https://marketing.csdn.net/p/0ada836ca30caa924b9baae0fd33857c
catalogue
Picture code project introduction and problems
TDengine exploration feasibility study
Installation and use of TDengine
Picture code project introduction and problems
The image code joint detection system is based on the in-depth application of video surveillance technology and combined with the important mobile device feature code IMSI in security. Even without the restriction of access to identity card, telephone number and other features, it can still obtain the matching relationship between each other through the collision algorithm between IMSI and portrait, and establish a "one person, one file" archive. Technically, the relationship between "image" and "code" is combined, and the correlation between them is established according to the collision algorithm; In the application scenario, in view of the current situation of difficult system docking and difficult data exchange in reality, compared with the large platform, it has the advantage of simple deployment. Through the establishment of the archives, it can quickly help the public security locate the identity of the observation object and greatly assist the public security technical investigation and case solving.
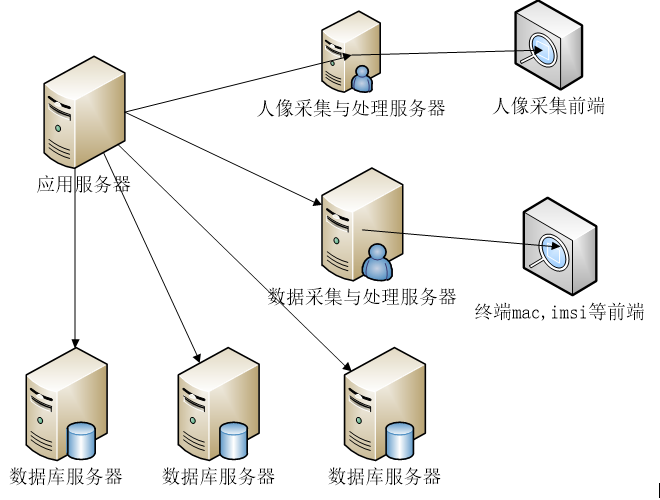
In big data processing, the architecture of mycat + mysql (active and standby) is adopted.
The advantage is to make full use of the technical advantages of the mature database, which can seamlessly replace the traditional non big data persistence layer and give programmers an imperceptible replacement; The threshold of this architecture is also relatively low. It only needs 8G8 cores to start and run normally. Unlike hadoop,spark and other big data architectures, it requires five high-performance hosts to ensure the basic operation.
Disadvantages: architects need to have strong professional knowledge, do a good job in the structure and deployment of this area, and related monitoring. For example, setting of primary and standby, load balancing, capacity expansion or replacement, data migration, etc; On the mass, it is limited by mycat1 Due to the limitation of X's 1 billion data, timely dynamic query will have performance problems.
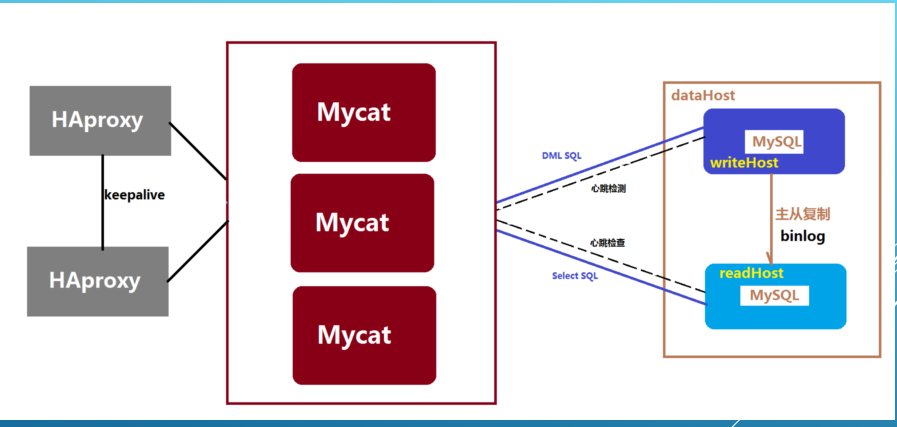
If there is a technology that can replace mycat+mysql without users considering the details of load balancing, capacity management and capacity constraints, it will reduce the burden on the product architecture and focus more on their own business.
At this time, I saw the introduction of Taosi technology TDengine on CSDN.
TDengine exploration feasibility study
Let's first introduce the product features of TDengine by Taosi Technology:
TDengine is a big data platform designed and optimized by Taosi data for the Internet of things, Internet of vehicles, industrial Internet, IT operation and maintenance, etc. In addition to the core time series database function that is more than 10 times faster, IT also provides functions such as caching, data subscription and streaming computing to minimize the complexity of R & D, operation and maintenance, and all core codes, including cluster functions, are open source (open source protocol, AGPL v3.0).
More than 10x performance improvement. An innovative data storage structure is defined. A single core can process at least 20000 requests per second, insert millions of data points and read more than 10 million data points, which is more than ten times faster than the existing general database.
Reduce hardware or cloud service costs to 1 / 5. Due to its super performance, the computing resources are less than 1 / 5 of the general big data scheme; Through column storage and advanced compression algorithm, the storage space is less than 1 / 10 of the general database.
Full stack sequential data processing engine. Integrating database, message queue, cache, streaming computing and other functions, the application does not need to integrate Kafka/Redis/HBase/Spark and other software, greatly reducing the cost of application development and maintenance.
Powerful analysis function. Whether it is data ten years ago or one second ago, you can query it within a specified time range. Data can be aggregated on the timeline or on multiple devices. Ad hoc queries can be performed at any time through Shell/Python/R/Matlab.
Seamless connection with third-party tools. It can be integrated with telegraf, grafana, EMQ x, Prometheus, MATLAB and R without one line of code. In the future, MQTT, OPC, Hadoop, Spark, etc. will be supported, and BI tools will be seamlessly connected.
Zero operation and maintenance cost and zero learning cost. The installation and cluster can be completed in one second, and there is no need to separate databases and tables, and real-time backup. Standard SQL, JDBC,RESTful, python / Java / C / C + + / go / node JS, similar to MySQL, has zero learning cost
Let's take a look at its applicable scenarios. For details, please refer to the link: https://www.taosdata.com/cn/documentation/evaluation#scenes
One of the words attracted me. "TDengine is an innovative big data processing product launched in the face of the fast-growing internet of things big data market and technical challenges." in this way, its positioning well matches the data characteristics of our image code joint investigation project, which is similar to the timing big data of IOT.
But see the following sentence:
”TDengine can significantly reduce the total cost of ownership of typical Internet of things, Internet of vehicles and industrial Internet big data platforms. However, it should be pointed out that because it makes full use of the characteristics of time series data of the Internet of things, it can not be used to process general data such as web crawler, microblog, wechat, e-commerce, ERP, CRM and so on. “
I think there will be big problems, because a system should not only have big data, but also deal with ordinary businesses such as CRM. Is it because another data source is defined to deal with these?
however, such doubts do not prevent me from continuing to explore TDengine.
Installation and use of TDengine
Source installation
You can refer to the record link of my previous experiment: https://blog.csdn.net/dualvencsdn/article/details/115202910
CentOS 7: sudo yum install -y gcc gcc-c++ make cmake git install OpenJDK 8: sudo yum install -y java-1.8.0-openjdk install Apache Maven: sudo yum install -y maven git clone https://github.com/taosdata/TDengine.git cd TDengine mkdir debug && cd debug cmake .. && cmake --build . stay debug catalogue make install /usr/bin/cmake -P cmake_install.cmake -- Install configuration: "Debug" make install script: /home/dualven/TDengine/packaging/tools/make_install.sh this is centos system source directory: /home/dualven/TDengine binary directory: /home/dualven/TDengine/debug Start to install TDEngine... TDengine is installed successfully! To configure TDengine : edit /etc/taos/taos.cfg To start TDengine : ./taosd To access TDengine : use taos in shell TDengine is installed successfully!
docker usage
Create container
docker run --name taos192 -p6030-6042:6030-6042/tcp -p6030-6042:6030-6042/udp -d tdengine/tdengine
Firewall release
firewall-cmd --zone=public --add-port=6030-6042/tcp --permanent
firewall-cmd --zone=public --add-port=6030-6042/udp --permanent
FQDN configuration
This is very important. Why should I configure it? Refer to my previous experimental records:
https://blog.csdn.net/dualvencsdn/article/details/118019565.
Is to let the client find it. However, Taos is sometimes used in its own DB operations The fqdn in CFG, so it's best to use its fqdn when accessing the remote client. If you use ip to access it first, but the internal program will report an error when using fqdn.
DB error: Unable to resolve FQDN (0.011791s)
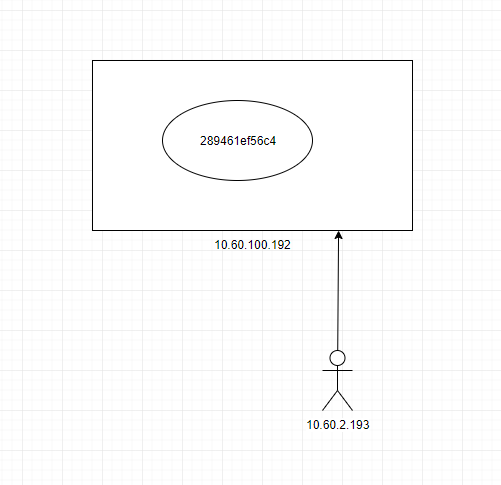
Therefore, we mapped the hosts file on the 192 host: 10.60.100.192 289461ef56c4
On the client file, also map the hosts file 10.60.100.192 289461ef56c4,
Pit: remember that the firewall can only release TCP and UDP on those ports.
Main operation
View configuration: docker exec -it taos192 taosd -C
[root@taos192 TDengine-server-2.1.2.0]# docker exec -it taos192 taosd -C taos global config: ================================== serverPort: 6030 arbitrator: numOfMnodes: 3 vnodeBak: 1 telemetryReporting: 1 balance: 1 balanceInterval: 300 maxTmrCtrl: 512 offlineThreshold: 864000(s) statusInterval: 1(s) minSlidingTime: 10(ms) minIntervalTime: 10(ms) maxStreamCompDelay: 20000(ms) maxFirstStreamCompDelay:10000(ms) retryStreamCompDelay: 10000(ms) streamCompDelayRatio: 0.100000 maxVgroupsPerDb: 0 maxTablesPerVnode: 1000000 minTablesPerVnode: 1000 tableIncStepPerVnode: 1000 cache: 16(Mb) blocks: 6 days: 10 keep: 3650 minRows: 100 maxRows: 4096 comp: 2 walLevel: 1 fsync: 3000 replica: 1 partitions: 4 quorum: 1 update: 0 compressMsgSize: -1 maxSQLLength: 1048576(byte) maxNumOfOrderedRes: 100000 queryBufferSize: -1(byte) retrieveBlockingModel: 0 keepColumnName: 0 timezone: locale: charset: maxShellConns: 50000 maxConnections: 5000 minimalLogDirGB: 1.000000(GB) minimalTmpDirGB: 1.000000(GB) minimalDataDirGB: 2.000000(GB) mnodeEqualVnodeNum: 4 flowctrl: 1 slaveQuery: 1 adjustMaster: 1 http: 1 mqtt: 0 monitor: 1 stream: 1 telegrafUseFieldNum: 0 gitinfo: 2019939bcc5567212d6e07af557c2c4ea540c091 gitinfoOfInternal: NULL buildinfo: Built at 2021-06-07 14:27 version: 2.1.2.0 taos local config: ================================== firstEp: secondEp: fqdn: configDir: /etc/taos logDir: /var/log/taos scriptDir: /etc/taos numOfThreadsPerCore: 1.000000 numOfCommitThreads: 4 ratioOfQueryCores: 1.000000 role: 0 monitorInterval: 30(s) rpcTimer: 300(ms) rpcForceTcp: 0 rpcMaxTime: 600(s) shellActivityTimer: 3(s) httpEnableRecordSql: 0 httpMaxThreads: 2 restfulRowLimit: 10240 numOfLogLines: 10000000 logKeepDays: 0 asyncLog: 1 debugFlag: 0 mDebugFlag: 131 dDebugFlag: 135 sDebugFlag: 135 wDebugFlag: 135 sdbDebugFlag: 131 rpcDebugFlag: 131 tmrDebugFlag: 131 cDebugFlag: 131 jniDebugFlag: 131 odbcDebugFlag: 131 uDebugFlag: 131 httpDebugFlag: 131 mqttDebugFlag: 131 monDebugFlag: 131 qDebugFlag: 131 vDebugFlag: 135 tsdbDebugFlag: 131 cqDebugFlag: 131 enableRecordSql: 0 enableCoreFile: 0 maxBinaryDisplayWidth: 30 tempDir: /tmp/
To create a database, create a table:
taos -s "CREATE DATABASE pdas KEEP 365 DAYS 10 BLOCKS 4 UPDATE 1;"
taos -d pdas -f onetable.txt
CREATE STABLE dw_reportimsi( \ ts timestamp,\ id bigint, \ device_name nchar(60),\ equip_id nchar(60), \ imsi nchar(60),\ imei nchar(60),\ source_tac bigint, \ cell_no bigint,\ mcc bigint,\ mnc bigint, \ equip_longitude nchar(60),\ equip_latitude nchar(60), \ belong nchar(60),\ address nchar(60),\ rssi nchar(60),\ phone_num nchar(60) \ )tags(location binary(64), groupdId int);
For others, please refer to my previous records: https://blog.csdn.net/dualvencsdn/article/details/118025718
JAVA client connection
As the main developer of java, it's a bit of a pit that there is no English document. I have been reading English at first, but I didn't find it. Later, there is this chapter in the Chinese document
https://www.taosdata.com/cn/documentation/connector/java
But the most complete code demo is actually in the docker project, which is a surprise: tdengine/tdengine
I sorted it out. It can be integrated into a project to meet the calls of various forms of java. You can confide in me if you need it.
1)connection pool
(2) mybatis plus
(3) jdbc
(4) mybatis
Performance considerations
In order to test the performance, I tried to use some import tools.
taosdump use
https://github.com/taosdata/TDengine
https://www.taosdata.com/blog/2020/03/09/1334.html
taosimport
According to the official R & D instructions, it is not very useful anymore. After a day of research, I contacted the official customer service to know. It's a little pit. Also misled by official documents: https://www.taosdata.com/blog/2020/01/18/1166.html.
howerver, or record it
https://github.com/taosdata/TDengine/tree/develop/importSampleData
bin/taosimport -cfg config/cfg.toml -db pdas -cases pdas -hnum 1 -vnum 10 -port 6030 -user root -password taosdata -host 10.60.100.192
It's really not easy to use. For example, the taos client does not need to enter the default account password and host. It must be entered.
The error report is not obvious. No problem can be found.
2021/06/22 18:00:13 main.go:404: create table error: invalid operation: illegal value or data overflow
taosdemo
After tossing around, I found that I can experience the data reading and writing speed of taos through taosdemo. Please refer to:
https://www.taosdata.com/cn/documentation/getting-started
Shortcomings and conclusions
Because at the beginning, I didn't have a deep understanding
"TDengine can significantly reduce the total cost of ownership of typical Internet of things, Internet of vehicles and industrial Internet big data platforms. However, it should be pointed out that because it makes full use of the characteristics of time series data of the Internet of things, it can not be used to process general data such as web crawler, microblog, wechat, e-commerce, ERP, CRM and so on. "The meaning of this sentence is to actively establish and test some common tables in the experiment, so as to deeply experience some of its defects:
Record of official conversation
Conclusions: (1) delete is not supported, and it will be supported later. (2) update is completed by inserting the same timestamp
(3) For the usage mode of intermediate database, frequent deletion and update of millions of single tables are not supported temporarily.
Small T: Modify the data that can currently use the same timestamp update Small T: delete I just haven't been able to support it yet Small T: This is us 3.0 Version plan Small T: There will be some in the future Small T: actually Small T: The data of the table and the time range of the database are approximately close Small T: This is limited Small T: Your table can't insert data of any time period at will Small T: So they were unified keep influence Small T: For example, keep 3650 day Small T: You cannot insert data before 3650 days Small T: The other is mainly at present mysql The efficiency of deleting and modifying millions of indexed data in a single table is relatively low - now TDengine For data updates, only the same timestamp can be overwritten. Deletion can only be automatically deleted through the time period (it will be supported in the future) delete). As for the low efficiency you mentioned, we have to wait until our functions are completed Small T: As a special big data engine, it will be more efficient than mysql Tall
Architecture recommendations:
(1) For ordinary business tables, it can be similar to MySQL. Mongo allows users to use ordinary tables without specifying the characteristics of time series database. Do I have to establish a set of database access logic for some of the most common table businesses in a project? Of course, at this stage, if you use TDengine, it seems that you can only use this scheme.
(2) For the 6030-6042 TCP/UDP ports in this article, I think the TDengine should adopt the blocking application access mode (I don't read the source code, but speculate). It is recommended to refer to the architecture of netty and the selector mode, so there should be no need for so many ports.
https://marketing.csdn.net/p/0ada836ca30caa924b9baae0fd33857c