[source code analysis] deep learning distributed training framework horovod (6) - background thread architecture
0x00 summary
Horovod is an easy-to-use high-performance distributed training framework released by Uber in 2017, which has been widely used in the industry.
This series will lead you to understand Horovod through source code analysis. This article, the sixth in a series, looks at the background thread architecture of Horovod.
The links to the previous articles are as follows:
[Source code analysis] deep learning distributed training framework Horovod (1) - basic knowledge
[source code analysis] deep learning distributed training framework horovod (5) - Fusion Framework
0x01 primer
As we saw earlier, during training, the Execution Thread will pass tensor & operation to the background thread through a series of operations. The process is roughly as follows:
IndexedSlices
+
|
|
v
allreduce
+
|
|
v
allgather
+
|
|
v
HorovodAllgather
+
|
v
HorovodAllgatherOp
+
|
|
v
EnqueueTensorAllgather
+
|
|
v
+-------+-------------+
| HorovodGlobalState |
| |
| message_queue |
| |
| tensor_table |
| |
+---------------------+
Or as shown in the figure below, the left side is the execution thread, which is the training thread, and the right side is the background thread, which is used for ring allreduce:
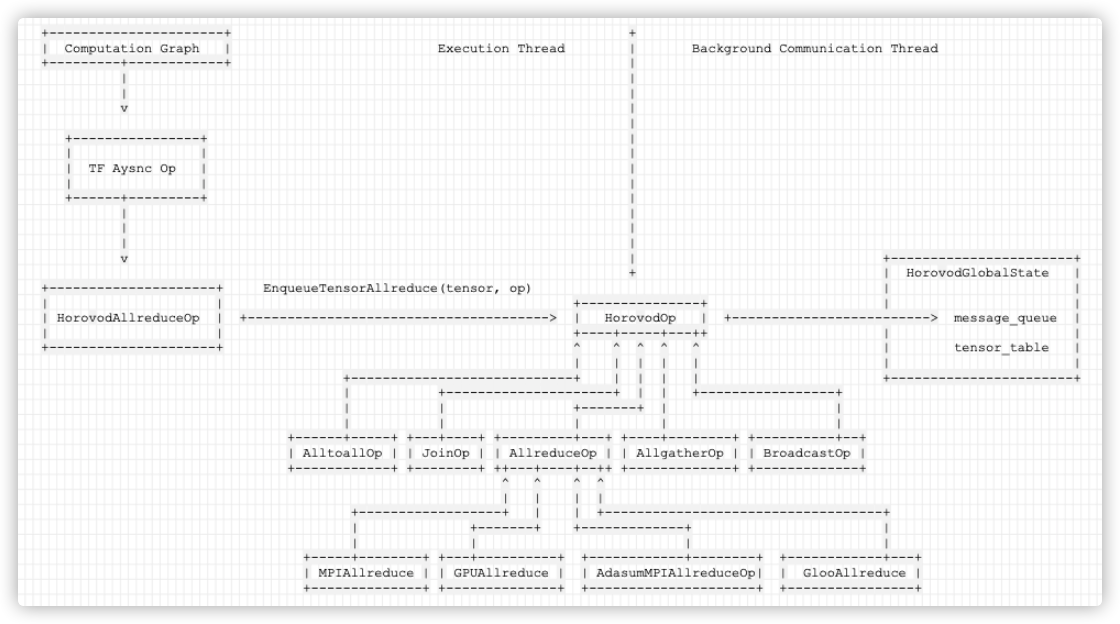
Let's continue to see how the background works.
0x02 key points of design
2.1 problems
Because the computing framework often adopts the calculation diagram of multi-threaded execution training, in the case of multiple nodes, take the allreduce operation as an example. We can't guarantee that the allreduce requests on each node are orderly. Therefore, MPI_Allreduce cannot be used directly.
2.2 scheme
In order to solve this problem, a master-slave mode is designed in HVDC. rank 0 is the master node and rank 1 ~ rank n is the worker node.
- The master node performs synchronization and coordination to ensure that the allreduce requests for some tensor s are finally orderly & complete and can continue to be processed.
- After deciding which tensors to communicate with, the master will send the names and order of tensors that can communicate back to each node.
- When all nodes get the tensor and order of the upcoming MPI, MPI communication can be carried out.
First, review the concept of synchronous gradient update, which means that after all the gradients of Rank are calculated, the global gradient accumulation can be done uniformly, which involves message communication in the cluster. Therefore, HVD has done two aspects of work.
- In Horovod, each card corresponds to a training process, which is called rank. For example, for 4 cards, the rank of each process is [0,1,2,3].
- Coordination: in HVD, rank0 is used as coordinator (master), and other processes are worker s. Rank0 coordinates the progress of all rank.
- Background thread: in order not to block normal OP calculation, a background communication thread is created in HVD, which is specially used for message synchronization between Rank and AllReduce operation.
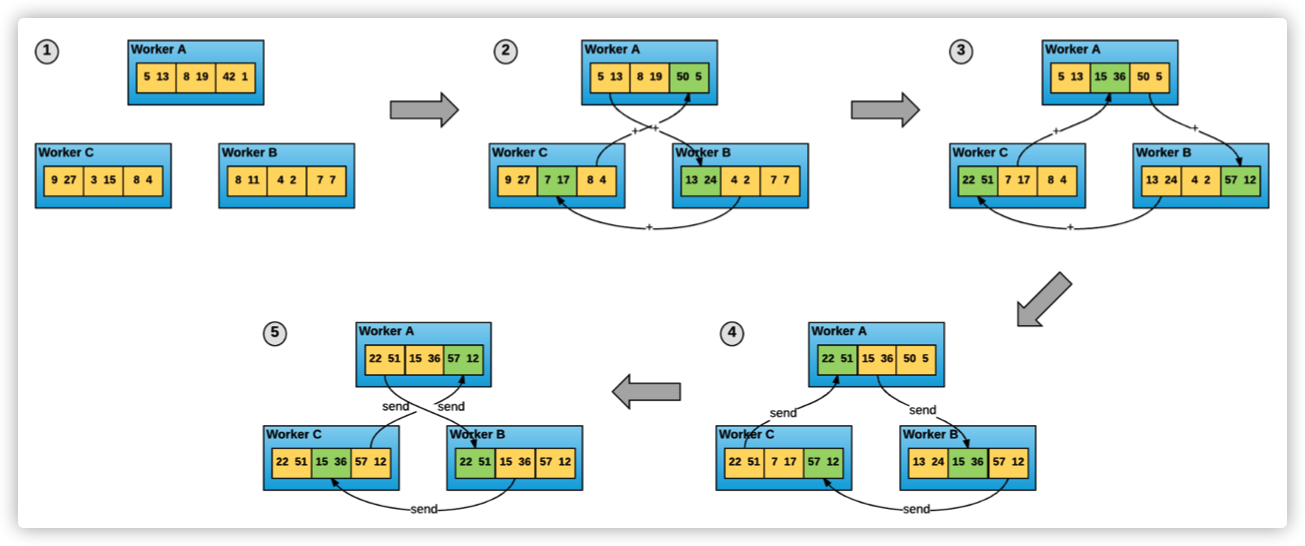
In Horovod, the training process is equal participants. Each process is responsible for both gradient distribution and specific gradient calculation. As shown in the figure below, the gradients in the three workers are evenly divided into three parts. Through four communications, the calculation and synchronization of cluster gradients can be completed.
2.3 coordination
2.3.1 design
The coordination process is also described in great detail in the document, and I will translate it together.
The coordinator currently adopts the master worker paradigm. Rank 0 is the master (i.e. "coordinator") and other rank is the worker. Each rank runs in its own background thread, and the time slice circularly schedules processing. In each time slice, the following operations will be performed:
-
Workers will send MPIRequests to the coordinator. MPIRequests explicitly indicate what the worker wants to do (such as what to do on which tensor, whether to gather or reduce, and the shape and type of tensor). After the collective op of the tensor has executed ComputeAsync, the worker will send an MPIRequest for each tensor.
-
When there are no more tensors to process, workers will send an empty "DONE" message to the coordinator;
-
After receiving MPIRequests and TensorFlow ops from the worker, the coordinator stores them in the request table. The coordinator continues to receive MPIRequest until MPI is received_ Size "DONE" messages;
-
The Coordinator collects all prepared reductions, gather tensors, or all operations that cause errors. For each vector or operation. The Coordinator sends MPIResponse to all staff. When there are no more mpiresponses, the Coordinator will send a "done" response to the worker. If the process is shutting down, it will send a "shutdown" response.
-
Workers listen to MPIResponse messages and do the required reduce or gather operations one by one until they receive "DONE" response. At this point, the time slice ends. If you receive "SHUTDOWN" instead of "DONE", exit the background loop
In short:
- The Coordinator collects MPIRequests of all worker s (including the Coordinator himself, because he is also training) and puts them into the request table.
- When MPI is collected_ After the size "DONE" message, the Coordinator will find the ready tensor (find it in the message_table) to construct a read_to_reduce the list, and then issue a size MPIResponse to tell the process to calculate.
- The worker receives the response and starts the real calculation process (through the op_manager).
- This is the overall synchronization process. If you open horovod's trace log(HOROVOD_LOG_LEVEL=trace), you can see the synchronization process.
2.3.2 realization
Let's look at the implementation.
In Horovod, each card corresponds to a training process, which is called rank. For example, for 4 cards, the rank of each process is [0,1,2,3].
HVDC designs a master-slave mode, using rank0 as the coordinator (Master), and the rest of the processes are workers. Rank0 coordinates the progress of all ranks. Each worker node has a message queue, while the master node has a message map in addition to a message queue.
Whenever a communication request is sent by the computing framework, instead of directly executing MPI, HVDC encapsulates the message and pushes it into its own message queue.
- The Request and Response mechanism of message is adopted as a whole;
- When the gradient calculation of an OP is completed and waits for global AllReduce, the rank will wrap a request, call ComputeResponseList, and put the request (that is, this is a ready tensor) into the message of the rank_ In the queue, the background thread of each rank periodically trains its own message_queue, and then send the request in the queue to Rank 0. Because it is synchronous MPI, each node will block and wait for MPI to complete.
- Rank 0 has message_table, which is used to save the request information of other rank. Rank 0 will process the message_ All requests in the table.
- When rank 0 receives requests from all ranks for an op allreduce, it indicates that the tensor is ready in all ranks. It indicates that all nodes have sent communication requests to the tensor, so the tensor needs and can communicate.
- After determining the tensor, the master will send the names and order of tensors that can communicate back to each node.
- Rank 0 node will select all qualified tensor s for MPI communication:
- Unqualified tensor s remain in the message map until the conditions are met.
- When there is a tenor that meets the requirements, Rank 0 will then send a Response to other ranks, indicating that all local gradients of the current OP & Tenor are Ready. You can perform collective operations on this tenor, such as allReduce.
- So far, all nodes have obtained the tensor and order of the upcoming MPI, and the MPI communication can be carried out.
The general logic is as follows:
Rank 0 Rank 1 Rank 2
+ + +
| | |
| | |
| | |
+ Tensor 1 request | |
message_table <---------------------+ |
+ | |
| | |
| | |
v | |
| |
message_table[tensor 1] | |
+ | |
| | |
| Tensor 1 request | |
| <--------------------------------------------+
+ | |
message_table[tensor 1, tensor 1] | |
+ | |
| | |
| Tensor 1 request | |
+-------------------------+ | |
| | | |
| | | |
| <-----------------------+ | |
| | |
v | |
message_table[tensor 1, tensor 1, tensor 1] | |
+ | |
| | |
| | |
| Tensor 1 response | |
+-----------------------------> | |
| | |
| Tensor 1 response | |
+--------------------------------------------> |
| | |
| Tensor 1 response | |
+-------------------------v | |
| | | |
| | | |
| <-----------------------+ | |
| | |
| | |
v v v
2.4 Background Thread
Each rank has two threads, and we usually use hvd. Net in python files Init() to initialize the HV, in fact, a background thread and an MPI thread are opened.
- Execution thread (MPI thread) is used for machine learning calculation.
- Background thread is used for synchronous communication between rank and allreduce operation. When Baidu designed, it had an MPI background thread. Horovod followed this design and its name was BackgroundThreadLoop.
2.4.1 design
About the design thinking, baidu wrote it very clearly in the source code comments (tensorflow allreduce master / tensorflow / contrib / mpi_collections / mpi_ops. CC), which I roughly translated.
MPI background thread is used to coordinate all MPI processes and tensor reduction. This design is based on several considerations:
- Some MPI implementations require that all MPI calls must be in a single thread. Because Tensorflow may use several threads when processing graphs, we must use our own specific threads to process MPI;
- For some errors (such as mismatched types), MPI sometimes does not have a definite way to deal with them, but we also want to deal with them gracefully. In order to achieve elegant processing, MPI processes need to know the shape and type of tensor s on other processes;
- MPI reductions and gathers may be processed in parallel with other operations. Because MPI uses an internal GPU stream separated from TF GPUDevice streams, we cannot explicitly synchronize memcpys or kernels. Therefore, MPIAllreduce and MPIAllgather must be of asyncopckernels type to ensure a reasonable order of memcpys or kernels;
- Note: we cannot ensure that all MPI processes reduce their tensors in the same order. Therefore, there must be a way to ensure that reduction memcpys and kernels can be done across all ranks at the same time. We use rank ID 0 as the coordinator to coordinate those prepared and executable operations (gather and trigger the reduction operations);
Streamline the following:
- Some MPI implementation mechanisms require that all MPI calls must be in a single thread.
- In order to handle errors, MPI processes need to know the shape and type of tensor s on other processes.
- MPIAllreduce and MPIAllgather must be of type asyncopckernels to ensure a reasonable order of memcpys or kernels.
Therefore, a background thread is necessary. horovod_global.message_queue and Horovod_ global. tensor_ All tables are processed in the background thread BackgroundThreadLoop of Horovod.
2.4.2 realization
At the bottom layer, AllReduce is registered as Op, and in ComputeAsync, computing requests are queued to a queue. This queue will be processed by a unified background thread.
During the initialization of this background thread, it will use the shared global state in the process to create some objects and some logical judgments in its own memory. For example, whether to carry out Hierarchical AllReduce, AutoTune, etc. Here is the log of the initialization phase.
During initialization, some important objects will be constructed, such as various controllers.
Next, we will specifically analyze the background thread.
0x03 auxiliary functions
Let's first introduce some auxiliary functions.
3.1 how to judge the coordinator
Because the background thread code is common to all workers, it is necessary to distinguish between rank 0 and other workers to execute different code processes.
Here is used_ Coordinator is used to determine whether it is Rank0.
is_coordinator_ The assignment of is as follows:
void MPIController::DoInitialization() {
......
// Get MPI rank to determine if we are rank zero.
MPI_Comm_rank(mpi_ctx_.mpi_comm, &rank_);
is_coordinator_ = rank_ == 0;
is_coordinator_ An example of how to use is as follows. It can be seen that when synchronizing parameters, the parameters are obtained from rank 0 and then broadcast to other rank, that is, workers:
void Controller::SynchronizeParameters() {
ParameterManager::Params param;
if (is_coordinator_) { // rank 0 performs the operation
param = parameter_manager_.GetParams();
}
void* buffer = (void*)(¶m);
size_t param_size = sizeof(param);
Bcast(buffer, param_size, 0, Communicator::GLOBAL);
if (!is_coordinator_) { // worker execution
parameter_manager_.SetParams(param);
}
}
3.2 coordination cache & Information
In the ComputeResponseList function, the following code will be used to coordinate the cache to sort out the tensor s common to all rank.
CoordinateCacheAndState(cache_coordinator);
Cache is mainly used_ Coordinator operation.
void Controller::CoordinateCacheAndState(CacheCoordinator& cache_coordinator) {
// Sync cache and state information across workers.
cache_coordinator.sync(shared_from_this(), timeline_enabled_);
}
3.2.1 calculation of common tensor
The CoordinateCacheAndState function is as follows:
- Each worker arranges his own bitdirector;
- Use crossrank bitwise and sort out the shared tensor s;
- Sort out the common invalid tensor s using CrossRankBitwiseOr;
void CacheCoordinator::sync(std::shared_ptr<Controller> controller,
bool timeline_enabled) {
// Resize and initialize bit vector.
int nbits = num_active_bits_ + NUM_STATUS_BITS;
int count = (nbits + sizeof(long long) * CHAR_BIT - 1) /
(sizeof(long long) * CHAR_BIT);
......
// Each worker organizes his own bitvector
// For each cache hit on this worker, flip associated bit in bit vector.
for (auto bit : cache_hits_) {
int shifted_bit = bit + NUM_STATUS_BITS;
int shift = shifted_bit / (sizeof(long long) * CHAR_BIT);
bitvector_[shift] |=
(1ull << (shifted_bit % (sizeof(long long) * CHAR_BIT)));
if (timeline_enabled) {
// Set corresponding bit in extended section for timeline if needed.
bitvector_[count + shift] ^=
(1ull << (shifted_bit % (sizeof(long long) * CHAR_BIT)));
}
}
// Sort out the common tensor
// Global AND operation to get intersected bit array.
controller->CrossRankBitwiseAnd(bitvector_, fullcount);
// Search for flipped bits to populate common cache hit set. There will never
// be invalid bits in this set.
cache_hits_.clear();
for (int i = 0; i < count; ++i) {
int shift = i * sizeof(long long) * CHAR_BIT;
long long ll = bitvector_[i];
while (ll) {
int idx = __builtin_ffsll(ll);
int shifted_bit = shift + idx - 1;
cache_hits_.insert(shifted_bit - NUM_STATUS_BITS);
ll &= ~(1ull << (idx - 1));
}
}
......
// If any worker has invalid cache entries, communicate invalid bits across
// workers using a second bit-wise allreduce operation.
if (invalid_in_queue_) {
std::memset(&bitvector_[0], 0, count * sizeof(long long));
for (auto bit : invalid_bits_) {
int shift = bit / (sizeof(long long) * CHAR_BIT);
bitvector_[shift] |= (1ull << (bit % (sizeof(long long) * CHAR_BIT)));
}
// Global OR operation to get common invalid bits.
controller->CrossRankBitwiseOr(bitvector_, count);
// Search for flipped bits to populate common invalid bit set.
invalid_bits_.clear();
for (int i = 0; i < count; ++i) {
int shift = i * sizeof(long long) * CHAR_BIT;
long long ll = bitvector_[i];
while (ll) {
int idx = __builtin_ffsll(ll);
int bit = shift + idx - 1;
invalid_bits_.insert(bit);
ll &= ~(1ull << (idx - 1));
}
}
}
synced_ = true;
}
3.2.2 MPI operation
The function of crossrankbitwise and is to call the bitdirector shared by MPI merging.
void MPIController::CrossRankBitwiseAnd(std::vector<long long>& bitvector,
int count) {
int ret_code = MPI_Allreduce(MPI_IN_PLACE, bitvector.data(), count,
MPI_LONG_LONG_INT, MPI_BAND, mpi_ctx_.mpi_comm);
}
3.3 MPIContext
mpi_context is created when C + + code is loaded, and other contexts (nccl_context, gpu_context) are created, mainly to maintain the necessary environment information and settings for MPI communication on some nodes, such as:
- 3 MPI communicator s, mpi_comm,local_comm,cross_comm is respectively responsible for horovod mpi transmission, intra node transmission and inter node hierarchical transmission (mainly used for hierarchical allreduce).
- mpi_float16_t: horovod is mainly transmitted in float16.
- mpi_float16_sum: the sum operation corresponding to float16.
When horovod uses mpi, it will use the above communicator for data transmission.
3.4 Parameter_manager
Parameter_manager is mainly a manager of GlobalState, which is used to manage some parameters to adjust the performance of horovod. It is initialized with other GlobalState elements in BackgroundThreadLoop, and then it will read the following corresponding environment variables and set them.
-
HOROVOD_FUSION_THRESHOLD: refers to the size of the transmission data slice. The default value is 64M. If the slice is too large, the pipeline cannot be transmitted well during transmission. If it is too small, a tensor needs to be transmitted multiple times to increase the IO overhead.
-
HOROVOD_CYCLE_TIME: refers to the sleep duration of RunLoopOnce, which is 5ms by default. The ideal sleep time should be the time of other logic processing of RunLoopOnce + HOROVOD_CYCLE_TIME is just equal to the time taken for a forward propagation and a backward propagation, because if you sleep too long, the front end will wait for RunLoopOnce to wake up; If you sleep too short, keep running RunLoopOnce, tensor_ There will be no new elements in the queue, just for nothing.
-
HOROVOD_ CACHE_ Capability: refers to the size of the cache, which may be related to the number of model layers.
-
HOROVOD_HIERARCHICAL_ALLGATHER: whether to use layered allgather, etc
Parameter_manager also provides the function of automatically adjusting these parameters. Through Parameter_manager.SetAutoTuning is set. After setting, different parameter combinations will be tried for communication in the initial batch, and then it will converge to a set of optimal parameter values.
0x04 overall code
4.1 background thread
BackgroundThreadLoop is a background thread in the training process. It is mainly responsible for communicating with other nodes and processing the communication request s from the front end. It will poll and call RunLoopOnce to constantly check the tensor_ Are there any tensors in the queue that need communication? If so, update them synchronously with other nodes, and then perform communication operations.
You can see the basic logic in the BackgroundThreadLoop function:
- Determine how to initialize according to the compilation configuration, such as mpi_context.Initialize is initialized only when MPI is compiled.
- Initialize the controller and create the corresponding controller for globalstate according to the loaded collective communication library (mpi or gloo);
- Get various configurations, such as local_rank;
- Set background thread affinity;
- Set GPU stream;
- Set the timeline configuration;
- Set Tensor Fusion threshold, cycle time, response cache capacity, flag for hierarchical allreduce;
- Set auto tuning, chunk size;
- Reset the operation manager;
- Enter the key code RunLoopOnce;
The reduced version code is as follows:
BackgroundThreadLoop(HorovodGlobalState& state) {
......
#if HAVE_MPI
// Initialize mpi context
#if HAVE_DDL
// If DDL is enabled, let DDL ops manage MPI environment.
auto mpi_ctx_manager = DDL_MPIContextManager(ddl_context, gpu_context);
#else
// Otherwise, let MPI ops be in charge.
auto mpi_ctx_manager = MPIContextManager();
#endif
// mpi_context will create MPI threads and some mpiOps according to the information passed from the front end and environment variables
mpi_context.Initialize(state.controller->GetRanks(), mpi_ctx_manager);
#endif
......
// The global of different node s will be synchronized_ size, local_ size, rank, is_ Coordinator and other information
// Initialize controller
state.controller->Initialize();
int local_size = state.controller->GetLocalSize();
int local_rank = state.controller->GetLocalRank();
......
// Set op_manager, which mainly registers ops of different collective communication libraries
op_manager.reset(CreateOperationManager(state));
// Signal that initialization is completed.
state.initialization_done = true;
// Iterate until shutdown.
try {
while (RunLoopOnce(state));
} catch (const std::exception& ex) {
LOG(ERROR) << "Horovod background loop uncaught exception: " << ex.what();
}
}
4.2 where to build a ring
You may have questions. Since Horovod is ring Allreduce, where on earth is the ring established? Let's choose several implementations to have a general look. Because if we study carefully, we need to go deep into MPI, gloo, etc., which is beyond the scope of this article, so we only have a general understanding.
4.2.1 NCCL call
Let's first look at NCCL.
4.2.1.1 NCCL
NCCL is the abbreviation of Nvidia collective multi GPU communication library. It is a collective communication (all gather, reduce, broadcast) library that realizes multi GPU. Nvidia has made many optimizations to achieve high communication speed on PCIe, Nvlink and InfiniBand.
4.2.1.2 Horovod
In NCCLAllreduce::Execute, we can see that ncclAllReduce is called, which is the API of nccl, so we can infer that its parameter * nccl_op_context_.nccl_comm_ Should be the key.
Status NCCLAllreduce::Execute(std::vector<TensorTableEntry>& entries,
const Response& response) {
// Do allreduce.
auto nccl_result = ncclAllReduce(fused_input_data, buffer_data,
(size_t) num_elements,
GetNCCLDataType(first_entry.tensor), ncclSum,
*nccl_op_context_.nccl_comm_, *gpu_op_context_.stream);
}
nccl_op_context_ It is the NCCLOpContext type. The simplified version of NCCLOpContext is defined as follows:
class NCCLOpContext {
public:
void InitNCCLComm(const std::vector<TensorTableEntry>& entries,
const std::vector<int32_t>& nccl_device_map);
ncclComm_t* nccl_comm_;
};
So let's look at the parameter nccl_comm_ You can see how to initialize by calling ncclcominitrank.
void NCCLOpContext::InitNCCLComm(const std::vector<TensorTableEntry>& entries,
const std::vector<int32_t>& nccl_device_map) {
// Ensure NCCL communicator is in the map before executing operation.
ncclComm_t& nccl_comm = nccl_context_->nccl_comms[global_state_->current_nccl_stream][nccl_device_map];
if (nccl_comm == nullptr) {
auto& timeline = global_state_->timeline;
timeline.ActivityStartAll(entries, INIT_NCCL);
int nccl_rank, nccl_size;
Communicator nccl_id_bcast_comm;
// Get rank related information
PopulateNCCLCommStrategy(nccl_rank, nccl_size, nccl_id_bcast_comm);
ncclUniqueId nccl_id;
global_state_->controller->Bcast((void*)&nccl_id, sizeof(nccl_id), 0,
nccl_id_bcast_comm);
ncclComm_t new_nccl_comm;
// Here, nccl is called and rank information is passed
auto nccl_result = ncclCommInitRank(&new_nccl_comm, nccl_size, nccl_id, nccl_rank);
nccl_context_->ErrorCheck("ncclCommInitRank", nccl_result, nccl_comm);
nccl_comm = new_nccl_comm;
// Barrier helps NCCL to synchronize after initialization and avoid
// deadlock that we've been seeing without it.
global_state_->controller->Barrier(Communicator::GLOBAL);
timeline.ActivityEndAll(entries);
}
nccl_comm_ = &nccl_comm;
}
Populatencclccommstrategy is to obtain rank information from the global state.
void NCCLOpContext::PopulateNCCLCommStrategy(int& nccl_rank, int& nccl_size,
Communicator& nccl_id_bcast_comm) {
if (communicator_type_ == Communicator::GLOBAL) {
nccl_rank = global_state_->controller->GetRank();
nccl_size = global_state_->controller->GetSize();
} else if (communicator_type_ == Communicator::LOCAL) {
nccl_rank = global_state_->controller->GetLocalRank();
nccl_size = global_state_->controller->GetLocalSize();
} else {
throw std::logic_error("Communicator type " + std::to_string(communicator_type_) +
" is not supported in NCCL mode.");
}
nccl_id_bcast_comm = communicator_type_;
}
So we have to go to the NCCL source code.
4.2.1.3 In NCCL
In init You can see in CC
NCCL_API(ncclResult_t, ncclCommInitRank, ncclComm_t* newcomm, int nranks, ncclUniqueId commId, int myrank);
ncclResult_t ncclCommInitRank(ncclComm_t* newcomm, int nranks, ncclUniqueId commId, int myrank) {
NVTX3_FUNC_RANGE_IN(nccl_domain);
int cudaDev;
CUDACHECK(cudaGetDevice(&cudaDev));
// Initialization here
NCCLCHECK(ncclCommInitRankDev(newcomm, nranks, commId, myrank, cudaDev));
return ncclSuccess;
}
Continue to look, ncclAsyncInit is called to complete the final initialization, and the total number of rank and myrank of the process itself are passed in.
static ncclResult_t ncclCommInitRankDev(ncclComm_t* newcomm, int nranks, ncclUniqueId commId, int myrank, int cudaDev) {
ncclResult_t res;
char* env = getenv("NCCL_COMM_ID");
NCCLCHECKGOTO(ncclInit(), res, end);
// Make sure the CUDA runtime is initialized.
CUDACHECKGOTO(cudaFree(NULL), res, end);
NCCLCHECKGOTO(PtrCheck(newcomm, "CommInitRank", "newcomm"), res, end);
if (ncclAsyncMode()) {
// ncclAsyncInit is called to complete the final initialization. The total number of rank and myrank of the process itself are passed in
NCCLCHECKGOTO(ncclAsyncInit(ncclCommInitRankSync, newcomm, nranks, commId, myrank, cudaDev), res, end);
} else {
NCCLCHECKGOTO(ncclCommInitRankSync(newcomm, nranks, commId, myrank, cudaDev), res, end);
}
end:
if (ncclAsyncMode()) return ncclAsyncErrCheck(res);
else return res;
}
ncclComm_t is actually the typedef of ncclcomm, so let's take a look at the ncclcomm definition, which includes the total number of rank and the myrank of the process itself.
struct ncclComm {
struct ncclChannel channels[MAXCHANNELS];
...
// Bitmasks for ncclTransportP2pSetup
int connect;
uint32_t* connectSend;
uint32_t* connectRecv;
int rank; // my rank in the communicator
int nRanks; // number of GPUs in communicator
int cudaDev; // my cuda device index
int64_t busId; // my PCI bus ID in int format
int node;
int nNodes;
int localRanks;
// Intra-process sync
int intraRank;
int intraRanks;
int* intraBarrier;
int intraPhase;
....
};
Therefore, we can roughly understand that horovod transmits the rank information, and NCCL will form a ring accordingly.
4.2.2 GLOO
From GlooContext::Initialize, we can see that Horovod sends the rank information to Rendezvous Server through Rendezvous.
Loop assembly will be carried out inside Gloo.
Where, cross_rank is required by hierarchical allreduce.
void GlooContext::Initialize(const std::string& gloo_iface) {
attr device_attr;
device_attr.iface = gloo_iface;
device_attr.ai_family = AF_UNSPEC;
auto dev = CreateDevice(device_attr);
auto timeout = GetTimeoutFromEnv();
auto host_env = std::getenv(HOROVOD_HOSTNAME);
std::string hostname = host_env != nullptr ? std::string(host_env) : std::string("localhost");
int rank = GetIntEnvOrDefault(HOROVOD_RANK, 0);
int size = GetIntEnvOrDefault(HOROVOD_SIZE, 1);
int local_rank = GetIntEnvOrDefault(HOROVOD_LOCAL_RANK, 0);
int local_size = GetIntEnvOrDefault(HOROVOD_LOCAL_SIZE, 1);
int cross_rank = GetIntEnvOrDefault(HOROVOD_CROSS_RANK, 0);
int cross_size = GetIntEnvOrDefault(HOROVOD_CROSS_SIZE, 1);
auto rendezvous_addr_env = std::getenv(HOROVOD_GLOO_RENDEZVOUS_ADDR);
auto rendezvous_port = GetIntEnvOrDefault(HOROVOD_GLOO_RENDEZVOUS_PORT, -1);
bool elastic = GetBoolEnvOrDefault(HOROVOD_ELASTIC, false);
if (elastic && reset_) {
std::string server_addr = rendezvous_addr_env;
std::string scope = HOROVOD_GLOO_GET_RANK_AND_SIZE;
HTTPStore init_store(server_addr, rendezvous_port, scope, rank);
auto key = hostname + ":" + std::to_string(local_rank);
std::vector<char> result = init_store.get(key);
std::string s(result.begin(), result.end());
std::stringstream ss(s);
int last_rank = rank;
int last_size = size;
int last_local_rank = local_rank;
int last_local_size = local_size;
int last_cross_rank = cross_rank;
int last_cross_size = cross_size;
rank = ParseNextInt(ss);
size = ParseNextInt(ss);
local_rank = ParseNextInt(ss);
local_size = ParseNextInt(ss);
cross_rank = ParseNextInt(ss);
cross_size = ParseNextInt(ss);
SetEnv(HOROVOD_RANK, std::to_string(rank).c_str());
SetEnv(HOROVOD_SIZE, std::to_string(size).c_str());
SetEnv(HOROVOD_LOCAL_RANK, std::to_string(local_rank).c_str());
SetEnv(HOROVOD_LOCAL_SIZE, std::to_string(local_size).c_str());
SetEnv(HOROVOD_CROSS_RANK, std::to_string(cross_rank).c_str());
SetEnv(HOROVOD_CROSS_SIZE, std::to_string(cross_size).c_str());
}
// Different rendezvous servers are set
ctx = Rendezvous(HOROVOD_GLOO_GLOBAL_PREFIX,
rendezvous_addr_env, rendezvous_port,
rank, size, dev, timeout);
local_ctx = Rendezvous(HOROVOD_GLOO_LOCAL_PREFIX + hostname,
rendezvous_addr_env, rendezvous_port,
local_rank, local_size, dev, timeout);
cross_ctx = Rendezvous(HOROVOD_GLOO_CROSS_PREFIX + std::to_string(local_rank),
rendezvous_addr_env, rendezvous_port,
cross_rank, cross_size, dev, timeout);
}
4.2.3 MPI
As you can see in MPIContext::Initialize, various ranges will be set here.
void MPIContext::Initialize(const std::vector<int>& ranks,
MPIContextManager& ctx_manager) {
auto mpi_threads_disable = std::getenv(HOROVOD_MPI_THREADS_DISABLE);
int required = MPI_THREAD_MULTIPLE;
if (mpi_threads_disable != nullptr &&
std::strtol(mpi_threads_disable, nullptr, 10) > 0) {
required = MPI_THREAD_SINGLE;
}
int is_mpi_initialized = 0;
MPI_Initialized(&is_mpi_initialized);
if (is_mpi_initialized) {
int provided;
MPI_Query_thread(&provided);
} else {
// MPI environment has not been created, using manager to initialize.
ctx_manager.EnvInitialize(required);
should_finalize = true;
}
if (!ranks.empty()) {
MPI_Group world_group;
MPI_Comm_group(MPI_COMM_WORLD, &world_group);
MPI_Group work_group;
MPI_Group_incl(world_group, ranks.size(), ranks.data(), &work_group);
MPI_Comm_create_group(MPI_COMM_WORLD, work_group, 0, &(mpi_comm));
if (mpi_comm == MPI_COMM_NULL) {
mpi_comm = MPI_COMM_WORLD;
}
MPI_Group_free(&world_group);
MPI_Group_free(&work_group);
} else if (!mpi_comm) {
// No ranks were given and no communicator provided to horovod_init() so use
// MPI_COMM_WORLD
MPI_Comm_dup(MPI_COMM_WORLD, &mpi_comm);
}
// Create local comm, Determine local rank by querying the local communicator.
MPI_Comm_split_type(mpi_comm, MPI_COMM_TYPE_SHARED, 0, MPI_INFO_NULL,
&local_comm);
// Get local rank and world rank for cross comm establishment.
int local_rank, world_rank;
MPI_Comm_rank(mpi_comm, &world_rank);
MPI_Comm_rank(local_comm, &local_rank);
// Create cross node communicator.
MPI_Comm_split(mpi_comm, local_rank, world_rank, &cross_comm);
// Create custom MPI float16 data type.
MPI_Type_contiguous(2, MPI_BYTE, &mpi_float16_t);
MPI_Type_commit(&mpi_float16_t);
// Create custom MPI float16 summation op.
MPI_Op_create(&float16_sum, 1, &mpi_float16_sum);
}
0x05 business logic
Let's look at the business logic.
5.1 overall business of runlooponce
RunLoopOnce is responsible for the overall business logic, and its functions are as follows:
-
Calculate whether sleep is still required, that is, check whether it has been more than one cycle since the last cycle;
-
Use ComputeResponseList to coordinate rank 0 with the worker, obtain the Request and calculate the response;
rank 0 will traverse the response_list, and perform operations one by one for the response.
response_list is processed by rank 0, and response cache is processed by other rank.
-
Use PerformOperation to perform collective operations for each response
-
If auto tune is required, synchronize the parameters;
We can see that Horovod's workflow is roughly as mentioned before, which is a model of producers and consumers. The controller does coordination work here: it will communicate which requests of each rank are ready, and execute collective operations for the ready requests.
The reduced version code is as follows:
bool RunLoopOnce(HorovodGlobalState& state) {
// This delay determines thread frequency and communication message latency
.....
// Ask rank 0 to coordinate with the worker, obtain the Request and calculate the response
auto response_list =
state.controller->ComputeResponseList(horovod_global.shut_down, state);
// Get tensor name and size data for autotuning.
.....
// Perform the collective operation. All nodes should end up performing
// the same operation.
// For each response, perform a collective operation
int rank = state.controller->GetRank();
for (auto& response : response_list.responses()) {
PerformOperation(response, horovod_global);
}
// If auto tune is required, synchronize the parameters
if (state.parameter_manager.IsAutoTuning()) {
bool should_sync =
state.parameter_manager.Update(tensor_names, total_tensor_size);
if (should_sync) {
state.controller->SynchronizeParameters();
}
}
return !response_list.shutdown();
}
The process is as follows:
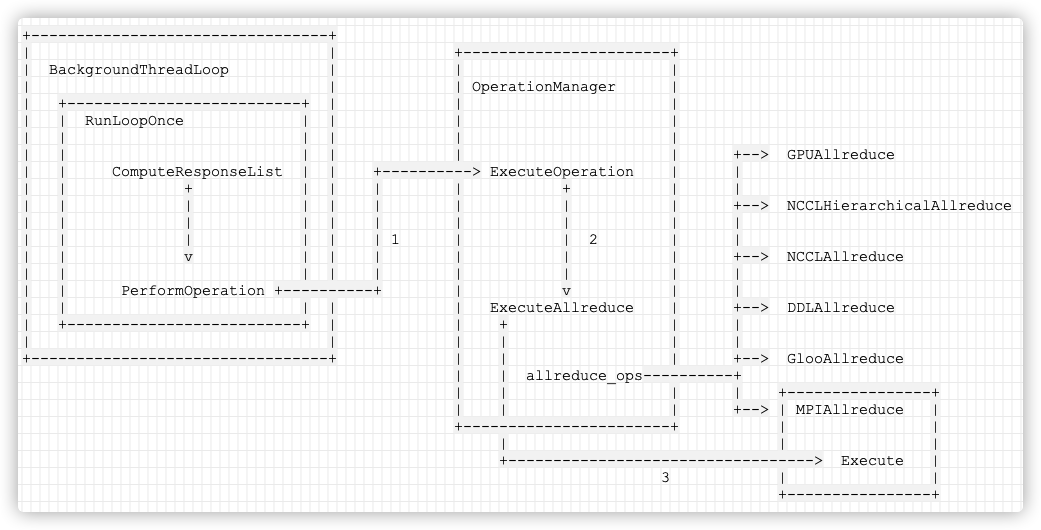
+---------------------------------+ | | +-----------------------------+ | BackgroundThreadLoop | | | | | | OperationManager | | +--------------------------+ | | | | | RunLoopOnce | | | | | | | | | | | | | | | | | | ComputeResponseList | | +----------> ExecuteOperation | | | + | | | | | | | | | | | | | | | | | | | | | | | | | | | 1 | | | | v | | | | | | | | | | | | | | PerformOperation +----------+ | | | | | | | | | +--------------------------+ | | | | | | | +---------------------------------+ +-----------------------------+
5.2 ComputeResponseList calculate response
In the background thread, the most important function call is ComputeResponseList. ComputeResponseList implements the coordination process, that is, to coordinate rank 0 with the worker, obtain the Request and calculate the response.
Horovod also follows the design of Coordinator, which is similar to Baidu. The Coordinator in both Baidu and horovod is similar to the Actor mode, which mainly coordinates the work of multiple processes. Horovod also introduces a new abstraction when it comes to computing_ manager. To some extent, we can regard controller as an abstraction of communication and coordination management capabilities, rather than op_manager is an abstraction of actual computing.
5.2.1 general idea
The function of Controller::ComputeResponseList is: the worker sends a request to rank 0, then the coordinator processes the requests of all workers, finds the ready ones, merges them, and finally sends the results to other ranks:
- Use PopMessagesFromQueue to take all the current requests from the tensor queue of the GlobalState of your own process for processing. The cache is used for specific processing, and then it is cached to message through a series of processing_ queue_ TMP;
- Synchronize cache information with each other to get the response list stored by each worker;
- Judge whether further synchronization is needed, such as whether all response s are in the cache;
- If synchronization is not required, then
- It indicates that all messages in the queue are in the cache and no other coordination is required. Therefore, the cached response is directly fused and put into the response_list, the next round of time slice will continue to be processed;
- If synchronization is required, then
-
If it's rank 0,
- Because rank 0 will also participate in machine learning training, it is necessary to add the Request of rank 0 to the message table. Accept requests from other rank and add requests from other rank to message_table_ in Here the synchronization is blocked.
- Rank 0 uses recvreadytensers to accept requests from other ranks and adds requests from other ranks to ready_to_reduce. Here synchronization is blocked. The coordinator will continue to receive this information until the number of Done is equal to global_size.
- Then traverse rank 0+1 ~ rank n, and process the response of each rank one by one;
- Finally, the message table has all the lists that can be reduce d. The sources of responses are the following three parts:
- Source 1, response_cache_ in rank 0;
- Source 2, process ready one by one_ to_ reduce;
- Source 3, join_response
- Fuse the tensors with FuseResponses: merge some tensors into a large tensor, and then do the collective operation.
- The coordinator will find all tensors ready for reduce and return a response to all worker s through sendfinal tensors (response_list). If the information is misunderstood, an error will be returned and a Done will be sent after sending.
-
In case of other rank:
- When the worker reaches the front end_ When you use the sentence "reduce", you will use message_queue_tmp is organized into a message_list sends a Request to the primary node (coordinator, Rank 0) through the sendreadytensers function, indicating that I intend to reduce the Request, and then sends the tensor information ready for reduce through message_ The list is sent iteratively. Finally, there is a Done Request, and then the synchronization is blocked.
- The Worker uses RecvFinalTensors(response_list) to listen for the response information, receives the ready response list from Rank 0, and blocks synchronization. When receiving Done, it will try to call performance to reduce.
-
Both the coordinator and the worker will organize the synchronized information into an array of responses to the subsequent PerformOperation operation.
-
Here's how mpi is implemented, that is, the coordinator and the corresponding worker will block to the same instruction:
- Sendreadytensers and recvreadytensers block to MPI_Gather;
- SendFinalTensors and RecvFinalTensors to MPI_Bcast ;
It can be distinguished as follows: if the coordinator sends it, it is MPI_Bcast, if the worker sends MPI_Gather. For communication, first synchronize the size length of the message to be communicated, and then synchronize the message.
See the following figure for details:
+
|
ComputeResponseList in rank 0 | ComputeResponseList in worker(rank n)
|
|
message_queue_tmp | message_queue_tmp
|
+ | +
| | |
|PopMessagesFromQueue | | PopMessagesFromQueue
| | |
| | |
| CoordinateCacheAndState |
| | |
| <--------------------------------> |
| | |
v | v
|
RecvReadyTensors(ready_to_reduce, ready_list) <-------------> SendReadyTensors(message_list)
+ | +
| | |
| | |
| | |
| | |
v | |
message_table_ | |
+ | |
| | |
| | |
v | |
FuseResponses | |
+ | |
| | |
| | |
v | v
SendFinalTensors(response_list) <----------------> RecvFinalTensors(response_list)
+ | +
| | |
| | |
| | |
v | v
PerformOperation | PerformOperation
|
+
The mobile phone is shown in the figure:

5.2.2 detailed analysis
The following is a more detailed analysis, with reference to the online materials, I have also made an interpretation.
ResponseList Controller::ComputeResponseList(std::atomic_bool& shut_down,
HorovodGlobalState& state) {
// Update cache capacity if autotuning is active.
if (parameter_manager_.IsAutoTuning()) {
response_cache_.set_capacity((int)parameter_manager_.CacheEnabled() *
cache_capacity_);
}
// Copy the data structures out from parameters.
// However, don't keep the lock for the rest of the loop, so that
// enqueued stream callbacks can continue.
CacheCoordinator cache_coordinator(response_cache_.num_active_bits());
// Take out the current requests from tensor queue and process them
// message queue used only in this cycle
std::deque<Request> message_queue_tmp;
tensor_queue_.PopMessagesFromQueue(message_queue_tmp);
for (auto& message : message_queue_tmp) {
if (message.request_type() == Request::JOIN) {
state.joined = true;
// set_ uncached_ in_ The queue record has no cache
cache_coordinator.set_uncached_in_queue(true);
continue;
}
// Cache is used here to cache how many response s the rank has received.
// Keep track of cache hits
if (response_cache_.capacity() > 0) {
// You need to see if the tensor has received the corresponding response. Why cache? After all are ready, all reduce is performed immediately.
// The cached function is complex. It depends not only on whether the new tensor has been cached, but also on whether the parameters of the new tensor are consistent with those of the cached tensor with the same name, such as device, dtype, shape, etc. If inconsistent, the cache is identified as INVALID. Will these change in deep learning training?
auto cache_ = response_cache_.cached(message);
if (cache_ == ResponseCache::CacheState::HIT) {
uint32_t cache_bit = response_cache_.peek_cache_bit(message);
cache_coordinator.record_hit(cache_bit);
// Record initial time cached tensor is encountered in queue.
stall_inspector_.RecordCachedTensorStart(message.tensor_name());
} else {
// If there is no cache
if (cache_ == ResponseCache::CacheState::INVALID) {
// Processing invalid cache records
uint32_t cache_bit = response_cache_.peek_cache_bit(message);
cache_coordinator.record_invalid_bit(cache_bit);
}
// If there is no cache, it is added to set_uncached_in_queue
cache_coordinator.set_uncached_in_queue(true);
// Remove from stall
// Remove timing entry if uncached or marked invalid.
stall_inspector_.RemoveCachedTensor(message.tensor_name());
}
}
}
if (state.joined && response_cache_.capacity() > 0) {
for (uint32_t bit : response_cache_.list_all_bits()) {
cache_coordinator.record_hit(bit);
}
}
// Flag indicating that the background thread should shut down.
bool should_shut_down = shut_down;
// Handling stalled
// Check for stalled tensors.
if (stall_inspector_.ShouldPerformCheck()) {
if (is_coordinator_) {
should_shut_down |= stall_inspector_.CheckForStalledTensors(size_);
}
if (response_cache_.capacity() > 0) {
stall_inspector_.InvalidateStalledCachedTensors(cache_coordinator);
}
stall_inspector_.UpdateCheckTime();
}
cache_coordinator.set_should_shut_down(should_shut_down);
if (response_cache_.capacity() > 0) {
// Why synchronize cache information with each other?
// Obtain common cache hits and cache invalidations across workers. Also,
// determine if any worker has uncached messages in queue or requests
// a shutdown. This function removes any invalid cache entries, if they
// exist.
// Synchronization will be performed here, and the response will be sent from the_ cache_ Remove invalid from.
// The purpose is to get the response list stored by each worker
CoordinateCacheAndState(cache_coordinator);
// Remove uncommon cached tensors from queue and replace to state
// queue for next cycle. Skip adding common cached tensors to
// queue as they are handled separately.
// Cache at this time_ The coordinator is already a response list shared by all worker s. You need to remove those responses that are not in the common response list.
// Why do some worker s have no response?
// We will check whether there is a cache in the tensor request messages, and then update the tensor accordingly_ queue_.
std::deque<Request> messages_to_replace;
size_t num_messages = message_queue_tmp.size();
for (size_t i = 0; i < num_messages; ++i) {
auto& message = message_queue_tmp.front();
if (response_cache_.cached(message) == ResponseCache::CacheState::HIT) {
uint32_t cache_bit = response_cache_.peek_cache_bit(message);
if (cache_coordinator.cache_hits().find(cache_bit) ==
cache_coordinator.cache_hits().end()) {
// Try to process again in next cycle.
messages_to_replace.push_back(std::move(message));
} else {
// Remove timing entry for messages being handled this cycle.
stall_inspector_.RemoveCachedTensor(message.tensor_name());
}
} else {
// Remove timing entry for messages being handled this cycle.
stall_inspector_.RemoveCachedTensor(message.tensor_name());
message_queue_tmp.push_back(std::move(message));
}
message_queue_tmp.pop_front();
}
tensor_queue_.PushMessagesToQueue(messages_to_replace);
}
// End of response_cache_.capacity()
ResponseList response_list;
response_list.set_shutdown(cache_coordinator.should_shut_down());
bool need_communication = true;
// Judge whether further synchronization is needed. For example, the response is all in the cache.
if (response_cache_.capacity() > 0 &&
!cache_coordinator.uncached_in_queue()) {
// if cache is enabled and no uncached new message coming in, no need for
// additional communications
need_communication = false;
// If no messages to send, we can simply return an empty response list;
if (cache_coordinator.cache_hits().empty()) {
return response_list;
}
// otherwise we need to add cached messages to response list.
}
if (!need_communication) {
// All messages in the queue are cached and no other coordination is required. Therefore, the cached response is directly fused and put into the response_list
// If all messages in queue have responses in cache, use fast path with
// no additional coordination.
// If group fusion is disabled, fuse tensors in groups separately
if (state.disable_group_fusion && !group_table_.empty()) {
// Note: need group order to be based on position in cache for global consistency
std::vector<int> common_ready_groups;
std::unordered_set<int> processed;
for (auto bit : cache_coordinator.cache_hits()) {
const auto& tensor_name = response_cache_.peek_response(bit).tensor_names()[0];
int group_id = group_table_.GetGroupIDFromTensorName(tensor_name);
if (group_id != NULL_GROUP_ID && processed.find(group_id) == processed.end()) {
common_ready_groups.push_back(group_id);
processed.insert(group_id);
}
}
for (auto id : common_ready_groups) {
std::deque<Response> responses;
for (const auto &tensor_name : group_table_.GetGroupTensorNames(id)) {
auto bit = response_cache_.peek_cache_bit(tensor_name);
responses.push_back(response_cache_.get_response(bit));
// Erase cache hit to avoid processing a second time.
cache_coordinator.erase_hit(bit);
}
FuseResponses(responses, state, response_list);
}
}
std::deque<Response> responses;
// Convert cache hits to responses. Populate so that least
// recently used responses get priority. All workers call the code
// here so we use the get method here to consistently update the cache
// order.
for (auto bit : cache_coordinator.cache_hits()) {
responses.push_back(response_cache_.get_response(bit));
}
// Fuse responses as normal.
FuseResponses(responses, state, response_list);
response_list.set_shutdown(cache_coordinator.should_shut_down());
} else {
// If there are any cached messages entering, you need to find out whether these can be reduce d.
// There are uncached messages coming in, need communication to figure out
// whether those are ready to be reduced.
// Collect all tensors that are ready to be reduced. Record them in the
// tensor count table (rank zero) or send them to rank zero to be
// recorded (everyone else).
std::vector<std::string> ready_to_reduce;
if (is_coordinator_) {
// My name is rank 0. For the master process, I record the tensor that has been ready.
// Rank 0 will also participate in machine learning training, so you need to add the request of rank 0 to the message table.
while (!message_queue_tmp.empty()) { // Note the message at this time_ queue_ The request in TMP is from the master process
// Pop the first available message
Request message = message_queue_tmp.front();
message_queue_tmp.pop_front();
if (message.request_type() == Request::JOIN) {
state.joined_size++;
continue;
}
bool reduce = IncrementTensorCount(message, state.joined_size);
stall_inspector_.RecordUncachedTensorStart(
message.tensor_name(), message.request_rank(), size_);
if (reduce) {
ready_to_reduce.push_back(message.tensor_name());
}
}
// Accept requests from other rank and add ready requests from other rank to message_table_ in
// Here the synchronization is blocked
// Receive ready tensors from other ranks
std::vector<RequestList> ready_list;
RecvReadyTensors(ready_to_reduce, ready_list);
// Process all rank requests.
// Process messages.
// Traverse rank 0+1 ~ rank n, and process the response of each rank one by one
for (int i = 1; i < size_; ++i) { // size_ How many rank are there
// response list of each rank.
auto received_message_list = ready_list[i];
for (auto& received_message : received_message_list.requests()) {
auto& received_name = received_message.tensor_name();
// Join type messages refer to new rank joining, and Horovod supports elasticity
if (received_message.request_type() == Request::JOIN) {
state.joined_size++; // Increase the number of ranks that have been ready for the tensor. If all ranks are ready, send them to other ranks
continue;
}
bool reduce = IncrementTensorCount(received_message, state.joined_size);
stall_inspector_.RecordUncachedTensorStart(
received_message.tensor_name(), received_message.request_rank(),
size_);
// If the maximum value has been reached, you can reduce and add it to ready_to_reduce.
if (reduce) {
ready_to_reduce.push_back(received_name);
}
}
if (received_message_list.shutdown()) {
// Received SHUTDOWN request from one of the workers.
should_shut_down = true;
}
}
// Check if tensors from previous ticks are ready to reduce after Joins.
// Traverse message_table_, The purpose is to see if the response processed in the last round can be reduce d in this round
if (state.joined_size > 0) {
for (auto& table_iter : message_table_) {
int count = (int)table_iter.second.size();
if (count == (size_ - state.joined_size) &&
std::find(ready_to_reduce.begin(), ready_to_reduce.end(),
table_iter.first) == ready_to_reduce.end()) {
state.timeline.NegotiateEnd(table_iter.first);
ready_to_reduce.push_back(table_iter.first);
}
}
}
// Fuse tensors in groups before processing others.
if (state.disable_group_fusion && !group_table_.empty()) {
// Extract set of common groups from coordinator tensor list and cache hits.
std::vector<int> common_ready_groups;
std::unordered_set<int> processed;
for (const auto& tensor_name : ready_to_reduce) {
int group_id = group_table_.GetGroupIDFromTensorName(tensor_name);
if (group_id != NULL_GROUP_ID && processed.find(group_id) == processed.end()) {
common_ready_groups.push_back(group_id);
processed.insert(group_id);
// Leaving name in list, to be skipped later.
}
}
if (response_cache_.capacity() > 0) {
for (auto bit : cache_coordinator.cache_hits()) {
const auto& tensor_name = response_cache_.peek_response(bit).tensor_names()[0];
int group_id = group_table_.GetGroupIDFromTensorName(tensor_name);
if (group_id != NULL_GROUP_ID && processed.find(group_id) == processed.end()) {
common_ready_groups.push_back(group_id);
processed.insert(group_id);
}
}
}
// For each ready group, form and fuse response lists independently
for (auto id : common_ready_groups) {
std::deque<Response> responses;
for (const auto &tensor_name : group_table_.GetGroupTensorNames(id)) {
if (message_table_.find(tensor_name) != message_table_.end()) {
// Uncached message
Response response = ConstructResponse(tensor_name, state.joined_size);
responses.push_back(std::move(response));
} else {
// Cached message
auto bit = response_cache_.peek_cache_bit(tensor_name);
responses.push_back(response_cache_.get_response(bit));
// Erase cache hit to avoid processing a second time.
cache_coordinator.erase_hit(bit);
}
}
FuseResponses(responses, state, response_list);
}
}
// At this point, the message table has all the lists that can be reduce d
// At this point, rank zero should have a fully updated tensor count
// table and should know all the tensors that need to be reduced or
// gathered, and everyone else should have sent all their information
// to rank zero. We can now do reductions and gathers; rank zero will
// choose which ones and in what order, and will notify the other ranks
// before doing each reduction.
std::deque<Response> responses;
// The sources of responses are the following three parts
// Source 1, response_cache_ in rank 0
if (response_cache_.capacity() > 0) {
// Prepopulate response list with cached responses. Populate so that
// least recently used responses get priority. Since only the
// coordinator rank calls this code, use peek instead of get here to
// preserve cache order across workers.
// No need to do this when all ranks did Join.
if (state.joined_size < size_) {
for (auto bit : cache_coordinator.cache_hits()) {
responses.push_back(response_cache_.peek_response(bit));
}
}
}
// Source 2, process ready one by one_ to_ reduce
for (auto& tensor_name : ready_to_reduce) {
// Skip tensors in group that were handled earlier.
if (state.disable_group_fusion &&
!group_table_.empty() &&
group_table_.GetGroupIDFromTensorName(tensor_name) != NULL_GROUP_ID) {
continue;
}
Response response = ConstructResponse(tensor_name, state.joined_size);
responses.push_back(std::move(response));
}
// Source 3, join_response
if (state.joined_size == size_) {
// All ranks did Join(). Send the response, reset joined size.
Response join_response;
join_response.set_response_type(Response::JOIN);
join_response.add_tensor_name(JOIN_TENSOR_NAME);
responses.push_back(std::move(join_response));
state.joined_size = 0;
}
// Fusion
FuseResponses(responses, state, response_list);
response_list.set_shutdown(should_shut_down);
// Broadcast final results to other ranks.
SendFinalTensors(response_list);
} else {
// If I am another rank and not a master, I will send my ready tensors to the master and then receive the list of ready tensors
RequestList message_list;
message_list.set_shutdown(should_shut_down);
while (!message_queue_tmp.empty()) {
message_list.add_request(message_queue_tmp.front());
message_queue_tmp.pop_front();
}
// Send Request to Rank 0, synchronization blocked
// Send ready tensors to rank zero
SendReadyTensors(message_list);
// Accept the ready response list from Rank 0, and the synchronization is blocked
// Receive final tensors to be processed from rank zero
RecvFinalTensors(response_list);
}
}
if (!response_list.responses().empty()) {
std::string tensors_ready;
for (const auto& r : response_list.responses()) {
tensors_ready += r.tensor_names_string() + "; ";
}
}
// If need_communication is false, meaning no uncached message coming in,
// thus no need to update cache.
if (need_communication && response_cache_.capacity() > 0) {
// All workers add supported responses to cache. This updates the cache
// order consistently across workers.
for (auto& response : response_list.responses()) {
if ((response.response_type() == Response::ResponseType::ALLREDUCE ||
response.response_type() == Response::ResponseType::ADASUM ||
response.response_type() == Response::ResponseType::ALLTOALL) &&
(int)response.devices().size() == size_) {
response_cache_.put(response, tensor_queue_, state.joined);
}
}
}
// Reassign cache bits based on current cache order.
response_cache_.update_cache_bits();
return response_list;
}
Let's focus on a few functions.
5.2.3 IncrementTensorCount
IncrementTensorCount is used to calculate whether all tensors are ready.
If bool ready_to_reduce = count == (size_ - joined_size), you will know that this can be allreduce.
bool Controller::IncrementTensorCount(const Request& msg, int joined_size) {
auto& name = msg.tensor_name();
auto table_iter = message_table_.find(name);
if (table_iter == message_table_.end()) {
std::vector<Request> messages = {msg};
messages.reserve(static_cast<unsigned long>(size_));
message_table_.emplace(name, std::move(messages));
table_iter = message_table_.find(name);
} else {
std::vector<Request>& messages = table_iter->second;
messages.push_back(msg);
}
std::vector<Request>& messages = table_iter->second;
int count = (int)messages.size();
bool ready_to_reduce = count == (size_ - joined_size); // Determine whether you can allreduce
return ready_to_reduce;
}
The specific call is rank 0 to see if it is allreduce.
That is, if IncrementTensorCount is, it indicates that it is complete. You can add the Request to the message_table_ in
if (is_coordinator_) {
while (!message_queue_tmp.empty()) {
// Pop the first available message
Request message = message_queue_tmp.front();
message_queue_tmp.pop_front();
if (message.request_type() == Request::JOIN) {
state.joined_size++;
continue;
}
// Call here
bool reduce = IncrementTensorCount(message, state.joined_size);
stall_inspector_.RecordUncachedTensorStart(
message.tensor_name(), message.request_rank(), size_);
if (reduce) {
ready_to_reduce.push_back(message.tensor_name());
}
}
5.2.4 RecvReadyTensors
This function is used to collect requests from other rank.
- Use MPI_Gather determines the message length;
- Use MPI_Gatherv collects messages;
- Because rank 0 has been processed, rank 0 is not processed here;
void MPIController::RecvReadyTensors(std::vector<std::string>& ready_to_reduce,
std::vector<RequestList>& ready_list) {
// Rank zero has put all its own tensors in the tensor count table.
// Now, it should count all the tensors that are coming from other
// ranks at this tick.
// 1. Get message lengths from every rank.
auto recvcounts = new int[size_];
recvcounts[0] = 0;
MPI_Gather(MPI_IN_PLACE, 1, MPI_INT, recvcounts, 1, MPI_INT, RANK_ZERO,
mpi_ctx_.mpi_comm);
// 2. Compute displacements.
auto displcmnts = new int[size_];
size_t total_size = 0;
for (int i = 0; i < size_; ++i) {
if (i == 0) {
displcmnts[i] = 0;
} else {
displcmnts[i] = recvcounts[i - 1] + displcmnts[i - 1];
}
total_size += recvcounts[i];
}
// 3. Collect messages from every rank.
auto buffer = new uint8_t[total_size];
MPI_Gatherv(nullptr, 0, MPI_BYTE, buffer, recvcounts, displcmnts, MPI_BYTE,
RANK_ZERO, mpi_ctx_.mpi_comm);
// 4. Process messages.
// create a dummy list for rank 0
ready_list.emplace_back();
for (int i = 1; i < size_; ++i) {
auto rank_buffer_ptr = buffer + displcmnts[i];
RequestList received_message_list;
RequestList::ParseFromBytes(received_message_list, rank_buffer_ptr);
ready_list.push_back(std::move(received_message_list));
}
// 5. Free buffers.
delete[] recvcounts;
delete[] displcmnts;
delete[] buffer;
}
5.2.5 SendReadyTensors
This function synchronizes requests from other rank to rank 0.
- Use MPI_Gather determines the message length;
- Use MPI_Gatherv collects messages;
void MPIController::SendReadyTensors(RequestList& message_list) {
std::string encoded_message;
RequestList::SerializeToString(message_list, encoded_message);
int encoded_message_length = (int)encoded_message.length() + 1;
int ret_code = MPI_Gather(&encoded_message_length, 1, MPI_INT, nullptr, 1,
MPI_INT, RANK_ZERO, mpi_ctx_.mpi_comm);
ret_code = MPI_Gatherv((void*)encoded_message.c_str(), encoded_message_length,
MPI_BYTE, nullptr, nullptr, nullptr, MPI_BYTE,
RANK_ZERO, mpi_ctx_.mpi_comm);
}
5.2.6 SendFinalTensors
This function is used for rank 0 to send the final result to other rank;
void MPIController::SendFinalTensors(ResponseList& response_list) {
// Notify all nodes which tensors we'd like to reduce at this step.
std::string encoded_response;
ResponseList::SerializeToString(response_list, encoded_response);
int encoded_response_length = (int)encoded_response.length() + 1;
MPI_Bcast(&encoded_response_length, 1, MPI_INT, RANK_ZERO, mpi_ctx_.mpi_comm);
MPI_Bcast((void*)encoded_response.c_str(), encoded_response_length, MPI_BYTE,
RANK_ZERO, mpi_ctx_.mpi_comm);
}
5.2.7 RecvFinalTensors
This function is used to receive the ready response list from Rank 0 to synchronize blocking
void MPIController::RecvFinalTensors(ResponseList& response_list) {
int msg_length;
int ret_code =
MPI_Bcast(&msg_length, 1, MPI_INT, RANK_ZERO, mpi_ctx_.mpi_comm);
auto buffer = new uint8_t[msg_length];
ret_code =
MPI_Bcast(buffer, msg_length, MPI_BYTE, RANK_ZERO, mpi_ctx_.mpi_comm);
ResponseList::ParseFromBytes(response_list, buffer);
delete[] buffer;
}
5.3 perform the operation according to the response
Next, we'll look at another important operation PerformOperation, which is to perform operations according to the response.
The calling sequence is:
- BackgroundThreadLoop calls RunLoopOnce;
- RunLoopOnce if it is rank 0, process the response_list, then call PerformOperation;
- PerformOperation in turn calls Op_ manager -> ExecuteOperation------ ExecuteAllreduce;
We can see that ComputeResponseList returns a response_list is the tensor corresponding to these responses. You can do allreduce. Then, each response will be traversed to perform operation.
auto response_list =
state.controller->ComputeResponseList(horovod_global.shut_down, state);
int rank = state.controller->GetRank();
for (auto& response : response_list.responses()) {
PerformOperation(response, horovod_global);
}
5.3.1 PerformOperation
Continue to run RunLoopOnce from the ComputeResponseList, and the worker node will respond according to the response returned by the previous ComputeResponseList_ List calls PerformOperation for each response poll to complete the corresponding reduce work.
Main call status = op_ manager->ExecuteOperation(entries, response); The details are as follows:
-
PerformOperation will start from horovod_global.tensor_queue retrieves the corresponding TensorEntry through the function GetTensorEntriesFromResponse;
-
If the buffer has not been initialized, call horovod_global.fusion_buffer.InitializeBuffer initialization;
-
Then status = op_ Manager - > executeoperation (entries, response) will call different op - > execute (entries, response) to perform the reduce operation;
-
Then calling the callback of different entries, callback is usually front-end corresponding operation.
// Process a Response by doing a reduction, a gather, a broadcast, or
// raising an error.
void PerformOperation(Response response, HorovodGlobalState& state) {
std::vector<TensorTableEntry> entries;
auto& timeline = horovod_global.timeline;
if (response.response_type() != Response::JOIN) {
horovod_global.tensor_queue.GetTensorEntriesFromResponse(response, entries,
state.joined);
if (entries.size() > 1) { // If there are more than one, fuse can be performed to improve throughput
auto first_entry = entries[0];
Status status = horovod_global.fusion_buffer.InitializeBuffer(
horovod_global.controller->TensorFusionThresholdBytes(),
first_entry.device, first_entry.context,
horovod_global.current_nccl_stream,
[&]() { timeline.ActivityStartAll(entries, INIT_FUSION_BUFFER); },
[&]() { timeline.ActivityEndAll(entries); });
if (!status.ok()) {
for (auto& e : entries) {
timeline.End(e.tensor_name, nullptr);
// Callback can be null if the rank sent Join request.
if (e.callback != nullptr) {
e.callback(status);
}
}
return;
}
}
// On GPU data readiness is signalled by ready_event.
// Even if the tensor can operate, you need to wait for the data to be synchronized to the video memory
std::vector<TensorTableEntry> waiting_tensors;
for (auto& e : entries) {
if (e.ready_event != nullptr) {
timeline.ActivityStart(e.tensor_name, WAIT_FOR_DATA);
waiting_tensors.push_back(e);
}
}
while (!waiting_tensors.empty()) {
for (auto it = waiting_tensors.begin(); it != waiting_tensors.end();) {
if (it->ready_event->Ready()) {
timeline.ActivityEnd(it->tensor_name);
timeline.ActivityStart(it->tensor_name, WAIT_FOR_OTHER_TENSOR_DATA);
it = waiting_tensors.erase(it);
} else {
++it;
}
}
std::this_thread::sleep_for(std::chrono::nanoseconds(100));
}
}
Status status;
try {
// Perform a collective operation
status = op_manager->ExecuteOperation(entries, response);
} catch (const std::exception& ex) {
status = Status::UnknownError(ex.what());
}
... // Call the callback function
}
5.3.2 ExecuteOperation
Then status = op_ Manager - > executeoperation (entries, response) will call different op - > execute (entries, response) to perform the reduce operation.
Here comes operation manager.
Status OperationManager::ExecuteOperation(std::vector<TensorTableEntry>& entries,
const Response& response) const {
if (response.response_type() == Response::ALLREDUCE) {
return ExecuteAllreduce(entries, response);
} else if (response.response_type() == Response::ALLGATHER) {
return ExecuteAllgather(entries, response);
} else if (response.response_type() == Response::BROADCAST) {
return ExecuteBroadcast(entries, response);
} else if (response.response_type() == Response::ALLTOALL) {
return ExecuteAlltoall(entries, response);
} else if (response.response_type() == Response::JOIN) {
return ExecuteJoin(entries, response);
} else if (response.response_type() == Response::ADASUM) {
return ExecuteAdasum(entries, response);
} else if (response.response_type() == Response::ERROR) {
return ExecuteError(entries, response);
} else {
throw std::logic_error("No operation found for response type provided");
}
}
5.3.3 ExecuteAllreduce
op->Execute(entries, response); It calls mpiallreduce Execute.
Status OperationManager::ExecuteAllreduce(std::vector<TensorTableEntry>& entries,
const Response& response) const {
for (auto& op : allreduce_ops_) {
if (op->Enabled(*param_manager_, entries, response)) {
return op->Execute(entries, response);
}
}
}
allreduce_ops_ Where did it come from? There are in the operation manager build function.
allreduce_ops_(std::move(allreduce_ops)),
So let's look at allreduce_ops.
5.3.4 allreduce_ops
Allreduce in CreateOperationManager_ OPS to add.
You can see that the types added are roughly as follows:
- MPI_GPUAllreduce
- NCCLHierarchicalAllreduce
- NCCLAllreduce
- DDLAllreduce
- GlooAllreduce
- CCLAllreduce
- MPIAllreduce
- ...
OperationManager* CreateOperationManager(HorovodGlobalState& state) {
// Order of these operations is very important. Operations will be checked
// sequentially from the first to the last. The first 'Enabled' operation will
// be executed.
std::vector<std::shared_ptr<AllreduceOp>> allreduce_ops;
std::vector<std::shared_ptr<AllgatherOp>> allgather_ops;
std::vector<std::shared_ptr<BroadcastOp>> broadcast_ops;
std::vector<std::shared_ptr<AllreduceOp>> adasum_ops;
std::vector<std::shared_ptr<AlltoallOp>> alltoall_ops;
#if HAVE_ MPI && HAVE_ GPU / / if MPI is built, add the corresponding MPI_GPUAllreduce
if (mpi_context.IsEnabled()) {
#if HOROVOD_GPU_ALLREDUCE == 'M'
allreduce_ops.push_back(std::shared_ptr<AllreduceOp>(
new MPI_GPUAllreduce(&mpi_context, &gpu_context, &state)));
#elif HAVE_ NCCL && HOROVOD_ GPU_ Allreduce = ='n '/ / if nccl is compiled, add adasumgpualreduceop
adasum_ops.push_back(std::shared_ptr<AllreduceOp>(new AdasumGpuAllreduceOp(&mpi_context, &nccl_context, &gpu_context, &state)));
allreduce_ops.push_back(
std::shared_ptr<AllreduceOp>(new NCCLHierarchicalAllreduce(
&nccl_context, &mpi_context, &gpu_context, &state)));
#elif HAVE_ DDL && HOROVOD_ GPU_ Allreduce = ='d '/ / if DDL is compiled, add DDLAllreduce
allreduce_ops.push_back(std::shared_ptr<AllreduceOp>(
new DDLAllreduce(&ddl_context, &gpu_context, &state)));
#endif
#if HAVE_ NCCL && HOROVOD_ GPU_ Allreduce = ='n '/ / if nccl is compiled, add NCCLAllreduce
allreduce_ops.push_back(std::shared_ptr<AllreduceOp>(
new NCCLAllreduce(&nccl_context, &gpu_context, &state)));
#endif
5.3.5 MPIAllreduce
Because allreduce_ There are many types of OPS, so we take MPIAllreduce as an example:
class MPIAllreduce : public AllreduceOp {
public:
MPIAllreduce(MPIContext* mpi_context, HorovodGlobalState* global_state);
virtual ~MPIAllreduce() = default;
Status Execute(std::vector<TensorTableEntry>& entries, const Response& response) override;
bool Enabled(const ParameterManager& param_manager,
const std::vector<TensorTableEntry>& entries,
const Response& response) const override;
protected:
MPIContext* mpi_context_;
};
MPIAllreduce::Execute MPI is used here_ Allreduce also handles fusion, such as MemcpyOutFusionBuffer.
#include "mpi_operations.h"
Status MPIAllreduce::Execute(std::vector<TensorTableEntry>& entries, const Response& response) {
auto& first_entry = entries[0];
const void* fused_input_data;
void* buffer_data;
size_t buffer_len;
int64_t num_elements = NumElements(entries);
// Copy memory into the fusion buffer.
auto& timeline = global_state_->timeline;
if (entries.size() > 1) {
timeline.ActivityStartAll(entries, MEMCPY_IN_FUSION_BUFFER);
MemcpyInFusionBuffer(entries, fused_input_data, buffer_data, buffer_len);
timeline.ActivityEndAll(entries);
} else {
fused_input_data = first_entry.tensor->data();
buffer_data = (void*) first_entry.output->data();
buffer_len = (size_t) first_entry.output->size();
}
if (response.prescale_factor() != 1.0) {
// Execute prescaling op
ScaleBuffer(response.prescale_factor(), entries, fused_input_data, buffer_data, num_elements);
fused_input_data = buffer_data; // for unfused, scale is done out of place
}
// Do allreduce.
timeline.ActivityStartAll(entries, MPI_ALLREDUCE);
const void* sendbuf = entries.size() > 1 || fused_input_data == buffer_data
? MPI_IN_PLACE : fused_input_data;
int op = MPI_Allreduce(sendbuf, buffer_data,
(int) num_elements,
mpi_context_->GetMPIDataType(first_entry.tensor),
mpi_context_->GetMPISumOp(first_entry.tensor->dtype()),
mpi_context_->GetMPICommunicator(Communicator::GLOBAL));
timeline.ActivityEndAll(entries);
if (response.postscale_factor() != 1.0) {
// Execute postscaling op
ScaleBuffer(response.postscale_factor(), entries, buffer_data, buffer_data, num_elements);
}
// Copy memory out of the fusion buffer.
if (entries.size() > 1) {
timeline.ActivityStartAll(entries, MEMCPY_OUT_FUSION_BUFFER);
MemcpyOutFusionBuffer(buffer_data, entries);
timeline.ActivityEndAll(entries);
}
return Status::OK();
}
The specific logic is as follows:
+---------------------------------+
| | +-----------------------+
| BackgroundThreadLoop | | |
| | | OperationManager |
| +--------------------------+ | | |
| | RunLoopOnce | | | |
| | | | | |
| | | | | | +--> GPUAllreduce
| | ComputeResponseList | | +----------> ExecuteOperation | |
| | + | | | | + | |
| | | | | | | | | +--> NCCLHierarchicalAllreduce
| | | | | | | | | |
| | | | | | 1 | | 2 | |
| | v | | | | | | +--> NCCLAllreduce
| | | | | | | | |
| | PerformOperation +----------+ | v | |
| | | | | ExecuteAllreduce | +--> DDLAllreduce
| +--------------------------+ | | + | |
| | | | | |
+---------------------------------+ | | | +--> GlooAllreduce
| | allreduce_ops----------+
| | | | +----------------+
| | | +--> | MPIAllreduce |
+-----------------------+ | |
| | |
+----------------------------------> Execute |
3 | |
+----------------+
Mobile phones are as follows:
So far, the background thread architecture has been basically clarified. We need to go back to see how the optimizer implements it in the next article.
0xEE personal information
★★★★★★★ thinking about life and technology ★★★★★★
Wechat public account: Rossi's thinking
If you want to get the news push of personal articles in time, or want to see the technical materials recommended by yourself, please pay attention.

0xFF reference
Learn about Pytorch distributed training, this one is enough!
Horovod use_ Distributed model training with horovod
Spark's new vision: making deep learning easier to use
Scaling model training in PyTorch using distributed data parallel
Parallel scaling model training in PyTorch using distributed data
A developer-friendly guide to mixed precision training with PyTorch
Developer friendly PyTorch hybrid accuracy training guide
It's 2020, why isn't deep learning 100% on the cloud yet?
By 2020, why not conduct 100% in-depth learning on the cloud?
Take you to know the Horovod distributed training framework of danghong fried chicken
Multi GPU distributed training using Horovod in Amazon SageMaker pipeline mode
Kubernetes training_ Distributed deep learning training using horovod on kubernetes
Horovod distributed deep learning framework based on TensorFlow
This article clearly states the necessary knowledge of Tensorflow distributed training
Horovod source code analysis (I)