
Introduction concurrent programming has always been one of the topics that developers pay most attention to. As a programming language with its own "high concurrency" aura, the implementation principle of concurrent programming is certainly worth our in-depth exploration. This paper mainly introduces the implementation of Goroutine and channel.
Go concurrent programming model is supported by the thread library provided by the operating system at the bottom. Here we briefly introduce the related concepts of thread implementation model.
1, Implementation model of thread
There are three main thread implementation models: user level thread model, kernel level thread model and two-level thread model. The biggest difference between them lies in the correspondence between user threads and kernel scheduling entities (kses). Kernel scheduling entity is the object that can be scheduled by the operating system kernel scheduler, also known as kernel level thread. It is the smallest scheduling unit of the operating system kernel.
(1) User level thread model
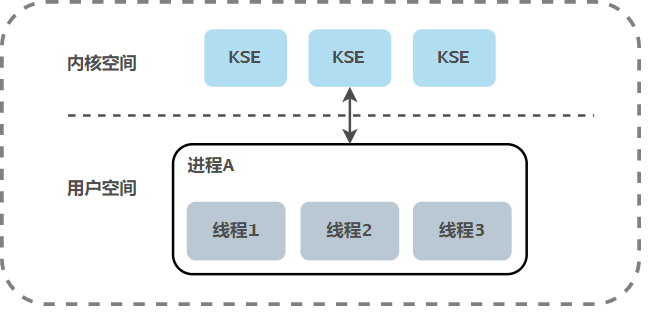
The mapping relationship between user thread and KSE is many to one (N:1). The threads under this model are managed by the user level thread library. The thread library is stored in the user space of the process. The existence of these threads is imperceptible to the kernel, so these threads are not the objects scheduled by the kernel scheduler. All threads created in a process are only dynamically bound to the same KSE at runtime, and all scheduling of the kernel is based on user processes. The thread scheduling is completed at the user level. Compared with the kernel scheduling, it does not need to switch the CPU between user state and kernel state. Compared with the kernel level thread model, this implementation can be very lightweight, consume much less system resources, and cost much less for context switching. Many language implemented collaborative libraries basically belong to this way. However, multithreading under this model can not really run concurrently. For example, if a thread is blocked during I/O operation, all threads in its own process are blocked and the whole process will be suspended.
(2) Kernel level threading model
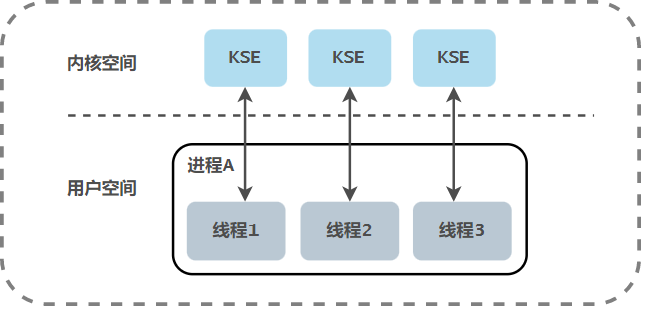
The mapping relationship between user thread and KSE is one-to-one (1:1). The threads under this model are managed by the kernel. The creation, termination and synchronization of threads by the application must be completed through the system call provided by the kernel. The kernel can schedule each thread separately. Therefore, the one-to-one thread model can truly realize the concurrent operation of threads, and the thread libraries implemented by most languages basically belong to this way. However, the creation, switching and synchronization of threads in this model need to spend more kernel resources and time. If a process contains a large number of threads, it will cause a great burden to the kernel scheduler and even affect the overall performance of the operating system.
(3) Two level thread model

The mapping relationship between user thread and KSE is many to many (N:M). The two-level thread model absorbs the advantages of the first two thread models and avoids their disadvantages as much as possible. Different from the user level thread model, the process in the two-level thread model can be associated with multiple kernel threads KSE, that is, multiple threads in a process can bind their own KSE respectively, which is similar to the kernel level thread model; Secondly, different from the kernel level thread model, the threads in its process are not uniquely bound to KSE, but can be mapped to the same KSE. When a KSE is dispatched from the CPU by the kernel because of the blocking operation of its bound thread, the other user threads in its associated process can be bound to other kses again. Therefore, the two-level thread model is neither the user level thread model that is completely scheduled by itself, nor the kernel level thread model that is completely scheduled by the operating system, but an intermediate state in which self scheduling and system scheduling work together, that is, the user scheduler realizes the scheduling of user threads to KSE, and the kernel scheduler realizes the scheduling of KSE to CPU.
2, Concurrency mechanism of Go
In the concurrent programming model of Go, the independent control flow not managed by the operating system kernel is not called user thread or thread, but called goroutine. Goroutine is usually regarded as the Go implementation of the collaborative process. In fact, goroutine is not a collaborative process in the traditional sense. The traditional collaborative process library belongs to the user level thread model, while the underlying implementation of goroutine combined with Go scheduler belongs to the two-level thread model.
Go builds a unique two-level threading model. The go scheduler realizes the scheduling from Goroutine to KSE, and the kernel scheduler realizes the scheduling from KSE to CPU. The scheduler of go uses three structures G, M and P to realize the scheduling of Goroutine, also known as GMP model.
(1) GMP model
G: Means Goroutine. Each Goroutine corresponds to a G structure. G stores the running stack, state and task function of Goroutine, which can be reused. When Goroutine is transferred out of the CPU, the scheduler code is responsible for saving the value of the CPU register in the member variable of the G object. When Goroutine is scheduled to run, the scheduler code is responsible for restoring the value of the register saved by the member variable of the G object to the register of the CPU.
M: The abstraction of OS underlying thread, which itself is bound with a kernel thread. Each working thread has a unique instance object of M structure corresponding to it. It represents the resources that really perform computing and is scheduled and managed by the scheduler of the operating system. In addition to recording the status information of the working thread, such as the start and end position of the stack, the currently executing Goroutine and whether it is idle, the M structure object also maintains the binding relationship with the instance object of the P structure through the pointer.
P: Represents a logical processor. For G, P is equivalent to the CPU core. G can be scheduled only if it is bound to P (in P's local runq). For M, P provides relevant execution environment (Context), such as memory allocation status (mcache), task queue (G), etc. It maintains a local Goroutine runnable g queue. The worker thread gives priority to using its own local runnable queue and will access the global runnable queue only when necessary, which can greatly reduce lock conflicts, improve the concurrency of the worker thread, and make good use of the locality principle of the program.
The implementation of a G requires the support of P and m. After an M is associated with a P, it forms an effective g running environment (kernel thread + context). Each P contains a runq queue of rungs. The G in the queue will be passed to the M associated with the local P in turn and get the running time.
There is always a one-to-one correspondence between M and KSE. An M can only represent a kernel thread. The relationship between M and KSE is very stable. During its life cycle, an M will be associated with only one KSE, while the relationship between M and P, P and G is variable. M and P are also one-to-one, and P and G are one to many.
- G
At runtime, G plays the same role in the scheduler as thread in the operating system, but it takes up less memory space and reduces the overhead of context switching. It is a thread provided by Go language in user mode. As a resource scheduling unit with finer granularity, it can be used properly and make more efficient use of the machine's CPU in high concurrency scenarios.

g structure part source code (src/runtime/runtime2.go):
type g struct { stack stack // Goroutine's stack memory range [stack.lo, stack. HI) stackguard0 uintptr / / used for scheduler preemptive scheduling m * m / / threads occupied by goroutine sched gobuf / / goroutine's scheduling related data atomicstatus uint32 / / goroutine's status...}
type gobuf struct { sp uintptr // Stack pointer PC uintptr / / program counter g guintptr / / goroutine RET sys corresponding to gobuf Uinetwg / / return value of system call...}The contents saved in gobuf will be used when the scheduler saves or restores the context. The stack pointer and program counter will be used to store or restore the values in the register and change the code to be executed by the program.
The atomicstatus field stores the current goroutine status. Goroutine may be in the following states:
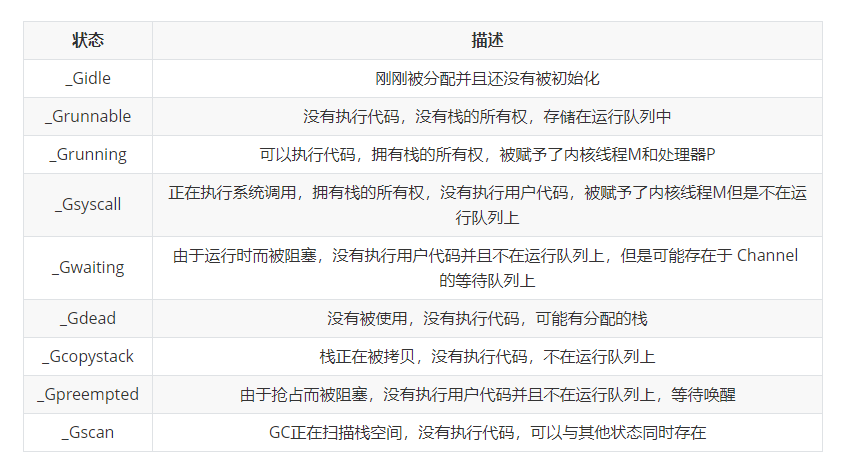
Goroutine's state migration is a very complex process, and there are many methods to trigger state migration. Here are five common states_ Grunnable,_ Grunning,_ Gsyscall,_ Gwaiting and_ Gpreempted.
These different states can be aggregated into three types: waiting, running and running. They will be switched back and forth during operation:
- Waiting: Goroutine is waiting for some conditions to be met, such as the end of system call, including_ Gwaiting,_ Gsyscall and_ Gpreempted several states;
- Runnable: goroutines are ready to run in threads. If there are many goroutines in the current program, each Goroutine may wait more time, i.e_ Grunnable;
- Running: Goroutine is running on a thread, i.e_ Grunning.
G common state transition diagram:
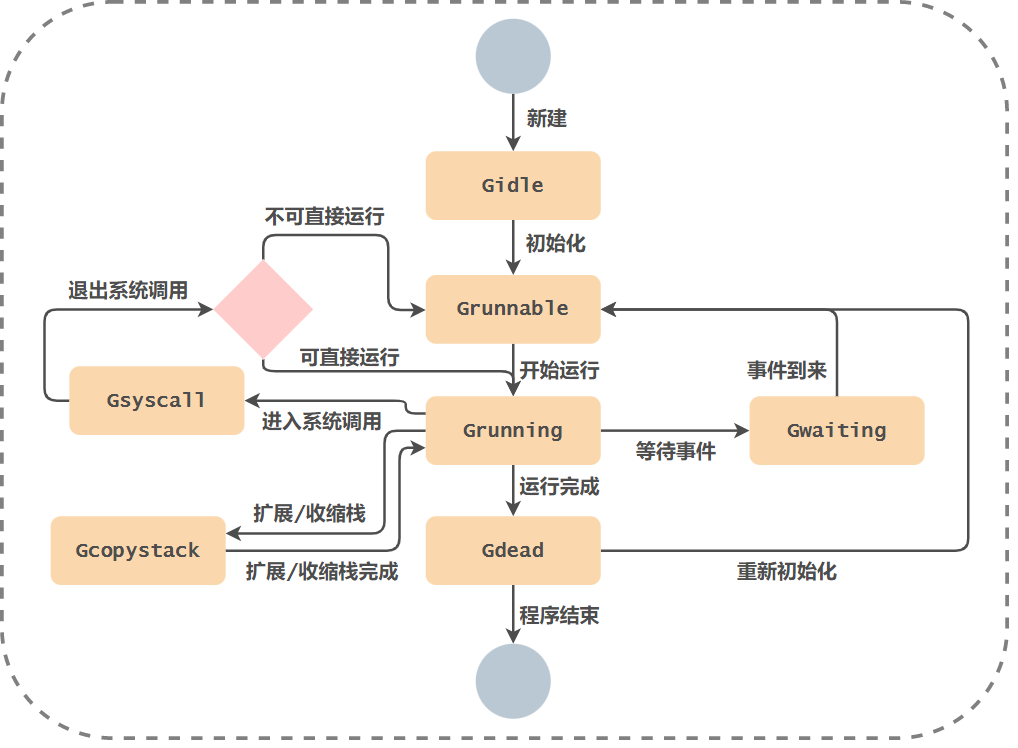
G in the dead state can be reinitialized and used.
- M
M in the concurrency model of Go language is the operating system thread. The scheduler can create up to 10000 threads, but only up to GOMAXPROCS (number of P) active threads can run normally. By default, the runtime will set GOMAXPROCS to the number of cores of the current machine. We can also use runtime in the program GOMAXPROCS to change the maximum number of active threads.
For example, for a four core machine, runtime will create four active operating system threads, and each thread corresponds to the runtime in a runtime M structure. In most cases, we will use the default setting of Go, that is, the number of threads is equal to the number of CPU s. The default setting will not frequently trigger the thread scheduling and context switching of the operating system. All scheduling will occur in the user state and triggered by the Go language scheduler, which can reduce a lot of additional overhead.
m structure source code (part):
type m struct { g0 *g // A special goroutine, Execute some runtime tasks gsignal * g / / process the G curg * g of the signal / / the pointer P puintptr of the running g of the current M / / the P nextp puintptr associated with the current M / / the P oldp puintptr potentially associated with the current M / / use the P spinning bool of the thread before executing the system call / / whether the current M is looking for transportability G locked g * g / / of the line is the same as the G locked by the current M}g0 represents a special Goroutine, which is created by the Go runtime system at the startup. It will deeply participate in the scheduling process of the runtime, including the creation of Goroutine, large memory allocation and the execution of CGO functions. curg is the user Goroutine running on the current thread.
- P
Processor P in the scheduler is the middle layer between threads and Goroutine. It can provide the context environment required by threads and will also be responsible for scheduling the waiting queue on threads. Through the scheduling of processor P, each kernel thread can execute multiple goroutines. It can give up computing resources in time when Goroutine performs some I/O operations to improve the utilization of threads.
The number of P is equal to GOMAXPROCS. Setting the value of GOMAXPROCS can only limit the maximum number of P, and there is no constraint on the number of M and G. When the G running on M enters the system call and causes m to be blocked, the runtime system will separate the m from the associated P. at this time, if there are non running G on the runnable g queue of the P, the runtime system will find an idle m or create a new m associated with the p to meet the running needs of these G. Therefore, the number of M is often more than P.
p structure source code (part):
type p struct { // p's status status uint32 / / corresponds to the associated m m muintptr / / the runnable Goroutine queue can be accessed without lock. Runqhead uint32 runqtail uint32 runq [256] guinptr / / cache the immediately executable g runnext guinptr / / the available g list. The G status is equal to gdead gfree struct {glist n int32}...}P may be in the following states:

3, Scheduler
Some scheduling tasks in the two-level thread model will be undertaken by programs outside the operating system. In the Go language, schedulers are responsible for this part of the scheduling task. The main objects of scheduling are instances of G, M and P. Each M (i.e. each kernel thread) will execute some scheduling tasks during operation, and they jointly realize the scheduling function of the go scheduler.
(1) g0 and m0
Each m in the runtime system will have a special g, commonly known as the g0 of M. The g0 of M is not generated indirectly by the code in the Go program, but created and assigned to m by the go runtime system when initializing M. M's g0 is generally used to perform tasks such as scheduling, garbage collection, stack management, etc. M will also have a G dedicated to processing signals, called gsignal.
In addition to g0 and gsignal, other G run by M can be regarded as user level g, which can be referred to as user g for short. g0 and gsignal can be called system G. When Go is running, the system will switch so that each m can alternately run user g and its g0. This is the reason why "every m will run the scheduler" mentioned earlier.
In addition to each m having its own G0, there is also a runtime g0. runtime.g0 is used to execute the boot program. It runs in the first kernel thread owned by the Go program, which is also called runtime m0,runtime.g0 of M0 is runtime g0.
(2) Container for core elements
The three core elements in Go's thread implementation model - G, M and P - are described above. Let's take a look at the container that hosts these element instances:
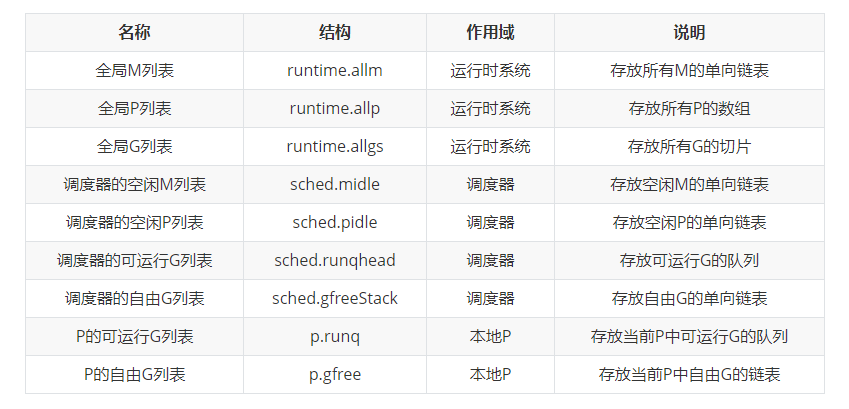
The four containers related to G deserve our special attention. Any g will exist in the global g list, and the other four containers will only store g with a certain state in the current scope. G in the two runnable g lists have almost equal running opportunities, but scheduling at different times will put g in different places. For example, G transferred from Gsyscall state will be put into the runnable g queue of the scheduler, and G just initialized will be put into the runnable g queue of local P. In addition, the two runnable g queues will also transfer g to each other. For example, when the runnable g queue of the local P is full, half of the G will be transferred to the runnable g queue of the scheduler.
The free M list and free P list of the scheduler are used to store element instances that are not used temporarily. When the runtime system needs it, it will get an instance of the corresponding element from it and re enable it.
(3) Scheduling cycle
Call runtime Schedule enters the scheduling cycle:
func schedule() { _g_ := getg()
top: var gp *g var inheritTime bool
if gp == nil { // In order to be fair, if must be obtained from the global runnable g queue every 61 calls to the schedule function_ g_. m.P.ptr(). schedtick%61 == 0 && sched. Runqsize > 0 {lock (_g_.m.P.ptr()) GP = globrunqget (_g_.m.P.ptr()), 1) unlock (_sched. Lock)}} / / get g tasks locally from P if GP = = nil {GP, inherittime = runqget (_g_.m.P.ptr())} / / running here indicates that G if GP = = nil needs to be run is not found from the local run queue or the whole run queue {/ / find available g GP, inherittime = findrunnable()} / / execute the G task function execute(gp, inheritTime)}runtime. The schedule function will find the Goroutine to be executed from the following places:
- In order to ensure fairness, when there are goroutines to be executed in the global operation queue, it is guaranteed that there is a certain chance to find the corresponding goroutines from the global operation queue through schedtick;
- Find the Goroutine to be executed from the local run queue of the processor;
- If G is not found in the first two methods, it will be executed by "stealing" some G from other P through findrunnable function. If "stealing" is not found, the search will be blocked until there is a runnable G.
Next, run time Execute Goroutine obtained by execution:
func execute(gp *g, inheritTime bool) { _g_ := getg()
// Bind g to current M_ g_.m.curg = gp gp.m = _g_.m / / switch g to_ Running status caststatus (GP, _grunnable, _running) GP Waitsince = 0 / / preemption signal GP preempt = false gp. stackguard0 = gp. stack. lo + _ StackGuard if ! Inherittime {/ / scheduler scheduling times increase by 1 _g_. M.p.ptr(). Schedtick + +}// Gogo completes the switch from g0 to GP gogo & gp.sched}When execute is started, G will be switched to_ Running status, bind M and G, and finally call runtime Gogo schedules Goroutine to the current thread. runtime.gogo will start from runtime Get the runtime from gobuf The program counter of goexit and the program counter of the function to be executed, and will:
- runtime. The program counter of goexit is placed on the stack SP;
- The program counter of the function to be executed is placed on register BX.
MOVL gobuf_sp(BX), SP // Set runtime The PC of goexit function is restored to movl gobuf in SP_ PC (BX), BX / / get the program counter of the function to be executed JMP BX / / start execution
When the function running in Goroutine returns, the program will jump to runtime At the location of goexit, the runtime is finally called on the stack of g0 of the current thread Goexit0 function, which converts Goroutine to_ Gdead state, clean up the fields in it, remove the association between Goroutine and thread, and call runtime Gfput adds g back to the processor's Goroutine free list gFree:
func goexit0(gp *g) { _g_ := getg() // Set the current g status to_ Gdead caststatus (GP, _running, _gdead) / / clean up g GP m = nil ... gp. writebuf = nil gp. waitreason = 0 gp. param = nil gp. labels = nil gp. Timer = nil / / unbind m and G dropg()// Throw g into the gfree linked list and wait for reuse gfput (_g_. M.p.ptr()) / / schedule again ()}Finally, run time Goexit0 will call runtime again Schedule triggers a new round of Goroutine scheduling, and the scheduler starts from runtime Schedule starts and eventually returns to runtime Schedule, which is the scheduling loop of Go language.
4, Channel
A design pattern often mentioned in Go: do not communicate through shared memory, but share memory through communication. Goroutine s transmit data through channel. As the core data structure of Go language and the communication mode between goroutines, channel is an important structure supporting the high-performance concurrent programming model of Go language.
The internal representation of channel at runtime is runtime hchan, which contains mutex locks for protecting member variables. To some extent, channel is a locked queue for synchronization and communication. hchan structure source code:
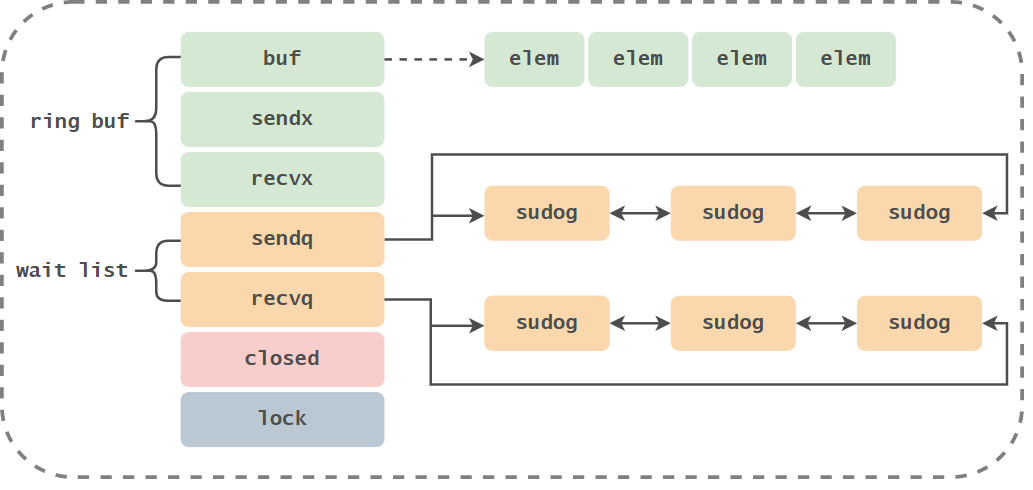
type hchan struct { qcount uint // Number of circular list elements dataqsiz uint / / size of circular queue buf unsafe Pointer / / pointer of circular queue elemsize uint16 / / size of element in Chan closed uint32 / / whether ElemType is closed*_ Type / / element type in Chan sendx uint / / location processed by the send operation of Chan recvx uint / / location processed by the receive operation of Chan recvq waitq / / Goroutine list waiting to receive data sendq waitq / / Goroutine list waiting to send data lock mutex / / mutex}
type waitq struct { // Bidirectional linked list first * sudog last * sudog}A sudog two-way linked list is connected in waitq, and the Goroutine waiting is saved.
(1) Create chan
Use the make keyword to create a pipeline, and make (Chan, int, 3) will call runtime In the makechan function:
const ( maxAlign = 8 hchanSize = unsafe.Sizeof(hchan{}) + uintptr(-int(unsafe.Sizeof(hchan{}))&(maxAlign-1)))
func makechan(t *chantype, size int) *hchan { elem := t.elem // Calculate the size of buf space to be allocated MEM, overflow: = math MulUintptr(elem.size, uintptr(size)) if overflow || mem > maxAlloc-hchanSize || size < 0 { panic(plainError("makechan: size out of range")) }
var c *hchan switch { case mem == 0: // If the size of chan or elem is 0, buf C = (* hchan) (mallocgc (hchansize, nil, true)) / / race detector uses this location for synchronization c.buf = c.raceaddr() case elem. Ptrdata = = 0: / / elem contains no pointers. Allocate a piece of continuous memory to hchan data structure and buf C = (* hchan) (mallocgc (hchansize + MEM, nil, true)) c.buf = add (unsafe. Pointer (c), hchansize) default: / / elem contains pointers. Allocate BUF C = new (hchan) c.buf = mallocgc (MEM, elem, true)}
// Update the elemsize, ElemType and dataqsiz fields of hchan c.elemsize = uint16 (elem. Size) c.elemtype = elem c.dataqsiz = uint (size) return c}The above code initializes the runtime according to the type of sending and receiving elements in the channel and the size of the buffer Hchan and buffer:
- If the required size of the buffer is 0, only a section of memory will be allocated for hchan;
- If the required size of the buffer is not 0 and elem does not contain a pointer, a continuous memory will be allocated for hchan and buf;
- If the required size of the buffer is not 0 and elem contains pointers, memory will be allocated separately for hchan and buf.
(2) Send data to chan
Send data to channel, ch < - I will call runtime In the chansend function, this function contains all the logic of sending data:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool { if c == nil { // For non blocking transmission, directly return if! Block {return false} / / for blocked channels, suspend goroutine gopark (nil, nil, waitreasonchannel, sendnilchannel, traceevgostop, 2) throw ("unreachable")} / / lock (& c.lock) / / the channel is closed, panic if c.closed= 0 { unlock(&c.lock) panic(plainError("send on closed channel")) } ...}block indicates whether the current send operation is a blocking call. If the channel is empty, it will directly return false for non blocking transmission. For blocking transmission, it will suspend goroutine and never return. Lock the channel to prevent multiple threads from modifying data concurrently. If the channel is closed, an error is reported and the program is terminated.
runtime. The execution process of chansend function can be divided into the following three parts:
- When there is a waiting receiver, it can be sent through runtime Send directly sends the data to the blocked receiver;
- When there is free space in the buffer, write the transmitted data into the buffer;
- When there is no buffer or the buffer is full, wait for other goroutines to receive data from the channel.
- Direct transmission
If the target channel is not closed and there are goroutines waiting for reading in the recvq queue, the runtime Chansend will take the Goroutine that falls into waiting first from the receiving queue recvq and send data directly to it. Note that since there are receivers waiting, if there is a buffer, the buffer must be empty:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool { ... // Get a receiver from recvq if SG: = c.recvq dequeue(); sg != Nil {/ / if the receiver exists, send data directly to the receiver, bypassing buf send (C, SG, EP, func() {unlock (& c.lock)}, 3) return true}...}Sending directly invokes runtime Send function:
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) { ... if sg.elem != nil { // Directly copy the data to be sent to the receiver's stack space senddirect (c.elemtype, SG, EP) SG elem = nil } gp := sg. g unlockf() gp. param = unsafe. Pointer(sg) if sg. releasetime != 0 {SG. Releasetime = cputicks()} / / set the corresponding goroutine to runnable status goready(gp, skip+1)}The sendDirect method calls memmove to copy the data in memory. The goready method marks the Goroutine waiting to receive data as runnable and sends the Goroutine to the runnext of the processor where the sender is located for execution. The processor will wake up the receiver of the data immediately during the next scheduling. Note that it is only put into runnext, and the Goroutine is not executed immediately.
- Send to buffer
If the buffer is not full, write data to the buffer:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool { ... // If the buffer is not full, Directly copy the data to be sent to the buffer if c.qcount < c.dataqsiz {/ / find the index location of the data to be filled in buf QP: = chanbuf (C, c.sendx)... / / copy the data to the typedmemove (c.elemtype, QP, EP) in buf. / / the data index moves forward. If it reaches the end, it starts from 0. C.sendx + + if c.sendx = = c.dataqsiz {c.sendx = 0} //Add 1 to the number of elements, release the lock and return c.qcount + + unlock (& c.lock) return true}...}Find the index position of the data to be filled in the buffer, call the typedmemmove method to copy the data into the buffer, and then reset the sendx offset.
- Blocking transmission
When no receiver in the channel can process data, sending data to the channel will be blocked by the downstream. Use the select keyword to send messages to the channel non blocking:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool { ... // There is no space in the buffer. For non blocking calls, return if directly! Block {unlock (& c.lock) return false} / / create sudog object GP: = getg () mysg: = acquiresudog () mysg releasetime = 0 if t0 != 0 { mysg.releasetime = -1 } mysg. elem = ep mysg. waitlink = nil mysg. g = gp mysg. isSelect = false mysg. c = c gp. waiting = mysg gp. Param = nil / / queue sudog object c.sendq Enqueue (mysg) / / enter the waiting state gopark (changparkcommit, unsafe. Pointer (& c.lock), waitreasonchansend, traceevgoblocksend, 2)...}For non blocking calls, it will return directly. For blocking calls, it will create sudog object and add sudog object to the send waiting queue. Call gopark to turn the current Goroutine into waiting state. After gopark is called, in the user's opinion, the code statement sending data to the channel will be blocked.
The whole process of sending data is roughly as follows:
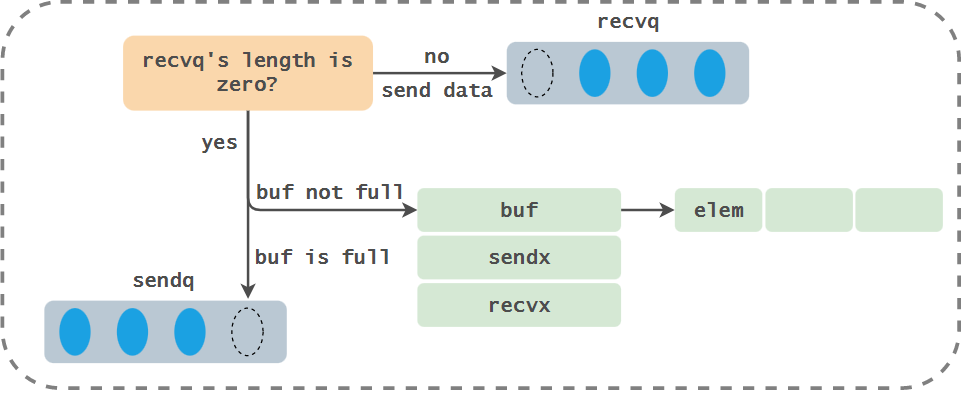
Note that the process of sending data includes several opportunities that will trigger Goroutine scheduling:
- When sending data, it is found that there is a Goroutine waiting to receive data from the channel, and the runnext attribute of the processor is set immediately, but the scheduling will not be triggered immediately;
- When the receiver is not found when sending data and the buffer is full, you will add yourself to the sendq queue of the channel and call gopark to trigger the scheduling of Goroutine to give up the use right of the processor.
(3) Receive data from chan
Get the data from the channel and finally call the runtime Chanrecv function:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) { if c == nil { // If C is empty and non blocking, return if! Block {return} / / block the call and wait for gopark (nil, nil, waitreasonchanreceivenilchan, traceevgostop, 2) throw ("unreachable")} ···· lock (& c.lock) / / if c.closed is returned if c.closed= 0 && c.qcount == 0 { unlock(&c.lock) if ep != nil { typedmemclr(c.elemtype, ep) } return true, false } ···}When receiving data from an empty channel, call gopark directly to give up the processor access. If the current channel has been closed and there is no data in the buffer, it will be returned directly.
runtime. The specific execution process of the chanrecv function can be divided into the following three parts:
- When there is a waiting sender, through runtime Recv obtains data from the blocked sender or buffer;
- When there is data in the buffer, receive data from the buffer of the channel;
- When there is no data in the buffer, wait for other goroutines to send data to the channel.
- Direct reception
When the sendq queue of the channel contains Goroutine in the send waiting state, call runtime Recv extracts data directly from the sender. Note that since there is a sender waiting, if there is a buffer, the buffer must be full.
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) { ... // Get data from sender queue if SG: = c.sendq dequeue(); sg != Nil {/ / the sender queue is not empty. Directly extract data from the sender recv (C, SG, EP, func() {unlock (& c.lock)}, 3) return true, true}...}Mainly look at runtime Implementation of recv:
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) { // If there is no buffer Chan if c.dataqsiz = = 0 {if EP! = nil {/ / copy data directly from the sender recvDirect(c.elemtype, sg, ep)} / / there is buffer Chan} else {/ / get the stored data pointer of buf QP: = chanbuf (C, c.recvx) / / copy data directly from the buffer to the receiver if EP! = nil {typedmemove (c.elemtype, EP, QP)} / / copy data from the sender to the buffer typedmemove (c.elemtype, QP, SG. Elem) c.recvx + + c.sendx = c.recvx / / c.sendx = (c.sendx + 1)% c.dataqsiz} GP: = SG g gp. param = unsafe. Pointer (SG) / / set the corresponding goroutine to the runnable state goready(gp, skip+1)}This function will handle different situations according to the size of the buffer:
- If there is no buffer in the channel: extract data directly from the sender.
- If a buffer exists in the channel:
- Copy the data in the buffer to the memory address of the receiver;
- Copy the sender's data to the buffer and wake up the sender.
No matter what happens, the runtime will call goready to mark the Goroutine waiting to send data as runnable, and set the runnext of the current processor as the Goroutine sending data, so as to wake up the blocked sender in the next scheduling of the scheduler.
- Receive from buffer
If there is data in the channel buffer and there is no Goroutine waiting to be sent in the sender queue, take the data directly from the index position of recvx in the buffer:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) { ... // If there is data in the buffer if c.qcount > 0 {QP: = chanbuf (C, c.recvx) / / copy data from the buffer to EP if EP! = nil {typedmemmove (c.elemtype, EP, QP)} typedmemclr (c.elemtype, QP) / / the pointer of the received data moves forward c.recvx + + / / ring queue. If it reaches the end, Start from 0 if c.recvx = = c.dataqsiz {c.recvx = 0} / / the existing data in the buffer minus one c.qcount -- unlock (& c.lock) return true, true}...}- Blocking reception
When there is no waiting Goroutine in the send queue of the channel and there is no data in the buffer, the operation of receiving data from the pipeline will be blocked. Use the select keyword to receive messages non blocking:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) { ... // Non blocking, direct return if! Block {unlock (& c.lock) return false, false} / / create sudog GP: = getg() mysg: = acquiresudog() ···· GP waiting = mysg mysg. g = gp mysg. isSelect = false mysg. c = c gp. Param = nil / / add sudog to the waiting to receive queue c.recvq Enqueue (mysg) / / block Goroutine and wait for wake-up gopark (changparkcommit, unsafe. Pointer (& c.lock), waitreasonchanreceive, traceevgoblockrecv, 2)...}If it is a non blocking call, it returns directly. The blocking call will encapsulate the current Goroutine into sudog, then add sudog to the waiting queue, invoke gopark to let the processor use and wait for the scheduler to schedule.
Note that the process of receiving data includes several opportunities that will trigger Goroutine scheduling:
- When channel is empty
- When there is no data in the buffer of channel and there is no waiting sender in sendq
(4) Close chan
Closing the channel will call runtime Closechan method:
func closechan(c *hchan) { // Check logic Lock & c.lock / / set chan closed c.closed = 1 var glist glist / / get all recipients for {SG: = c.recvq. Dequeue () if SG = = nil {break} if SG elem != nil { typedmemclr(c.elemtype, sg.elem) sg.elem = nil } gp := sg. g gp. param = nil glist. Push (GP)} / / get all senders for {SG: = c.sendq. Dequeue()...} Unlock (& c.lock) / / wake up goroutine for all glist! glist. empty() { gp := glist.pop() gp.schedlink = 0 goready(gp, 3) }}Add Goroutine from the recvq and sendq queues to the glist and clear all unprocessed elements on sudog. Finally, the goroutines in all glists are added to the scheduling queue and wait to be awakened. Note that the sender will panic after being awakened.
Summarize the possible results of send / receive / close operations:
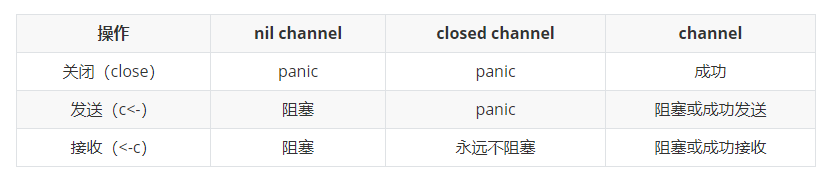
The combination of Goroutine+channel is very strong. The implementation of both supports the concurrency mechanism of Go language.
reference material:
1.Go concurrent programming practice
2.Go language design and Implementation