Reading guide
I've always been curious that all files can be viewed in the Sources tab of Chrome debugging tool. How can I get all file information and content?

Scheme 1: export the HAR scheme through the Network tag of Chrome console. The operation is cumbersome and the data types processed are limited.
Scheme 2: through chromecacheview Exe to obtain files. This tool is indeed effective, but it also has the following disadvantages:
- Invalid for localhost.
- Unable to program.
Other solutions: fiddler and other packet capture tools, selenium (too cumbersome), etc.
cdp scheme: recent research found that the Chrome console is the file data obtained through cdp. Then we can obtain relevant information through PyChromeDevTools and save it in a certain format. The final effect is as follows:.
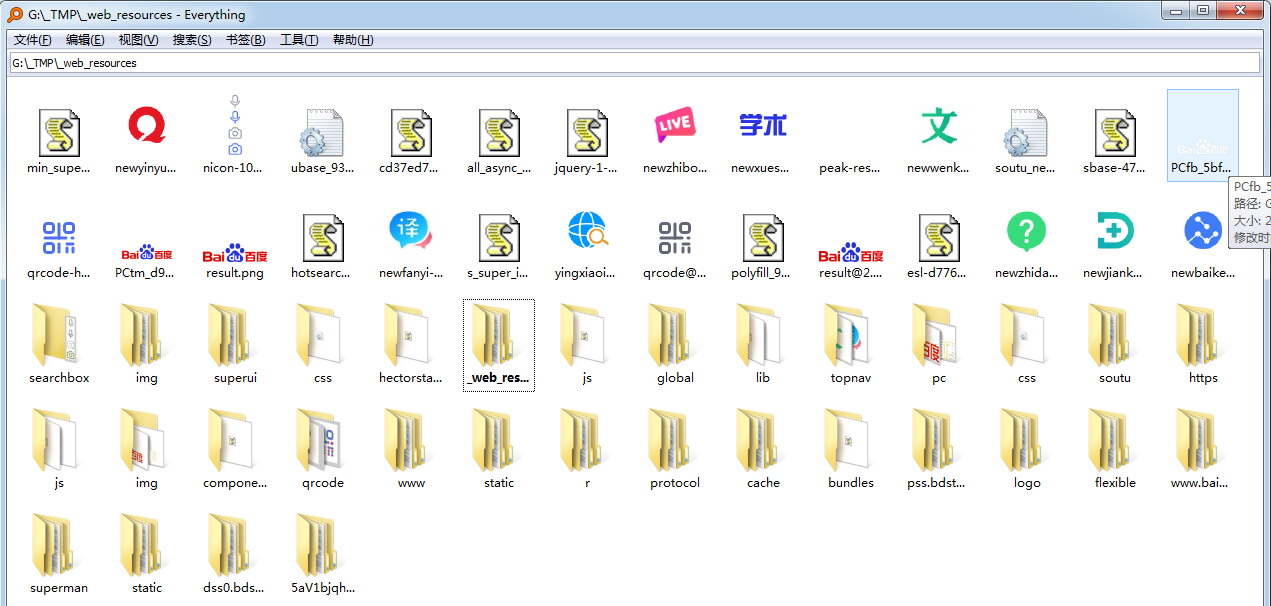
development environment
| Version number | describe | |
|---|---|---|
| operating system | Win10-1607 | |
| Google Chrome | 96.0.4664.110 (official version) (64 bit) (cohort: 97_Win_99) | |
| Python(venv) | Python3.8.6(virtualenv) | |
| PyChromeDevTools | 0.4 |
Core principles
preparation
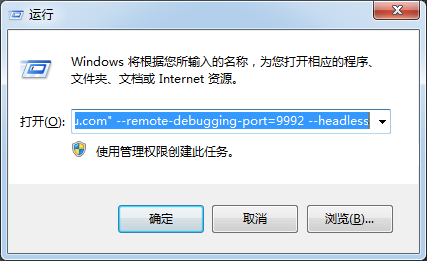
- Press Win+R to open the operation dialog box
- Execute the command "C: \ program files \ Google \ chrome \ application \ chrome. Exe"“ https://www.baidu.com " --remote-debugging-port=9992 --headless
The principle can refer to the article PyChromeDevTools source code analysis .
Open web page through browser http://localhost:9992/ , click Baidu page to view the content of headless browser.
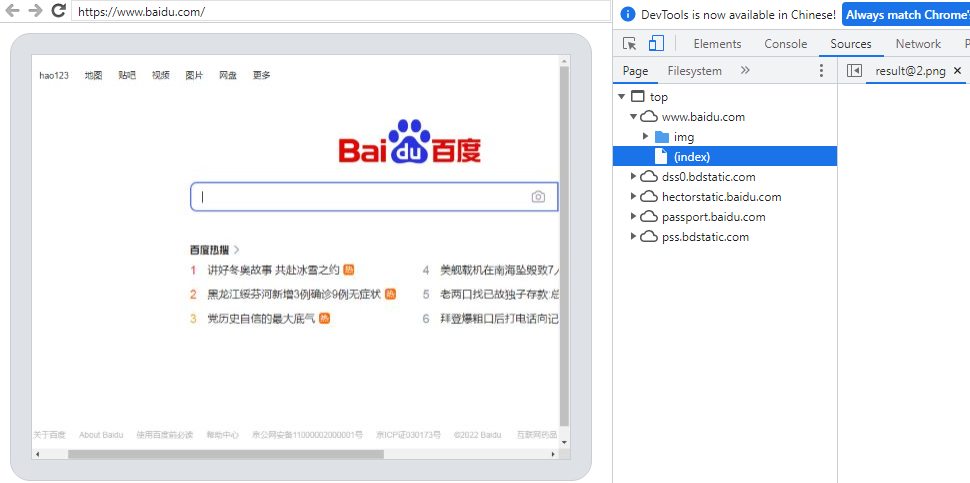
chrome.Page.getResourceTree()
This command is to get all the contents in the Page of the current connection (only one Page of baidu is opened in this example, and PyChromeDevTools.ChromeInterface(port=9992) will connect to this Page by default). The structure is as follows:
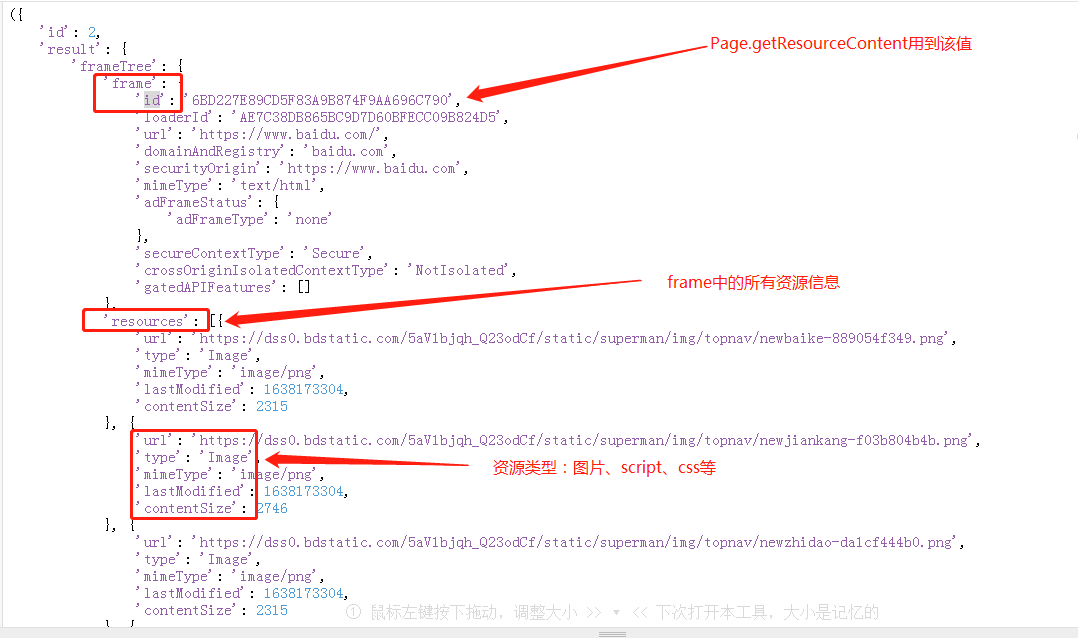
chrome.Page.getResourceContent()
After parsing getResourceTree, get all resource information, and then parse the content of each resource information.
Instruction page Getresourcecontent, including two parameters:
- frameId: the id marked in the above figure
- url: each item of resources in the figure above
An example of the protocol content is as follows. The content needs to judge whether base64 decryption is required according to base64Encoded:

chrome.Page.enable()
Calling instruction Page. during compiling process Getresourcecontent, error {"error": {"code": - 32000, "message": "Agent is not enabled.}, "id":1}. The term Agent is a bit misleading. The protocol document talks about the domains that need to be enabled to debug them, that is, the need to execute chrome before calling the instruction Page. Enable() instruction.
Source code
import base64
import os
import urllib
import PyChromeDevTools
def ez_get_object(j, list_keys):
"""
Quick access json Converted object child elements
j = {
'a':
{'b':{
b1: {'name':'xiao'},
b2: {'name':'2b'}
}}
}
>>> ez_get_object(j, 'a,b,b2')
{'name':'2b'}
j: json Converted object
list_keys: Comma separated string
"""
ret = j
for k in list_keys.split(','):
ret = ret.get(k.strip())
return ret
def Download all resources on the web page_unit_content(url, content):
url_parsed = urllib.parse.urlparse(url)
full_path = r'G:/_TMP/_web_resources/{}/'.format(url_parsed.hostname) + url_parsed.path
# For those that have been downloaded, return directly
if os.path.isfile(full_path):
return
dirname = os.path.dirname(full_path)
# basename = os.path.basename(full_path)
print('\t\tfull_path', full_path)
if not os.path.isdir(dirname):
os.makedirs(dirname)
with open(full_path, 'wb') as wf:
return wf.write(content)
def Download all resources on the web page_unit(url, _type, unit):
if _type in ['Script', 'Stylesheet', 'Image']:
if unit.get('base64Encoded'):
content = base64.b64decode(unit.get('content'))
else:
content = unit.get('content').encode('utf-8')
Download all resources on the web page_unit_content(url, content)
else:
print('\t[Warning] Unprocessed_type ', _type)
def Download all resources on the web page():
chrome = PyChromeDevTools.ChromeInterface(port=9992)
chrome.Page.enable()
result, messages = chrome.Page.getResourceTree()
frame_id = ez_get_object(result, 'result,frameTree,frame,id')
resources = ez_get_object(result, 'result,frameTree,resources')
for resource in resources:
url = resource.get('url')
_type = resource.get('type')
result_, messages_ = chrome.Page.getResourceContent(frameId=frame_id, url=url)
print('chrome.Page.getResourceContent', _type, url, result_)
if result_:
Download all resources on the web page_unit(url, _type, result_.get('result'))
else:
print('[Warning] chrome.Page.getResourceContent result_ is False')
reference material
- Error reason: Agent is not enabled https://stackoverflow.com/questions/38693379/how-to-get-webpage-resource-content-via-chrome-remote-debugging
- [automation] PyChromeDevTools source code analysis https://blog.csdn.net/kinghzking/article/details/122650766
- qq group: night owl dream chasing technology exchange skirt / 953949723

**ps: * * the content in the article is only for technical exchange, and should not be used for illegal acts.