Study Preface
Visual Transformer is very hot recently. I'll learn from VIT first.

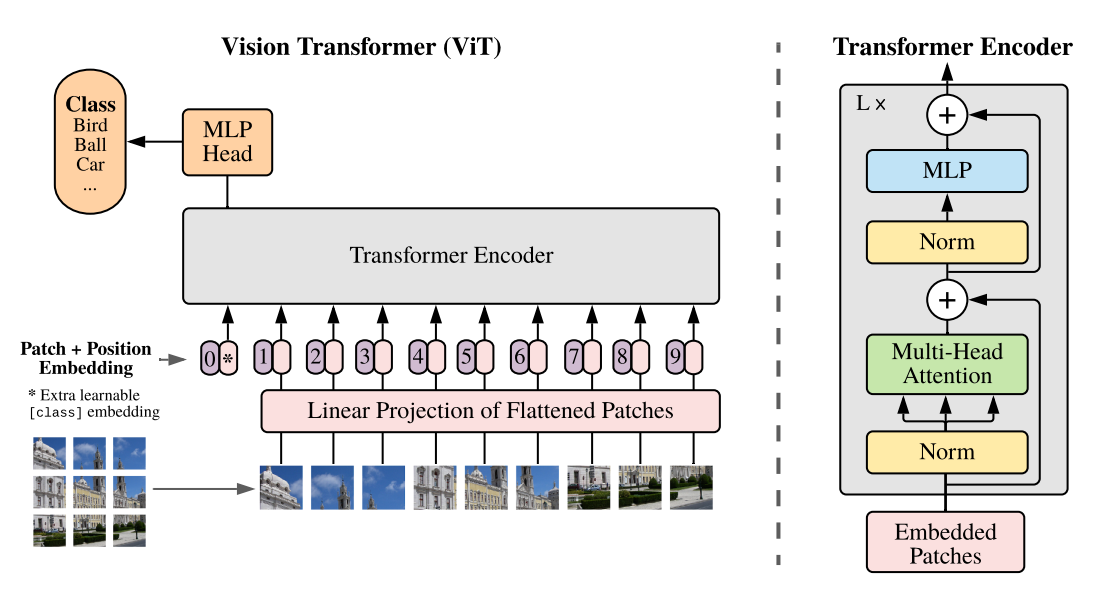
What is Vision Transformer (VIT)
Vision Transformer is the visual version of transformer. Transformer has basically become the standard configuration of natural language processing, but its application in vision is still limited.
Vision Transformer breaks the isolation between NLP and CV, and applies Transformer to image patch sequence to further complete the task of image classification. To understand it simply, vision Transformer is to divide the input picture into picture blocks every certain area size. Then, the divided picture blocks are combined into sequences, and the combined results are transmitted to Transformer's unique multi head self attention for feature extraction. Finally, Cls Token is used for classification.
Code download
Github source code download address is:
https://github.com/bubbliiiing/classification-pytorch
Copy the path to the address bar to jump.
Implementation idea of vision transform
1, Overall structure analysis
Similar to ordinary classification networks, the whole Vision Transformer can be divided into two parts: one is feature extraction and the other is classification.
In the part of feature extraction, what VIT does is feature extraction. The corresponding regions of the feature extraction part in the picture are Patch+Position Embedding and Transformer Encoder. Patch+Position Embedding is mainly used to block the input pictures and divide the picture blocks every certain area size. Then, the divided picture blocks are combined into sequences. After the sequence information is obtained, it is passed into Transformer Encoder for feature extraction. This is Transformer's unique multi head self attention structure, which pays attention to the importance of each picture block through self attention mechanism.
In the classification part, the work of VIT is to use the extracted features for classification. During feature extraction, we will add Cls Token to the picture sequence, which will be used as the sequence information of a unit for feature extraction. In the process of extraction, the Cls Token will interact with other features and integrate the features of other picture sequences. Finally, we use the Cls Token extracted by multi head self attention structure for full connection classification.
2, Network structure analysis
1. Introduction to feature extraction
a,Patch+Position Embedding
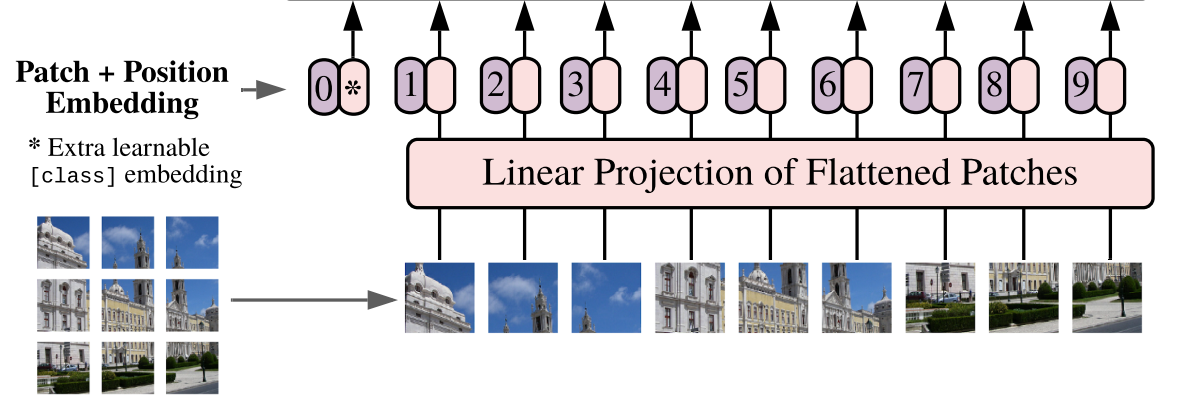
Patch+Position Embedding is mainly used to block the input pictures and divide the picture blocks every certain area size. Then, the divided picture blocks are combined into sequences.
This part first carries out block processing on the input pictures. In fact, the processing method is very simple, and the ready-made convolution is used. Because the convolution uses the idea of sliding window, we only need to set a specific step size to block the input pictures.
In VIT, we often set the convolution kernel size of this convolution to 16x16 and the step size to 16x16. At this time, the convolution will carry out feature extraction every 16 pixels. Since the convolution kernel size is 16x16, the feature extraction process of the two image regions will not overlap. When the input image is 224, 224, 3, we can obtain a feature layer of 14, 14, 768.
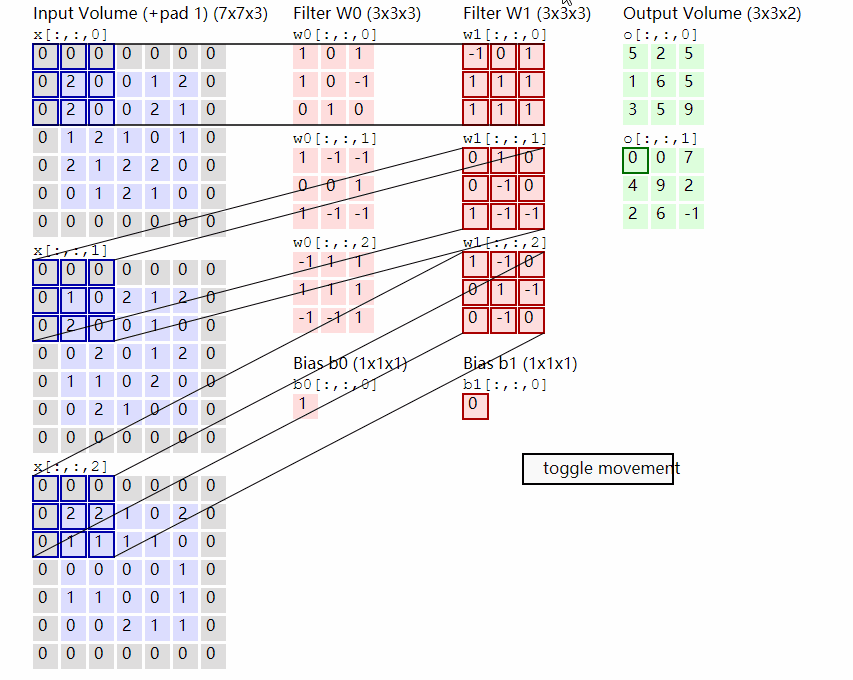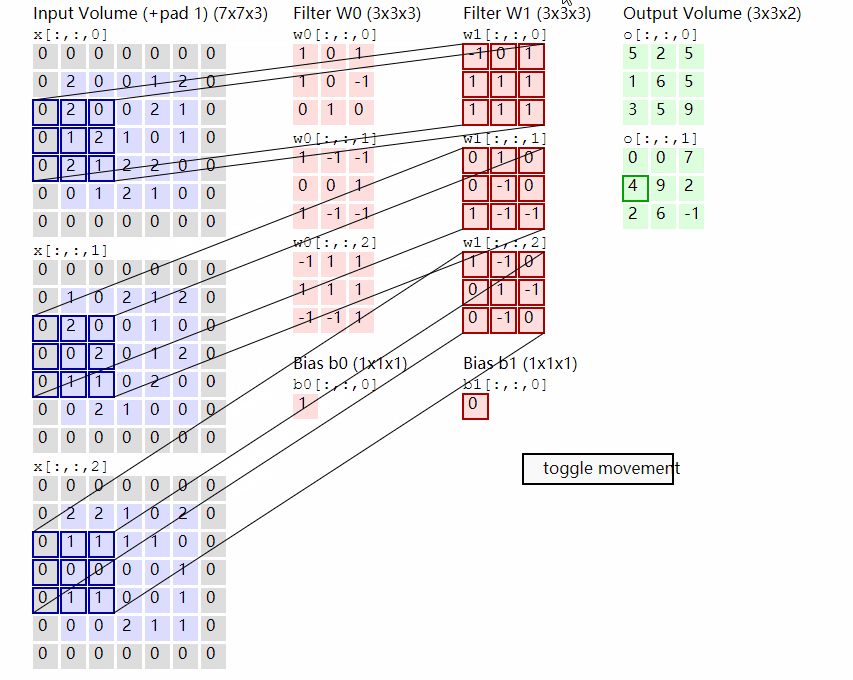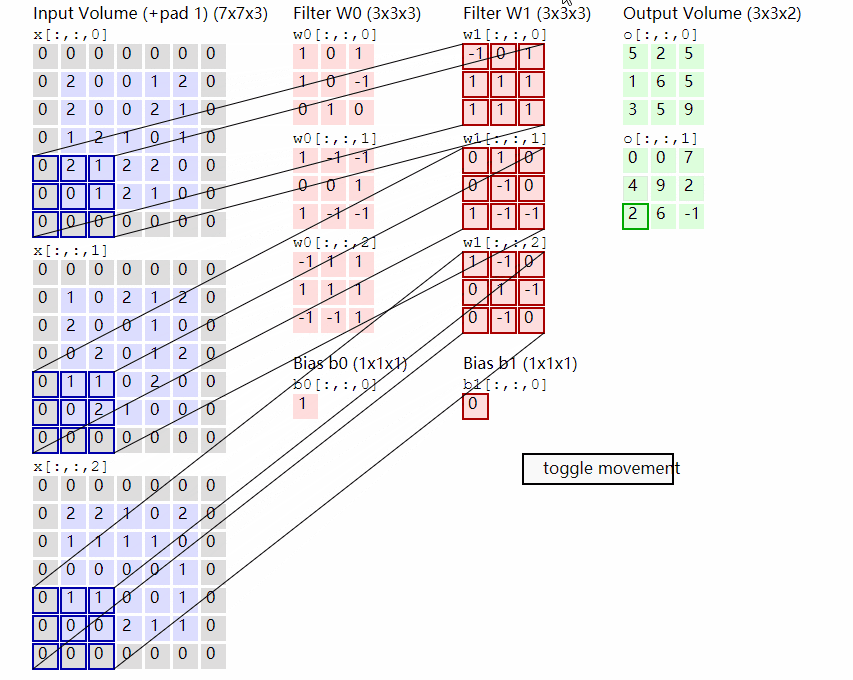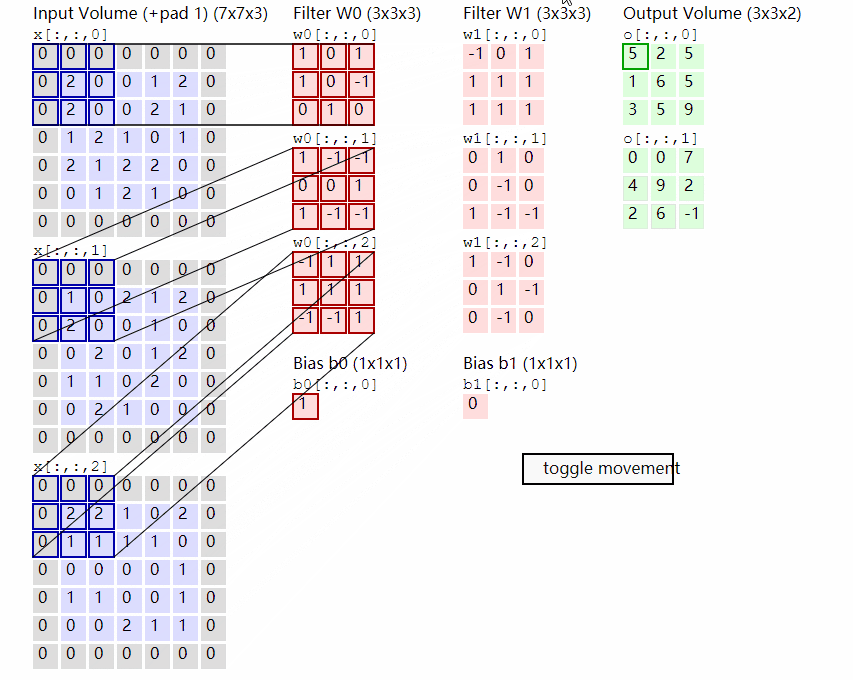
The next step is to combine this feature layer into a sequence. The combination method is very simple, that is, tile the height and width dimensions. After tiling the height and width dimensions, 14, 14 and 768, a 196 and 768 feature layer is obtained. After tiling, we will add Cls Token to the image sequence, which will be used as a unit of sequence information for feature extraction. The 0 * in the figure is Cls Token. At this time, we obtain a 197, 768 feature layer.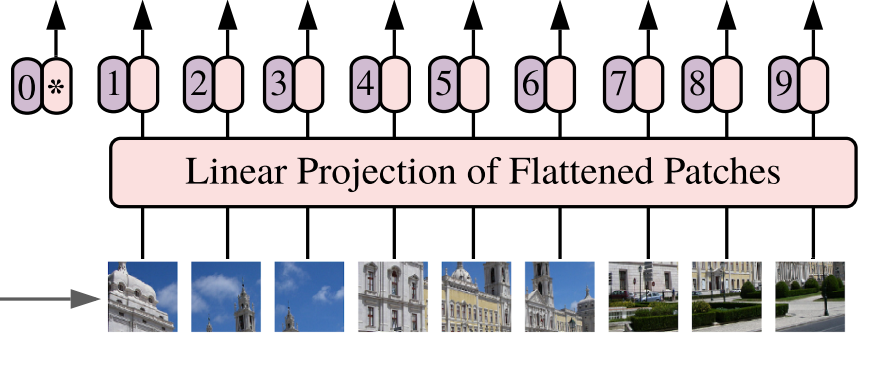
After adding Cls Token, add location information for all features, so that the network can distinguish different regions. The addition method is also very simple. We generate a parameter matrix of 197 and 768. This parameter matrix is trainable. Add the characteristic layer of 197 and 768 to this matrix.
Here, the Patch+Position Embedding is built. The construction code is as follows:
class PatchEmbed(nn.Module):
def __init__(self, input_shape=[224, 224], patch_size=16, in_chans=3, num_features=768, norm_layer=None, flatten=True):
super().__init__()
self.num_patches = (input_shape[0] // patch_size) * (input_shape[1] // patch_size)
self.flatten = flatten
self.proj = nn.Conv2d(in_chans, num_features, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(num_features) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
if self.flatten:
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
x = self.norm(x)
return x
class VisionTransformer(nn.Module):
def __init__(
self, input_shape=[224, 224], patch_size=16, in_chans=3, num_classes=1000, num_features=768,
depth=12, num_heads=12, mlp_ratio=4., qkv_bias=True, drop_rate=0.1, attn_drop_rate=0.1, drop_path_rate=0.1,
norm_layer=partial(nn.LayerNorm, eps=1e-6), act_layer=GELU
):
super().__init__()
#-----------------------------------------------#
# 224, 224, 3 -> 196, 768
#-----------------------------------------------#
self.patch_embed = PatchEmbed(input_shape=input_shape, patch_size=patch_size, in_chans=in_chans, num_features=num_features)
num_patches = (224 // patch_size) * (224 // patch_size)
self.num_features = num_features
self.new_feature_shape = [int(input_shape[0] // patch_size), int(input_shape[1] // patch_size)]
self.old_feature_shape = [int(224 // patch_size), int(224 // patch_size)]
#--------------------------------------------------------------------------------------------------------------------#
# The classtoken part is the classification feature of the transformer. It is used to stack into the serialized picture features and extract the features as a unit of sequence features.
#
# After the input picture is divided into 14x14 parts by convolution with a step size of 16x16, the features of 14x14 parts are tiled, and a picture will have features with a sequence length of 196.
# At this time, a classtoken is generated, and the classtoken is stacked on the feature with sequence length of 196 to obtain a feature with sequence length of 197.
# In the process of feature extraction, classtoken will interact with picture features. In the final classification, we take out the characteristics of classtoken and use full connection classification.
#--------------------------------------------------------------------------------------------------------------------#
# 196, 768 -> 197, 768
self.cls_token = nn.Parameter(torch.zeros(1, 1, num_features))
#--------------------------------------------------------------------------------------------------------------------#
# Add location information to the features extracted by the network.
# Taking the input pictures 224, 224, 3 as an example, the serialized picture features we obtained are 196, 768. After adding classtoken, it is 197, 768
# POS generated at this time_ The embedded shape is also 197 and 768, representing the location information of each feature.
#--------------------------------------------------------------------------------------------------------------------#
# 197, 768 -> 197, 768
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, num_features))
def forward_features(self, x):
x = self.patch_embed(x)
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_token, x), dim=1)
cls_token_pe = self.pos_embed[:, 0:1, :]
img_token_pe = self.pos_embed[:, 1: , :]
img_token_pe = img_token_pe.view(1, *self.old_feature_shape, -1).permute(0, 3, 1, 2)
img_token_pe = F.interpolate(img_token_pe, size=self.new_feature_shape, mode='bicubic', align_corners=False)
img_token_pe = img_token_pe.permute(0, 2, 3, 1).flatten(1, 2)
pos_embed = torch.cat([cls_token_pe, img_token_pe], dim=1)
x = self.pos_drop(x + pos_embed)
b,Transformer Encoder
After obtaining the sequence information with shape s 197 and 768 in the previous step, the sequence information is transmitted to Transformer Encoder for feature extraction. This is the Transformer's unique multi head self attention structure, which pays attention to the importance of each picture block through the self attention mechanism.
1. Analysis of self attention structure
To understand the self attention structure, you can actually understand the following dynamic graph. There are three unit inputs of a sequence in the dynamic graph. The input of each sequence unit can obtain query, Key and Value through three processes (such as full connection). Query is the query vector, Key is the Key vector and Value vector.

If we want to get the output of input-1, let's do the following steps:
1. Using the query vector of input-1, multiply the key vectors of input-1, input-2 and input-3 respectively. At this time, we obtain three score s.
2. Then take softmax for these three score s to obtain the importance of input-1, input-2 and input-3.
3. Then multiply this importance by the value vectors of input-1, input-2 and input-3 to sum.
4. At this point, we get the output of input-1.
As shown in the figure, we carry out the following steps:
1. The query vector of input-1 is [1, 0, 2]. Multiply the key vectors of input-1, input-2 and input-3 respectively to obtain three score s of 2, 4 and 4.
2. Then take softmax for these three score s to obtain the respective importance of input-1, input-2 and input-3. The three importance degrees are 0.0, 0.5 and 0.5.
3. Then multiply this importance by the value vectors of input-1, input-2 and input-3 to sum, that is
0.0
∗
[
1
,
2
,
3
]
+
0.5
∗
[
2
,
8
,
0
]
+
0.5
∗
[
2
,
6
,
3
]
=
[
2.0
,
7.0
,
1.5
]
0.0 * [1, 2, 3] + 0.5 * [2, 8, 0] + 0.5 * [2, 6, 3] = [2.0, 7.0, 1.5]
0.0∗[1,2,3]+0.5∗[2,8,0]+0.5∗[2,6,3]=[2.0,7.0,1.5].
4. At this point, we get the output of input-1 [2.0, 7.0, 1.5].
In the above example, the sequence length is only 3 and the feature length of each unit sequence is only 3. In the Transformer Encoder of VIT, the sequence length is 197 and the feature length of each unit sequence is 768 // num_heads. But the calculation process is the same. In practical operation, we use matrix for operation.
2. Matrix operation of self attention
The actual matrix operation process is shown in the figure below. I take the actual matrix as an example to analyze:
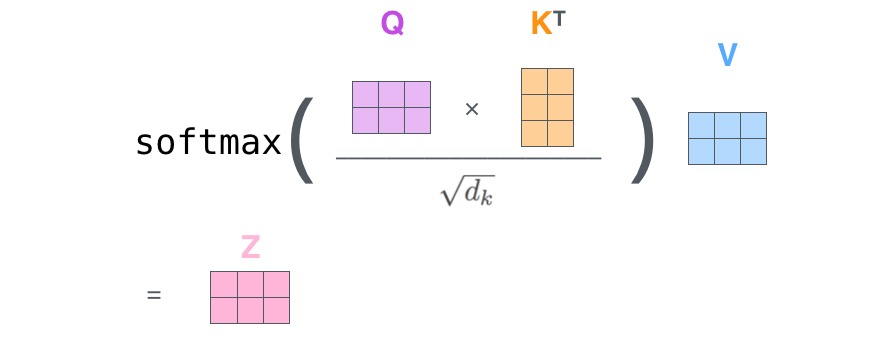
The entered Query, Key and Value are shown in the following figure:
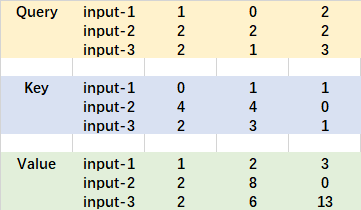
First, use the query vector query point to multiply the transposed key vector key. This step can be popularly understood as using the query vector to query the characteristics of the sequence and obtain the importance score of each part of the sequence.
Each output line represents the contribution of input-1, input-2 and input-3 to the current input. We take a softmax for this contribution value.


Then use the score point to multiply the value. This step can be popularly understood as reapplying the importance of each part of the sequence to the value of the sequence.

The code of this matrix operation is as follows. You can try it yourself.
import numpy as np
def soft_max(z):
t = np.exp(z)
a = np.exp(z) / np.expand_dims(np.sum(t, axis=1), 1)
return a
Query = np.array([
[1,0,2],
[2,2,2],
[2,1,3]
])
Key = np.array([
[0,1,1],
[4,4,0],
[2,3,1]
])
Value = np.array([
[1,2,3],
[2,8,0],
[2,6,3]
])
scores = Query @ Key.T
print(scores)
scores = soft_max(scores)
print(scores)
out = scores @ Value
print(out)
3. MultiHead multi head attention mechanism
The schematic diagram of multi head attention mechanism is shown in the figure:
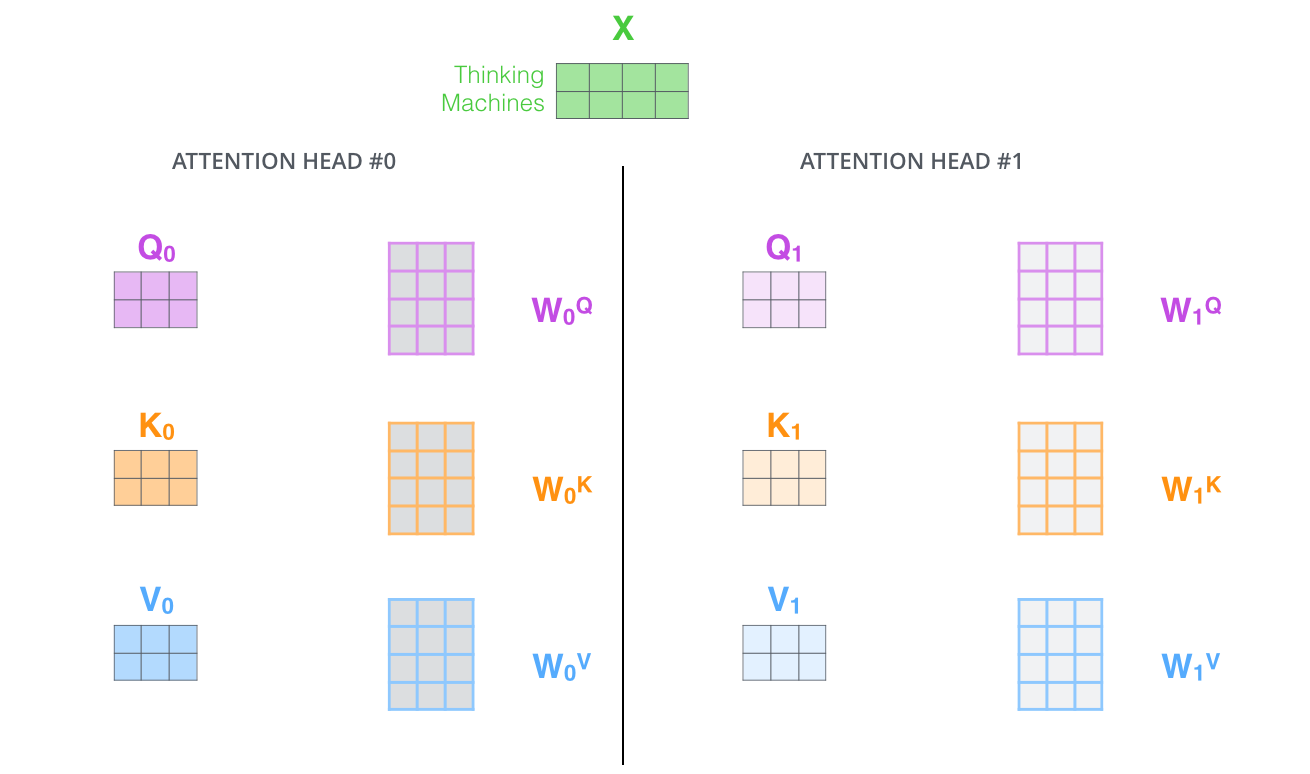
This picture gives people a slightly confused feeling. If we jump out of this picture and start directly from the shape of the matrix, it will be much clearer.
After the first step of image segmentation, we obtain 197 and 768 feature layers.
When applying multiple heads, we directly divide the last dimension of 196, 768. For example, if we want to divide into 12 heads, the shepe of the matrix becomes 196, 12, 64.
Then we transpose 196, 12 and 64, put 12 in front, and the feature layer is 12, 196 and 64. After that, we ignore this 12, treat it the same as the batch dimension, and only deal with 196 and 64, which is actually the process of the above attention mechanism.
#--------------------------------------------------------------------------------------------------------------------#
# Attention mechanism
# Divide the input feature qkv features and generate query, key and value first. Query is the query vector, key is the key vector, and v is the value vector.
# Then, use the query vector query point to multiply the transposed key vector key. This step can be popularly understood as using the query vector to query the characteristics of the sequence and obtain the importance score of each part of the sequence.
# Then use the score point to multiply the value. This step can be popularly understood as reapplying the importance of each part of the sequence to the value of the sequence.
#--------------------------------------------------------------------------------------------------------------------#
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
self.scale = (dim // num_heads) ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
4. Construction of TransformerBlock.
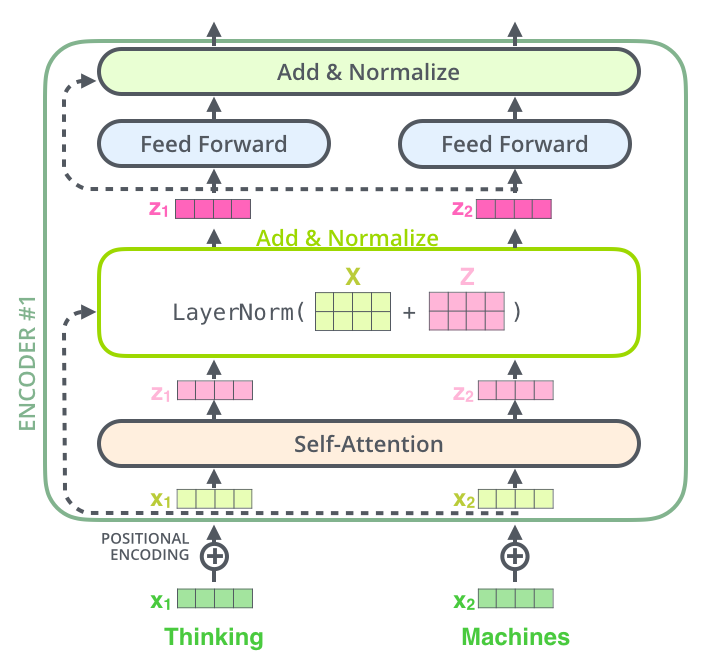
After completing the construction of MultiHeadSelfAttention, we need to add two full connections. The entire transformer block is built.
class Mlp(nn.Module):
""" MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
drop_probs = (drop, drop)
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.drop1 = nn.Dropout(drop_probs[0])
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop2 = nn.Dropout(drop_probs[1])
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0.,
drop_path=0., act_layer=GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
c. Construction of the whole VIT model
The whole VIT model consists of a Patch+Position Embedding plus multiple transformerblocks. The number of typical transforerblocks is 12.
class VisionTransformer(nn.Module):
def __init__(
self, input_shape=[224, 224], patch_size=16, in_chans=3, num_classes=1000, num_features=768,
depth=12, num_heads=12, mlp_ratio=4., qkv_bias=True, drop_rate=0.1, attn_drop_rate=0.1, drop_path_rate=0.1,
norm_layer=partial(nn.LayerNorm, eps=1e-6), act_layer=GELU
):
super().__init__()
#-----------------------------------------------#
# 224, 224, 3 -> 196, 768
#-----------------------------------------------#
self.patch_embed = PatchEmbed(input_shape=input_shape, patch_size=patch_size, in_chans=in_chans, num_features=num_features)
num_patches = (224 // patch_size) * (224 // patch_size)
self.num_features = num_features
self.new_feature_shape = [int(input_shape[0] // patch_size), int(input_shape[1] // patch_size)]
self.old_feature_shape = [int(224 // patch_size), int(224 // patch_size)]
#--------------------------------------------------------------------------------------------------------------------#
# The classtoken part is the classification feature of the transformer. It is used to stack into the serialized picture features and extract the features as a unit of sequence features.
#
# After the input picture is divided into 14x14 parts by convolution with a step size of 16x16, the features of 14x14 parts are tiled, and a picture will have features with a sequence length of 196.
# At this time, a classtoken is generated, and the classtoken is stacked on the feature with sequence length of 196 to obtain a feature with sequence length of 197.
# In the process of feature extraction, classtoken will interact with picture features. In the final classification, we take out the characteristics of classtoken and use full connection classification.
#--------------------------------------------------------------------------------------------------------------------#
# 196, 768 -> 197, 768
self.cls_token = nn.Parameter(torch.zeros(1, 1, num_features))
#--------------------------------------------------------------------------------------------------------------------#
# Add location information to the features extracted by the network.
# Taking the input pictures 224, 224, 3 as an example, the serialized picture features we obtained are 196, 768. After adding classtoken, it is 197, 768
# POS generated at this time_ The embedded shape is also 197 and 768, representing the location information of each feature.
#--------------------------------------------------------------------------------------------------------------------#
# 197, 768 -> 197, 768
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, num_features))
self.pos_drop = nn.Dropout(p=drop_rate)
#-----------------------------------------------#
# 197, 768 - > 197, 768 12 times
#-----------------------------------------------#
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]
self.blocks = nn.Sequential(
*[
Block(
dim = num_features,
num_heads = num_heads,
mlp_ratio = mlp_ratio,
qkv_bias = qkv_bias,
drop = drop_rate,
attn_drop = attn_drop_rate,
drop_path = dpr[i],
norm_layer = norm_layer,
act_layer = act_layer
)for i in range(depth)
]
)
self.norm = norm_layer(num_features)
self.head = nn.Linear(num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
x = self.patch_embed(x)
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_token, x), dim=1)
cls_token_pe = self.pos_embed[:, 0:1, :]
img_token_pe = self.pos_embed[:, 1: , :]
img_token_pe = img_token_pe.view(1, *self.old_feature_shape, -1).permute(0, 3, 1, 2)
img_token_pe = F.interpolate(img_token_pe, size=self.new_feature_shape, mode='bicubic', align_corners=False)
img_token_pe = img_token_pe.permute(0, 2, 3, 1).flatten(1, 2)
pos_embed = torch.cat([cls_token_pe, img_token_pe], dim=1)
x = self.pos_drop(x + pos_embed)
x = self.blocks(x)
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def freeze_backbone(self):
backbone = [self.patch_embed, self.cls_token, self.pos_embed, self.pos_drop, self.blocks[:8]]
for module in backbone:
try:
for param in module.parameters():
param.requires_grad = False
except:
module.requires_grad = False
def Unfreeze_backbone(self):
backbone = [self.patch_embed, self.cls_token, self.pos_embed, self.pos_drop, self.blocks[:8]]
for module in backbone:
try:
for param in module.parameters():
param.requires_grad = True
except:
module.requires_grad = True
2. Classification part
In the classification part, the work of VIT is to use the extracted features for classification.
During feature extraction, we will add Cls Token to the picture sequence, which will be used as the sequence information of a unit for feature extraction. In the process of extraction, the Cls Token will interact with other features and integrate the features of other picture sequences.
Finally, we use the Cls Token extracted by multi head self attention structure for full connection classification.
class VisionTransformer(nn.Module):
def __init__(
self, input_shape=[224, 224], patch_size=16, in_chans=3, num_classes=1000, num_features=768,
depth=12, num_heads=12, mlp_ratio=4., qkv_bias=True, drop_rate=0.1, attn_drop_rate=0.1, drop_path_rate=0.1,
norm_layer=partial(nn.LayerNorm, eps=1e-6), act_layer=GELU
):
super().__init__()
#-----------------------------------------------#
# 224, 224, 3 -> 196, 768
#-----------------------------------------------#
self.patch_embed = PatchEmbed(input_shape=input_shape, patch_size=patch_size, in_chans=in_chans, num_features=num_features)
num_patches = (224 // patch_size) * (224 // patch_size)
self.num_features = num_features
self.new_feature_shape = [int(input_shape[0] // patch_size), int(input_shape[1] // patch_size)]
self.old_feature_shape = [int(224 // patch_size), int(224 // patch_size)]
#--------------------------------------------------------------------------------------------------------------------#
# The classtoken part is the classification feature of the transformer. It is used to stack into the serialized picture features and extract the features as a unit of sequence features.
#
# After the input picture is divided into 14x14 parts by convolution with a step size of 16x16, the features of 14x14 parts are tiled, and a picture will have features with a sequence length of 196.
# At this time, a classtoken is generated, and the classtoken is stacked on the feature with sequence length of 196 to obtain a feature with sequence length of 197.
# In the process of feature extraction, classtoken will interact with picture features. In the final classification, we take out the characteristics of classtoken and use full connection classification.
#--------------------------------------------------------------------------------------------------------------------#
# 196, 768 -> 197, 768
self.cls_token = nn.Parameter(torch.zeros(1, 1, num_features))
#--------------------------------------------------------------------------------------------------------------------#
# Add location information to the features extracted by the network.
# Taking the input pictures 224, 224, 3 as an example, the serialized picture features we obtained are 196, 768. After adding classtoken, it is 197, 768
# POS generated at this time_ The embedded shape is also 197 and 768, representing the location information of each feature.
#--------------------------------------------------------------------------------------------------------------------#
# 197, 768 -> 197, 768
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, num_features))
self.pos_drop = nn.Dropout(p=drop_rate)
#-----------------------------------------------#
# 197, 768 - > 197, 768 12 times
#-----------------------------------------------#
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]
self.blocks = nn.Sequential(
*[
Block(
dim = num_features,
num_heads = num_heads,
mlp_ratio = mlp_ratio,
qkv_bias = qkv_bias,
drop = drop_rate,
attn_drop = attn_drop_rate,
drop_path = dpr[i],
norm_layer = norm_layer,
act_layer = act_layer
)for i in range(depth)
]
)
self.norm = norm_layer(num_features)
self.head = nn.Linear(num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
x = self.patch_embed(x)
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_token, x), dim=1)
cls_token_pe = self.pos_embed[:, 0:1, :]
img_token_pe = self.pos_embed[:, 1: , :]
img_token_pe = img_token_pe.view(1, *self.old_feature_shape, -1).permute(0, 3, 1, 2)
img_token_pe = F.interpolate(img_token_pe, size=self.new_feature_shape, mode='bicubic', align_corners=False)
img_token_pe = img_token_pe.permute(0, 2, 3, 1).flatten(1, 2)
pos_embed = torch.cat([cls_token_pe, img_token_pe], dim=1)
x = self.pos_drop(x + pos_embed)
x = self.blocks(x)
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def freeze_backbone(self):
backbone = [self.patch_embed, self.cls_token, self.pos_embed, self.pos_drop, self.blocks[:8]]
for module in backbone:
try:
for param in module.parameters():
param.requires_grad = False
except:
module.requires_grad = False
def Unfreeze_backbone(self):
backbone = [self.patch_embed, self.cls_token, self.pos_embed, self.pos_drop, self.blocks[:8]]
for module in backbone:
try:
for param in module.parameters():
param.requires_grad = True
except:
module.requires_grad = True
Build code for vision transform
import math
from collections import OrderedDict
from functools import partial
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
#--------------------------------------#
# Implementation of Gelu activation function
# Using approximate mathematical formulas
#--------------------------------------#
class GELU(nn.Module):
def __init__(self):
super(GELU, self).__init__()
def forward(self, x):
return 0.5 * x * (1 + F.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * torch.pow(x,3))))
def drop_path(x, drop_prob: float = 0., training: bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_()
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class PatchEmbed(nn.Module):
def __init__(self, input_shape=[224, 224], patch_size=16, in_chans=3, num_features=768, norm_layer=None, flatten=True):
super().__init__()
self.num_patches = (input_shape[0] // patch_size) * (input_shape[1] // patch_size)
self.flatten = flatten
self.proj = nn.Conv2d(in_chans, num_features, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(num_features) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
if self.flatten:
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
x = self.norm(x)
return x
#--------------------------------------------------------------------------------------------------------------------#
# Attention mechanism
# Divide the input feature qkv features and generate query, key and value first. Query is the query vector, key is the key vector, and v is the value vector.
# Then, use the query vector query point to multiply the transposed key vector key. This step can be popularly understood as using the query vector to query the characteristics of the sequence and obtain the importance score of each part of the sequence.
# Then use the score point to multiply the value. This step can be popularly understood as reapplying the importance of each part of the sequence to the value of the sequence.
#--------------------------------------------------------------------------------------------------------------------#
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
self.scale = (dim // num_heads) ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Mlp(nn.Module):
""" MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
drop_probs = (drop, drop)
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.drop1 = nn.Dropout(drop_probs[0])
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop2 = nn.Dropout(drop_probs[1])
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0.,
drop_path=0., act_layer=GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class VisionTransformer(nn.Module):
def __init__(
self, input_shape=[224, 224], patch_size=16, in_chans=3, num_classes=1000, num_features=768,
depth=12, num_heads=12, mlp_ratio=4., qkv_bias=True, drop_rate=0.1, attn_drop_rate=0.1, drop_path_rate=0.1,
norm_layer=partial(nn.LayerNorm, eps=1e-6), act_layer=GELU
):
super().__init__()
#-----------------------------------------------#
# 224, 224, 3 -> 196, 768
#-----------------------------------------------#
self.patch_embed = PatchEmbed(input_shape=input_shape, patch_size=patch_size, in_chans=in_chans, num_features=num_features)
num_patches = (224 // patch_size) * (224 // patch_size)
self.num_features = num_features
self.new_feature_shape = [int(input_shape[0] // patch_size), int(input_shape[1] // patch_size)]
self.old_feature_shape = [int(224 // patch_size), int(224 // patch_size)]
#--------------------------------------------------------------------------------------------------------------------#
# The classtoken part is the classification feature of the transformer. It is used to stack into the serialized picture features and extract the features as a unit of sequence features.
#
# After the input picture is divided into 14x14 parts by convolution with a step size of 16x16, the features of 14x14 parts are tiled, and a picture will have features with a sequence length of 196.
# At this time, a classtoken is generated, and the classtoken is stacked on the feature with sequence length of 196 to obtain a feature with sequence length of 197.
# In the process of feature extraction, classtoken will interact with picture features. In the final classification, we take out the characteristics of classtoken and use full connection classification.
#--------------------------------------------------------------------------------------------------------------------#
# 196, 768 -> 197, 768
self.cls_token = nn.Parameter(torch.zeros(1, 1, num_features))
#--------------------------------------------------------------------------------------------------------------------#
# Add location information to the features extracted by the network.
# Taking the input pictures 224, 224, 3 as an example, the serialized picture features we obtained are 196, 768. After adding classtoken, it is 197, 768
# POS generated at this time_ The embedded shape is also 197 and 768, representing the location information of each feature.
#--------------------------------------------------------------------------------------------------------------------#
# 197, 768 -> 197, 768
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, num_features))
self.pos_drop = nn.Dropout(p=drop_rate)
#-----------------------------------------------#
# 197, 768 - > 197, 768 12 times
#-----------------------------------------------#
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]
self.blocks = nn.Sequential(
*[
Block(
dim = num_features,
num_heads = num_heads,
mlp_ratio = mlp_ratio,
qkv_bias = qkv_bias,
drop = drop_rate,
attn_drop = attn_drop_rate,
drop_path = dpr[i],
norm_layer = norm_layer,
act_layer = act_layer
)for i in range(depth)
]
)
self.norm = norm_layer(num_features)
self.head = nn.Linear(num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
x = self.patch_embed(x)
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_token, x), dim=1)
cls_token_pe = self.pos_embed[:, 0:1, :]
img_token_pe = self.pos_embed[:, 1: , :]
img_token_pe = img_token_pe.view(1, *self.old_feature_shape, -1).permute(0, 3, 1, 2)
img_token_pe = F.interpolate(img_token_pe, size=self.new_feature_shape, mode='bicubic', align_corners=False)
img_token_pe = img_token_pe.permute(0, 2, 3, 1).flatten(1, 2)
pos_embed = torch.cat([cls_token_pe, img_token_pe], dim=1)
x = self.pos_drop(x + pos_embed)
x = self.blocks(x)
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def freeze_backbone(self):
backbone = [self.patch_embed, self.cls_token, self.pos_embed, self.pos_drop, self.blocks[:8]]
for module in backbone:
try:
for param in module.parameters():
param.requires_grad = False
except:
module.requires_grad = False
def Unfreeze_backbone(self):
backbone = [self.patch_embed, self.cls_token, self.pos_embed, self.pos_drop, self.blocks[:8]]
for module in backbone:
try:
for param in module.parameters():
param.requires_grad = True
except:
module.requires_grad = True
def vit(input_shape=[224, 224], pretrained=False, num_classes=1000):
model = VisionTransformer(input_shape)
if pretrained:
model.load_state_dict(torch.load("model_data/vit-patch_16.pth"))
if num_classes!=1000:
model.head = nn.Linear(model.num_features, num_classes)
return model