Based on the previous learning, the training of CNN using convolutional neural network has greatly improved the accuracy.
The difference from before is that two layers of convolution neural network are added. The full connection layer that was not understood by the previous learning theory is also understood after writing this code.
Moreover, dropout is used to solve the over fitting problem.
Finally, the accuracy reached 0.9688, much higher than the previous 0.87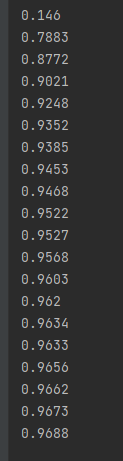
The following are important codes
1, Define conv2d and max_pool_2x2 function
X is the input, W is the weight, stripe = [1,1,1,1] is the front and back up and down steps are 1, padding = 'SAME', which means that the output size remains unchanged after convolution. Assuming that the original image is 28x28, the output is still 28x28. If padding is used, the image features can be better preserved. If you don't understand it, please search by yourself,
def conv2d(x,W):
#Step [1,x,y,1]
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
Pooling process: X is the input, ksize is the size of the pool core, which is 2x2, and the other two parameters are the same as conv2d
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
2, Two convolution layers
The first layer consists of 32 convolution cores with a size of 5x5. Because it is a gray image, the convolution cores are single channel and the bias is also 32.
The second layer has 64 convolution cores. The number of convolution cores is self-determined, but it is 32 channels, which is determined by the output of the previous layer, that is, the input of this layer. Since the input is 32, there are 32 channels, and the size is also set to 5x5
Both layers need to use the relu function, and then pool. Here, Max is used_ pool. After pooling, each output is reduced to 0.5x.
Take the first example of output.
First, a single channel image of 28x28 is input. After convolution, 32 channels of 28x28 are output. After pooling, it becomes 14x14x32. 32 is 32 channels
#conv1 W_conv1 = weight_variable([5,5,1,32])#The convolution kernel size is 5x5, single channel, 32 convolution kernels, and the number of convolution kernels is generally a multiple of 2 b_conv1 = bias_variable([32]) h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1) h_pool1 = max_pool_2x2(h_conv1) #conv2 W_conv2 = weight_variable([5,5,32,64]) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2) h_pool2 = max_pool_2x2(h_conv2)
The final pooled output is 7x7x64
2, Full connection layer
The first layer first processes the data from the convolution laminar flow, reshape s it into one-dimensional 7764, and the output is one-dimensional 1024. Then, it uses the relu function, and finally solves the over fitting
The second layer is the output layer. 1024 rows and columns are input and 10 rows and columns are output. The excitation function of this layer uses softmax because it is a multi classification task
##func1 layer W_fc1=weight_variable([7*7*64,1024]) b_fc1 = bias_variable([1024]) h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1) h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob) #func2_layer W_fc2 = weight_variable([1024,10]) b_fc2 = bias_variable([10]) prediction = tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2) cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1])) train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
Last total code
import random
import tensorflow as tff
import tensorflow._api.v2.compat.v1 as tf
from keras.utils.np_utils import to_categorical
import matplotlib.pyplot as plt
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
tf.disable_v2_behavior()
(train_images, train_labels), (test_images, test_labels) = tff.keras.datasets.mnist.load_data()
train_images, test_images = train_images / 255.0, test_images / 255.0#image normalization
train_labels, test_labels = to_categorical(train_labels), to_categorical(test_labels)
#Convert to 784 columns
train_images = train_images.reshape([-1, 784])
test_images = test_images.reshape([-1, 784])
def compute_accuracy(v_xs, v_ys):
global prediction
y_pre = sess.run(prediction, feed_dict={xs: v_xs,keep_prob:1})
correct_prediction = tf.equal(tf.argmax(y_pre, 1), tf.argmax(v_ys, 1))#True if the predicted value is the same as the maximum element of each row of the true value of the test
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))#After converting to float32, calculate the average value to get the accuracy
return sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys,keep_prob:1})
def weight_variable(shape):
inital = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(inital)
def bias_variable(shape):
inital = tf.constant(0.1, shape=shape)
return tf.Variable(inital)
def conv2d(x,W):
#Step [1,x,y,1]
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')#ksize is the pool core size 2x2
xs = tf.placeholder(tf.float32, [None, 784])
ys = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
x_image=tf.reshape(xs,[-1,28,28,1])
#conv1
W_conv1 = weight_variable([5,5,1,32])#The convolution kernel size is 5x5, single channel, 32 convolution kernels, and the number of convolution kernels is generally a multiple of 2
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
#conv2
W_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
##func1 layer
W_fc1=weight_variable([7*7*64,1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob)
#func2_layer
W_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(1000):
index = random.sample(range(train_images.shape[0]), 100)
batch_xs = train_images[index,]
batch_ys = train_labels[index,]
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys,keep_prob:0.5})
if i % 50 == 0:
print(compute_accuracy(test_images, test_labels))