Implementation of Pytorch single machine multi card GPU (principle overview, basic framework and common error reporting)
usually, when large-scale training tasks are required such as pre training, it is difficult for a single card to meet the needs. Therefore, resources such as clusters need to be used to meet the needs of acceleration. Usually, when completing some personal tasks, you can apply for 4 ~ 8 GPU cards for a single machine (the better configuration is V100 and 32G at present), while multi machine and multi card may be involved in the industrial level. This paper mainly describes the use of single machine multi card parallel based on pytorch.
Pytoch provides a better performance distributed data parallel (DDP) module, which is more stable and efficient than DataParallel. Therefore, this paper mainly completes parallelism based on distributed data parallel.
1, Overview of single machine multi card principle
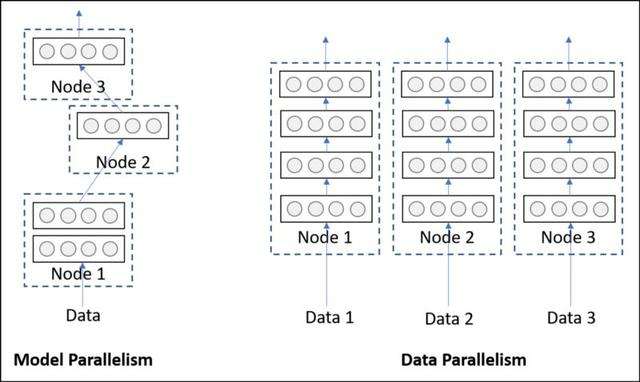
there are two modes of parallelism, model parallelism and data parallelism, as shown in the figure above.
GPU parallelism of pytorch based on dynamic graph is mainly "data parallelism", that is, the models (parameters) saved on each device are exactly the same at the same time, but the data fed into the models on each device is different. After a forward propagation calculation is completed on all devices, the corresponding loss loss is obtained respectively. The distributed data parallel (DDP) will automatically unify the gradients on all devices to a device (such as device 0) to update the parameters (usually the loss of all devices will be updated automatically by taking the average value), and then synchronize to the models of all devices.
therefore, theoretically, after each batch, the model on each device is the same, and the gradient and loss obtained on each device are different due to different data, but they are automatically completed by DDP.
2, Basic framework
we take the most classic MNIST handwritten numeral recognition as an example. First, define the convolution function class, which will be used as subsequent models:
#Define convolutional neural network
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# batch*1*28*28 (batch samples will be sent each time, the number of input channels is 1 (black and white image), and the image resolution is 28x28)
# The first parameter of the lower convolution layer Conv2d refers to the number of input channels, the second parameter refers to the number of output channels, and the third parameter refers to the size of the convolution kernel
self.conv1 = nn.Conv2d(1, 10, 5) # The number of input channels is 1, the number of output channels is 10, and the size of the core is 5
self.conv2 = nn.Conv2d(10, 20, 3) # The number of input channels is 10, the number of output channels is 20, and the size of the core is 3
# The first parameter of the following full connection layer Linear refers to the number of input channels, and the second parameter refers to the number of output channels
self.fc1 = nn.Linear(20*10*10, 500) # The number of input channels is 2000 and the number of output channels is 500
self.fc2 = nn.Linear(500, 10) # The number of input channels is 500 and the number of output channels is 10, that is, 10 classification
def forward(self,x):
in_size = x.size(0) # In this case, in_size=512, that is, batch_ The value of size. The input x can be regarded as a 512 * 1 * 28 * 28 tensor.
out = self.conv1(x) # Batch * 1 * 28 * 28 - > batch * 10 * 24 * 24 (after a convolution with 5x5 kernel, the output of 28x28 image becomes 24x24)
out = F.relu(out) # batch*10*24*24 (the activation function ReLU does not change the shape))
out = F.max_pool2d(out, 2, 2) # Batch * 10 * 24 * 24 - > batch * 10 * 12 * 12 (the pool layer of 2 * 2 will be halved)
out = self.conv2(out) # Batch * 10 * 12 * 12 - > batch * 20 * 10 * 10 (convolute again, the size of the kernel is 3)
out = F.relu(out) # batch*20*10*10
out = out.view(in_size, -1) # Batch * 20 * 10 * 10 - > batch * 2000 (the second dimension of out is - 1, indicating automatic calculation. In this example, the second dimension is 20 * 10 * 10)
out = self.fc1(out) # batch*2000 -> batch*500
out = F.relu(out) # batch*500
out = self.fc2(out) # batch*500 -> batch*10
out = F.log_softmax(out, dim=1) # Calculate log(softmax(x))
return out
first look at the training task code of single machine and single card:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
torch.__version__
import ConvNet # Custom convolution network model
BATCH_SIZE=512 #About 2G of video memory is required
EPOCHS=20 # Total training batches
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") # Let torch judge whether to use GPU. It is recommended to use GPU environment because it will be much faster
#Download training set
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)
#Download test set
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)
#train
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if(batch_idx+1)%30 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
#test
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # Add up the losses of a batch
pred = output.max(1, keepdim=True)[1] # Find the subscript with the highest probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__ == '__main__':
model = ConvNet().to(DEVICE)
optimizer = optim.Adam(model.parameters())
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch)
test(model, DEVICE, test_loader)
#Save the model after training
torch.save(model, './MNIST.pth')
in the code of single machine and single card, you usually only need to define Datasets and DataLoader. In the multi card parallel task, we just said that GPU parallelism is essentially data parallelism, so the main changes are Datasets and DataLoader. The contents involved are as follows:
- Get the number of all GPUs: torch cuda. device_ Count(), get the number of currently available GPUs (number of processes): dist.get_world_size()
- local_ Rank: you need to explicitly define ArgumentParser and add the parameter: parser add_ argument('--local_rank', default=-1, type=int)
local_ The rank parameter needs to be explicitly defined, but the user does not need to specify its value when executing the script. This parameter is automatically numbered by the system according to all available GPU cards (devices), so local_rank is represented as the equipment number. Usually the default is local_rank=0 is the basic card. For example, when the model is processing some data and saving the disk, or when the model is reasoning, it only needs to be in local_ It can be completed on the card with rank = 0.
When training, a single card is usually used for tensor directly CUDA () implements the transfer of tensor to GPU. For multi card training, it is tensor cuda(args.local_rank).
- batch_size specification: single machine batch_size indicates the number of samples fed into the model at one time, while batch in DDP_ Size is the number of data fed on each card.
Batch is usually used in open source projects_ Size can be named "batch_size_per_gpu". Of course, batch can also be used_ SIZE = bz // dist.get_ world_ Calculate the batch of each ka with the method of size (). However, you should pay attention to the GPU video memory size of each card. For example, when completing the Bert large pre training, if there are only 16G cards, the batch of each card_ Size can only be set to 8.
- DistributedSampler: used for data sampling during distributed training. It usually ensures that the sampling data on each card is at the same time but will not be repeated. By default, it is random sampling;
- DataLoader: different from single machine and single card, it needs to specify sampler=DistributedSampler as sampler and explicitly set shuffle=False.
- dist.barrier(): used for synchronization, that is, ensure that the programs on all devices are executed to this position before continuing.
change to multi GPU version code as follows:
import argparse
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch import distributed as dist
torch.__version__
print(torch.cuda.device_count()) # Print gpu quantity
dist.init_process_group(backend="nccl") # Parallel training initialization, recommended 'nccl' mode
print('world_size', dist.get_world_size()) # Print current processes
# The following parameter needs to be added. This parameter will be used when multiple processes are called inside torch. For each gpu process, its local_rank is different;
parser = argparse.ArgumentParser(description="Command")
parser.add_argument('--local_rank', default=-1, type=int)
args = parser.parse_args()
torch.cuda.set_device(args.local_rank) # Set the gpu number to local_rank; This sentence may also see local_ What is the value of rank
BATCH_SIZE = 512 // dist.get_world_size() # probably needs 2G of video memory
EPOCHS = 20 # Total training batches
# DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") # Let torch judge whether to use GPU. It is recommended to use GPU environment, because it will be much faster
# Download training set
train_dataset = datasets.MNIST('data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
# Download test set
test_dataset = datasets.MNIST('data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=BATCH_SIZE, shuffle=False,
sampler=train_sampler)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=BATCH_SIZE, shuffle=False)
# train
def train(model, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.cuda(args.local_rank), target.cuda(args.local_rank)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 30 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# test
def test(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.cuda(args.local_rank), target.cuda(args.local_rank)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # Add up the losses of a batch
pred = output.max(1, keepdim=True)[1] # Find the subscript with the highest probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__ == '__main__':
model = ConvNet().cuda(args.local_rank)
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model) # Set BN synchronization of multiple GPUs
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[args.local_rank],
output_device=args.local_rank,
find_unused_parameters=False,
broadcast_buffers=False)
optimizer = optim.Adam(model.parameters())
for epoch in range(1, EPOCHS + 1):
train_sampler.set_epoch(epoch) # Don't forget this sentence, otherwise it is equivalent to no shuffle data
train(model, train_loader, optimizer, epoch)
if args.local_rank == 0:
test(model, test_loader)
dist.barrier()
# Save the model after training
torch.save(model, './MNIST.pth')
therefore, the single card multi card framework code can be summarized as follows:
import torch
import argparse
from torch import distributed as dist
print(torch.cuda.device_count()) # Print gpu quantity
dist.init_process_group(backend="nccl") # Parallel training initialization, recommended 'nccl' mode
print('world_size', dist.get_world_size()) # Print current processes
# The following parameter needs to be added. This parameter will be used when multiple processes are called inside torch. For each gpu process, its local_rank is different;
parser.add_argument('--local_rank', default=-1, type=int)
args = parser.parse_args()
torch.cuda.set_device(args.local_rank) # Set the gpu number to local_rank; This sentence may also see local_ What is the value of rank
def reduce_mean(tensor, nprocs): # It is used to average the running results on all GPUs, such as loss
rt = tensor.clone()
dist.all_reduce(rt, op=dist.ReduceOp.SUM)
rt /= nprocs
return rt
'''
Multi card training loading data:
# The design of Dataset is consistent with that of single gpu, but it is different from that of DataLoader. First, explain the reason: multi gpu training is what we want
# The data on each gpu is different at the same time, which is equivalent to the N-fold expansion of batch size, so it plays a role in accelerating training.
# In DataLoader, how to ensure that the data on each GPU is different, and how to ensure that the data trained on gpu1 is not used by others next
# The gou trained again. At this time, the DistributedSampler is required.
# The setting method of dataloader is as follows. Note that shuffle conflicts with sampler, and sampler needs to be set for parallel training. At this time, be sure to
# Set shuffle to False. However, shuffle=False here does not mean that the data will not be out of order, but will be handed over to the user in an out of order manner
# In fact, the data is still out of order.
'''
train_sampler = torch.utils.data.distributed.DistributedSampler(My_Dataset)
dataloader = torch.utils.data.DataLoader(ds,
batch_size=batch_size,
shuffle=False,
num_workers=16,
pin_memory=True,
drop_last=True,
sampler=self.train_sampler)
'''
Model setting of multi card training:
# The most important thing is find_unused_parameters and broadcast_buffers parameter;
# find_unused_parameters: set this parameter to True if the output of the model does not need to be backfilled; If your code runs
# It is basically the problem of this parameter when it is stuck in a certain place.
# broadcast_buffers: when set to True, gpu0 will overwrite all parameter values in the buffer before the model executes forward
# To another gpu. Note that this is not the same as synchronizing BN. Synchronizing BN should use the above code.
'''
My_model = My_model.cuda(args.local_rank) # Copy the model to each gpu
My_model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(My_model) # Set BN synchronization of multiple GPUs
My_model = torch.nn.parallel.DistributedDataParallel(My_model,
device_ids=[args.local_rank],
output_device=args.local_rank,
find_unused_parameters=False,
broadcast_buffers=False)
'''Start multi card training:'''
for epoch in range(200):
train_sampler.set_epoch(epoch) # Don't forget this sentence, otherwise it is equivalent to no shuffle data
My_model.train()
for idx, sample in enumerate(dataloader):
inputs, targets = sample[0].cuda(local_rank, non_blocking=True), sample[1].cuda(local_rank, non_blocking=True)
opt.zero_grad()
output = My_model(inputs)
loss = My_loss(output, targets) #
loss.backward()
opt.step()
loss = reduce_mean(loss, dist.get_world_size()) # The loss of multiple GPUs is averaged.
'''Multi card test(evaluation): '''
if local_rank == 0:
My_model.eval()
with torch.no_grad():
acc = My_eval(My_model)
torch.save(My_model.module.state_dict(), model_save_path)
dist.barrier() # The function of this sentence is: the code below this sentence will not be executed until the code on all processes (gpu) is executed
The execution of the procedure is:
- Code run:
python3 -m torch.distributed.launch --nproc_per_node=2 main.py
- Set visible devices:
CUDA_VISIBLE_DEVICES=0,1 python3 -m torch.distributed.launch --nproc_per_node=2 main.py
- Combined with nohup:
CUDA_VISIBLE_DEVICES=0,1 nohup python3 -m torch.distributed.launch --nproc_per_node=2 main.py >> log.log &
3, Common errors
several common errors based on DDP are briefly listed, and this part will be continuously updated.
1,Expected to have finished reduction in the prior iteration before starting a new one.
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your module has parameters that were not used in producing loss. You can enable unused parameter detection by (1) passing the key ...
reference resources: https://blog.csdn.net/qxqxqzzz/article/details/116076355
Error reason:
- Usually, when using multiple GPU s, there is a BUG in the program or model, which needs to be debug ged carefully;
- When using multitasking training, the necessary module loss is not updated by gradient; At this point, you can use torch nn. parallel. Distributeddataparallel() add parameter find_unused_parameters=True.
2,RuntimeError: Address already in use
reference resources: https://blog.csdn.net/j___t/article/details/107774289
Error reason:
- A DDP program already exists on a port.
Solution:
- You can open a new port and add a parameter - master_port. For example:
python3 -m torch.distributed.launch --nproc_per_node=2 --master_port 8848 main.py
3. Multi GPU video memory and memory leakage
Solution:
- tensor.cuda(non_blocking=True) stores the tensor in cuda and does not take it out;
- Feed torch utils. data. When using dataset and dataloader, do not convert to tensor first:
For example:
feature_dict = {
'input_ids': [f.input_ids for f in features],
'attention_masks': [f.attention_mask for f in features],
'token_type_ids': [f.token_type_ids for f in features],
}
Dataset(feature_dict)
class DictDataset(Dataset):
"""A dataset of tensors that uses a dictionary for key-value mappings"""
def __init__(self, **tensors):
# tensors.values()
# assert all(next(iter(tensors.values())).size(0) == tensor.size(0) for tensor in tensors.values())
self.tensors = tensors
def __getitem__(self, index):
bool_list = ['is_mlms']
return {key: torch.tensor(tensor[index], dtype=torch.bool) if key in bool_list else torch.tensor(tensor[index], dtype=torch.long) for key, tensor in self.tensors.items()}
def __len__(self):
return len(next(iter(self.tensors.values())))
You can also specify the customized batch processing function collate in the Dataloader_ Implement tensor conversion in FN.
- Explicit use of GC mechanism: GC is the garbage collection mechanism module of Python. Usually, python automatically recovers useless variables, but it may inevitably fail in multi GPU scenarios. Therefore, it can be explicitly called:
import gc gc.collect()
- Clean up GPU cache: use torch cuda. empty_ Cache () cleans up useless variables that exist on the GPU.
reference:
[1]Distributed dataparallel for pytorch parallel training (code sample and explanation)
[2]https://blog.csdn.net/qxqxqzzz/article/details/116076355
[3]https://blog.csdn.net/j___t/article/details/107774289
[4]pytorch multi gpu parallel training