Emotion analysis competition: score 0.7943

Here, the high-level API of the propeller is used to quickly build a model to submit the results of the emotion analysis competition. Please refer to the specific principle and analysis NLP punch in camp practice lesson 5: text emotion analysis . The following will be divided into three parts: sentence level affective analysis (nlpcc14-sc, chnenticorp); Objective emotion analysis (se-absa16_phns, se-absa16_case); And viewpoint extraction (COTE-BD, COTE-DP, COTE-MFW). For specific data set introduction, see Game link
The use of the project is very simple. Change the data of the corresponding chapter_ Name, and adjust batch by yourself_ Size and epochs to achieve the best training effect, and run all the codes in the corresponding chapters to get the prediction results of the corresponding data set. After all data predictions are completed, download the submission folder and submit it.
!pip install --upgrade paddlenlp -i https://pypi.org/simple
1. Sentence level emotion analysis
Sentence level emotion analysis is to judge the emotional tendency of an input paragraph, which is generally positive (1) or negative (0).
As we all know, human natural language contains rich emotional colors: expressing people's emotions (such as sadness and happiness), expressing people's feelings (such as burnout and depression), expressing people's preferences (such as like and hate), expressing people's personality characteristics and expressing people's position, etc. Affective analysis is applied in commodity preference, consumption decision-making, public opinion analysis and other scenarios. Using machines to automatically analyze these emotional tendencies will not only help enterprises understand consumers' feelings about their products, but also provide a basis for product improvement; At the same time, it also helps enterprises analyze the attitudes of business partners in order to make better business decisions.
The well-known emotion analysis task is to classify a paragraph of text, such as three classification problems with positive emotion polarity, negative emotion polarity and others:

Emotion analysis task
- Positive: it means positive emotions, such as happiness, surprise, expectation, etc.
- Negative: indicates negative emotions, such as sadness, sadness, anger, panic, etc.
- Other: other types of emotions.
In fact, the above familiar emotion analysis tasks are sentence level emotion analysis tasks.
Affective analysis tasks can be further divided into sentence level affective analysis, target level affective analysis and so on.
1.0 loading model and Tokenizer
Call paddlenlp transformers. SkepForTokenClassification. from_ The pre trained ('skep_ernie_1.0_large_ch ') method only needs to specify the model name and the number of categories of text classification to be used to define the model network.
PaddleNLP supports not only Skep pre training model, but also BERT, RoBERTa, Electra and other pre training models.
The following table summarizes the various pre training models currently supported by PaddleNLP. Users can use the model provided by PaddleNLP to complete tasks such as text classification, sequence annotation, question and answer, etc. At the same time, we provide 22 kinds of pre training parameter weights for users, including the pre training weights of 11 Chinese language models.
| Model | Tokenizer | Supported Task | Model Name |
|---|---|---|---|
| BERT | BertTokenizer | BertModel BertForQuestionAnswering BertForSequenceClassification BertForTokenClassification | bert-base-uncased bert-large-uncased bert-base-multilingual-uncased bert-base-cased bert-base-chinese bert-base-multilingual-cased bert-large-cased bert-wwm-chinese bert-wwm-ext-chinese |
| ERNIE | ErnieTokenizer ErnieTinyTokenizer | ErnieModel ErnieForQuestionAnswering ErnieForSequenceClassification ErnieForTokenClassification | ernie-1.0 ernie-tiny ernie-2.0-en ernie-2.0-large-en |
| RoBERTa | RobertaTokenizer | RobertaModel RobertaForQuestionAnswering RobertaForSequenceClassification RobertaForTokenClassification | roberta-wwm-ext roberta-wwm-ext-large rbt3 rbtl3 |
| ELECTRA | ElectraTokenizer | ElectraModel ElectraForSequenceClassification ElectraForTokenClassification | electra-small electra-base electra-large chinese-electra-small chinese-electra-base |
Note: the Chinese pre training models include Bert base Chinese, Bert WwM Chinese, Bert WwM ext Chinese, ernie-1.0, Ernie tiny, Roberta WwM ext, Roberta WwM ext large, rbt3, rbtl3, China electric base, China Electric small, etc.
More pre training model references: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/model_zoo/transformers.rst
For more usage methods of pre training model fine tune downstream tasks, please refer to https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples
import paddlenlp from paddlenlp.transformers import SkepForSequenceClassification, SkepTokenizer # from paddlenlp.transformers import ErnieForSequenceClassification, ErnieTokenizer # from paddlenlp.transformers import BertForSequenceClassification, BertTokenizer
print(paddlenlp.__version__)
1.1 data processing
Although some data sets already exist in paddelnlp, for consistency in data processing, they are uniformly processed from uploaded datasets. For the existing data sets of PaddleNLP, it is strongly recommended to call them directly with API, which is very convenient.
# Decompress data !unzip -o datasets/ChnSentiCorp !unzip -o datasets/NLPCC14-SC
Data internal structure analysis:
ChnSentiCorp: train: label text_a 0 The room is too small. Everything else is average......... 1 Light, easy to carry, good performance, can meet the usual work needs, very good for business travelers dev: qid label text_a 0 1 The environment and service attitude of this hotel are also quite good,But the room space is too small~... test: qid text_a 0 This hotel is rather old, and the special rooms are also very ordinary. Generally speaking, it is average ... ... NLPCC14-SC: train: label text_a 1 Excuse me, isn't this machine equipped with a remote control? 0 It's all truth test: qid text_a 0 I finally found someone in the same line~~~~Since junior high school, I have been... ... ...
It can be seen from the above that the two data sets can define the same reading method, but nlpcc14 SC has no dev data set, so dev data is no longer defined
# Get dataset dictionary
def open_func(file_path):
return [line.strip() for line in open(file_path, 'r', encoding='utf8').readlines()[1:] if len(line.strip().split('\t')) >= 2]
data_dict = {'chnsenticorp': {'test': open_func('ChnSentiCorp/test.tsv'),
'dev': open_func('ChnSentiCorp/dev.tsv'),
'train': open_func('ChnSentiCorp/train.tsv')},
'nlpcc14sc': {'test': open_func('NLPCC14-SC/test.tsv'),
'train': open_func('NLPCC14-SC/train.tsv')}}
1.2 defining data readers
# Define dataset
from paddle.io import Dataset, DataLoader
from paddlenlp.data import Pad, Stack, Tuple
import numpy as np
label_list = [0, 1]
# Note that since token type does not work in this task, it will not be considered here. Let the model fill in by itself.
class MyDataset(Dataset):
def __init__(self, data, tokenizer, max_len=512, for_test=False):
super().__init__()
self._data = data
self._tokenizer = tokenizer
self._max_len = max_len
self._for_test = for_test
def __len__(self):
return len(self._data)
def __getitem__(self, idx):
samples = self._data[idx].split('\t')
label = samples[-2]
text = samples[-1]
label = int(label)
text = self._tokenizer.encode(text, max_seq_len=self._max_len)['input_ids']
if self._for_test:
return np.array(text, dtype='int64')
else:
return np.array(text, dtype='int64'), np.array(label, dtype='int64')
def batchify_fn(for_test=False):
if for_test:
return lambda samples, fn=Pad(axis=0, pad_val=tokenizer.pad_token_id): np.row_stack([data for data in fn(samples)])
else:
return lambda samples, fn=Tuple(Pad(axis=0, pad_val=tokenizer.pad_token_id),
Stack()): [data for data in fn(samples)]
def get_data_loader(data, tokenizer, batch_size=32, max_len=512, for_test=False):
dataset = MyDataset(data, tokenizer, max_len, for_test)
shuffle = True if not for_test else False
data_loader = DataLoader(dataset=dataset, batch_size=batch_size, collate_fn=batchify_fn(for_test), shuffle=shuffle)
return data_loader
1.3 model building and training
The model is very simple. We only need to call the corresponding sequence classification tool. In order to facilitate the training, the high-level API Model is directly used to complete the training.
import paddle
from paddle.static import InputSpec
# Model and word segmentation
model = SkepForSequenceClassification.from_pretrained('skep_ernie_1.0_large_ch', num_classes=2)
tokenizer = SkepTokenizer.from_pretrained('skep_ernie_1.0_large_ch')
# model = ErnieForTokenClassification.from_pretrained('ernie-1.0', num_classes=2)
# tokenizer = ErnieTokenizer.from_pretrained('ernie-1.0')
# model = BertForSequenceClassification.from_pretrained('bert-wwm-ext-chinese', num_classes=2)
# tokenizer = BertTokenizer.from_pretrained('bert-wwm-ext-chinese')
# Parameter setting # Change this option to change the dataset chnsenticorp,nlpcc14sc
# data_name = 'chnsenticorp'
data_name = 'nlpcc14sc'
# Training related
epochs = 5
learning_rate = 2e-5 # chnsenticorp 2e-5 /nlpcc14sc 2e-5
batch_size = 48 #chnsenticorp 64 / nlpcc14sc 128
max_len = 224 # 92 / 96
## Data correlation
train_dataloader = get_data_loader(data_dict[data_name]['train'], tokenizer, batch_size, max_len, for_test=False)
if data_name == 'chnsenticorp':
dev_dataloader = get_data_loader(data_dict[data_name]['dev'], tokenizer, batch_size, max_len, for_test=False)
else:
dev_dataloader = None
input = InputSpec((-1, -1), dtype='int64', name='input')
label = InputSpec((-1, 2), dtype='int64', name='label')
model = paddle.Model(model, [input], [label])
# Model preparation
# Data set chnsenticorp, add regularization 5e-4
# Dataset nlpcc14sc, add regularization 6e-4
optimizer = paddle.optimizer.Adam(learning_rate=learning_rate, parameters=model.parameters(),
weight_decay=paddle.regularizer.L2Decay(5e-4))
model.prepare(optimizer, loss=paddle.nn.CrossEntropyLoss(), metrics=[paddle.metric.Accuracy()])
print(len(train_dataloader))
Train chnsenticorp
# Start training chnsenticorp model.fit(train_dataloader, dev_dataloader, batch_size, epochs=12, save_freq=20,verbose=2, save_dir='./ckpt/chnsenticorp')
Training nlpcc14sc
# Start training nlpcc14sc model.fit(train_dataloader, dev_dataloader, batch_size, epochs=8, save_freq=20,verbose=2, save_dir='./ckpt/nlpcc14sc')
1.4 forecast and save
import os
# Change the special data set and predict the corresponding results chnsenticorp,nlpcc14sc
# data_name = 'chnsenticorp'
data_name = 'nlpcc14sc'
# Import pre training model
checkpoint_path = "./ckpt/" + data_name + "/final"
model = SkepForSequenceClassification.from_pretrained('skep_ernie_1.0_large_ch', num_classes=2)
# model = ErnieForSequenceClassification.from_pretrained('ernie-1.0', num_classes=2)
# model = BertForSequenceClassification.from_pretrained('bert-wwm-ext-chinese', num_classes=2)
input = InputSpec((-1, -1), dtype='int64', name='input')
model = paddle.Model(model, input)
model.load(checkpoint_path)
# Import test set
test_dataloader = get_data_loader(data_dict[data_name]['test'], tokenizer, batch_size, max_len, for_test=True)
# Save forecast results
save_dir = './submission'
save_file = {'chnsenticorp': 'ChnSentiCorp.tsv', 'nlpcc14sc': 'NLPCC14-SC.tsv'}
if not os.path.exists(save_dir):
os.makedirs(save_dir)
predicts = []
for batch in test_dataloader:
predict = model.predict_batch(batch)
predicts += predict[0].argmax(axis=-1).tolist()
with open(os.path.join(save_dir,save_file[data_name]), 'w', encoding='utf8') as f:
f.write("index\tprediction\n")
for idx, sample in enumerate(data_dict[data_name]['test']):
qid = sample.split('\t')[0]
f.write(qid + '\t' + str(predicts[idx]) + '\n')
f.close()
2. Goal level emotion analysis
Target level affective analysis expands the affective tendency of the whole sentence to the affective tendency of multiple specific attributes. In essence, it is still sequence classification, but it needs to be classified multiple times for the same sequence and different attributes. The idea here is to introduce the targeted attributes into the model as part of the input, and predict the emotional tendency.
In recent years, a large number of studies have shown that pre trained models (PTM) based on large corpus can learn general language representation, which is conducive to downstream NLP tasks, and can avoid training models from scratch. With the development of computing power, the emergence of depth model (i.e. Transformer) and the enhancement of training skills, PTM continues to develop from shallow to deep.
Emotional pre training model SKEP (sentimental knowledge enhanced pre training for sentimental analysis). SKEP uses emotional knowledge to enhance the pre training model and comprehensively surpasses SOTA in 14 typical tasks of Chinese and British emotional analysis. This work has been employed by ACL 2020. SKEP is an emotional pre training algorithm based on emotional knowledge enhancement proposed by Baidu research team. This algorithm uses unsupervised method to automatically mine emotional knowledge, and then uses emotional knowledge to construct pre training objectives, so that machines can learn to understand emotional semantics. SKEP provides a unified and powerful emotional semantic representation for all kinds of emotional analysis tasks.
Thesis address: https://arxiv.org/abs/2005.05635
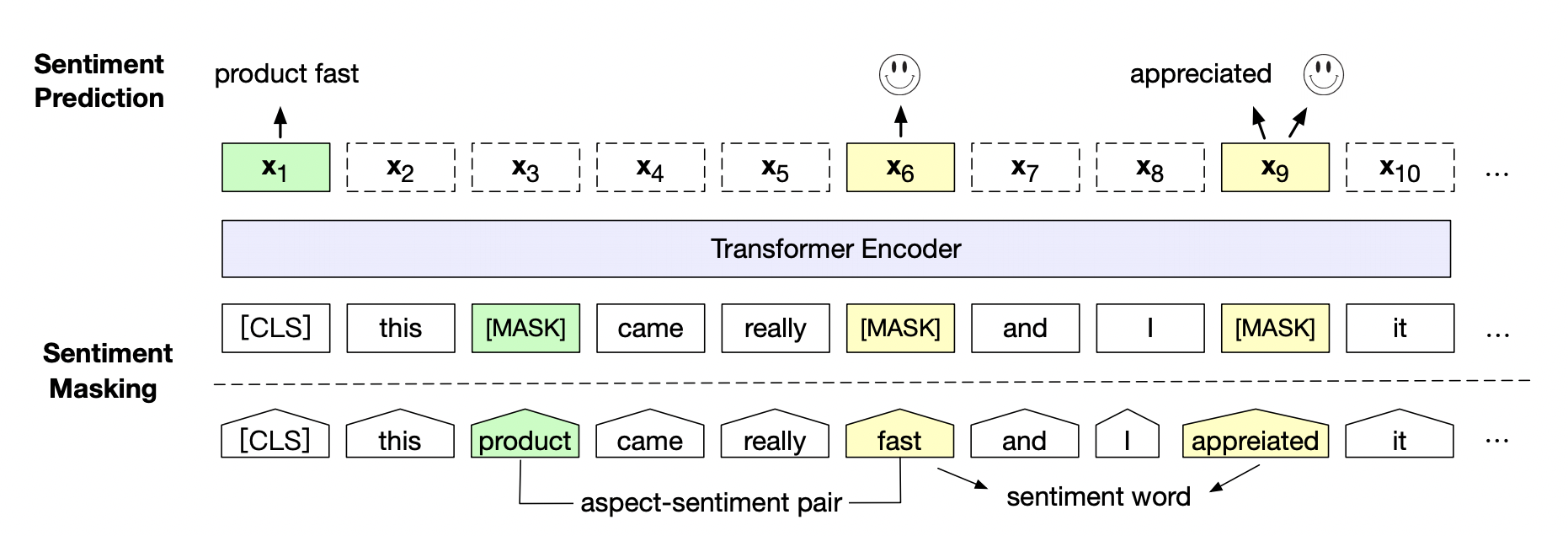
Baidu research team further verified the effect of emotion pre training model SKEP on 14 Chinese and English data from three typical emotion analysis tasks, sentence level emotion classification, aspect level emotion classification and Opinion Role Labeling.
Specific experimental effect reference: https://github.com/baidu/Senta#skep
2.0 loading model and Tokenizer
import paddlenlp from paddlenlp.transformers import SkepForSequenceClassification, SkepTokenizer # from paddlenlp.transformers import ErnieForSequenceClassification, ErnieTokenizer # from paddlenlp.transformers import BertForSequenceClassification,BertTokenizer
2.1 data processing
# Decompress data !unzip -o datasets/SE-ABSA16_CAME !unzip -o datasets/SE-ABSA16_PHNS
with open("SE-ABSA16_CAME/train.tsv", 'r',encoding="UTF-8") as f:
lines = f.readlines()
for line in lines[:5]:
print(line)
Analysis of internal data structure (the structures of the two data sets are the same):
train:
label text_a text_b
1 phone#design_features Today, I was lucky to get the real Hong Kong version of white iPhone 5. I tried it. Let's talk about my feelings: 1 The size and width of the real machine are consistent with 4/4s, and there is no change
0 software#operation_performance Apple's new iPhone 5 comes to hand. Compared with the 4S, it feels 1 and looks good. At first, looking at the press conference and online photos, I was the same as most people: little change, a little disappointed
test:
qid text_a text_b
0 software#usability Just started 8600, experience. Just bought from Taobao, 1635 yuan (including mail). 1. Brand new
... ... ...
```python
# Get dataset dictionary
def open_func(file_path):
return [line.strip() for line in open(file_path, 'r', encoding='utf8').readlines()[1:] if len(line.strip().split('\t')) >= 2]
data_dict = {'seabsa16phns': {'test': open_func('SE-ABSA16_PHNS/test.tsv'),
'train': open_func('SE-ABSA16_PHNS/train.tsv')},
'seabsa16came': {'test': open_func('SE-ABSA16_CAME/test.tsv'),
'train': open_func('SE-ABSA16_CAME/train.tsv')}}
2.2 defining data readers
The method is similar to that in 1.2, which is basically completely pasted and copied. Note that two text s are required here, and the token should be considered_ type_ I'm sorry.
# Define dataset
from paddle.io import Dataset, DataLoader
from paddlenlp.data import Pad, Stack, Tuple
import numpy as np
label_list = [0, 1]
# Consider token_type_id
class MyDataset(Dataset):
def __init__(self, data, tokenizer, max_len=512, for_test=False):
super().__init__()
self._data = data
self._tokenizer = tokenizer
self._max_len = max_len
self._for_test = for_test
def __len__(self):
return len(self._data)
def __getitem__(self, idx):
samples = self._data[idx].split('\t')
label = samples[-3]
text_b = samples[-1]
text_a = samples[-2]
label = int(label)
encoder_out = self._tokenizer.encode(text_a, text_b, max_seq_len=self._max_len)
text = encoder_out['input_ids']
token_type = encoder_out['token_type_ids']
if self._for_test:
return np.array(text, dtype='int64'), np.array(token_type, dtype='int64')
else:
return np.array(text, dtype='int64'), np.array(token_type, dtype='int64'), np.array(label, dtype='int64')
def batchify_fn(for_test=False):
if for_test:
return lambda samples, fn=Tuple(Pad(axis=0, pad_val=tokenizer.pad_token_id),
Pad(axis=0, pad_val=tokenizer.pad_token_type_id)): [data for data in fn(samples)]
else:
return lambda samples, fn=Tuple(Pad(axis=0, pad_val=tokenizer.pad_token_id),
Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
Stack()): [data for data in fn(samples)]
def get_data_loader(data, tokenizer, batch_size=32, max_len=512, for_test=False):
dataset = MyDataset(data, tokenizer, max_len, for_test)
shuffle = True if not for_test else False
data_loader = DataLoader(dataset=dataset, batch_size=batch_size, collate_fn=batchify_fn(for_test), shuffle=shuffle)
return data_loader
2.3 model building and training
Paste the copy of 1.3, pay attention to the data set name and add a token_ type_ Input of ID.
import paddle
from paddle.static import InputSpec
# Model and word segmentation
# model = ErnieForSequenceClassification.from_pretrained('ernie-1.0', num_classes=2)
# tokenizer = ErnieTokenizer.from_pretrained('ernie-1.0') # 0.5652
model = SkepForSequenceClassification.from_pretrained('skep_ernie_1.0_large_ch', num_classes=2)
tokenizer = SkepTokenizer.from_pretrained('skep_ernie_1.0_large_ch')
# model = BertForTokenClassification.from_pretrained('bert-wwm-ext-chinese', num_classes=2)
# tokenizer = BertTokenizer.from_pretrained('bert-wwm-ext-chinese')
# Parameter setting, change this option to change the dataset
# data_name = 'seabsa16phns'
data_name = 'seabsa16came'
## Training related
epochs = 20
learning_rate = 1e-5 # seabsa16phns 2e-5 /seabsa16came 2e-5
batch_size = 48 # seabsa16phns 36 36/seabsa16came 32 36
max_len = 204 # seabsa16phns 114 124/ seabsa16came 128 96
# Data correlation
train_dataloader = get_data_loader(data_dict[data_name]['train'], tokenizer, batch_size, max_len, for_test=False)
input = InputSpec((-1, -1), dtype='int64', name='input')
token_type = InputSpec((-1, -1), dtype='int64', name='token_type')
label = InputSpec((-1, 2), dtype='int64', name='label')
model = paddle.Model(model, [input, token_type], [label])
# Model preparation
#Dataset seabsa16phns seabsa16cam
# step_each_epoch = len(train_dataloader)
# lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate,
# T_max=step_each_epoch * epochs)
# optimizer = paddle.optimizer.Adam(learning_rate=lr, parameters=model.parameters())
optimizer = paddle.optimizer.AdamW(weight_decay=0.01, learning_rate=learning_rate,parameters=model.parameters())
model.prepare(optimizer, loss=paddle.nn.CrossEntropyLoss(), metrics=[paddle.metric.Accuracy()])
Training seabsa16phns
# Start training model.fit(train_dataloader, batch_size=batch_size, epochs=epochs, save_freq=epochs, verbose=2,save_dir='./ckpt/seabsa16phns')
Training seabsa16cam
# Start training model.fit(train_dataloader, batch_size=batch_size, epochs=20, save_freq=20, verbose=2,save_dir='./ckpt/seabsa16came')
2.4 forecast and save
# Import pre training model
checkpoint_path = "./ckpt/" + data_name + "/final"
model = SkepForSequenceClassification.from_pretrained('skep_ernie_1.0_large_ch', num_classes=2)
# model = ErnieForSequenceClassification.from_pretrained('ernie-1.0', num_classes=2)
input = InputSpec((-1, -1), dtype='int64', name='input')
token_type = InputSpec((-1, -1), dtype='int64', name='token_type')
model = paddle.Model(model, [input, token_type])
model.load(checkpoint_path)
# Import test set
test_dataloader = get_data_loader(data_dict[data_name]['test'], tokenizer, batch_size, max_len, for_test=True)
# Forecast saving
save_file = {'seabsa16phns': './submission/SE-ABSA16_PHNS.tsv', 'seabsa16came': './submission/SE-ABSA16_CAME.tsv'}
predicts = []
for batch in test_dataloader:
predict = model.predict_batch(batch)
predicts += predict[0].argmax(axis=-1).tolist()
with open(save_file[data_name], 'w', encoding='utf8') as f:
f.write("index\tprediction\n")
for idx, sample in enumerate(data_dict[data_name]['test']):
qid = sample.split('\t')[0]
f.write(qid + '\t' + str(predicts[idx]) + '\n')
f.close()
3. Opinion extraction
Information extraction aims to extract structured knowledge from unstructured natural language texts, such as entities, relationships, events and so on.
3.0 loading model and Tokenizer
import paddlenlp from paddlenlp.transformers import SkepForTokenClassification, SkepTokenizer # from paddlenlp.transformers import ErnieForTokenClassification, ErnieTokenizer # from paddlenlp.transformers import BertForTokenClassification, BertTokenizer
3.1 data processing
# Decompress data !unzip -o datasets/COTE-BD !unzip -o datasets/COTE-DP !unzip -o datasets/COTE-MFW
with open("COTE-DP/train.tsv", 'r',encoding="UTF-8") as f:
lines = f.readlines()
print('Data size:',len(lines))
for line in lines[:3]:
print(line)
with open("COTE-BD/train.tsv", 'r',encoding="UTF-8") as f:
lines = f.readlines()
print('Data size:',len(lines))
for line in lines[:3]:
print(line)
with open("COTE-MFW/train.tsv", 'r',encoding="UTF-8") as f:
lines = f.readlines()
print('Data size:',len(lines))
for line in lines[:3]:
print(line)
Analysis of internal data structure (the structures of the three data sets are the same):
train:
label text_a
not a good guy <The book "bird man" takes the experience of Dr. bird as the main line, and mainly describes various absurd experiences of Dr. bird after he came out of campus.
... ...
test:
qid text_a
0 The scenery of bipenggou has been heard for a long time, especially in autumn. However, it was late this time. All the red leaves fell off, and the yellow leaves could not be seen. It only snowed...
... ...
```python
# Get dataset dictionary
def open_func(file_path):
return [line.strip() for line in open(file_path, 'r', encoding='utf8').readlines()[1:] if len(line.strip().split('\t')) >= 2]
data_dict = {'cotebd': {'test': open_func('COTE-BD/test.tsv'),
'train': open_func('COTE-BD/train.tsv')},
'cotedp': {'test': open_func('COTE-DP/test.tsv'),
'train': open_func('COTE-DP/train.tsv')},
'cotemfw': {'test': open_func('COTE-MFW/test.tsv'),
'train': open_func('COTE-MFW/train.tsv')}}
3.2 defining data readers
The idea is similar. It should be noted that this time it is a token level classification. In the data reader, the label is written in the form of BIO, and each token corresponds to a label.
# Define dataset
from paddle.io import Dataset, DataLoader
from paddlenlp.data import Pad, Stack, Tuple
import numpy as np
label_list = {'B': 0, 'I': 1, 'O': 2}
index2label = {0: 'B', 1: 'I', 2: 'O'}
# Consider token_type_id
class MyDataset(Dataset):
def __init__(self, data, tokenizer, max_len=512, for_test=False):
super().__init__()
self._data = data
self._tokenizer = tokenizer
self._max_len = max_len
self._for_test = for_test
def __len__(self):
return len(self._data)
def __getitem__(self, idx):
samples = self._data[idx].split('\t')
label = samples[-2]
text = samples[-1]
if self._for_test:
origin_enc = self._tokenizer.encode(text, max_seq_len=self._max_len)['input_ids']
return np.array(origin_enc, dtype='int64')
else:
# Since not every word is a token, a simple processing method is adopted here. First encode label, then encode words other than label in text, and finally combine them together
texts = text.split(label)
label_enc = self._tokenizer.encode(label)['input_ids']
cls_enc = label_enc[0]
sep_enc = label_enc[-1]
label_enc = label_enc[1:-1]
# merge
origin_enc = []
label_ids = []
for index, text in enumerate(texts):
text_enc = self._tokenizer.encode(text)['input_ids']
text_enc = text_enc[1:-1]
origin_enc += text_enc
label_ids += [label_list['O']] * len(text_enc)
if index != len(texts) - 1:
origin_enc += label_enc
label_ids += [label_list['B']] + [label_list['I']] * (len(label_enc) - 1)
origin_enc = [cls_enc] + origin_enc + [sep_enc]
label_ids = [label_list['O']] + label_ids + [label_list['O']]
# truncation
if len(origin_enc) > self._max_len:
origin_enc = origin_enc[:self._max_len-1] + origin_enc[-1:]
label_ids = label_ids[:self._max_len-1] + label_ids[-1:]
return np.array(origin_enc, dtype='int64'), np.array(label_ids, dtype='int64')
def batchify_fn(for_test=False):
if for_test:
return lambda samples, fn=Pad(axis=0, pad_val=tokenizer.pad_token_id): np.row_stack([data for data in fn(samples)])
else:
return lambda samples, fn=Tuple(Pad(axis=0, pad_val=tokenizer.pad_token_id),
Pad(axis=0, pad_val=label_list['O'])): [data for data in fn(samples)]
def get_data_loader(data, tokenizer, batch_size=32, max_len=512, for_test=False):
dataset = MyDataset(data, tokenizer, max_len, for_test)
shuffle = True if not for_test else False
data_loader = DataLoader(dataset=dataset, batch_size=batch_size, collate_fn=batchify_fn(for_test), shuffle=shuffle)
return data_loader
3.3 model building and training
The difference is that the model is replaced by Token classification. Since Accuracy is no longer applicable to Token classification, we use Accuracy to roughly measure the Accuracy of prediction (close to 1 is the best).
import paddle
from paddle.static import InputSpec
from paddlenlp.metrics import Perplexity
# Model and word segmentation
model = SkepForTokenClassification.from_pretrained('skep_ernie_1.0_large_ch', num_classes=3)
tokenizer = SkepTokenizer.from_pretrained('skep_ernie_1.0_large_ch')
# model = ErnieForTokenClassification.from_pretrained('ernie-1.0', num_classes=3)
# tokenizer = ErnieTokenizer.from_pretrained('ernie-1.0')
# model = BertForTokenClassification.from_pretrained('bert-wwm-ext-chinese', num_classes=3)
# tokenizer = BertTokenizer.from_pretrained('bert-wwm-ext-chinese')
# Parameter setting, change this option to change the dataset
# data_name = 'cotedp'
# data_name = 'cotebd'
data_name = 'cotemfw'
# Training related
epochs = 10 # cotedp / cotebd10 16/
learning_rate = 2e-5 #2e-5 / 2e-5 /4e-5
batch_size = 56 # codedp 128 156 /codebd 128 156 /codemfw 156 196
max_len = 196 # 96 144 / 96 / 96
## Data correlation
train_dataloader = get_data_loader(data_dict[data_name]['train'], tokenizer, batch_size, max_len, for_test=False)
input = InputSpec((-1, -1), dtype='int64', name='input')
label = InputSpec((-1, -1, 3), dtype='int64', name='label')
model = paddle.Model(model, [input], [label])
# Model preparation # 1 2e-5
# step_each_epoch = len(train_dataloader)
# lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate,
# T_max=step_each_epoch * epochs)
# optimizer = paddle.optimizer.Adam(learning_rate=lr, parameters=model.parameters()
# ,weight_decay=paddle.regularizer.L2Decay(3e-5)) # weight_decay=paddle.regularizer.L2Decay(3e-4)
# optimizer = paddle.optimizer.Adam(learning_rate=learning_rate, parameters=model.parameters(),weight_decay=paddle.regularizer.L2Decay(3e-4))
optimizer = paddle.optimizer.AdamW(learning_rate=learning_rate,parameters=model.parameters(),weight_decay=0.01)
model.prepare(optimizer, loss=paddle.nn.CrossEntropyLoss(), metrics=[Perplexity()])
Training codedp
# Start training cotedp model.fit(train_dataloader, batch_size=batch_size, epochs=epochs, save_freq=epochs, save_dir='./ckpt/cotedp')
Training cotebd
# Start training cotebd model.fit(train_dataloader, batch_size=batch_size, epochs=epochs, save_freq=epochs, save_dir='./ckpt/cotebd')
Training codefw
# Start training cotemfw model.fit(train_dataloader, batch_size=batch_size, epochs=epochs, save_freq=epochs, save_dir='./ckpt/cotemfw')
3.4 forecast and save
# Parameter setting, change this option to change the dataset cotedp cotebd cotemfw
# data_name = 'cotedp'
# data_name = 'cotebd'
data_name = 'cotemfw'
# Import pre training model
checkpoint_path = "./ckpt/" + data_name + "/final" # Fill in the saving path of the pre training model
model = SkepForTokenClassification.from_pretrained('skep_ernie_1.0_large_ch', num_classes=3)
# model = ErnieForTokenClassification.from_pretrained('ernie-1.0', num_classes=3)
input = InputSpec((-1, -1), dtype='int64', name='input')
model = paddle.Model(model, [input])
model.load(checkpoint_path)
# Import test set
test_dataloader = get_data_loader(data_dict[data_name]['test'], tokenizer, batch_size, max_len, for_test=True)
# Save results
save_file = {'cotebd': './submission/COTE_BD.tsv', 'cotedp': './submission/COTE_DP.tsv', 'cotemfw': './submission/COTE_MFW.tsv'}
predicts = []
input_ids = []
for batch in test_dataloader:
predict = model.predict_batch(batch)
predicts += predict[0].argmax(axis=-1).tolist()
input_ids += batch.numpy().tolist()
# First find the position of B, that is, the position with label 0, and then find all I along the position, that is, the position with label 1.
def find_entity(prediction, input_ids):
entity = []
entity_ids = []
for index, idx in enumerate(prediction):
if idx == label_list['B']:
entity_ids = [input_ids[index]]
elif idx == label_list['I']:
if entity_ids:
entity_ids.append(input_ids[index])
elif idx == label_list['O']:
if entity_ids:
entity.append(''.join(tokenizer.convert_ids_to_tokens(entity_ids)))
entity_ids = []
return entity
with open(save_file[data_name], 'w', encoding='utf8') as f:
f.write("index\tprediction\n")
for idx, sample in enumerate(data_dict[data_name]['test']):
qid = sample.split('\t')[0]
entity = find_entity(predicts[idx], input_ids[idx])
f.write(qid + '\t' + '\x01'.join(entity) + '\n')
f.close()
Compress the forecast results into a zip file and submit Thousand words competition website
Note: NLPCC14-SC.tsv, se-absa16 in the results folder_ CAME. tsv,COTE_BD.tsv,COTE_MFW.tsv,COTE_DP.tsv and other documents are for smooth submission and supplement.
The results need to be improved.
#Compress the forecast results into a zip file and submit
t']):
qid = sample.split('\t')[0]
entity = find_entity(predicts[idx], input_ids[idx])
f.write(qid + '\t' + '\x01'.join(entity) + '\n')
f.close()
Compress the forecast results into a zip file and submit Thousand words competition website
Note: NLPCC14-SC.tsv, se-absa16 in the results folder_ CAME. tsv,COTE_BD.tsv,COTE_MFW.tsv,COTE_DP.tsv and other documents are for smooth submission and supplement.
The results need to be improved.
#Compress the forecast results into a zip file and submit !zip -r submission.zip submission
References & Courses
1)Baidu PaddlePaddle - Natural Language Processing based on deep learning
2) NLP live lesson Day 5: emotion analysis pre training model SKEP