In many problems, obtaining a large amount of accurate data needs a high cost, which often limits the application of deep learning. Active learning can use a small amount of labeled data to achieve high learning accuracy by filtering the unlabeled data. This paper will provide code implementation, show experimental results and some thoughts.
Code address: https://github.com/hgliyuhao/ActiveLearing4NER
Reference paper: Deep Active Learning for Named Entity Recognition 2018
Subsequence Based Deep Active Learning for Named Entity Recognition 2021
Reference article: http://www.woshipm.com/kol/1020880.html
principle
The unlabeled data is predicted by the named entity recognition model, and the confidence (probability) of the prediction results of the data is calculated according to different evaluation annotation models. For samples with low confidence, they often contain more unknown information of the model. These samples with low confidence are selected for priority labeling. For more detailed principles, you can read the reference articles.
model design
In the upstream of the model, bert is used to classify the token level in the most common way of sequence annotation. To solve the problem of entity overlap, Sigmoid is used instead of SoftMax. At the same time, the crf layer is not used, and the crf layer is not used in the original paper. The main reason for this is that active learning is to select the most valuable data, not to pursue the accuracy of the model. crf layer will increase the prediction time of the model, so it is not used.
Specific models can be referred to https://blog.csdn.net/HGlyh/article/details/115233797 , there is a more detailed introduction
How to calculate the confidence of the model in the prediction results
Here are two calculation methods mentioned in the paper: Least Confidence (LC) and maximum normalized log probability (MNLP)
Where LC is the corresponding probability value of the maximum probability sequence in the calculation prediction.
MNLP is based on LC and considering the influence of sequence length in generation on uncertainty, we make a normalization (i.e. divide by the length of each sentence), and the probability is replaced by the sum of log values output by the probability of each point.
In the paper, the author said that MNLP is a very ideal method.
In practical experiments, MNLP is more "fair" than LC ", the longer the sentence, the higher the score for LC. MNLP will not. However, after studying the case s with higher and lower scores given by MNLP, it will be found that MNLP is very sensitive to the number of entities predicted in the sentence. If there are few predicted entities, the score will be very high. Compared with a large number of entities, the score will be very low.
Therefore, the implementation of this paper provides a compensation scheme, which compensates according to the number of entities on the basis of MNLP, making it less sensitive to the number of entities. The specific method is to divide by a compensation parameter, which is mainly determined by the number of entities predicted in the sentence.
code
lc_confidence = 0
MNLP_confidence = 0
for lable in labels:
lc_con = 1
mnlp_con = 1
for l in lable:
if l <= 0.5:
l = 1 - l
lc_con *= l
mnlp_con += math.log(l)
lc_confidence += lc_con
MNLP_confidence += mnlp_con
MNLP_confidence = MNLP_confidence/(len(labels))
entry_MNLP_confidence = 1 - (1 - MNLP_confidence)/((len(res) + 2)**0.5) * (2)Where labels is the prediction result of the model on the sentence sequence. Please refer to the following example, where the number in the cell represents the prediction probability of whether the corresponding label category belongs to its own category.
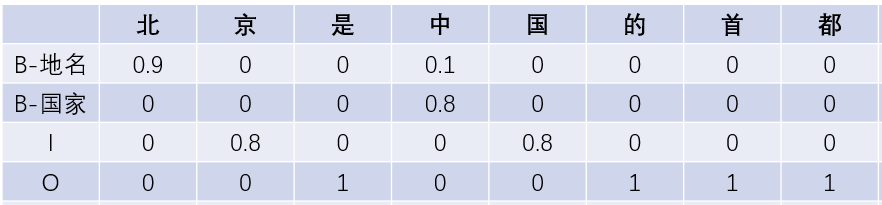
For example, 0.9 represents that the probability that the model predicts that the word 'North' is a 'B-place name' label is 0.9
LC for B-place name label = 0.9 * 1 * 1 * 0.9 * 1 * 1 * 1 * 1
result
"'Announcement No.: 2021-067 Announcement of Zhongnan Red Culture Group Co., Ltd. on the resignation of employee representative supervisors and by election of employee representative supervisors of the company. The company and all members of the board of supervisors guarantee that the information disclosure is true, accurate and complete without false records, misleading statements or major omissions. The board of supervisors of Zhongnan Red Culture Group Co., Ltd. (hereinafter referred to as "the company") received a written resignation report submitted by Ms. Wang Zhe, the employee representative supervisor of the company, on June 11, 2021. Ms. Wang Zhe applied for resignation from the position of employee representative supervisor of the 5th board of supervisors of the company for personal reasons. After Ms. Wang Zhe resigned, she no longer held any position in the company. As of the date of this announcement, Ms. Wang Zhe did not hold shares of the company.": {
"res": [
[
"Zhongnan Red Culture Group Co., Ltd",
"Job change_resignation_company"
],
[
"Employee Representative Supervisor",
"Job change_resignation_position"
],
[
"Wang Zhe",
"Job change_resignation_character"
]
],
"LC": 217.5803241119802,
"MNLP_confidence": 0.9695068267227575,
"entry_MNLP_confidence": 0.9863630383404811
},
"3 On March 31, King Kong Glass issued an announcement again. The board of directors received the detention notice served by Shantou Public Security Bureau on March 29. Director Zhuang Yuxin was criminally detained on suspicion of illegal disclosure and non disclosure of important information. Photo source: in the face of the resignation of the board secretary and the criminal detention of the directors, the Shenzhen Stock Exchange announced on April 7 that the board of directors of the company would be elected in advance. Previously, King Kong glass was punished by the CSRC for violation of letter phi. In April 2020, Guangdong Securities Regulatory Bureau issued the decision on administrative punishment and the decision on banning market entry to Jingang glass. After investigation, 2015-2018 During the year, there were illegal acts such as falsely increasing revenue, profits, monetary funds and failing to disclose related party transactions as required.": {
"res": [
[
"Gorilla Glass ",
"Job change_resignation_company"
]
],
"LC": 219.0427916272391,
"MNLP_confidence": 0.9781149683847055,
"entry_MNLP_confidence": 0.9873646711056863
},reflection
Through the results of active learning, we can get the samples with the least confidence for labeling. At the same time, the samples with the greatest confidence also need our attention. If there are obvious errors in these samples, can we think that the model has learned some wrong information and has special confidence? For example, we will have the illusion that I can kill myself