PandaDB R & D team recently launched PandaDB community version v0 3. This version independently designs and implements distributed graph storage and graph query engine, removes the dependence on Neo4j community version storage and query engine, and is seamlessly compatible with Neo4j client call interface and graph query syntax Cypher.

PandaDB is a heterogeneous data intelligent fusion management system developed by the computer network information center of the Chinese Academy of Sciences. In addition to the graph data management capability based on attribute graph model, PandaDB also supports the semantic analysis of unstructured data (BLOB) based on AI model, heterogeneous data association query and other functions.
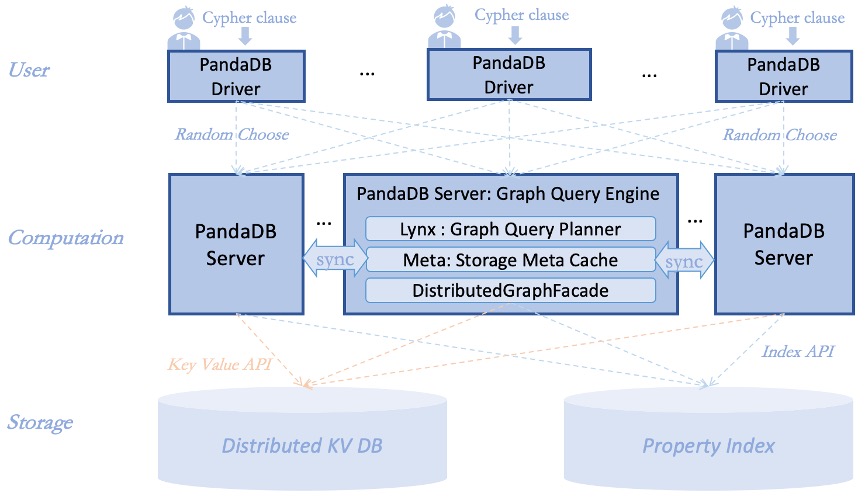
PandaDB community version v0 3 architecture diagram
PandaDB community version v0 3 realize the distribution of graph storage and graph query. Of which:
- The storage engine is built based on distributed KV storage (TiKV) and full-text index (ElasticSearch), with horizontally scalable attribute graph data storage capacity;
- The query engine supports multi instance deployment and operation, and realizes the balanced distribution of graph computing load and the high availability of query services.
1, Deployment and startup of pandadb server
Add PandaDB community version v0 3 download the installation package to one or more servers to run PandaDB server and unzip it. The download address is: https://github.com/grapheco/pandadb-v0.3/releases/download/v0.3-20220113/pandadb-server-0.3-unix.tar.gz

1. Deploy and start ElasticSearch and TiKV
2. Modify the configuration file conf / pandadb. For each server conf:
- Modify DBMS index. The value of hosts is host address of ElasticSearch
- Modify DBMS kv. The value of hosts is the host address of TiKV PD
- Modify DBMS panda. The value of nodes is the host address of the PandaDB cluster
3. Start pandadb server for each server:
$ bin/pandadb.sh start
2, PandaDB Demo database use case
1. The user can create a sample database (sample data of LDBC) with one click through the following commands:
$ bin/demo-importer.sh
After the import is completed, all panddb servers must be restarted.
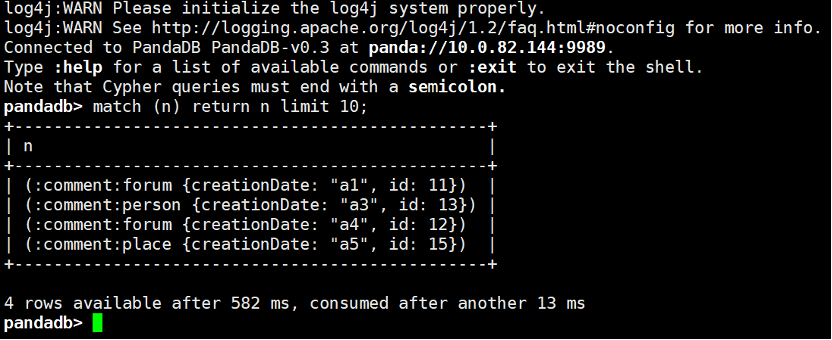
2. The user can initiate cypher query to the panddb server deployed on the local port 9989 through the following command:
$ bin/cypher-shell -a "panda://127.0.0.1:9989" -p "" -u "" pandadb> match(n) return n limit 10;
3. Users can also query the sample database by using the graph data browser pandadb browser. Fill in the Connect URL as shown in the figure below, where ip:port is replaced by the running address of pandadb server: port number. Then click Connect to enter the query interface. The download address of pandadb browser is: https://github.com/grapheco/pandadb-browser/releases/download/alpha3/pandadb-browser-0.0.3-binary.zip . After decompression, according to readme MD deployment installation.
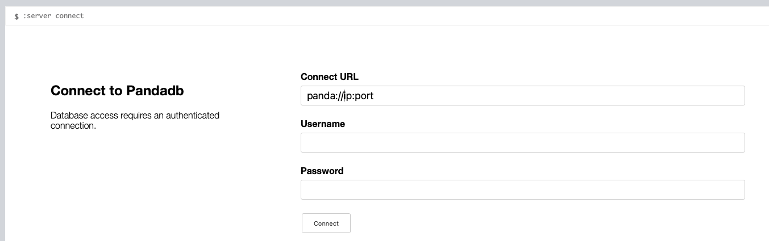
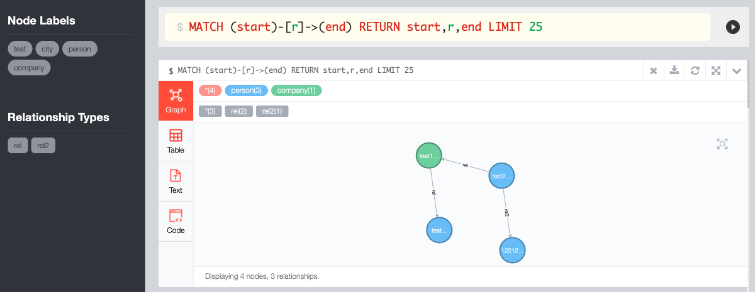
User interface of pandadb browser
3, Figure application development example
PandaDB provides a java version of graph data query driver PandaDB Java driver. Graph application developers can introduce it into their own development projects through maven pom configuration files. The following is the pom configuration method:
<dependencies>
......
<dependency>
<groupId>org.grapheco.pandadb</groupId>
<artifactId>pandadb-java-driver</artifactId>
<version>0.3.2</version>
</dependency>
......
</dependencies>
The following is an example code for accessing pandadb server through pandadb Java driver:
import org.neo4j.driver.v1.*;
import org.neo4j.driver.v1.types.Node;
import org.neo4j.driver.v1.types.Relationship;
public class DriverDemo {
public static void main(String[] args) {
Driver driver =
GraphDatabase.driver(
/* panda://Followed by "ip: Port" of all pandadb server nodes*/
"panda://127.0.0.1:9989,127.0.0.2:9989,127.0.0.3:9989",
AuthTokens.basic("", "")
);
Session session = driver.session();
StatementResult result1 =
session.run("match (n) return n limit 10");
while (result1.hasNext()){
Record next = result1.next();
Node n = next.get("n").asNode();
System.out.println("node properties: " + n.asMap());
}
StatementResult result2 =
session.run("match (n)-[r]->(m) return r limit 10");
while (result2.hasNext()){
Record next = result2.next();
Relationship r = next.get("r").asRelationship();
System.out.println("rel properties: " + r.asMap());
}
session.close();
driver.close();
}
}4, Participating communities
PandaDB community version v0 3. The source codes of PandaDB Java driver and PandaDB browser are open source using Apache-2.0 protocol. Welcome to submit issues and PR. Code warehouse address:
project | Warehouse address |
PandaDB community version v0 three | https://github.com/grapheco/pandadb-v0.3 |
PandaDB-Java-Driver | https://github.com/grapheco/pandaDB-java-driver |
PandaDB-Browser | https://github.com/grapheco/pandadb-browser |