preface
Based on Some optimization on improving the accuracy of OCR recognition Some improvements and attempts have been made, mainly divided into the following two points:
1. Using paddleocr direction classifier to judge text direction
2. Training a direction classifier with paddlex to judge the text direction
1, Why judge the direction?
In our data set, there are many pictures uploaded by users, but some of these pictures are reversed. If this kind of pictures are not preprocessed, the recognition effect will be very poor. For example, the recognition results are in the wrong order and the missing recognition rate is very high. After testing, it is found that the recognition effect will be much better after turning the picture to regular. Therefore, it is necessary to judge the direction and correct it
2, paddleocr direction classifier
1. Method introduction
Quote the official introduction of paddleocr:
Text angle classification is mainly used in the scene where the picture is not 0 degrees. In this scene, it is necessary to convert the text lines detected in the picture to positive. In the PaddleOCR system, the text line images obtained after text detection are sent to the recognition model after affine transformation. At this time, only one angle classification of 0 and 180 degrees is required. Therefore, the built-in text angle classifier in PaddleOCR only supports the classification of 0 and 180 degrees. If you want to support more angles, you can modify the algorithm to support it.
Examples of 0 and 180 degree data samples:
2. Actual effect test

 Figure 2. paddleocr detection is 180 degrees, and the actual is 90 degrees
! [insert picture description here]( https://img-blog.csdnimg.cn/20210626083646980.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ0MTkzOTY5,size_16,color_FFFFFF,t_70#pic_center)
Figure 3. paddleocr detection is 180 degrees, the actual 180 degrees
Figure 2. paddleocr detection is 180 degrees, and the actual is 90 degrees
! [insert picture description here]( https://img-blog.csdnimg.cn/20210626083646980.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ0MTkzOTY5,size_16,color_FFFFFF,t_70#pic_center)
Figure 3. paddleocr detection is 180 degrees, the actual 180 degrees

3. Text box detection actual effect
4. Result analysis
1. Although the pad only supports text direction detection of 0 degrees and 180 degrees, it can be found that although both are detected as 180 degrees, their rectangular boxes are different from each other
2. By observing Fig. 1 and Fig. 3, it can be found that although the rectangular boxes of the two are the same, the paddleocr can completely detect that the directions of the two are different
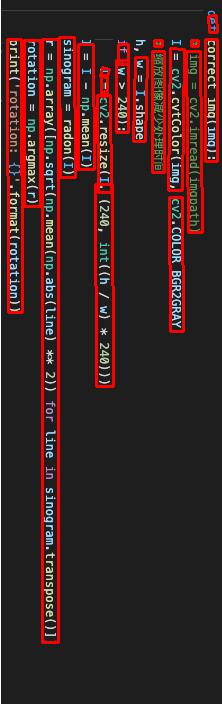
3. Combined with the above analysis results, we can use the aspect ratio of the rectangular box to determine the direction of the text.
5. Solution
Let's look at the code. It's all in the comments, as follows:
def get_real_rotation(rect_list):
w_div_h_sum = 0
count = 0
for rect in rect_list:
p0 = rect[0] #P0, P1, P2 and P3 are the coordinates of the four corners of the rectangular box
p1 = rect[1]
p2 = rect[2]
p3 = rect[3]
width = abs(p1[0] - p0[0])
height = abs(p3[1] - p0[1])
w_div_h = width / height #Calculate the length ratio
if abs(w_div_h - 1.0) < 0.5: #Filter rectangular boxes with an aspect ratio gap close to 1 to avoid affecting the detection accuracy
count +=1
continue
w_div_h_sum += w_div_h
if w_div_h_sum / (len(rect_list) - count) >= 1.5: #If the aspect ratio is greater than 1.5, the detection result of paddleocr is reliable
return 1
else:
return 0
def get_img_real_angle(img_path):
ocr = PaddleOCR(use_angle_cls=True)
angle_cls = ocr.ocr(img_path, det=False, rec=False, cls=True) #The paddleocr detection angle is obtained
print(angle_cls)
rect_list = ocr.ocr(img_path, rec=False) #Get the corner coordinates of all rectangular boxes
real_angle_flag = get_real_rotation_new(rect_list)
if angle_cls[0][0] == '0':
if real_angle_flag:
ret_angle = 0
else:
ret_angle = 270
if angle_cls[0][0] == '180':
if real_angle_flag:
ret_angle = 180
else:
ret_angle = 90
return ret_angle
6. Direction detection test results
1. After testing dozens of pictures, it was found that the accuracy was only 60%, and the effect was not very good.
2. Possible causes:
- Our data is special, so we need to re train the paddleocr direction classifier
- The direction classifier of paddleocr is inaccurate, which has nothing to do with our data
3, paddlex image classification
1. Training
1. I have to talk about paddlex: it can complete an image multi classification task in one minute
2. So I immediately took the official example and tried it. The code is as follows:
#%%
# Set to use GPU card 0 (if there is no GPU, the CPU training model will still be used after executing this code)
import matplotlib
matplotlib.use('Agg')
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import paddlex as pdx
# %%
from paddlex.cls import transforms
train_transforms = transforms.Compose([
transforms.RandomCrop(crop_size=224),
transforms.RandomHorizontalFlip(),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByShort(short_size=256),
transforms.CenterCrop(crop_size=224),
transforms.Normalize()
])
# %%
train_dataset = pdx.datasets.ImageNet(
data_dir='train_paddlex',
file_list='train_paddlex/train_list.txt',
label_list='train_paddlex/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='train_paddlex',
file_list='train_paddlex/val_list.txt',
label_list='train_paddlex/labels.txt',
shuffle=True,
transforms=eval_transforms)
# %%
num_classes = len(train_dataset.labels)
model = pdx.cls.MobileNetV3_small_ssld(num_classes=num_classes)
#%%
model.train(num_epochs=20,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
save_dir='output/mobilenetv3_small_ssld',
use_vdl=True)
# %%
import paddlex as pdx
model = pdx.load_model('output/mobilenetv3_small_ssld/best_model')
result = model.predict('train_paddlex/0/img_0.PNG')
print("Predict Result: ", result)
3. After running.................
Errors are reported as follows:

4. So I went to the paddlex communication group and asked the reason for the error. The result was that there was a problem with the input data path.
5. After some investigation, it is found that the path is completely right. My machine is mac, so I thought it might be the system, so I took the code to linux to run.
6. It runs perfectly on linux, so it can be determined that paddlex is not friendly to mac, resulting in an error
2. Analysis of test results
1. Each category is trained with 200 pieces of data, and the accuracy of the training set is 24%
2. Each category is trained with 2000 pieces of data, and the accuracy of the training set is 40%
3. The accuracy of the test set is 10%
Possible causes:
It is wrong to train text direction classifier directly using text images
4, Subsequent optimization direction
1. After a week of various optimization tests, the ocr recognition accuracy has not been greatly improved. However, it can be determined that the image recognition effect after becoming a regular is much higher than that of non regular images. Therefore, we will make a breakthrough in the future.
2. Consider training paddleocr with your own data
summary
Although the recognition effect of ocr was not improved this week, the optimization direction to improve the recognition effect of ocr was clarified. Stepping on some pits is also a harvest.