It has been more than ten days since my undergraduate defense passed smoothly. I have decided to make a summary of the last small achievements of my undergraduate course and share them with the small partners who want to do the project in this direction. I hope you want to have projects for reference and ideas for implementation for learning when you do the practical work. Demo Video Show you first.
I. Purpose and Significance of Research
(1) Status quo
- Graduates pay attention to the key and difficult points: finding a job + renting a house
- The recruitment website is complex: pull hook net, BOSS direct employment, no worry about the future, etc.
- Maturity of employment information websites at various universities
- There are many rental websites: Chain Home, I love my home, etc.
(2) Disadvantages
- Information only, single function
- The information is scattered and the overall situation is unknown.
- Text and numeric forms are not intuitive
- Recruitment is not associated with renting
(3) Improvement
- Integrate information, statistics
- Partition Data Visualization
- Rich Chart Rendering
- Set recruitment rental in one
Therefore, there is an urgent need for a platform that can integrate as much information as possible, and this platform needs strong statistical data and data visualization capabilities, so that users can retrieve recruitment information and housing source information through this platform, and understand the overall situation through chart visualization. For the growing employment force each year, we can clearly understand the current status of Internet industry and rental in first-line cities, new-line cities and second-line cities from the system, which can help us make the right choice for our own situation.
2. Implementation ideas and related technologies
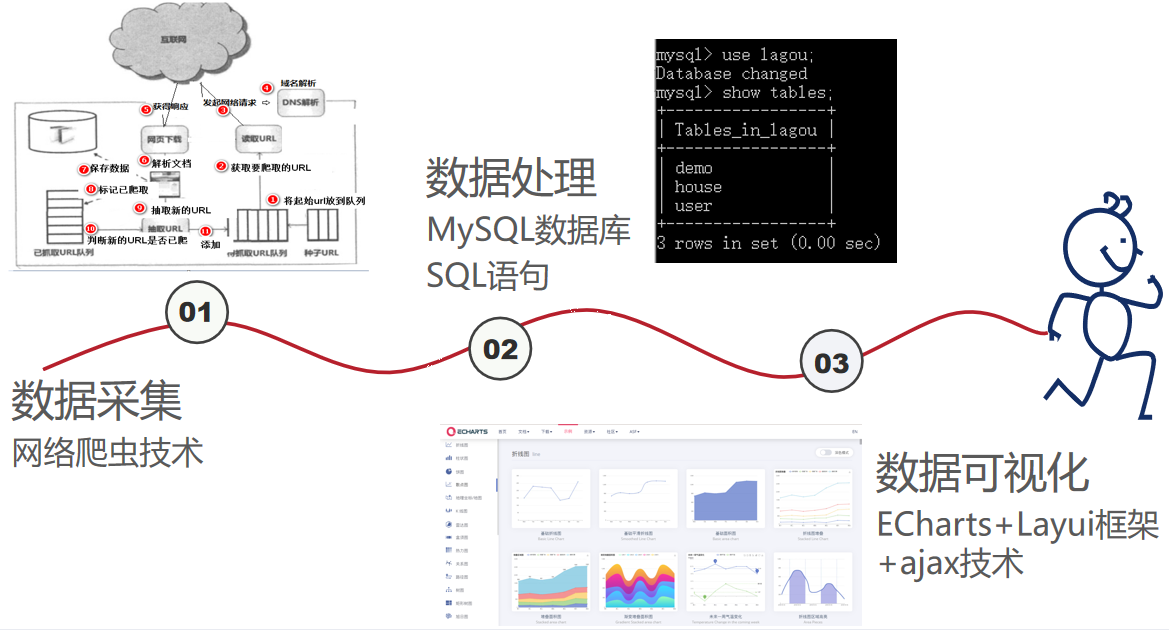
Realization of Front-end and Back-end Data Interaction--ajax Technology
Passing parameters through ajax is an intermediate layer between users and servers, which asynchronizes user actions and server responses. The front end converts the parameters it needs to pass into a JSON string (json.stringify), then sends a request to the server via get/post and passes the parameters directly to the back end, which responds to the front end requests and receives data. The data is queried as a condition, and the result set of query in JSON string format is returned to the front end, which receives the data returned in the background to make conditional judgment and make corresponding page display.
Differences in how get/post requests are requested
They all submit data to the server, and they all get data from the server. Get request, browser will send the response header and data together, server response 200 indicates the request is successful, return data. Post-style requests, the browser will first send a response header, the server responds 100, the browser then sends the data body, the server responds 200, the request succeeds, and the data is returned. Post is safer.
When do I use get and when do I use post requests?
Sign-in registration, modify information section use post mode, data overview display, visual display section use get mode. That is, data query uses get mode, and data addition, deletion and modification uses post mode to be more secure.
Data Visualization Chart Display - ECharts Chart Gallery (with all the chart generation code you want to support online debugging, great looking charts, this website is absolutely absolute. Share it with everyone)
Website: ECharts Open Source Visual Chart Library
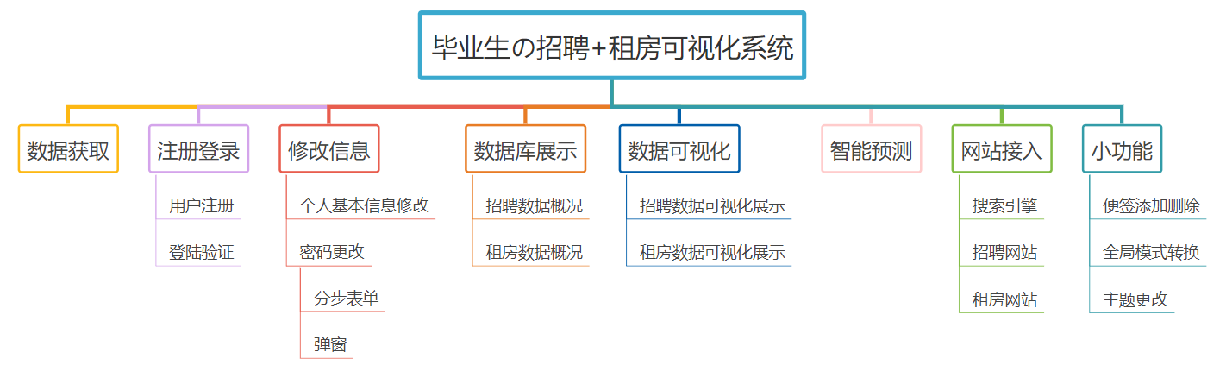
3. System Overall Functional Framework
4. Detailed implementation
(1) Data acquisition
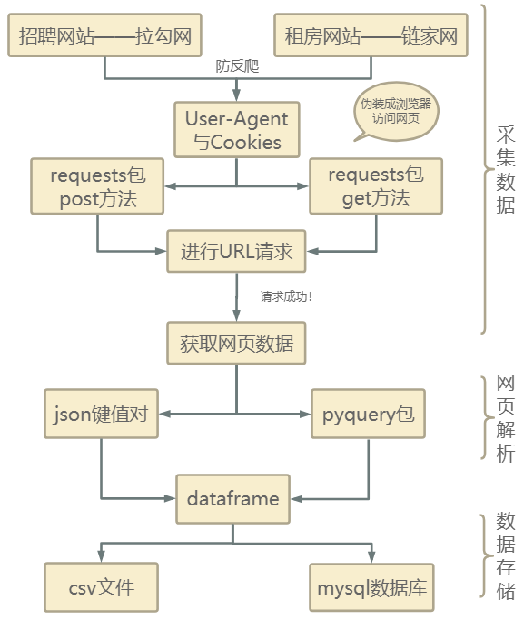
1. Get Recruitment Information
Because of the strong anti-crawling mechanism of the pull-hook network, the header information is encapsulated using user-agent and cookies, the crawler is disguised as a browser to access the web page, the request is made through the post method of the requests package, the request is successfully returned to the json format string, and the data is read directly using the dictionary method to get the information about the python position we want. You can read the total number of positions, through the total number of positions and the number of positions that can be displayed on each page. We can calculate the total number of pages, then use a circular page-by-page crawl to summarize the job information and write it to a CSV-formatted file as well as a local mysql database.
import requests
import math
import time
import pandas as pd
import pymysql
from sqlalchemy import create_engine
def get_json(url, num):
"""
From the specified url Medium Pass requests Request to carry request header and body to get information on a Web page,
:return:
"""
url1 = 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest',
'Cookie':'user_trace_token=20210218203227-35e936a1-f40f-410d-8400-b87f9fb4be0f; _ga=GA1.2.331665492.1613651550; LGUID=20210218203230-39948353-de3f-4545-aa01-43d147708c69; LG_HAS_LOGIN=1; hasDeliver=0; privacyPolicyPopup=false; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; RECOMMEND_TIP=true; index_location_city=%E5%85%A8%E5%9B%BD; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1613651550,1613652253,1613806244,1614497914; _putrc=52ABCFBE36E5D0BD123F89F2B170EADC; gate_login_token=ea312e017beac7fe72547a32956420b07d6d5b1816bc766035dd0f325ba92b91; JSESSIONID=ABAAAECAAEBABII8D8278DB16CB050FD656DD1816247B43; login=true; unick=%E7%94%A8%E6%88%B72933; WEBTJ-ID=20210228%E4%B8%8B%E5%8D%883:38:37153837-177e7932b7f618-05a12d1b3d5e8c-53e356a-1296000-177e7932b8071; sensorsdata2015session=%7B%7D; _gid=GA1.2.1359196614.1614497918; __lg_stoken__=bb184dd5d959320e9e61d943e802ac98a8538d44699751621e807e93fe0ffea4c1a57e923c71c93a13c90e5abda7a51873c2e488a4b9d76e67e0533fe9e14020734016c0dcf2; X_MIDDLE_TOKEN=90b85c3630b92280c3ad7a96c881482e; LGSID=20210228161834-659d6267-94a3-4a5c-9857-aaea0d5ae2ed; TG-TRACK-CODE=index_navigation; SEARCH_ID=092c1fd19be24d7cafb501684c482047; X_HTTP_TOKEN=fdb10b04b25b767756070541617f658231fd72d78b; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2220600756%22%2C%22first_id%22%3A%22177b521c02a552-08c4a0f886d188-73e356b-1296000-177b521c02b467%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24os%22%3A%22Linux%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%2288.0.4324.190%22%2C%22lagou_company_id%22%3A%22%22%7D%2C%22%24device_id%22%3A%22177b521c02a552-08c4a0f886d188-73e356b-1296000-177b521c02b467%22%7D; _gat=1; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1614507066; LGRID=20210228181106-f2d71d85-74fe-4b43-b87e-d78a33c872ad'
}
data = {
'first': 'true',
'pn': num,
'kd': 'BI Engineer'}
#Get Cookies Information
s = requests.Session()
print('establish session: ', s, '\n\n')
s.get(url=url1, headers=headers, timeout=3)
cookie = s.cookies
print('Obtain cookie: ', cookie, '\n\n')
#Add request parameters and information such as headers, Cookies to make url requests
res = requests.post(url, headers=headers, data=data, cookies=cookie, timeout=3)
res.raise_for_status()
res.encoding = 'utf-8'
page_data = res.json()
print('Request response results:', page_data, '\n\n')
return page_data
def get_page_num(count):
"""
Calculates the number of pages to be captured, and by entering keyword information in a pull-down grid, you can see up to 30 pages of information displayed,Display up to 15 job information per page
:return:
"""
page_num = math.ceil(count / 15)
if page_num > 29:
return 29
else:
return page_num
def get_page_info(jobs_list):
"""
Get Positions
:param jobs_list:
:return:
"""
page_info_list = []
for i in jobs_list: # Cycle through all job information on each page
job_info = []
job_info.append(i['companyFullName'])
job_info.append(i['companyShortName'])
job_info.append(i['companySize'])
job_info.append(i['financeStage'])
job_info.append(i['district'])
job_info.append(i['positionName'])
job_info.append(i['workYear'])
job_info.append(i['education'])
job_info.append(i['salary'])
job_info.append(i['positionAdvantage'])
job_info.append(i['industryField'])
job_info.append(i['firstType'])
job_info.append(",".join(i['companyLabelList']))
job_info.append(i['secondType'])
job_info.append(i['city'])
page_info_list.append(job_info)
return page_info_list
def unique(old_list):
newList = []
for x in old_list:
if x not in newList :
newList.append(x)
return newList
def main():
connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format("root", "123456", "localhost", "3366",
"lagou")
engine = create_engine(connect_info)
url = ' https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
first_page = get_json(url, 1)
total_page_count = first_page['content']['positionResult']['totalCount']
num = get_page_num(total_page_count)
total_info = []
time.sleep(10)
for num in range(1, num + 1):
# Get job-related information for each page
page_data = get_json(url, num) # Get response json
jobs_list = page_data['content']['positionResult']['result'] # Get all python-related job information on each page
page_info = get_page_info(jobs_list)
total_info += page_info
print('Crawled to{}Page, total number of positions{}'.format(num, len(total_info)))
time.sleep(20)
#Convert the total data to a data frame and output it, then write it to a csv-formatted file and to a local database
df = pd.DataFrame(data=unique(total_info),
columns=['companyFullName', 'companyShortName', 'companySize', 'financeStage',
'district', 'positionName', 'workYear', 'education',
'salary', 'positionAdvantage', 'industryField',
'firstType', 'companyLabelList', 'secondType', 'city'])
df.to_csv('bi.csv', index=True)
print('Job information saved locally')
df.to_sql(name='demo', con=engine, if_exists='append', index=False)
print('Job information saved database')
if __name__ == '__main__':
main()
2. Get rental housing source information
Use user-agent and cookies to encapsulate header information to disguise the crawler as a browser to access web pages, make url requests through the request package get method to get web page data, add Web page data parsed by pyquery package into the dataframe by field, and then save the dataframe into csv file and local database.
import requests
from pyquery import PyQuery as pq
from fake_useragent import UserAgent
import time
import pandas as pd
import random
import pymysql
from sqlalchemy import create_engine
UA = UserAgent()
headers = {
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cookie': 'lianjia_uuid=6383a9ce-19b9-47af-82fb-e8ec386eb872; UM_distinctid=1777521dc541e1-09601796872657-53e3566-13c680-1777521dc5547a; _smt_uid=601dfc61.4fcfbc4b; _ga=GA1.2.894053512.1612577894; _jzqc=1; _jzqckmp=1; _gid=GA1.2.1480435812.1614959594; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1614049202,1614959743; csrfSecret=lqKM3_19PiKkYOfJSv6ldr_c; activity_ke_com=undefined; ljisid=6383a9ce-19b9-47af-82fb-e8ec386eb872; select_nation=1; crosSdkDT2019DeviceId=-kkiavn-2dq4ie-j9ekagryvmo7rd3-qjvjm0hxo; Hm_lpvt_9152f8221cb6243a53c83b956842be8a=1615004691; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221777521e37421a-0e1d8d530671de-53e3566-1296000-1777521e375321%22%2C%22%24device_id%22%3A%221777521e37421a-0e1d8d530671de-53e3566-1296000-1777521e375321%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%22%2C%22%24latest_referrer_host%22%3A%22www.baidu.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%2C%22%24latest_utm_source%22%3A%22guanwang%22%2C%22%24latest_utm_medium%22%3A%22pinzhuan%22%2C%22%24latest_utm_campaign%22%3A%22wybeijing%22%2C%22%24latest_utm_content%22%3A%22biaotimiaoshu%22%2C%22%24latest_utm_term%22%3A%22biaoti%22%7D%7D; lianjia_ssid=7a179929-0f9a-40a4-9537-d1ddc5164864; _jzqa=1.3310829580005876700.1612577889.1615003848.1615013370.6; _jzqy=1.1612577889.1615013370.2.jzqsr=baidu|jzqct=%E9%93%BE%E5%AE%B6.jzqsr=baidu; select_city=440300; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiZjdiNTI1Yjk4YjI3MGNhNjRjMGMzOWZkNDc4NjE4MWJkZjVjNTZiMWYxYTM4ZTJkNzMxN2I0Njc1MDEyY2FiOWMzNTIzZTE1ZjEyZTE3NjlkNTRkMTA2MWExZmIzMWM5YzQ3ZmQxM2M3NTM5YTQ1YzM5OWU0N2IyMmFjM2ZhZmExOGU3ZTc1YWU0NDQ4NTdjY2RiMjEwNTQyMDQzM2JiM2UxZDQwZWQwNzZjMWQ4OTRlMGRkNzdmYjExZDQwZTExNTg5NTFkODIxNWQzMzdmZTA4YmYyOTFhNWQ2OWQ1OWM4ZmFlNjc0OTQzYjA3NDBjNjNlNDYyNTZiOWNhZmM4ZDZlMDdhNzdlMTY1NmM0ZmM4ZGI4ZGNlZjg2OTE2MmU4M2MwYThhNTljMGNkODYxYjliNGYwNGM0NzJhNGM3MmVmZDUwMTJmNmEwZWMwZjBhMzBjNWE2OWFjNzEzMzM4M1wiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCJhYWEyMjhiNVwifSIsInIiOiJodHRwczovL20ubGlhbmppYS5jb20vY2h1enUvc3ovenVmYW5nL3BnJTdCJTdELyIsIm9zIjoid2ViIiwidiI6IjAuMSJ9',
'Host': 'sz.lianjia.com',
'Referer': 'https://sz.lianjia.com/zufang/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36',
}
num_page = 2
class Lianjia_Crawer:
def __init__(self, txt_path):
super(Lianjia_Crawer, self).__init__()
self.file = str(txt_path)
self.df = pd.DataFrame(columns = ['title', 'district', 'area', 'orient', 'floor', 'price', 'city'])
def run(self):
'''Startup script'''
connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format("root", "123456", "localhost", "3366", "lagou")
engine = create_engine(connect_info)
for i in range(100):
url = "https://sz.lianjia.com/zufang/pg{}/".format(str(i))
self.parse_url(url)
time.sleep(random.randint(2, 5))
print('Crawling url by {}'.format(url))
print('Finished crawling!!!!!!!!!!!!!!')
self.df.to_csv(self.file, encoding='utf-8')
print('Rent information saved locally')
self.df.to_sql(name='house', con=engine, if_exists='append', index=False)
print('Rental Information Saved Database')
def parse_url(self, url):
headers['User-Agent'] = UA.chrome
res = requests.get(url, headers=headers)
#Declare pq objects
doc = pq(res.text)
for i in doc('.content__list--item .content__list--item--main'):
try:
pq_i = pq(i)
# House Title
title = pq_i('.content__list--item--title a').text()
# Specific information
houseinfo = pq_i('.content__list--item--des').text()
# Administrative Region
address = str(houseinfo).split('/')[0]
district = str(address).split('-')[0]
# House area
full_area = str(houseinfo).split('/')[1]
area = str(full_area)[:-1]
# Orientation
orient = str(houseinfo).split('/')[2]
# floor
floor = str(houseinfo).split('/')[-1]
# Price
price = pq_i('.content__list--item-price').text()
#City
city = 'Shenzhen'
data_dict = {'title': title, 'district': district, 'area': area, 'orient': orient, 'floor': floor, 'price': price, 'city': city}
self.df = self.df.append(data_dict, ignore_index=True)
print([title, district, area, orient, floor, price, city])
except Exception as e:
print(e)
print("Index extraction failed, please try again!!!!!!!!!!!!!")
if __name__ =="__main__":
txt_path = "zufang_shenzhen.csv"
Crawer = Lianjia_Crawer(txt_path)
Crawer.run() # Start crawler script
(2) Database
You need to create three database tables to store recruitment information, housing information, and user information.
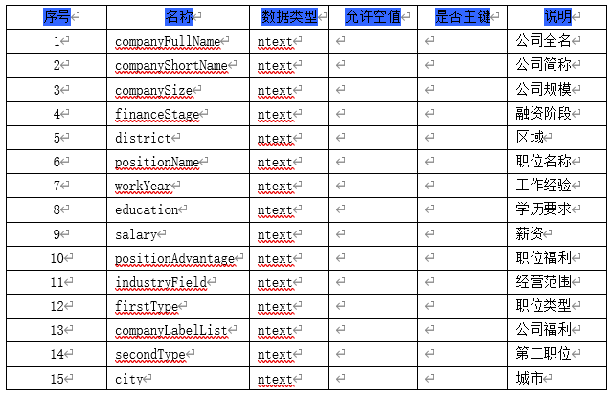
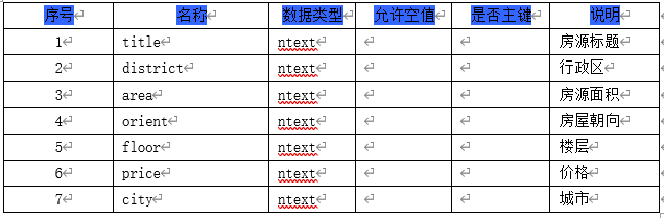
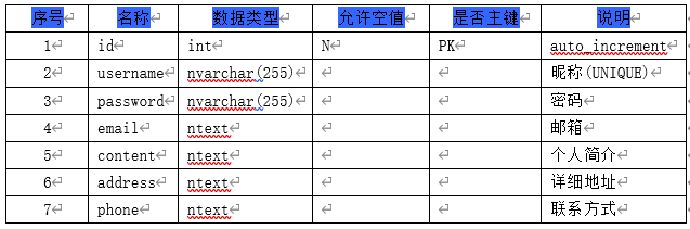
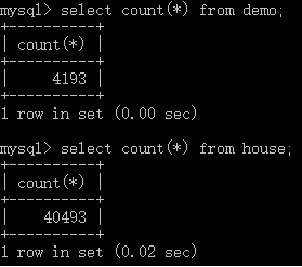
The crawled data is stored in a csv file and a local mysql database, some of which are shown in the following figure:


Database to Background Connection
Using pymysql to connect to the local mysql database, first install pymysql through pip and create the database and database tables, import the pymysql package, open the database connection, create a cursor object using cursor() method, and execute() method to execute the SQL query.
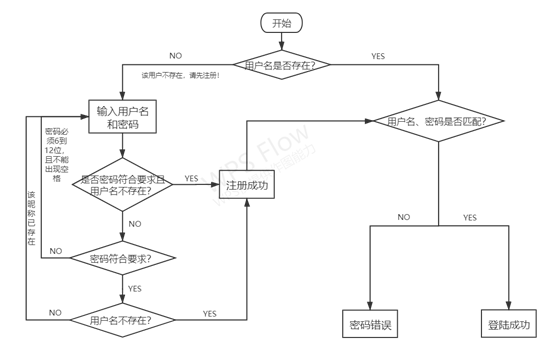
(3) Registration and login
Registration login process:

Implementation Code (Backend Response):
#Registered User
@app.route('/addUser',methods=['POST'])
def addUser():
#Server-side get json
get_json = request.get_json()
name = get_json['name']
password = get_json['password']
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("select count(*) from `user` where `username` = '" + name + "'")
count = cursor.fetchall()
#The nickname already exists
if (count[0][0]!= 0):
table_result = {"code": 500, "msg": "The nickname already exists!"}
cursor.close()
else:
add = conn.cursor()
sql = "insert into `user`(username,password) values('"+name+"','"+password+"');"
add.execute(sql)
conn.commit()
table_result = {"code": 200, "msg": "login was successful"}
add.close()
conn.close()
return jsonify(table_result)
#User Login
@app.route('/loginByPassword',methods=['POST'])
def loginByPassword():
get_json = request.get_json()
name = get_json['name']
password = get_json['password']
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("select count(*) from `user` where `username` = '" + name +"' and password = '" + password+"';")
count = cursor.fetchall()
if(count[0][0] != 0):
table_result = {"code": 200, "msg": name}
cursor.close()
else:
name_cursor = conn.cursor()
name_cursor.execute("select count(*) from `user` where `username` = '" + name +"';")
name_count = name_cursor.fetchall()
#print(name_count)
if(name_count[0][0] != 0):
table_result = {"code":500, "msg": "Wrong password!"}
else:
table_result = {"code":500, "msg":"This user does not exist, please register first!"}
name_cursor.close()
conn.close()
print(name)
return jsonify(table_result)
(4) Home page functions
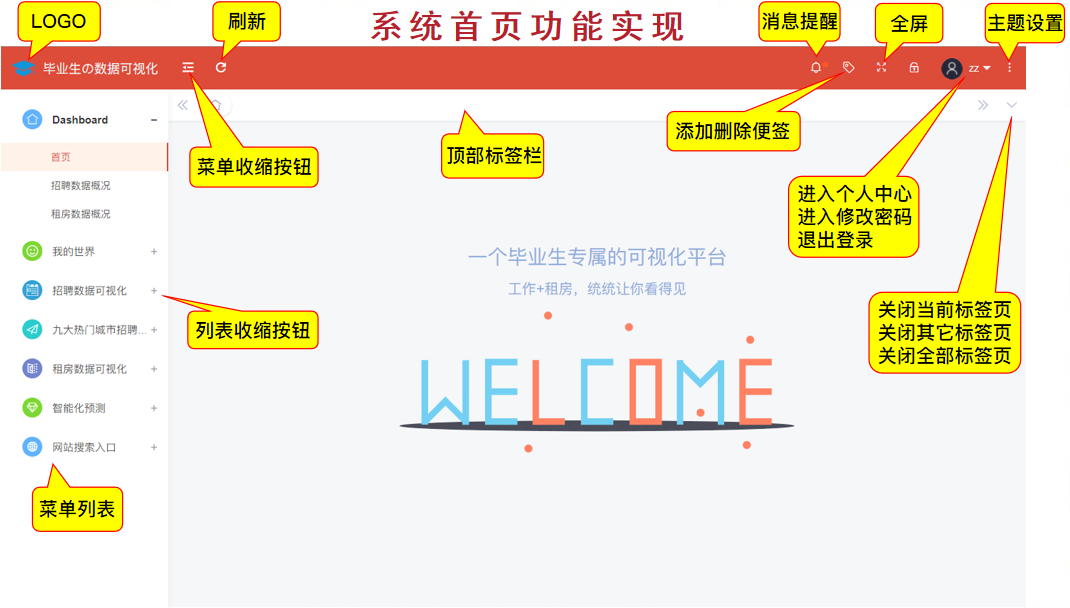
(5) Modifying personal information
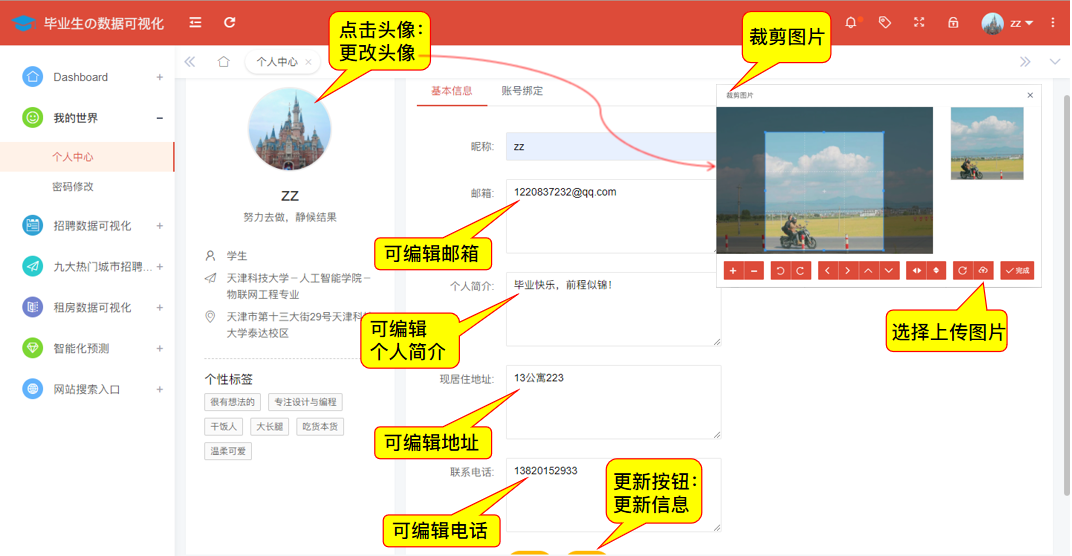
#Personal Information Modification
@app.route('/updateUserInfo',methods=['POST'])
def updateUserInfo():
get_json = request.get_json()
name = get_json['name']
print(name)
email = get_json['email']
content = get_json['content']
address = get_json['address']
phone = get_json['phone']
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("update `user` set email = '"+email+"',content = '"+content+"',address = '"+address+"',phone = '"+phone+"' where username = '"+ name +"';")
conn.commit()
table_result = {"code": 200, "msg": "Update successful!","youxiang": email, "tel": phone}
cursor.close()
conn.close()
print(table_result)
return jsonify(table_result)
(6) Modify password
Passwords can be modified in two ways, requiring security validation
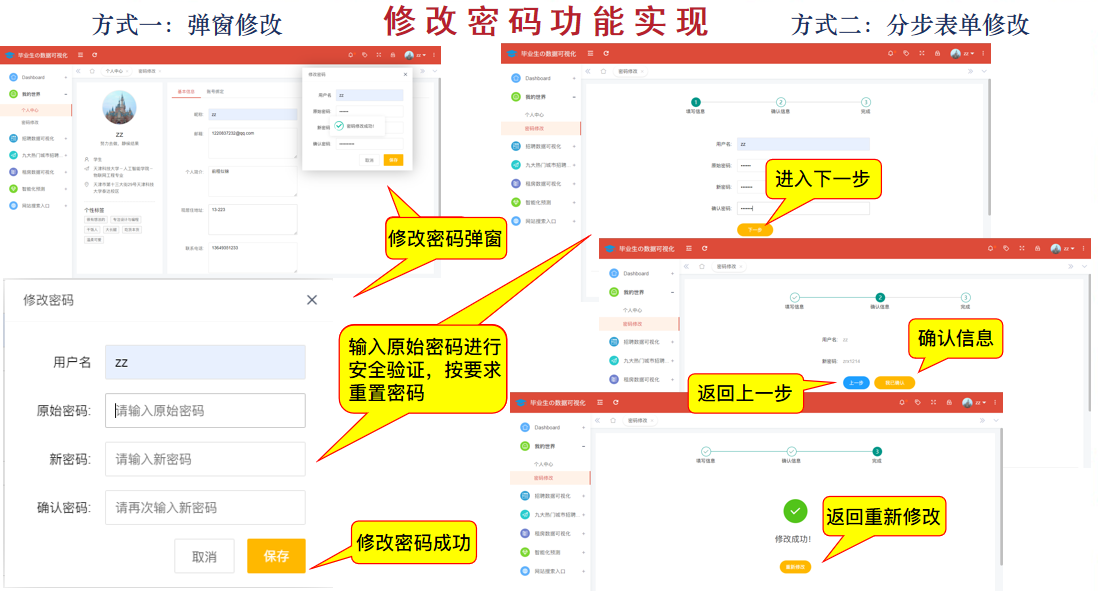
#Password modification
@app.route('/updatePass',methods=['POST'])
def updatePass():
get_json = request.get_json()
name = get_json['name']
oldPsw = get_json['oldPsw']
newPsw = get_json['newPsw']
rePsw = get_json['rePsw']
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("select count(*) from `user` where `username` = '" + name + "' and password = '" + oldPsw+"';")
count = cursor.fetchall()
print(count[0][0])
#Determine nickname password correspondence
if (count[0][0] == 0):
table_result = {"code": 500, "msg": "The original password is wrong!"}
cursor.close()
else:
updatepass = conn.cursor()
sql = "update `user` set password = '"+newPsw+"' where username = '"+ name +"';"
updatepass.execute(sql)
conn.commit()
table_result = {"code": 200, "msg": "Password modified successfully!", "username": name, "new_password": newPsw}
updatepass.close()
conn.close()
return jsonify(table_result)
(7) Data overview display
Note: Only research Internet job recruitment information
Take the recruitment data profile as an example:
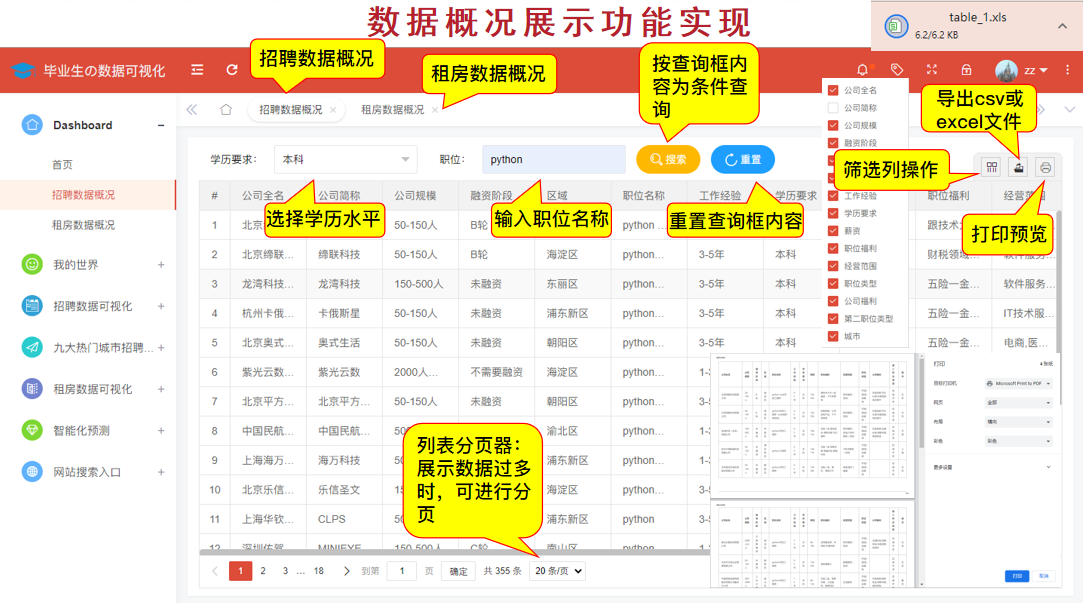
@app.route('/data',methods=['GET'])
def data():
limit = int(request.args['limit'])
page = int(request.args['page'])
page = (page-1)*limit
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',charset='utf8mb4')
cursor = conn.cursor()
if (len(request.args) == 2):
cursor.execute("select count(*) from demo")
count = cursor.fetchall()
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select * from demo limit "+str(page)+","+str(limit))
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field)
else:
education = str(request.args['education'])
positionName = str(request.args['positionName']).lower()
if(education=='Unlimited'):
cursor.execute("select count(*) from demo where positionName like '%"+positionName+"%'")
count = cursor.fetchall()
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select * from demo where positionName like '%"+positionName+"%' limit " + str(page) + "," + str(limit))
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field)
else:
cursor.execute("select count(*) from demo where positionName like '%"+positionName+"%' and education = '"+education+"'")
count = cursor.fetchall()
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select * from demo where positionName like '%"+positionName+"%' and education = '"+education+"' limit " + str(page) + "," + str(limit))
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field)
table_result = {"code": 0, "msg": None, "count": count[0], "data": data_dict}
cursor.close()
conn.close()
return jsonify(table_result)
(8) Visualization of recruitment data
From four perspectives: national, first-line city, new-line city and second-line city.
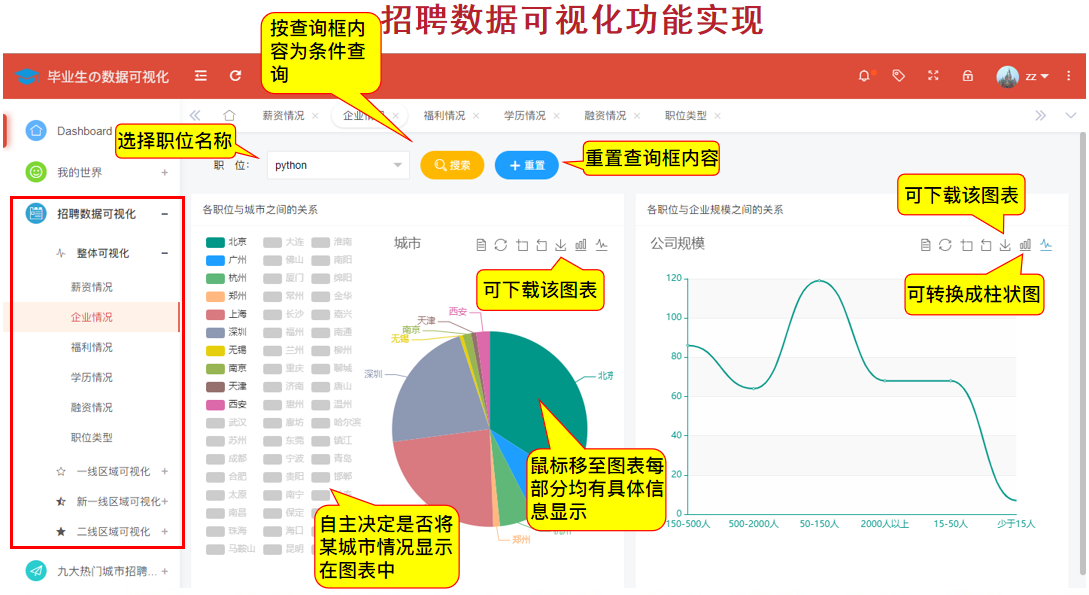
Take a chestnut and the analysis of the enterprise situation nationwide is as follows:
@app.route('/qiye',methods=['GET'])
def qiye():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("SELECT DISTINCT(city) from demo")
result = cursor.fetchall()
city = []
city_result = []
companySize = []
companySizeResult = []
selected = {}
# Captured Cities
for field in result:
city.append(field[0])
if (len(request.args) == 0):
# No query criteria
# Get the number of cities
for i in city:
cursor.execute("SELECT count(*) from demo where city = '" + i + "'")
count = cursor.fetchall()
dict = {'value': count[0][0], 'name': i}
city_result.append(dict)
# Initialize initial display of several cities
for i in city[10:]:
selected[i] = False
# Acquire several company sizes
cursor.execute("SELECT DISTINCT(companySize) from demo")
company = cursor.fetchall()
for field in company:
companySize.append(field[0])
# Number of companies of each size
cursor.execute("SELECT count(*) from demo where companySize = '" + field[0] + "'")
count = cursor.fetchall()
companySizeResult.append(count[0][0])
else:
positionName = str(request.args['positionName']).lower()
# Query criteria: a certain occupation
# Number of certain occupations per city
for i in city:
cursor.execute("SELECT count(*) from demo where city = '" + i + "' and positionName like '%"+positionName+"%'")
count = cursor.fetchall()
dict = {'value': count[0][0], 'name': i}
city_result.append(dict)
for i in city[10:]:
selected[i] = False
cursor.execute("SELECT DISTINCT(companySize) from demo")
company = cursor.fetchall()
for field in company:
companySize.append(field[0])
cursor.execute("SELECT count(*) from demo where companySize = '" + field[0] + "' and positionName like '%"+positionName+"%'")
count = cursor.fetchall()
companySizeResult.append(count[0][0])
result = {"city": city, "city_result": city_result, "selected": selected, "companySize": companySize, "companySizeResult": companySizeResult}
cursor.close()
return jsonify(result)
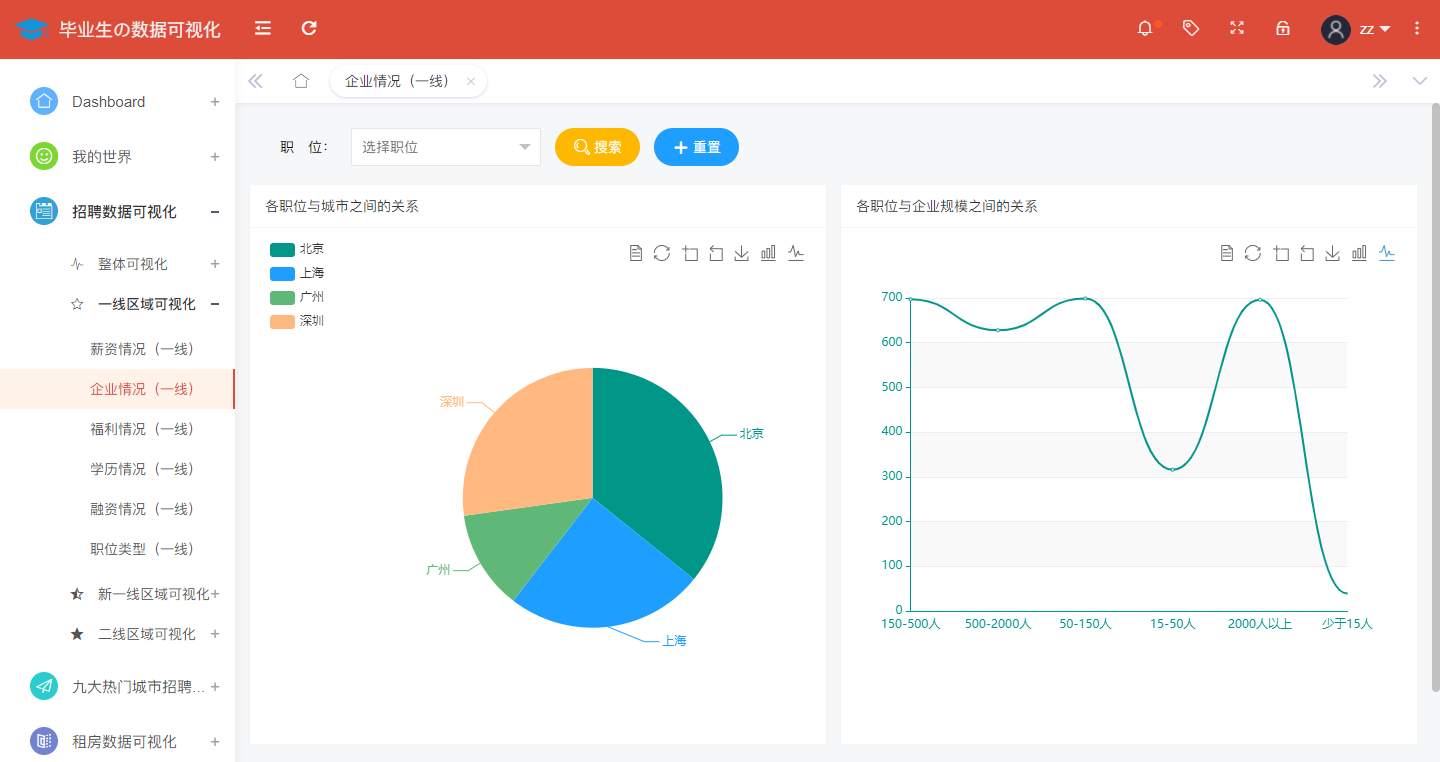
Enterprise analysis in first-tier cities is shown in the following figure:
@app.route('/qiye_first',methods=['GET'])
def qiye_first():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
#cursor.execute("SELECT DISTINCT(city) from demo")
#result = cursor.fetchall()
city = ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen']
city_result = []
companySize = []
companySizeResult = []
selected = {}
# Captured Cities
#for field in result:
#city.append(field[0])
if (len(request.args) == 0):
# No query criteria
# Get the number of cities
for i in city:
cursor.execute("SELECT count(*) from demo where city = '" + i + "'")
count = cursor.fetchall()
dict = {'value': count[0][0], 'name': i}
city_result.append(dict)
# Initialize initial display of several cities
for i in city[4:]:
selected[i] = False
# Acquire several company sizes
cursor.execute("SELECT DISTINCT(companySize) from demo where city in ('Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen');")
company = cursor.fetchall()
for field in company:
companySize.append(field[0])
# Number of companies of each size
cursor.execute("SELECT count(*) from demo where companySize = '" + field[0] + "' and city in ('Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen');")
count = cursor.fetchall()
companySizeResult.append(count[0][0])
else:
positionName = str(request.args['positionName']).lower()
# Query criteria: a certain occupation
# Number of certain occupations per city
for i in city:
cursor.execute("SELECT count(*) from demo where city = '" + i + "' and positionName like '%"+positionName+"%'")
count = cursor.fetchall()
dict = {'value': count[0][0], 'name': i}
city_result.append(dict)
for i in city[4:]:
selected[i] = False
cursor.execute("SELECT DISTINCT(companySize) from demo where city in ('Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen');")
company = cursor.fetchall()
for field in company:
companySize.append(field[0])
cursor.execute("SELECT count(*) from demo where companySize = '" + field[0] + "' and positionName like '%"+positionName+"%' and city in ('Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen');")
count = cursor.fetchall()
companySizeResult.append(count[0][0])
result = {"city": city, "city_result": city_result, "selected": selected, "companySize": companySize, "companySizeResult": companySizeResult}
cursor.close()
return jsonify(result)
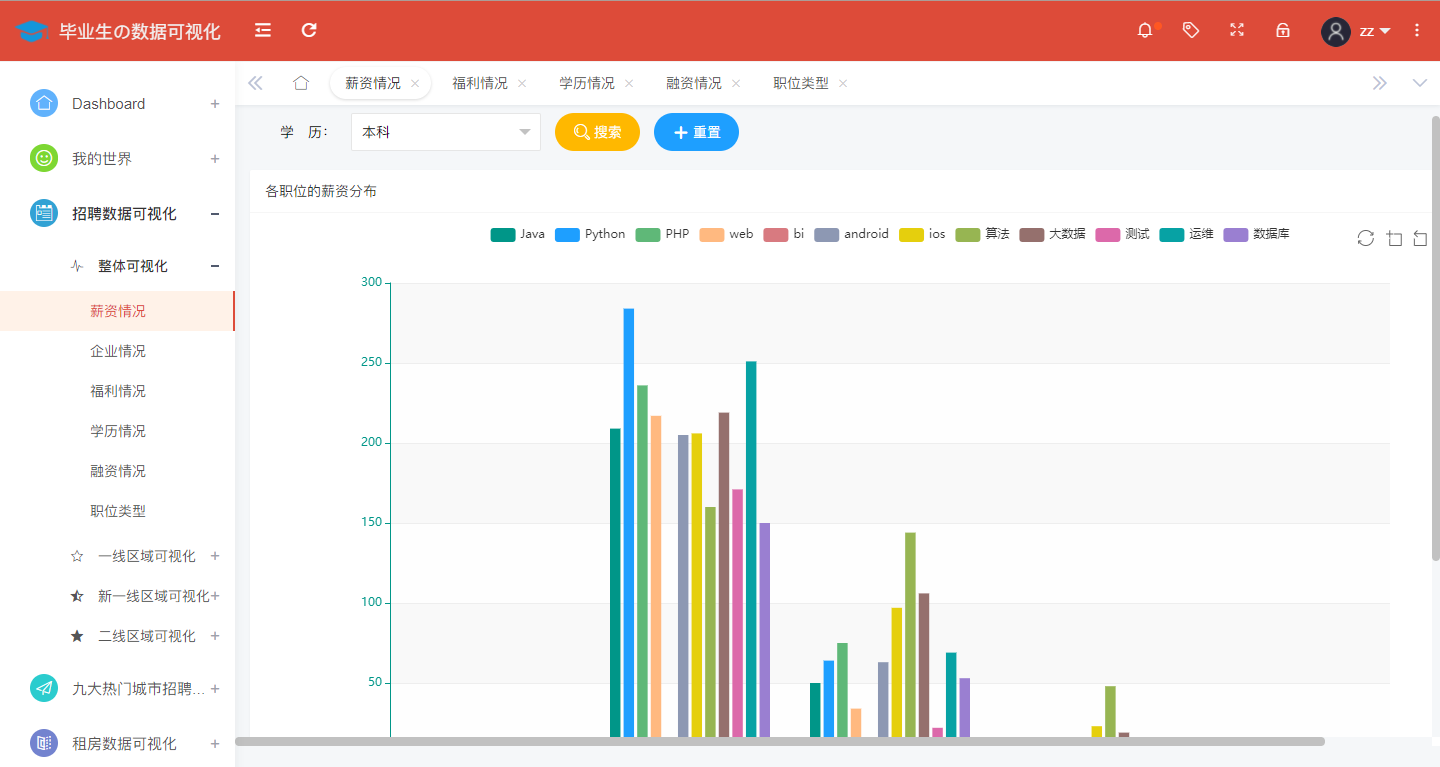
An analysis of salaries for undergraduate degree in China is shown in the figure:
@app.route('/xinzi',methods=['GET'])
def xinzi():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
positionName = ['java', 'python', 'php', 'web', 'bi', 'android', 'ios', 'algorithm', 'Big data', 'test', 'Operation and maintenance', 'data base']
#Column chart return list
zzt_list = []
zzt_list.append(['product', 'Java', 'Python', 'PHP', 'web', 'bi', 'android', 'ios', 'algorithm', 'Big data', 'test', 'Operation and maintenance', 'data base'])
if (len(request.args) == 0 or str(request.args['education'])=='Unlimited'):
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) like '%K%' and positionName like '%"+i+"%';")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['0—10K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 10 AND 20 and positionName like '%"+i+"%';")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['10—20K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 20 AND 30 and positionName like '%"+i+"%';")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['20—30K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute(
"SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 30 AND 40 and positionName like '%" + i + "%';")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['30—40K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute(
"SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) > 40 and positionName like '%" + i + "%';")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['40 Above', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
else:
education = str(request.args['education'])
temp_list = []
for i in positionName:
cursor.execute(
"SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) like '%K%' and positionName like '%" + i + "%' and education = '"+education+"'")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['0—10K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute(
"SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 10 AND 20 and positionName like '%" + i + "%' and education = '"+education+"'")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['10—20K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute(
"SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 20 AND 30 and positionName like '%" + i + "%' and education = '"+education+"'")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['20—30K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute(
"SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 30 AND 40 and positionName like '%" + i + "%' and education = '"+education+"'")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['30—40K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute(
"SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) > 40 and positionName like '%" + i + "%' and education = '"+education+"'")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['40 Above', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
result = {"zzt": zzt_list}
cursor.close()
return jsonify(result)
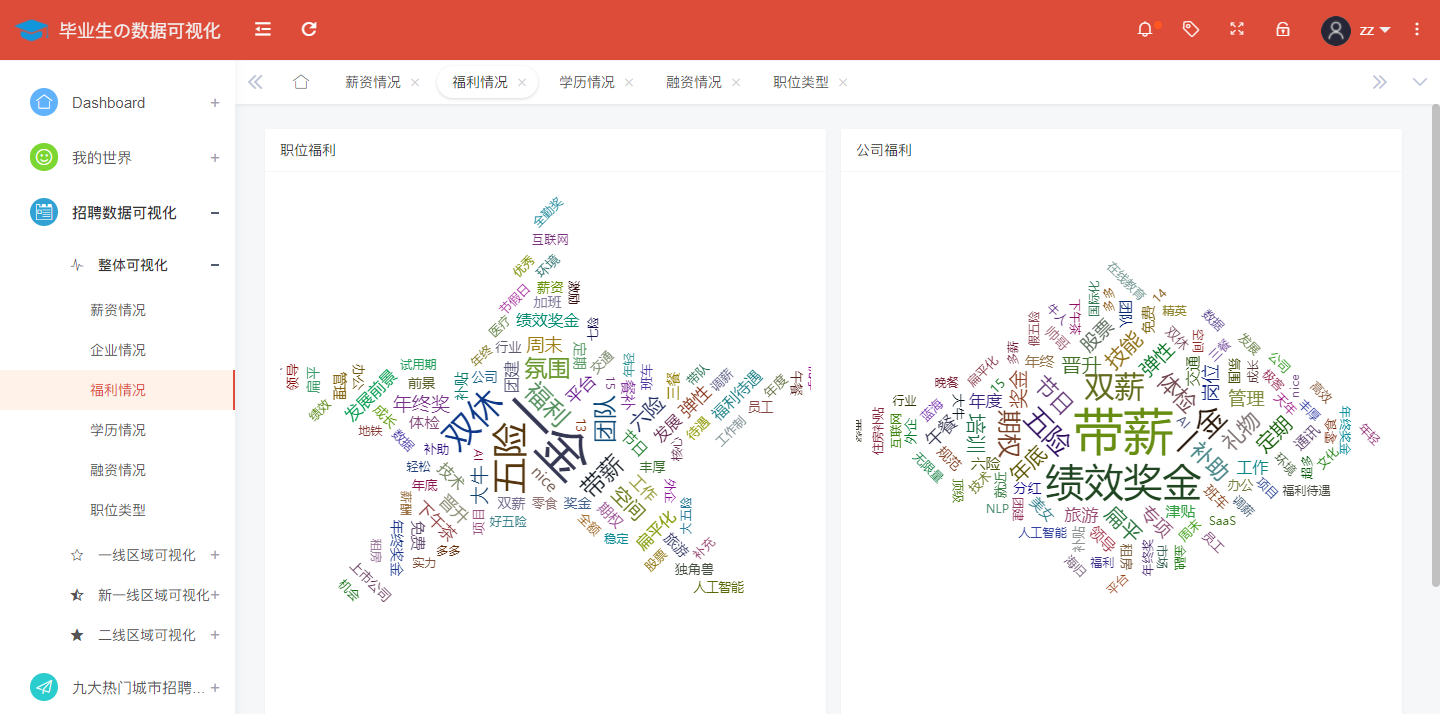
An analysis of the national welfare situation is shown in the figure:
@app.route('/fuli',methods=['GET'])
def fuli():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select positionAdvantage from `demo`")
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field['positionAdvantage'])
content = ''.join(data_dict)
positionAdvantage = []
jieba.analyse.set_stop_words('./stopwords.txt')
tags = jieba.analyse.extract_tags(content, topK=100, withWeight=True)
for v, n in tags:
mydict = {}
mydict["name"] = v
mydict["value"] = str(int(n * 10000))
positionAdvantage.append(mydict)
cursor.execute("select companyLabelList from `demo`")
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field['companyLabelList'])
content = ''.join(data_dict)
companyLabelList = []
jieba.analyse.set_stop_words('./stopwords.txt')
tags = jieba.analyse.extract_tags(content, topK=100, withWeight=True)
for v, n in tags:
mydict = {}
mydict["name"] = v
mydict["value"] = str(int(n * 10000))
companyLabelList.append(mydict)
cursor.close()
return jsonify({"zwfl": positionAdvantage, "gsfl": companyLabelList})
The analysis and display of the requirements of Internet job qualification and work experience nationwide is shown in the figure:
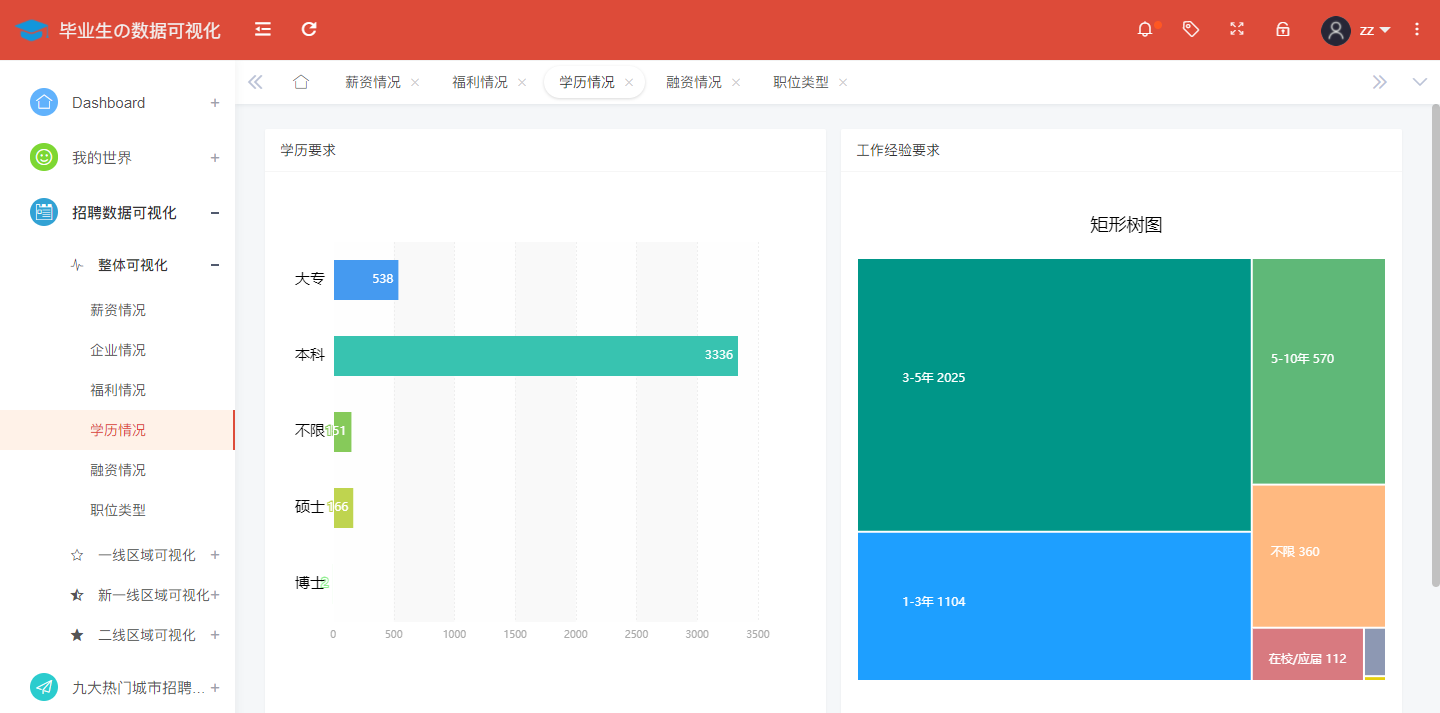
@app.route('/xueli',methods=['GET'])
def xueli():
#Open database connection
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
#Create a cursor object cursor
cursor = conn.cursor()
#Execute sql statement
cursor.execute("SELECT DISTINCT(education) from demo")
#Get a list of all records
result = cursor.fetchall()
education = []
education_data = []
color_list = ['#459AF0', '#38C3B0', '#86CA5A', '#BFD44F', ' #90EE90']
#Five situations of obtaining academic qualifications: unlimited, junior college, undergraduate, master, doctor
for field in result:
education.append(field[0])
#Number of corresponding degrees obtained
for i in range(len(education)):
cursor.execute("SELECT count(*) from demo where education = '" + education[i] + "'")
count = cursor.fetchall()
education_data.append({'value': count[0][0], 'itemStyle': {'color': color_list[i]}})
cursor.execute("SELECT DISTINCT(workYear) from demo")
result = cursor.fetchall()
workYear = []
workYear_data = []
#Several experience gained
for field in result:
workYear.append(field[0])
#Get the number for each work experience
for i in workYear:
cursor.execute("SELECT count(*) from demo where workYear = '" + i + "'")
count = cursor.fetchall()
workYear_data.append({'value': count[0][0], 'name': i})
cursor.close()
return jsonify({"education":education, "education_data":education_data, "workYear_data":workYear_data})
An analysis of the distribution of the financing stages of Internet companies throughout the country is shown in the figure:
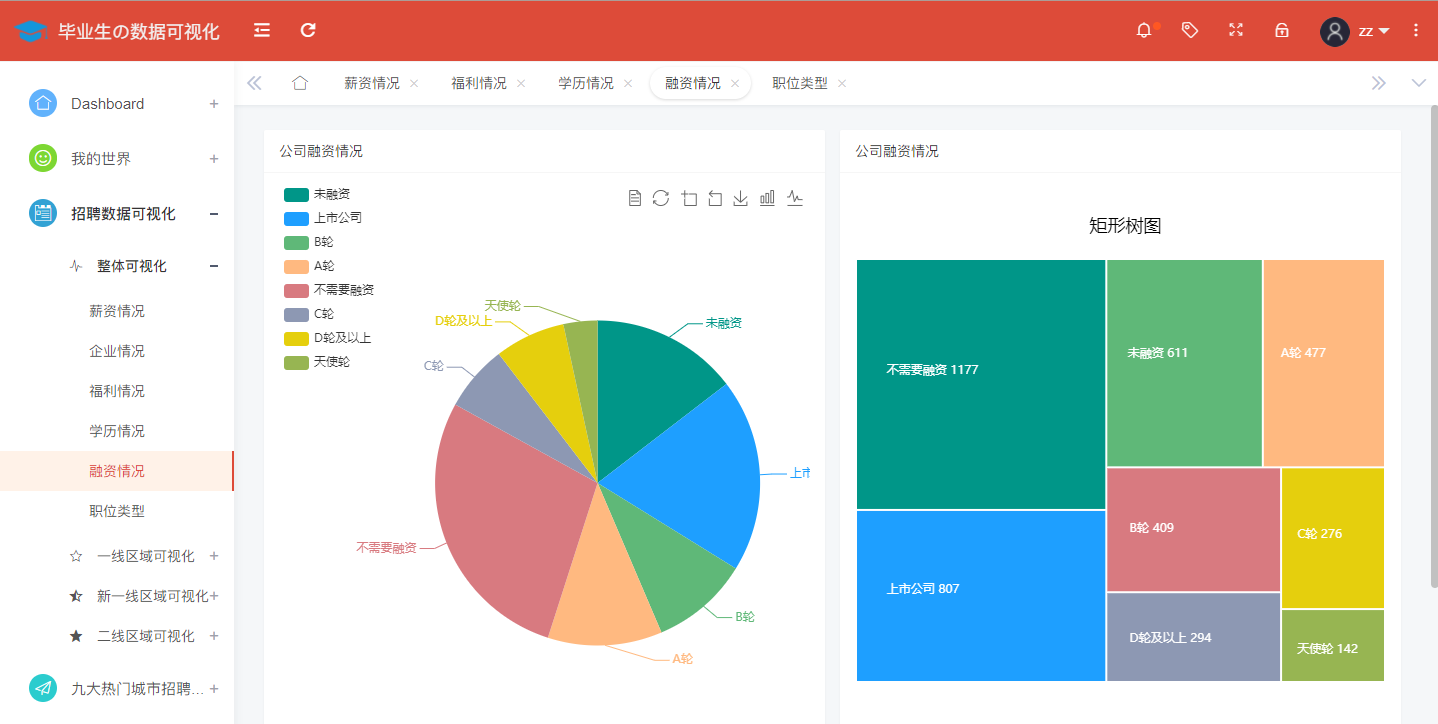
@app.route('/rongzi',methods=['GET'])
def rongzi():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("SELECT DISTINCT(financeStage) from demo")
result = cursor.fetchall()
finance = []
finance_data = []
# Several scenarios for obtaining financing
for field in result:
finance.append(field[0])
# Get the number for each financing
for i in range(len(finance)):
cursor.execute("SELECT count(*) from demo where financeStage = '" + finance[i] + "'")
count = cursor.fetchall()
finance_data.append({'value': count[0][0], 'name': finance[i]})
cursor.close()
return jsonify({"finance": finance, "finance_data": finance_data})
An analysis of the distribution of job types in Internet companies across the country is shown in the figure:
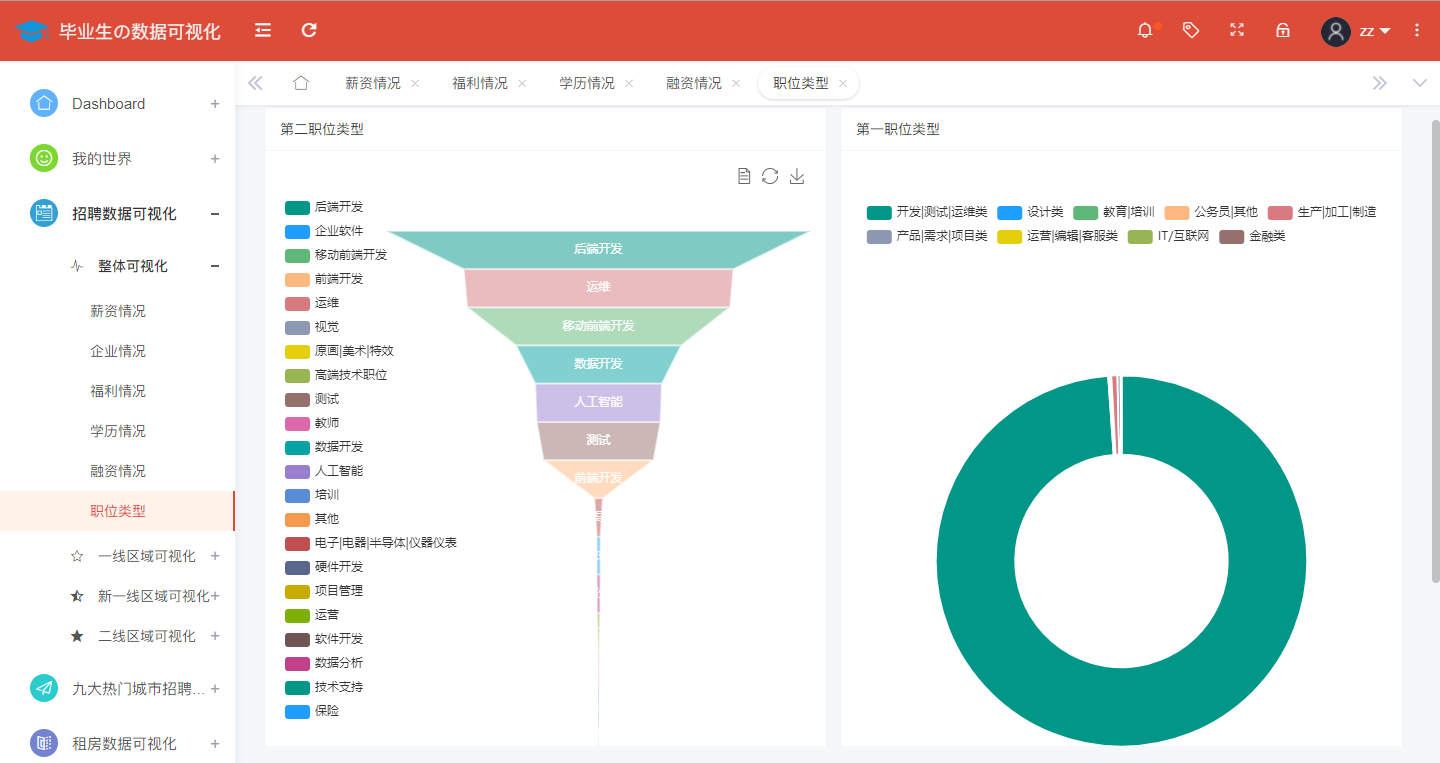
@app.route('/poststyle',methods=['GET'])
def poststyle():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("SELECT DISTINCT(firstType) from demo")
result = cursor.fetchall()
firstType = []
firstType_data = []
# Several cases of job type acquisition
for field in result:
firstType.append(field[0])
# Get the number for each job type
for i in range(len(firstType)):
cursor.execute("SELECT count(*) from demo where firstType = '" + firstType[i] + "'")
count = cursor.fetchall()
firstType_data.append({'value': count[0][0], 'name': firstType[i]})
cursor.execute("SELECT DISTINCT(secondType) from demo")
second = cursor.fetchall()
secondType = []
secondType_data = []
# Several cases of job type acquisition
for field in second:
secondType.append(field[0])
# Get the number for each job type
for i in range(len(secondType)):
cursor.execute("SELECT count(*) from demo where secondType = '" + secondType[i] + "'")
count = cursor.fetchall()
secondType_data.append({'value': count[0][0], 'name': secondType[i]})
cursor.close()
return jsonify({"firstType": firstType, "firstType_data": firstType_data, "secondType": secondType, "secondType_data": secondType_data})
(9) Comparison of recruitment in nine popular cities
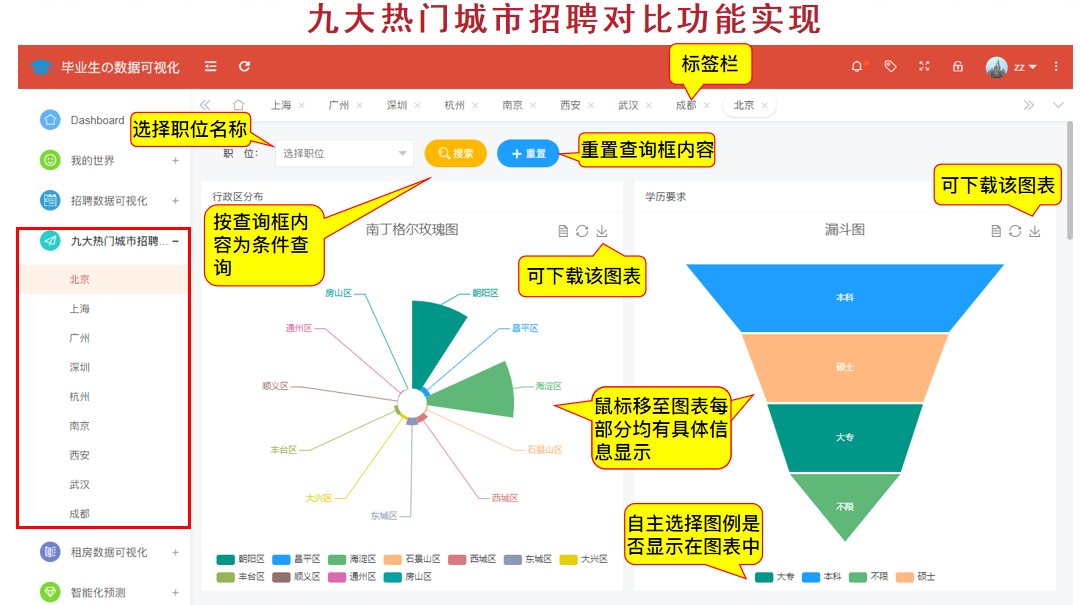
A pie chart texture can be used to show the size of an Internet company in a city, a funnel chart can show the academic requirements of a job in a city, etc.
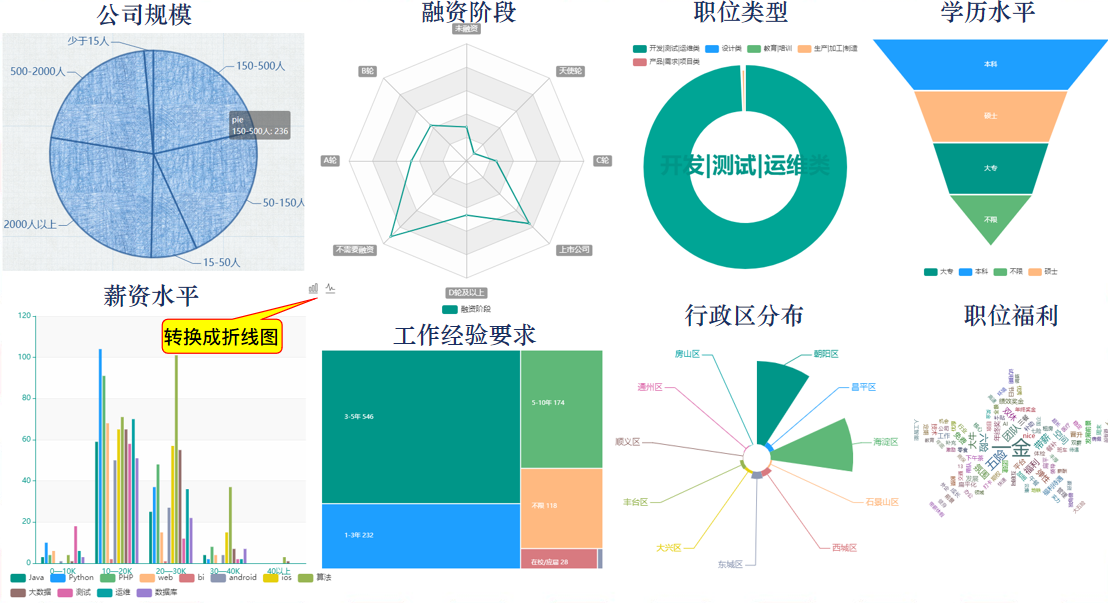
Take Beijing for example:
@app.route('/beijing',methods=['GET'])
def beijing():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
district = []
district_result = []
companySize = []
companySizeResult = []
education = []
educationResult = []
workYear = []
workYear_data = []
firstType = []
firstType_data = []
finance = []
finance_data = []
leida_max_dict = []
# Accessed Administrative Areas
cursor.execute("SELECT DISTINCT(district) from demo where city='Beijing';")
result = cursor.fetchall()
for field in result:
district.append(field[0])
if (len(request.args) == 0):
# No query criteria
# Get the corresponding number of administrative areas
for i in district:
cursor.execute("SELECT count(*) from demo where district = '" + i + "';")
count = cursor.fetchall()
dict = {'value': count[0][0], 'name': i}
district_result.append(dict)
# Acquire several company sizes
cursor.execute("SELECT DISTINCT(companySize) from demo where city = 'Beijing';")
company = cursor.fetchall()
for field in company:
companySize.append(field[0])
# Number of companies of each size
cursor.execute("SELECT count(*) from demo where companySize = '" + field[0] + "' and city = 'Beijing';")
count = cursor.fetchall()
dict = {'value': count[0][0], 'name': field[0]}
companySizeResult.append(dict)
# Acquire several academic qualifications
cursor.execute("SELECT DISTINCT(education) from demo where city = 'Beijing';")
eduresult = cursor.fetchall()
for field in eduresult:
education.append(field[0])
# Number of corresponding academic qualifications
cursor.execute("SELECT count(*) from demo where education = '" + field[0] + "' and city = 'Beijing';")
count = cursor.fetchall()
dict = {'value': count[0][0], 'name': field[0]}
educationResult.append(dict)
cursor.execute("SELECT DISTINCT(workYear) from demo where city = 'Beijing';")
workyear = cursor.fetchall()
# Several experience gained
for field in workyear:
workYear.append(field[0])
# Get the number for each work experience
for i in workYear:
cursor.execute("SELECT count(*) from demo where workYear = '" + i + "' and city = 'Beijing';")
count = cursor.fetchall()
workYear_data.append({'value': count[0][0], 'name': i})
cursor.execute("SELECT DISTINCT(financeStage) from demo where city = 'Beijing';")
result = cursor.fetchall()
# Several scenarios for obtaining financing
for field in result:
finance.append(field[0])
leida_max_dict.append({'name': field[0], 'max': 300})
# Get the number for each financing
for i in range(len(finance)):
cursor.execute("SELECT count(*) from demo where financeStage = '" + finance[i] + "' and city = 'Beijing';")
count = cursor.fetchall()
finance_data.append(count[0][0])
# Job Benefits
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select positionAdvantage from `demo` where city = 'Beijing';")
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field['positionAdvantage'])
content = ''.join(data_dict)
positionAdvantage = []
jieba.analyse.set_stop_words('./stopwords.txt')
tags = jieba.analyse.extract_tags(content, topK=100, withWeight=True)
for v, n in tags:
mydict = {}
mydict["name"] = v
mydict["value"] = str(int(n * 10000))
positionAdvantage.append(mydict)
# Job Type
cursor.execute("SELECT DISTINCT(firstType) from demo where city = 'Beijing';")
result = cursor.fetchall()
# Several cases of job type acquisition
for field in result:
for i in field.keys():
firstType.append(field[i])
# Get the number for each job type
for i in range(len(firstType)):
cursor.execute("SELECT count(*) from demo where firstType = '" + firstType[i] + "' and city = 'Beijing';")
count = cursor.fetchall()
for field in count:
for j in field.keys():
value = field[j]
firstType_data.append({'value': value, 'name': firstType[i]})
#Salary
positionName = ['java', 'python', 'php', 'web', 'bi', 'android', 'ios', 'algorithm', 'Big data', 'test', 'Operation and maintenance', 'data base']
# Column chart return list
zzt_list = []
zzt_list.append(
['product', 'Java', 'Python', 'PHP', 'web', 'bi', 'android', 'ios', 'algorithm', 'Big data', 'test', 'Operation and maintenance', 'data base'])
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) like '%k%' and positionName like '%" + i + "%' and city = 'Beijing';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
temp_list.append(value)
zzt_list.append(
['0—10K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 10 AND 20 and positionName like '%" + i + "%' and city = 'Beijing';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
temp_list.append(value)
zzt_list.append(['10—20K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 20 AND 30 and positionName like '%" + i + "%' and city = 'Beijing';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
temp_list.append(value)
zzt_list.append(['20—30K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 30 AND 40 and positionName like '%" + i + "%' and city = 'Beijing';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
temp_list.append(value)
zzt_list.append(['30—40K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) > 40 and positionName like '%" + i + "%' and city = 'Beijing';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
temp_list.append(value)
zzt_list.append(['40 Above', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
else:
positionName = str(request.args['positionName']).lower()
print(positionName)
# Query criteria: a certain occupation
# Administrative Region
for i in district:
cursor.execute("SELECT count(*) from demo where district = '" + i + "' and positionName like '%"+positionName+"%';")
count = cursor.fetchall()
dict = {'value': count[0][0], 'name': i}
district_result.append(dict)
# company size
cursor.execute("SELECT DISTINCT(companySize) from demo where city = 'Beijing';")
company = cursor.fetchall()
for field in company:
companySize.append(field[0])
cursor.execute("SELECT count(*) from demo where companySize = '" + field[0] + "' and positionName like '%"+positionName+"%' and city = 'Beijing';")
count = cursor.fetchall()
dict = {'value': count[0][0], 'name': field[0]}
companySizeResult.append(dict)
# Educational requirements
cursor.execute("SELECT DISTINCT(education) from demo where city = 'Beijing';")
eduresult = cursor.fetchall()
for field in eduresult:
education.append(field[0])
cursor.execute("SELECT count(*) from demo where education = '" + field[0] + "' and positionName like '%" + positionName + "%' and city = 'Beijing';")
count = cursor.fetchall()
dict = {'value': count[0][0], 'name': field[0]}
educationResult.append(dict)
#Hands-on background
cursor.execute("SELECT DISTINCT(workYear) from demo where city = 'Beijing';")
workyear = cursor.fetchall()
for field in workyear:
workYear.append(field[0])
cursor.execute("SELECT count(*) from demo where workYear = '" + field[0] + "' and positionName like '%" + positionName + "%' and city = 'Beijing';")
count = cursor.fetchall()
workYear_data.append({'value': count[0][0], 'name': field[0]})
# Financing Phase
cursor.execute("SELECT DISTINCT(financeStage) from demo where city = 'Beijing';")
result = cursor.fetchall()
# Several scenarios for obtaining financing
for field in result:
finance.append(field[0])
leida_max_dict.append({'name': field[0], 'max': 300})
# Get the number for each financing
for i in range(len(finance)):
cursor.execute("SELECT count(*) from demo where financeStage = '" + finance[i] + "' and positionName like '%" + positionName + "%' and city = 'Beijing';")
count = cursor.fetchall()
finance_data.append(count[0][0])
# Job Type
cursor.execute("SELECT DISTINCT(firstType) from demo where city = 'Beijing';")
result = cursor.fetchall()
# Several cases of job type acquisition
for field in result:
firstType.append(field[0])
# Get the number for each job type
for i in range(len(firstType)):
cursor.execute("SELECT count(*) from demo where firstType = '" + firstType[i] + "' and positionName like '%" + positionName + "%' and city = 'Beijing';")
count = cursor.fetchall()
firstType_data.append({'value': count[0][0], 'name': firstType[i]})
# Job Benefits
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select positionAdvantage from `demo` where city = 'Beijing' and positionName like '%" + positionName + "%' ;")
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field['positionAdvantage'])
content = ''.join(data_dict)
positionAdvantage = []
jieba.analyse.set_stop_words('./stopwords.txt')
tags = jieba.analyse.extract_tags(content, topK=100, withWeight=True)
for v, n in tags:
mydict = {}
mydict["name"] = v
mydict["value"] = str(int(n * 10000))
positionAdvantage.append(mydict)
# Salary
positionName_sample = ['java', 'python', 'php', 'web', 'bi', 'android', 'ios', 'algorithm', 'Big data', 'test', 'Operation and maintenance', 'data base']
# Column chart return list
zzt_list = []
zzt_list.append(['product', 'Java', 'Python', 'PHP', 'Web', 'BI', 'Android', 'ios', 'algorithm', 'Big data', 'test', 'Operation and maintenance', 'data base'])
# <10k
temp_list = []
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) like '%k%' and positionName like '%" + positionName + "%' and city = 'Beijing';")
count = cursor.fetchall()
#print(count)
for i in count[0].keys():
value = count[0][i]
print(value)
for num in range(len(positionName_sample)):
if positionName == positionName_sample[num]:
temp_list.append(value)
else:
temp_list.append(0)
# print(temp_list)
# temp_list.append(value)
zzt_list.append(['0—10K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
# 10-20k
temp_list = []
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 10 AND 20 and positionName like '%" + positionName + "%' and city = 'Beijing';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
for num in range(len(positionName_sample)):
if positionName == positionName_sample[num]:
temp_list.append(value)
else:
temp_list.append(0)
# temp_list.append(value)
zzt_list.append(['10—20K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
# 20-30k
temp_list = []
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 20 AND 30 and positionName like '%" + positionName + "%' and city = 'Beijing';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
for num in range(len(positionName_sample)):
if positionName == positionName_sample[num]:
temp_list.append(value)
else:
temp_list.append(0)
#temp_list.append(value)
zzt_list.append(['20—30K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
# 30-40k
temp_list = []
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 30 AND 40 and positionName like '%" + positionName + "%' and city = 'Beijing';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
for num in range(len(positionName_sample)):
if positionName == positionName_sample[num]:
temp_list.append(value)
else:
temp_list.append(0)
#temp_list.append(value)
zzt_list.append(['30—40K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
# >40k
temp_list = []
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) > 40 and positionName like '%" + positionName + "%' and city = 'Beijing';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
for num in range(len(positionName_sample)):
if positionName == positionName_sample[num]:
temp_list.append(value)
else:
temp_list.append(0)
#temp_list.append(value)
zzt_list.append(['>40K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
print(zzt_list)
result = {"district": district, "district_result": district_result, "companySize": companySize, "companySizeResult": companySizeResult, "education": education, "educationResult": educationResult, "workYear_data":workYear_data, "firstType": firstType, "firstType_data": firstType_data, "leida_max_dict":leida_max_dict, "cyt": positionAdvantage, "finance": finance, "finance_data": finance_data, "zzt": zzt_list}
cursor.close()
return jsonify(result)
(10) Visualization of rental data
From four perspectives: national, first-line city, new-line city and second-line city.
Take a chestnut and analyze the rental housing area nationwide as shown in the following figure:
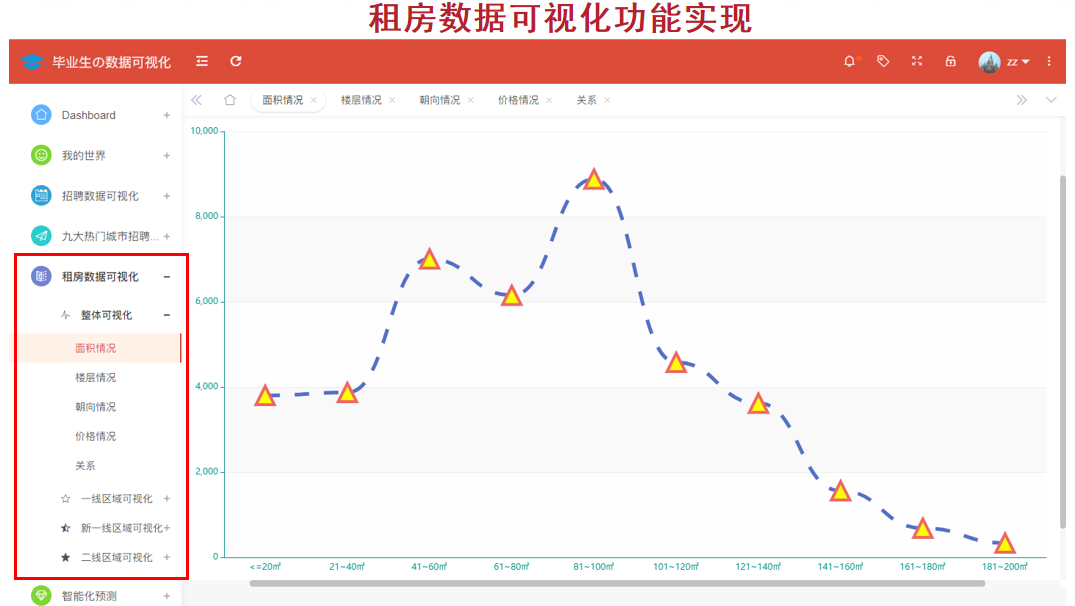
@app.route('/area',methods=['GET'])
def area():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
area_kind = ['<=20㎡', '21~40㎡', '41~60㎡', '61~80㎡', '81~100㎡', '101~120㎡', '121~140㎡', '141~160㎡', '161~180㎡', '181~200㎡']
area_data = []
# Get the number corresponding to each area category
#<=20㎡
cursor.execute("SELECT count(*) from house where area between 0 and 20;")
count = cursor.fetchall()
area_data.append(count[0][0])
#21~40㎡
cursor.execute("SELECT count(*) from house where area between 21 and 40;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 41~60㎡
cursor.execute("SELECT count(*) from house where area between 41 and 60;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 61~80㎡
cursor.execute("SELECT count(*) from house where area between 61 and 80;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 81~100㎡
cursor.execute("SELECT count(*) from house where area between 81 and 100;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 101~120㎡
cursor.execute("SELECT count(*) from house where area between 101 and 120;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 121~140㎡
cursor.execute("SELECT count(*) from house where area between 121 and 140;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 141~160㎡
cursor.execute("SELECT count(*) from house where area between 141 and 160;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 161~180㎡
cursor.execute("SELECT count(*) from house where area between 161 and 180;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 181~200㎡
cursor.execute("SELECT count(*) from house where area between 181 and 200;")
count = cursor.fetchall()
area_data.append(count[0][0])
cursor.close()
print(area_data)
return jsonify({"area_kind": area_kind, "area_data": area_data})
National analysis of rental housing floors shows as shown in the figure:
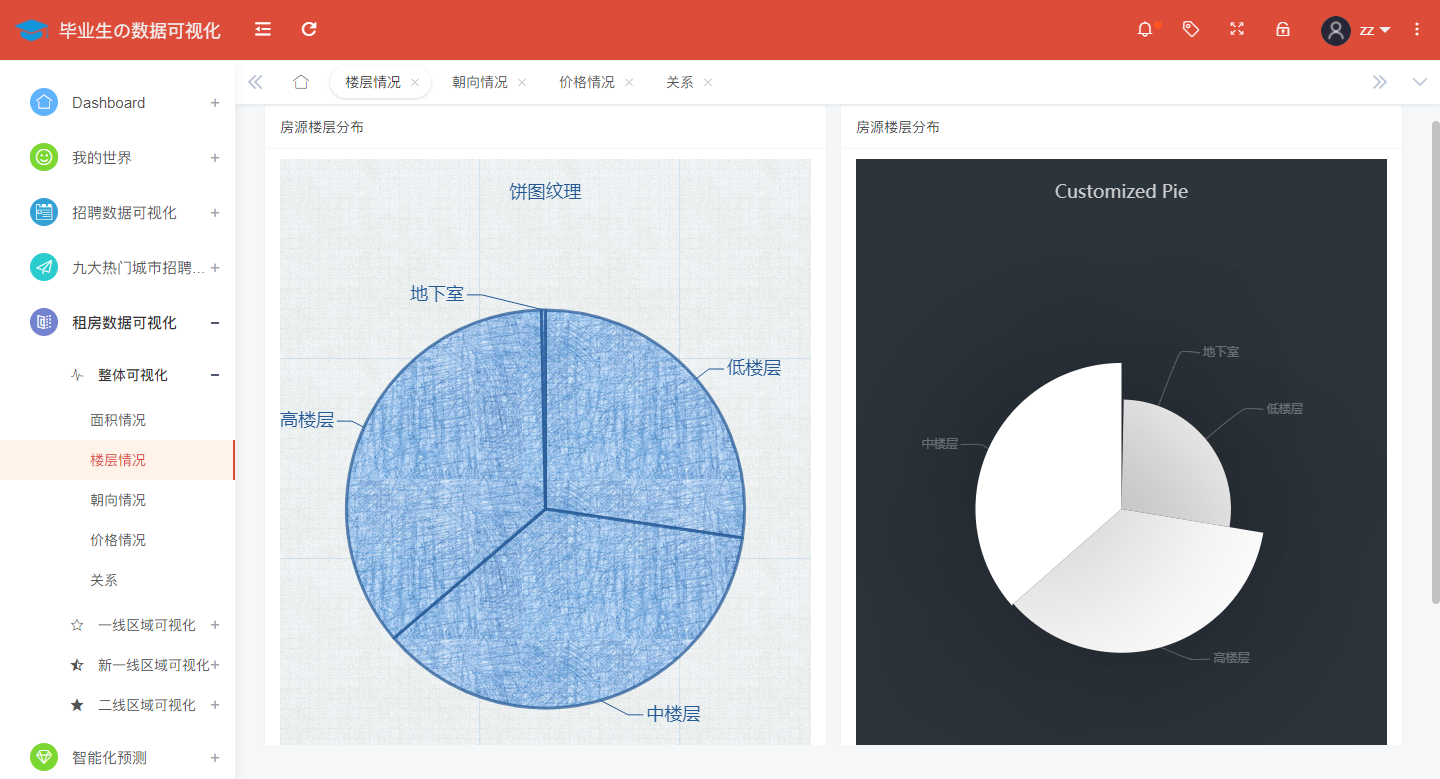
@app.route('/floor',methods=['GET'])
def floor():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("SELECT DISTINCT(floor) from house;")
result = cursor.fetchall()
floor_kind = []
floor_data = []
# Several cases of obtaining floors
for field in result:
floor_kind.append(field[0])
# Get the number corresponding to each floor type
for i in range(len(floor_kind)):
cursor.execute("SELECT count(*) from house where floor = '" + floor_kind[i] + "'")
count = cursor.fetchall()
floor_data.append({'value': count[0][0], 'name': floor_kind[i]})
cursor.close()
return jsonify({"floor_kind": floor_kind, "floor_data": floor_data})
An analysis of rental housing orientation nationwide is shown in the figure:
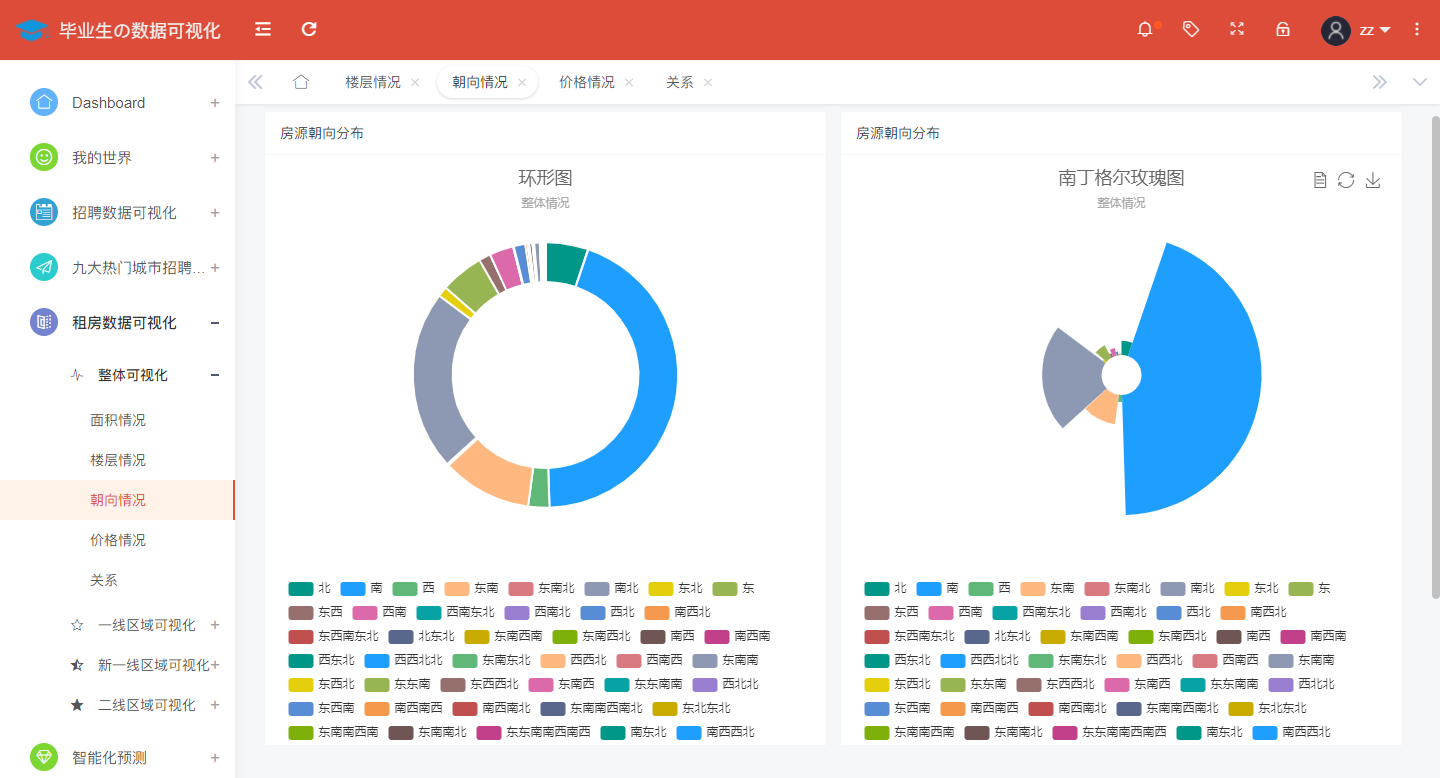
@app.route('/orient',methods=['GET'])
def orient():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("SELECT DISTINCT(orient) from house;")
result = cursor.fetchall()
orient_kind = []
orient_data = []
# Get several cases of orientation
for field in result:
orient_kind.append(field[0])
# Get the number corresponding to each orientation type
for i in range(len(orient_kind)):
cursor.execute("SELECT count(*) from house where orient = '" + orient_kind[i] + "'")
count = cursor.fetchall()
orient_data.append({'value': count[0][0], 'name': orient_kind[i]})
cursor.close()
print(orient_data)
return jsonify({"orient_kind": orient_kind, "orient_data": orient_data})
The nationwide analysis of rental housing prices shows as follows:
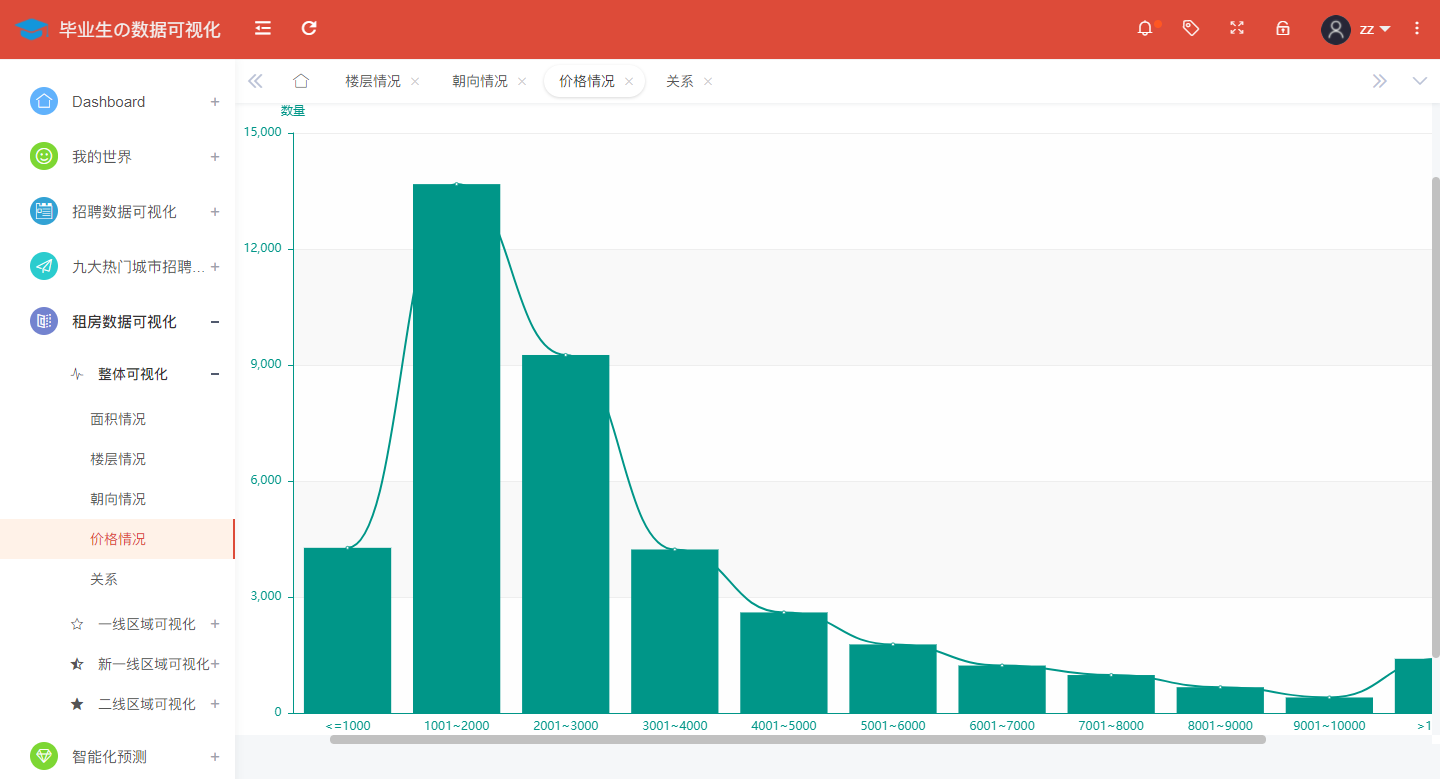
@app.route('/price',methods=['GET'])
def price():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
price_kind = ['<=1000', '1001~2000', '2001~3000', '3001~4000', '4001~5000', '5001~6000', '6001~7000', '7001~8000', '8001~9000', '9001~10000', '>10000']
price_data = []
# Get the number corresponding to each price category
# <=1000
cursor.execute("SELECT count(*) from house where price between 0 and 1000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 1001~2000
cursor.execute("SELECT count(*) from house where price between 1001 and 2000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 2001~3000
cursor.execute("SELECT count(*) from house where price between 2001 and 3000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 3001~4000
cursor.execute("SELECT count(*) from house where price between 3001 and 4000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 4001~5000
cursor.execute("SELECT count(*) from house where price between 4001 and 5000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 5001~6000
cursor.execute("SELECT count(*) from house where price between 5001 and 6000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 6001~7000
cursor.execute("SELECT count(*) from house where price between 6001 and 7000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 7001~8000
cursor.execute("SELECT count(*) from house where price between 7001 and 8000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 8001~9000
cursor.execute("SELECT count(*) from house where price between 8001 and 9000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 9001~10000
cursor.execute("SELECT count(*) from house where price between 9001 and 10000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# >10000
cursor.execute("SELECT count(*) from house where price >10000;")
count = cursor.fetchall()
price_data.append(count[0][0])
cursor.close()
print(price_data)
return jsonify({"price_kind": price_kind, "price_data": price_data})
The analysis of the relationship between rental housing price and housing area nationwide is shown in the figure:
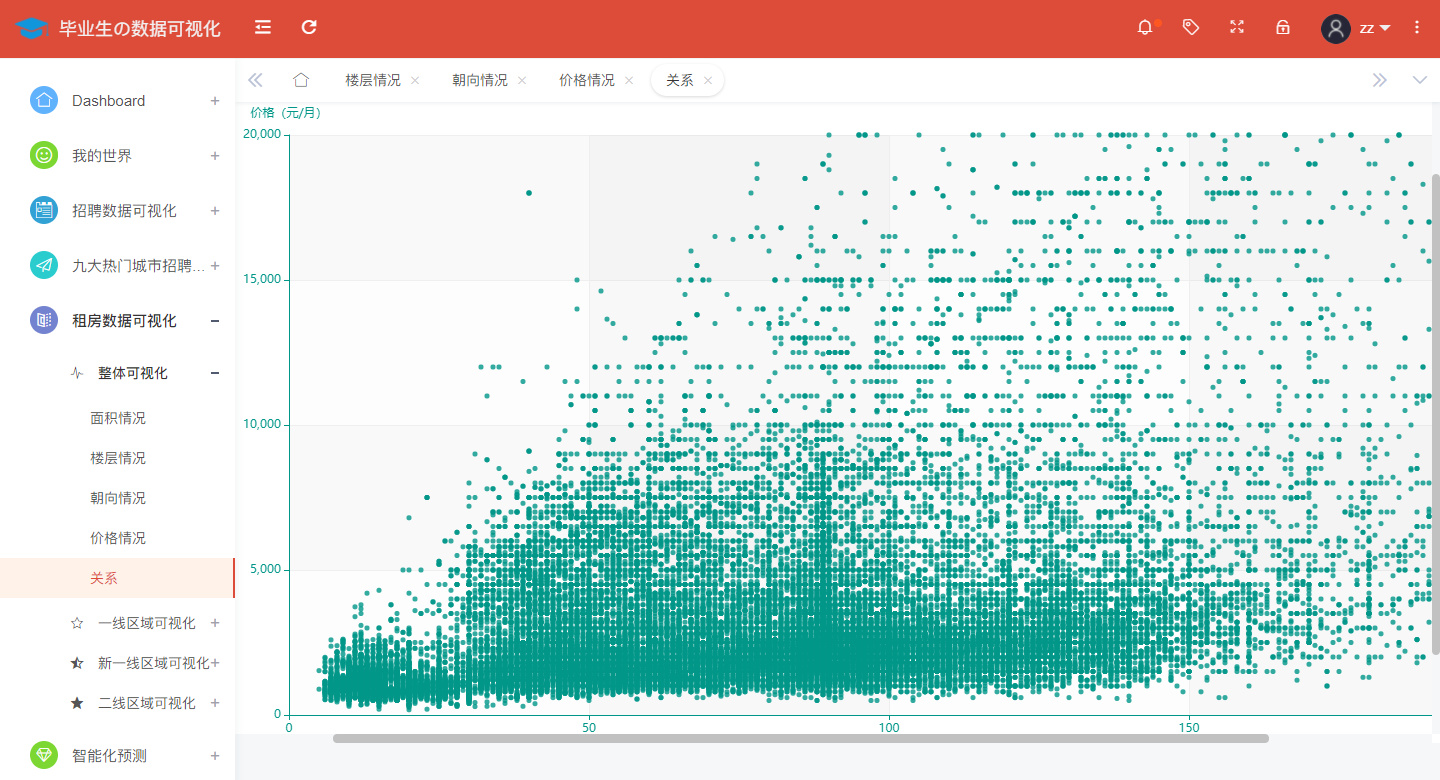
@app.route('/relation',methods=['GET'])
def relation():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
relation_data = []
cursor.execute("select count(*) from house;")
count = cursor.fetchall()
#print(count[0][0])
cursor.execute("SELECT area,price from house;")
result = cursor.fetchall()
for i in range(count[0][0]):
relation_data.append(list(result[i]))
#print(relation_data)
cursor.close()
return jsonify({"relation_data": relation_data})
(11) Intelligent prediction
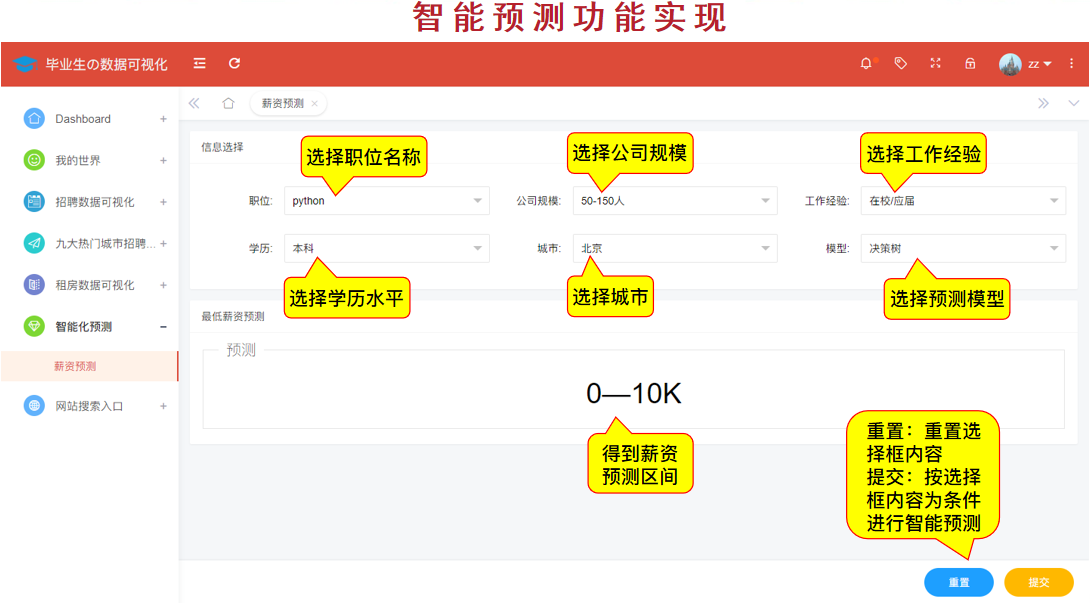
@app.route('/predict',methods=['GET'])
def predict():
y_data = ['0—10K', '10—20K', '20—30K', '30—40K', '40K Above']
positionName = str(request.args['positionName']).lower()
model = str(request.args['model'])
with open(positionName+'_'+model+'.model', 'rb') as fr:
selected_model = pickle.load(fr)
companySize = int(request.args['companySize'])
workYear = int(request.args['workYear'])
education = int(request.args['education'])
city = int(request.args['city'])
x = [companySize, workYear, education, city]
x = np.array(x)
y = selected_model.predict(x.reshape(1, -1))
return jsonify(y_data[y[0]])
(12) Web site access
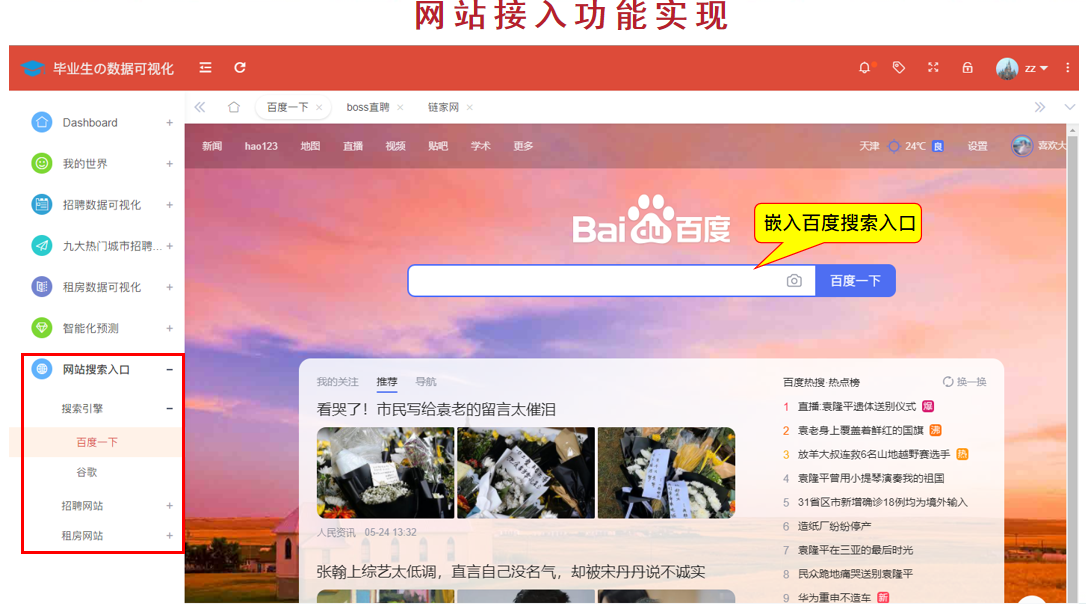
The project also has some shortcomings:
1. There is less job information in the recruitment database, the types of crawling websites are single, only Internet jobs are studied.
2. The system can only crawl the web address manually by crawling recruitment information and rental information
3. Job information and rental information of this system have not been intersected yet. It would be better to recommend nearby houses intelligently according to company address.