Python wechat ordering applet course video
https://edu.csdn.net/course/detail/36074
Python actual combat quantitative transaction financial management system
https://edu.csdn.net/course/detail/35475
Does anyone else not understand Bloom filters?
1. Introduction
When using cache, we will inevitably consider how to deal with cache avalanche, cache penetration and cache breakdown. Here we will talk about how to solve cache penetration.
Cache penetration means that when someone illegally requests non-existent data, the cache will not take effect because the data does not exist. The request will be directly hit to the database. When a large number of requests are concentrated on the non-existent data, the database will hang up.
There are several solutions:
- When the database cannot be queried, an empty object corresponding to the request is automatically created in the cache with a short expiration time
- Use bloom filter to reduce the burden of database.
So what's the origin of the bloom filter?
Bloom Filter was proposed by bloom in 1970. It is mainly used to judge whether an element is in a set. By converting the element into a hash function, and then through a series of calculations, multiple subscripts are finally obtained, and then the value of the subscript is modified to 1 in the array with length n.
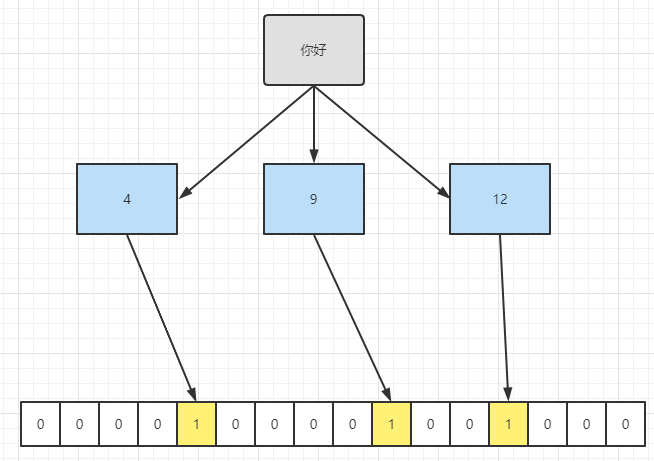
So how to judge whether the element is in this set only needs to judge whether the calculated subscript value is 1.
Of course, bloom filter is not perfect. Its disadvantage is that it has misjudgment and difficult to delete
| advantage | shortcoming |
|---|---|
| There is no need to store the key value, which takes up less space | There is misjudgment, and the element cannot be 100% judged |
| The space efficiency and query time are far beyond the general algorithm | Delete difficulty |
Principle of Bloom filter: when an element is added to the set, map the element into K points in a Bit array through K hash functions and set them to 1. When searching, you only need to see if these points are all 1 to know whether the element is in the set; If any of these points has 0, the inspected element must not be present; If they are all 1, the tested element is likely to be (the reason why "possible" is the existence of error).
So why does the error exist? Because when the storage capacity is large, the subscripts calculated by hash may be the same, so when the hash subscripts obtained by two elements are the same, it is impossible to judge whether the element must exist.
The same is true for deletion difficulties, because the subscript may be repeated. When you reset the value of the subscript to zero, it may also affect other elements.
In response to cache penetration, we only need to judge whether the element exists on the bloom filter. If it does not exist, it will be returned directly. If it does exist, we will query the cache and database. Although it has the impact of misjudgment rate, it can also greatly reduce the burden of the database and block most illegal requests.
2. Practice
2.1 Redis implements bloom filter
Redis has a series of bit operation commands, such as setbit and getbit, which can set the value of bit group. This feature can well implement bloom filter. There are ready-made dependencies that have implemented bloom filter.
| | <dependency> | | | <groupId>org.redissongroupId> | | | <artifactId>redissonartifactId> | | | <version>3.16.0version> | | | dependency> |
The following is the test code. We first fill in the 8W number, and then recycle the next 2W number to test its misjudgment rate
| | import org.redisson.Redisson; |
| | import org.redisson.api.RBloomFilter; |
| | import org.redisson.api.RedissonClient; |
| | import org.redisson.config.Config; |
| | |
| | public class RedisBloomFilter { |
| | |
| | public static void main(String[] args) { |
| | |
| | Config config = new Config(); |
| | config.useSingleServer().setAddress("redis://localhost:6379"); |
| | config.useSingleServer().setPassword("123456"); |
| | //Create redis connection|
| | RedissonClient redissonClient = Redisson.create(config); |
| | |
| | |
| | //Initialize the bloom filter and pass in the custom name of the filter|
| | RBloomFilter bloomFilter = redissonClient.getBloomFilter("BloomFilter"); |
| | |
| | //Initialize bloom filter parameters and set the number of elements and misjudgment rate|
| | bloomFilter.tryInit(110000,0.1); |
| | |
| | //Fill 800W number|
| | for (int i = 0; i < 80000; i++) { |
| | bloomFilter.add(i); |
| | } |
| | |
| | //Start from 8000001 to check whether it exists and test the misjudgment rate|
| | double count = 0; |
| | for (int i = 80001; i < 100000; i++) { |
| | if (bloomFilter.contains(i)) { |
| | count++; |
| | } |
| | } |
| | |
| | // The misjudgment rate can be obtained by counting / (1000000-8000001)|
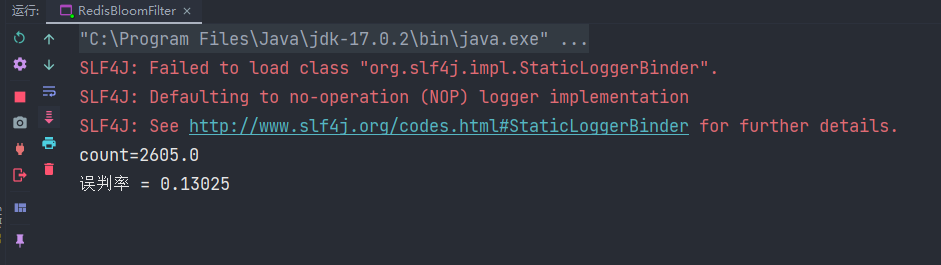
| | System.out.println("count=" + count); |
| | System.out.println("Misjudgment rate = " + count / (100000 - 80001)); |
| | |
| | } |
| | |
| | } |
| | |
It is concluded that under the rounding, the misjudgment rate is 0.1
2.2 Google Guava tool class implements bloom filter
Add Guava tool class dependency
| | <dependency> | | | <groupId>com.google.guavagroupId> | | | <artifactId>guavaartifactId> | | | <version>30.1.1-jreversion> | | | dependency> |
Write test code:
| | import com.google.common.base.Charsets; |
| | import com.google.common.hash.BloomFilter; |
| | import com.google.common.hash.Funnels; |
| | |
| | public class GuavaBloomFilter { |
| | public static void main(String[] args) { |
| | |
| | //Initialize bloom filter|
| | BloomFilter bloomFilter = BloomFilter.create(Funnels.integerFunnel(), |
| | 110000,0.1); |
| | |
| | //Fill data|
| | for (int i = 0; i < 80000; i++) { |
| | bloomFilter.put(i); |
| | } |
| | |
| | //Detection misjudgment|
| | double count = 0; |
| | for (int i = 80000; i < 100000; i++) { |
| | if (bloomFilter.mightContain(i)) { |
| | count++; |
| | } |
| | } |
| | |
| | System.out.println("count="+ count); |
| | System.out.println("The misjudgment rate is" + count / (100000-80000)); |
| | |
| | } |
| | } |
| | |
result:
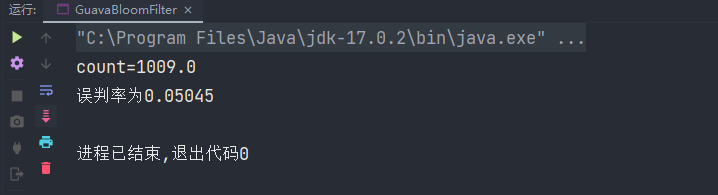
The result is lower than the set misjudgment rate. I guess it may be caused by the different hash algorithms used at the bottom of the two. Moreover, it can be clearly concluded that the bloom filter using Guava tool class is much faster than redisson. This may be because Guava operates memory directly and redisson interacts with Redis, It's definitely faster than Guava, which operates memory directly.
2.3 handwritten bloom filter
We use Java to create an encapsulated BitSet. BitSet provides a large number of API s. The basic operations include:
- Empty array data
- Flip a bit of data
- Set the data of a bit
- Get the data of a bit
- Gets the number of bits of the current bitSet
The following points to consider when writing a bloom filter:
- The size space of the bit group needs to be specified. The larger the space, the smaller the probability of hash conflict and the lower the misjudgment rate
- For multiple hash functions, we should use multiple different prime numbers as seeds
- Implement two methods: one is to add an element to the filter, and the other is to judge whether the element exists in the bloom filter
The hash value is exclusive or for the high and low bits, then multiplied by the seed, and then the remainder of the bit array size is taken.
| | import java.util.BitSet; |
| | |
| | public class MyBloomFilter { |
| | |
| | // Default size|
| | private static final int DEFAULT\_SIZE = Integer.MAX\_VALUE; |
| | |
| | // Minimum size|
| | private static final int MIN\_SIZE = 1000; |
| | |
| | // The size is the default size|
| | private int SIZE = DEFAULT\_SIZE; |
| | |
| | // Seed factor of hash function|
| | private static final int[] HASH\_SEEDS = new int[]{3, 5, 7, 11, 13, 17, 19, 23, 29, 31}; |
| | |
| | // Digit group, 0 / 1, representing characteristics|
| | private BitSet bitSet = null; |
| | |
| | // hash function|
| | private HashFunction[] hashFunctions = new HashFunction[HASH\_SEEDS.length]; |
| | |
| | // No parameter initialization|
| | public MyBloomFilter() { |
| | // By default size|
| | init(); |
| | } |
| | |
| | // Initialization with parameters|
| | public MyBloomFilter(int size) { |
| | // Initialization size is less than the minimum size|
| | if (size >= MIN\_SIZE) { |
| | SIZE = size; |
| | } |
| | init(); |
| | } |
| | |
| | private void init() { |
| | // Initialization bit size|
| | bitSet = new BitSet(SIZE); |
| | // Initialize hash function|
| | for (int i = 0; i < HASH\_SEEDS.length; i++) { |
| | hashFunctions[i] = new HashFunction(SIZE, HASH\_SEEDS[i]); |
| | } |
| | } |
| | |
| | // Adding elements is equivalent to adding the characteristics of elements to the array in place|
| | public void add(Object value) { |
| | for (HashFunction f : hashFunctions) { |
| | // The calculated position of hash is true|
| | bitSet.set(f.hash(value), true); |
| | } |
| | } |
| | |
| | // Determine whether the characteristics of the element exist in the bit array|
| | public boolean contains(Object value) { |
| | boolean result = true; |
| | for (HashFunction f : hashFunctions) { |
| | result = result && bitSet.get(f.hash(value)); |
| | // As long as one of the hash functions is calculated to be false, it will return directly|
| | if (!result) { |
| | return result; |
| | } |
| | } |
| | return result; |
| | } |
| | |
| | // hash function|
| | public static class HashFunction { |
| | // Digit group size|
| | private int size; |
| | // hash seed|
| | private int seed; |
| | |
| | public HashFunction(int size, int seed) { |
| | this.size = size; |
| | this.seed = seed; |
| | } |
| | |
| | // hash function|
| | public int hash(Object value) { |
| | if (value == null) { |
| | return 0; |
| | } else { |
| | // hash value|
| | int hash1 = value.hashCode(); |
| | // High hash value|
| | int hash2 = hash1 >>> 16; |
| | // Merge hash values (equivalent to combining high and low features)|
| | int combine = hash1 ^ hash1; |
| | // Multiply and then take the remainder|
| | return Math.abs(combine * seed) % size; |
| | } |
| | } |
| | |
| | } |
| | |
| | public static void main(String[] args) { |
| | Integer num1 = 12321; |
| | Integer num2 = 12345; |
| | MyBloomFilter myBloomFilter = new MyBloomFilter(); |
| | System.out.println(myBloomFilter.contains(num1)); |
| | System.out.println(myBloomFilter.contains(num2)); |
| | |
| | myBloomFilter.add(num1); |
| | myBloomFilter.add(num2); |
| | |
| | System.out.println(myBloomFilter.contains(num1)); |
| | System.out.println(myBloomFilter.contains(num2)); |
| | |
| | } |
| | } |
Handwritten code is from https://juejin.cn/post/6961681011423838221
Through the code, it can be concluded that the implementation of a simple bloom filter requires a bit group, multiple hash functions, and the method of adding elements to the filter and judging whether the elements exist. The larger the bit group space is, the smaller the probability of hash collision is. Therefore, the misjudgment rate in bloom filter is related to the size of space. The lower the misjudgment rate is, the larger the space is needed.
2.4 practical application scenarios of Bloom filter
The function of Bloom filter is very clear, which is to judge whether elements exist in the collection. Some interviewers may ask how I can quickly determine whether a certain data exists in the set if I give you a set of 10W data. This problem can be solved by using Bloom filter. After all, although bloom filter has misjudgment, it can be 100% sure that the data does not exist. Compared with its shortcomings, it is completely acceptable.
There are also some application scenarios:
- Determine whether a mailbox is in the mailbox blacklist
- The crawled URL is de duplicated in the crawler
To solve cache penetration, we can preheat in advance and store the data into the bloom filter. After the request comes in, we first query whether the bloom filter exists the data. If the data does not exist, we will return it directly. If the data exists, we will query Redis first. If Redis does not exist, we will query the database. If there is new data added, we can also add data into the bloom filter. Of course, if there is a large amount of data to be updated, it is best to rebuild the bloom filter.
3. Summary
- The bloom filter uses an n-length bit array to obtain multiple subscript values by hashing the elements, and modifies the subscript value to 1 in the bit array to complete the storage of the elements
- The error rate of Bloom filter is negatively correlated with its bit array. The lower the error rate is, the larger the bit array is needed
- Bloom filter has the advantages of high storage space efficiency and fast query time. Its disadvantages are difficult to delete and misjudgment
- Redis is easy to implement bloom filter, Github also has bloom filter module that can be installed on redis, and Google's Guava tool class in Java also has bloom filter implementation
- Bloom filter is one of the solutions to solve cache penetration. The existence of query elements can be judged by Bloom filter
4. Reference articles
- https://juejin.cn/post/6961681011423838221
- Detailed explanation of Redis (13) -- Redis bloom filter YSOcean blog Park (cnblogs.com)
- Bloom filter, this article tells you clearly - Alibaba cloud developer community (aliyun.com)
- Brief introduction and application of Bloom filter - GeaoZhang - blog Park (cnblogs.com)