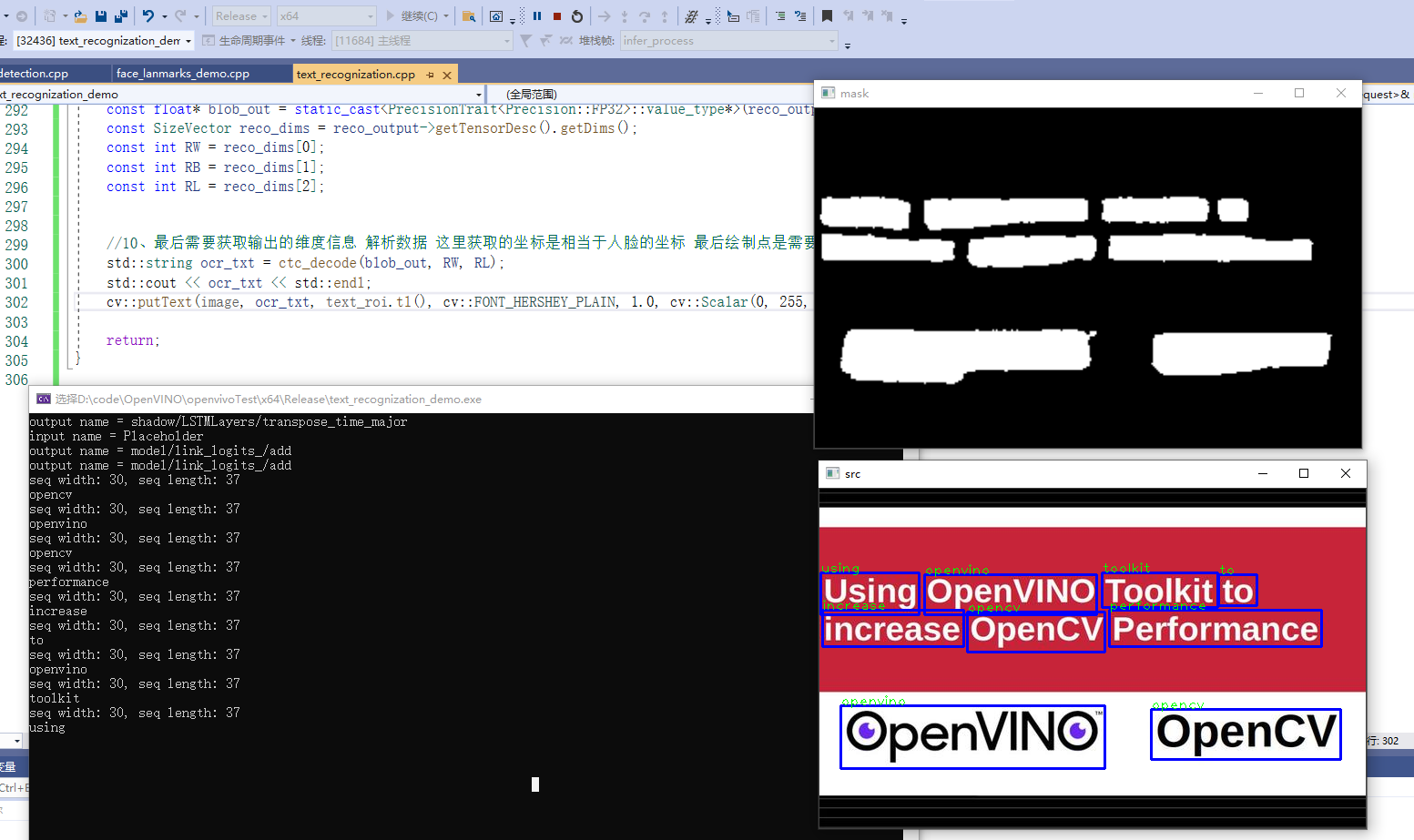
Figure 46
Code practice
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
//Convert the U8 type data from mat to Blob. Because Blob is of any type, it is also declared as a template
template <typename T> void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
//CTC algorithm for character recognition
std::string alphabet = "0123456789abcdefghijklmnopqrstuvwxyz#";
std::string ctc_decode(const float* blob_out, int seq_w, int seq_l) {
printf("seq width: %d, seq length: %d \n", seq_w, seq_l);
std::string res = "";
bool prev_pad = false;
const int num_classes = alphabet.length();
int seq_len = seq_w * seq_l;
for (int i = 0; i < seq_w; i++) {
int argmax = 0;
int max_prob = blob_out[i * seq_l];
for (int j = 0; j < num_classes; j++) {
if (blob_out[i * seq_l + j] > max_prob) {//seq_w instances seq_l category: take the one with the largest confidence ratio of 37 categories for each instance as the result
max_prob = blob_out[i * seq_l + j];
argmax = j;
}
}
auto symbol = alphabet[argmax];
if (symbol == '#') {
prev_pad = true;
}
else {
if (res.empty() || prev_pad || (!res.empty() && symbol != res.back())) {
prev_pad = false;
res += symbol;
}
}
}
return res;
}
//Load the model of character recognition, outgoing reasoning and input / output names
void load_textRecognization_model(std::string xmlFilename, std::string binFilename, std::shared_ptr<InferenceEngine::InferRequest>& request, std::string& input_name, std::string& output_name);
//Character recognition setting input reasoning analysis output
void text_recognization_text(std::shared_ptr<InferenceEngine::InferRequest>& request, std::string& input_name, std::string& output_name, cv::Mat& image, cv::Rect& face_roi);
//After asynchronous reasoning of character recognition, the results are processed
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name, std::vector<cv::Rect>& vc_RoiRect);
//The input reasoning setting function of SSD MobileNetV2 model is to convert the input src into the corresponding format and set it to infer_ Blob of request
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name);
int main(int argc, char** argv)
{
//Load the model of character recognition
std::shared_ptr<InferenceEngine::InferRequest> text_detection_request;
std::string text_detection_input_name;
std::string text_detection_output_name;
std::string text_detection_xmlFilename = "D:/code/OpenVINO/text-recognition-0012/FP32/text-recognition-0012.xml";
std::string text_detection_binFilename = "D:/code/OpenVINO/text-recognition-0012/FP32/text-recognition-0012.bin";
load_textRecognization_model(text_detection_xmlFilename, text_detection_binFilename, text_detection_request, text_detection_input_name, text_detection_output_name);
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
std::string xmlFilename = "D:/code/OpenVINO/text-detection-0003/FP32/text-detection-0003.xml";
std::string binFilename = "D:/code/OpenVINO/text-detection-0003/FP32/text-detection-0003.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name1 = "";
std::string output_name2 = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
input_data->setPrecision(Precision::U8);//The input image data format is unsigned char, which is the precision of 8 bits
//This is also the input data mode set according to the model
input_data->setLayout(Layout::NCHW);
//ColorFormat is also input according to the model settings
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//The model specifies that the input picture is BGR
std::cout << "input name = " << input_name << std::endl;
}
int out_index = 0;
for (auto item : outputs)
{
if (out_index == 1)
{
output_name2 = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << output_name1 << std::endl;
}
else
{
output_name1 = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << output_name1 << std::endl;
}
out_index++;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
auto curr_infer_request = executable_network.CreateInferRequestPtr();
//6. Preprocessing of input image data (including BGR - > RGB, size floating point calculation conversion, image sequence conversion HWC - > nchw)
//Picture reading
cv::Mat curr_frame = cv::imread("D:/openvino_ocr.jpg");
std::vector<cv::Rect> vc_RoiRect;
frameToBlob(curr_frame, curr_infer_request, input_name);
curr_infer_request->Infer();
infer_process(curr_frame, curr_infer_request, output_name2, vc_RoiRect);
//Conduct character recognition setting input for the rectangular box of the returned text area, and conduct reasoning analysis output
for (int i = 0; i < vc_RoiRect.size(); i++)
{
//If (vc_roirect [i]. Width > 32 & & vc_roirect [i]. Height > 120 & & vc_roirect [i]. X > 0 & & vc_roirect [i]. Y > 0) / / protection is required, otherwise it is easy to run away
text_recognization_text(text_detection_request, text_detection_input_name, text_detection_output_name, curr_frame, vc_RoiRect[i]);
}
cv::imshow("src", curr_frame);
char c = cv::waitKey(0);
return 0;
}
// SSD MobileNetV2 model input reasoning setting function encapsulation because the infer needs to be modified_ All requests still need to pass pointers, smart pointers
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name)
{
//1. Through the incoming reasoning engine; Gets the input Blob format conversion class object
auto input = infer_request->GetBlob(input_name);//Get the blob of input (class object for input formatting)
matU8ToBlob<uchar>(src, input);
return;
}
// SSD MobileNetV2 model output reasoning function encapsulation
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name, std::vector<cv::Rect>& vc_RoiRect)
{
//1. Executive reasoning
//infer_ request->Infer(); Asynchronous reasoning does not need this step
cv::Rect box;
//2. Get our output
auto output = infer_request->GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//Output result of detection
//3. Finally, you need to obtain the output dimension information and parse the data
//detection_out is a set of 2*w*h values. We want to analyze that the 2 categories of each corresponding pixel of h*w are text and non text
const SizeVector outputDims = output->getTensorDesc().getDims();
const int out_c = outputDims[1];//2 types of values per pixel
const int out_h = outputDims[2];
const int out_w = outputDims[3];
cv::Mat mask = cv::Mat::zeros(cv::Size(out_w, out_h), CV_8U);//Storing results 0-1
int step = out_h * out_w;
for (int row = 0; row < out_h; row++)
{
for (int col = 0; col < out_w; col++)
{
//The text detection model has only two categories
float p1 = detection_out[row * out_w + col];//The probability value of the first category of the pixel
float p2 = detection_out[step + row * out_w + col];//The address of the second category possibility value of the pixel is text
if (p2 > 1.0) {
mask.at<uchar>(row, col) = 255;//0 - 255 is stored between to mask the text area
}
}
}
cv::resize(mask, mask, cv::Size(src.cols, src.rows));//Size conversion for easy stacking
//Become a binary image
//mask = mask * 255;// The value multiplied by 255 changes from 0-1 to 0-255
//mask.convertTo(mask, CV_8U);// Data type conversion
//cv::threshold(mask, mask, 200, 255, cv::THRESH_BINARY);
//Draw outline
std::vector<std::vector<cv::Point>> contours;
cv::findContours(mask, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);
for (int i = 0; i < contours.size(); i++)
{
cv::Rect box = cv::boundingRect(contours[i]);//Gets the bounding rectangle of the profile
box.x = box.x - 4;
box.y = box.y - 4;
box.width = box.width + 8;
box.height = box.height + 8;
cv::rectangle(src, box, cv::Scalar(255, 0, 0), 2, 8, 0);
vc_RoiRect.push_back(box);
}
cv::imshow("mask", mask);
return;
}
void load_textRecognization_model(std::string xmlFilename, std::string binFilename, std::shared_ptr<InferenceEngine::InferRequest>& request, std::string& input_name, std::string& output_name)
{
//1. Initialize Core ie
InferenceEngine::Core ie;//The core class of IE is actually ie
//2. ie.ReadNetwork needs two files in the CNN network model to read resnet18 bin resnet18. xml
/*std::string xmlFilename = "D:/code/OpenVINO/facial-landmarks-35-adas-0002/FP32/facial-landmarks-35-adas-0002.xml";
std::string binFilename = "D:/code/OpenVINO/facial-landmarks-35-adas-0002/FP32/facial-landmarks-35-adas-0002.bin";*/
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//After reading and loading the CNN network, the network structure will be automatically parsed, and then the input and output can be obtained
//3. Gets the input and output formats and sets the precision
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap is essentially an array of vector s. If you have multiple inputs, it corresponds to each
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
/*std::string input_name = "";
std::string output_name = "";*/
for (auto item : inputs)//Because this model has two inputs, it will cycle twice
{
input_name = item.first;
auto input_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
input_data->setPrecision(Precision::U8);//The input image data format is unsigned char, which is the precision of 8 bits
//This is also the input data mode set according to the model
input_data->setLayout(Layout::NCHW);
//ColorFormat is also input according to the model settings
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//The model specifies that the input picture is BGR
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//It is a data structure. Auto auto inference of C++11 is temporarily used. Because there is only one input, it is temporarily defined in this way to set its accuracy
output_data->setPrecision(Precision::FP32);//Output or floating point output
std::cout << "output name = " << output_name << std::endl;
}
//4. Get executable network and link hardware
auto executable_network = ie.LoadNetwork(network, "CPU");//The network will be loaded into the CPU hardware, which can also be set to GPU
//5. After creating a reasoning request, you can try reasoning, but there are still many things to do before reasoning, such as format setting
request = executable_network.CreateInferRequestPtr();
}
void text_recognization_text(std::shared_ptr<InferenceEngine::InferRequest>& request, std::string& input_name, std::string& output_name, cv::Mat& image, cv::Rect& text_roi)
{
//Set input
cv::Mat gray;
cv::cvtColor(image, gray, cv::COLOR_BGR2GRAY);
cv::Mat faceROI = gray(text_roi);//Because the model of text recognition needs gray image as input
// frameToBlob(faceROI, face_lanmarks_request, face_lanmarks_input_name);
auto reco_input_blob = request->GetBlob(input_name);
size_t num_channels = reco_input_blob->getTensorDesc().getDims()[1];
size_t h = reco_input_blob->getTensorDesc().getDims()[2];
size_t w = reco_input_blob->getTensorDesc().getDims()[3];
size_t image_size = h * w;
cv::Mat blob_image;
cv::resize(faceROI, blob_image, cv::Size(w, h));
// HWC =>NCHW
unsigned char* data = static_cast<unsigned char*>(reco_input_blob->buffer());
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
data[row * w + col] = blob_image.at<uchar>(row, col);//Is of type unchar
}
}
//Executive reasoning
request->Infer();
//Output string result return
auto reco_output = request->GetBlob(output_name);
const float* blob_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(reco_output->buffer());
const SizeVector reco_dims = reco_output->getTensorDesc().getDims();
const int RW = reco_dims[0];
const int RB = reco_dims[1];
const int RL = reco_dims[2];
//10. Finally, it is necessary to obtain the output dimension information and analyze the data. The coordinates obtained here are equivalent to the coordinates of the face, and the last drawing point is the coordinates of the picture
std::string ocr_txt = ctc_decode(blob_out, RW, RL);
std::cout << ocr_txt << std::endl;
cv::putText(image, ocr_txt, text_roi.tl(), cv::FONT_HERSHEY_PLAIN, 1.0, cv::Scalar(0, 255, 0), 1);
return;
}
11. pytorch model transformation and deployment
For many previous detection and recognition, we can quickly develop demos based on OpenVINO, but there is another kind of network that does not have some pre training models, so we can train through other deep learning frameworks. After training the generated models, we will redeploy them to our OpenVINO for reasoning to accelerate the deployment of such a deep model, This piece needs an underlying support. This support requires an automasz in OpenVINO, We talked about IE (interface engine inference engine) in OpenVINO, and this example is to talk about how to convert a python model into an onnx model, then let OpenVINO load the onnx model or turn it into an IR model, let OpenVINO load the IR model, and finally realize the steps of reasoning and demonstration of a model.
Some links given by group friends about environmental deployment, because they learn by themselves openVINO Just as a reserve technology, Therefore, the relevant of these parts will not be understood and practiced for the time being. https://www.cnblogs.com/qianwangxingfu/p/13582884.html https://www.bilibili.com/video/BV1UE411N7gS anconda to configure pytorch and tensorflow install Pycharm stay Pycharm Just select the interpreter
11.1 ONNX and support
If you are a model trained with Pytorch, you can convert it to onnx. Now that you have trained the python model and have pth files, how can you turn it into an onnx or an IR. (you can call the API in pytoch for conversion). In previous cases, we loaded bin and xml, that is, the intermediate file of IR. In fact, we can also load the onnx format file of the model to complete reasoning, which has the same effect.
11.2 pth file to ONNX format file
11.3. ONNX conversion IR file (binxml file)
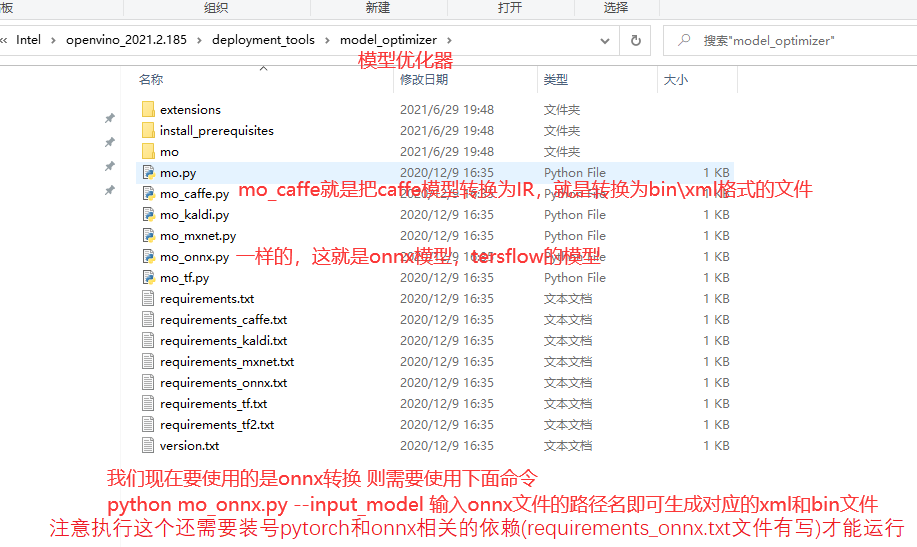
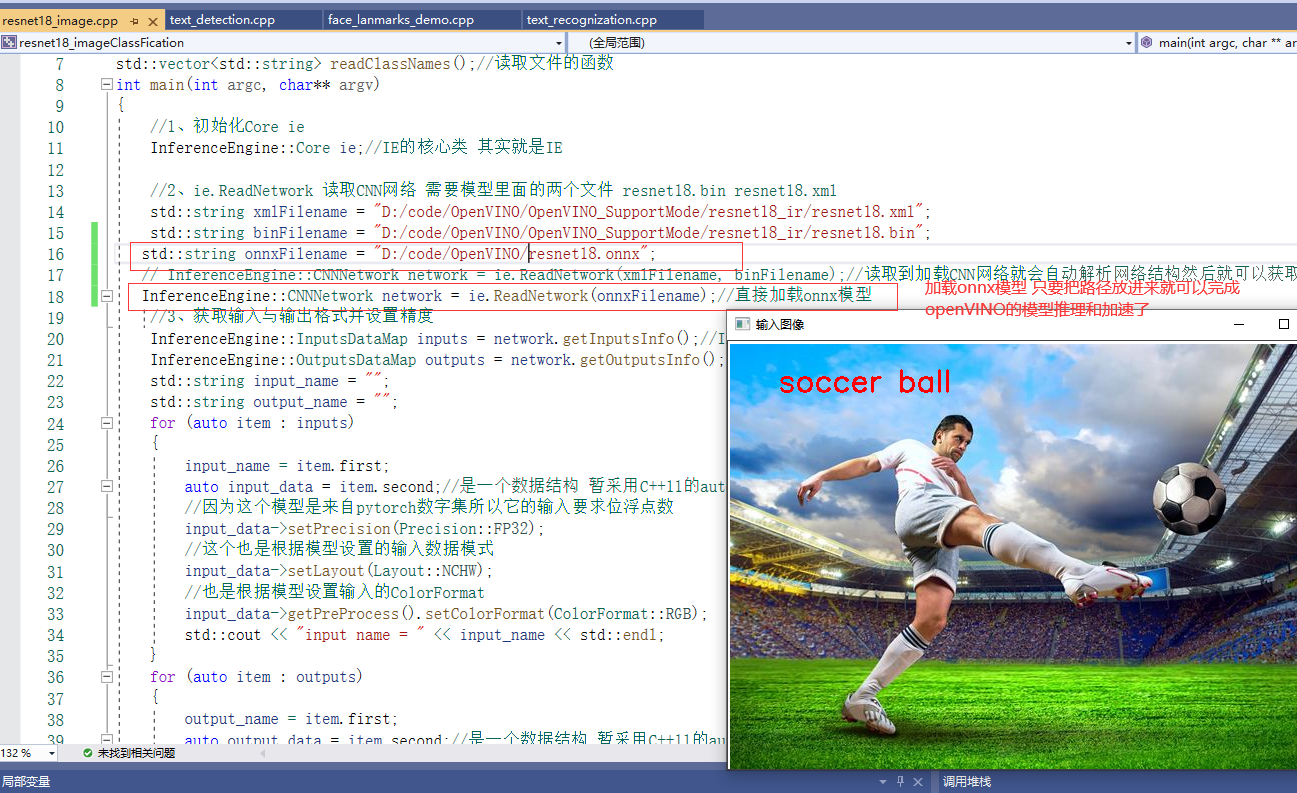
·Figure 47 48
12. Transformation and deployment of tensorflow model
13. YOLOv5 model deployment and reasoning
Summary:
Introduction of OpenVINO: landing requirements of the model, especially on edge devices
Environment construction of C + + practice: configuration header file path, library path, library dependency, and environment variable configuration of related applications
ResNet18 image classification model: set model input and analyze two-dimensional output [11000];
Vehicle and license plate detection and recognition: the key is analytical thinking output [1,1,N,7], multi model reasoning support, ROI region transfer
Pedestrian detection: the key is the real-time encapsulation of video, input reasoning and analysis, and the encapsulation of input interface, and the generalization of C + +
Face detection: asynchronous reasoning in video
Expression recognition: multi model reasoning support and asynchronous reasoning to ensure real-time
Face landmark 35 key points detection; Pay attention to the returned ROI region judgment and the extended development of facial features
Real time semantic road segmentation: the key is to analyze the multi-channel output of the segmentation network, which is in the format of 1:4:h:w, and how to get the address position of the corresponding type of the corresponding pixel. And related opencv skills to complete the result output
Instance segmentation: both RCNN models have two input layers to be set, and analyze the category mask generation of the instance ROI area and complete the instance output with relevant opencv technology
Scene text detection: the key to the parsing skills of PixelLink model output is the conversion between floating point number and uchar type
Scene character recognition: the key lies in the requirements of gray image input, output structure analysis of CTC greedy algorithm, and ROI interception of character area.
In the follow-up, there are model transformation, Python and other related contents. Because there is no relevant technical reserve for the time being, we will put them here for the time being, and then learn the knowledge related to openVINO after the relevant in-depth learning model and python language have been systematically studied.
The code project has been tested, and the material will be in the csdn resource last time
Blog notes from; Teacher Jia Zhigang's openVINO course