1, Introduction to hadoop
1. Description
Hadoop is a distributed system infrastructure developed by the Apache foundation. Users can develop distributed programs without knowing the details of the distributed bottom layer. Make full use of the power of cluster for high-speed computing and storage. Hadoop implements a Distributed File System, one of which is HDFS (Hadoop Distributed File System). HDFS has the characteristics of high fault tolerance and is designed to be deployed on low-cost hardware; Moreover, it provides high throughput to access application data, which is suitable for applications with large data set s. HDFS relax es the requirements of POSIX and can access the data in the file system in the form of streaming access. The core design of Hadoop framework is HDFS and MapReduce. HDFS provides storage for massive data, while MapReduce provides computing for massive data.
2. Advantages
Hadoop is a software framework that can process a large amount of data distributed. Hadoop handles data in a reliable, efficient and scalable way.
Hadoop is reliable because it assumes that computing elements and storage will fail, so it maintains multiple copies of working data to ensure that processing can be redistributed for failed nodes.
Hadoop is efficient because it works in parallel and speeds up processing through parallel processing.
Hadoop is also scalable and can handle petabytes of data.
In addition, Hadoop relies on community services, so its cost is relatively low and can be used by anyone.
Hadoop is a distributed computing platform that allows users to easily architecture and use. Users can easily develop and run applications dealing with massive data on Hadoop.
It has the following advantages:
1.High reliability. Hadoop The ability to store and process data by bit is trustworthy. 2.High scalability. Hadoop It allocates data among available computer clusters and completes computing tasks. These clusters can be easily extended to thousands of nodes. 3.Efficiency. Hadoop It can dynamically move data between nodes and ensure the dynamic balance of each node, so the processing speed is very fast. 4.High fault tolerance. Hadoop It can automatically save multiple copies of data and automatically reassign failed tasks. 5.Low cost. With all-in-one machine, commercial data warehouse and QlikView,Yonghong Z-Suite Compared with the data mart, hadoop It is open source, so the software cost of the project will be greatly reduced.
Hadoop has a framework written in Java language, so it is ideal to run on Linux production platform. Applications on Hadoop can also be written in other languages, such as C + +.
3. Core architecture
Hadoop consists of many elements. At the bottom is the Hadoop Distributed File System (HDFS), which stores files on all storage nodes in the Hadoop cluster. The upper layer of HDFS is MapReduce engine, which is composed of JobTrackers and TaskTrackers. Through the introduction of the core distributed file system HDFS and MapReduce processing process of Hadoop distributed computing platform, as well as the data warehouse tool Hive and distributed database Hbase, it basically covers all the technical cores of Hadoop distributed platform
HDFS For external clients, HDFS It's like a traditional hierarchical file system. You can create, delete, move, or rename files, and so on. however HDFS The architecture of is based on a specific set of nodes, which is determined by its own characteristics. These nodes include NameNode(Only one), it's in HDFS Provide metadata services internally; DataNode,It is HDFS Provide storage blocks. Because there is only one NameNode,So this is HDFS 1.x One disadvantage of Version (single point of failure). stay Hadoop 2.x There can be two versions NameNode,The problem of single node failure is solved
NameNode NameNode Is a usually HDFS Software running on a separate machine in the instance. It is responsible for managing file system namespaces and controlling access to external clients. NameNode Decide whether to map files to DataNode Copy block on. For the three most common copy blocks, the first copy block is stored on different nodes in the same rack, and the last copy block is stored on a node in different racks
DataNode DataNode It's also a common HDFS Software running on a separate machine in the instance. Hadoop The cluster contains a NameNode And a lot DataNode. DataNode It is usually organized in the form of a rack, which connects all systems through a switch. Hadoop An assumption is that the transmission speed between nodes in the rack is faster than that between nodes in the rack
2, Stand alone deployment of HDFS distributed file storage system
1. Installation
[root@server1 ~]# ls hadoop-3.2.1.tar.gz jdk-8u181-linux-x64.tar.gz [root@server1 ~]# mv hadoop-3.2.1.tar.gz jdk-8u181-linux-x64.tar.gz /home/hadoop/ [root@server1 ~]# su - hadoop Last login: Thu Jul 8 23:36:31 EDT 2021 on pts/0 [hadoop@server1 ~]$ ls hadoop-3.2.1.tar.gz jdk-8u181-linux-x64.tar.gz [hadoop@server1 ~]$ tar zxf jdk-8u181-linux-x64.tar.gz [hadoop@server1 ~]$ ls hadoop-3.2.1.tar.gz jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz [hadoop@server1 ~]$ ln -s jdk1.8.0_181/ java [hadoop@server1 ~]$ ls hadoop-3.2.1.tar.gz java jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz [hadoop@server1 ~]$ ll total 532076 -rw-r--r-- 1 root root 359196911 Jul 8 23:35 hadoop-3.2.1.tar.gz lrwxrwxrwx 1 hadoop hadoop 13 Jul 8 23:39 java -> jdk1.8.0_181/ drwxr-xr-x 7 hadoop hadoop 245 Jul 7 2018 jdk1.8.0_181 -rw-r--r-- 1 root root 185646832 Jul 8 23:35 jdk-8u181-linux-x64.tar.gz [hadoop@server1 ~]$ tar zxf hadoop-3.2.1.tar.gz [hadoop@server1 ~]$ ln -s hadoop-3.2.1 hadoop

2. Start the cluster
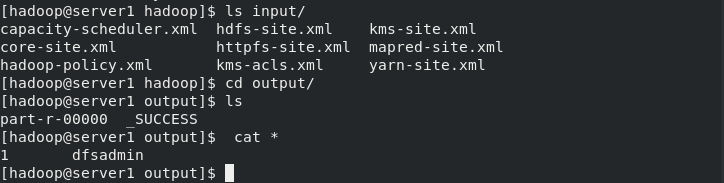
The following example copies the unpackaged conf directory as input, and then finds and displays each match for a given general expression. The output has been written to the given output directory.
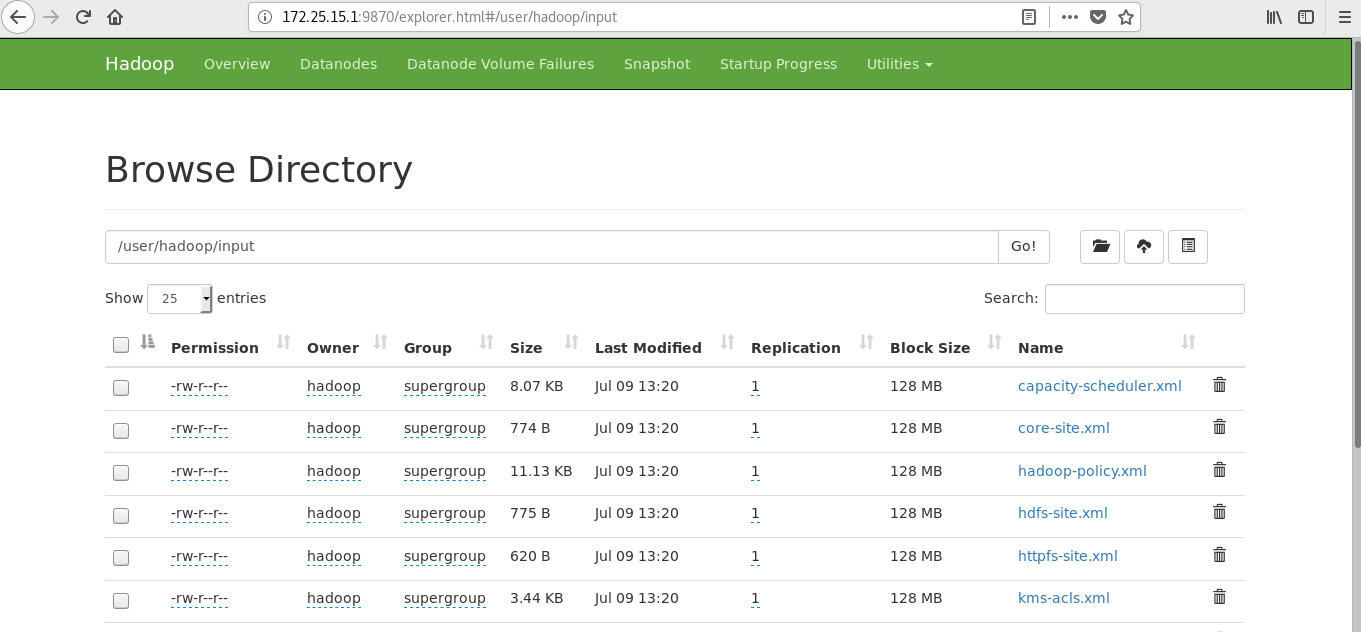
[hadoop@server1 ~]$ cd hadoop [hadoop@server1 hadoop]$ cd etc/hadoop/ [hadoop@server1 hadoop]$ vim hadoop-env.sh export JAVA_HOME=/home/hadoop/java # Location of Hadoop. By default, Hadoop will attempt to determine # this location based upon its execution path. export HADOOP_HOME=/home/hadoop/hadoop [hadoop@server1 hadoop]$ mkdir input [hadoop@server1 hadoop]$ pwd /home/hadoop/hadoop [hadoop@server1 hadoop]$ cp etc/hadoop/*.xml input/ [hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+' ##Use the jar package given by the system for testing [hadoop@server1 hadoop]$ ls input/ capacity-scheduler.xml hdfs-site.xml kms-site.xml core-site.xml httpfs-site.xml mapred-site.xml hadoop-policy.xml kms-acls.xml yarn-site.xml [hadoop@server1 hadoop]$ cd output/ [hadoop@server1 output]$ ls part-r-00000 _SUCCESS [hadoop@server1 output]$ cat * 1 dfsadmin [hadoop@server1 output]$
3, Pseudo distributed storage system deployment
1. Edit profile
Hadoop It can also run on a single node in pseudo distributed mode, where each Hadoop daemon In separate Java Run in process.
[hadoop@server1 output]$ cd ..
[hadoop@server1 hadoop]$ cd etc/hadoop/
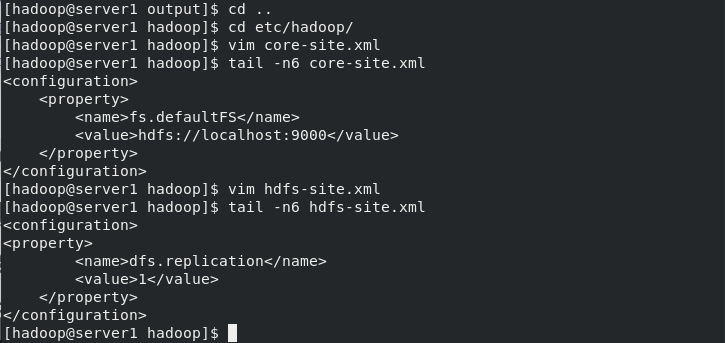
[hadoop@server1 hadoop]$ vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
[hadoop@server1 hadoop]$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> ##The number of copies stored is three by default. Now we use one node for pseudo distribution, so it is set to one copy
</property>
</configuration>
2. Make local secret free
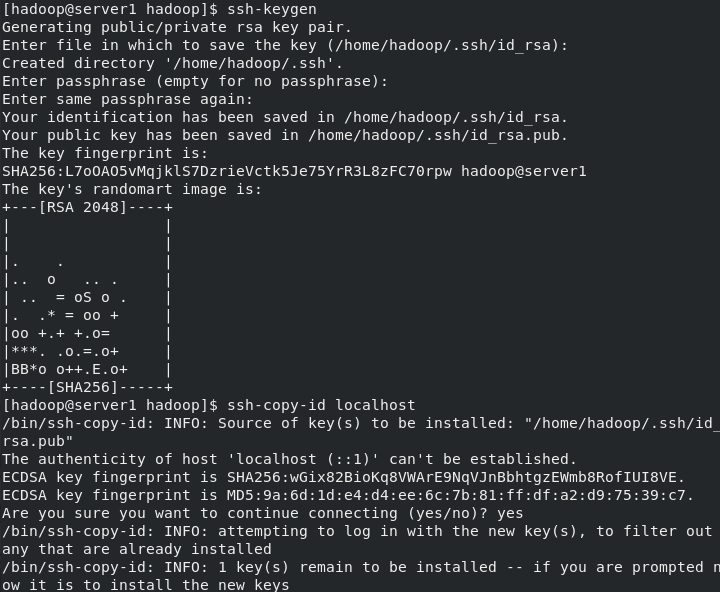
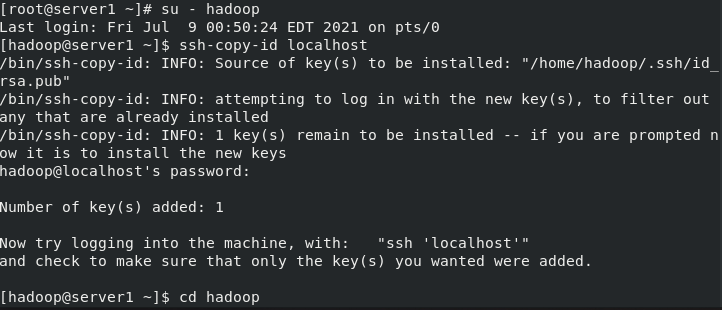
By default, hdfs It will be connected through a secret free connection worker Node (data storage node) to start the corresponding process. stay hadoop/etc/There will be in the directory workers File that specifies worker node [hadoop@server1 hadoop]$ ssh-keygen ##Local secret free [hadoop@server1 hadoop]$ ssh-copy-id localhost [hadoop@server1 hadoop]$ ll workers -rw-r--r-- 1 hadoop hadoop 10 Sep 10 2019 workers [hadoop@server1 hadoop]$ cat workers localhost [hadoop@server1 hadoop]$ ssh localhost Last login: Fri Jul 9 00:53:18 2021 from localhost [hadoop@server1 ~]$ logout Connection to localhost closed. [hadoop@server1 hadoop]$


3. Start the process
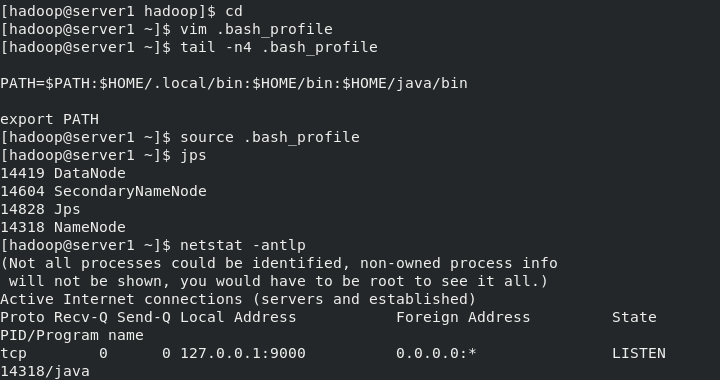
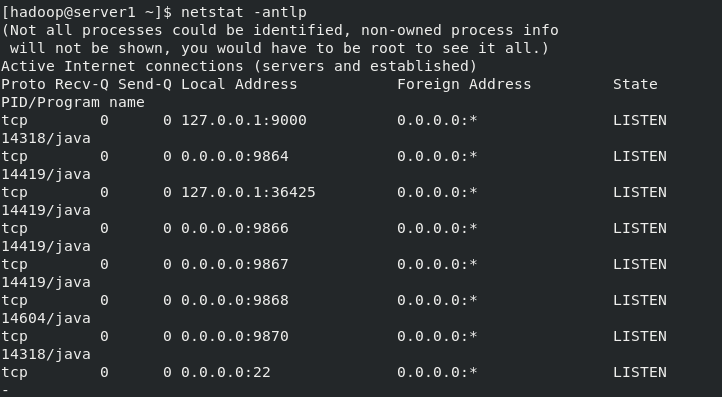
[hadoop@server1 hadoop]$ bin/hdfs namenode -format ##Format the file system and store the generated data in the / tmp / directory [hadoop@server1 hadoop]$ id uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop) [hadoop@server1 hadoop]$ sbin/start-dfs.sh ##Start the NameNode process and DataNode process Starting namenodes on [localhost] Starting datanodes Starting secondary namenodes [server1] [hadoop@server1 hadoop]$ cd [hadoop@server1 ~]$ vim .bash_profile [hadoop@server1 ~]$ tail -n4 .bash_profile PATH=$PATH:$HOME/.local/bin:$HOME/bin:$HOME/java/bin #Setting environment variables export PATH [hadoop@server1 ~]$ source .bash_profile [hadoop@server1 ~]$ jps ##Displays the java processes opened by the current system 14419 DataNode #The metadata of the entire distributed file system is cached on the namenode node. The datanode stores real data. When the namenode is hung, the SecondaryNameNode will take over. 14604 SecondaryNameNode 14828 Jps 14318 NameNode [hadoop@server1 ~]$ netstat -antlp
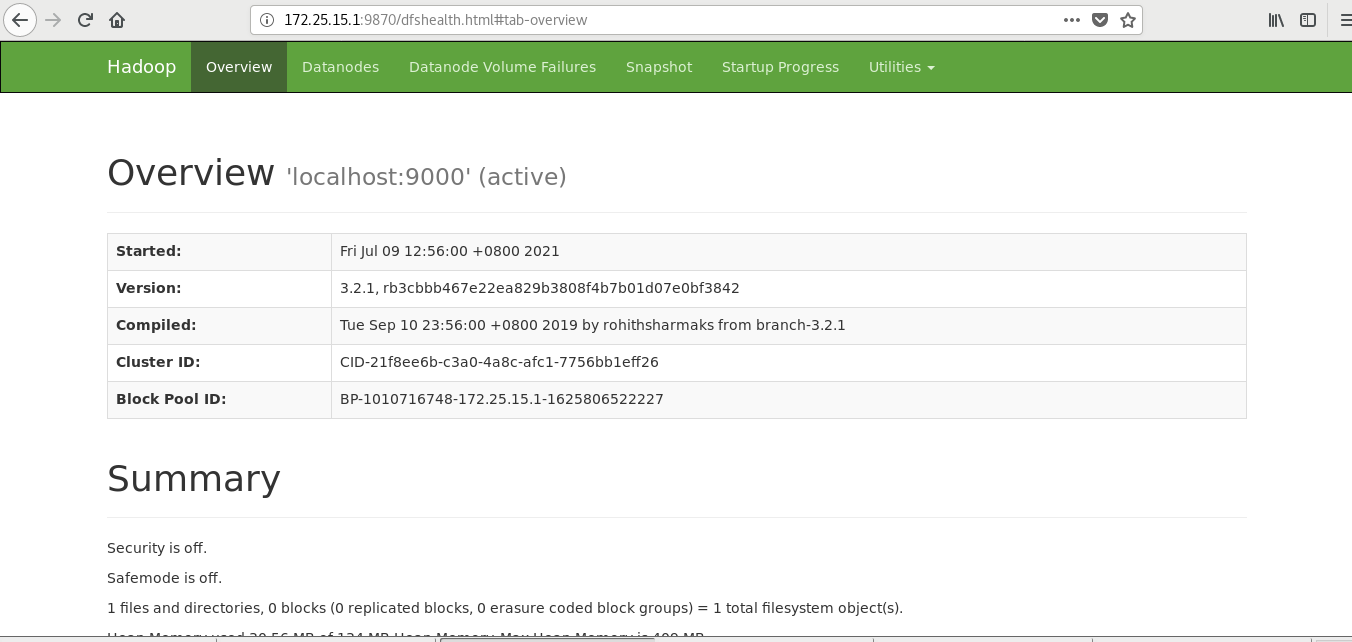
4. Visit the web page for testing
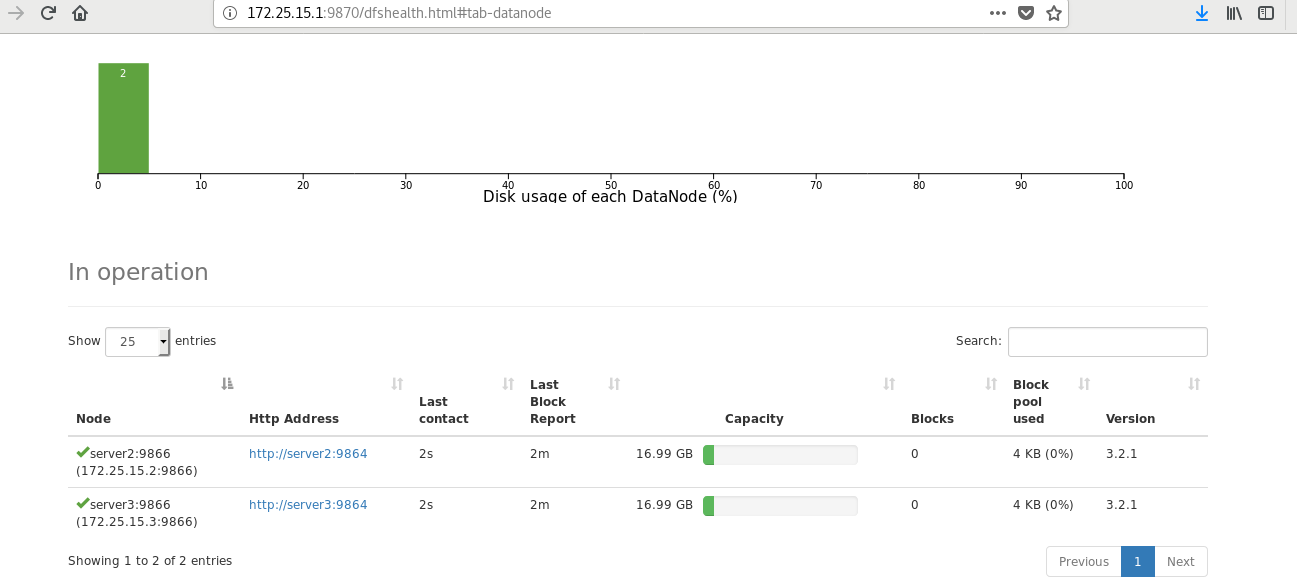
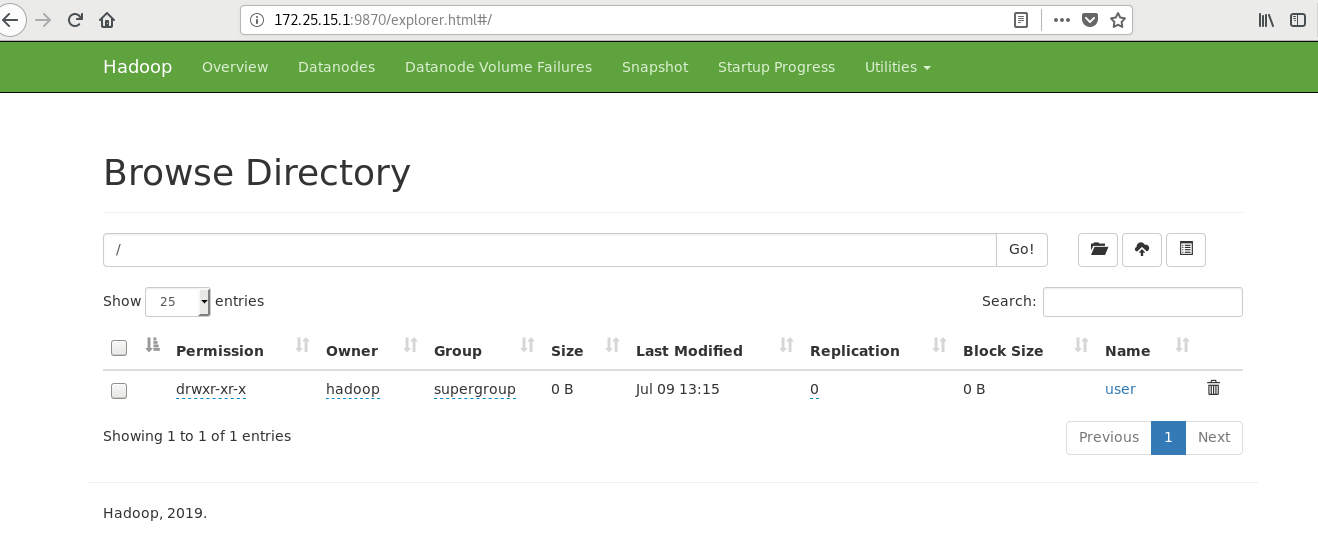
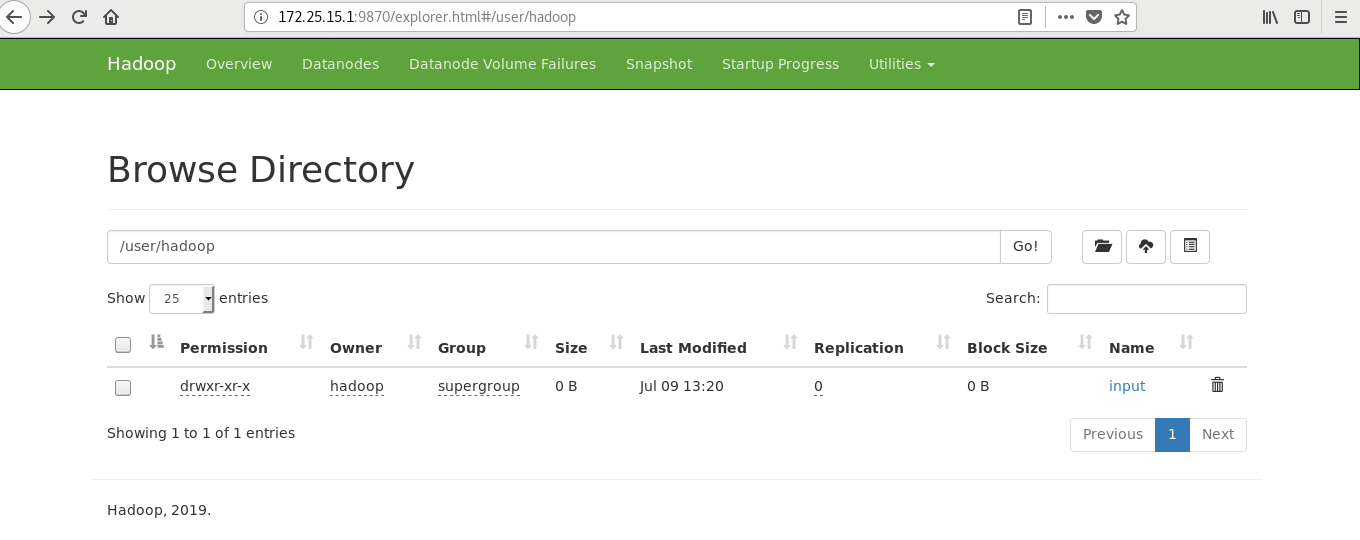
Visit the web page to test: http://172.25.15.1:9870
5. Create storage directory
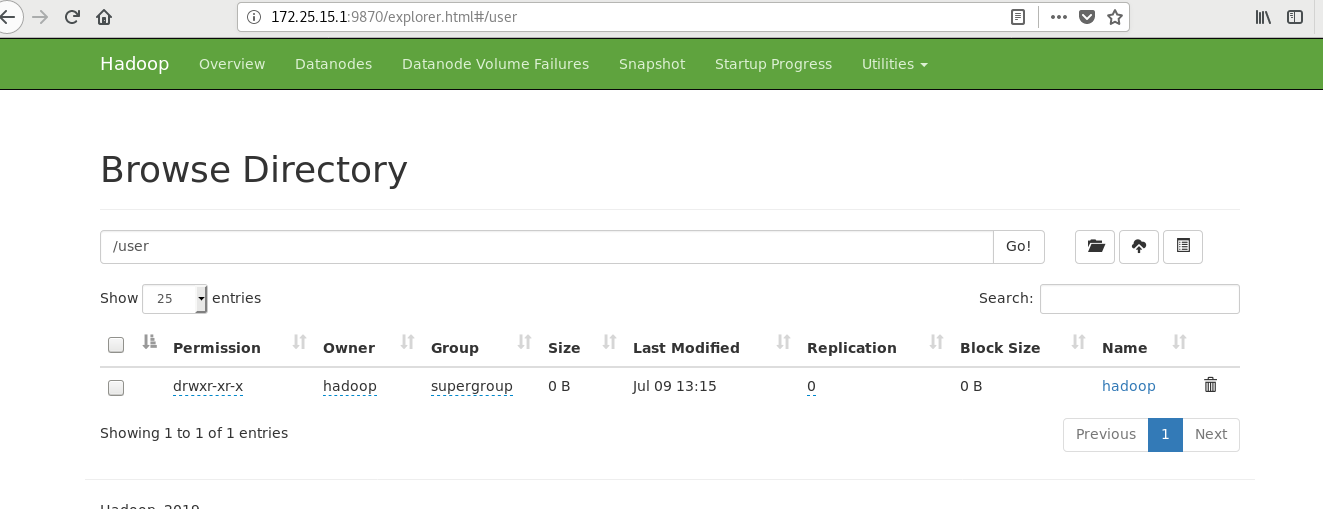
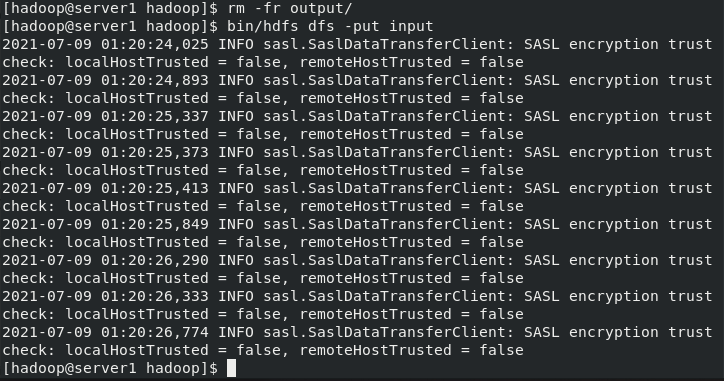
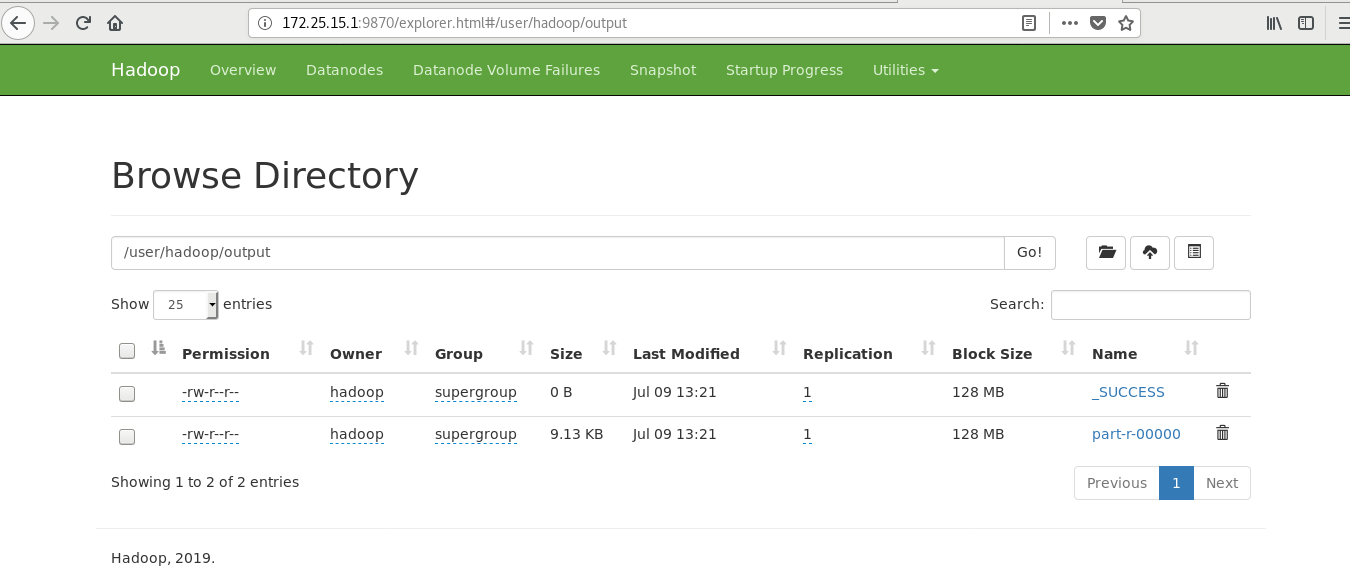
[hadoop@server1 ~]$ cd hadoop/ [hadoop@server1 hadoop]$ bin/hdfs [hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user [hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user/hadoop ##It is equivalent to creating the user's home directory in the distributed file system [hadoop@server1 hadoop]$ bin/hdfs dfs -ls [hadoop@server1 hadoop]$ ls bin etc include input lib libexec LICENSE.txt logs NOTICE.txt output README.txt sbin share [hadoop@server1 hadoop]$ rm -fr output/ [hadoop@server1 hadoop]$ bin/hdfs dfs -put input ##Upload the contents of the input directory to the distributed file storage system
When starting the distributed file system, ensure that the time of all nodes must be synchronized, and there must be parsing, otherwise an error will be reported. Moreover, the output directory cannot be created in advance in the distributed file system. The web page should ensure that there is no output directory before

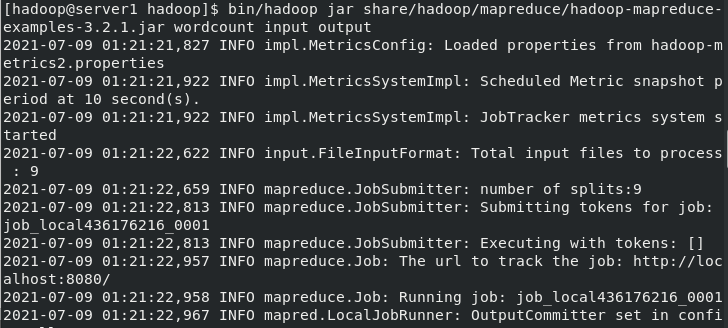
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount input output
6. Copy the output file to the local file system
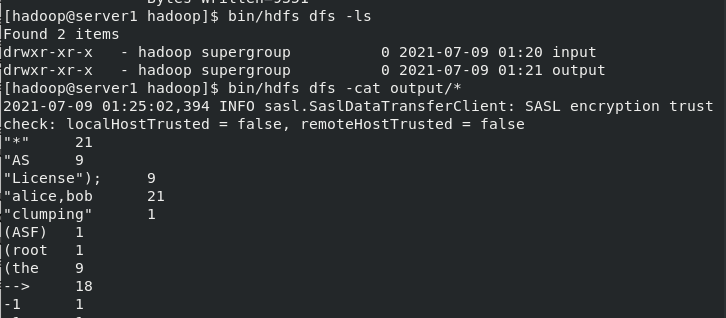
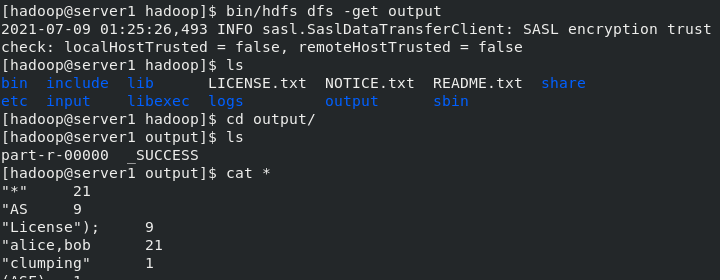
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls [hadoop@server1 hadoop]$ bin/hdfs dfs -cat output/* #Word frequency statistics, directly listed [hadoop@server1 hadoop]$ bin/hdfs dfs -get output #Download it 2021-05-11 05:23:58,659 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false [hadoop@server1 hadoop]$ ls bin etc include lib libexec LICENSE.txt logs NOTICE.txt output README.txt sbin share [hadoop@server1 hadoop]$ cd output/ [hadoop@server1 output]$ cat * #View all [hadoop@server1 output]$ ls part-r-00000 _SUCCESS [hadoop@server1 output]$ cd .. [hadoop@server1 hadoop]$ rm -fr output/ ##Deleting local storage does not delete storage in a distributed storage system [hadoop@server1 hadoop]$ bin/hdfs dfs -rm -r output ##Delete storage in a distributed storage system Deleted output

4, Fully distributed storage system deployment
1. Start two new virtual machines server2 and server3
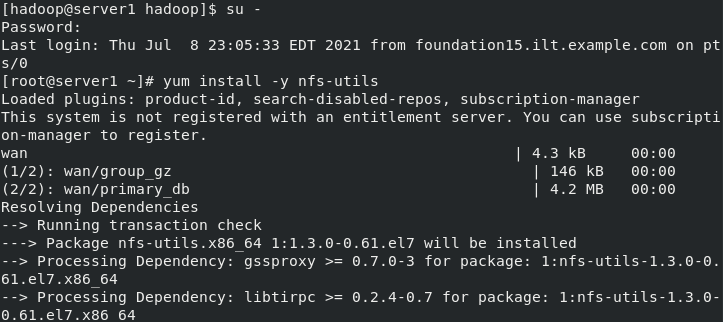
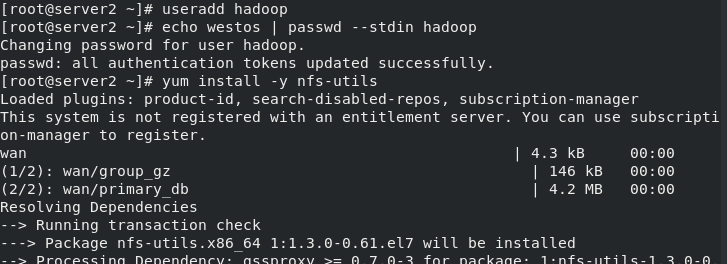
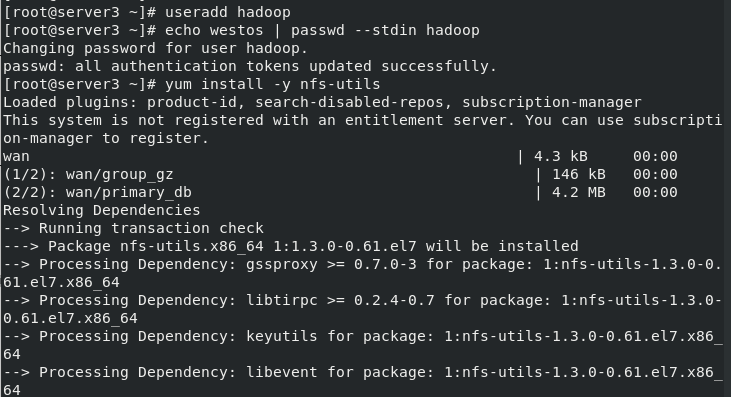
(1)Create the same on the newly opened virtual machine hadoop user (2)server1 Upper hdfs Stop first (3)build nfs File sharing system, server1 by nfs The server (4)server2 and server3 mount server1 of hadoop Directory to the specified directory to achieve data synchronization [hadoop@server1 hadoop]$ sbin/stop-dfs.sh Stopping namenodes on [localhost] Stopping datanodes Stopping secondary namenodes [server1] [hadoop@server1 hadoop]$ su - root Password: Last login: Thu Jul 8 23:05:33 EDT 2021 from foundation15.ilt.example.com on pts/0 [root@server1 ~]# yum install -y nfs-utils server2 server3 [root@server2 ~]# useradd hadoop [root@server2 ~]# echo westos | passwd --stdin hadoop Changing password for user hadoop. passwd: all authentication tokens updated successfully. [root@server2 ~]# yum install -y nfs-utils [root@server3 ~]# useradd hadoop [root@server3 ~]# echo westos | passwd --stdin hadoop Changing password for user hadoop. passwd: all authentication tokens updated successfully. [root@server3 ~]# yum install -y nfs-utils

2. Edit the file sharing policy and specify the hadoop user
[hadoop@server1 hadoop]$ pwd /home/hadoop/hadoop [hadoop@server1 hadoop]$ sbin/stop-dfs.sh Stopping namenodes on [localhost] Stopping datanodes Stopping secondary namenodes [server1] [hadoop@server1 hadoop]$ logout [root@server1 ~]# yum install -y nfs-utils [root@server1 ~]# vim /etc/exports /home/hadoop *(rw,anonuid=1000,anongid=1000) [root@server1 ~]# systemctl start nfs [root@server1 ~]# exportfs -r [root@server1 ~]# exportfs -rv exporting *:/home/hadoop [root@server1 ~]# showmount -e Export list for server1: /home/hadoop * [root@server1 ~]#
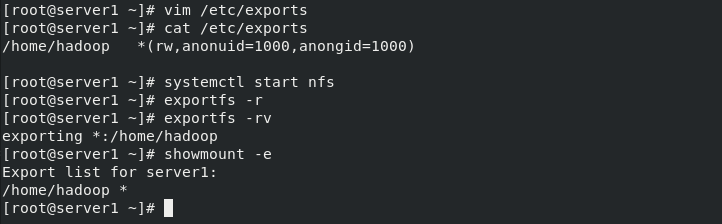
3. Check whether the synchronization is effective
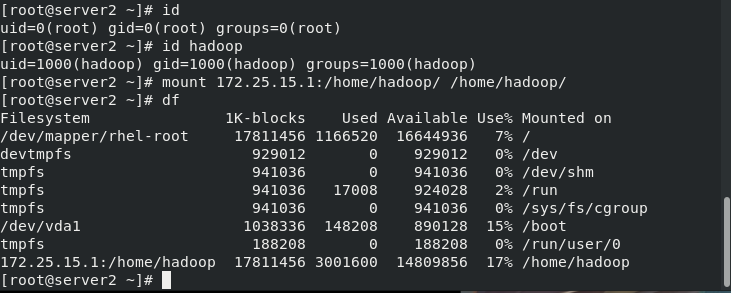
server2
[root@server2 ~]# id uid=0(root) gid=0(root) groups=0(root) [root@server2 ~]# id hadoop uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop) [root@server2 ~]# mount 172.25.15.1:/home/hadoop/ /home/hadoop/ [root@server2 ~]# df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/rhel-root 17811456 1166520 16644936 7% / devtmpfs 929012 0 929012 0% /dev tmpfs 941036 0 941036 0% /dev/shm tmpfs 941036 17008 924028 2% /run tmpfs 941036 0 941036 0% /sys/fs/cgroup /dev/vda1 1038336 148208 890128 15% /boot tmpfs 188208 0 188208 0% /run/user/0 172.25.15.1:/home/hadoop 17811456 3001600 14809856 17% /home/hadoop [root@server2 ~]#
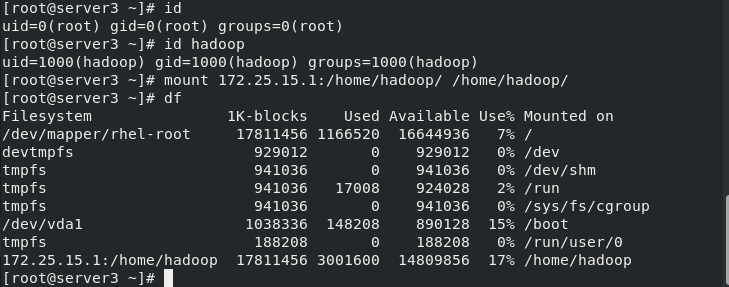
server3
[root@server3 ~]# id uid=0(root) gid=0(root) groups=0(root) [root@server3 ~]# id hadoop uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop) [root@server3 ~]# mount 172.25.15.1:/home/hadoop/ /home/hadoop/ [root@server3 ~]# df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/rhel-root 17811456 1166520 16644936 7% / devtmpfs 929012 0 929012 0% /dev tmpfs 941036 0 941036 0% /dev/shm tmpfs 941036 17008 924028 2% /run tmpfs 941036 0 941036 0% /sys/fs/cgroup /dev/vda1 1038336 148208 890128 15% /boot tmpfs 188208 0 188208 0% /run/user/0 172.25.15.1:/home/hadoop 17811456 3001600 14809856 17% /home/hadoop [root@server3 ~]#
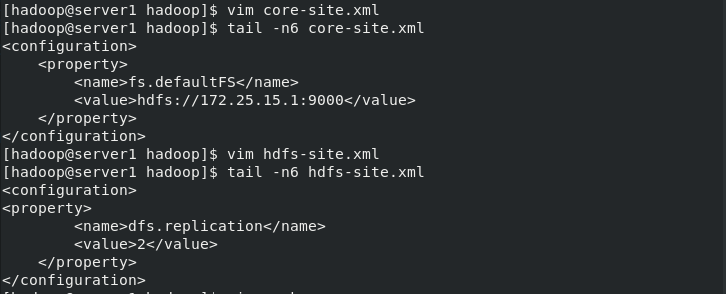
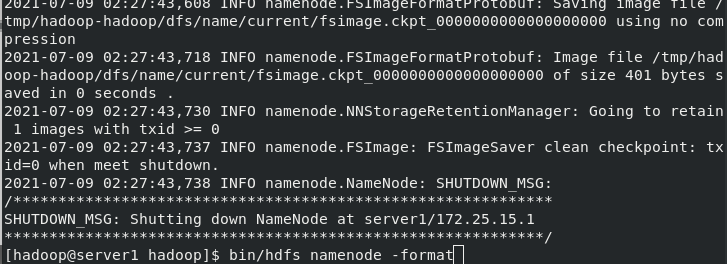
Modify the hadoop related configuration files on server1, delete the files generated by the last initialization in the / tmp / directory, re initialize and start hdfs
[hadoop@server1 ~]$ cd hadoop/etc/hadoop/ [hadoop@server1 hadoop]$ vim core-site.xml [hadoop@server1 hadoop]$ vim workers [hadoop@server1 hadoop]$ vim hdfs-site.xml [hadoop@server1 hadoop]$ cd .. [hadoop@server1 hadoop]$ cd .. [hadoop@server1 hadoop]$ bin/hdfs namenode -format [hadoop@server1 hadoop]$ ssh 172.25.15.2 The authenticity of host '172.25.15.2 (172.25.15.2)' can't be established. ECDSA key fingerprint is SHA256:OSdVXtO5BVPkuh1MYLNhhVkGDiLkFmrjDSo8ysMRRr0. ECDSA key fingerprint is MD5:f4:9e:26:78:0e:ef:5c:8e:cd:08:f5:5a:15:d1:0e:3c. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '172.25.15.2' (ECDSA) to the list of known hosts. [hadoop@server2 ~]$ ssh 172.25.15.3 The authenticity of host '172.25.15.3 (172.25.15.3)' can't be established. ECDSA key fingerprint is SHA256:6N3DRBCV5LeHzl8RGj3iOtnqVL+xzKNRJc0J+jz/yqc. ECDSA key fingerprint is MD5:2d:df:2c:de:6a:e4:6b:bd:b9:49:da:a1:31:43:7b:57. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '172.25.15.3' (ECDSA) to the list of known hosts. [hadoop@server3 ~]$ ssh 172.25.15.1 Last login: Fri Jul 9 00:53:37 2021 from localhost

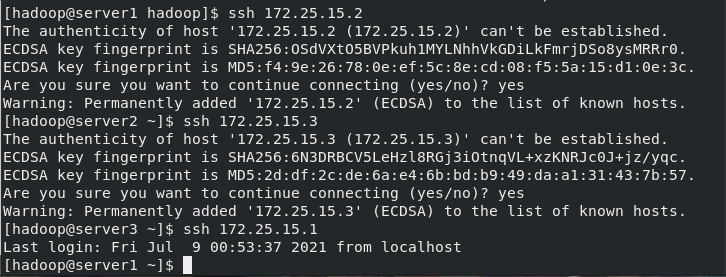
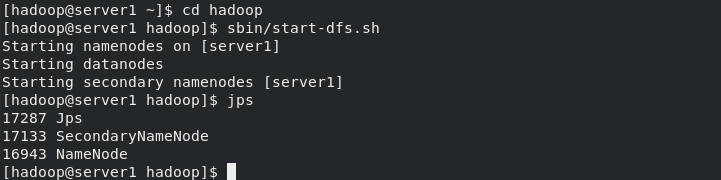
start-up
[hadoop@server1 ~]$ cd hadoop [hadoop@server1 hadoop]$ sbin/start-dfs.sh Starting namenodes on [server1] Starting datanodes Starting secondary namenodes [server1] [root@server2 ~]# su - hadoop Last login: Fri Jul 9 02:29:17 EDT 2021 from server1 on pts/1 [hadoop@server2 ~]$ cd hadoop [hadoop@server2 hadoop]$ jps 14178 Jps 14089 DataNode [hadoop@server2 hadoop]$ [root@server3 ~]# su - hadoop Last login: Fri Jul 9 02:29:40 EDT 2021 from server2 on pts/1 [hadoop@server3 ~]$ cd hadoop [hadoop@server3 hadoop]$ jps 14148 Jps 14056 DataNode [hadoop@server3 hadoop]$


Test browser access http://172.25.15.1:9870/