preface
Blogger I have been wandering in Niuke's facial classics area all year round and summarized the high-frequency examination questions of big factories such as byte, Alibaba, Baidu, Tencent, meituan, etc. but today, I teach you how to crawl facial classics. If you can help your little partners, please give me a lot of support three times a day. Thank you for your disrespect!!!
This time, taking Java facial Sutra as an example, the little partner of the society can climb any facial Sutra of Niuke according to the law


teaching
Enter the Java area and open the console refresh request
It can be found that the response content obtained by sending the URL in the browser is not face-to-face, so where does the face-to-face data come from??? Don't worry, so many requests, let's keep looking!
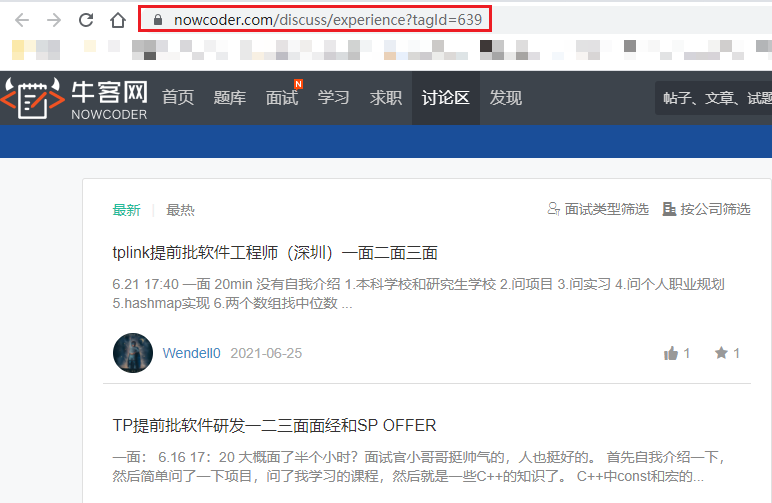
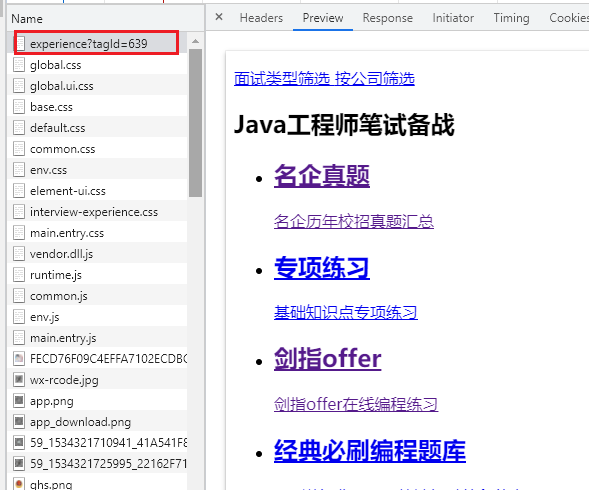
Sliding down, you can see the request with json. Experience tells me that this is the request
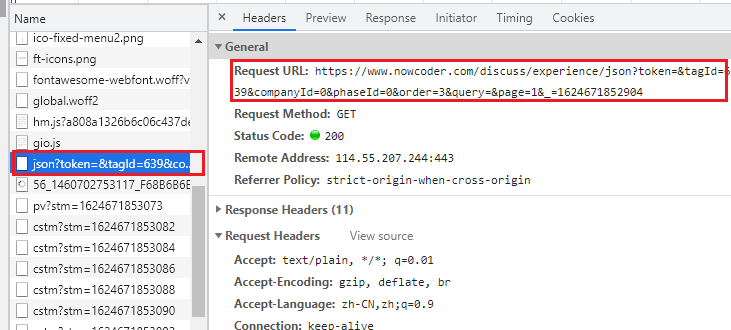
Copy the URL, we go to the browser to request the URL, and we can find that we have obtained the face-to-face data

However, the surface is in JSON format, which can be copied to the online JSON parsing tool for viewing, as shown below

You can see that all posts, namely face-to-face information, are saved under discussPosts under data
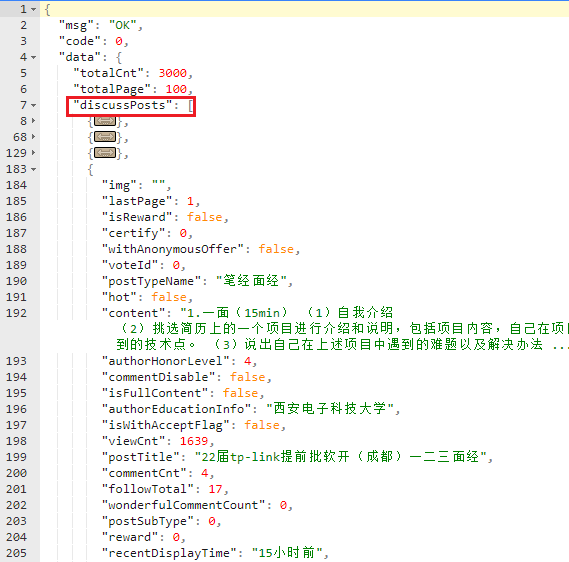
However, unlike what I have seen before, this json string does not directly save the URL of the post details page, but we can provide access path discovery rules

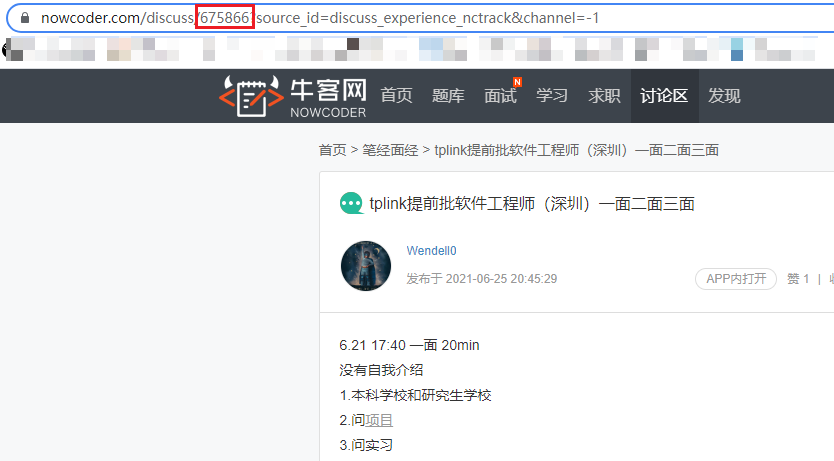
You can see that the access path has a 675866, which corresponds to the postId in the json string, and the following parameters can be omitted
antic
It must be that a single page can't satisfy all of you. So if you crawl multiple pages, don't worry. I'll summarize the rules for you. I also hope you can click three times in a row!!!

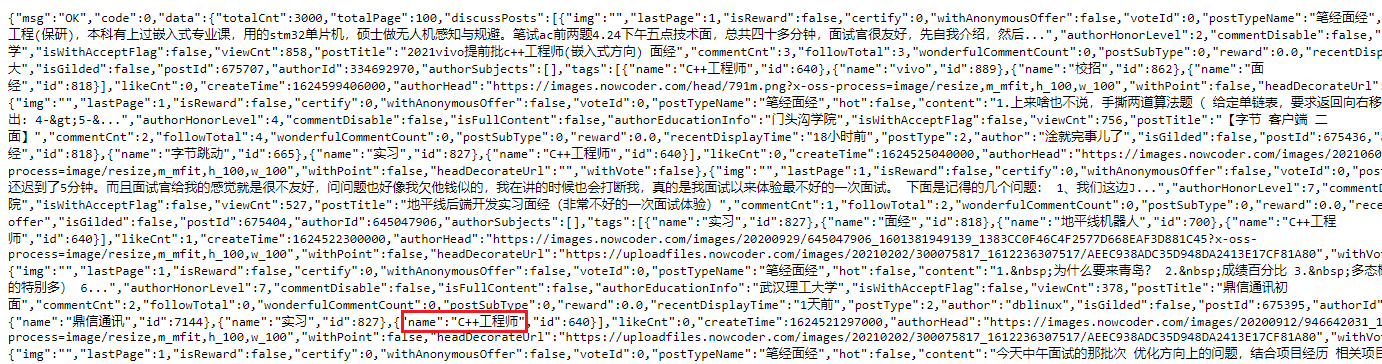
The same routine, as shown in the figure below, is the face warp JSON string of the C + + area. I don't need to teach you more
Complete code
If you are a novice, you can see my crawler teaching index. After practicing, you can master it well!!!
Open source crawler instance tutorial directory index
import requests
import json
import os
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36"
}
path = "./Facial meridian"
symbol_list = ["\\", "/", "<", ":", "*", "?", "<", ">", "|","\"","&"]
#Replace the title characters, because if there are these characters, they cannot be saved to txt
def replaceTitle(title):
for i in symbol_list:
if title.find(str(i)) != -1:
title = title.replace(str(i)," ")
return title
#Get details page URL
def getDetail_Url(tmp_path,json_str):
discussPosts = json_str['data']['discussPosts']
for discussPost in discussPosts:
title = discussPost['postTitle']
detail_url = "https://www.nowcoder.com/discuss/" + str(discussPost['postId'])
detail_response = requests.get(url=detail_url,headers=headers)
getDetailData(tmp_path,title,detail_response)
#Request details page for data
def getDetailData(tmp_path,title,detail_response):
detailData = BeautifulSoup(detail_response.text,"html.parser")
div_data = detailData.find(class_="post-topic-main").find_all("div")
title = replaceTitle(title)
print("Saving" + tmp_path + ":" + title)
with open(tmp_path + "/" + title + ".txt",'w',encoding='utf-8') as f:
for i in div_data:
try:
#If you encounter a tag with class clearfix, you can jump out of the loop, because the required data has been obtained, and the data under the tag is unnecessary
if i['class'].count('clearfix') != 0:
break
except:
pass
tmp_text = i.text.strip('\n').strip()
f.write(tmp_text + "\n")
f.close()
# start
if __name__ == '__main__':
url = "https://www.nowcoder.com/discuss/experience/json?token=&tagId=639&companyId=0&phaseId=0&order=3&query=&page=1"
for i in range(1,3):
url = url + str(i)
if not os.path.exists(path):
os.mkdir(path)
tmp_path = path + "/The first" + str(i) + "Page questions"
if not os.path.exists(tmp_path):
os.mkdir(tmp_path)
response = requests.get(url=url,headers=headers)
json_str = json.loads(response.text)
getDetail_Url(tmp_path,json_str)
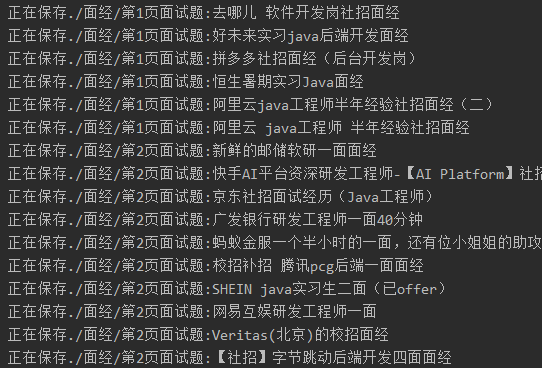
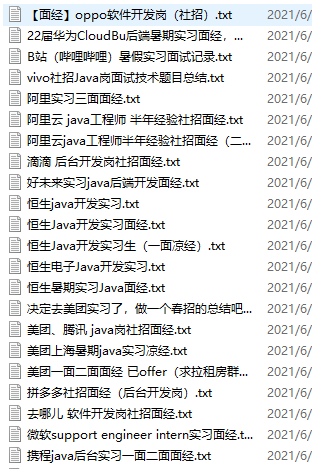
Result display

CSDN exclusive benefits come!!!
Recently, CSDN has an exclusive activity, that is, the following full stack knowledge map of Python. The route planning is very detailed. The size is 870mm x 560mm. Small partners can learn systematically according to the above process. Don't look for a book to learn. They should learn systematically and regularly. Its foundation is the most solid in our business, "Weak foundation, earth shaking and mountains shaking" is particularly obvious.
Finally, if you are interested, you can buy it as appropriate to pave the way for the future!!!

last
I am Skin shrimp , a shrimp lover who loves to share knowledge, we will constantly update blog posts that are beneficial to you in the future. We look forward to your attention!!!
It's not easy to create. If this blog is helpful to you, I hope you can click three times!, Thanks for your support. I'll see you next time~~~
Sharing outline
Interview question column of large factory
Directory index of Java learning route from getting started to entering the grave
Open source crawler instance tutorial directory index
For more wonderful content sharing, please click Hello World (●'◡'●)