day02-03_ Stream batch integration API
Today's goal
-
Preliminary study on the principle of stream processing
-
Stream processing concept (understanding)
-
Data Source of program structure (Master)
-
Data Transformation of program structure
-
Data landing Sink of program structure (Master)
-
Flink Connectors (understand)
Preliminary study on the principle of stream processing
-
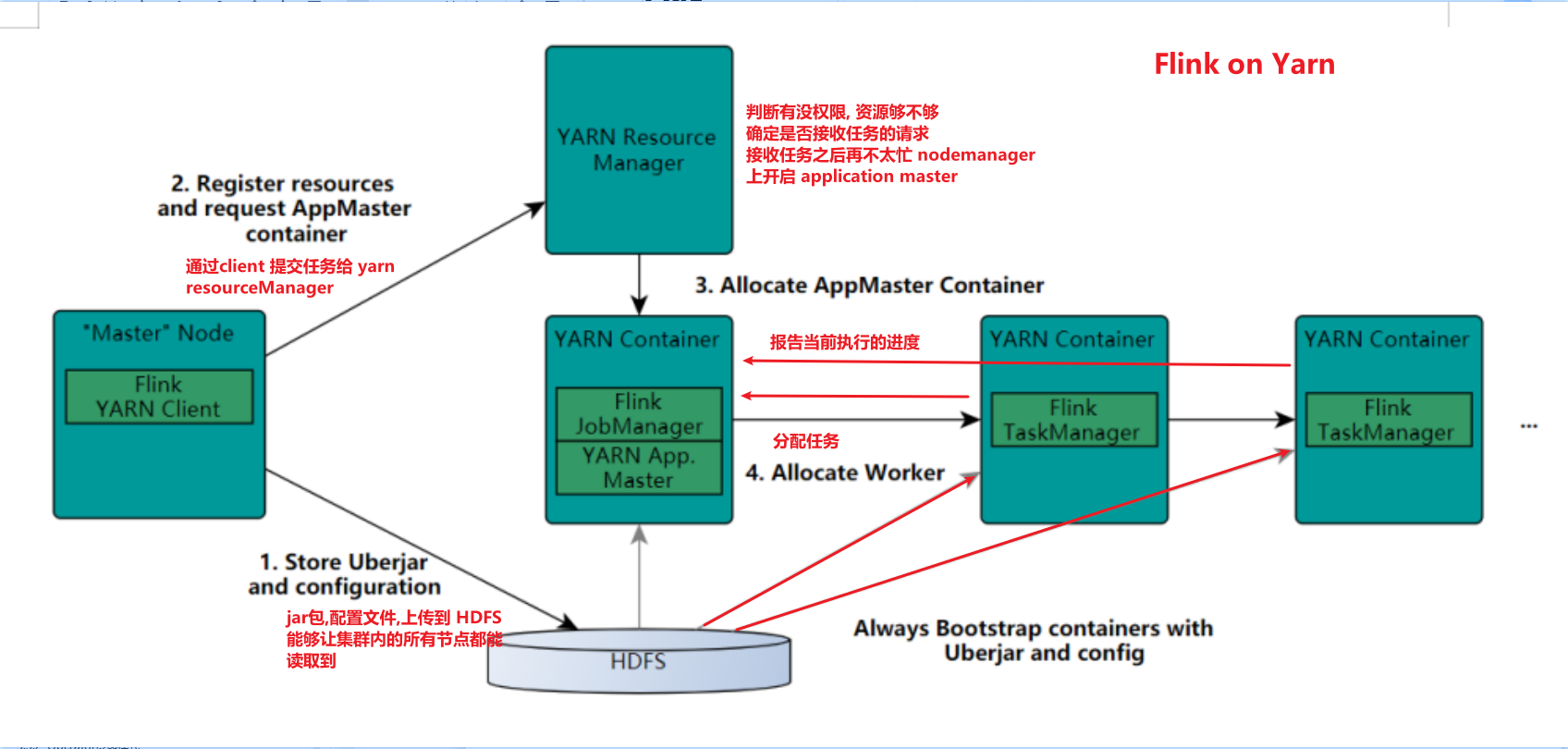
Flink's role assignment
- The boss of JobMaster is mainly responsible for cluster management, fault recovery and checkpoint setting
- taskmanager worker is responsible for the execution node of tasks
- client task submission interface
-
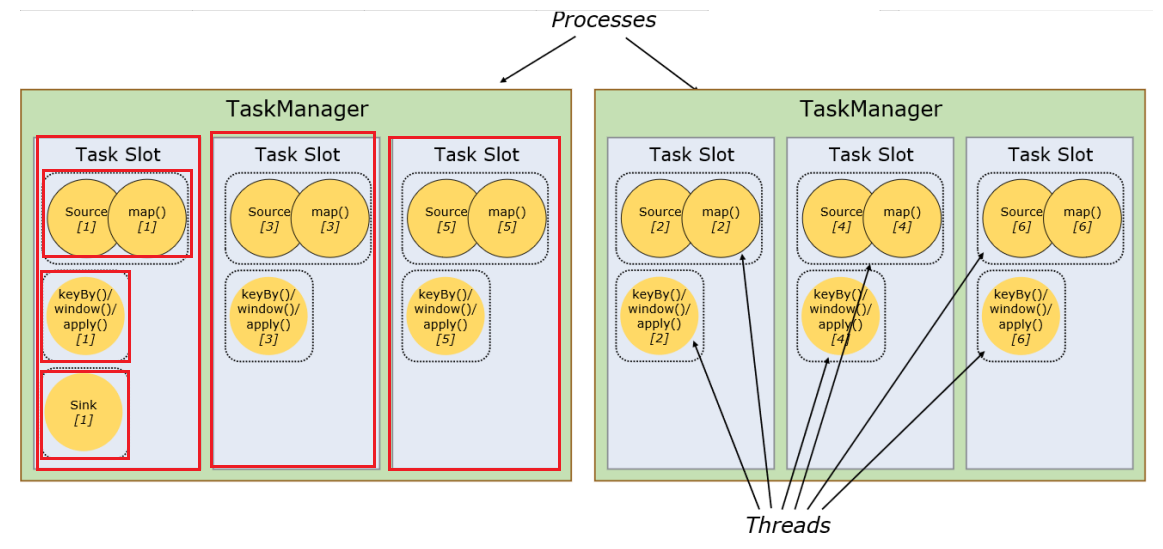
taskmanager execution capability
- The static concept of taskslot
- parallelism dynamic concept
-
Each node is a task
Each task is divided into multiple parallel processing tasks. Multiple threads have multiple subtasks, which are called subtasks
-
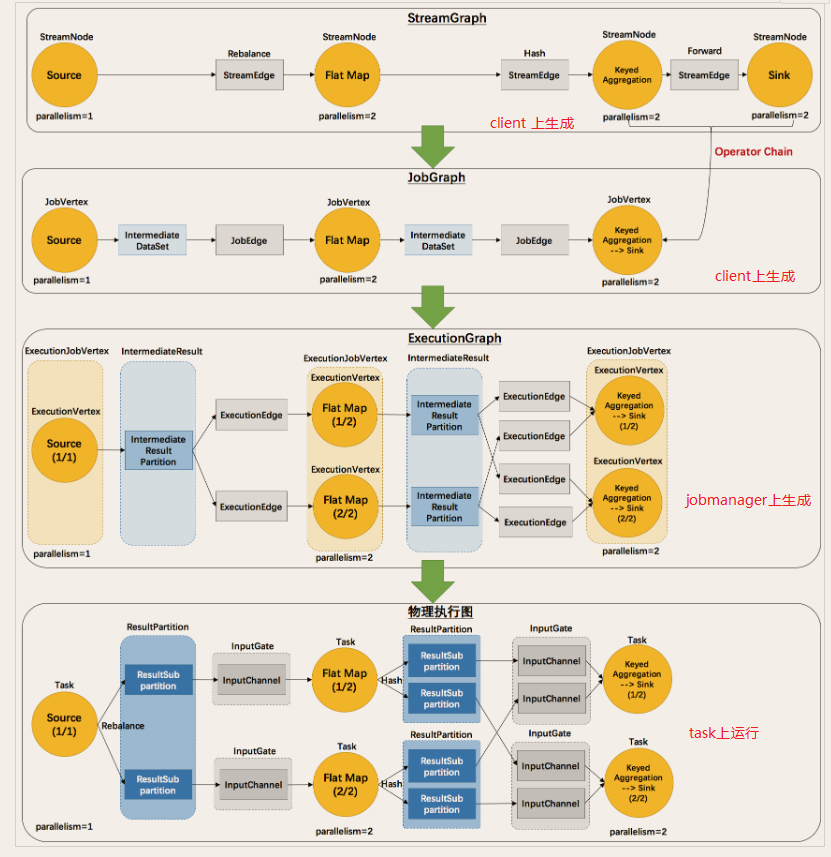
Flow graph StreamGraph logic execution flow graph DataFlow
operator chain
-
JobGraph
ExecuteGraph physical execution plan
-
Event events are time stamped
-
Operator transfer mode: one to one mode, redistributing mode
- Execution diagram of Flink
Stream processing concept
Timeliness of data
-
The emphasis is on the timeliness of data processing
Processing time window, by month, by day, by hour or by second
Stream and batch processing
-
Batch processing is bounded data
- Process complete data sets, such as sorting data, calculating global status, and generating final input overview
- Batch calculation: collect data uniformly - > store in DB - > batch process data
-
Stream processing is unbounded data
- Window operation to divide the boundary of data for calculation
- Stream computing, as its name suggests, is to process data streams
-
At flink1 At 12:00, it supports both stream processing and batch processing.

-
Flow batch integration flink1 12. X batch and stream processing
- Reusability: the job can switch freely in stream mode or batch mode without rewriting any code
- Simple maintenance: a unified API means that streams and batches can share the same set of connector s and maintain the same set of code
Programming model
- Source - read data source
- transformation - data conversion map flatMap groupBy keyBy sum
- sink - landing data addSink print
Source
Collection based Source
-
Development and test use
-
classification
1.env.fromElements(Variable parameter); 2.env.fromColletion(Various sets); # be overdue 3.env.generateSequence(start,end); 4.env.fromSequence(start,end);
-
Use collection Source
import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.ArrayList; /** * Author itcast * Date 2021/6/16 9:29 * Requirements: print the results through the collection source to see how to use it * Development steps: * 1. Create a streaming environment * 2. Read data from collection * 3. Printout * 4. Run execution */ public class SourceDemo01 { public static void main(String[] args) throws Exception { //1. Create a streaming environment StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2. Read data from collection //2.1 fromElement from element set DataStreamSource<String> source1 = env.fromElements("hello world", "hello spark", "hello flink"); //2.2 from collection list ArrayList<String> strings = new ArrayList<>(); strings.add("hello world"); strings.add("hello flink"); DataStreamSource<String> source2 = env.fromCollection(strings); //2.3 fromSequence DataStreamSource<Long> source3 = env.fromSequence(1, 10); //3. Printout source1.print(); //4. Operation execution env.execute(); } } -
socket data source wordcount statistics
/** * Author itcast * Desc * SocketSource */ public class SourceDemo03 { public static void main(String[] args) throws Exception { //1.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); //2.source DataStream<String> linesDS = env.socketTextStream("node1", 9999); //3. Data processing - transformation //3.1 each line of data is divided into words according to the space to form a set DataStream<String> wordsDS = linesDS.flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String value, Collector<String> out) throws Exception { //value is row by row data String[] words = value.split(" "); for (String word : words) { out.collect(word);//Collect and return the cut words one by one } } }); //3.2 mark each word in the set as 1 DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> map(String value) throws Exception { //value is the word that comes in one by one return Tuple2.of(value, 1); } }); //3.3 group the data according to the word (key) //KeyedStream<Tuple2<String, Integer>, Tuple> groupedDS = wordAndOnesDS.keyBy(0); KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0); //3.4 aggregate the data in each group according to the quantity (value), that is, sum DataStream<Tuple2<String, Integer>> result = groupedDS.sum(1); //4. Output result - sink result.print(); //5. Trigger execute env.execute(); } } -
Custom data source - random data
import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction; import java.util.Random; import java.util.UUID; /** * Author itcast * Date 2021/6/16 10:18 * An order information (order ID, user ID, order amount, time stamp) is randomly generated every 1 second * requirement: * - Randomly generated order ID(UUID) * - Randomly generated user ID(0-2) * - Randomly generated order amount (0-100) * - The timestamp is the current system time * * SourceFunction:Non parallel data source (parallelism can only be = 1) * RichSourceFunction:Multifunctional non parallel data source (parallelism can only be = 1) * ParallelSourceFunction:Parallel data source (parallelism > = 1) * RichParallelSourceFunction:Multifunctional parallel data source (parallelism > = 1) -- the Kafka data source for subsequent learning uses this interface */ public class CustomSource01 { public static void main(String[] args) throws Exception { //1.env create streamexection StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //2.source to create an automatically generated Order data source DataStreamSource<Order> source = env.addSource(new MyOrderSource()); //3. Print data source source.print(); //4. Implementation env.execute(); //Defining the entity class Order includes four fields oid uid money currentTime //Define a static inner class MyOrderSource that inherits RichParallelSourceFunction //An order information (order ID, user ID, order amount, time stamp) is randomly generated every 1 second //requirement: //-Randomly generated order ID(UUID) //-Randomly generated user ID(0-2) //-Randomly generated order amount (0-100) //-The timestamp is the current system time } public static class MyOrderSource extends RichParallelSourceFunction<Order> { boolean flag = true; Random rn = new Random(); @Override public void run(SourceContext<Order> ctx) throws Exception { //An order information (order ID, user ID, order amount, time stamp) is randomly generated every 1 second //requirement: while(flag) { //-Randomly generated order ID(UUID) String oid = UUID.randomUUID().toString(); //-Randomly generated user ID(0-2) int uid = rn.nextInt(3); //-Randomly generated order amount (0-100) int money = rn.nextInt(101); //-The timestamp is the current system time long currentTime = System.currentTimeMillis(); ctx.collect(new Order(oid,uid,money,currentTime)); //Take a second off Thread.sleep(1000); } } @Override public void cancel() { flag = false; } } //Create Order object @AllArgsConstructor @NoArgsConstructor @Data public static class Order{ private String oid; private int uid; private int money; private long currentTime; } } -
Custom data source - read t data from MySQL database_ Data in student table (this scenario uses very little - custom data source)
import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.RichSourceFunction; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; /** * Author itcast * Date 2021/6/16 10:37 * Requirements: * Read t from MySql database_ Student table data * Development steps: * //1.env Set the parallelism to 1 * //2.source,Create a data source connecting to MySQL data source, and generate a piece of data every 2 seconds * //3.Print data source * //4.implement * //Create a static internal class Student with the field id:int name:String age:int * //Create a static inner class MySQLSource to inherit richparallelsourcefunction < student > * // Implement the open method and create connection and prepareStatement * // Get database connection mysql5 Version 7 * jdbc:mysql://192.168.88.163:3306/bigdata?useSSL=false * // Implement the run method and create a piece of data every 5 seconds * // Implement the close method */ public class CustomSourceMySQL { public static void main(String[] args) throws Exception { //1.env sets the parallelism to 1 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //2.source, create a data source connected to MySQL data source, and generate a piece of data every 2 seconds DataStreamSource<Student> source = env.addSource(new MySQLSource()); //3. Print data source source.print(); //4. Implementation env.execute(); //Create a static internal class Student with the field id:int name:String age:int //Create a static inner class MySQLSource to inherit richparallelsourcefunction < student > // Implement the open method and create connection and prepareStatement // Get database connection mysql5 Version 7 jdbc:mysql://192.168.88.163:3306/bigdata?useSSL=false // Implement the run method and create a piece of data every 5 seconds // Implement the close method } public static class MySQLSource extends RichSourceFunction<Student> { boolean flag = true; Connection conn = null; PreparedStatement ps = null; // At the beginning of the open life cycle, do it only once @Override public void open(Configuration parameters) throws Exception { conn = DriverManager.getConnection("jdbc:mysql://192.168.88.163:3306/bigdata?useSSL=false", "root", "123456"); String sql = "select id,name,age from t_student"; // Execute preparation ps = conn.prepareStatement(sql); } @Override public void run(SourceContext<Student> ctx) throws Exception { while(flag){ // Query result set ResultSet rs = ps.executeQuery(); while(rs.next()){ int id = rs.getInt("id"); String name = rs.getString("name"); int age = rs.getInt("age"); ctx.collect(new Student(id,name,age)); Thread.sleep(5000); } } } @Override public void cancel() { flag = false; } //Close the database only once in the whole life cycle @Override public void close() throws Exception { if(!ps.isClosed()) ps.close(); if(!conn.isClosed()) conn.close(); } } //Define student @AllArgsConstructor @NoArgsConstructor @Data public static class Student{ private int id; private String name ; private int age; } }
Merge split
-
Merge data streams merge two data streams into one data stream
-
Application scenario
① Statistical analysis and mining of all order information from different data sources, computers, apps, iPads and wechat applets
② Collect and analyze the behavior trajectories of different handheld devices and computer users
-
The difference between union and connect
union and connect merge
union operator requires that the type of data stream must be consistent
The connect operator requires that the types of data streams can be inconsistent
-
Requirement: merge two data streams together
/** * Author itcast * Desc */ public class TransformationDemo02 { public static void main(String[] args) throws Exception { //1.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); env.setParallelism(1); //2.Source DataStream<String> ds1 = env.fromElements("hadoop", "spark", "flink"); DataStream<String> ds2 = env.fromElements("oozie", "flume", "flink"); DataStream<Long> ds3 = env.fromElements(1L, 2L, 3L); //3.Transformation // The union operator ensures that the two data flow types are consistent DataStream<String> result1 = ds1.union(ds2);//Merge without redoing https://blog.csdn.net/valada/article/details/104367378 // The two data flow types of connect operator can be different ConnectedStreams<String, Long> tempResult = ds1.connect(ds3); //interface CoMapFunction<IN1, IN2, OUT> DataStream<String> result2 = tempResult.map(new CoMapFunction<String, Long, String>() { @Override public String map1(String value) throws Exception { return "String->String:" + value; } @Override public String map2(Long value) throws Exception { return "Long->String:" + value.toString(); } }); //4.Sink //result1.print(); result2.print(); //5.execute env.execute(); } }
Shunt select and outputside
-
Dividing a data stream into multiple data streams
-
Application scenario
① The server log is divided into normal log, alarm log and error report log
-
Requirements - split the data flow into even and odd numbers
-
Development steps
import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag; /** * Author itcast * Date 2021/6/16 11:29 * Requirements: split data * Development steps: * //1.env * //2.Source For example, a number between 1 and 20 * //Define two output tag s, an odd number and an even number, and specify the type as Long * //process the data of source to distinguish odd and even numbers * //3.Get two side output streams * //4.sink Printout * //5.execute */ public class SplitDataStream { public static void main(String[] args) throws Exception { //1.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //2. For example, the number between 1 and 20 DataStreamSource<Long> source = env.fromSequence(1, 21); //Define two side output streams, an odd number and an even number, and specify the type as Long // The corresponding data type needs to be specified. The default OutputTag will use the general type and needs to be manually selected OutputTag<Long> odd = new OutputTag<Long>("odd", TypeInformation.of(Long.class)); OutputTag<Long> even = new OutputTag<Long>("even", TypeInformation.of(Long.class)); //process the data of source to distinguish odd and even numbers SingleOutputStreamOperator<Long> result = source.process(new ProcessFunction<Long, Long>() { @Override public void processElement(Long value, Context ctx, Collector<Long> out) throws Exception { if (value % 2 == 0) { ctx.output(even, value); } else { ctx.output(odd, value); } } }); //3. Obtain two side output streams //result.print(); result.getSideOutput(even).print("even numbers"); result.getSideOutput(odd).print("Odd number"); //4.sink printout //5.execute env.execute(); } }
Data rebalance
-
Spread the data evenly to each node to make the calculation more uniform.
-
Requirements: use 3 threads to calculate 100 90 numbers greater than 10 evenly
-
code
import org.apache.flink.api.common.functions.RichMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * Author itcast * Date 2021/6/17 15:00 * Requirements: three threads handle 90 numbers, and numbers greater than 10 */ public class RebalanceDemo { public static void main(String[] args) throws Exception { //1.env sets the parallelism to 3 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(3); //2.source fromSequence 1-100 DataStreamSource<Long> source = env.fromSequence(1, 100); //3.Transformation //The following operations are equivalent to randomly distributing the data. There may be data skew, and the filtered data is greater than 10 DataStream<Long> filterDS = source.filter(s -> s > 10); //3.1 next, use the map operation to convert the Long data to tuple2 (partition number / subtask number, 1) /*SingleOutputStreamOperator<Tuple2<Integer, Integer>> mapDS = filterDS.map(new RichMapFunction<Long, Tuple2<Integer*//**CPU Core number of*//*, Integer>>() { @Override public Tuple2<Integer, Integer> map(Long value) throws Exception { //Get the task Index through getRuntimeContext int idx = getRuntimeContext().getIndexOfThisSubtask(); //Return tuple2 (task Index,1) return Tuple2.of(idx, 1); } }); //Group according to the subtask id / partition number, and count the number of elements in each subtask / partition SingleOutputStreamOperator<Tuple2<Integer, Integer>> result1 = mapDS.keyBy(i -> i.f0) //Group and aggregate the current data stream according to the key .sum(1);*/ //3.2 perform the above operations again. rebalance before map after filter, as above SingleOutputStreamOperator<Tuple2<Integer, Integer>> mapDS = filterDS .rebalance() .map(new RichMapFunction<Long, Tuple2<Integer/**CPU Core number of*/, Integer>>() { @Override public Tuple2<Integer, Integer> map(Long value) throws Exception { //Get the task Index through getRuntimeContext int idx = getRuntimeContext().getIndexOfThisSubtask(); //Return tuple2 (task Index,1) return Tuple2.of(idx, 1); } }); //Group according to the subtask id / partition number, and count the number of elements in each subtask / partition SingleOutputStreamOperator<Tuple2<Integer, Integer>> result2 = mapDS.keyBy(i -> i.f0) //Group and aggregate the current data stream according to the key .sum(1); //4.sink //result1.print("no repartition"); result2.print("Repartition"); //5.execute env.execute(); } }
Sink
Predefined Sink
/**
* Author itcast
* Desc
* 1.ds.print Direct output to console
* 2.ds.printToErr() Output directly to the console in red
* 3.ds.collect Collect distributed data into local collections
* 4.ds.setParallelism(1).writeAsText("Path "of local / HDFS (writemode. Overwrite)
*/
public class SinkDemo01 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.source
//DataStream<String> ds = env.fromElements("hadoop", "flink");
DataStream<String> ds = env.readTextFile("data/input/words.txt");
//3.transformation
//4.sink
ds.print();
ds.printToErr();
ds.writeAsText("data/output/test", FileSystem.WriteMode.OVERWRITE).setParallelism(2);
//be careful:
//Parallelism=1 is a file
//Parallelism > 1 is a folder
//5.execute
env.execute();
}
}
Custom Sink
-
demand
Write the data in the collection to MySQL
-
Development steps
import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.RichSinkFunction; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; /** * Author itcast * Date 2021/6/17 15:43 * Desc TODO */ public class CustomSinkMySQL { public static void main(String[] args) throws Exception { //1.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.Source DataStream<Student> studentDS = env.fromElements(new Student(null, "tonyma", 18)); //3.Transformation //4.Sink studentDS.addSink(new MySQLSink()); //5.execute env.execute(); } //Implement RichSinkFunction to insert data into MySQL t_student table public static class MySQLSink extends RichSinkFunction<Student>{ Connection conn ; PreparedStatement ps; //Connect database @Override public void open(Configuration parameters) throws Exception { conn = DriverManager.getConnection("jdbc:mysql://192.168.88.163:3306/bigdata?useSSL=false", "root", "123456"); String sql = "INSERT INTO `t_student` (`id`, `name`, `age`) VALUES (null, ?, ?)"; ps = conn.prepareStatement(sql); } //Insert data into database @Override public void invoke(Student value, Context context) throws Exception { ps.setString(1,value.name); ps.setInt(2,value.age); ps.executeUpdate(); } //close database @Override public void close() throws Exception { if(!ps.isClosed()) ps.close(); if(!conn.isClosed()) conn.close(); } } @Data @NoArgsConstructor @AllArgsConstructor public static class Student { private Integer id; private String name; private Integer age; } }
Connector
- The connector officially provided by Flink is used to connect JDBC or Kafka, MQ, etc
JDBC connection mode
-
Requirement: store data elements in MySQL database through JDBC
/** * Author itcast * Date 2021/6/17 15:59 * Desc TODO */ public class JDBCSinkMySQL { public static void main(String[] args) throws Exception { //1.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.Source DataStreamSource<Student> source = env.fromElements(new Student(null, "JackMa", 42)); //3. Insert data into mysql database through jdbc source.addSink(JdbcSink.sink( // Enter SQL execute insert SQL statement "INSERT INTO t_student(id,name,age) values (null,?,?)", // Perform inserted assignment (ps, student) -> { ps.setString(1,student.name); ps.setInt(2,student.age); }, //constructor // Set parameters such as batch size for the options to execute JdbcExecutionOptions.builder() .withBatchSize(1000) .withBatchIntervalMs(200) .withMaxRetries(5) .build(), //4. Parameter configuration connection parameters new JdbcConnectionOptions.JdbcConnectionOptionsBuilder() .withUrl("jdbc:mysql://192.168.88.163:3306/bigdata?useSSL=false") .withUsername("root") .withPassword("123456") .withDriverName("com.mysql.jdbc.Driver") .build())); //5. Implementation environment env.execute(); } @Data @NoArgsConstructor @AllArgsConstructor public static class Student { private Integer id; private String name; private Integer age; } }
Kafka connection mode
-
Kafka is a message queue
-
Requirements:
Write data elements to Kafka through Flink
package cn.itcast.flink.sink; import com.alibaba.fastjson.JSON; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import org.apache.flink.streaming.connectors.kafka.internals.KafkaSerializationSchemaWrapper; import org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner; import org.apache.kafka.clients.producer.ProducerConfig; import java.util.Properties; /** * Author itcast * Date 2021/6/17 16:46 * Requirement: encapsulate data elements into JSON strings and produce them into Kafka * Steps: * */ public class KafkaProducerDemo { public static void main(String[] args) throws Exception { //1.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.Source generates an element Student DataStreamSource<Student> studentDS = env.fromElements(new Student(102, "Oking", 25)); //3.Transformation //Note: at present, the serialization and deserialization used by Kafka directly use the simplest string, so first convert the Student to a string //3.1 map method converts Student into string SingleOutputStreamOperator<String> mapDS = studentDS.map(new MapFunction<Student, String>() { @Override public String map(Student value) throws Exception { //You can directly call toJsonString of JSON or convert it to JSON String json = JSON.toJSONString(value); return json; } }); //4.Sink Properties props = new Properties(); props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.88.161:9092"); //Instantiate FlinkKafkaProducer according to parameters //4.1 if you do not need complex parameter settings, you only need to store the data in the kafka message queue and use the first overload method // If you need to set the configuration of complex kafka, use the overload method except the first one // If you need to set Semantic only once, you can use the last two /*FlinkKafkaProducer producer = new FlinkKafkaProducer( "192.168.88.161:9092,192.168.88.162:9092,192.168.88.163:9092", "flink_kafka", new SimpleStringSchema() );*/ FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<String>( "flink_kafka", new KafkaSerializationSchemaWrapper( "flink_kafka", new FlinkFixedPartitioner(), false, new SimpleStringSchema() ), props, //It supports submitting data in a semantic way only once FlinkKafkaProducer.Semantic.EXACTLY_ONCE ); mapDS.addSink(producer); // ds.addSink landed in kafka cluster //5.execute env.execute(); //Test / export / server / Kafka / bin / Kafka console consumer sh --bootstrap-server node1:9092 --topic flink_ kafka } @Data @NoArgsConstructor @AllArgsConstructor public static class Student { private Integer id; private String name; private Integer age; } }
Consumption data from kafka cluster
-
demand
Read data from kafka to console
-
Development steps
/** * Author itcast * Date 2021/6/17 16:46 * Requirement: encapsulate data elements into JSON strings and produce them into Kafka * Steps: * */ public class KafkaProducerDemo { public static void main(String[] args) throws Exception { //1.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.Source generates an element Student DataStreamSource<Student> studentDS = env.fromElements(new Student(104, "chaoxian", 25)); //3.Transformation //Note: at present, the serialization and deserialization used by Kafka directly use the simplest string, so first convert the Student to a string //3.1 map method converts Student into string SingleOutputStreamOperator<String> mapDS = studentDS.map(new MapFunction<Student, String>() { @Override public String map(Student value) throws Exception { //You can directly call toJsonString of JSON or convert it to JSON String json = JSON.toJSONString(value); return json; } }); //4.Sink Properties props = new Properties(); props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.88.161:9092"); //Instantiate FlinkKafkaProducer according to parameters //4.1 if you do not need complex parameter settings, you only need to store the data in the kafka message queue and use the first overload method // If you need to set the configuration of complex kafka, use the overload method except the first one // If you need to set Semantic only once, you can use the last two /*FlinkKafkaProducer producer = new FlinkKafkaProducer( "192.168.88.161:9092,192.168.88.162:9092,192.168.88.163:9092", "flink_kafka", new SimpleStringSchema() );*/ FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<String>( "flink_kafka", new KafkaSerializationSchemaWrapper( "flink_kafka", new FlinkFixedPartitioner(), false, new SimpleStringSchema() ), props, //It supports submitting data in a semantic way only once FlinkKafkaProducer.Semantic.EXACTLY_ONCE ); mapDS.addSink(producer); // ds.addSink landed in kafka cluster //5.execute env.execute(); //Test / export / server / Kafka / bin / Kafka console consumer sh --bootstrap-server node1:9092 --topic flink_ kafka } @Data @NoArgsConstructor @AllArgsConstructor public static class Student { private Integer id; private String name; private Integer age; } }
Flink writes to Redis database
-
Redis is an in memory database that supports caching and persistence
-
Usage scenario
- Thermal data processing, caching mechanism
- duplicate removal
- Five data types String Hash set Zset List
-
Requirements:
Write data to Redis through Flink
package cn.itcast.flink.sink; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.redis.RedisSink; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper; import org.apache.flink.util.Collector; /** * Author itcast * Desc * Requirements: * Receive the message and make WordCount, * Finally, save the results to Redis * Note: the data structure stored in Redis: use hash, that is, map * key value * WordCount ((words, number) */ public class ConnectorsDemo_Redis { public static void main(String[] args) throws Exception { //1.env execution environment StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.Source reads data from socket DataStream<String> linesDS = env.socketTextStream("192.168.88.163", 9999); //3.Transformation //3.1 cut and record as 1 SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOneDS = linesDS .flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception { String[] words = value.split(" "); for (String word : words) { out.collect(Tuple2.of(word, 1)); } } }); //3.2 grouping KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOneDS.keyBy(t -> t.f0); //3.3 polymerization SingleOutputStreamOperator<Tuple2<String, Integer>> result = groupedDS.sum(1); //4.Sink result.print(); // *Finally, save the results to Redis // *Note: the data structure stored in Redis: use hash, that is, map // * key value // *WordCount (word, number) //-1. Before creating RedisSink, you need to create RedisConfig //Connect to stand-alone Redis FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder() .setHost("192.168.88.163") .setDatabase(2) .build(); //-3. Create and use RedisSink result.addSink(new RedisSink<Tuple2<String, Integer>>(conf, new RedisWordCountMapper())); //5.execute env.execute(); } /** * -2.Define a Mapper to specify the data structure stored in Redis */ public static class RedisWordCountMapper implements RedisMapper<Tuple2<String, Integer>> { @Override public RedisCommandDescription getCommandDescription() { //Which data type to use, key:WordCount return new RedisCommandDescription(RedisCommand.HSET, "WordCount"); } @Override public String getKeyFromData(Tuple2<String, Integer> data) { // key to store data return data.f0; } @Override public String getValueFromData(Tuple2<String, Integer> data) { // value of stored data return data.f1.toString(); } } }
problem
-
vmware opens the image file 15.5 X is upgraded to 16.1.0, which can be upgraded to
-
Fromsequence (1,10), CPU 12 thread, from < = to
The set parallelism is greater than the generated data. The parallelism is 12. There are only 10 generated data. Report this.
-
Flink Standalone HA highly available
jobmanager -> log