be based on Estimation of battery SOH based on LSTM neural network
unlike BP neural network, RNN network not only considers the input of the previous time, but also gives the network the ability to remember the information of the previous time. Although RNN network has high accuracy, it has the problem of gradient disappearance. In this regard, there are a series of improved RNN networks, and LSTM neural network is the best one. The battery SOH estimation method based on LSTM neural network is as follows:
(1) cycle life data of lithium ion battery
the data comes from the lithium-ion battery test platform built by NASA research center. No. 5 lithium-ion battery (rated capacity: 2Ah) is selected. The cycle test experiment is carried out at room temperature: charge the battery with a constant current of 1.5A until the charging cut-off voltage (4.2V), and charge with a constant voltage current until the charging current drops to 20mA; Discharge in 2A constant current (CC) mode until the battery drops to 2.7V, 2.5V, 2.2V and 2.5V respectively. When the battery reaches the EOL (end of life, EOL) standard, the experiment stops and the rated capacity decreases by 30%.
(2) data preprocessing
use the maximum and minimum normalization method to reduce the data to between 0 and 1.
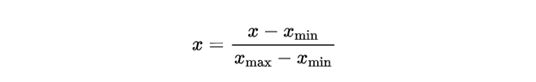
where xmax is the maximum value of input data x and xmin is the minimum value of input data x.
(3) simulation analysis
take the charging capacity in NASA lithium ion battery experimental data as the model input, and the output of the model is the battery SOH with the discharge capacity as the reference. After training, the neural network can iteratively obtain the specific parameters of network weight and bias.
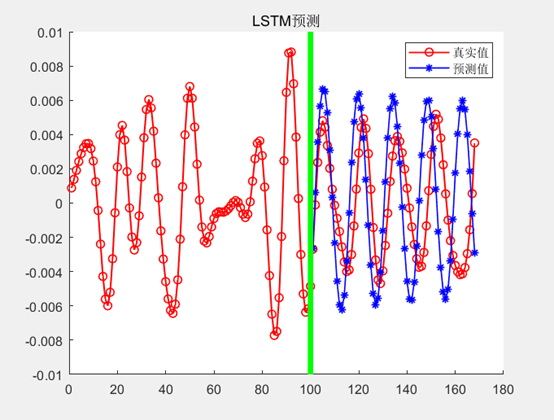
as can be seen from the figure, the model is very accurate in predicting the overall trend of battery capacity attenuation. The specific code is as follows:
function pre_data = LSTM_main(d,h,train_data,test_data)
%% Pretreatment
lag = 8;
% d = 51;
[train_input,train_output] = LSTM_data_process(d,train_data,lag); %data processing
[train_input,min_input,max_input,train_output,min_output,max_output] = premnmx(train_input',train_output');
input_length = size(train_input,1); %Sample input length
output_length = size(train_output,1); %Sample output length
train_num = size(train_input,2); %Number of training samples
test_num = size(test_data,2); %Number of test samples
%% Network parameter initialization
% Node number setting
input_num = input_length;
cell_num = 10;
output_num = output_length;
% Offset of gate in network
bias_input_gate = rand(1,cell_num);
bias_forget_gate = rand(1,cell_num);
bias_output_gate = rand(1,cell_num);
%Network weight initialization
ab = 20;
weight_input_x = rand(input_num,cell_num)/ab;
weight_input_h = rand(output_num,cell_num)/ab;
weight_inputgate_x = rand(input_num,cell_num)/ab;
weight_inputgate_h = rand(cell_num,cell_num)/ab;
weight_forgetgate_x = rand(input_num,cell_num)/ab;
weight_forgetgate_h = rand(cell_num,cell_num)/ab;
weight_outputgate_x = rand(input_num,cell_num)/ab;
weight_outputgate_h = rand(cell_num,cell_num)/ab;
%hidden_output weight
weight_preh_h = rand(cell_num,output_num);
%Network state initialization
cost_gate = 1e-6;
h_state = rand(output_num,train_num+test_num);
cell_state = rand(cell_num,train_num+test_num);
%% Network training and learning
for iter = 1:3000 %Number of iterations
yita = 0.01; %Weight adjustment scale for each iteration
for m = 1:train_num
%Feedforward part
if(m==1)
gate = tanh(train_input(:,m)' * weight_input_x);
input_gate_input = train_input(:,m)' * weight_inputgate_x + bias_input_gate;
output_gate_input = train_input(:,m)' * weight_outputgate_x + bias_output_gate;
for n = 1:cell_num
input_gate(1,n) = 1 / (1 + exp(-input_gate_input(1,n)));%Input gate
output_gate(1,n) = 1 / (1 + exp(-output_gate_input(1,n)));%Output gate
%sigmoid function
end
forget_gate = zeros(1,cell_num);
forget_gate_input = zeros(1,cell_num);
cell_state(:,m) = (input_gate .* gate)';
else
gate = tanh(train_input(:,m)' * weight_input_x + h_state(:,m-1)' * weight_input_h);
input_gate_input = train_input(:,m)' * weight_inputgate_x + cell_state(:,m-1)' * weight_inputgate_h + bias_input_gate;
forget_gate_input = train_input(:,m)' * weight_forgetgate_x + cell_state(:,m-1)' * weight_forgetgate_h + bias_forget_gate;
output_gate_input = train_input(:,m)' * weight_outputgate_x + cell_state(:,m-1)' * weight_outputgate_h + bias_output_gate;
for n = 1:cell_num
input_gate(1,n) = 1/(1+exp(-input_gate_input(1,n)));
forget_gate(1,n) = 1/(1+exp(-forget_gate_input(1,n)));
output_gate(1,n) = 1/(1+exp(-output_gate_input(1,n)));
end
cell_state(:,m) = (input_gate .* gate + cell_state(:,m-1)' .* forget_gate)';
end
pre_h_state = tanh(cell_state(:,m)') .* output_gate;
h_state(:,m) = (pre_h_state * weight_preh_h)';
%Error calculation
Error = h_state(:,m) - train_output(:,m);
Error_Cost(1,iter)=sum(Error.^2); %Sum of squares of errors (sum of squares of 4 points)
if(Error_Cost(1,iter)<cost_gate) %Judge whether the minimum error condition is met
flag = 1;
break;
else
[ weight_input_x,...
weight_input_h,...
weight_inputgate_x,...
weight_inputgate_h,...
weight_forgetgate_x,...
weight_forgetgate_h,...
weight_outputgate_x,...
weight_outputgate_h,...
weight_preh_h ] = LSTM_updata_weight(m,yita,Error,...
weight_input_x,...
weight_input_h,...
weight_inputgate_x,...
weight_inputgate_h,...
weight_forgetgate_x,...
weight_forgetgate_h,...
weight_outputgate_x,...
weight_outputgate_h,...
weight_preh_h,...
cell_state,h_state,...
input_gate,forget_gate,...
output_gate,gate,...
train_input,pre_h_state,...
input_gate_input,...
output_gate_input,...
forget_gate_input,input_num,cell_num);
end
end
if(Error_Cost(1,iter)<cost_gate)
break;
end
end
%% Test phase
%Data loading
test_input = train_data(end-lag+1:end);
test_input = tramnmx(test_input',min_input,max_input);
% test_input = mapminmax('apply',test_input',ps_input);
%feedforward
for m = train_num + 1:train_num + test_num
gate = tanh(test_input' * weight_input_x + h_state(:,m-1)' * weight_input_h);
input_gate_input = test_input' * weight_inputgate_x + h_state(:,m-1)' * weight_inputgate_h + bias_input_gate;
forget_gate_input = test_input' * weight_forgetgate_x + h_state(:,m-1)' * weight_forgetgate_h + bias_forget_gate;
output_gate_input = test_input' * weight_outputgate_x + h_state(:,m-1)' * weight_outputgate_h + bias_output_gate;
for n = 1:cell_num
input_gate(1,n) = 1/(1+exp(-input_gate_input(1,n)));
forget_gate(1,n) = 1/(1+exp(-forget_gate_input(1,n)));
output_gate(1,n) = 1/(1+exp(-output_gate_input(1,n)));
end
cell_state(:,m) = (input_gate .* gate + cell_state(:,m-1)' .* forget_gate)';
pre_h_state = tanh(cell_state(:,m)') .* output_gate;
h_state(:,m) = (pre_h_state * weight_preh_h)';
% Take the current forecast point as the next input data
test_input = postmnmx(test_input,min_input,max_input);
now_prepoint = postmnmx(h_state(:,m),min_output,max_output);
%test_input = mapminmax('reverse',test_input,ps_input);
test_input = [test_input(2:end); now_prepoint];
test_input = tramnmx(test_input,min_input,max_input);
end
pre_data = postmnmx(h_state(:,train_num + h:h:train_num + test_num),min_output,max_output);
all_pre = postmnmx(h_state(:,1:h:train_num + test_num),min_output,max_output);
% Drawing
figure
title('LSTM forecast')
hold on
plot(1:size([train_data test_data],2),[train_data test_data], 'o-', 'color','r', 'linewidth', 1);
plot(size(train_data,2) + h:h:size([train_data test_data],2),pre_data, '*-','color','b','linewidth', 1);
plot([size(train_data,2) size(train_data,2)],[-0.01 0.01],'g-','LineWidth',4);
legend({ 'True value', 'Estimate'});
end
I want to know more about the simulation, and I can pay attention to my WeChat official account.
