ConcurrentHashMap is a multi-threaded version of HashMap. HashMap will have various problems during concurrent operation, such as dead circulation, data coverage and so on. These problems can be perfectly solved by using ConcurrentHashMap. Here's the problem. How does ConcurrentHashMap ensure thread safety? How is its bottom layer realized? Next, let's take a look.
JDK 1.7 bottom layer implementation
ConcurrentHashMap is implemented differently in different JDK versions. In JDK 1.7, it is implemented in the form of array and linked list, and the array is divided into large array Segment and small array HashEntry. The large array Segment can be understood as a database in MySQL, and there are many hashentries in each database, and there are multiple pieces of data in each HashEntry. These data are connected by linked lists, as shown in the following figure:
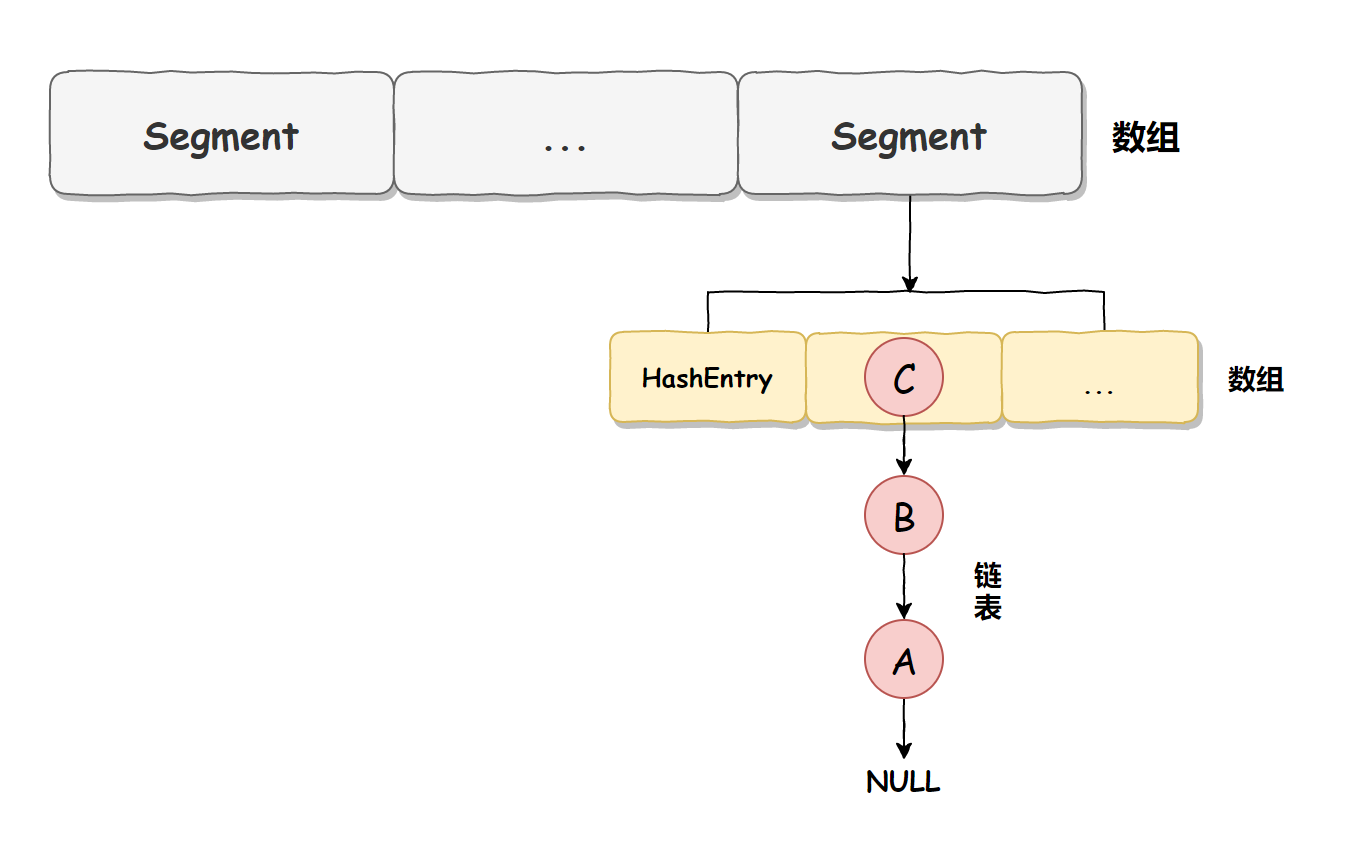
JDK 1.7 thread safety implementation
Understand the underlying implementation of ConcurrentHashMap, and then look at its thread safety implementation.
Next, by adding the element put method, we can see how ConcurrentHashMap in JDK 1.7 ensures thread safety. The specific implementation source code is as follows:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// Before writing to the Segment, ensure that the lock is obtained
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
// Segment internal array
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// Update existing values
}
else {
// Place the HashEntry to a specific location, and rehash if the threshold is exceeded
// Ignore other code
}
}
} finally {
// Release lock
unlock();
}
return oldValue;
}
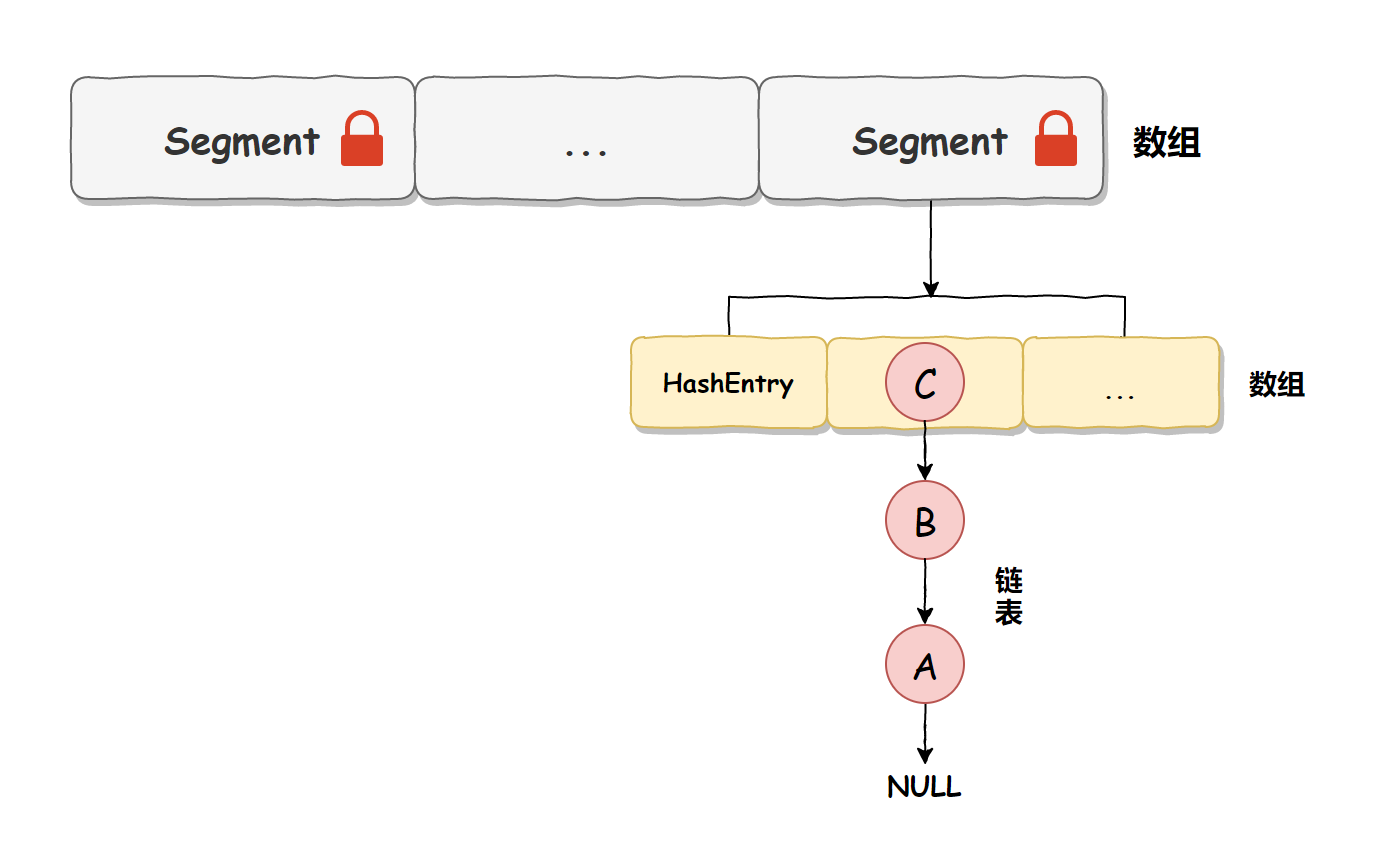
From the above source code, we can see that Segment itself is a lock adding and lock releasing operation based on ReentrantLock, which can ensure that when multiple threads access ConcurrentHashMap at the same time, only one thread can operate the corresponding node at the same time, so as to ensure the thread safety of ConcurrentHashMap.
In other words, the thread safety of ConcurrentHashMap is based on Segment locking, so we call it Segment lock or fragment lock, as shown in the following figure:
JDK 1.8 bottom layer implementation
In JDK 1.7, although ConcurrentHashMap is thread safe, because its underlying implementation is in the form of array + linked list, it is very slow to access when there are a lot of data, because it needs to traverse the whole linked list, while JDK 1.8 uses the method of array + linked list / red black tree to optimize the implementation of ConcurrentHashMap. The specific implementation structure is as follows:
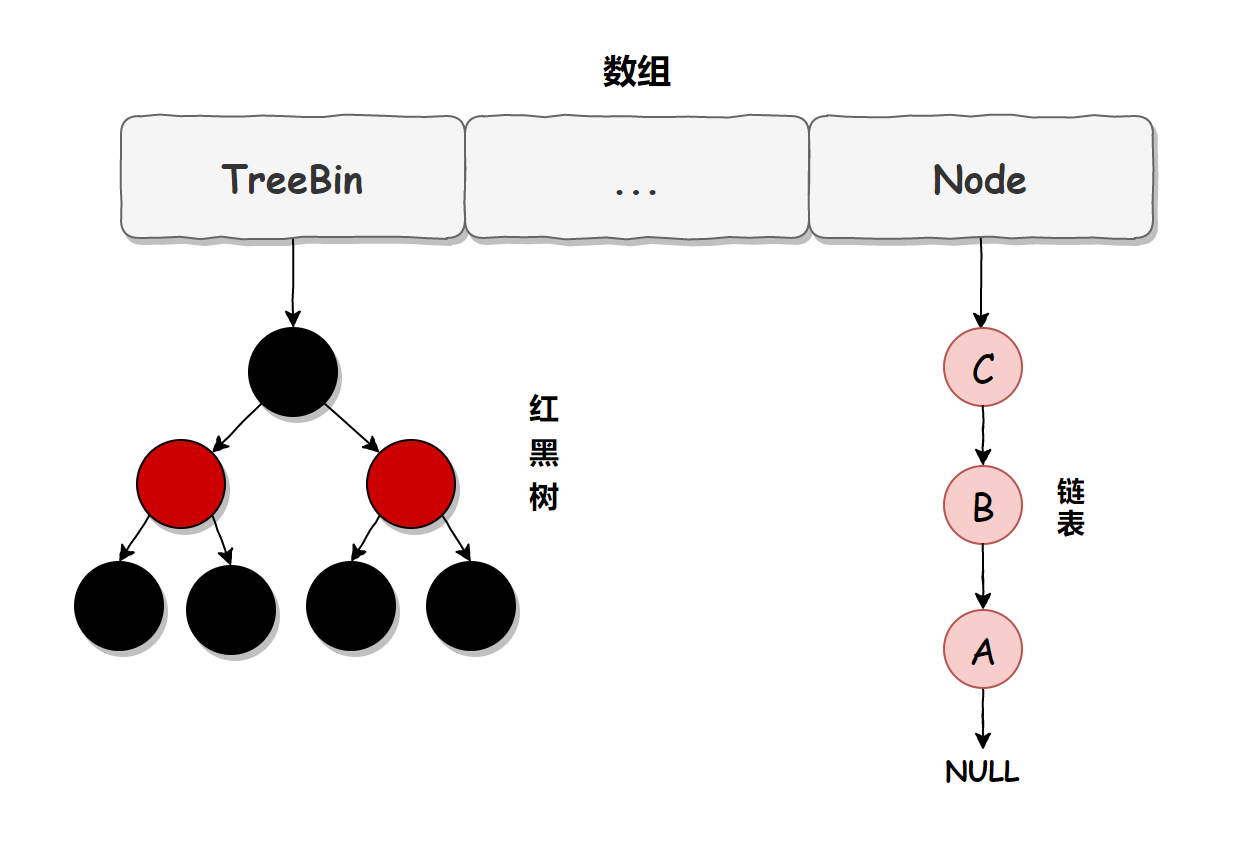
Rules for upgrading a linked list to a red black tree: when the length of the linked list is greater than 8 and the length of the array is greater than 64, the linked list will be upgraded to a red black tree structure.
PS: Although concurrent HashMap retains the definition of Segment in JDK 1.8, it is only to ensure the compatibility during serialization and is no longer structurally useful.
JDK 1.8 thread safety implementation
In JDK 1.8, concurrent HashMap uses CAS + volatile or synchronized to ensure thread safety. Its core implementation source code is as follows:
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // Node is empty
// Use CAS for lockless thread safe operation. If bin is empty
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break;
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
// Fine grained synchronous modification
}
}
// If the threshold is exceeded, upgrade to red black tree
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
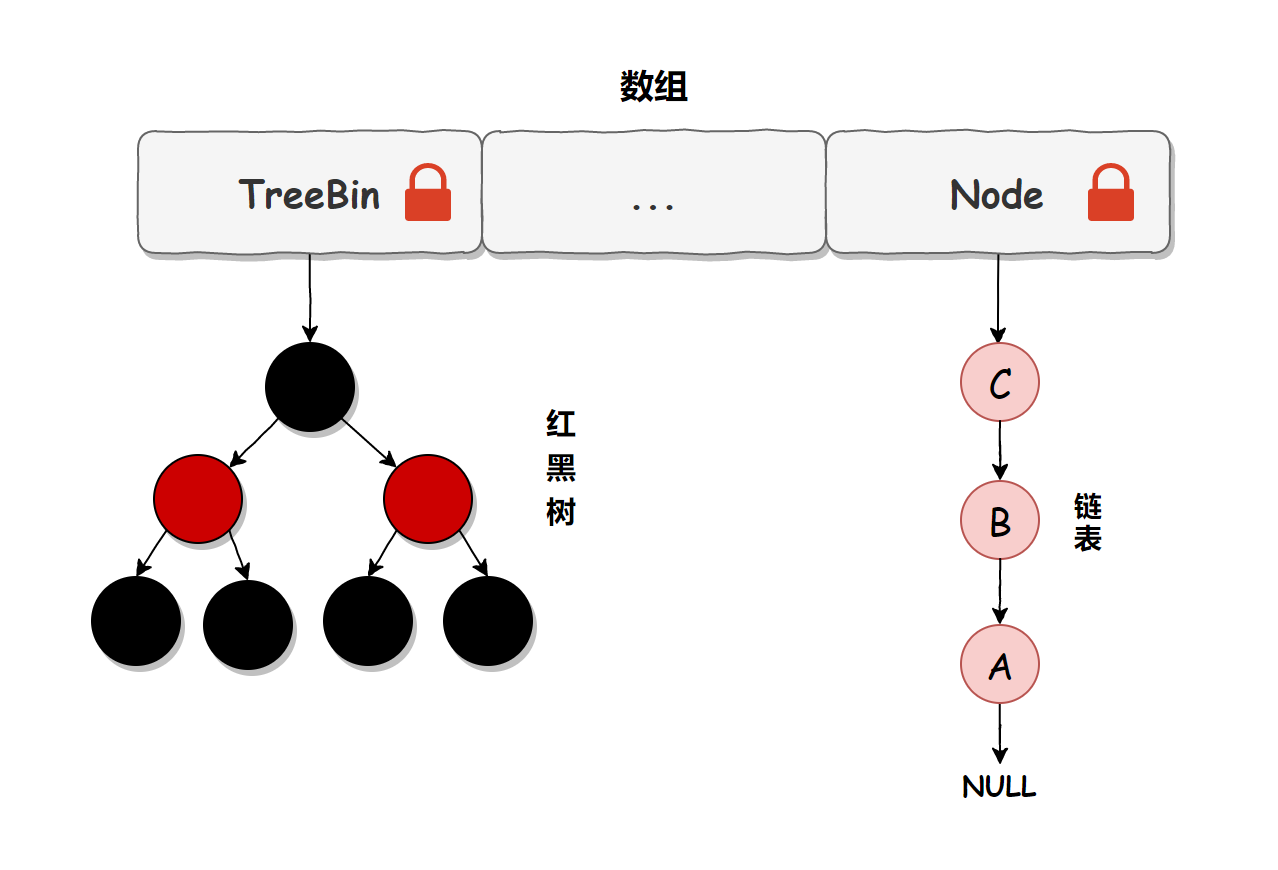
From the above source code, we can see that in JDK 1.8, when adding elements, we will first judge whether the container is empty. If it is empty, we will use volatile plus CAS to initialize. If the container is not empty, calculate whether the location is empty according to the stored elements. If it is empty, use CAS to set the node; If it is not empty, use synchronize to lock, traverse the data in the bucket, replace or add nodes to the bucket, and finally judge whether it needs to be turned into a red black tree, so as to ensure thread safety during concurrent access.
Let's simplify the above process. We can simply think that in JDK 1.8, ConcurrentHashMap locks the head node to ensure thread safety. The granularity of the lock is smaller than that of Segment, the frequency of conflict and locking is reduced, and the performance of concurrent operations is improved. Moreover, JDK 1.8 uses the red black tree to optimize the previous fixed linked list. When the amount of data is large, the query performance has also been greatly improved. The time complexity from the previous O(n) optimization to O(logn) is as follows:
summary
Concurrent HashMap is implemented in the form of data and linked list in JDK 1.7. Arrays are divided into two types: large array Segment and small array HashEntry. Locking is achieved by adding ReentrantLock lock lock to Segment to achieve thread safety. In JDK 1.8, ConcurrentHashMap is implemented in the way of array + linked list / red black tree. It is thread safe through CAS or synchronized, with smaller lock granularity and higher query performance.
Original address: https://www.cnblogs.com/vipstone/p/15838164.html