Some time ago, there was a problem with the company's Android packaging service. The phenomenon is that when uploading the 360 server for reinforcement, it is very likely to get stuck in the upload stage, retry for a long time, and finally fail. I have conducted some troubleshooting and Analysis on this situation, solved this problem, wrote this long article and reviewed the troubleshooting experience, which will involve the following contents.
- Docker bridge mode network model
- Netfilter and NAT Principle
- Usage of Systemtap in kernel probe
Phenomenon description
The deployment structure of the packaging service is as follows: the Android packaging environment is packaged as a docker image and deployed on a physical machine. This image will complete the functions of code compilation and packaging, reinforcement, signature and channel package generation, as shown in the following figure:
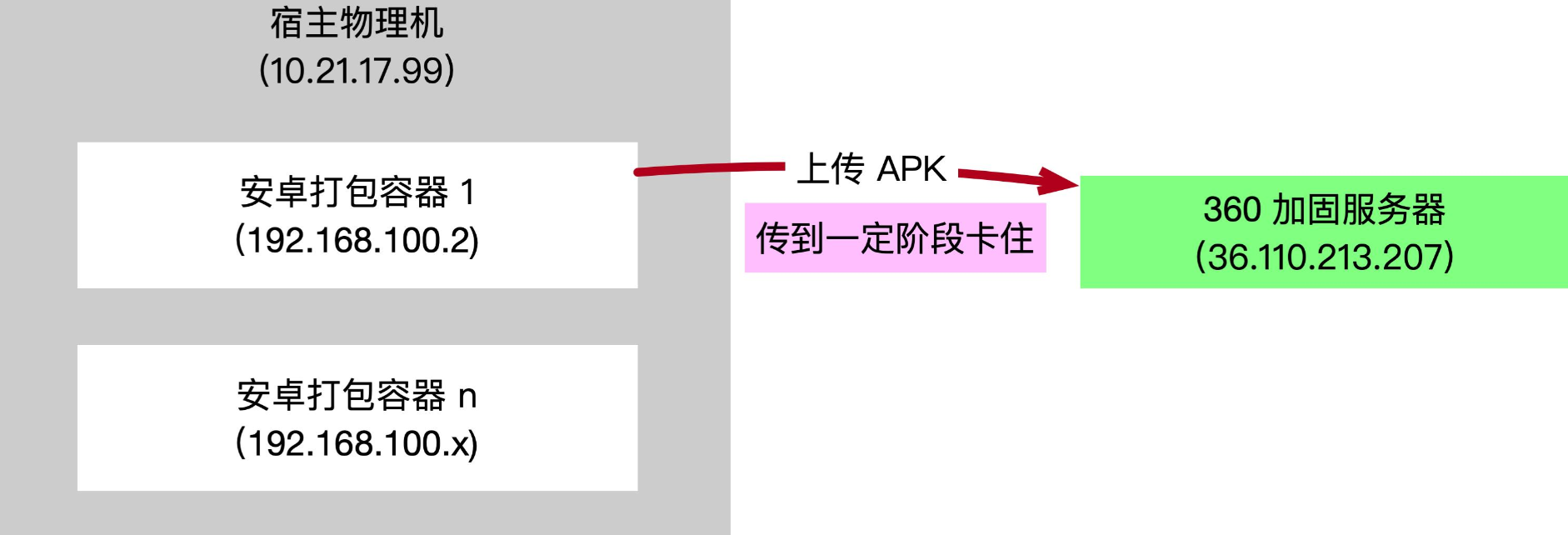
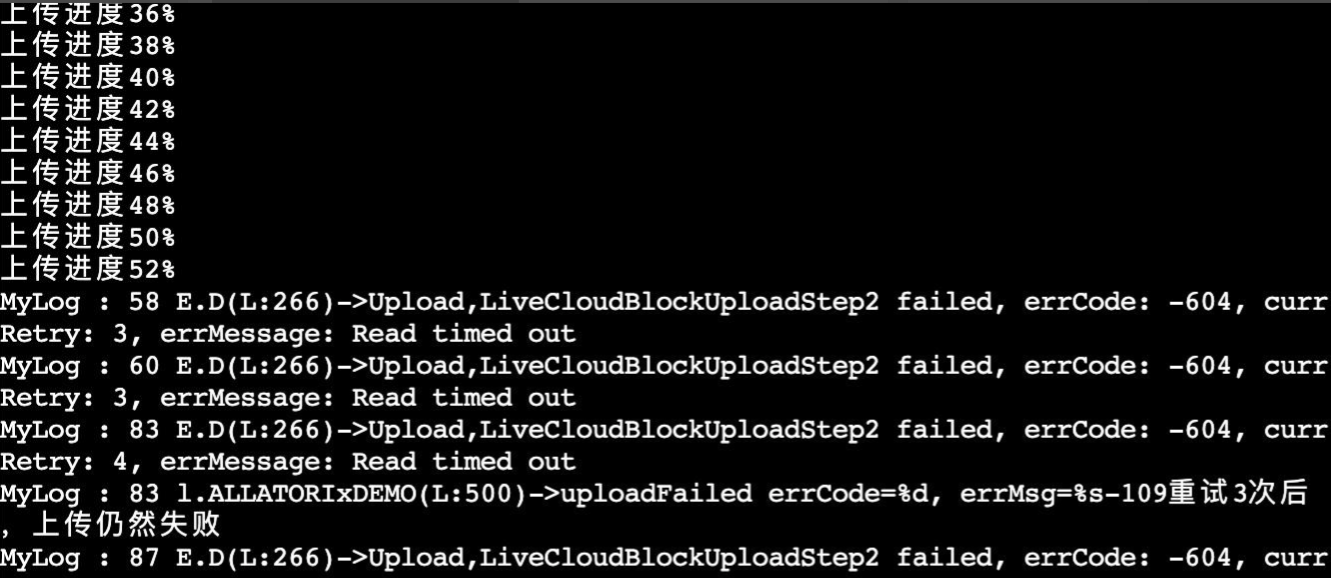
The problem lies in the step of uploading APK. Part of the APK gets stuck. The sdk of 360 prompts timeout and other exceptions, as shown in the figure below.
By capturing packets in the host and container respectively, we found such phenomena.
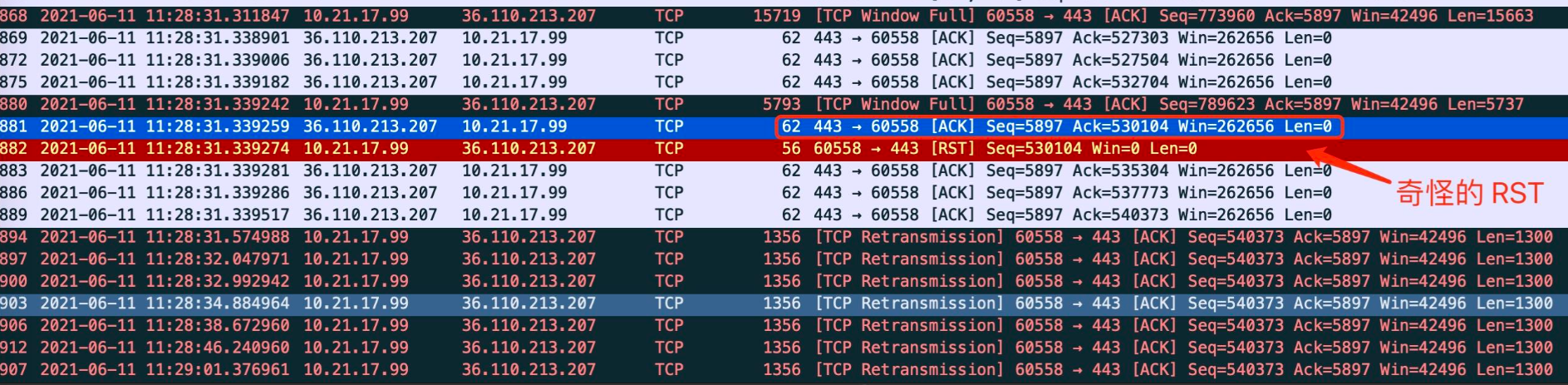
The packet capture of the host is as follows. The packet with serial number 881 is a delayed ACK, and its ack value is 530104. The packet with serial number 875 larger than this ack number has been confirmed (serial number 532704). Then the host sends an RST, including a remote 360 reinforcement server.
Then there is the continuous retry of sending data. The upload jam corresponds to the stage of constantly retry sending data, as shown in the figure below
This RST does not appear when capturing packets on the container side. It is the same as other packets, as shown in the figure below
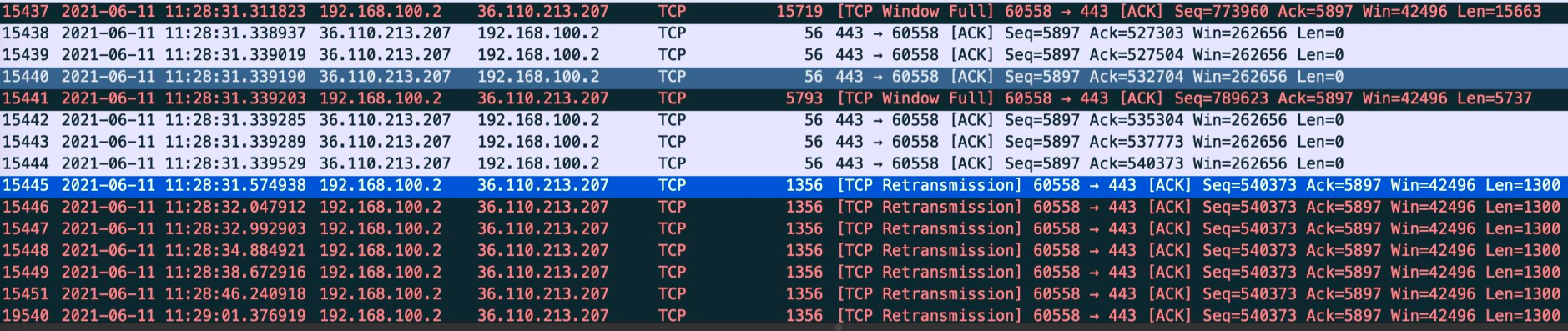
Because the container side does not perceive the connection exception, the service in the container has been trying to upload again and again. After repeated retries, it still fails.
Preliminary troubleshooting and analysis
At first, I wondered if I replied to RST because I received an ACK with delayed arrival?
This should not be. In the TCP protocol specification, if you receive an ACK with delayed arrival, you can ignore it and don't have to reply to the ACK. Then why do you send an RST packet?
Is this bag illegal? After careful analysis of the information of this package, no exceptions were found. From the existing knowledge of TCP principle, it is impossible to infer this phenomenon.
There are no skills and no ideas. At this time, you should use systemtap to see where the rst package is sent.
By looking at the kernel code, the following two functions are used to send rst packets
tcp_v4_send_reset@net/ipv4/tcp_ipv4.c
static void tcp_v4_send_reset(struct sock *sk, struct sk_buff *skb) {
}
tcp_send_active_reset@net/ipv4/tcp_output.c
void tcp_send_active_reset(struct sock *sk, gfp_t priority) {
}
Next, systemtap can inject these two functions.
probe kernel.function("tcp_send_active_reset@net/ipv4/tcp_output.c").call {
printf ("\n%-25s %s<-%s\n", ctime(gettimeofday_s()) ,execname(), ppfunc());
if ($sk) {
src_addr = tcp_src_addr($sk);
src_port = tcp_src_port($sk);
dst_addr = tcp_dst_addr($sk);
dst_port = tcp_dst_port($sk);
if (src_port == 443 || dst_port == 443) {
printf (">>>>>>>>>[%s->%s] %s<-%s %d\n", str_addr(src_addr, src_port), str_addr(dst_addr, dst_port), execname(), ppfunc(), dst_port);
print_backtrace();
}
}
}
probe kernel.function("tcp_v4_send_reset@net/ipv4/tcp_ipv4.c").call {
printf ("\n%-25s %s<-%s\n", ctime(gettimeofday_s()) ,execname(), ppfunc());
if ($sk) {
src_addr = tcp_src_addr($sk);
src_port = tcp_src_port($sk);
dst_addr = tcp_dst_addr($sk);
dst_port = tcp_dst_port($sk);
if (src_port == 443 || dst_port == 443) {
printf (">>>>>>>>>[%s->%s] %s<-%s %d\n", str_addr(src_addr, src_port), str_addr(dst_addr, dst_port), execname(), ppfunc(), dst_port);
print_backtrace();
}
} else if ($skb) {
header = __get_skb_tcphdr($skb);
src_port = __tcp_skb_sport(header)
dst_port = __tcp_skb_dport(header)
if (src_port == 443 || dst_port == 443) {
try {
iphdr = __get_skb_iphdr($skb)
src_addr_str = format_ipaddr(__ip_skb_saddr(iphdr), @const("AF_INET"))
dst_addr_str = format_ipaddr(__ip_skb_daddr(iphdr), @const("AF_INET"))
tcphdr = __get_skb_tcphdr($skb)
urg = __tcp_skb_urg(tcphdr)
ack = __tcp_skb_ack(tcphdr)
psh = __tcp_skb_psh(tcphdr)
rst = __tcp_skb_rst(tcphdr)
syn = __tcp_skb_syn(tcphdr)
fin = __tcp_skb_fin(tcphdr)
printf ("skb [%s:%d->%s:%d] ack:%d, psh:%d, rst:%d, syn:%d fin:%d %s<-%s %d\n",
src_addr_str, src_port, dst_addr_str, dst_port, ack, psh, rst, syn, fin, execname(), ppfunc(), dst_port);
print_backtrace();
}
catch { }
}
} else {
printf ("tcp_v4_send_reset else\n");
print_backtrace();
}
}
As soon as it runs, it is found that when there is a problem, TCP is entered_ v4_ send_ Reset this function, the call stack is
Tue Jun 15 11:23:04 2021 swapper/6<-tcp_v4_send_reset skb [36.110.213.207:443->10.21.17.99:39700] ack:1, psh:0, rst:0, syn:0 fin:0 swapper/6<-tcp_v4_send_reset 39700 0xffffffff99e5bc50 : tcp_v4_send_reset+0x0/0x460 [kernel] 0xffffffff99e5d756 : tcp_v4_rcv+0x596/0x9c0 [kernel] 0xffffffff99e3685d : ip_local_deliver_finish+0xbd/0x200 [kernel] 0xffffffff99e36b49 : ip_local_deliver+0x59/0xd0 [kernel] 0xffffffff99e364c0 : ip_rcv_finish+0x90/0x370 [kernel] 0xffffffff99e36e79 : ip_rcv+0x2b9/0x410 [kernel] 0xffffffff99df0b79 : __netif_receive_skb_core+0x729/0xa20 [kernel] 0xffffffff99df0e88 : __netif_receive_skb+0x18/0x60 [kernel] 0xffffffff99df0f10 : netif_receive_skb_internal+0x40/0xc0 [kernel] ...
You can see that after receiving the ACK package, call tcp_. v4_ Which line is the RST sent when RCV is used to process?
This requires a powerful tool faddr2line to restore the information in the stack to the number of lines corresponding to the source code.
wget https://raw.githubusercontent.com/torvalds/linux/master/scripts/faddr2line bash faddr2line /usr/lib/debug/lib/modules/`uname -r`/vmlinux tcp_v4_rcv+0x536/0x9c0 tcp_v4_rcv+0x596/0x9c0: tcp_v4_rcv in net/ipv4/tcp_ipv4.c:1740
You can see it's in TCP_ ipv4. Line 1740 of C calls tcp_v4_send_reset function,
int tcp_v4_rcv(struct sk_buff *skb)
{
struct sock *sk;
sk = __inet_lookup_skb(&tcp_hashinfo, skb, th->source, th->dest);
if (!sk)
goto no_tcp_socket;
...
no_tcp_socket:
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb))
goto discard_it;
if (skb->len < (th->doff << 2) || tcp_checksum_complete(skb)) {
csum_error:
TCP_INC_STATS_BH(net, TCP_MIB_CSUMERRORS);
bad_packet:
TCP_INC_STATS_BH(net, TCP_MIB_INERRS);
} else {
tcp_v4_send_reset(NULL, skb); // Line 1739
}
}
The only logic that can be called is that the socket information corresponding to this package cannot be found, sk is NULL, and then go to no_tcp_socket tag, and then go to else process.
How is this possible? The connection exists well. How can you receive an ack packet that arrives late and cannot find the connection socket when processing it? Next, let's look at INET_ lookup_ The bottom implementation of SKB function finally comes to inet_lookup_established this function.
struct sock *__inet_lookup_established(struct net *net, struct inet_hashinfo *hashinfo, const __be32 saddr, const __be16 sport, const __be32 daddr, const u16 hnum, const int dif)
After removing the existing phenomenon, a very similar RST scenario is to send packets to a service that does not listen to a port. If the packet has no corresponding connection, the kernel will reply to RST and tell the sender that it cannot process the packet.
Here, the investigation has reached an impasse. Why can't the kernel protocol stack be found when the connection is still there?
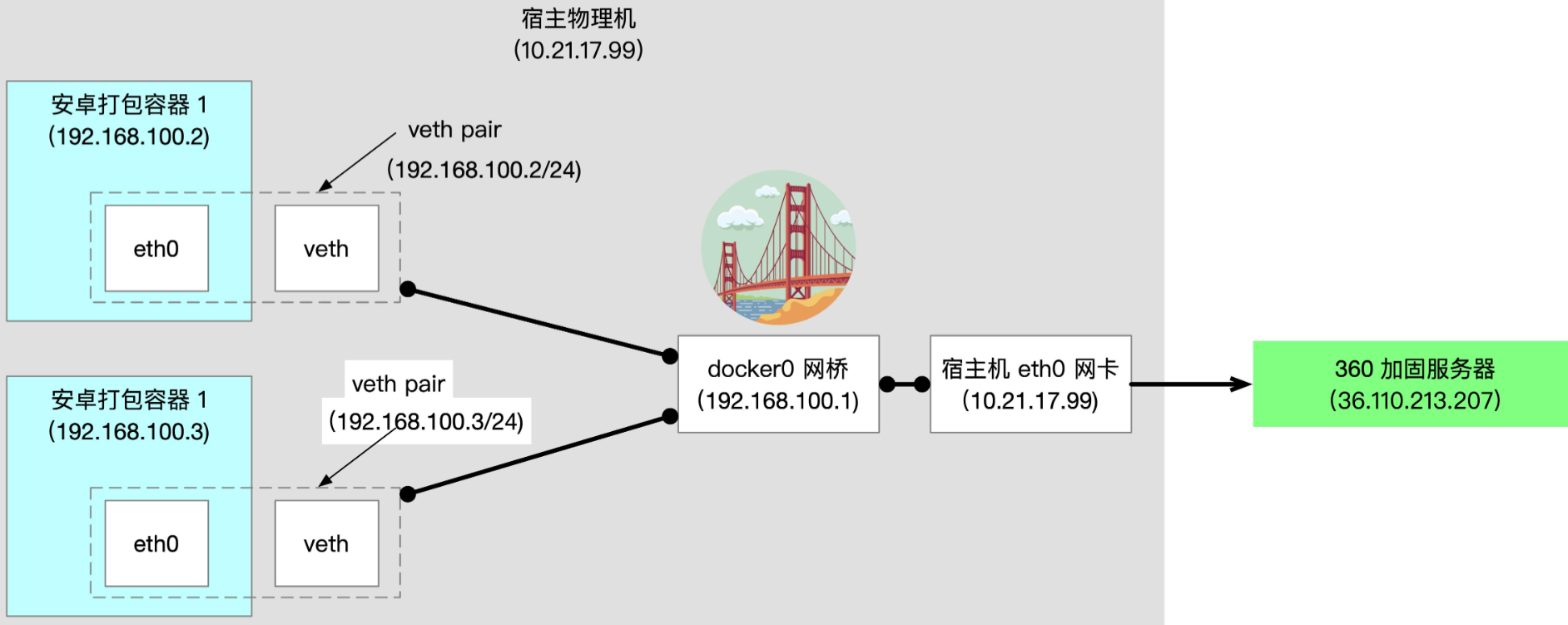
Docker bridge mode network packet circulation mode
When the docker process starts, a virtual bridge named docker0 will be created on the host, and the docker container on the host will be connected to the virtual bridge.
After the container is started, docker will generate a pair of veth interfaces, which is essentially equivalent to the Ethernet connection realized by software. Docker connects eth0 in the container to docker0 bridge through veth. External connections can be provided through IP masquerading. IP masquerading is a way of network address translation (NAT), which is established by IP forwarding and iptables rules.
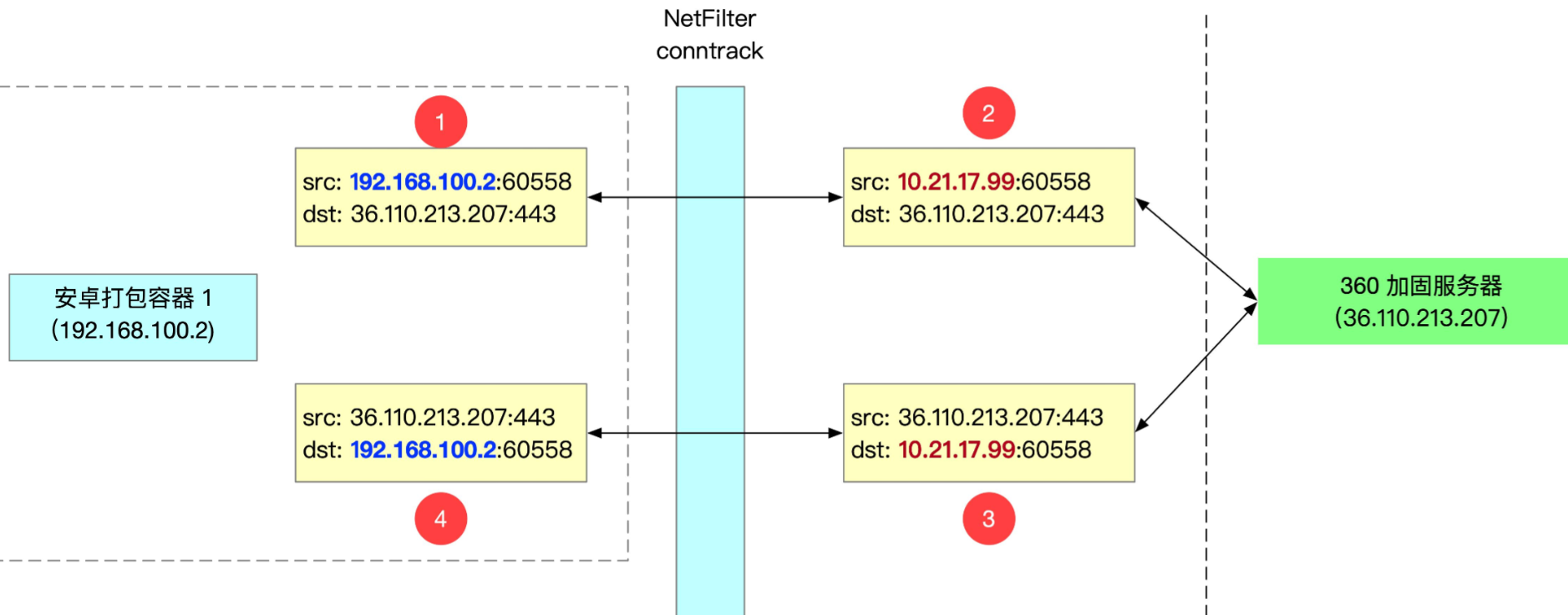
Go deep into Netfilter and NAT
Netfilter is a Linux kernel framework. It sets several hook points in the kernel protocol stack to intercept, filter or otherwise process data packets. It can be implemented from a simple firewall to a detailed analysis of network communication data to a complex state dependent packet filter.
Docker uses its NAT (network address translation) feature to convert the source address and target address according to some rules. iptables is a tool for managing these netfilters in user mode.
After checking the netfilter code, it is found that it will mark the out of window package as INVALID. For the source code, see
net/netfilter/nf_conntrack_proto_tcp.c:
/* Returns verdict for packet, or -1 for invalid. */
static int tcp_packet(struct nf_conn *ct,
const struct sk_buff *skb,
unsigned int dataoff,
enum ip_conntrack_info ctinfo,
u_int8_t pf,
unsigned int hooknum,
unsigned int *timeouts) {
// ...
if (!tcp_in_window(ct, &ct->proto.tcp, dir, index,
skb, dataoff, th, pf)) {
spin_unlock_bh(&ct->lock);
return -NF_ACCEPT;
}
}
It's just a theoretical analysis. How can you say it's an invalid package caused by an ACK?
We can print the invalid package through iptables rules.
iptables -A INPUT -m conntrack --ctstate INVALID -m limit --limit 1/sec -j LOG --log-prefix "invalid: " --log-level 7
After adding the above rules, run the script of reinforcement upload again and start capturing packets at the same time. The phenomenon reappears.

Then view the corresponding log in dmesg.

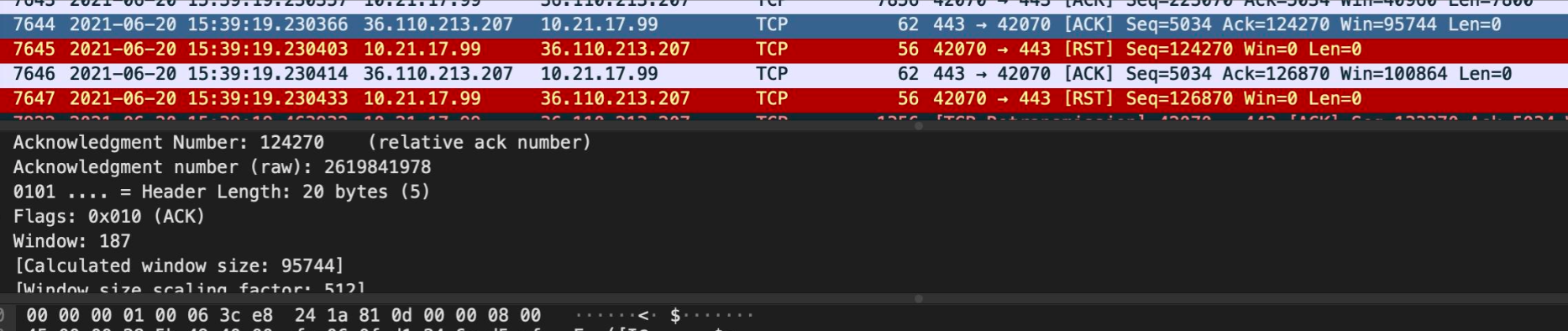
Take the first behavior as an example, its LEN=40, that is, 20 IP header + 20 byte TCP header. The ACK bit is set, indicating that this is an ACK packet without any content, which corresponds to the previous ACK packet of RST packet in the above figure. The details of this package are shown in the figure below. It is also right that window is equal to 187.
If it is a packet in INVALID state, netfilter will not perform NAT conversion between ip and port. In this way, when the protocol stack looks for the connection of the packet according to ip + port, it will not be found. At this time, an RST will be restored, as shown in the following figure.
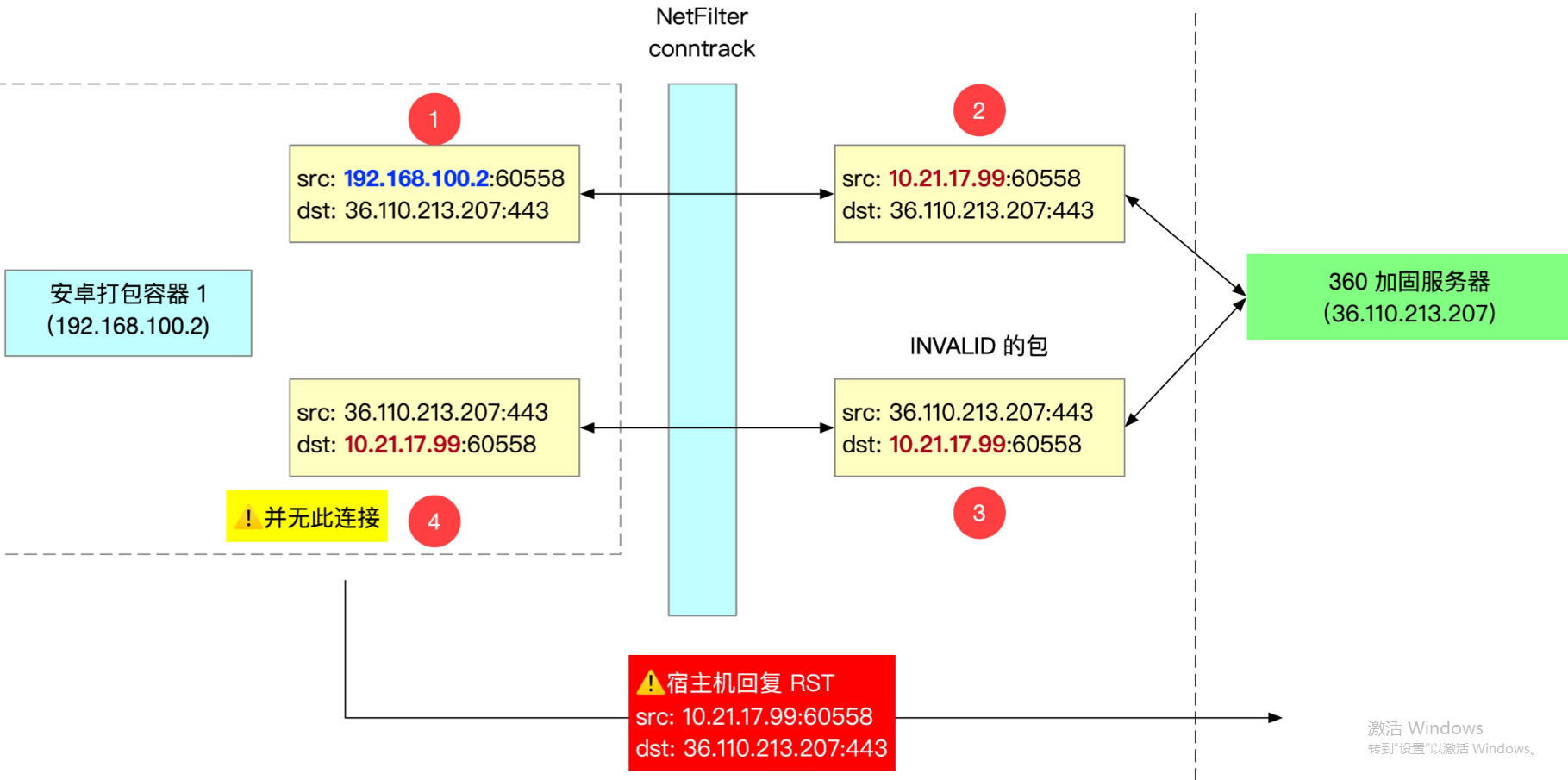
This also confirms the front of us__ inet_lookup_skb is null, and then send the code logic of RST.
How to modify
Knowing the reason, the modification is very simple. There are two modifications. The first modification is a little rough. Use iptables to drop the invalid package to prevent it from generating RST.
iptables -A INPUT -m conntrack --ctstate INVALID -j DROP
After this modification, the problem was solved instantly. After dozens of tests, there was no upload timeout or failure.
There is a small problem with this modification, which may accidentally damage the FIN package and some other really invalid packages. A more elegant modification is to modify the kernel options
net. netfilter. nf_ conntrack_ tcp_ be_ Set liberal to 1:
sysctl -w "net.netfilter.nf_conntrack_tcp_be_liberal=1" net.netfilter.nf_conntrack_tcp_be_liberal = 1
After setting this parameter value to 1, packages outside the window will not be marked as INVALID. See for the source code
net/netfilter/nf_conntrack_proto_tcp.c:
static bool tcp_in_window(const struct nf_conn *ct,
struct ip_ct_tcp *state,
enum ip_conntrack_dir dir,
unsigned int index,
const struct sk_buff *skb,
unsigned int dataoff,
const struct tcphdr *tcph,
u_int8_t pf) {
...
res = false;
if (sender->flags & IP_CT_TCP_FLAG_BE_LIBERAL ||
tn->tcp_be_liberal)
res = true;
...
return res;
}
Finally, a silky upload screenshot ends this article.
Postscript
Look at the code and doubt some impossible phenomena. The above may be wrong. Just look at the method.