catalogue
Pt1.3 implementation principle
Pt2.3 implementation principle
Pt3.3 implementation principle
Pt4.3 implementation principle
Pt5.3 implementation principle
04 Redis data type
Pt1 STRING
String is the most commonly used data type in redis. Redis's string based operations are binary safe. We will specifically analyze redis's string data type.
Pt1.1 storage type
String type can store three data types:
-
INT (integer)
-
FLOAT (single precision floating point)
-
String (string)
Pt1.2 operation command
## String - operation command set mvp steveNash # Set string value getrange mvp 0 2 # Gets the characters in the specified range of string values strlen mvp # Gets the length of the value append mvp Twice # String append setnx champion kobe # Set the value. If the key exists, it will return failure. If it does not exist, it will succeed (distributed lock) del champion # Delete the data whose key is champion, or release the distributed lock mset spurs 96 lakers 92 # Set multiple values (batch operation, atomicity) mget spurs lakers # Get multiple values incr spurs # (integer) value increment (from 0 to 1 when the value does not exist) incrby lakers 3 # (integer) value increment decr spurs # (integer) value decrement decrby spurs 2 # (integer) value decrement set score 92.6 # Floating point number incrbyfloat score 7.3 # Sex point increment set key value [expiration EX seconds|PX milliseconds][NX|XX] # Expiration time
Pt1.3 implementation principle
Let's take a look at an example:
127.0.0.1:6379[1]> set name lucas OK 127.0.0.1:6379[1]> type name string 127.0.0.1:6379[1]> object encoding name "embstr"
Data with Key as name is externally represented as string type, but there is also an embstr type encoding type. Why do you design it like this? Let's take a look at the internal implementation of Redis.
(1) Disadvantages of C language array
Redis is implemented based on C language, but C language itself has no string type and can only be implemented with character array char []. However, character array has the following disadvantages in operation:
-
When using character array, enough memory space must be allocated to the target variable in advance, otherwise it may overflow;
-
If you want to get the string length, you must traverse the array. The time complexity is O(n), and the performance is poor;
-
The change of string length in C language will reallocate the memory of character array, and the performance will decline;
-
C language marks the end of the string by the first '\ 0' encountered from the beginning to the end of the string. When storing binary data such as pictures, compressed files, audio and video, binary security cannot be guaranteed;
(2)Simple Dynamic String
Char [] storage has so many disadvantages that it must not be used, otherwise redis will not have such outstanding performance. Redis implements a data type class called Simple Dynamic String (SDS) to store string values. Of course, SDS is essentially implemented through char [] of C language.
Let's look at the source code implementation:
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* The length of the current character array */
uint8_t alloc; /* The total amount of memory allocated by the current character array */
unsigned char flags; /* The lower 3 bit s are used to indicate the type of header. There are five types of headers in SDS Constant definition in H. */
char buf[]; /* Store string real data */
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};It can be seen from the source code that there are five types of SDS structures, sdshdr5, sdshdr8, sdshdr16, sdshdr32 and sdshdr64, which are used to store strings of different lengths. They can store 2^5=32byte, 2^8=256byte, 2^16=65536byte=64K and 2^32byte=4GB respectively.
(3) Advantages of SDS
SDS has the following advantages over char []:
-
Do not worry about memory overflow. If necessary, the SDS will be expanded;
-
The len attribute is defined, and the time complexity of obtaining the string length is O(1);
-
Prevent multiple reallocation of memory through "space pre allocation" and "inert space release";
-
Read data according to len length, binary security;
What is space pre allocation?
Space pre allocation is used to optimize the string growth operation of SDS: when the API of SDS modifies an SDS and needs to expand the space of SDS, the program will not only allocate the space necessary for modification, but also allocate additional unused space for SDS.
The amount of extra unused space allocated is determined by the following formula:
-
If the length of SDS (that is, the value of len attribute) will be less than 1 MB after SDS modification, the program will allocate unused space of the same size as len attribute. At this time, the value of SDS len attribute will be the same as that of free attribute. For example, if the len of SDS will become 13 bytes after modification, the program will also allocate 13 bytes of unused space, and the actual length of the buf array of SDS will become 13 + 13 + 1 = 27 bytes (an additional byte is used to save empty characters).
-
If the length of the SDS is greater than or equal to 1 MB after the SDS is modified, the program will allocate 1 MB of unused space. For example, if the len of SDS becomes 30 MB after modification, the program will allocate 1 MB of unused space, and the actual length of the buf array of SDS will be 30 MB + 1 MB + 1 byte.
Through the space pre allocation strategy, Redis can reduce the number of memory reallocations required for continuous string growth operations.
What is inert space release?
The lazy space is released to optimize the string shortening operation of SDS: when the SDS API needs to shorten the string saved by SDS, the program does not immediately use memory reallocation to recover the shortened extra bytes, but uses the free attribute to record the number of these bytes and wait for future use. The reason for this is that releasing memory space also requires performance consumption, and the string may be expanded next time. Nevertheless, Redis also provides corresponding APIs to release the inert space.
(4) KV storage structure
Are KV values stored in SDS? When you ask, you must know it's not so simple. The boss's design is really awesome.
String type storage. The key value (must be a string) is stored using SDS, but the value value is not. The value value is stored in the data structure of redisObject. Let's look at the specific source code implementation:
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
#define LRU_BITS 24
typedef struct redisObject {
unsigned type:4; /* Type of object, including OBJ_STRING, OBJ_LIST, OBJ_SET, OBJ_ZSET, OBJ_HASH */
unsigned encoding:4; /* The specific data structures are defined as constants above. The string mainly involves raw, embstr and int */
unsigned lru:LRU_BITS; /* 24bit,The time when the object was last accessed by the application, related to the garbage collection operation */
int refcount; /* A reference count of 0 indicates that the object is no longer referenced by any other object, and garbage collection can be performed*/
void *ptr; /* Point to the actual data structure of the object */
} robj;Therefore, when value stores a string, Redis does not directly use SDS storage, but stores it in redisobject. The values of the five common data types are stored through redisobject. Redisobject points to the SDS where the data is actually stored through a pointer, as shown in the following figure.
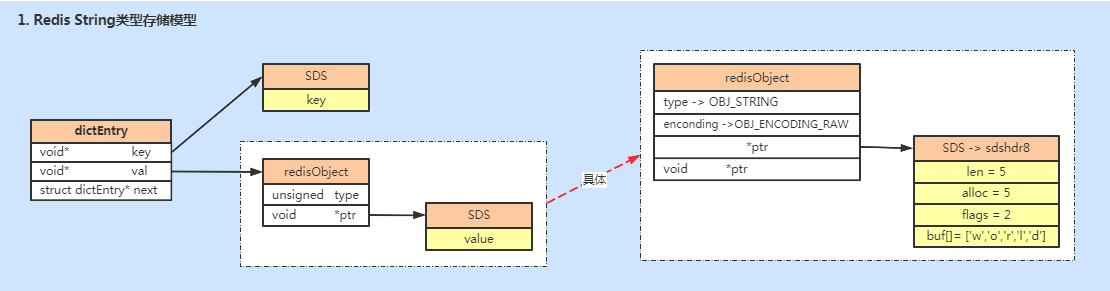
redisObject and sds are designed to select different storage methods according to different storage contents, which has achieved the goal of saving memory space and improving query speed as much as possible.
(5) Internal coding
In addition to the design of redisObject and SDS, Redis also provides internally coded attributes, that is, redisObject encoding. There are three types of encoding in string types:
-
int, storing 8-byte long integers (long, 2^63 - 1);
-
Embstr, representing sds in embstr format, storing string s less than 44 bytes;
-
raw, storing string s greater than 44 bytes;
# Source code object Defined in C # define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
# Code example 127.0.0.1:6379> set str1 1 OK 127.0.0.1:6379> set str3 "12345678901234567890123456789012345678901234" OK 127.0.0.1:6379> set str4 "123456789012345678901234567890123456789012345" OK 127.0.0.1:6379> type str1 string 127.0.0.1:6379> type str3 string 127.0.0.1:6379> type str4 string 127.0.0.1:6379> object encoding str1 "int" 127.0.0.1:6379> object encoding str3 "embstr" 127.0.0.1:6379> object encoding str4 "raw"
int code types are different and easy to understand. What's the difference between embstr and raw? Look at the picture below first.
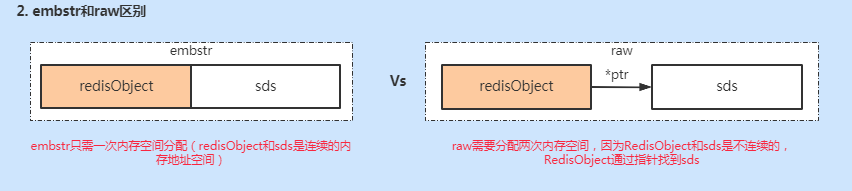
Embstr only needs to allocate memory space once, because RedisObject and sds are continuous. Raw is different because RedisObject finds sds through pointers. They are not continuous in space allocation, so it needs to allocate memory space twice. Therefore, compared with embstr, raw allocates more memory space when it is created and releases more memory space when it is deleted. When the objects are not together, it needs more memory lookup. On the whole, the performance of embstr is better.
However, compared with embstr, raw only needs to reallocate the memory of sds and then change the RedisObject pointer because the string length increases through pointer Association. However, embstr does not work. When the string length increases and memory needs to be reallocated, the entire RedisObject and sds need to reallocate memory space. Therefore, the implementation of embstr is more suitable for read-only data.
In the following scenario, int and embstr are converted to raw (the process is irreversible):
-
int data is no longer an integer and will be converted to raw;
-
If the int size exceeds the range of long (2 ^ 63 - 1), it will be converted to embstr;
-
If the length of embstr exceeds 44 bytes, it will be converted to raw;
-
If the embstr object is modified (the original value is modified by using the append command, etc., and will not be changed if the value is reset by using set), it will be converted to raw;
127.0.0.1:6379> set key1 1 OK 127.0.0.1:6379> set key2 9223372036854775807 OK 127.0.0.1:6379> set key3 9223372036854775808 OK 127.0.0.1:6379> set key4 abc OK 127.0.0.1:6379> set key4 abcd OK 127.0.0.1:6379> append key1 a (integer) 2 127.0.0.1:6379> object encoding key1 "raw" 127.0.0.1:6379> object encoding key2 "int" 127.0.0.1:6379> object encoding key3 "embstr" 127.0.0.1:6379> object encoding key4 "embstr" 127.0.0.1:6379> append key4 e (integer) 5 127.0.0.1:6379> object encoding key4 "raw"
Due to the change, the encoding conversion is completed when redis writes data, and the conversion process is irreversible. It can only be converted from small memory encoding to large memory encoding (excluding using set to reset the value).
Pt1.4 application scenarios
(1) Data cache
string type can cache hotspot data, such as dictionary data and hotspot access data, which can significantly improve the access speed of hotspot data. If it is persistent data, it can also reduce the performance pressure of back-end database.
(2) Distributed data sharing
Multiple nodes of distributed applications usually face the problem of data sharing. The most common problem is accessing session sharing. There may be data consistency problems in the local data of application nodes. Using Redis, a third-party independent service, can share data among multiple applications or multiple nodes of applications and ensure data consistency.
(3) Distributed lock
When Redis operates the setnx method of string, it will return success only if the data does not exist. This function is usually used as the implementation of distributed lock.
(4) Global ID
INT type incr/incrby operation is atomic and can be used to realize global self increment ID. Using incrby, you can take a piece of data at one time to improve performance, similar to the cache of database sequence.
(5) Counter
It is also applicable to INT type INCR operation, which can realize the function of counter, such as counting the reading amount and likes of articles, writing to redis first, and then synchronizing to the database.
(6) Current limiting
Use the incr method of INT type, such as using IP and function id information as the key. Each time you access, increase the technology, and return false after the number of times. All of these make use of the relevant features and storage structure of Redis to realize business logical judgment.
Pt2 HASH
Pt2.1 storage type
Hash is used to store multiple unordered key value pairs. The maximum storage quantity is 2 ^ 32 - 1 (about 4 billion). The structure is as follows:
As described earlier, dictht is the implementation of Redis Hash table, which is an outer Hash and can store KV key value pair dictEntry. The Hash here is the Hash table stored in the key value pair and belongs to the inner Hash. In this space, the Hash we talk about refers to the inner Hash structure.
The value of Hash can only store String types and cannot nest other complex types. It also stores strings. What's the difference between Hash and String?
-
Gather all relevant values into a key, which has a clear structure and saves memory space;
-
Reduce the number of keys and reduce KEY conflicts;
-
Data can be obtained in batches by using a single command to reduce the consumption of memory / IO/CPU;
The following scenario Hash does not apply:
-
Field cannot set the expiration time separately, but can only be placed at the KEY level;
Pt2.2 operation command
hset h1 f 6 # Set data key:field:value hmset h1 a 1 b 2 c 3 d 4 # Set multiple groups of data key:field1:value1:field2:value2:field3:value3 hget h1 a # Get data key:field hmget h1 a b c d # Get multiple groups of data key:field1:field2:field3 hkeys h1 # Get all fields of key hvals h1 # Get all values of the key hgetall h1 # Get all field s and value s of key hdel h1 a # Delete the corresponding field data of the key hlen h1 # Number of key s del h1 # Delete all data of key
Pt2.3 implementation principle
In the string, we mentioned that the value s of the five basic data types are stored redisobject, and then redisobject saves the pointer to the actual data. Therefore, the design of external data type and internal 3 coding is realized. The same is true for hash. Hash can also be implemented in two data structures:
-
ziplist: OBJ_ENCODING_ZIPLIST (compressed table)
-
hashtable: OBJ_ENCODING_HT (hash table)
(1) ziplist
Ziplist is the most widely used of the five common data structures in redis, including LIST, ZET and ZSET. Ziplist has been used or used to implement its data structure. Let's focus on the data structure of ziplist.
The ziplist storage structure is as follows:
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
ziplist is a specially coded bidirectional linked list composed of continuous memory blocks. However, it does not store pointers to the front and back linked list nodes, but stores the length of the previous node and the length of the current node. When reading and writing, it usually calculates the length to find the location. By changing time and space, although the calculation length will lose some performance, it can save memory space.
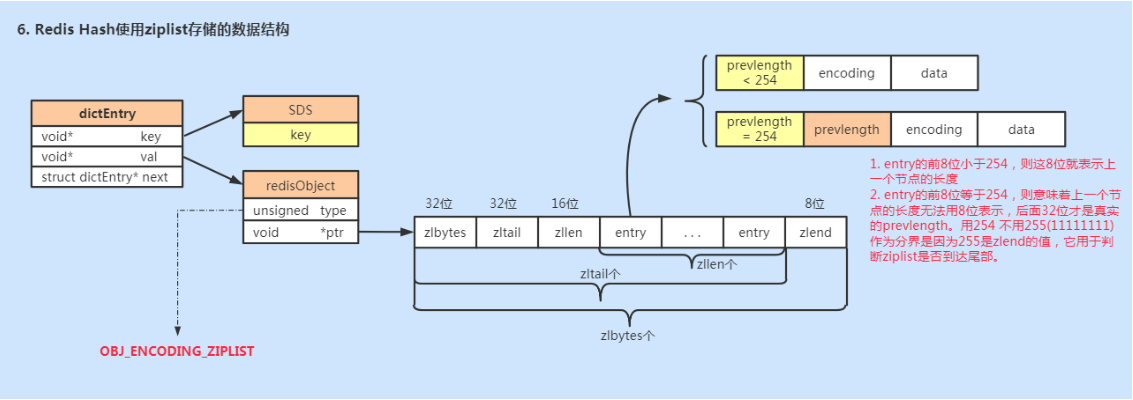
-
Zlbytes: the length of the ziplost (in bytes), which is a 32-bit unsigned integer
-
Zltail: the offset of the last node of the ziplost. It is useful when traversing the ziplost or pop tail node in reverse.
-
Zllen: number of nodes (entries) in ziplost
-
entry: node
-
zlend: the value is 0xFF, which is used to mark the end of the ziplost
See how Redis source code is implemented:
typedef struct zlentry {
unsigned int prevrawlensize; /* The number of bytes required to store the length value of the previous linked list node*/
unsigned int prevrawlen; /* Length of previous linked list node */
unsigned int lensize; /* The number of bytes required to store the length value of the current linked list node*/
unsigned int len; /* The length occupied by the current linked list node */
unsigned int headersize; /* Current linked list header size (non data field) prevrawlensize + lensize */
unsigned char encoding; /* Coding mode */
unsigned char *p; /* ziplist Save as a string, and change the pointer to the actual position of the current node */
} zlentry;Each node consists of three parts: prevlength, encoding and data
-
prevlengh: record the length of the last node to facilitate reverse traversal of the ziplost
-
Encoding: encoding rule of current node
-
data: the value of the current node, which can be a number or a string
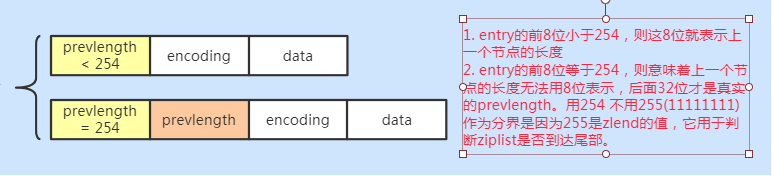
To save memory, according to the length of the previous node, prevlength can divide the ziplost node into two categories:
-
If the first 8 bits of entry are less than 254, these 8 bits represent the length of the previous node
-
The first 8 bits of the entry are equal to 254, which means that the length of the previous node cannot be represented by 8 bits, and the last 32 bits are the real prevlength. Use 254 instead of 255 (11111111) as the boundary because 255 is the value of zlend, which is used to judge whether the ziplost reaches the tail.
There are 8 types of encoding (int5 + string3), which respectively represent the storage of data of different lengths:
#define ZIP_ INT_ 16b (0xc0 | 0 < < 4) / / integer data, accounting for 16 bits (2 bytes) #define ZIP_ INT_ 32B (0xc0 | 1 < < 4) / / integer data, accounting for 32 bits (4 bytes) #define ZIP_ INT_ 64b (0xc0 | 2 < < 4) / / integer data, accounting for 64 bits (8 bytes) #define ZIP_ INT_ 24B (0xc0 | 3 < < 4) / / integer data, accounting for 24 bits (3 bytes) #define ZIP_INT_8B 0xfe / / integer data, occupying 8 bits (1 byte) #define ZIP_ STR_ 06B (0 < < 6) / / string data, up to 2 ^ 6 bytes (the length of the second half of encoding has 6 bits, and length determines how many bytes data has) #define ZIP_ STR_ 14b (1 < < 6) / / string data, up to 2 ^ 14 bytes #define ZIP_ STR_ 32B (2 < < 6) / / string data, up to 2 ^ 32 bytes
(2) hashtable
hashtable uses dict structure, as shown in the figure below.
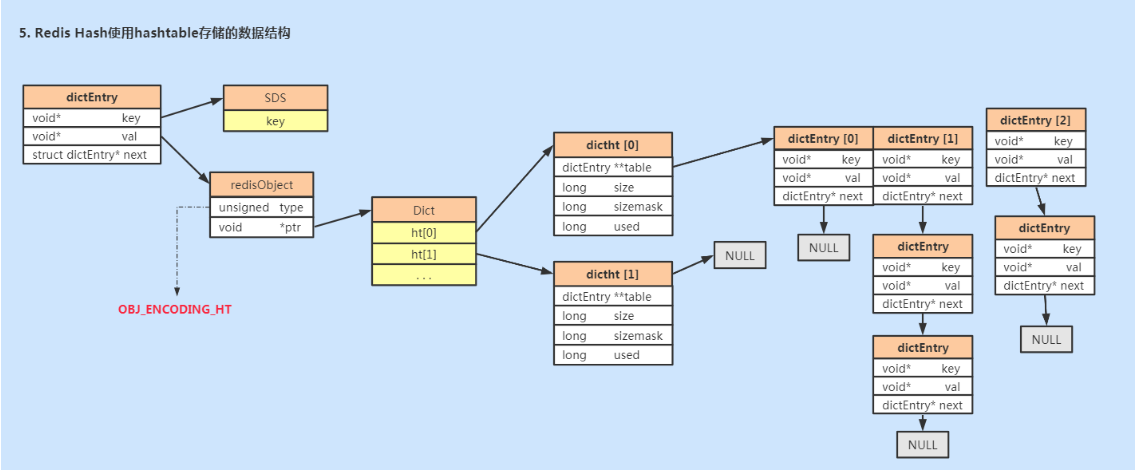
Load factor
Like hashmap in Java, the zipper method is used to solve the problem of hash conflict. However, if there are too many hash conflicts, the efficiency of hashtable will decline. When there are no conflicts, the efficiency is the best. Therefore, when the amount of data is increasing and hash conflicts are serious, capacity expansion is required.
hashtable also has a load factor. When the length of the linked list caused by hash conflict exceeds 5, capacity expansion will be triggered.
// dict.c static int dict_can_resize = 1; // Need to expand capacity static unsigned int dict_force_resize_ration = 5; // Expansion factor
Capacity expansion steps
-
The Dict object saves two hash tables ht[0] and ht[1]. ht[0] is used by default, and ht[1] will not initialize and separate space.
-
When capacity expansion is required, allocate space for ht[1], ht[1] = HT [0] Used * 2, find the second power greater than or equal to this number;
-
rehash the debit and credit data on ht[0] to ht[1], and recalculate the hash value and index;
-
After the migration of ht[0] data, free the space of ht[0] and set ht[1] to ht[0];
(3) Instructions for use
When the hash object satisfies two conditions at the same time, zip list encoding is used:
-
The number of key value pairs saved by hash object < 512;
-
The string length of keys and values of all key value pairs is < 64 bytes;
On redis Conf can configure these two parameters
hash-max-ziplist-value 64 # The maximum length of the value that can be stored in the ziplost hash-max-ziplist-entries 512 # The maximum number of entry nodes that can be stored in the ziplost
Pt2.4 application scenarios
string can handle all the scenarios supported by hash. In addition, hash can also handle more complex scenarios.
(1) Shopping cart
# key (user): filed (commodity id): value (commodity quantity) 127.0.0.1:6379> hset lucas table 2 (integer) 1 127.0.0.1:6379> hset lucas tv 1 (integer) 1 127.0.0.1:6379> hset lucas phone 3 (integer) 1 127.0.0.1:6379> hkeys lucas 1) "table" 2) "tv" 3) "phone"
Pt3 LIST
Pt3.1 storage type
Store ordered strings (from left to right). Elements can be repeated. The maximum number of stored strings is 2 ^ 32 - 1 (about 4 billion).

Pt3.2 operation command
LIST is an ordered data LIST. Redis also provides a very convenient API. You can perform various operations at the head of the LIST or at the end of the LIST, which makes the use of LIST very flexible.
# Add element in LIST header (left) lpush queue a # Add multiple elements to the LIST header lpush queue b c # Add elements at the end of LIST (right) rpush queue d # Add multiple elements at the end of LIST rpush queue e f # Get data from LIST header lpop queue # Get data from the tail of LIST rpop queue # Gets the data at the specified location lindex queue 0 # Get the data of the range subscript lrange queue 0 -1 # Blocking popup: producer consumer queue blpop queue 1 brpop queue 1
Pt3.3 implementation principle
In the early versions of Redis, ziplost was used to implement LIST when the data volume was small. When the data volume reached a certain critical point, LinkedList was used to implement LIST. After version 3.2, Redis uniformly uses quicklist to store LIST type data.
(1) quicklist
quicklist stores a two-way linked list. Each node in the list points to a ziplost, so quicklist is a combination of ziplost and linkedlist.
The overall structure of quicklist is shown in the figure below:
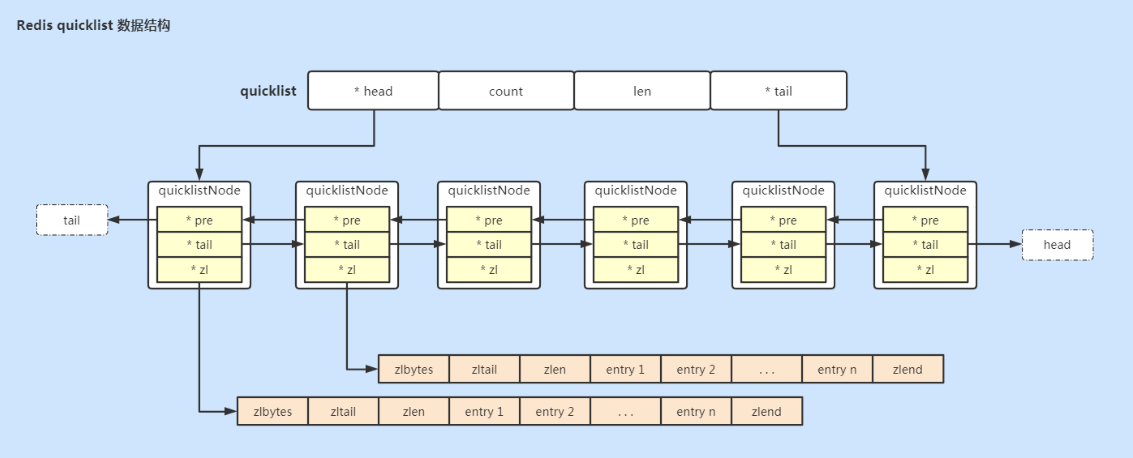
Let's look at the implementation of the source code:
# quicklist is the outermost data structure, which contains quickNode nodes in a two-way linked list.
typedef struct quicklist {
quicklistNode *head; /* Point to the header position of the two-way linked list */
quicklistNode *tail; /* Point to the footer position of the two-way linked list */
unsigned long count; /* Number of ziplist elements stored in all quicklistnodes */
unsigned long len; /* Length of bidirectional linked list, number of quicklistNode nodes */
int fill : QL_FILL_BITS; /* ziplist Maximum size, corresponding to list Max ziplist size */
unsigned int compress : QL_COMP_BITS; /* Compression depth, corresponding to list compress depth */
unsigned int bookmark_count: QL_BM_BITS;/* 4 Bits, bookmarks array size */
quicklistBookmark bookmarks[]; /* Optional field, used when quicklist reallocates memory space, and does not occupy memory space when it is not used */
} quicklist;
# quicklistNode is a node of a two-way linked list, pointing to a specific ziplost data structure.
typedef struct quicklistNode {
struct quicklistNode *prev; /* Point to previous node */
struct quicklistNode *next; /* Point to the next node */
unsigned char *zl; /* Pointer to the ziplist where the data is actually stored */
unsigned int sz; /* How many bytes does the ziplost pointed to by the current node occupy */
unsigned int count : 16; /* How many elements are stored in the ziplost pointed to by the current node, accounting for 16 bits, up to 65535 */
unsigned int encoding : 2; /* Whether to use LZF compression algorithm to compress nodes, RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* Has the current ziplost been extracted for temporary use */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* More bits to steel for future usage */
} quicklistNode;(2) Insert data
quicklist can choose to insert data in the head or tail (quicklistPushHead and quicklistPushTail). Whether inserting data in the head or tail, there are two cases:
-
If the size of the ziplist on the head node (or tail node) does not exceed the limit (that is, _quicklistnodeallowensertreturns 1), the new data is directly inserted into the ziplist (call ziplistPush).
-
If the zip list on the head node (or tail node) is too large, create a new quicklistNode node (a new zip list will be created accordingly), and then insert the newly created node into the quicklist two-way linked list.
You can also insert from any specified location. quicklistInsertAfter and quicklistInsertBefore insert data items after and before the specified location respectively. The operation of inserting data at any specified position is more complex than that at the head and tail.
-
When the size of the ziplost where the insertion location is located does not exceed the limit, it is good to insert it directly into the ziplost;
-
When the size of the ziplost at the insertion location exceeds the limit, but the insertion location is at both ends of the ziplost, and the ziplost size of the adjacent quicklist node does not exceed the limit, it will be inserted into the ziplost of the adjacent quicklist node instead;
-
When the size of the ziplost where the insertion location is located exceeds the limit, but the insertion location is located at both ends of the ziplost, and the ziplost size of adjacent quicklist nodes also exceeds the limit, a new quicklist node needs to be created.
-
For other cases where the size of the zip list where the insertion location is located exceeds the limit (mainly corresponding to the case of inserting data in the middle of the zip list), you need to split the current zip list into two nodes, and then insert data on one of the nodes.
(3) Search
quicklist nodes are composed of one ziplist, and each ziplist has a size, so we only need to find the corresponding ziplist according to the number of each quicklistnode, and call the index of ziplist to find it successfully.
(4) Delete
The function for deleting interval elements is quicklistDelRange
When the quicklist is deleted in the interval, it will first find the quicklistNode where the start is located and calculate whether the deleted elements are less than the count to be deleted. If the number of deleted elements is not satisfied, it will move to the next quicklistNode to continue deletion, and cycle successively until the deletion is completed.
The return value of quicklistDelRange function is of type int. when 1 is returned, it means that the elements in the specified interval have been successfully deleted, and when 0 is returned, it means that no elements have been deleted.
Pt3.4 application scenarios
(1) Ordered list
LIST is mainly used to store ordered data, such as comment LIST, message LIST, etc.
# Add article comments to the comment list 127.0.0.1:6379> rpush comments good (integer) 1 127.0.0.1:6379> rpush comments better (integer) 2 127.0.0.1:6379> rpush comments best (integer) 3 # View all comments 127.0.0.1:6379> lrange comments 0 -1 1) "good" 2) "better" 3) "best"
(2) Queue / stack
As mentioned earlier, LIST supports various operations at the head and at the tail, which makes LIST very flexible and possible. For example, first in first out queue, first in first out stack, etc.
LIST also provides two blocked pop operations: BLPOP and BRPOP. You can set the timeout (in seconds).
-
blpop key timeout: remove and get the first element in the list. If there is no element, it will be blocked until timeout or there is an element;
-
brpop key timeout: remove and get the last element in the list. If there is no element, it will be blocked until timeout or there is an element;
Does it feel familiar, or does it seem similar to the producer consumer queue:
# Add element 127.0.0.1:6379> rpush workqueue 1 (integer) 1 # Blocking pop-up elements 127.0.0.1:6379> blpop workqueue 5 1) "workqueue" 2) "1" # Wait timeout without element or element 127.0.0.1:6379> blpop workqueue 5 (nil) (5.04s)
Pt4 SET
Pt4.1 storage type
Set stores an unordered set of string type, and the elements in set cannot be repeated. The maximum storage quantity is 2 ^ 32 - 1 (about 4 billion).
Pt4.2 operation command
# Set set basic commands sadd myset a b c d e f g # Add one or more elements smembers myset # Get all elements scard myset # Number of statistical elements srandmember myset # Get an element at random (the element is still in the Set) spop myset # Pop up an element at random srem myset d e f # Remove one or more elements sismember myset a # Check whether the element exists in the Set del myset # Delete Set # Processing for Set collection sdiff set1 set2 # Gets the difference Set of two sets sinter set1 set2 # Gets the intersection of two sets sunion set1 set2 # Get Union
Pt4.3 implementation principle
Redis uses intset or hashtable to store Set types. If all elements are integer types, redis uses intset to store them. If they are not integer types, redis uses hashtable to store them.
hashtable storage is relatively simple. In the key field value structure, value is null. Let's look at the structure of intset.
intset is an integer set, which can only store integer type data. It can be 16 bits, 32 bits, or 64 bits. It is an array arranged in ascending order to save data
typedef struct intset {
/*code*/
uint32_t encoding;
/*length*/
uint32_t length;
/*Collection contents, array in ascending order*/
int8_t contents[];
} intset;The essence of intset is an ordered array (using binary search). It can be seen that adding and deleting elements are time-consuming. The time complexity of finding elements is O(logN). When the amount of data is large, the performance is very poor. Therefore, the storage structure is related to the data type. If the number of elements exceeds a certain number, hashtable storage will also be used (search efficiency O(1)), redis Conf has related configurations:
set-max-intset-entries 512
It can be seen that using hashtable has better performance, but it will waste a lot of space, such as unused value, pointer data, etc. intset saves memory space, but the performance is slightly poor. Therefore, considering that intset is used to store a small number of integer types, the sorting is simple, and the binary search performance is not particularly poor.
Pt4.4 application scenarios
(1) Draw
Use Set to store non repeated results, and the spop command can randomly obtain elements for lucky draw.
(2) Like, sign in, punch in
For example, when clocking in on a certain day, the date and other information are used as the key, and the clocking user add s to set to count the clocking information;
Or count a microblog friend's circle like record, use the unique ID of the information as the key, and add the like user ID to the set;
Other scenarios are similar.
# Use date as key and domain account as clock in Voucher: # Simulated punch in 127.0.0.1:6379> sadd 20201222 tracy.chen (integer) 1 127.0.0.1:6379> sadd 20201222 zhouzhongmao (integer) 1 127.0.0.1:6379> sadd 20201222 sunhao (integer) 1 127.0.0.1:6379> sadd 20201222 kobe (integer) 1 # View the number of punch outs 127.0.0.1:6379> scard 20201222 (integer) 4 # View specific clock in information 127.0.0.1:6379> smembers 20201222 1) "tracy.chen" 2) "kobe" 3) "sunhao" 4) "zhouzhongmao"
(3) Implementation of tag information on jd.com and tmall commodity evaluation pages
# Use tag:i5001 to maintain all labels of goods (you can further expand and add the statistical information of each label) 127.0.0.1:6379> sadd tag1:i5001 beautiful (integer) 1 127.0.0.1:6379> sadd tag1:i5001 clear (integer) 1 127.0.0.1:6379> sadd tag1:i5001 good (integer) 1 127.0.0.1:6379> smembers tag1:i5001 1) "clear" 2) "beautiful" 3) "good"
(4) User focused recommendation model
The people I care about, the people you care about, the people we all care about
127.0.0.1:6379> sadd ikown kobe tim shark tracy (integer) 4 127.0.0.1:6379> sadd ukown kobe james durant tracy (integer) 4 127.0.0.1:6379> sinter ikown ukown 1) "tracy" 2) "kobe"
In the above model, in the e-commerce scenario, different labels are selected for searching goods, and different filtering results can also be solved.
Pt5 ZSET
Pt5.1 storage type
ZSET is an ordered set that stores ordered elements. Each element has a score value and is ranked from small to large according to the score. If the scores are the same, they are sorted according to the ASCII code of the key.
Pt5.2 operation command
# Add element zadd myzset 10 java 20 php 30 ruby 40 cpp 50 python # Get all elements zrange myzset 0 -1 withscores zrevrange myzset 0 -1 withscores # Get elements according to score range zrangebyscore myzset 20 30 # Removing Elements zrem myzset php cpp # Number of statistical elements zcard myzset # Score increment zincrby myzset 5 python # Count the number according to the score zcount myzset 20 60 # Get element rank zrank myzset python # Get element score zscore myzset python
Pt5.3 implementation principle
ZSET also has two storage methods, ziplist and skiplist. If the element data is less than 128 and the element length is less than 64 bytes, use ziplist; otherwise, use skiplist.
redis. Conf G has specific configuration:
zset-max-ziplist-entries 128 zset-max-ziplist-value 64
The change of score will lead to the movement of ziplist and skiplist elements. Ziplist has been introduced earlier. Let's see what skiplist is.
What is SkipList
For a single linked list, even if the data has been ordered, if you want to query one of the data, you can only traverse the linked list from scratch, which is very inefficient and the time complexity is O(n). We can build an "index" for the linked list to improve the efficiency of query.

As shown in the figure below, on the basis of the original linked list, we extract a node from every two nodes to establish an index. We call the extracted node the index layer or index, and down represents the pointer to the original linked list node. When the amount of data increases to a certain extent, the efficiency will be significantly improved. If we add more levels of indexes, the efficiency will be further improved. This structure of linked list and multi-level index is called jump table.
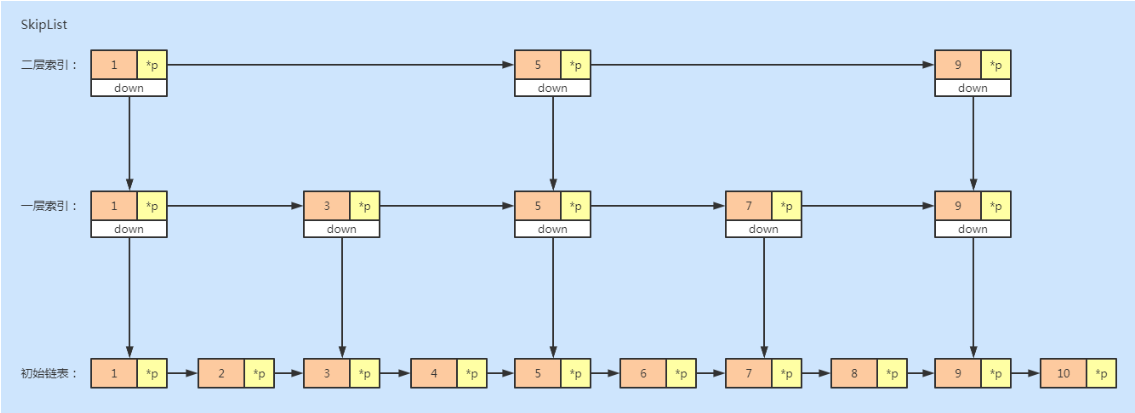
Jump table is to trade space for time
The efficiency of the jump table is higher than that of the linked list, but the jump table needs to store additional multi-level indexes, so it needs more memory space.
The spatial complexity analysis of the jump table is not difficult. If a linked list has n nodes and one node is extracted from every two nodes to establish an index, the number of nodes of the first level index is about n/2, the number of nodes of the second level index is about n/4, and so on. The number of nodes of the M-level index is about n/(2^m). We can see that this is an equal ratio sequence.
The node sum of these indexes is n/2+n/4+n/8... + 8+4+2=n-2, so the spatial complexity of the jump table is o(n).
So is there any way to reduce the memory space occupied by the index? Yes, we can extract an index every three nodes or no five nodes. In this way, the number of index nodes is reduced and the space occupied is less.
Insertion and deletion of skip table
If we want to insert or delete data for the jump table, we first need to find the insertion or deletion location, and then perform the insertion or deletion operation. As we know, the time complexity of the jump table query is O(logn), because the time complexity of the insertion and deletion after finding the location is very low, which is O(1), Therefore, the time complexity of final insertion and deletion is also O(longn).
If this node also appears in the index, we should delete not only the nodes in the original linked list, but also the nodes in the index. Because the deletion operation in the single linked list needs to get the precursor node of the node to be deleted, and then complete the deletion through pointer operation. Therefore, when looking for the node to be deleted, we must obtain the precursor node. Of course, if we use a two-way linked list, we don't need to consider this problem.
If we keep inserting elements into the jump table, there may be too many nodes between the two index points. If there are too many nodes, our advantage of establishing index will be lost. Therefore, we need to maintain the size balance between the index and the original linked list, that is, when the number of nodes increases, the index increases accordingly, so as to avoid too many nodes between the two indexes and reduce the search efficiency.
The jump table maintains this balance through a random function. When we insert data into the jump table, we can choose to insert the data into the index at the same time. What level of index do we insert? This requires a random function to determine which level of index we insert into.
This can effectively prevent the degradation of the jump table, resulting in low efficiency.
Pt5.4 application scenarios
(1) Ranking list
ZSET is suitable for list scenarios where the order will change dynamically, such as Baidu hot list, microblog hot search, etc. the implementation is also relatively simple.
# Initialize Leaderboard 127.0.0.1:6379> zadd hotrank 0 new1 0 new2 0 new3 (integer) 3 127.0.0.1:6379> zrange hotrank 0 -1 withscores 1) "new1" 2) "0" 3) "new2" 4) "0" 5) "new3" 6) "0" # When a click event occurs, the score is increased [root@VM-0-17-centos redis]# ./redisCli.sh 127.0.0.1:6379> zincrby hotrank 1 new1 "1" 127.0.0.1:6379> zincrby hotrank 1 new1 "2" 127.0.0.1:6379> zincrby hotrank 1 new3 "1" # View Leaderboard 127.0.0.1:6379> zrevrange hotrank 0 -1 withscores 1) "new1" 2) "2" 3) "new3" 4) "1" 5) "new2" 6) "0"
Pt6 other data types
In addition to the five basic data types, Redis also provides BitMaps, hyperlogs, Geo and Stream, which are not particularly commonly used and are only used in specific scenarios. For a brief description.
Pt6.1 BitMaps
Bitmaps is a bit operation defined on the string type. A byte is composed of 8 binary bits. Each binary bit of a byte can be operated based on bitmaps.
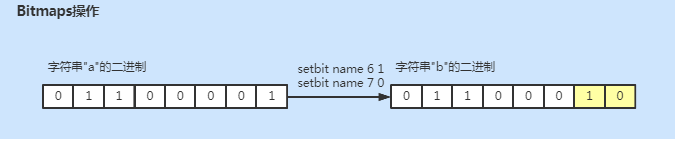
# Define string, View binary 127.0.0.1:6379> set name a OK 127.0.0.1:6379> getbit name 1 (integer) 1 127.0.0.1:6379> getbit name 2 (integer) 1 # Modify the binary of the corresponding bit 127.0.0.1:6379> setbit name 6 1 (integer) 0 127.0.0.1:6379> setbit name 7 0 (integer) 1 127.0.0.1:6379> get name "b" # View the number of 1 bits in binary 127.0.0.1:6379> bitcount name (integer) 3 # Gets the binary position of the first 1 127.0.0.1:6379> bitpos name 1 (integer) 1
Bitmaps also supports bitwise and, bitwise or operations. Using bitmaps is equivalent to using a string as an 8-bit binary, 1MB=8388608 bits, which can count a large amount of data and save space.
Pt6.2 Hyperloglogs/Geo/Stream
Hyperlogs: it provides an imprecise cardinality statistics method to count the number of non repeating elements in a collection, such as website UV, application daily life, monthly life, etc., with slight errors.
Geo: used to store longitude and latitude information, and provides API longitude and latitude based calculation.
Stream: a persistent message queue that supports multicast.
Redis's data types are very important, especially in scenarios with high cache requirements. Only by being familiar with each data type can we better select and realize more complex capabilities.