1. Preface
Hello, everyone
In the daily process of dealing with Python, it is inevitable to involve data reading and writing business. For example, when doing crawler, you need to store the crawled data locally first, and then do the next step of processing; When doing data visualization analysis, you need to read the data from the hard disk into the memory, and then carry out subsequent steps such as data cleaning, visualization and modeling
When reading and writing data, we have many choices for storage objects. The most convenient ones are local document types: csv, txt, etc. the advantages are simple, but the disadvantages are also obvious: document data is easy to be lost, damaged, deleted and unrecoverable, and it is not convenient for data sharing among multiple people;
Another large class of storage objects are databases. At present, MongoDB and Mysql are more flow persistent databases; Compared with document storage, the biggest advantage of database is that data is not easy to lose and easy to retrieve. In the face of a huge amount of data, CRUD (add, read, modify and delete) function can be realized with only a few lines of SQL statements
In this Python tutorial, we will summarize the reading and writing methods of Python data. There are four types of storage objects involved: txt, csv, MongoDV and MySQL
2. Python document reading and writing
For local document data reading and writing, this paper lists two common document types: txt and csv; The test data comes from the second-hand housing supply of Lianjia. For details of housing supply data crawling, please refer to the old news Python collected 3000 second-hand housing data in Beijing. Let's see what I have analyzed?

2.1 txt reading and writing
Among the several data storage objects introduced in this article, txt reading and writing is the simplest one. I won't introduce the reading and writing method in detail here. For those who don't know much about it, please refer to the following test code:
#txt data source, remember to add the {encoding='utf-8 'parameter to prevent random code
dataSource = open('data.txt',encoding='utf-8',mode='r')
#txt data read / write operation
savePath = 'save.txt'
f = open(savePath,encoding='utf-8',mode='w+')#Read
for lineData in dataSource.readlines():
dataList = lineData.replace('\n','').split(',')
print(dataList)
f.write('\t'.join(dataList) +'\n')
f.close()
The whole process of txt reading and writing is completed by means of file flow. It should be noted that if Chinese garbled code occurs during reading and writing, the parameter encoding = 'utf-8' needs to be added to effectively avoid:
2.2 csv reading and writing
Compared with txt, python enthusiasts prefer to store data in csv or xlsx, which is relatively more standardized, especially for numerical data. For students with poor programming foundation, they can directly carry out visual analysis without Python and Excel;
There are many ways to read and write csv in Python. In the following examples, I list two common ways. One is based on Python csv and the other is based on pandas
csv data reading
When reading tests, data is read from csv
Method 1: read with Python CSV
#Using Python CSV to read data
csvPath = 'save.csv'
with open(csvPath, newline='',encoding='utf-8') as csvfile:
spamreader = csv.reader(csvfile, delimiter=',', quotechar='|')
for row in spamreader:
print(', '.join(row))
Method 2: read with the help of pandas
csvPath = 'save.csv' df = pandas.read_csv(csvPath,header=0) print(df)
csv data writing
Method 1, with the help of Python CSV
#txt data source, remember to add the {encoding='utf-8 'parameter to prevent random code
dataSource = open('data.txt',encoding='utf-8',mode='r')
#Using {Python csv} to write} csv} files
csvPath = 'save.csv'
with open(csvPath, 'w', newline='',encoding='utf-8') as csvfile:
spamwriter = csv.writer(csvfile, delimiter=' ',
quotechar='|', quoting=csv.QUOTE_MINIMAL)
for index, lineData in enumerate(dataSource.readlines()):
dataList = lineData.replace('\n', '').split(',')
spamwriter.writerow(dataList)
Method 2, with the help of pandas
dataSource = open('data.txt',encoding='utf-8',mode='r')
#Using "pandas" to write "csv" file
csvPath = 'save.csv'
data = []
columnName = []
for index,lineData in enumerate(dataSource.readlines()):
if(index==0):#The first row is the column name
columnName = lineData.replace('\n','').split(',')
continue
dataList = lineData.replace('\n','').split(',')
data.append(dataList)
df =pandas.DataFrame(data,columns =columnName)
#Prevent garbled code
df.to_csv(csvPath,encoding="utf_8_sig",index=False)
As for the operation of csv files with Python, I prefer to use pandas. In pandas, the data are displayed in the type of "DataFrame" or "Series". For most numerical calculation or statistical analysis methods, there are encapsulated functions, which can be called directly, which is very convenient
3. Python database reading and writing
After introducing Python's reading and writing methods in local documents, the following will introduce Python's processing in the database; Here I choose MongoDB and MySQL, two popular databases; Before the formal introduction, please make sure that everyone's environment is ready
3.1 MongoDB data reading and writing
Mongodb is a kind of document oriented database, belonging to the NoSQL camp, which is often referred to as non relational database,
Data acceptance during storage is composed of key value pairs (key = > value), similar to JSON objects; That is, when Python interacts with Mongodb data, it needs to be passed in the form of a dictionary
How to connect MongoDB with Python? We don't need to worry about this. Python's biggest advantage is that it can rely on a huge third-party library. pymongo can help us realize CRUD business operations on the data in MongoDB
MongoDB connection initialization
After the local MongoDB download is completed, the default port of the database is {127017 and the host address is} loclhost. Before reading and writing data, you need to complete the initialization connection to the database. The code is as follows
import pymongo
#Connect to the database and create a data table
myclient = pymongo.MongoClient("mongodb://localhost:27017")
database = myclient["database"]#Connect to database
collection = database["table"]#collection , is similar to , table in Mysql
"Database" and "table" in the code represent the database name and table name respectively. If there is no corresponding database or data table during data writing, MongoDB will automatically create it
MongoDB data write
When I introduced MongoDB earlier, I mentioned that its data structure is composed of key value pairs, which is similar to JSON objects; Therefore, in the data insertion step, it is necessary to convert the data into dictionary form (column name as key and column value as value). The data style is as follows:
Data writing Python code implementation
dataSource = open('data.txt',encoding='utf-8',mode='r')
readlines = dataSource.readlines()
keys_list = readlines[0].replace('\n', '').split(',')
for lineData in readlines[1:]:
dataList = lineData.replace('\n', '').split(',')
#Data dictionary formatting
dataDict = dict(zip(keys_list, dataList))
if collection.find_one(dataDict):#Judge whether the data record exists in the data table before insertion;
print("Insert done......")
else:#Insert when not present
collection.insert_one(dataDict)
The effect after data writing is as follows. The GUI tool here uses the official mongo compass
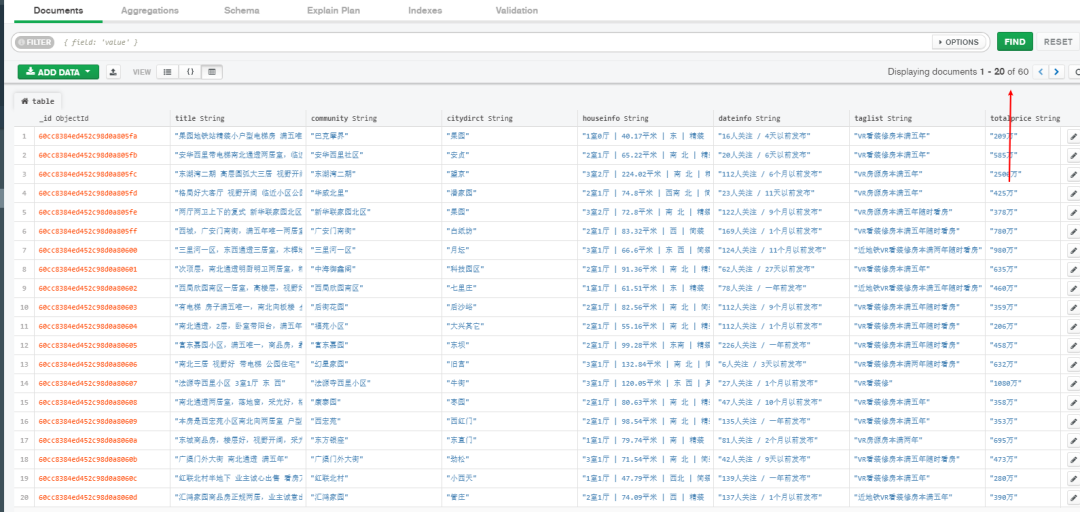
pymongo data insertion can be done in two ways
-
insert_one() insert one piece of data at a time;
-
insert_many() inserts multiple pieces of data each time, and the inserted pieces of data need to be stored in the form of a list;
MongoDB data reading
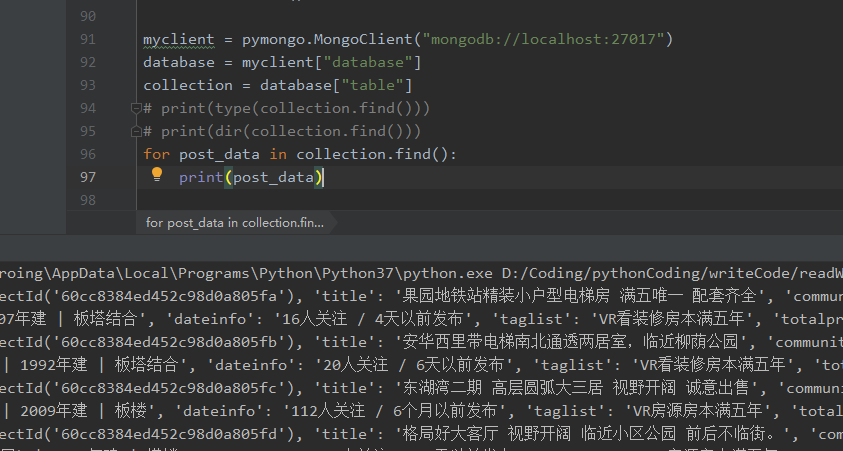
MongoDB data reading can be understood as unconditional query, and a {cursor} object is returned through} find(); Cursor means cursor in Chinese. Similar to iterator, it can return database data in an iterative manner
The data reading method is as follows:
myclient = pymongo.MongoClient("mongodb://localhost:27017")
database = myclient["database"]
collection = database["table"]
for post_data in collection.find():
print(post_data)
In addition to unconditional query, you can add some filter criteria as follows:
-
When querying, only the first 10 pieces of data are returned
for post_data in collection.find()[:10]: print(post_data)
-
When querying, you need to return a field value in reverse order, such as_ id field
for post_data in collection.find().sort('_id',pymongo.ASCENDING):
print(post_data)
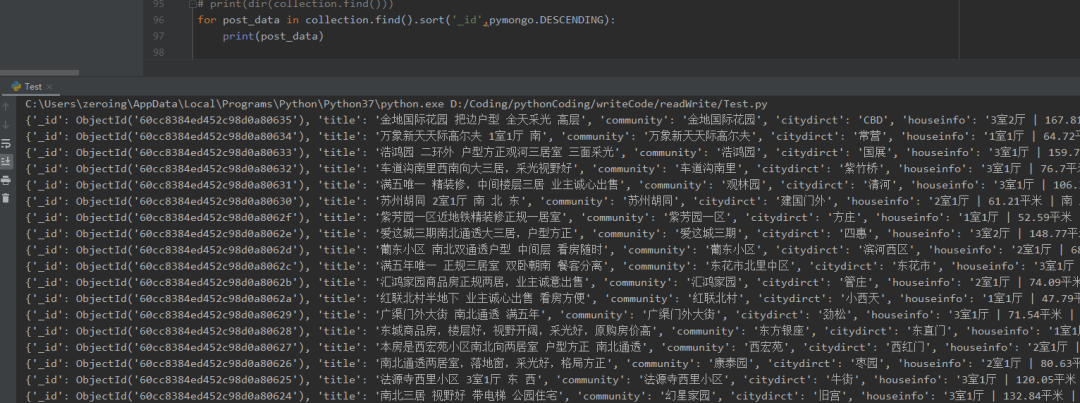
-
Only the data with "community" as "xihongyuan" will be returned
for post_data in collection.find({"community":"Xihongyuan"}):
print(post_data)
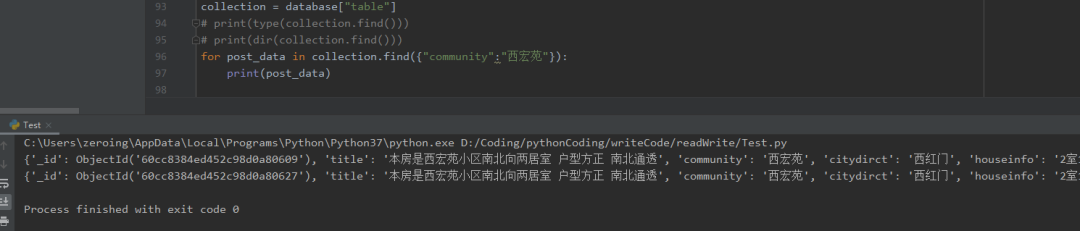
There are many practical methods on how to operate MongoDB with pymongo. Here I only introduce a small part. For details, please refer to the official pymongo documentation:
https://pymongo.readthedocs.io/en/stable/api/pymongo/collection.html
3.2 MySQL read / write
MySQL is a typical relational database. Data tables can be linked through foreign keys. In this way, when a field is updated in a table, other associated data tables will be updated automatically. The business logic of data addition, deletion, modification and query is mainly completed through SQL statements,
At present, there are two types of libraries that Python can use to manipulate MySQL: MySQL LDB and pymysql. The two libraries operate MySQL in similar ways. Their core functions depend on sql statements. It can be considered that they provide an interface between Python and mysql,
In this article, pymysql is selected as the test library. Before reading and writing with pymysql, it is recommended to test whether the MySQL database on the machine is available through the command line. The test method is as follows:
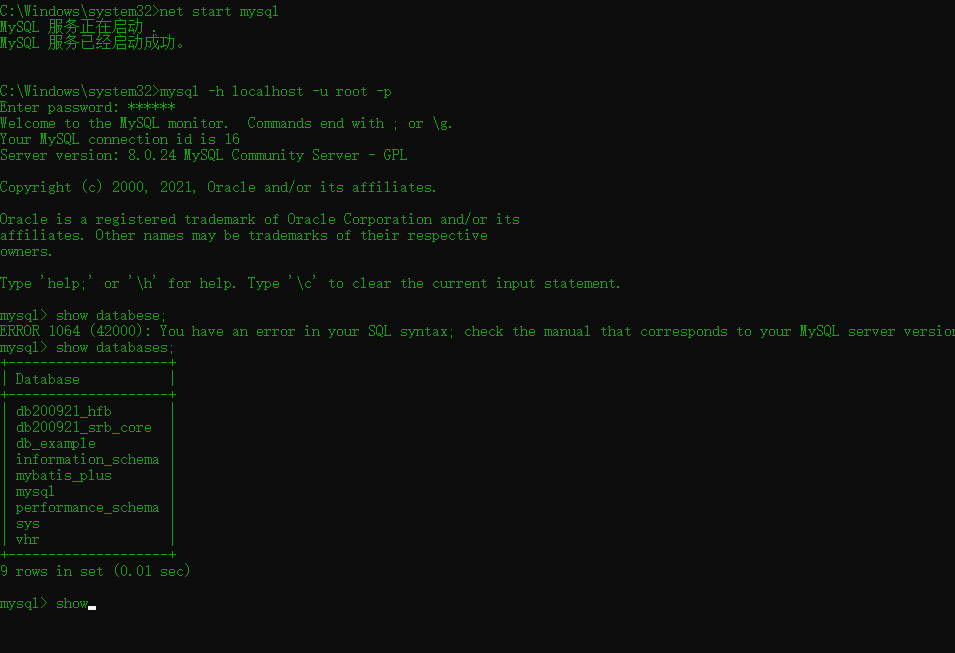
MySQL connection initialization
When pymysql connects to MySQL, you need to configure ip, port, user name, password and database name (unlike MongoDB, MySQL database needs to be created in advance)
import pymysql db_conn = pymysql.connect(host= '127.0.0.1', port= 3306, user= 'root', password= '123456', db= 'db_example')
MySQL data insertion
When inserting data into MySQL, you can create a new table or insert based on the table in the original database. In the following test code, I use the former
#Create table data_table sql1 = " drop table if exists %s;" sql2 ='''CREATE TABLE %s ( title varchar(1000), community varchar(1000), citydirct varchar(1000), houseinfo varchar(1000), dateinfo varchar(1000), taglist varchar(1000), totalprice varchar(1000), unitprice varchar(1000) ) ''' try: with db_conn.cursor() as cursor: cursor.execute(sql1,"data_table") cursor.execute(sql2,"data_table") db_conn.commit() except Exception as e: db_conn.rollback()
MySQL data insertion code
for lineData in dataSource.readlines()[1:]:
dataList = lineData.replace('\n', '').split(',')
#Insert sql insert statement
insert_sql = 'INSERT data_table (title,community,citydirct,houseinfo,dateinfo,taglist,totalprice,unitprice) VALUES ' + \
'("' + '","'.join(dataList) + '")'
print(insert_sql)
#Execute sql} statements
with db_conn.cursor() as cursor:
cursor.execute(insert_sql)
#Close database
db_conn.close()
The data insertion effect is as follows. The following is the mysql UI interface using Navicat:
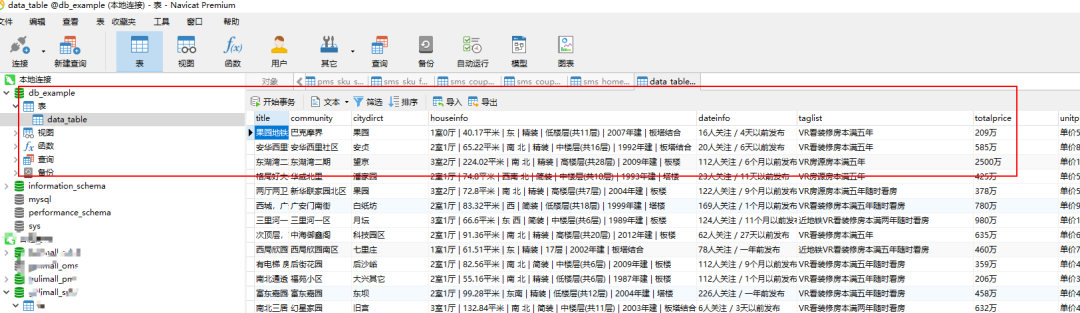
From the above code block, we can see that in the step of connecting MySQL with MySQL and inserting data, the business function mainly depends on the SQL statement, that is, if you want to operate MySQL with python, you need to master the SQL statement in advance
INSERT data_table (title,community,citydirct,houseinfo,dateinfo,taglist,totalprice,unitprice) VALUES ' + \
'("' + '","'.join(dataList) + '")
pymysql operation MySQL needs to be noted that every time one or more sql statements are executed, you need to commit() once, otherwise the execution will be invalid
cursor.execute(sql2,"data_table") db_conn.commit()
MySQL data query
Select * from data_ The data table data can be queried by using the table statement_ All data in table:
import pymysql db_conn = pymysql.connect(host= 'localhost', port=3308, user= 'root', password= '123456', db= 'db_example', charset='utf8mb4') findSql = 'SELECT * FROM data_table' try: with db_conn.cursor() as cursor: cursor.execute(findSql) db_conn.commit() results = cursor.fetchall() for itemData in results: print(itemData) except Exception as e: db_conn.rollback()
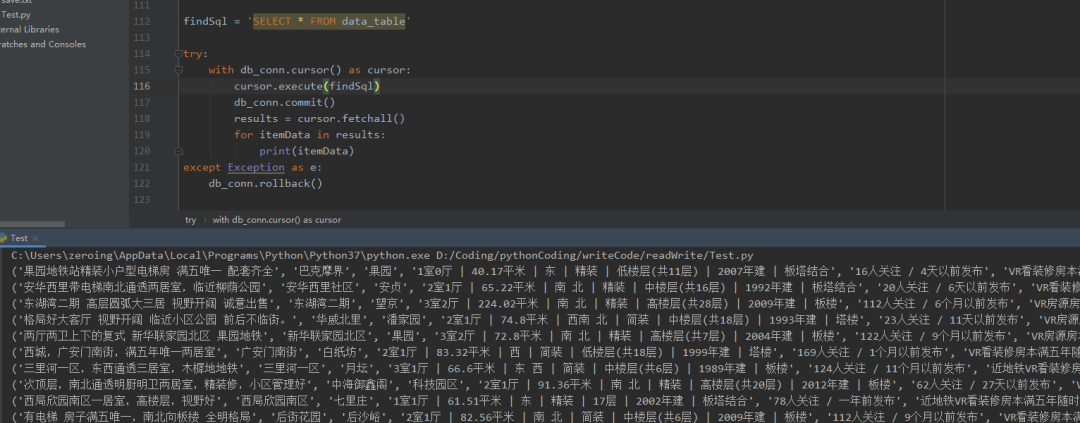
In addition to unconditional query, you can also use SELECT * FROM data_table where .... Statement to implement conditional query Represents the conditional statement to be added
In addition to basic reading and writing, you can also do some business functions such as updating and deleting with the help of sql statements; The trouble is that when splicing sql statements in Python, syntax errors are easy to occur, which is far inferior to Java,
There are encapsulated jar packages in Java. For some common addition, deletion, modification and query businesses, you only need to pass in parameters, and you don't need to care about whether the sql statement is legal. It's very convenient! Compared with Java, there is still much room for improvement in the interaction between Python and MySQL~
Summary
This paper introduces the reading and writing methods of Python for four types of storage objects, which are divided into two categories: document and database, from txt to csv and from MongoDB to MySQL, covering most business scenarios in daily life; For the convenience of most little partners learning python, TXT, csv and other documents will be preferred as storage objects when processing data in Python;
However, once the amount of data becomes huge, or there are many documents storing data, the disadvantages of document object storage will be revealed: document data is easy to be deleted by mistake, the relationship between data is easy to be confused, documents are placed disorderly and so on; At this point, the advantages of the database can be revealed:
1. Huge data storage on MySQL 3 In version 22, the maximum storage space of a single table is 4GB. One database can create multiple data tables, and MySQL can also create multiple databases, as shown in the following figure
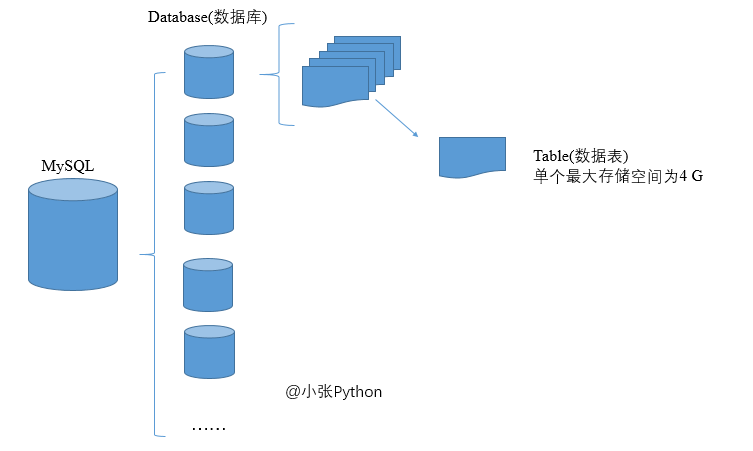
2. The relationship between data tables is clear and easy to retrieve quickly; A database can aggregate multiple data tables to one place for easy search; With the increase of data volume, the data can also be divided into multiple databases for storage according to attributes and usage scenarios;
3. If the data in the database is deleted by mistake, it can also be recovered by technical means. Therefore, it is necessary to understand the basic operation mode of database data!
Well, that's all about Python data storage. If the content is helpful to you, you might as well give me a praise to encourage me~
Friends who want more learning materials can add wechat V: xy07201017 to get them (Note: Data Collection)