PaddleDetection
introduce
PaddleDetection is an end to end object detection development kit based on PaddlePaddle, which is designed to help developers provide help in the whole development of training models, optimizing performance and reasoning speed, and deploying models. Paddedetection provides various object detection architectures in modular design, and provides rich data enhancement methods, network components, loss functions and so on. Paddedetection supports practical projects, such as industrial quality inspection, remote sensing image object detection and automatic inspection with practical functions such as models. Compression and multi platform deployment.
Now all models in PaddleDetection require 1.8 or later versions of PaddlePaddle or the appropriate development version.
GitHub address: https://github.com/PaddlePaddle/PaddleDetection
features
Rich models:
Paddedetection provides a wealth of models, including more than 100 pre trained models, such as object detection, instance segmentation, face detection and so on. It covers the champion model, a practical detection model suitable for cloud and edge devices.
Production ready:
The key operation is implemented in C + + and CUDA, plus the efficient inference engine of PaddlePaddle, which can be deployed easily in the server environment.
Highly flexible:
The components are designed to be modular. The model architecture and data preprocessing pipeline can be easily customized through simple configuration changes.
Performance Optimization:
With the help of the basic PaddlePaddle framework, we can speed up the training and reduce the memory footprint of GPU. It is worth noting that YOLOv3 training is much faster than other frameworks. Another example is mask RCNN (ResNet50). During multi GPU training, we try to accommodate up to 4 images for each GPU (Tesla V100 16GB).
Experimental steps and results of this project
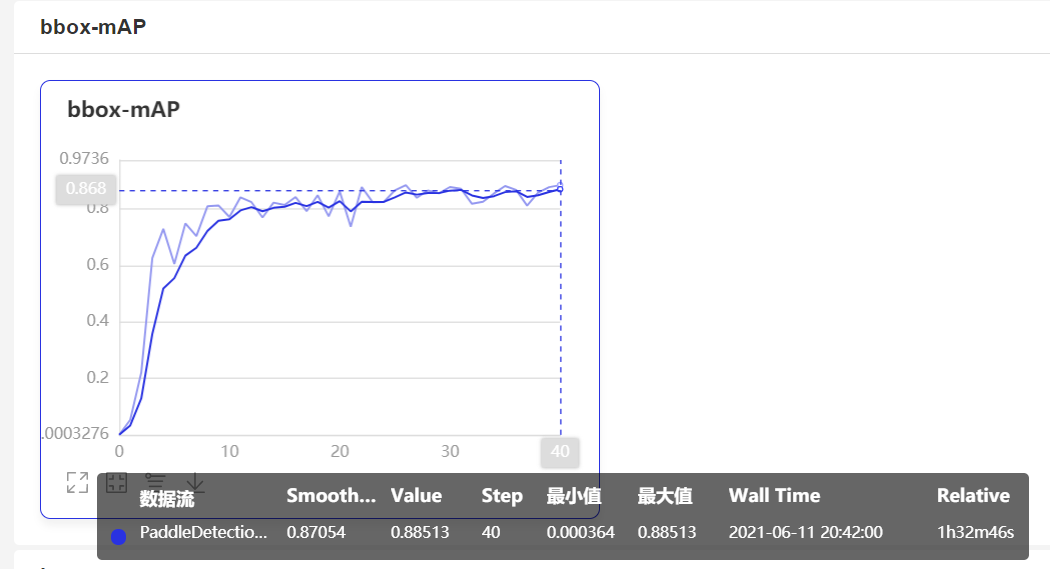
This experiment uses paddedetection2 Yolov3 (the backbone network is the lightweight model of mobilenetv3) in 0 can realize the target detection of smoking through a few lines of code. In the later stage, it can be deployed to monitor non-smoking areas in public places, and the mAP value reaches 88.51%

Experimental steps
-
Unzip the customized data set;
-
Download and install the paddedetection package;
-
User defined dataset partition;
-
Select the model (YOLO-v3 is selected this time) for training: description of training configuration file;
5. Effect visualization: use the trained model to predict and visualize the results;
6. Model evaluation and prediction: evaluate the model effect;
7. Prediction results
experimental result
The detection effect is shown in the figure below:


1 unzip the custom dataset
The labeled smoking pictures (VOC data set) will be decompressed.
It is recommended to upload the compressed package
File format:
pp_somke:
–Annotations
1.xml 2.xml .......
–images:
1.jpg 2.jpg .......
!unzip -oq data/data94796/pp_smoke.zip -d work/
2 download and install the paddedetection package
! git clone https://gitee.com/paddlepaddle/PaddleDetection.git
Cloning into 'PaddleDetection'... remote: Enumerating objects: 14575, done.[K remote: Counting objects: 100% (14575/14575), done.[K remote: Compressing objects: 100% (6264/6264), done.[K remote: Total 14575 (delta 10732), reused 11456 (delta 8175), pack-reused 0[K Receiving objects: 100% (14575/14575), 132.71 MiB | 15.26 MiB/s, done. Resolving deltas: 100% (10732/10732), done. Checking connectivity... done.
3. Division of user-defined data sets
Divide the data set according to the ratio of 9:1, and generate the training set train Txt and validation set val.txt for training
import random
import os
#Generate train Txt and val.txt
random.seed(2020)
xml_dir = '/home/aistudio/work/Annotations'#Label file address
img_dir = '/home/aistudio/work/images'#Image file address
path_list = list()
for img in os.listdir(img_dir):
img_path = os.path.join(img_dir,img)
xml_path = os.path.join(xml_dir,img.replace('jpg', 'xml'))
path_list.append((img_path, xml_path))
random.shuffle(path_list)
ratio = 0.9
train_f = open('/home/aistudio/work/train.txt','w') #Generate training files
val_f = open('/home/aistudio/work/val.txt' ,'w')#Generate validation file
for i ,content in enumerate(path_list):
img, xml = content
text = img + ' ' + xml + '\n'
if i < len(path_list) * ratio:
train_f.write(text)
else:
val_f.write(text)
train_f.close()
val_f.close()
#Generate label document
label = ['smoke']#Set the category you want to detect
with open('/home/aistudio/work/label_list.txt', 'w') as f:
for text in label:
f.write(text+'\n')
%cd PaddleDetection
/home/aistudio/PaddleDetection
4. Select model (YOLO-v3 is selected this time) for training: description of training configuration file
After selecting the model, the user only needs to change the corresponding configuration file and run train Py file, you can achieve training.
In this project, YOLOv3 in YOLOv3 model is used_ mobilenet_ v3_ large_ ssld_ 270e_ voc. YML training
4.1 configuration file example
We use configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml configuration for training.
In paddedetection2 0, modularization is better. You can freely modify and cover the configuration of each module for free combination.
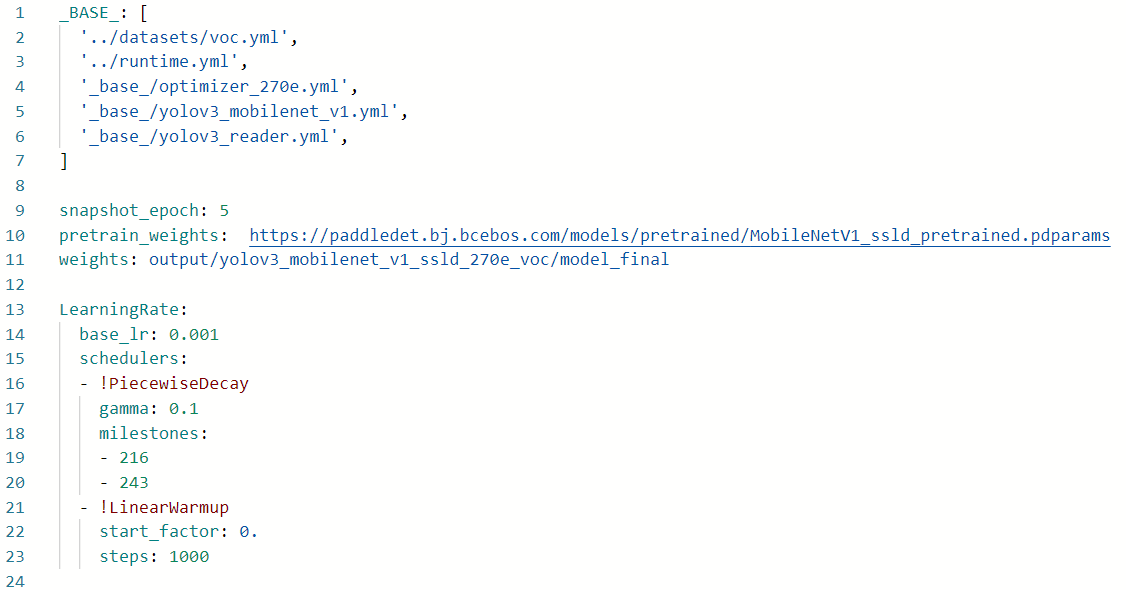
4.2 detailed description of configuration file
You can see yolov3 from the above figure_ mobilenet_ v3_ large_ ssld_ 270e_ voc. YML configuration depends on other configuration files. In this example, you need to rely on:

Before modifying the file, explain the functions of each dependent file:
'../datasets/voc.yml'It mainly explains the path of training data and verification data, including data format(coco,voc etc.) '../runtime.yml',It mainly describes the operation status of the public, such as whether to use it or not GPU,Number of iteration rounds, etc '_base_/optimizer_270e.yml',It mainly describes the configuration and setting of learning rate and optimizer epochs. In other training configurations, the learning rate and optimizer are placed in a new configuration file. '_base_/yolov3_mobilenet_v3_large.yml',It mainly describes the model, and backbone network '_base_/yolov3_reader.yml', It mainly describes the preprocessing operations after reading, such as resize,Data enhancement, etc.
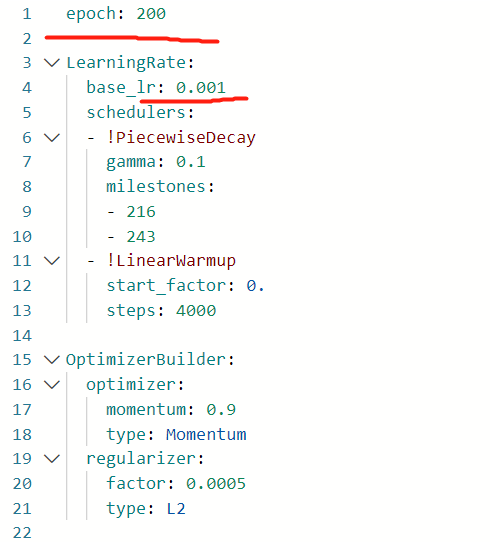
Introduce several places that need to be modified (places with red lines):
.../datasets/voc.yml

base/optimizer_270e.yml
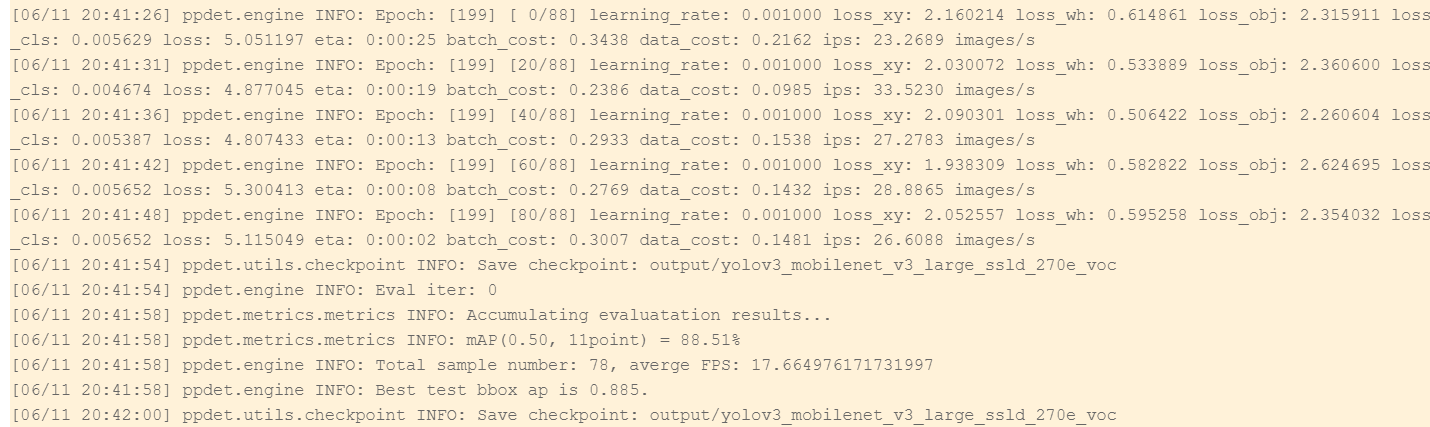
4.3 execution training
Execute the following command to quickly train and start vdl recording
!python tools/train.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml --eval --use_vdl=True --vdl_log_dir="./output"
5. Effect visualization: use the trained model to predict and visualize the results at the same time
When open use_ After VDL is switched on and off, paddedetection will write the data in the training process to the VisualDL file, which can view the log in the training process in real time. The recorded data include:
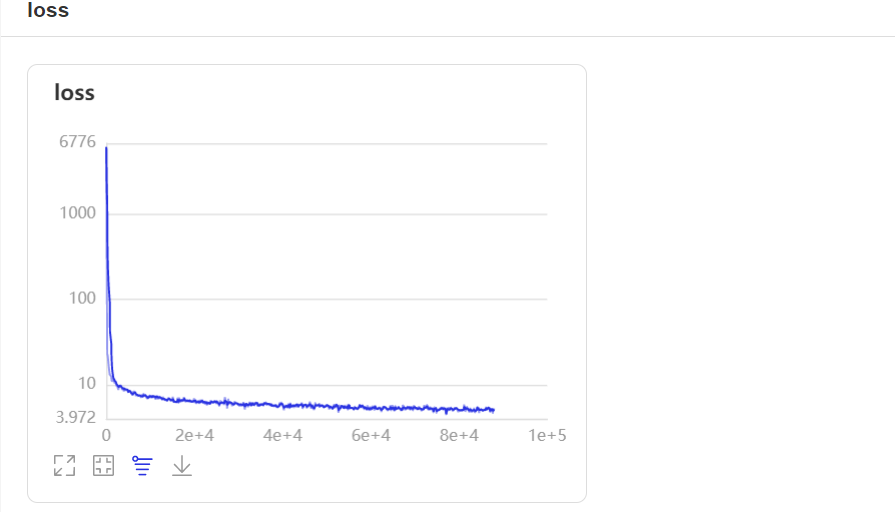
- loss trend
- mAP change trend
Start VisualDL to view the log using the following command
# The following command will start a service on 127.0.0.1 and support viewing through the front-end web page. You can specify the actual ip address through the -- host parameter visualdl --logdir output/
Enter the prompted web address in the browser. The effect is as follows:
visualdl --logdir output/
File "<ipython-input-68-4b7c990a0c4d>", line 1
visualdl --logdir output/
^
SyntaxError: invalid syntax
If the above code is not executed successfully, you can view it through the left interface control
You can check this website for specific operations: https://my.oschina.net/u/4067628/blog/4839747 (step 3)
6. Model evaluation
python -u tools/eval.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml \ -o weights=output/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams
!python -u tools/eval.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml -o weights=output/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams

7. Model prediction
Execute tools / infer After py, the corresponding prediction results will be generated in the output folder
python tools/infer.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml \ -o weights=output/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams \ --infer_img=dataset/113.jpg(Pictures to be detected)
!python tools/infer.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml -o weights=output/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams --infer_img=/home/aistudio/work/xiayan2.jpg
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:125: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if data.dtype == np.object: W0611 21:05:17.302584 21170 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0611 21:05:17.307160 21170 device_context.cc:422] device: 0, cuDNN Version: 7.6. [06/11 21:05:21] ppdet.utils.checkpoint INFO: Finish loading model weights: output/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams [06/11 21:05:21] ppdet.engine INFO: Detection bbox results save in output/xiayan2.jpg
-Result display
Original drawing


Prediction chart


summary
As can be seen from the above figure, the target recognition and detection of smoking has been completed using paddedetection, and the mAP has reached 88.51%.
Optimization scheme
The number of training can be increased by adding data sets and selecting more optimized models.
Late application
Voice can be added after recognition. If it is recognized that someone is smoking, voice can be broadcast for warning
In the later stage, it can be deployed to the monitoring of public places in non-smoking areas to detect smoking and other items.
For details, see the detailed tutorial of paddedetection:
https://paddledetection.readthedocs.io/tutorials/GETTING_STARTED_cn.html
About the author
The directions of interest are: target detection, classification tasks, etc
AIstudio home page: I get silver level in AI Studio, light up 3 badges to close each other ~ I get gold level in AI Studio, light up 7 badges to close each other~
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/474269
Github home page: https://github.com/Niki173
Welcome everyone to leave a message with questions, exchange and learn, and make progress and growth together.