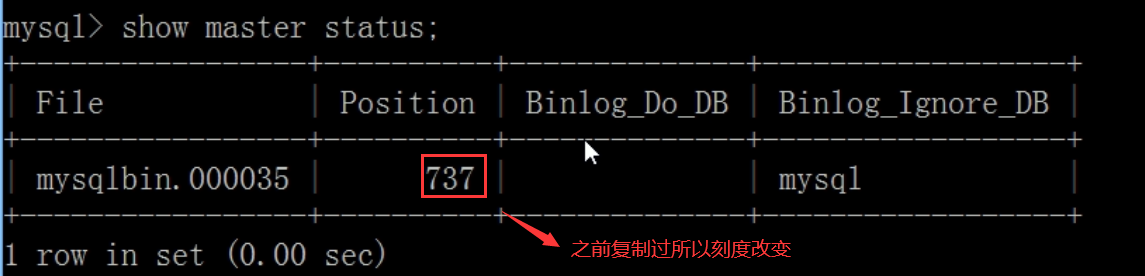
0 storage engine introduction
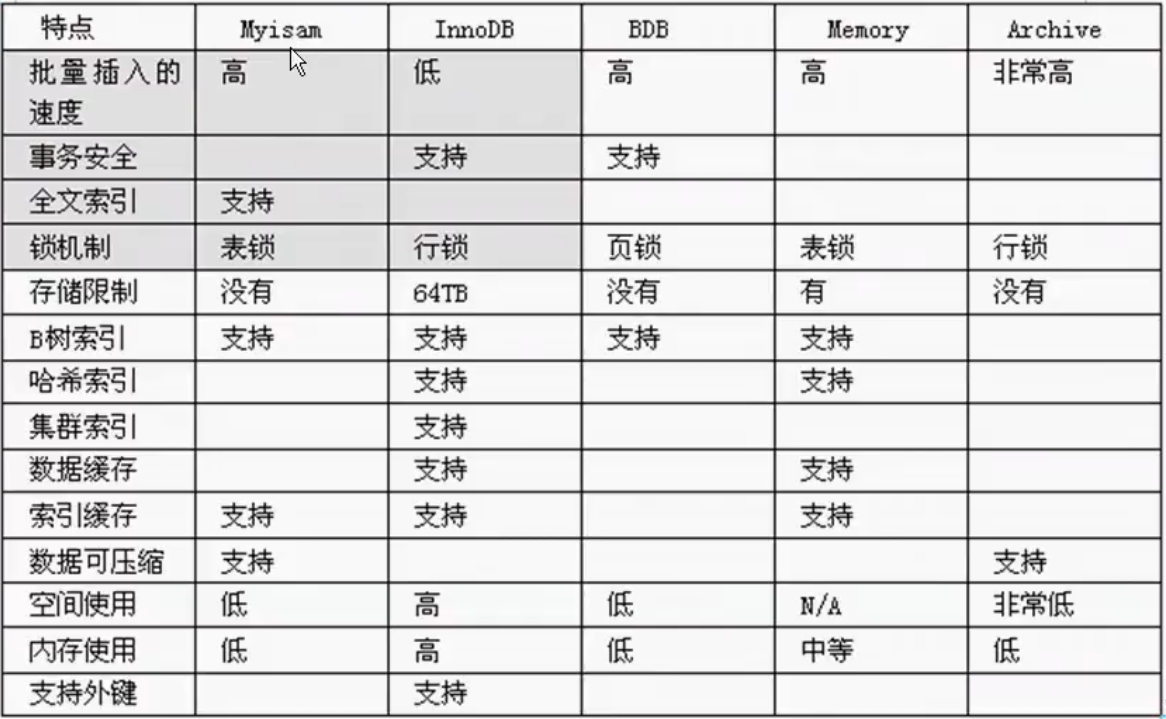
myisam storage: if the table does not have high transaction requirements and is mainly query and addition, we consider using myisam storage engine, such as posting table and reply table in bbs
- Regular defragmentation is required (because the deleted data still exists): optimize table_ name;
InnoDB storage: it has high transaction requirements, and the saved data are important data. We recommend using inno0db, such as order table and account table
The interview asked the difference between MyISAM and INNODB:
- 1. Transaction security
- 2. Query and add speed
- 3. Support full-text indexing
- 4. Locking mechanism
- 5. MyISAM does not support foreign keys, and INNODB supports foreign keys
Mermory storage: for example, our data changes frequently and does not need to be stored. At the same time, we consider using memory
View what storage engines mysql provides: show engines;
View the current default mysql storage engine: Show variables like '% storage'_ engine%';
1 SQL performance analysis
Reasons for SQL performance degradation:
- 1. The query statement is badly written
- 2. Index failure (data change)
- 3. Too many join (design defect or unavoidable requirement) for association query
- 4. Server tuning and parameter settings (buffer, number of threads, etc.)
Generally, SQL tuning process:
- Observe and run for at least 1 day to see how slow the production is.
- Open the slow query log, set the threshold value, for example, slow SQL for more than 5 seconds, and grab it.
- explain + slow SQL analysis.
- show profile.
- The operation and maintenance manager or DBA is responsible for tuning the parameters of the SQL database server.
Summary:
- 1. Enable and capture slow queries
- 2. explain + slow SQL analysis
- 3. show profile queries the execution details and life cycle of SQL in the Mysql server
- 4. Parameter tuning of SQL database server
2. Common JOIN queries
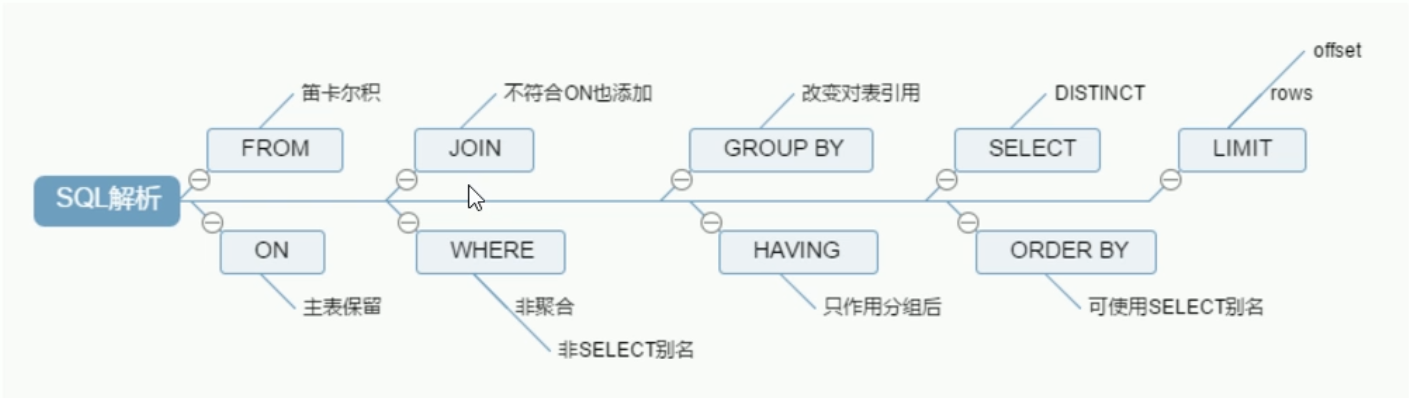
SQL execution load order
Handwriting order:
SELECT DISTINCT
<select_list>
FROM
<left_table> <join_type>
JOIN <right_table> on <join_codition> //join_ Code: for example, the Department ID of an employee is the same as the primary key ID of the Department table
WHERE
<where_condition>
GROUP BY
<group_by_list>
HAVING
<having_condition>
ORDER BY
<order_by_condition>
LIMIT
<limit_number>
MySQL machine reading order:
1 FROM <left_table> 2 ON <join_condition> 3 <join_type> JOIN <right_table> 4 WHERE <where_condition> 5 GROUP BY <group_by_list> 6 HAVING <having_condition> 7 SELECT 8 DISTINCT <select_list> 9 ORDER BY <order_by_condition> 10 LIMIT <limit_number>
Summary:
- The running sequence is up and down
Seven JOIN writing methods
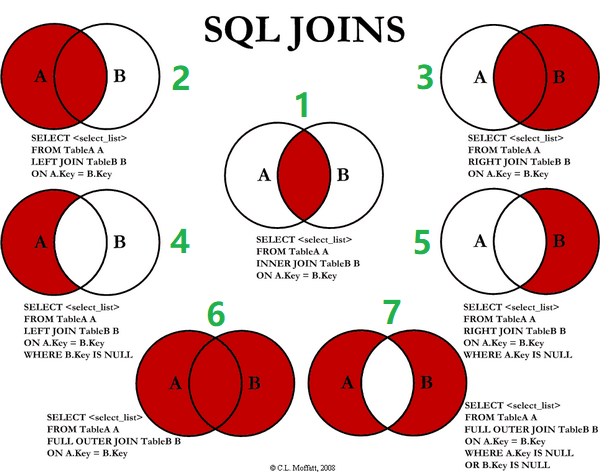
Create a table to insert data (left and right primary foreign keys are connected):
CREATE TABLE tbl_dept(
id INT(11) NOT NULL AUTO_INCREMENT,
deptName VARCHAR(30) DEFAULT NULL,
locAdd VARCHAR(40) DEFAULT NULL,
PRIMARY KEY(id)
)ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
//Set the storage engine, primary key automatic growth and default text character set
CREATE TABLE tbl_emp (
id INT(11) NOT NULL AUTO_INCREMENT,
NAME VARCHAR(20) DEFAULT NULL,
deptId INT(11) DEFAULT NULL,
PRIMARY KEY (id),
KEY fk_dept_Id (deptId)
#CONSTRAINT 'fk_dept_Id' foreign key ('deptId') references 'tbl_dept'('Id')
)ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO tbl_dept(deptName,locAdd) VALUES('RD',11);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('HR',12);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('MK',13);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('MIS',14);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('FD',15);
INSERT INTO tbl_emp(NAME,deptId) VALUES('z3',1);
INSERT INTO tbl_emp(NAME,deptId) VALUES('z4',1);
INSERT INTO tbl_emp(NAME,deptId) VALUES('z5',1);
INSERT INTO tbl_emp(NAME,deptId) VALUES('w5',2);
INSERT INTO tbl_emp(NAME,deptId) VALUES('w6',2);
INSERT INTO tbl_emp(NAME,deptId) VALUES('s7',3);
INSERT INTO tbl_emp(NAME,deptId) VALUES('s8',4);
INSERT INTO tbl_emp(NAME,deptId) VALUES('s9',51);
#Query results after execution
mysql> select * from tbl_dept;
+----+----------+--------+
| id | deptName | locAdd |
+----+----------+--------+
| 1 | RD | 11 |
| 2 | HR | 12 |
| 3 | MK | 13 |
| 4 | MIS | 14 |
| 5 | FD | 15 |
+----+----------+--------+
5 rows in set (0.00 sec)
mysql> select * from tbl_emp;
+----+------+--------+
| id | NAME | deptId |
+----+------+--------+
| 1 | z3 | 1 |
| 2 | z4 | 1 |
| 3 | z5 | 1 |
| 4 | w5 | 2 |
| 5 | w6 | 2 |
| 6 | s7 | 3 |
| 7 | s8 | 4 |
| 8 | s9 | 51 |
+----+------+--------+
8 rows in set (0.00 sec)
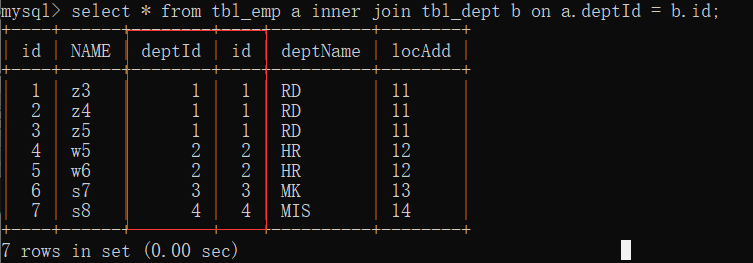
1. inner join: only the common part of deptId and id
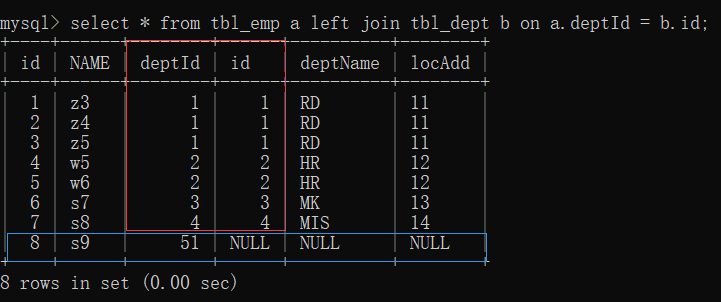
2. left join (all a): common data of the first seven articles; Article 8 table a has unique data, and table b has null
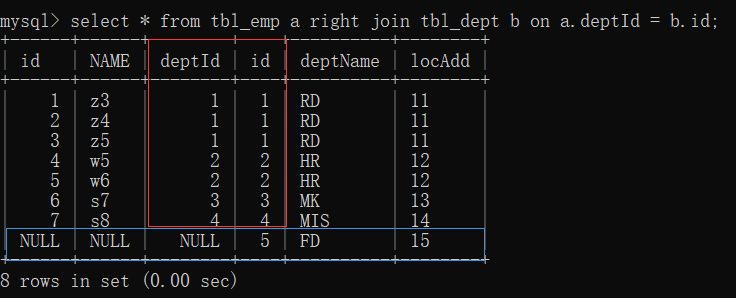
3. right join (all B): common data of the first seven articles; Article 8 table B has unique data, and table a has null
4. Left join: unique part of table A

5. Right join: unique part of table B

6. Full join: MySQL does not support full join. Use all a + all b and union to duplicate the middle part
- union keyword can be merged and de duplicated
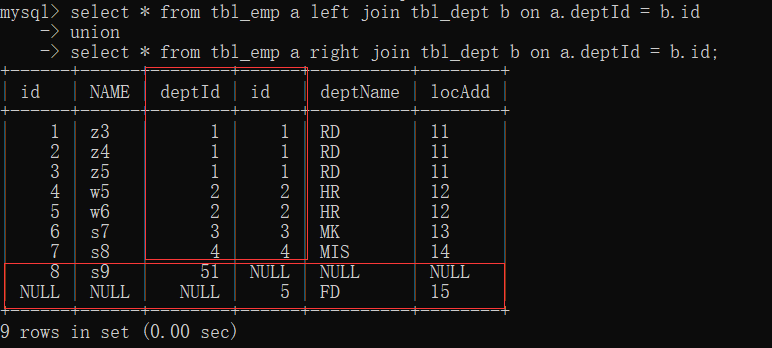
7. Each unique set of A and B
3 index introduction
3.1 what is the index
MySQL's official definition of Index is: Index is a data structure that helps MySQL obtain data efficiently (the essence of Index is data structure, with two functions of sorting + query).
The purpose of index is to improve query efficiency, which can be compared with dictionary.
If we want to check the word "mysql", we must locate the letter m, then find the letter y from the bottom, and then find the remaining sql.
If there is no index, you may need to look for it one by one. What if I want to find the word beginning with Java? Or the word that begins with Oracle?
Do you think this can't be done without an index?
An index can be understood as a data structure for fast searching in good order
The following figure is an example of a possible indexing method:
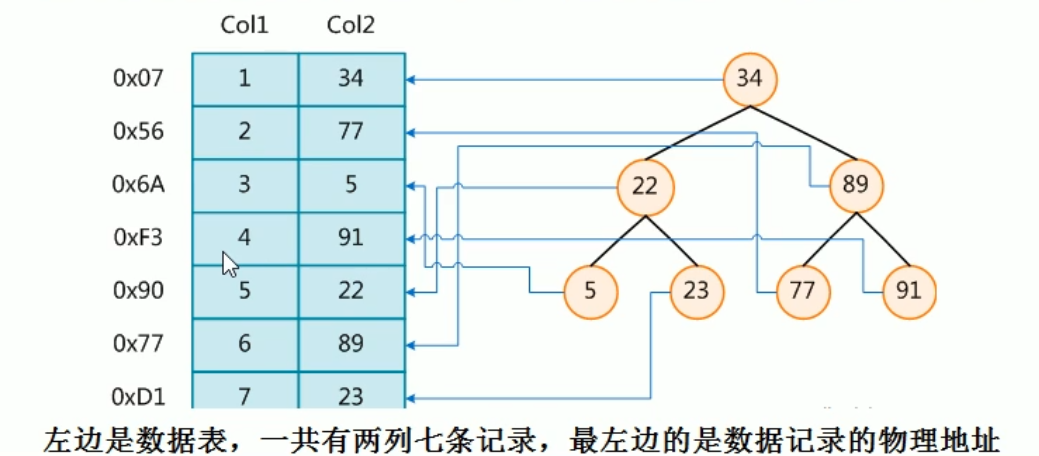
If you look for the book No. 4, scan the code to get the corresponding number 91. 91 is larger than 34, look to the right, 91 is larger than 89, look to the right, and then find it (you can find it after three comparisons, and then retrieve the corresponding physical address)
In order to speed up the search of Col2, a binary search tree shown on the right can be maintained. Each node contains an index key value and a pointer to the physical address of the corresponding data record. In this way, the binary search can be used to obtain the corresponding data within a certain complexity, so as to quickly retrieve the qualified records
Conclusion: in addition to the data, the database system also maintains the data structures that meet the specific search algorithm. These data structures refer to (point to) the data in some way, so that the advanced search algorithm can be realized on these data structures. This data structure is the index
Generally speaking, the index itself is also large, and it is impossible to store it all in memory. Therefore, the index is often stored on the disk in the form of index file.
The index we usually refer to, if not specified, refers to the index organized by B-tree (multi-channel search tree, not necessarily binary) structure. Among them, clustered index, secondary index, overlay index, composite index, prefix index and unique index all use B + tree index by default, collectively referred to as index. Of course, in addition to the B + tree index, there are hash index and so on
3.2 advantages and disadvantages of index
Advantages:
- Similar to the construction of bibliographic index in university library, it can improve the efficiency of data retrieval and reduce the cost of database.
- Sorting data by index column reduces the cost of data sorting and CPU consumption.
inferiority:
- In fact, the index is also a table, which saves the primary key and index fields and points to the records of the entity table, so the index column also takes up space (space)
- Although the index greatly improves the query speed, it will reduce the speed of updating the table, such as INSERT, UPDATE and DELETE. When updating a table, MySQL should not only save the data, but also save the index file. Every time the field with index column is updated, the index information after the key value changes caused by the UPDATE will be adjusted.
- Index is only a factor to improve efficiency. If your MysQL has a large amount of tables, you need to spend time studying and building the best index or optimizing queries
3.3 index classification and index creation command statements
Primary key index: the index value must be unique and cannot be NULL
- First: create table_ name(id int PRIMARY KEY aoto_increment,name varchar(10));
- Second: alter table_ name ADD PRIMARY KEY (columnName);
Normal index: the index value can appear multiple times
- First: create index_ name on table_ name(columnName);
- Second: alter table_ name ADD INDEX index_ name (columnName);
Full text index: mainly for text retrieval, such as articles. Full text index is only valid for MyISAM engine and only for English content
-
Create when creating tables
#Build table CREATE TABLE articles( id INT UNSIGNED ATUO_INCREMENT NOT NULL PRIMARY KEY, title VARCHAR(200), body TEXT, FULLTEXT(title,body) )engine=myisam charset utf8; #Specify engine #use select * from articles where match(title,body) against('English content'); #Effective only for English content #explain #1. In mysql, the fultext index only works for myisam #2. The flltext provided by mysq1 is only valid for English - > Sphinx (coreseek) technology to process Chinese workers #3. The use method is match (field name...) against('keyword ') #4. A full-text index is called a stop word. Because creating an index in a text is an infinite number, some common words and characters will not be created. These words are called stop words -
ALTER TABLE table_name ADD FULLTEXT index_name (columnName);
Unique index: the value of index column must be unique, but NULL value is allowed, and there can be multiple.
- First: create unique index_ name ON table_ name(columnName);
- Second: alter table_ name ADD UNIQUE INDEX index_ name ON (columnName);
Single value index: that is, an index contains only a single column, and a table can have multiple single column indexes.
- First: create index_ name ON table_ name(columnName);
- Second: alter table_ name ADD INDEX index_ name ON (columnName);
select * from user where name=''; //Frequently check the name field and build an index for it create index idx_user_name on user(name);
Composite index: that is, an index contains multiple columns
- First: create index_ name ON table_ name(columnName1,columnName2...);
- Second: alter table_ name ADD INDEX index_ name ON (columnName1,columnName2...);
select * from user where name='' and email=''; //Often check the name and email fields and build indexes for them create index idx_user_name on user(name, email);
Query index
- First: SHOW INDEX FROM table_name;
- Second: SHOW KEYS FROM table_name;
Delete index
- First: drop index_ name ON table_ name;
- Second: alter table_ name DROP INDEX index_ name;
- Delete primary key index: ALTER TBALE table_name DROP PRIMARY KEY;
3.4 index structure and retrieval principle
MySQL index structure:
- BTree index
- Hash index
- Full text index
- R-Tree index
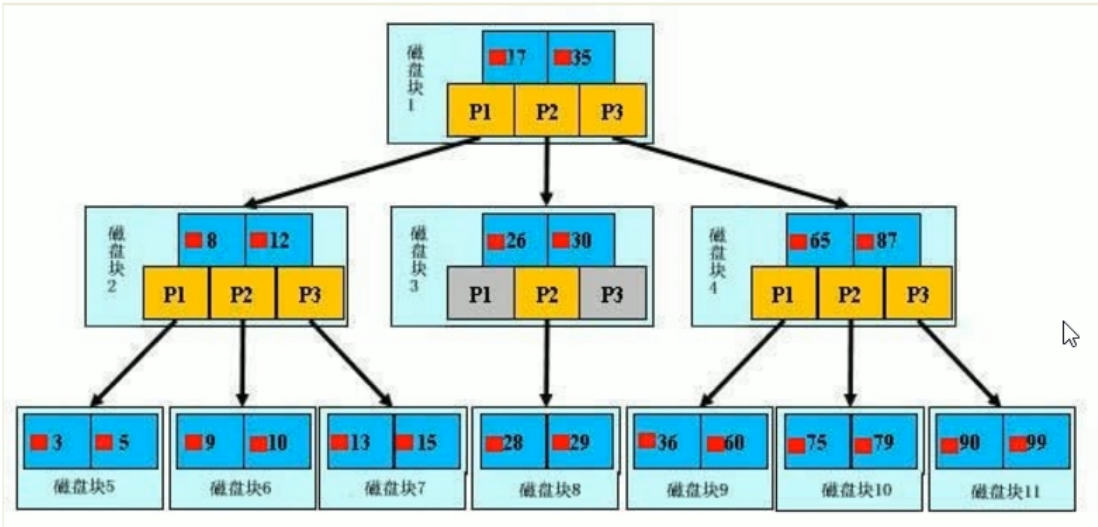
Initialization introduction
A b + tree with light blue blocks is called a disk block. You can see that each disk block contains several data items (shown in dark blue) and pointers (shown in yellow). For example, disk block 1 contains data items 17 and 35, including pointers P1, P2 and P3,
P1 represents a disk block less than 17, P2 represents a disk block between 17 and 35, and P3 represents a disk block greater than 35.
Real data exists in leaf nodes: 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90, 99.
Non leaf nodes only store real data, and only store data items that guide the search direction. For example, 17 and 35 do not really exist in the data table.
Search process
If you want to find data item 29, disk block 1 will first be loaded from the disk into memory, and an IO occurs. Use binary search in the memory to determine that 29 is between 17 and 35, lock the P2 pointer of disk block 1, and the memory time is negligible because it is very short (compared with the IO of the disk). Load disk block 3 from the disk to the memory through the disk address of the P2 pointer of disk block 1, and the second IO occurs. When 29 is between 26 and 30, lock the P2 pointer of disk block 3, Load disk block 8 to the memory through the pointer, and the third IO occurs. At the same time, do a binary search in the memory to find 29, and end the query. There are three IOS in total
The real situation is that the three-tier b + tree can represent millions of data. If millions of data searches only need three IO, the performance improvement will be huge. If there is no index and each data item needs one IO, then a total of millions of IO are required. Obviously, the cost is very high
3.5 what conditions are suitable for indexing
- The primary key automatically creates a unique index
- Fields frequently used as query criteria should be indexed
- The fields associated with other tables in the query are indexed by foreign key relationships
- Single key / combination index selection, who? (create composite index in high and low tendency)
- For the sorted fields in the query, if the sorted fields are accessed through the index, the sorting speed will be greatly improved
- Statistics or grouping fields in query
3.6 what is not suitable for indexing
- No index will be created for fields that are not used in the Where condition
- Too few records in the table (built above 300w)
- Frequently added, deleted and modified tables (which improves the query speed, but reduces the speed of updating tables, such as INSERT, UPDATE and DELETE. When updating tables, MySQL should not only save data, but also save index files)
- Table fields with repeated data and evenly distributed should be indexed only for the most frequently queried and sorted data columns. Note that if a data column contains a lot of duplicate content, indexing it will not have much practical effect. (e.g. nationality, gender)
If A table has 100000 rows of records, A field A has only T and F values, and the distribution probability of each value is about 50%, indexing the field A of this table generally will not improve the query speed of the database.
Index selectivity refers to the ratio of the number of different values in the index column to the number of records in the table. If there are 2000 records in a table and the table index column has 1980 different values, the selectivity of the index is 1980 / 2000 = 0.99. The closer the selectivity of an index is to 1, the higher the efficiency of the index
4 performance analysis
4.1 prerequisite knowledge of performance analysis
MySQL Query Optimizer[ ˈ kw ɪə ri] [ ˈɒ pt ɪ ma ɪ z ə]
The optimizer module in Mysql is specifically responsible for optimizing the SELECT statement. Its main function is to provide the Query requested by the client with the best execution plan (he thinks the best data retrieval method, but it is not necessarily the DBA thinks it is the best, which is the most time-consuming part) by calculating and analyzing the statistical information collected in the system
When the client requests a Query from mysql, the command parser module completes the request classification, distinguishes it from SELECT and forwards it to MySQL Query Optimizer, MySQL Query Optimizer will first optimize the whole Query, dispose of some constant expressions and directly convert the budget into constant values. And simplify and transform the Query conditions in Query, such as removing some useless or obvious conditions, structural adjustment, etc. Then analyze the Hint information (if any) in the Query to see if displaying the Hint information can completely determine the execution plan of the Query. If there is no Hint or Hint information is not enough to completely determine the execution plan, the statistical information of the involved objects will be read, the corresponding calculation and analysis will be written according to the Query, and then the final execution plan will be obtained
Common MySQL bottlenecks:
- CPU: CPU saturation usually occurs when data is loaded into memory or read from disk
- IO: the disk I/O bottleneck occurs when the loaded data is much larger than the memory capacity
- Performance bottlenecks of server hardware: top, free, iostat and vmstat to view the performance status of the system
4.2 introduction to explain
Use the EXPLAIN keyword to simulate the optimizer to execute SQL query statements, so as to know how MySQL handles your SQL statements. Analyze the performance bottleneck of your query statement or table structure
Explain's role:
- Read order of table
- Operation type of data read operation
- Which indexes can be used
- Which indexes are actually used
- References between tables
- How many rows per table are queried by the optimizer
Use Explain:
- explain + sql statement
- Information contained in the execution plan (key points): | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
mysql> select * from tbl_emp; +----+------+--------+ | id | NAME | deptId | +----+------+--------+ | 1 | z3 | 1 | | 2 | z4 | 1 | | 3 | z5 | 1 | | 4 | w5 | 2 | | 5 | w6 | 2 | | 6 | s7 | 3 | | 7 | s8 | 4 | | 8 | s9 | 51 | +----+------+--------+ 8 rows in set (0.00 sec) mysql> explain select * from tbl_emp; +----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------+ | 1 | SIMPLE | tbl_emp | NULL | ALL | NULL | NULL | NULL | NULL | 8 | 100.00 | NULL | +----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec)
4.3 explanation of information fields contained in the execution plan (top priority)
Information contained in the execution plan (key points): | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
Interview focus: id, type, key, rows, Extra
id (read order of the table)
The sequence number of the select query, including a set of numbers, indicating the order in which the select clause or operation table is executed in the query
Three cases:
-
1. The id is the same, and the execution order is from top to bottom (t1, t3, t2)
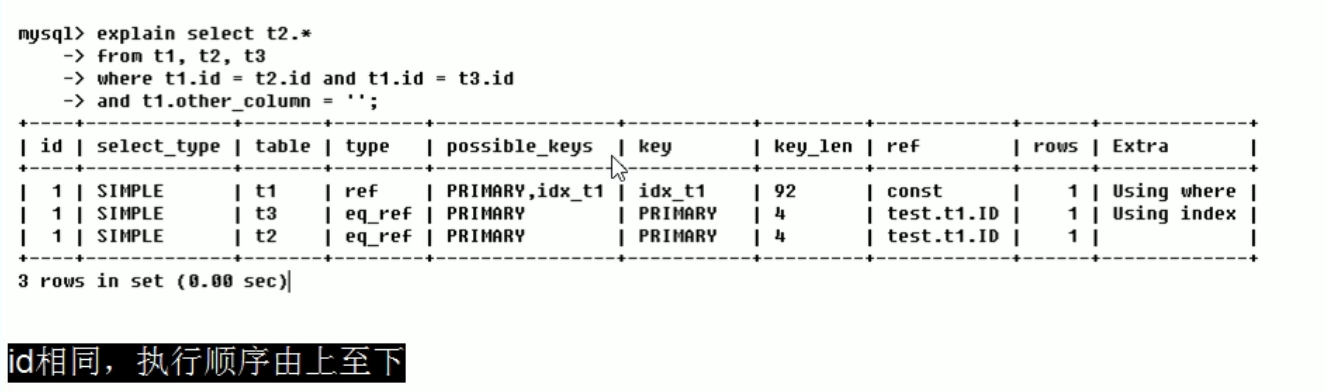
-
2. The id is different. If it is a sub query, the id sequence number will increase. The larger the id value, the higher the priority, and the earlier it is executed (t3, t1, t2)

-
3. The IDs are the same but different and exist at the same time. First go to those with large numbers and those with the same numbers from top to bottom (t3, s1, t2)

select_type (operation type of data reading operation)
The query type is mainly used to distinguish complex queries such as ordinary queries, joint queries and sub queries.
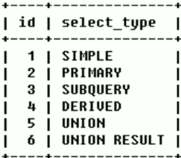
- SIMPLE [ ˈ s ɪ npl]: a simple select query that does not contain subqueries or unions
- PRIMARY: if the query contains any complex sub parts, the outermost query is marked as (the last one loaded)
- SUBQUERY [ ˈ kw ɪə ri]: contains a subquery in the SELECT or WHERE list
- DERIVED [d ɪˈ ra ɪ vd]: the sub queries contained in the FROM list are marked as derived. MySQL will recursively execute these sub queries and put the results in the temporary table
- UNION [ ˈ ju ː ni ə n] : if the second SELECT appears after union, it is marked as union; If union is included in subquery of the FROM clause, outer layer SELECT will be marked as: DERIVED
- UNION RESULT [r ɪˈ z ʌ lt]: select the result from the union table (two select statements are merged with Union)
Table (displays the name of the executed table)
Which table does the data in this row show about
Type (access type arrangement)
Displays what type of query is used
Access type arrangement: system > const > EQ_ ref > ref > fulltext > ref_ or_ null > index_ merge > unique_ subquery > index_ subquery > range > index >ALL
type there are eight common types:
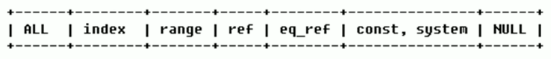
The result values from the best to the worst are (key points):: system > const > Eq_ ref > ref > range > index > ALL
Generally speaking, it is necessary to ensure that the query reaches at least the range level, preferably ref
detailed description
-
System: the table has only one row of records (equal to the system table). This is a special column of const type, which will not appear at ordinary times. This can also be ignored.
-
const: indicates that the index can be found once. const is used to compare the primary key or unique index. Because only one row of data is matched, MySQL can quickly convert the query into a constant if the primary key is placed in the where list.

-
eq_ref: unique index scan. For each index key, only one record in the table matches it. Common in primary key or unique index scans.
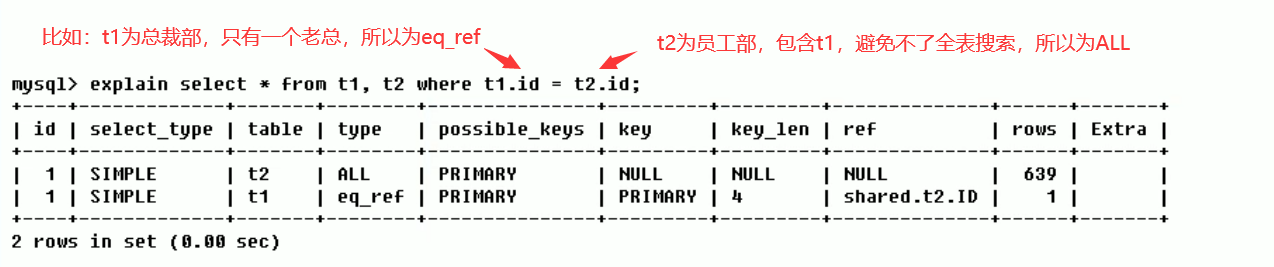
-
ref: non unique index scan, which returns all rows matching an individual value. In essence, it is also an index access. It returns all rows matching an individual value. However, it may find multiple qualified rows, so it should belong to the mixture of search and scan

-
Range: retrieve only rows in a given range, using an index to select rows. The key column shows which index is used. Generally, queries such as between, <, >, in appear in your where statement. This range scan index scan is better than full table scan because it only needs to start at one point of the index and end at another point without scanning all the indexes
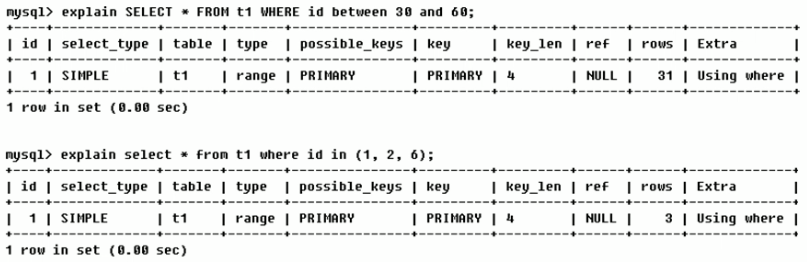
-
Index: Full Index Scan. The difference between index and all is that the index type only traverses the index column. This is usually faster than all because the index file is usually smaller than the data file (that is, although all and index read the full table, index reads from the index and all reads from the hard disk)

-
all: Full Table Scan, which will traverse the whole table to find matching rows

Work case: I ran Explain analysis for the manager's SQL. There may be ALL full table scanning on the system. It is recommended to try optimization. I changed this SQL. After optimization, I wrote it like this. This effect has changed from ALL to
possible_keys (which indexes can be used)
Displays one or more indexes that may be applied to this table. If there is an index for the fields involved in the query, the index will be listed, but it may not be actually used by the query (the system believes that some indexes will be used in theory)
key (which indexes are actually used)
The index actually used. If NULL, the index is not used (either not built or invalid)
If an overlay index is used in the query, the index will only appear in the key list
Overwrite index: the index fields created are consistent with those queried, as shown in the following figure
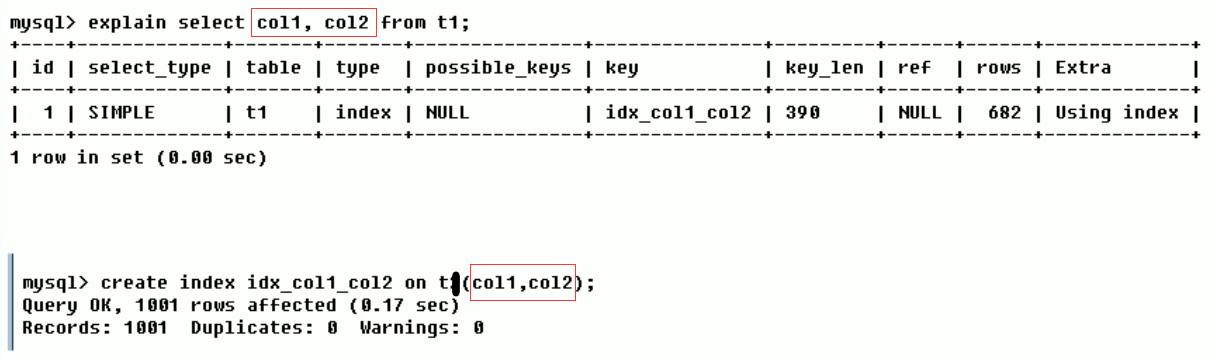
key_len (bytes consumed)
Represents the number of bytes used in the index. This column can be used to calculate the length of the index used in the query. The shorter the length, the better without losing accuracy
key_ The value displayed by Len is the maximum possible length of the index field, not the actual length, that is, key_len is calculated according to the table definition, not retrieved from the table

ref (Reference between tables)
Displays which column of the index is used, if possible, as a constant. Which columns or constants are used to find values on indexed columns.

Rows (how many rows per table are queried by the optimizer)
According to table statistics and index selection, roughly estimate the number of rows to read to find the required records (the smaller the better)
When not indexed:

After indexing: the number of rows scanned decreases
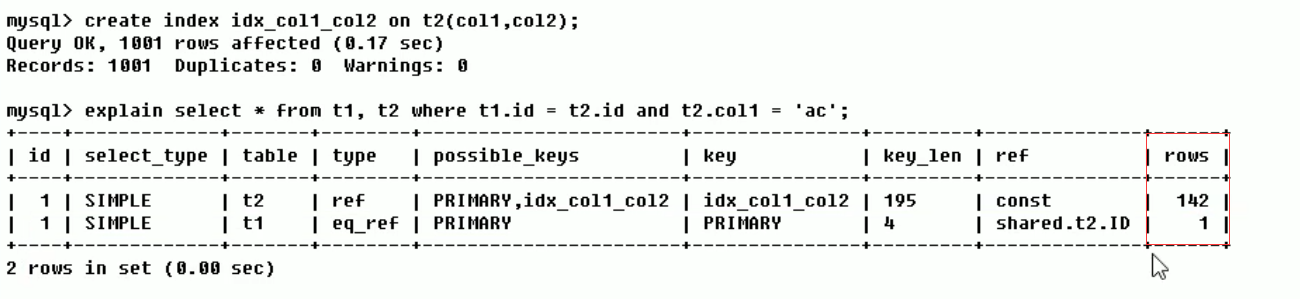
Extra [ˈekstrə]
Contains additional information that is not suitable for display in other columns but is important
Information types: Using filesort, Using temporary, Using index, Using where, Using join buffer, impossible where, select tables optimized away, distinct
Using filesort (to be optimized)
Note MySQL will use an external index to sort the data instead of reading it according to the index order in the table. The sort operation that cannot be completed by index in MySQL is called "file sort"
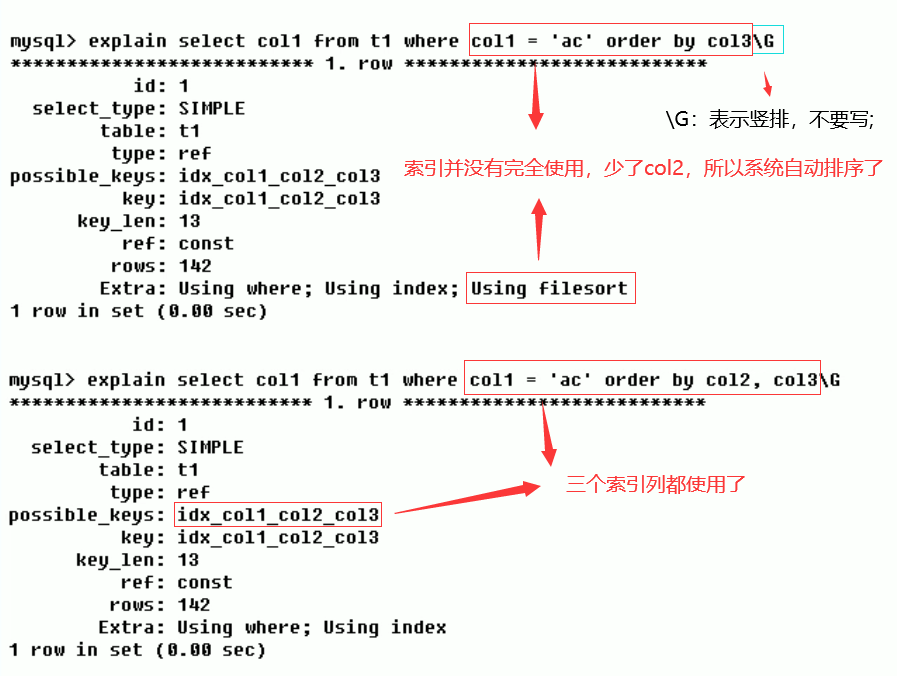
Using temporary
The temporary table is used to save intermediate results, and MysQL uses the temporary table when sorting query results. It is common in sorting order by and grouping query group by
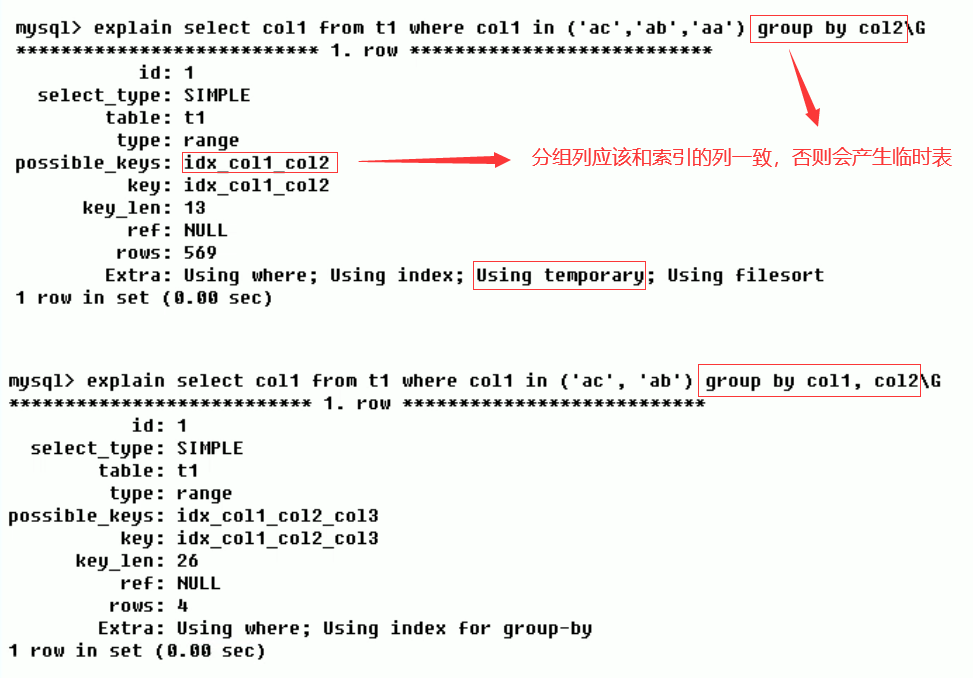
Using index(good)
It means that the Covering Index is used in the corresponding select operation to avoid accessing the data rows of the table. The efficiency is good!
-
Case 1:

-
Case 2:

Overwrite index / Covering Index.
- Understanding method 1: the selected data column can be obtained only from the index without reading the data row. MySQL can use the index to return the fields in the select list without reading the data file again according to the index. In other words, the query column should be overwritten by the built index.
- Understanding method 2: index is an efficient way to find rows, but general databases can also use index to find the data of a column, so it does not have to read the whole row. After all, index leaf nodes store the data they index; When the desired data can be obtained by reading the index, there is no need to read rows. An index that contains (or overwrites) data that meets the query results is called an overlay index.
be careful:
- If you want to use an overlay index, you must note that only the required columns are retrieved from the select list and cannot be selected*
- Because if all fields are indexed together, the index file will be too large and the query performance will be degraded
Using where: indicates where filtering is used.
Using join buffer: connection cache is used

impossible where: the value of the where clause is always false and cannot be used to obtain any tuples

select tables optimized away
Without the group by clause, the MIN/MAX operation is optimized based on the index or the COUNT(*) operation is optimized for the MyISAM storage engine. The calculation does not have to wait until the execution stage. The optimization is completed at the stage of query execution plan generation.
distinct
Optimize the distinct operation, and stop finding the same value after finding the first matching tuple.
practice
Write out the execution order of the following table
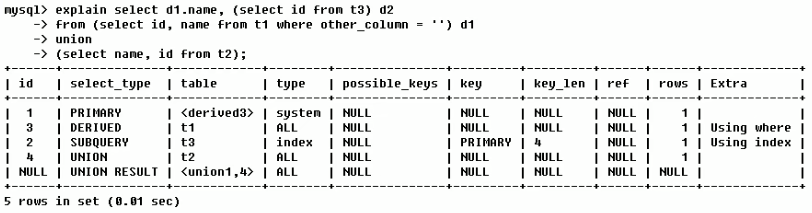
The first row (execution order 4): the id column is 1, indicating that it is the first select in the union_ The primary of the type column indicates that the query is an outer query, and the table column is marked as, indicating that the query result comes from a derived table, where 3 in derived3 indicates that the query is derived from the third select query, that is, the select with id 3. [select d1.name… ]
The second line (execution order 2): ID is 3, which is part of the third select in the whole query. Because the query is contained in from, it is derived. [select id,namefrom t1 where other_column=’’]
The third line (execution order 3): select the sub query in the select list_ The type is subquery, which is the second select in the whole query. [select id from t3]
Line 4 (execution order 1): Select_ If the type is union, it means that the fourth select is the second one in the union. First execute [select name,id from t2]
The fifth row (execution order 5): represents the stage of reading rows from the temporary table of the union. The < union1,4 > of the table column indicates that the union operation is performed with the results of the first and fourth select. [two result union operation]
5 index optimization
5.1 single index table optimization cases
Table creation:
CREATE TABLE IF NOT EXISTS article( id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, author_id INT(10) UNSIGNED NOT NULL, category_id INT(10) UNSIGNED NOT NULL, views INT(10) UNSIGNED NOT NULL, comments INT(10) UNSIGNED NOT NULL, title VARCHAR(255) NOT NULL, content TEXT NOT NULL ); INSERT INTO article(author_id,category_id,views,comments,title,content) VALUES (1,1,1,1,'1','1'), (2,2,2,2,'2','2'), (1,1,3,3,'3','3'); //query mysql> select * from article; +----+-----------+-------------+-------+----------+-------+---------+ | id | author_id | category_id | views | comments | title | content | +----+-----------+-------------+-------+----------+-------+---------+ | 1 | 1 | 1 | 1 | 1 | 1 | 1 | | 2 | 2 | 2 | 2 | 2 | 2 | 2 | | 3 | 1 | 1 | 3 | 3 | 3 | 3 | +----+-----------+-------------+-------+----------+-------+---------+ 3 rows in set (0.00 sec)
case
Requirement: query category_ When ID is 1 and comments is greater than 1, the articles with the most views_ id
//Function realization mysql> SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1; +----+-----------+ | id | author_id | +----+-----------+ | 3 | 1 | +----+-----------+ 1 row in set (0.00 sec) //explain analysis mysql> explain SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1; +----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+ | 1 | SIMPLE | article | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where; Using filesort | +----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+ 1 row in set, 1 warning (0.00 sec)
Conclusion: obviously, type is ALL, that is, the worst case. Using filesort also appears in Extra, which is also the worst case. Optimization is necessary
Start optimization
New index (add an index to the field used after the WHERE statement)
Creation method:
- create index idx_article_ccv on article(category_id,comments,views);
- ALTER TABLE 'article' ADD INDEX idx_article_ccv ( 'category_id , 'comments', 'views' );
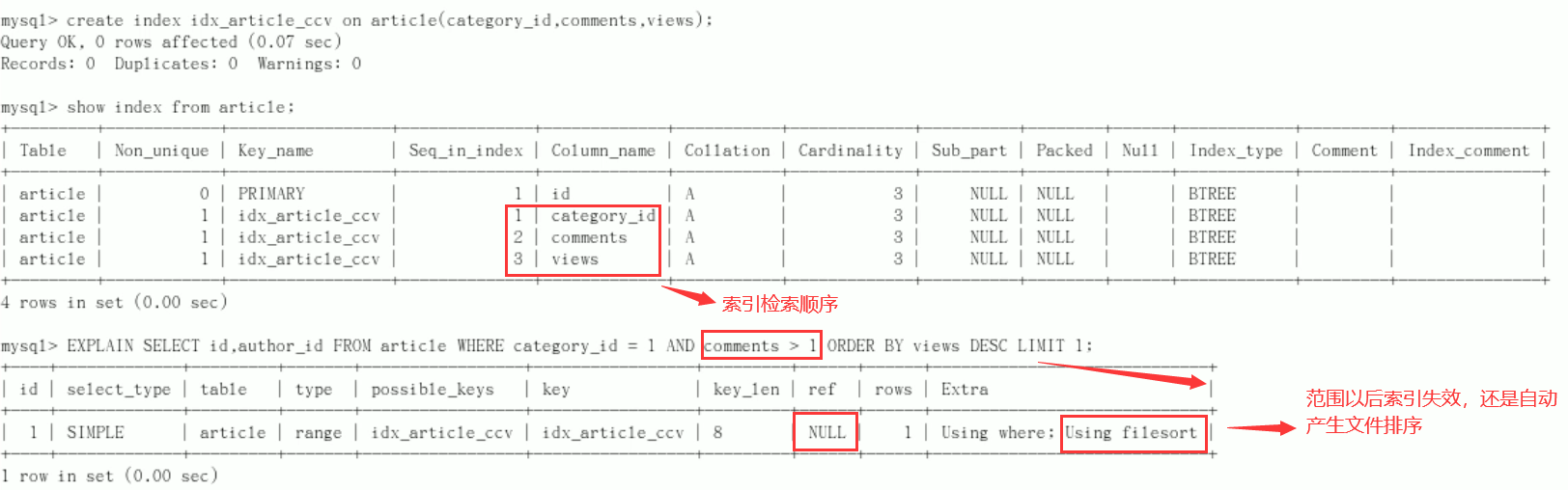
The index is of little use. Delete: DROP INDEX idx_article_ccv ON article;
Conclusion:
-
type becomes range, which is tolerable. However, Using filesort in extra is still unacceptable.
-
But we've built an index. Why doesn't it work?
-
This is because the category is sorted first according to the working principle of BTree index_ ID, if the same category is encountered_ ID, then sort comments. If the same comments are encountered, then sort views.
-
When the comments field is in the middle of the joint index, MySQL cannot use the index to retrieve the following views because the conditions of comments > 1 are a range value (so-called range), that is, the index behind the range type query field is invalid.
improvement
The comments field will not be indexed this time compared to the index created last time
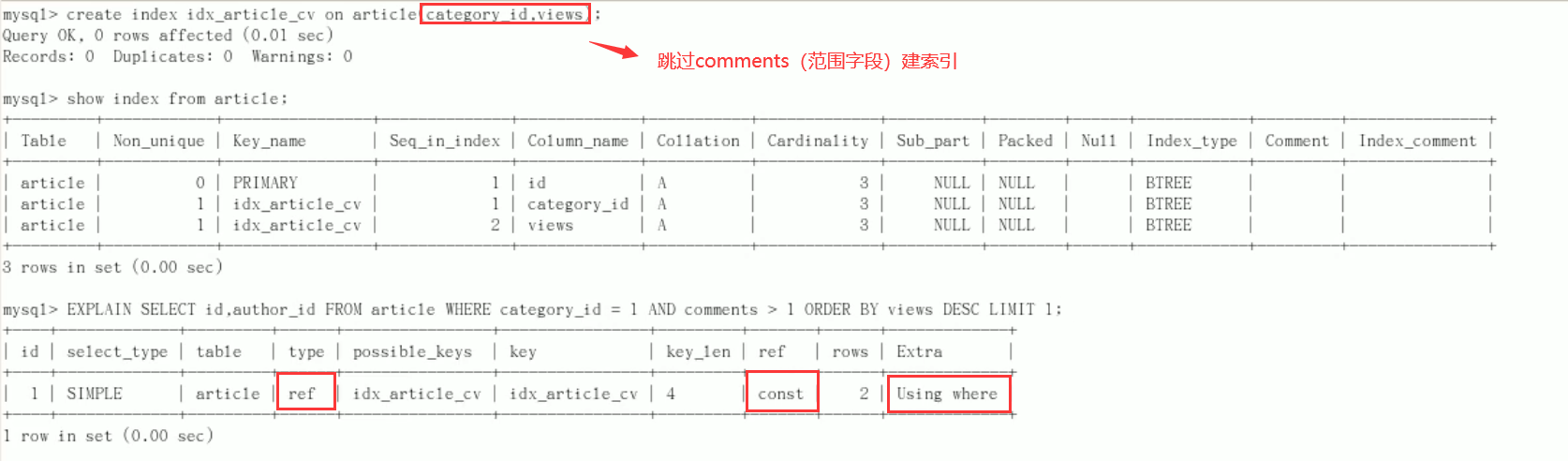
Conclusion: type changes to ref, const in ref, and Using filesort in Extra disappears. The result is very ideal
5.2 optimization cases of two index tables
Table creation:
CREATE TABLE IF NOT EXISTS class( id INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, card INT(10) UNSIGNED NOT NULL, PRIMARY KEY(id) ); CREATE TABLE IF NOT EXISTS book( bookid INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, card INT(10) UNSIGNED NOT NULL, PRIMARY KEY(bookid) ); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20))); //query mysql> select * from class; +----+------+ | id | card | +----+------+ | 1 | 17 | | 2 | 2 | | 3 | 18 | | 4 | 4 | | 5 | 4 | | 6 | 8 | | 7 | 9 | | 8 | 1 | | 9 | 18 | | 10 | 6 | | 11 | 15 | | 12 | 15 | | 13 | 12 | | 14 | 15 | | 15 | 18 | | 16 | 2 | | 17 | 18 | | 18 | 5 | | 19 | 7 | | 20 | 1 | | 21 | 2 | +----+------+ 21 rows in set (0.00 sec) mysql> select * from book; +--------+------+ | bookid | card | +--------+------+ | 1 | 8 | | 2 | 14 | | 3 | 3 | | 4 | 16 | | 5 | 8 | | 6 | 12 | | 7 | 17 | | 8 | 8 | | 9 | 10 | | 10 | 3 | | 11 | 4 | | 12 | 12 | | 13 | 9 | | 14 | 7 | | 15 | 6 | | 16 | 8 | | 17 | 3 | | 18 | 11 | | 19 | 5 | | 20 | 11 | +--------+------+ 20 rows in set (0.00 sec)
Start Explain analysis: all type s need to be optimized (there is always a table to add index driver)

- The left connection is the left table reference

drop index y on class;
- The left join adds an index to the right table

drop index Y on book;
- Case: if the index position created by others is wrong, you only need to adjust the order of the left and right tables during your own query
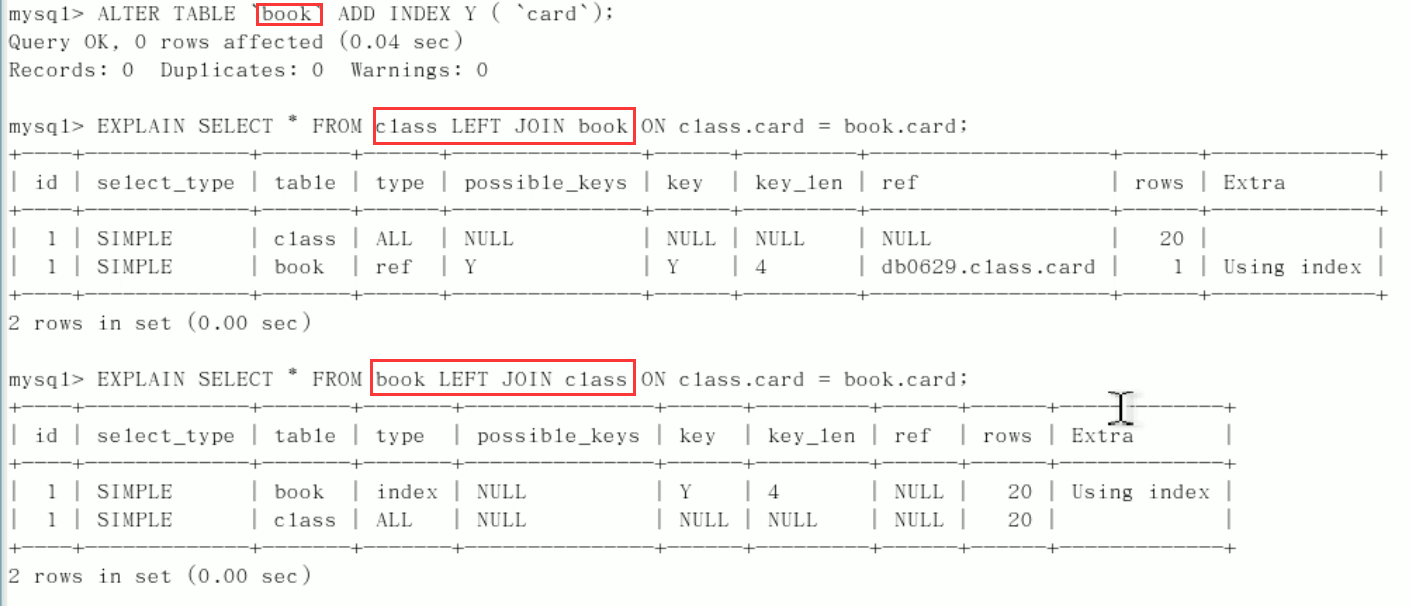
Conclusion:
- In the second line, the type is changed to ref, and the rows are reduced. The optimization is obvious. This is determined by the left connection feature. The LEFT JOIN condition is used to determine how to search rows from the right table. There must be rows on the left, so the right is our key point. We must establish an index in the right table (small table drives large table).
- Left connection, right table
- The same principle: right connection, left table citation
5.3 optimization cases of index three tables
Table creation:
CREATE TABLE IF NOT EXISTS phone( phoneid INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, card INT(10) UNSIGNED NOT NULL, PRIMARY KEY(phoneid) )ENGINE=INNODB; INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20))); //query mysql> select * from phone; +---------+------+ | phoneid | card | +---------+------+ | 1 | 10 | | 2 | 13 | | 3 | 17 | | 4 | 5 | | 5 | 12 | | 6 | 7 | | 7 | 15 | | 8 | 17 | | 9 | 17 | | 10 | 14 | | 11 | 19 | | 12 | 13 | | 13 | 5 | | 14 | 8 | | 15 | 2 | | 16 | 8 | | 17 | 11 | | 18 | 14 | | 19 | 13 | | 20 | 5 | +---------+------+ 20 rows in set (0.00 sec)
Use the two tables in the previous section to delete their indexes:

The three table query statement should be: select * from class left join book on class card = book. card LEFT JOIN phone ON book. card = phone. card;
Create index:
-
You should index the right table book of the first LFET JOIN
alter table `book` add index Y(`card`);
-
The right table phone of the second LFET JOIN should be indexed
alter table `phone` add index z(`card`);
Explain analysis:

The type of the last two lines is ref, and the total rows optimization is very good, and the effect is good. Therefore, it is best to set the index in the field that needs to be queried frequently
Conclusion:
- Optimization of Join statement
- Minimize the total number of NestedLoop loops in the Join statement: "always drive a large result set with a small result set (for example, the book type table drives the book name table)".
- Give priority to optimizing the inner loop of NestedLoop to ensure that the Join condition field on the driven table in the Join statement has been indexed.
- When it is impossible to ensure that the Join condition field of the driven table is indexed and the memory resources are sufficient, do not hesitate to set the JoinBuffer
5.4 index failure
Table creation:
CREATE TABLE staffs(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(24) NOT NULL DEFAULT'' COMMENT'full name',
`age` INT NOT NULL DEFAULT 0 COMMENT'Age',
`pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'position',
`add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'Entry time'
)CHARSET utf8 COMMENT'Employee record form';
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('z3',22,'manager',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('July',23,'dev',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('2000',23,'dev',NOW());
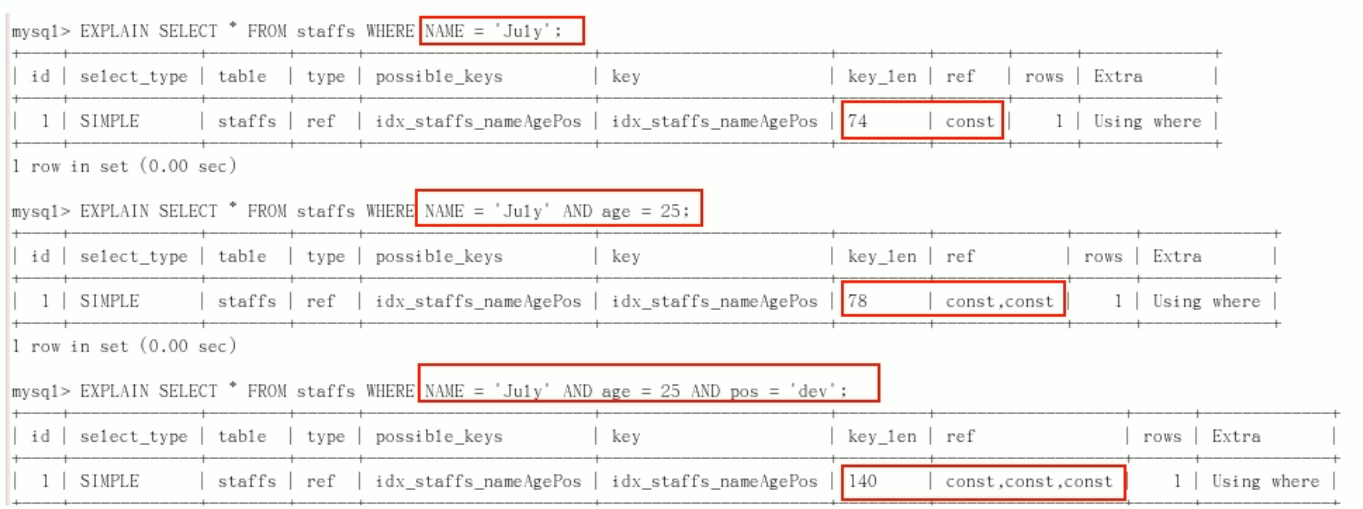
ALTER TABLE staffs ADD INDEX index_staffs_nameAgePos(`name`,`age`,`pos`);
Index failure cases:
-
1. Full value match my favorite
-
2. Best left prefix rule (important!): If multiple columns are indexed, follow the leftmost prefix rule. This means that the query starts at the top left of the index and does not skip the middle column of the composite index.
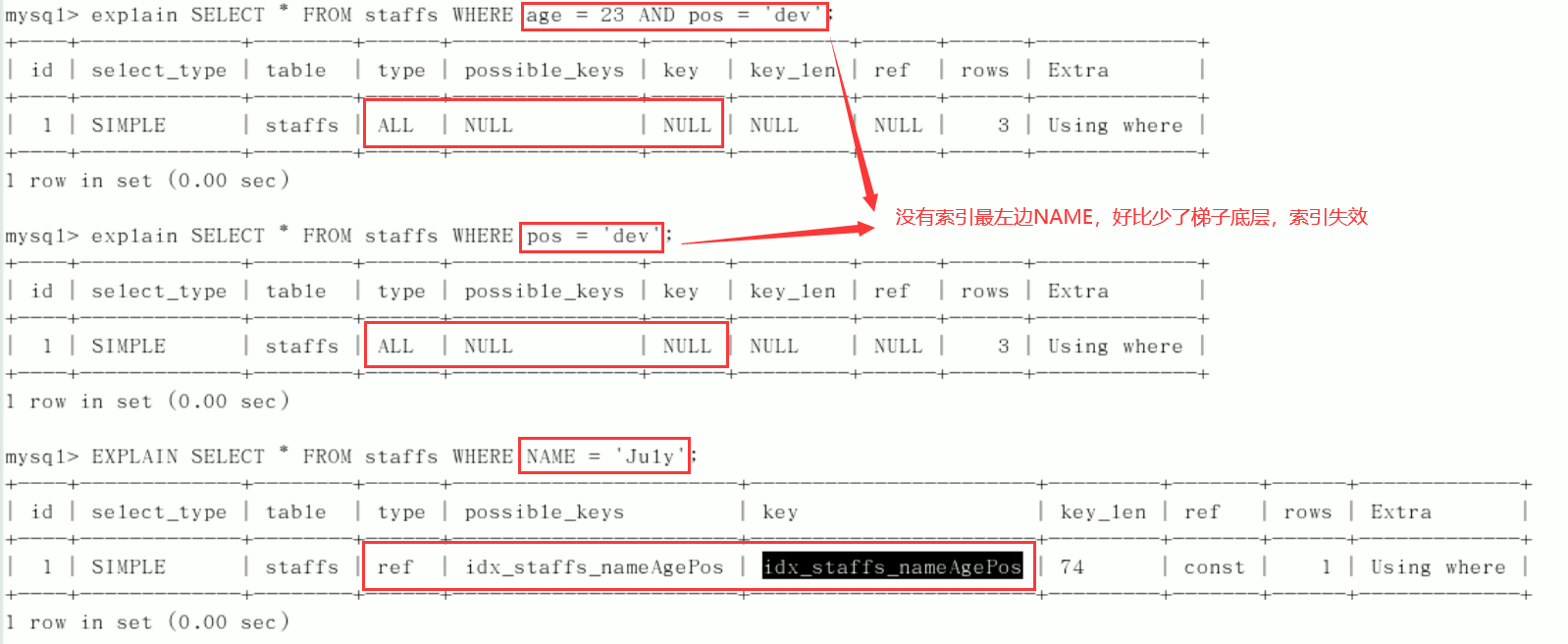 The middle column cannot be broken:
The middle column cannot be broken:

-
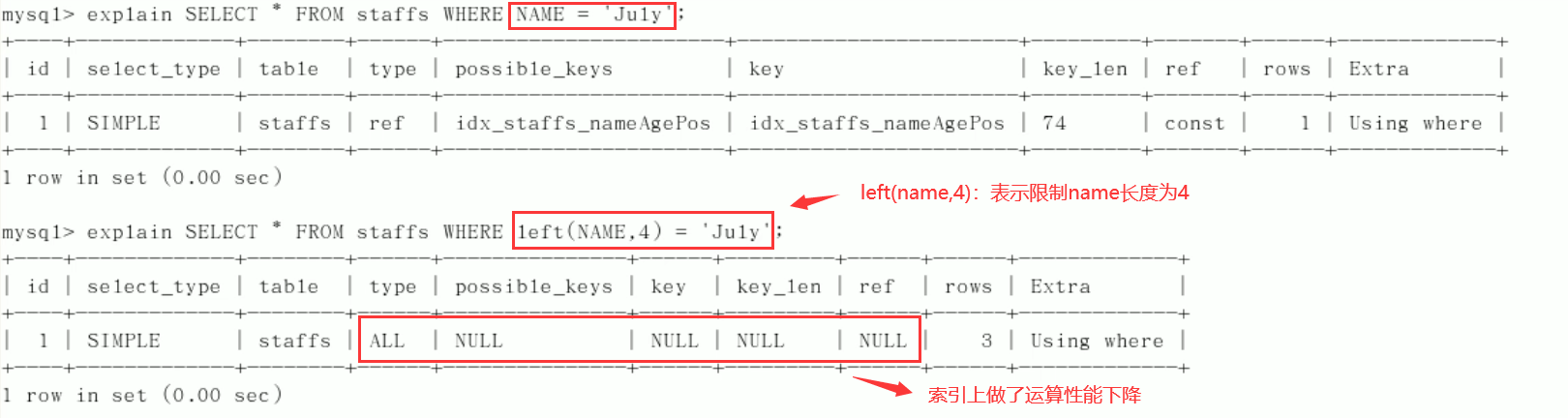
3. Failure to do any operation (calculation, function, (automatic or manual) type conversion) on the index column will lead to index failure and turn to full table scanning.
-
4. The storage engine cannot use the column on the right of the range condition in the index (all the columns after the range are invalid, and the range column is not a query, but a sort).
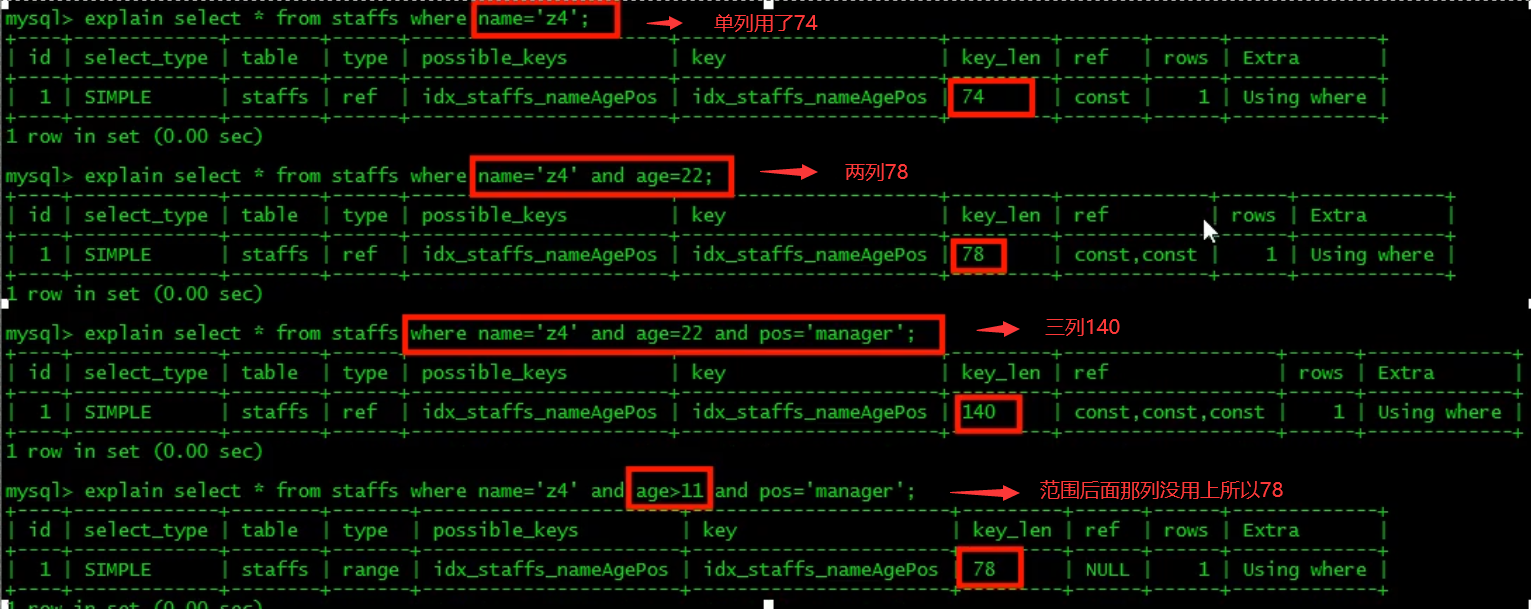
-
5. Try to use the overlay index (only the query accessing the index (the index column is consistent with the query column)) and reduce the select *.
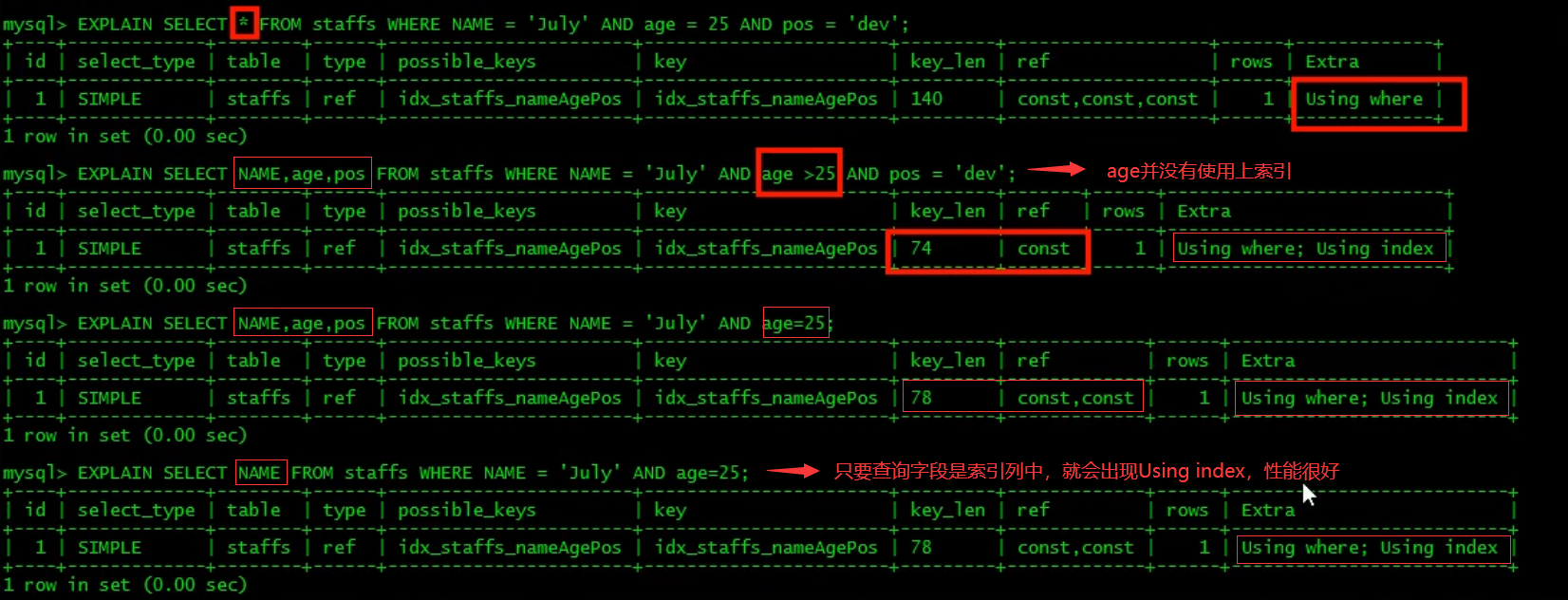
-
6. mysql cannot use the index when it is not equal to (! = or < >), which will lead to full table scanning.
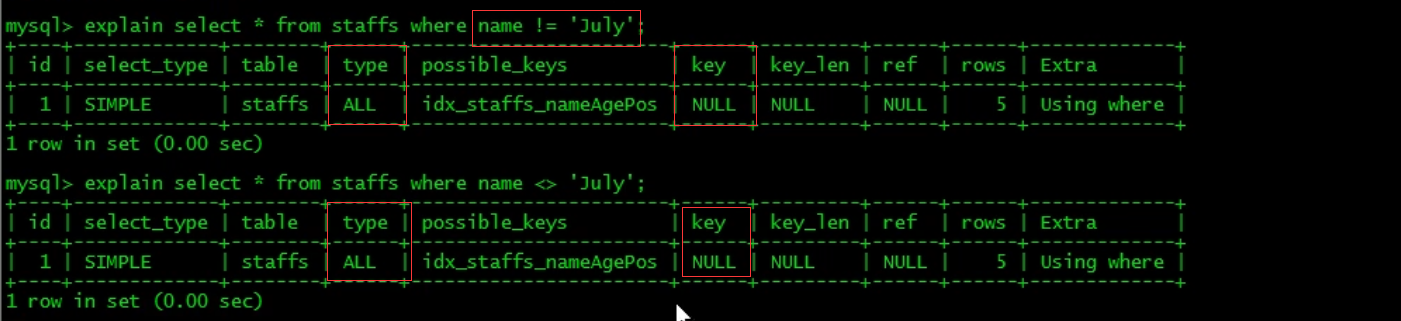
-
7. Is null and is not null cannot use the index.
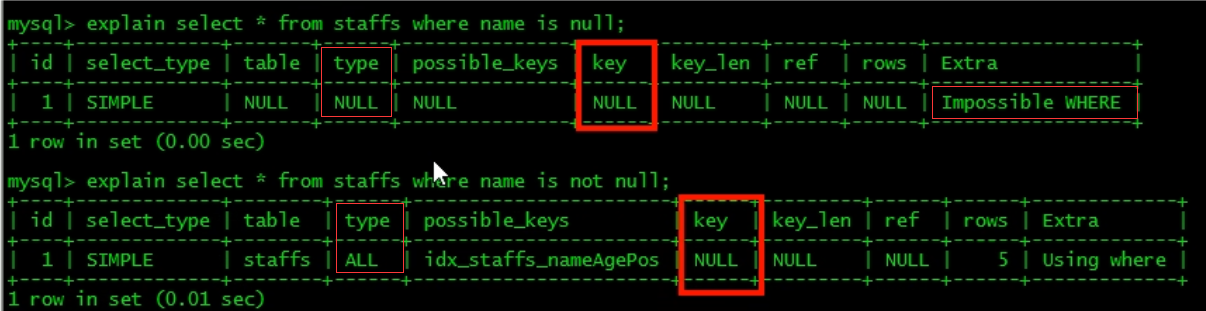
-
8. like starts with a wildcard character ('% abc...'). If the mysql index fails, it will become a full table scan operation (% the index written on the far right will not fail, or the index will be overwritten).

Question: how to solve the problem that the index is not used when like '% string%'? Use the method of overwriting the index!
Table creation:CREATE TABLE `tbl_user`( `id` INT(11) NOT NULL AUTO_INCREMENT, `name` VARCHAR(20) DEFAULT NULL, `age`INT(11) DEFAULT NULL, `email` VARCHAR(20) DEFAULT NULL, PRIMARY KEY(`id`) )ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; INSERT INTO tbl_user(`name`,`age`,`email`)VALUES('1aa1',21,'a@163.com'); INSERT INTO tbl_user(`name`,`age`,`email`)VALUES('2bb2',23,'b@163.com'); INSERT INTO tbl_user(`name`,`age`,`email`)VALUES('3cc3',24,'c@163.com'); INSERT INTO tbl_user(`name`,`age`,`email`)VALUES('4dd4',26,'d@163.com'); //query mysql> select * from tbl_user; +----+------+------+-----------+ | id | name | age | email | +----+------+------+-----------+ | 1 | 1aa1 | 21 | a@163.com | | 2 | 2bb2 | 23 | b@163.com | | 3 | 3cc3 | 24 | c@163.com | | 4 | 4dd4 | 26 | d@163.com | +----+------+------+-----------+ 4 rows in set (0.00 sec)Create index:
CREATE INDEX idx_user_nameAge ON tbl_user(NAME,age);
Index used successfully:
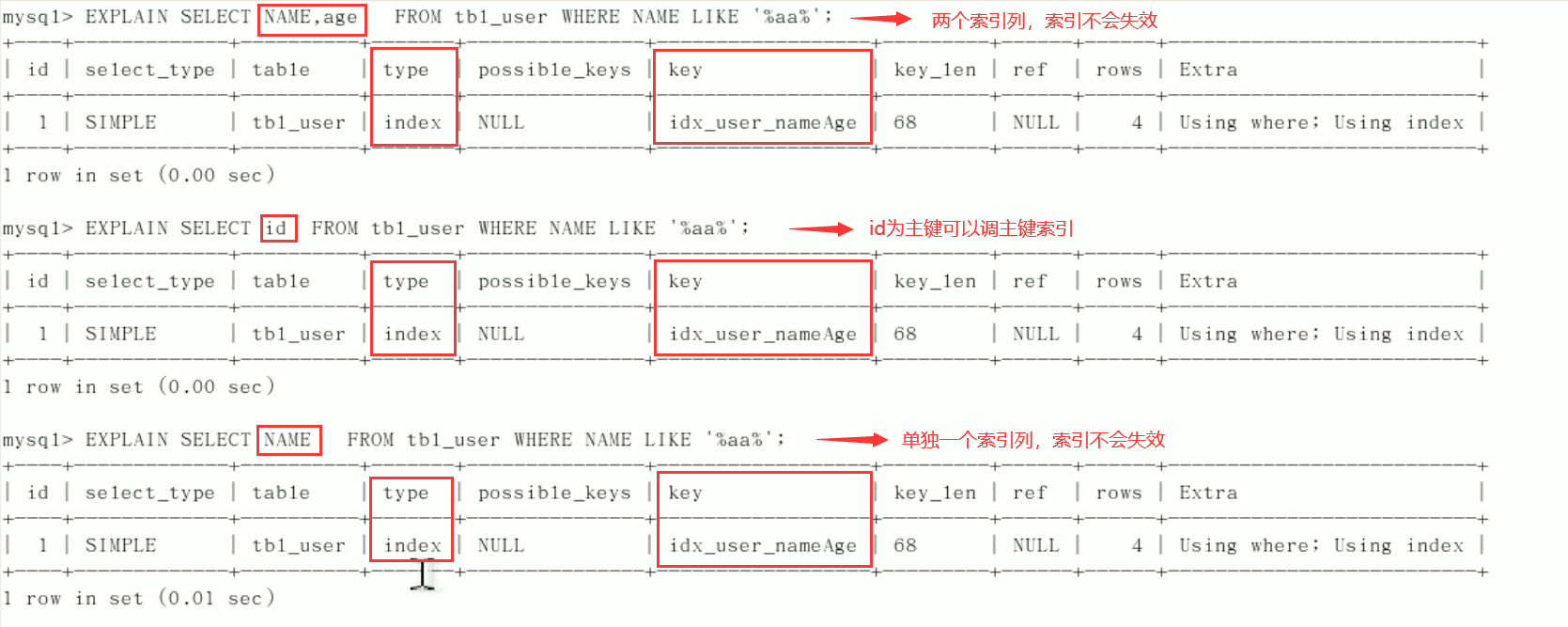
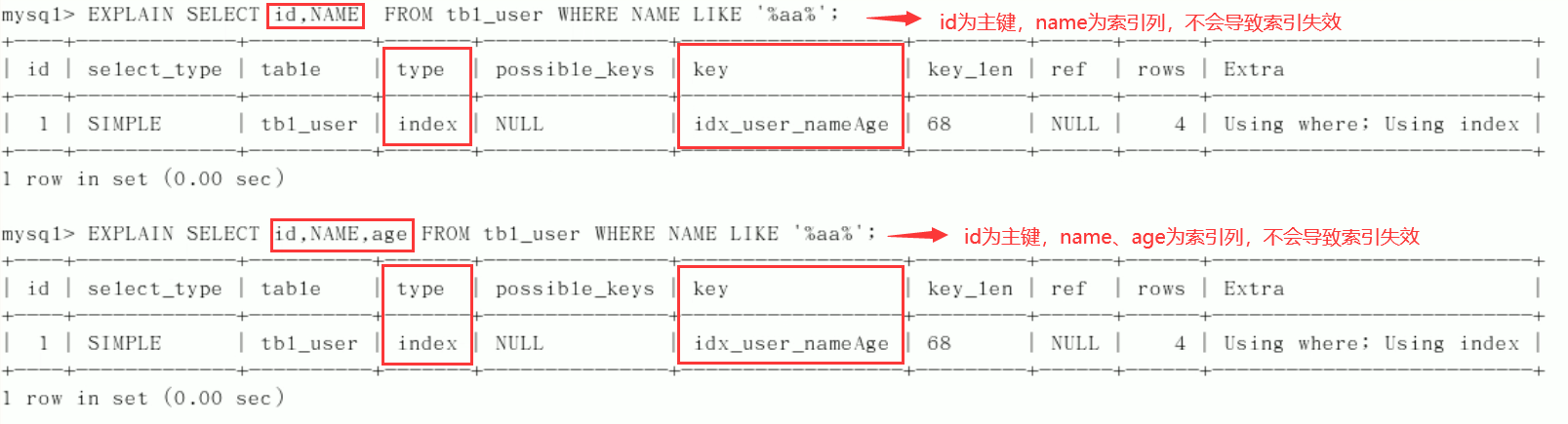
Index failure:

 Summary:% write on the far right. If you have to write on the far left, use the overlay index
Summary:% write on the far right. If you have to write on the far left, use the overlay index -
9. The string index is invalid without single quotation marks.
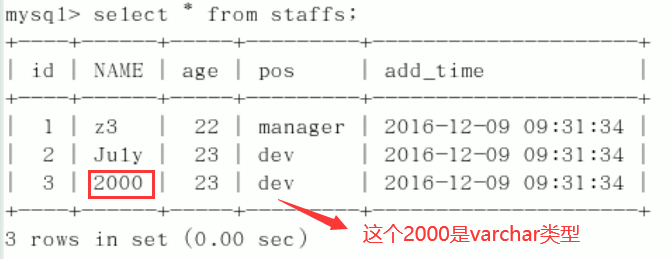
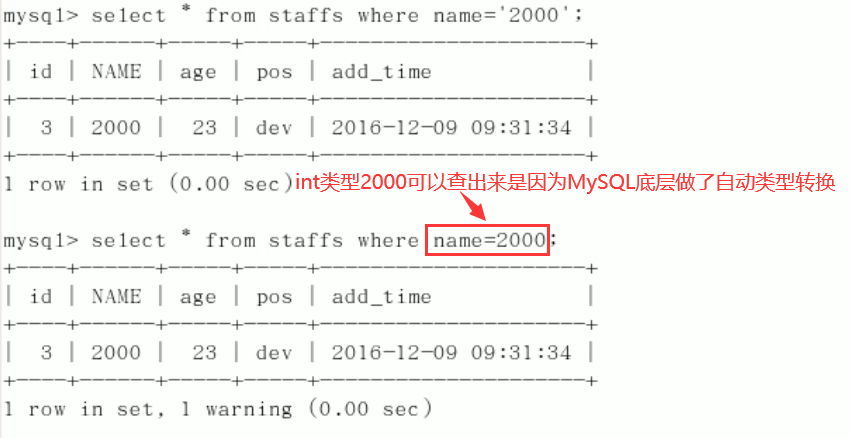
Explain analysis:
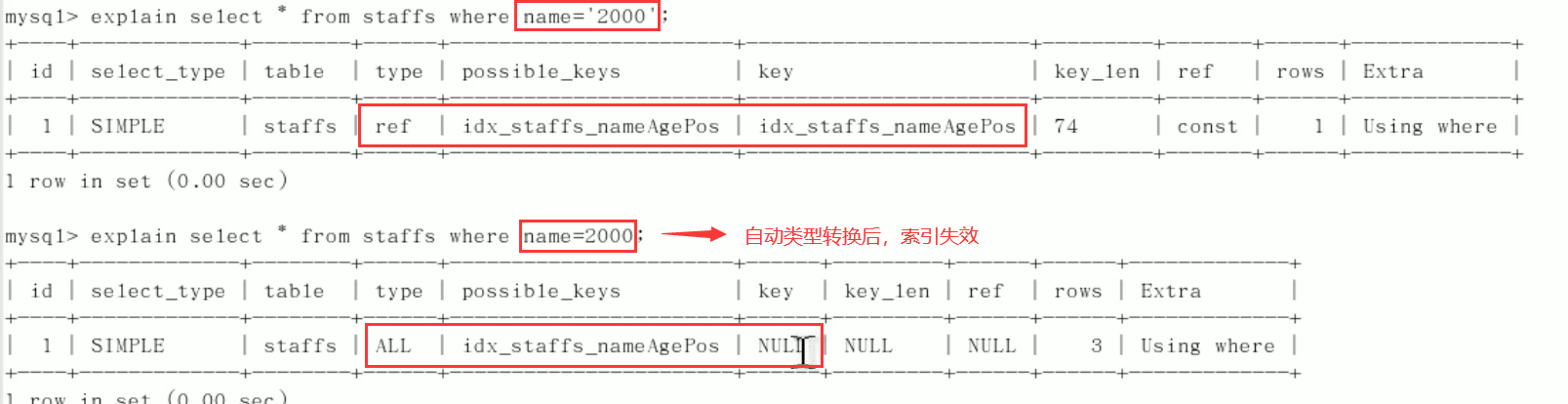
-
10. Use less or, which will invalidate the index when using it to connect
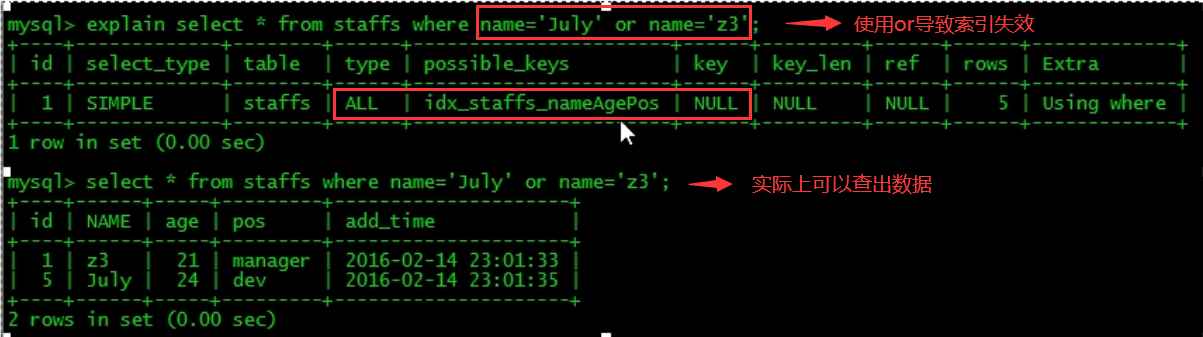
5.5 analysis of index questions
Table creation:
create table test03(
id int primary key not null auto_increment,
c1 char(10),
c2 char(10),
c3 char(10),
c4 char(10),
c5 char(10)
);
insert into test03(c1,c2,c3,c4,c5) values ('a1','a2','a3','a4','a5');
insert into test03(c1,c2,c3,c4,c5) values ('b1','b2','b3','b4','b5');
insert into test03(c1,c2,c3,c4,c5) values ('c1','c2','c3','c4','c5');
insert into test03(c1,c2,c3,c4,c5) values ('d1','d2','d3','d4','d5');
insert into test03(c1,c2,c3,c4,c5) values ('e1','e2','e3','e4','e5');
//View table structure
mysql> select * from test03;
+----+------+------+------+------+------+
| id | c1 | c2 | c3 | c4 | c5 |
+----+------+------+------+------+------+
| 1 | a1 | a2 | a3 | a4 | a5 |
| 2 | b1 | b2 | b3 | b4 | b5 |
| 3 | c1 | c2 | c3 | c4 | c5 |
| 4 | d1 | d2 | d3 | d4 | d5 |
| 5 | e1 | e2 | e3 | e4 | e5 |
+----+------+------+------+------+------+
5 rows in set (0.00 sec)
Indexing:
create index idx_test03_c1234 on test03(c1,c2,c3,c4); //View index mysql> show index from test03; +--------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +--------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | test03 | 0 | PRIMARY | 1 | id | A | 2 | NULL | NULL | | BTREE | | | | test03 | 1 | idx_test03_c1234 | 1 | c1 | A | 5 | NULL | NULL | YES | BTREE | | | | test03 | 1 | idx_test03_c1234 | 2 | c2 | A | 5 | NULL | NULL | YES | BTREE | | | | test03 | 1 | idx_test03_c1234 | 3 | c3 | A | 5 | NULL | NULL | YES | BTREE | | | | test03 | 1 | idx_test03_c1234 | 4 | c4 | A | 5 | NULL | NULL | YES | BTREE | | | +--------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 5 rows in set (0.00 sec)
1) Add columns one by one
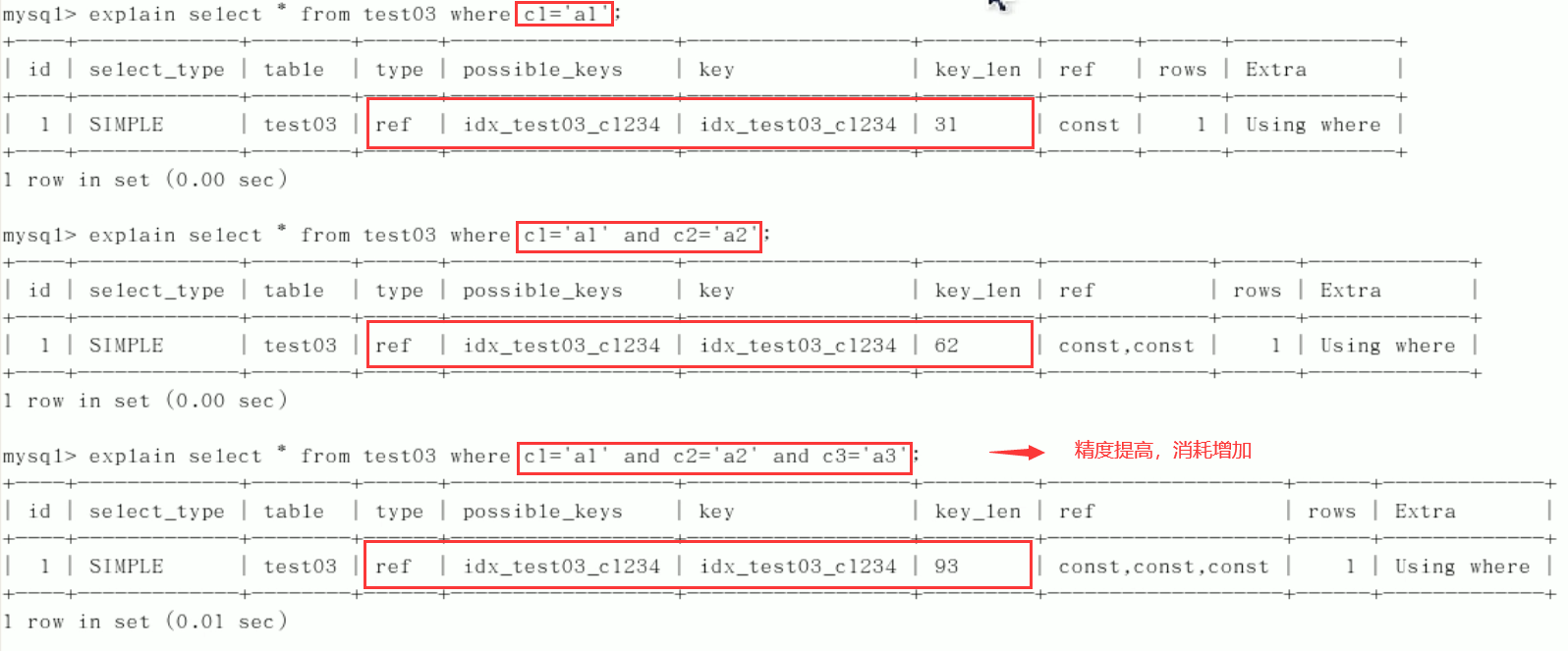
2) The order of exchange conditions does not affect the index, but it is best to write SQL in the order of index creation

3) Limited scope
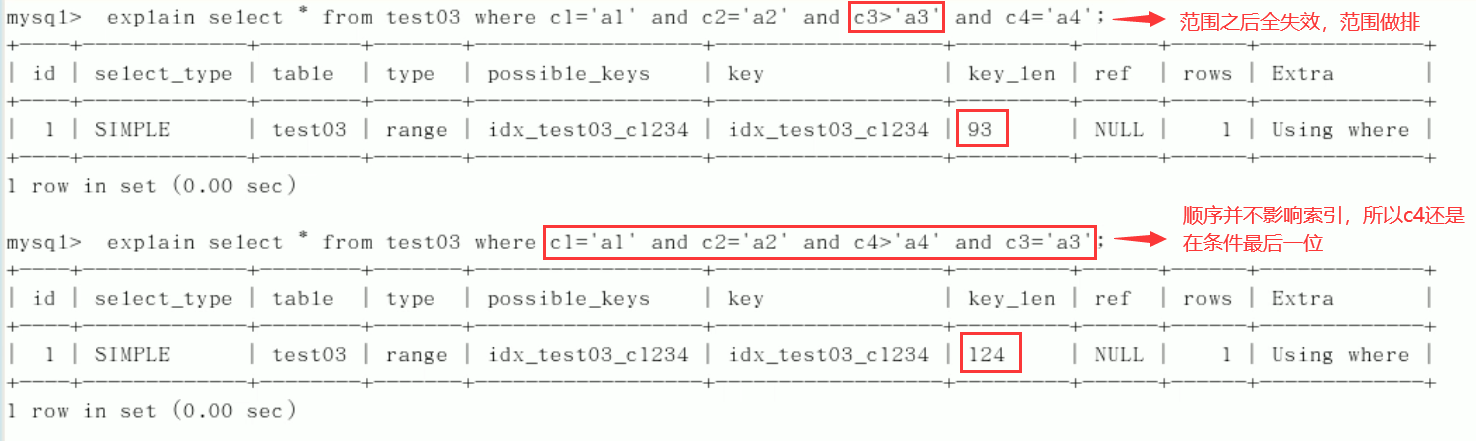
4)order by
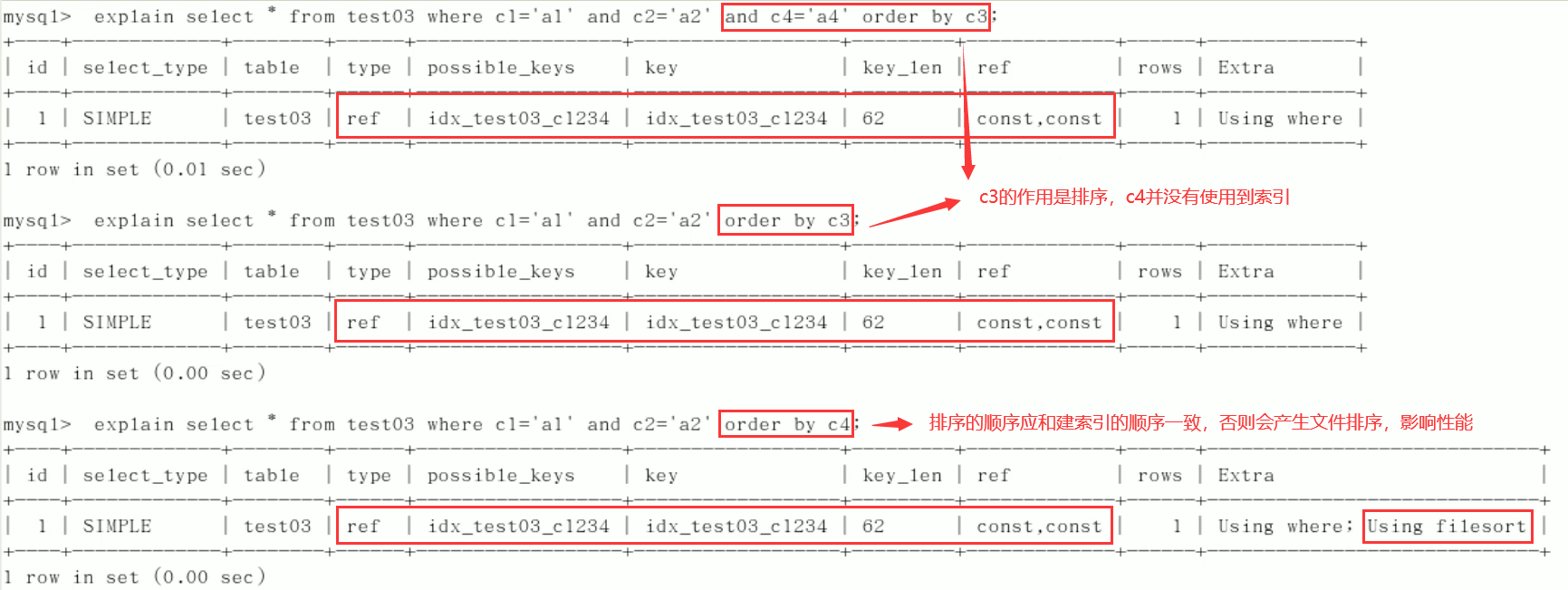

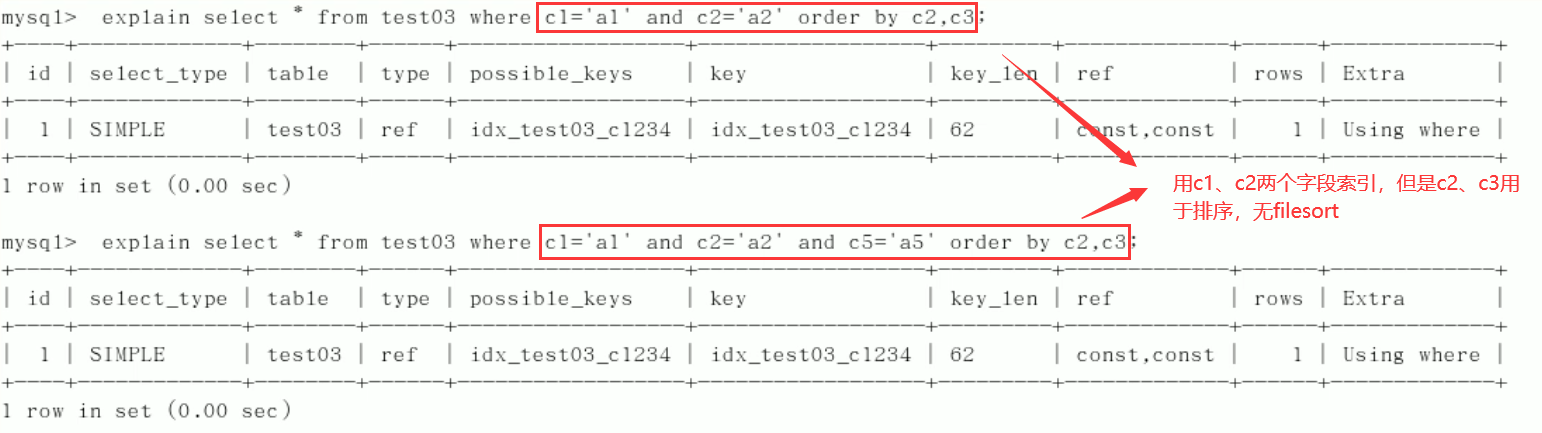
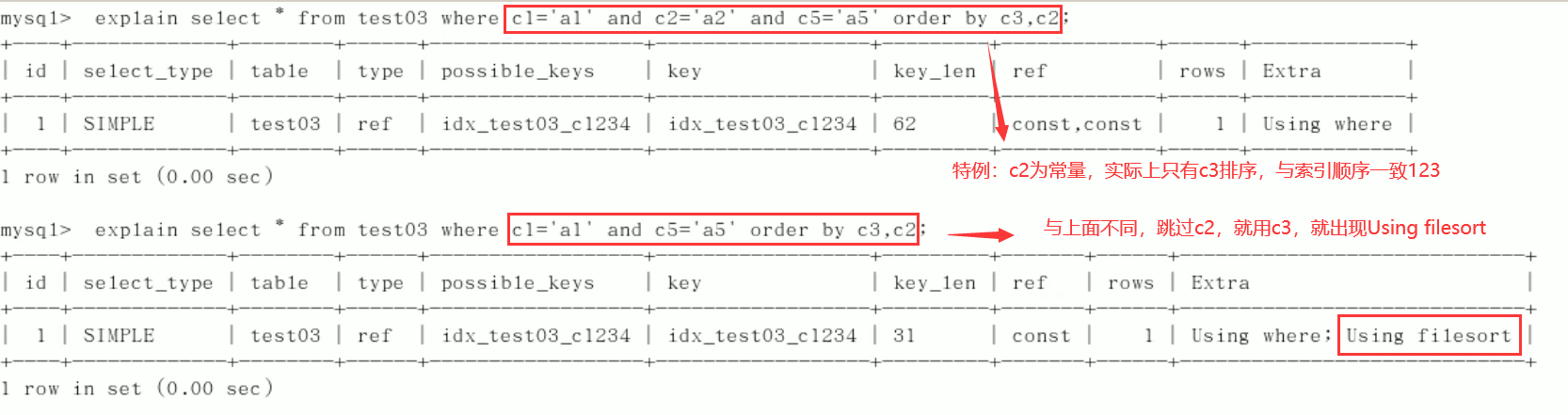
5)group by

Fixed value, range or sorting. Generally, order by gives a range
group by basically needs to be sorted, and temporary tables will be generated
Recommendations:
- For single valued indexes, try to select indexes with better filtering for the current query.
- When selecting a combined index, the fields with the best filtering performance in the current Query are in the order of index fields. The left position is better.
- When selecting a combined index, try to select an index that can contain more fields in the where clause in the current query.
- Try to select the appropriate index by analyzing the statistical information and adjusting the writing method of query.
5.6 summary


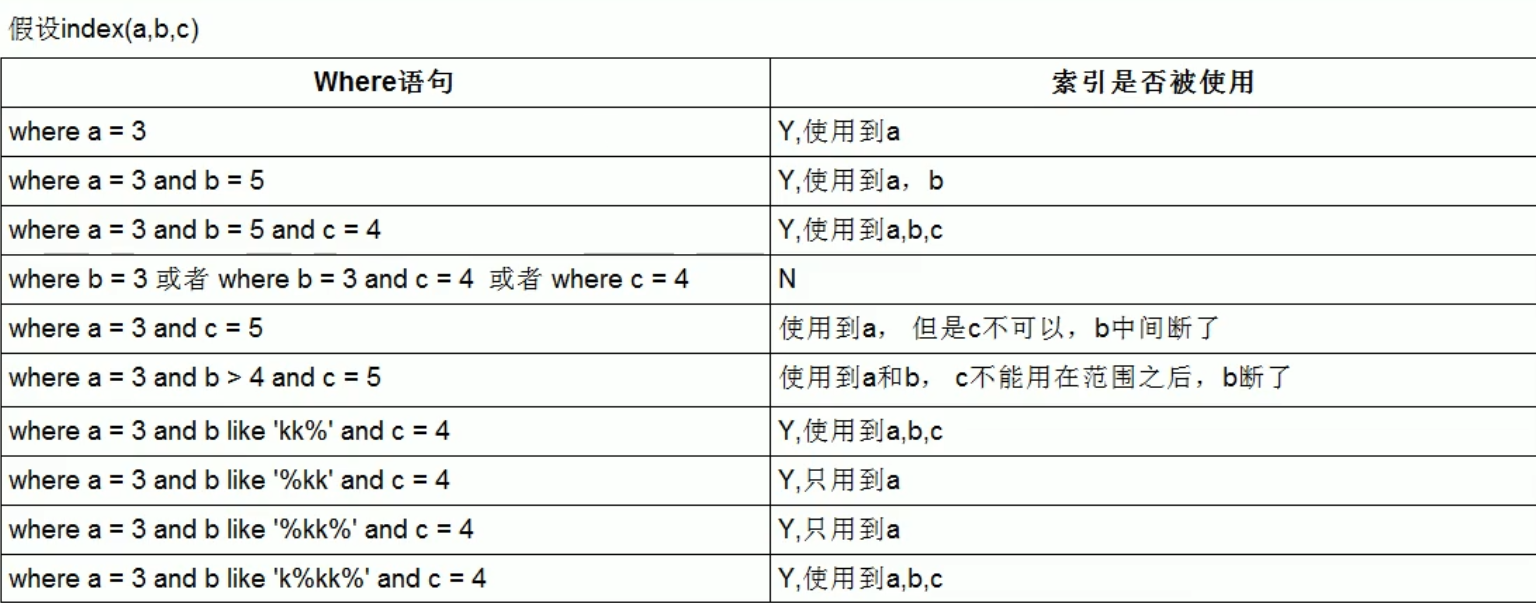
Optimization summary formula
Full value matching is my favorite, and the leftmost prefix should be observed;
The leading elder brother cannot die, and the middle brother cannot break;
The index column is less calculated, and the range is invalid;
LIKE percentage is written to the right, and the overlay index is not written *;
Unequal null values also have OR, and attention should be paid to the impact of index;
VAR quotation marks should not be lost. There are tricks for SQL optimization.
6 query interception analysis
6.1 small meter drives large meter

EXISTS [ ɪɡˈ z ɪ sts] syntax: Select FROM table WHERE EXISTS (subquery)
This syntax can be understood as: put the data of the main query into the sub query for conditional verification, and determine whether the data result of the main query can be retained according to the verification result (TRUE or FALSE)
Tips:
- Exsts (subquery) only returns TRUE or FALSE, so the SELECT * in the subquery can also be SELECT 1 or SELECT 'X'. The official saying is that the SELECT list will be ignored during actual execution, so there is no difference.
- The actual execution process of EXISTS sub query may have been optimized instead of comparing one by one in our understanding. If you are worried about efficiency problems, you can conduct actual inspection to determine whether there are efficiency problems.
- EXISTS subqueries can also be replaced by conditional expressions, other subqueries or joins. What is the best one needs specific analysis
in and exists usage:

6.2 Order by keyword sorting optimization
1. After the ORDER BY clause, try to sort by Index and avoid sorting by FileSort
Table creation:
create table tblA(
#id int primary key not null auto_increment,
age int,
birth timestamp not null
);
insert into tblA(age, birth) values(22, now());
insert into tblA(age, birth) values(23, now());
insert into tblA(age, birth) values(24, now());
create index idx_A_ageBirth on tblA(age, birth);
//query
mysql> select * from tblA;
+------+---------------------+
| age | birth |
+------+---------------------+
| 22 | 2021-04-04 19:31:45 |
| 23 | 2021-04-04 19:31:45 |
| 24 | 2021-04-04 19:31:45 |
+------+---------------------+
3 rows in set (0.00 sec)
mysql> show index from tblA;
+-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| tbla | 1 | idx_A_ageBirth | 1 | age | A | 3 | NULL | NULL | YES | BTREE | | |
| tbla | 1 | idx_A_ageBirth | 2 | birth | A | 3 | NULL | NULL | | BTREE | | |
+-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
Focus: will Using filesort be generated after order by
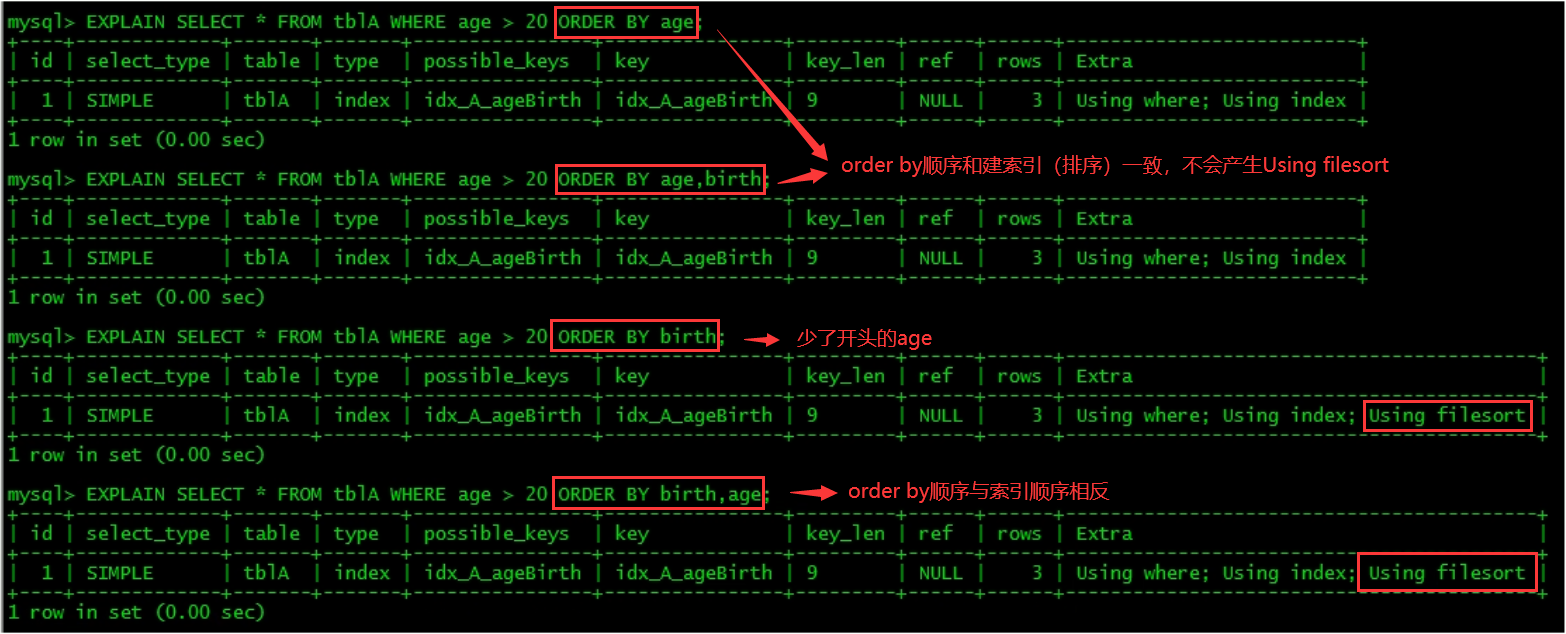
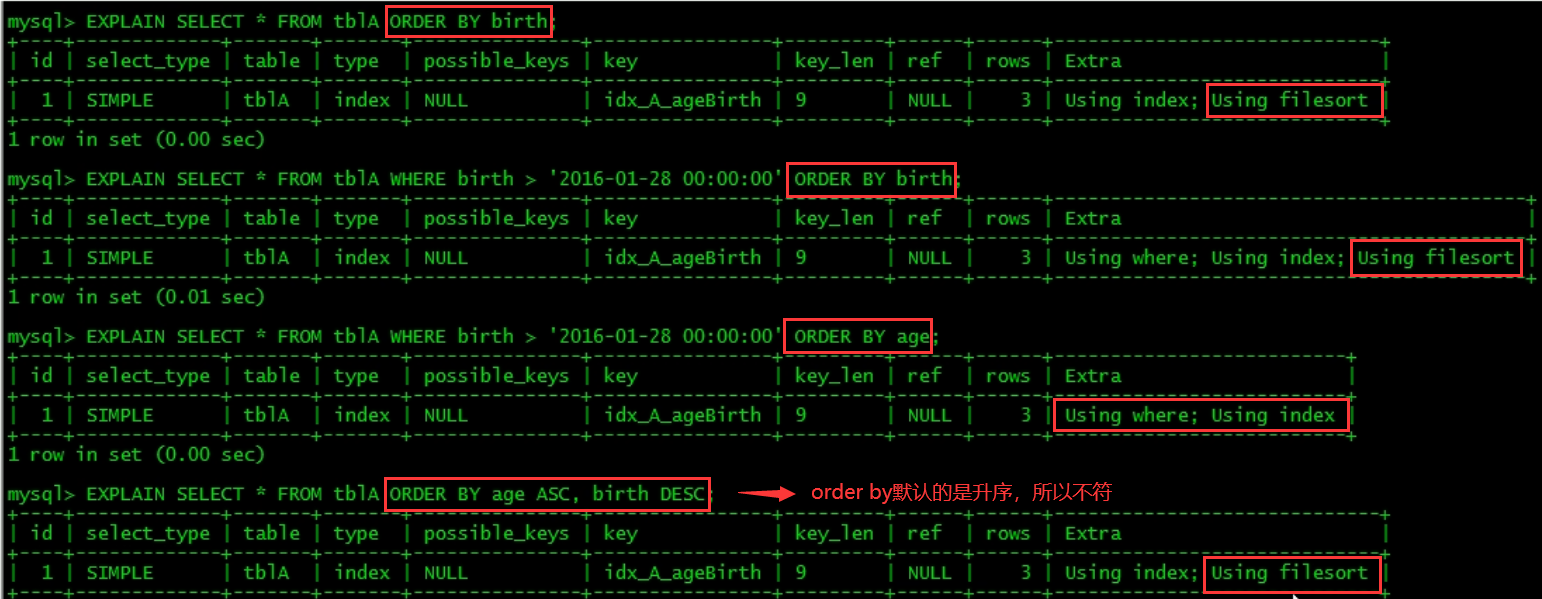
MySQL supports two sorting methods, FileSort and lIndex. The Index is efficient. It means that MySQL scans the Index itself to complete sorting. FileSort is inefficient.
ORDER BY meets two conditions and will be sorted by Index:
- The ORDER BY statement uses the leftmost row of the index.
- Use the combination of where clause and Order BY clause condition columns to satisfy the leftmost row of the index.
2. Sort on the index as much as possible and follow the best left prefix for indexing
3. If it is not on the index column, mysql's filesort has two algorithms (auto start)
-
Two way sorting
MySQL4. Before 1, two-way sorting was used, which literally means to scan the disk twice to finally get the data, read the row pointer and OrderBy column, sort them, then scan the sorted list, and re read the corresponding data output from the list according to the values in the list.
Get the sort field from the disk, sort in the buffer, and then get other fields from the disk.
Take a batch of data and scan the disk twice. As we all know, I\O is very time-consuming, so in MySQL4 After 1, a second improved algorithm appeared, which is one-way sorting
-
One way sorting
Read all the columns required for the query from the disk, sort them in the buffer according to the order by column, and then scan the sorted list for output. It is more efficient and avoids reading data for the second time. And it turns random IO into sequential IO, but it uses more space because it saves each line in memory
-
Conclusion and extended problems
Since single channel is backward, it is better than double channel in general
But there is a problem with using one-way, in sort_ In the buffer, method B occupies a lot more space than method A. because method B takes out all fields, it is possible that the total size of the data taken out exceeds sort_ The capacity of the buffer causes that only sort can be accessed each time_ The data of buffer capacity is sorted (creating tmp files and merging multiple channels), and then retrieved after scheduling
sort_buffer capacity size, and then row... So that multiple I/O.Originally, I wanted to save an I/O operation, but it led to a large number of I/O operations, but the gain is not worth the loss
4. Optimization strategy
- Increase sort_ buffer_ Setting of size parameter
- Increase Max_ length_ for_ sort_ Setting of data parameters
- Why?

5. Summary:

6.3 Group by optimization
The essence of group by is to sort first and then group, and follow the best left prefix built by index.
When the index column cannot be used, increase max_length_for_sort_data parameter setting + increase sort_ buffer_ Setting of size parameter.
If where is higher than having, don't limit the conditions that can be written in where
6.4 slow query log (key)
Introduction:
- MySQL's slow query log is a kind of log record provided by mysql. It is used to record statements whose response time exceeds the threshold in MySQL. Specifically, it refers to statements whose running time exceeds long_ query_ SQL with time value will be recorded in the slow query log.
- Specifically, the running time exceeds long_query_time value, it will be recorded in the slow query log. long_ query_ The default value of time is 10, which means to run statements for more than 10 seconds.
- It is up to him to check which SQL exceeds our maximum endurance time. For example, if an SQL executes for more than 5 seconds, we will be slow. We hope to collect SQL for more than 5 seconds and conduct a comprehensive analysis in combination with the previous explain
Operating instructions:
By default, MySQL database does not enable slow query daily speed, so we need to set this parameter manually.
Of course, if it is not necessary for tuning, it is generally not recommended to start this parameter, because starting the slow query log will more or less have a certain performance impact. Slow query log supports writing log records to files.
Check whether and how to open:
- Default: Show variables like '% slow'_ query_ log%'; [ ˈ ve ə ri ə bls]
- Enable: set global slow_query_log=1;, It only takes effect for the current database. If MySQL is restarted, it will become invalid
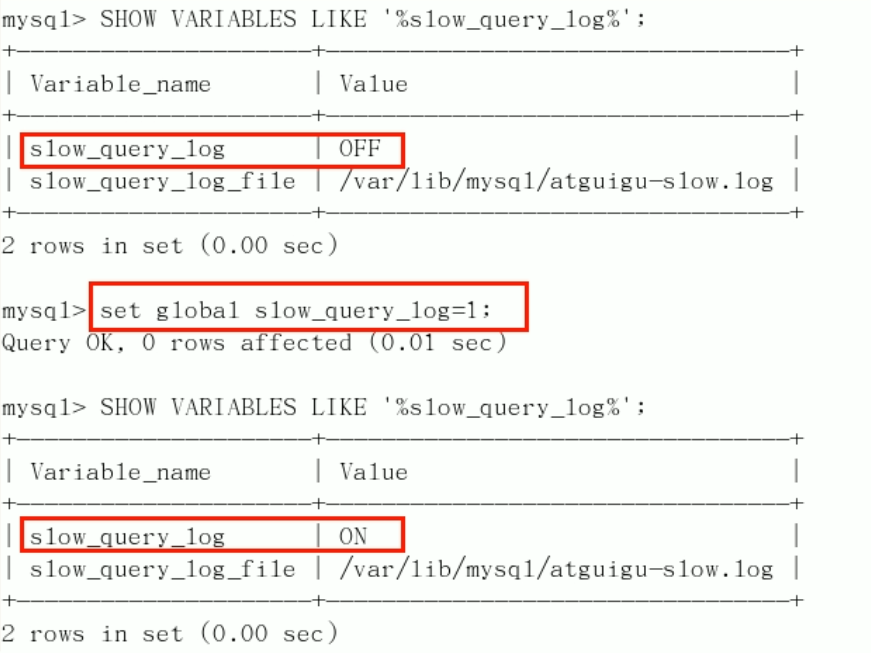
If you want to take effect permanently, you must modify the configuration file my CNF (the same is true for other system variables)
Modify my CNF file, add or modify the parameter slow under [mysqld]_ query_ Log and slow_query_log_file, and then restart the MySQL server. I will also configure the following two lines into my CNF file
slow_query_log =1 slow_query_log_file=/var/lib/mysqatguigu-slow.log
On the parameter slow of slow query_ query_ log_ File, which specifies the storage path of the slow query log file. The system will give a default file host by default_ name-slow. Log (if the parameter slow_query_log_file is not specified)
After the slow query log is enabled, what kind of SQL will be recorded in the slow query log?
This is determined by the parameter long_query_time control, long by default_ query_ The value of time is 10 seconds, and the command is SHOW VARIABLES LIKE 'long_query_time%';

You can modify it with the command or in my Modify the CNF parameter.
If the running time is exactly equal to long_query_time will not be recorded. In other words, in the mysql source code, it is judged to be greater than long_query_time, not greater than or equal to.
Name modification slow SQL threshold time: set global long_query_time=3; [ ˈɡ l əʊ bl]

If you can't see the changes, reopen the connection, or change a statement: show global variables like 'long_query_time';

Record slow SQL and subsequent analysis:
Suppose we successfully set the slow SQL threshold time to 3 seconds (set global long_query_time=3;).
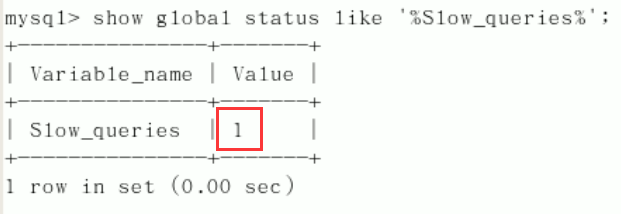
Simulation timeout SQL: select sleep(4);
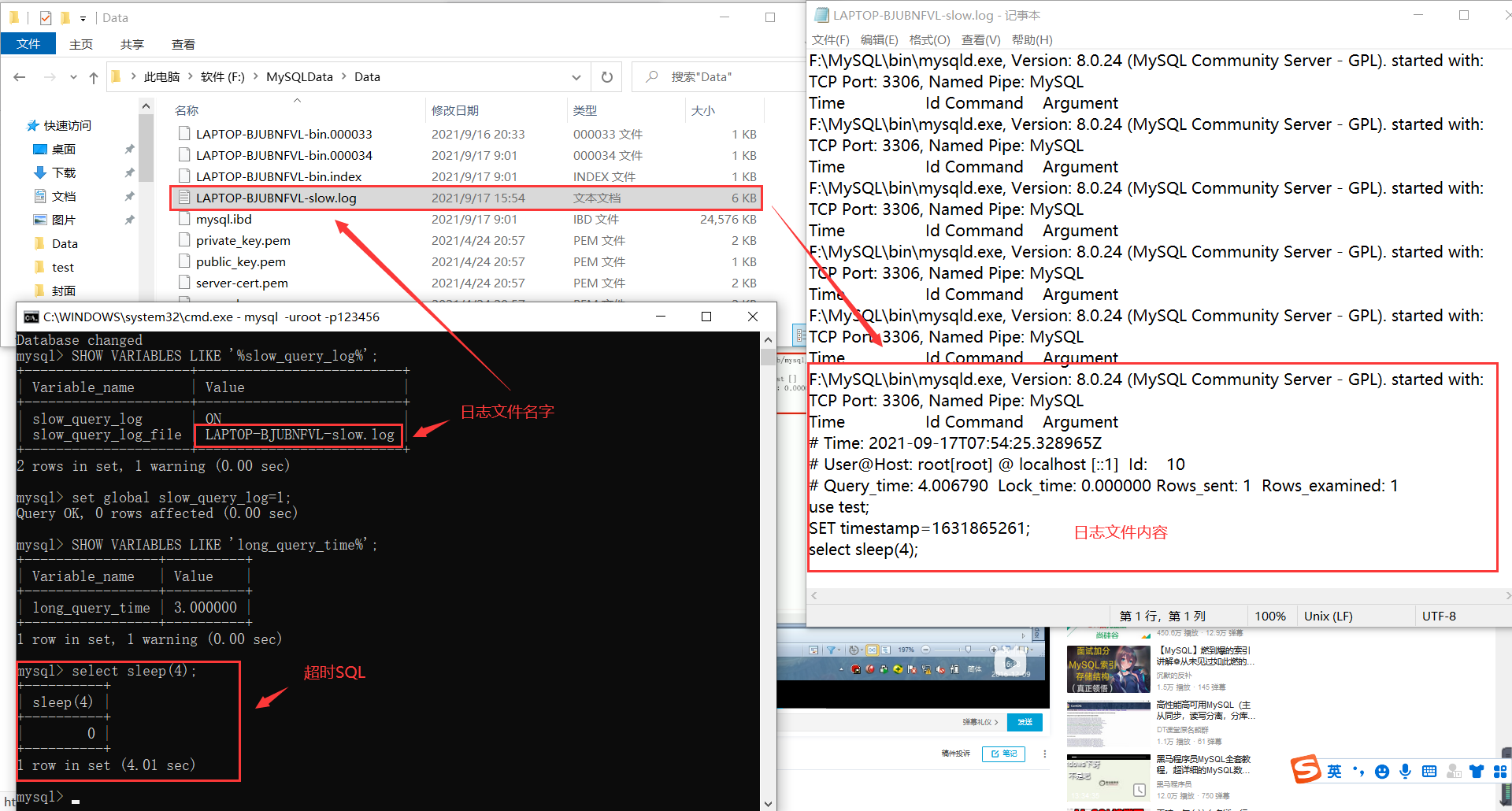
Query the number of slow query records in the current system: show global status like '% slow'_ queries%'; [ ˈ ste ɪ t ə s]
Set the slow SQL threshold time in the configuration file (permanently effective):
#Configuration under [mysqld]: slow_query_log=1; slow_query_log_file=/var/lib/mysql/atguigu-slow.log long_query_time=3; log_output=FILE;
Log analysis tool mysqldumpslow
In the production environment, if you want to manually analyze logs, find and analyze SQL, it is obviously an individual effort. MySQL provides a log analysis tool mysqldumpslow.
View the help information of mysqldumpslow, mysqldumpslow --help.

Common mysqldumpslow help information:
- s: Yes indicates how to sort
- c: Number of visits
- l: Lock time
- r: Return record
- t: Query time
- al: average locking time
- ar: average number of returned records
- at: average query time
- t: That is, the number of previous data returned
- g: The back is matched with a regular matching pattern, which is case insensitive
Common reference for work:
- Get the 10 SQL with the most recordsets returned: mysqldumpslow - s R - t 10 / var / lib / MySQL / atguigu slow log
- Get the top 10 SQL accessed: mysqldumpslow - S C - t 10 / var / lib / MySQL / atguigu slow log
- Get the top 10 query statements with left join sorted by time: mysqldumpslow - S T - t 10 - G "left join" / var / lib / MySQL / atguigu slow log
- In addition, it is recommended to use these commands in combination with │ and more, otherwise the screen may explode: ` mysqldumpslow - s R-T 10 / Ar / lib / MySQL / atguigu slow log | more
6.5 batch insert data script
1. Table creation:
create database bigData;
use bigData;
//Department table
CREATE TABLE dept(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20)NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
)ENGINE=INNODB DEFAULT CHARSET=utf8;
//Employee table
CREATE TABLE emp(
id int unsigned primary key auto_increment,
empno mediumint unsigned not null default 0, //number
ename varchar(20) not null default "", //name
job varchar(9) not null default "", //work
mgr mediumint unsigned not null default 0, //Superior number
hiredate date not null, //Entry time
sal decimal(7,2) not null, //salary
comm decimal(7,2) not null, //dividend
deptno mediumint unsigned not null default 0 //Department number
)ENGINE=INNODB DEFAULT CHARSET=utf8;
2. Set parameter log_bin_trust_function_creators
This function has none of DETERMINISTIC
Since it is too slow to start the query log, because we have started bin log, we must specify a parameter for our function
show variables like 'log_bin_trust_function_creators'; set global log_bin_trust_function_creators=1;
After the parameters are added, if mysqld restarts, the above parameters will disappear again, and the permanent method:
- Under windows: my Ini [mysqld] plus log_bin_trust_function_creators=1
- Under linux: / etc / my CNF under my CNF [mysqld] plus log_bin_trust_function_creators=1
3. Create functions to ensure that each data is different
- Randomly generated string
delimiter $$ #In order for the stored procedure to run normally, modify the command terminator. Two $$indicates the end create function rand_string(n int) returns varchar(255) begin declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyz'; declare return_str varchar(255) default ''; declare i int default 0; while i < n do set return_str = concat(return_str,substring(chars_str,floor(1+rand()*52),1)); set i=i+1; end while; return return_str; end $$ - Randomly generated department number
delimiter $$ create function rand_num() returns int(5) begin declare i int default 0; set i=floor(100+rand()*10); return i; end $$
4. Create stored procedure
-
Create a stored procedure that inserts data into the emp table
delimiter $$ create procedure insert_emp(in start int(10),in max_num int(10)) #max_num: indicates how many pieces of data are inserted begin declare i int default 0; set autocommit = 0; #Turn off automatic submission to avoid writing an insert and submitting it once, and 50w entries are submitted at one time repeat set i = i+1; insert into emp(empno,ename,job,mgr,hiredate,sal,comm,deptno) values((start+i),rand_string(6),'salesman',0001,curdate(),2000,400,rand_num()); until i=max_num end repeat; commit; end $$ -
Create a stored procedure that inserts data into the dept table
delimiter $$ create procedure insert_dept(in start int(10),in max_num int(10)) begin declare i int default 0; set autocommit = 0; repeat set i = i+1; insert into dept(deptno,dname,loc) values((start+i),rand_string(10),rand_string(8)); until i=max_num end repeat; commit; end $$
5. Call stored procedure
-
Insert data into the dept table
mysql> DELIMITER ; # Modify the default end symbol to(;),It was changed to## mysql> CALL insert_dept(100, 10); Query OK, 0 rows affected (0.01 sec)
-
Insert 500000 data into emp table
mysql> DELIMITER ; mysql> CALL insert_emp(100001, 500000); Query OK, 0 rows affected (27.00 sec)
-
View run results
mysql> select * from dept; +----+--------+---------+--------+ | id | deptno | dname | loc | +----+--------+---------+--------+ | 1 | 101 | mqgfy | ck | | 2 | 102 | wgighsr | kbq | | 3 | 103 | gjgdyj | brb | | 4 | 104 | gzfug | p | | 5 | 105 | keitu | cib | | 6 | 106 | nndvuv | csue | | 7 | 107 | cdudl | tw | | 8 | 108 | aafyea | aqq | | 9 | 109 | zuqezjx | dpqoyo | | 10 | 110 | pam | cses | +----+--------+---------+--------+ 10 rows in set (0.00 sec) mysql> select * from emp limit 10; #View the first 10 pieces of data (too many 50W) +----+--------+-------+----------+-----+------------+---------+--------+--------+ | id | empno | ename | job | mgr | hiredate | sal | comm | deptno | +----+--------+-------+----------+-----+------------+---------+--------+--------+ | 1 | 100002 | xmbva | salesman | 1 | 2021-04-05 | 2000.00 | 400.00 | 108 | | 2 | 100003 | aeq | salesman | 1 | 2021-04-05 | 2000.00 | 400.00 | 109 | | 3 | 100004 | cnjfz | salesman | 1 | 2021-04-05 | 2000.00 | 400.00 | 105 | | 4 | 100005 | wwhd | salesman | 1 | 2021-04-05 | 2000.00 | 400.00 | 100 | | 5 | 100006 | e | salesman | 1 | 2021-04-05 | 2000.00 | 400.00 | 107 | | 6 | 100007 | yjfr | salesman | 1 | 2021-04-05 | 2000.00 | 400.00 | 108 | | 7 | 100008 | xlp | salesman | 1 | 2021-04-05 | 2000.00 | 400.00 | 102 | | 8 | 100009 | mp | salesman | 1 | 2021-04-05 | 2000.00 | 400.00 | 102 | | 9 | 100010 | tcdl | salesman | 1 | 2021-04-05 | 2000.00 | 400.00 | 107 | | 10 | 100011 | akw | salesman | 1 | 2021-04-05 | 2000.00 | 400.00 | 106 | +----+--------+-------+----------+-----+------------+---------+--------+--------+ 10 rows in set (0.00 sec)
6.6 sql analysis with show profile (top priority)
Show Profile is provided by mysql and can be used to analyze the resource consumption of statement execution in the current session. Measurements that can be used for SQL tuning
By default, the parameters are turned off and the results of the last 15 runs are saved
Analysis steps:
-
1. Check whether the current mysql version supports: show variables like 'profiling';

It is off by default and needs to be on before use
-
2. The on function is off by default. It needs to be on before use: set profiling=on;

-
3. Run SQL (for testing)
mysql> select * from emp group by id%10 limit 150000; mysql> select * from emp group by id%20 order by 5;
-
4. View results: show profiles;
mysql> show profiles; +----------+------------+-----------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+-----------------------------------------------+ | 1 | 0.00204000 | show variables like 'profiling' | | 2 | 0.55134250 | select * from emp group by id%10 limit 150000 | | 3 | 0.56902000 | select * from emp group by id%20 order by 5 | +----------+------------+-----------------------------------------------+ 3 rows in set, 1 warning (0.00 sec)
-
5. Diagnose SQL, show profile cpu,block io for query ID number; (the ID number is the number in the Query_ID column in step 4)
mysql> show profile cpu,block io for query 3; +----------------------+----------+----------+------------+--------------+---------------+ | Status | Duration | CPU_user | CPU_system | Block_ops_in | Block_ops_out | +----------------------+----------+----------+------------+--------------+---------------+ | starting | 0.000049 | 0.000000 | 0.000000 | NULL | NULL | | checking permissions | 0.000005 | 0.000000 | 0.000000 | NULL | NULL | | Opening tables | 0.000012 | 0.000000 | 0.000000 | NULL | NULL | | init | 0.000021 | 0.000000 | 0.000000 | NULL | NULL | | System lock | 0.000009 | 0.000000 | 0.000000 | NULL | NULL | | optimizing | 0.000003 | 0.000000 | 0.000000 | NULL | NULL | | statistics | 0.000017 | 0.000000 | 0.000000 | NULL | NULL | | preparing | 0.000008 | 0.000000 | 0.000000 | NULL | NULL | | Creating tmp table | 0.000045 | 0.000000 | 0.000000 | NULL | NULL | | Sorting result | 0.000004 | 0.000000 | 0.000000 | NULL | NULL | | executing | 0.000002 | 0.000000 | 0.000000 | NULL | NULL | | Sending data | 0.568704 | 0.546875 | 0.046875 | NULL | NULL | | Creating sort index | 0.000048 | 0.000000 | 0.000000 | NULL | NULL | | end | 0.000003 | 0.000000 | 0.000000 | NULL | NULL | | query end | 0.000005 | 0.000000 | 0.000000 | NULL | NULL | | removing tmp table | 0.000006 | 0.000000 | 0.000000 | NULL | NULL | | query end | 0.000003 | 0.000000 | 0.000000 | NULL | NULL | | closing tables | 0.000004 | 0.000000 | 0.000000 | NULL | NULL | | freeing items | 0.000061 | 0.000000 | 0.000000 | NULL | NULL | | cleaning up | 0.000015 | 0.000000 | 0.000000 | NULL | NULL | +----------------------+----------+----------+------------+--------------+---------------+ 20 rows in set, 1 warning (0.00 sec)
Parameter remarks (written in the code): show profile cpu,block io for query 3; (CPU in this code, block)
- ALL: displays ALL overhead information.
- BLOCK IO: displays the overhead associated with block lO.
- CONTEXT SWITCHES: context switching related overhead.
- CPU: displays CPU related overhead information.
- IPC: displays the cost information related to sending and receiving.
- MEMORY: displays MEMORY related overhead information.
- PAGE FAULTS: displays overhead information related to page errors.
- SOURCE: display and Source_function,Source_file,Source_line related overhead information.
- Swap: displays the cost information related to the number of exchanges.
-
6. Conclusions for daily development (these four problems are serious in the Status column)
- converting HEAP to MyISAM: the query result is too large. There is not enough memory. It is moved to disk.
- Creating tmp table: create a temporary table, copy data to the temporary table, and delete after use
- Copying to tmp table on disk: copying temporary tables in memory to disk is dangerous!
- Locked: locked
6.7 global query log
Never enable this function in the production environment. It can only be used in the test environment!
-
The first is to enable the configuration file. In mysq l's my In CNF, the settings are as follows:
#open general_log=1 #Path to log file general_log_file=/path/logfile #Output format log_output=FILE
-
Second: enable encoding. The command is as follows:
- set global general_log=1;
- set global log_output='TABLE';

After that, the sql statements you write will be recorded in the generic in the mysql database_ Log table, which can be viewed with the following command:
mysql> select * from mysql.general_log; +----------------------------+------------------------------+-----------+-----------+--------------+---------------------------------+ | event_time | user_host | thread_id | server_id | command_type | argument | +----------------------------+------------------------------+-----------+-----------+--------------+---------------------------------+ | 2021-04-05 19:57:28.182473 | root[root] @ localhost [::1] | 5 | 1 | Query | select * from mysql.general_log | +----------------------------+------------------------------+-----------+-----------+--------------+---------------------------------+ 1 row in set (0.00 sec)
8 MySQL lock mechanism
8.1 general
definition:
A lock is a mechanism by which a computer coordinates multiple processes or threads to access a resource concurrently.
In the database, in addition to the contention of traditional computing resources (such as CPU, RAM, I/O, etc.), data is also a resource shared by many users. How to ensure the consistency and effectiveness of data concurrent access is a problem that all databases must solve. Lock conflict is also an important factor affecting the performance of database concurrent access. From this point of view, locks are particularly important and more complex for databases
Example: Jingdong shopping
For example, when we go to Jingdong to buy a commodity, there is only one inventory. At this time, if another person buys it, how to solve the problem of whether you buy it or another person?
Transactions must be used here. We first take the item quantity from the inventory table, then insert the order, insert the payment table information after payment, and then update the commodity quantity. In this process, using locks can protect limited resources and solve the contradiction between isolation and concurrency
Classification of locks:
-
From the type of data operation (read / write)
- Read lock (shared lock): for the same data, multiple read operations can be performed simultaneously without affecting each other.
- Write lock (exclusive lock): it will block other write locks and read locks before the current write operation is completed.
-
From the granularity of data operation
- Watch lock
- Row lock
8.2 meter lock (partial reading)
Features: biased towards MyISAM storage engine, low overhead and fast locking; No deadlock; The locking granularity is large, the probability of lock conflict is the highest, and the concurrency is the lowest.
Lock reading case explanation 1
case analysis
Build table
create table mylock (
id int not null primary key auto_increment,
name varchar(20) default ''
) engine myisam;
insert into mylock(name) values('a');
insert into mylock(name) values('b');
insert into mylock(name) values('c');
insert into mylock(name) values('d');
insert into mylock(name) values('e');
#query
mysql> select * from mylock;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
| 5 | e |
+----+------+
5 rows in set (0.00 sec)
Manually add table locks: lock table name read(write), table name 2 read(write), others;
mysql> lock table mylock read; Query OK, 0 rows affected (0.00 sec)
View the locks on the table: show open tables;
mysql> show open tables; +--------------------+------------------------------------------------------+--------+-------------+ | Database | Table | In_use | Name_locked | +--------------------+------------------------------------------------------+--------+-------------+ | performance_schema | events_waits_summary_by_user_by_event_name | 0 | 0 | | performance_schema | events_waits_summary_global_by_event_name | 0 | 0 | | performance_schema | events_transactions_summary_global_by_event_name | 0 | 0 | | performance_schema | replication_connection_status | 0 | 0 | | mysql | time_zone_leap_second | 0 | 0 | | mysql | columns_priv | 0 | 0 | | my | test03 | 0 | 0 | | bigdata | mylock | 1 | 0 | # In_ When use is 1, it means it is locked
Release lock: unlock tables;
mysql> unlock tables; Query OK, 0 rows affected (0.00 sec) # View again mysql> show open tables; +--------------------+------------------------------------------------------+--------+-------------+ | Database | Table | In_use | Name_locked | +--------------------+------------------------------------------------------+--------+-------------+ | performance_schema | events_waits_summary_by_user_by_event_name | 0 | 0 | | performance_schema | events_waits_summary_global_by_event_name | 0 | 0 | | performance_schema | events_transactions_summary_global_by_event_name | 0 | 0 | | performance_schema | replication_connection_status | 0 | 0 | | mysql | time_zone_leap_second | 0 | 0 | | mysql | columns_priv | 0 | 0 | | my | test03 | 0 | 0 | | bigdata | mylock | 0 | 0 |
Add read lock - add read lock to mylock table (example of read blocking write)
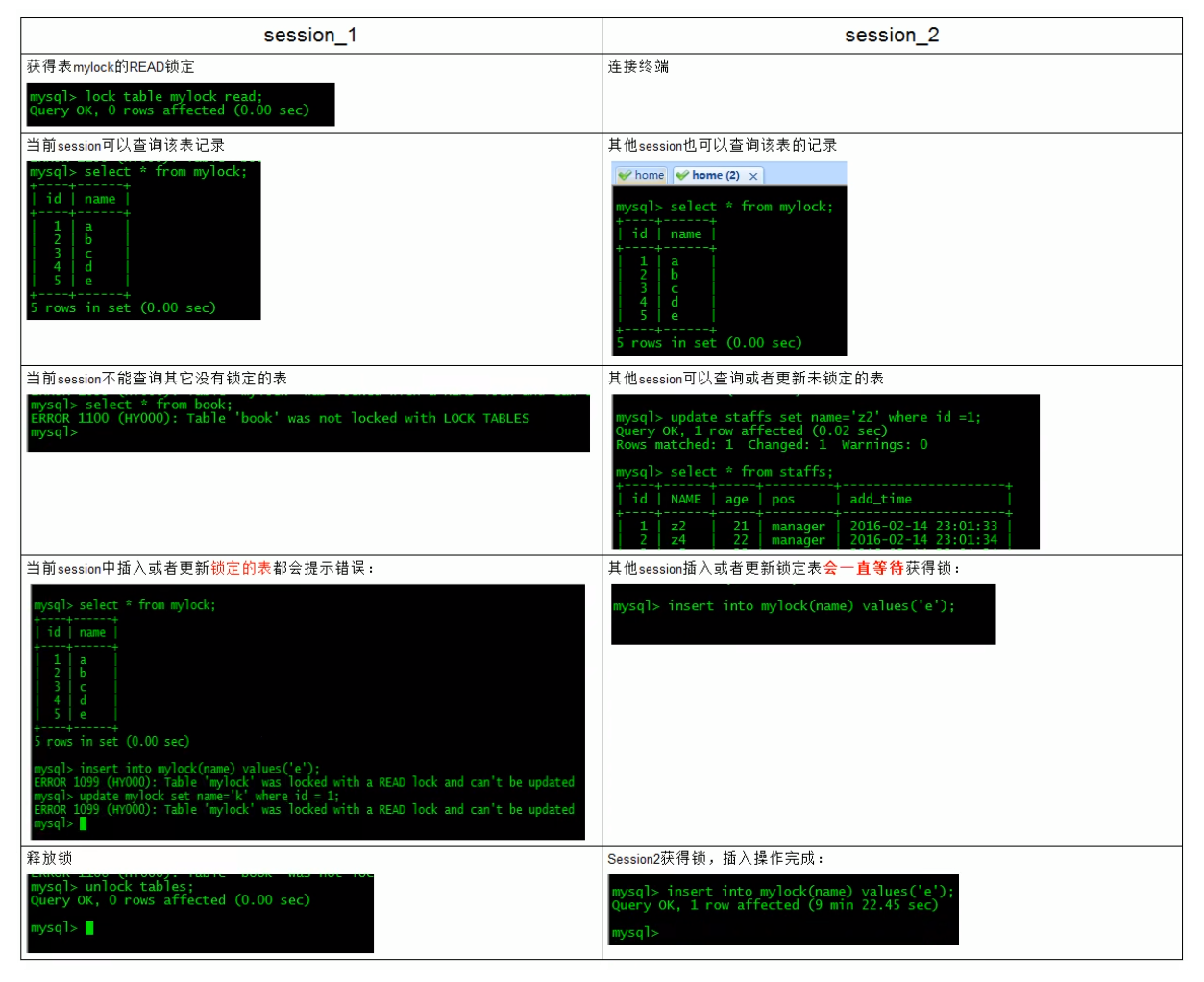
Lock reading case explanation 2
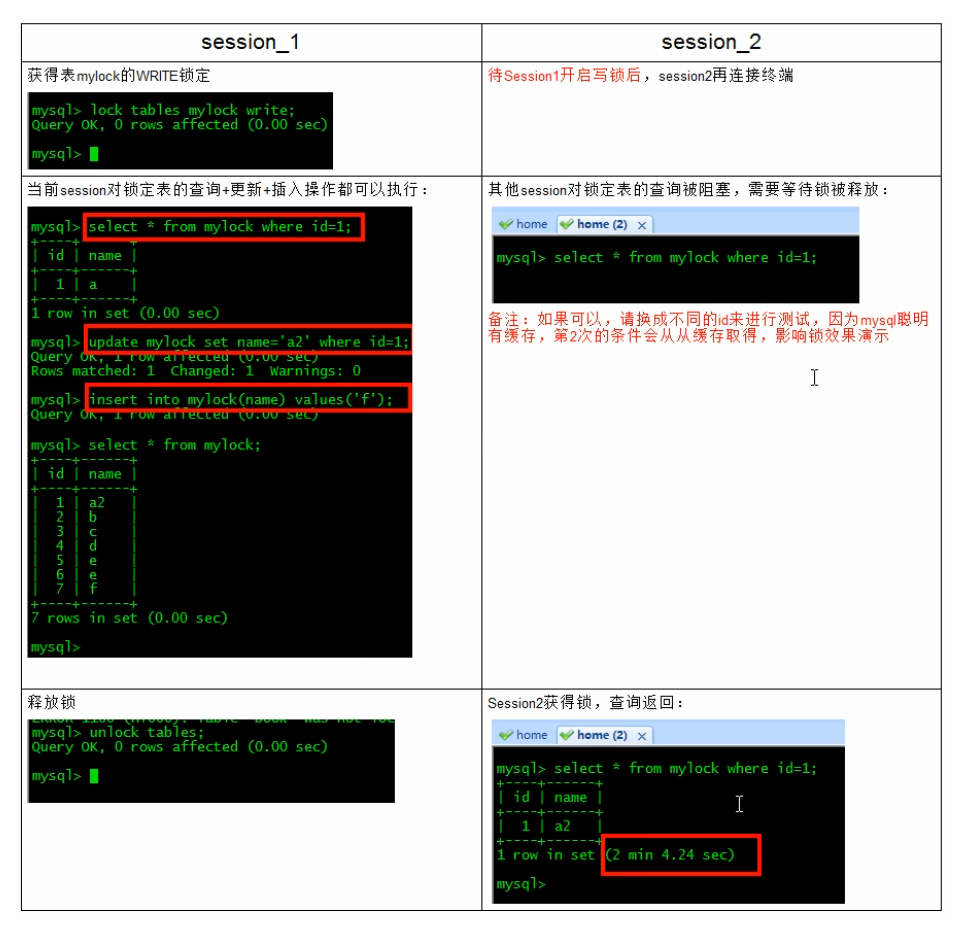
Add a write lock to the mylock table (the write blocking read example of the MylSAM storage engine)
Before executing the query statement (SELECT), MyISAM will automatically add read locks to all the tables involved, and will automatically add write locks to the tables involved before adding, deleting and modifying.
There are two modes of MySQL table level locks:
- Table read lock
- Table write lock

In combination with the above table, the MyISAM table can be operated as follows:
-
The read operation (adding read lock) on the MyISAM table will not block the read requests of other processes to the same table, but will block the write requests to the same table. Only when the read lock is released will the write operation of other processes be performed.
-
The write operation (write lock) on the MyISAM table will block the read and write operations of other processes on the same table. The read and write operations of other processes will be executed only after the write lock is released.
a key!: In short, read locks block writes, but not reads. The write lock blocks both reading and writing
Table lock summary
See which tables are locked: show open tables;
How to analyze table locking
You can check the table_locks_waited and table_locks_immediate state variable to analyze table locks on the system
mysql> show status like 'table_locks%'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | Table_locks_immediate | 170 | | Table_locks_waited | 0 | +-----------------------+-------+ 2 rows in set (0.00 sec)
Here are two status variables to record the internal table level locking of MySQL. The descriptions of the two variables are as follows:
- Table_locks_immediate: the number of times table level locks are generated, indicating the number of queries that can obtain locks immediately. Add 1 for each lock value obtained immediately;
- Table_locks_waited: the number of times a table level lock contention occurs and waits (the number of times a lock cannot be obtained immediately, and the lock value is increased by 1 for each wait). A high value indicates that there is a serious table level lock contention;
In addition, the read-write lock scheduling of MyISAM is write first, which is also that MyISAM is not suitable for writing to the main table. Because other threads cannot do anything after writing the lock, a large number of updates will make it difficult for the query to get the lock, resulting in permanent blocking
8.3 line lock (write off)
It is biased towards InnoDB storage engine, which has high overhead and slow locking; Deadlock will occur; The locking granularity is the smallest, the probability of lock conflict is the lowest, and the concurrency is the highest.
There are two major differences between InnoDB and MyISAM: one is transaction support; Second, row level lock is adopted
Because row locks support transactions, review the old knowledge:
- Transaction and its ACID attribute
- Problems caused by concurrent transaction processing
- Transaction isolation level
1) A transaction is a logical processing unit composed of a group of SQL statements. A transaction has the following four attributes, usually referred to as the ACID attribute of a transaction:
- Atomicity: a transaction is an atomic operation unit whose modifications to data are either executed or not executed.
- Consistency: data must be Consistent at the beginning and completion of a transaction. This means that all relevant data rules must be applied to transaction modification to maintain data integrity; At the end of the transaction, all internal data structures (such as B-tree index or two-way linked list) must also be correct.
- Isolation: the database system provides a certain isolation mechanism to ensure that transactions are executed in an "independent" environment that is not affected by external concurrent operations. This means that the intermediate state in the transaction process is invisible to the outside, and vice versa.
- Durable: after the transaction is completed, its modification to the data is permanent and can be maintained even in case of system failure.
2) Problems caused by concurrent transaction processing
-
Lost update
When two or more transactions select the same row and then update the row based on the initially selected value, the problem of missing updates will occur because each transaction is unaware of the existence of other transactions - the last update overwrites the updates made by other transactions.
For example, two programmers modify the same java file. Each programmer independently changes its copy, and then saves the changed copy, overwriting the original document. Finally, the editor who saved a copy of his changes overwrites the changes made by the previous programmer.
This problem can be avoided if another programmer cannot access the same file before one programmer completes and commits the transaction.
-
Dirty reads
A transaction is modifying a record. Before the transaction is completed and committed, the data of the record is in an inconsistent state; At this time, another transaction also reads the same record. If it is not controlled, the second transaction reads these "dirty" data and makes further processing accordingly, which will produce uncommitted data dependencies. This phenomenon is vividly called "dirty reading".
Bottom line: transaction A reads the modified but uncommitted data of transaction B and operates on this data. At this time, if transaction B rolls back, the data read by A is invalid and does not meet the consistency requirements
-
Non repeatable reads
At a certain time after reading some data, a transaction reads the previously read data again, but finds that the read data has changed or some records have been deleted. This phenomenon is called "unrepeatable reading".
Bottom line: transaction A reads the modified data submitted by transaction B, which does not comply with isolation.
-
Phantom reads
A transaction re reads the previously retrieved data with the same query criteria, but finds that other transactions insert new data that meets its query criteria. This phenomenon is called "unreal reading".
Bottom line: transaction A reads the new data submitted by transaction B, which does not comply with isolation
One more word: Fantasy reading is a little similar to dirty reading. Dirty reading refers to the modification of data in transaction B; Unreal reading is the addition of data in transaction B.
3) Transaction isolation level
”Dirty reading, non repeatable reading, and unreal reading are all database read consistency problems, which must be solved by the database providing a certain transaction isolation mechanism

The stricter the transaction isolation of the database, the smaller the side effects of concurrency, but the greater the cost, because transaction isolation essentially makes transactions "serialized" to a certain extent, which is obviously contradictory to "concurrency". At the same time, different applications have different requirements for read consistency and transaction isolation. For example, many applications are not sensitive to "non repeatable reading" and "phantom reading", and may be more concerned about the ability of concurrent data access.
Often see the transaction isolation level of the current database: show variables like 'tx_isolation';
mysql> show variables like 'tx_isolation'; +---------------+-----------------+ | Variable_name | Value | +---------------+-----------------+ | tx_isolation | REPEATABLE-READ | +---------------+-----------------+ 1 row in set, 1 warning (0.00 sec) # By default: MySQL avoids dirty reads and non repeatable reads
Explanation of row lock cases
Table creation:
CREATE TABLE test_innodb_lock (a INT(11),b VARCHAR(16))ENGINE=INNODB; INSERT INTO test_innodb_lock VALUES(1,'b2'); INSERT INTO test_innodb_lock VALUES(3,'3'); INSERT INTO test_innodb_lock VALUES(4, '4000'); INSERT INTO test_innodb_lock VALUES(5,'5000'); INSERT INTO test_innodb_lock VALUES(6, '6000'); INSERT INTO test_innodb_lock VALUES(7,'7000'); INSERT INTO test_innodb_lock VALUES(8, '8000'); INSERT INTO test_innodb_lock VALUES(9,'9000'); INSERT INTO test_innodb_lock VALUES(1,'b1'); CREATE INDEX test_innodb_a_ind ON test_innodb_lock(a); CREATE INDEX test_innodb_lock_b_ind ON test_innodb_lock(b); //see mysql> select * from test_innodb_lock; +------+------+ | a | b | +------+------+ | 1 | b2 | | 3 | 3 | | 4 | 4000 | | 5 | 5000 | | 6 | 6000 | | 7 | 7000 | | 8 | 8000 | | 9 | 9000 | | 1 | b1 | +------+------+ 9 rows in set (0.00 sec) mysql> show index from test_innodb_lock; +------------------+------------+------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +------------------+------------+------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | test_innodb_lock | 1 | test_innodb_a_ind | 1 | a | A | 8 | NULL | NULL | YES | BTREE | | | | test_innodb_lock | 1 | test_innodb_lock_b_ind | 1 | b | A | 9 | NULL | NULL | YES | BTREE | | | +------------------+------------+------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
Basic demonstration of row locking (two clients update the same row record)
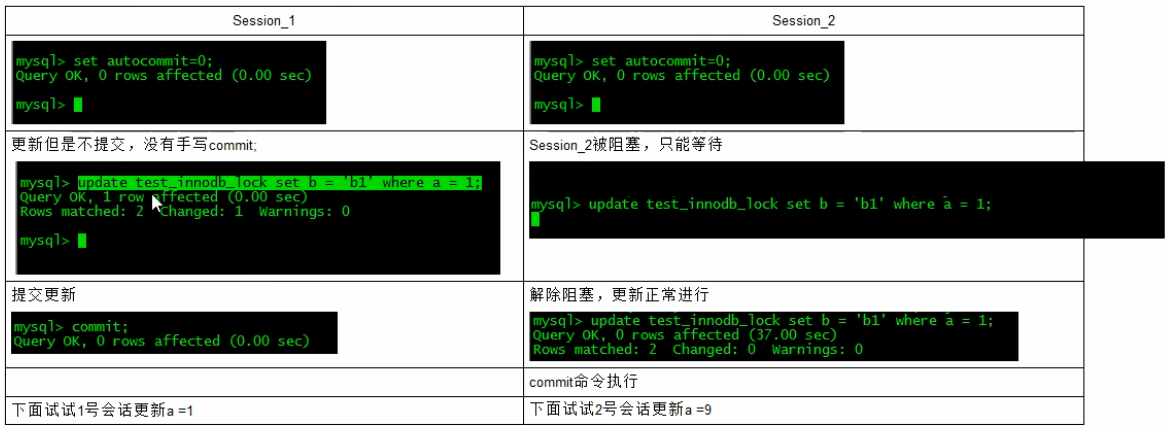
Why should both command
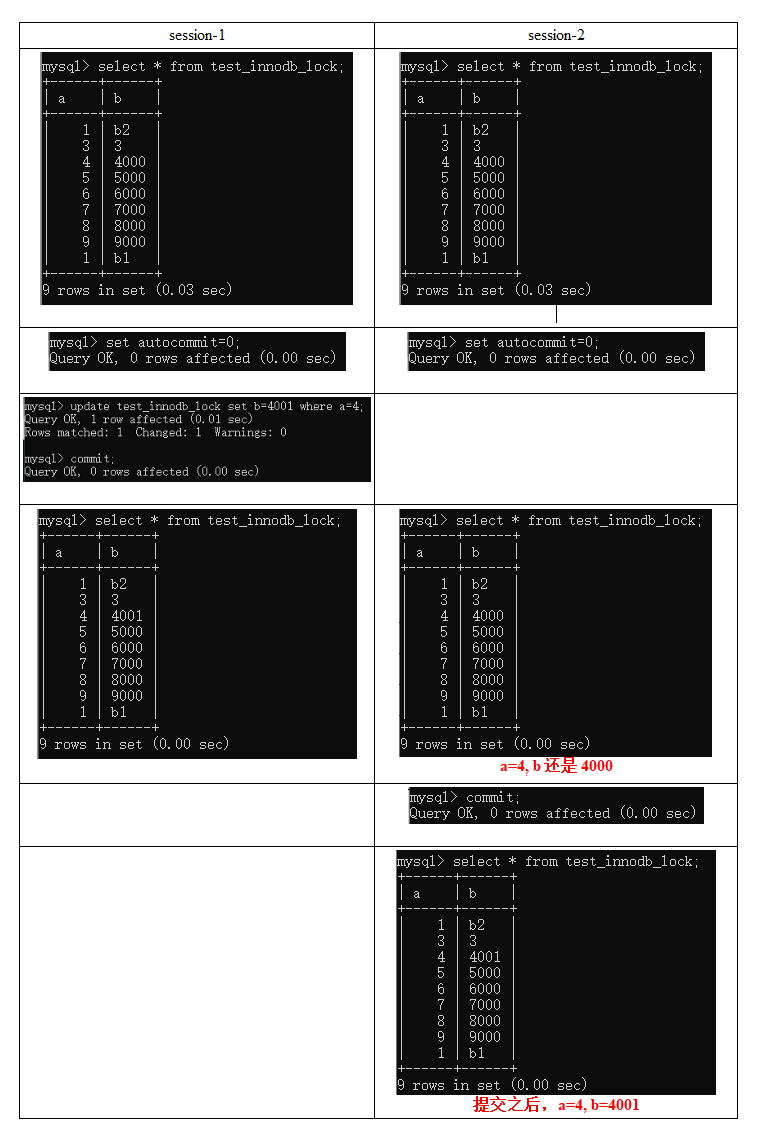
Index failure row lock to table lock
An indexless row lock is promoted to a table lock

Clearance lock

What is a clearance lock
When we use the range condition instead of the equal condition to retrieve data and request a shared or exclusive lock, InnoDB will lock the index entries of existing data records that meet the conditions. The records whose key values are within the condition range but do not exist are called "GAP".
InnoDB will also lock this "gap". This locking mechanism is the so-called next key lock.
harm
Because if the Query passes the range search during execution, it will lock all index key values in the whole range, even if the key value does not exist.
A fatal weakness of gap lock is that when a range key value is locked, even some nonexistent key values will be locked innocently, resulting in the inability to insert any data within the range of locked key values during locking. In some scenarios, this may cause great harm to performance
Interview question: how to lock a line
begin (write your own operation in the middle) commit
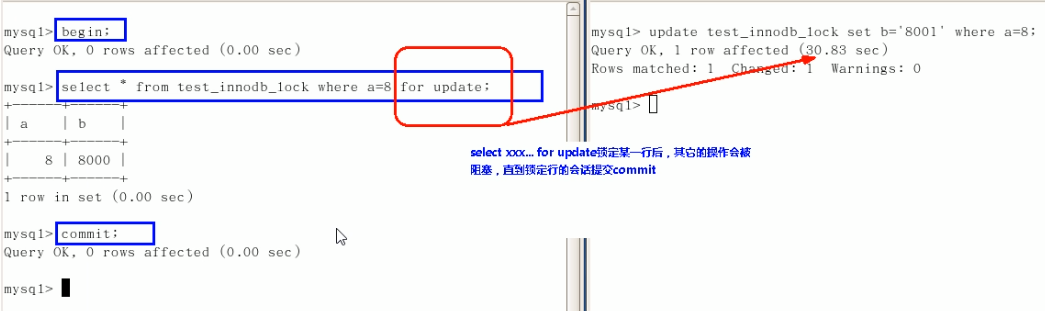
Row lock summary
Summary:
Because Innodb storage engine implements row level locking, although the performance loss caused by the implementation of locking mechanism may be higher than that of table level locking, it is much better than that of table level locking of MyISAM in terms of overall concurrent processing capacity. When the system concurrency is high, the overall performance of Innodb will have obvious advantages over MylISAM.
However, Innodb's row level locking also has its weak side. When we use it improperly, the overall performance of Innodb may not be higher than MyISAM, or even worse
How to analyze row locking?
By checking lnnoDB_row_lock state variable to analyze the contention of row locks on the system: show status like 'innodb_row_lock%';
mysql> show status like 'innodb_row_lock%'; +-------------------------------+-------+ | Variable_name | Value | +-------------------------------+-------+ | Innodb_row_lock_current_waits | 0 | | Innodb_row_lock_time | 0 | | Innodb_row_lock_time_avg | 0 | | Innodb_row_lock_time_max | 0 | | Innodb_row_lock_waits | 0 | +-------------------------------+-------+ 5 rows in set (0.00 sec)
The description of each state quantity is as follows:
- Innodb_row_lock_current_waits: the number of currently waiting locks;
- Innodb_row_lock_time: total lock time from system startup to now;
- Innodb_row_lock_time_avg: average time spent waiting each time;
- Innodb_row_lock_time_max: time spent waiting for the most frequent time from system startup to now;
- Innodb_row_lock_waits: the total number of waits since system startup;
For these five state variables, the more important ones are:
- lnnodb_row_lock_time (total waiting time)
- Innodb_row_lock_time_avg (average waiting time)
- lnnodb_row_lock_waits (total number of waits)
Especially when the waiting times are high and the waiting time is not small, we need to analyze why there are so many waiting in the Show Profile system, and then start to specify the optimization plan according to the analysis results.
Optimization suggestions
- Let all data retrieval be completed through the index as far as possible to avoid upgrading the non indexed row lock to a table lock.
- Reasonably design the index to minimize the scope of the lock
- Search conditions shall be as few as possible to avoid gap lock
- Try to control the transaction size and reduce the amount of locking resources and time length
- Low level transaction isolation as possible
Page lock
The overhead and locking time are bounded between table lock and row lock; Deadlock will occur; The locking granularity is between table lock and row lock, and the concurrency is general. (just find out)
9 master slave replication
9.1 fundamentals of replication
slave will read binlog from master for data synchronization
schematic diagram:
MySQL replication is divided into three steps:
- 1. The master logs the changes to the binary log. These recording processes are called binary log events;
- 2. slave copies the binary log events of the master to its relay log;
- 3. slave redoes the events in the relay log and applies the changes to its own database. MySQL replication is asynchronous and serialized
9.2 basic principles of reproduction
- Each slave has only one master
- Each slave can only have a unique server ID
- Each master can have multiple salve s
The biggest problem with replication is latency.
9.3 common configurations of one master and one slave
1, The mysql version is consistent and the background runs as a service
2, Both the master and slave are configured under the [mysqld] node and are lowercase
Host modify my Ini configuration file:
1. [required] primary server unique ID: server id = 1
2. [must] enable binary logging
- Log bin = local path / mysqlbin
- log-bin=D:/devSoft/MySQLServer5.5/data/mysqlbin
3. [optional] enable error logging
- Log err = local path / mysqlerr
- log-err=D:/devSoft/MySQLServer5.5/data/mysqlerr
4. [optional] root directory
- basedir = "local path"
- basedir="D:/devSoft/MySQLServer5.5/"
5. [optional] temporary directory
- tmpdir = "own local path"
- tmpdir="D:/devSoft/MySQLServer5.5/"
6. [optional] data directory
- datadir = "local path / Data /"
- datadir="D:/devSoft/MySQLServer5.5/Data/"
7. The host can read and write
- read-only=O
8. [optional] set the database not to be copied
- binlog-ignore-db=mysql
9. [optional] set the database to be copied
- Binlog do DB = name of the primary database to be replicated
Slave modify my CNF profile:
1. [must] slave server unique ID: VIM etc / my CNF (enter modify configuration file)
... #Server id = 1 / / Notes ... server-id=1 //open ...
2. [optional] enable binary logging
3, Configuration file, please restart the background mysql service for both host and slave
Host: manual restart
Linux slave naming:
- service mysql stop
- service mysql start
4, Turn off the firewall for both host and slave computers
windows manual shutdown
Close the linux Firewall of the virtual machine: service iptables stop
5, Establish an account on the Windows host and authorize the slave
- GRANT REPLICATION SLAVE ON . TO 'zhangsan' @ 'from machine database IP' IDENTIFIED BY '123456';
- Refresh: flush privileges;
- Query the status of the master
- show master status;
- Record the values of File and Position
- After this step, do not operate the master server MYSQL to prevent the master server status value from changing
6, Configure the host to be copied on the Linux slave
-
CHANGE MASTER TO MASTER_HOST = 'host IP',
MASTER_USER='zhangsan',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='File name ',
MASTER_LOG_POS=Position number; -
Start the slave server copy function: start slave;
-
show slave status\G (if the following two parameters are Yes, the master-slave configuration is successful!)
- Slave_IO_Running: Yes
- Slave_SQL_Running: Yes
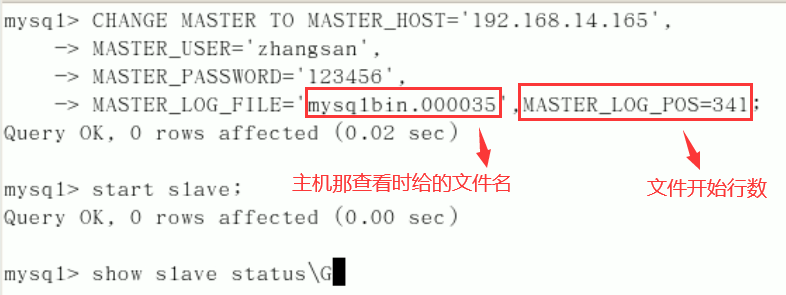
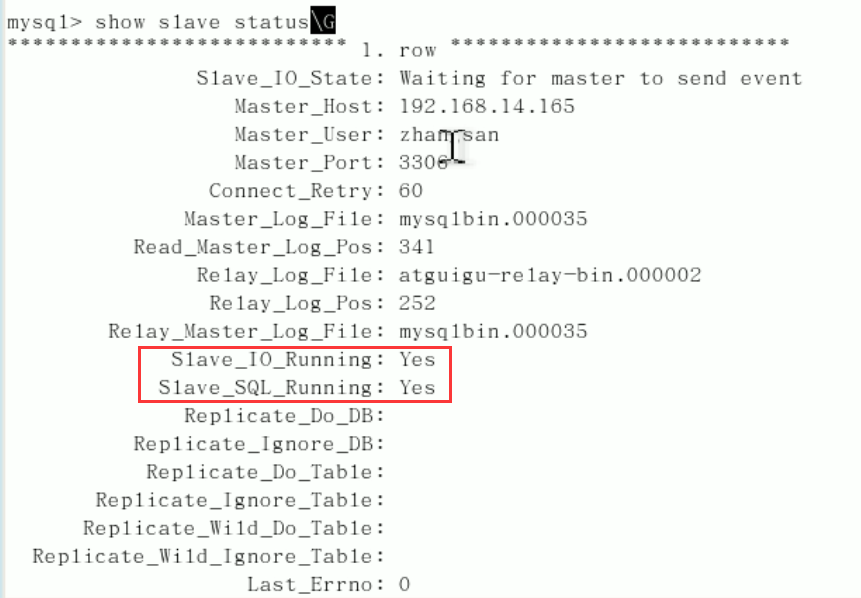
7, Create a new database, table and insert record on the host, and copy from the host
- Host operation
- Slave (automatic synchronization)
8, How to stop copying from a service: stop slave;
If there is a piece of data, do not use it for the time being?
Slave:
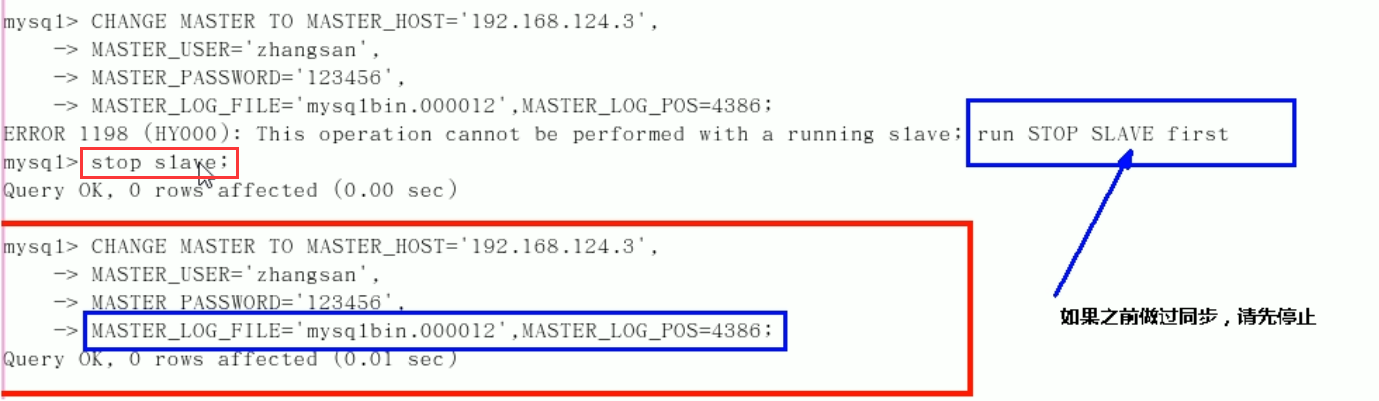
Host (need to check the scale again):